1905.08108_NGCF: Neural Graph Collaborative Filtering¶
引用: 4015(2025-09-12)
组织:
National University of Singapore
University of Science and Technology of China
Hefei University of Technology
GitHub: https://github.com/xiangwang1223/neural_graph_collaborative_filtering
总结¶
总结
看图1和它对应的说明
背景
个性化推荐系统
核心任务是通过用户的历史行为(如购买、点击)来预测他/她喜欢某个物品的可能性
协同过滤(CF) 是解决这个问题的核心思想,它基于一个基本假设:行为相似的用户,对物品的喜好也相似
协同过滤模型的两个关键组件
Embedding(嵌入):将用户和物品ID(或属性)转换为向量化的表示。
Interaction Modeling(交互建模):用一个函数(如内积、神经网络)根据嵌入向量来预测用户和物品之间交互的可能性。
示例
矩阵分解(MF):用ID嵌入 + 内积交互
协同深度学习:用ID+属性等辅助信息做嵌入 + 内积交互
神经协同过滤(NCF):用ID嵌入 + 神经网络交互
翻译模型:用ID嵌入 + 欧几里得距离交互
传统方法缺点
传统方法(从矩阵分解到深度学习)通常通过用户或物品的已有特征(如 ID 和属性)来生成其嵌入表示。
关键问题:
只使用了描述性特征(如ID、属性),而没有显式地使用协同信号(Collaborative Signal)
协同信号:隐藏在用户-物品交互行为中,能揭示用户之间或物品之间行为相似性的信息
结果:
由于嵌入本身没能很好地捕捉到协同过滤的本质,模型就只能过度依赖“交互函数”这个组件来弥补嵌入的不足。
这相当于让一个部分(交互函数)去干两个部分的活,效果受限。
NGCF模型
核心思想:
不是把图展开成复杂的树结构,而是设计一个神经网络来在图上递归地传播嵌入。
这受到了图神经网络(GNN) 的启发。
一种新的预测模型,它直接将高阶连接信息集成到了模型架构(嵌入函数)本身中
具体技术:
嵌入传播层(Embedding Propagation Layer):
通过聚合一个节点(用户或物品)的邻居节点的嵌入,来优化该节点自身的嵌入。
例如,用户的嵌入通过聚合他交互过的所有物品的嵌入来更新。
堆叠多层(Stacking Multiple Layers):
通过堆叠多个传播层,信息可以传播得更远,从而让最终的用户和物品嵌入捕获到 高阶的协同信号(如图1中的三阶、四阶连接)。
可学习的权重:
层与层之间的权重是可以通过训练学习的,这可以让模型自动判断不同路径的重要性(例如,决定是推荐
i4还是i5的优先级)。
包含三个核心组件
