2304.13343_SCMemory: Enhancing Large Language Model with Self-Controlled Memory Framework¶
引用: 23(2025-08-26)
组织:
1State Key Lab of Software Development Environment, Beihang University, Beijing, China
2Harbin Institute of Technology, Harbin, China
3ByteDance AI Lab, Beijing, China
总结¶
总结
Self-Controlled Memory(自控记忆,SCM)
SCM框架
三个核心组件构成:
LLM-based agent:作为处理文本的核心
Memory stream:存储模型的记忆信息,并支持高速访问
Memory controller:负责更新记忆并决定何时、如何使用这些记忆
工作流程包含六个明确步骤,如图 2 所示
获取观察(Observation):代理在第 T 轮获取用户输入。
记忆激活判断(Memory Activation):记忆控制器判断是否需要激活记忆。
记忆检索(Memory Retrieval):使用当前观察作为查询,从记忆流中检索 Top-K 的记忆。
记忆重组(Memory Reorganization):控制器决定是否使用原始记忆或其摘要。
输入融合(Input Fusion):将重组后的记忆和当前观察融合,作为模型的输入。
生成响应(Response Generation):基于上述信息,代理生成响应,并将当前交互存入记忆流。
数据集
涵盖以下三种任务:
长期对话(long-term dialogues)
书籍摘要(book summarization)
会议摘要(meeting summarization)
每个任务中的文本长度从2万到200万个token不等,远超传统LLMs(如ChatGPT)的上下文窗口
Abstract¶
本研究针对大型语言模型(LLMs)在处理长文本输入时的限制,提出了一个名为Self-Controlled Memory (SCM) 的框架。该框架旨在提升LLMs在长期记忆维持和信息回忆方面的能力。SCM框架由三个主要组件组成:
LLM-based agent:作为框架的核心支撑。
Memory stream:用于存储代理的记忆。
Memory controller:负责更新记忆,并决定何时以及如何使用记忆。
此外,SCM框架的一个重要特点是无需对模型进行修改或微调,即可处理超长文本,并能即插即用地集成到任何遵循指令的LLMs中。为了验证SCM的有效性,作者还标注了一个数据集,涵盖以下三种任务:
长期对话
书籍摘要
会议摘要
1 Introduction¶
本文介绍了大型语言模型(Large Language Models, LLMs)的最新发展,并指出虽然LLMs在多种任务中表现出色,但其在处理超长文本输入和长期对话时仍存在显著挑战。为了解决这些问题,作者提出了一个新的框架——Self-Controlled Memory(自控记忆,SCM)。
1.1 LLMs的发展与挑战¶
近年来,LLMs(如ChatGPT、text-davinci-003等)因在自然语言处理任务中表现出色而受到广泛关注。指令微调(Instruction-tuning) 和 基于人类反馈的强化学习(RLHF) 等技术使LLMs更好地理解任务描述并生成符合人类偏好的文本。
然而,LLMs在处理超长文本时面临两个主要限制:
最大输入长度限制:大多数LLMs存在输入长度上限(如4096个token)。
注意力机制的复杂性:自注意力(self-attention)机制随着输入长度增长,计算复杂度呈平方级上升。
