2205.12035_RetroMAE: Pre-Training Retrieval-oriented Language Models Via Masked Auto-Encoder¶
引用: 199(2025-09-13)
组织:
¹ 北京邮电大学,北京,中国
² 华为技术有限公司,深圳,中国
总结¶
总结
MAE: Masked Auto-Encoder
重构了 Abstract 的内容,核心点都已讲清楚
重构了 3.Methodology 章节,但其中的 增强解码(enhanced decoding) 还没完全弄明白
RetroMAE
三个关键设计(创新点)
新颖的MAE工作流程
与传统的 MAE 不同,RetroMAE 对输入句子在编码器和解码器中使用不同的掩码
编码器从部分掩码的输入中生成句子嵌入(sentence embedding),
解码器通过这种句子嵌入和另一个掩码输入,利用**掩码语言建模(Masked Language Modeling)**来恢复原始句子
不对称的模型结构
编码器:是一个大型、深层的Transformer(像BERT一样),功能强大,负责提炼精华信息
解码器:是一个非常小的、只有一层的Transformer,功能简单
好处:这种“大编码器,小解码器”的结构迫使信息瓶颈集中在那个“句子嵌入”向量上
不对称的掩码比率
编码器:掩码比例较低(15~30%)。输入信息相对完整,让它能较好地理解句子,生成高质量的嵌入。
解码器:掩码比例极高(50~70%)。输入信息极度残缺,重建任务非常困难。
好处:极高的解码器掩码比率是成功的关键。它把重建任务的难度推到极致,从而最大程度地压榨编码器,让它生成尽可能精准和包含信息的句子嵌入。
Abstract¶
这段话的核心是:虽然预训练模型在NLP的很多任务上都很成功,但如何为“密集检索”任务专门设计一个有效的预训练方法,仍然是一个需要探索的问题。本文提出的RetroMAE就是为了解决这个问题。
段落大意总结¶
RetroMAE 是一种专门为密集检索(Dense Retrieval)任务设计的新型预训练方法。它基于掩码自编码器(MAE)的思想,但进行了三项关键改进,使得预训练后的模型能更好地理解句子含义,从而在检索任务中表现出色,在多个权威评测基准上都达到了新的最高水平。
关键概念解析¶
密集检索 (Dense Retrieval):
是什么:一种现代的信息检索技术。传统检索是关键词匹配(比如百度搜索),而密集检索先将文档和查询语句都转换成一系列 高维数字向量(即“密集向量”),然后通过计算向量之间的相似度来找到最相关的文档。
例子:你搜索“如何做一道好吃的番茄炒蛋”,系统不是找包含“好吃”、“番茄”、“炒蛋”这些词的文章,而是理解这个句子的“语义”,然后去找讨论“烹饪技巧”、“家常菜谱”的文档。
为什么需要专门预训练:要让模型学会把语义相似的句子转换成空间上接近的向量,这需要模型有极强的语言理解能力,而通用的预训练模型(如BERT)可能不是最优的。
