2508.19828_Memory-R1: Enhancing Large Language Model Agents to Manage and Utilize Memories via Reinforcement Learning¶
引用: 28(2026-01-09)
组织:
1Ludwig Maximilian University of Munich,
2Munich Center for Machine Learning,
3Technical University of Munich,
4University of Cambridge,
5University of Hong Kong,
6Technical University of Darmstadt,
7University of Edinburgh
总结¶
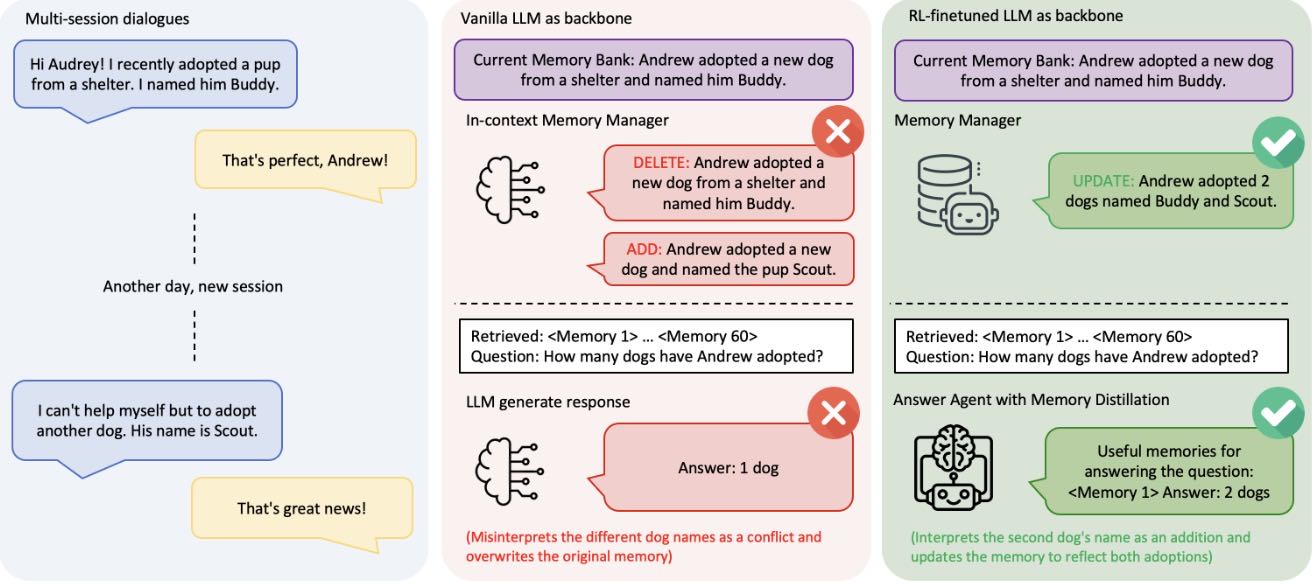
Figure 1: Comparison of Memory-R1 and a vanilla LLM memory system.
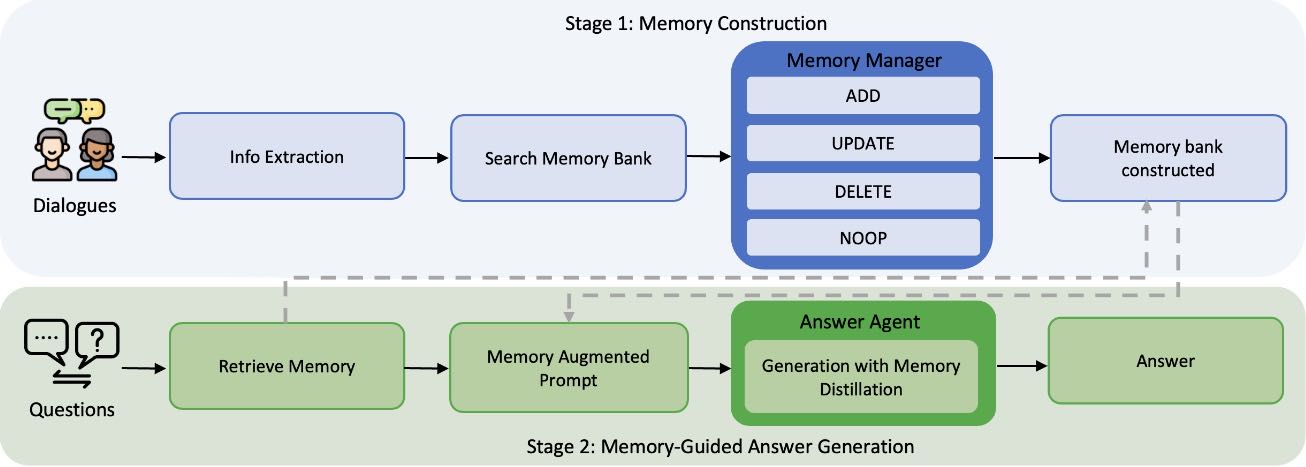
Figure 2: Overview of the Memory-R1 framework.
总结
RL微调显著提升了记忆管理器的决策能力,使其能更智能地选择ADD、UPDATE、DELETE操作,避免记忆丢失和碎片化。
记忆蒸馏机制增强了回答代理的信息筛选能力,使其在面对大量记忆时能聚焦关键信息,提升回答准确率。
**重点:**整理了用到的 prompt 和对应的算法
From Moonlight¶
三句摘要¶
🧠 Memory-R1引入了一个基于强化学习(RL)的框架,通过训练Memory Manager和Answer Agent,使大型语言模型(LLMs)能够主动管理和利用外部记忆。
⚙️ 该框架的核心是RL微调的Memory Manager和Answer Agent,前者学习执行结构化记忆操作(ADD、UPDATE、DELETE、NOOP),后者通过Memory Distillation策略选择并推理相关信息。
✨ 仅通过152个训练QA对,Memory-R1在LoCoMo基准测试中取得了SOTA性能,并在多种模型规模和新任务上展现了强大的泛化能力,证明了强化学习在记忆增强型LLM中的高效性。
关键词¶
大型语言模型 (LLMs):
记忆管理:
强化学习 (RL): 在本文中,RL被用作训练LLM代理来主动管理和利用外部记忆的关键技术。通过优化基于最终结果的奖励信号,模型能够学会何时添加、更新、删除或保留信息,以及如何有效利用检索到的记忆来进行推理。
记忆管理器代理 (Memory Manager Agent): Memory-R1框架中的一个专用代理。它的核心职责是主动管理外部记忆库,学习并执行结构化的记忆操作,包括添加(ADD)、更新(UPDATE)、删除(DELETE)或不操作(NOOP)。它接收从对话中提取的新信息,并根据当前记忆状态,决定如何修改记忆库,从而维护和演变记忆的状态。
回答代理 (Answer Agent): Memory-R1框架中的另一个专用代理。在回答问题时,它负责应用“记忆蒸馏”策略,从检索到的众多记忆条目中筛选出最相关的部分,然后基于这些精炼后的信息进行推理并生成最终答案。
检索增强生成 (Retrieval-Augmented Generation, RAG): 一种结合了信息检索和语言模型生成的技术。它首先从外部知识库(如记忆库)中检索与用户查询(问题)相关的条目,然后将这些检索到的信息与原始查询一起输入给语言模型,以增强模型的生成能力。在Memory-R1中,RAG用于获取潜在的记忆信息,以便被后续的代理处理。
近端策略优化 (Proximal Policy Optimization, PPO): 一种用于强化学习的策略优化算法。它通过限制策略更新的幅度来确保训练的稳定性和效率。在Memory-R1中,PPO被用来微调记忆管理器和回答代理,使其能够通过最大化与回答正确性相关的奖励来学习其行为策略。
组相对策略优化 (Group Relative Policy Optimization, GRPO): 另一种强化学习策略优化算法,它是PPO的一个变体。GRPO通过在每次更新时,比较同一批次内不同动作的相对优势来工作,这种方式避免了显式地学习价值函数,同时保持了类似PPO的稳定性。本文将GRPO与PPO一起用于训练Memory-R1的两个代理。
记忆蒸馏 (Memory Distillation): 在Memory-R1框架中,这是回答代理(Answer Agent)使用的策略。它指的是从检索到的大量(例如60个)可能不完全相关的记忆条目中,进行筛选和提炼,只保留与当前问题最相关的核心信息。这样做是为了减少噪声干扰,让代理能够更专注于关键证据,从而生成更准确的答案。
多轮对话 (Multi-session Dialogue): Memory-R1主要应用于此类场景,以解决长时期记忆管理和推理的挑战。
摘要¶
Memory-R1旨在解决大型语言模型(LLMs)固有的无状态性以及有限上下文窗口导致的长期推理障碍。现有方法通常通过外部记忆库增强LLMs,但其管理和利用机制大多是静态且基于启发式规则的,缺乏学习能力来决定何时存储、更新或检索信息。
该论文提出了Memory-R1,一个基于强化学习(RL)的框架,赋予LLMs主动管理和利用外部记忆的能力。该框架包含两个专门的Agent:
Memory Manager(记忆管理器):学习结构化的记忆操作,包括ADD(添加)、UPDATE(更新)、DELETE(删除)和NOOP(无操作)。
Answer Agent(回答代理):预选择并基于相关记忆条目进行推理。
这两个Agent都通过成果驱动型RL(PPO和GRPO算法)进行微调,实现了自适应的记忆管理,且仅需最少量的监督。
核心方法学
Memory-R1的RL微调分为两个主要部分,分别针对Memory Manager和Answer Agent:
1. Memory Manager的RL微调
任务定义:Memory Manager通过选择ADD、UPDATE、DELETE、NOOP操作之一来维护记忆库,并输出更新后的内容 \(m'\)。其目标是学习何种操作能产生一个记忆状态,从而使下游的Answer Agent能正确回答问题。
输入与输出:Memory Manager被建模为一个策略\(\pi_{\theta}\),它接收提取出的新信息 \(x\) 和当前记忆库 \(M_{old}\) 作为输入,并输出操作 \(o\) 及其内容 \(m'\): \((o, m') \sim \pi_{\theta}(\cdot | x, M_{old})\)
RL算法:
PPO (Proximal Policy Optimization):通过裁剪代理目标函数来稳定训练。给定候选记忆 \(x\) 和记忆库 \(M_{old}\),管理器从策略 \(\pi_{\theta}\) 中采样操作 \(o\) 和内容 \(m'\),将其应用于记忆库,并将结果转发给冻结的Answer Agent。答案的正确性提供标量奖励 \(r\),由此估计优势函数 \(A\)。PPO目标函数为: \(J(\theta) = E [\min (\rho_{\theta}A, \text{clip}(\rho_{\theta}, 1 - \epsilon, 1 + \epsilon)A)]\) 其中,\(\rho_{\theta} = \frac{\pi_{\theta}(o,m'|x,M_{old})}{\pi_{old}(o,m'|x,M_{old})}\) 是重要性采样比,\(\epsilon\) 是裁剪阈值。
GRPO (Group Relative Policy Optimization):每状态采样一组 \(G\) 个候选动作,并计算它们的相对优势。这种方法避免了显式价值函数,同时保持了类似PPO的稳定性。对于状态 \(s = (x, M_{old})\),GRPO目标函数为: \(J(\theta) = E[\frac{1}{G}\sum_{i=1}^{G}\rho^{(i)}_{\theta}A_i - \beta D_{KL}[\pi_{\theta} \| \pi_{ref}]]\) 其中,\(A_i = \frac{r_i - \text{mean}(r)}{\text{std}(r)}\) 是标准化后的组内相对优势,\(\rho^{(i)}_{\theta}\) 是每个动作的重要性采样比。KL项用于正则化更新以防止策略漂移。
奖励设计:采用成果驱动型奖励。Memory Manager操作的有效性通过其对下游问答性能的影响来评判。在应用操作 \(o\) 和提议内容 \(m'\) 后,更新后的记忆库传递给冻结的Answer Agent,奖励基于答案的正确性: \(R_{answer} = EM(y_{pred}, y_{gold})\) 其中,\(y_{pred}\) 是预测答案,\(y_{gold}\) 是真实答案。
2. Answer Agent的RL微调
任务定义:Answer Agent利用Memory Manager维护的记忆库回答多会话对话中的问题。针对每个问题,模型会检索60个候选记忆,Answer Agent会执行记忆蒸馏(Memory Distillation)策略,选择最相关的条目,然后生成答案。
