2507.02259_MemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent¶
引用: 18(2025-10-24)
组织:
1ByteDance Seed
2Institute for AI Industry Research (AIR), Tsinghua University
3SIA-Lab of Tsinghua AIR and ByteDance Seed
总结¶
背景
长上下文处理的挑战
上下文窗口不足:长文本(如整本书籍、复杂推理链、代理系统的长期记忆等)生成的内容远超过当前LLM模型的上下文限制;
计算复杂度高:许多方法在处理极长文本时,计算复杂度为O(n²),导致处理速度慢、性能下降。
当前处理长上下文的方法主要包括三种:
RoPE-based LLMs 长度外推法(Length Extrapolation)
包括 NTK、PI、YaRN 和 DCA。
这些方法通过对位置嵌入中的频率、位置索引等组件进行调整,使模型能够捕捉长距离语义依赖关系。
线性注意力机制(Linear Attention)
线性注意力、RNN 和 状态空间模型(SSMs)。
这些方法通过不同的架构设计,将计算复杂度从 \(O(N^2)\) 降低到 \(O(N)\),从而可以高效处理超长上下文。
稀疏注意力(Sparse Attention)
使用滑动窗口等模式来减少不相关注意力计算。
但由于这些模式通常基于预定义的启发式规则,灵活性较差。
近年来提出了动态稀疏注意力(dynamic sparse attention),进一步提高了注意力机制的灵活性。
上下文压缩(Context Compression)
如记忆机制
通过外部模块(如外部记忆或数据库)来增强 Transformer 模型
好的长上下文 LLM 需要具备
处理无限长度的文本
在不降低性能的情况下进行扩展
具有线性复杂性的高效解码
Reinforcement Learning for LLMs
奖励信号的演变
早期使用人类偏好并由此蒸馏出的奖励模型
近年转向基于规则的反馈,这种机制在提升模型推理能力方面表现出巨大潜力
关键算法
PPO(Proximal Policy Optimization),基于 GAE(Generalized Advantage Estimation)。
Actor-Critic 框架。
GRPO,使用了 Group Normalization。
MemAgent:
核心机制:
在推理过程中,将输入文本分成多个块(chunk),逐块处理,并使用一个固定长度的动态更新的“记忆”模块来记录关键信息;
优势:
可以灵活处理任意长度的文本;
固定长度的记忆模块使得模型在推理时保持线性时间复杂度;
支持多轮记忆更新和最终输出生成。
本文提出使用强化学习使 LLM 本身具备记忆能力,这是研究的创新点
主要贡献:
新方法:提出一种在固定上下文窗口内,以线性时间复杂度处理任意长度输入的新方法;
训练框架:设计了一种基于多对话DAPO算法的端到端训练流程;
实证验证:通过实验展示了该方法在长文档上的高效性和可扩展性
设计目标
Unlimited length
No performance cliff
Linear cost
Abstract¶
尽管已有通过长度外推、高效注意力机制和记忆模块的改进,但如何在处理无限长文档时,以线性复杂度运行且在长度外推时不显著降低性能,依然是长文本处理中的终极挑战。
本文直接以端到端的方式优化长文本任务,并提出了一种新的代理工作流——MemAgent。MemAgent通过分段读取文本并采用覆盖策略更新记忆,实现对长上下文的处理。同时,作者将DAPO算法扩展,用于通过独立上下文的多对话生成来辅助训练。
MemAgent展示了卓越的长上下文能力,例如从训练时的8K上下文扩展到3.5M的问答任务时,性能损失小于5%。在512K的RULER测试中,MemAgent达到了95%以上的准确率。
