❇️2305.18290_DPO: Direct Preference Optimization: Your Language Model is Secretly a Reward Model¶
引用: 6253(2025-11-15)
组织:
†Stanford University
‡CZ Biohub
总结¶
总结¶
背景
主流方法是基于人类反馈的强化学习(RLHF):
首先训练一个奖励模型(reward model),基于人类对不同回复的偏好。
然后使用强化学习(如PPO)优化语言模型策略,使其最大化奖励。
缺点:流程复杂,涉及多个模型训练和循环采样,计算成本高。
使用人类偏好数据集对语言模型进行微调通常分为两个阶段:
第一阶段:使用偏好模型(如Bradley-Terry模型)训练一个神经网络作为奖励函数;
第二阶段:使用强化学习算法(如REINFORCE、PPO等)优化语言模型以最大化该奖励。
RLHF(基于人类反馈的强化学习)的基本流程,分为三个阶段:
监督微调(SFT):构建初始任务模型;
偏好采样与奖励建模:通过人类偏好数据训练奖励函数;
强化学习优化:利用奖励模型指导模型优化,同时控制模型稳定性。
RLHF 的痛点:
极其复杂: 需要训练和维护多个模型(策略模型、奖励模型、价值模型)。
不稳定: PPO 阶段的训练非常不稳定,对超参数敏感,容易“崩坏”。
计算成本高: 整个过程需要大量的计算和内存。
DPO
总结
无需显式奖励建模或强化学习,即可直接优化语言模型以符合人类偏好
一句话:DPO 是一种绕过复杂强化学习过程,直接利用人类偏好数据来微调语言模型的技术。
目标:解决 RLHF 的复杂性,找到一个更简单、更稳定、更高效的替代方案
核心思想:
基于偏好数据(如成对的回复与人类偏好标签),直接优化一个二分类交叉熵目标函数
该目标函数隐式地优化与RLHF相同的目标(最大化奖励,同时限制与原始模型的偏离)
DPO通过动态调整每个样本的重要性权重,避免模型退化(如过度偏向偏好样本)
理论基础:
使用偏好模型(如Bradley-Terry模型)衡量奖励函数与偏好数据的匹配程度。
与传统方法不同的是,DPO直接将偏好损失定义为策略的函数,而非通过中间奖励模型
核心创新:
DPO算法通过简单分类目标实现与RLHF等效的优化,无需奖励模型或强化学习。
算法流程
将 RLHF 的后两步合二为一:
准备偏好数据: 收集形如 (提示, 获胜回答, 失败回答) 的数据对。这是与 RLHF 相同的。
直接优化模型: 使用 DPO 损失函数,直接在这些偏好数据上微调语言模型本身。
DPO 损失函数:
公式: \(L_{DPO} = -\mathbb{E} \left[ \log \sigma \left( \beta \log \frac{\pi_\theta(y_w | x)}{\pi_{ref}(y_w | x)} - \beta \log \frac{\pi_\theta(y_l | x)}{\pi_{ref}(y_l | x)} \right) \right]\)
我们来拆解这个公式:
\(x\): 提示。
\(y_w\): 偏好的回答。
\(y_l\): 不被偏好的回答。
\(\pi_\theta\): 我们正在训练的模型。
\(\pi_{ref}\): 参考模型,通常是第一步监督微调后的模型,在训练过程中被冻结。
\(\beta\): 一个超参数,控制模型与参考模型的偏离程度。
\(\log \frac{\pi_\theta(y | x)}{\pi_{ref}(y | x)}\): 这是对数概率比,它隐式地衡量了当前模型相对于参考模型对某个回答的“偏好程度”。
损失函数的直观理解:
损失函数的核心是一个 Bradley-Terry 模型,它通过一个逻辑函数来比较两个项目的得分。
在这里,我们比较的是当前模型对“好回答”和“坏回答”的相对偏好。
我们要最大化
模型对好回答的偏好 - 模型对坏回答的偏好这个差值。通过最小化这个损失函数,我们实际上是在拉大好回答和坏回答之间的得分差距,同时通过参考模型来防止模型为了得高分而走向极端。
三行摘要¶
🌟 本文提出了一种名为直接偏好优化(DPO)的新方法,旨在通过将强化学习从人类反馈(RLHF)问题转化为简单的分类损失,直接优化语言模型以符合人类偏好。
💡 DPO通过对奖励模型进行创新性参数化,使得最优策略可以以封闭形式直接从该模型中提取,从而省去了传统RLHF中复杂的奖励模型训练和强化学习优化步骤。
🚀 实验结果表明,DPO算法稳定、计算效率高,且在情感控制、文本摘要和对话等任务上达到了与现有RLHF方法(如PPO)相当甚至更好的性能,同时显著简化了实现和训练过程。
摘要¶
《Direct Preference Optimization: Your Language Model is Secretly a Reward Model》一文提出了一种名为Direct Preference Optimization (DPO) 的新型算法,旨在简化大型语言模型 (LLM) 与人类偏好对齐的复杂过程,特别是在强化学习 (RL) 框架下从人类反馈中学习(RLHF)的场景。
背景与动机 大型无监督语言模型虽然能学习到广泛的世界知识和推理能力,但精确控制其行为仍具挑战。现有的对齐方法,如RLHF,通过收集人类对模型生成文本质量的相对偏好,然后微调模型以符合这些偏好。然而,RLHF流程复杂且不稳定,通常涉及两个阶段:首先训练一个奖励模型(reward model)来量化人类偏好,然后使用强化学习(如PPO)微调语言模型(策略模型)以最大化这个估计的奖励,同时防止模型偏离初始模型过远(通过KL散度约束)。这种方法计算成本高昂,需要循环采样,并且超参数调整困难。本文的目标是提出一种更简单、更稳定、计算更轻量的方法来直接优化策略,使其满足人类偏好。
核心方法论 (Direct Preference Optimization, DPO)
