2510.18866_❇️LightMem: Lightweight and Efficient Memory-Augmented Generation¶
引用: 14(2025-12-09)
组织:
♠Zhejiang University
♢National University of Singapore
♣State Key Lab. for Novel Software Technology, Nanjing University
其他
总结¶
总结
设计灵感来自人类记忆的Atkinson–Shiffrin记忆模型
将记忆分为三个互补阶段:
认知启发的感官记忆:通过轻量级压缩快速过滤无关信息,并按主题对信息进行分类。
主题感知的短期记忆:对主题分组的信息进行整合与摘要,使其结构更清晰、便于访问。
带“睡眠更新”的长期记忆:采用离线方式更新长期记忆,将记忆巩固过程与在线推理解耦,降低实时开销。
Atkinson–Shiffrin 人类记忆模型
感官记忆(Sensory Memory):短暂保留环境信息,进行初步特征提取和过滤,起到预压缩作用。
短期记忆(STM):保留信息数十秒至数分钟,支持进一步处理和筛选。
长期记忆(LTM):持久存储,通过更新、抽象和遗忘不断重组。
重点:文中特别指出,睡眠在记忆重组中起关键作用,通过睡眠中的振荡活动促进记忆整合。
核心设计理念
预压缩的感觉记忆模块:
过滤原始输入中的冗余或低价值token;
缓存精炼后的内容,供后续处理使用。
实验结果
性能与开销(Performance and Overhead)
预压缩模块高效,仅占用不到2GB GPU内存,对整体运行时间影响极小。
在压缩比(rr)为50%–80%时,压缩与未压缩内容的问答准确率相当
STM缓冲区阈值(t_h)和压缩比(rr)对性能的影响
小阈值(t_h ∈ {0,256})时,rr=0.6效果最好;
大阈值(t_h ∈ {512,1024})时,rr=0.7更优。
主题感知的短期记忆模块:
利用语义和主题相似性,将相关对话内容动态分组;
自适应确定分段边界,生成更集中、有意义的记忆单元;
减少记忆构建频率,提升检索效率。
“睡眠”时间的长期记忆更新机制:
新记忆先以时间戳形式暂存,支持即时更新;
在“离线”时间(即“睡眠”)进行去重、抽象和整合;
解耦记忆维护与实时推理,避免延迟,提升更新质量。
未来方向
离线更新加速(Offline Update Acceleration)
基于知识图谱的记忆模块(Knowledge Graph-based Memory)
多模态记忆扩展(Multimodal Memory Extension)
参数化与非参数化记忆协同(Parametric–Nonparametric Synergy)
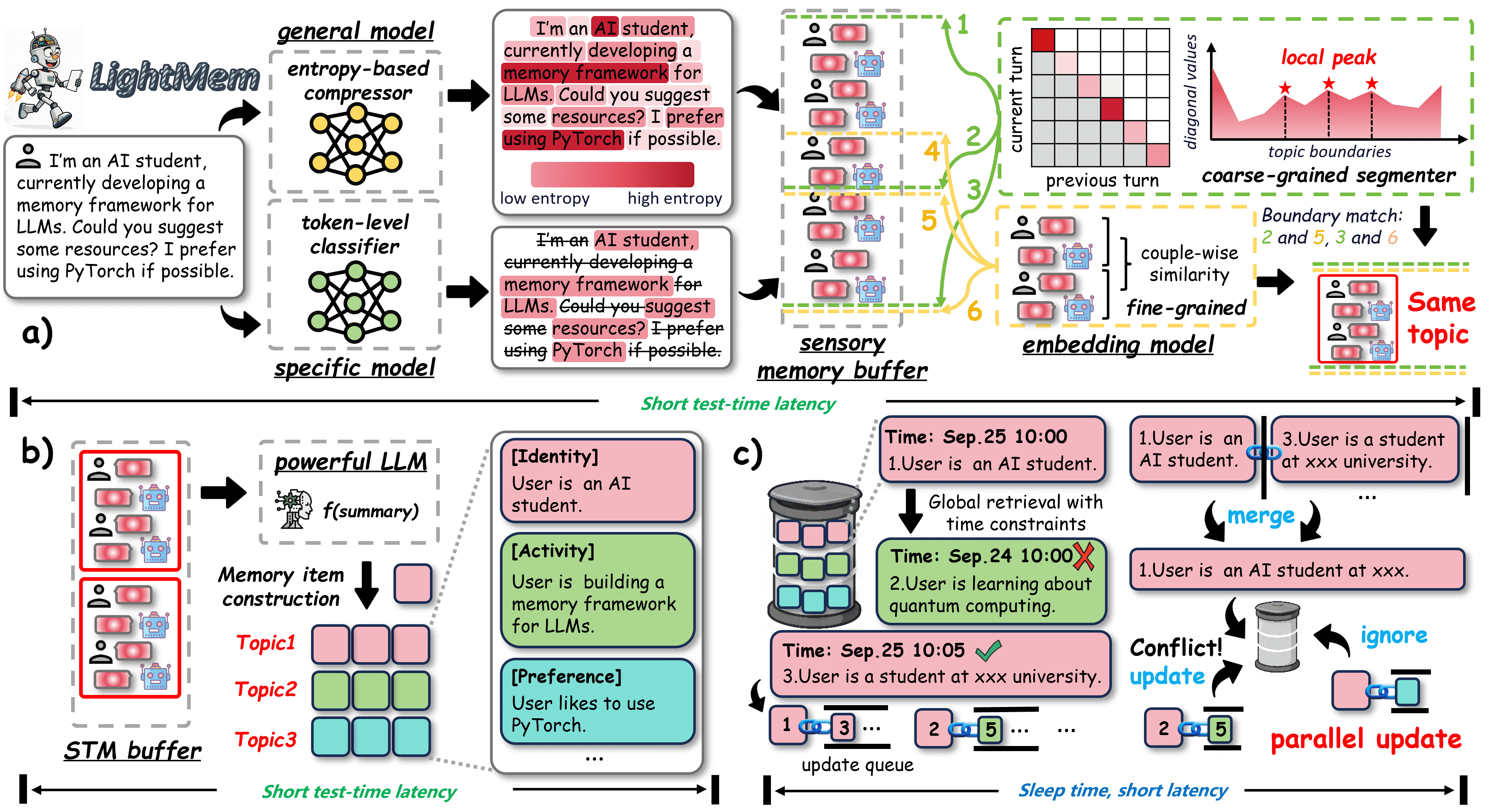
Figure 2:The LightMem architecture. LightMem consists of three modules: a) An efficient Sensory Memory Module, b) a topic aware STM Module, and c) an LTM module updated in sleep time.
