2510.27246_BEAM: Beyond a Million Tokens: Benchmarking and Enhancing Long-Term Memory in LLMs¶
引用: 0
组织:
1University of Alberta
2University of Massachusetts Amherst
总结¶
From Moonlight¶
关键词¶
BEAM: 是一个新提出的基准(benchmark),包含 100 个对话,每个对话的长度从 100K 到 10M 个 token 不等,并附带 2000 个经过验证的问题,用于评估大型语言模型(LLM)在长期记忆方面的能力。该基准旨在解决现有评估工具在叙事连贯性、领域多样性和测试任务类型方面的局限性。
LIGHT: 是一个受人类认知科学启发的框架,旨在增强大型语言模型(LLM)在处理长对话时的记忆能力。它通过集成三种互补的记忆系统来实现:长期情景记忆(episodic memory)、短期工作记忆(working memory)和用于积累关键事实的记忆板(scratchpad)。
Memory abilities: 是指大型语言模型(LLM)在处理和记忆信息时所展现出的多种能力。该论文提出的 BEAM 基准评估了十种特定的记忆能力,包括:Abstention(在信息缺失时弃权)、Contradiction Resolution(解决矛盾)、Event Ordering(事件排序)、Information Extraction(信息提取)、Instruction Following(指令遵循)、Information Update(信息更新)、Multi-hop Reasoning(多跳推理)、Preference Following(偏好遵循)、Summarization(总结)和 Temporal Reasoning(时间推理)。
Episodic memory: 是 LIGHT 框架中的一个组成部分,它是一个用于长期检索的完整对话索引。它模拟了人类回忆特定经历及其上下文的能力,通过将对话内容提取为关键-值对并存储在向量数据库中,以便在需要时进行检索。
Working memory: 是 LIGHT 框架中的另一个组成部分,它捕捉了对话中最近期用户-助手轮次的信息。它负责保留和处理最近发生的交流内容,以供 LLM 在生成响应时参考。
Scratchpad: 是 LIGHT 框架中的第三个记忆系统,它充当一个外部记录,用于在每次对话轮次后,模型对其进行推理并记录下重要的事实。这些记录有助于长期的回忆和未来的检索,类似于人类的笔记习惯。
Narrative coherence: 指的是对话或文本内容在故事线、主题和逻辑上保持一致性、流畅性和连贯性的程度。在评估 LLM 的长对话能力时,具有高叙事连贯性的数据集能够更真实地反映模型在真实世界交流中的表现,而不是人工拼接的、缺乏逻辑联系的文本片段。
Nugget evaluation: 是一种用于评估长文本生成结果的常用方法,在本文中用于评估 LLM 对探测性问题的回答质量。在这种方法中,理想的参考答案被分解成原子化的、自包含的标准(称为“nuggets”)。然后,LLM 的生成响应会根据这些 nuggets 进行评分(0、0.5 或 1 分),最终得分是对所有 nuggets 的平均值,以量化模型响应的准确性。
三行摘要¶
💡 本文针对LLM长期记忆现有基准测试的局限性,提出了一种生成长达10M tokens的连贯、主题多样的对话的框架,并构建了BEAM基准来评估LLM的记忆能力。
🧠 受人类认知启发,该研究引入了LIGHT框架,通过结合episodic memory、working memory和scratchpad三种互补的记忆系统,以提升LLM在长对话中的表现。
📈 在BEAM基准上的实验表明,即使是长上下文LLM也面临挑战,而LIGHT显著提升了模型性能,平均提高了3.5%–12.69%,尤其在需要长期回忆和信息整合的任务上表现突出。
摘要¶
本文介绍了一种全面的解决方案,用于评估和增强大型语言模型(LLMs)处理长对话情境下的长期记忆能力,尤其针对需要长期推理的任务。
1. BEAM基准测试:构建与评估
1.1 现有基准的局限性 目前的LLM记忆基准存在以下问题:
缺乏叙事连贯性: 通常通过简单拼接短对话段来延长上下文,导致主题突变。
领域狭窄: 大多集中于个人生活场景,真实世界应用覆盖不足。
测试能力有限: 主要侧重于简单信息回忆,忽略了矛盾解决、信息演变识别和指令遵循等关键记忆能力。
1.2 BEAM构建框架 本文提出了一个自动生成框架,用于创建长达1000万(10M)token、连贯且主题多样化的对话,并配有探测问题。框架流程如图1所示:
对话计划生成(Conversation Plan Generation):
高层计划: 基于种子信息(领域、标题、主题、子主题、叙事集、用户档案、关系图、时间线)由LLM生成。叙事集定义对话中不断演变的主题。
递归分解: 计划分解为子计划(sub-plans),每个子计划包含M个项目点(bullet points),描述故事线发展和时间锚点。
长对话处理: 对于128K、500K、1M token对话,生成单个计划。对于10M token对话,生成十个相互关联的计划,通过“序列扩展”(Sequential Expansion)或“分层分解”(Hierarchical Decomposition)策略确保连贯性。生成新计划时,LLM会基于之前计划的摘要和未来种子的信息进行条件化,以保持上下文一致性。
