2308.11131_ReLLa: Retrieval-enhanced Large Language Models for Lifelong Sequential Behavior Comprehension in Recommendation¶
引用: 32(2025-09-10)
组织:
Shanghai Jiao Tong University
Huawei Noah’s Ark Lab
总结¶
总结
第3章用 deepseek 进行了优化,值的一看
ReLLa
零样本推荐中的改进方法(Zero-shot Recommendation)
语义用户行为检索(SUBR):取代传统的“最近K个行为”截取方式,采用语义上与目标物品相关的行为,以提高样本质量
少样本推荐中的改进方法(Few-shot Recommendation)
在SUBR的基础上,进一步提出检索增强的指令微调(ReiT)
两种策略
语义用户行为检索 (SUBR):用于 零样本(Zero-shot)推荐。在推理阶段直接优化输入给LLM的数据质量。
检索增强的指令微调 (ReiT):用于 少样本(Few-shot)推荐。在训练阶段利用SUBR来增强数据,防止模型过拟合。
SUBR
目标:在不对LLM进行额外训练的情况下,提升其推荐效果。
问题:用户的历史行为(如看过的电影、买过的商品)可能非常长,但LLM有输入长度限制,通常只能截取最近的K个行为。然而,最近的行为不一定与用户当前想买的东西(目标项目)最相关。
解决方案 (SUBR):
给每个物品编码:使用LLM为每个物品(如电影)生成一个“语义向量”。这个向量代表了该物品的深层语义特征。
先为每个物品创建一个描述性文本(例如,使用模板:“这是一部由[导演]执导,[演员]主演的关于[主题]的电影”)。然后将这个文本输入LLM,从它的最后一层隐藏状态中提取出语义向量。
降维:这个向量维度很高,所以再用PCA技术进行降维和去噪,得到最终的物品语义表示。
计算相关性:通过计算语义向量之间的余弦相似度,可以衡量任何两个物品之间的语义相关性。
替换历史序列:对于一个测试样本(比如用户想预测是否喜欢《阿凡达》),不再简单地截取他最近看过的K部电影,而是从他的整个历史中,检索出与《阿凡达》语义最相关的K部电影,组成一个新的、更短的序列输入给LLM。
ReiT
目标:在只有少量训练样本(N个)的情况下,对LLM进行指令微调,并防止其过拟合或遗忘原有知识。
问题:直接用小样本数据微调LLM,很容易过拟合(只记住了训练数据中的噪声而非规律),并发生灾难性遗忘(忘了自己原本的语言能力)。
解决方案 (ReiT):
数据增强:对每一个训练样本,都使用上述的SUBR方法,为其创建一个“检索增强版”的副本。原始样本使用“最近K个行为”,增强版样本使用“最相关K个行为”。
混合数据集:将原始的训练集(N个样本)和增强后的训练集(另外N个样本)合并,形成一个包含 2N 个样本的混合训练集。
指令微调:在这个混合数据集上对LLM进行标准的指令微调(训练它根据输入x预测输出y)。
Main Contributions
首次系统提出并定义了“长期顺序行为理解难题”
提出ReLLa框架
实验验证
Abstract¶
本节主要介绍了研究的背景、提出的问题、解决方法(ReLLa框架)、实验验证以及研究成果。
背景(Background)¶
随着 **大语言模型(LLMs)**在自然语言处理(NLP)领域取得显著突破,基于LLM的推荐系统受到了广泛关注并被积极研究。然而,在推荐场景中,LLMs仍面临一定的挑战,尤其是在零样本(zero-shot)和少样本(few-shot)推荐任务中。
问题定义(Problem Formulation)¶
作者首先识别并提出了一个关键问题——LLMs在推荐场景中的“终身序列行为理解不足问题”(lifelong sequential behavior incomprehension problem)。即使用户行为序列的长度未达到LLMs的上下文限制,LLMs仍难以从该长文本上下文中提取有用的推荐信息。
解决方案(Proposed Solution)¶
为了解决上述问题并提升LLM在推荐任务中的表现,作者提出了一种新的框架——ReLLa(Retrieval-enhanced Large Language models),适用于零样本和少样本推荐任务。
零样本推荐(Zero-shot Recommendation)
为提升测试样本的数据质量,作者设计了语义用户行为检索(SUBR)方法。通过该方法,系统能够筛选出与当前用户行为语义更相关的样本,从而降低LLMs提取关键信息的难度。
少样本推荐(Few-shot Recommendation)
在少样本推荐任务中,作者进一步设计了检索增强的指令微调(ReiT)方法。该方法利用SUBR作为数据增强技术,将原始训练样本与其通过SUBR增强后的样本混合,构建混合训练数据集,从而提升模型的训练效果。
实验验证(Experiments)& 关键结果(Key Results)¶
作者在三个真实世界公开数据集上进行了大量实验,验证了ReLLa框架的优越性,包括其在终身序列行为理解能力上的提升。
实验结果显示,在仅使用不到10%训练样本的情况下,ReLLa在少样本设置下,表现优于传统CTR模型(如DCNv2、DIN、SIM),这些模型是基于完整训练集训练的。这说明ReLLa在样本稀缺的情况下仍具有强大的推荐能力。
副标题与关键词(Keywords & Metadata)¶
关键词:Large Language Models(大语言模型)、Recommender Systems(推荐系统)、User Modeling(用户建模)
会议信息:ACM Web Conference 2024,2024年5月13日至17日,新加坡
论文标题:Proceedings of the ACM Web Conference 2024 (WWW ’24)
DOI:10.1145/3589334.3645467
ISBN:979-8-4007-0171-9/24/05
分类号:Information systems → Recommender systems