Abstract¶
本论文指出,尽管大语言模型(LLMs)具备强大的能力,但在动态复杂的环境中,它们难以有效利用历史交互信息。为了解决这一问题,研究引入了记忆系统,使LLMs能够通过持久的信息存储、检索和使用机制,摆脱无状态交互的限制。
然而,现有的记忆系统往往带来较大的时间和计算开销。为此,作者提出了一种新的高效记忆系统——LightMem,在性能与效率之间取得了良好平衡。
LightMem的设计灵感来自人类记忆的Atkinson–Shiffrin记忆模型,将记忆分为三个互补阶段:
认知启发的感官记忆:通过轻量级压缩快速过滤无关信息,并按主题对信息进行分类。
主题感知的短期记忆:对主题分组的信息进行整合与摘要,使其结构更清晰、便于访问。
带“睡眠更新”的长期记忆:采用离线方式更新长期记忆,将记忆巩固过程与在线推理解耦,降低实时开销。
实验结果表明,在LongMemEval数据集上,基于GPT和Qwen模型的LightMem在准确率上优于现有方法(最高提升10.9%),同时显著减少了:
token使用量(最多减少117倍),
API调用次数(最多减少159倍),
运行时间(超过12倍)。
1 Introduction¶
核心观点:¶
本节介绍了记忆系统在大型语言模型(LLMs)中的重要性,并指出现有记忆系统存在的问题,进而引出本文提出的LightMem架构。
1.1 记忆对LLMs的重要性¶
记忆是智能体的核心能力,它使得模型能够整合过往经验、上下文信息和任务相关知识,从而实现更稳健的推理与决策。
尽管LLMs在多种任务中表现出色,但在长上下文或多轮对话场景中存在明显局限,如:
上下文窗口固定;
出现“中间信息丢失”问题(lost in the middle)。
为解决这些问题,记忆系统被引入,使LLMs能够在长时间交互中保持状态。
1.2 现有记忆系统的做法¶
当前研究通过显式构建外部记忆(如数据库、知识图谱)来扩展LLMs的记忆能力。
典型流程包括:
信息处理:将原始交互数据(如对话)切分为可管理的单元(如每轮对话);
组织存储:将信息索引后存入长期记忆;
动态更新:添加新信息、删除过时或冲突内容;
记忆检索:在后续任务中检索相关记忆,提升连贯性和个性化能力。
1.3 存在的问题(Challenges)¶
尽管已有进展,但当前记忆系统仍存在以下主要问题:
1.3.1 信息冗余与噪声干扰¶
用户输入和模型输出中常包含大量冗余或无关信息;
这些信息不仅无益于任务,还可能影响模型的上下文学习能力;
当前方法通常直接处理原始信息,缺乏过滤或提炼,导致:
token消耗高;
推理质量提升有限。
1.3.2 语义连接建模不足¶
现有方法通常孤立处理每轮对话,或依赖固定上下文窗口;
忽略了不同轮次之间的语义关联;
导致生成的记忆单元不准确或不完整,丢失关键上下文信息。
1.3.3 实时更新带来的延迟¶
记忆更新和遗忘通常在推理过程中实时进行;
这种紧耦合方式导致:
长任务测试时延迟高;
无法进行更深层次的反思性处理。
1.4 人类记忆的启发¶
人类记忆具有高效与适应性强的特点,其结构包括:
感觉记忆:初步过滤输入信息;
短期记忆:整合与处理任务相关信息;
长期记忆:在“睡眠”期间进行信息巩固与抽象。