DPO的核心思想是发现奖励模型的一种特定参数化形式,该形式允许直接以闭式解(closed-form)导出对应的最优策略,从而将标准的RLHF问题转化为一个简单的分类损失问题。
标准的RLHF目标函数回顾: RLHF通常优化以下带有KL散度约束的奖励最大化目标: $\( \max_{\pi_\theta} \mathbb{E}_{x \sim D, y \sim \pi_\theta(y|x)} [r_\phi(x, y)] - \beta D_{KL}[\pi_\theta(y|x) || \pi_{\text{ref}}(y|x)] \)\( 其中,\)r_\phi(x, y)\( 是学习到的奖励函数,\)\pi_\theta\( 是待优化的策略(语言模型),\)\pi_{\text{ref}}\( 是参考策略(通常是SFT模型),\)\beta$ 是控制策略偏离参考策略程度的超参数。
最优策略的闭式解: 该论文首先指出,上述KL约束的奖励最大化问题的最优策略\(\pi_r(y|x)\) 可以被解析地表示为: $\( \pi_r(y|x) = \frac{1}{Z(x)} \pi_{\text{ref}}(y|x) \exp\left(\frac{1}{\beta} r(x, y)\right) \)\( 其中,\)Z(x) = \sum_y \pi_{\text{ref}}(y|x) \exp\left(\frac{1}{\beta} r(x, y)\right)\( 是配分函数(partition function)。这个公式表明,给定一个奖励函数\)r(x,y)$,与其对应的最优策略是明确定义的。
奖励函数的重新参数化: 通过对上述闭式解进行代数变换,可以将奖励函数\(r(x,y)\) 表示为最优策略\(\pi_r(y|x)\)、参考策略\(\pi_{\text{ref}}(y|x)\) 和配分函数\(Z(x)\) 的函数: $\( r(x, y) = \beta \log \frac{\pi_r(y|x)}{\pi_{\text{ref}}(y|x)} + \beta \log Z(x) \)$ 这个关键的重新参数化是DPO方法的基础。它将奖励函数与策略模型之间建立了一个直接的联系。
融入Bradley-Terry偏好模型: 人类偏好数据通常使用Bradley-Terry模型进行建模,其形式为: $\( p^*(y_1 \succ y_2 | x) = \frac{\exp(r^*(x, y_1))}{\exp(r^*(x, y_1)) + \exp(r^*(x, y_2))} = \sigma(r^*(x, y_1) - r^*(x, y_2)) \)\( 其中,\)r^(x, y)\( 是真实的潜在奖励函数。 将上一步导出的奖励函数重新参数化表达式代入Bradley-Terry模型,奇妙的是,配分函数\)\beta \log Z(x)\( 在奖励差分中被抵消了: \)\( p^*(y_1 \succ y_2 | x) = \sigma\left(\beta \log \frac{\pi_r(y_1|x)}{\pi_{\text{ref}}(y_1|x)} - \beta \log \frac{\pi_r(y_2|x)}{\pi_{\text{ref}}(y_2|x)}\right) \)\( 这意味着,人类偏好概率可以直接通过最优策略\)\pi_r\( 和参考策略\)\pi_{\text{ref}}\( 来表达,而无需显式地建模奖励函数\)r^(x, y)$。
DPO损失函数: 基于上述推导,DPO算法通过最大化人类偏好数据的对数似然来直接优化策略\(\pi_\theta\),其损失函数(负对数似然)为: $\( L_{\text{DPO}}(\pi_\theta; \pi_{\text{ref}}) = -\mathbb{E}_{(x,y_w,y_l) \sim D} \left[ \log \sigma \left( \beta \log \frac{\pi_\theta(y_w|x)}{\pi_{\text{ref}}(y_w|x)} - \beta \log \frac{\pi_\theta(y_l|x)}{\pi_{\text{ref}}(y_l|x)} \right) \right] \)\( 其中,\)D\( 是由偏好对\)(x, y_w, y_l)\( 组成的数据集,\)y_w\( 是偏好的响应,\)y_l$ 是不偏好的响应。这个损失函数是一个简单的二元交叉熵损失。
DPO更新的直观理解 DPO的梯度更新会增加偏好响应\(y_w\) 的对数概率,同时减少不偏好响应\(y_l\) 的对数概率。重要的是,这种更新是动态加权的。权重项\(\sigma(\hat{r}_\theta(x, y_l) - \hat{r}_\theta(x, y_w))\) (其中\(\hat{r}_\theta(x, y) = \beta \log \frac{\pi_\theta(y|x)}{\pi_{\text{ref}}(y|x)}\) 是由当前策略隐式定义的奖励)意味着当模型错误地将不偏好的响应赋予更高(隐式)奖励时,该样本的权重会更高,从而促使模型更强烈地纠正其偏好。
理论分析 DPO通过这种重新参数化,实现了策略模型同时扮演语言模型和隐式奖励模型的角色。它展示了奖励函数存在等价类,并且DPO选择的是每个等价类中一个特殊的、使得最优策略可以解析表示的奖励函数。DPO方法避免了RLHF中常用的actor-critic算法(如PPO)可能出现的训练不稳定问题,因为DPO直接优化策略,无需估计价值函数或进行采样。
实验 作者在三个开放式文本生成任务上评估了DPO:
情感生成 (IMDb):在一个受控环境中,使用预训练情感分类器作为真值奖励函数。DPO在奖励-KL散度权衡曲线上表现出最高的效率,严格优于PPO(包括能访问真值奖励的PPO-GT),在实现相同奖励水平时,KL散度更小。
