2506.18095_ShareGPT-4o-Image: Aligning Multimodal Models with GPT-4o-Level Image Generation¶
引用: 0(2025-07-22)
组织: The Chinese University of Hong Kong, Shenzhen
GitHub: https://github.com/FreedomIntelligence/ShareGPT-4o-Image
Huggingface: https://huggingface.co/datasets/FreedomIntelligence/ShareGPT-4o-Image
总结¶
数据集
ShareGPT-4o-Image 数据集
第一个大规模的合成数据集,使用 GPT-4o 图像生成变体 GPT-4o-Image 的图像生成能力合成
包含 45,000 个文本到图像和 46,000 个文本与图像到图像的样本
使用 Gemini-Pro-2.5 作为主要的大语言模型来完成文本合成任务
模型
Janus-4o 模型
基于 ShareGPT-4o-Image 数据集,作者调优 Janus-Pro 开发了 Janus-4o
一个支持文本到图像和文本与图像到图像生成的多模态大语言模型
相比其前身 Janus-Pro,Janus-4o 在图像生成方面有显著提升,并新增了文本与图像到图像的生成能力
Abstract¶
该论文的主要内容总结如下:
研究背景与动机:
近年来,多模态生成模型在生成逼真图像方面取得了进展,但目前领先的模型(如 GPT-4o-Image)仍然是专有且无法公开访问的。为推动这一技术的开放研究,作者提出了一个开源的解决方案。主要贡献:
ShareGPT-4o-Image 数据集:
这是第一个大规模的合成数据集,包含 45,000 个文本到图像和 46,000 个文本与图像到图像的样本。所有数据均使用 GPT-4o 的图像生成能力合成,用于提炼其先进的图像生成能力。Janus-4o 模型:
基于 ShareGPT-4o-Image 数据集,作者开发了 Janus-4o,这是一个支持文本到图像和文本与图像到图像生成的多模态大语言模型。相比其前身 Janus-Pro,Janus-4o 在图像生成方面有显著提升,并新增了文本与图像到图像的生成能力。
实验与结果:
Janus-4o 在文本与图像到图像的生成任务中表现出色,仅使用 91,000 个合成样本和 6 小时训练(8×A800 GPU),即可实现高质量生成。
使用 ShareGPT-4o-Image 微调 Janus-Pro 后,模型性能明显提升,并在多个基准上优于其他模型。
研究意义与展望:
作者希望通过开源数据集 ShareGPT-4o-Image 和模型 Janus-4o,推动高质量、指令对齐的图像生成研究,促进该领域的开放与创新。
总体而言,该研究通过构建高质量的合成数据集和训练强大的图像生成模型,为多模态生成研究提供了重要的资源和方法。
