1804.08771_SacreBLEU: A Call for Clarity in Reporting BLEU Scores¶
组织: Amazon Research Berlin, Germany
引用: 3243(2025-07-15)
BLEU¶
定义¶
BLEU(Bilingual Evaluation Understudy),即双语评估替换,是一种用于评估机器翻译质量的算法。
它通过比较机器生成的翻译文本与一个或多个参考译文之间的相似度来打分。
BLEU分数范围从0到1,其中1表示完全匹配参考译文的理想情况。
实际上,完美的匹配很少见,因此一个较高的分数(如0.7或以上)通常被认为是高质量的翻译。
BLEU评分主要考虑的是n-gram的精确度,即检查候选翻译中的n-gram在参考译文中出现的比例。
核心计算步骤¶
n-gram精确度
分别计算n=1(unigram)、2(bigram)、3(trigram)、4(four-gram)时,生成文本中n-gram在参考文本中出现的比例(匹配数/生成文本总n-gram数)
例:生成文本1-gram匹配数为4,总1-gram数为7,则1-gram精确度为4/7
几何平均值
对4个n-gram精确度取几何平均值,避免单一n-gram匹配度过低对整体评分的过度影响
长度惩罚(Brevity Penalty, BP)
若生成文本短于参考文本,施加惩罚
若长度相等或更长,不惩罚,防止过短文本获高分
最终得分
BLEU = 长度惩罚 × exp(1/4 × (log(p1) + log(p2) + log(p3) + log(p4)))
其中p1-p4为各n-gram精确度
n-gram¶
指连续的 n 个词的组合,是两者计算的基础
n=1:unigram(单个词,如 “今天”)
n=2:bigram(两个连续词,如 “今天天气”)
n=3:trigram(三个连续词)
n=4:four-gram(四个连续词)
总结¶
BLEU 不是一个固定指标,而是一个参数化指标,不同参数设置会导致结果显著不同(差异最高可达 1.8 分)。
参数设置不透明,许多研究未报告所使用的具体参数和预处理方式,导致评估结果不可比。
预处理方式对 BLEU 分数影响巨大,尤其是用户自定义的分词和归一化方法。
建议统一使用 WMT 的标准 BLEU 计算方式,避免用户自定义参考文本处理,提升一致性。
提出工具 SacreBLEU,提供标准化的 BLEU 计算流程,支持自动下载测试集、统一预处理、记录参数设置。
呼吁提升研究的严谨性和可重复性,包括报告完整参数、参考译文信息、统计显著性检验及软件版本。
Abstract¶
本论文指出机器翻译领域存在一个被低估的问题:
由于主流评估指标BLEU的使用不一致,导致不同研究之间BLEU得分难以直接比较。
尽管人们通常认为BLEU是一个固定的指标,但实际上它是一个参数化指标,其结果会因参数设置的不同而大幅变化。
作者发现,不同常用配置下BLEU得分差异最高可达1.8。
造成这一问题的主要原因在于对参考文本使用的分词和归一化处理方式不同。
作者借鉴自然语言处理中解析领域的成功经验,建议机器翻译研究者统一采用WMT会议所使用的BLEU计算方式,这种方式不允许用户自定义参考文本处理。
为此,作者开发了一个新工具 SacreBLEU ,以促进这一统一标准的实施。
1 Introduction¶
