2508.09834❇️_Overview_LLM: Speed Always Wins: A Survey on Efficient Architectures for Large Language Models¶
引用:1(2025-09-16)
组织:
1Shanghai AI Laboratory
2HKUST (GZ) (香港科技大学(广州))
3University of Macau
4Institute of Automation Chinese Academy of Sciences (中国科学院自动化研究所)
5Soochow University(苏州大学)
6KTH Royal Institute of Technology(瑞典皇家理工学院)
7Peking University
8The Chinese University of Hong Kong
总结¶
总结
本文是 LLM 的论述文章,全部用 deepseek 生成并手工修改,值的反复看
Abstract¶
本文综述了大型语言模型(LLMs) 的创新架构,旨在解决传统Transformer架构在计算效率和扩展性方面的局限性,提升模型的效率与实用性。
大型语言模型已经在语言理解、生成和推理等方面取得了显著成果,并推动了多模态模型的能力边界。Transformer模型作为现代LLMs的基础,具有出色的扩展性能和良好的基线表现。然而,传统Transformer架构需要大量计算资源,给大规模训练和实际部署带来了显著挑战。
本文系统地探讨了多种创新的LLM架构,旨在克服Transformer的固有局限、提高模型效率。从语言建模出发,本文涵盖了以下几类方法的技术背景与细节:
线性和稀疏序列建模方法(重点):这些方法通过减少序列处理的计算复杂度,显著提升了模型效率;
高效的全注意力变体(重点):改进传统自注意力机制,降低计算开销;
稀疏混合专家架构(MoE)(重点):通过选择性激活模型中的一部分参数,提高模型规模的同时保持计算效率;
混合模型架构:结合上述技术,进一步优化模型性能;
扩散型LLMs(Diffusion LLMs)(新兴技术):作为新兴方向,值得关注其未来潜力。
此外,文章还讨论了这些高效架构在其他模态(如视觉、音频等)中的应用,并探讨了其对构建可扩展、资源敏感型基础模型的更广泛影响。
最后,作者将近期研究按上述类别进行了系统归纳,提出了一个现代高效LLM架构的蓝图,期望为未来研究更高效、更通用的AI系统提供方向与参考。
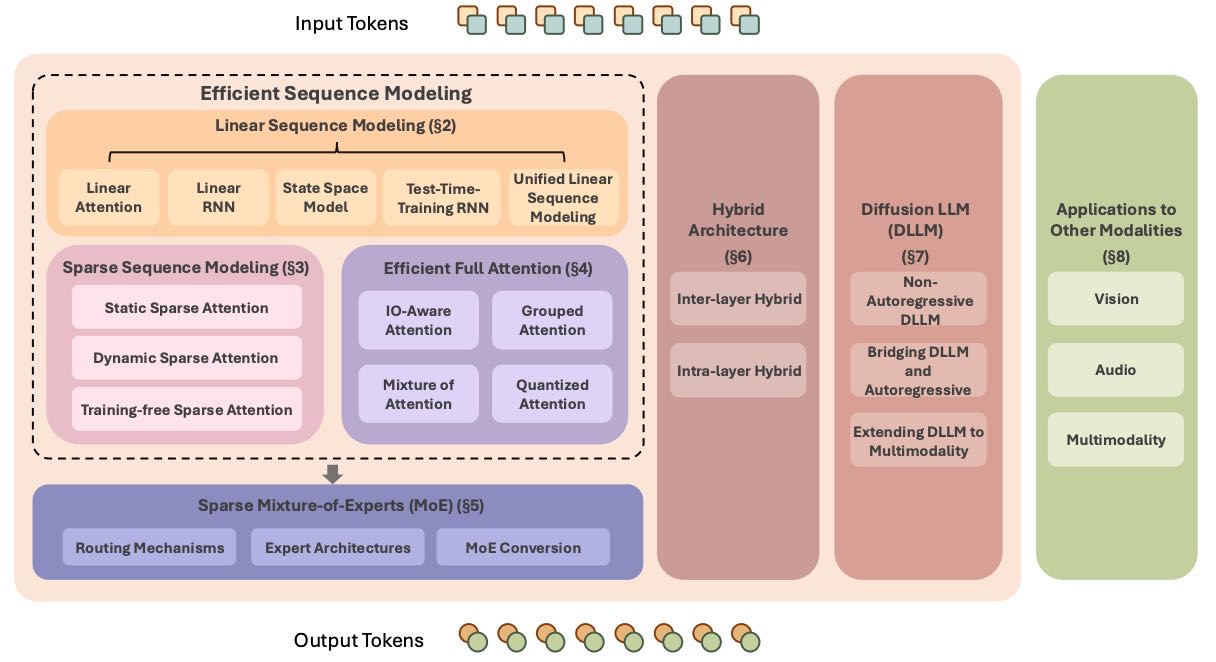
Figure 1:Overview of Efficient Architectures for Large Language Models.
1 Introduction¶
1. 核心主旨 (The Core Message)¶
这篇论文的核心议题是:在追求大语言模型(LLM)强大能力的同时,其巨大的计算成本和低效问题已成为不可忽视的障碍。因此,研究界正在积极探索各种“高效架构”来突破这一瓶颈。
简单来说,论文的主题就是 “如何让大模型变得更便宜、更快,同时尽量保持其强大能力”。
2. 主要内容分解¶
第一部分:LLM的成功与演进 (背景)¶
取得了什么成功? LLM在自然语言处理(NLP)的各项任务(文本生成、代码生成、问答等)上取得了巨大进步。涌现了ChatGPT, Claude, Gemini, LLaMA等一系列著名模型。
正在向何处发展? LLM的发展有两个重要趋势:
多模态(Multimodality):从纯文本扩展到能理解和生成图像、视频、音频(例如Qwen-VL等视觉语言模型)。
复杂推理(Complex Reasoning):发展出“大推理模型(LRM)”,通过“思维链(CoT)”等技术进行多步骤、更复杂的逻辑推理(例如OpenAI的o1/o3系列)。
第二部分:面临的巨大问题 (挑战)¶
问题是什么? 模型能力越强,带来的计算成本( computational demands) 也越高。无论是训练还是部署(推理),都变得非常昂贵,阻碍了其广泛应用。
根本原因在哪? 问题的核心在于当前主流模型的基础架构——Transformer。
Transformer的自注意力(Self-Attention)机制 存在一个致命缺陷:其计算复杂度是输入序列长度(N)的平方(O(N²))。这意味着处理长文本时(比如一整本书),计算量会爆炸式增长,又慢又贵。
前馈网络(FFN) 随着模型参数增长,也变得难以高效训练和推理。
为什么这个问题越来越严重? 因为现实应用恰恰需要处理长序列,例如:
检索增强生成(RAG):需要模型阅读大量文档。
AI智能体(Agents):需要多次调用工具和生成内容。
复杂推理(LRM):生成长长的思维链。
多模态:高分辨率图像和视频包含海量信息。
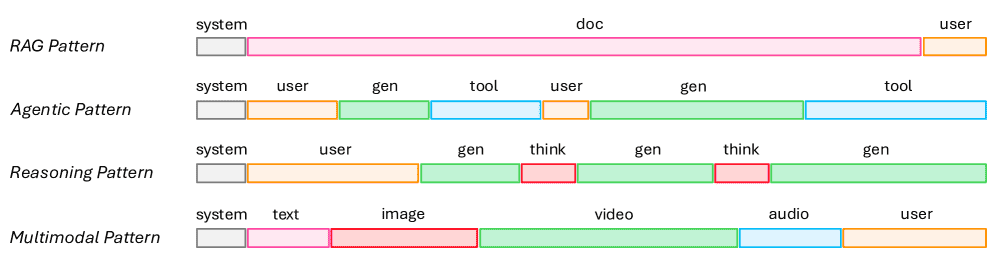
Figure 2:Long Context Patterns. We provide representative examples of long-context usage patterns across various scenarios, including retrieval-augmented generation (RAG), agentic, reasoning, and multimodal applications.