1 Introduction¶
本文介绍了ShareGPT-4o-Image 数据集及其基于该数据集训练的多模态大语言模型 Janus-4o,旨在提升开源模型在图像生成方面的能力,使其更接近当前最先进的专有模型(如 GPT-4o-Image)。
主要内容总结:¶
背景与动机:
大规模生成模型在多模态合成任务中取得了显著进展,尤其是图像生成能力显著提升。
尽管专有模型(如 GPT-4o-Image)在文本到图像(text-to-image)和文本加图像到图像(text-and-image-to-image)生成方面表现优异,但其模型架构和训练过程不透明,限制了研究社区的使用。
当前开源模型(如 Janus-Pro)在图像生成任务上仍与专有模型存在较大差距。
ShareGPT-4o-Image 数据集:
包含 45,000 个文本到图像和 46,000 个文本加图像到图像的高质量语句对,共计 91,000 张图像。
图像由 GPT-4o 生成,覆盖多种风格与视觉推理任务,体现出 GPT-4o 在指令理解和视觉美感方面的优势。
数据集设计注重多样性和质量,旨在为开源模型提供高质量训练数据。
Janus-4o 模型:
基于 Janus-Pro 模型,并利用 ShareGPT-4o-Image 数据集进行微调,开发出支持文本到图像和文本加图像到图像生成的新多模态模型。
在多个基准测试(如 EvalGen、DPG-Bench、ImgEdit-Bench)中,Janus-4o 显著优于 Janus-Pro,特别是在图像编辑任务上表现突出。
尽管仅使用 91,000 个合成样本和 6 小时的训练时间(8×A800 GPU),Janus-4o 仍实现了令人满意的性能。
贡献:
首次发布高质量的多模态图像生成数据集 ShareGPT-4o-Image。
开发出支持多种图像生成任务的开源模型 Janus-4o。
通过实验验证,证明了该数据集和模型在图像生成和编辑方面的有效性。
总结:¶
本文通过引入高质量的合成数据集和训练出性能优越的开源模型,推动了开源多模态生成模型的发展,缩小了与专有模型之间的差距,为后续研究提供了宝贵的资源和方法。
2 ShareGPT-4o-Image¶
本文第二章介绍了 ShareGPT-4o-Image 数据集的构建过程,该数据集旨在提炼 GPT-4o-Image 的先进生成能力。数据集包含 45,000 个文生图对 和 46,000 个指令引导的图像编辑三元组,整个生成过程依赖于 Gemini-Pro-2.5 作为主要的大语言模型来完成文本合成任务。
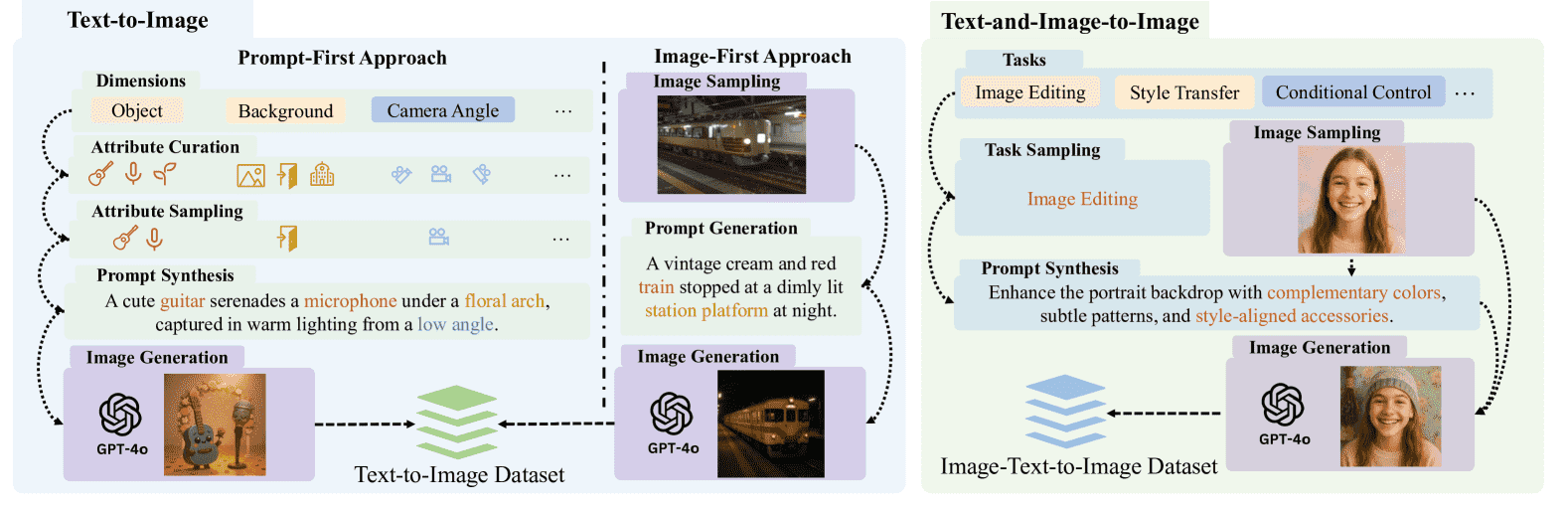
Figure 3:The flow diagram for the dataset construction process. The prompt in the diagram is the simplified version.