图1:即使使用了长上下文持续预训练和外推技术的模型,也无法保持稳定的性能。相比之下,MemAgent结合强化学习实现了几乎无损的性能外推。
总结:本研究提出了一种针对长文本处理的新方法MemAgent,结合端到端训练与强化学习,显著提升了长上下文任务中的性能与外推能力。
1 Introduction¶
本章节主要介绍当前大型语言模型(LLM)在处理长上下文任务时所面临的挑战,并提出本文提出的MemAgent方法,以解决这一问题。
1.1 长上下文处理的挑战¶
工业级的LLM系统虽然在很多方面表现出色,但在处理长文本(如整本书籍、复杂推理链、代理系统的长期记忆等)时面临关键难题:
上下文窗口不足:长文本生成的内容远超过当前LLM模型的上下文限制;
计算复杂度高:许多方法在处理极长文本时,计算复杂度为O(n²),导致处理速度慢、性能下降。
1.2 现有方法概述¶
当前处理长上下文的方法主要包括三种:
长度外推法(Length Extrapolation)
通过修改位置嵌入(positional embeddings)来扩展模型的上下文长度,或继续预训练模型;
缺点:在极端长文本上性能下降,处理速度慢。
稀疏注意力和线性注意力机制(Sparse/Linear Attention)
通过减少注意力机制的复杂度来提升处理效率;
缺点:通常需要从头训练,存在线性注意力的并行训练困难或稀疏注意力依赖人工定义模式等问题。
上下文压缩(Context Compression)
通过压缩信息(如在token级别或外部模块内)来减少文本长度;
缺点:压缩后的信息难以外推,且需要额外模块,破坏标准生成流程,影响兼容性和并行化。
1.3 人类处理长上下文的启发¶
作者提出:人类在处理长上下文时,倾向于提取关键信息,而非记忆所有细节。这种选择性注意机制可以启发LLM的长上下文处理方法。
1.4 MemAgent 的提出¶
基于上述人类处理长文本的机制,作者提出 MemAgent:
核心机制:在推理过程中,将输入文本分成多个块(chunk),逐块处理,并使用一个固定长度的动态更新的“记忆”模块来记录关键信息;
优势:
可以灵活处理任意长度的文本;
固定长度的记忆模块使得模型在推理时保持线性时间复杂度;
支持多轮记忆更新和最终输出生成。
1.5 多对话DAPO 训练方法¶
MemAgent 的训练采用基于 DAPO(Decentralized Actor-Critic Policy Optimization) 的多对话扩展方法;
每个独立的上下文对话被视为一个优化目标;
与现有方法(如简单拼接或滑动窗口)相比,更具灵活性和可扩展性。
1.6 实验结果¶
模型设置:使用一个8K上下文窗口的LLM,配合1024 token的记忆模块和5000 token的文档块;
训练数据:在32K篇文档上进行训练;
测试任务:在高达4百万token的文档上执行问答任务;
结果:模型表现出色,无性能下降,且计算成本保持线性增长。
1.7 贡献总结¶
本文的三个主要贡献包括:
新方法:提出一种在固定上下文窗口内,以线性时间复杂度处理任意长度输入的新方法;
训练框架:设计了一种基于多对话DAPO算法的端到端训练流程;
实证验证:通过实验展示了该方法在长文档上的高效性和可扩展性,显著超越现有LLM系统的能力边界。
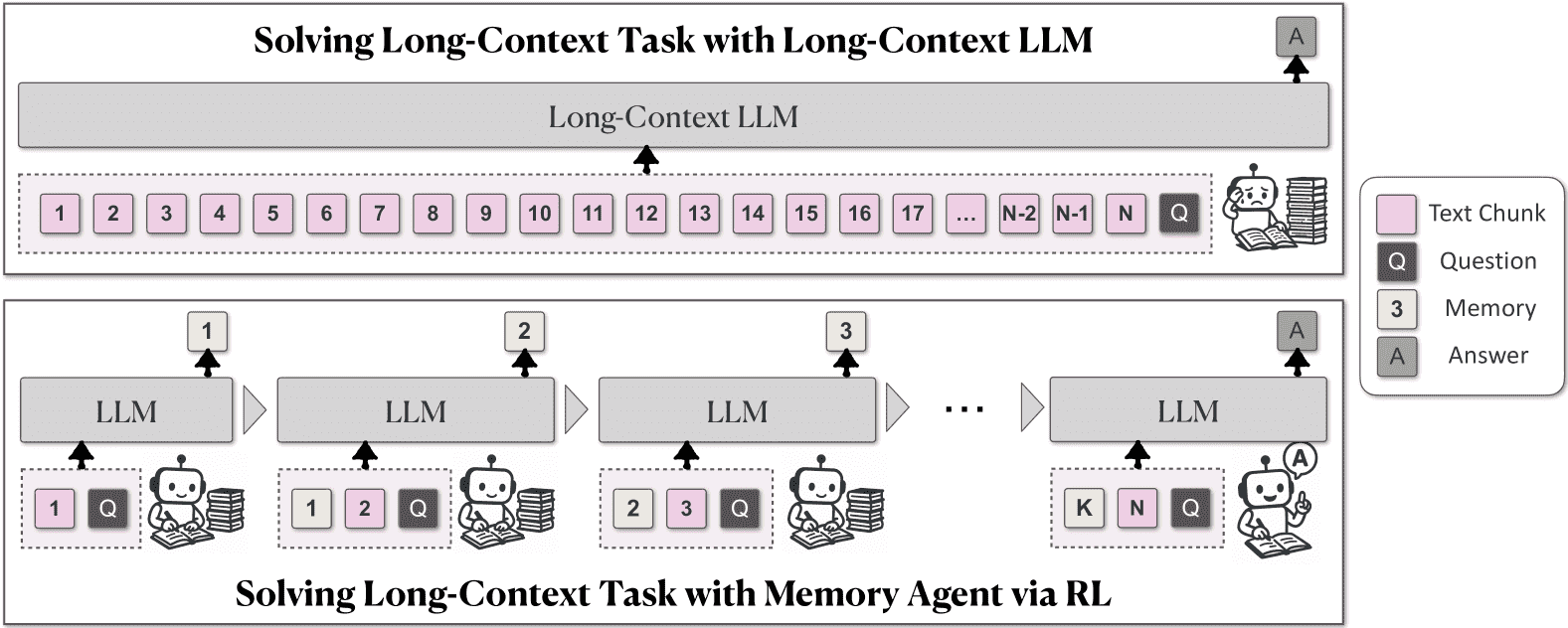
Figure 2:MemAgent is inspired by the way humans process long documents. It divides the document into multiple chunks and allows LLMs to process them iteratively, recording relevant information in memory. Finally, LLMs generate answers based on the information stored in the memory.