能力增强: 初始计划生成后,使用GPT-4.1-mini对子计划进行二次增强,增加专门用于评估矛盾解决、信息更新和指令遵循的附加项目点。
用户话语生成(User Utterance Generation):
每个子计划的M个项目点被分成K个批次。
对于每个批次,LLaMA-3.3 70B模型根据对话种子、当前批次、先前批次和早期子计划的上下文生成I个用户问题。
根据领域(如编程、数学)引入特定的问题类型(如代码片段、数学问题)。
助手话语生成(Assistant Utterance Generation):
采用角色扮演模式迭代生成。助手LLM根据对话种子、先前子计划、最近M个对话轮次摘要及早期轮次压缩摘要生成响应。
问题检测模块: 检测助手响应是否包含反问(利用提示词Listing 35),若有则用户LLM生成回复,形成问答循环,直至无反问或达到\(\delta_1=2\)的阈值。
跟进检测模块: 判断用户是否需要提出澄清或详细说明的跟进问题(利用提示词Listing 36),若需要则用户LLM生成跟进问题,助手LLM回复,直至无跟进或达到\(\delta_2=2\)的阈值。
探测问题生成(Probing Questions Generation):
对话生成后,GPT-4.1-mini根据对话计划和聊天内容,针对特定记忆能力选择候选项目点。
基于选定的项目点和对话片段,生成探测问题、候选答案和来源标识符。
人工验证并筛选问题,确保质量和一致性。
评估方法(Evaluation):
采用“Nugget评估”(nugget evaluation)方法,将理想参考答案分解为原子化的“Nuggets”。
LLM评估器(如Listing 20所示的Judge LLM)对模型响应中的每个Nugget进行评分(0, 0.5, 1),计算平均得分。
事件排序(Event Ordering)能力使用Kendall tau-b系数进行评估,结合召回率和排序准确性。
1.3 BEAM基准测试集
规模: 包含100个对话,长度从100K到10M token不等,伴随2000个经过验证的探测问题。
记忆能力: 评估10种记忆能力:
现有7种:信息提取(Information Extraction)、多跳推理(Multi-hop Reasoning)、知识更新(Knowledge Update)、偏好遵循(Preference Following)、摘要(Summarization)、时间推理(Temporal Reasoning)、弃权(Abstention)。
新增3种:指令遵循(Instruction Following)、事件排序(Event Ordering)、矛盾解决(Contradiction Resolution)。
领域多样性: 覆盖编码、数学、健康、金融、个人生活等19个不同领域。
2. LIGHT框架:LLM记忆能力增强
2.1 设计理念 LIGHT框架灵感来源于人类认知科学中的记忆系统,旨在模拟人类的记忆和回忆过程。它整合了三种互补的记忆系统:
情景记忆(Episodic Memory): 长期记忆,存储完整的对话索引,用于检索。
工作记忆(Working Memory): 短期记忆,捕获最近的对话轮次。
草稿本(Scratchpad): 外部记录,用于积累显著事实,支持长期回忆。
2.2 核心方法学 框架总览如图2所示。给定一个关于对话\(T = \{t_i\}_{i=1}^{|T|}\)的问题\(x\):
情景记忆检索(Retrieval from the Conversation):
索引: 在每次用户-助手对话轮次后,使用Qwen2.5-32B-AWQ模型(如Listing 40提示词所示)提取键值对和交互摘要。这些键值对和摘要通过BAAI/bge-small-en-v1.5嵌入模型进行嵌入,并存储在向量数据库中。原始对话片段作为值存储,以确保真实性。
检索: 查询问题\(x\)也被嵌入,与数据库中的键进行相似性比较,返回最相关的\(k\)个对话片段作为情景记忆\(E = R(x, k, T)\)。
工作记忆(Working Memory):
选择对话中最近的\(z\)个对话对构成工作记忆\(W = \{t_{|T|-i}\}_{i=0}^z\)。
草稿本形成与利用(Scratchpad Formation and Utilization):
构建: 对于每个对话对,使用Qwen2.5-32B-AWQ模型(如Listing 41提示词所示)从当前和先前轮次中提取显著内容,形成“草稿本”。当内容超过30K token阈值时,使用GPT-4.1-nano压缩为15K token的摘要(如Listing 42提示词所示),模拟人类语义记忆的抽象过程。草稿本不存储在检索数据库中,而是在推理时作为上下文直接提供。
过滤: 在推理时,草稿本会根据问题进行选择性过滤。它首先被分成语义连贯的块。每个块由Qwen2.5-32B-AWQ模型(如Listing 43提示词所示)评估其与问题的相关性,只有相关块才被保留,生成一个精简的草稿本表示\(S_x = f(S_{|T|}, x)\)。
答案生成:
LLM \(\pi\) 通过对问题\(x\)和这三个记忆组件(\(E\), \(W\), \(S_x\))进行条件化来生成答案\(y = \pi(x, E, W, S_x)\)(如Listing 44提示词所示)。