输入与输出:Agent被建模为一个策略 \(\pi_{ans}\),将问题 \(q\) 和检索到的记忆集合 \(M_{ret}\) 映射到答案 \(y\): \(y \sim \pi_{ans}(\cdot | q, M_{ret})\)
RL算法:同样使用PPO和GRPO算法进行微调。目标函数形式与Memory Manager类似,但应用于生成的答案序列。PPO的重要性采样比为: \(\rho_{\theta}(q, M_{ret}) = \frac{\pi_{\theta}(y | q, M_{ret})}{\pi_{old}(y | q, M_{ret})}\) GRPO则根据每组候选答案的相对优势进行训练。
奖励设计:采用预测答案 \(y_{pred}\) 和真实答案 \(y_{gold}\) 之间的精确匹配(EM)得分作为奖励: \(R_{answer} = EM(y_{pred}, y_{gold})\) 这种设计直接将奖励与最终答案的正确性挂钩,鼓励Agent选择并推理记忆,以产生准确的输出。
训练策略 Memory-R1的训练是数据高效的,仅使用152个训练问答对。Memory Manager和Answer Agent的训练是解耦的。在训练Memory Manager时,Answer Agent被冻结,仅用于提供成果奖励。在训练Answer Agent时,Memory Manager被固定,以确保稳定的记忆输入。这种解耦设置避免了归因模糊性,同时允许两个组件在交替训练阶段共同适应。
实验与结果
数据集:LoCoMo(主要训练和评估)、MSC和LongMemEval(用于泛化能力测试)。
模型骨干:LLaMA-3.1-8B-Instruct和Qwen-2.5 instruct模型(3B, 7B, 14B)。
评估指标:Token级别的F1分数、BLEU-1(B1)以及LLM-as-a-Judge(J)。
基线:包括LoCoMo (RAG)、Zep、A-Mem、Mem0和Memory-SFT(Memory-R1的监督微调版本)。
主要发现:
Memory-R1在LoCoMo基准测试上持续取得最先进的性能。例如,在LLaMA-3.1-8B上,Memory-R1-GRPO相较于最强基线Mem0,在F1、B1和J指标上分别实现了48%、69%和37%的显著提升。
Memory-R1展现出强大的泛化能力,在未经额外训练的情况下,直接应用于MSC和LongMemEval也能取得持续改进。
消融实验证实了Memory Manager、Answer Agent和记忆蒸馏(Memory Distillation)机制对整体性能的贡献。RL训练相较于In-context或监督微调能带来显著提升。
GRPO在训练初期比PPO收敛更快,但最终都能达到相似的奖励水平。
与更强的Memory Manager(例如GPT-4o-mini)结合,Answer Agent的性能提升更为显著,表明系统在记忆质量提高时能获得复合收益。
Memory-R1通过RL在LLMs中实现了主动、自适应的记忆管理和利用,为长期知识保持和更具Agent能力的LLM行为开辟了新方向。
Prompt¶
Figure 9: Memory Manager Prompt (Part 1): Overview and ADD/UPDATE operation instruction.¶
You are a smart memory manager which controls the memory of a system.
You can perform four operations: (1) add into the memory, (2) update the
memory, (3) delete from the memory, and (4) no change.
Based on the above four operations, the memory will change.
Compare newly retrieved facts with the existing memory. For each new fact,
decide whether to:
- ADD: Add it to the memory as a new element
- UPDATE: Update an existing memory element
- DELETE: Delete an existing memory element
- NONE: Make no change (if the fact is already present or irrelevant)
1. **Add**: If the retrieved facts contain new information not present
in the memory, then you have to add it by generating a new ID in the id field.
- Example:
Old Memory:
[
{"id" : "0", "text" : "User is a software engineer"}
]
Retrieved facts: ["Name is John"]
New Memory:
{
"memory" : [
{"id" : "0", "text" : "User is a software engineer", "event" : "NONE"},
{"id" : "1", "text" : "Name is John", "event" : "ADD"}
]
}
2. **Update**: If the retrieved facts contain information that is already
present in the memory but the information is totally different, then
you have to update it.
If the retrieved fact contains information that conveys the same thing as
the memory, keep the version with more detail.
Example (a) – if the memory contains "User likes to play cricket" and the
retrieved fact is "Loves to play cricket with friends", then update the
memory with the retrieved fact.
Example (b) – if the memory contains "Likes cheese pizza" and the
retrieved fact is "Loves cheese pizza", then do NOT update it because they
convey the same information.
Important: When updating, keep the same ID and preserve old_memory.
- Example:
Old Memory:
[
{"id" : "0", "text" : "I really like cheese pizza"},
{"id" : "2", "text" : "User likes to play cricket"}
]
Retrieved facts: ["Loves chicken pizza", "Loves to play cricket with friends"]
New Memory:
{
"memory" : [
{"id" : "0", "text" : "Loves cheese and chicken pizza", "event" : "UPDATE",
"old_memory" : "I really like cheese pizza"},
{"id" : "2", "text" : "Loves to play cricket with friends", "event" : "UPDATE",
"old_memory" : "User likes to play cricket"}
]
}
3. **Delete**: If the retrieved facts contain information that contradicts
the memory, delete it. When deleting, return the same IDs — do not generate new IDs.
- Example:
Old Memory:
[
{"id" : "1", "text" : "Loves cheese pizza"}
]
Retrieved facts: ["Dislikes cheese pizza"]
New Memory:
{
"memory" : [
{"id" : "1", "text" : "Loves cheese pizza", "event" : "DELETE"}
]
}
4. **No Change**: If the retrieved facts are already present, make no change.