2.1 文本到图像数据¶
文本到图像数据通过两种互为补充的流程生成:
提示优先(Prompt-First)流程
该流程通过定义一个六维的属性空间(如物体、背景、风格等),并从中采样属性组合,通过 LLM 生成结构化的自然语言提示。这些提示再由 GPT-4o-Image 生成对应的图像。该方法控制了生成内容的复杂度和多样性,确保生成的提示和图像具有系统性和可控性。图像优先(Image-First)流程
该流程从现有高质量图像数据集(如 ALLaVA)中获取图像,再通过 LLM 生成能够准确描述图像内容的文本提示。这种方式使得数据集中的文本分布能够覆盖对自然场景的描述语言,增强多样性与真实性。
2.2 指令引导的图像编辑数据¶
该部分生成用于图像编辑的三元组(源图像、编辑指令、编辑后图像),具体流程如下:
定义了 14 种图像编辑任务,归类为 5 个高层次类别(如物体操作、风格迁移等)。
源图像来自自建的文生图数据或精选的真实图像。
根据图像内容和任务类型,LLM 生成一个具体的自然语言编辑指令。
GPT-4o-Image 根据指令对源图像进行编辑,生成最终结果。
该方法生成了覆盖常见图像编辑场景的 46,000 个三元组,为训练和评估具有指令跟随能力的图像编辑模型提供了丰富的数据支持。
总结¶
本章详细介绍了 ShareGPT-4o-Image 数据集的构建方法,通过两种互补的文生图生成流程和系统化的图像编辑任务分类,构建了一个结构清晰、内容多样、覆盖广泛图像生成和编辑场景的数据集,为多模态模型的训练和对齐提供了坚实基础。
3 Janus-4o: Fine-Tuning with ShareGPT-4o-Image¶
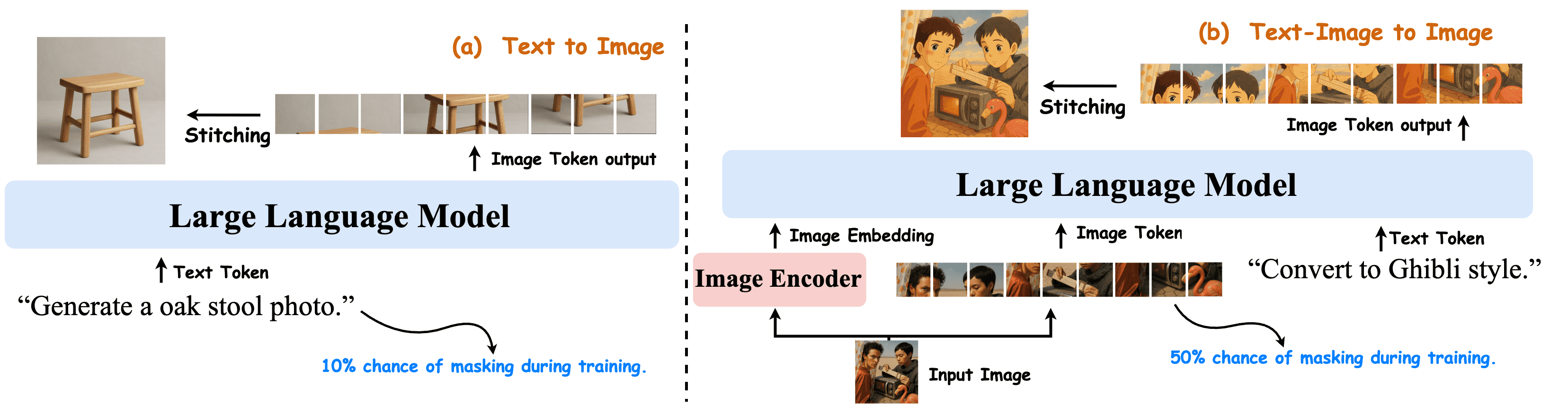
Figure 4:Overview of Janus-4o model. Built upon Janus-Pro, it is constructed via fine-tuning on ShareGPT-4o-Image. It incorporates enhancements to support text-and-image-to-image generation. Both text-to-image and text-and-image-to-image tasks are jointly trained.