图2(图示)进一步说明了MemAgent的机制:将长文档分割处理,记录关键信息到记忆模块,最终根据记忆生成答案。
3 The Proposed MemAgent¶
模块 |
核心思想 |
|---|---|
MemAgent Workflow (3.1) |
通过“固定长度记忆 + 流式输入”让 LLM 具备无限上下文理解能力。 |
Multi-Conv RL (3.2) |
用强化学习训练模型优化记忆更新策略,通过共享奖励信号跨多轮优化所有记忆更新步骤。 |
奖励建模 (3.3) |
决定了 memory 中信息选择的策略——哪些信息值得保留,哪些可以丢弃。 |
自回归重构 (3.4) |
保证了即使 memory 是压缩后的固定长度,模型依然可以高效处理无限长文本,并且理论上可以“保持重要信息的完整性”。 |
3.1 MemAgent 工作流程:基于强化学习的无界上下文记忆¶
1. 背景问题¶
长上下文任务(long-context tasks)对普通 LLM 是个难题,因为:
上下文长度越长,注意力计算复杂度是 O(N²);
模型容易“遗忘”前文或被无关信息干扰。
MemAgent 的目标: ➡️ 让模型能处理任意长度的文本, 同时保持 线性计算复杂度 (O(N))。
2. MemAgent 的关键思路¶
MemAgent 的核心思想是:
把长文档“分块”处理,每次只读一小段(chunk),并用一个固定长度的 memory(摘要)保存“之前的重要信息”。
也就是说,模型在任意时刻只看到:
当前文本块 chunk_t
上一步生成的 memory_{t-1}
3. 工作流程¶
每处理一个 chunk:
模型读取
chunk_t+memory_{t-1}输出一个新的 memory(即“更新后的摘要”)
覆盖掉旧的 memory:
memory_t ← new_memory
→ 因此整个流程的内存大小是 固定的 O(1),无论输入多长(百万 tokens 也可以处理)。
最后,等所有 chunk 都处理完,进入第二阶段:
模型只看问题 (problem) + 最终 memory
生成最终答案(boxed answer)
⚙️ 推理分两阶段¶
1️⃣ Context-Processing 模块
逐步读入 chunk,反复更新 memory。
提示模板如下(表1上半):
<problem> {prompt} </problem>
<memory> {memory} </memory>
<section> {chunk} </section>
Updated memory:
2️⃣ Answer-Generation 模块
当所有 chunk 读完后,模型用:
问题(problem)
最终记忆(final memory)
来生成最终答案。
<problem> {prompt} </problem>
<memory> {memory} </memory>
Your answer: \boxed{...}