此外,即使某些模型(如GPT-3.5)支持长输入,仍可能因历史信息过长、噪音过多而丢失关键上下文。如图1所示,ChatGPT在长期对话中可能会忘记之前提到的关键信息。
1.2 提出的解决方案:SCM框架¶
为了解决LLMs在处理超长文本时的局限性,作者提出了SCM(Self-Controlled Memory)框架。该框架具备以下特点:
无需修改或微调LLM本身,具有高度可扩展性;
由三个核心组件构成:
LLM-based agent:作为处理文本的核心;
Memory stream:存储模型的记忆信息;
Memory controller:负责更新记忆并决定何时、如何使用这些记忆。
SCM框架通过将输入文本切分为片段(segment),逐步输入LLM进行处理。每个片段处理时会使用两种类型的内存:
长时记忆(activation memory):存储历史信息;
短时记忆(flash memory):存储上一阶段的实时信息。
Memory controller在处理每个片段时决定是否引入记忆信息,从而避免引入不必要的噪音。
1.3 实验数据与结果¶
为了验证SCM框架的有效性,作者构建了一个标注数据集,涵盖以下三种任务:
长期对话(long-term dialogues)
书籍摘要(book summarization)
会议摘要(meeting summarization)
每个任务中的文本长度从2万到200万个token不等,远超传统LLMs(如ChatGPT)的上下文窗口(通常小于4096 token)。
实验结果表明:
将SCM框架与text-davinci-003(非对话优化的LLM)结合,其在处理超长输入和长期对话时的表现优于ChatGPT;
在摘要任务中,SCM在连贯性和覆盖度方面显著优于基线模型。
1.4 本文的贡献¶
作者总结了本文的三大贡献:
提出SCM框架:使LLMs具备处理无限长度输入的能力,并可控制何时和如何引入记忆信息;
构建并公开了数据集:用于评估SCM在长期对话、书籍摘要和会议摘要任务中的性能;
SCM框架无需修改或微调LLM:便于扩展和部署。
附图说明¶
图1:展示ChatGPT在长期对话中因历史信息过长而遗忘关键内容的示例;
图2:展示SCM框架的六步处理流程,包括输入获取、记忆激活、记忆检索、记忆重组、输入融合和响应生成。
2 Self-Controlled Memory¶
本节详细描述了作者提出的 自控记忆(Self-Controlled Memory, SCM)框架,框架结构如图 2 所示。
本节分为四个小节,分别介绍框架的工作流程、三个关键组件:基于大语言模型的代理(LLM-based Agent)、记忆流(Memory Stream)和记忆控制器(Memory Controller)。
2.1 Workflow of SCM(SCM 的工作流程)¶
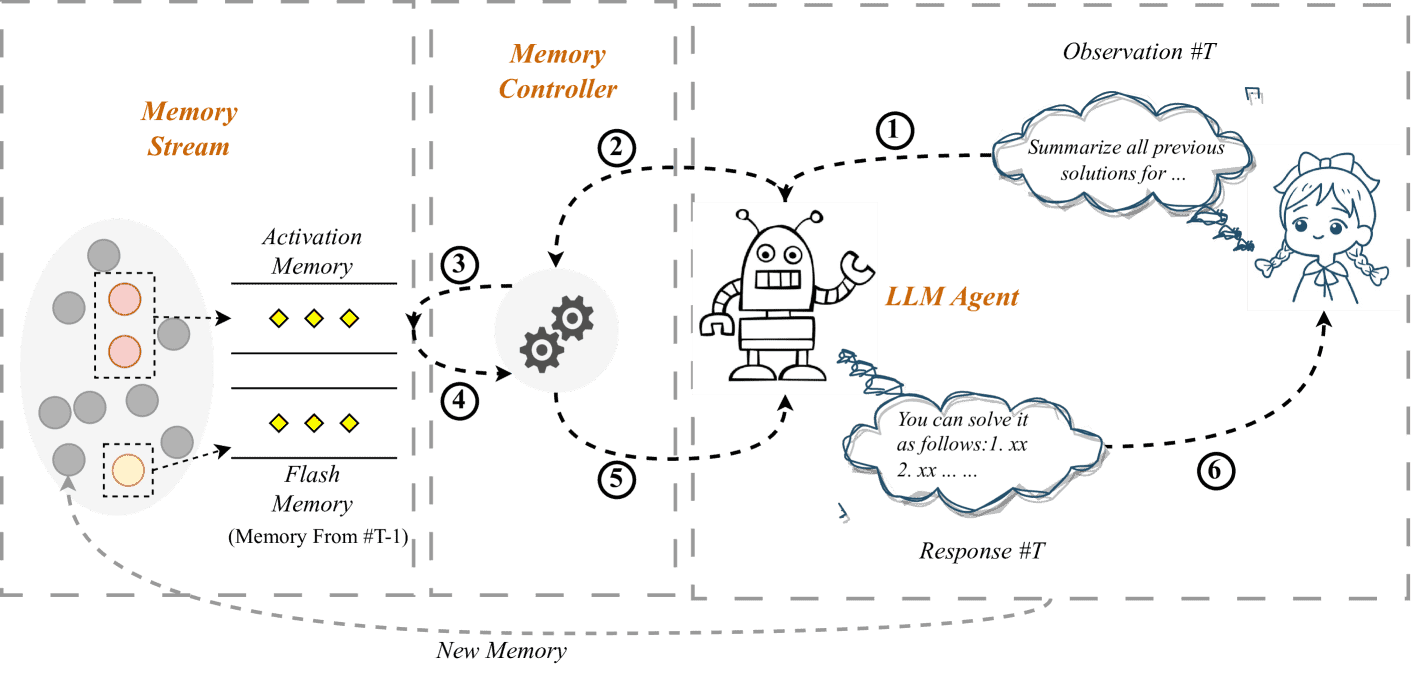
Figure 2:The workflow of our proposed Self-Controlled Memory(SCM) framework, where numbers 1-6 represent the six explicit steps of one iteration with new observation #T. These steps are (1) Input Acquisition; (2) Memory Activation; (3) Memory Retrieval; (4) Memory Reorganization; (5) Input Fusion; (6) Response Generation.
