2001.10167_RGCF: Revisiting Graph based Collaborative Filtering: A Linear Residual Graph Convolutional Network Approach¶
引用: 716(2025-09-13)
组织:
Hefei University of Technology
University of Science and Technology of China
总结¶
总结
以下章节进行了优化
Abstract
Preliminaries and Related Work
Linear Residual Graph Convolutional Collaborative Filtering(LR-GCCF)
背景
GCN 在推荐系统中取得了一定成功,但仍存在两个关键问题尚未解决
问题一:非线性变换是否必要?
问题二:图卷积的过平滑问题
RGCF
主要贡献
贡献一:去除非线性提升性能
贡献二:引入残差结构缓解过平滑
基于线性残差设计的模型可简化为一个线性模型,该模型能够有效利用图结构进行推荐。相较于现有 GCN 推荐模型,该模型训练更简单、扩展性更强。
Abstract¶
1. 背景与现状(问题是什么?)¶
(Graph Convolutional Networks, GCNs)是什么?
它是一种先进的图结构数据学习模型,通过堆叠多层“卷积聚合”和“非线性激活”操作来学习图中节点的表示。
GCN如何用于推荐系统(RS)?
推荐系统中的一个核心是协同过滤(Collaborative Filtering, CF)。
研究人员将用户(User)和物品(Item)之间的交互(如点击、购买)看作一个 二部图(用户和物品之间有边,但用户之间或物品之间没有边)。
运用GCN可以很好地捕捉用户和物品之间高阶的、复杂的协同信号(例如:“喜欢A物品的用户也喜欢B物品”这种一层关系,通过多层GCN可以扩展到更远的关系)。
现有GCN模型的两个主要问题:
训练困难: 对于大型的用户-物品图(例如数百万用户和物品),使用非线性激活函数会让模型变得非常复杂,难以训练。
过平滑: 这是GCN的一个经典问题。当堆叠的层数过多时,通过多次卷积聚合,所有节点的表示会变得越来越相似,最终无法区分。这使得模型无法做得更深(无法使用更多层),从而限制了其捕捉更远关系的能力。
2. 本文的解决方案(作者做了什么?)¶
作者从两个方面重新审视并改进了基于GCN的CF模型:
第一点:简化模型(去除非线性)
做法: 他们去除了GCN中的非线性激活函数。
结果: 实验证明,这样做反而提高了推荐性能。
依据: 这个发现与之前一些关于“简单图卷积网络”的理论研究结论一致。这表明对于推荐任务,一个更简单、更线性的模型可能更有效。
第二点:解决过平滑(设计新的网络结构)
做法: 他们提出了一种专门为用户-物品交互建模设计的残差网络结构。
原理: 残差连接(Residual Connection)是深度学习中的一种常用技术,它允许信息从一层直接跳传到更后面的层。在这篇文章的语境下,这种结构可以缓解在稀疏的交互数据(即大多数用户只与极少数物品有交互)上进行图卷积时造成的过平滑问题,使得网络能够做得更深而不失效。
3. 本文模型的优势(效果怎么样?)¶
作者最终提出的模型是一个线性模型,它具有以下优点:
易于训练: 模型结构简单,没有复杂的非线性变换,训练过程更稳定。
可扩展性: 能够扩展到大型数据集。
高效且有效: 在两个真实数据集上的实验表明,该模型不仅效率高,而且效果(性能)也更好。
Introduction¶
近年来,图卷积网络(GCNs)在处理图结构数据方面取得了显著进展。GCNs 是 CNN 的图结构变体,其核心思想是通过堆叠多层网络,每层迭代执行两个步骤:节点嵌入的图卷积邻域聚合,以及通过神经网络进行非线性变换。这种结构能够有效捕捉节点的高阶相似性。目前,GCNs 已在无监督节点/图表示学习、半监督节点/图学习等任务中表现出色。
由于许多现实世界的数据具有图结构,GCNs 已被广泛应用于社交网络分析、交通网络、推荐系统等领域。本文关注 GCNs 在基于协同过滤(CF)的推荐系统中的应用。
GCNs 在推荐系统中的应用¶
协同过滤(CF)通过学习用户和物品的嵌入表示,基于用户的历史行为数据提供个性化推荐。将用户-物品交互关系视为一个二分图,CF 可以自然转化为图中的边预测问题。相比传统的用户-物品交互矩阵,图结构能够更好地表达高阶用户与物品之间的关联,同时借助图建模缓解数据稀疏性问题。
早期的研究使用了个性化随机游走或基于图正则化的辅助图数据(如社交网络)来提升推荐效果。但这些方法存在计算复杂度高、需要精心设计随机游走过程等问题。近年来,越来越多的研究者将 GCNs 应用于推荐系统。例如:
PinSage:通过设计采样技术来优化图卷积聚合,以降低推荐过程的计算负担。
NGCF:专门为 GCN 基于的 CF 设计的模型,通过在图中迭代传播用户和物品嵌入来提取协同信号。
这些基于 GCN 的推荐模型在性能上优于传统模型。
存在的两个问题¶
尽管 GCN 在推荐系统中取得了一定成功,但仍存在两个关键问题尚未解决:
问题一:非线性变换是否必要?¶
在 GCN 中,用户和物品嵌入通过两个步骤更新:邻域聚合(图卷积操作)和非线性变换。虽然图卷积操作有效捕捉邻居信息,但非线性变换是否必要仍存疑问。作者认为,CF 任务与大多数图任务不同,简化模型结构可能反而提升性能。这与近期关于简化 GCN 的理论研究相吻合。
问题二:图卷积的过平滑问题¶
当前大多数 GCN 推荐模型仅堆叠2~3 层,因为图卷积本质上是一种图拉普拉斯平滑操作。随着层数增加,节点嵌入会趋向于其多跳邻居的平均,导致过平滑问题。在推荐系统中,由于用户-物品交互数据本身非常稀疏,过平滑问题会更加严重。初期增加层数可能缓解稀疏性,但进一步增加层数会导致用户个性化特征丢失,从而降低推荐效果。如何在建模图结构的同时避免过平滑,是一个尚未解决的挑战。
本文的贡献与方法¶
为了解决上述两个问题,本文提出了线性残差图卷积的协同过滤模型,主要贡献如下:
贡献一:去除非线性提升性能¶
作者通过实验发现,在 CF 任务中,去除 GCN 中的非线性变换反而能提升推荐性能,且模型复杂度更低。这与近期简化 GCN 的理论研究相一致,说明 CF 任务对模型的非线性需求不高。
贡献二:引入残差结构缓解过平滑¶
为了解决过平滑问题,本文提出在每一层学习用户-物品的残差偏好。具体而言:
低层网络:保留用户个性化特征(类似 ResNet 中的残差连接)。
高层网络:学习用户未被低层捕获的残差偏好。
该结构借鉴了 ResNet 的残差思想,但专门针对推荐系统的用户-物品交互预测进行设计和优化。
模型简化与可扩展性¶