总结¶
本文针对LLMs在推荐系统中难以理解用户长期行为序列的问题,提出了ReLLa框架。通过结合语义用户行为检索(SUBR)和检索增强指令微调(ReiT),ReLLa显著提升了LLM在零样本和少样本推荐任务中的性能。实验结果表明,ReLLa在少量数据下仍能超越传统推荐模型,并具有良好的可复现性和实际应用潜力。
1. Introduction¶
1.1 背景介绍¶
推荐系统在缓解信息过载、满足用户信息需求方面起着重要作用(Guo et al., 2017;Xi et al., 2023a,b)。与此同时,大语言模型(LLMs) 在自然语言处理(NLP)领域表现出色,能够生成高质量的人类文本(Brown et al., 2020;Touvron et al., 2023;Wang et al., 2023;Zhang et al., 2023c)。
近年来,研究者开始探索LLMs在推荐系统中的潜力(Lin et al., 2023a;Hou et al., 2023b;Bao et al., 2023),尝试将其用于不同推荐任务(如列表排序、逐点评分),并且发现LLMs在零样本(zero-shot)和少样本(few-shot)设置下具有良好的表现(Zhang et al., 2023b;Bao et al., 2023)。
1.2 问题提出:LLM在长序列行为理解上的不足¶
文章重点指出,LLMs在处理长用户行为序列时存在一个严重的问题:“lifelong sequential behavior incomprehension problem”(长期顺序行为理解难题)。具体而言,即使用户行为序列的长度远未达到LLMs的上下文窗口限制(如2048 tokens),LLMs也无法有效从这些文本上下文中提取出有用信息用于推荐任务。
如图1所示,对比了SIM(传统推荐模型)和Vicuna-13B(一个开源LLM)在MovieLens-1M数据集上的AUC性能。SIM模型的性能随着行为序列长度K的增加而稳定提升,而Vicuna-13B在K=15时达到性能峰值,当K>15后性能反而下降,尽管总token数远未达到2048的限制。
核心结论:这一问题在推荐系统中尤为突出,因为推荐任务本质上是一个基于用户历史行为推理用户偏好的复杂任务,而LLMs在长序列情境下的表现不佳,限制了其在推荐系统中的应用潜力。
1.3 解决方案:ReLLa框架¶
为了解决上述问题,本文提出一个新的框架:ReLLa(Retrieval-enhanced Large Language Models),用于在zero-shot和few-shot设置下的推荐任务。
零样本推荐中的改进方法(Zero-shot Recommendation)¶
语义用户行为检索(SUBR):取代传统的“最近K个行为”截取方式,采用语义上与目标物品相关的行为,以提高样本质量。
通过这种方式,减少了LLMs从长序列中提取有用信息的难度,从而缓解了理解问题。
少样本推荐中的改进方法(Few-shot Recommendation)¶
在SUBR的基础上,进一步提出检索增强的指令微调(ReiT)。
通过将原始样本与检索增强样本混合,构建一个混合训练集,提升了LLMs在长序列输入下的鲁棒性和泛化能力。
实验结果表明,即使在仅有8,192个样本的MovieLens-25M数据集中,ReLLa的性能也优于使用全部训练数据(近20M样本)训练的主流推荐模型(如DCNv2、DIN、SIM)。
1.4 主要贡献(Main Contributions)¶
本文的贡献主要体现在三个方面:
首次系统提出并定义了“长期顺序行为理解难题”:即LLMs在推荐任务中对长用户行为序列的理解能力不足,即使上下文长度远未达到模型限制。
提出ReLLa框架,通过语义行为检索(SUBR)和检索增强微调(ReiT),有效缓解LLMs在长序列行为上的理解问题。
实验验证:在三个真实世界数据集上,ReLLa在few-shot设置下的性能超越了full-shot设置下的传统推荐模型,证明了该方法的有效性。
总结¶
本节介绍了一个LLMs在推荐系统中尚未被广泛认识的问题——长序列行为理解难题,并通过引入ReLLa框架给出了解决思路,特别强调了语义行为检索和混合数据训练在提升LLMs推荐性能中的作用。实验表明,该方法在资源极其有限的情况下仍能取得优于传统模型的性能,具有重要的研究和应用价值。
2. Preliminaries¶
本文主要聚焦于 点击率预测(CTR prediction) 问题,这是推荐系统中的核心任务,用于估计用户在特定上下文中点击目标物品的概率(Lin et al., 2023b; Guo et al., 2017)。
训练数据集表示为 \(\{(x_i, y_i)\}_{i=1}^{N}\),其中 \(N\) 是样本数量(即样本数)。
当将一个纯大语言模型(LLM)用于此类逐点评分任务时,需要明确以下三个方面:
零样本和少样本推荐的定义;
如何将输入输出转化为文本形式;
如何利用LLM进行逐点评分。
2.1 零样本与少样本推荐(Zero-shot and Few-shot Recommendations)¶
零样本推荐(Zero-shot Recommendation) 指的是模型在不使用目标领域训练数据的情况下,直接对任务进行推荐。传统推荐模型由于是随机初始化的,无法完成此类任务。
大语言模型(LLM) 拥有大量开放世界的知识和推理能力,能够根据用户的用户画像和物品描述,推断用户是否可能点击目标项目。
少样本推荐(Few-shot Recommendation) 指的是训练样本数量非常有限的情形(通常 \(N\) 较小)。在这种情况下,算法需要具备高效利用少量样本的能力,以获得更好的推荐性能。
基于少样本的定义,还可以定义全样本推荐(Full-shot Recommendation),即在完整的训练集上进行模型训练的情形。
2.2 文本输入输出对的构建(Textual Input-Output Pair Formulation)¶

Figure 2.Illustration of textual input-output pair.