嵌入层 (Embedding Layer):对用户和物品进行初始化嵌入
多层嵌入传播层 (Embedding Propagation Layers):通过图神经网络的方式,在用户-物品交互图中传播嵌入信息,注入高阶连接信息
预测层 (Prediction Layer):聚合不同传播层的嵌入表示,输出用户-物品对的亲和力得分
核心是一个新提出的嵌入传播层,该层允许用户和商品的嵌入相互作用,从而提取协同信号。
Abstract¶
该段落主要介绍了 神经图协同过滤(Neural Graph Collaborative Filtering, NGCF) 这一推荐系统模型的背景、动机、方法及其实验结果。
背景与动机¶
用户和物品的向量表示(Embeddings)是现代推荐系统的核心。传统方法(从矩阵分解到深度学习)通常通过用户或物品的已有特征(如 ID 和属性)来生成其嵌入表示。
关键问题:这些方法的一个固有缺陷是:没有将用户-物品交互中隐含的协同信号(collaborative signal)纳入嵌入过程,导致生成的嵌入可能无法有效捕捉协同过滤效果。
方法与创新¶
本文提出:将用户-物品交互结构(更具体地说,是二部图结构)直接整合进嵌入过程。
NGCF 框架:利用图结构,通过在用户-物品图上传播嵌入信息,从而学习用户和物品的表示。
优势:这种方法能够显式地注入协同信号,并有效建模高阶连接性(high-order connectivity),从而提升推荐效果。
实验与结果¶
在三个公开数据集上进行了广泛实验,结果表明 NGCF 显著优于多个先进的模型,例如:
HOP-Rec (Yang et al., 2018)
Collaborative Memory Network (Ebesu et al., 2018)
进一步分析也证实了嵌入传播对学习更好表示的重要性,支持了 NGCF 的合理性与有效性。
其他信息¶
关键词:Collaborative Filtering, Recommendation, High-order Connectivity, Embedding Propagation, Graph Neural Network
发表信息:2019 年 ACM SIGIR 会议,会议地点:法国巴黎。
重点总结¶
核心问题:传统方法未利用用户-物品交互的协同信号。
核心方法:通过图结构传播嵌入,学习更高质量的用户和物品表示。
核心贡献:提出 NGCF 模型,在多个基准上取得显著效果提升。
重要验证:实验和分析均支持嵌入传播的必要性与有效性。
1. Introduction¶
核心摘要¶
这段文字介绍了一种新的推荐系统算法(NGCF)。它认为现有的主流方法有一个根本缺陷:没有将“用户-物品”的交互信息直接编码到用户和物品的“嵌入表示”(Embedding)中。为了解决这个问题,NGCF创新性地使用图神经网络(GNN) 技术,通过模拟用户在交互图中的高阶连接关系,来学习更丰富、更精确的嵌入表示,从而提升推荐效果。
