2502.12110_A-Mem: Agentic Memory for LLM Agents¶
引用: 46(2025-08-10)
组织:
1Rutgers University(罗格斯大学)
2Independent Researcher
3AIOS Foundation
GitHub:
Code for Benchmark Evaluation: https://github.com/WujiangXu/A-mem
Code for Production-ready Agentic Memory: https://github.com/WujiangXu/A-mem-sys
总结¶
灵感来源于Zettelkasten方法(一种知识管理方法)
根据第3章Methodolodgy整理的架构图: https://qcn3wi057vzm.feishu.cn/wiki/KiD9wh4ipiJeTBkPfpdc4Sn1nQe
在附录 B 中有整理的 prompt
From Deepseek¶
研究背景:
大型语言模型(LLM)智能体在复杂任务中能有效利用外部工具,但其性能高度依赖记忆系统以存储和利用历史经验。现有记忆系统(如简单存储检索或图数据库)缺乏动态组织能力,且固定结构和操作限制了跨任务的适应性。
核心创新:
本文提出 A-MEM(Agentic Memory),一种新型的智能体记忆系统,基于 Zettelkasten(卡片盒笔记法) 的动态索引与链接机制,构建互联知识网络。关键设计包括:
结构化记忆表示:新记忆以多属性笔记形式存储(如上下文描述、关键词、标签)。
动态关联分析:自动分析历史记忆,建立语义关联链接。
记忆演化机制:新记忆的加入可触发旧记忆的上下文与属性更新,实现知识网络的持续优化。
技术优势:
智能体驱动(Agentic):结合 Zettelkasten 的结构化组织与 LLM 的决策灵活性,支持动态、情境感知的记忆管理。
可扩展性:适用于多样化任务,优于静态记忆系统。
实验结果:
在 6 个基础模型 上的实验表明,A-MEM 显著超越现有 SOTA 基线(如传统检索或图数据库方法),尤其在复杂任务中展现更强的记忆关联与演化能力。
意义:
为 LLM 智能体提供了更高效、自适应的记忆系统,推动其在长期交互与复杂推理任务中的应用。
Abstract¶
本文探讨了大型语言模型(LLM)代理在处理复杂现实任务时,如何通过外部工具提升性能,同时指出这些代理需要具备记忆系统以便利用历史经验。当前的记忆系统虽然能够实现基本的存储和检索功能,但其在记忆组织方面较为初级,缺乏复杂的结构。尽管已有研究尝试引入图数据库等结构化工具,现有系统仍然存在操作和结构固定的问题,这限制了其在不同任务间的适应能力。
为了解决上述问题,本文提出了一种新的代理式记忆系统(agentic memory system),能够以一种动态的方式组织记忆。该系统的灵感来源于Zettelkasten方法(一种知识管理方法),通过动态索引和链接,构建互联的知识网络。每当系统添加新记忆时,会生成一个包含多种结构化属性的综合笔记,如上下文描述、关键词和标签等。系统随后分析历史记忆,识别相关性并建立有意义的链接。
特别值得注意的是,该系统支持记忆进化:新记忆的加入可以触发对已有记忆的上下文和属性的更新,从而实现记忆网络的持续优化和理解提升。通过将Zettelkasten的结构化组织原则与代理驱动的决策机制相结合,该系统实现了更适应性强、上下文感知的记忆管理。
实验部分在六个基础模型上进行,结果表明,该方法在多个基准测试中显著优于现有最先进(SOTA)的方法。文中还提供了代码链接,用于基准评估和实际应用的记忆系统实现。
1 Introduction¶
LLM agents 的能力与挑战:
大型语言模型(LLM)代理在多种任务中表现出了卓越的能力。近期的研究使它们能够与环境交互、执行任务并自主决策。这些代理通过将 LLM 与外部工具和复杂的工作流程结合,提升了推理和规划能力。尽管 LLM 代理具有出色的推理能力,但为了实现与外部环境的长期交互,仍需要一个有效的记忆系统。
现有记忆系统的局限性:
当前的 LLM 代理记忆系统提供了基本的记忆存储功能,但它们要求开发者预先定义存储结构、指定工作流中的存储点,并设定检索时间。
Mem0 等系统尝试引入图数据库,以提升结构化组织能力,其原理借鉴了 RAG(Retrieval-Augmented Generation)技术。然而,图数据库依赖预设的模式和关系,这在实际应用中限制了其灵活性。例如,当代理学习到一种新的数学解法时,现有系统只能将其归类到预设框架中,无法建立新的联系或演化知识结构。这种刚性结构与固定的工作流严重限制了系统在新环境中的泛化能力和长期交互的有效性。

Figure 1:Traditional memory systems require predefined memory access patterns specified in the workflow, limiting their adaptability to diverse scenarios. Contrastly, our A-Mem enhances the flexibility of LLM agents by enabling dynamic memory operations.