最终,作者指出,基于线性残差设计的模型可简化为一个线性模型,该模型能够有效利用图结构进行推荐。相较于现有 GCN 推荐模型,该模型训练更简单、扩展性更强。
实验验证¶
作者在两个大规模真实世界推荐数据集上进行了实验,结果表明:
所提模型在推荐性能和训练效率方面均优于现有基于 GCN 的推荐模型。
证明了模型在去除非线性与引入残差结构方面的有效性。
总结¶
本章主要围绕 GCN 在推荐系统中的应用展开,指出现有模型面临的两个关键问题:非线性变换是否必要和过平滑问题。作者提出了一种基于线性残差图卷积的协同过滤模型,通过简化模型结构和引入残差学习机制,有效提升了模型性能并缓解了过平滑问题,为 GCN 在推荐系统中的应用提供了新的思路。
Linear Residual Graph Convolutional Collaborative Filtering¶
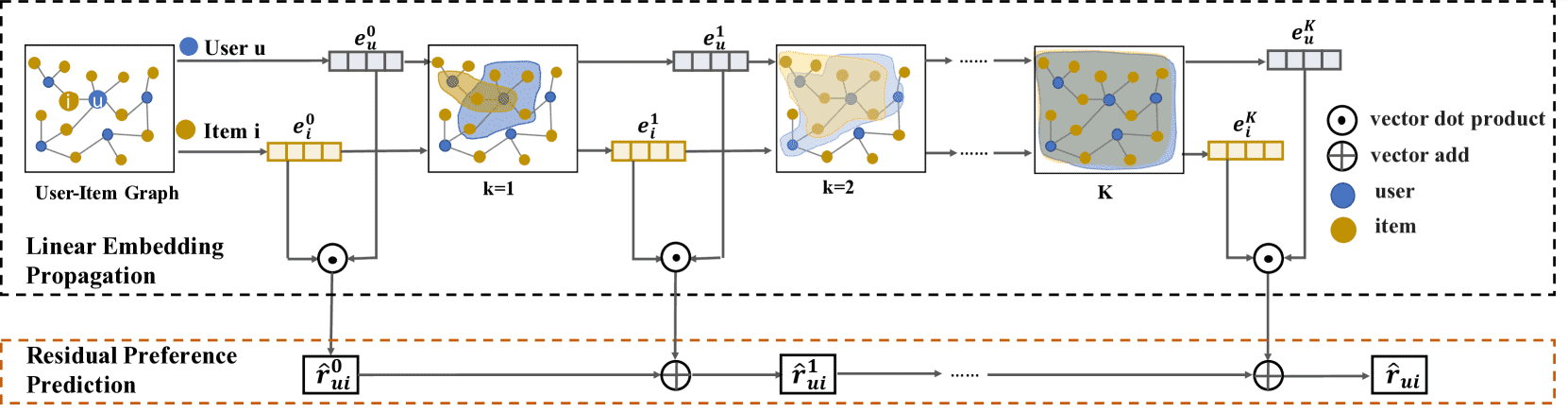
Figure 1:The overall architecture of our proposed model.
好的,我们来逐段解析这篇关于 LR-GCCF(线性残差图卷积协同过滤) 模型的文章。这段文字主要介绍了该模型的整体结构、核心创新点以及与其他模型的对比。
核心摘要¶
这篇文章提出了一种新的基于图卷积网络(GCN)的推荐系统模型,名为 LR-GCCF。它旨在解决传统 GCN 推荐模型的两个主要问题:
过度平滑(Over-smoothing):当 GCN 层数过深时,图中所有节点的表征会变得非常相似,丢失独特性,导致模型性能下降。
训练复杂度:使用非线性激活函数的深度 GCN 模型训练起来计算量大且复杂。
LR-GCCF 通过两大核心设计来解决这些问题:
线性嵌入传播(Linear Embedding Propagation):去除了每层 GCN 中的非线性变换,使模型更简单、更高效。
残差偏好预测(Residual Preference Prediction):不直接使用最后一层的输出来预测用户偏好,而是将每一层学到的新信息作为“残差”逐步累加,有效利用了浅层和深层的信息,缓解了过度平滑。
分段详细解释¶
1. 总体介绍 (Overall Structure)¶
目标:提出一个通用的、基于 GCN 的协同过滤(CF)模型。
两大创新:
线性传播:在特征传播的每一层,使用简单的线性聚合,没有非线性变换(如 ReLU)。
残差结构:设计了一个基于残差的网络结构来预测用户偏好,以克服之前模型(层数加深后性能下降)的局限。
2. 线性嵌入传播 (Linear Embedding Propagation)¶
输入:用户和物品的自由嵌入矩阵 \(\mathbf{E}\)。这个矩阵不是预先给定的特征,而是模型需要学习的参数。
传播规则:每一层(k+1 层)的嵌入通过一个简单的线性变换得到: \(\mathbf{E}^{k+1} = \mathbf{S}\mathbf{E}^{k}\mathbf{W}^{k}\)
\(\mathbf{S}\):是归一化并添加了自环的邻接矩阵(user-item 二分图),负责聚合邻居信息。
\(\mathbf{W}^{k}\):是一个可学习的线性变换矩阵。
关键点:这个公式没有非线性激活函数,这与传统 GCN 不同。这使得模型更像一个线性模型,理论上有图光谱滤波的连接,并且训练起来更简单、更快。