总结:Janus-4o 模型的微调与文本-图像生成能力的增强¶
本章介绍了 Janus-4o 模型的构建过程,该模型基于 Janus-Pro,并通过对 ShareGPT-4o-Image 数据集进行微调,增强了其对 文本生成图像(text-to-image)和 文本-图像生成图像(text-and-image-to-image)任务的支持能力。
1. Janus-4o 概述¶
Janus-4o 是 Janus-Pro 的增强版本,通过在 ShareGPT-4o-Image 上进行微调而来。
它不仅支持文本到图像生成,还新增了对文本-图像到图像生成的支持。
两种任务在训练过程中是联合优化的,提高了模型的多模态生成能力。
2. 文本到图像的微调¶
训练:将文本提示编码为 token 序列,并将图像压缩为图像 token 序列。模型通过预测图像 token 实现图像生成。训练过程中对文本 token 的 10% 进行随机掩码,以增强像素级别的依赖建模。
损失函数:采用自回归训练方式,目标是最小化图像 token 的预测损失。
推理:在生成过程中,使用条件与无条件 logits 的线性插值,提升生成质量,控制生成的多样性与稳定性。
3. 文本-图像到图像的微调¶
训练:输入包括文本、输入图像及其语义嵌入和 token 表示。模型需要在这些信息的指导下生成目标图像。训练中对图像 token 的 50% 进行掩码,防止模型过度依赖输入图像。
损失函数:结合文本、输入图像的嵌入和 token 信息,训练模型生成目标图像。
推理:在生成时,输入图像被编码为语义嵌入和 token,模型通过自回归方式生成新的图像。推理过程引入了多个 scaling 因子,用于控制生成结果对输入图像的保留程度和创造性。
4. 联合微调¶
训练细节:使用 45K 的文本到图像样本和 46K 的文本-图像到图像样本,共 3 个 epoch 进行联合训练。
训练配置:全量微调 Janus-Pro-7B 模型,学习率为 \(5 \times 10^{-6}\),批量大小为 128。
训练效率:仅需 6 小时即可在单个 8×A800 GPU 上完成训练。
5. 总体评价¶
Janus-4o 通过在 ShareGPT-4o-Image 上进行高效的微调,在保持原有文本生成图像能力的基础上,新增了对图像编辑的支持。其训练方式兼顾了生成质量与多样性,推理过程灵活可控,具有较强的实用价值。
4 Experiments¶
本论文的第4章“实验”部分主要评估了Janus-4o在文本到图像生成(Text-to-Image)和文本与图像到图像生成(Text-and-Image-to-Image)任务中的性能。
实验设置¶
基准测试:使用GenEval和DPG-Bench评估Janus-4o的图像生成能力,涵盖组合性和语义对齐。此外,使用ImgEdit评估其在文本与图像联合输入生成图像任务中的表现。
人工评估:通过比较Janus-4o与Janus-Pro-7B和UltraEdit的输出,评估其与人类偏好的一致性。实验数据来自真实的Twitter帖子,共52个文本到图像任务和35个文本与图像到图像任务。经过人工评估,结果以偏好比例(preference ratio)形式呈现。