A-Mem 的核心思想:
本文提出了一种新的代理记忆系统 A-Mem,该系统无需静态预设的记忆操作,而是支持动态的记忆结构。A-Mem 的设计灵感来源于 Zettelkasten 方法,这是一种通过原子笔记和灵活链接机制构建信息网络的知识管理系统。A-Mem 构建了包含结构化文本属性和嵌入向量的综合笔记,并通过语义相似性和共享属性分析历史记忆库,建立有意义的联系。新记忆的加入会触发现有记忆的更新,使整个记忆库能够不断优化和深化。
主要贡献总结:
提出的 A-Mem 系统:它支持 LLM 代理自主生成上下文描述、动态建立记忆连接,并基于新经验智能演化现有记忆,为长期交互提供了能力。
设计了记忆更新机制:新记忆自动触发两个关键操作,一是通过识别共享属性和相似描述建立链接,二是使现有记忆动态适应新经验,从而形成更高阶的模式和属性。
进行了系统评估:使用长期对话数据集对 A-Mem 进行了全面评估,通过六个基础模型和六个不同指标,展示了显著的性能提升,并提供了 T-SNE 可视化以说明其结构化组织能力。
重点强调:
A-Mem 的创新点在于其 动态性 和 自主性,无需预设操作即可适应复杂、开放的任务环境,这是现有记忆系统所缺乏的核心能力。
3 Methodolodgy¶
本节介绍了所提出的A-Mem(Agentic Memory)系统的设计与实现。该系统受Zettelkasten方法启发,旨在为大型语言模型(LLM)构建一个动态、自我演化的长时记忆系统。系统设计强调原子化笔记记录、灵活的链接机制和知识结构的持续演化。
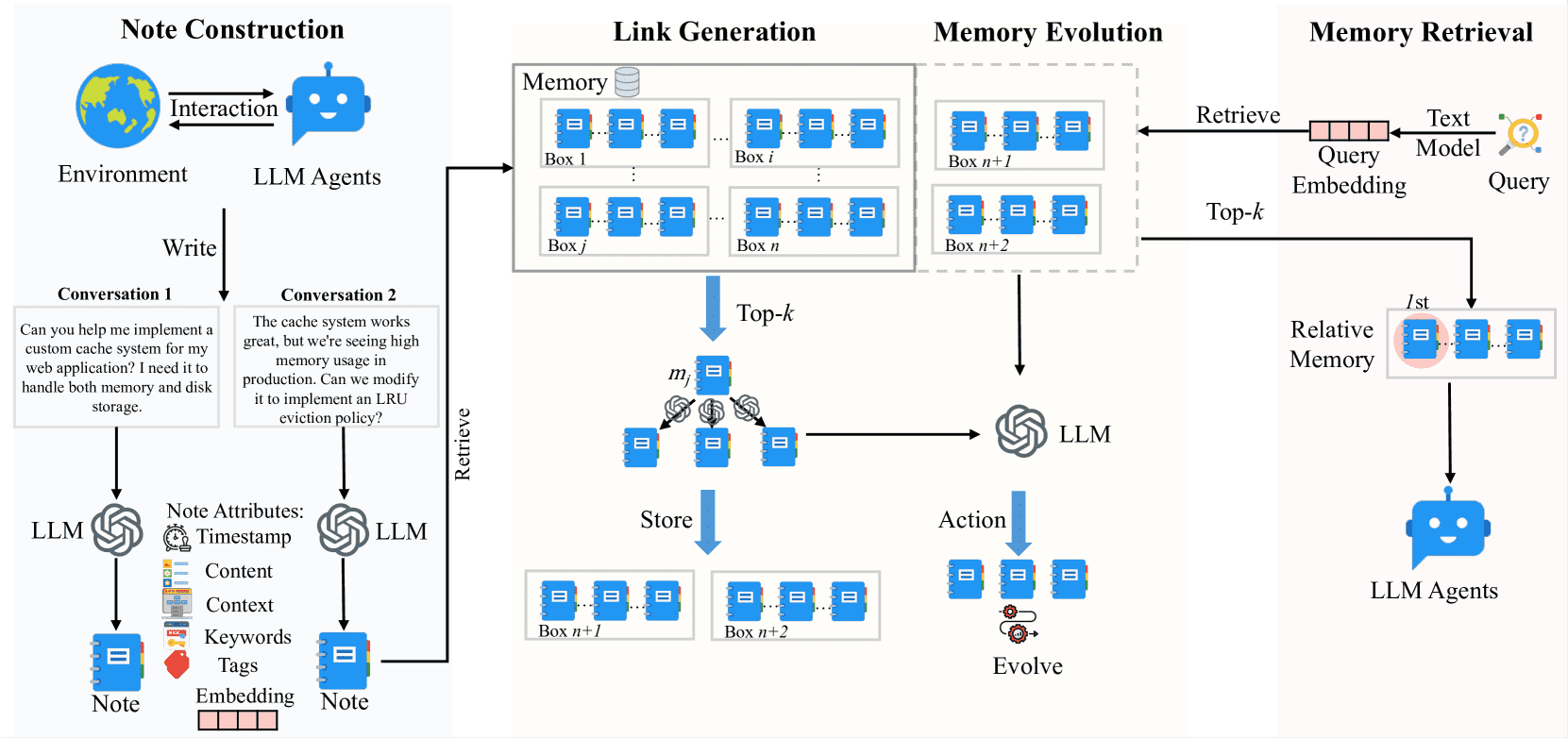
Figure 2:Our A-Mem architecture comprises three integral parts in memory storage. During note construction, the system processes new interaction memories and stores them as notes with multiple attributes. The link generation process first retrieves the most relevant historical memories and then employs an LLM to determine whether connections should be established between them. The concept of a ’box’ describes that related memories become interconnected through their similar contextual descriptions, analogous to the Zettelkasten method. However, our approach allows individual memories to exist simultaneously within multiple different boxes. During the memory retrieval stage, we extract query embeddings using a text encoding model and search the memory database for relevant matches. When related memory is retrieved, similar memories that are linked within the same box are also automatically accessed.