背景介绍¶
主要内容:介绍了个性化推荐系统无处不在,其核心任务是通过用户的历史行为(如购买、点击)来预测他/她喜欢某个物品的可能性。
关键概念:协同过滤(CF) 是解决这个问题的核心思想,它基于一个基本假设:行为相似的用户,对物品的喜好也相似。
实现方式:为了实现这个假设,通常的做法是为每个用户和物品学习一个参数化的表示(即嵌入,Embedding),然后用这些参数来重建历史交互记录并进行预测。
CF模型的两个组成部分¶
主要内容:指出了可学习的CF模型包含两个关键部分:
嵌入(Embedding):将用户和物品ID(或属性)转换为向量化的表示。
交互建模(Interaction Modeling):用一个函数(如内积、神经网络)根据嵌入向量来预测用户和物品之间交互的可能性。
举例:列举了几个经典模型来说明这两个组件是如何演进的:
矩阵分解(MF):用ID嵌入 + 内积交互。
协同深度学习:用ID+属性等辅助信息做嵌入 + 内积交互。
神经协同过滤(NCF):用ID嵌入 + 神经网络交互。
翻译模型:用ID嵌入 + 欧几里得距离交互。
现有方法的缺陷¶
核心论点:作者认为,上述方法都有一个根本性的缺陷——它们的嵌入表示不够好。
原因:在构建嵌入表示时,只使用了描述性特征(如ID、属性),而没有显式地编码协同信号(Collaborative Signal)。
协同信号:隐藏在用户-物品交互行为中,能揭示用户之间或物品之间行为相似性的信息。
后果:交互数据仅仅被用来定义模型训练的损失函数。由于嵌入本身没能很好地捕捉到协同过滤的本质,模型就只能过度依赖“交互函数”这个组件来弥补嵌入的不足。这相当于让一个部分(交互函数)去干两个部分的活,效果受限。
运行示例:解决方案的直觉(高阶连接)¶
挑战:直接把海量的交互数据编码到嵌入中非常困难。
解决方案:利用用户-物品交互图中天然的高阶连接(High-order Connectivity) 来编码协同信号。
图1示例:
用户
u1和u2都交互过物品i2,这构成了一条二阶路径u1 <- i2 <- u2。这条路径表明u1和u2是行为相似的用户。路径
u1 <- i2 <- u2 <- i4是一条三阶路径。它表明,因为u1的相似用户u2喜欢i4,所以u1也可能喜欢i4。路径越多、越短,这种关联性就越强。例如,通往
i4的路径比通往i5的多,所以u1更可能喜欢i4。
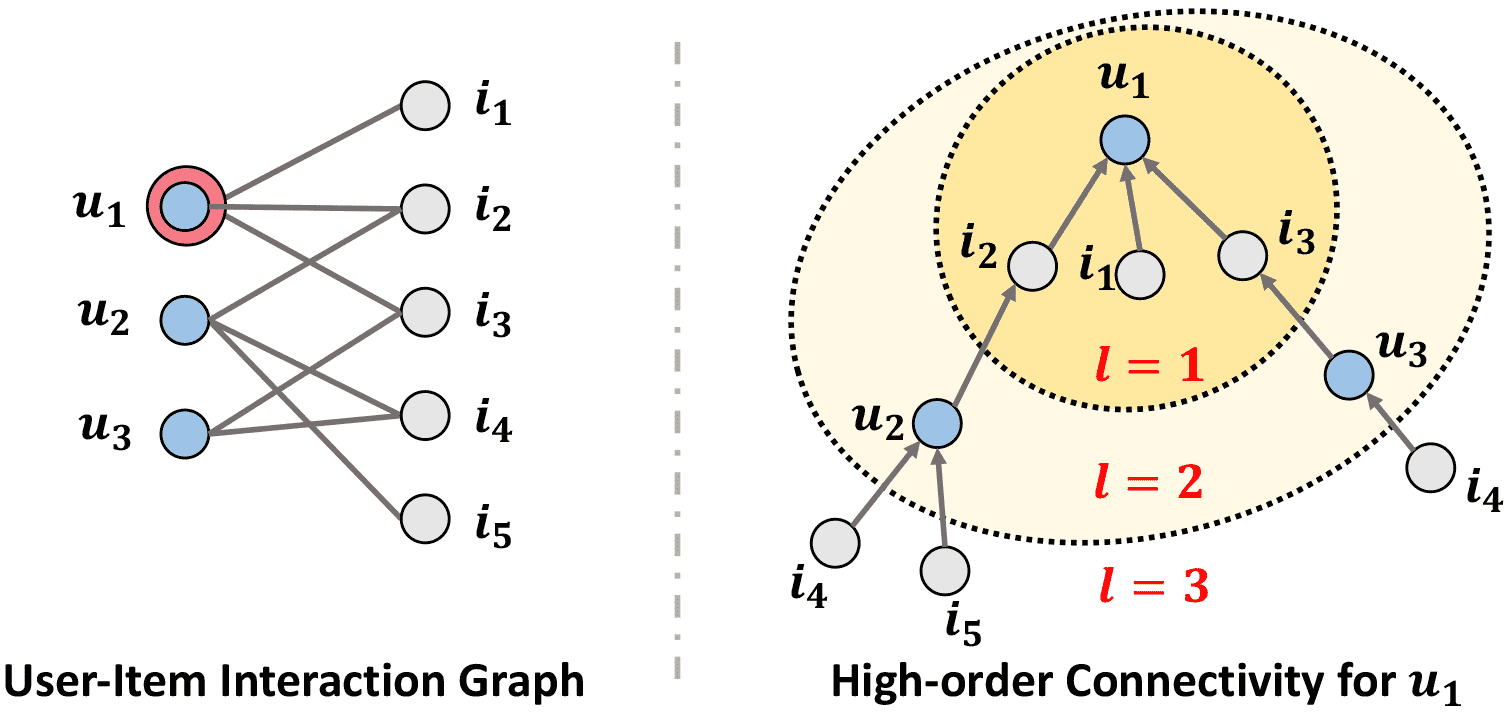
Figure 1 An illustration of the user-item interaction graph and the high-order connectivity. The node \(u_1\) is the target user to provide recommendations for.