这种多阶段系统在保留、压缩与检索之间取得良好平衡。
1.5 LightMem的设计理念¶
受人类记忆启发,本文提出LightMem,其核心设计包括三个模块:
预压缩的感觉记忆模块:
过滤原始输入中的冗余或低价值token;
缓存精炼后的内容,供后续处理使用。
主题感知的短期记忆模块:
利用语义和主题相似性,将相关对话内容动态分组;
自适应确定分段边界,生成更集中、有意义的记忆单元;
减少记忆构建频率,提升检索效率。
“睡眠”时间的长期记忆更新机制:
新记忆先以时间戳形式暂存,支持即时更新;
在“离线”时间(即“睡眠”)进行去重、抽象和整合;
解耦记忆维护与实时推理,避免延迟,提升更新质量。
1.6 效果与评估(Results and Evaluation)¶
在LongMemEval数据集上,LightMem相比最强基线模型:
QA准确率提升 2.70%–9.65%;
token使用量减少 32×–117×;
API调用减少 17×–177×;
运行时间减少 1.67×–12.45×;
且这些优势在“睡眠”更新后仍保持;
案例研究表明,“睡眠”机制有助于缓解信息丢失与不一致问题,提升长期知识更新的可靠性。
总结¶
本节从LLMs的记忆需求出发,分析了现有记忆系统的局限性,并提出基于人类记忆结构的LightMem轻量记忆架构。通过预压缩、主题感知分段、离线更新三大机制,LightMem在保证推理质量的同时,显著提升了效率与稳定性。
2 Preliminary¶
2.1 传统大语言模型(LLM)的记忆系统¶
本节介绍了当前LLM记忆系统的通用结构,通常分为三个阶段:
(I) 数据粒度处理:原始数据 \(D\) 会根据不同的粒度(如对话轮次 turn、会话 session、主题 topic)进行分割处理,形成结构化的上下文信息。
(II) 记忆单元生成与存储:分割后的数据通过摘要或提取生成记忆单元 \(U\),并存储在向量数据库或知识图谱中,实现长期记忆的保留。
(III) 记忆更新机制:通过更新函数 \(M' = f_{\text{update}}(M, R; U)\) 来处理记忆冲突或过时信息,其中 \(M\) 是已有记忆库,\(R\) 是新生成的记忆单元,\(U\) 是更新策略。
重点:该三阶段模型为后续提出LightMem架构提供了对比基础。
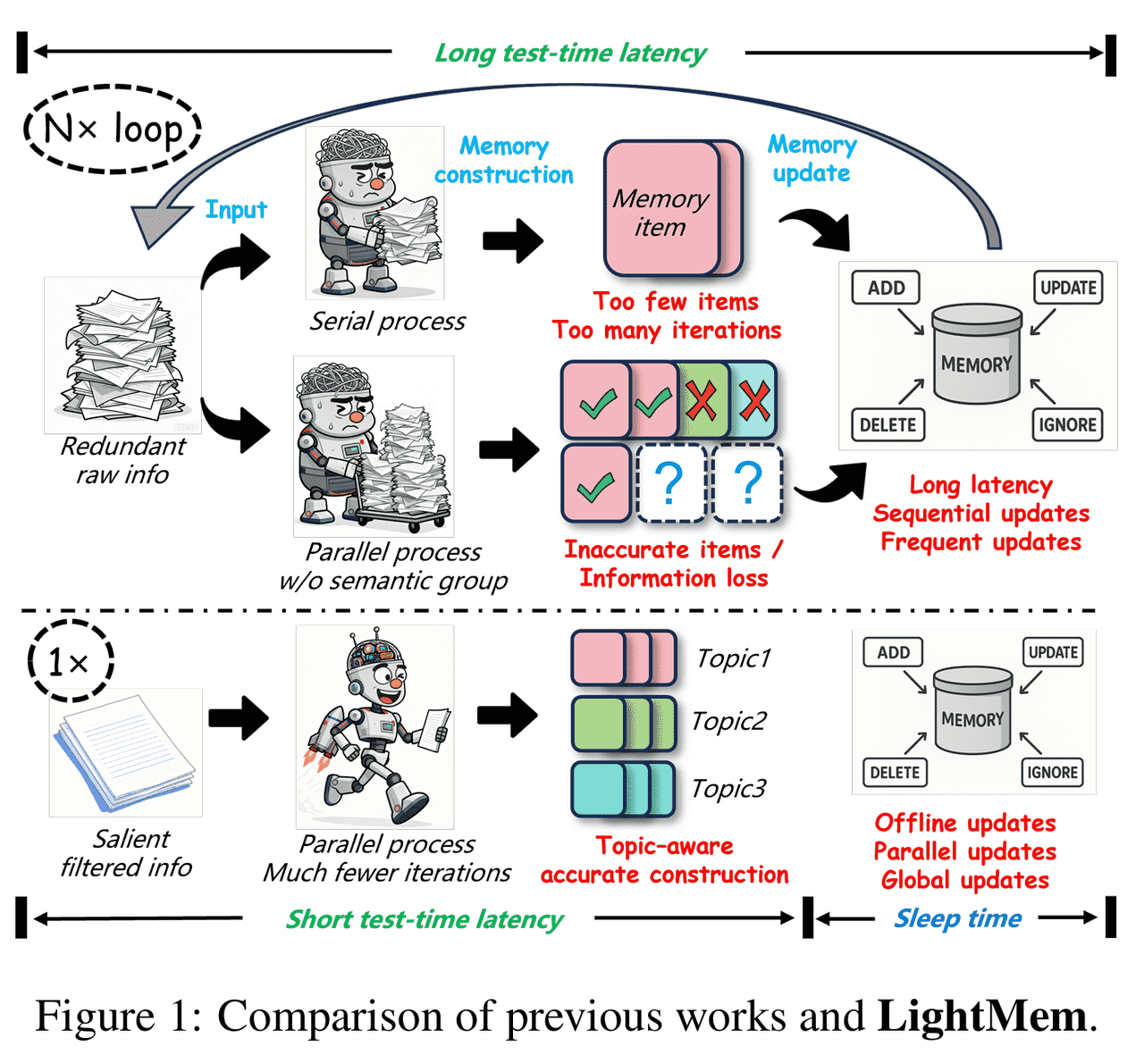
figure 1: Comparison of previous works and LightMem.
2.2 Atkinson–Shiffrin 人类记忆模型¶
本节介绍了经典的三阶段人类记忆模型:
感觉记忆(Sensory Memory):短暂保留环境信息,进行初步特征提取和过滤,起到预压缩作用。
短期记忆(STM):保留信息数十秒至数分钟,支持进一步处理和筛选。
长期记忆(LTM):持久存储,通过更新、抽象和遗忘不断重组。
重点:文中特别指出,睡眠在记忆重组中起关键作用,通过睡眠中的振荡活动促进记忆整合。
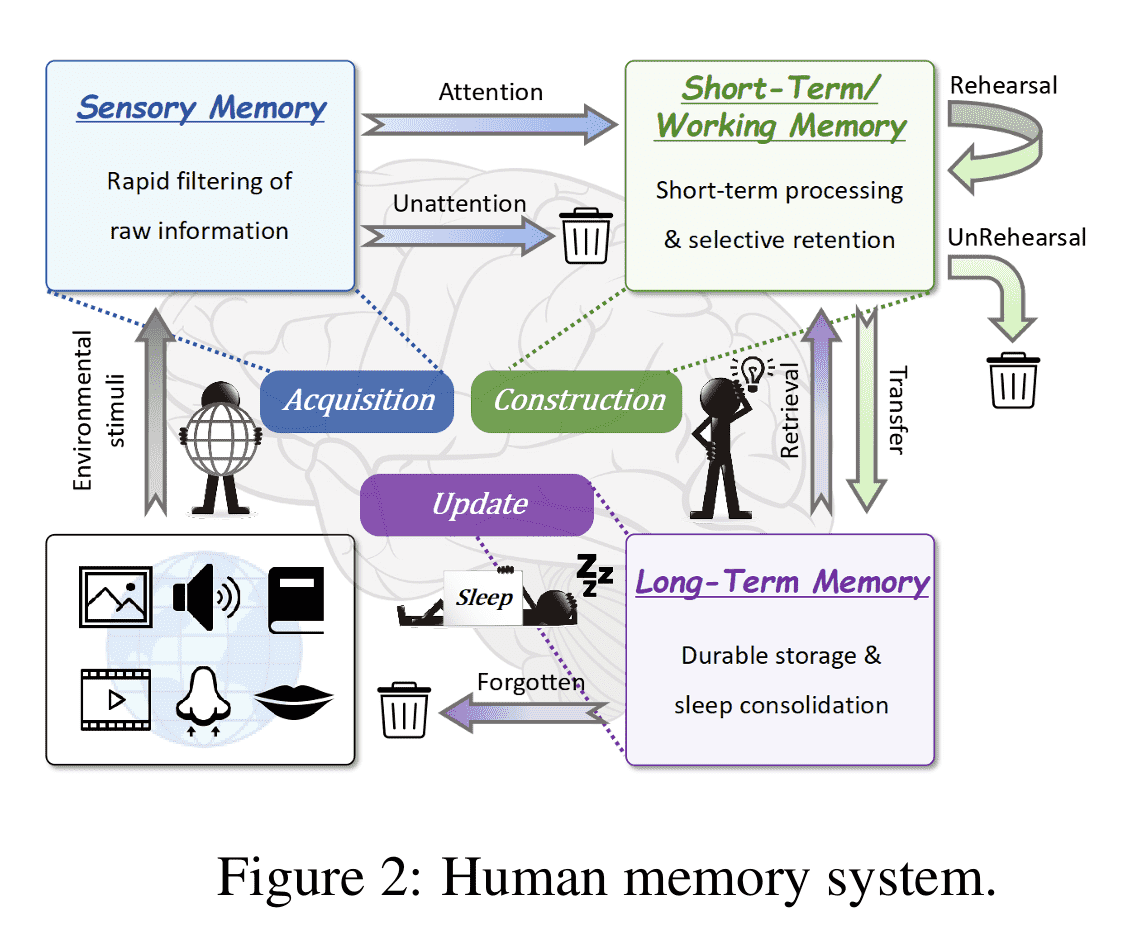
图2: Human memory system.