对于 LLM 模型来说,每个样本 \(x_i\) 需要被转化为文本句子 \(x_i^{\text{text}}\),而二值标签 \(y_i \in \{0,1\}\) 则对应为文本形式的“是”或“否”,记为 \(y_i^{\text{text}} \in \{\text{``Yes''}, \text{``No''}\}\)。
一个输入输出对的例子如图 2 所示,其中 \(x_i^{\text{text}}\) 包含了用户画像、用户行为序列、目标物品和任务描述等文本描述。
用户行为序列是影响上下文长度的主要因素,长度可能从几十到几百不等。因此,对于每个输入 \(x_i\),我们将其行为序列截断为长度 \(K\)(例如图中 \(K=4\))。
传统方法通常采用最近的 K 个行为,而本文提出的 ReLLa 模型 提出应通过语义检索用户行为,选取与目标物品最相关的 K 个行为来构造输入文本。
2.3 基于 LLM 的逐点评分(Pointwise Scoring with LLMs)¶
LLM 接收文本 \(x_i^{\text{text}}\) 的离散 token 作为输入,然后预测下一个 token \( \hat{y}_i^{\text{text}} \),其过程如下:
其中,\(V\) 为词汇表大小,\(\hat{y}_i^{\text{text}}\) 为从概率分布 \(p_i\) 中采样的下一个 token。
然而,CTR 预测需要的是一个连续的点击概率值 \( \hat{y}_i \in [0,1] \),而不是离散 token。因此,借鉴已有工作(Bao et al., 2023; Zhang and Wang, 2023),本文提出:
截取 LLM 输出的 logit 向量中对应“是”和“否”两个关键词的得分;
然后通过二维 softmax 计算点击概率:
其中,\(a\) 和 \(b\) 分别是“是”和“否”在词汇表中的索引。
注意:该点击率估计值 \( \hat{y}_i \) 仅用于测试集的评估。在训练过程中,若涉及训练,则仍保留 LLM 的常规训练范式(如指令微调和因果语言建模)。
总结来说,本节主要介绍了将 LLM 用于 CTR 预测任务时的三个关键问题:任务适应的定义、文本输入输出的构建方式,以及如何将 LLM 的输出转换为连续的点击概率。这些为后续研究奠定了基础。
3. Methodology¶
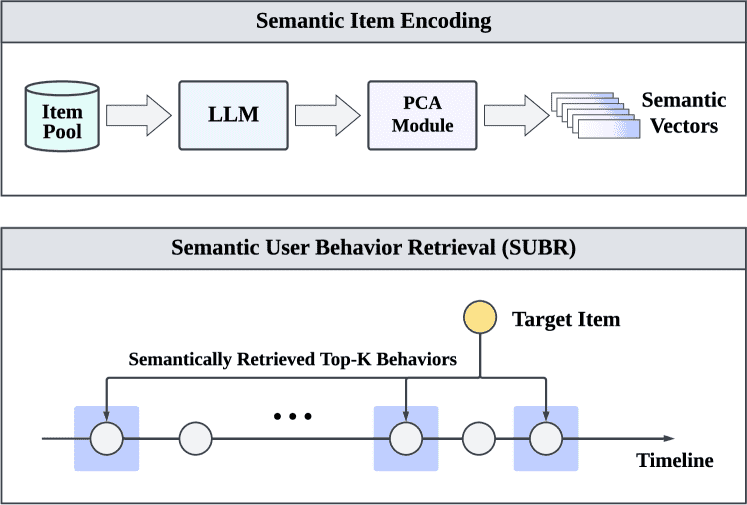
Figure 3.Illustration of semantic user behavior retrieval (SUBR), which improves the data quality by retrieving the top-K semantically relevant behaviors towards the target item. This reduces the difficulty for LLMs to extract useful information from the user history, and therefore alleviates the long user behavior sequence incomprehension problem.