3. 实验结果
3.1 主要发现
基线表现: 即使是拥有长上下文窗口的LLMs(包括GPT-4.1-nano和Gemini-2.0-flash等),在对话长度增加时性能显著下降。RAG基线表现优于纯LLM基线。
LIGHT框架优势: LIGHT在所有对话长度(100K-10M token)下持续优于LLM基线和RAG基线。
在100K token时,对Llama-4-Maverick和GPT-4.1-nano分别有49.1%和44.3%的显著提升。
在1M token时,对GPT-4.1-nano和Qwen2.5-32B分别有75.9%和60.1%的提升。
在10M token(无基线原生支持全上下文)时,提升更为显著,对Llama-4-Maverick和GPT-4.1-nano分别提升155.7%和107.3%。
平均性能提升3.5%-12.69%。
记忆能力分析: LIGHT在摘要(+160.6%)、多跳推理(+27.2%)和偏好遵循(+76.5%)方面提升最大,表明其在需要长距离召回和信息整合的任务中尤其有效。所有方法在弃权(Abstention)上表现最佳,但在矛盾解决(Contradiction Resolution)上最弱,凸显该问题仍具挑战性。
3.2 消融研究
组件贡献: 随着上下文长度的增加,LIGHT的每个组件(情景记忆、草稿本、工作记忆、噪声过滤)都变得越来越重要。
在100K token时,移除检索效果略有提升(+0.28%),可能因引入噪声。移除草稿本和噪声过滤则降低性能。工作记忆在此阶段用处有限。
在500K token时,移除任何组件都会导致性能下降。
在1M token时,检索、草稿本和噪声过滤仍有益,但移除工作记忆略微改善性能。
在10M token时,所有组件都至关重要,移除任何一个都会导致大幅度性能下降(检索-8.5%,草稿本-3.7%,工作记忆-5.7%,噪声过滤-8.3%)。
完整架构: 完整LIGHT架构在所有情况下均实现最佳性能。
3.3 检索预算(K)影响
性能随着\(K\)从5增加到15而持续提升,在\(K=15\)时达到最佳,在100K、500K、1M和10M token下分别提升8.5%、7.3%、6.6%和6.1%。
进一步增加\(K\)到20会略微降低性能,可能是由于引入了噪声上下文。
3.4 人工评估 对生成对话进行人工评估,Coherence and Flow(连贯性和流畅性)、Dialogue Realism(对话真实性)和Complexity and Depth(复杂性和深度)的平均得分分别为4.53、4.57和4.64(5分制),表明高质量的对话生成。
Abstract¶
现有基准测试在评估大语言模型(LLMs)执行需要长期记忆及长上下文推理任务(如对话场景)的能力时存在阻碍,因其常缺乏叙事连贯性、覆盖领域狭窄且仅测试简单的面向回忆的任务。本文针对这些挑战提出全面解决方案。
构建新基准:首先提出一个新颖框架,可自动生成篇幅长(达1000万词元)、连贯且主题多样的对话,并配有针对多种记忆能力的探测性问题。据此构建了BEAM这一新基准,包含100个对话和2000个经过验证的问题。
提升模型性能:其次提出LIGHT框架,受人类认知启发,为大语言模型配备三个互补的记忆系统,即长期情景记忆、短期工作记忆和用于积累关键事实的便签本。在BEAM上的实验表明,即便上下文窗口达100万词元的大语言模型(有无检索增强),随着对话变长也会遇到困难。相比之下,LIGHT在各种模型上持续提升性能,相较于最强基线,依基础大语言模型不同,平均提升3.5% - 12.69%。消融研究进一步证实了每个记忆组件的作用。
1 Introduction¶
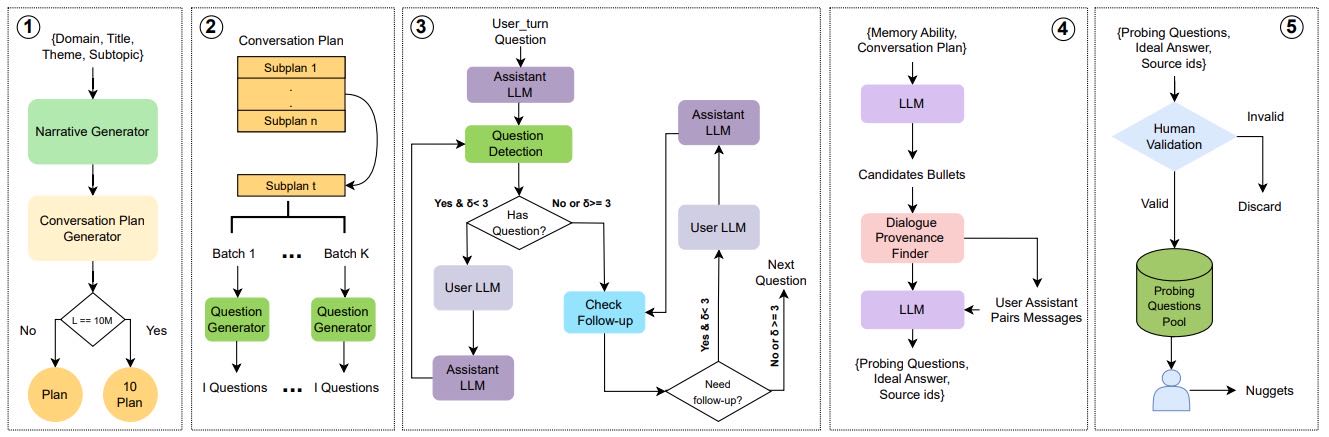
Figure 1: Overview of data generation.
大语言模型(LLMs)的应用领域:LLMs已广泛应用于多种场景,如开放域对话代理、开放域问答和事实核查的检索增强生成(RAG)、长文档与代码分析以及科学或法律研究等,许多任务要求模型能处理长输入,促使出现如Gemini这类输入窗口可达100万令牌的LLMs。在这些领域中,对话系统对扩展上下文有直观且关键的需求,因为用户常进行长时间、多会话的对话,这就需要LLMs在长交互中保持一致的记忆,因此评估LLMs对长对话历史的推理和利用能力很重要。
现有研究的局限性:虽之前有不少研究LLMs长期记忆的工作,但现有基准测试存在根本缺陷。多数通过人工拼接不同用户的短会话来延长对话长度,导致对话主题突变、叙事连贯性差,这种构建方式简化了评估,因为不同片段易分离,减少了对真正长距离推理的需求。而且这些数据集通常针对狭窄领域,多限于个人生活场景,许多现实应用领域未得到充分体现。此外,它们只强调简单的上下文回忆,忽略了如矛盾解决、识别演变信息和指令跟随等其他关键记忆能力。
本文的贡献:
提出数据生成框架:本文提出一个自动生成用户与AI助手间长连贯对话的框架,可扩展到1000万令牌,涵盖多样领域,并设计了一组探测问题,用于评估任何LLM在生成对话上的多样记忆能力。该框架先定义高级对话计划,即特定领域和模拟用户属性的叙事,勾勒对话整体流程,再递归分解为更细的子计划,明确故事情节及其进展,据此生成按时间顺序的用户轮次,并扩展相应的助手回复,为增加真实性,系统还注入双方的后续问题和澄清。最后自动创建针对十个不同记忆维度的探测问题,经人工标注验证以确保高质量,借此构建了BEAM数据集,包含100个长度从10万到1000万令牌不等的多样对话,以及2000个评估LLMs记忆能力的探测问题。