本文方法(NGCF)¶
核心思想:不是把图展开成复杂的树结构,而是设计一个神经网络来在图上递归地传播嵌入。这受到了图神经网络(GNN) 的启发。
具体技术:
嵌入传播层(Embedding Propagation Layer):通过聚合一个节点(用户或物品)的邻居节点的嵌入,来优化该节点自身的嵌入。
例如,用户的嵌入通过聚合他交互过的所有物品的嵌入来更新。
堆叠多层(Stacking Multiple Layers):通过堆叠多个传播层,信息可以传播得更远,从而让最终的用户和物品嵌入捕获到高阶的协同信号(如图1中的三阶、四阶连接)。
可学习的权重:层与层之间的权重是可以通过训练学习的,这可以让模型自动判断不同路径的重要性(例如,决定是推荐
i4还是i5的优先级)。
与相近工作的区别¶
与HOP-Rec的区别:另一个利用了高阶连接的方法HOP-Rec,只是用这些连接来增强训练数据,其预测模型本身还是传统的MF。
本文的贡献:NGCF是一种新的预测模型,它直接将高阶连接信息集成到了模型架构(嵌入函数)本身中,因此能学到比HOP-Rec更好的嵌入表示。
贡献总结¶
作者总结了本文的三个主要贡献:
强调了在嵌入函数中显式编码协同信号的重要性。
提出了一个基于GNN的新框架NGCF,通过嵌入传播来编码高阶连接。
在三个大规模数据集上验证了NGCF的先进性和有效性。
打个比方帮助你理解¶
想象一下在一个大型派对上推荐朋友:
传统方法(如MF):只了解每个人的基本信息(ID、职业、爱好等),然后猜测谁和谁可能合得来。他们之间是否真的交流过(交互数据),只用来事后验证猜测的对错。
NGCF方法:不仅了解基本信息,还会仔细观察派对上的社交互动。它会发现:
“A和B都跟C聊过天”(二阶连接)→ 所以A和B可能是一类人。
“A和C聊过,C又和D聊过,而D喜欢玩桌游”(三阶连接)→ 所以A可能也有兴趣玩桌游。
通过一层层地观察这些互动关系,NGCF对每个人的了解(嵌入表示)会变得异常深入和准确,从而做出更靠谱的推荐。
2. Methodology¶
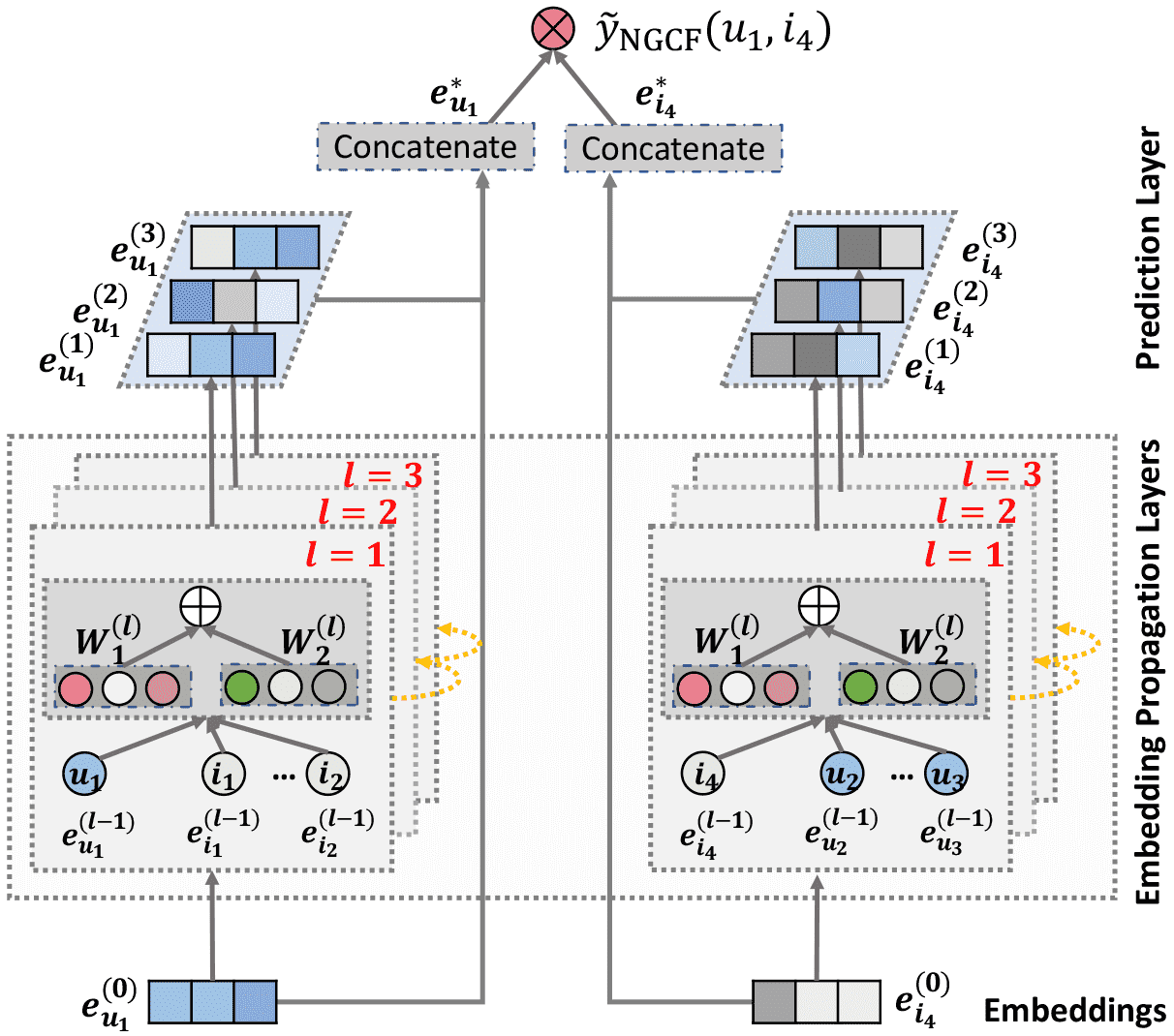
Figure 2. An illustration of NGCF model architecture (the arrowed lines present the flow of information). The representations of user \(u_{1}\) (left) and item \(i_{4}\) (right) are refined with multiple embedding propagation layers, whose outputs are concatenated to make the final prediction.
NGCF 模型包含三个核心组件:
嵌入层 (Embedding Layer):对用户和物品进行初始化嵌入;
多层嵌入传播层 (Embedding Propagation Layers):通过图神经网络的方式,在用户-物品交互图中传播嵌入信息,注入高阶连接信息;
预测层 (Prediction Layer):聚合不同传播层的嵌入表示,输出用户-物品对的亲和力得分。
核心思想概括¶
传统的推荐模型(如矩阵分解MF)直接使用用户和物品的初始嵌入向量来计算匹配分数。而NGCF的核心创新在于,它将用户-物品的交互关系视为一个图,然后通过多层图神经网络(GNN) 的消息传递(Message Passing) 机制,让用户和物品的嵌入向量在这个图上传播和交互。通过这种方式,最终的嵌入向量不仅包含了自身的信息,还聚合了其高阶邻居(High-order Neighbors)的信息,从而显式地编码了更丰富的协同信号(Collaborative Signal)。