3.1 笔记构建(Note Construction)¶
本系统借鉴 Zettelkasten 的原子化笔记理念,引入 LLM 驱动的笔记构建机制。每次交互后,系统生成一个结构化的记忆笔记 \( m_i = \{c_i, t_i, K_i, G_i, X_i, e_i, L_i\} \),其中各字段含义如下:
\( c_i \):原始交互内容;
\( t_i \):交互时间戳;
\( K_i \):LLM 提取的关键词,捕捉核心概念;
\( G_i \):LLM 生成的标签,用于分类;
\( X_i \):LLM 生成的语义描述,提供上下文理解;
\( e_i \):通过文本编码器生成的密集向量表示,便于相似性计算;
\( L_i \):与其他语义相关的记忆链接集合。
这些语义组件(\( K_i, G_i, X_i \))由 LLM 根据输入模板 \( P_{s1} \) 自动生成。此外,系统通过公式 (3) 对原始内容与文本语义组件(K_i, G_i, X_i)进行拼接后,使用文本编码器生成嵌入向量 \( e_i \),以支持高效的相似性计算。
公式3: \(e_i = f_{\text{enc}}\left[ \text{concat}(c_i, K_i, G_i, X_i) \right]\)
\(P_{s1}\) 查看附录 B1
重点:通过 LLM 构建多维度语义组件,不仅提升了记忆的语义丰富性,也增强了检索的灵活性。
3.2 链接生成(Link Generation)¶
系统通过自主链接生成机制,在无预设规则的情况下,为新记忆建立语义关联。当新记忆 \( m_n \) 加入系统后,系统首先使用嵌入向量 \( e_n \) 与已有记忆 \( m_j \) 计算相似度(公式 (4)),找出 top-k 个语义最相关的候选笔记(公式 (5))。
接下来,系统将新记忆 \( m_n \) 与候选记忆集合 \( \mathcal{M}_{\text{near}}^n \) 一同输入 LLM,由 LLM 判断是否建立链接(公式 (6))。每个链接 \( l_i \) 是结构化的记忆集合 \( L_i = \{m_i, ..., m_k\} \)。
公式6: \(L_i \leftarrow \text{LLM}\left( m_n \; \|\; \mathcal{M}_{\text{near}}^n \; \|\; P_{s2} \right)\)
\(P_{s2}\) 查看附录 B2
重点:链接生成机制结合了嵌入相似性与 LLM 的语义分析能力,避免了机械化的链接,实现了更加自然、语义丰富的知识组织。
3.3 记忆演化(Memory Evolution)¶
在新记忆与相关记忆建立链接后,系统进一步引导相关记忆的演化更新。对于每个与新记忆相关的记忆 \( m_j \),系统使用公式 (7) 向 LLM 提供新记忆 \( m_n \)、其他相关记忆 \( \mathcal{M}_{\text{near}}^n \setminus m_j \) 以及自身 \( m_j \) 作为输入,判断是否更新其上下文、关键词和标签。
更新后的记忆 \( m_j^* \) 将替代原记忆 \( m_j \),并重新加入记忆集合 \( \mathcal{M} \)。这种演化机制模拟了人类学习过程,使系统能够不断优化其知识结构。
公式7: \(m_j^* \leftarrow \text{LLM}\left( m_n \; \|\; \mathcal{M}_{\text{near}}^n \setminus m_j \; \|\; m_j \; \|\; P_{s3} \right)\)
\(P_{s3}\) 查看附录 B3
重点:记忆演化机制实现知识的自我更新与深化,使系统具备“学习”能力,随着时间推移构建出更复杂、更高级的知识网络。
3.4 相关记忆检索(Retrieve Relative Memory)¶
在每次交互中,系统通过上下文感知的记忆检索为代理提供相关历史信息。对于当前查询 \( q \),系统首先生成嵌入向量 \( e_q \)(公式 (8)),然后计算其与所有记忆 \( m_i \) 的相似度(公式 (9)),找到 top-k 个最相关的记忆(公式 (10))。
重点:检索过程依赖于嵌入向量的相似性计算,并结合上下文信息,使得代理能够基于历史经验做出更合理的响应。
总结¶
本章详细介绍了 A-Mem 系统的四个核心模块:笔记构建、链接生成、记忆演化和相关记忆检索。系统通过 LLM 生成语义化记忆单元,并实现记忆之间的动态连接与演化,从而构建出一个自我增强、语义丰富、结构灵活的长时记忆架构。
4 Experiment¶
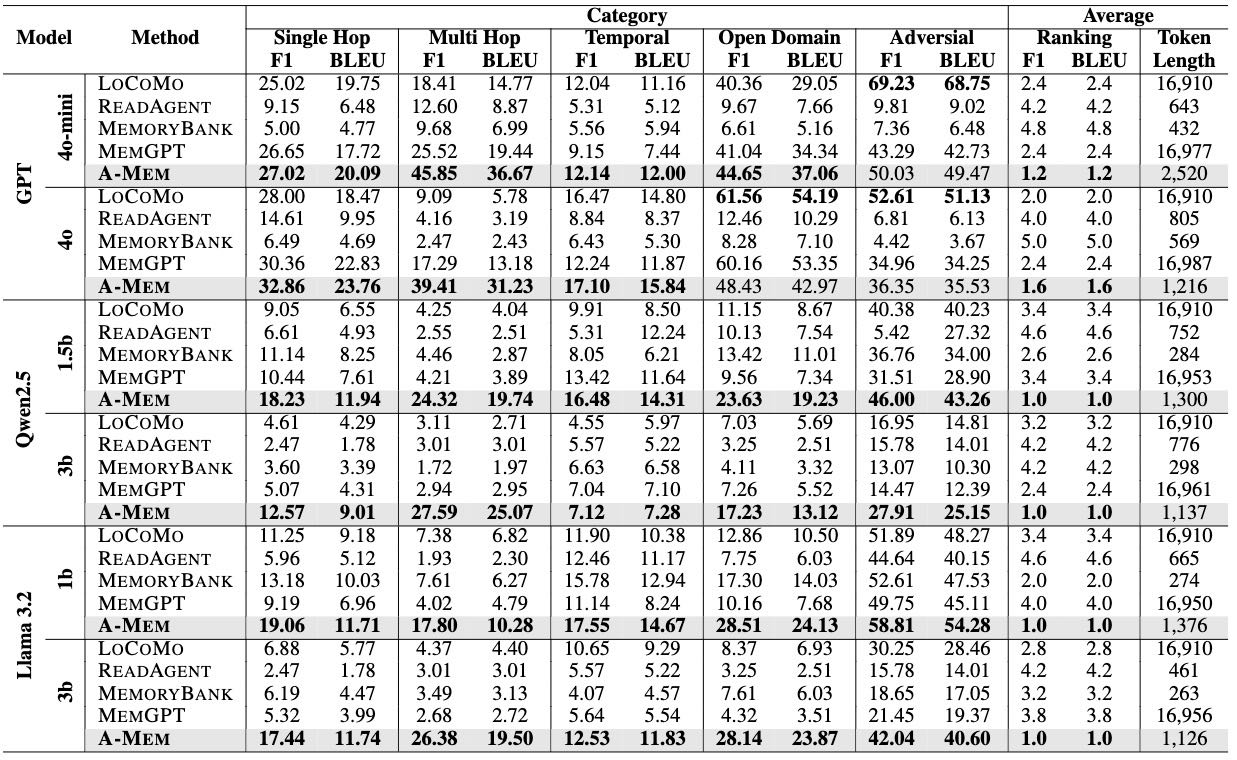
Table 1: Experimental results on LoCoMo dataset of QA tasks across five categories (Single Hop, Multi Hop, Temporal, Open Domain, and Adversial) using different methods.
4.1 Dataset and Evaluation¶