掩码自编码器 (Masked Auto-Encoder, MAE):
这是一种自监督学习范式。核心思想是:把输入的一部分掩盖掉,然后让模型学习如何重建(预测)被掩盖的部分。
最著名的例子就是BERT:把一句话里的一些词用
[MASK]替换,然后训练模型去预测这些被掩盖的词是什么。
RetroMAE 的三个关键设计(创新点)¶
原文强调了三个设计,这正是它成功的原因:
新颖的MAE工作流程:
步骤一(编码):对 输入句子 进行掩码(比如随机盖住15%的词),然后送入编码器,得到一个代表整个句子核心含义的句子嵌入(Sentence Embedding)(即那个向量)。
步骤二(解码):对 同一个输入句子 进行一次 不同的、更严重的 掩码(比如盖住70%的词),然后把这个被严重破坏的句子和之前步骤一得到的句子嵌入一起送给解码器。
目标:解码器的任务是基于那一点点残缺的输入和代表句子核心含义的“句子嵌入”,完整地重建出原始的句子。
好处:这个过程强迫编码器产生的“句子嵌入”必须包含非常丰富和准确的语义信息,否则解码器根本没法完成如此艰难的重建任务。
不对称的模型结构:
编码器:是一个大型、深层的Transformer(像BERT一样),功能强大,负责提炼精华信息。
解码器:是一个非常小的、只有一层的Transformer,功能简单。
好处:这种“大编码器,小解码器”的结构迫使信息瓶颈集中在那个“句子嵌入”向量上。解码器本身很弱,它要想成功重建句子,就必须极度依赖编码器提供的优质“句子嵌入”。这进一步强化了编码器的学习效果。
不对称的掩码比率:
编码器:掩码比例较低(15~30%)。输入信息相对完整,让它能较好地理解句子,生成高质量的嵌入。
解码器:掩码比例极高(50~70%)。输入信息极度残缺,重建任务非常困难。
好处:极高的解码器掩码比率是成功的关键。它把重建任务的难度推到极致,从而最大程度地压榨编码器,让它生成尽可能精准和包含信息的句子嵌入。
成果与意义¶
效果:用RetroMAE方法预训练出来的模型,在BEIR和MS MARCO(这些都是评估检索系统性能的权威基准数据集)上表现极佳,刷新了多项纪录(SOTA)。
特点:方法简单,但效果惊人。
1 Introduction¶
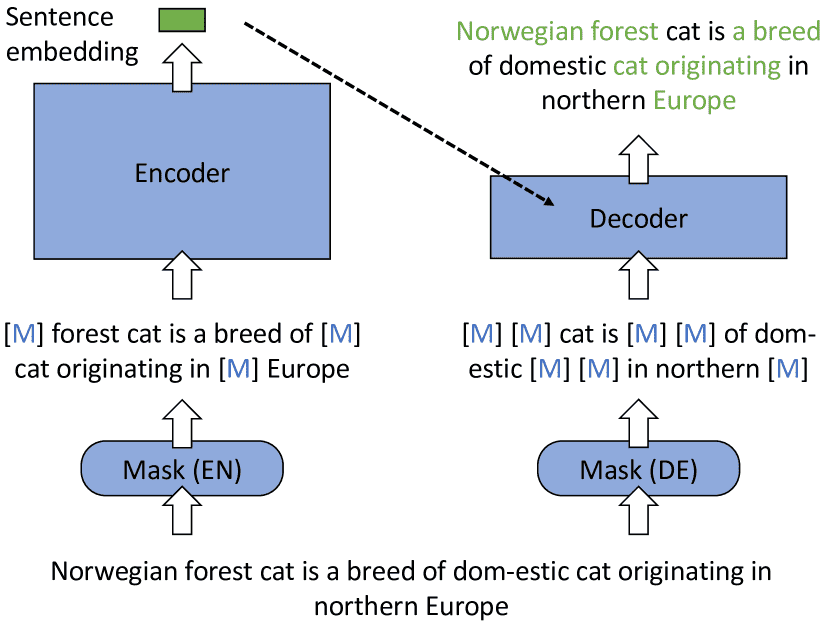
Figure 1:RetroMAE. The encoder utilizes a full-scale BERT, whose input is moderately masked. The decoder is a one-layer transformer, whose input is aggressively masked. The original input is recovered based on the sentence embedding and the decoder’s input via MLM.
