2406.12045_τ-bench: A Benchmark for Tool-Agent-User¶
引用: 69(2025-07-20)
组织: Sierra
总结¶
方法
τ-bench
模拟真实用户(通过大模型)和程序API交互
要求代理遵循具体领域的政策规则(如航班政策)
使用真实数据库、API、规则文件和用户请求模拟场景
新指标 pass^k,用于衡量智能体在多次尝试中表现是否稳定可靠
数据集
τ-retail
τ-airline
Abstract¶
目前的评测方法并没有考察语言智能体与人互动的能力,或者它们是否能遵守特定领域的规则,而这两点对于实际应用很重要。
为了解决这个问题,作者提出了一个新的评测方法 τ-bench,它模拟用户(由语言模型扮演)与语言智能体之间的动态对话,智能体有特定的 API 工具和规则可以用。
评估方式是看对话结束后数据库的状态,是否达到了预设的目标状态。他们还设计了一个新指标 pass^k,用于衡量智能体在多次尝试中表现是否稳定可靠。
实验发现,即使是像 GPT-4o 这样的最先进模型,成功率也不到 50%,在某些领域(如零售),稳定性更差(pass^8 低于 25%)。
因此,作者认为现在的智能体在“稳定执行”和“严格遵守规则”方面还有很大改进空间。
1.Introduction¶
🌟 语言代理(Language Agents)的潜力与挑战¶
背景: 语言代理被认为可以大幅提升各行各业的自动化水平,但要真正投入实际应用,需要满足几个关键条件,比如能长时间与人类和程序接口交互、遵守复杂规则、保持一致性和可靠性。
问题: 现有评测方法太简单,不能真实反映语言代理在现实环境中面对复杂对话、政策规则、API调用等情况的表现。
🧪 新提出的 τ-bench 评测框架¶
τ-bench 介绍: 这是一个用于评估语言代理真实交互能力的基准测试,特点包括:
模拟真实用户(通过大模型)和程序API交互;
要求代理遵循具体领域的政策规则(如航班政策);
使用真实数据库、API、规则文件和用户请求模拟场景。
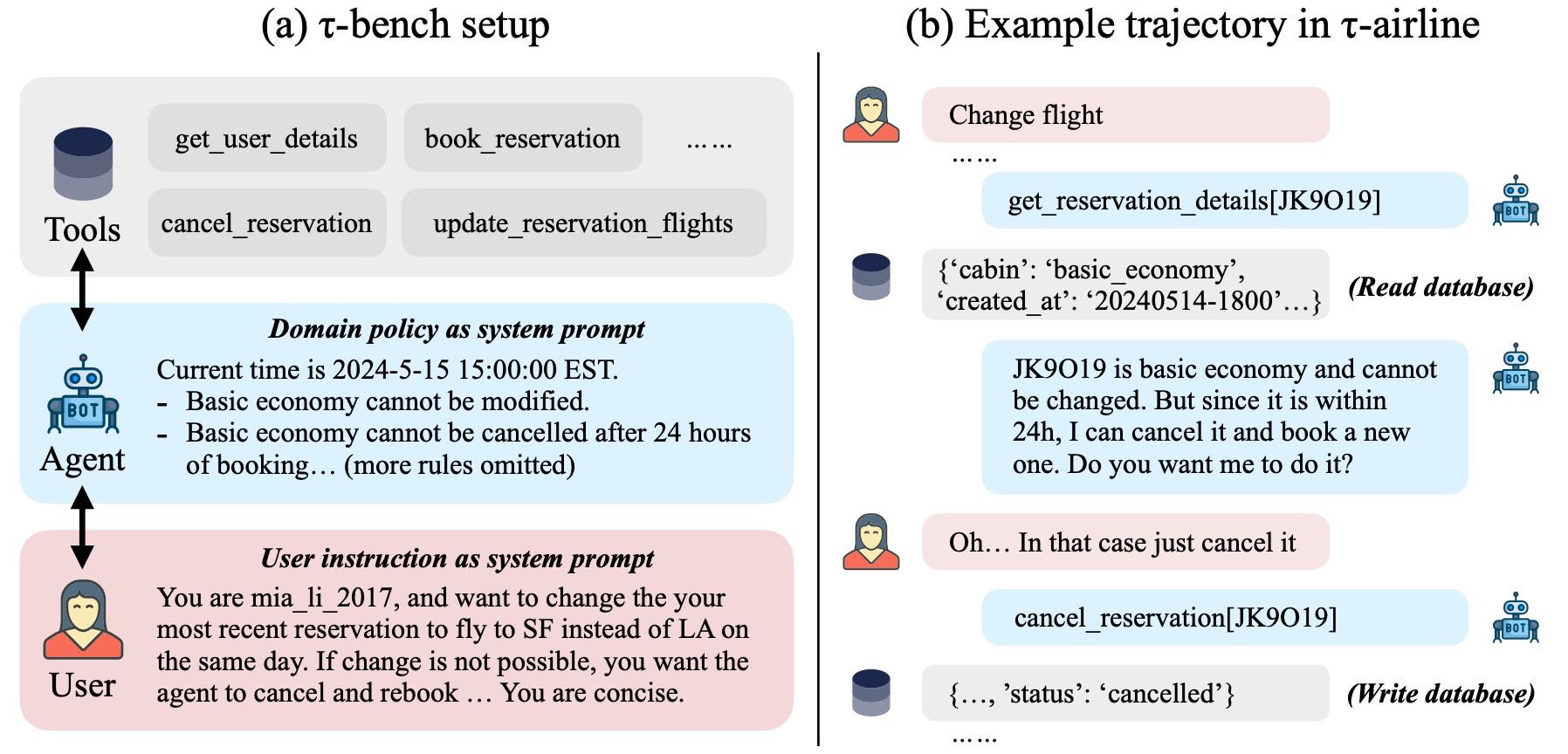
Figure 1: (a) In τ-bench, an agent interacts with database API tools and an LM-simulated user to complete tasks. The benchmark tests an agent’s ability to collate and convey all required information from/to users through multiple interactions, and solve complex issues on the fly while ensuring it follows guidelines laid out in a domain-specific policy document. (b) An example trajectory in τ-airline, where an agent needs to reject the user request (change a basic economy flight) following domain policies and propose a new solution (cancel and rebook). This challenges the agent in long-context zero-shot reasoning over complex databases, rules, and user intents.