SCM 的工作流程包含六个明确步骤,如图2 所示。具体流程如下:
获取观察(Observation):代理在第 T 轮获取用户输入。
记忆激活判断(Memory Activation):记忆控制器判断是否需要激活记忆。
记忆检索(Memory Retrieval):使用当前观察作为查询,从记忆流中检索 Top-K 的记忆。
记忆重组(Memory Reorganization):控制器决定是否使用原始记忆或其摘要。
输入融合(Input Fusion):将重组后的记忆和当前观察融合,作为模型的输入。
生成响应(Response Generation):基于上述信息,代理生成响应,并将当前交互存入记忆流。
其中,输入融合阶段的 Prompt 结构 如图7 所示。
2.2 LLM-based Agent(基于大语言模型的代理)¶
该代理是 SCM 框架的核心组件,负责根据设计良好的指令生成连贯且准确的响应。文中使用了两个强大的 LLM 模型作为代理:
text-davinci-003
gpt-3.5-turbo
代理负责接收输入、处理记忆信息并生成最终的输出响应。
2.3 Memory Stream(记忆流)¶
记忆流用于存储所有历史记忆项,并支持高速访问,通常使用 Redis 或 Pinecone 等缓存/向量数据库技术实现。
每个记忆项包含以下五部分:
交互索引(Interaction Index)
用户观察(Observation)
系统响应(System Response)
记忆摘要(Memory Summarization)
交互嵌入向量(Interaction Embedding)
交互嵌入通过将观察和系统响应的文本内容拼接,并使用 text-embedding-ada-002 模型生成语义向量。
在记忆检索时,记忆流会返回两类记忆项:
Activation Memory:与当前观察相关的记忆;
Flash Memory:前一轮(T-1)的交互记忆。
Memory Summarization(记忆摘要)¶
记忆摘要在处理长文本输入(如单次对话超过 3000 个 tokens)时至关重要。通过逐轮摘要提取关键信息,可以在模型的有限上下文窗口内集成多轮信息。
提示模版详见图 3,并提供了多语言版本(见附录 A)。
Memory Retrieval(记忆检索)¶
为获取记忆项的语义表示,文中采用观察摘要 + 系统响应摘要的拼接方式,以平衡两者在长度和语义上的信息分布。
由于原始观察和系统响应可能长度差异较大,直接使用其嵌入向量可能导致语义不平衡,因此采用拼接摘要的方式。
2.4 Memory Controller(记忆控制器)¶
记忆控制器是 SCM 的核心组件,其工作流程如 图4 所示。控制器的目标是引入最小必要信息,以避免引入干扰模型性能的噪声。
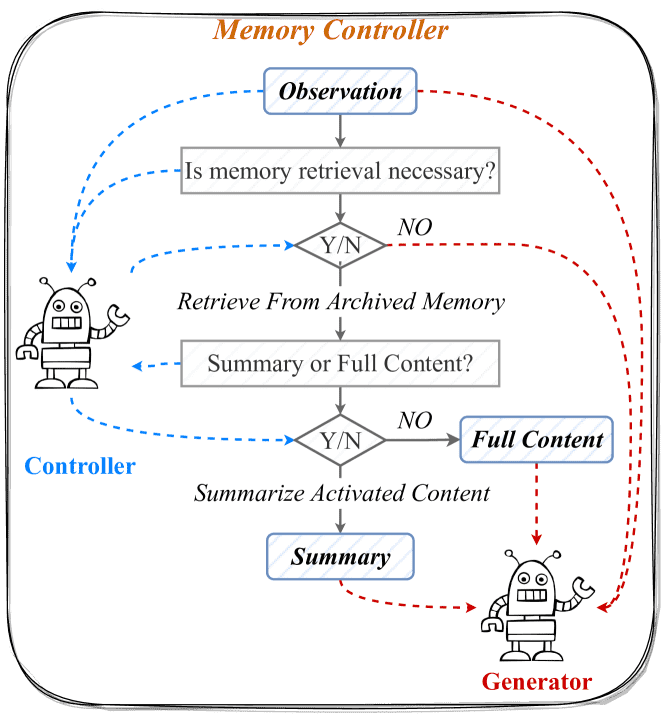
Figure 4:Workflow of the Memory Controller.