第三部分:论文的解决方案概述 (本文要 survey 的内容)¶
为了应对上述挑战,研究者们提出了多种高效架构方案。论文图3展示了完整的分类法,并在此进行了简要介绍:
线性序列建模(Linear Sequence Modeling):目标是将计算复杂度从O(N²)降到O(N)。包括线性注意力、线性RNN、状态空间模型(如著名的Mamba)等。这类方法在推理时还不需要存储巨大的KV缓存,极大降低了部署成本。
稀疏序列建模(Sparse Sequence Modeling):不完全计算所有token之间的关系,而是有选择地(稀疏地)计算一部分,从而减少计算量。包括静态、动态和无须训练的稀疏注意力。
高效全注意力(Efficient Full Attention):不改变O(N²)的复杂度,但通过工程优化让它跑得更快。例如FlashAttention(优化GPU内存读写)、分组查询注意力GQA(减少KV缓存大小)等。
稀疏专家混合(Sparse Mixture-of-Experts, MoE):“专家”模式。一个模型由许多“子模型”(专家)组成,每次处理输入时只激活一部分专家。这样可以在参数量巨大的情况下,保持每次计算量可控。
混合架构(Hybrid Architectures):“组合拳”。将上述高效架构(如Mamba)和传统的Transformer注意力层组合在一起使用,兼顾二者的优势。
扩散LLM(Diffusion LLM):一个新兴方向,尝试用扩散模型(类似AI绘画的原理)来生成文本,可能提供新的高效生成路径。
多模态应用:上述高效架构不仅用于文本,也正被应用到视觉、音频等多模态领域。
第四部分:本文的贡献与定位 (为什么写这篇综述)¶
定位:之前已有一些综述文章,但它们通常只关注某一个特定方向(如只讲高效Transformer,或只讲状态空间模型SSM)。
本文贡献:本文声称提供了一个更全面、更有组织(more comprehensive and organized) 的综述。它从Transformer的核心组件出发,系统性地梳理了所有旨在提升效率的架构创新,并涵盖了它们在多模态领域的应用。
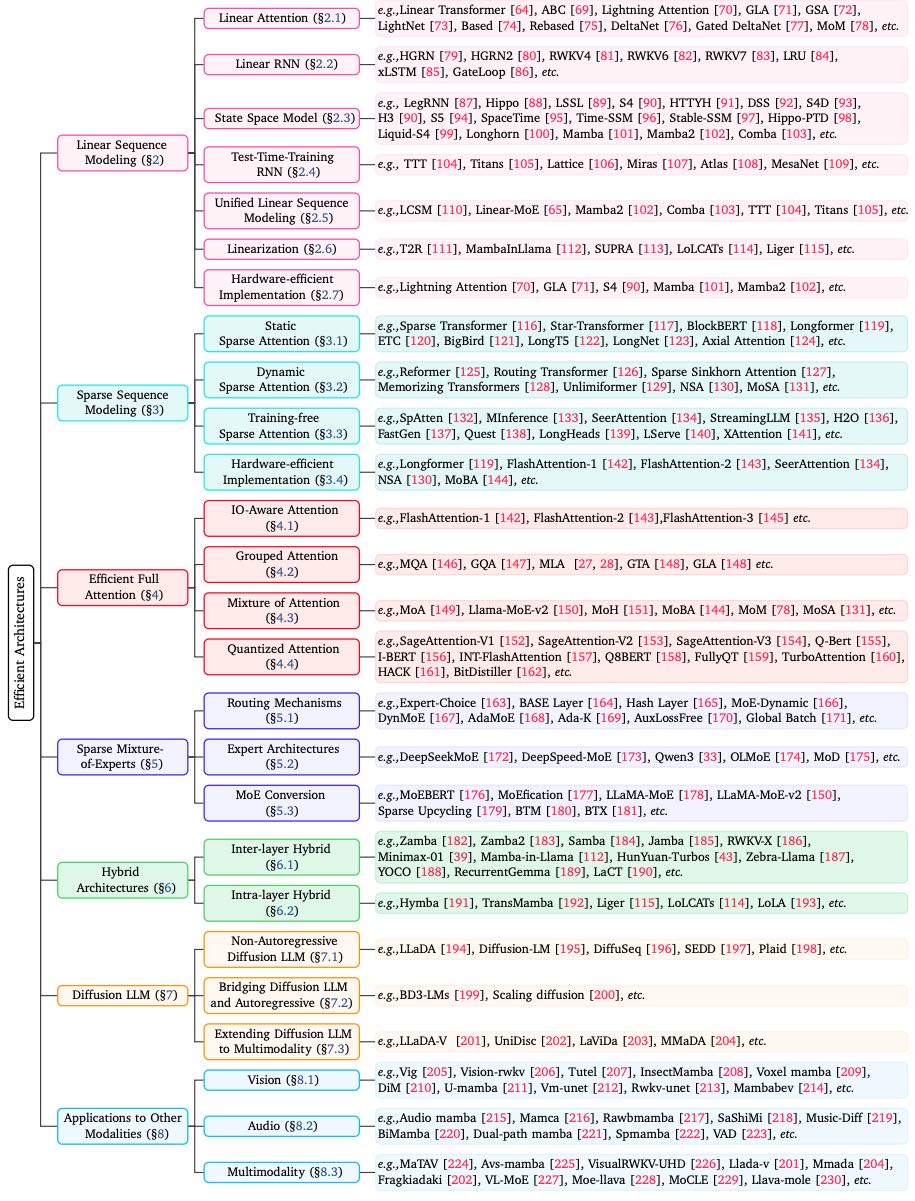
Figure 3:A Comprehensive Taxonomy of Efficient Architectures for Large Language Models.
2 Linear Sequence Modeling¶
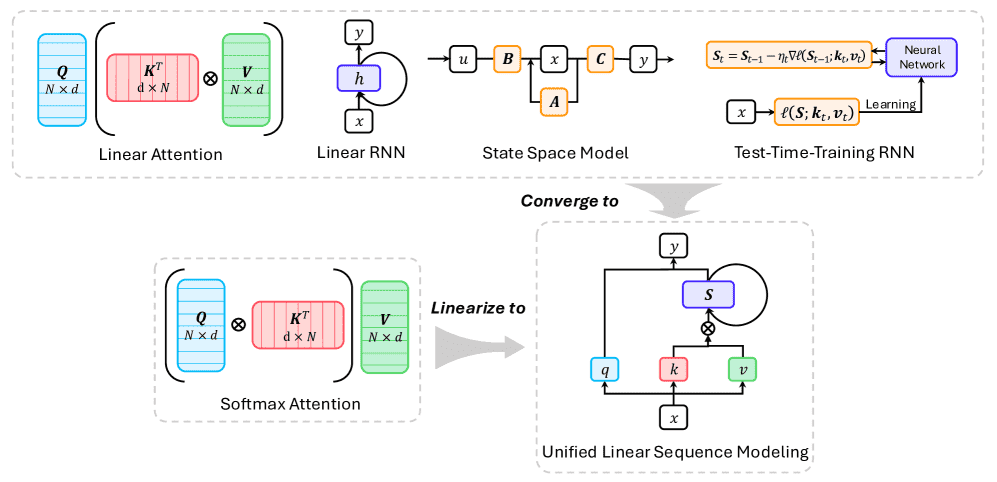
Figure 4:Linear Sequence Modeling Methods and Their Connections. The formulations of linear attention, linear RNNs, state space models, and test-time training RNNs have gradually converged toward a unified representation. Moreover, softmax attention can also be transformed into a linear sequence modeling form through the linearization techniques.
主要介绍了 线性序列建模(Linear Sequence Modeling) 的各种方法,并阐述了它们如何从不同的起点逐渐趋同,最终可以被一个统一的框架所理解。
核心摘要¶
这段文字的核心论点是:为了提升处理长序列的效率(从Transformer的平方复杂度 O(N²) 降到线性复杂度 O(N)),研究者们从四个主要方向(线性注意力、线性RNN、状态空间模型SSM、测试时训练RNN)提出了不同的模型。尽管起点不同,但这些模型的数学 formulation 和内存更新机制正在逐渐收敛,变得越来越相似。文章旨在梳理这些方法,并将它们统一到一个共同的“线性序列建模”框架下来理解。
此外,文章还介绍了线性化(Linearization) 技术(将预训练好的标准Transformer转化为线性模型)和硬件高效实现策略。
引言¶
目标:处理序列数据(如文本)。
问题:标准的Transformer使用Softmax注意力机制,计算量和内存占用随序列长度呈平方级增长(
O(N²)),这使其在处理超长序列时非常昂贵。解决方案:线性序列建模方法。它们通过不同的数学技巧,将计算复杂度降低到线性(
O(N))。四大类别:文章将现有方法分为四类:
Linear Attention (线性注意力):2.1
Linear RNN (线性循环神经网络):2.2
State Space Model - SSM (状态空间模型):2.3
Test-Time-Training RNN - TTT RNN (测试时训练RNN):2.4
统一趋势:如图4所示,这四类方法的 formulation 正在收敛,变得越来越像。甚至可以通过“线性化”技术把Softmax Attention也变成线性形式。
分节详解¶
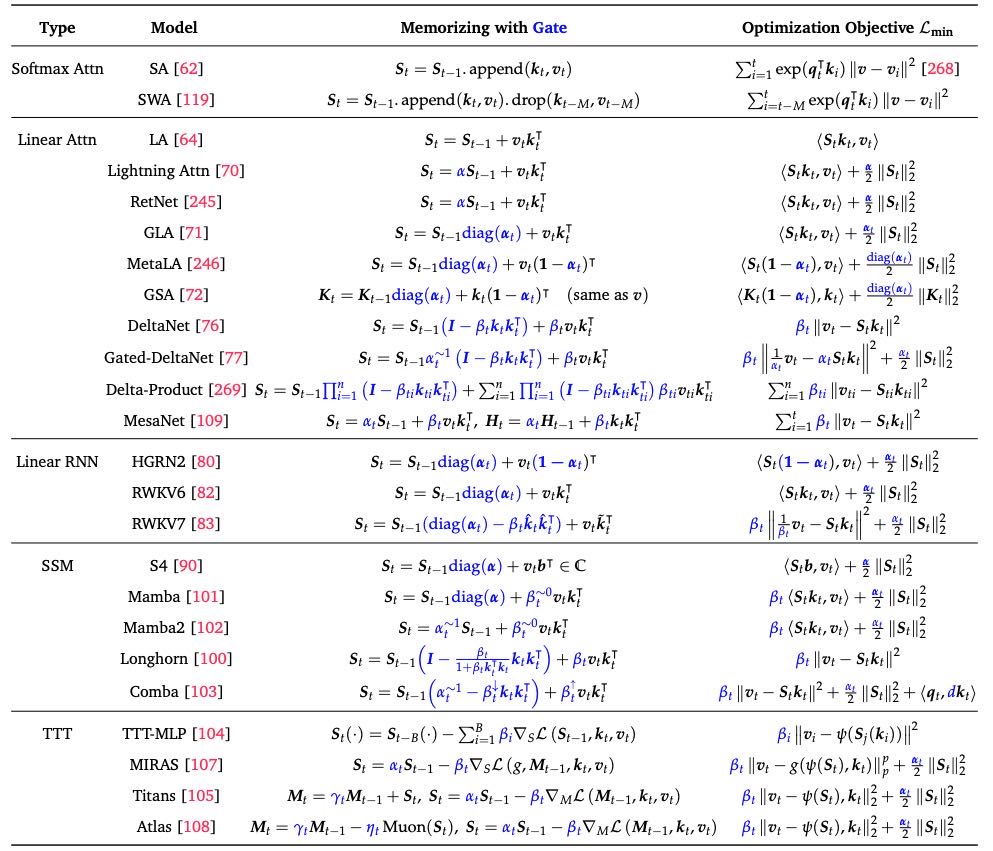
Table 1:A comparative overview of various linear sequence modeling approaches in terms of their memory update rules and optimization objectives.
