2505.22101_❇️MemOS: A Memory OS for AI System¶
引用:
00(2025-07-27)
16(2025-11-25)
组织:
1MemTensor (Shanghai) Technology Co., Ltd.,
2Shanghai Jiao Tong University,
3Institute for Advanced Algorithms Research, Shanghai,
4Tongji University,
5Zhejiang University,
6University of Science and Technology of China,
7Peking University,
8Renmin University of China,
9Beihang University,
10Research Institute of China Telecom
Project Website: https://memos.openmem.net/
总结¶
简介
MemOS 建立了以记忆为中心的系统框架
为 LLM 带来了可控性、可塑性和可进化性,为持续学习和个性化建模奠定了基础
核心理念
为了充分利用时间和空间分布的信息,模型需要一个统一的框架来组织记忆、维护内部状态并支持长期自适应
三大核心功能
Controllability
Plasticity
Evolvability
MemCube
封装了记忆内容以及诸如来源和版本控制之类的元数据
可以随时间推移进行组合、迁移和融合
从而实现记忆类型之间的灵活转换,并将检索与基于参数的学习连接起来
LLM展望
从时间上看
模型将从无状态、基于会话的工具转变为嵌入在长期运行工作流中的持久代理
与人类一样,它们需要积累交互历史、调整内部状态,并基于扩展的上下文进行推理
从空间上看
LLM 正在演变为跨用户、平台和生态系统的基础智能层
无论是部署在云服务中还是嵌入在企业系统中,它们都必须支持跨用户、角色和任务的一致性、适应性和个性化
挑战
随着这种无处不在成为常态,一个关键挑战随之而来:知识应该如何组织、存储和检索?
演进
记忆管理
将由模型定义而非人为定义
从硬编码流程(例如 RAG)向可学习策略转变
未来的智能体
将自主决定是否检索记忆、将交互总结为可重用的规则、抽象偏好或跨情境迁移知识
四种典型场景
Long-range Dependency Modeling
三大障碍
有限的上下文窗口限制了输入容量
自注意力成本导致高昂的计算开销
用户指令在较长时间内经常与模型行为脱节
示例
在复杂的任务中,用户定义的代码结构或写作风格经常被遗忘,模型输出会恢复到默认模式
Adapting to Knowledge Evolution
现实世界的知识不断演进(例如,法律更新、科学发现、时事),但静态参数阻碍了及时反映
RAG 允许动态检索,但仍然是一种无状态的修补机制,缺乏统一的版本控制、出处或时间感知
例如,它可能会同时引用过时和新的法规,无法淘汰过时的事实
Personalization and Multi-role Support
LLM 缺乏跨用户、角色或任务的持久“记忆痕迹”
每次会话都会重置为空白状态,忽略累积的偏好或风格
Cross-platform Memory Migration and Ecosystem Diversity
用户记忆无法在不同平台之间迁移,形成“记忆孤岛”,限制了记忆的复用和持续性发展
记忆研究的四个阶段(每个阶段都有多个论文探索)
定义与探索阶段
类人记忆发展阶段
工具化记忆管理阶段
系统化记忆治理阶段(作者提出的MemOS)
Design Philosophy
以记忆为中心的设计范式
Mem-training 范式
一种以记忆为中心的训练策略
不仅仅依赖于参数更新,而是通过显式、可控的记忆单元驱动持续演进
允许在运行时收集、重构和传播知识,从而实现跨任务、时间范围和部署环境的自适应
愿景
让 MemOS 成为下一代智能代理的基础记忆基础设施
核心使命体现在以下三大支柱上
Memory as a System Resource
Evolution as a Core Capability
Governance as the Foundation for Safety
LLM 总结:¶
本文介绍了 MemOS,这是一个专为 AI 系统设计的 Memory OS(记操作系统)。MemOS 的核心目标是通过优化记忆管理和计算资源的使用,提高 AI 系统的效率和性能。文章可能围绕 MemOS 的架构设计、关键功能、与传统操作系统的对比,以及其在 AI 应用中的实际效果等方面展开讨论。
Abstract¶
本文提出了一种名为 MemOS 的记忆操作系统,旨在解决大型语言模型(LLMs)在记忆管理方面的不足,从而提升其在长上下文推理、持续个性化和知识一致性等方面的能力。传统LLMs依赖静态参数和短时上下文状态,难以跟踪用户偏好或长期更新知识。虽然检索增强生成(RAG)引入了外部知识,但缺乏生命周期管理和持久表示的整合。本文从记忆层级的角度出发,提出通过引入显式的记忆层,将特定知识外部化,从而在计算效率上取得优化。MemOS 将记忆视为一种可管理的系统资源,统一了不同形式记忆(文本、激活状态、参数)的表示、调度与演化。其核心单元 MemCube 封装了记忆内容及其元数据(如来源和版本),支持记忆的组合、迁移与融合,实现了不同类型记忆之间的灵活转换,连接了检索与参数学习。最终,MemOS 构建了一个以记忆为中心的系统框架,提升了LLMs的可控性、可塑性与可进化性,为持续学习和个性化建模奠定了基础。
1 Introduction¶
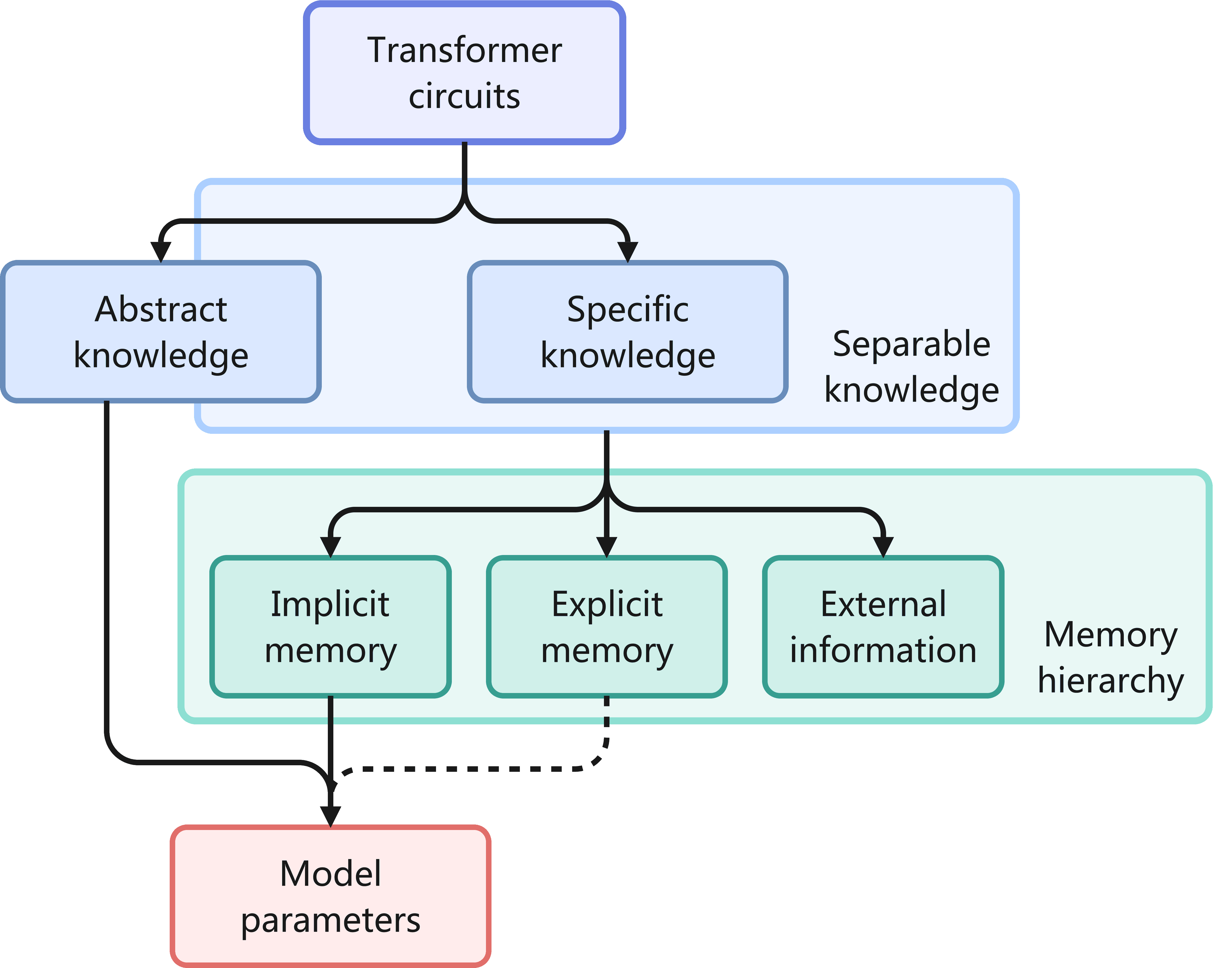
Figure 2: Categorization of LLM knowledge, including the memory hierarchy. The explicit memories, extracted from model activations, lie half-way between raw data and model parameters, so a dotted line is used to indicate that they may or may not be regarded as parameters.