- Example:
Old Memory:
[
{"id" : "0", "text" : "Name is John"}
]
Retrieved facts: ["Name is John"]
New Memory:
{
"memory" : [
{"id" : "0", "text" : "Name is John", "event" : "NONE"}
]
}
Figure 11: Prompt and retrieved memories used in the case study, showing all instructions, context, and memory entries provided to the model.¶
You are an intelligent memory assistant tasked with retrieving
accurate information from conversation memories.
# CONTEXT:
You have access to memories from two speakers in a conversation.
These memories contain timestamped information that may be relevant
to answering the question.
# INSTRUCTIONS:
1. Carefully analyze all provided memories from both speakers
2. Pay special attention to the timestamps to determine the answer
3. If the question asks about a specific event or fact, look for direct evidence
4. If the memories contain contradictory information, prioritize the most recent memory
5. If there is a question about time references (like "last year", "two months ago"),
calculate the actual date based on the memory timestamp.
6. Always convert relative time references to specific dates, months, or years.
7. Focus only on the content of the memories. Do not confuse character names
8. The answer should be less than 5-6 words.
9. IMPORTANT: Select memories you found that are useful for answering the questions,
and output it before you answer questions.
10. IMPORTANT: Output the final answer after **Answer:**
# APPROACH (Think step by step):
1. Examine all relevant memories
2. Examine the timestamps carefully
3. Look for explicit mentions that answer the question
4. Convert relative references if needed
5. Formulate a concise answer
6. Double-check the answer correctness
7. Ensure the final answer is specific
8. First output the memories that you found are important before you answer questions
Memories for user John:
- 7:20 pm on 16 June, 2023: John has a special memory of a vacation to California where he experienced a
gorgeous sunset and an enjoyable night strolling the shore, creating meaningful memories with loved ones.
- 6:13 pm on 10 April, 2023: John explored the coast in the Pacific Northwest and visited some national
parks, finding the beauty of nature absolutely breathtaking.
- 3:14 pm on 13 August, 2023: John enjoys spending time outdoors with his family, including activities
such as hiking, hanging out at the park, and having picnics. He also values indoor family activities like
playing board games and having movie nights at home.
... (In total 30 most relevant memories from John's Memory Bank are provided) ...
Memories for user Maria:
- 6:29 pm on 7 July, 2023: John experienced a severe flood in his old area last week, which caused
significant damage to homes due to poor infrastructure.
- 1:24 pm on 25 May, 2023: Maria appreciates the beauty of small, meaningful moments in life, as reflected
in her reaction to a family beach photo shared by John.
- 3:14 pm on 13 August, 2023: Maria appreciates family bonding and is interested in the activities that
John and his family enjoy doing together.
... (In total 30 most relevant memories from Maria's Memory Bank are provided) ...
Question: Does John live close to a beach or the mountains?
Figure 12: LLM-as-a-Judge prompt used to evaluate model answers.¶
Your task is to label an answer to a question as 'CORRECT' or 'WRONG'.
You will be given the following data:
(1) a question (posed by one user to another user),
(2) a 'gold' (ground truth) answer,
(3) a generated answer,
which you will score as CORRECT or WRONG.
The point of the question is to ask about something one user should know about the other user based on their
prior conversations.
The gold answer will usually be a concise and short answer that includes the referenced topic, for example:
Question: Do you remember what I got the last time I went to Hawaii?
Gold answer: A shell necklace
The generated answer might be longer, but you should be generous with your grading — as long as it touches
on the same topic as the gold answer, it should be counted as CORRECT.
For time-related questions, the gold answer will be a specific date, month, or year. The generated answer
might include relative references (e.g., "last Tuesday"), but you should be generous — if it refers to
the same time period as the gold answer, mark it CORRECT, even if the format differs (e.g., "May 7th" vs.
"7 May").
Now it's time for the real question:
Question: {question}
Gold answer: {gold_answer}
Generated answer: {generated_answer}
First, provide a short (one sentence) explanation of your reasoning, then finish with CORRECT or WRONG.
Do NOT include both CORRECT and WRONG in your response, or it will break the evaluation script.
Return the label in JSON format with the key as "label".
Algorithm¶
Algorithm 1 Data Construction for Memory-R1 Training¶
核心任务是为 Memory-R1 模型的训练构建高质量的训练数据,它把多轮对话转换成适合训练「记忆管理器(Memory Manager)」的三元组格式:
(dialogue turn, temporal memory bank, QA)
输入:
LoCoMo multi-turn dialogues 𝒟这是一个包含多轮对话的数据集输出:
Training tuples for the Memory Manager输出是一批训练元组,每个元组都包含当前对话轮次、对应的时序记忆库和关联的问答对,直接供记忆管理器训练使用。
核心步骤拆解
for each dialogue d ∈ 𝒟 do
for each turn t in d do
Build a temporal memory bank using the previous 50 turns with GPT-4o-mini