Table 1: Template of MemAgent for context processing (top part) and final answer generation (bottom). Curly-brace placeholders {} will be replaced with actual content.
📄 Table 1 展示了它的提示模板:
模块 |
作用 |
|---|---|
上半部分 |
更新 memory:读 chunk,输出新的摘要 |
下半部分 |
用最终 memory 回答问题 |
4. 为什么这样设计有效¶
无窗口限制(Unlimited length):文本流式输入,可处理百万 token。
无性能断崖(No performance cliff):RL 奖励模型保留关键信息、丢弃无关内容。
线性成本(Linear cost):每步固定计算量,整体随输入长度线性增长。
🔍 总结一句话: MemAgent 通过“强化学习驱动的动态摘要(RL-shaped memory)”,让普通 LLM 具备了无限上下文阅读能力,而无需改模型结构。 MemAgent 像人类一样“边读边记”,用强化学习控制记忆压缩,从而把普通 LLM 变成可无限阅读的长程推理模型。
3.2 通过多会话强化学习训练 MemAgent¶
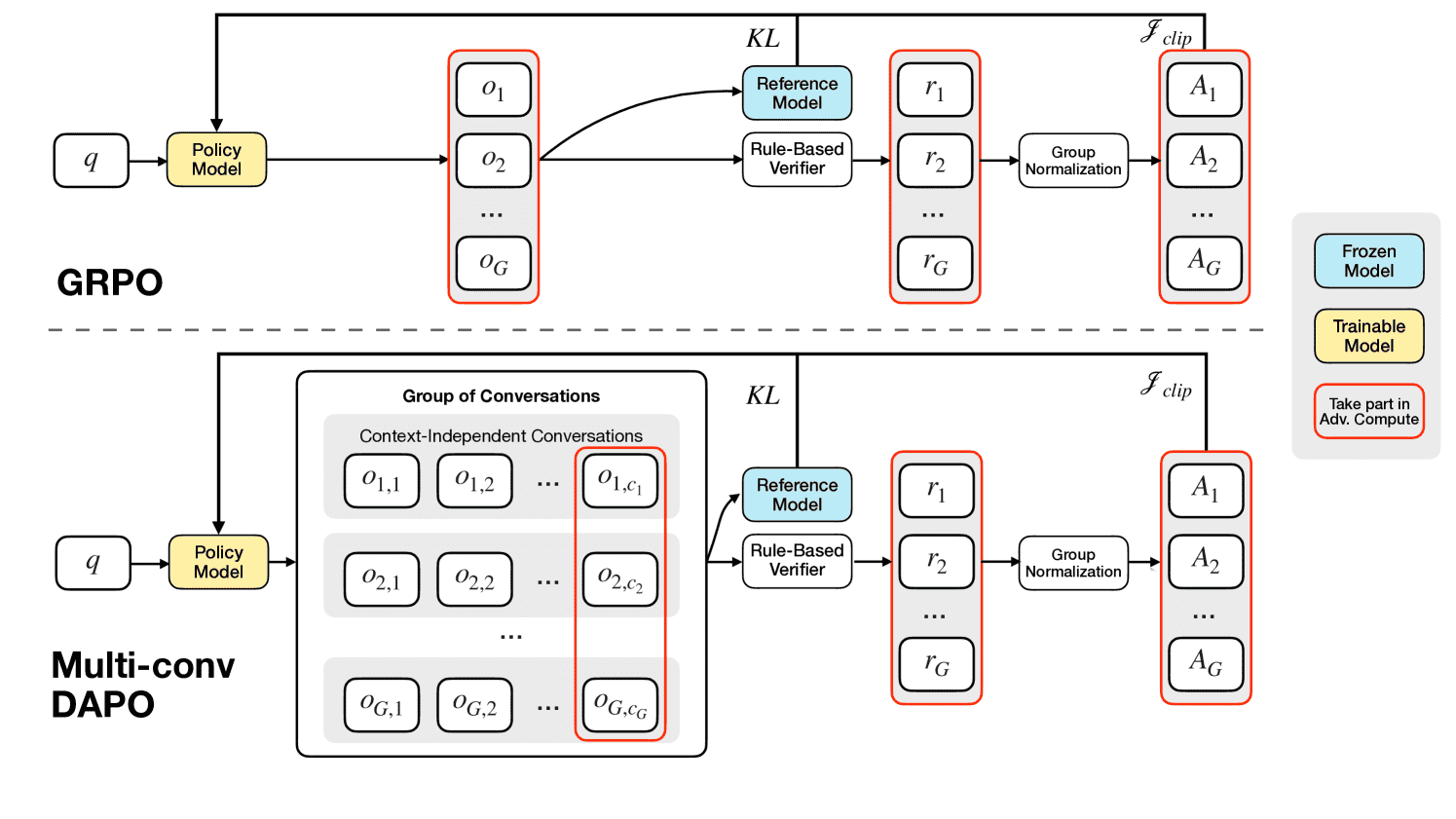
Figure 3:Comparison between vanilla GRPO and Multi-Conv DAPO. During the rollout phase of Multi-conv DAPO, each sample generates multiple conversations. The answer contained in the final conversation is used to compute the reward and advantage, which are then employed to optimize all preceding conversations.
MemAgent 把“如何更新 memory”视为一个强化学习(RL)任务。
1. 基础算法:GRPO(Group Relative Policy Optimization)¶
它基于 PPO(Proximal Policy Optimization)的一个变种:
每次采样一组输出(G 个样本)
计算每个样本的奖励 ( R_i )
优势函数(Advantage)定义为: $\( [ \hat{A}_{i,t} = \frac{r_i - \text{mean}({R_i})}{\text{std}({R_i})} ] \)$
用“裁剪目标函数 + KL 惩罚”稳定更新策略。
2. MemAgent 的挑战¶
普通 GRPO 只优化“单轮对话”,但 MemAgent 会在一个任务里生成多个独立对话(multi-conv):
例如:
Conv 1: 处理 chunk 1 -> memory_1
Conv 2: 处理 chunk 2 -> memory_2
...