这篇文章的引言部分主要介绍了**MemOS(Memory Operating System)**的背景、动机和其在大语言模型(LLMs)发展中的关键作用。以下是该章节的总结:
1. 背景与动机¶
LLMs的发展现状:随着Transformer架构的普及和自监督预训练的成熟,大语言模型已成为现代自然语言处理(NLP)的核心。它们在开放域问答、文本生成、跨模态推理等多个任务中表现出接近人类的性能。
LLMs未来的演变趋势:未来的LLMs将从“无状态”的短期工具向“有状态”的长期智能代理发展,必须具备持续交互、状态积累和长上下文推理的能力。同时,它们将在更多用户、平台和生态系统中部署,需要支持一致性、可扩展性和个性化。
知识管理的核心挑战:随着交互历史的扩展和上下文复杂性的增加,LLMs面临着如何组织、存储和检索知识的问题。传统方式(如参数记忆或RAG)难以满足长期、动态和多任务环境下的需求。
2. 现有方法的不足¶
参数记忆的局限性:主流LLMs依赖于模型权重中的隐式知识存储,但这种方式更新成本高、可解释性差、灵活性不足,且存在灾难性遗忘的风险。
RAG的局限性:虽然RAG通过引入外部检索模块增强了模型对实时信息的访问能力,但它本质上是“即时检索+临时组合”的流水线,缺乏生命周期管理、版本控制、权限感知等核心功能,难以支撑长期、自适应的知识系统。
缺乏显式、层次化的记忆结构:研究指出,LLMs缺乏中间的显式记忆层,无法在参数存储和外部检索之间进行高效的平衡。这导致模型在长依赖建模、知识演化、个性化和跨平台迁移等方面存在瓶颈。
3. 四大典型挑战¶
长距离依赖建模:模型难以在长对话或多阶段任务中保持状态一致性,受限于上下文窗口、注意力计算开销和用户指令与行为的脱节。
知识演化适应性:现实世界知识不断更新,但模型参数固定,RAG也缺乏版本控制和时间感知,无法有效应对知识的演化和更新。
个性化和多角色支持:模型缺乏持久的记忆痕迹,每次会话都重置为初始状态,无法保存用户偏好或风格,现有记忆机制存在容量限制、访问不稳定等问题。
跨平台记忆迁移与生态多样性:用户记忆无法在不同平台之间迁移,形成“记忆孤岛”,限制了记忆的复用和持续性发展。
4. MemOS的提出与核心理念¶
核心思想:MemOS是一个专为大型语言模型设计的记忆操作系统,旨在将记忆视为一种可调度、可演化的系统级资源,从操作系统(OS)的视角重构记忆的组织、管理和调度。
类比操作系统:MemOS借鉴操作系统对CPU、存储和I/O资源的统一调度机制,将记忆划分为可操作的模块(如工作记忆、长期存储、冷存档),支持生命周期管理、权限控制、迁移和复用。
三大核心能力:
可控性(Controllability):提供完整的记忆生命周期管理,包括创建、激活、融合、销毁,并通过权限控制和操作审计保障安全性与可追溯性。
可塑性(Plasticity):支持记忆在任务和角色间的重组与迁移,允许开发者构建灵活的记忆结构,适应不同推理目标。
可演化性(Evolvability):支持不同记忆形式(参数记忆、激活记忆、明文记忆)之间的动态转换和统一调度,促进知识整合、自主学习和模型演化。
5. 总结与意义¶
MemOS的提出标志着大模型发展从“感知与生成”向“记忆与演化”的关键转变。它通过系统级的架构设计,解决了现有方法在结构化记忆、生命周期管理、多源集成等方面的不足,为构建具备长期记忆和持续演化的下一代AGI系统奠定了基础。
2 Memory in Large Language Models¶
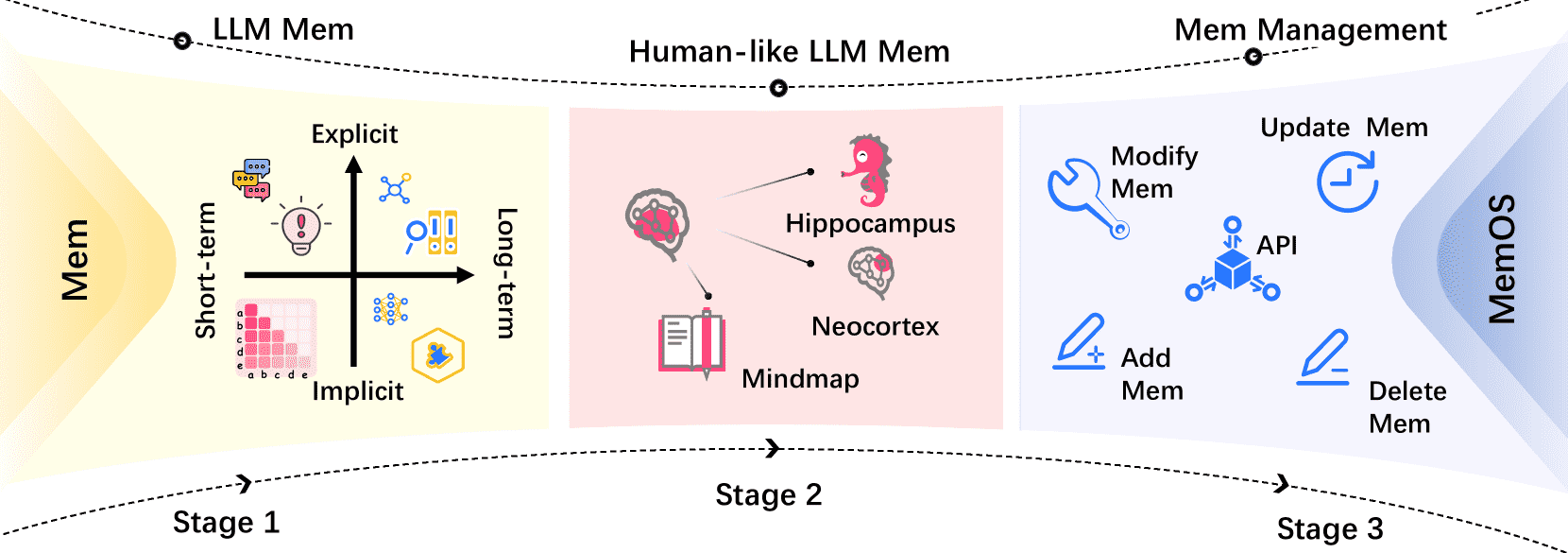
Figure 3:Illustration of the evolution of memory systems in large language models, highlighting the progression from definition and exploration, to human-like memory development, and to tool-based memory management.
该论文章节综述了大型语言模型(LLM)中“记忆”能力的研究进展,主要分为四个阶段,并详细阐述了第一阶段(记忆定义与探索)中的内容,重点分析了隐式记忆和显式记忆的分类、机制及其代表性技术。
记忆研究的四个阶段¶
定义与探索阶段
研究者从多个维度对LLM的记忆系统进行分类,探索其优化机制,为后续研究打下基础。类人记忆发展阶段
为弥补LLM与人类在复杂任务中的表现差距,研究者引入受认知启发的记忆机制,使模型更接近人类的记忆处理方式。工具化记忆管理阶段
开始出现模块化接口,实现对已有记忆结构的插入、删除和更新操作,但功能仍较为基础。系统化记忆治理阶段(作者提出的MemOS)
引入操作系统式资源管理机制,提供标准化、统一的全生命周期管理接口,推动记忆系统向结构化、抽象化和安全控制发展。
2.1 第一阶段:记忆定义与探索(Stage 1)¶
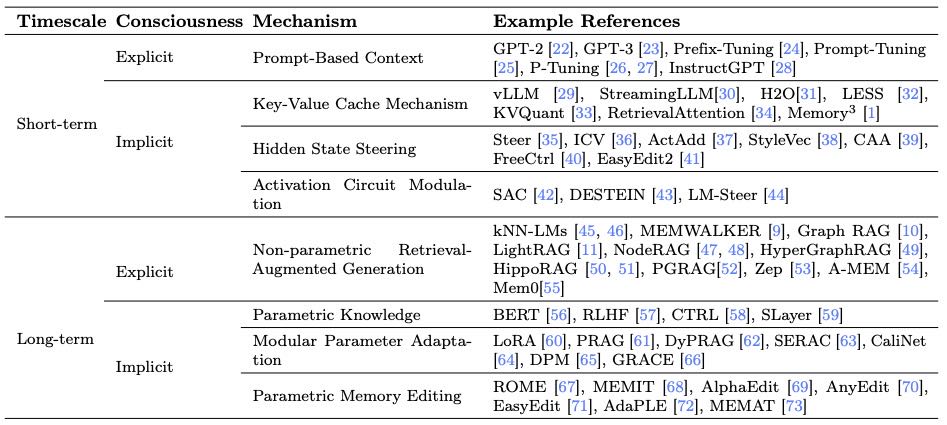
Table 1 Classification of Memory Types, Mechanisms, and Example References
1. 记忆分类与框架¶
提出从两个维度理解记忆:
显式 vs 隐式记忆
短期 vs 长期记忆
将短期记忆细分为:
感觉记忆(瞬时、无意识)
显式短期记忆(如提示、文本上下文)
长期记忆分为:
隐式长期记忆(参数化知识)
显式长期记忆(如外部检索增强生成)
2. 隐式记忆¶
隐式长期记忆¶
通过大规模训练,模型将语言结构、语义关系等编码进参数中,形成内部化的长期记忆。
主要技术包括:
训练与微调(如BERT、RLHF、SLayer)
适配器方法(如LoRA、PRAG、DyPRAG),用于快速适应新知识,无需重新训练全部参数
记忆编辑(如ROME、MEMIT、EasyEdit),通过定位并修改模型参数来更新知识或行为
隐式短期记忆¶
包括KV-cache(键值缓存)和隐藏状态(Hidden States),在推理过程中动态生成,影响注意力分布和生成行为。
KV-cache优化:压缩、量化、动态剪枝、检索增强等(如vLLM、Memory3)
隐藏状态控制:通过“引导向量”(Steering Vectors)干预模型输出方向,实现对生成内容的细粒度控制(如ACT、ITI、IFS)
3. 显式记忆¶
显式短期记忆¶
存在于输入上下文(提示、历史对话、参考文档)中,由用户直接提供,模型在推理中直接使用。
随着模型规模扩大,管理机制从静态提示演进到参数化提示和指令跟随模型(如InstructGPT)。
限制在于上下文窗口长度,长文本或多轮对话中易出现内容截断和语义丢失问题。
现有应对方法包括:扩大上下文长度、外部检索、缓存优化等,但显式短期记忆容量仍是关键瓶颈。
显式长期记忆¶
早期方法主要依赖独立的检索器如 BM25、DPR 及其混合版本。
**检索-生成(Retrieve-then-Generate)**范式存在内容整合瓶颈。
部分研究转向更紧密的检索与推理结合,如 kNN-LM 将检索结果线性融合到模型输出中,提高参考准确度。