2.1 线性注意力 (Linear Attention)¶
核心思想:替换掉标准注意力中的
softmax和exp操作。怎么做:使用一个特征映射函数
φ(·)(例如elu(x)+1或随机特征),将查询(Q)和键(K)映射到另一个空间,使得相似度函数可以分解为sim(q, k) = φ(q)·φ(k)^T。关键技巧:利用矩阵乘法的结合律,将
(Q·K^T)·V的计算顺序改为Q·(K^T·V)。这样,K^T·V可以提前计算并递归地更新(见公式5),避免了计算巨大的N×N注意力矩阵。挑战与改进:
近似保真度:线性近似可能无法完全捕捉标准注意力的“尖峰”特性(专注于少数几个关键token)。后续工作通过混合架构(如结合滑动窗口注意力)、更好的特征映射(如Hedgehog)和归一化来解决。
门控机制:单纯累加历史信息会导致“记忆冲突”。引入数据依赖的门控(如GLA, GSA中的遗忘门)可以让模型选择性地忘记过时信息,显著提升性能。
Delta学习规则:受神经科学中的Widrow-Hoff规则启发,像DeltaNet这样的模型将记忆更新视为一个在线学习过程,根据当前预测的误差来调整记忆,增强了记忆能力。
对数线性记忆:为了突破固定大小状态的记忆容量限制,一些模型(如Log-Linear Attention)让隐藏状态的数量随序列长度对数增长,在效率和表达能力间取得平衡。
2.2 线性RNN (Linear RNN)¶
核心思想:改造传统RNN,移除隐藏状态更新过程中的非线性激活函数,使其能够并行训练(传统RNN因为串行递归无法高效并行)。
典型结构:如GRU的线性变体(公式7),使用门控(输入门、遗忘门、输出门)进行元素级的线性更新。
演进:
早期模型(如LRU)使用对角化矩阵等进行高效递归。
为了增加表达能力和记忆容量,后续模型(如HGRN2, RWKV6, xLSTM)将隐藏状态从向量扩展为矩阵(通过外积等方式)。这使得它们的记忆结构与线性注意力非常相似(见公式8)。
RWKV7等模型进一步引入了类似测试时训练的梯度下降机制来更新状态。
2.3 状态空间模型 (State Space Model - SSM)¶
起源:源自控制理论,用于描述动态系统(公式10:
x' = Ax + Bu, y = Cx + Du)。与深度学习的结合:HiPPO理论为其提供了数学基础,旨在如何更好地用多项式基函数来近似历史信息。
关键步骤:
离散化:因为数据是离散的,需要将连续时间的SSM(公式10)通过方法如ZOH(零阶保持)转换为离散形式(公式11,12)。
对角化:为了让计算高效,将系统矩阵
A设为对角矩阵(或对角+低秩),这大大简化了计算,并可以表示为卷积形式(公式13)。时间变化(选择性):早期的SSM(如S4)参数是固定不变的。Mamba 的突破在于让SSM的参数(
B, C, Δ)依赖于输入数据,从而具备了像注意力一样“选择性地关注或忽略信息”的能力,极大提升了性能。Comba 等模型进一步引入了Delta规则和更复杂的矩阵结构(标量+低秩)来增强表达力和解决记忆冲突。
2.4 测试时训练RNN (TTT RNN)¶
核心思想:最“激进”的一类。直接将模型的隐藏状态视为可训练的权重,并在推理阶段(Test-Time) 使用一个可学习的优化器(而不仅仅是简单的递归规则)来更新它。
形式:类似于元学习和快速权重编程,其更新规则看起来像是在做梯度下降(公式14)。
特点:理论上表达能力最强,但通常计算效率较低,需要块状(chunk-wise)的梯度下降,硬件利用率不高。
2.5 统一的线性序列建模 (Unified Linear Sequence Modeling)¶
这是文章的精华部分,它从两个高级视角统一了上述所有模型。
记忆视角:
所有线性序列模型都在维护一个隐藏状态(记忆)
S_t,并通过写(Write) 和读(Read) 操作来与序列交互。线性更新规则:如线性注意力和早期SSM。更新是输入
(k, v)的线性函数。S_t = f(S_{t-1}, k_t, v_t)。双线性更新规则:如DeltaNet、Comba。更新规则中包含
S_{t-1} * k_t这样的项,使其关于状态和输入是双线性的。这对应于Delta学习规则,能实现更精确的监督记忆。非线性更新规则:如TTT系列。使用非线性优化算法(如SGD)更新状态,理论上最强大但计算成本最高。
优化器视角:
可以将这些模型的隐藏状态更新过程,看作是在每一步最小化某个损失函数:
局部L1损失:早期线性注意力,不稳定。
局部L2损失:加入L2正则化(对应门控/衰减),更稳定。被Mamba、GLA等广泛使用。
全局L2损失:如MesaNet,考虑从序列开始到现在所有时间的全局最优解,类似递归最小二乘法。
2.6 线性化 (Linearization)¶
动机:从头预训练一个大模型成本极高。线性化旨在将已有的、预训练好的标准Transformer模型,转换为高效的线性架构,从而以较低成本获得高效模型。
两种主要方法:
微调式:直接替换Transformer中的注意力模块为线性模块,然后对整个模型进行微调。例如T2R、SUPRA、Liger。
蒸馏式:将原始Transformer作为教师模型,训练一个线性架构的学生模型来模仿教师的行为。例如LoLCATs、MOHAWK。
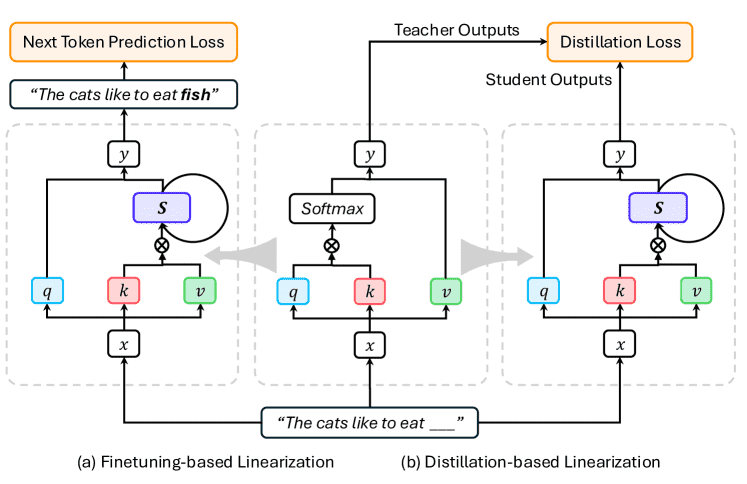
Figure 5:Mechanism Comparison of Finetuning-based and Distillation-based Linearization Procedures.
2.7 硬件高效实现 (Hardware-efficient Implementation)¶
为什么需要:理论上的线性复杂度不等于实际运行速度快。需要针对GPU等硬件进行优化。
关键技术:
快速递归:使用Blelloch并行扫描算法等来加速递归计算。
分块并行:受FlashAttention启发,将序列分成块(Chunk)。块内使用高效的矩阵乘法并行计算,块间进行递归。这极大地提升了训练和前向填充(prefill)阶段的效率。这是许多现代高效实现(如FlashLinearAttention)的基础。
常数内存解码:在推理阶段(生成token时),线性模型可以以
O(1)的常数额外内存和每步计算成本来运行,极具优势。
总结与比喻¶
目标:建造更快、更省油的“序列处理汽车”(处理长文本)。
传统汽车 (Transformer):引擎强大(性能好),但耗油极高(
O(N²)计算),跑长途(长文本)成本巨大。新一代汽车 (线性序列模型):都在努力打造省油引擎(
O(N)计算)。线性注意力:改造了传统引擎的“燃烧方式”(用特征映射代替softmax)。
线性RNN:简化了传统手动变速箱(RNN),使其变成可以自动并行操作的变速箱。
SSM:引入了一套来自控制理论的精密电控系统(状态方程)。
TTT RNN:给引擎装上了一个AI,让它能在行驶中自己学习调整参数。
趋同:尽管一开始思路各异,但大家发现最好的省油引擎最终都采用了类似的核心设计(门控机制、矩阵状态、Delta规则)。
线性化:不是从头造新车,而是把现有的豪华跑车(预训练Transformer)的引擎改装成省油引擎。
硬件优化:为这些新引擎设计更匹配的变速箱和底盘(算法实现),让它们在现实路况(GPU硬件)上能真正跑出理论上的高效率。
3 Sparse Sequence Modeling¶
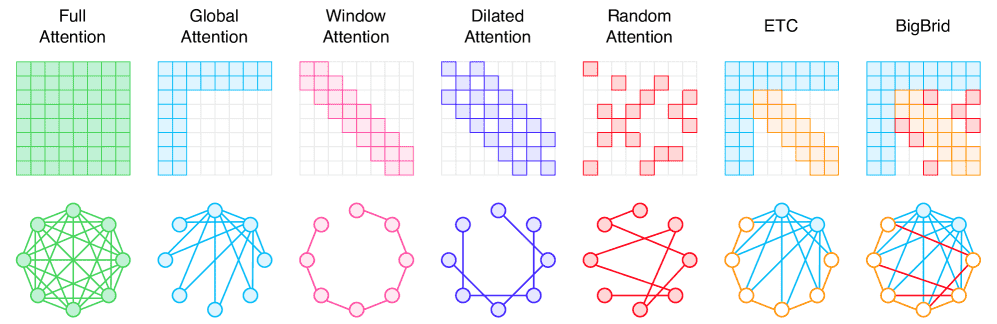
Figure 7:Example Patterns of Static Sparse Attention. ETC and BigBird are representative examples of mixed static sparse attention mechanisms, which combine multiple fixed sparsity patterns within a single attention framework.