实验结果与分析¶
文本到图像生成性能:
在GenEval基准上,Janus-4o整体准确率达到80%,比Janus-Pro提升了4个百分点,表现优于大多数现有模型。
在DPG-Bench上,Janus-4o得分为85.71,比Janus-Pro提升了1.6个百分点,显示出其在复杂指令理解和生成上的优势。
结果表明,引入ShareGPT-4o-Image数据不仅提升了图像生成质量,还增强了模型对复杂指令的理解和执行能力。
文本与图像到图像生成性能:
在ImgEdit-Bench上,Janus-4o得分为3.26,在**运动变化(Motion Change)和风格迁移(Style Transfer)**等任务上表现突出。
尽管仅使用91K训练样本(远少于其他模型的数百万数据),其性能仍可与其他方法竞争,这证明了高质量数据的重要性,以及ShareGPT-4o-Image数据集的有效性。
人工评估结果:
Janus-4o在图像质量和指令遵循方面明显优于Janus-Pro,在文本与图像到图像生成任务中能够更准确地执行用户指令。
人工评估结果显示,Janus-4o更符合人类的审美偏好和任务需求。
总结¶
该章节通过多个基准测试和人工评估,全面验证了Janus-4o在文本到图像和文本与图像到图像生成任务中的优越性能。它不仅在多个指标上优于当前最先进的模型,而且在实际应用中更贴近用户的期望和需求。这主要得益于引入的高质量训练数据集ShareGPT-4o-Image,以及对模型生成能力和指令理解能力的显著提升。
5 conclusion¶
本章总结如下:
本文介绍了 ShareGPT-4o-Image,这是首个大规模数据集,全面捕捉了 GPT-4o 在文本生成图像和图文生成图像方面的先进能力。基于该数据集,研究人员开发了 Janus-4o,这是一种多模态大语言模型(MLLM),能够从纯文本或结合图像与文本的输入中生成高质量图像。实验结果表明,Janus-4o 在文本生成图像任务中表现出显著提升,并在图文生成图像任务中也取得了具有竞争力的结果,充分证明了 ShareGPT-4o-Image 数据集的高质量和实用性。此外,借助基于 MLLM 的自回归图像生成方法的高效性,Janus-4o 仅需在 8×A800 GPU 机器上训练 6 小时,便能取得显著的性能提升,计算资源消耗极低。
Appendix B Image Generation Categories¶
本附录总结了图像生成任务中的两个主要类别:文本到图像生成(Text-to-Image) 和 文本加图像到图像生成(Text-and-Image-to-Image),以及在多对象生成中使用的 指数衰减分布(Exponential Decay Distribution) 的采样方法。
一、文本到图像生成(Text-to-Image)分类¶
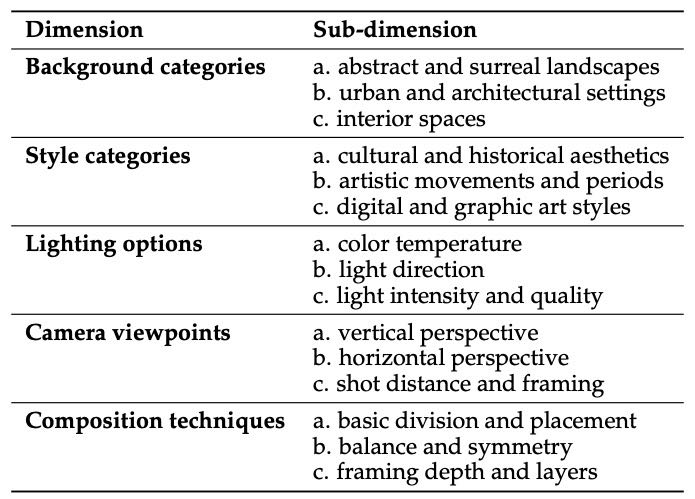
Table 4: Text-to-Image Dimensions and Sub-dimensions.
文本到图像生成任务被细分为以下五个维度,每个维度下又有多个子维度:
维度 |
子维度 |
|---|---|
背景类别 |
抽象与超现实景观、城市与建筑场景、室内空间 |