本节介绍了实验中使用的数据集和评估方法。研究者使用了LoCoMo和DialSim两个数据集来评估A-Mem模型在长对话中的指令感知推荐效果。
LoCoMo:相比现有对话数据集更加长,平均每个对话包含9K token,最多可达35轮会话,非常适合评估模型处理长距离依赖和对话一致性能力。该数据集涵盖五类问题:单跳问题(Single Hop)、多跳问题(Multi Hop)、时序推理问题(Temporal)、开放领域问题(Open Domain)和对抗性问题(Adversarial),共计7,512对问答。
DialSim:由电视剧对白衍生出的QA数据集,包含1,300个会话,约350,000 token,用于评估记忆系统的有效性。
在基线模型方面,比较了LoCoMo、ReadAgent、MemoryBank和MemGPT。评估指标包括:
F1 score:评估答案的准确性;
BLEU-1:评估生成答案与参考答案的重合度;
ROUGE-L、ROUGE-2、METEOR、SBERT Similarity:作为补充指标;
平均token长度:评估模型生成答案的效率。
4.2 Implementation Details¶
本节提供了模型实现的细节。
Prompt统一性:所有基线模型与A-Mem使用相同的系统提示,确保实验公平性。
模型部署:
小型模型(如Qwen和Llama)通过Ollama和LiteLLM部署;
GPT模型使用官方结构化输出API。
记忆检索参数:使用top-k检索,k设为10以保持计算效率,具体数值在附录中调整优化。
文本嵌入:所有实验使用all-minilm-l6-v2模型进行文本嵌入。
4.3 Empirical Results¶
本节展示了A-Mem与其他基线模型在LoCoMo和DialSim数据集上的实验结果。
性能表现:
A-Mem在非GPT模型中全面超越所有基线,尤其在多跳推理任务中表现突出。
在GPT模型中,虽然LoCoMo和MemGPT在简单事实检索任务中表现较好,但A-Mem在多跳推理任务中的表现是其两倍以上。
在DialSim数据集上,A-Mem的F1得分达到3.45,比LoCoMo(2.55)和MemGPT(1.18)分别高出35%和192%。
A-Mem的有效性:
依赖其代理记忆架构,支持动态、结构化的记忆管理;
利用原子笔记构建互联记忆网络,提升多跳推理能力;
具有动态连接建立和记忆描述更新机制,能更有效地捕捉信息间关系。
4.4 Ablation Study¶
本节通过移除关键模块(Link Generation和Memory Evolution)进行消融实验,评估其对模型性能的影响。
关键发现:
移除两个模块后,性能显著下降,尤其是在多跳和开放领域任务中;
仅保留Link Generation模块时,性能有所恢复,但仍不如完整模型;
A-Mem在所有任务类别中表现最优,验证了两个模块的协同作用。
4.5 Hyperparameter Analysis¶
本节分析了记忆检索参数k对模型性能的影响。
实验范围:k值取10到50,评估不同值对五类任务的影响。
结论:
增加k值通常有助于提升性能,但达到一定阈值后效果趋于平缓;
太大的k值可能引入噪声,影响模型处理能力;
表明存在上下文丰富性与处理效率之间的平衡点。
4.6 Scaling Analysis¶
本节评估了随着记忆数量增长,存储开销与检索时间的变化情况。
存储复杂度:所有模型均为线性增长(O(N)),A-Mem没有额外存储开销。
检索时间:随着记忆数量增加,A-Mem的检索时间增长极小,即使在百万级记忆规模下(3.70μs),仍表现优异。
结论:
A-Mem具备良好可扩展性;
检索效率高,适合大规模对话系统。
4.7 Memory Analysis¶
本节通过t-SNE可视化对比了A-Mem与基线模型的记忆嵌入分布。
可视化结果:
A-Mem(蓝色)的记忆嵌入表现出更好的聚类结构;
基线模型(红色)的记忆分布较为分散,缺乏结构组织;
说明A-Mem的链接生成和记忆演化机制能有效构建有意义的记忆结构。
总结¶
本章通过详尽的实验设计、消融分析和可视化验证,系统评估了A-Mem模型在长对话场景下的记忆管理能力。实验结果表明,A-Mem在性能、效率和可扩展性方面均优于现有方法,尤其在多跳推理和开放领域任务中表现突出。其核心机制——动态记忆链接和演化,为构建具备长期记忆能力的LLM代理系统提供了有力支持。
5 Conclusions¶
在本研究中,我们提出了 A-Mem,一种全新的智能记忆系统,使 LLM(大语言模型)代理能够在不依赖预定义结构的前提下,动态组织和演化其记忆。该系统的设计灵感来源于“Zettelkasten 方法”,通过动态索引和链接机制,构建了一个能够适应多种现实任务的互联知识网络。
系统的核心架构包括两个关键功能:一是自主生成新记忆的上下文描述,二是基于共享属性智能地与已有记忆建立连接。这使得系统具备高度的灵活性和自适应性。此外,我们的方法还能够通过持续的交互,不断演化历史记忆,并从新体验中发展出更高阶的属性。
通过在六种基础模型上的广泛实证评估,我们证明了 A-Mem 在长期对话任务中表现优于现有最先进的基线方法。进一步的可视化分析也验证了我们记忆组织方式的有效性。