Conv n: 生成最终答案
每个 chunk 的处理都是一个“小对话”,它们之间没有直接的 attention 连接。 → 所以传统多轮 RL 的“attention mask”做法不适用。
3. 解决方案:Multi-Conv DAPO¶
作者提出了 Multi-Conversation DAPO (Distributed Advantage Policy Optimization):
把每个对话(Conv)视作独立优化单元
每个样本 (q_i, a_i) 可能包含多个对话 (o_{i,1}, …, o_{i,n_i})
只根据最后一轮的回答计算 reward ( R_i )
然后把该奖励的“优势值”平均分配给前面所有的对话(每步都共享同一个 reward)
📊 图 3 展示了:
左:普通 GRPO → 单对话优化
右:Multi-Conv DAPO → 多对话共享奖励信号
4. 最终的优化目标¶
新的 loss 函数如下: $$ [ \mathcal{J}{\text{DAPO}}(\theta) = \mathbb{E}{(q,a)\sim \mathcal{D},{o_{i,j}}} \Bigg[ \frac{1}{G}\sum_{i=1}^{G}\frac{1}{n_i}\sum_{j=1}^{n_i} \frac{1}{|o_{i,j}|}\sum_{t} \big( \min(r_{i,j,t}(\theta)\hat{A}_{i,j,t}, \text{clip}(…))
\beta D_{KL}(\pi_\theta || \pi_{ref}) \big) \Bigg] ] $$
这相当于在三维空间上取平均:
group (G)
conversation (n)
token (t)
5. 本质理解¶
MemAgent 不是简单的记忆管理,而是通过 RL 训练模型:
学会在长文本流中抽取“关键信息”
学会在有限记忆窗口中“保留重要、丢弃噪声”
最终用一个压缩但充分的 memory 得出正确答案
这使它成为一种“强化学习驱动的长上下文压缩机制”。
🔍 总结整体逻辑图¶
阶段 |
内容 |
方法 |
|---|---|---|
推理阶段 |
分块读取文本 + 更新记忆 |
通过模板控制,流式输入 |
学习阶段 |
记忆更新建模为 RL 策略 |
使用 GRPO → 改进为 Multi-conv DAPO |
奖励机制 |
以最终答案质量为依据 |
将奖励反向传播给所有相关对话 |
目标 |
学到高效的记忆压缩策略 |
长文档处理能力 + O(N)复杂度 |
3.3 奖励建模(Reward Modeling)¶
核心思想:¶
MemAgent 采用 强化学习(RL) 来优化记忆的更新策略,最终目标是让模型只保留对最终回答有用的信息,丢掉无用信息。
最终奖励计算(Outcome Reward)
对问答类任务:如果存在多个正确答案(ground-truth),只要模型生成的答案与任意一个正确答案等价,就能获得奖励。
\[ R(\hat{y}, Y) = \max_{y \in Y} \mathbb{I}(\text{is\_equiv}(y, \hat{y})) \]\(\hat{y}\):模型生成的答案
Y:正确答案集合
\(\mathbb{I}\):指示函数,答案匹配为 1,否则 0
对“多值查找”类任务(例如需要找出所有关键值的任务):奖励按模型覆盖正确答案的比例给出: $\( R(\hat{y},Y) = \frac{|{y \in Y \mid y \in \hat{y}}|}{|Y|} \)$
也就是正确找到多少答案,占总答案数的比例。
作用:¶
RL的信号来源:奖励函数告诉 MemAgent 哪些记忆是“有价值”的。
目标驱动记忆压缩:通过奖励,模型学会保留重要信息,忽略干扰信息,实现高效长上下文处理。
3.4 从自回归建模视角重新思考 MemAgent¶
核心思想:¶
标准 自回归 LLM 计算序列概率时,需要保存所有历史隐藏状态或上下文: $\( [ p(x_{1:N}) = \prod_{n=1}^{N} p(x_n | x_{1:n-1}) ] \)$
问题:上下文越长,注意力计算成本越高,导致二次复杂度 (O(N^2))。
MemAgent 的改进:
用固定长度的 memory 替代历史上下文:
Memory \(\mathbf{m} \in \mathbb{V}^M\) 长度固定,不随上下文增长。
文本分块处理:
文本被分成 K 个 chunk \((c^1, c^2, ..., c^K)\)
每读完一个 chunk,MemAgent 就更新 memory:\(\mathbf{m}^{k} = f(\mathbf{m}^{k-1}, c^k)\)