分组件详解¶
1. 嵌入层 (Embedding Layer)¶
目的:初始化用户和物品的向量表示。
做法:为每个用户 \(u\) 和每个物品 \(i\) 随机初始化一个 \(d\) 维的嵌入向量 \(\mathbf{e}_u\) 和 \(\mathbf{e}_i\)。所有这些向量组合成一个大的嵌入查询表 \(\mathbf{E}\)。
与传统模型的区别:在MF等模型中,这些初始嵌入会直接用于预测;而在NGCF中,它们只是起点,后续会被图结构进一步优化。
2. 嵌入传播层 (Embedding Propagation Layers)¶
备注
这是模型的核心
这部分旨在利用用户-物品交互图来优化嵌入。它分为一阶传播和高阶传播。
a) 一阶传播 (First-order Propagation) 处理直接相连的邻居(即用户交互过的物品,或喜欢某个物品的用户)。包含两个步骤:
消息构建 (Message Construction):
对于一对相连的用户和物品 \((u, i)\),定义从物品 \(i\) 传到用户 \(u\) 的消息 \(\mathbf{m}_{u \leftarrow i}\)。
消息的计算公式(公式3)是NGCF的一个关键创新: $\(\mathbf{m}_{u \leftarrow i} = \frac{1}{\sqrt{|\mathcal{N}_u||\mathcal{N}_i|}} \Big( \mathbf{W}_1 \mathbf{e}_i + \mathbf{W}_2 (\mathbf{e}_i \odot \mathbf{e}_u) \Big)\)$
公式解读:
\(\mathbf{W}_1, \mathbf{W}_2\):可训练的权重矩阵,用于提取有用信息。
\(\frac{1}{\sqrt{|\mathcal{N}_u||\mathcal{N}_i|}}\):归一化系数(拉普拉斯范数),用于控制消息的衰减强度。邻居越多,单条消息的贡献越小。
\(\mathbf{e}_i\):物品自身的特征。
\(\mathbf{e}_i \odot \mathbf{e}_u\):物品和用户向量的元素积(Element-wise Product)。这编码了二者之间的亲和力(affinity),相似的用户和物品会产生更强的消息。这是对标准图卷积网络(GCN)的改进。
消息聚合 (Message Aggregation):
用户 \(u\) 的新表示通过聚合来自所有邻居物品的消息以及自连接(self-connection) 的消息得到。
公式:\(\mathbf{e}^{(1)}_u = \text{LeakyReLU} \Big( \mathbf{m}_{u \leftarrow u} + \sum_{i \in \mathcal{N}_u} \mathbf{m}_{u \leftarrow i} \Big)\)
\(\mathbf{m}_{u \leftarrow u} = \mathbf{W}_1 \mathbf{e}_u\) 是自连接,保留用户原有的特征。
同样地,物品的表示也通过聚合来自其邻居用户的消息得到。
b) 高阶传播 (High-order Propagation)
目的:通过堆叠多层传播层,捕获更远的、多跳的协同信号(例如:
用户A <- 物品B <- 用户C <- 物品D)。这使得用户A的最终表示中包含了物品D的某些信息。做法:将第 \(l-1\) 层的输出 \(\mathbf{e}^{(l-1)}\) 作为第 \(l\) 层的输入,重复进行消息构建和聚合的过程(公式5, 6)。每一层都有自己独立的可训练权重矩阵 \(\mathbf{W}_1^{(l)}, \mathbf{W}_2^{(l)}\)。
矩阵形式 (Matrix Form):为了高效计算,作者给出了等效的矩阵运算形式(公式7, 8),可以一次性更新所有用户和物品的表示,无需繁琐的逐节点采样,非常适合大规模图。
3. 预测层 (Prediction Layer)¶
目的:利用学习到的最终嵌入向量预测用户对物品的偏好分数。
做法:
层聚合 (Layer Aggregation):将同一用户(或物品)在所有层(包括第0层初始层) 的输出表示 \(\mathbf{e}^{(0)}, \mathbf{e}^{(1)}, ..., \mathbf{e}^{(L)}\) 拼接(Concatenate) 起来,形成最终的综合表示 \(\mathbf{e}^*_u\) 和 \(\mathbf{e}^*_i\)。
原因:不同层的表示捕获了不同阶数的连通性信息,拼接可以保留所有这些信息。
交互计算:通过简单的内积(Inner Product) 计算用户和物品最终向度的相似度,作为预测分数 \(\hat{y}(u,i)\)。
4. 模型优化 (Optimization)¶
损失函数:使用BPR(Bayesian Personalized Ranking)损失(公式11)。它的核心思想是:让观测到的(用户,正样本物品)对的预测分数,高于未观测到的(用户,负样本物品)对的预测分数。
正则化:
L2正则化:防止过拟合。
Dropout技术:
消息丢弃(Message Dropout):随机丢弃一部分传播过程中的消息。
节点丢弃(Node Dropout):随机屏蔽一部分节点及其所有传出消息。
这两种Dropout都只在训练时使用,为了增强模型的鲁棒性。
总结与亮点¶
图结构建模:显式地将用户-物品交互视为图,利用图结构。
高阶协同信号:通过多层GNN传播,捕获超越直接交互的、更深层次的协同信息。
创新消息传递:消息构建公式中的元素积 \(\mathbf{e}_i \odot \mathbf{e}_u\) 考虑了交互双方的特征亲和力,比标准GCN更强大。
层聚合机制:拼接所有层的输出,充分利用了从直接邻居到远距离邻居的多尺度信息。
高效且简洁:矩阵运算实现,效率高;相比MF,增加的参数量很少,主要只是各层的变换矩阵。
4. Experiments¶
本节对提出的**NGCF(Neural Graph Collaborative Filtering)方法进行了广泛的实验评估。实验重点在于验证NGCF在推荐系统中的性能,尤其是其图结构中的嵌入传播层(embedding propagation layer)**的效果。作者针对以下三个研究问题(RQ)进行了分析:
4.1. 数据集描述¶
实验在三个真实世界的数据集上进行,分别是 Gowalla(位置签到数据)、Yelp2018(本地商家评论数据)和 Amazon-Book(图书评论数据)。为了保证数据质量,每个数据集都使用了“10-core”设置,即只保留至少与10个物品或用户有交互的用户或物品。
Gowalla:29,858 个用户,40,981 个物品,1,027,370 次交互,密度为 0.00084。
Yelp2018:31,668 个用户,38,048 个物品,1,561,406 次交互,密度为 0.00130。