随着研究深入,记忆结构从扁平格式转向层次化、图结构化形式,如树、图、异构图、超图等,以提升表达和泛化能力。
Zep 与 A-MEM 等系统引入了时间线建模与动态更新机制,实现记忆的演变与持久化。
2.2 第二阶段:人脑式记忆机制的引入(Stage 2)¶
本阶段研究者借鉴人类记忆机制(如海马体理论、记忆层次结构),提出类人记忆结构与行为,增强LLMs在复杂任务中的记忆能力。
HippoRAG 结合 LLM、知识图谱与个性化PageRank算法,模拟大脑皮层与海马体功能。
Memory3 将注意力机制中的KV-cache显式作为记忆载体,降低成本并提升效率。
PGRAG 模拟人类笔记行为,自动生成思维导图作为长期记忆。
Second-Me 提出三层记忆架构(L0-L2),实现从原始数据到个性化推理的演进。
AutoGen 引入多智能体协作框架,模拟人类协作行为,提升复杂任务处理能力。
2.3 第三阶段:基于工具的记忆管理(Stage 3)¶
本阶段关注的是对记忆的显式编辑与操作,推动从隐式表征走向工具接口化管理。
提出标准化的记忆编辑框架,支持插入、修改、删除等操作,如 EasyEdit 和 Mem0。
Mem0 通过提取-更新流程管理外部记忆模块,后续版本进一步结构化记忆为图。
Letta 受操作系统启发,引入模块化上下文与函数式分页机制,实现动态记忆访问。
尽管提供了基本的 CRUD 操作,但工具化管理缺乏系统性建模与治理,难以支持记忆的演化、协作与安全控制。
2.4 第四阶段:系统化记忆治理(Stage 4)¶
本阶段提出MemOS,一个面向 LLM 的记忆操作系统,标志着进入系统化记忆治理的新阶段。
MemOS 将记忆单元视为第一类资源,借鉴操作系统设计原则,构建包含调度、分层、API抽象、权限控制、异常处理的治理机制。
与工具化管理不同,MemOS 不仅支持操作,还强调记忆的跨任务、跨会话、跨角色演化与整合。
核心模块如 MemScheduler、Memory Layering、Memory Governance 实现异构记忆的统一调度与行为驱动进化。
MemOS 所提出的“记忆即操作系统(Memory-as-OS)”范式,被视为构建通用人工智能(AGI)长期认知结构的关键基础设施。
总结¶
本文系统梳理了 LLM 显式长期记忆的发展路径,从初期的记忆定义与探索,到类人记忆机制设计,再到工具化编辑与管理,最终进入系统化、操作系统级的记忆治理。MemOS 的提出不仅为当前 LLM 记忆管理提供了统一框架,也为未来构建可持续、自演进的智能系统奠定了基础。
3 MemOS Design Philosophy¶
这篇论文章节主要介绍了 MemOS(Memory Operating System) 的设计理念及其在下一代智能系统中的作用。以下是内容的总结:
一、MemOS 的愿景(3.1 Vision of MemOS)¶
随着人工智能(尤其是 AGI)系统变得越来越复杂,涉及多任务、多角色和多模态,传统的大语言模型(LLM)已显现出局限性。当前主流的 LLM 架构缺乏对“记忆”这一核心智能能力的系统性支持,表现为知识固化、上下文无法跨会话保存、个性化无法持续、知识更新成本高等问题。
作者提出,下一代 LLM 架构必须采用以记忆为中心的设计范式。通过引入连续记忆建模(continual memory modeling) 和 动态记忆调度(dynamic memory scheduling),使模型具备长期知识积累、任务适应和行为进化的能力。
此外,记忆训练(Mem-training)还带来了空间扩展效应:多个异构部署的模型实例可以通过交换紧凑的记忆单元而非昂贵的参数或梯度,构建集体知识库,从而实现系统规模下的分布式智能生态。
该范式面临两个技术挑战:
高效的知识交换机制,特别是在高度异构的环境中;
严格的治理机制,在保护隐私和敏感数据的同时最大化共享效用。
作者提出了Mem-training 范式,强调通过可控制的记忆单元实现持续进化,而不是依赖传统的参数更新。MemOS 作为基础架构,支持记忆的生成、调度、融合与更新,实现长期知识积累和任务自适应。
MemOS 设计的三大核心支柱是:
记忆作为系统资源:将记忆抽象为可调度、可管理的资源,打破平台间的“记忆孤岛”,提升记忆管理的效率与可访问性。
进化作为核心能力:支持模型与记忆的协同进化,使 LLM 能够根据任务、环境和反馈自我适应和升级,实现可持续演化的智能。
治理作为安全基础:提供全生命周期的记忆治理机制,包括访问控制、版本管理、溯源审计等,确保记忆的可控性、可追踪性和可解释性,为智能系统提供信任基础。
作者认为,MemOS 将推动智能系统从“基于感知的反应式系统”向“基于记忆的主动式进化代理”的范式转变,成为下一代智能体的基础设施。
二、从传统操作系统到记忆操作系统(3.2 From Computer OS to Memory OS)¶
在传统计算机系统中,操作系统(OS)负责统一管理 CPU、记忆、存储等资源,为应用程序提供稳定、高效的运行环境。其资源抽象、统一调度和生命周期管理是现代计算基础设施可扩展和可靠性的基础。
随着 LLM 系统的复杂性提升,其内部和外部的“记忆资源”也变得越来越动态和异构,包括静态参数记忆、运行时激活记忆和动态检索的记忆模块。这些记忆资源不仅支撑推理,还随着任务和知识更新而持续演化。
因此,LLM 需要一个类似传统操作系统的系统化资源管理框架,以支持记忆资源的标准化抽象、动态调度和自主治理。MemOS 借鉴了传统操作系统中的成熟机制(如资源调度、接口抽象、访问控制等),提出了统一的 LLM 记忆资源管理理念。
三、总结¶
本章系统阐述了 MemOS 的设计理念,提出将“记忆”从模型的内部隐式依赖转变为可调度、可管理的系统级资源。MemOS 通过引入Mem-training 范式,实现模型的持续进化与自适应能力,推动智能系统从“被动感知”向“主动记忆驱动”转变。同时,MemOS 借鉴传统操作系统的架构思想,构建了一套完整的记忆管理系统,为下一代 LLM 和 AGI 提供了坚实的基础架构支持。
4 Memory Modeling in MemOS¶
本章节介绍了 MemOS 中的记忆建模(Memory Modeling)机制,通过系统化地划分和管理三种核心记忆类型(Plaintext Memory、Activation Memory 和 Parameter Memory),并引入统一的记忆抽象单元 MemCube,为 AI 系统提供了一个结构清晰、可控、可演化的语义记忆体系。以下是该章节的总结:
4.1 记忆类型与语义演化路径¶
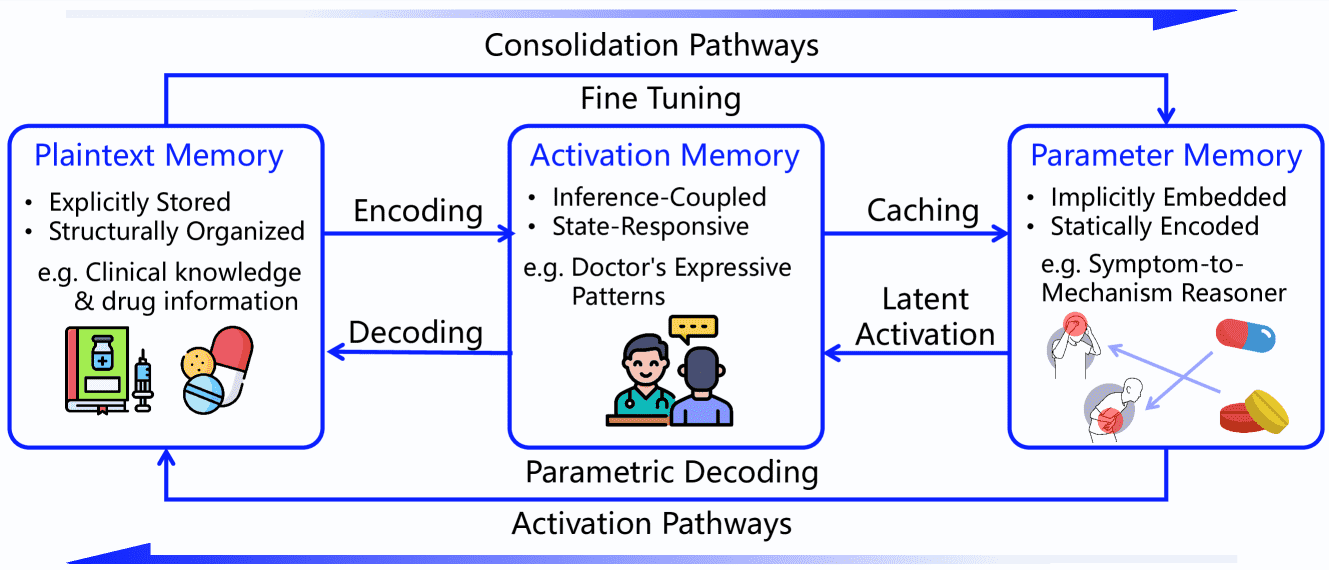
Figure 5:Transformation paths among three types of memory, forming a unified, controllable, and evolvable memory space.