物理意义:公式 (9) 和 (10) 解释了矩阵形式的具体含义——每个用户/物品的新嵌入是其自身和其一阶邻居上一轮嵌入的加权平均(归一化后的度),然后再做一个线性变换。
3. 残差偏好预测 (Residual Preference Prediction)¶
问题背景:
传统方法(公式 11)直接用最后一层(K 层)的用户和物品嵌入做内积来预测偏好 \(\hat{r}_{ui}\)。
实验发现,GCN 推荐模型在层数
K=2左右效果最好,更深(如 K=3,4,…)时性能会急剧下降,原因是过度平滑——所有用户的表征、所有物品的表征都变得非常相似,无法区分。甚至发现,最简单的
K=0(即不进行任何图传播,直接使用初始嵌入 \(\mathbf{E}^0\))的模型(BPR)效果已经相当不错。
解决方案 - 残差学习:
核心思想:不指望深层网络直接输出完整的预测值,而是让每一层学习对上一层预测结果的残差(修正量)。这通常比直接学习完整的目标更容易。
具体做法(公式 12):最终的预测分数是由第 0 层的预测分数,加上第 1 层、第 2 层……直到第 K 层计算出的内积残差累加而成。 \(\hat{r}^{k+1}_{ui} = \hat{r}^{k}_{ui} + <\mathbf{e}^{k+1}_{u}, \mathbf{e}^{k+1}_{i}>\)
等效操作(公式 13):这种残差累加的方式,等价于将每个用户(或物品)在第 0、1、2…K 所有层的嵌入向量拼接(concatenate) 起来,形成一个更长的最终向量,然后用这对长向量做内积来预测。 \(\hat{r}_{ui} = <\mathbf{e}_{u}^{0}||\mathbf{e}_{u}^{1}||...||\mathbf{e}_{u}^{K}, \mathbf{e}_{i}^{0}||\mathbf{e}_{i}^{1}||...||\mathbf{e}_{i}^{K}>\)
为什么有效:这样既保留了浅层(K=0)模型中已经很好的个性化信息,又融入了深层模型捕获的高阶图结构信息,从而避免了仅使用最后一层平滑过的嵌入所带来的问题。
4. 模型学习 (Model Learning) 与 模型讨论 (Model Discussion)¶
损失函数:采用 BPR 的成对排序损失,鼓励模型对用户交互过的物品(正样本)的打分高于未交互过的物品(负样本)。
模型性质:作者指出,由于使用了线性传播,LR-GCCF 实际上是一个宽的线性模型(wide linear model),而不是一个深度非线性模型。这使其具有以下优点:
理论优美:与图频谱滤波理论有联系。
易于训练:没有复杂的非线性层,训练更简单稳定。
高效:不需要复杂的反向传播,可以用更快的随机梯度下降(SGD)优化。
与其他模型对比(Table 1):
GC-MC:只使用一阶邻居,没有高阶传播,没有残差。
PinSage:使用了高阶邻居,但传播过程是非线性的,且通过采样来提高效率。
NGCF:使用了高阶邻居和非线性传播,也使用了残差预测(即拼接各层嵌入)。LR-GCCF 的关键区别在于线性传播,并对此给出了详细的理论和实证解释。
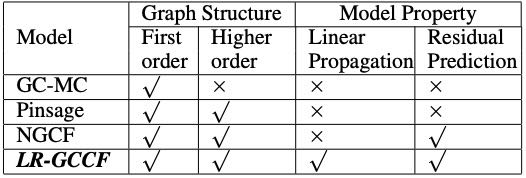
Table 1: Comparisons of different graph based recommendation models.