2.3 现有LLM记忆系统的局限性¶
与人类记忆相比,当前LLM记忆系统存在以下主要问题:
冗余的感觉记忆机制
当前系统使用大模型执行摘要和粒度处理,直接处理原始数据造成资源浪费,并影响上下文学习效果。
重点问题:需要设计轻量级机制进行输入预压缩和语义单元提取。
短期记忆(STM)中的效率与效果平衡
固定粒度下,数据必须经过完整处理流程。
粒度过细:增加延迟,浪费STM容量。
粒度过粗:语义混杂,导致记忆构建不准确。
重点问题:需要更有效的策略来平衡STM的处理效率与记忆质量。
低效的长期记忆(LTM)更新机制
实时更新带来显著延迟,而STM可暂代其职。
更新机制受顺序限制,无法动态触发。
重点问题:如何设计更高效、轻量级的记忆系统,是当前研究的核心问题。
总结性问题提出:是否可以借鉴人类记忆机制,设计出既高效又轻量的LLM记忆系统?这为后续提出的LightMem架构奠定了研究动机。
3 lightmem architecture¶
Figure 2:The LightMem architecture. LightMem consists of three modules: a) An efficient Sensory Memory Module, b) a topic aware STM Module, and c) an LTM module updated in sleep time.
图解
路径a (Light1: 感官记忆):
预压缩:原始对话输入被压缩,冗余Token被移除。
主题分割:压缩后的对话被分割成基于主题的片段(Topic 1, Topic 2…)。
路径b (Light2: 短期记忆):
主题片段被送入STM缓冲区。
当缓冲区满时,触发LLM对每个主题进行摘要,生成结构化的记忆条目。
路径c (Light3: 长期记忆):
在线软更新:新的记忆条目被直接插入LTM。
离线并行更新:在“睡眠时”,系统并行地处理更新队列,对LTM进行重组、去重和抽象。
LightMem 的设计灵感来源于人类记忆系统,包含三个轻量级模块:Light1(感知记忆模块)、Light2(短时记忆模块) 和 Light3(长时记忆模块),分别用于高效处理输入信息、构建结构化记忆索引和优化记忆更新与检索。
3.1 Light1:认知启发的感知记忆¶
核心目标:在长对话等场景中,去除冗余信息,提取关键语义内容,为后续记忆构建打下基础。
3.1.1 预压缩子模块(Pre-Compressing Submodule)¶
目标:从原始输入中淘汰冗余Token,保留信息密集的精华内容。
核心方法:使用一个轻量级的压缩模型(如论文中采用的LLMLingua-2)来对输入序列 x 中的每个token xi 进行二分类(保留或丢弃)
方法:
每个 token 的保留概率由 softmax(ℓi)₁ 计算,保留概率高于动态阈值 τ 的 token 被保留。
τ 为压缩率 r 对应的百分位数。
扩展机制:也可使用生成式 LLM,通过交叉熵衡量 token 的信息重要性,保留语义独特性强的 token。
关键点:此步骤使用小模型快速过滤,避免了直接将海量原始数据喂给大模型,极大地减少了后续处理的token数量。
公式解释:
压缩模型 θ 为每个token输出一个保留概率 P(retain xi∣x;θ)。
设置一个动态阈值 τ,该阈值是序列中所有token保留概率的 r-分位数(r为压缩率)。
决策规则:只保留那些概率高于阈值 τ 的token,形成压缩后的序列 x^。
论文还提到了一种基于信息熵的替代方法,旨在保留那些在上下文中信息量更大、更不可预测的独特token。
3.1.2 主题分割子模块(Topic Segmentation Submodule)¶
目标:将压缩后的、连续的对话流,按照语义主题的边界切分成连贯的片段。这解决了按固定窗口分割导致的语义混杂问题。
作用:将压缩后的信息按主题进行分割,提升记忆系统性能。
方法:
使用注意力矩阵和语义相似度联合判断主题边界。
注意力边界 ℬ₁:通过局部最大注意力值识别潜在主题切换点。
相似度边界 ℬ₂:相邻对话轮次语义相似度低于阈值 τ 的点。
最终边界 ℬ = ℬ₁ ∩ ℬ₂,确保分割准确。
3.2 Light2:主题感知的短时记忆¶
核心目标:对每个主题段进行结构化摘要,形成 LTM 的索引条目。
处理流程:¶
缓冲:将主题片段(包含多个user-model的对话轮次)存入STM缓冲区。
触发:当缓冲区中的token数量达到预设的容量阈值 th时,触发调用 LLM(fsum)生成摘要。
摘要与索引构建:调用LLM fsumfsum 为每个主题片段生成一个简洁的摘要 sumisumi。
形成记忆条目:最终构建一个结构化的记忆条目,准备存入LTM:
构建索引结构:
{topic, {sumi, useri, modeli}}其中 sumi 为摘要,ei 为摘要的 embedding。
优势:¶
主题约束输入粒度:相比单轮或整段输入,主题级输入在减少 API 调用的同时,保持摘要准确性,避免语义混杂。
3.3 Light3:带“睡眠更新”的长时记忆¶
核心目标:优化记忆更新机制,降低在线推理延迟,提升整体效率。