这段文字的核心是介绍了一种利用大语言模型(LLM)做推荐系统的新方法,它主要解决了用户历史行为序列太长,LLM难以理解和提取有用信息的难题。
核心思想总结¶
简单来说,ReLLa 框架的核心思想是:“与其让LLM费力地从用户长长的历史记录里大海捞针,不如我们先帮它把最相关的‘针’(行为)挑出来,让它直接分析这些高质量的‘针’。”
它通过两种关键技术来实现这一目标,分别对应两种应用场景:
语义用户行为检索 (SUBR):用于 零样本(Zero-shot)推荐。在推理阶段直接优化输入给LLM的数据质量。
检索增强的指令微调 (ReiT):用于 少样本(Few-shot)推荐。在训练阶段利用SUBR来增强数据,防止模型过拟合。
分步详解¶
1. 语义用户行为检索 (SUBR) - 用于零样本推荐¶
目标:在不对LLM进行额外训练的情况下,提升其推荐效果。
问题:用户的历史行为(如看过的电影、买过的商品)可能非常长,但LLM有输入长度限制,通常只能截取最近的K个行为。然而,最近的行为不一定与用户当前想买的东西(目标项目)最相关。
解决方案 (SUBR):
给每个物品编码:使用LLM为每个物品(如电影)生成一个“语义向量”。这个向量代表了该物品的深层语义特征。
如何生成?先为每个物品创建一个描述性文本(例如,使用模板:“这是一部由[导演]执导,[演员]主演的关于[主题]的电影”)。然后将这个文本输入LLM,从它的最后一层隐藏状态中提取出语义向量。
降维:这个向量维度很高,所以再用PCA技术进行降维和去噪,得到最终的物品语义表示。
计算相关性:通过计算语义向量之间的余弦相似度,可以衡量任何两个物品之间的语义相关性。
替换历史序列:对于一个测试样本(比如用户想预测是否喜欢《阿凡达》),不再简单地截取他最近看过的K部电影,而是从他的整个历史中,检索出与《阿凡达》语义最相关的K部电影,组成一个新的、更短的序列输入给LLM。
好处:
降噪与提纯:新的序列剔除了不相关的干扰项,只包含能清晰表达用户对“此类”物品兴趣的行为。
缓解长度问题:输入长度不变(还是K个),但信息密度和质量大大提升,让LLM更容易理解。
2. 检索增强的指令微调 (ReiT) - 用于少样本推荐¶
目标:在只有少量训练样本(N个)的情况下,对LLM进行指令微调,并防止其过拟合或遗忘原有知识。
问题:直接用小样本数据微调LLM,很容易过拟合(只记住了训练数据中的噪声而非规律),并发生灾难性遗忘(忘了自己原本的语言能力)。
解决方案 (ReiT):
数据增强:对每一个训练样本,都使用上述的SUBR方法,为其创建一个“检索增强版”的副本。原始样本使用“最近K个行为”,增强版样本使用“最相关K个行为”。
混合数据集:将原始的训练集(N个样本)和增强后的训练集(另外N个样本)合并,形成一个包含 2N 个样本的混合训练集。
指令微调:在这个混合数据集上对LLM进行标准的指令微调(训练它根据输入x预测输出y)。
好处:
模式丰富:混合数据集提供了更多样化的用户行为模式(既有按时间顺序的,也有按语义聚合的),相当于一种高效的数据增强。
正则化效果:这种多样性起到了正则化的作用,迫使模型学习更通用、更本质的规律,而不是死记硬背有限的训练数据,从而提高了模型的鲁棒性和泛化能力。
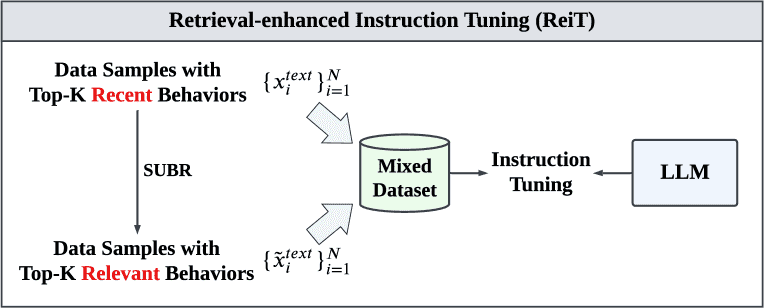
Figure 5.Illustration of retrieval-enhanced instruction tuning, where we construct a mixed training dataset. The mixed dataset consists of both the original textual input-output samples and their retrieval-enhanced counterparts obtained via semantic user behavior retrieval (SUBR).
3. 重要澄清与讨论¶
训练与测试的不一致性?:作者认为这不是问题。在训练时看到两种数据(原始+增强),在测试时只看到一种(增强),这正是一种常见的正则化技术(如图像中的随机裁剪)。只要增强方法是合理的,模型就能学会从各种输入中提取有效信息,从而更好地泛化到测试数据上。
效果来自数据翻倍还是模式丰富?:两者都有贡献,但作者通过实验证明,模式丰富(正则化)是更重要的因素。仅仅把数据简单复制一份(数量翻倍但模式不变)带来的效果提升,不如SUBR带来的模式增强。
总结¶
你可以把ReLLa框架想象成一个为LLM配备的智能秘书:
在零样本场景下(秘书直接帮忙):秘书(SUBR)会先快速浏览用户的一生(长序列),找出与当前任务最相关的文件(K个行为),整理好放在老板(LLM)桌上。老板无需培训,直接就能基于这些高质量文件做出决策。
在少样本场景下(秘书和老板一起培训):在培训老板时,秘书不仅给他看原始文件(最近行为),还会给他看自己整理好的精华版文件(相关行为)。这样培训出来的老板,见识更广,更能抓住重点,即使以后只给他看精华版文件,他也能做得很好。
4. Experiment¶
本节通过广泛的实验,回答了以下五个研究问题(Research Questions, RQs):
RQ1:ReLLa 相比现有基线模型的性能如何?