举例: 用户想改签航班,但由于订的是“基本经济舱”,不能更改。但代理能识别出该票是在24小时内购买的,可以先取消再重新预订。这测试了代理对规则的理解和灵活处理能力。
📊 实验发现¶
目前的代理(包括使用 GPT-4o 的)在复杂任务中的成功率很低;
例如,在 τ-airline 中,仅有 35% 成功率;
多轮交互中成功率会进一步下降(例如 8 次尝试中成功一次的概率仅 ~25%);
失败原因:
无法处理复杂数据库查询、
难以理解和遵守领域规则、
无法应对多个复合请求。
🎯 目标与贡献¶
τ-bench 为构建更强大、更稳定、能适应真实环境的人机交互代理提供了评估和改进的基准平台。
3.τ-bench: A benchmark for T ool-A gent-U ser Interaction¶
🔁 任务建模¶
每个任务被建模为一个部分可观测马尔可夫决策过程(POMDP),由状态S、动作A、观测O、转移T、奖励R、用户指令U组成。
智能体需要和两个对象交互完成任务:
数据库(db):通过API工具访问。
模拟用户(user):使用自然语言交互。
🔧 数据库和API工具¶
数据库存的是状态,智能体无法直接看到,只能通过API(如 Python 函数)来读写。
每个API调用是确定性的(输入确定输出)。
📜 领域规则(Policy)¶
每个任务域有一份规则文档,告诉智能体有哪些限制和操作流程。
有些限制在API中自动检查(如找不到付款ID时返回错误),有些需要智能体自己理解处理(如行李规定等)。
👤 模拟用户¶
使用语言模型(GPT-4)模拟人类用户。
用户只看到与智能体的对话,不知道API调用的内容。
用户行为是随机生成的(基于上下文),直到用户发出”###STOP###”结束对话。
🧩 任务实例¶
每个任务都有:
一个用户模拟指令(设定用户身份、意图、偏好)。
一个正确的数据库操作答案(作为评估依据)。
智能体必须完成这些操作,并向用户提供正确信息。
🏆 奖励计算¶
总分
r = r_action × r_output ∈ {0,1},包括两个部分:数据库操作是否正确(
r_action)对用户的回复是否包含必要信息(
r_output)
📈 评价指标(pass^k)¶
类似代码任务的 pass@k(至少成功1次),pass^k 更严格:要求 k次都成功。
衡量的是智能体在同一任务、不同对话变化下的稳定性与可靠性。
参数
n是某个任务被运行的总次数(即智能体尝试的次数)。c是这n次尝试中成功的次数(reward = 1)。k是我们关注的子集大小,比如“要求连续成功 3 次”就是k=3。E_task[·]是对所有任务求平均。分子 \(\binom{c}{k}\) 是:在
c个成功中,选k个成功组合的数量。分母 \(\binom{n}{k}\) 是:在
n个总尝试中,任意选k个组合的数量。\(\binom{n-c}{k}\):从失败的尝试中选出 k 个组合数(即“全失败”的组合)。
\(\binom{n}{k}\):总的所有组合数。
说明
pass^k 的定义
所以这个比值就是k次全成功的概率。
再对所有任务取平均,就是最终的 pass^k 值。
pass@k 的定义
所以 \(\frac{\binom{n-c}{k}}{\binom{n}{k}}\) 是k次都失败的概率。
所以
1 - 这个值就是至少有一次成功的概率,即 pass@k。
📊 示例:两个任务领域¶
任务域 |
用户数 |
数据条目 |
API工具数 |
任务数 |
|---|---|---|---|---|
零售(τ-retail) |
500用户 |
1000订单 |
写操作7个,读操作8个 |
115 |
航空(τ-airline) |
500用户 |
2000预订 |
写操作6个,读操作7个 |
50 |
4. Benchmark Construction¶
基准构建流程(三个阶段)¶
第一阶段:手动设计
设计数据库结构、API 和规则,尽量保持简单,便于标注和逻辑一致。
每个领域需要几十个 schema、API 和规则,足够挑战现有智能体。
第二阶段:用大模型生成数据
在已有 schema 基础上,用 GPT-4 自动生成批量数据(如产品或航班条目)
再手动修复小问题。
第三阶段:手动标注任务并用智能体验证