Combine (i) the temporal memory bank, (ii) the current turn t, and (iii) any QA pairs linked to t
Store the combined package as a single training tuple
end for
end for
Algorithm 2 Data Construction for Answer Agent Training¶
核心任务是为「答案生成代理(Answer Agent)」构建训练数据,它利用已经训练好的「记忆管理器(Memory Manager)」,从多轮对话中提取出包含问题、关联记忆和标准答案的三元组,用于后续 Answer Agent 的微调。
输入
LoCoMo multi-turn dialogues 𝒟:多轮对话数据集,和 Algorithm 1 是同一个数据源。trained Memory Manager:已经训练好的记忆管理器(由 Algorithm 1 训练得到)。
输出
Training tuples for the Answer Agent:训练元组格式为(question, retrieved memories, gold answer),直接用于 Answer Agent 的微调。对LoCoMo 数据集,一问一答2个参与者,所以要提取 30×2=60 条记忆
核心步骤拆解
for each dialogue d ∈ 𝒟 do
Use the Memory Manager to maintain an up-to-date memory bank across turns
end for
for each question q in d do
Use the question q as a query to retrieve the top 30 most relevant candidate memories for each participant from the memory bank
Pair (i) the question q, (ii) the 60 retrieved memories, and (iii) the gold answer a_gold
Store the triplet as a single training tuple for Answer Agent fine-tuning
end for
Algorithm 3 Memory Bank Construction via Memory Manager¶
本算法描述了记忆管理器的核心执行逻辑,它定义了如何动态构建和维护一个对话记忆库,让模型能够在多轮对话中持续、智能地更新记忆。
核心目标:把一段多轮对话,通过提取关键信息、检索关联记忆、执行动态操作这三步,转化为一个不断进化的记忆库。这个记忆库会作为后续答案生成的核心上下文来源。
输入
Multi-turn dialogue D = {t₁, t₂, ..., tₙ}:一段包含n个轮次的完整对话。Initial empty memory bank M:一个初始为空的记忆库。
输出
Updated memory bank M:经过所有对话轮次处理后,最终的记忆库。
核心步骤拆解
procedure CONSTRUCTMEMORYBANK(D, M)
for each dialogue turn t_i ∈ D do
Extract key info: f_i ← LLMExtract(t_i)
Retrieve memories: M_old ← TopK(f_i, M)
Determine operation: o_i ← MemoryManager(f_i, M_old) where o_i ∈ {ADD, UPDATE, DELETE, NOOP}
if o_i = ADD then
M ← M ∪ {f_i}
else if o_i = UPDATE then
M_tmp ← Merge(M_old, f_i)
M ← M \ M_old ∪ M_tmp
else if o_i = DELETE then
M ← M \ M_old
else if o_i = NOOP then
M ← M
end if
end for
return M
end procedure
Algorithm 4 Memory-augmented Generation via Answer Agent¶
算法是整个记忆增强对话系统的最终执行阶段,它利用前面步骤构建的记忆库,让 Answer Agent 生成带有记忆增强的精准回答。
核心目标:对每个输入的问题,从记忆库中检索出最相关的上下文,然后生成一个融合了记忆信息的高质量回答。这让模型的回答不再依赖单轮信息,而是能结合整个对话历史。
输入
Question set Q = {q₁, q₂, ..., qₘ}:需要回答的问题集合。Memory bank M:由 Algorithm 3 构建并维护的记忆库。Generation instruction text t:生成指令文本,用来指导 Answer Agent 的回答风格和格式。
输出
Answer set Â:最终生成的回答集合,每个问题对应一个回答。
核心步骤拆解
procedure GENERATEANSWERS(Q, M, t)
 ← {}
for each question q_i ∈ Q do
M_ret ← TopK(q_i, M)
# 将「生成指令 t」、「问题 q_i」和「检索到的记忆 M_ret」拼接成一个完整的提示词 p_i
p_i ← Concat(t, q_i, M_ret) ▷ p_i is the memory augmented prompt
# M_distill:提炼后的记忆(可以用于后续优化记忆库)â_i:针对当前问题的最终回答
M_distill, â_i ← AnswerAgent(p_i)
 ←  ∪ {â_i}
end for
return Â
end procedure
Algorithm 5 Memory-R1 Pipeline for Memory Manager¶
整个系统的训练中枢
核心目标:它的作用是端到端地训练记忆管理器,让它学会在多轮对话中动态执行「增 / 删 / 改 / 无操作」,最终生成一个能精准维护记忆库的模型。这个训练过程引入了强化学习,用答案生成的质量作为反馈来优化记忆管理策略。
输入
Dataset D:包含对话轮次ds、问答对的训练数据集(q_i, a_i)。Temp memory bank M:临时记忆库,每轮训练开始时会清空。Memory Manager LLM 𝒫ₘ:待训练的记忆管理器大模型。Answer LLM 𝒫ₐ:已经训练好的答案生成模型。Reward Function 𝒫:用来评估回答质量的奖励函数。Generation instruction text t:指导回答生成的指令文本。
输出
Fine-tuned Memory Manager LLM 𝒫ₘ:经过强化学习优化后的记忆管理器。
核心步骤拆解
procedure TrainMemoryManager(D, 𝒫ₘ, 𝒫ₐ, 𝒫)
for each tuple (ds, q_i, a_i) ∈ D do
M ← {}
for d_i ∈ ds do
# 事实提取:从当前对话轮次 d_i 中提取关键信息 f_i
Facts Extraction: f_i ← LLMExtract(d_i)
# 记忆检索:用 f_i 从记忆库中检索最相关的记忆 M_ret
Memory Retrieval: M_ret ← TopK(f_i, M)
# 决策操作:由记忆管理器 𝒫ₘ 决定执行 ADD/UPDATE/DELETE/NOOP 中的哪一种
Determine operation: o_i ~ 𝒫ₘ(f_i, M_ret)
if o_i = ADD then
M ← M ∪ {f_i}
else if o_i = UPDATE then
M_tmp ← Merge(M_ret, f_i)
M ← M ∪ M_tmp
else if o_i = DELETE then
M ← M \ M_ret
else if o_i = NOOP then
M ← M
end if
end for
# 获取上下文:用问题 q_i 从记忆库中检索最相关的上下文 C_ret
Get Context: C_ret ← TopK(q_i, M)
# 构建提示词:将指令 t、问题 q_i 和上下文 C_ret 拼接成提示词 p_i
Update Prompt: p_i ← Concat(t, q_i, C_ret)
Get Response: r_i ~ 𝒫ₐ(p_i)
# 强化学习更新策略:
# 用奖励函数 𝒫 来比较生成回答 r_i 和标准答案 a_i,计算出一个奖励值
# 然后用强化学习算法(如 PPO 或 GRPO)来更新记忆管理器 𝒫ₘ 的策略,
# 让它在未来能生成更优的记忆库,从而让 Answer LLM 生成更接近标准答案的回答
Policy Update: 𝒫ₘ ← RL_step(𝒫ₘ, 𝒫, a_i, r_i), where RL ∈ {PPO, GRPO}
end for
return 𝒫ₘ
end procedure
Abstract¶
本论文提出了一种名为 Memory-R1 的强化学习框架,旨在增强大型语言模型(LLMs)对外部记忆系统的管理与利用能力。LLMs 虽然在多种自然语言处理任务中表现出色,但其状态无记忆性和上下文窗口有限的问题限制了其在长时序推理任务中的表现。为解决这一问题,已有研究尝试引入外部记忆库,但大多数方法依赖于静态规则或启发式机制,缺乏对记忆内容的动态学习决策机制。
Memory-R1 的核心创新在于引入了两个专门的智能体(agent):
记忆管理器(Memory Manager):负责学习对记忆条目的操作,包括:
ADD(添加)
UPDATE(更新)
DELETE(删除)
NOOP(无操作)
该模块通过结构化操作策略,实现对记忆内容的动态管理。
回答代理(Answer Agent):负责从大量记忆条目中预筛选出相关条目并进行推理,从而提升回答的准确性和效率。
这两个智能体均通过结果驱动的强化学习算法(PPO 和 GRPO)进行微调,使得系统能够在监督数据极少(仅152个训练问答对)的情况下实现高效的自适应记忆管理。
实验与结果¶
数据集与任务:
在三个基准数据集上进行了测试:LoCoMo、MSC、LongMemEval
支持多类型问题和不同规模模型(3B–14B参数)
性能表现:
Memory-R1 显著优于多个强基线模型
展现出良好的泛化能力
案例分析:
图1展示了 Memory-R1 与传统 LLM 记忆系统的对比:
传统方法容易将跨会话信息误解为矛盾,导致记忆碎片化(DELETE+ADD)
Memory-R1 的记忆管理器通过 UPDATE 操作整合信息,回答代理从60条记忆中筛选出关键信息,准确回答“2只狗”
重点内容强调¶
强化学习机制:使用 PPO 和 GRPO 算法训练两个智能体,实现端到端的记忆管理与推理,是本文的核心技术亮点。
结构化记忆操作:ADD/UPDATE/DELETE/NOOP 提供了更细粒度的记忆控制,优于传统静态方法。
高效记忆筛选机制:Answer Agent 能从大量记忆中提取关键信息,显著提升回答质量。
小样本训练能力:仅使用152个训练样本即可达到良好性能,说明模型具有较强的泛化与学习效率。
总结¶
Memory-R1 是一种创新的 LLM 增强框架,通过引入强化学习机制,使 LLM 能够主动、智能地管理外部记忆系统。该方法在多个任务和模型规模上均表现出色,尤其在处理跨会话、长时序记忆整合方面具有显著优势。
1 Introduction¶
1 引言(Introduction)¶
1.1 大型语言模型(LLMs)的现状与局限性¶