RQ2:ReLLa 是否能提升大语言模型(LLMs)在推荐任务中的终身序列行为理解能力?
RQ3:样本数量(Shots N)如何影响性能?
RQ4:ReLLa 中不同组件的影响是什么?
RQ5:ReLLa 如何帮助 LLM 更好地理解用户行为序列?
由于篇幅限制,论文在附录 D 中提供了额外实验,验证了以下核心问题:
终身序列行为理解问题的普遍性以及 ReLLa 的 泛化能力。
对模型 参数量 和 推理时间 的分析。
对 SUBR 中 PCA 降维 和 距离度量 的消融实验。
不理解问题的潜在原因 分析。
4.1 实验设置¶
4.1.1 数据集¶
实验在三个真实世界推荐数据集上进行:
数据集 |
用户数 |
物品数 |
样本数 |
字段数 |
特征数 |
|---|---|---|---|---|---|
BookCrossing |
278,858 |
271,375 |
17,714 |
10 |
912,279 |
MovieLens-1M |
6,040 |
3,706 |
970,009 |
10 |
16,944 |
MovieLens-25M |
162,541 |
59,047 |
25,000,095 |
6 |
280,576 |
4.1.2 评估指标¶
使用以下指标评估模型性能:
AUC(ROC 曲线下面积)
Log Loss(二分类交叉熵损失)
ACC(准确率)
在点击率(CTR)预测任务中,AUC 提升 0.001 通常被认为具有显著改善(Lian et al., 2018;Wang et al., 2021)。
4.1.3 基线模型¶
基线模型分为两类:
传统CTR模型:
特征交互模型:DeepFM、AutoInt、DCNv2
用户行为模型:GRU4Rec、Caser、SASRec、DIN、SIM
基于语言模型(LM)的CTR模型:
CTR-BERT、PTab、P5
TALLRec(用于对比 ReLLa 的指令微调效果)
4.1.4 实现细节¶
使用 Vicuna-13B 作为 LLM 基础模型。
使用 8-bit 量化和 LoRA(低秩适应)进行 参数高效微调(PEFT)。
指令微调使用 AdamW 优化器,无权重衰减。
去除用户 ID 和物品 ID 字段,因为 LLM 对纯 ID 的理解能力有限。
构建文本输入输出对时,保留用户和物品的描述性信息。
4.2 总体性能(RQ1)¶
在多个数据集上的实验结果表明:
ReLLa 相比 Vicuna-13B 的零样本性能显著提升,尤其在 BookCrossing 和 MovieLens-1M 上。
在 全样本设置 下,ReLLa 在 AUC、Log Loss 和 ACC 上均优于大多数传统和基于 LM 的模型。
在 少样本设置 下,ReLLa 只使用不到 10% 的训练样本即可超越 SIM 等全样本模型,展现了良好的数据效率。
SIM 模型表现最优,但其性能依赖于完整的训练数据。
4.3 序列行为理解(RQ2)¶
随着用户行为序列长度(K)的增加,SIM 的性能逐步提升。
Vicuna-13B 的零样本性能在 K > 30 时下降,说明 LLM 在处理长行为序列时存在理解困难。
ReLLa 的性能随 K 的增长持续提升,表明其有效缓解了 LLM 对长序列的不理解问题。
SUBR(语义行为检索) 能有效减少行为序列中的噪声,提升模型对关键历史行为的关注。
4.4 数据效率(RQ3)¶
在 少样本设置(如 N = 128)下,SIM 几乎无法完成任务(AUC ≈ 0.5),而 ReLLa 仍能取得显著性能。
ReLLa 仅使用少量样本(如 N = 256)即可达到接近全样本模型的性能,体现其出色的 数据效率。
随着样本数增加,ReLLa 性能持续提升,且在相同样本数下显著优于 SIM。
4.5 消融研究(RQ4)¶
为了评估 ReLLa 各组件的作用,设计了多个变体:
模型变体 |
AUC |
Log Loss |
ACC |
|---|---|---|---|
ReLLa (Ours) |
0.7482 |
0.6265 |
0.6800 |
ReLLa (w/o Mixture) |
0.7399 |
0.6002 |
0.6715 |
ReLLa (w/o Retrieval) |
0.7167 |
0.9293 |
0.4898 |
ReLLa (1/2 N-shot) |
0.7415 |
0.6268 |
0.6462 |
ReLLa (w/o IT) |
0.7253 |
0.9277 |
0.5750 |
ReLLa (w/o IT & Retrieval) |
0.7176 |
0.9507 |
0.5649 |
观察结论:
数据混合策略(包含原始样本和检索增强样本)显著提升性能,且 模式丰富(pattern enrichment)比样本数量更重要。
SUBR(语义行为检索) 显著提升样本质量,帮助 LLM 提取更相关的信息。
指令微调(IT)在零样本设置下也能带来性能提升,说明 LLM 的语言理解和推理能力本身具有优势。
4.6 案例研究(RQ5)¶
通过可视化不同模型在最后隐藏层对历史物品的注意力分布,发现:
Vicuna-13B(零样本) 将注意力集中在与目标物品无关的电影上,导致预测失败。
ReLLa(零样本) 更关注语义相关的超级英雄电影(如 Iron Man 3),但仍存在非相关电影的干扰。
ReLLa(少样本) 经过 SUBR 和 ReiT 后,注意力显著集中在与目标电影(如 Thor: Ragnarok)语义相关且同为 Marvel 作品的电影上,说明模型能够更准确地理解用户行为序列。
总结¶
ReLLa 在多种设置下均优于现有基线模型,尤其是在少样本和长序列任务中表现突出。
SUBR 和 ReiT 是提升性能的核心组件,分别通过减少噪声和提升泛化能力来帮助 LLM 更好理解用户行为。
本实验验证了 终身序列行为理解问题的广泛存在,并表明 ReLLa 具备良好的 泛化性 和 数据效率。
6. Conclusion¶
本文的重点在于将大语言模型(LLMs)适配并强化为推荐任务中的评分/排序函数。
首先,我们识别并定义了LLMs在处理长期用户行为序列时的“不理解”问题。也就是说,即使用户行为序列的长度尚未接近LLMs的上下文限制,LLMs也难以从这种长文本上下文中提取有用信息。
因此,我们提出了一种新颖的框架ReLLa,该框架包含两个关键组件:语义用户行为检索(SUBR) 和 检索增强的指令微调(ReiT)。这两个模块旨在解决上述问题,从而提升推荐效果。
通过广泛的实验,我们验证了所提出的ReLLa相比现有基线方法的有效性。特别是,在使用不到10%训练样本的“少样本”设置下,ReLLa的性能超过了所有基于完整训练集训练的“全样本”传统CTR模型。这一结果表明,ReLLa在数据效率方面具有显著优势,并展现出对长用户行为序列的优异理解能力。
致谢¶
上海交通大学团队的部分研究得到了以下支持:
中国国家重点研发计划项目(2022ZD0114804)
上海市科技重大专项(2021SHZDZX0102)
国家自然科学基金(62177033, 62322603)
本研究还得到了华为创新研究计划的支持。
我们感谢MindSpore(min, 2020)对本工作的部分支持,这是一个新的深度学习计算框架。
Appendix A Prompt Illustration¶
本节通过几个示例展示了 ReLLa 在三个数据集上使用的硬提示模板(hard prompt templates)。
图 9:不带 SUBR 的硬提示模板示例¶
图 9 展示了**未使用语义用户行为检索(Semantic User Behavior Retrieval, SUBR)**时的文本输入输出对。
用户行为序列被截断为最近的 K 个行为(例如图中 K=4)。
这是基础版本的提示模板,仅基于时间最近性选择用户行为,不考虑行为与目标项的语义相关性。
图 10:带 SUBR 的硬提示模板示例¶
图 10 展示了使用了 SUBR 后的提示模板示例。
用户行为序列被替换为与目标项语义最相关的 K 个历史行为项。
重点强调:SUBR 能够检索出与目标项在语义上高度相关的行为,例如在 MovieLens-25M 数据集中,目标电影为 “Thor: Ragnaro”,检索出的历史行为都与超级英雄或漫威相关。
注意:SUBR 生成的用户行为序列保持了原始用户行为的时序顺序。
图 11:物品描述的硬提示模板示例¶
图 11 展示了为三个数据集中的物品描述设计的硬提示模板。
这些模板用于从 LLM 中获得语义物品嵌入(semantic item embedding)。
语义嵌入将被用于 SUBR 模块,以检索与目标物品语义相关的历史用户行为。
小结(重点)¶
SUBR 是 ReLLa 模型的核心机制之一,通过语义检索提升行为序列的相关性。
通过对比图 9 和图 10,可以看出:SUBR 能显著增强模型对用户行为与目标项之间语义关系的理解。
图 11 强调了物品描述的语义嵌入是 SUBR 的输入之一,说明模型不仅依赖行为序列,也依赖物品内容信息。
Appendix B Data Preprocessing¶
本实验使用了三个真实世界的公开数据集,分别为 BookCrossing、MovieLens-1M 和 MovieLens-25M。预处理后的数据集统计信息可参考表1。以下是对各数据集的预处理方法的详细说明:
数据集划分¶
MovieLens-1M 和 MovieLens-25M 数据集根据全局时间戳,按照 8:1 的比例划分为训练集和测试集(参考 Qin 等人,2021)。
BookCrossing 数据集由于没有提供时间戳,因此按照以往研究的做法(参考 Bao 等人,2023),采用随机划分的方式,按照 9:1 的比例划分为训练集和测试集。
行为序列过滤¶
对三个数据集中的用户行为序列进行过滤,只保留长度大于等于5的样本,以确保用户有足够的历史记录用于模型训练和评估。
标签定义¶
以下为各数据集中评分的处理方式:
BookCrossing:评分范围为 0 到 10,评分大于5的样本被标记为正样本,其余为负样本。
MovieLens-1M:评分范围为 0 到 5,评分4和5的样本被标记为正样本,其余为负样本(参考 Zhou 等人,2018;Xi 等人,2023b)。