MemOS 在 Memory3 研究的基础上,进一步系统化地提出了三种核心记忆类型,并构建了从感知(perception)到巩固(consolidation)的语义演化路径:
Plaintext Memory(明文记忆)
定义:通过外部接口动态获取的可编辑、可追踪的知识模块。
特点:适用于事实密集型、个性化和多代理任务,支持快速更新和任务定制。
管理方式:封装为 MemCube,支持版本控制、冲突检测、多模态融合等。
优势:可与 Activation Memory 交互,高频内容可转为激活路径,实现知识的动态外部化与内部化。
Activation Memory(激活记忆)
定义:推理过程中生成的中间状态,核心是 KV 缓存。
特点:短时、动态、隐式激活,用于长依赖建模、递归推理和上下文响应。
管理方式:支持延迟加载、选择性冻结和优先级调整。
应用场景:如多轮对话、代码辅助、医疗系统中的患者历史记录缓存等,有助于保持上下文连贯性与响应控制。
详细内容
激活记忆由推理过程中生成的中间状态构成,其核心结构是KV缓存(Key-Value Cache)
该机制通过保留上下文的关键值表征,实现了高效的long-range dependency modeling and recursive reasoning
依托缓存稳定行为,它既支持即时语境响应,也支持可复用的推理路径
其他组件还包括隐藏状态(\(h^l_i\))和注意力权重(\(α^l_{ij}\)),共同构成模型的运行时语义感知系统
这些特征都有短期性、动态性和隐式激活性
MemOS为激活内存提供统一的调度与生命周期管理
支持延迟加载、选择性冻结和优先级驱动的动态调整
高频出现的KV模式会被缓存为低延迟的”即时记忆路径(instant memory paths)”
除KV模式外,反复触发的策略行为也可抽象为持久内存结构(如导向向量或语义模板)
KV内存在多轮对话、代码辅助和运行时安全管理中具有显著价值
以医疗代理系统为例,稳定高频访问的知识(如病史记录、常规诊断流程或临床常识)可抽象为KV缓存片段
既能实现快速召回,又能减少冗余解码
该机制对保持上下文连续性、风格一致性和响应精确控制至关重要
Parameter Memory(参数记忆)
定义:模型参数中编码的长期知识,如语言结构、常识和语义表示。
特点:隐式激活,无需检索,是零样本推理、问答和语言生成的基础。
管理方式:支持模块化增强(如 LoRA)、知识蒸馏与能力模块化(如法律助理、摘要专家等)。
优势:适合能力密集型代理,支持长期稳定的能力,但更新成本高、可解释性差。
4.2 Memory Cube(MemCube):记忆的核心资源单元¶
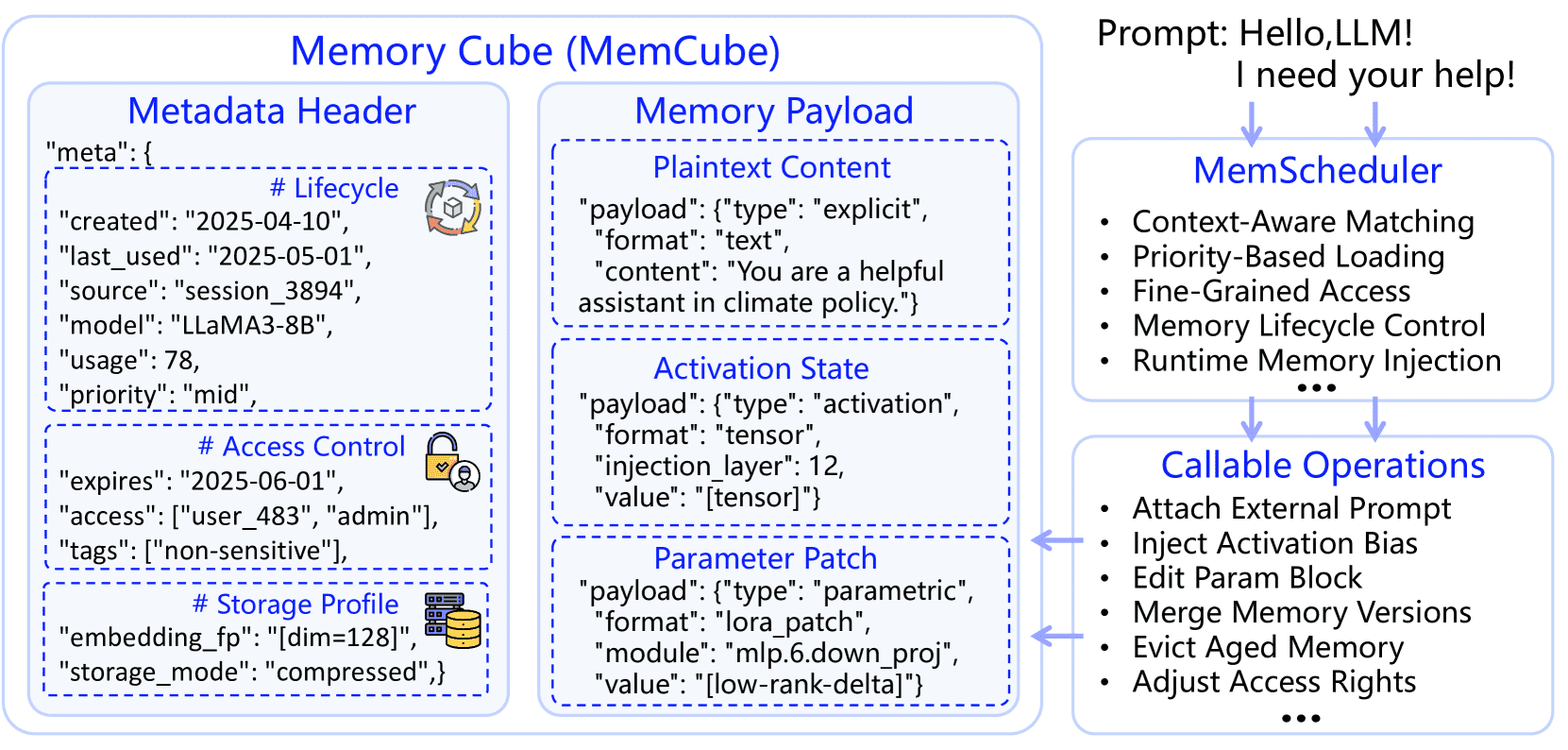
Figure 6:MemCube: A unified encapsulation structure for heterogeneous memory scheduling.
图片理解
Each MemCube consists of
a structured Metadata Header (supporting lifecycle, permission,
and storage policy) and a Memory Payload (encapsulating plaintext, activation states, or parameter deltas).
It is the minimal memory unit within MemOS that can be scheduled and composed for downstream reasoning.
为了统一管理异构记忆资源,MemOS 引入了 MemCube,作为所有记忆类型的封装和调度单位。
组成结构:
Memory Payload:承载语义内容(明文、激活状态或参数差异)。
Metadata:包含三个关键类别:
Descriptive Identifiers(描述性标识符):
标识记忆块的来源、类型和组织形式(如时间戳、语义类型、来源签名等)。
Governance Attributes(治理属性):
控制记忆的访问权限、生命周期、优先级、合规性和可追溯性。
Behavioral Usage Indicators(行为使用指标):
反映推理过程中的使用频率、访问模式等,用于动态调度和跨类型转换。
功能特点:
统一调度:MemCube 为所有记忆类型提供标准化接口,支持异构记忆的统一管理。
动态演进:
支持记忆单元在不同记忆类型之间的动态转换(如明文→激活、激活→参数、参数→明文)。
明文 ⇒ 激活
经常使用的明文记忆可以预先转换为激活向量或注意力模板,以便更快地解码
明文/激活 ⇒ 参数
跨任务的稳定知识可以提炼为参数模块,内化为高效的功能插件
参数 ⇒ 明文
冷参数或过时的参数可以卸载到外部明文存储中,以增加灵活性并减少结构开销
策略感知调度(Policy-Aware Scheduling):根据使用频率、上下文依赖和任务匹配,动态调整记忆的层级与格式。
上下文指纹(Contextual Fingerprint)与版本链(Version Chain):用于快速检索与任务对齐,支持版本控制、冲突解决与回滚。
总结¶
MemOS 通过构建 Plaintext、Activation 和 Parameter 三种核心记忆类型,结合 MemCube 作为统一调度与管理的抽象单元,实现了记忆资源的结构化封装、策略化治理和行为驱动的演化。这种设计不仅提升了记忆系统的可控性和可扩展性,也为 AI 代理提供了更灵活、更智能的知识管理和推理能力,是构建透明、协作型 AI 系统的重要基础。
5 Architecture of MemOS¶
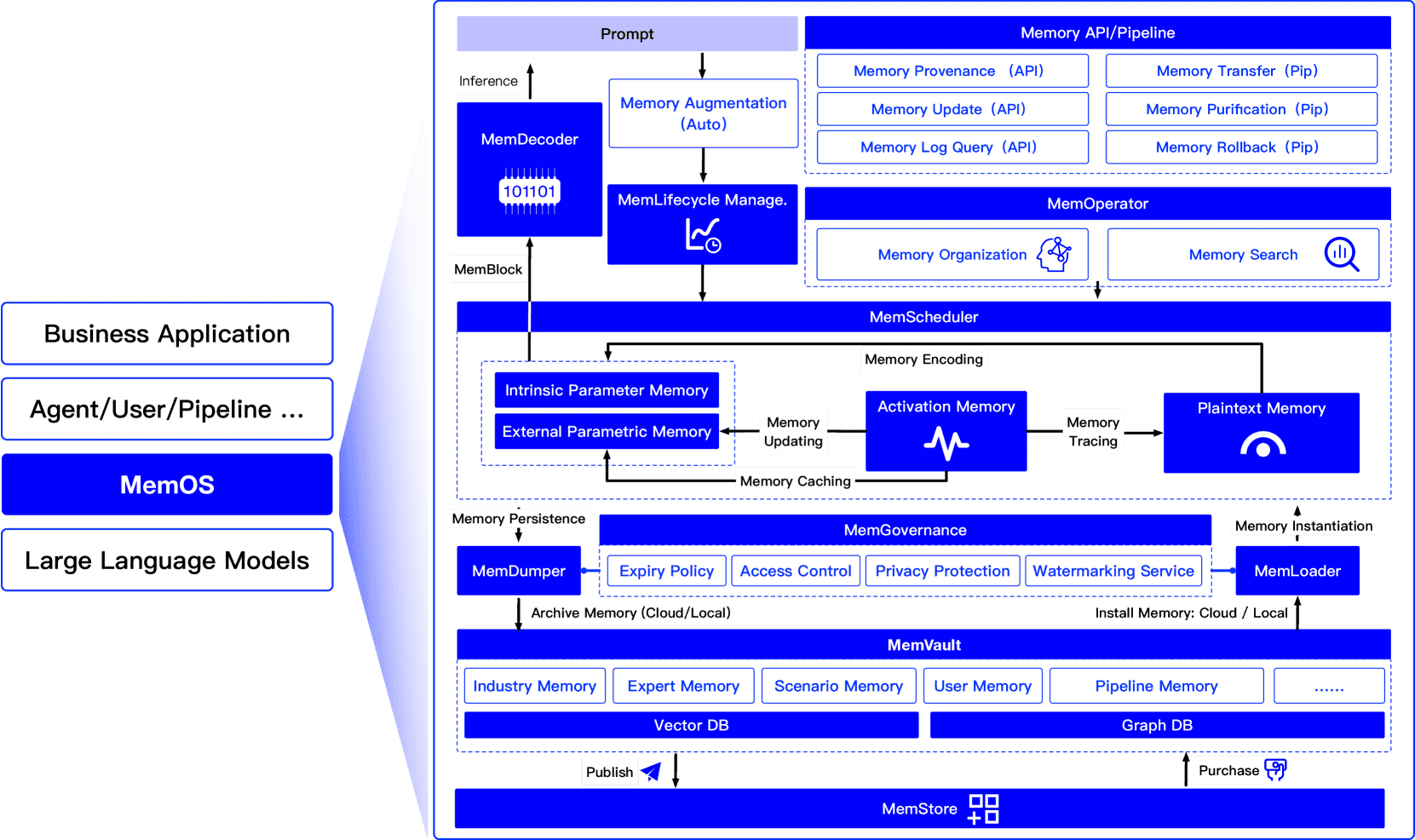
Figure 7:Overview of the MemOS framework. The architecture illustrates the full pipeline from user input through semantic parsing and API abstraction in the interface layer, to memory scheduling and lifecycle control in the operation layer, and finally interaction with the infrastructure layer for memory injection, retrieval, and governance. The unified data structure, MemCube, serves as the foundation for dynamic memory flow throughout model execution.