风格类别 |
文化与历史美学、艺术运动与时期、数字与图形艺术风格 |
光照选项 |
光色温度、光照方向、光强与质量 |
相机视角 |
垂直视角、水平视角、拍摄距离与构图 |
构图技巧 |
基本分割与布局、平衡与对称、构图深度与层次 |
这些维度用于描述生成图像的多样性与复杂性,分布情况通过图表展示(图6)。
二、文本加图像到图像生成(Text-and-Image-to-Image)分类¶
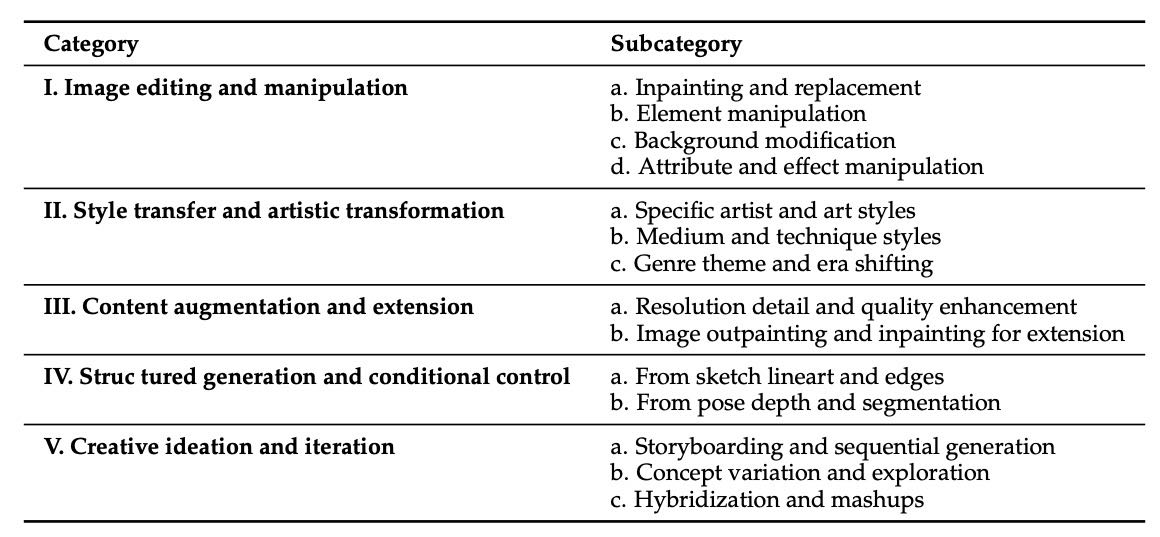
Table 5: Categories and subcategories for Text-and-Image-to-Image tasks.
该任务分为五个主要类别,每个类别下包含多个子类别:
类别 |
子类别 |
|---|---|
图像编辑与修改 |
补绘与替换、元素操作、背景修改、属性与特效操作 |
风格迁移与艺术化 |
特定艺术家与艺术风格、媒介与技法风格、题材与时代转换 |
内容增强与扩展 |
分辨率与细节增强、图像扩展(补边与补绘) |
结构化生成与条件控制 |
基于草图、线稿与边缘、基于姿态、深度与分割图 |
创意构思与迭代 |
分镜与序列生成、概念变体与探索、混合与跨风格创作 |
这些类别展示了在已有图像基础上进行修改与扩展的多种方式,其分布也通过饼图展示(图7)。
三、对象类别数量 k 的分布(Exponential Decay Distribution)¶
在多对象生成任务中,对象类别的数量 k 被从 1 到 100 的范围内进行采样。为了确保样本多样性,尤其是当多个对象交互时,采用了指数衰减分布来控制选择的概率。
指数衰减分布公式: $\( w(x) = \exp(-\lambda(x-1)) \)$ 其中,λ 是控制衰减速率的参数。λ 值越大,概率下降越快,适用于“少量类别更常见”的场景。
该分布通过图形(图8)展示其概率随类别数量增加而指数下降的特点。
总结¶
本附录系统梳理了图像生成任务的分类体系,包括文本到图像和文本加图像到图像的主要任务维度与子类别,并介绍了用于多对象生成任务中的指数衰减分布方法,以实现更自然、多样化的采样模式。这些内容为图像生成模型的设计与评估提供了结构化的参考。
Appendix C Prompts for Generation¶
主要介绍了用于图像生成的提示(prompt)设计方法和流程,分为三个部分:
C.1 Image-First Prompt¶
这一部分提供了一个用于图像描述的提示模板,要求用一句话简明扼要地描述图像的主要内容。该描述将被用作图像再生的提示,因此需准确捕捉图像的关键视觉信息,要求仅输出这句话,不添加任何额外内容。
Please describe the main content of the image in one sentence.
This sentence will be used as a prompt to regenerate the image, so it should clearly capture the key visual information.
Only provide the sentence,no extra text.