MovieLens-25M:评分范围为 0 到 5,步长为 0.5,评分高于3.0的样本被标记为正样本,其余为负样本。
少样本设置(Few-Shot Setting)¶
在少样本设置中,设定一个特定的样本数量 N,从训练集中均匀采样 N 个数据样本,并固定用于 ReLLa 的少样本微调。
值得注意的是,当 N 较小时,其采样的样本会包含在所有较大 N 的少样本训练集中,以提高数据采样的一致性和效率。
总结重点¶
使用了三个真实世界数据集,分别来自书籍和电影推荐领域。
数据划分依据时间戳(MovieLens)或随机划分(BookCrossing)。
对用户行为序列长度设置了过滤条件(≥5)。
评分被统一处理为二分类标签(正/负样本)。
在少样本设置中采用均匀采样,且采样结果具有包含性,以提升模型训练效果。
Appendix C Baseline Implementation¶
本节介绍两类基线模型的超参数配置:(1)传统的CTR模型,(2)基于语言模型(LM)的模型。
C.1 传统CTR模型¶
对于传统CTR模型,超参数配置根据数据集的不同有所差异。主要的通用设置如下:
嵌入层大小(embedding size):在BookCrossing数据集上选择 {8, 16, 32},在MovieLens-1M和MovieLens-25M上选择 {32, 64}。
Dropout率:选择范围为 {0.0, 0.1, 0.2}。
激活函数:固定为ReLU。
学习率:设置为 \(1 \times 10^{-3}\)。
优化器:统一使用AdamW。
批量大小(batch size):在BookCrossing数据集上选择 {32, 64},在MovieLens-1M和MovieLens-25M上选择 {256, 512}。
各模型的特殊配置:¶
DeepFM:
BookCrossing:DNN层大小 {32, 64, 128},DNN层数 {1, 2, 3}。
MovieLens-1M/25M:DNN层大小 {128, 256},DNN层数 {3, 6, 9, 12}。
AutoInt:
BookCrossing:注意力层数 {1, 2},注意力大小 32。
MovieLens-1M/25M:注意力层数 {3, 6, 9, 12},注意力大小 {64, 128, 256}。注意力头数为1。
DCNv2:
BookCrossing:DNN层大小 {32, 64, 128},DNN层数和交叉层数 {1, 2, 3}。
MovieLens-1M/25M:DNN层大小 {128, 256},DNN层数和交叉层数 {3, 6, 9, 12}。
GRU4Rec:
GRU层数 {1, 2, 3}。
BookCrossing:GRU和DNN隐藏层大小 {32, 64}。
MovieLens-1M/25M:GRU和DNN隐藏层大小 {64, 128, 256}。
Caser:
垂直卷积核数量 {2, 4, 8},水平卷积核数量 {4, 8, 16}。
DNN层数 {1, 2, 3}。
DNN隐藏大小:BookCrossing {32, 64},MovieLens-1M/25M {64, 128, 256}。
SASRec:
注意力头数 {1, 2, 4}。
注意力层数 {1, 2, 3}。
注意力大小:BookCrossing {32, 64, 128},MovieLens-1M/25M {64, 128, 256}。
DNN层数和隐藏大小同Caser。
DIN:
DIN注意力层和DNN层数 {1, 2, 3}。
DNN隐藏大小:BookCrossing {32, 64},MovieLens-1M/25M {64, 128, 256}。
SIM:
注意力层和DNN层数 {1, 2, 3}。
DNN隐藏大小:BookCrossing {32, 64},MovieLens-1M/25M {64, 128, 256}。
C.2 基于语言模型(LM)的模型¶
此类模型保留了预训练语言模型的结构,并使用统一的AdamW优化器。
具体配置如下:¶
CTR-BERT:
基于BERT模型构建双塔结构,分别编码用户和物品信息。
训练周期为10,批量大小为1024。
学习率为 \(5 \times 10^{-5}\)(线性衰减),Warmup比例为0.05。
P5:
使用T5作为预训练语言模型,是一个统一的序列到序列框架,适用于多种推荐任务。
本文中仅用于CTR预测任务。
训练周期为10,批量大小为32。
学习率选择范围为 \(\{5 \times 10^{-4}, 1 \times 10^{-3}\}\)(线性衰减),Warmup比例为0.05。
采用梯度裁剪(threshold=1.0)。
PTab:
基于BERT模型,采用预训练-微调的方案。
预训练阶段:使用文本化的CTR数据训练10个周期,批量大小为1024,学习率为 \(5 \times 10^{-5}\)(线性衰减),Warmup比例为0.05。
微调阶段:训练10个周期,批量大小为1024,学习率为 \(5 \times 10^{-5}\)(线性衰减),Warmup比例为0.01。