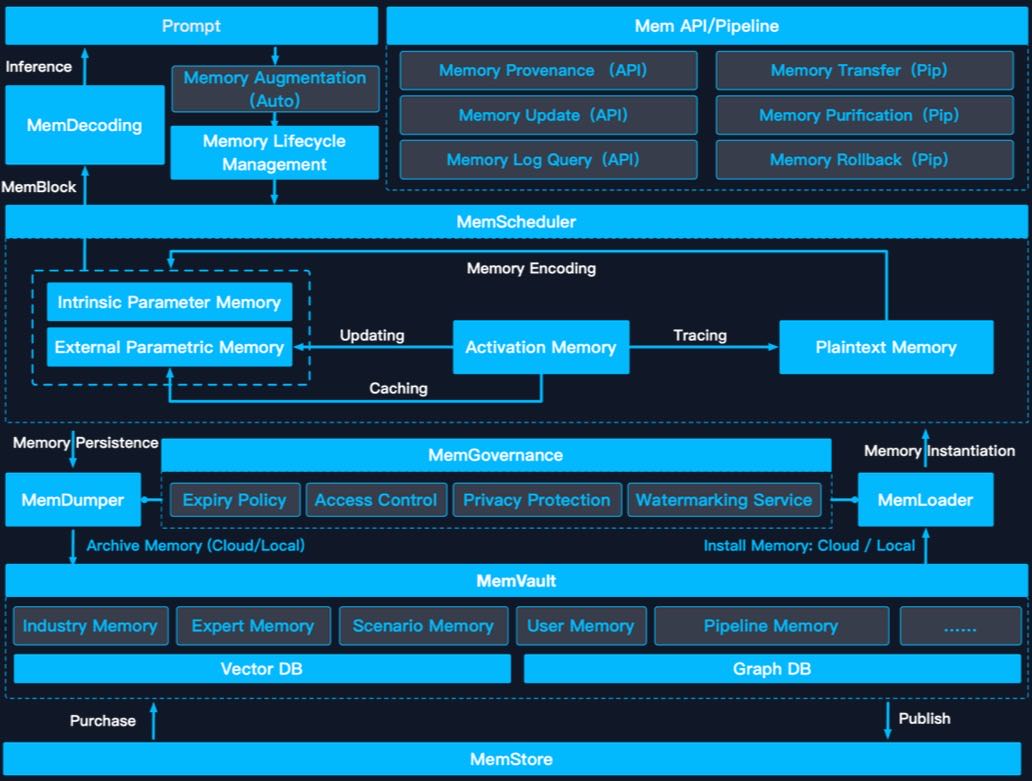
总结:MemOS 架构与执行流程¶
MemOS 是一个为 AI 系统设计的 记忆操作系统(Memory OS),其架构旨在实现高效、动态和合规的记忆操作管理,支持复杂任务的智能代理性能。系统基于三层架构:接口层(Interface Layer)、操作层(Operation Layer) 和 基础设施层(Infrastructure Layer),并通过统一的数据结构 MemCube 实现记忆的动态流动与管理。
5.1 Overview: Three-layer Architecture of MemOS¶
1. 接口层(Interface Layer)¶
功能:作为用户或系统任务的入口,解析自然语言输入,生成结构化的记忆操作请求。
核心组件:
MemReader:解析用户输入,提取任务意图、时间范围、实体、上下文锚点等,生成结构化指令(MemoryCall)。
Memory API:提供统一的记忆操作接口(如创建、更新、查询、审计),支持版本控制、日志追踪和权限管理。
Memory Pipeline:支持将多个记忆操作组合为流程(如检索-更新-归档),实现任务自动化和记忆流的可审计性。
特点:支持对话上下文推理、提示重写和多回合交互。
2. 操作层(Operation Layer)¶
功能:控制记忆的组织、调度与生命周期管理,是 MemOS 的“控制中心”。
核心组件:
MemOperator:通过标签、图结构、分层抽象组织记忆数据,支持混合检索(符号和语义)。
MemScheduler:根据任务语义、资源和优先级动态调度记忆类型(如 KV 缓存、文本、参数),决定加载和调用顺序。
MemLifecycle:管理记忆状态转换(生成、激活、合并、归档、过期),支持版本回滚与记忆冻结机制(用于合规或审计)。
特点:实现任务导向的记忆路由、跨类型记忆迁移、执行路径整合及与模型的交互。
3. 基础设施层(Infrastructure Layer)¶
功能:负责记忆数据的存储、迁移、安全和共享,是系统执行的基础。
核心组件:
MemGovernance:控制访问权限、数据保留策略、审计日志和敏感内容处理。
MemVault:管理多类记忆仓库(如用户专属、领域知识、共享管道),提供统一的访问接口。
MemStore/MemLoader/MemDumper:实现记忆导入导出、跨平台同步和发布-订阅机制,支持多代理之间的记忆共享。
特点:支持组织级知识管理、跨平台同步和智能代理间的开放共享。
5.2 Execution Path and Interaction Flow of MemOS¶
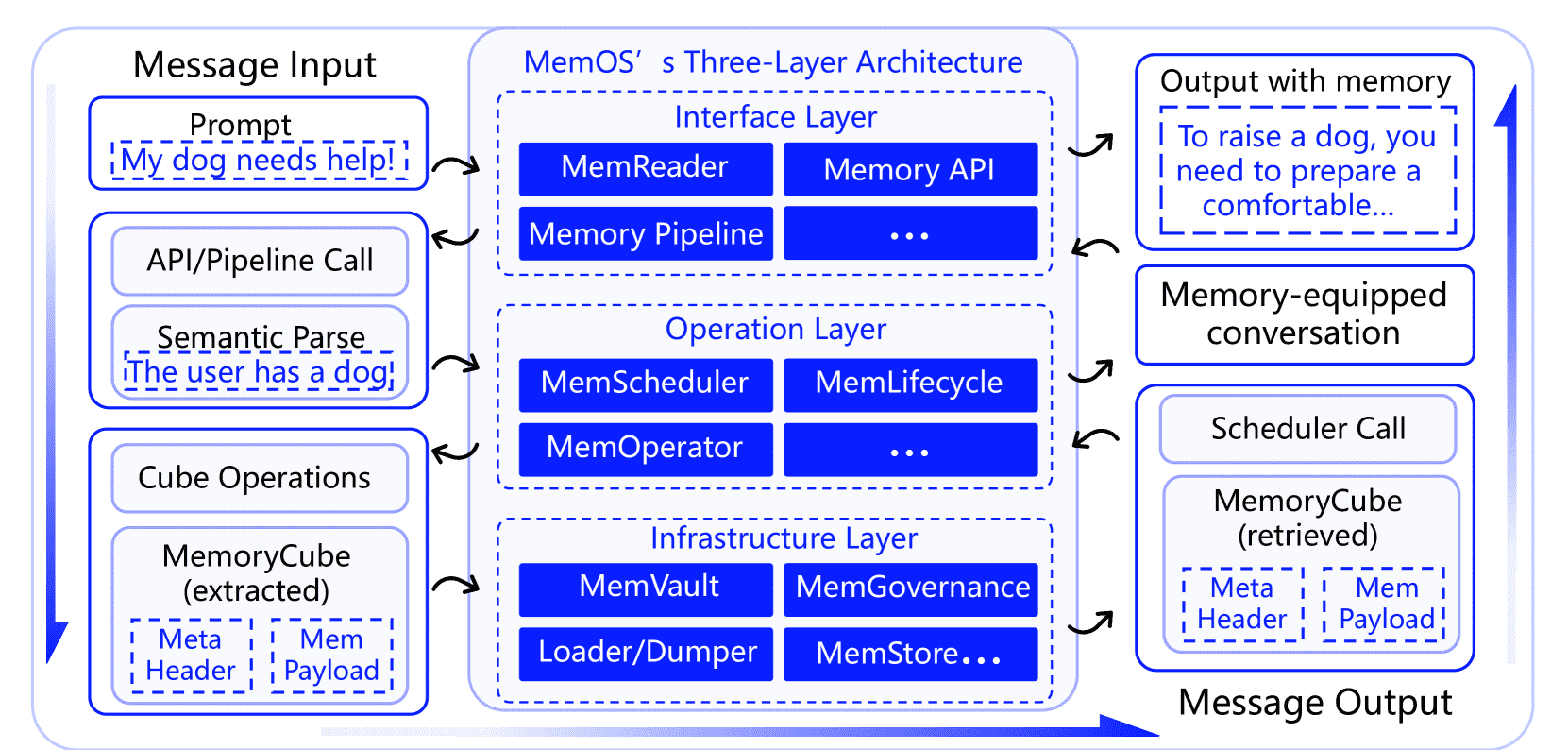
Figure 8:Overview of MemOS architecture and memory interaction flow.