总结¶
你可以将 LR-GCCF 理解为一个 “轻量级”且“高效” 的图神经网络推荐模型。
它做了什么:它通过在用户-物品关系图上进行线性的信息传播,来学习用户和物品的嵌入表示。
它怎么做的:
用线性代替非线性:简化模型,加快训练。
用残差(拼接)代替最终输出:巧妙地将各层输出组合起来,既利用了深层信息,又避免了过度平滑问题。
为什么好:最终它取得了与复杂深度模型相当甚至更好的性能,同时训练速度更快、更易于理解和实现。
Experiments¶
实验设置¶
数据集¶
本研究使用了两个公开数据集进行实验:Amazon Books 和 Gowalla。在数据预处理阶段,去除了用户或物品交互记录少于10次的样本。然后将数据随机分为训练集(80%)、验证集(10%)和测试集(10%)。
Amazon Books:52,643个用户,91,599个物品,2,984,108条评分,评分密度0.062%。
Gowalla:29,859个用户,40,981个物品,1,027,370条评分,评分密度0.084%。
评估指标与基线模型¶
本研究采用HR@N和NDCG@N两个指标评估推荐效果。所有未评分的物品作为负样本,与正样本一起用于排序评估。比较的基线模型包括:
BPR:经典推荐模型。
GC-MC、PinSage、NGCF:基于图卷积的推荐模型,其中NGCF采用了残差学习。
本研究还设计了L-GC-MC和R-GC-MC两个变体,分别用于测试线性传播和残差学习的效果。
本研究提出的模型LR-GCCF还设计了一个简化版本L-GCCF,去除了残差学习部分。
参数设置¶
本研究使用PyTorch实现LR-GCCF模型。重要参数包括:
嵌入维度:所有模型固定为64。
正则化参数:在[0.0001, 0.001, 0.01, 0.1]范围内测试,最终选择λ=0.01。
模型参数初始化为均值0、标准差0.01的高斯分布。
对于基线模型,也进行了参数调优以保证公平比较。
整体对比结果¶
在Amazon Books和Gowalla两个数据集上,不同模型的HR@N和NDCG@N表现如表3和表4所示:
GC-MC、PinSage、NGCF相比BPR的推荐效果有显著提升,体现出图结构在推荐中的重要性。
NGCF相较于其他基线表现更好,因为它捕捉了更高阶的图结构。
LR-GCCF在所有对比模型中表现最优,说明其提出的线性嵌入传播和残差偏好预测机制是有效的。
模型机制分析¶
线性嵌入传播:L-GC-MC表现优于GC-MC,说明线性传播在图卷积推荐模型中更有效。
残差学习:LR-GCCF与L-GCCF的对比显示,残差学习有助于缓解过平滑问题,尤其在深层图结构中。
模型效率:LR-GCCF相比其他模型训练更快,尤其是在增加图传播深度时,依然能保持较短的运行时间。
详细模型分析¶
传播深度 K 的影响¶
通过改变图嵌入传播的深度 \( K \),观察模型性能变化(见表5):
当 \( K = 0 \) 时,模型等价于BPR,表现最差。
随着 \( K \) 增大,性能逐渐提升,最佳性能出现在 \( K = 4 \)(Amazon Books)和 \( K = 3 \)(Gowalla)。
当 \( K \) 超过最佳值后,性能略有下降,说明存在过平滑问题。
残差偏好预测的影响¶
通过对比LR-GCCF和L-GCCF(无残差结构),发现:
LR-GCCF在用户-用户嵌入相似度上具有更大的方差,说明残差学习有助于缓解过平滑问题。
该结果在Gowalla上的趋势也一致,但由于篇幅限制未展示。
总结¶
本实验验证了LR-GCCF模型在多个推荐指标上优于现有基线模型,主要归功于其创新的线性嵌入传播机制和残差偏好预测结构。同时,模型具有良好的训练效率,尤其适合处理大规模用户-物品图结构数据。
Conclusions¶
本文回顾了当前基于图卷积网络(GCN)的推荐模型,并提出了一种新的基于协同过滤(CF)的推荐模型 LR-GCCF。该模型主要由两个部分组成:
第一部分:借鉴最近简单 GCN 的研究成果,作者在实验中去除了 GCN 中的非线性变换,改用线性嵌入传播(linear embedding propagation)来替代。这一改动简化了模型结构,同时保留了图神经网络的优势。
第二部分:为缓解图卷积层数增加带来的过平滑问题(over-smoothing effect),作者设计了一个残差偏好预测模块(residual preference prediction part),在每一层中引入残差偏好学习过程(residual preference learning process),从而有效保留每一层的信息表达能力。
实验结果表明,所提出的 LR-GCCF 模型在多个指标上均表现出优越的有效性和高效性。
未来工作方面,作者希望进一步探索如何更好地将不同图卷积层的表示进行整合,并结合结构明确的深度神经网络架构,以进一步提升基于协同过滤的推荐效果。
致谢(Acknowledgments)¶
本研究工作得到了以下项目的资助支持:
中国国家重点研发计划项目(2018YFB0804205);
国家自然科学基金项目(编号:61725203、61972125、61602147、61932009、61732008、61722204);
浙江实验室(编号:2019KE0AB04)。
这些支持对本研究的顺利完成起到了重要作用。