计算和内存开销固定:
每一步的计算量 \(O(C + M)\),C 为 chunk 长度,M 为 memory 长度
整体线性增长:\(O(K(C + M))\),避免了传统自回归模型的二次复杂度。
优势:
无限长度支持:文档可以非常长,因为 memory 固定长度,模型不会崩掉。
高效且可扩展:不修改模型架构即可实现长上下文推理。
可解释性:Memory 就像是对过去重要信息的浓缩总结。
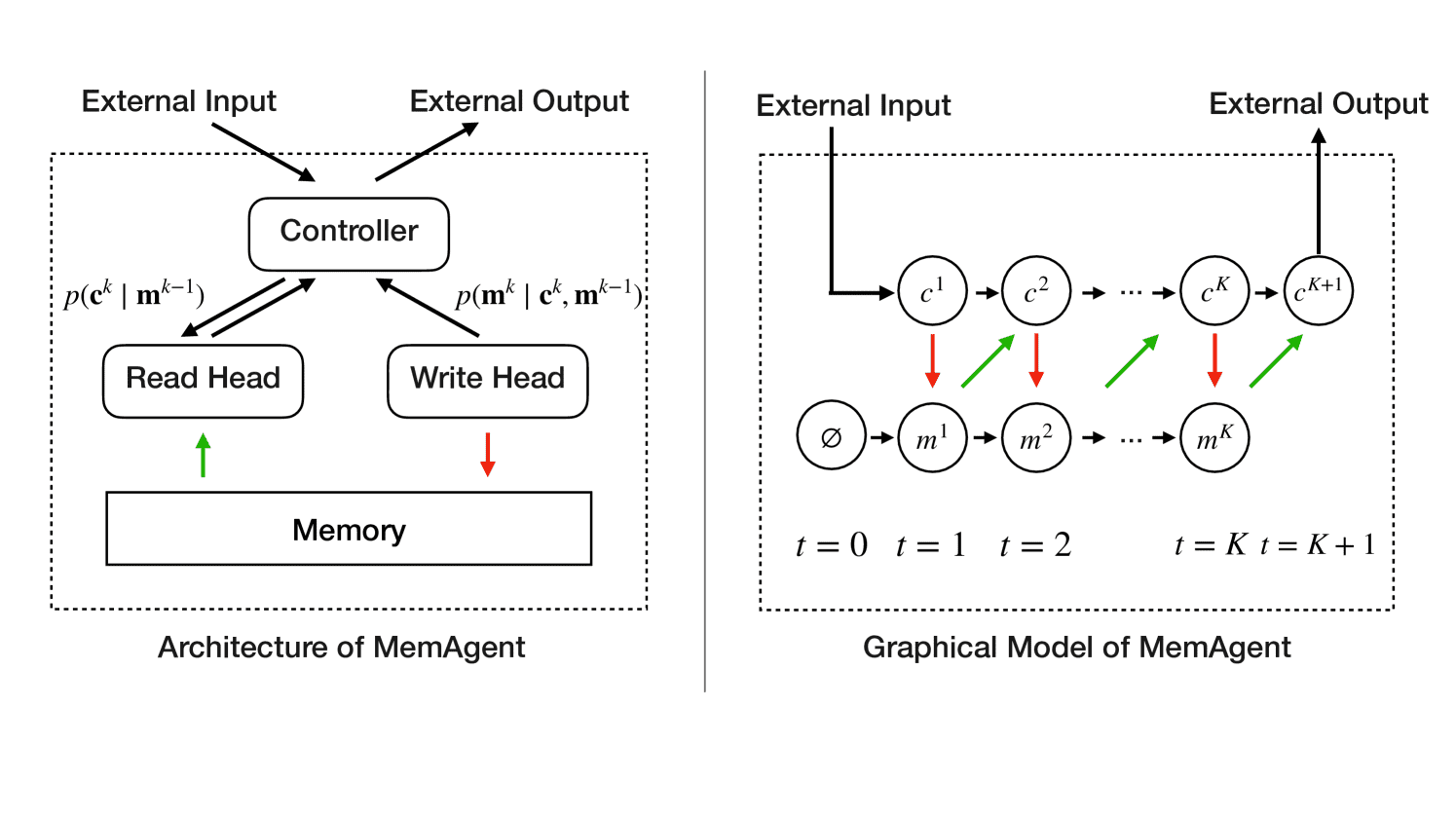
Figure 4:The architecture and graphic model of MemAgent. The memory is modeled as a latent memory variable, thereby enabling the decomposition of the autoregressive language model into multiple steps of reading from and writing to the memory.
总结¶
MemAgent 是一种基于强化学习和固定长度记忆机制的新型长上下文处理框架,具有以下优势:
无限上下文支持:通过流式处理和记忆压缩,支持任意长度的文档;
线性复杂度:计算和内存消耗与输入长度成线性关系;
无需架构修改:仅需在原始大模型基础上添加记忆模块和强化学习训练;
多任务适用性:通过灵活的奖励建模,支持问答、抽取等多种任务;
记忆可解释性:记忆是 token 级别的,便于人工干预和奖励设计。
该方法为构建高效的长上下文推理模型提供了一个实用的工程方案。
4 Experiments¶
本节总结了论文中关于 MemAgent 模型在长文本任务中的实验设计、数据集、实验设置、主要结果、消融研究以及案例分析等部分的内容,重点突出模型在 长上下文推理和记忆机制 上的表现和优势。
4.1 数据集¶
本研究主要使用了 RULER 数据集,该数据集支持对模型在不同长度上下文中表现的评估。RULER 中包含一个 QA 子集,通过对 HotpotQA 等数据集进行合成,生成长上下文问答任务。其设计灵感来源于“针在 haystack 中”的范式,即在一个长文档中嵌入正确答案段落(needle),并添加大量干扰段落(haystack)。
合成数据:使用 HotpotQA 生成了包含 200 篇文章、约 28K token 的训练数据。
数据清洗:过滤掉无需上下文即可回答的问题(如常识性问题),保留了 32,768 个样本用于训练。
测试样本生成:从 HotpotQA 的验证集中生成 128 个样本,并合成多个长度的测试集,上下文长度从 7K 增至 3.5M tokens。
4.2 实验设置¶
训练细节¶
使用 Qwen2.5-7B-Instruct 和 Qwen2.5-14B-Instruct 作为基础模型。
使用 verl 框架 实现多轮对话中的独立上下文处理。
训练时限制上下文窗口为 8K token,分配如下:
查询:1024 token
上下文块:5000 token
记忆:1024 token
输出:1024 token
剩余用于聊天模板
模型通常需要 5~7 轮对话来处理完整上下文。
超参数¶
使用 GRPO 算法 进行训练,KL factor 设置为 1e-3,禁用熵损失。
使用 AdamW 优化器,学习率为 1e-6,线性 warm-up。
批次大小分别为 128(7B)和 256(14B),组大小为 16。
批次比例为 16。
模型配置¶
对比的基线模型包括:
DeepSeek-R1-Distill-Qwen(128K 上下文)
Qwen2.5-Instruct-1M(1M 上下文,使用 DCA 扩展)
QwenLong-L1(128K 上下文)
4.3 主要结果¶
主要实验结果总结在 Table 2 中,评估了不同模型在 7K 到 3.5M token 上下文长度下的性能表现。
核心发现:¶
MemAgent 模型 在上下文长度增加时性能几乎无下降,尤其是在 1.75M 和 3.5M tokens 上仍保持高水平准确率。
基线模型 在超出训练长度后性能显著下降:
QwenLong-L1-32B:性能在 28K token 后急剧下降。
Qwen2.5-Instruct-1M:在 896K token 时性能归零,远低于其理论最大上下文长度。
DS-Distill-Qwen 系列:性能在 112K token 开始明显恶化。
Table 2 简化总结(部分数据):¶
模型 |
7K |
14K |
28K |
56K |
112K |
896K |
1.75M |
3.5M |