图片解析
The system is composed of the interface layer, operation layer, and infrastructure layer.
From left to right, it shows the complete memory processing pipeline from user input to parsing, scheduling, injection, and response generation.
Each stage corresponds to coordinated module invocation, with MemoryCube serving as the carrier across layers for structured, governable, and traceable memory lifecycle management.
MemOS 的执行由用户交互或自动化任务触发。它遵循一个闭环流程,包括输入解析、记忆调度、状态管理和存储归档
Prompt Input and Memory API Packaging¶
系统从用户的自然语言指令或自动任务开始。接口层的MemReader模块负责解析输入,识别任务意图、时间范围、话题实体及上下文锚点,判断是否涉及记忆访问。若涉及,则将指令转换成结构化的MemoryCall,包括调用者ID、上下文范围、记忆类型、访问意图和时间窗口,封装成统一的Memory API请求,传给操作层执行。 示例:医疗场景中,患者说“帮我查去年住院记录”,MemReader会提取“去年”、“诊断记录”等信息,生成对应MemoryCall,进入后续检索流程。
Memory Retrieval and Organization¶
操作层的MemOperator根据Memory API中的意图和上下文做语义匹配,构建任务相关的索引(如用户偏好、关键词向量)和记忆图谱(时间链、实体关系等),筛选相关记忆单元。 示例:患者要求系统参考以往病例,操作层会检索含症状关键词、治疗时间和医生备注的记忆块,形成结构化检索路径。
Memory Scheduling and Activation¶
MemScheduler基于上下文相似度、访问频率、时间衰减和优先级标签等指标优化记忆选择,动态计算最优注入策略。 示例:复诊时,系统会注入近期咨询摘要(激活记忆)、诊断模板(参数记忆)和生活建议(纯文本记忆),确保信息整合且语义连贯。
Lifecycle Modeling and State Transitions¶
MemLifecycle负责记忆单元的状态管理,每个记忆经历五个状态:生成(Generated)、激活(Activated)、合并(Merged)、归档(Archived)和过期(Expired),状态变化依据访问模式、时间衰减和任务标签。 示例:医疗中,生成的用药建议先处于“生成”状态,频繁访问后变成“激活”,经用户多次确认后合并进常用建议,最后归档或过期。
Storage Archiving and Access Governance¶
演变后的记忆被存入MemVault,按用户、任务或上下文分类归档。归档可由策略、用户命令或调度触发,保持热数据活跃、冷数据长期存储。 归档阶段同时调用MemGovernance,实施访问权限管理与合规检查。每条记忆配备访问控制列表(ACL)、存活时间(TTL)和条件激活策略,依据用户角色和任务上下文决定可用性。 示例:治疗总结对护理团队完全开放,对患者部分开放,经过脱敏和水印处理后存入MemStore,实现跨机构共享。
总结¶
该执行路径和交互流程保证了多模态、多代理记忆单元的结构化、透明和可追踪管理,实现高效合规的协同环境,特别适用于复杂场景如医疗系统。
5.3 Interface Layer¶
5.3.1 MemReader¶
MemReader是MemOS中解析自然语言输入的第一步,负责对用户或系统任务的指令进行语义抽象和记忆级推理。它提取关键记忆相关特征——任务意图、时间范围、实体焦点、记忆类型和上下文锚点——并输出结构化的中间表示(MemoryCall)。 举例来说,输入“提醒我去年住院期间医生关于用药的建议”,MemReader会解析出检索意图、时间范围(去年)、主题(用药指导)、上下文锚点(住院期),生成结构化访问计划传递给操作层。 此外,MemReader支持多轮对话的指代消解、提示重写和记忆槽填充,既是意图识别器,也是记忆调用的协调者,确保系统发出精准、可追踪的记忆调用。
5.3.2 Memory API¶
接口层核心是统一且可组合的Memory API,连接上层任务和后端记忆操作。所有记忆相关操作(创建、更新、检索、审计)均通过标准API执行,保证扩展性、组合性与治理能力。
Provenance API:嵌入元数据(事件触发、上下文状态、模型ID、外部链接等),为记忆对象赋予唯一溯源ID,支持可解释性、调试、访问控制和记忆血统追踪。
Update API:支持追加、合并、覆盖等变更操作,具备版本感知能力,能触发状态变化和索引刷新。
LogQuery API:结构化访问记忆访问日志和执行轨迹,支持按时间、调用者、记忆类型和操作类别过滤,便于调试、热点分析和治理执行。 所有API调用均以MemoryCube为参数和响应载体,支持事务安全、结构化状态报告,由MemGovernance负责基于用户、角色、模型和任务的访问控制。
5.3.3 Memory Pipeline¶
为支持企业级和多代理复杂工作流,MemOS提供流水线式记忆操作组合机制。开发者或代理系统可定义一系列记忆动作(如检索→增强→更新→归档),作为整体流水线执行。 每个步骤基于共享的MemoryCube对象,传递输入输出状态和中间数据。例如,医疗助理可定义流水线依次(1)通过LogQuery检索过去用药记录,(2)用Update添加最新医嘱,(3)打上新的溯源标签,(4)诊后归档。 流水线支持事务一致性、回滚和故障隔离,既可用领域专用语言声明式定义,也可程序化构建。MemScheduler负责解析步骤依赖和调度协调。模板可在不同代理间复用,如客户支持的跟进生成或临床分诊的诊断跟踪。 通过组合式记忆流程,MemOS赋能开发者模拟高级认知模式、任务知识塑造及可审计的记忆工作流。
总结¶
接口层实现了从自然语言理解到记忆操作的标准化桥梁,支持复杂、多步和可治理的记忆管理流程,是MemOS灵活且高效运作的基础。
5.4 Operation Layer¶
5.4.1 MemOperator¶
MemOperator负责记忆的高效组织和精准检索,是实现智能行为生成、上下文推理和知识复用的核心模块。它通过标签注解、图结构连接和层次抽象,支持多视角的记忆建模,并提供统一接口实现混合检索,服务于不同任务、模型和用户上下文。
多视角记忆结构
标签系统:为记忆单元打上主题、来源、可信度、情感等元数据标签,支持用户定义和模型预测。
知识图谱:将记忆节点用语义边连接,形成可遍历的关系网络。
语义分层:将记忆分为私有、共享和全局层,保证任务与角色间的隔离与协调访问。
混合检索与动态分发 结构化检索基于标签、时间、布尔条件和访问策略做规则过滤;语义检索基于向量相似度进行上下文相关记忆筛选。两者可组合形成复杂查询,支持多轮对话、问答及知识整合等应用。
流水线耦合与缓存策略 检索出的记忆传递给执行流水线,与Memory API和MemoryCube紧密集成。为降低延迟,MemOS实现了本地索引缓存,频繁访问的记忆自动迁移至高速中间存储。缓存失效由使用频率和上下文漂移启发式管理,MemScheduler负责动态刷新。
任务对齐的记忆路由 采用三级任务结构(主题-概念-事实),MemoryPathResolver基于层次语义目标制定检索策略,回答“搜什么”“去哪搜”“按什么顺序搜”,提升解释性和调度相关性,确保记忆选择与任务意图对齐。
5.4.2 MemScheduler¶
MemScheduler是操作层的核心调度器,负责根据任务语义、调用频率和内容稳定性,动态转换并加载记忆到运行时上下文,保障高性能和适应性。
类型感知的转换与加载 MemScheduler依据任务语义、窗口大小和资源限制,选择合适的记忆类型:
稳定且频繁访问的内容转为激活记忆(KV缓存),减少预填充延迟。
抽象规则和可复用模式编码为参数记忆(如蒸馏模型权重中的适配器)。
时效性或会话相关知识保持为纯文本记忆,插入提示。 调度策略依任务类型灵活调整,多轮对话优先KV缓存,程序流程优先参数模块,事实查询优先纯文本。所有操作均记录至MemoryCube,配合MemOperator保持可追踪性。