3.3.1 测试时软更新(Soft Updating at Test Time)¶
机制:新记忆条目直接插入 LTM,不参与在线推理过程。
更新队列:
每个条目 ei 的更新队列 𝒬(ei) 包含与其语义相似且时间戳更晚的 top-k 条目。
更新仅允许“后更新前”,符合时间逻辑。
优点:更新过程仅涉及检索,可并行执行,延迟低。
3.3.2 离线并行更新(Offline Parallel Update)¶
传统问题:现有系统更新为串行,延迟随更新次数线性增长。
LightMem 改进:
每个记忆条目维护独立更新队列,更新任务可并行执行。
显著降低整体更新延迟,提升系统吞吐量。
总结¶
LightMem 通过三个轻量模块实现了高效、低延迟的记忆增强生成系统:
Light1:有效压缩输入并按主题分割,提升后续处理效率。
Light2:主题级结构化摘要减少 API 调用,保持语义完整性。
Light3:软更新与离线并行更新机制极大降低系统延迟,提升整体性能。
实验结果表明,LightMem 在准确率、token 使用、API 调用和运行时间等方面均优于现有方法,是轻量级记忆增强生成系统的有效解决方案。
4 experiments¶
4.1 实验设置(Experimental Setup)¶
实验细节(Experimental Details)
评估场景:采用 “增量式对话轮次输入” 设置。这意味着对话轮次是模拟实时对话,一个接一个地顺序处理的,而不是一次性获得全部历史。这更贴合智能体在真实世界中的应用场景。
为了兼顾效率与效果,所有实验中使用LLMLingua-2作为预压缩模型。
使用LLMLingua-2获取注意力分数进行话题分割,因此短时记忆缓冲区(STM buffer)的大小与模型上下文窗口一致,为512个token。
数据集与基线方法(Dataset & Baseline Methods)
使用LongMemEval-S数据集评估记忆能力,包含500个对话历史,平均每个对话有50个会话、110k个token。
对比方法包括:Full Text、Naive RAG、LangMem、A-MEM、MemoryOS、Mem0。
所有方法均使用GPT-4o-mini和Qwen3-30B-A3B-Instruct-2507作为LLM后端。
更多细节见附录C。
评估指标(Metrics)
有效性指标:准确率(ACC),由GPT-4o-mini作为评判模型。
效率指标:LLM调用的输入token数、输出token数、总token数(单位为千)、API调用次数、运行时间(秒)。
重点关注记忆管理(Summary和Update)的开销,不分析检索和问答阶段的开销。
表1:性能与效率对比分析(精简)¶
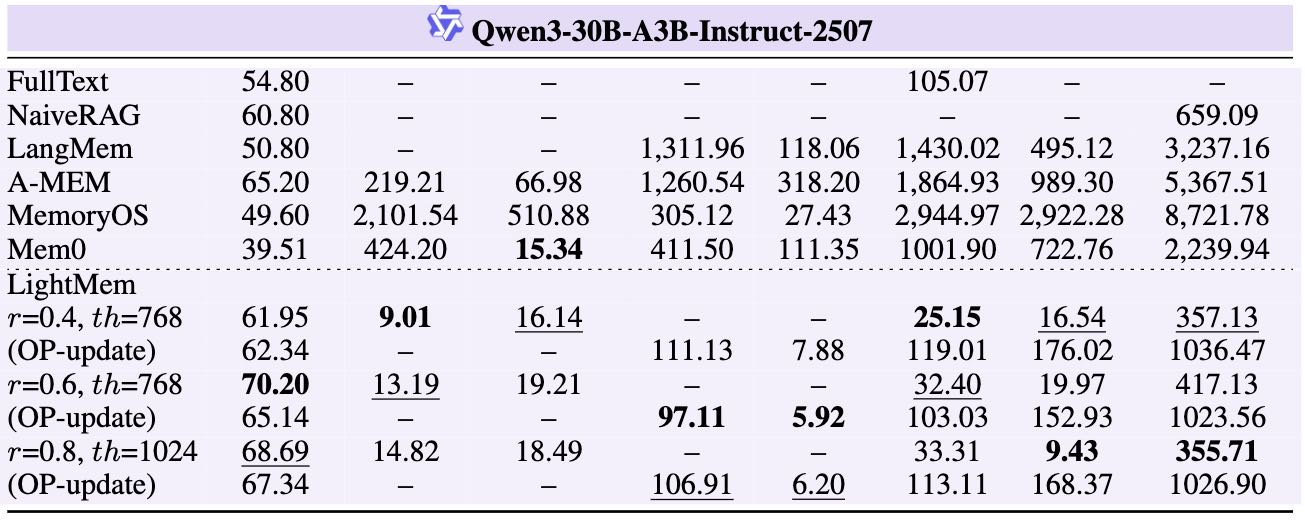
Table 2: Effectiveness and efficiency comparison on LONGMEMEVAL-S.
不同压缩率(rr)与 STM 缓冲阈值(th)组合:
压缩率越高,token 使用越少,但准确率略有下降。
离线更新(OP-update)进一步提升准确率,但略微增加 token 使用。
LightMem 在多个配置下均表现最优,尤其在效率方面显著优于其他方法。
4.2 主要结果(Main Results)¶
LightMem在GPT和Qwen两个模型上都表现出色,在三个参数设置下均优于所有基线方法。
分为两个阶段评估:在线软更新阶段(Online Soft Update)和离线更新后(Sleep-Time Update)。
在线软更新阶段(Online Soft Update)
在问答任务中,LightMem比最强基线A-Mem准确率提升2.70%–9.65%(GPT)和最高7.67%(Qwen)。
效率方面,相比其他方法,LightMem在GPT上减少32×–106×的token消耗和17×–159×的API调用;Qwen上减少29×–117× token和19×–177× API调用。
离线更新阶段(Sleep-Time Update)
更新后保持相近准确率,仍优于所有基线。
GPT上总token减少10×–38×,API调用减少3.6×–30×;
Qwen上总token减少29×–117×,API调用减少3.3×–20×;
运行时间减少1.67×–12.45×。
结论:LightMem在几乎所有指标和两个LLM模型上都表现优异,具有高鲁棒性和灵活性。
4.3 预压缩子模块分析(Analysis of Pre-Compressing Submodule)¶
性能与开销(Performance and Overhead)
使用LLMLingua-2进行预压缩,在压缩比(rr)为50%–80%时,压缩与未压缩内容的问答准确率相当,说明LLM能有效理解压缩内容。
预压缩模块高效,仅占用不到2GB GPU内存,对整体运行时间影响极小。
压缩比(rr)对性能的影响
最佳rr值依赖于STM缓冲区阈值(t_h):
小阈值(t_h ∈ {0,256})时,rr=0.6效果最好;
大阈值(t_h ∈ {512,1024})时,rr=0.7更优。