引入LIGHT框架:为提高LLMs在探测问题上的性能,受人类认知科学及人类记忆与回忆过程研究启发,引入LIGHT框架,该框架适用于开源和专有LLMs 。它整合了三种互补记忆:用于检索的完整对话长期索引即情景记忆;捕捉最新用户 - 助手轮次的工作记忆;模型在每轮对话后进行推理并记录显著事实供未来使用的便签本。推理时,LLM联合利用检索到的情景内容、工作记忆和积累的便签本生成准确答案。
实验与开源:为评估LLMs记忆能力及方法有效性,在构建的BEAM数据集上使用开源和专有模型进行实验。结果表明,即使是有长上下文窗口的LLMs,随着对话长度增加性能也大幅下降,本文方法相比最佳性能基线,平均能将LLMs回答探测问题的性能提高3.5% - 12.69%,消融研究还揭示了LIGHT框架各组件对性能的贡献。为支持未来研究,作者发布了所有代码、数据和评估脚本。
2 BEAM: Benchmarking memory Capabilities of LLMs¶
该部分围绕BEAM(Benchmarking memory Capabilities of LLMs)展开,介绍了对大语言模型(LLMs)内存能力进行基准测试的相关内容,具体如下:
问题表述:
用\(\mathcal{D}=\{T_{i}\}_{i=1}^{|\mathcal{D}|}\)表示用户与对话代理\(\pi\)间的对话集合,每个对话\(\mathcal{T}=\{t_{i}\}_{i=1}^{|\mathcal{T}|}\),\(t_{i}\)为对话中的第\(i\)个话轮。
目标是系统评估\(\pi\)在对话中展现的预定义内存能力集合\(\mathcal{M}\)。对每个\(m \in \mathcal{M}\),构建规模为\(N\)的探测数据集\(\mathcal{Q}_{m}=\{(x_{i},y_{i})\}_{i=1}^{N}\),将探测问题\((x,y) \in \mathcal{Q}_{m}\)作为对话的第\((|\mathcal{T}| + 1)\)个话轮,系统基于对话生成响应\(\hat{y}=\pi(x;\mathcal{T})\),并用特定能力评分函数\(\mu_{m}\)评估,得到性能分数\(s=\mu_{m}(x,y,\hat{y})\),以量化对话系统在每个内存能力上的表现。
基准创建:
目标与能力:旨在评估LLMs回答依赖长期对话记忆问题的能力,通过十个互补能力进行衡量,其中七个来自先前基准,三个新引入,包括指令跟随、事件排序和矛盾解决等。这些能力共同评估系统在长时间对话中维护、更新和处理信息的能力。基准创建需用户 - 助手对话、针对关键内存能力的探测问题以及评估模型响应的方法三个组件。
概述:创建对话、探测问题和评估策略的框架,先生成模拟对话,通过结构化对话计划引导合成交互,利用问题检测和跟进检测模块使对话更自然。对话生成后,自动构建候选探测问题集,由人类评估者筛选并制定评估规则。
对话计划生成:对话计划为对话提供连贯故事线,基于种子信息由LLM生成,种子信息包括对话领域、标题主题、子主题、叙事、用户资料、关系图和时间线等。不同长度对话生成计划方式不同,10M - 令牌对话通过顺序扩展或层次分解创建十个相互关联计划。每个对话计划有明确主题和时间边界,为保证连贯性,生成新计划时会参考先前计划和未来种子摘要。初始计划可能无法充分测试某些关键能力,因此采用两阶段增强。
用户话语生成:根据对话计划的子计划合成用户话语,将子计划的要点分批,由LLM基于对话种子、当前批次、先前批次和早期子计划上下文生成用户问题,通过手动指定参数控制用户交互密度,使用开源LLaMA - 3.3 70B模型生成问题以平衡质量和成本。
助手话语生成:在角色扮演设置中迭代生成助手响应,助手LLM基于多种信息生成对用户最新问题的响应,问题检测模块判断响应中是否有反问,若有则由用户LLM生成回复,循环直至无反问或达到阈值。跟进检测模块评估是否需要澄清或详细说明的用户跟进,若需要则生成跟进查询并传递给助手LLM,通过两个阈值限制跟进交流次数,使对话更逼真。
探测问题生成:通过自动化合成与人工验证相结合的方式生成探测问题。先由LLM根据对话计划和评估能力选择候选要点,再生成探测问题、候选答案和来源标识符,10M - 令牌对话通过滑动窗口处理。最后由人类评估者选择有效且与对话一致的候选问题。
评估:使用金块评估法评估LLMs对探测问题的回答。人工验证每个探测问题,从验证集中为每个对话的每个内存能力选择两个问题,得到20个探测问题,为每个问题导出评估金块。金块是系统响应必须满足的原子、自包含标准,由注释者将理想答案分解得到。系统响应由LLM裁判根据金块评分,分数在0(不满足)、0.5(部分满足)、1(完全满足)间,能力级指标由金块分数平均得出。事件排序能力评估使用肯德尔tau - b系数,通过LLM等价检测器对齐系统响应和金块中的事件后计算得出。
3 LIGHT: Improving Memory Capabilities of LLMs¶
受人类认知科学研究启发,人类通过情景记忆(回忆特定个人经历及其背景的能力)、工作记忆(短期保留和处理近期事件信息的能力)以及在便签上记录信息以辅助长期回忆和检索这三种机制来记忆和运用知识。由于长上下文对话中回答问题同样需要整合过往经验和积累的知识,因此作者引入一种结合情景回忆、短期工作记忆和外部便签机制的方法。