这篇论文的引言部分主要讨论了机器翻译研究中广泛使用的BLEU指标的问题。作者指出,尽管BLEU因其语言独立性、计算简便和与人工评估的合理相关性而被广泛采用,但它在实际使用中存在一些问题。这些主要问题包括:
BLEU不是一个单一指标:它依赖于多个参数,不同参数设置会导致结果不同。
预处理方案影响评分:不同方式处理参考文本会导致BLEU得分不可比较。
隐藏参数缺乏报告:许多研究论文未明确说明所使用的参数和预处理方法,导致结果难以复现和比较。
这些问题导致了论文之间BLEU得分的不可比性,从而影响了研究的可重复性和评估的准确性。作者指出这些差异在很多情况下甚至超过了论文中报告的性能提升。为了解决这些问题,作者建议:
在共享BLEU得分时,使用metric-supplied(指标自带的)参考分词方式,避免用户自定义的分词方式带来的不一致性。
提出了一个名为SacreBLEU的Python包,能够自动下载并处理标准测试集的参考文本,并记录参数设置,以提高透明度和可重复性。
最后,作者通过表格展示了在不同预处理方式下,BLEU得分在不同语言对的差异,进一步说明了问题的严重性。
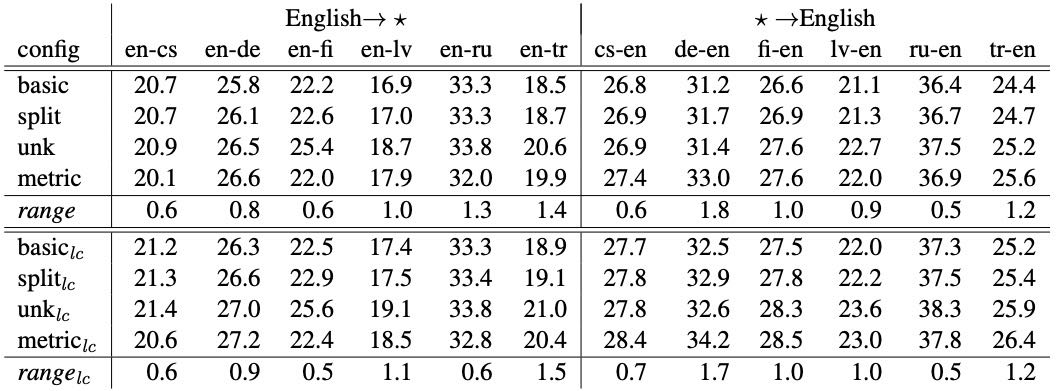
Table 1: BLEU score variation across WMT’17 language arcs for cased (top) and uncased (bottom) BLEU
2 Problem Description¶
该章节主要讨论了在使用BLEU评分时存在的四个主要问题,以及这些问题对研究结果的可比性和透明性造成的负面影响:
1. BLEU定义不明确¶
BLEU不是一个固定的方法,而是一系列依赖参数的组合。常见的参数包括参考句数量、长度惩罚计算方式、最大n-gram长度以及对零计数n-gram的平滑处理。这些参数在实际使用中往往被忽略,导致不同研究之间BLEU分数的可比性下降。例如,参考句数量不同(如WMT 2017中英–芬兰有2个参考句)会显著影响BLEU分数,但这一点很少被明确说明,造成对不同语言对性能的误解。
2. 参考句预处理方式不同导致不可比¶
BLEU的计算依赖于参考句和系统输出的分词处理,而不同的预处理方法(如大小写处理、分词方式、未登录词处理等)会显著影响结果。当用户自行预处理参考句时,容易引入误差,导致不同论文之间的BLEU分数难以比较。作者指出,一些研究可能误将参考句中的未知词替换为UNK,造成BLEU分数虚高,这种错误在研究流程中并不罕见。
3. 论文中缺乏明确的配置说明¶
由于多数论文没有详细说明BLEU的配置(如使用的是内部预处理还是自定义预处理),读者难以复现或比较不同研究的BLEU分数。作者列举了一些著名论文,发现它们在报告BLEU配置时存在模糊不清的情况,这进一步加剧了结果不可比的问题。
4. 数据集版本不明确¶
不同版本的测试集(如WMT’14英→德的两个版本,句子数分别为2,737和3,004)也会影响BLEU分数,但很多研究并未明确说明使用的是哪个版本,这进一步增加了结果的不确定性。
总结¶
该章节指出,BLEU评分在实际使用中存在定义不明确、预处理方式不统一、配置信息不透明和数据集版本不一致等问题,导致不同研究结果难以比较。作者建议采用统一的预处理流程(由BLEU评分接口自身处理),避免用户对参考句进行自定义处理,并在论文中明确说明BLEU的配置参数,以提高研究的可比性和可复现性。
3 A way forward¶
本章节主要探讨了如何在自然语言处理领域中建立公平、可重复的评估体系,并以具体的项目和工具为例,说明了实现这一目标的方法和工具。