平均最佳rr为0.6,是信息压缩率与STM缓冲区信息量之间的权衡。
效率方面:rr越低,效率越高,因为触发缓冲区更新的频率更低。
备注
缓冲区越大,能容纳更多信息,就越能承受较低的压缩率(即保留更多信息,r值更高)
4.4 话题分割子模块分析(Analysis of Topic Segmentation Submodule)¶
分割准确性(Segmentation Accuracy)
提出的混合话题分割方法(结合注意力和相似度)优于仅使用注意力或相似度的方法。
在LongMemEval数据集上,准确率超过80%,验证了方法的有效性。
消融实验(Ablation Study)
移除话题分割模块会略微提升效率,但显著降低准确率(GPT下降6.3%,Qwen下降5.4%)。
说明该模块有助于模型理解输入的语义单元,提升后续记忆单元生成效果。
4.5 STM阈值影响分析(Analysis of the STM Threshold’s Impact)¶
STM缓冲区阈值(t_h)对效率和性能有显著影响:
效率方面:t_h越大,效率越高;
准确率方面:非单调变化,最佳值因模型和压缩比而异。
权衡关系:更大的缓冲区有助于降低计算成本,但要获得最佳准确率需仔细调参。
4.6 睡眠更新分析(Analysis of Sleep-Time Update)¶
为何软更新有效(Why Soft Updates Work)
LLM在实时更新复杂记忆时可能出错,例如将相关但不冲突的信息误判为冲突,导致信息丢失。
LightMem采用软更新机制,仅进行增量添加,保留完整语义和全局信息。
案例研究(Case Study)
历史1:用户计划去东京旅行;
历史2:用户询问去京都的火车;
硬更新:覆盖旧记忆,变为“用户计划去京都旅行”,丢失东京信息;
LightMem软更新:追加信息,变为“东京旅行 + 京都询问”,保留完整上下文。

总结:LightMem在多个维度上均表现优异,尤其在效率与准确率的平衡、模块设计的合理性以及更新机制的稳定性方面具有显著优势。
6 conclusion and Future Work¶
主要结论:¶
本研究提出了 LightMem,这是一个轻量级、高效的记忆框架,旨在解决大语言模型(LLM)代理在记忆系统中产生的显著开销。
LightMem 的设计灵感来自人类记忆的多阶段 Atkinson-Shiffrin 模型,通过信息的过滤、组织与整合,有效提升了记忆系统的效率。
实验结果表明,LightMem 在保持任务性能的同时,显著降低了计算成本。
未来工作方向:¶
1. 离线更新加速(Offline Update Acceleration)¶
重点内容:计划通过引入**预计算的键值缓存(KV Cache)**来提升 LightMem 更新阶段的效率。
优势:KV 缓存可离线预计算,从而加速记忆整合,减少交互时的运行时开销。
2. 基于知识图谱的记忆模块(Knowledge Graph-based Memory)¶
重点内容:未来将集成一个轻量级的知识图谱记忆模块,以应对多跳推理等复杂任务。
功能:支持显式关系推理和结构化信息检索,提升模型在知识实体间进行组合推理的能力。
3. 多模态记忆扩展(Multimodal Memory Extension)¶
重点内容:计划开发多模态记忆机制,使 LightMem 能适应多模态模型和场景。
应用场景:适用于具身智能体和真实世界应用,其中视觉、听觉和文本信息共同参与记忆的形成与检索。
4. 参数化与非参数化记忆协同(Parametric–Nonparametric Synergy)¶
重点内容:探索参数化记忆与非参数化记忆之间的协同机制。
目标:弥合两者之间的差距,实现知识利用的灵活性,结合参数化模型的高效性与非参数化存储的可解释性和适应性。
Appendix A Usage of LLMs¶
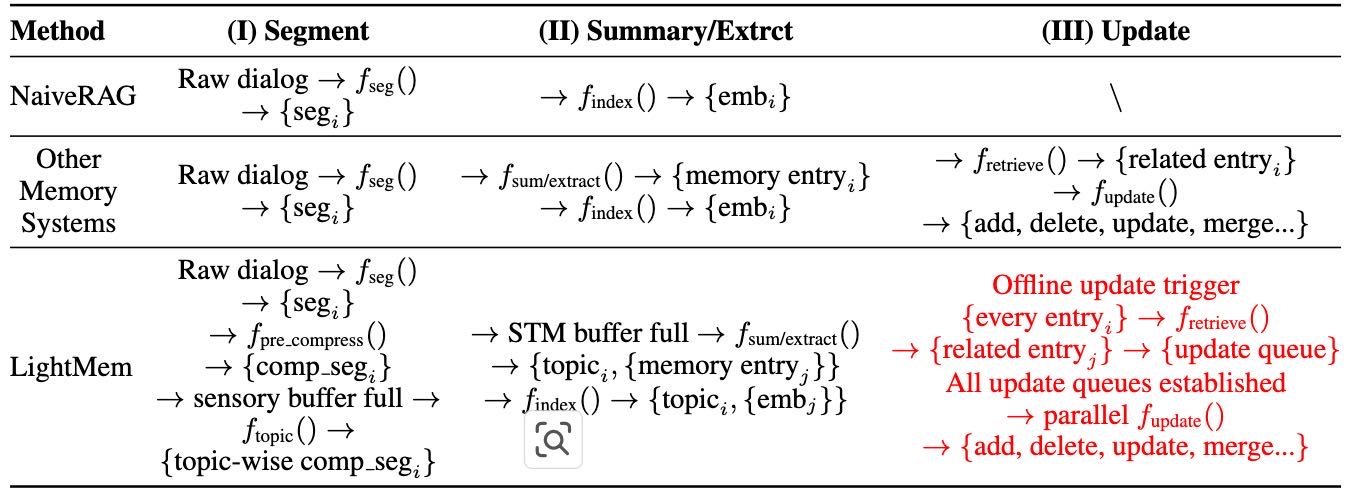
Table 4:The mainstream memory architectures and the LightMem pipeline of memory bank construction stage. Black-font processes denote those executed during online test-time interactions, whereas red-font processes denote those executed offline.
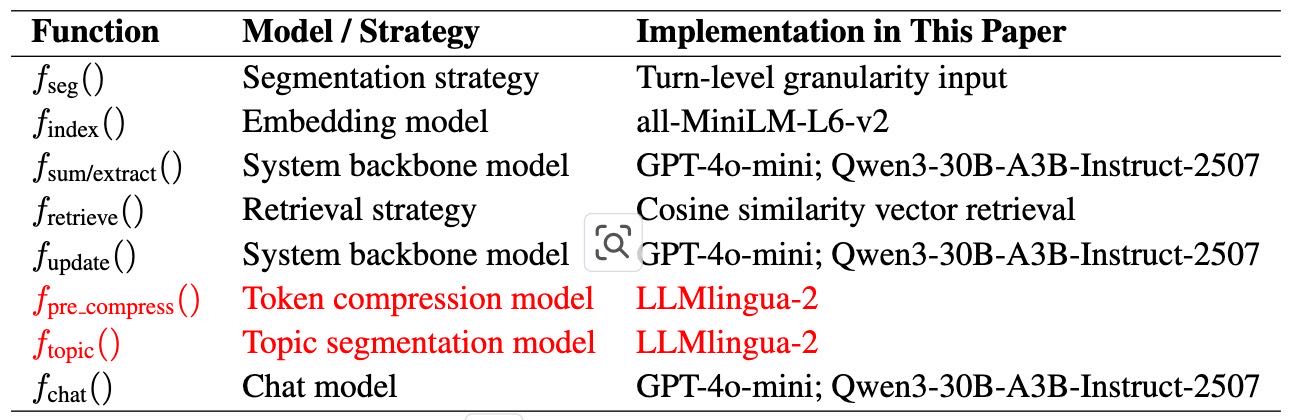
Table 5:Mapping between functions, their roles, and the concrete models used in this paper. Black-font entries denote models shared by both LightMem and baseline methods, whereas red-font entries denote models unique to LightMem.