控制器的三个关键场景¶
并非所有用户输入都需要记忆:例如,用户输入 “Tell me a joke” 不需要检索历史记忆,而 “Do you remember the conclusion we made last week…” 则需要。
记忆数据量可能非常大(数百到数万个),需要控制器进行检索与过滤。
模型输入长度有限,控制器需决定使用原始全文还是摘要,以避免超出模型最大长度限制。
Memory Controller Workflow(控制器工作流程)¶
控制器是一个语言模型,通过自问两个关键问题来控制记忆的使用:
是否需要激活记忆?
通过 图5 的提示判断是否需要激活记忆。若模型回答 “yes(A)”,则激活相关记忆。
激活记忆基于两个评分:时间近度(Recency) 和 相关性(Relevance)。
最终得分 = 近度得分 + 相关性得分。
根据长度限制选择 Top-K 个记忆项(K 通常在 3~10 之间)。
是否使用记忆摘要?
通过 图6 的提示判断是否可以用摘要回答问题。
仅在激活记忆总 tokens 超过 2000 时进行评估。
若评估结果为“可用摘要”,则使用摘要代替原始记忆。
图片参考说明¶
图 [3-7] 为提示模板、记忆控制器流程等示意图,展示了不同阶段使用的英文 Prompt 和流程结构,对于理解记忆摘要、检索和控制器逻辑非常关键。
总结¶
SCM 框架通过 LLM 代理、记忆流和记忆控制器 的协同工作,实现对历史记忆的智能管理与使用。控制器负责判断是否激活记忆、如何检索记忆以及是否使用摘要,从而在保证模型性能的同时,增强其对长期对话和复杂任务的理解与处理能力。
3 Experiments¶
本节通过对三个任务(长期对话、书籍摘要和会议摘要)的实验,评估SCM(Self-Controlled Memory)框架的有效性和鲁棒性,同时比较记忆增强型大语言模型(LLM)与传统LLM在处理长文本摘要任务时的表现。
3.1 评估基准¶
为了评估SCM在不同场景下的性能,作者收集了开源数据,包括:
对话数据:来自ShareChat平台(中英文混合);
书籍数据:来自古腾堡计划(中英文混合);
会议数据:来自VCSUM数据集(中文)。
通过人工标注方式,构建了探索性问题和摘要内容。表格显示了各数据集的基本统计信息:
对话 |
书籍 |
会议 |
|
|---|---|---|---|
实例数 |
18 |
10 |
20 |
最大token数 |
34k |
2M |
50k |
总token数 |
420k |
8M |
632k |
最大轮次 |
200 |
- |
80 |
语言 |
中英文 |
中英文 |
中文 |
3.2 基线模型¶
为公平比较SCM的性能,作者设计了多个基线模型:
SCM turbo:基于gpt-3.5-turbo-0301的SCM框架;
SCM davinci003:基于text-davinci-003的SCM框架;
SCM davinci003 w/o memory controller:移除记忆控制器;
SCM davinci003 w/o flash memory:移除闪存(短期记忆);
SCM davinci003 w/o activation memory:移除激活记忆(长期记忆)。
表2显示了长期对话的评估结果,主要指标包括:
Answer Accuracy:回答准确率;
Memory Retrieval Recall:记忆检索召回率;
Single Turn Accuracy:单轮问题回答准确率;
Multi Turn Accuracy:多轮问题回答准确率。
结果显示:
SCM davinci003性能最优;
移除激活记忆导致性能大幅下降(下降约60%),因为大多数问题依赖长期记忆;
移除记忆控制器对多轮问题影响更大,因为导致信息丢失;
移除闪存对性能影响较小,因为其提供的线索较少。
3.3 主要实验结果¶
评估指标¶
长期对话任务:使用Answer Accuracy、Memory Retrieval Recall、Single Turn Accuracy、Multi Turn Accuracy;
摘要任务:使用**覆盖率(coverage)和连贯性(coherence)**两个指标;
与基线模型(RecursiveSum)比较模型的胜率(win rate)。
对话任务结果¶
SCM davinci003优于SCM turbo,因为后者较为保守;
激活记忆对性能影响最大,缺失后准确性大幅下降;
记忆控制器缺失导致多轮问题性能显著下降;
闪存缺失影响较小。
摘要任务结果¶
SCM davinci003的摘要覆盖范围优于SCM turbo;
两者在连贯性上表现相近;
缺失记忆模块的模型摘要质量较差;
SCM davinci003因其简洁、清晰、内容丰富的摘要更受好评。
3.4 进一步分析¶
研究问题(RQs)验证¶
RQ1:SCM能否在一定token限制下与ChatGPT竞争甚至超越?