研究结果表明,智能记忆系统可以显著提升 LLM 代理在复杂环境中利用长期知识的能力,为构建更高效、更智能的代理系统提供了新的方向。
6 Limitations¶
本节讨论了当前代理记忆系统的一些局限性,并指出未来可能的改进方向。
首先,系统虽然能够动态组织记忆,但其组织质量仍受限于底层语言模型的能力。不同的大语言模型(LLMs)在生成上下文描述或建立记忆之间的联系时,可能会产生细微的差异。这意味着系统的表现在一定程度上依赖于所使用模型的性能,这一因素可能会限制系统的稳定性和一致性。
此外,当前的实现专注于文本交互,尚未支持多模态信息的处理。未来的研究可以考虑将系统扩展到处理图像、音频等多模态数据。这种扩展将有助于系统获取更丰富的上下文表示,从而提升其在复杂场景下的表现。
总结来看,尽管系统在记忆管理方面取得了一定成效,但仍存在模型依赖性和模态限制等关键问题,这些问题为未来的研究提供了明确的方向。
Appendix A Experiment¶
A.1 详细基线方法介绍¶
本节介绍了几种用于问答任务的基线方法,重点分析其设计特点和应用场景:
LoCoMo
直接使用基础模型进行问答,不依赖记忆机制。它将整段对话和问题一并作为输入提示提供给模型,检验其推理能力。适用于单跳问题,但在处理长上下文或复杂推理时表现较差。ReadAgent
针对长文档处理,采用三步法:分段(episode pagination)、摘要(memory gisting) 和 检索(interactive look-up)。适用于需要从大量文本中提取信息的任务,但对长时记忆管理和结构化信息组织的支持有限。MemoryBank
引入创新的记忆管理系统,基于艾宾浩斯遗忘曲线调整记忆强度,并结合用户画像系统。能够动态维护历史交互,强化个性化理解,适用于需要长期记忆支持的场景。MemGPT
模拟操作系统内存分层结构,提出双层上下文管理:主上下文(RAM)用于即时推理,外部上下文(disk)用于存储超出固定上下文窗口的信息。适用于需要处理大量输入信息的场景,但对结构化记忆组织的支持不足。
A.2 评估指标¶
本节介绍了用于评估问答系统性能的多种指标及其计算公式,重点包括:
F1 Score
F1 是精确率(precision) 和 召回率(recall) 的调和平均,适合评估生成答案与参考答案的完全匹配度,特别适用于span-based QA(片段匹配)任务。BLEU-1
评估生成答案与参考答案在单字匹配上的精确度,适用于生成型回答任务,但对语序和语义理解考虑较少。ROUGE-L & ROUGE-2
ROUGE-L 基于最长公共子序列(LCS)评估,适用于评估语义连贯性。
ROUGE-2 基于双字重叠度评估,更关注局部词序,适合评估短文本的相似性。
METEOR
综合考虑同义词、语义相似性、句子结构等因素,通过惩罚机制(Penalty) 和 召回/精确调和因子 提供更全面的评价,适合评估语义理解和生成答案的多样性。SBERT Similarity
基于句子嵌入的余弦相似度,衡量生成答案与参考答案的语义相似程度,适合评估语义理解能力强的系统。
A.3 对比实验结果¶
本节总结了 A-Mem 在多个模型和任务上的性能表现,结果表明:
A-Mem 在非 GPT 模型(如 Qwen2.5、Llama 3.2)中表现显著优越,特别是在Multi-Hop(多跳)任务中。例如,Qwen2.5-15b 使用 A-Mem 在 ROUGE-L 上达到 27.23,远超 LoCoMo 的 4.68 和 ReadAgent 的 2.81(提升近 6 倍)。
在 GPT 系列模型中,A-Mem 在 Multi-Hop 任务中表现尤为突出。以 GPT-4o-mini 为例,A-Mem 在 Multi-Hop 中的 ROUGE-L 得分为 44.27,远高于 LoCoMo 的 18.09,且在 METEOR 和 SBERT 上也有显著优势。
A-Mem 在计算效率上也表现出色,仅需 1,200-2,500 tokens,而 LoCoMo 和 MemGPT 需要 16,900 tokens。这是由于 A-Mem 的两种创新设计:
代理记忆架构(Agentic Memory Architecture):通过原子笔记和上下文描述构建记忆网络,提升信息关系的捕获与利用能力。
选择性 top-k 检索机制:实现动态记忆演化和结构化组织。
A-Mem 在多个模型上均展示了稳定优异的性能,包括 DeepSeek-R1-32B、Claude 3.0/3.5 Haiku。
A.4 记忆分析¶
通过 T-SNE 可视化,展示了 A-Mem 记忆嵌入在不同对话中的结构分布。与基线系统(无链接生成和记忆演化)相比:
A-Mem 产生更连贯的聚类结构,尤其是在长对话中,说明其记忆演化机制和上下文描述生成有效。
基线系统记忆嵌入分布较为分散,说明缺乏结构组织能力。
A.5 超参数设置¶
本节展示了不同模型和任务类别中检索器参数 k 的设置。例如:
对于已达到 SOTA(SOTA:State-of-the-Art,最先进水平)的模型(如 Qwen2.5-1.5b),k 值默认为 10。
对于 GPT 系列模型,k 值在多跳和时间任务中设为 50,以提升复杂推理能力。