大型语言模型在自然语言理解和生成方面表现出色,成为当前人工智能发展的核心(OpenAI et al., 2024;Qwen et al., 2025)。然而,LLMs本质上是无状态的(stateless),其记忆能力受限于固定的上下文窗口,超出该窗口的信息会被遗忘,导致其无法在长时间对话或任务演化中维持知识(Yu et al., 2025;Fan et al., 2025;Goodyear et al., 2025;Wang et al., 2024;Fei et al., 2023)。
1.2 外部记忆增强的尝试¶
早期尝试包括Tensor Brain框架(Tresp et al., 2023),它使用双层张量网络建模情景记忆、语义记忆和工作记忆。近年来,研究者尝试通过显式外部记忆模块增强LLMs,其中最主流的是检索增强生成(RAG)范式(Zhang et al., 2024;Pan et al., 2025;Salama et al., 2025),即将检索到的记忆条目附加到输入提示中。
但这种方法存在两个核心问题:
检索问题:启发式检索可能返回太少(遗漏关键信息)或太多(引入噪声)记忆条目,导致模型在推理时被无关信息干扰。
记忆管理问题:决定哪些信息应被保留、更新或删除。一些系统采用类似数据库的CRUD操作(创建、读取、更新、删除)(Packer et al., 2023;Modarressi et al., 2024;Xiong et al., 2025),而Mem0(Chhikara et al., 2025)则引入了{ADD, UPDATE, DELETE, NOOP}操作集。
1.3 现有方法的不足¶
现有方法主要依赖LLM根据上下文指令选择操作,缺乏学习信号,导致在简单场景下也可能出错。例如,用户先后说“我收养了一只叫Buddy的狗”和“我又收养了一只叫Scout的狗”,一个未训练的系统可能误判为矛盾,执行DELETE+ADD操作,覆盖原始记忆;而训练后的系统则能通过UPDATE操作合并为“Andrew收养了两只狗,Buddy和Scout”。
1.4 强化学习(RL)的引入¶
监督微调难以解决记忆操作和检索决策的标注问题,而强化学习(RL)已被证明在对齐LLM行为与高层目标方面具有潜力,如工具使用(Qian et al., 2025)、网页导航(Wei et al., 2025)、搜索优化(Jin et al., 2025;Song et al., 2025)等。因此,作者提出:RL是实现LLM代理自适应记忆的关键。
1.5 Memory-R1框架概述¶
本文提出Memory-R1,一个基于RL微调的记忆增强LLM框架,包含两个专门代理:
记忆管理器(Memory Manager):执行结构化记忆操作(如添加、更新、删除),维护和演化记忆库。
回答代理(Answer Agent):应用记忆蒸馏策略(Memory Distillation)过滤RAG检索到的记忆条目,并进行推理以生成答案。
两个代理均使用PPO(Schulman et al., 2017)或GRPO(Shao et al., 2024)进行微调,仅需152个问答对即可实现良好性能。
1.6 实验结果¶
在LoCoMo基准测试(Maharana et al., 2024)中,Memory-R1显著优于Mem0(Chhikara et al., 2025):
使用LLaMA-3.1-8B-Instruct作为主干模型,Memory-R1-GRPO实现了:
F1值提升48%
BLEU-1提升69%
LLM-as-a-Judge评分提升37%
这些结果表明,Memory-R1能够在极少量监督数据下实现显著性能提升,树立了LoCoMo的新标杆。
1.7 主要贡献总结¶
提出Memory-R1:首个基于RL的记忆增强LLM框架,包含记忆管理器和回答代理。
开发高效微调策略:使用PPO/GRPO,在仅152个问答对下实现高性能,验证了RL在记忆增强中的有效性。
深入分析RL策略、模型规模与记忆设计:为构建下一代具备记忆与推理能力的LLM代理提供实用见解。
2 相关工作(Related Work)总结¶
本章节主要回顾了两个方向的研究:基于记忆增强的LLM代理(Memory Augmented LLM-based Agents)和LLM与强化学习的结合(LLM and Reinforcement Learning),并提出了本文工作的创新点:将记忆操作建模为强化学习问题(Memory-R1)。
2.1 基于记忆增强的LLM代理(Memory Augmented LLM-based Agents)¶
重点内容:
问题背景:虽然大语言模型(LLMs)在多轮对话、任务分解和决策制定方面表现出色,但其固定长度的上下文窗口限制了长期记忆能力。
解决方案:引入外部记忆模块,实现信息的选择性存储、检索与更新,从而支持长期推理和知识积累。
代表性工作:
LoCoMo:构建了一个评估代理在远距离对话历史中检索与推理能力的基准。
ReadAgent:引入基于记忆的对话检索机制。
MemoryBank:提出用于终身记忆的组合式记忆控制器。
MemGPT:设计了工作记忆与长期记忆缓冲区,并引入调度策略。
总结:现有方法多采用静态记忆机制,而本文提出的是可学习的记忆系统,通过强化学习进行训练。
2.2 LLM与强化学习(LLM and Reinforcement Learning)¶
重点内容:
研究趋势:越来越多研究尝试将强化学习(RL)应用于LLM,以超越静态监督微调,使模型能从动态交互反馈中学习。
代表性方法:
RLHF(Reinforcement Learning from Human Feedback):对齐LLM输出与人类偏好。
Toolformer、ReAct-style agents:将工具调用建模为RL问题。
Search-R1:使用RL训练LLM优化网页搜索查询以提高答案准确性。
Trial and Error方法:通过RL优化推理路径选择。
研究空白:尽管RL在LLM行为优化方面取得进展,但记忆管理与利用仍主要依赖启发式策略,缺乏自适应性与长期优化能力。
本文贡献:提出Memory-R1,首次将记忆操作选择与记忆利用建模为RL问题。
图2:Memory-R1框架概述(图示说明)¶
阶段1(蓝色):通过RL微调的记忆管理器(Memory Manager)构建和更新记忆库,选择操作 {ADD, UPDATE, DELETE, NOOP}。
阶段2(绿色):回答代理(Answer Agent)使用记忆蒸馏策略(Memory Distillation)对检索到的记忆进行推理。
总结: 本节系统回顾了当前LLM代理中记忆机制与强化学习的应用现状,指出已有方法在记忆管理方面缺乏可学习性和长期优化。本文提出的Memory-R1框架,通过将记忆操作建模为强化学习问题,填补了这一研究空白。
3 Method¶
3 方法总结¶
3. 方法概述¶
本节介绍了 Memory-R1,一种用于多会话对话任务的强化学习框架。每个对话包含多个会话(在不同时间发生的独立交互),每个会话由多个回合(两个用户之间的来回交流)组成。回答问题需要综合跨会话的信息,这对长期记忆管理和推理提出了挑战。图2展示了整体流程:在每个对话回合中,LLM 提取并总结值得记忆的信息,并从记忆库中检索相关内容作为检索增强生成(RAG)的一部分。记忆管理器(Memory Manager)决定是添加(ADD)、更新(UPDATE)、删除(DELETE)还是不操作(NOOP),从而维护和更新记忆状态。答案代理(Answer Agent)则对检索到的记忆进行提炼,过滤噪声并推理最相关的内容。两个代理都通过 PPO 或 GRPO 进行微调,实现基于结果的记忆操作学习和选择性利用。
3.1 记忆管理器的强化学习微调¶
任务建模¶
目标:训练记忆管理器选择 ADD、UPDATE、DELETE 或 NOOP 操作,以维护记忆库,使答案代理能够正确回答问题。
输入:新信息 \( x \) 和当前记忆库 \( \mathcal{M}_{\text{old}} \)
输出:操作 \( o \) 和更新后的内容 \( m' \)
策略建模: $\( (o, m') \sim \pi_\theta(\cdot \mid x, \mathcal{M}_{\text{old}}) \)$
PPO 优化¶
使用 Proximal Policy Optimization (PPO) 进行微调。
目标函数: $\( \mathcal{J}(\theta) = \mathbb{E}\left[\min\left(\rho_\theta A, \text{clip}(\rho_\theta, 1-\epsilon, 1+\epsilon) A\right)\right] \)$ 其中:
\( \rho_\theta = \frac{\pi_\theta(o, m' \mid x, \mathcal{M}_{\text{old}})}{\pi_{\text{old}}(o, m' \mid x, \mathcal{M}_{\text{old}})} \):重要性比率
\( A \):基于答案正确性的优势估计
\( \epsilon \):剪切阈值,用于稳定更新
GRPO 优化¶
使用 Group Relative Policy Optimization (GRPO),每状态采样 G 个候选动作,计算其相对优势。
目标函数: $\( \mathcal{J}(\theta) = \mathbb{E}\left[\frac{1}{G}\sum_{i=1}^{G} \rho_\theta^{(i)} A_i - \beta \, \mathbb{D}_{\text{KL}}[\pi_\theta \| \pi_{\text{ref}}]\right] \)$ 其中:
\( A_i = \frac{r_i - \text{mean}(\mathbf{r})}{\text{std}(\mathbf{r})} \):标准化的组相对优势
\( \rho_\theta^{(i)} \):每个动作的重要性比率
KL 项用于防止策略偏离参考策略 \( \pi_{\text{ref}} \)
奖励设计¶
基于结果的奖励:记忆操作的效果通过下游 QA 的正确性来评估。
奖励函数: $\( R_{\text{answer}} = \text{EM}(y_{\text{pred}}, y_{\text{gold}}) \)$ 其中:
\( y_{\text{pred}} \):预测答案
\( y_{\text{gold}} \):真实答案
EM:精确匹配得分
3.2 答案代理的强化学习微调¶
任务建模¶
目标:利用记忆管理器维护的记忆库回答多会话对话中的问题。
方法:使用基于相似度的 RAG 检索 60 条候选记忆,进行记忆提炼,选择最相关条目生成答案。
策略建模: $\( y \sim \pi_{\text{ans}}(\cdot \mid q, \mathcal{M}_{\text{ret}}) \)$
PPO 优化¶
使用与 3.1 相同的 PPO 算法。
目标函数: $\( \mathcal{J}(\theta) = \mathbb{E}\left[\min\left(\rho_\theta A, \text{clip}(\rho_\theta, 1-\epsilon, 1+\epsilon) A\right)\right] \)$ 其中:
\( \rho_\theta(q, \mathcal{M}_{\text{ret}}) = \frac{\pi_\theta(y \mid q, \mathcal{M}_{\text{ret}})}{\pi_{\text{old}}(y \mid q, \mathcal{M}_{\text{ret}})} \)
\( A \):基于答案质量(如 EM)的优势估计
GRPO 优化¶
每个问题 \( q \) 和检索记忆 \( \mathcal{M}_{\text{ret}} \) 采样 G 个候选答案 \( \{y_i\} \)
计算其与真实答案 \( y_{\text{gt}} \) 的 EM 奖励,归一化为组相对优势
使用与 PPO 相同的重要性比率,通过组内比较稳定训练
奖励设计¶
奖励函数: $\( R_{\text{answer}} = \text{EM}(y_{\text{pred}}, y_{\text{gold}}) \)$