✅ 是的。SCM davinci003在大量记忆中准确检索关键信息,生成准确回答。RQ2:SCM能否处理数百甚至数千轮次的历史上下文问题?
✅ 是的。实验中展示了一个超过100轮、10k token的对话,SCM准确回忆了用户最初提到的运动目标。RQ3:SCM能否泛化到其他长输入任务?
✅ 是的。SCM使用分块-迭代-层级摘要策略处理长文本(如书籍和会议记录),结合上下文记忆,实现了良好的连贯性和全面性。
总结¶
本实验通过多个任务验证了SCM框架的有效性,尤其是其对长文本处理和多轮对话支持的能力。结果表明:
激活记忆和记忆控制器是SCM性能的关键模块;
SCM davinci003在多个指标上优于其他变体;
SCM框架在摘要任务中表现出更好的内容覆盖和连贯性;
SCM在长对话和长文本任务中展现出良好的泛化能力。
5 Conclusion¶
在本文中,作者提出了一种名为Self-Controlled Memory (SCM)的框架,该框架可将任意大语言模型(LLMs)的输入长度扩展至无限长度,并能有效地从所有历史信息中捕捉有用的内容。这是本文的重点贡献之一,说明SCM具有显著的泛化能力与实用性。
SCM的一大优势在于不需要对模型进行任何训练或修改,这使得它在实际应用中更加便捷和通用,无需额外的资源投入。
此外,作者还标注了一个包含三个任务的评估数据集。虽然任务细节未详细说明,但通过该数据集可以系统地评估SCM的效果。
实验结果表明,SCM使得那些未针对多轮对话进行优化的LLMs,能够在多轮对话任务中达到与ChatGPT相当的水平。更进一步,在长文档摘要任务中,SCM甚至超越了ChatGPT的性能。这一结果突显了SCM在处理长文本任务上的优势。
Limitations¶
本研究的一个限制在于,尽管SCM框架具备处理无限轮对话的能力,但我们仅在有限的环境下对其性能进行了评估,最多包含200轮对话,且总对话长度不超过34,000个token。造成这一限制的主要原因是,对非常长的文本进行定性和定量评估都非常困难,这是研究中的重点难点。
另一个限制是,SCM框架需要依赖功能强大且能很好遵循指令的大型语言模型(LLM),例如text-davinci-003和gpt-3.5-turbo-0301。但随着未来更强大且更小型的LLM的发展,这一问题有望得到解决。
总结来说,本研究在对话长度和模型依赖性方面存在一定限制,但这并非不可克服的问题,未来随着技术发展可以进一步改进。
Ethical Considerations¶
本节主要说明了论文中所使用的评估数据集在伦理方面采取的措施。重点强调数据集来源于公开数据,并经过人工核查和筛选,以去除任何可能涉及伦理风险或敏感内容的数据。这一过程确保了数据内容符合现行法规和法律的要求,从而保障研究的合规性和伦理性。
Appendix A Prompt List¶
本章节提供了几个中英文的 Prompt 示例,分别涉及不同的任务领域。以下是对原文内容的总结:
图 11:记忆控制器(Memory Controller)的中文 Prompt¶
重点内容:
图中显示了一个针对“记忆控制器”任务的中文 Prompt。
Prompt 设计的目的是帮助模型在处理长时间对话时,有效管理上下文信息,避免信息遗忘。
该 Prompt 通过明确的指令和结构,指导模型在对话中“记住”关键信息。
精简内容:
图片内容为 Prompt 的具体文字,主要为任务描述和示例对话。
图 12:超长对话生成(Ultra-long Dialogue Generation)的中文 Prompt¶
重点内容:
该 Prompt 用于生成极长的、连贯的多轮对话。
Prompt 中提供了清晰的上下文引导,以确保在生成过程中保持角色一致性与情节连贯性。
强调了模型在生成超长对话时应避免重复或逻辑断裂。
精简内容:
内容为具体的对话示例和生成要求,用于训练模型在长对话场景下的表现。