跨类型转换与迁移 支持记忆类型间迁移,保证长期性能和资源最优利用:
频繁调用的纯文本记忆升级为激活记忆。
重复使用的稳定模板蒸馏为参数记忆。
低频KV条目降级为纯文本并归档冷存储。
执行路径集成与治理 上游配合MemReader和Memory API解析结构化调用,下游协同模型执行路径决定记忆注入方式和位置。调度逻辑实时优化,考虑任务类型、模型负载、缓存命中和访问历史。所有调度受MemGovernance管控,确保用户角色边界、速率限制和生命周期政策执行,实现记忆隔离和安全使用,并记录可审计交互。
5.4.3 MemLifecycle¶
MemLifecycle将每条记忆视为动态实体,通过有限状态机管理其生命周期,支持语义演进和资源调度稳定。
状态建模与演化逻辑 记忆状态包括:生成(Generated)、激活(Activated)、合并(Merged)、归档(Archived)。状态转换由系统策略和用户行为触发。 例:智能会议助理生成的摘要初为“生成”,若被后续任务引用,转为“激活”;用户补充信息或发现语义重叠则“合并”新版本;长时间未访问则“归档”冷存储。
时间机与冻结机制 提供“时间机”功能,可快照记忆状态并支持历史回滚,便于恢复旧版本,处理模型遗忘或用户撤回。 支持“冻结”状态,关键记忆(如法律协议)不可更新,保存完整修改记录,满足审计和合规要求。
调度与存储集成策略 状态直接影响调度优先级和存储位置:“激活”状态优先缓存于本地或高效MemoryCube,“归档”“冻结”则迁移至MemVault冷存储。系统根据生命周期规则批量触发清理、压缩和迁移操作,平衡调用可用性与资源效率。
总结¶
操作层以MemOperator、MemScheduler和MemLifecycle三大模块协同工作,实现记忆内容的多维结构化、高效检索、智能调度及生命周期管理,保障MemOS在复杂多任务环境下的性能、灵活性和安全合规。
5.5 Infrastructure Layer¶
5.5.1 MemGovernance¶
MemGovernance是MemOS中的核心访问控制和合规模块,负责记忆访问权限管理、合规执行及审计能力。
采用三元权限模型,关联用户身份、记忆对象和调用上下文,支持私有、共享及只读访问策略。
每次记忆请求均通过身份认证和上下文校验,防止未授权访问。
管理生命周期策略,如TTL(存活时间)和基于访问频率的垃圾回收或归档。
跟踪高频访问热点,隐私控制包括敏感内容检测、自动脱敏和访问日志记录。
所有记忆对象带有完整溯源元数据(创建来源、调用血统、变更日志),支持语义水印和行为指纹,便于多平台归属和版权追踪。
提供审计接口,方便集成企业合规系统,支持访问日志导出和权限审查报告,满足医疗、金融等高风险领域的监管要求。
5.5.2 MemVault¶
MemVault是MemOS的核心存储和路由基础设施,负责管理多类别记忆。
记忆按命名空间分类:用户私有、专家知识库、行业共享库、上下文池及流水线缓存,各自独立路径,方便高效访问和权限控制。
通过统一的MemoryAdapter抽象支持多后端存储,包括向量数据库、关系库和对象存储,保证API一致性。
存储配置灵活,可设为只读缓存或可写仓库,满足延迟和学习需求。
运行时配合MemScheduler和MemLifecycle动态加载记忆,支持基于标签、语义及全文检索,自动触发冷热数据迁移。
架构支撑多模型协作、领域知识融合和多轮对话一致性,是可扩展智能系统的知识骨干。
5.5.3 MemLoader & MemDumper¶
MemLoader与MemDumper构成MemOS中跨平台记忆迁移的双向通道。
支持MemoryCube等结构化单元的注入、导出与同步,关键于系统切换、边缘云整合和分布式代理的知识连续性。
MemLoader从本地缓存、第三方系统或归档导入记忆,自动补全溯源元数据、标签和生命周期状态,确保治理就绪。
MemDumper导出记忆为便携格式,带权限元数据、脱敏字段和访问日志,支持定期或事件驱动的更新(如标签激活触发导出)。
迁移过程受MemGovernance监管,确保策略验证、操作追踪和敏感数据隔离。
例如,移动设备可导出患者交互日志至云端,远程代理随后加载以保持任务上下文。
5.5.4 MemStore¶
MemStore是MemOS中的开放访问接口,支持记忆单元的受控发布、订阅和分发。
用户可声明记忆可发布,定义可见性、使用条件和访问控制规则。
每个共享单元附带唯一ID和溯源元数据,MemGovernance负责传播时的脱敏、水印和策略校验。
支持主动推送和订阅拉取模式,消费者可用标签或语义过滤器定义订阅,系统主动推送匹配更新。
许可记忆资产可执行合同绑定的访问频率和过期策略,所有访问均有调用追踪支持审计和责任追溯。
例如,医院可发布脱敏的诊断记录供远程分诊代理使用,每次调用均验证上下文和溯源。
总结¶
本节详细介绍了 MemOS 的核心组件:MemGovernance 负责安全与合规性,MemVault 构建灵活存储与路由,MemLoader 与 MemDumper 实现跨平台迁移,MemStore 支持记忆的发布与分发。这些模块共同构成了一个安全、可控、可扩展的智能记忆管理系统,为多用户、多任务、多平台的协作提供了坚实的技术基础。
6 Evaluation¶
6.1. End-to-End Evaluation on LOCOMO¶
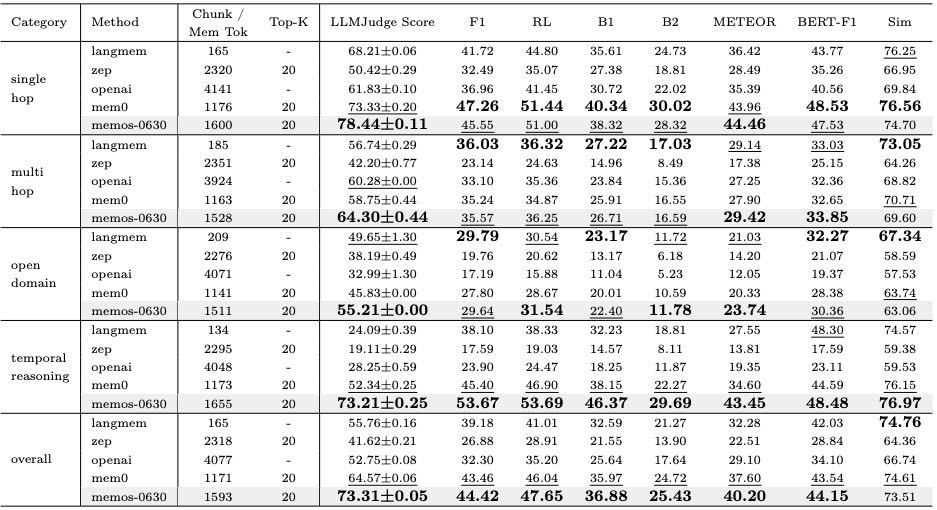
Table 3: Comparison of LLM Judge Scores across five major tasks in the LOCOMO benchmark. Each bar shows the mean evaluation score judged by LLMs for a given method-task pair, with standard deviation as error bars. MemOS-0630 consistently outperforms baseline methods (LangMem, Zep, OpenAI, Mem0) across all task types, especially in multi-hop and temporal reasoning scenarios.To ensure architectural parity, all methods are implemented over the same LLM backbone (GPT-4o-mini)
评估方法:在LOCOMO基准套件上对MemOS进行全面评估,比较其与多个先进基线(如LangMem、Zep、OpenAI-Memory、Mem0)在记忆密集型推理任务中的表现。
评估指标:使用LLM-Judge评分(主要指标),配合F1、ROUGE-L、BLEU、METEOR、BERTScore-F1、余弦相似度等生成质量与语义对齐度指标。
主要结论:
MemOS-0630在所有任务类型(如单跳、多跳、开放域、时间推理)中均表现最佳,尤其在多跳与时间推理任务中优势显著。
在记忆配置(Top-K、Chunk大小)变化下,MemOS始终维持较高性能,且生成质量稳定,语义对齐度高。
通过消融实验验证,随着记忆容量增加,MemOS的性能持续提升,尤其在需要长期记忆与上下文整合的任务中表现最佳。
6.2. Evaluation of Memory Retrieval¶
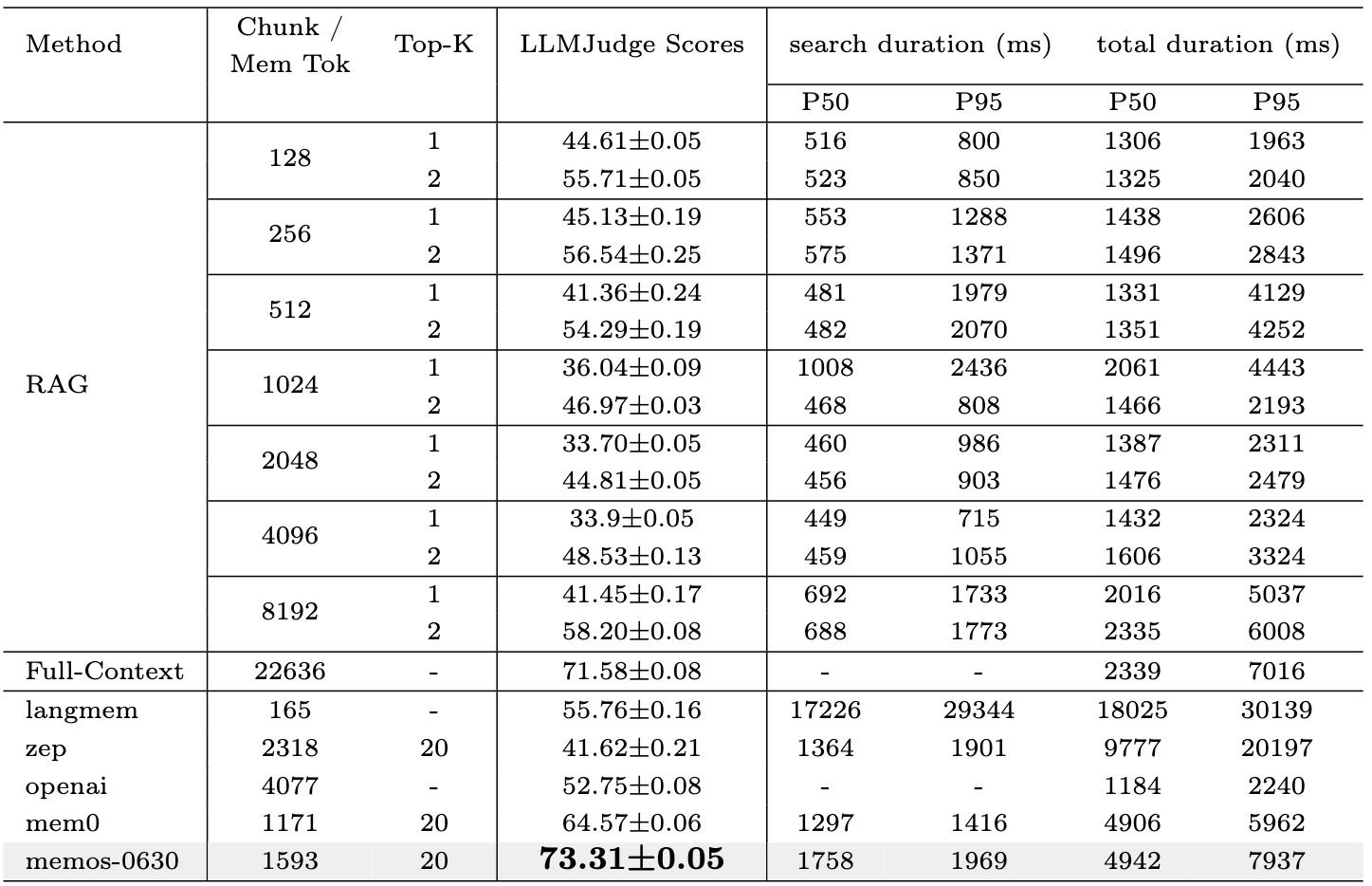
Table 4: Latency and LLM evaluation scores across various methods on the LOCOMO benchmark. RAG is evaluated under different chunk sizes and retrieval depths (Top-K = 1 or 2), while other baselines include standard retrieval systems and memory-augmented models. Metrics include LLMJudge scores (evaluating answer quality), search latency (P50/P95), and total end-to-end latency (P50/P95). MemOS-0630 achieves the highest LLM score with competitive latency performance.