可以把这段内容想象成一个 解决“注意力太贵”问题的“工具箱”,这个工具箱分成了四层,每层有不同的工具:
核心问题:为什么需要“稀疏”?¶
传统的 Transformer 模型使用“全注意力”机制,每个 token(可以理解为词或数据点)都要和序列中所有其他的 token 进行计算。这会导致计算量和内存占用随着序列长度呈平方级增长(O(n²))。处理很长的文本、高分辨率图像或视频时,这几乎不可行。
“稀疏注意力”的核心思想是: 没必要让每个 token 都关注所有其他 token。只让它关注最重要的一部分,就能大幅降低计算成本,同时尽量保持模型性能。
四类解决方案(工具箱的四层)¶
1. 静态稀疏注意力 (3.1 Static Sparse Attention) - “固定规则”¶
特点:注意力模式是预先设计好的、固定的,训练和推理时都不变。就像给每个 token 发一个固定的“通讯录”,它只能联系通讯录上的人。
优点:效率极高,易于实现和部署。
常见模式:
局部窗口 (Window):只关注相邻的 token(像卷积神经网络)。
全局 token (Global):设置几个特殊的 token(如 [CLS]),所有 token 都关注它,它关注所有 token,作为信息交换的“枢纽”。
随机连接 (Random):随机关注一些 token,保证网络的连通性。
扩张 (Dilated):像扩张卷积一样,跳跃着关注更远的 token,扩大感受野。
代表模型:
BigBird:结合了局部、全局、随机三种模式,被誉为“集大成者”,有理论保证。
Longformer:滑动窗口 + 全局 token,非常经典。
ETC:把 token 分成“局部流”和“全局流”,分别处理。
2. 动态稀疏注意力 (3.2 Dynamic Sparse Attention) - “看内容下菜”¶
特点:注意力模式根据输入内容动态决定。模型会自己判断当前 token 应该和哪些 token 最相关。就像根据每次谈话的主题,动态地拉一个相关的“微信群”进行讨论。
优点:更灵活,能更好地近似全注意力的效果。
实现方法:
聚类/哈希:如 Reformer 用“局部敏感哈希”把相似的 token 分到同一个“桶”里,只关注同桶的 token。
路由:如 Routing Transformer 用在线 k-means 聚类来分组。
学习机制:后期模型引入学习到的路由器,智能选择重要的 token 进行精细处理(如 CoLT5)。
3. 免训练稀疏注意力 (3.3 Training-free Sparse Attention) - “推理加速器”¶
特点:不改变已经训练好的模型权重,只在推理时采用一些技巧来加速。主要针对推理的两个阶段:
预填充阶段:处理用户输入的初始提示(Prompt),计算量大。
解码阶段:逐个生成 token,内存带宽是瓶颈(因为要不断读取越来越长的历史信息,即 KV Cache)。
加速方法:
预填充加速:分析注意力图,发现它们常有固定模式(如对角线、竖条),然后用定制化的内核来计算这些模式,跳过不必要的计算。
解码加速(重点):智能地压缩或修剪 KV Cache。
注意力 sink:发现开头几个 token 总是很重要(StreamingLLM),保留它们和最近 token,就能稳定生成极长内容。
淘汰策略:淘汰掉注意力分数最低的 token(H2O, TOVA)。
检索:把大部分 KV Cache 放在慢速内存(如 CPU)里,只用快速检索方法拿回当前最需要的部分(RetrievalAttention)。
4. 硬件高效实现 (3.4 Hardware-efficient Implementation) - “底层优化”¶
特点:在软件和硬件层面对稀疏计算进行极致优化,确保理论上的效率增益能转化为实际的运行速度提升。
核心工作:
FlashAttention:革命性的工作,通过分块计算和避免中间结果读写来大幅降低内存访问开销。它的“块稀疏”版本可以直接跳过被掩码屏蔽的块。
后续优化:如 NSA 通过更好的数据加载和共享策略,在 FlashAttention 基础上进一步提速。
总结与类比¶
为了帮你更好地理解,这里有一个简单的类比:
全注意力:在一个大会上,每个人都要和全场所有人挨个交流一遍。效率极低。
静态稀疏注意力:大会开始前就规定好,每个人只能和自己前后左右5个人、主席台上的3位嘉宾、以及随机分配的10个人交流。规则固定。
动态稀疏注意力:每个人可以自由走动,根据自己的话题,去寻找最相关的专家组成小组讨论。规则灵活。
免训练稀疏注意力:大会进行中,主持人(推理系统)为了加快进度,规定大家只讨论核心议题(压缩KV Cache),或者只允许最有见地的人发言(修剪token)。
硬件高效实现:优化会场布局和交通流线(软件内核),让大家交流起来更顺畅,减少走路和等待的时间。
本质上,这一切都是为了在效率和性能之间找到一个完美的平衡点,让 AI 模型能够处理更长的序列信息。
4 Efficient Full Attention¶
本章节概述: 本章主要讨论了如何优化Transformer模型中的自注意力机制,使其在计算和内存使用上更加高效。自注意力机制原本的计算和内存复杂度与序列长度N的平方成正比(O(N²)),这在处理长序列时成为主要瓶颈。本章介绍了一系列技术,包括IO感知注意力、分组注意力、混合注意力和量化注意力,来克服这一瓶颈。
4.1 IO-Aware Attention¶
本节概述: 传统注意力机制在GPU上的计算效率受限于高带宽内存(HBM)的读写速度,而不是计算速度本身。IO感知注意力的核心思想是优化GPU内部不同级别内存(如HBM和SRAM)之间的数据移动,从而大幅减少内存读写次数和总量,实现加速。
标准注意力计算的问题:
高内存使用:Q、K矩阵很大时,难以全部放入快速的SRAM中计算。
过多的HBM访问:标准计算流程需要多次在HBM和SRAM之间读写中间结果(如S和P),导致性能瓶颈。
S、P、O 指的是三个巨大的中间矩阵
S - Score Matrix(分数矩阵)
计算方式:
S = Q * Kᵀ它的每个元素
S[i][j]表示第i个查询向量(Query)与第j个键向量(Key)的点积(相似度分数)。大小:
[序列长度 N, 序列长度 N]。这是一个巨大的矩阵,因为序列长度N可能达到数万甚至更长。
P - Probability Matrix(概率矩阵)
计算方式:
P = softmax(S)对 S 矩阵的每一行进行softmax操作,将其归一化为一个概率分布,表示每个查询对所有键的注意力权重。
大小:和 S 一样大,也是
[N, N]。
O - Output Matrix(输出矩阵)
计算方式:
O = P * V将注意力权重矩阵 P 与值向量矩阵 V 相乘,得到最终的注意力输出。
大小:
[N, 模型维度 d]。
为什么说“融合”避免了多次读写HBM?
在标准的实现中(例如使用PyTorch的标准算子),这三个步骤是分开的:
从HBM读取 Q, K → 计算 S → 将 S 写回HBM。
从HBM读取 S → 计算 P → 将 P 写回HBM。
从HBM读取 P, V → 计算 O → 将 O 写回HBM。
这导致了大量的HBM读写,因为巨大的中间矩阵 S 和 P 被反复写入和读取。
FlashAttention的“融合”做法是:
它将整个计算过程重写为一个单一的自定义CUDA内核(Kernel)。
这个内核的工作流程如下:
将输入(Q, K, V)从HBM加载到快速的SRAM(共享内存)中。
在SRAM内部,按分块(Tiles)的顺序进行所有计算:
计算一个 S 的小分块。
立即对这个分块进行 softmax(得到 P 的一个分块)。
立刻用这个 P 的分块去计算 O 的一个分块。
最终,只将结果 O 写回HBM。
关键优势:
巨大的中间矩阵 S 和 P 永远不会被写回(或读取自)缓慢的HBM。它们只在快速的SRAM中被生成和使用,然后就被丢弃。
整个过程只需要:
从HBM读取一次 Q, K, V。
将最终结果 O 写回一次HBM。
这种将多个计算步骤融合到一个内核中、并避免中间结果读写的技术,是FlashAttention性能飞跃的核心,也被称为 “核融合(Kernel Fusion)”。
4.1.1 FlashAttention-1¶
核心思想: 通过分块计算(Tiling) 和核融合(Kernel Fusion) 来优化内存读写。
三大关键贡献:
在线Softmax(Online Softmax):不存储巨大的中间注意力分数矩阵S,而是分块计算Softmax,并通过维护 运行最大值(Running Max) 和 运行总和(Running Sum) 来保证数值稳定性。
融合注意力计算(Fused Attention Computation):将计算S、P、O的三个步骤融合到一个CU内核中执行,避免了多次读写HBM。
反向传播重计算(Recomputation in Backward Pass):在反向传播时,不存储前向传播中的中间结果(如S和P),而是根据保存的归一化统计量(最大值和总和)重新计算它们。这是一种用计算换内存的策略,显著减少了内存占用。
4.1.2 FlashAttention-2¶
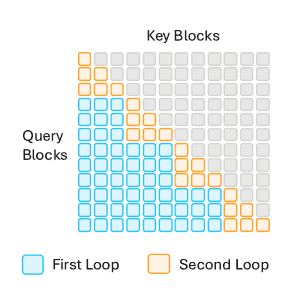
Figure 8:Attention Map Computation in FlashAttention-2.
核心思想: 在FlashAttention-1的基础上,进一步优化GPU的硬件利用率,特别是针对Tensor Cores(专门用于高效矩阵乘法的硬件单元)。
主要优化点:
减少非矩阵乘法操作:减少Softmax计算中的簿记开销(如记录中间值),并将一些操作直接融合到Tensor Core的流水线中。
改进循环结构:采用 “查询在外,键值在内”(Query-Outer, Key-Value-Inner) 的循环方式,提升了并行度。
行式计算(Row-wise Computation):并行处理每个查询块与所有键值块的计算。对于因果注意力,分两步计算:先计算非掩码部分,再处理对角线上的掩码部分(公式24)。
4.1.3 FlashAttention-3¶
核心思想: 专为新一代Hopper架构GPU(如H100)设计,利用了其两个新硬件特性:Tensor Memory Accelerator (TMA) 和 WGMMA指令。
三大关键创新:
生产者-消费者异步(Producer-Consumer Asynchrony):
生产者(Producer Warps):专门负责使用TMA高效地从HBM中预取数据。
消费者(Consumer Warps):专门负责进行矩阵乘法和Softmax等计算。
这种分工使得数据加载和计算可以同时进行,大大减少了等待时间,提升了硬件利用率。
交错矩阵乘法和Softmax(Interleaved Matmul+Softmax):使用双缓冲(Double-Buffering) 技术,在计算当前块的Softmax时,同时用WGMMA计算下一个块的分数,让计算单元时刻保持忙碌。
分块FP8量化与非相干处理(Block-Wise FP8 Quantization with Incoherent Processing):所有计算使用8位浮点数(FP8) 以提升速度和减少内存。每个数据块独立选择自己的缩放因子,有效控制了累积误差,在享受FP8好处的同时保持了精度。
4.2 Grouped Attention¶
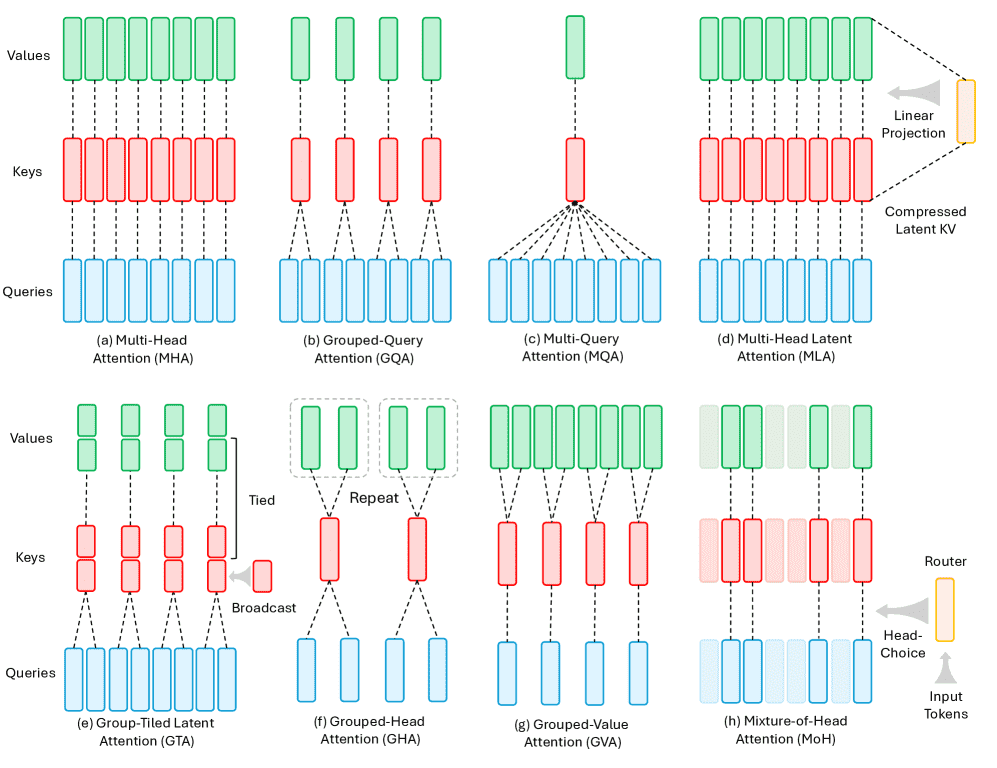
Figure 9:Mechanism Comparison of Primary Grouped Attention Methods.