C.2 Content Generation Process¶
该部分详细描述了生成视觉模板提示的四步流程:
选择主题和文档类型:根据给定主题,选择一个核心文档类别,并进一步具体化为一个特定的文档类型(如“科技会议的标题幻灯片”)。
选择字体与视觉风格:根据文档类型和主题,选择适合的字体和视觉风格,强调清晰性、专业性和功能性,避免不必要的复杂或过时风格。
生成视觉模板提示:根据上述信息生成一个简洁、专业、符合用途的英文图像生成提示,描述包括整体美学、布局、配色、纹理等视觉元素。
输出规范:以明确格式输出所生成的提示与主题信息。
You are an expert document concept designer and text-to-image prompt generator. Your goal is to create concepts that are clear, professional, and highly appropriate for the intended use.
Your task is to perform the following steps IN ORDER:
STEP 1: Use the Given Theme and Choose a Core Document Category
- Use the following theme: "{{selected\_theme}}"
- Choose ONE core document category that best fits this theme from the following list:
{’, ’.join(CORE\_DOCUMENT\_CATEGORIES)}
- Based on the chosen core category and theme, \*\*conceive and clearly state a MORE SPECIFIC document type or application.\*\*
For example:
[previous examples remain the same...]
STEP 2: Select an Appropriate Font Style and Visual Characteristics
- Choose and incorporate this font style: "{{selected\_font}}"
- Based on the \*\*Specific Document Type\*\* from STEP 1 and the Theme, internally determine the most FITTING and EFFECTIVE visual style characteristics.
- \*\*Priority is on CLARITY, PROFESSIONALISM, and FUNCTIONALITY for the specific document type.\*\*
- Avoid overly ornate or unnecessarily complex styles unless the theme and specific type genuinely call for it (e.g., a historical document recreation).
- \*\*Minimize generic "parchment paper" or "old paper" styles for most modern professional contexts.\*\*
- The visual style should serve the content and the document’s purpose.
STEP 3: Generate a Clear and Fitting Visual Template Prompt
- Now, generate a single, compelling text-to-image prompt (in English) for creating a visual template.
- This prompt MUST be based on the Theme AND the \*\*Specific Document Type\*\* (from STEP 1).
- The prompt MUST reflect a visual style that is \*\*highly appropriate, clear, and professional\*\* for the specific document type and theme (informed by STEP 2).
- The prompt should describe:
- Overall aesthetic (e.g., "clean and modern," "formal and academic," "bold and clear," "data-focused and organized").
- Layout and composition (e.g., "standard slide layout with title and content areas," "two-column academic paper layout," "grid-based infographic structure").
- Color palette (e.g., "corporate blues and grays," "high-contrast for readability," "theme-appropriate accent colors").
- Textures (if any: "smooth untextured background," "subtle professional texture like fine linen," "no distracting textures").
- Placeholder elements and their style, suitable for the specific document type (e.g., "placeholders for a large title, speaker name, and event logo for a title slide").
- Do NOT include any specific readable text in this visual template prompt itself.
- The prompt should be a single, coherent sentence.
STEP 4: State Your Outputs Clearly
- Provide your outputs in the following exact format, with each item on a new line:
Visual Template Prompt: [The visual template prompt you generated in STEP 3]
Conceived Theme: [The theme you conceived in STEP 1]
Document Type: [The CORE DOCUMENT CATEGORY chosen in STEP 1, followed by the SPECIFIC document type/application you conceived in STEP 1, e.g., "Slide - Title Slide for a Tech Conference"]
Now, follow these steps carefully, focusing on CLARITY, PROFESSIONALISM, and APPROPRIATENESS for the document type, and generate a new set:
"""
C.3 Meta Prompts for Image Text Instruction¶
该部分提供了一个元提示模板(meta prompt),用于指导AI生成高质量的图像描述句。该提示强调:
输出应为单句英文描述,准确传达图像的核心视觉信息和氛围;
若有附加任务(如“添加生物”),应自然融合到描述中;
优先考虑图像的视觉吸引力和描述的结构性,而非机械地遵循任务;
输出格式应简洁,只输出一个句子,无任何解释、列表或格式符号。
meta_prompt_system = (
"You are an AI assistant that creates a single, concise, complete, and descriptive English sentence to be used as a prompt for image generation models. "
"This sentence should beautifully capture the essence, mood, and key visual elements of the provided input image. "
"If a ’Base Task’ is provided, consider integrating it naturally into this single descriptive sentence. "
"However, prioritizing the image’s core visual appeal and the formation of a well-structured, impactful sentence is more important than rigidly following the task. "
"If the task doesn’t fit well or makes the sentence awkward or verbose, focus on crafting the best single descriptive sentence for the image itself. "
"Output ONLY this single English sentence. No explanations, no preambles, no bullet points, no numbered lists. Just one sentence. "
"For example, for an image of a misty forest (task: ’add creature’): ’A mystical deer steps softly through the sun-dappled, misty ancient forest.’ "
"Or if the task is awkward: ’Sunlight filters mysteriously through the tall trees in the quiet, misty forest.’ "
"For a portrait (task: ’change background to space’): ’Her serene gaze is complemented by a backdrop of swirling cosmic stardust.’ "
"Or without task: ’A soft light illuminates her thoughtful expression in this intimate portrait.’"