总结¶
本附录通过详细的方法介绍、评估指标、实验结果和可视化分析,全面验证了 A-Mem 在问答任务中的优越性能。其代理式记忆结构和高效检索机制使其在多个模型和任务中都表现出色,尤其是在多跳推理方面显著超越现有基线方法。
Appendix B Prompt Templates and Examples¶
B.1 Prompt Template of Note Construction¶
The prompt template in Note Construction: \(P_{s1}\)
Generate a structured analysis of the following content by:
1. Identifying the most salient keywords (focus on nouns, verbs, and key concepts)
2. Extracting core themes and contextual elements
3. Creating relevant categorical tags
Format the response as a JSON object:
{
"keywords": [
// several specific, distinct keywords that capture key concepts and terminology
// Order from most to least important
// Don’t include keywords that are the name of the speaker or time
// At least three keywords, but don’t be too redundant.
],
"context":
// one sentence summarizing:
// - Main topic/domain
// - Key arguments/points
// - Intended audience/purpose
,
"tags": [
// several broad categories/themes for classification
// Include domain, format, and type tags
// At least three tags, but don’t be too redundant.
]
}
Content for analysis:
中文版
对以下内容进行结构化分析,要求:
1. 识别最显著的关键词(重点关注名词、动词和关键概念)
2. 提取核心主题和上下文要素
3. 创建相关分类标签
响应格式为JSON对象:
{
"keywords": [
// 若干个具体、独特的关键词,用于捕捉关键概念和术语
// 按重要性从高到低排序
// 不要包含说话者姓名或时间类关键词
// 至少三个关键词,但不要过于冗余
],
"context":
// 用一句话总结:
// - 主要话题/领域
// - 关键论点/要点
// - 目标受众/目的
,
"tags": [
// 若干个用于分类的广泛类别/主题
// 包含领域、格式和类型标签
// 至少三个标签,但不要过于冗余
]
}
待分析内容:
示例
待分析内容:监督学习需要标注数据,而无监督学习直接从无标签数据中发现模式。
输出
{
"keywords": [
"监督学习",
"无监督学习",
"标注数据",
"无标签数据",
"模式发现"
],
"context": "该内容属于机器学习领域,阐述了监督学习需要标注数据、无监督学习从无标签数据中发现模式这两个关键要点,旨在向读者介绍两种学习方式的核心区别",
"tags": [
"机器学习",
"技术知识",
"学习方法"
]
}
B.2 Prompt Template of Link Generation¶
The prompt template in Link Generation: \(P_{s2}\)
备注
实际的代码是 B2, B3合并在一起
You are an AI memory evolution agent responsible for managing and evolving a knowledge base.
Analyze the the new memory note according to keywords and context, also with their several nearest neighbors memory.
The new memory context:
{context}
content: {content}
keywords: {keywords}
The nearest neighbors memories:
{nearest_neighbors_memories}
Based on this information, determine:
Should this memory be evolved? Consider its relationships with other memories.