图 13:超长对话摘要(Ultra-long Dialogue Summarization)的中文 Prompt¶
重点内容:
该 Prompt 用于对超长对话进行摘要生成,提取关键信息。
Prompt 强调了摘要应包含时间、人物、事件等关键要素。
旨在评估模型对长文本的理解与概括能力。
精简内容:
包含具体对话内容及其对应的摘要示例,用于训练和评估摘要生成模型。
总结:
Appendix A 提供了三种中文 Prompt 的示例,分别对应记忆控制器、超长对话生成与超长对话摘要任务。这些 Prompt 的设计重点在于实现模型在长文本处理、上下文管理和信息提取方面的能力,是模型训练和评估的重要参考。
Appendix B Long-term Dialogue QA Cases¶
本节展示了长期对话中的问答案例,通过具体的对话实例说明模型在处理连续上下文时的表现。
重点内容讲解:
图14:对话问题示例
图14提供了一个具体的长期对话问答示例,用于展示模型在理解多轮对话上下文后,对问题的准确理解和回答能力。这是评估模型在长期对话中保持上下文连贯性和语义理解能力的重要参考。
总结:
本节通过图示方式,展示了长期对话中的问答实例,帮助读者更直观地理解模型在复杂对话场景中的表现。图14中的示例是本节的重点,体现了模型对多轮对话上下文的理解和响应能力。
Appendix C Book Summarization Cases¶
本附录展示了两个书籍摘要的案例,分别来自中文书籍和英文书籍,用以说明系统在不同语言和文化背景下的摘要生成能力。
图15:中文书籍《三体》的摘要¶
该图展示了中文科幻小说《三体》的自动摘要结果。《三体》是中国作家刘慈欣的代表作之一,内容涉及宇宙文明、社会哲学与科学幻想。摘要部分涵盖了小说的主要情节、核心人物以及关键主题,如“三体文明”的背景设定、“面壁计划”的展开以及人类与外星文明的互动。摘要内容较为完整,能够帮助读者快速理解小说的主要内容和思想内涵。
该案例的重点在于展示系统在处理中文复杂句式和科幻类文本时的准确性与理解能力。
图16:英文书籍《飘》的摘要¶
此图展示了英文经典文学作品《飘》(Gone With The Wind)的自动摘要结果。该书由玛格丽特·米切尔创作,讲述了美国南北战争期间与战后重建时期一位女性斯嘉丽的成长历程。摘要内容涵盖了斯嘉丽与瑞德·巴特勒、梅兰妮和阿希礼之间的情感纠葛,以及她在乱世中如何挣扎求生并实现自我成长。
该案例的重点在于展示系统在处理英文长篇叙事类文学作品时的信息提取能力和语言组织能力。
总结:
附录C通过两个不同语言和类型的书籍摘要案例(中文科幻与英文文学),验证了系统在多语言环境下的摘要生成能力,尤其在处理复杂情节和人物关系方面表现突出。这些案例展示了系统在内容理解和语言表达方面的强大功能。
Appendix D Meeting Summarization Cases¶
本附录展示了一个会议摘要的案例,具体是关于区块链主题的会议摘要。由于附录中仅提供了一张图片(Figure 17),内容未以文字形式展开,因此以下总结基于附录标题和图注进行简要说明。
图17:区块链会议摘要¶
重点内容:这是对一次讨论区块链技术的会议进行的摘要。会议摘要通常包含会议的核心讨论点、参与者的观点、达成的共识以及可能的下一步行动。
摘要的意义:会议摘要的目的是为未能参会的人员提供一个简明扼要的记录,同时帮助参会者回顾会议内容。这种形式在技术交流、项目管理和学术研究中尤为重要。
总体说明¶
由于图片内容未提供详细文字,无法对会议的具体讨论内容、参与人员或结论做进一步说明。
附录的目的是提供一个实际案例,帮助读者理解如何对技术类会议内容进行结构化摘要。
总结:本附录通过“图17”提供了一个区块链会议摘要的示例,强调了会议摘要在信息整理与传递中的作用。由于图片内容限制,未展开具体摘要内容。