摘要生成 (Reddit TL;DR):在Reddit帖子摘要任务中,使用GPT-4作为评估器(代理人类判断)。DPO在不同采样温度下均表现出色,其胜率(win rate)超过PPO和“Best of N”基线,并且对采样温度变化更鲁棒。
单轮对话 (Anthropic-HH):在Anthropic Helpful and Harmless数据集上进行单轮对话。DPO是唯一一个在计算效率上能超越数据集中“chosen”响应的方法,并与计算成本高昂的“Best of 128”基线表现相当或更好。 此外,通过人类研究验证,GPT-4的判断与人类判断高度相关,证实了使用GPT-4进行自动评估的有效性。
结论 DPO提供了一个无需强化学习的、简单而有效的从偏好中训练语言模型的范式。它通过对奖励模型的巧妙重新参数化,将复杂的RLHF问题转化为一个直接优化策略的二元交叉熵分类问题。DPO在性能上与现有RLHF算法(包括基于PPO的方法)相当或更优,同时显著降低了实现和训练的复杂性与计算成本,为从人类偏好中训练对齐的语言模型提供了一条更易于实现且高效的途径。
Abstract¶
本节介绍了当前大型无监督语言模型(LMs)虽然能够学习广泛的世界知识和一定的推理能力,但由于训练过程完全无监督,难以实现对其行为的精确控制。为了解决这一问题,现有方法通常依赖于人类对模型生成结果的偏好标签,并通过**基于人类反馈的强化学习(RLHF)**来微调模型。
RLHF方法通常包括两个步骤:
训练一个奖励模型(reward model),用于反映人类偏好;
使用强化学习对原始语言模型进行微调,以最大化该奖励,同时避免偏离原始模型太远。
然而,RLHF方法复杂且训练不稳定。
本文提出了一种新的RLHF奖励模型参数化方法,使得可以直接通过闭式解(closed-form)提取对应的最优策略。基于此方法提出的新算法称为直接偏好优化(Direct Preference Optimization, DPO),它通过一个简单的分类损失函数即可解决标准RLHF问题。
DPO具有以下优势:
稳定性强
性能良好
计算开销小
无需在微调过程中从语言模型中采样
无需大量超参数调优
实验结果表明,DPO在对齐人类偏好方面表现优于或等同于现有方法。
在控制生成内容情感方面优于基于PPO的RLHF
在摘要生成和单轮对话任务中表现相当或更优
实现和训练更为简单
重点内容:DPO算法的提出及其在稳定性、性能和实现简便性方面的优势。
次要内容:RLHF的基本流程和其局限性简要介绍。
1 Introduction¶
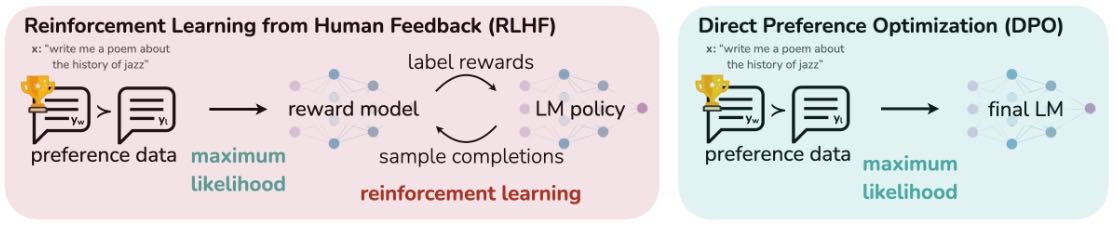
Figure 1: DPO optimizes for human preferences while avoiding reinforcement learning.
核心问题与背景¶
本节介绍了当前大型语言模型(LMs)在无监督训练后展现出强大能力,但其训练数据来源广泛,包含人类多样甚至可能不理想的目标与行为。因此,如何从模型广泛的知识中选择出“期望的行为”是构建安全、可控AI系统的关键。
例如:
模型需要理解常见的编程错误以便纠正,但生成代码时应偏向高质量代码。
模型可以知晓某种被50%人误信的错误观点,但不能在50%的查询中都默认它为正确。
这说明,在模型训练中如何体现人类偏好,是当前研究的重点。
现有方法及其局限¶
目前主流方法是基于人类反馈的强化学习(RLHF):
首先训练一个奖励模型(reward model),基于人类对不同回复的偏好。
然后使用强化学习(如PPO)优化语言模型策略,使其最大化奖励。
虽然RLHF在对话和编程任务中表现优异,但其流程复杂,涉及多个模型训练和循环采样,计算成本高。
本文提出的方法:DPO(Direct Preference Optimization)¶
作者提出DPO算法,无需显式奖励建模或强化学习,即可直接优化语言模型以符合人类偏好。
DPO的核心思想:¶
基于偏好数据(如成对的回复与人类偏好标签),直接优化一个二分类交叉熵目标函数。
该目标函数隐式地优化与RLHF相同的目标(最大化奖励,同时限制与原始模型的偏离)。
DPO通过动态调整每个样本的重要性权重,避免模型退化(如过度偏向偏好样本)。
理论基础:¶
使用偏好模型(如Bradley-Terry模型)衡量奖励函数与偏好数据的匹配程度。
与传统方法不同的是,DPO直接将偏好损失定义为策略的函数,而非通过中间奖励模型。
主要贡献¶
提出DPO算法:一种无需强化学习、流程简单、易于训练的偏好优化方法。
实验验证:DPO在情感调节、摘要生成、对话等任务上表现与RLHF相当或更优,适用于最多6B参数的语言模型。
总结(重点)¶
关键问题:如何从模型广泛知识中选择符合人类期望的行为。
现有方法问题:RLHF流程复杂、计算成本高。
核心创新:DPO算法通过简单分类目标实现与RLHF等效的优化,无需奖励模型或强化学习。
实验结果:DPO表现优异,简化了偏好学习流程,具有广泛应用潜力。
3 Preliminaries¶
本节主要回顾了RLHF(基于人类反馈的强化学习)的基本流程,分为三个阶段:监督微调(SFT)、偏好采样与奖励建模、以及强化学习优化。
3.1 监督微调(SFT)¶
核心内容:RLHF的第一步是对预训练语言模型进行监督微调,使用高质量的下游任务数据(如对话、摘要等),得到初始模型 π^SFT。
说明:这是整个流程的基础,目的是让模型具备完成特定任务的能力。
3.2 奖励建模阶段(Reward Modelling Phase)¶
核心内容:
使用SFT模型生成多个回答对 (y₁, y₂),由人工标注者选择更优回答,形成偏好数据 yw ≻ yl ∣ x。
假设这些偏好由一个潜在奖励函数 r*(x, y) 生成,目标是通过这些偏好数据训练一个可学习的奖励模型 rϕ(x, y)。
重点方法:
Bradley-Terry (BT) 模型:最常用的方法,将偏好建模为: $\( p^*(y_1 \succ y_2 \mid x) = \frac{\exp(r^*(x, y_1))}{\exp(r^*(x, y_1)) + \exp(r^*(x, y_2))} \)$
损失函数:使用负对数似然损失进行最大似然估计,形式为: $\( \mathcal{L}_R(r_\phi, \mathcal{D}) = -\mathbb{E}_{(x, y_w, y_l) \sim \mathcal{D}} \left[ \log \sigma(r_\phi(x, y_w) - r_\phi(x, y_l)) \right] \)$
实现细节:
奖励模型通常在SFT模型基础上加一个线性层输出标量奖励值。
为减少方差,会对奖励进行归一化处理,使整体均值为0。
3.3 强化学习微调阶段(RL Fine-Tuning Phase)¶
核心内容:
使用训练好的奖励模型 rϕ(x, y) 来指导语言模型的优化。
优化目标是最大化奖励,同时限制模型与初始SFT模型之间的偏离。
优化目标: $\( \max_{\pi_\theta} \mathbb{E}_{x \sim \mathcal{D}, y \sim \pi_\theta} [r_\phi(x, y)] - \beta \mathbb{D}_{\text{KL}}[\pi_\theta(y \mid x) \parallel \pi_{\text{ref}}(y \mid x)] \)$
β 控制模型偏离参考策略 π_ref(即SFT模型)的程度。
KL散度项防止模型偏离奖励模型训练时的数据分布,也避免生成结果过于单一。
实现方法:
由于语言生成是离散的,目标函数不可导,通常使用强化学习算法优化。
最常用的是PPO算法,构建的奖励函数为: $\( r(x, y) = r_\phi(x, y) - \beta (\log \pi_\theta(y \mid x) - \log \pi_{\text{ref}}(y \mid x)) \)$
总结¶
本节系统介绍了RLHF的三个标准阶段:
SFT:构建初始任务模型;
奖励建模:通过人类偏好数据训练奖励函数;
强化学习优化:利用奖励模型指导模型优化,同时控制模型稳定性。
其中,奖励建模和RL优化是RLHF的核心环节,分别依赖于BT模型和PPO算法来实现。
4 Direct Preference Optimization¶
概述¶
本节提出了一种新的策略优化方法——直接偏好优化(DPO),旨在避免传统强化学习(RL)在大规模语言模型微调中的复杂性。与以往的RLHF方法(先学习奖励函数再通过RL优化)不同,DPO通过特定的奖励模型参数化方式,直接从偏好数据中提取最优策略,无需显式的RL训练循环。其核心思想是利用奖励函数到最优策略的解析映射,将对奖励函数的优化转化为对策略的优化。
DPO目标函数的推导¶
最优策略形式
基于KL约束下的奖励最大化目标(Eq. 3),最优策略形式如下:\[ \pi_r(y|x) = \frac{1}{Z(x)} \pi_{\text{ref}}(y|x) \exp\left(\frac{1}{\beta} r(x,y)\right) \]其中 \( Z(x) \) 是归一化因子(配分函数)。然而,估计 \( Z(x) \) 在实践中代价高昂。
奖励函数的重新参数化
将上述公式转换为以策略表示的奖励函数形式:\[ r(x,y) = \beta \log \frac{\pi_r(y|x)}{\pi_{\text{ref}}(y|x)} + \beta \log Z(x) \]由于Bradley-Terry偏好模型只依赖两个完成之间的奖励差值,因此在计算偏好概率时,\( Z(x) \) 会被抵消。
偏好模型的策略表示
将重新参数化的奖励函数代入偏好模型,得到仅依赖于策略的偏好概率表达式:\[ p^*(y_1 \succ y_2 | x) = \frac{1}{1 + \exp\left(\beta \log \frac{\pi^*(y_2|x)}{\pi_{\text{ref}}(y_2|x)} - \beta \log \frac{\pi^*(y_1|x)}{\pi_{\text{ref}}(y_1|x)}\right)} \]这使得我们可以直接基于策略建模偏好数据,而无需显式建模奖励函数。
DPO目标函数
基于上述表达式,定义策略参数化下的最大似然目标函数:\[ \mathcal{L}_{\text{DPO}}(\pi_\theta; \pi_{\text{ref}}) = -\mathbb{E}_{(x, y_w, y_l) \sim \mathcal{D}} \left[ \log \sigma\left( \beta \log \frac{\pi_\theta(y_w|x)}{\pi_{\text{ref}}(y_w|x)} - \beta \log \frac{\pi_\theta(y_l|x)}{\pi_{\text{ref}}(y_l|x)} \right) \right] \]该目标函数等价于拟合一个重新参数化的Bradley-Terry模型,具有良好的理论性质(如一致性)。
DPO更新机制分析¶
梯度形式
DPO损失函数对参数 \( \theta \) 的梯度如下:\[ \nabla_\theta \mathcal{L}_{\text{DPO}} = -\beta \mathbb{E}_{(x, y_w, y_l)} \left[ \sigma(r_\theta(x, y_l) - r_\theta(x, y_w)) \left( \nabla_\theta \log \pi(y_w|x) - \nabla_\theta \log \pi(y_l|x) \right) \right] \]其中 \( r_\theta(x, y) = \beta \log \frac{\pi_\theta(y|x)}{\pi_{\text{ref}}(y|x)} \) 是隐式定义的奖励。
直观解释