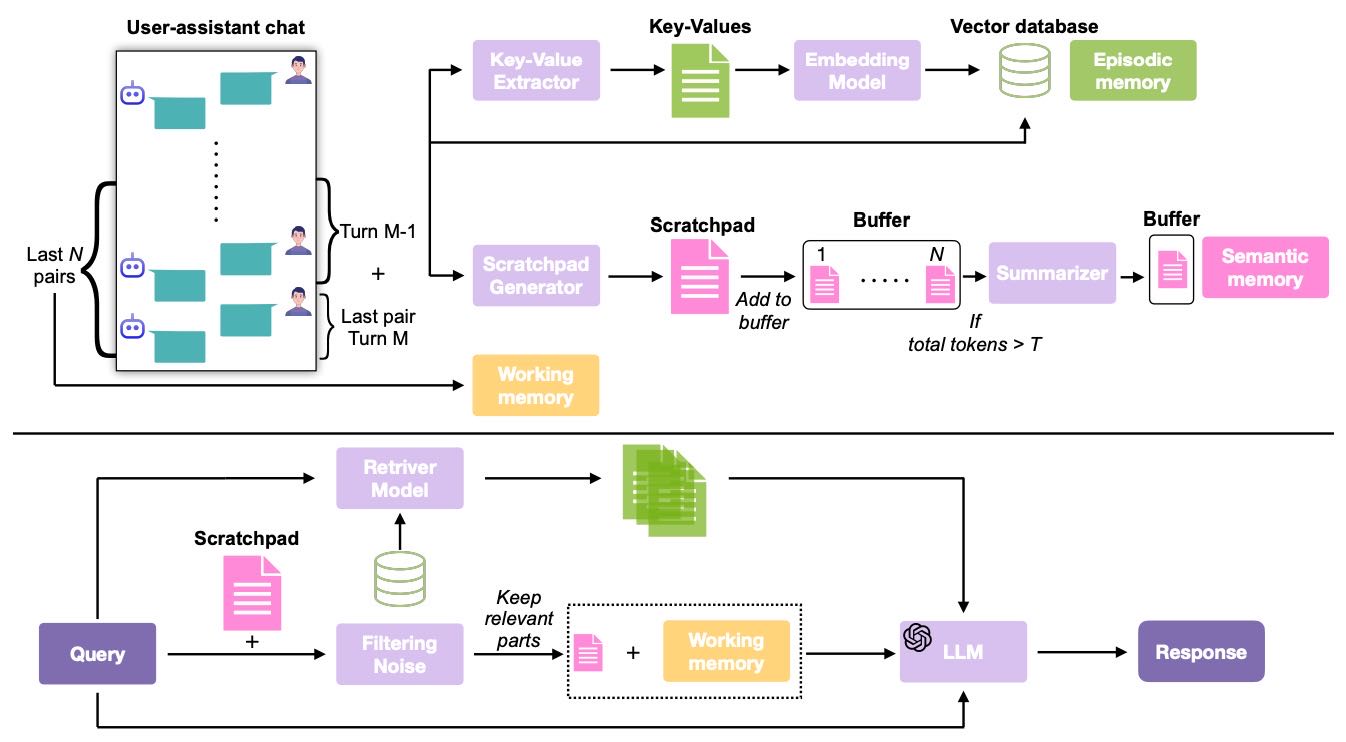
Figure 2: Overview of the LIGHT framework.
概述:¶
该方法流程如图2所示。给定关于对话\(\mathcal{T}=\{t_{i}\}_{i=1}^{|\mathcal{T}|}\)的问题\(x\)(\(|\mathcal{T}|\)为对话轮数),框架首先通过检索模型\(R\)从\(\mathcal{T}\)中获取\(k\)个相关片段,模拟情景记忆检索,即\(E = R(x,k,\mathcal{T})\);接着选取对话中最近的\(z\)个对话对形成工作记忆\(W = \{t_{|\mathcal{T}|-i}\}_{i=0}^{z}\);同时,预构建的便签\(S_{|\mathcal{T}|}\)包含最多\(m\)条重要记录,通过过滤函数\(f\)得到与问题\(x\)相关的内容\(S_{x}=f(S_{|\mathcal{T}|},x)\);最后,大语言模型\(\pi\)基于问题\(x\)以及这三个记忆组件生成答案\(y=\pi(x,E,W,S_{x})\),使用附录G中清单44的提示。本节后续将详细介绍该流程中各组件的构建和逻辑。
3.1 从对话中检索¶
对话索引:¶
在每次用户 - 助手交互轮次后(图2顶部),使用Qwen2.5 - 32B - AWQ模型和附录G清单40的提示,提取交互的键值对和摘要。键代表实体,值捕获属性或描述细节,类似海马体记忆痕迹。这些键值对和摘要通过BAAI/bge - small - en - v1.5嵌入模型嵌入后作为键存储在向量数据库中,原始对话片段作为值存储以确保忠实性。
从索引中检索:¶
为从对话中检索信息作为情景记忆,使用相同嵌入模型嵌入问题\(x\),与索引中存储的键进行比较,返回与\(k\)个最近邻对应的原始对话片段。
3.2 便签的形成与使用¶
构建:¶
除情景记忆外(图2中间路径),构建一个更高级别的表示,整合语义知识、自传细节、前瞻性记忆和上下文元数据。对于每个对话对,使用Qwen2.5 - 32B - AWQ模型和附录G清单41的提示,推理当前及前一轮对话并提取重要内容。生成的“便签”与早期版本迭代合并,一旦内容超过30K令牌阈值(远短于原始对话),使用GPT - 4.1 - nano和清单42的提示将其压缩为15K令牌的摘要,此过程类似于人类语义记忆的逐步抽象。与情景索引不同,便签不存储在检索数据库中,而是在推理时直接作为上下文输入。
便签过滤(函数\(f\)):¶
推理时,便签会根据问题进行选择性过滤。首先使用语义分块(LangChain中的222SemanticChunker,基于语义而非固定令牌窗口将文本分割为可变长度段落)将便签划分为语义连贯的块。每个块由Qwen2.5 - 32B - AWQ模型和清单43的提示评估,赋予二元相关标签(是/否)。仅保留被判断为相关的块,生成便签的浓缩表示并传递给响应生成器。
4 Experiments¶
4实验¶
4.1实验设置¶
基线:
对比两种基线评估方法,即长上下文大语言模型(LLMs)和检索增强生成(RAG)方法。
长上下文LLMs:实验使用两个专有LLMs(GPT - 4.1 - nano、Gemini - 2.0 - flash,均为1M上下文)和两个开源模型(Qwen2.5 - 32B - AWQ、Llama - 4 - Maverick - fp8)。Qwen2.5 - 32B - AWQ在长上下文实验中使用128K上下文长度,在10M令牌长度时,因现有模型无支持,各模型在其窗口允许的最大最近对话段评估。
RAG基线:将每对用户 - 助手轮次视为文档,嵌入并存储在向量数据库。推理时,检索最相似的五个文档,并按特定提示传递给LLM。同时给出不同LLMs和方法在不同对话长度和记忆能力下的对比表格。
推理设置:
推理时,除对话计划、用户轮次和助手轮次生成使用温度0.1以增加多样性外,其余使用核采样(Nucleus)且温度为0。所有开源LLMs通过VLLM进行高效推理。
Llama3.3 - 70B在用户轮次生成时最大输出长度设为6K令牌,其他LLMs采用默认最大输出长度。RAG基线和所提方法实验中,使用FAISS作为向量数据库,密集检索使用BAAI/bge - small - en - v1.5嵌入模型。
4.2实证发现¶
主要结果:
在所有四种对话长度(100K - 10M令牌)下,所提方法始终优于长上下文LLMs和RAG基线。在较短上下文(100K)时就有显著提升,随着上下文长度增加优势更明显,在10M令牌长度时提升尤为显著,唯一例外是Gemini - 2.0 - flash在10M长度时略落后于RAG。
在十种记忆能力评估中,所提方法在总结(+160.6%)、多跳推理(+27.2%)和偏好跟随(+76.5%)方面相对提升最大,在信息提取(+56.7%)、指令跟随(+39.5%)和时间推理(+56.3%)方面也有显著提升。所有方法在弃权任务中表现最强,在矛盾解决任务中表现最弱。
消融实验:
评估情景记忆、暂存器、工作记忆和噪声过滤各组件在不同对话长度下的作用。100K时,检索因引入噪声对性能提升有限,去除暂存器、噪声过滤或工作记忆会降低性能;500K时,去除任何组件都会降低性能;1M时,去除工作记忆性能略有提升;10M时,所有组件都至关重要,去除会导致性能大幅下降。实验表明各模块随上下文长度增长作用愈发重要,完整架构性能最佳。