)
总结:本附录系统地介绍了从图像描述到视觉模板提示生成的标准化流程,强调描述的清晰性、专业性和实用性,并提供了可重复使用的元提示模板,适用于图像生成模型的高质量输入。
Appendix D Document Pipeline¶
本章节主要介绍了文档图像生成的**文档管道(Document Pipeline)**流程及其核心文档类别。
总结:¶
文档提示生成流程:
内容生成:首先,利用大语言模型(LLM)根据特定文档类型的元提示(meta-prompts)生成具有真实感的文档内容,包括标题、段落和数据片段等。
提示合成:在此基础上,LLM进一步生成详细的视觉提示,描述所需文档图像的布局、字体、配色方案和整体外观。
核心文档类别:
该管道支持五种主要的文档类型:
幻灯片(Slide)
论文(Paper)
文档(Document)
信息图表/图表(Infographic/Chart)
海报(Poster)
此流程通过专门的提示设计,使生成的图像能够更好地捕捉文档类图像在结构和语义上的独特性。
Appendix E Ethical Considerations and Societal Impact¶
本章节《附录E:伦理考量与社会影响》主要探讨了在开发和发布 ShareGPT-4o-Image 多模态数据集过程中涉及的伦理问题及其潜在的社会影响,具体总结如下:
数据来源与透明度:
ShareGPT-4o-Image 中的图像数据来源于专有模型 GPT-4o-Image 的合成输出。尽管研究团队详细公开了生成图像的提示词方法(见附录B和C),以提高数据生成过程的透明度和可复现性,但 GPT-4o-Image 本身的内部机制并不透明。该数据集的目的是转移能力,而非复制原模型。生成图像中的潜在偏见:
由于 GPT-4o-Image 是基于大规模网络数据训练的,可能会继承或放大与性别、种族、年龄、职业等相关的社会偏见。特别是涉及人类形象的图像,可能会反映出这些偏见。偏见缓解措施:
在生成“人物”类图像的提示词设计中,研究团队尝试使用多样的描述符(如种族、年龄等),以提升多样性。
但最终生成图像是否达到平衡,仍取决于底层模型的行为。
未对生成图像进行事后偏见过滤,因为这可能引入主观判断和新的偏见,团队建议用户自行进行偏见分析。
内容生成的潜在风险:
文本内容由大型语言模型(Gemini 2.5 Pro)生成,尽管设计为生成虚构和通用内容,但仍可能存在因训练数据而产生的无意偏见或可能引起误解的文本。使用目的与滥用风险:
该数据集仅限学术研究用途,用于研究开源生成模型的指令遵循、图像质量和多模态条件。研究团队明确反对将该数据集或其训练模型用于生成有害内容、强化刻板印象、制造虚假信息或侵犯个人权利的行为。使用该数据集的用户需遵守伦理AI实践。未来工作与社区责任:
鼓励社区对 ShareGPT-4o-Image 进行系统性偏见审计和进一步研究。发布该数据集旨在赋能开源社区,同时也强调社区在探索和减轻先进生成式AI潜在负面影响方面的共同责任。
总结来说,该附录强调了在开发和使用先进多模态AI数据集过程中,必须认真考虑数据来源、偏见风险、使用伦理与社会责任等关键问题。