3.1 The example of PARSEVAL¶
PARSEVAL 是一种用于评估英语句法分析结果的指标,已有数十年历史,广泛用于不同论文之间的比较。其核心思想是通过比较解析器输出的结构与标准答案(gold-standard)之间的匹配程度,计算出精确率(precision)、召回率(recall),再综合为 F1 值。
虽然实现原理简单,但实践中存在许多边界问题,例如是否考虑 TOP 节点、-NONE- 节点或标点符号等。通过社区采用标准代码库 evalb,这些问题得以统一解决,从而确保了评估的一致性和可比性。该工具在如 Penn Treebank 等语料库中被广泛应用,促进了三十多年的句法分析研究和比较。
3.2 Existing scripts¶
目前,Moses 等工具提供了一些评估脚本,但存在诸多问题:
multi-bleu.perl和MultEval需要用户手动进行分词预处理;mteval-v13a.pl虽然内部处理了预处理,但要求数据以 XML 格式包装,使用不便;multi-bleu-detok.perl虽移除了 XML 限制,但仍需用户手动处理参考译文。
这些问题表明,当前的评估脚本在自动化和易用性方面仍有不足。
3.3 SacreBLEU¶
为了解决上述问题,SacreBLEU 应运而生。它是基于 Python 的 BLEU 评估工具,具有以下优点:
内置预处理:自动进行分词和标准化处理,无需用户手动干预;
自动下载测试数据集:支持 WMT(2008–2018)和 IWSLT 2017 等标准测试集,免除用户手动处理参考译文;
记录评估参数:输出中包含版本字符串,记录所有评估设置,提高结果的可追溯性和可重复性;
支持 CHRF 等其他指标:可通过
-m参数选择使用 CHRF。
SacreBLEU 的使用简单,可通过 pip 安装,并提供命令行接口进行 BLEU 评分计算。例如,对 WMT14 英德翻译任务的评估可通过如下命令完成:
cat output.detok | sacrebleu -t wmt14 -l en-de
输出结果示例如下:
BLEU+c.mixed+l.en-de+#.1+s.exp+t.wmt14+tok.13a+v.1.2.10
其中详细记录了评估设置(如语言对、参考数量、平滑方式、分词方式等)和版本信息。
SacreBLEU 以 Apache 2.0 开源协议发布,是目前 NLP 领域中推动评估标准统一和透明的重要工具之一。
总结¶
本章强调了在 NLP 领域建立标准化、自动化、可重复的评估体系的重要性,并通过 PARSEVAL 与 SacreBLEU 两个成功案例,展示了如何通过统一的评估标准、透明的参数设置和自动化工具来实现这一目标。SacreBLEU 的出现,使得 BLEU 评估更易于使用、更可靠,是当前机器翻译评估领域的一个重要进步。
4 Summary¶
本章节总结如下:
当前机器翻译研究受益于来自学术界、政府和产业界提供的多种语言对测试集的不断引入。然而,这些测试集之间难以直接比较得分,这一问题令人遗憾。尽管表面上看这似乎是个细枝末节,但实际上,评分差异非常显著,常常远超过新方法所带来的性能提升。
解决这一问题相对简单。研究团队在报告BLEU得分时,应统一使用基于度量标准内部的分词和预处理方案,并明确说明所使用的BLEU参数设置。这样,得分就能实现跨研究的直接比较。为兼容WMT的旧结果,作者建议采用WMT使用的处理方案,并提供了一个新工具以简化这一过程。