本节概述: 这类方法通过让多个查询头(Query Heads)共享更少的键值头(Key/Value Heads)来减少推理时KV缓存(KV Cache)的大小,从而提升推理速度和内存效率。
MQA (Multi-Query Attention):所有查询头共享一组键头和值头。极大减少了KV缓存,但有时会导致模型质量下降。
GQA (Grouped-Query Attention):是MHA和MQA的折中方案。将查询头分成若干组,每组共享一组键头和值头。在几乎保持MHA质量的同时,获得了接近MQA的推理速度。支持通过“上行训练(Uptraining)”将现有MHA模型低成本地转换为GQA模型。
MLA (Multi-head Latent Attention):将KV缓存压缩到一个低秩潜在向量中,比MQA压缩得更狠。它将位置信息从压缩的KV中解耦出来。
GTA (Group Tied Attention):在GQA基础上,将键和值投影合并为一个共享表示,进一步减少缓存。它巧妙处理了RoPE,只将一半的绑定状态用于非RoPE部分。
GLA (Group Latent Attention):改进了MLA,将其潜在KV缓存分片(Sharding),允许在不同设备上并行计算,解决了MLA在张量并行时的效率问题,推理速度更快。
4.3 Mixture of Attention¶
本节概述: “混合专家”(MoE)的思想被引入到注意力机制中。核心是动态和稀疏化:不是对所有token或所有头都进行完整的注意力计算,而是让模型学会根据输入动态地选择最合适的计算路径。
MoA (Mixture-of-Attention):为不同的头分配不同的稀疏注意力模式,自动选择以扩展上下文长度。
SwitchHead & MoH (Mixture-of-Heads):将注意力头视为“专家”,每个token只激活一部分头(硬路由或软加权),减少计算量。
LLaMA-MoE v2:将MoE扩展到整个LLM的注意力和前馈层。
MoBA (Mixture of Block Attention):在块级别进行路由,每个token块可以动态选择使用全注意力还是稀疏注意力。
MoM (Mixture-of-Memories):将MoE应用于线性序列建模的记忆状态,使用多个稀疏激活的记忆槽。
MoSA (Mixture of Sparse Attention):在token级别进行稀疏化,每个头为每个查询动态选择最相关的k个token。
演进趋势: 从固定的稀疏模式 -> 头级别的动态选择 -> 块级别的动态选择 -> token级别的动态选择,越来越灵活和高效。
4.4 Quantized Attention¶
本节概述: 通过降低数值精度(如从FP16到INT8甚至INT4)来表示权重和激活值,从而减少内存占用和计算量,提升效率。分为训练后量化(PTQ) 和量化感知训练(QAT) 两大类。
训练后量化(PTQ):直接对训练好的模型进行量化,无需重新训练。
SageAttention:将QKᵀ计算量化为INT8,但softmax和与V的乘法保持在FP16(混合精度)。
INT-FlashAttention:将Q、K、V和softmax输入全部量化为INT8,整个注意力在INT8中完成。
Q-BERT:使用基于Hessian矩阵的分析来确定各层的最佳量化精度,甚至可以实现2-4比特的超低比特量化。
量化感知训练(QAT):在训练过程中模拟量化效应,让模型适应低精度。
Q8BERT:在8比特约束下微调BERT模型。
I-BERT:用整数近似所有操作(包括GELU和softmax),实现真正的端到端INT8推理。
FullyQT:量化所有矩阵乘,甚至用位移来近似softmax中的指数计算。
混合精度注意力:根据操作对精度的敏感程度,在不同步骤使用不同的精度(如QKᵀ用INT8,与V相乘用FP16),平衡速度和精度。
超低比特(<4bit)注意力:
SageAttention2/3:使用INT4/FP4等精度,并配合每块缩放(Block-wise Scaling)等技术来抑制误差。
BitDistiller:使用QAT和知识蒸馏来训练2-3比特的模型。
5 Sparse Mixture-of-Experts¶
核心理解: 这一章是总览,介绍了MoE的核心思想和价值。
目标:用一种高性价比的方式扩大模型能力(参数更多、更聪明),但不显著增加计算消耗(每次计算只使用一部分参数)。
基本组成:一个门控(Gate) 和多个专家(Experts)。
门控 像一个路由器,接收输入,并智能地选择最相关的几个专家来处理它。
专家 是小型神经网络(通常是前馈网络FFN),每个专家可能擅长处理不同类型的输入(如不同主题的文本)。
优势:通过这种“稀疏激活”机制(每次只用少数专家),可以极大地扩展模型总参数量,从而提升任务性能。因此,MoE被广泛应用于现今的大型语言模型(LLMs)中。
本章节还提到,接下来将详细介绍两个核心组件(门控和专家)以及如何从现有“稠密”模型(Dense Model,即普通模型)构建MoE,以节省从头训练的巨大成本。
5.1 Routing Mechanisms¶
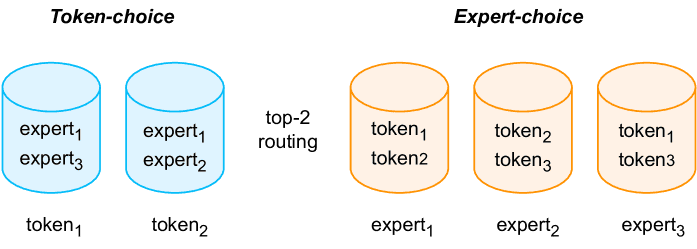
Figure 10:MoE Routing Strategies.
核心理解: 这一节详细讲解了门控(Gate) 是如何工作的,即“路由”机制——如何决定哪个输入由哪个专家处理。
1. 基本门控函数¶
门控本质上是一个可学习的函数。最常见的形式是一个线性变换加一个Softmax函数(见公式25),它会为每个输入token计算一个概率分布,表示它被分配到每个专家的可能性。
为了数值稳定,这个计算通常需要较高的精度(FP32)。
也有一些变体,比如用更复杂的网络(带非线性激活的FFN)代替线性变换,或用Sigmoid、余弦相似度函数代替Softmax,以解决某些问题(如表示坍塌、专家竞争)。
2. 引入稀疏性:Top-k 选择¶
得到概率分布后,MoE不会让所有专家都工作。它只选择概率最高的 k个专家(例如top-2)来实际处理当前输入。这是“稀疏性”的关键(公式26)。
通常会对这k个专家的概率进行重新归一化,让它们的和为1,以利于模型训练。
3. 路由策略(Routing Strategies)¶
Token-Choice(令牌选择):这是最常用的策略。每个输入token自己选择k个专家。如图10左侧所示。
问题:容易导致负载不均衡。热门专家可能被大量token选择,忙不过来;冷门专家可能无事可做,造成计算资源浪费。甚至可能因为单个专家的处理能力上限而导致某些token被丢弃。
Expert-Choice(专家选择):每个专家自己选择k个最想要的token。如图10右侧所示。
优点:可以实现完美的负载均衡,每个专家处理的任务量完全一样。
缺点:在自回归语言建模(逐个生成token)中,专家无法看到完整的未来序列,可能导致它过早地“招满”了token,没有名额处理后面更重要的token。因此需要额外的机制来为未来预留空间。
4. 其他路由方案¶
BASE Layer:将路由变成一个线性分配问题,在训练时强制每个专家处理完全等量的token,从而无需额外的均衡损失函数。推理时使用更简单的贪心分配。
Hash Layer:不使用可学习的门控,而是用一个固定的哈希函数(如预先根据词频分配好的查找表)来决定token的去向。试图实现均衡,但受语言本身的 Zipf 定律(少数词出现频率极高)影响,完美均衡很难。
5. 自适应 Top-k 路由(Adaptive Top-k Routing)¶
核心思想:根据输入任务的难易程度,动态调整每个token使用的专家数量(k)。简单的任务少用点专家省计算,复杂的任务多用点专家保效果。 分为三类:
可微分激活:用ReLU、Sigmoid等可微分函数代替不可微的Top-k操作,让模型能直接学习如何稀疏化。需要加正则化来控制稀疏度。
专家激活估计:动态估计k的值。例如:
MoE-Dynamic:设定一个置信度阈值p,从概率最高的专家开始选,直到累计概率超过p为止。
Ada-K:用一个额外的“分配器”模块来为每个token预测一个最优的k值。
零计算专家:引入一些不做任何计算的“空专家”(Null Experts)。门控仍然选择固定数量的k个“专家”,但其中可能包含几个空专家。这样,不重要的token实际上就被分配到了空专家,相当于跳过了计算,实现了动态计算分配。
6. 负载均衡(Load Balancing)¶
为什么重要:在Token-Choice策略中,负载不均衡会导致某些专家训练不足(MoE坍塌),并降低训练效率(专家间等待)。
常见方法:辅助损失函数:在主要的目标函数(如交叉熵损失)之外,增加一个额外的损失项来鼓励负载均衡。
早期方法(Shazeer et al.):使用门控概率和专家负载的变异系数(CV) 作为损失项。
流行方法(GShard):计算专家负载和门控重要性分数的乘积的均值。这是目前很多LLM的默认设置。
无需辅助损失的方法:
动态偏置:根据每个专家近期的负载,动态地给它的路由分数加一个偏置(忙的专家减分,闲的专家加分),直接调整路由决策来实现均衡,避免了辅助损失可能带来的梯度干扰。
全局负载均衡:指出在微批次级别计算均衡损失会迫使即使是领域特定的token也要均匀分布,抑制了专家的专业化。提出在全局批次级别同步所有并行微批次的专家负载后再计算损失,这样可以在整个语料库级别实现均衡,从而让专家更好地专业化。
5.2 Expert Architectures¶
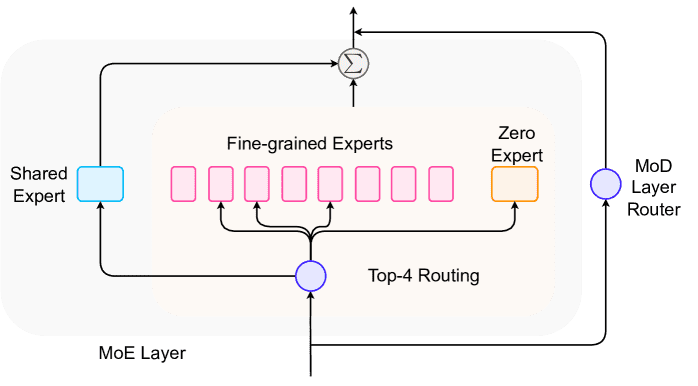
Figure 11:MoE Expert Architectures.