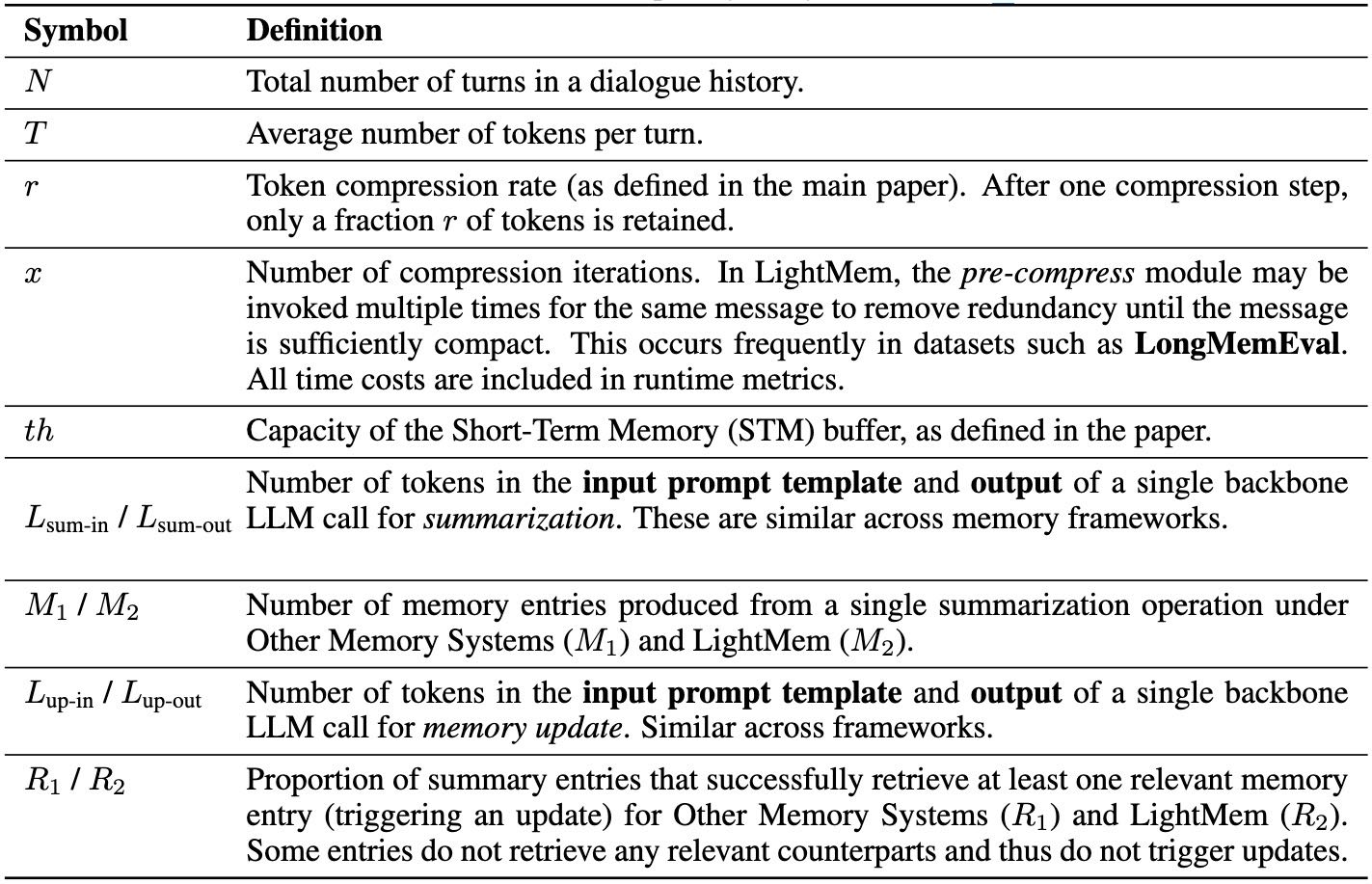
Table 6: Notation used in complexity analysis (§Section 4).