直接与最终答案的正确性挂钩,鼓励代理选择和推理能产生准确输出的记忆
表格 1:实验结果¶
模型 |
方法 |
单跳 |
多跳 |
开放域 |
时间 |
总体 |
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
F1↑ |
B1↑ |
J↑ |
F1↑ |
B1↑ |
J↑ |
F1↑ |
B1↑ |
J↑ |
F1↑ |
B1↑ |
J↑ |
F1↑ |
B1↑ |
J↑ |
模型对比:在 LLaMA-3.1-8B-Instruct 和 Qwen-2.5-7B-Instruct 上对比了多个基线模型(如 LoCoMo、Zep、A-Mem、Mem0、Memory-SFT)与 Memory-R1-PPO 和 Memory-R1-GRPO。
指标:F1、BLEU-1(B1)、LLM-as-a-Judge(J),数值越高越好。
结论:
Memory-R1-GRPO 在大多数指标上表现最佳,尤其在多跳和时间类问题上显著优于其他方法。
Memory-R1-PPO 也表现优异,尤其在 LLaMA-3.1 上的 F1 和 J 指标上接近 GRPO。
总结¶
Memory-R1 是一个基于强化学习的多会话对话记忆管理框架,结合 PPO 和 GRPO 微调记忆管理器和答案代理。
核心创新:
动态记忆操作(ADD/UPDATE/DELETE/NOOP)
基于最终答案质量的奖励机制
GRPO 在多跳和时间推理任务中表现突出
实验结果:Memory-R1 尤其是 GRPO 版本在 LoCoMo 基准测试中显著优于现有方法,验证了其在长期记忆管理和推理任务中的有效性。
4 Experiments¶
4 实验(Experiments)¶
4.1 实验设置(Experimental Setup)¶
数据集与模型(Dataset and Model)¶
本研究在三个基准数据集上评估 Memory-R1 的性能:
LoCoMo(Maharana et al., 2024):包含长对话(约600轮,平均26k token),涵盖单跳、多跳、开放域和时间推理问题。
MSC(Packer et al., 2023)与 LongMemEval(Wu et al., 2024):用于测试模型的泛化能力。
数据划分采用1:1:8的训练/验证/测试比(152/81/1307个问题),排除对抗样本。模型使用 LLaMA-3.1-8B-Instruct 和 Qwen-2.5 系列(3B、7B、14B)。
评估指标(Evaluation Metrics)¶
采用三种互补指标:
F1 Score(F1):衡量预测答案与真实答案的token重合度。
BLEU-1(B1):衡量一元词(unigram)的词汇相似度。
LLM-as-a-Judge(J):使用另一个LLM评估答案的事实准确性、相关性、完整性和上下文合适性,更贴近人类判断。
基线方法(Baselines)¶
对比方法包括:
LoCoMo(RAG风格)
Zep(结构化记忆访问)
A-Mem(动态记忆系统)
Mem0(模块化记忆系统)
Memory-SFT(监督微调版本)
所有方法均使用 LLaMA-3.1-8B 和 Qwen-2.5-7B 模型,温度设为0,最大token数2048,确保公平比较。
实现细节(Implementation Details)¶
使用 PPO 和 GRPO 算法进行强化学习微调,基于 VERL框架。
Prompt模板来自 Chhikara et al. (2025),完整提示见附录C。
所有实验在 NVIDIA H100 GPU 上进行,训练配置和超参数见附录D。
4.2 主要结果(Main Results)¶
表1展示了 Memory-R1 在 LoCoMo 数据集上的表现,使用 LLaMA-3.1-8B 和 Qwen-2.5-7B 模型,涵盖多种问题类型。
LLaMA-3.1-8B:
Memory-R1-GRPO 表现最优,F1 提升 68.9%,B1 提升 48.3%,Judge 提升 37.1%。
Memory-R1-PPO 也有显著提升,F1 提升 47.9%,B1 提升 35.3%,Judge 提升 26.5%。
Qwen-2.5-7B:
Memory-R1-GRPO 同样最优,F1 提升 57.3%,B1 提升 41.5%,Judge 提升 33.8%。
Memory-SFT 虽基于GPT-5生成数据训练,但性能仍低于 Memory-R1,说明强化学习优于监督学习。
4.3 泛化性与可扩展性(Generalization and Scalability)¶
模型规模扩展(Figure 3)¶
在 Qwen-2.5 系列(3B、7B、14B)上,Memory-R1 在所有模型规模上均优于基线模型,PPO 和 GRPO 在 F1、BLEU-1 和 Judge 指标上均有提升,说明强化学习对不同规模模型均有效。
跨任务泛化(Figure 4)¶
在未训练的 MSC 和 LongMemEval 数据集上,Memory-R1 仍表现优异,说明其具备良好的零样本迁移能力,适用于多种问题类型(单跳、多跳、开放域、时间推理)。
4.4 消融实验(Ablation Studies)¶
记忆管理器(Memory Manager)的作用(Figure 5a)¶
使用 RL 微调的记忆管理器显著优于上下文基线。
PPO:F1=24.60,B1=32.55,J=59.37。
GRPO:F1=24.91,B1=33.05,J=59.91。
说明 RL 能提升记忆操作的准确性。
答案代理(Answer Agent)的作用(Figure 5b)¶
RL 微调显著提升原始 LLM 的回答质量。
PPO:F1=32.91,B1=41.05,J=57.54。
GRPO:F1=37.51,B1=45.02,J=62.74。
说明 RL 优化比静态检索更有效。
记忆蒸馏(Memory Distillation)的作用(Figure 5c)¶
引入记忆蒸馏后,F1 从 34.37 提升至 37.51,B1 从 40.95 提升至 45.02,Judge 从 60.14 提升至 62.74。
说明过滤无关记忆可减少噪声,提升推理质量。
答案代理与记忆管理器的关系(Figure 7)¶
使用更强的记忆管理器(如 GPT-4o-mini)时,答案代理的提升更明显。
说明 Memory-R1 的效果具有“复合优势”。
PPO 与 GRPO 的比较(Figure 6)¶
GRPO 初期收敛更快,但最终两者性能接近。
GRPO 的分组回报归一化提供了更强的早期引导。
奖励设计分析(Table 2)¶
使用 Judge-based reward 可提升 Judge 分数(63.58),但 F1 和 B1 较低,因其生成更长答案。
使用 EM-based reward 更平衡,F1=41.05,B1=32.91,J=57.54。
最终采用 EM-based reward,避免单一指标偏差。
总结:Memory-R1 在多个数据集和模型上均显著优于现有方法,具备良好的泛化性和可扩展性。消融实验验证了各组件的有效性,尤其是 RL 微调和记忆蒸馏机制。
5 Conclusion¶
5 结论(Conclusion)¶
本节总结了论文提出的一种基于强化学习的框架 Memory-R1,该框架使基于大语言模型(LLM)的智能体能够有效地管理和利用外部记忆。与依赖启发式规则的传统方法不同,Memory-R1 通过强化学习(RL)自动学习记忆操作、提炼和使用策略,从而在问答任务中取得优异表现。
主要成果与贡献:¶
高效学习能力:Memory-R1 在仅使用 152 个训练样本 的情况下,就在 LoCoMo 数据集上达到了 SOTA(state-of-the-art)性能。
良好的扩展性:该方法在不同大小的模型上均表现稳定,说明其具有良好的可扩展性。
强泛化能力:无需重新训练,Memory-R1 即可在 MSC 和 LongMemEval 等其他任务上表现良好,说明其具备跨任务泛化能力。
消融实验(Ablation Studies):¶
通过消融实验验证了强化学习对系统各个组件的提升作用,表明 RL 在记忆管理的各个环节(如读取、写入、更新)中都起到了积极作用。
研究意义与未来方向:¶
作者指出,Memory-R1 为以下方向的研究提供了新思路:
组合式记忆架构(compositional memory architectures)
长期知识保留(long-term knowledge retention)
更具“代理性”的 LLM 行为(more agentic LLM behavior)
并强调,强化学习是实现自适应记忆能力的一条有前景的路径。
总结:本节高度概括了 Memory-R1 的创新点、实验效果与理论价值,强调其在小样本学习、泛化能力和记忆管理自动化方面的突破,为未来 LLM 的记忆机制研究提供了重要参考。
Limitations¶
局限性(Limitations)总结¶
本节讨论了Memory-R1模型在当前研究中存在的一些局限性。
1. 数据集的局限性:
作者指出,当前的评估主要集中在**对话为中心的数据集(dialogue-centric datasets)上。虽然这些基准测试涵盖了多种推理类型,但将Memory-R1扩展到多模态数据(multimodal data)**可能会带来新的挑战,这些挑战超出了本文的研究范围。
2. 训练方式的局限性:
为了在稀疏奖励(sparse rewards)条件下保证训练稳定性,作者分别训练了记忆管理器(Memory Manager)和回答代理(Answer Agent)。虽然这种分离是必要的,但它使得整个训练过程变得不够直接和复杂。
3. 未来改进方向:
作者提出,采用**端到端的多智能体强化学习方法(end-to-end multi-agent reinforcement learning)**可能简化训练流程,并实现更丰富的协作机制。这被视为未来研究的一个有前景的方向。
本节未涉及数学公式、算法步骤或表格数据。
Appendix A Case Study of Behavior of Agents before and after Fine-tuning¶
附录A:微调前后智能体行为的案例研究总结¶
本附录通过两个主要部分展示了强化学习(RL)微调对记忆管理器和回答代理的改进效果。以下是对各部分的结构化总结:
A.1 从上下文记忆管理器到RL微调记忆管理器¶
本节通过两个真实对话案例,对比了原始LLM记忆管理器(Vanilla Memory Manager)与RL微调后的记忆管理器(Memory-R1)在处理记忆操作(ADD、UPDATE、DELETE)时的表现差异。
案例1:用户领养两只狗(Buddy 和 Scout)¶
对话背景:用户Andrew先领养了Buddy,之后又领养了Scout。
Vanilla Memory Manager行为:
错误地将“领养Scout”视为对“领养Buddy”的替代。
执行了两次DELETE(删除Buddy相关信息)和一次ADD(添加Scout)。
导致记忆碎片化,丢失了用户拥有两只狗的事实。
Memory-R1行为:
正确识别为补充信息,执行一次UPDATE操作。
将两条信息合并为:“Andrew领养了Buddy,并后来又领养了Scout。”
结论:
RL微调使模型能更好地区分ADD、UPDATE、DELETE的适用场景,提升记忆一致性。
案例2:Joanna喜欢乌龟但对其过敏¶
对话背景:Joanna表达对乌龟的喜爱,但因过敏无法养宠物。
Vanilla Memory Manager行为:
将“过敏于大多数爬行动物”与“过敏于乌龟”视为矛盾。
删除了Joanna对乌龟的喜爱和养宠物的愿望,仅保留新过敏信息。
Memory-R1行为:
识别为补充信息,执行两次UPDATE。
合并后保留了Joanna对乌龟的喜爱,同时更新了过敏信息。
结论:
RL微调使模型能同时保留事实信息与情感信息,避免记忆碎片化。
A.2 从原始LLM到基于记忆蒸馏的RL回答代理¶
本节通过一个问答任务,展示了RL微调结合记忆蒸馏(Memory Distillation)如何提升回答准确性。
问答任务示例¶
问题:John是住在海边还是山边?