核心理解: 这一节讲解了专家(Experts) 本身的不同设计架构。
传统专家:就是多个FFN块。但仍有改进空间。
专家专业化:在预训练后,每个专家会变得专业化(例如处理特定领域或模式的token)。这催生了一种高效的微调(PEFT)范式:只微调与任务相关的特定专家,可以极大降低成本。
如图11所示,专家架构有多种类型:
细粒度专家(Fine-grained Experts):
思想:在总参数量不变的情况下,创建更多但更小的专家(例如64个小型专家,而不是16个大型专家)。
优势:专家组合的选择更多(从120种激增到44亿种),带来了更好的性能和的清晰缩放规律。
挑战:更多的专家带来了路由和训练/推理框架设计上的新挑战。
共享专家(Shared Experts):
思想:引入一个或几个所有token都会经过的固定专家。
作用:像一个共享的基础设施或残差连接,可以处理通用特征,可能提高模型的稳健性和性能。不同模型(DeepSpeed-MoE, Qwen2-MoE, DeepSeekMoE)有不同的方式将共享专家的输出与特定专家的输出结合起来。
混合深度(Mixture-of-Depths, MoD):
思想:从“层”的视角进行垂直分布。将Transformer的 层本身视为专家,用一个门控为每一层选择top-k的token进行处理。
效果:跳过某些层的计算,显著减少总计算量。与MoE正交,可以结合成MoDE。
其他特殊专家:
SoftMoE:将token混合到“软槽位”中,让专家处理这些槽位。
MoE++:引入零计算、复制、常数专家等。
模块化:可以动态添加新的专家,或使用LoRA等轻量级模块作为专家,甚至可以将专家数量扩展到百万级。
5.3 MoE Conversion¶

Figure 12:MoE Conversion Strategies.
核心理解: 这一节讲解了如何从 现有的、训练好的稠密模型 出发,转换成MoE模型,从而 避免从头训练MoE的巨大成本。
如图12所示,主要有三种策略:
切分(Splitting):将一个稠密模型中的大型FFN 切分 成多个小FFN,作为MoE中的多个专家。例如MoEfication, LLaMA-MoE。
复制(Copying):将稠密模型中的FFN 复制 多份,作为MoE的专家,然后初始化一个新的门控。这被称为“稀疏升级循环”(Sparse Upcycling)。例如Komatsuzaki et al.的工作。
合并(Merging):将两个已有的稠密模型合并成一个MoE模型。
这部分还特别介绍了 “稀疏模型路由”:
Branch-Train-Merge (BTM):先在不同领域数据上分别训练多个专家模型。推理时,根据输入问题的领域,加权平均这些专家模型的参数,临时组合成一个新模型来生成回答。
Branch-Train-MiX (BTX):更直接地将多个专家模型的FFN直接聚合成MoE的各个专家,并为每一层训练一个新的门控来动态选择专家。这更像一个真正的MoE模型。
总结: 这段内容系统地阐述了MoE技术。第5.1节(路由) 是核心,解决了“如何智能分配任务”的问题;第5.2节(专家) 解决了“专家本身如何设计”的问题;第5.3节(转换) 则提供了降低应用MoE成本的实用方案。三者共同构成了MoE从理论到实践的全貌。
6 Hybrid Architectures¶
核心思想: 这一章主要介绍了为了解决Transformer模型(特别是其核心组件softmax attention)在长序列处理时效率低下的问题,而诞生的一种新模型设计思路——混合架构。其目标是 将线性模型的高效性和标准softmax attention的强大表达能力结合起来,在性能和效率之间取得更好的平衡。
详细解释:
背景与问题 (第一段):
Softmax Attention的优点与缺点: Transformer里的softmax注意力机制虽然性能强大,但它的计算量会随着序列长度呈平方级增长(二次复杂度)。同时,在生成任务中,需要缓存越来越多的键值对(KV-Cache),这都使得处理长序列时非常低效。
线性模型的优点与缺点: 线性模型(如Mamba, RWKV等)的计算复杂度是线性的,因此在效率上取得了重大突破。但它们的缺点是在某些需要精确记忆、检索稀疏信息或进行长序列建模的任务上,效果不如标准的softmax attention。
解决方案: 为了取长补短,研究人员开始开发混合模型。
核心挑战与分类 (第二段及图表):
挑战: 如何高效且有效(effectively)地将两者融合。
分类: 根据融合的粒度,混合模型分为两大类:
Inter-layer Hybrid (层间混合): 在不同的网络层之间进行混合。比如,每隔几层线性层,就插入一层softmax注意力层。
Intra-layer Hybrid (层内混合): 在单个网络层内部进行混合。比如,在同一层里,让一部分注意力头用线性注意力,另一部分用标准注意力。
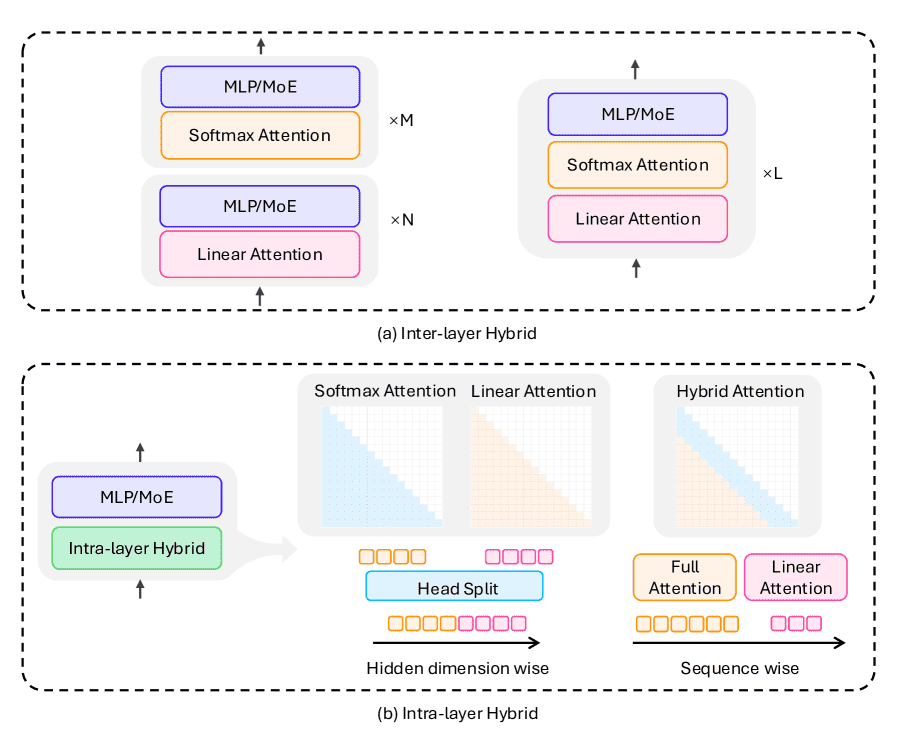
Figure 13:Hybrid Model Architectures. (a) illustrates the classical paradigm of inter-layer hybrid approach. (b) demonstrates the classical paradigm of intra-layer hybrid approach.
图解
The left side of (b) represents a pattern similar to Hymba, which employs head-wise partitioning with either softmax attention or linear attention.
The right side, depicts a pattern analogous to LoLCATs, featuring sequence-wise partitioning where local regions utilize softmax attention while distant regions employ linear attention.
6.1 Inter-layer Hybrid (层间混合)¶
核心思想: 按照一个预设的比例,将softmax注意力层和线性序列建模层(如Mamba层)交替堆叠起来。这种方法简单直接,且被证明非常有效,是目前的主流方法之一。
详细解释: 这一段列举了大量基于这种思想的模型实例,它们很多都基于Mamba架构:
Zamba: 在Mamba层中周期性地插入一个全局共享的自注意力块。
Zamba2: Zamba的升级版,改用Mamba2,并插入两个交替的共享注意力块。
Jamba: 一个更复杂的混合体,结合了Mamba、标准注意力和混合专家 (MoE),以7:1的比例交错排列,实现了高效推理和超长上下文。
Samba: 结合了Mamba和滑动窗口注意力 (Sliding Window Attention),完全不用全局注意力,也能处理极长序列。
Mamba-in-Llama: 通过知识蒸馏,将预训练好的Transformer的能力“教”给Mamba块,并构建混合模型。
Hunyuan-TurboS: 一个超大规模模型,使用了交错排列的Attention层、Mamba2层和前馈网络层。
Zebra-Llama: 结合Mamba2和另一种高效注意力MLA,并使用策略性地替换层来优化效率。
除了基于Mamba的模型,还有与其他线性模型结合的:
RWKV-X: 在RWKV(一种线性RNN模型)中穿插稀疏注意力层。
YOCO: 结合滑动窗口注意力和标准注意力,并创新地在层间共享KV缓存,极大提升长上下文效率。
RecurrentGemma: 结合Griffin(一种循环模型)和滑动窗口注意力,完全不用全局注意力,但性能媲美Transformer。
MiniMax-01: 一个巨型的MoE模型,集成** Lightning Attention**(一种线性注意力)和标准注意力来处理超长序列(400万token!)。
LaCT: 结合大块 tensor-train 和局部窗口注意力,高效建模长序列,应用于像视频生成这样的任务。
6.2 Intra-layer Hybrid (层内混合)¶
核心思想: 在单个层内部实现线性注意力和标准注意力的融合。主要分为两种设计模式:
Head-wise split (按头划分): 让同一个层中的一部分注意力头使用线性注意力,另一部分头使用标准注意力。
Sequence-wise split (按序列划分): 对输入序列的不同部分应用不同的注意力机制。例如,对最近的token用标准注意力(保证局部精度),对过去的遥远token用线性注意力(保证全局效率)。
详细解释:
Head-wise split (按头划分) 的例子:
Hymba: 经典代表。直接将一个层中的注意力头分成两组,一组用Mamba,另一组用标准注意力。还包含其他创新如可学习的元 token 等。
WuNeng: 结合RWKV和Transformer注意力,并通过头间的交互来平衡效果和效率。
Sequence-wise split (按序列划分) 的例子:
LoLCATs: 对序列中较早的token使用线性注意力,对最近的一些token使用滑动窗口注意力。它通过一种叫“注意力迁移”的技术来训练,只用很少的数据和参数更新就能改造超大模型(如405B)。
Liger: 通过重用原有Transformer的权重(如Key投影权重),将预训练模型改造成门控线性循环结构,混合了线性注意力和滑动窗口注意力。只需极少的微调就能恢复原模型大部分性能。
TransMamba: 用一个学习到的转换点来动态决定:序列的开头部分用标准注意力(追求精度),后续部分用Mamba(追求长程效率)。
LoLA: 集成了三种记忆系统:低秩线性注意力(存全局)、滑动窗口注意力(抓局部)、稀疏全局缓存(存重要细节),以此来克服单一线性模型的局限。
总结¶
特性 |
Inter-layer Hybrid (层间混合) |
Intra-layer Hybrid (层内混合) |
|---|---|---|
混合粒度 |
层间:不同层使用不同机制 |
层内:同一层内部使用不同机制 |
实现方式 |
交替堆叠Softmax Attention层和线性层 |
1. 按头划分:不同注意力头用不同机制 |
优点 |
结构简单,易于实现,是当前主流 |
融合更细粒度,可能找到更优的效-率平衡点 |
例子 |
Jamba, Zamba, Samba, RWKV-X |
Hymba (头划分), LoLCATs (序列划分) |
7 Diffusion Large Language Models¶
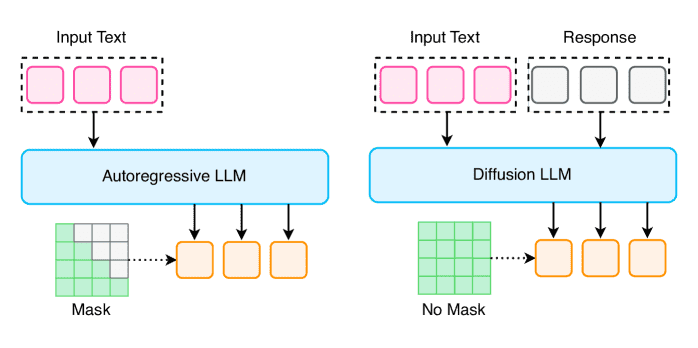
Figure 14:Mechanism Comparison of Autoregressive Models and Diffusion LLMs.