中文版
你是一个AI记忆进化代理,负责管理和优化知识库。
请根据关键词和上下文分析新记忆笔记,同时结合其若干最近邻记忆。
新记忆内容:
{context}
内容:{content}
关键词:{keywords}
最近邻记忆:
{nearest_neighbors_memories}
基于以上信息,判断:
这条记忆是否需要进化?请考虑它与其他记忆的关联性。
示例
你是一个AI记忆进化代理,负责管理和优化知识库。
请根据关键词和上下文分析新记忆笔记,同时结合其若干最近邻记忆。
新记忆内容:
该内容属于机器学习领域,阐述了监督学习需要标注数据、无监督学习从无标签数据中发现模式这两个关键要点,旨在向读者介绍两种学习方式的核心区别
内容: 监督学习需要标注数据,而无监督学习直接从无标签数据中发现模式。
关键词: 监督学习、无监督学习、标注数据、无标签数据、模式发现
最近邻记忆:
1. "冷战时期的间谍技术发展"
2. "现代加密算法的军事应用"
3. "计算机科学起源与战争的关系"
4. "社交媒体使用与青少年心理健康的关系引发广泛讨论。"
基于以上信息,判断:
这条记忆是否需要进化?请考虑它与其他记忆的关联性。
输出
这条记忆**需要进化**,主要基于其与其他记忆的关联性分析如下:
1. **与“计算机科学起源与战争的关系”的强关联性**
新记忆中“图灵团队破解恩尼格玛密码”是计算机科学发展的重要里程碑——图灵被视为计算机科学的奠基人之一,其在二战中对密码的破解直接推动了早期计算机理论与技术的诞生。两者核心主题均围绕“战争对科技(尤其是计算机科学)的催生作用”,可通过补充关联信息(如图灵的工作如何为计算机科学奠基)强化记忆网络。
2. **与“现代加密算法的军事应用”的间接关联性**
二战中的密码学(如恩尼格玛密码的破解)是现代军事加密技术的历史源头之一,两者同属“密码学在军事领域的应用”脉络。可通过进化补充“历史密码学对现代算法的影响”等衔接内容,完善从历史到现代的逻辑链条。
3. **与“冷战时期的间谍技术发展”的潜在关联性**
冷战的间谍技术(如情报加密与解密)是二战密码学的延续与升级,两者均属于“战争背景下的情报安全技术”范畴。进化时可提及这种技术发展的延续性,丰富记忆的历史纵深。
4. **排除无关记忆**
“社交媒体使用与青少年心理健康的关系”与新记忆在主题、领域上均无关联,无需纳入进化考虑。
综上,新记忆与多条相关记忆存在明确的历史、技术或主题关联,通过补充关联性信息进行进化,可增强知识库的逻辑性和整体性。
B.3 Prompt Template of Memory Evolution¶
The prompt template in Memory Evolution: \(P_{s3}\)
You are an AI memory evolution agent responsible for managing and evolving a knowledge base.
Analyze the the new memory note according to keywords and context, also with their several nearest neighbors memory.
Make decisions about its evolution.
The new memory context:
{context}
content: {content}
keywords: {keywords}
The nearest neighbors memories:
{nearest_neighbors_memories}
Based on this information, determine:
1. What specific actions should be taken (strengthen, update_neighbor)?
1.1 If choose to strengthen the connection, which memory should it be connected to? Can you give the updated tags of this memory?
1.2 If choose to update neighbor, you can update the context and tags of these memories based on the understanding of these memories.
Tags should be determined by the content of these characteristic of these memories, which can be used to retrieve them later and categorize them.
All the above information should be returned in a list format according to the sequence: [[new_memory],[neighbor_memory_1],
...[neighbor_memory_n]]
These actions can be combined.
Return your decision in JSON format with the following structure:
{{
"should_evolve": true/false,
"actions": ["strengthen", "merge", "prune"],
"suggested_connections": ["neighbor_memory_ids"],
"tags_to_update": ["tag_1",..."tag_n"],
"new_context_neighborhood": ["new context",...,"new context"],
"new_tags_neighborhood": [["tag_1",...,"tag_n"],...["tag_1",...,"tag_n"]],
}}
中文版
你是一个负责管理和进化知识库的AI记忆进化代理。
需要根据关键词和上下文分析新记忆笔记,并结合其若干最近邻记忆进行分析。
制定关于该记忆的进化决策。
新记忆上下文:{context}
内容:{content}
关键词:{keywords}
最近邻记忆:{nearest_neighbors_memories}
根据以上信息,请确定:
1. 应该采取哪些具体行动(强化连接、更新邻居)?
1.1 如果选择强化连接,应该与哪个记忆建立连接?能否提供该记忆更新后的标签?