|---|---|---|---|---|---|---|---|---|
RL-MemAgent-14B |
83.59 |
82.03 |
84.38 |
80.47 |
76.56 |
77.34 |
76.56 |
78.12 |
Qwen2.5-Instruct-14B-1M |
60.16 |
60.94 |
50.00 |
57.03 |
50.00 |
0.00 |
N/A |
N/A |
MemAgent 明显优于基线模型,尤其是在超出训练长度的极端上下文长度下表现稳定。
4.4 消融研究¶
强化学习的影响¶
未使用 RL 的记忆机制 虽然比原始模型好,但在上下文长度超过 112K token 后性能下降明显。
使用 RL 的模型(MemAgent) 能在长上下文中保持稳定高准确率,说明 强化学习是有效利用记忆的关键。
OOD 任务泛化能力¶
在 RULER 的 OOD 任务中(如 needle-in-a-haystack、变量跟踪、高频词提取、QA 任务等),MemAgent 在 8K~512K token 范围内的平均准确率超过 95%。
尤其在 SQuAD 基础的 QA 任务中,MemAgent-7B 和 MemAgent-14B 均表现出色,优于 32B 的非 RL 模型。
对比基线模型,MemAgent 在所有任务中都能保持稳定性能,说明其 记忆机制具有良好的泛化能力。
4.5 案例研究¶
通过一个具体案例展示了 MemAgent-14B 在处理两跳 QA 问题时的推理过程:
问题:浪漫喜剧《Big Stone Gap》的导演基于纽约市的哪个区域?
模型在三轮对话中逐步检索并更新记忆,最终正确识别出导演 Adriana Trigiani 并准确回答其位于 Greenwich Village, New York City。
案例要点:¶
第一轮:记住“Ghost”团队的信息,为后续对话做准备。
第二轮:无新信息,记忆保持不变。
第三轮:识别到关键文档,更新记忆,得出最终答案。
该案例说明:MemAgent 的记忆机制能主动识别并存储有用信息,并在后续对话中使用,且不受无关信息干扰。这种能力是由 RL 培养出来的,而非传统注意力机制。
总结(按章节结构)¶
章节 |
要点 |
重点 |
|---|---|---|
4.1 数据集 |
使用 RULER 数据集,合成 HotpotQA 数据,测试长度从 7K 到 3.5M tokens |
合成数据与上下文长度设计 |
4.2 实验设置 |
选择 Qwen2.5 系列模型,设置 8K 上下文限制,使用 RL 训练 |
模型配置与 RL 训练机制 |
4.3 主要结果 |
MemAgent 在长上下文中性能稳定,基线模型在超出训练长度后性能下降 |
MemAgent 的长度外推能力 |
4.4 消融研究 |
RL 显著提升记忆机制,MemAgent 在 OOD 任务中泛化能力强 |
强化学习与泛化能力 |
4.5 案例研究 |
展示 MemAgent 多轮推理与记忆更新流程 |
模型在实际 QA 场景中的应用能力 |
结论¶
本研究通过一系列实验和分析验证了 MemAgent 模型 在长上下文处理任务中的优越性。其核心创新在于利用 强化学习驱动的记忆机制,使得模型在远超训练长度的上下文中仍能保持高精度,并在多种任务中展现出良好的泛化能力。相比现有方法,MemAgent 在处理真实世界长文本任务中具有更强的实用性和鲁棒性。
5 Conclusion¶
本文提出了一种新颖的长上下文任务建模方法,通过引入潜在变量记忆(latent variable memory)实现。该方法将连续的自回归生成过程分解为一系列从记忆中逐步生成上下文的步骤,从而实现对无限长文本的处理。与现有方法相比,这种方法在基于 Dense-Attention Transformer 的基础上,无需改变生成范式或引入额外模型结构,即可达到 O(N) 的计算复杂度。
重点强调的是,我们开发了一个名为MemAgent 的系统,通过强化学习训练的记忆(RL-trained memory)赋予大语言模型(LLMs)记录相关信息并忽略无关细节的能力。实验表明,在训练阶段处理长度为 32K 的数据(包括 8K 的上下文,其中包含 1024 个 token 的记忆和每步处理 5000 个 token 的输入)时,模型能够外推至 3.5M token 的长度,并且在测试中几乎保持性能不变。
此外,消融实验验证了将记忆本身作为长上下文处理机制的有效性,并进一步表明在记忆基础上进行的强化学习训练具有显著优势。在领域内和领域外任务上的结果表明,MemAgent 的表现优于长上下文后训练模型、推理模型以及其他基线模型,在长上下文任务中达到了最先进的性能。