梯度会提升偏好完成 \( y_w \) 的似然,降低非偏好完成 \( y_l \) 的似然。
权重项 \( \sigma(r_\theta(x, y_l) - r_\theta(x, y_w)) \) 表示当前奖励模型对偏好顺序的错误程度,错误越大,更新越强。
实验表明,这种加权机制对模型性能至关重要,缺乏它会导致模型退化。
DPO流程概述¶
数据准备
对每个提示 \( x \),从参考策略 \( \pi_{\text{ref}} \) 中采样完成 \( y_1, y_2 \)。
通过人工标注偏好,构建离线偏好数据集 \( \mathcal{D} = \{(x^{(i)}, y_w^{(i)}, y_l^{(i)})\} \)。
模型训练
优化语言模型 \( \pi_\theta \),最小化 DPO 损失函数 \( \mathcal{L}_{\text{DPO}} \),给定参考策略 \( \pi_{\text{ref}} \)、偏好数据集 \( \mathcal{D} \) 和参数 \( \beta \)。
参考策略的初始化
若有SFT模型 \( \pi^{\text{SFT}} \),则设 \( \pi_{\text{ref}} = \pi^{\text{SFT}} \)。
否则,通过最大化偏好完成的似然来估计 \( \pi_{\text{ref}} \),以缓解分布偏移问题。
总结¶
DPO 的核心思想:通过将奖励函数与策略之间的解析关系嵌入目标函数,直接从偏好数据中优化策略,无需显式训练奖励模型。
优势:简化训练流程、避免RL训练、具有理论一致性。
关键机制:通过梯度加权机制,强调对错误奖励排序的修正。
实现流程:使用偏好数据集和参考策略,直接优化语言模型参数。
该方法为基于人类偏好的语言模型微调提供了一种高效、简洁的新路径。
5 Theoretical Analysis of DPO¶
本节进一步解释DPO方法,提供理论支持,并将DPO的优势与RLHF中常用的actor-critic算法(如PPO)的问题联系起来。
5.1 你的语言模型其实是一个奖励模型¶
重点内容:
DPO方法通过一个最大似然目标,绕过了显式拟合奖励函数和进行强化学习(RL)的步骤。其优化目标等价于使用Bradley-Terry模型,并通过参数化形式
$\(
r^*(x, y) = \beta \log \frac{\pi^*_\theta(y|x)}{\pi_{\text{ref}}(y|x)}
\)$
来等价于奖励模型的优化。这表明,DPO通过重新参数化,可以直接从偏好数据中学习最优策略,而无需显式建模奖励函数。
理论支撑:
定义1:两个奖励函数 \( r(x, y) \) 和 \( r'(x, y) \) 是等价的,如果它们的差值仅是输入 \( x \) 的函数。
引理1:在Plackett-Luce(尤其是Bradley-Terry)框架下,同一等价类的奖励函数会诱导出相同的偏好分布。
引理2:在约束RL问题中,同一等价类的奖励函数也会诱导出相同的最优策略。
这说明我们只需学习一个等价类中的任意奖励函数即可达到目标。
定理1(关键理论): 在温和假设下,所有与Plackett-Luce模型一致的奖励函数类都可以用如下形式表示: $\( r(x, y) = \beta \log \frac{\pi(y|x)}{\pi_{\text{ref}}(y|x)} \)$ 即,DPO的重新参数化不会损失任何表达能力,并且可以精确恢复最优策略。
证明思路简述: 通过对任意奖励函数进行归一化处理,可以将其转换为上述形式,从而证明该形式可以表示所有等价类中的奖励函数。
进一步理解: 该定理也说明了DPO选择的是满足如下约束的奖励函数: $\( \sum_y \pi_{\text{ref}}(y|x) \exp\left(\frac{1}{\beta} r(x, y)\right) = 1 \)\( 即,使得对应的策略 \) \pi(y|x) $ 是一个合法的概率分布。这使得DPO能够在不损失表达能力的前提下,使最优策略解析可解。
5.2 Actor-Critic算法的不稳定性¶
重点内容:
本节通过DPO框架分析了标准actor-critic算法(如PPO)在RLHF中的不稳定性问题。
在RLHF流程中,通常使用KL散度最小化来逼近最优策略 \( \pi^*(y|x) \),该策略由奖励函数 \( r_\phi(x, y) \) 诱导。
最终优化目标为: $\( \max_{\pi_\theta} \mathbb{E}_{\pi_\theta(y|x)}\left[ r_\phi(x, y) - \beta \log \sum_y \pi_{\text{ref}}(y|x) \exp\left(\frac{1}{\beta} r_\phi(x, y)\right) - \beta \log \frac{\pi_\theta(y|x)}{\pi_{\text{ref}}(y|x)} \right] \)$
其中,第一项是奖励函数,第二项是归一化项(可视为参考策略的软值函数),第三项是KL散度项。
问题分析:
归一化项虽然不影响最优解,但会影响策略梯度的方差,导致训练不稳定。
传统方法通过引入学习的值函数或使用人类完成的基线(human completion baseline)来估计该归一化项,但这些方法都存在优化困难。
DPO的优势在于其重新参数化的奖励函数天然避免了对基线的依赖,从而提升了训练的稳定性和效率。
总结:
DPO通过重新参数化,将语言模型直接视为奖励模型,绕过了传统RLHF中奖励建模和强化学习的复杂流程。
理论上,DPO保证了奖励函数类的表达能力,并能精确恢复最优策略。
相比之下,传统actor-critic方法(如PPO)由于归一化项的估计问题,容易导致训练不稳定,而DPO则避免了这一问题。
6 Experiments¶