Amazon-Book:52,643 个用户,91,599 个物品,2,984,108 次交互,密度为 0.00062。
对于每个数据集,作者随机划分训练集(80%)、验证集(10%)和测试集(10%)。同时,对每个正样本进行负采样以生成负样本,用于模型训练和评估。
4.2. 实验设置¶
4.2.1. 评估指标¶
评估使用两个常见的推荐系统指标:
Recall@K:衡量推荐列表中包含真实正样本的比例。
nDCG@K:衡量推荐列表中排序的优劣,考虑物品的相对重要性。
默认设置为 K=20,并报告所有测试用户在各个指标的平均表现。
4.2.2. 基线方法¶
作者将 NGCF 与以下六种基线方法进行比较:
MF(Matrix Factorization):基于贝叶斯个性化排序(BPR)的矩阵分解方法。
NeuMF:一种基于神经网络的协同过滤方法,结合了元素乘积和拼接方式。
CMN(Collaborative Memory Networks):使用注意力机制聚合邻近用户的记忆槽。
HOP-Rec:基于图的模型,利用随机游走生成高阶邻居。
PinSage:基于图卷积神经网络,用于图结构数据。
GC-MC(Graph Convolution for Collaborative Filtering):结合图卷积的推荐模型。
此外,作者也尝试了 SpectralCF,但由于其在大数据集上的高计算开销,最终未将其纳入比较。
4.2.3. 参数设置¶
模型使用 Tensorflow 实现,嵌入维度固定为 64。
所有模型(除 HOP-Rec)使用 Adam 优化器,批量大小为 1024。
超参数通过网格搜索进行调优,包括学习率、L2正则化系数、Dropout 比例等。
NGCF 的深度设置为 3,使用 3 个嵌入传播层,消息 Dropout 比例为 0.1,节点 Dropout 比例为 0.0。
采用早停策略,若验证集 recall@20 不再提升超过 50 个 epoch,则提前终止训练。
参数初始化使用 Xavier 初始化,并使用 MF 的嵌入作为初始化以加快训练过程。
4.3. 性能比较(RQ1)¶
4.3.1. 整体比较¶
表2展示了各方法在三个数据集上的性能比较。主要发现如下:
MF 表现最差,表明其内积方式难以捕捉用户与物品之间的复杂关系。
NeuMF 在所有数据集上均优于 MF,说明非线性交互的重要性。
GC-MC 优于 NeuMF,说明引入邻接信息有助于推荐质量。
PinSage 在 Yelp2018 中表现较好,HOP-Rec 在多个数据集上的表现也较好。
NGCF 在所有数据集上均取得最佳性能,改进幅度显著(如 Gowalla 的 recall@20 提升 11.68%)。
NGCF 通过多层嵌入传播显式建模高阶连接性,优于仅使用一阶邻接的模型。
4.3.2. 不同稀疏度下的性能比较¶
作者进一步分析了不同交互稀疏度下的用户表现(例如稀疏用户 vs 频繁用户)。发现:
NGCF 和 HOP-Rec 在所有稀疏度组中的表现均优于其他基线。
对于低交互用户(如交互数小于 24 的用户),NGCF 的提升更为显著。
表明:建模高阶连接性有助于缓解稀疏性问题。
4.4. NGCF 模型研究(RQ2)¶
4.4.1. 层数的影响¶
通过比较不同层数的 NGCF(NGCF-1、NGCF-2、NGCF-3、NGCF-4),发现:
增加层数有助于提高推荐性能,但 NGCF-3 表现最好。
NGCF-4 在 Yelp2018 上出现过拟合,说明过多层数会引入噪声。