总结¶
本附录详细列出了在不同推荐数据集上使用的传统CTR模型和基于语言模型的基线实现的超参数配置。不同模型根据数据集的规模和复杂度,对嵌入大小、DNN层结构、注意力机制、学习率和批量大小等进行了适配。对于传统模型,重点在于网络结构的调整;对于LM模型,则强调预训练和微调阶段的参数设置。这些配置为模型训练提供了一致的实验基础。
Appendix D Additional Experiments¶
本节进一步提供了额外实验,以验证以下几个核心点:
长程行为不理解问题的普遍性 以及所提出方法 ReLLa 的泛化能力;
模型参数和推理时间的分析;
SUBR 中 PCA 降维维度和距离度量的消融实验;
行为不理解问题的潜在原因分析与讨论。
D.1. Universality & Generalization(普遍性与泛化能力)¶
本部分通过使用不同架构和规模的大型语言模型(LLM)来验证 长程行为不理解问题的普遍性 以及 ReLLa 的泛化能力。实验中使用的 LLM 包括 Falcon-7B、Mistral-7B、Vicuna-7B、Vicuna-13B 和 LLaMA-2-70B-Chat。
D.1.1. Incomprehension Problem 的普遍性¶
在 MovieLens-1M 数据集上,对不同长度(K=5 到 K=30)的用户行为序列进行分析,发现所有五个模型在较短序列(如 K=15)时性能达到峰值,远低于其最大上下文长度。这表明 长程行为不理解问题具有普遍性,且不同模型之间的性能差异可能与其本身的指令遵循能力有关。
D.1.2. ReLLa 的泛化能力¶
通过在多个 LLM 上应用语义行为检索(SUBR)和检索增强指令微调(ReiT),验证了 ReLLa 的泛化性。实验结果显示:
ReLLa 能显著提升推荐性能,无论是在 零样本(zero-shot) 还是 小样本(few-shot) 设置下;
Mistral-7B、Vicuna-7B 和 Vicuna-13B 在小样本设置下甚至优于全样本训练的传统推荐模型;
Falcon-7B 的性能提升有限,可能与其模型能力或调参策略有关;
ReLLa 能显著改善长序列下的推荐性能(K=30)。
D.2. Model Parameter & Inference Time(模型参数与推理时间)¶
本部分分析了 ReLLa 和传统推荐模型 SIM 在 MovieLens-1M 上的 模型复杂度与推理时间。
核心结论:¶
ReLLa 参数量高达 13B,可训练参数为 650M,推理时间约为 500ms;
对比之下,SIM 模型参数量仅为 1.44M,推理时间仅 3.21ms;
ReLLa 推理较慢,但其在性能和样本效率上的优势,使其适用于对延迟容忍度较高的实际应用场景,如对话式推荐。
这种计算开销是大语言模型(LLM)本身的特性,不是 ReLLa 独有的问题。
D.3. Ablation on PCA & Distance Metric(PCA 与距离度量消融实验)¶
本部分对 PCA 降维维度与距离度量方式 进行了消融实验,以分析其对 SUBR 性能的影响。
D.3.1. PCA 降维维度的影响¶
使用不同 PCA 维度(64、128、256、512)进行实验,发现 512 维度在性能与存储/计算成本之间达到最佳平衡;
降维会带来语义信息损失,维度越低,性能越差。
D.3.2. 距离度量的影响¶
实验比较了 余弦距离、L2 距离和 L1 距离;
余弦距离在高维空间中表现更优,因为它不受向量模长影响,能更好捕捉语义相似性;
L1 和 L2 距离在高维空间中受“维度灾难”影响,相似度评估效果较差。
D.4. Potential Reason for Incomprehension(行为不理解问题的潜在原因)¶
本部分对 LLM 在推荐任务中行为不理解问题的 潜在原因 进行分析和假设。
核心观点:¶
行为序列的 异质性(heterogeneity) 是影响理解的关键因素;
LLM 对高异质性序列的理解能力有限,导致推荐性能下降;
SUBR 检索技术通过“同质化”序列(仅保留与目标项目相关的行为)来降低异质性,从而提升 LLM 对长序列的理解能力。
实验验证:¶
定义异质性得分(如电影类型数量);
比较“最近行为序列”与“相关行为序列”的异质性得分;
结果显示,SUBR 检索后序列的异质性显著降低,解释了 ReLLa 为何在长序列下表现更优。
小结:¶
“Appendix D” 通过一系列实验和分析,验证了:
长程行为不理解问题具有普遍性,且不同 LLM 的表现存在差异;
ReLLa 具有良好的泛化能力,适用于多种 LLM,并在性能和样本效率上显著优于传统模型;
ReLLa 的参数开销较大,推理时间较长,但适合对延迟容忍度高的实际场景;
PCA 降维与余弦距离的使用 对模型性能有显著影响;
行为序列的异质性是 LLM 理解困难的主要原因,ReLLa 通过检索机制有效降低异质性,从而提升理解能力。
该附录为 ReLLa 提供了扎实的实证和理论支持,增强了其在推荐系统中的可行性与实用价值。