本节对DPO(Direct Preference Optimization)从偏好数据中直接训练策略的能力进行实证评估。首先,在一个受控的文本生成环境中,我们探讨DPO在最大化奖励与最小化与参考策略的KL散度之间的权衡效率,与PPO等常见偏好学习算法相比如何。接着,我们在更大模型和更复杂的RLHF任务(如摘要生成和对话)上评估DPO的表现。我们发现,几乎无需调整超参数,DPO的表现通常与RLHF结合PPO等强基线方法相当或更优,并且在使用学习到的奖励函数时,能够返回NN采样轨迹中的最佳结果。在展示这些结果之前,我们先介绍实验设置;更多细节见附录C。
任务¶
我们的实验涵盖三种不同的开放式文本生成任务。所有算法都从偏好数据集𝒟 = {x(i), yw(i), yl(i)}i=1N中学习策略。
控制情感生成:输入x是来自IMDb数据集的电影评论前缀,策略需生成具有正面情感的输出y。为了进行受控评估,我们使用预训练的情感分类器生成偏好对,其中p(positive|x, yw) > p(positive|x, yl)。我们使用GPT-2-large在IMDb训练集上进行SFT微调。
摘要生成:输入x是Reddit论坛帖子,策略需生成其摘要y。我们使用Reddit TL;DR数据集和Stiennon等人收集的人类偏好数据。SFT模型基于TRLX框架微调,人类偏好数据来自不同但类似训练的SFT模型。
单轮对话:输入x是用户查询,策略需生成有帮助的响应y。我们使用Anthropic的“Helpful and Harmless”对话数据集,包含170k人类与AI助手的对话。每个对话以一对响应和偏好标签结束。由于没有预训练的SFT模型,我们仅基于偏好响应微调一个现成的语言模型。
评估方法¶
我们采用两种评估方式:
奖励-KL前沿分析:在控制情感生成任务中,由于我们拥有真实的奖励函数(情感分类器),可以计算每个算法的奖励和KL散度前沿。
胜率评估:在摘要和对话任务中,使用GPT-4作为代理评估模型质量与响应有用性。摘要任务中使用测试集中的参考摘要作为基线,对话任务中使用测试集中人类偏好的响应作为基线。我们还进行了人类研究,验证GPT-4评估与人类判断的一致性,发现其相关性较强,甚至高于人类标注者之间的一致性。
方法对比¶
除了DPO,我们还评估了以下方法:
零样本提示(GPT-J) 和 两样本提示(Pythia-2.8B)
SFT模型 和 Preferred-FT(仅在偏好响应上微调)
Unlikelihood方法:最大化yw的概率,最小化yl的概率,使用系数α控制“反似然”项
PPO 和 PPO-GT(使用真实奖励函数)
Best of NN:从SFT模型中采样NN个响应,选择奖励函数评分最高的响应
6.1 DPO如何优化RLHF目标?¶
典型的RLHF算法使用KL约束的奖励最大化目标,平衡奖励利用与策略偏离参考策略的程度。因此,比较算法时需同时考虑奖励和KL散度。图2展示了不同算法在情感生成任务中的奖励-KL前沿。我们对每个算法执行多个训练运行,使用不同的保守性超参数(如PPO的目标KL ∈ {3,6,9,12},DPO的β ∈ {0.05,0.1,1,5},Unlikelihood的α ∈ {0.05,0.1,0.5,1}等),共22次运行。每100步评估一次,计算平均奖励和序列级KL散度。
结果表明,DPO在奖励-KL前沿上表现最优,奖励最高且KL最低。这说明:
DPO和PPO优化相同目标,但DPO更高效,其奖励/KL权衡优于PPO
即使PPO可以访问真实奖励函数(PPO-GT),DPO仍表现更好
6.2 DPO能否扩展到真实偏好数据集?¶
我们在摘要和单轮对话任务上评估DPO的微调性能。
摘要任务:使用GPT-J SFT模型,DPO在温度0时胜率约61%,优于PPO在最佳温度下的57%。DPO也优于Best of NN基线,且对采样温度更鲁棒。未调优DPO的β参数,结果可能低估其潜力。在人类评估中,DPO在温度0.25下胜率58%超过PPO在温度0下的表现。
对话任务:使用Pythia-2.8B模型,DPO在最佳温度下表现与Best of 128基线相当或更优。我们还尝试使用PPO训练的RLHF模型,但未找到优于基础模型的配置。DPO是唯一在Anthropic HH数据集中优于偏好响应的计算高效方法。
图3显示DPO收敛速度较快。
6.3 在新输入分布上的泛化能力¶
我们在Reddit TL;DR摘要实验中,将PPO和DPO策略应用于CNN/DailyMail新闻文章测试集,使用TL;DR任务中最佳采样温度(0和0.25)。表1显示,DPO在新分布上仍显著优于PPO,表明其泛化能力较强,尽管DPO未使用PPO使用的未标注Reddit数据。
6.4 验证GPT-4判断与人类判断的一致性¶
我们进行人类研究,验证GPT-4在TL;DR摘要任务中的判断可靠性。使用两种GPT-4提示:
GPT-4 (S):询问哪个摘要更好地总结了帖子的重要信息
GPT-4 (C):额外要求更简洁的摘要
结果显示,GPT-4与人类判断的一致性与人类之间的一致性相当,甚至更高。GPT-4 (C)提示的胜率更接近人类判断,因此我们在主结果中使用该提示。
7 Discussion¶
本节主要讨论了DPO(Direct Preference Optimization,直接偏好优化)方法的意义、优势及其与现有方法(如RLHF和PPO)的比较,并指出了其局限性和未来研究方向。
核心内容讲解:¶
DPO的优势与意义:
DPO是一种无需强化学习(RL)即可从人类偏好中训练语言模型的新方法。它通过建立语言模型策略与奖励函数之间的映射关系,使得可以直接使用交叉熵损失函数来优化模型,从而满足人类偏好。相比传统的RLHF方法(如基于PPO的训练),DPO结构简单、几乎不需要调参,且在性能上表现相当甚至更优。这大大降低了从人类偏好数据中训练语言模型的技术门槛。
重点内容精简讲解:¶
局限性与未来工作:
分布外泛化能力:目前还不清楚DPO模型在面对分布外数据时的表现是否与通过显式奖励函数训练的模型相当,需要进一步研究。