原始模型输出:
回答“山边”,可能受到无关“登山”信息干扰。
Memory-R1输出:
通过记忆蒸馏机制,筛选出与“海边”相关的两条记忆:
John小时候在海边拍照的记忆。
John分享家庭在海边的照片。
正确回答“海边”。
讨论要点¶
原始模型无法有效过滤无关信息,导致错误。
Memory-R1通过RL训练和记忆蒸馏机制,提升了对相关信息的识别能力。
结果:回答更准确,记忆更聚焦。
总结¶
RL微调显著提升了记忆管理器的决策能力,使其能更智能地选择ADD、UPDATE、DELETE操作,避免记忆丢失和碎片化。
记忆蒸馏机制增强了回答代理的信息筛选能力,使其在面对大量记忆时能聚焦关键信息,提升回答准确率。
这两个改进共同体现了RL在增强LLM记忆管理和推理能力方面的有效性。
Appendix B Dataset Details¶
以下是对论文附录 B Dataset Details 的结构化总结,按照原文标题和结构进行讲解,重点内容详细说明,非重点内容适当精简,并特别关注数学公式、算法步骤和表格数据。
Appendix B Dataset Details¶
B.1 Test Data¶
LoCoMo¶
简介:LoCoMo(Maharana et al., 2024)是一个用于长期多会话对话的基准数据集。
特点:
平均每段对话有300轮(turns),约9000个token;
跨越最多35个会话(sessions)。
用途:作为本研究的主要实验数据集,所有详细实验结果均基于此数据集进行报告。
MSC¶
简介:Multi-Session Chat(MSC)数据集(Xu et al., 2021),包含跨多个会话的开放域对话。
修改版本:采用MemGPT中使用的记忆增强型评估设置,问题依赖于多个早期会话中的信息。
用途:测试模型是否能在时间分离的交互中保持连贯性。
LongMemEval¶
简介:LongMemEval(Wu et al., 2024)是一个用于测试LLM长期记忆能力的基准。
任务类型:
事实性回忆;
时间推理;
实体追踪。
特点:问题需要整合长且稀疏上下文中的信息。
用途:与LoCoMo和MSC互补,强调非对话中心任务的泛化能力。
使用版本:实验中采用的是Oracle版本(即理想检索结果)。
B.2 Training Data¶
数据集来源¶
主要来源:LoCoMo的多轮对话数据。
许可协议:LoCoMo采用CC BY-NC 4.0协议,作者对其进行了轻微的对话分段修改以适应强化学习流程,但仅用于非商业研究。
其他数据集:MSC和LongMemEval为公开研究基准,遵循其各自的许可协议。
Memory Manager Training Data¶
目标:训练记忆管理模块(Memory Manager),决定如何更新记忆库。
构建方法:
对于每个对话轮次 \( t_t \),GPT-4o-mini基于前24轮构建一个时间记忆库;
当前轮次 \( t_t \) 与该记忆库快照结合,作为输入;
不使用显式标签(如ADD、UPDATE、DELETE、NOOP);
通过强化学习优化Memory Manager,下游Answer Agent的输出正确性作为反馈信号。
算法参考:详见 Algorithm 1。
Answer Agent Training Data¶
目标:训练回答模块(Answer Agent),从记忆库中提取相关信息生成答案。
构建方法:
对每个问题 \( q_q \),使用检索增强生成(RAG)从时间记忆库中检索60条候选记忆;
将检索结果、问题和标准答案配对,作为训练输入;
Answer Agent学习从中提取关键信息并生成准确回答。
算法参考:详见 Algorithm 2。
Algorithm 1: Data Construction for Memory-R1 Training¶
输入:LoCoMo多轮对话集合 \( \mathcal{D} \)
输出:训练元组(对话轮次,时间记忆库,QA)
步骤:
遍历每段对话 \( d \in \mathcal{D} \)
对每轮对话 \( t \):
使用GPT-4o-mini基于前50轮构建时间记忆库;
合并(i)记忆库,(ii)当前轮次,(iii)相关QA对;
存储为一个训练元组。
Algorithm 2: Data Construction for Answer Agent Training¶
输入:LoCoMo对话集合 \( \mathcal{D} \),训练好的Memory Manager
输出:训练元组(问题,检索记忆,标准答案)
步骤:
使用Memory Manager在对话中维护最新的记忆库;
对每个问题 \( q_q \):
以问题为查询,从记忆库中检索每个参与者前30条最相关记忆(共60条);
配对(i)问题,(ii)检索记忆,(iii)标准答案;
存储为一个训练元组用于Answer Agent微调。
总结¶
本附录详细介绍了实验所用的测试数据集(LoCoMo、MSC、LongMemEval)和训练数据构建方法(Memory Manager与Answer Agent)。
重点内容:
LoCoMo是核心测试集,具有长对话和多会话结构;
使用强化学习训练Memory Manager,不依赖显式标签;
Answer Agent通过RAG检索记忆库生成答案;
提供了两个算法流程,清晰描述了训练数据的构造过程。
非重点内容:数据集的许可协议和使用目的等背景信息已适当简化。
Appendix C Prompts¶
附录 C 提示(Prompts)¶
本附录介绍了 Memory Manager Prompt、Answer Agent Prompt 和 LLM-as-a-Judge Prompt 的设计与使用,旨在指导模型执行记忆管理、回答生成和答案评估任务。
C.1 Memory Manager Prompt(记忆管理器提示)¶
目的:训练模型执行四种记忆操作:ADD(添加)、UPDATE(更新)、DELETE(删除)和 NOOP(无操作)。
重点内容:
ADD(添加):
当检索到的信息在现有记忆中不存在时,应添加新条目,并生成新的
id。示例:若旧记忆中无“Name is John”,则添加新条目,
id为 “1”。
UPDATE(更新):
若信息已存在但内容不同,需更新记忆,保留原
id并记录旧记忆(old_memory)。若新信息与旧信息表达相同但更详细,则更新。
示例:将“User likes to play cricket”更新为“Loves to play cricket with friends”。
DELETE(删除):
若新信息与记忆矛盾,则删除该条目,保留原
id,事件标记为 “DELETE”。示例:若记忆为“Loves cheese pizza”,而新信息为“Dislikes cheese pizza”,则标记删除。
NOOP(无操作):
若信息已存在或无关,则不做更改,事件标记为 “NONE”。
结构:提示分为两部分,分别介绍 ADD/UPDATE 和 DELETE/NOOP 操作,配有详细示例说明。
C.2 Answer Agent Prompt(回答代理提示)¶
目的:指导模型从对话记忆中检索信息并生成准确、简洁的回答。
重点内容:
上下文:模型可访问两个说话者的记忆,包含时间戳信息。
指令:
分析所有记忆,注意时间戳。
若问题涉及具体事件或事实,寻找直接证据。
若记忆矛盾,优先选择最近的记忆。
将相对时间(如“last year”)转换为具体日期。
答案应简短(5-6个词以内)。
必须先输出用于回答的记忆条目,再输出答案。
回答格式要求:
输出格式为:先列出相关记忆,再输出
**Answer:**后的答案。
示例:
提供了 John 和 Maria 的多个记忆条目(各30条),包括时间戳和内容。
问题示例:“Does John live close to a beach or the mountains?”
模型需根据记忆内容判断并回答。
C.3 LLM-as-a-Judge(LLM 作为评判者)Prompt¶
目的:使用大语言模型评估生成答案的正确性,标记为 “CORRECT” 或 “WRONG”。
重点内容:
输入数据:
问题(用户之间的对话问题)
金标准答案(ground truth)
生成的答案
评分标准:
只要生成答案与金标准答案涉及相同主题或时间范围,即可标记为正确。
对时间相关问题,允许相对时间表达(如“last Tuesday”)与具体日期(如“May 7th”)之间存在格式差异。
输出格式:
先给出简短的判断理由(一句话)。
最后输出 “CORRECT” 或 “WRONG”。
最终结果以 JSON 格式返回,键为
"label"。
示例:
问题:“Do you remember what I got the last time I went to Hawaii?”