检索预算的影响:
研究检索预算(K)的影响,测试K为5、10、15和20个文档的情况。K从5增加到15时性能持续提升,K = 15时效果最佳,K增加到20性能略有下降,K = 10时效果不一。同时进行的关于检索器选择影响的补充实验表明,稀疏和密集检索差异不大。
案例研究:在附录F中给出暂存器有用性的案例研究。
人类评估:从连贯性与流畅性、真实性、复杂性与深度三个维度对生成对话质量进行人类评估,平均得分分别为4.53、4.57和4.64,表明生成质量较高。评估细则和详细分数在附录B.2中给出。
6 Conclusion¶
6 结论¶
本文指出了现有用于评估对话系统长期记忆的基准测试的不足。
提出新基准测试框架:引入了一个可扩展的框架来生成BEAM,这是一个全新的基准测试,具备长且连贯的对话(多达1000万个标记)以及多样的记忆探测方式。
开发记忆增强框架:为提升大语言模型(LLMs)的性能,开发了LIGHT,这是一个受认知启发的框架,融合了情景记忆、工作记忆和暂存记忆。
实验结果:实验表明,标准的大语言模型在长上下文环境下性能会下降,而LIGHT带来显著提升,平均将记忆性能提高3.5% - 12.69%。
意义:通过提供更强大的评估方式和有效的记忆增强技术,本文助力开发更可靠的长上下文对话系统。
Acknowledgments¶
致谢¶
罗斯·米切尔担任艾伯塔省卫生服务机构的健康人工智能主席职位,其工作得到了加拿大高级研究院(CIFAR)、大学医院基金会、阿尔伯塔机器智能研究院(Amii)以及加拿大创新基金会的支持。穆罕默德·阿卜杜拉获得了CIFAR人工智能主席职位及Amii的资助。本研究得到了加拿大卫生研究院(资助编号FRF 196047)的支持。嘉莉·叶获得了加拿大风湿病协会基金会(CRAF,CIORA)与加拿大关节炎协会联合设立的临床研究员奖(奖项编号CI - 24 - 0013)的支持。
Appendix B Benchmark Design¶
该章节围绕基准设计展开,涵盖数据集统计、质量评估、创建细节、超参数、问题分布及记忆能力示例等方面,具体内容如下:
Dataset Statistics:通过表格展示生成数据集的统计信息,包括不同聊天规模下用户消息、助手消息、助手和用户后续问题以及对话轮次的平均值。
Benchmark Quality Evaluation:为评估生成对话的质量,安排两名注释者从连贯性与流畅度、对话真实性、复杂性与深度三个维度,以5分制(1分最低,5分最高)对所有对话进行人工评估,结果表明平均得分较高,整体质量良好。
Benchmark Creation Details:
Domain Coverage of the Dataset:数据集覆盖广泛领域,包括技术与非技术领域,共19个领域100个多轮聊天,每个领域有相关主题。
Conversation Plan Generation:
对话计划是对话的核心框架,由种子(含领域、标题、主题、子主题)、叙述集、用户资料、关系图和时间线构成。
生成标题和主题时,先由人工指定目标领域,再用GPT - 4.1生成候选,经人工筛选。叙述则用开源LLaMA - 3.3 70B生成。
对话计划由多个子计划组成,不同规模对话生成方式有别。128K、500K和1M规模的对话生成单个计划;10M规模对话通过顺序扩展或层次分解策略构建十个相互关联的计划。最后还会对初步生成的计划进行增强,以评估矛盾解决、知识更新和指令跟随等关键记忆能力。
User Utterance Generation:根据对话计划生成用户话语,将子计划划分为批次,用LLaMA - 3.3 70B模型按批次生成用户问题。针对编程和数学领域,采用特定提示生成符合领域特点的问题。
Assistant Utterance Generation:采用迭代的角色扮演框架生成助手回复。助手LLM依据种子、先前子计划、近期对话摘要等生成回答,若回答含反问,用户LLM生成回复,循环直至无反问或达阈值。同时有后续问题检测模块,根据需要生成后续问题并由助手回答,通过两个阈值控制循环次数,使对话更自然。
Algorithms:给出对话计划生成、用户问题生成和答案生成的算法步骤,详细展示各环节的输入、处理过程和输出。
User Utterance Generation Hyperparameters:通过表格说明不同聊天规模和领域类别下,用户问题生成的批处理配置,包括子计划数量、每个子计划的批数以及每批生成的问题数。
Created Probing Questions Distribution:将每个对话分为十个相等部分,记录每个探测问题的支持证据所在部分,以衡量对话中回答问题所需信息的位置分布。
Memory Abilities Examples:针对十种记忆能力,分别给出代表性的探测问题及理想答案,展示基准如何评估长期对话记忆的不同方面。
Appendix C Detailed Experiments¶
Appendix C详细实验¶
C.1消融研究¶
该部分展示了消融实验的完整结果。通过表8评估所提模块中各个组件的贡献,研究移除关键记忆组件(检索、暂存器、工作记忆和噪声过滤)对不同对话长度(100K - 10M)下各项记忆能力(如弃权、矛盾解决、事件排序等)性能的影响。从数据中可看出不同组件缺失对不同长度对话和能力的具体影响差异。
C.2检索预算¶
通过两组实验探究检索预算的影响:
改变检索深度:设置检索文档数量K∈{5, 10, 15, 20},表9呈现了不同检索深度对不同对话长度和记忆能力的性能影响,不同K值下各能力表现有所波动。
比较稠密检索器与稀疏检索器(SPLADE):基础架构采用稠密检索器,与稀疏的Splade - V2检索器对比。图5及表10表明,稀疏检索器在100K令牌时性能提升2.01%,1M时提升0.8%,但在500K时下降0.003%,10M时下降0.71%,总体在不同对话长度上有适度改进。
Appendix D Nugget Design¶
该部分为“Appendix D Nugget Design”,通过具体示例展示了如何从相应探测性问题中得出小块信息(nuggets),涵盖多种记忆能力,具体如下:
Abstention(弃权)
目标:承认所请求信息在给定对话中不存在。
评分标准模式:每个原子单元格式为“States that, based on the provided chat, there is no information about
”。 示例JSON:以询问特定建议但对话无相关信息为例,展示问题、理想回复、来源聊天ID及评分标准。
Contradiction Resolution(矛盾解决)
目标:大语言模型(LLM)应检测到矛盾,陈述矛盾信息并请求澄清。
评分标准模式:需表明存在矛盾信息、提及矛盾主张A和B并请求说明哪个陈述正确。
示例JSON:针对关于是否参加过房地产网络研讨会的矛盾表述问题,给出理想答案、来源聊天ID及评分标准。
Event Ordering(事件排序)
目标:模型按正确时间顺序列出事件/主题序列。
评分标准模式:LLM回复应提及各事件。
示例JSON:关于房产投资管理关注点发展顺序问题,给出答案、排序测试内容、来源聊天ID及评分标准。
Information Extraction(信息提取)
目标:LLM正确回答所问事实。
评分标准模式:依据理想答案为每个事实制定标准,以“LLM response should state/mention:”开头。
示例JSON:询问初始投资资本金额问题,给出理想答案、来源聊天ID及评分标准。
Instruction Following(指令遵循)
目标:LLM遵循对话中规定的格式和/或内容优先级。
评分标准模式:使用正在测试的指令,并将预期合规性分解为原子标准。
示例JSON:关于如何分配资金问题,给出正在测试的指令、预期合规内容、来源聊天ID及评分标准。
Knowledge Update(知识更新)
目标:当先前值随时间变化,LLM必须反映更新后的值。
评分标准模式:从理想答案推导标准,以“LLM response should state/mention:”表述更新值。
示例JSON:询问房地产投资初始资本问题,给出答案、来源聊天ID及评分标准。
Multi-hop Reasoning(多跳推理)
目标:LLM聚合或比较多个会话中的信息。
评分标准模式:从理想答案为每个所需中间或聚合事实制定标准。
示例JSON:询问考虑过的银行数量问题,给出答案、来源聊天ID及评分标准。
Preference Following(偏好遵循)
目标:LLM生成与用户指定偏好一致的内容。
评分标准模式:使用用户偏好并将预期合规性分解为原子标准。
示例JSON:关于如何有效比较房产问题,给出用户偏好、预期合规内容、来源聊天ID及评分标准。
Summarization(总结)
目标:LLM提供涵盖所需内容要素的全面总结。
评分标准模式:将理想总结分解为原子内容单元,以“LLM response should contain:”开头。
示例JSON:关于投资出租房产相关过程总结问题,给出理想总结、来源聊天ID及评分标准。
Temporal Reasoning(时间推理)
目标:LLM正确计算或重述持续时间和时间线关系。
评分标准模式:从理想答案推导标准,以“LLM response should state:”开头。
示例JSON:询问两次房产查看间隔天数问题,给出答案、计算内容、来源聊天ID及评分标准。
Appendix E Examples from Different Components of BEAM¶
Appendix E Examples from Different Components of BEAM¶
该部分通过在编码领域生成聊天的示例,展示BEAM不同组件如何相互作用形成连贯、长上下文的对话。
Chat Seed:设定聊天主题相关信息。
领域:Coding
标题:Automating Social Media Posts with Python
主题:Scheduling and posting content across multiple platforms
子主题:涵盖Twitter、Facebook、Instagram相关API使用、调度工具、图像处理、错误处理等多方面。
Narratives (Truncated):对涉及内容分类简述,如技术问题解决、学习知识、项目进展等多个类别,涉及调试、掌握工具、搭建框架等具体内容。
User Profile:介绍用户John Brooks的基本信息,包括年龄、性别、职业等,以及其性格特点,如乐于助人、注重传统秩序等。
Relationships:列举用户的父母、伴侣、好友、同事等社会关系。