建议使用 3 层传播 即可充分捕捉高阶协作信号。
4.4.2. 嵌入传播层与聚合机制的影响¶
作者比较了 NGCF 的嵌入传播层设计与其他方法(如 PinSage、GC-MC 和 SVD++)的变体。发现:
NGCF 的嵌入传播方式(包含节点与其邻居的表示交互)比线性变换更有效。
节点 dropout 比 消息 dropout 更有效,有助于提升模型鲁棒性。
在聚合机制上,将各层输出拼接(layer-aggregation)能显著提升性能。
4.4.3. Dropout 对性能的影响¶
通过实验,作者发现 节点 dropout(p2=0.2) 能带来更好的性能提升,相比消息 dropout 更有效。
4.4.4. 模型收敛性分析¶
NGCF 相比 MF 收敛更快,表明其模型结构更优,嵌入传播机制有效提升了模型的表达能力。
4.5. 高阶连接性效果分析(RQ3)¶
作者通过可视化用户和物品的嵌入表示(使用 t-SNE 降维),观察不同层数对表示的影响。发现:
NGCF-3 的表示在嵌入空间中表现出明显的聚类,说明高阶连接性有助于捕捉协作信号。
同一用户的历史物品在 NGCF-3 中更接近,表明模型能更好地保留用户历史行为信息。
总结¶
本章实验全面验证了 NGCF 在推荐系统中的优越性能。通过对比多个基线方法,作者展示了 NGCF 在建模高阶连接性和稀疏性用户上的显著优势。同时,通过研究嵌入传播层数、Dropout 技术和聚合机制,进一步揭示了 NGCF 的有效性和鲁棒性。这些实验结果验证了 NGCF 作为一种图神经网络推荐模型的潜力。
5. Conclusion and Future Work¶
核心贡献与方法总结¶
本研究首次将协同信号明确地整合进基于模型的协同过滤(CF)模型的嵌入函数中。为此,作者提出了一种新的框架 NGCF(Neural Graph Collaborative Filtering),该框架通过利用用户-商品整合图中的高阶连通性来实现目标。NGCF 的核心是一个新提出的嵌入传播层,该层允许用户和商品的嵌入相互作用,从而提取协同信号。
实验验证¶
作者在三个真实世界数据集上进行了大量实验,验证了将用户-商品图结构嵌入到嵌入学习过程中的合理性和有效性。
未来研究方向¶
(1)引入注意力机制¶
未来的工作将致力于通过引入注意力机制(Chen 等,2017)来进一步改进 NGCF。该机制将允许模型学习邻居节点在嵌入传播过程中的不同权重,以及不同阶连通性的变化权重。这一改进将有助于模型的泛化能力和可解释性。
(2)探索对抗学习¶
另外,作者还计划探索对抗学习(He 等,2018)在用户/商品嵌入和图结构中的应用,以增强 NGCF 的鲁棒性。
潜在研究方向¶
本研究是对基于消息传递机制的模型中利用结构知识的初步尝试,同时也为未来的研究打开了新的可能性。除了用户-商品图,还有许多其他形式的结构信息可用于理解用户行为,例如:
跨特征(Yang 等,2019)在上下文感知和语义丰富的推荐系统中的应用;
商品知识图谱(Wang 等,2019a);
社交网络(Wang 等,2017a)等。
例如,通过将商品知识图谱与用户-商品图结合,可以建立知识驱动的用户-商品连接性,从而揭示用户在选择商品时的决策过程。这些探索有望帮助模型更好地理解用户的在线行为,从而实现更有效且更可解释的推荐。
致谢¶
本研究是 NExT++ 研究计划的一部分,并得到了 千人计划(2018)的支持。NExT++ 还获得了新加坡国家研究基金会(Prime Minister’s Office)在 IRC@SG Funding Initiative 项目下的资助。