6 Computation Complexity¶
本节讨论了基线模型与MemAgent方法在不同上下文长度下的计算复杂度。通过采用浮点运算(FLOP)估算器,我们分析了Qwen2Model的计算成本,并重点比较了两种模型的复杂度表现。
1. FLOP 估算结果¶
我们使用 verl 提供的FLOP估算方法,计算了基线模型和MemAgent在不同上下文长度(从8K到4M)下的FLOP成本,结果如图7所示。
基线模型的复杂度为 \(O(n^2)\),意味着随着上下文长度 \(n\) 的增加,其计算成本呈平方增长。
MemAgent 的复杂度为 \(O(n)\),表示其计算成本随上下文长度线性增长,显著优于基线模型。
图7说明了MemAgent在处理长上下文任务时的高效性。
2. 基线模型的计算量¶
对于基线模型来说,输入的总token数量为 \(q + c + o\),其中:
\(q\):问题长度;
\(c\):上下文长度;
\(o\):输出长度。
由于其复杂度为 \(O(n^2)\),当 \(c\) 增大时,计算量迅速增加。
3. MemAgent 的计算量分解¶
MemAgent的总FLOP成本是各阶段成本的总和,包含以下三个主要阶段:
• 初始化阶段(Initializing)¶
输入长度为 \(q + 200 + o\);
其中 200 是一个固定值,用于提示模型遵循MemAgent流程。
• 内存更新阶段(Memory Updating)¶
重复次数为 \(k = \lceil \frac{c}{N} \rceil\),其中 \(c\) 是上下文长度,\(N\) 是每轮处理的最大长度(设置为5000);
每次循环的输入长度为 \(q + 200 + N + o\)。
• 最终回答阶段(Final Answering)¶
输入长度为 \(q + 100 + o\),其中包含前序步骤的累积输出。
4. 参数设置¶
实验中使用的参数设置如下:
\(q = 1024\):问题长度;
\(o = 1024\):输出长度;
\(N = 5000\):每轮处理的上下文块大小;
\(c\):上下文长度,范围从 8K 到 4M。
通过上述参数,计算得出MemAgent在不同上下文长度下的FLOP成本,验证其线性复杂度优势。
7 Complete Out-Of-Domain Task Results¶
本节总结了 RULER 基准测试 中涉及的四种主要任务类别及其评估方式:检索(Retrieval)、多跳追踪(Multi-hop Tracing)、聚合(Aggregation) 和 问答(Question Answering)。这些任务通过自动根据输入参数生成的示例来评估模型在长上下文建模方面的能力,参数包括序列长度和任务复杂度。任务复杂度可被理解为输出目标标记的数量与上下文中信号噪声比的函数。
NIAH(Needle-in-a-Haystack)模型评估¶
NIAH(针在 haystack 中) 是一种评估长上下文中检索能力的范式。它通过在大量干扰内容(haystack)中插入关键-值对(needles)来测试模型的检索效率。NIAH 包括以下四种变体:
Single NIAH:要求从干扰内容中检索一个 needle;
Multi-Keys NIAH:在多个干扰 key 中检索一个 needle;
Multi-Values NIAH:要求提取与某 key 关联的所有 values;
Multi-Queries NIAH:要求检索多个不同 key 对应的 needle。
通过不断增加干扰项的数量,任务难度逐步提升。图表(Figure 8-10)展示了模型在 Single-keys NIAH、Multi-keys NIAH 以及 Multi-queries NIAH 和 Multi-values NIAH 等变体中的表现情况,反映出模型在复杂检索任务中的能力。
7.2 变量追踪(Variable Tracking, VT)与高频词提取(Frequent Words Extraction, FWE)¶
VT(变量追踪):评估模型在长序列中追踪变量链的能力,即多跳推理能力;
FWE(高频词提取):要求模型识别在幂律分布下的高频词汇,用于评估其在语言数据中分析词频的能力。
图 11 展示了模型在这两项任务上的表现结果。
总结重点¶
RULER 基准测试 包含四种核心任务类型,用于评估模型在长上下文建模中的表现;
NIAH 是核心的检索任务,包含多个变体,用于测试模型在不同干扰密度下的检索能力;
VT 与 FWE 分别测试模型的多跳推理能力和词频分析能力;
图表详细展示了模型在不同任务难度下的表现,重点在于通过干扰项数量和任务复杂度的变化来评估模型能力。
不重要内容如图片描述及格式信息已简化或省略。