金标准答案:“A shell necklace”
若生成答案提及“shell necklace”或类似物品,则标记为正确。
总结¶
本附录详细描述了三个关键提示的设计与使用:
Memory Manager Prompt:实现对记忆的增、删、改、无操作,强调信息更新与冲突处理。
Answer Agent Prompt:指导模型从带时间戳的记忆中提取信息,生成简洁准确的回答。
LLM-as-a-Judge Prompt:通过对比生成答案与金标准答案,自动评估回答的正确性。
这些提示为模型在记忆管理、问答生成与评估方面提供了结构化指导,是实现 Memory-R1 系统功能的重要组成部分。
Appendix D Implementation Details¶
附录 D 实现细节(总结)¶
本节介绍了实验的实现配置,主要包括硬件环境、训练参数和推理策略。
硬件环境¶
实验主要在 4 块 NVIDIA H100 GPU(每块 80GB 显存)上进行,但 Qwen-2.5-14B 模型由于显存需求较大,需使用 8 块 GPU。
训练设置¶
批量大小:总 batch size 为 128,每块 GPU 的 micro-batch size 为 2。
序列长度:最大 prompt 长度为 4096 tokens,最大 response 长度为 2048 tokens。
PPO 训练细节¶
学习率:
Actor 网络学习率为 \(1 \times 10^{-6}\)
Critic 网络学习率为 \(1 \times 10^{-5}\)
使用 固定 warmup 调度策略。
解码温度:
在 RL 训练阶段使用 \(\tau = 1.0\),以增强探索性,收集多样化的奖励信号,有助于策略稳定学习。
在验证和测试阶段使用 \(\tau = 0\)(即贪心解码),确保结果的确定性和评估指标的一致性。
小结¶
本节重点包括:
明确了模型训练所用的硬件资源;
给出了 PPO 算法中的关键超参数(如学习率、batch size 和解码温度);
强调了解码策略在训练与评估阶段的不同设置及其目的。
非核心实现细节(如调度器的具体实现)未展开说明。
Appendix E Alogirthm¶
以下是对论文 Appendix E Algorithm 部分的结构化总结,按照原文标题和结构进行讲解,重点内容详细说明,次要内容精简处理,并特别关注数学公式、算法步骤和表格数据(如无表格则省略):
Appendix E Algorithm¶
本节详细描述了 Memory-R1 系统的算法流程,主要包括三个核心算法:
Algorithm 3:Memory Bank Construction(记忆库构建)
Algorithm 4:Memory-augmented Answer Generation(基于记忆增强的回答生成)
Algorithm 5:Memory Manager 的训练流程
Algorithm 3:Memory Bank Construction via Memory Manager¶
功能:该算法用于在对话过程中逐步构建和更新外部记忆库。
输入:多轮对话 D = {t₁, t₂, …, tₙ},初始为空的记忆库 M
输出:更新后的记忆库 M
主要步骤:
对每轮对话 ti:
使用 LLM 提取关键信息 fi(LLMExtract)
从记忆库中检索 top-k 相关条目 Mrₑₜ(TopK)
由 Memory Manager 决定操作 oi ∈ {ADD, UPDATE, DELETE, NOOP}
根据操作更新记忆库:
ADD:将新信息 fi 插入 M
UPDATE:将 Mrₑₜ 与 fi 合并后更新 M
DELETE:从 M 中删除 Mrₑₜ
NOOP:不更新 M
重点说明:
Memory Manager 是通过强化学习(RL)训练的,负责决策记忆更新操作。
TopK 检索机制用于获取语义相关记忆条目。
LLMExtract 是一个预训练语言模型,用于提取对话中的关键信息。
Algorithm 4:Memory-augmented Generation via Answer Agent¶
功能:利用构建好的记忆库生成增强型回答。
输入:问题集合 Q,记忆库 M,生成指令文本 t
输出:回答集合 Â
主要步骤:
对每个问题 qi:
从 M 中检索 top-k 相关记忆 Mrₑₜ
构造增强提示(prompt)pi = Concat(t, qi, Mrₑₜ)
由 Answer Agent 生成回答 a^i,并提取蒸馏后的记忆 Mdᵢₛₜ
将 a^i 加入回答集合 Â
重点说明:
Concat 是将问题、指令和记忆拼接为输入提示的过程。
Answer Agent 包含一个 Memory Distillation 策略,用于筛选最相关记忆。
生成的回答会用于后续训练过程中的奖励计算。
Algorithm 5:Memory-R1 Pipeline for Memory Manager¶
功能:训练 Memory Manager 的流程,使用 PPO 或 GRPO 算法进行强化学习。
输入:数据集 D(包含对话、问题-答案对)、临时记忆库 M、Memory Manager LLM ℒₘ、Answer LLM ℒₐ、奖励函数 ℱ、生成指令 t
输出:微调后的 Memory Manager ℒₘ
主要步骤:
对每个数据元组 (ds, qi, ai):
初始化空记忆库 M
对 ds 中的每个对话 di:
提取信息 fi
检索 Mrₑₜ
Memory Manager ℒₘ 决定操作 oi(采样方式)
根据 oi 更新 M
检索与 qi 相关的记忆 Crₑₜ
构造 prompt pi,由 Answer Agent ℒₐ 生成回答 ri
使用奖励函数 ℱ 比较 ai 与 ri,通过 RL(PPO/GRPO)更新 ℒₘ
重点说明:
训练分为两个阶段:先训练 Memory Manager,再训练 Answer Agent,避免训练过程中的归因模糊。
在训练 Memory Manager 时,Answer Agent 被冻结,仅用于提供基于结果的奖励信号。
RL 更新使用 PPO 或 GRPO 算法,基于回答的正确性来调整 Memory Manager 的策略。
总结¶
Memory-R1 的核心机制:
通过两个互补算法(Algorithm 3 和 4)分别管理记忆库和生成答案。
使用强化学习(RL)训练 Memory Manager,使其根据下游任务(回答质量)优化记忆更新策略。
训练策略:
分阶段训练:先固定 Answer Agent 训练 Memory Manager,再固定 Memory Manager 训练 Answer Agent。
使用 PPO 或 GRPO 进行策略梯度更新,提升记忆管理的决策能力。
关键技术点:
TopK 检索机制
LLM 提取关键信息
Memory Distillation 筛选关键记忆
奖励机制基于回答正确性
如无表格数据,本节未涉及具体数值结果,主要聚焦于算法流程与结构设计。
Appendix F Extended Results and Type-Level Analysis¶
附录 F 扩展结果与类型级分析¶
1. LoCoMo 基准的类型级评估(表3)¶
表3展示了在LoCoMo基准上,不同模型(Qwen-2.5系列)和方法(BASE、PPO、GRPO)在多种问题类型下的表现,包括单跳(Single-Hop)、多跳(Multi-Hop)、开放域(Open-Domain)和时间推理(Temporal)问题。评估指标包括F1、B1(BLEU-1)和J(Jaccard)。
主要发现:
Memory-R1 在所有推理类型上均表现出一致的提升,尤其在多跳问题和时间推理问题上提升最大,表明其在处理长距离信息整合方面具有优势。
GRPO 算法在多数情况下优于 PPO,特别是在需要处理多个或噪声记忆条目的推理任务中。
随着模型规模增大(从2.5-3B到2.5-14B),Memory-R1的表现持续提升,说明其在更大模型中仍能有效优化记忆管理。
重点数据:
在 Qwen-2.5-14B 模型下,GRPO 在 Temporal 类型的 F1 达到 50.50,显著高于 BASE(34.98)和 PPO(43.78)。
GRPO 在 Multi-Hop 类型的 Jaccard 指标上表现突出,例如 Qwen-2.5-7B 下达到 46.99。
2. LongMemEval 基准的类型级评估(表4)¶
表4展示了在LongMemEval基准上,使用LLaMA-3.1-8B和Qwen-2.5-7B作为主干模型的Memory-R1扩展评估结果。任务类型包括:
SSU(单会话用户)
SSP(单会话偏好)
OD(开放域)
MS(多会话)
KU(知识更新)
TR(时间推理)
主要发现:
Memory-R1 在多会话(MS) 和 事实回忆(SSU) 任务中提升显著,说明其在跨时间交互的连续性建模方面具有优势。
在知识更新(KU) 和 时间推理(TR) 任务中也有稳定提升。
GRPO 在 Qwen-2.5-7B 上的 SSU-F1 达到 80.9,显著优于 BASE(64.4)和 PPO(70.8)。
在 LLaMA-3.1-8B 上,GRPO 在 MS-F1 达到 50.0,优于 PPO(43.1)和 BASE(20.8)。
重点数据:
Qwen-2.5-7B + GRPO 在 KU-F1 达到 54.4,优于 BASE(40.5)和 PPO(52.3)。
LLaMA-3.1-8B + PPO 在 TR-F1 达到 37.0,而 GRPO 达到 41.5,显示 GRPO 在时间推理任务中的优势。
3. 总结¶
Memory-R1 在 LoCoMo 和 LongMemEval 两个长记忆基准上均表现出色,尤其在多跳推理、时间推理、多会话建模等需要长距离信息整合的任务中提升显著。
GRPO 算法在多数任务中优于 PPO,尤其在处理多个或噪声记忆条目时表现更优。
模型规模越大,Memory-R1 的性能提升越明显,说明其在大模型中具有良好的扩展性。
本附录结果补充了主文 Section 4.3 和 Figure 4 的结论,进一步验证了 Memory-R1 在多种推理类型、模型家族和任务上的泛化能力。