自标注能力:是否可以利用DPO模型自身对未标注提示进行标注,从而提升训练效率,是一个值得探索的方向。
奖励过拟合问题:在某些实验中(如图3右侧)观察到性能略有下降,可能与偏好优化过程中的过拟合有关,需进一步分析。
模型规模扩展:目前实验仅在最大6B参数的模型上进行,未来可探索DPO在更大规模模型中的表现。
评估方法改进:GPT-4生成的胜率受提示影响较大,未来可研究如何更有效地从自动化系统中获取高质量判断。
跨模态应用潜力:DPO不仅适用于语言模型,也可能用于其他模态的生成模型训练,具有广泛的应用前景。
总结:¶
本节强调了DPO作为一种新方法在训练对齐语言模型方面的潜力,同时提出了多个值得深入研究的方向,包括泛化能力、优化稳定性、模型扩展性以及评估方法的改进等。
Appendix A Mathematical Derivations¶
A.1 KL约束下奖励最大化目标的最优解推导¶
本节推导了论文中公式(4)的来源。目标是在给定奖励函数 \( r(x, y) \)、参考模型 \( \pi_{\text{ref}} \) 和非参数策略类的情况下,最大化以下目标:
通过一系列数学变换,将目标函数转化为最小化 KL 散度的形式,并引入归一化因子 \( Z(x) \):
定义最优策略 \( \pi^*(y|x) \) 为:
最终目标函数可表示为:
由于 \( Z(x) \) 与策略 \( \pi \) 无关,最小化该目标等价于最小化 KL 散度项。根据 Gibbs 不等式,当 \( \pi(y|x) = \pi^*(y|x) \) 时,KL 散度为 0,达到最小值。因此,最优解为:
重点总结:推导了在 KL 约束下,最优策略的形式,表明最优策略是参考策略与奖励函数的指数加权组合。
A.2 基于 Bradley-Terry 模型的 DPO 目标推导¶
Bradley-Terry 模型用于建模用户偏好,其形式为:
结合前文推导的最优策略与奖励函数的关系:
将其代入 Bradley-Terry 模型中,得到:
这正是论文中公式(7)所表示的 DPO 损失函数。
重点总结:展示了如何从 Bradley-Terry 模型推导出 DPO 的目标函数,强调了奖励函数与策略之间的关系。
A.3 基于 Plackett-Luce 模型的 DPO 目标推导¶
Plackett-Luce 模型是 Bradley-Terry 模型的扩展,用于处理多个选项的排序问题。其形式为:
当 \( K=2 \) 时,该模型退化为 Bradley-Terry 模型。将奖励函数用最优策略表示后,归一化常数 \( Z(x) \) 被抵消,最终得到:
若给定数据集 \( \mathcal{D} \),可使用最大似然估计优化该目标函数,得到 DPO 的扩展形式:
重点总结:展示了 DPO 在 Plackett-Luce 模型下的推广形式,强调了其与 Bradley-Terry 模型的统一性。
A.4 DPO 目标梯度推导¶
本节推导了 DPO 目标的梯度形式:
其中 \( u = \beta \log \frac{\pi_\theta(y_l|x)}{\pi_{\text{ref}}(y_l|x)} - \beta \log \frac{\pi_\theta(y_w|x)}{\pi_{\text{ref}}(y_w|x)} \)
利用 sigmoid 函数的性质 \( \sigma'(x) = \sigma(x)(1 - \sigma(x)) \),最终梯度形式为:
重点总结:推导了 DPO 损失函数的梯度形式,为后续优化提供了理论依据。
A.5 引理 1 与引理 2 的证明¶
引理 1(重述):¶
在 Plackett-Luce(包括 Bradley-Terry)模型下,属于同一等价类的奖励函数会诱导出相同的偏好分布。
证明思路:设两个奖励函数相差一个仅与 \( x \) 有关的函数 \( f(x) \),代入 Plackett-Luce 模型后,该函数被抵消,因此偏好分布不变。
引理 2(重述):¶
在 KL 约束的强化学习问题中,属于同一等价类的奖励函数会诱导出相同的最优策略。
证明思路:将奖励函数加上 \( f(x) \),代入最优策略公式后,该函数被抵消,因此最优策略不变。
重点总结:两个引理表明,奖励函数的等价类在偏好建模和策略优化中具有不变性。
A.6 定理 1 的证明¶
定理 1(重述):¶
若参考模型 \( \pi_{\text{ref}}(y|x) > 0 \),且 \( \beta > 0 \),则所有奖励函数等价类都可以表示为:
证明思路:从任意奖励函数出发,通过 KL 约束的最优策略公式,将其转换为上述形式,并引入操作符 \( f(r, \pi_{\text{ref}}, \beta) \),证明其映射到等价类中的唯一形式。
进一步结论:每个等价类中存在唯一的奖励函数可以表示为上述形式。
重点总结:定理 1 表明语言模型本质上可以被视为一个奖励模型,且奖励函数可以通过策略与参考模型的比值来表示。
总结¶
本附录从数学角度系统推导了 DPO 的理论基础,包括:
KL 约束下的最优策略形式
Bradley-Terry 和 Plackett-Luce 模型下的 DPO 目标函数
DPO 损失的梯度形式
奖励函数等价类的不变性
奖励函数与策略之间的映射关系
这些推导为 DPO 方法提供了坚实的理论支撑,表明语言模型可以隐式地建模为奖励模型。
Appendix B DPO Implementation Details and Hyperparameters¶
本节主要介绍了 DPO(Direct Preference Optimization)的实现细节和常用超参数设置。
DPO 损失函数实现¶
DPO 的实现相对简单,作者提供了基于 PyTorch 的损失函数代码。该函数计算两个模型(策略模型和参考模型)在偏好数据对上的对数概率差异,并通过 sigmoid 函数和 β 参数控制 KL 散度惩罚的强度。重点在于:
输入包括策略模型和参考模型的对数概率(log probabilities);