核心内容: 本章节是概述,介绍了扩散大语言模型(Diffusion LLMs)的基本概念、工作原理,并将其与传统的自回归模型进行对比,突出其优势。
详细解释:
背景(第一段): 前面章节讨论的基于Transformer的高效架构(如优化注意力机制、MoE)都是在自回归框架内改进的。自回归模型按顺序逐个生成token,这导致其推理速度存在根本性瓶颈(生成长序列需要很多次前向计算)。
引入(第二段): 本节将介绍一种新范式——扩散大语言模型。它与自回归模型不同,其生成过程类似于图像扩散模型:从一个充满噪声或掩码的序列开始,逐步去噪,最终得到一个连贯的文本输出。
优势(第三段):
并行解码: 可以在每一步去噪迭代中同时预测多个token,极大降低了推理延迟。
** superior controllability:** 由于生成是在一个固定长度的“画布”上进行去噪或填充,模型能更好地控制输出的长度、格式和结构。
双向注意力: 模型在每一步都能看到并修改整个序列的上下文,这有助于缓解自回归模型因单向注意力而产生的“逆转诅咒”等问题。
7.1 Non-Autoregressive Diffusion LLM¶
核心内容: 本节详细介绍了一个具体的非自回归扩散LLM模型——LLaDA,包括其工作原理、训练目标和理论依据。
详细解释:
LLaDA模型: 这是一个拥有80亿参数、从头开始训练的非自回归扩散模型。它通过一个前向过程(逐步掩码token)和一个反向去噪过程(每一步同时预测所有被掩码的token)来建模数据分布。
性能: 其表现与顶尖的自回归模型(如Llama3-8B)相当,并且克服了自回归模型的某些缺陷(如逆转诅咒)。
理论框架:
前向过程: 随“时间步”t从0到1,逐步随机掩码原始干净序列
x0中的token,得到带噪声的序列xt。反向过程: 模型学习一个参数化的掩码预测器
pθ(·|xt),其目标是根据带噪声的序列xt来 jointly 预测所有被掩码位置原来的token。训练目标(公式29): 通过最小化一个仅在掩码位置计算的交叉熵损失函数来优化模型参数θ。
理论依据(公式30): 这个训练目标
ℒ(θ)是模型负对数似然的一个变分上界。这意味着优化该目标就是在原则上进行密度估计,使LLaDA成为一个真正的生成模型,从而涌现出上下文学习等能力。
与BERT的区别: BERT使用固定掩码率进行训练,而LLaDA使用随机掩码率,这是其成为生成模型的关键设计。
强化学习增强(d1框架): 本节最后指出,通过一个名为d1的两阶段框架(先有监督微调,再用专为扩散模型设计的diffu-GRPO算法进行强化学习),扩散LLaDA模型在数学和逻辑推理任务上取得了巨大提升,证明了扩散模型在经过RL增强后也可以成为强大的“推理者”,挑战了自回归模型在该领域的统治地位。
7.2 Bridging Diffusion LLM and Autoregressive¶
核心内容: 本节讨论了如何结合扩散模型和自回归模型的优势,取长补短,并介绍了两种混合架构:BD3-LMs和DiffuLLaMA。
详细解释:
动机: 扩散模型(并行生成,可控性强)和自回归模型(似然建模能力强,支持可变长度输出)各有优缺点。本节研究如何将二者结合。
BD3-LMs(Blockwise Autoregressive Diffusion):
思想: 将序列分割成多个块。在块与块之间采用自回归的方式生成(一个块接一个块),而在每个块内部使用扩散过程来并行生成所有token。
好处: 结合了扩散的并行加速和自回归的可变长度生成优势。它还能利用自回归模型的KV缓存机制来提升效率。
形式化(公式31-34): 联合似然通过块间的自回归分解(公式31)和块内的扩散过程(公式32-33)来定义。训练目标同样是负对数似然的一个上界(公式34)。
DiffuLLaMA(转换预训练模型):
思想: 另一种思路是直接将现有的、丰富的预训练自回归模型(如GPT-2, LLaMA)转换成扩散模型架构。
好处: 无需从头训练,节省大量数据和算力。转换后的模型(DiffuGPT, DiffuLLaMA)性能优异,并能继承原模型的能力(如上下文学习、指令遵循)。同时,它们天然擅长“中间填充”任务。
7.3 Extending Diffusion LLM to Multimodality¶
核心内容: 本节探讨了将扩散大语言模型从纯文本领域扩展到多模态(文本+视觉)领域的最新进展,并介绍了几种不同的模型架构和训练策略。
详细解释:
基本方法: 多模态扩散LLM通常通过加入一个视觉编码器和一个投影层来实现。视觉编码器提取图像特征,投影层将这些特征映射到语言模型的嵌入空间中。
纯扩散方法:
LLaDA-V: 纯粹的基于扩散的多模态模型,通过视觉指令调优实现有效的多模态对齐。
UniDisc: 主张在文本和视觉域使用统一的离散扩散范式。它将文本和图像一起token化到共享词汇表中,使用完全自注意力,展现出强大的多模态修复和编辑能力。
LaViDa: 专注于解决多模态扩散模型的实际挑战,引入了 complementary masking、Prefix-Diffusion LLM decoding(支持KV缓存)和 timestep shifting 等技术来提升训练效率和生成质量。
混合方法:
Dimple (Autoregressive-then-Diffusion): 采用两阶段训练范式。第一阶段使用自回归训练来实现稳健的视觉-语言对齐和指令遵循能力。第二阶段转换为扩散训练,以重新获得并行解码的优势。在推理时还采用了Confident Decoding和Structure Priors等技术。
统一基础模型方法:
MMaDA: 这是一个更前沿的尝试,旨在构建一个统一的多模态扩散基础模型。它采用与模态无关的设计和共同的概率框架,消除了特定模态组件的需求。它还结合了“混合长链思维”微调方法和一个统一的RL算法(UniGRPO),能够在文本推理、多模态理解和文生图等不同任务上表现出色。
总结: 这段文字系统地介绍了扩散大语言模型这一新兴方向。它从基本概念和优势出发,然后深入一个具体模型(LLaDA)的实现细节和理论,接着探讨了与自回归模型结合的混合架构,最后展望了其在多模态领域的应用与创新。整个章节展示了扩散模型如何为LLM带来并行化、可控性和新能力,成为自回归模型之外的一个强大替代方案。
8 Applications to Other Modalities¶
核心主旨: 最初为文本领域开发的高效架构(如线性时间序列模型SSM、RWKV,以及稀疏计算策略MoE),因其强大的性能和高效率,正被广泛地迁移和应用到非文本数据中。这展示了这些模型的通用性,为人工智能领域解决了以前难以处理的大规模问题。
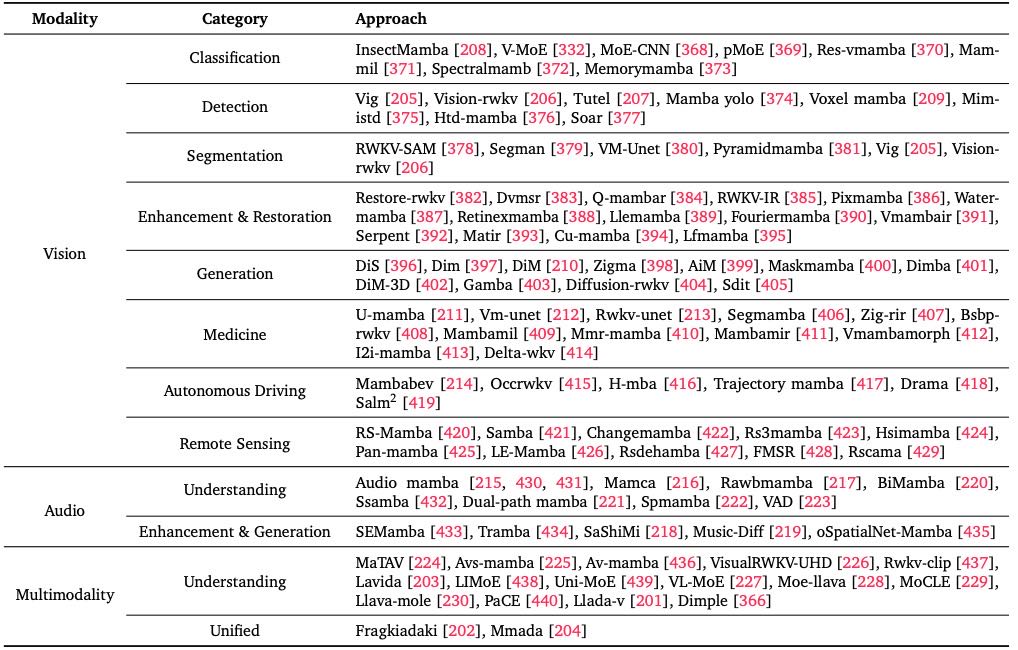
Table 2:Overview of Applications of Efficient Architectures Across Modalities and Categories.