1.2 如果选择更新邻居,可以根据对这些记忆的理解更新它们的上下文和标签。
标签应根据这些记忆的特征内容确定,以便后续检索和分类。
所有上述信息应按以下顺序以列表格式返回:
[[新记忆], [邻居记忆_1], ...[邻居记忆_n]]
这些行动可以组合使用。
请用JSON格式返回你的决策,结构如下:
{
"should_evolve": true/false,
"actions": ["strengthen", "merge", "prune"],
"suggested_connections": ["邻居记忆ID"],
"tags_to_update": ["标签_1",..."标签_n"],
"new_context_neighborhood": ["新上下文",...,"新上下文"],
"new_tags_neighborhood": [["标签_1",...,"标签_n"],...["标签_1",...,"标签_n"]],
}
示例
你是一个负责管理和进化知识库的AI记忆进化代理。
需要根据关键词和上下文分析新记忆笔记,并结合其若干最近邻记忆进行分析。
制定关于该记忆的进化决策。
新记忆上下文:讨论监督学习和无监督学习的区别
内容:监督学习需要标注数据,而无监督学习直接从无标签数据中发现模式。
关键词:["机器学习", "监督学习", "无监督学习", "数据标注"]
最近邻记忆:[
{
"id": "mem_001",
"content": "深度学习是机器学习的一个子领域,主要使用神经网络。",
"tags": ["机器学习", "深度学习", "神经网络"]
},
{
"id": "mem_002",
"content": "强化学习通过奖励机制优化决策策略。",
"tags": ["机器学习", "强化学习", "决策优化"]
}
]
根据以上信息,请确定:
1. 应该采取哪些具体行动(强化连接、更新邻居)?
1.1 如果选择强化连接,应该与哪个记忆建立连接?能否提供该记忆更新后的标签?
1.2 如果选择更新邻居,可以根据对这些记忆的理解更新它们的上下文和标签。
标签应根据这些记忆的特征内容确定,以便后续检索和分类。
所有上述信息应按以下顺序以列表格式返回:
[[新记忆], [邻居记忆_1], ...[邻居记忆_n]]
这些行动可以组合使用。
请用JSON格式返回你的决策,结构如下:
{
"should_evolve": true/false,
"actions": ["strengthen", "merge", "prune"],
"suggested_connections": ["邻居记忆ID"],
"tags_to_update": ["标签_1",..."标签_n"],
"new_context_neighborhood": ["新上下文",...,"新上下文"],
"new_tags_neighborhood": [["标签_1",...,"标签_n"],...["标签_1",...,"标签_n"]],
}
输出
{
"should_evolve": true,
"actions": ["strengthen"],
"suggested_connections": ["mem_001", "mem_002"],
"tags_to_update": [],
"new_context_neighborhood": [],
"new_tags_neighborhood": [
["机器学习", "深度学习", "神经网络", "监督学习相关", "无监督学习相关"],
["机器学习", "强化学习", "决策优化", "监督学习相关", "无监督学习相关"]
]
}
B.4 Examples of Q/A with A-Mem¶
Example:
Question 686: Which hobby did Dave pick up in October 2023?
Prediction: photography
Reference: photography
talk start time:10:54 am on 17 November, 2023
memory content:
Speaker Davesays : Hey Calvin, long time no talk! A lot has happened.
I’ve taken up photography and it’s been great - been taking pics of the scenery around here which is really cool.
memory context:
The main topic is the speaker’s new hobby of photography, highlighting their enjoyment of capturing local scenery,
aimed at engaging a friend in conversation about personal experiences.
memory keywords:
[’photography’, ’scenery’, ’conversation’, ’experience’, ’hobby’]
memory tags:
[’hobby’, ’photography’, ’personal development’, ’conversation’, ’leisure’]
talk start time:6:38 pm on 21 July, 2023
memory content:
Speaker Calvinsays : Thanks, Dave! It feels great having my own space to work in.
I’ve been experimenting with different genres lately, pushing myself out of my comfort zone.
Adding electronic elements to my songs gives them a fresh vibe.
It’s been an exciting process of self-discovery and growth!
memory context:
The speaker discusses their creative process in music,
highlighting experimentation with genres and the incorporation of electronic elements for personal growth and artistic evolution.
memory keywords:
[’space’, ’experimentation’, ’genres’, ’electronic’, ’self-discovery’, ’growth’]
memory tags:
[’music’, ’creativity’, ’self-improvement’, ’artistic expression’]
中文版
**问题686**:Dave在2023年10月培养了哪个新爱好?
**系统预测答案**:摄影
**参考答案**:摄影
**对话记忆支持**:
1. **对话时间**:2023年11月17日上午10:54
**记忆内容**:
Dave说:"嘿Calvin,好久没聊了!最近发生了不少事。我迷上了摄影,感觉特别棒——一直在拍周围的风景,真的很美。"
**记忆上下文**:
主题是说话者(Dave)的新爱好摄影,强调他对拍摄本地风景的喜爱,目的是与朋友分享个人经历。
**记忆关键词**:["摄影", "风景", "对话", "经历", "爱好"]
**记忆标签**:["爱好", "摄影", "个人发展", "社交对话", "休闲"]
2. **对话时间**:2023年7月21日下午6:38
**记忆内容**:
Calvin说:"谢啦Dave!有自己的创作空间感觉真好。最近我在尝试不同音乐风格,突破舒适区。给歌曲加入电子元素后,整体更有新鲜感了。这是个自我发现和成长的奇妙过程!"
**记忆上下文**:
讨论音乐创作中的实验性尝试,涉及多风格融合和电子元素,体现个人艺术成长。
**记忆关键词**:["空间", "实验", "音乐风格", "电子", "自我发现", "成长"]
**记忆标签**:["音乐", "创造力", "自我提升", "艺术表达"]
**解析说明**:
1. 系统通过检索时间接近的对话(2023年10月前后)锁定答案。
2. 精准区分说话者(Dave的摄影爱好 vs Calvin的音乐创作)。
3. 利用记忆中的关键词(如"爱好""摄影")和标签快速关联问题。
4. 无关记忆(Calvin的音乐内容)虽存在但被正确忽略,体现语义筛选能力。