编写任务指令,运行 GPT-4 Turbo 代理测试其是否总能得到唯一正确的数据库结果。
反复迭代修改指令,直到无歧义,并对任务进行标注。
4.1 Domains¶
τ-retail(零售)
智能体需要处理订单取消、退换货、地址变更等。
规则明确:一个订单只能取消一次,退换货也只能操作一次。
τ-airline(航空)
涉及航班预订、改签、退款等。
有更复杂的规则,如行李限额、支付方式组合、会员等级影响等。
4.2 Key Characteristics¶
真实感强:用户模拟自然、任务开放、数据复杂,利用大模型生成真实语句。
任务多样:虽然比真实世界简化,但仍支持高度开放和富有挑战的任务。
评估标准客观:通过数据库结果比对,代替主观人工判断,确保评估准确可复现。
模块化易扩展:支持轻松添加新领域、新规则、新任务,鼓励社区共同参与扩展。
5.Experiments¶
📌 实验内容概述¶
模型
OpenAI: gpt-4o, gpt-4-turbo, gpt-3.5 等
Anthropic: claude-3-opus 等
Google: gemini-1.5
Mistral 和 Meta (LLaMA-3)
只有 Mistral 和 Meta 模型开源。小模型(7B/13B)没测试,因为基准任务难度太高。
🧠 方法对比¶
主要方法:Function Calling(FC),大部分模型原生支持,除了 LLaMA-3。
对比方法:ReAct(思考 + 行动)和 Act-only(只行动)。
不适合使用的方法:如自反思和复杂计划,因为不适合实时用户交互。
📊 主要结果¶
模型表现(pass^1 得分,越高越好):
最好:gpt-4o
闭源比开源模型表现明显更好(如 llama3、mistral 仍有差距)
最难任务:航空类任务(gpt-4o 也只能完成 35.2%)
方法对比:
Function Calling(FC)> ReAct > Act-only
ReAct 添加“思考”内容能提高效果
可靠性问题(pass^k 趋势):
模型表现不稳定:即便 gpt-4o 平均能解决 60%,多试几次后(如 pass^8)成功率大降至 <25%。
成本:
每个任务成本:约 $0.38(agent)+ $0.23(user)
主要花费来自长系统提示词(如 policy、函数定义)
🧩 失败原因分析(gpt-4o)¶
在零售任务中,有约 36 个失败案例,主要分 3 类:
提供了错误的信息或参数(55%)
例:给了用户不需要的商品,或价格计算错误。
说明模型在理解数据库、用户意图上还需提升。
做了错误决策(违反规则)(25%)
例:应一次性处理多个退货项,但模型只处理了一个。
部分解决请求(19%)
例:用户要求修改所有订单地址,但模型只改了一个。
🧪 规则作用的对比实验¶
移除规则文档后:
零售场景:影响不大(靠常识也能完成)
航空场景:影响很大(需要理解复杂规则)
🔍 结论¶
闭源模型整体表现更好,但仍有改进空间
τ-bench 是一个很好的测试平台,因为任务难、差异大
未来改进方向:
增强推理能力
支持长对话记忆
针对特定领域微调或提供程序模板(agent scaffolding)
6.Disscussion¶
好的,这段内容主要讲的是一个名为 τ-bench 的新评测基准,用来测试智能体(agent)在现实动态环境中与人类和工具互动时的可靠性。下面是简洁的总结:
τ-bench 的作用:¶
用语言模型模拟用户,实现自动化测试;
测试智能体是否能持续地遵守特定领域的规则;
实验结果显示:即使是最先进的模型(SOTA)在真实场景中也不够可靠。
存在的改进空间:¶
模拟用户的不足:
指令可能有错别字或含糊;
用户通常不了解复杂规则,像现实生活中真实的用户;
模拟用户的语言模型可能在推理、计算、记忆上能力不足。
改进建议:
增加模拟器的系统性检查,确保结果唯一;
让领域规则更复杂,更贴近现实;
引入更多评估指标,比如是否遵守规则;
数据标注很难,需要深入理解任务和智能体;
当前的任务设计可能有偏见,未来可以探索更客观的方式。
智能体面临的挑战:¶
当前基于语言模型的 function calling 智能体不够稳定,经常无法遵守规则;
改进这些问题能极大促进现实任务的自动化;
还需要提升:长时间信息追踪能力、记忆能力、从上下文中提取关键信息的能力,尤其是在信息冲突的情况下。