在本论文的撰写过程中,我们使用了大语言模型(LLMs)来辅助改进文章部分段落的语法、表达清晰度和措辞。但LLMs的用途仅限于语言润色,论文中所有的观点、分析和结论均由作者独立完成。
图5展示了STM缓冲区阈值(thth)在不同压缩比(rr)下对性能与效率的影响。每一张雷达图代表一个特定模型配置(GPT-4o-mini 或 Qwen3)在固定压缩比下的表现。
雷达图的各个轴代表六个关键指标:准确率(ACC)、输入/输出/总token消耗(Input, Output, Total)、API调用次数以及运行时间(Runtime)。为了便于比较,所有数值都经过归一化处理以适应图表可视化。
重点说明:
该图旨在展示thth参数对模型在不同压缩比下的综合性能影响。
通过对比不同模型(GPT-4o-mini与Qwen3)的雷达图,可以评估模型在效率与准确性之间的权衡。
token消耗和API调用等效率指标被可视化,有助于理解压缩策略对资源使用的影响。
(注:由于图像内容无法查看,以上总结基于文字描述和图注信息。如需详细分析图表结果,需结合图像具体内容。)
Appendix B Methodology Details¶
B.1 主题分割¶
核心方法:
数据处理: 仅提取用户语句,因其更简洁且助手回复需与用户主题一致。由于LLMLingua-2模型最大输入长度为512 token,助手语句可能过长,因此将用户语句缓存并分段处理。
压缩策略: 若压缩后语句为空,则保留原句;若仍超限,则以0.5压缩率继续压缩,直到符合token限制。
注意力矩阵构建: 屏蔽每段首尾各3个token以减少注意力“sink”效应,使用LLMLingua-2的高层数(第8~11层)计算token级注意力,平均后得到句子间注意力得分,并归一化形成最终注意力矩阵。
分段逻辑: 关注当前句与前一句的注意力得分序列,若某句注意力得分高于前后句,视为局部峰值,作为新主题的起点,设置分段点。
效果验证:
图6展示了在50%压缩率下的三个分段示例,局部峰值出现在第5、8、11句等位置,实际分段边界与之高度吻合,说明方法能实现细粒度且可靠的主题边界检测。
B.2 分类准确率¶
主要结论:
信息整合类任务(如时间性、多会话、知识更新): 基于检索与记忆的方法(如A-MEM、Mem0、MemoryOS)优于“全文”方法。
单一用户/助手类任务: 轻量检索方法(如Naive RAG)表现良好,甚至更优。
偏好类任务: 样本量较小导致准确率波动较大。
数据支持:
表3展示了GPT和Qwen模型在不同方法下的准确率对比,LightMem在Temporal、Multi-Session等类别上表现突出,尤其在GPT配置下(r=0.7, th=512)达到67.18%和71.74%。
B.3 参数影响分析¶
参数设置:
压缩比 r: 控制文本压缩程度。
STM阈值 th: 控制短期记忆缓冲区大小。
性能影响:
表4展示了不同参数组合对准确率(ACC)、输入/输出token数、总token数、调用次数及处理时间的影响。
准确率趋势: 通常随着压缩比r增大,准确率先升后降,最佳表现出现在r=0.6~0.7之间。
资源消耗: 压缩比越高,输入token减少,但输出token变化不大,整体资源消耗下降。
模型差异: GPT和Qwen在不同参数下表现略有差异,但总体趋势一致。
推荐配置:
GPT建议使用r=0.7、th=512;
Qwen建议使用r=0.4、th=768,以在准确率与资源消耗间取得平衡。
Appendix C Experiment Details¶
附录 C 实验细节总结¶
C.1 数据集与基线方法¶
本节介绍了用于评估对话代理长期记忆能力的 LongMemEval 数据集及其版本设置。该数据集包含 500 个基于多轮对话构建的评估问题,具有两个版本:
LongMemEval-S:每个问题约 115k 个 token;
LongMemEval-M:每个问题可达 150 万个 token。
作者在实验中采用了 LongMemEval-S,因其在对话长度与计算可行性之间取得了平衡。每个样本包含多轮对话历史、后续提出的问题,以及带有支持证据段落的标准答案。问题类型包括:
信息抽取
多轮推理
知识更新
时间推理
拒答(abstention)
该数据集的特点是:
对话历史极长
时间跨度大
问题类型多样
因此,它是一个全面评估对话系统记忆能力的基准。
在实验过程中,有 5 个样本因包含乱码导致 LightMem 的压缩模型无法运行,这些样本被直接跳过,其准确率统一记为错误。它们的索引为:74、183、278、351 和 380。
此外,作者将所提出的方法与以下几种具有代表性的记忆建模基线方法进行了对比:
LangMem(LangChain, 2025):LangChain 的长期记忆模块。
A-MEM(Xu 等, 2025):通过构建以记忆为中心的知识图谱,将每次交互编码为结构化记忆节点,并通过 LLM 驱动的推理进行连接。
MemoryOS(Kang 等, 2025):采用类操作系统的分层结构组织对话记忆,将交互分为短期、中期和长期记忆层,通过“分页”和基于热度的更新机制管理。
Mem0(Chhikara 等, 2025):通过全局摘要与近期上下文结合的方式提取记忆,并通过 LLM 引导的操作进行维护。
重点内容总结:
LongMemEval 是一个用于评估对话系统长期记忆能力的综合性数据集,具有长对话、多问题类型等特点。
作者使用 LongMemEval-S 版本进行实验,并处理了其中 5 个异常样本。
与多个主流记忆建模方法进行了对比,包括结构化记忆图谱、分层记忆系统等。
C.2 实现细节¶
所有实验均在以下硬件环境下进行:
GPU:4 块 NVIDIA RTX 3090
CPU:双 Intel Xeon Gold 6133(共 40 核,80 线程)
内存:256 GB RAM
简要总结:
实验运行在高性能计算设备上,确保了大规模模型和长序列处理的可行性。
Appendix D Prompts¶
附录 D 提示(Prompt)设计¶
本节主要介绍了用于评估大语言模型(LLM)表现的多种任务类型的提示模板,每种任务都有特定的评估标准。以下是各子部分的总结:
D.1 作为评估者的LLM(LLM-as-Judge)¶
本节的核心是使用LLM作为判断模型输出是否正确的工具。LLM根据给定的标准判断模型响应是否包含正确答案或等价信息。
标准任务(Single-session-user/assistant & Multi-session)¶
任务描述:给LLM一个问题、一个正确答案和一个模型的回答,要求LLM判断该回答是否正确。
判断标准:
如果模型回答中包含正确答案,或等价表达,或包含所有推导步骤,则判为“yes”。
如果模型回答只包含部分信息,则判为“no”。
重点说明:强调等价答案和完整推导过程的接受性。
时间推理任务(Temporal Reasoning Tasks)¶
任务描述:与标准任务类似,但问题涉及时间推理。
特殊说明:
不惩罚“差一天”错误(off-by-one errors)。
若问题要求天数、周数等,模型回答与正确答案相差一天仍视为正确。
重点说明:时间推理任务中对数值误差的宽容性是其关键特征。
知识更新任务(Knowledge Update Tasks)¶
任务描述:判断模型是否提供了更新后的正确答案。
判断标准:
即使模型回答中包含旧信息,只要也包含更新后的正确答案,就视为正确。
重点说明:强调模型是否能提供最新的信息,而非仅依赖旧知识。
单会话偏好任务(Single-session Preference Tasks)¶
任务描述:判断模型是否能根据用户偏好生成个性化回答。
判断标准:
不要求模型覆盖所有偏好点,只要正确使用了用户的个人信息即可。
重点说明:个性化信息的正确使用是核心,不要求全面覆盖。
拒答任务(Abstention Tasks)¶
任务描述:判断模型是否能识别无法回答的问题。
判断标准:
如果模型指出问题无法回答(如信息不足),则判为“yes”。
重点说明:考察模型的“拒答能力”,即识别并拒绝回答不明确或信息不足的问题。
总结¶
本附录详细列出了多种任务类型的Prompt模板,旨在通过LLM自动评估其他模型的回答质量。这些任务涵盖了标准答案判断、时间推理、知识更新、个性化偏好响应和拒答识别等关键能力。每种任务都设定了明确的判断标准,其中一些任务(如时间推理)允许一定误差,而另一些(如拒答任务)则强调模型的不确定性识别能力。