8.1 视觉 (Vision)¶
核心主旨: 为了克服视觉Transformer(ViT)二次计算复杂度的瓶颈,研究者将SSM(如Mamba)和MoE等高效架构引入计算机视觉领域,在保持高性能的同时实现了计算效率的巨大提升。
8.1.1 图像分类、检测与分割¶
分类 (Classification):
主流方法是创建混合架构,将SSM与CNN等传统模块结合,以同时捕获局部特征和长程依赖。
为解决SSM一维特性处理二维图像的问题,提出了创新的数据扫描策略(如多路径扫描、拓扑感知扫描)。
MoE模型(如V-MoE)通过稀疏激活“专家”子网络,能以更低的计算成本缩放模型到数十亿参数。
检测 (Detection):
将SSM集成到现有检测器框架中(如Mamba-YOLO),实现实时性能。
应用于专业领域:如Voxel-Mamba用于3D点云检测,Fusion-Mamba用于RGB-红外跨模态融合检测。
其他高效架构(如ViG, Vision-RWKV)也展现出竞争力。
分割 (Segmentation):
采用编码器-解码器混合架构,用SSM/RWKV捕获全局上下文,配合卷积等局部机制保留细节。
同样成功应用于裂缝分割、遥感等专业领域。
8.1.2 图像增强、恢复与生成¶
增强与恢复 (Enhancement & Restoration):
基于U-Net框架,将Mamba/RWKV与物理原理(如Retinex理论)结合,用于低光增强、水下图像增强等。
针对去雾、超分等任务,创新点在于适应2D数据的扫描策略和混合架构。
其效率优势在处理高维数据(如4D光场、医学图像)时尤为明显。
生成 (Generation):
一个主导趋势是用Mamba等架构替换扩散模型中的Transformer主干网,以降低计算成本。
核心挑战是让一维SSM处理二维图像,催生了新颖扫描模式(之字形扫描、双向处理)。
应用扩展到自回归生成、3D生成等,RWKV也成为生成式AI的高效选择。
8.1.3 特定领域应用¶
医学 (Medicine):
核心:将Mamba/RWKV集成到U-Net中,用于2D/3D医学图像分割、分类和重建。
优势:在数据有限的医疗 settings 中表现出色,能有效处理 Whole-Slide Images 等极长序列。
应用:MRI重建、图像配准、多模态合成、内窥镜器械跟踪等。
自动驾驶 (Autonomous Driving):
应用于整个自动驾驶 pipeline:感知(3D检测、占据预测)、预测(轨迹预测)、规划(运动规划)。
其线性复杂度对于处理时序和空间信息、实现实时车内应用(如驾驶员监控)至关重要。
遥感 (Remote Sensing):
高效模型非常适合处理超高分辨率(VHR)和高光谱图像。
创新点在于开发** specialized 扫描机制**(如全方位扫描)以捕捉复杂的地物空间布局。
应用于分割、变化检测、分类、图像融合(pansharpening)、去雾、超分乃至图像描述生成。
8.2 音频 (Audio)¶
核心主旨: 音频领域广泛采用高效序列模型来处理长音频信号,利用其线性复杂度在理解、增强和生成任务中建立新的性能基准。
理解 (Understanding):
成功应用于音频标记、分类、调制分类等任务。
关键创新:开发双向Mamba模型以捕获音频的非因果上下文,用于深度伪造检测、语音处理。
作为自监督预训练的骨干网,学习到的音频表征优于之前的Transformer方法。
增强与生成 (Enhancement & Generation):
语音分离/增强: 用Mamba块替换SOTA模型中的注意力或循环模块,在降低复杂度的同时达到新SOTA。
生成: 其循环特性使其非常适合生成任务(如原始波形生成、符号音乐生成)。
流式处理: Mamba和RWKV用于构建低延迟流式系统,如多通道语音增强、语音活动检测(VAD)和自动语音识别(ASR)。
8.3 多模态 (Multimodality)¶
核心主旨: 在多模态学习中,高效架构对于对齐多种数据流和扩展大模型至关重要。主要使用线性时间模型(Mamba, RWKV)进行对齐与融合,并利用稀疏MoE来高效扩展模型规模。
理解 (Understanding):
Mamba 用于构建复杂的对齐和融合模块,同步文本、音频、视频特征,或进行跨模态注意力建模。
RWKV 被适配用于视觉-语言学习,如处理高分辨率图像(VisualRWKV-UHD)或构建高效的CLIP-like模型(RWKV-CLIP)。
生成与统一 (Generation & Unified):
趋势: 使用扩散模型作为自回归系统的替代品进行多模态生成(如LaViDa, MMaDA)。
子趋势: 离散扩散模型(如Dimple, UniDisc)将所有模态映射到离散令牌,支持并行解码和跨模态编辑等新功能。
高效扩展 (Scaling with MoE):
MoE 是扩展大型多模态模型的主导范式。
从头构建基础模型(如LIMoE, Uni-MoE)。
高效微调: 使用“MoE-Tuning”增加模型容量但保持计算成本不变(MoE-LLaVA),或使用混合LoRA专家来缓解任务/数据冲突。
组合专家: 将复杂任务分解为子技能,由不同的专家模块处理(如PaCE)。
总结¶
这段文字系统地阐述了高效架构如何从文本领域“破圈”,成为推动计算机视觉、音频和多模态学习发展的关键动力。其核心价值在于以线性或近似线性的计算复杂度,实现了处理长序列、高分辨率数据并捕获全局依赖的能力,从而使得在更多领域构建大规模、高性能的模型变得可行。
9 Conclusion and Future Directions¶
这段文字是一篇学术综述(Survey)的结论部分,它做了两件事:1. 总结全文;2. 展望未来。
第一部分:总结 (我们现在在哪里?)¶
作者首先总结了当前在提升Transformer模型效率方面所取得的进展。
核心问题:传统的Transformer模型(如GPT、BERT等)存在效率瓶颈。
计算成本高:自注意力机制的计算量随序列长度呈平方级增长。
内存需求大:前馈网络层也又大又多,加剧了计算和内存的消耗。
这些问题在处理长文本、多模态(如图文)和多步推理任务时尤其严重。
解决方案分类:为了应对以上问题,研究者们提出了多种方法,本文将其归纳为七大类别:
线性序列建模:用线性复杂度的方法替代注意力机制。
稀疏序列建模:让注意力只计算最重要的部分,而不是全部。
高效全注意力:优化技术,让完整的注意力计算得更快。
稀疏专家混合:一个模型由很多“小专家”组成,每次只激活一部分,大幅减少计算量。
混合架构:结合Transformer和其他高效架构(如RNN、状态空间模型)的优点。
扩散大模型:用扩散模型(类似AI画图的原理)来生成文本,可实现并行生成。
跨模态应用:将以上高效技术应用到图文、视频等多模态模型中。
本文贡献:作者系统性地梳理了这些方法,分析了它们核心思想、技术细节、优缺点,为读者描绘了一幅清晰的“技术地图”。
第二部分:未来方向 (我们要往哪里去?)¶
作者接着指出了未来值得探索的两大方向:
方向一:高效架构设计 (如何把模型本身造得更高效?)¶
这个方向关注的是底层技术和基础架构的创新,目标是打造更强大的“发动机”。
软硬结合:不再只设计算法,还要同时设计配套的系统和硬件(如专用芯片),尤其为手机等边缘设备优化。
动态调整:让注意力机制变得“智能”,能根据输入内容或设备性能动态调整计算量。
优化专家路由:让MoE中的“路由器”更聪明,更高效地分配任务,减少专家间的通信开销。
超大规模模型:研究如何支撑参数更多的模型(如万亿参数),重点在内存管理和稀疏激活。
分级记忆:给模型装上类似电脑的“内存+硬盘”系统,分层级地存储和调用历史信息和知识。
小型边缘模型:为手机、摄像头等设备专门设计轻量级小模型,通过裁剪、量化等技术实现。
非自回归扩散模型:继续发展扩散模型,以期在保持质量的同时,实现并行、快速的文本生成。
方向二:高效架构的应用 (用更高效的模型能做什么酷炫的新事情?)¶
这个方向关注的是 上层应用和功能,基于高效的模型,去实现以前难以完成的任务。
无限长上下文:高效处理极长甚至无限长的文档,极大增强检索、推理和多模态能力。
高效智能体:让AI智能体能够实时地使用工具、进行规划和多模态推理,实现低延迟交互。
高效推理模型:构建专门用于复杂推理任务的高效模型,减少冗余计算。
高效具身智能:打造高效的视觉-语言-动作模型,让机器人能进行实时视觉推理和实时控制。
高效全模态模型:用一个高效的统一模型处理所有类型的数据(文本、图片、音频、3D等)。
高效多模态生成:实现既能理解又能生成多模态内容的高效模型,输出更连贯、符合语境的结果。
持续与终身学习:让模型能够持续学习新知识而不会忘记旧知识,适应不断变化的环境。
核心要点总结¶
方面 |
核心思想 |
关键词 |
|---|---|---|
现状总结 |
Transformer有计算和内存效率问题,尤其在长序列、多模态场景。研究者已提出七大类方法来解决。 |
自注意力、FFN层、效率瓶颈、七大类别 |
未来方向1:设计 |
深耕底层技术,从算法、系统、硬件协同设计,让模型本身更快、更小、更智能。 |
软硬协同、动态调整、MoE路由、边缘计算、扩散模型 |
未来方向2:应用 |
拓展上层应用,利用高效模型实现以前做不到的酷炫功能,如无限长文本、实时智能体、机器人控制等。 |
无限上下文、智能体、多模态、终身学习、具身智能 |
简单来说,这段话讲的是:我们通过一系列技术解决了Transformer模型“又慢又胖”的问题,未来一方面要继续把模型造得更高效,另一方面要用这些高效模型去开启AI应用的新纪元。