Conversation Plan (Only a few representative bullets from each sub - plan):展示不同时间的对话计划要点,涉及项目初始化、技术问题解决、安全合规、性能优化等多方面工作,如不同时间点对各社交媒体API的操作、数据库设计、代码重构等。
Generated Dialogues (Exemplars, Truncated):给出聊天示例。
Turn 1 (Mar 1, 2024):用户询问项目规划,助手给出项目结构建议,用户提出增加小规模测试步骤,助手更新项目结构。
User (Mid - turn) -> Code Sharing:用户分享收集Instagram帖子参与度指标的代码并求帮助,助手进行代码审查并给出建议。
User -> Deployment:用户部署应用遇问题并分享Dockerfile片段求助,助手提供部署指导,用户追问自动化相关问题,助手建议使用GitHub Actions,用户又询问不同阶段环境变量处理方式,助手给出使用不同文件及AWS相关服务的建议。
Appendix F Case Study¶
Appendix F案例研究¶
便签本作为一个持久的、经过迭代压缩的语义层,具有以下作用:(i)整合分散的实体和事实(提升“信息提取”能力);(ii)在任务上下文旁边保留用户层面的元指令(提升“指令遵循”能力);(iii)记录状态变化和覆盖信息(提升“知识更新”能力);(iv)将时间线索标准化为明确的锚点(提升“时间推理”能力)。在基准测试的十种记忆能力中,本文针对上述四种能力进行案例研究,实际上便签本对其余六种能力也有类似益处。下面通过对比 “完整组件的LIGHT” 与 “无便签本的LIGHT” 在典型问题上的表现,并展示能得出正确答案的具体便签本提示信息。
信息提取:通过两个问题展示便签本作用。如问使用哪些工具启动项目,完整LIGHT能答出Python 3.10等工具版本,无便签本的LIGHT称无直接答案,便签本提示中列出了相关技术工具;问居住城市、国家及年龄,完整LIGHT能作答,无便签本的LIGHT称无相关信息,便签本提示列出了相关人物、地点等关键实体关系。
指令遵循:问题为讲述近期参与的指导活动,用户指令要求提及指导活动时提供团队成员数量。完整LIGHT能按要求回答指导3名初级编辑,无便签本的LIGHT称无相关活动,便签本提示记录了用户指令及指导活动相关内容。
知识更新:两个问题,如问批量简历处理每次会话的典型内存使用量,完整LIGHT能给出约140MB,无便签本的LIGHT给出复杂且不同答案,便签本提示记录了内存优化相关信息;问Instagram自动化原型冲刺的截止日期,完整LIGHT能给出正确的2024年4月5日,无便签本的LIGHT给出错误日期,便签本提示记录了项目流程中截止日期的变更。
时间推理:两个问题,如问见到妈妈和完成第一批酸面团之间相隔天数,完整LIGHT能算出5天,无便签本的LIGHT算出错误的37天,便签本提示列出了重要日期;问在咖啡馆敲定调查计划和参加创业见面会之间准备时间,完整LIGHT算出18天,无便签本的LIGHT算出错误的28天,便签本提示列出相关重要日期。
总结:在各项能力中,去掉便签本会导致完整模型可避免的失败。信息提取中,便签本聚合分散信息;指令遵循中,保留用户元偏好;知识更新中,编码覆盖信息;时间推理中,提供标准化日期锚点。这些例子表明便签本提供了高效用的语义框架,补充了工作(近期)和情景(检索)记忆,实现强大的长上下文处理能力。
Appendix G Prompts¶
该部分内容主要介绍了框架不同阶段所使用的各类提示(prompts),具体如下:
附录G提示:提供框架不同阶段使用的提示,列举了从候选选择信息提取提示到候选选择事件排序提示等7种提示(Listing 1 - Listing 7),并对如何从包含详细要点的计划中,选择用于测试大语言模型(LLM)总结能力的要点组进行说明。
输入数据:需分析的计划。
关键要求 - 早期批次优先级:按批次优先级选择要点组,批次1 - 3的组最高优先级(选60 - 70%),早期到中期批次的组为中优先级(选20 - 30%),仅来自后期批次的组为低优先级(选10 - 20%) 。
关键要求 - 基于内容的分析:分析要点文本,识别其中提及的实体、过程等,搜索所有批次中任何类别对这些实体的提及,按内容相似性分组,每组包含8 - 12个提及,聚焦能实现特定类型总结的完整主题簇。
输出格式:以特定JSON格式返回分析结果,每个对象含8 - 12个相关要点。
其他提示:还列举了从候选选择总结提示到数学领域对话计划生成提示等24种提示(Listing 8 - Listing 31),以及通用领域、编码领域、数学领域的问题生成提示(Listing 32 - Listing 34)。
判断助手回复是否含直接问题(Listing 35):判断AI助手回复是否包含用户必须立即回答的直接、具体问题,若是回复“YES”,若否回复“NO”。
判断是否追问(Listing 36):模拟用户,根据AI回复及对话上下文,决定是否追问。若因缺少信息、存在困惑或指导不完整则追问(回复“yes”),若信息足够继续则不追问(回复“no”)。
助手LLM答案生成提示(Listing 37):要求仅用英语回复用户消息,通过完整回答问题或回答后最多追问一个问题的方式回应,遵循特定规则并使用给定系统输入。
其他提示:还列出了用户LLM答案生成提示、用户LLM追问问题提示、键值提取提示等10种提示(Listing 38 - Listing 44) 。