输入还包括偏好对的索引(yw_idxs 表示更优的样本,yl_idxs 表示较差的样本);
核心是计算策略模型与参考模型在偏好对之间的对数概率比值差异;
最终损失通过负的 log-sigmoid 函数计算;
同时返回奖励值(reward),用于后续评估或分析。
超参数设置¶
默认情况下,使用以下超参数:
β(beta)= 0.1:控制 KL 散度惩罚的强度;
批量大小(batch size)= 64;
优化器为 RMSprop,学习率为 1e-6;
学习率从 0 线性预热(warmup)到 1e-6,持续 150 步。
特殊情况:在 TL;DR 摘要任务中,β 被调整为 0.5,其余参数保持不变。
总结:本节重点在于 DPO 损失函数的实现逻辑和关键参数设置,其中 β 的取值根据不同任务有所调整,而其他训练参数保持统一。
Appendix C Further Details on the Experimental Set-Up¶
C.1 IMDb 情感实验与基线细节¶
重点内容:
使用IMDB数据集中长度为2-8个token的前缀作为提示(prompt)。
使用预训练的情感分类器
siebert/sentiment-roberta-large-english作为真实奖励模型,gpt2-large作为基础模型。选择这些较大模型是因为默认模型生成的文本和奖励质量较低。首先对IMDB数据的一个子集进行监督微调(1个epoch)。
然后使用该模型为25000个前缀各生成4个补全文本,并利用真实奖励模型为每个前缀生成6个偏好对(preference pairs)。
RLHF奖励模型从
gpt2-large初始化,并在偏好数据集上训练3个epoch,选择验证集准确率最高的检查点。“TRL”运行使用TRL库中的超参数,但作者的实现使用了更大的批次大小(每个PPO步骤1024个样本)。
总结: 这一部分详细描述了IMDB情感实验的训练流程、模型选择和训练策略,强调了使用更大模型以提升生成质量和奖励准确性。
C.2 用于计算摘要与对话胜率的 GPT-4 提示¶
重点内容:
实验中使用 GPT-4(版本
gpt-4-0314)来评估摘要和对话的胜率(win rate),即比较两个生成结果并选择更优者。每次评估时,摘要或回复的顺序是随机的,以避免顺序偏差。
摘要胜率提示(S):
询问GPT-4哪个摘要更好地概括了论坛帖子的要点。
要求先给出一句话的比较和选择理由,然后单独一行输出“A”或“B”。
摘要胜率提示(C):
与S类似,但额外强调摘要应避免无关细节,做到精确且简洁。
对话胜率提示:
询问哪个回复对用户问题更有帮助。
同样要求先比较并解释,再给出选择。
总结: 本部分展示了GPT-4用于评估生成质量的具体提示模板,强调了评估的结构化和客观性。
C.3 不可能性基线(Unlikelihood Baseline)¶
重点内容:
在情感实验中使用了“不可能性”基线方法,即最大化偏好回复的概率,同时最小化不偏好回复的概率。
但在摘要和对话实验中未采用该方法,因为其生成的回复通常无意义,作者认为这是由于对似然的无约束最小化导致的。
非重点内容(简要说明):
表3展示了在TL;DR摘要任务中使用该方法在温度为1.0时的生成结果,显示其无法生成有意义的回复。
总结: 本部分说明了“不可能性”方法在复杂任务(如摘要和对话)中的局限性,并通过示例说明其生成效果不佳。
Appendix D Additional Empirical Results¶
以下是《Appendix D Additional Empirical Results》的结构化中文总结,按照原文结构进行整理,重点内容详细讲解,非重点内容精简讲解:
D.1 Best of NN 基线在不同 NN 下的性能¶
重点内容:
Best of NN 基线表现强劲:该方法虽然计算成本高(需要多次采样),但在实验中表现优异,是一个强有力的基线。
实验设置与结果:作者在 Anthropic-HH 对话任务和 TL;DR 摘要任务中评估了不同采样次数(N=1, 4, 16, 64, 128)下的 Best of NN 性能。
关键发现:当采样次数达到 64-128 时,性能趋于稳定,不再显著提升。
D.2 样本响应与 GPT-4 判断¶
重点内容:
目的:展示 DPO 与基线模型(如 PPO 或真实标签)在摘要和对话任务中的生成效果,并通过 GPT-4 进行判断。
摘要任务(TL;DR)示例(见 Tables 4-6):
DPO 在多个示例中生成更简洁、准确、聚焦核心内容的摘要。
相比之下,PPO 的输出有时重复、冗长或偏离重点。
对话任务(Anthropic-HH)示例(见 Tables 7-10):
DPO 在某些任务中表现优于真实标签(Ground Truth),如在隐私保护和信息提供方面。
但在某些事实性问题上(如二战美国参战原因、7+2 等),DPO 的回答存在错误,GPT-4 更倾向于选择真实标签。
总结:DPO 在多数任务中生成质量较高,但在事实准确性方面仍有改进空间。
D.3 人类评估细节¶
重点内容:
目的:验证使用 GPT-4 评估模型胜率的有效性,通过人类评估进行对比。
实验设计:
选取 DPO、SFT、PPO(不同温度)与参考模型 PPO(温度 0)进行对比。
共收集 25 名斯坦福大学志愿者对 25 组摘要进行评估,每组评估包含两个模型输出。
总共收集了约 500 条评估数据。
结果:
忽略“平局”后,计算人类之间和人类与 GPT-4 之间的胜率一致性。
结果显示 GPT-4 的判断与人类评估具有较高一致性,验证了其作为替代评估工具的可行性。
非重点内容:
志愿者名单和调查界面截图(Figure 5)仅作为补充信息,未对核心结论产生影响。
总结¶
本附录通过多个实证实验验证了 DPO 模型在生成质量和偏好对齐方面的优势,同时也揭示了其在事实准确性方面的局限。GPT-4 的评估结果与人类评估高度一致,为后续研究提供了有效的自动化评估手段。