评估内容:比较不同系统设计(包括RAG、完整上下文加载、商业系统)在记忆检索效率和生成质量上的表现。
评估指标:LLM-judge评分、搜索延迟(P50/P95)、端到端延迟(P50/P95)。
主要结论:
MemOS在检索效率和生成质量上均优于其他系统,尤其在处理大规模记忆时仍能保持较低延迟。
相比于加载全部上下文(Full-Context)的高延迟,MemOS的混合语义组织与激活式记忆加载机制显著提升了性能。
Mem0虽然延迟较低,但在生成质量上不如MemOS;OpenAI-Memory则因内部机制不透明限制了输出质量。
6.3. Evaluation of KV-Based Memory Acceleration¶
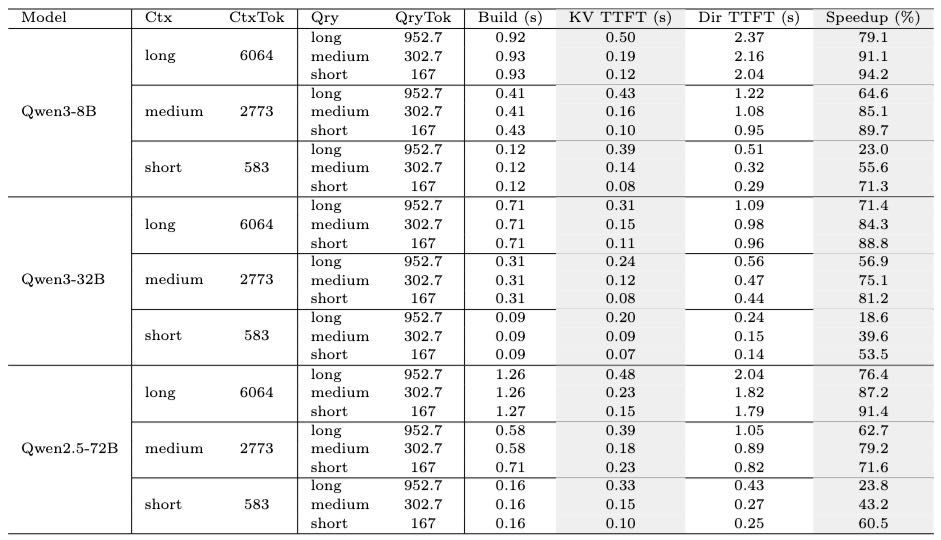
Table 5: Evaluation of Time to First Token (TTFT) and acceleration effect across different models, context lengths, and query lengths using the HuggingFace transformers library. We compare two memory injection strategies: direct prompt-based injection and KV-based attention cache injection. Gray-highlighted rows correspond to MemOS’s strategy, which uses KV-form memory injection and consistently achieves faster response without altering output semantics.
评估内容:比较两种记忆注入策略(Prompt-based vs. KV-cache)在不同模型和上下文长度下的性能。
评估指标:构建时间(Build)、TTFT(时间到第一词)、加速比(Speedup)。
主要结论:
KV缓存注入(将记忆直接注入模型的注意力机制)显著降低了TTFT,且输出语义一致,验证了其有效性。
加速效果随模型规模和上下文长度增加而增强,例如Qwen2.5-72B在长上下文、短查询条件下实现了91.4%的加速。
MemOS采用的KV注入策略(灰底行)在所有测试条件下均优于传统Prompt前缀方法。
总结¶
本章通过系统性实验验证了MemOS在多个维度上的卓越性能:
性能优势:在LOCOMO基准中全面领先,尤其在复杂推理任务中表现突出。
高效性:在大规模记忆处理和低延迟要求下仍能保持高效率,优于现有系统。
创新点验证:混合语义检索、任务对齐调度、KV缓存注入等关键技术有效提升了系统的响应质量与效率。
实用性:实验结果表明,MemOS的设计不仅在理论上先进,而且在实际系统部署中具有良好的可扩展性与实用性。
7 MemOS for Architecture Innovation and Applications¶
MemOS 将“记忆”视为一等公民资源,对各种形式的记忆进行统一生命周期管理与调度。这种抽象能力为以记忆为核心的模块与服务提供了新架构的可能性,使知识资产可以模块化、复用。
7.1 Architectural Innovations Enabled by MemOS¶
7.1.1 Paid Memory as Modular Installables (User-Facing Paradigm)¶
重点:记忆即插件,知识模块商品化 MemOS 通过模块化接口,将知识“资产化”,用户可像安装 App 一样加载经验知识,无需理解模型细节或进行手工对齐。
专家发布知识插件:如医生将诊断路径、案例经验封装为结构化记忆上传至 MemStore。
用户按需安装使用:学生或 AI 助理可搜索并加载这些知识插件,跳过构建知识图谱或本体结构的复杂流程。
标准接口 + 权限控制:使用统一加载接口,MemGovernance 控制访问权限,例如付费授权访问。
这类记忆被称为“Memory-as-a-Service”,极大拓展了知识复用场景和用户范围。
7.1.2 Painless Memory Management (Task-Oriented Paradigm)¶
重点:记忆管理像操作系统中的存储系统一样易用、统一、持久
MemOS 将记忆视作类似“存储子系统”的系统级基础设施:
提供统一协议、接口与持久化格式;
支持运行时灵活 读取 / 写入 / 替换 / 融合记忆块;
任务无需手动处理 KV 缓存、上下文拼接等低层细节。
案例:法律智能助理审合同分三个阶段,系统可根据上下文动态加载“合同模板记忆”“风险条款日志”“法规摘要”等记忆模块,无需用户干预,实现任务级别的智能记忆调度。
7.2 MemOS Application Scenarios¶
7.2.1 Supporting Multi-Turn Dialogue and Cross-Task Continuity¶
重点:解决传统 LLM 在多轮对话中“记不住”的问题 问题:传统模型基于静态上下文窗口,难以在长对话中保持语义状态。
MemOS 解决方案:
每轮对话提取关键信息(如预算、偏好)封装为结构化“会话记忆单元”;
通过 MemLink 关联到任务长期记忆路径;
推理时由 MemScheduler 调取相关历史记忆,防止语义漂移或逻辑断裂。
同时,支持跨任务记忆复用:如完成自动填表任务后,系统记住用户信息,在之后的签证申请中可直接复用。
7.2.2 Supporting Knowledge Evolution and Continuous Update¶
重点:知识动态更新而非静态训练;避免遗忘、提高可信度 传统 LLM 训练后知识固定,更新困难。
MemOS 引入记忆生命周期机制:
每个记忆块有生成、替换、融合、废弃等状态;
根据使用频率、语义对齐度自动安排更新;
可信来源发布的知识(如医疗指南)通过 MemStore 更新并标记;
推理时优先使用“活跃 + 可信”的版本,旧版本自动归档;
同时支持专家个性化知识发展,如医生记录个人治疗经验。
7.2.3 Enabling Personalization and Multi-Role Modeling¶
重点:记住用户身份与偏好,实现个性化、角色分离的行为
当前 LLM 无状态、无身份感知,用户每次都需重复输入信息。
MemOS 提供系统级的个性化支持:
每个用户绑定专属记忆空间;
一个用户下可同时拥有多个角色(如“父亲” vs “经理”);
系统根据上下文动态加载相应角色记忆;
记忆还可记录语言风格、价值倾向等个性信息。
在企业中,支持部署角色模板(如分析师、助理、项目负责人)配置其任务范围与权限策略。
7.2.4 Enabling Cross-Platform Memory Migration¶
重点:打破平台壁垒,让记忆可迁移、可复用 问题:多平台使用会产生“记忆孤岛”,造成知识碎片化。
MemOS 解决方案:
使用标准化格式、加密机制和平台无关挂载协议;
记忆块可在不同平台(手机、云端、企业内网)间迁移;
例如手机助手记录的“旅行偏好”可迁移到桌面上的公司差旅助手继续使用。
这使记忆从“模型私有资产”变成跨平台、可控、可用的智能基础层。
8 Conclusion¶
本文总结如下:
本文提出了一种专为大型语言模型(LLMs)设计的记忆操作系统(MemOS),旨在为下一代LLM应用构建基础性的记忆基础设施。MemOS提供了一个统一的抽象框架和综合管理机制,支持参数记忆、激活记忆和显式明文记忆等异构记忆类型的管理。文章提出了标准化的记忆单元MemCube,并实现了调度、生命周期管理、结构化存储和透明增强等关键模块,从而提升了LLM的推理一致性、适应能力和系统可扩展性。
在这一基础之上,作者展望了一个以模块化记忆资源为核心的未来智能生态系统,并设想了一个去中心化的记忆市场,支持记忆资产的交易、协作更新和分布式进化,推动可持续AI生态的发展。
未来的发展方向包括:
跨LLM记忆共享:通过扩展记忆交换协议(MIP),实现不同基础模型之间的参数与激活记忆共享,支持语义一致性和安全交换,促进智能体之间的知识协作。
自演化MemBlocks:开发可根据使用反馈进行自优化、自重构和自进化的记忆单元,减少人工维护需求。
可扩展的记忆市场:建立支持资产级交易和协作进化的去中心化记忆交换机制,推动AI生态的长期发展。
总体而言,MemOS的引入旨在将LLM从封闭、静态的生成系统转变为具备长期记忆、整合知识和行为可塑性的持续进化智能体。MemOS不仅解决了当前模型的关键架构限制,还为跨任务、跨平台和多智能体协作的智能系统奠定了基础。基于已有的研究成果(如显式记忆和层次化记忆表示在LLMs中的潜力),作者希望与社区合作,进一步推动MemOS的发展,使记忆成为通用人工智能时代的一等计算资源。