背景介绍¶
dense retrieval(密集检索) 在许多网络应用中具有重要作用。通过将语义相关的问题和文档表示为在嵌入空间中彼此接近的向量,密集检索可以借助近似最近邻搜索(如 PQ、HNSW)高效实现。
近年来,大规模语言模型 被广泛用作密集检索的编码器。主流模型如 BERT、RoBERTa 和 T5 通常通过 token 级任务(如 MLM、Seq2Seq)进行预训练,但这些任务并没有充分提升句子级别的表示能力,这限制了它们在密集检索中的潜力。
现有方法的局限性¶
为解决上述问题,研究者提出了检索导向的预训练模型。其中一种主流策略是自对比学习(self-contrastive learning),它依赖于数据增强,但这种方法受限于数据增强的质量,并且通常需要大量负样本,成本较高。
另一种策略是自编码(auto-encoding),如 MAE 等方法,无需依赖数据增强或负样本。当前的研究主要集中在编码-解码流程的设计上,但如何设计更有效的自编码框架仍是一个开放问题。
本文提出:RetroMAE¶
作者认为,基于自编码的预训练关键在于两个方面:
重建任务必须对编码质量提出高要求;
预训练数据必须被充分利用。
为此,作者提出了 RetroMAE,其核心设计包括:
新的 MAE 流程:输入句子被两次使用不同掩码污染。编码器使用中等掩码比例的输入生成句子嵌入,解码器使用高掩码比例的输入,结合句子嵌入进行 MLM 重建原句。
非对称结构:编码器使用完整的 BERT,生成高质量的嵌入;解码器结构极度简化,仅使用一层 Transformer,专注于重建原句。
非对称掩码比例:编码器输入掩码比例为 15%~30%,解码器输入掩码比例为 50%~70%,促使编码器学习更深层次的语义信息。
优势分析¶
RetroMAE 的设计具有以下优点:
提升编码质量要求:相比传统自回归和 MLM,RetroMAE 的解码输入被严重掩码,使得重建过程依赖于编码器生成的高质量句子嵌入。
充分利用输入信息:相比传统 MLM 仅利用 15% 的 token,RetroMAE 可以在 100% 的 token 上生成训练信号。
增强解码机制:采用双流注意力与位置特定掩码,进一步提升了重建效果。
实验结果¶
RetroMAE 实现简单且效果显著。仅使用 Wikipedia、BookCorpus 和 MS MARCO 数据进行预训练,使用 BERT base 编码器:
在零样本设置中,平均 BEIR 得分为 45.2;
在监督设置中,通过知识蒸馏,MS MARCO 任务的 MRR@10 达到 41.6。
这些成绩在相同模型规模和预训练条件下是前所未有的。作者还对各组件的影响进行了详细评估,为未来研究提供了有价值的见解。
3 Methodology¶
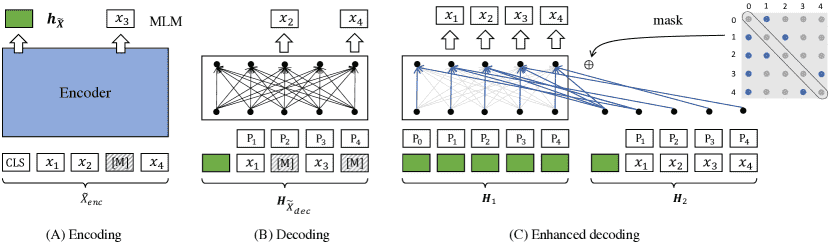
Figure 2:RetroMAE pre-training workflow.
图解
(A) Encoding: the input is moderately masked and encoded as the sentence embedding (the green rectangle).
(B) Decoding: the input is aggressively masked, and joined with the sentence embedding to reconstruct the masked tokens (the shadowed tokens).
(C) Enhanced encoding: all input tokens are reconstructed based on the sentence embedding and the visible context in each row (defined in Eq. 7); the main diagonal positions are filled with −∞ (grey), and positions for the visible context are filled with 0 (blue).
本章提出了一种新的面向检索的预训练模型 RetroMAE,它基于掩码自编码器(masked auto-encoder)架构。该模型由两个模块组成:
一个类似 BERT 的编码器 Φenc,用于生成句子嵌入;
一个单层 Transformer 解码器 Φdec,用于句子重建。
输入句子 X 首先被掩码为 X̃enc,输入编码器生成句子嵌入 h̃X;然后再次被掩码为 X̃dec,与 h̃X 一起输入解码器进行重建。整个预训练流程在图 2 中展示。
这段文字描述了一种名为 RetroMAE 的新型预训练模型,其核心目标是学习高质量的句子嵌入(Sentence Embedding),以便用于检索任务(例如,给定一个查询句子,从海量文本中找出最相关的句子)。
它的核心思想是:通过“破坏-重建”句子的过程,迫使模型学习到句子深层、本质的语义信息。 如果模型能仅凭一部分信息就高质量地重建原句,说明它提取的句子嵌入(h_{X~})一定包含了整个句子的精华。
核心概念比喻¶
你可以把整个过程想象成:
编码(老师快速浏览文章):老师快速浏览一篇被涂掉少量词语(15-30%)的文章,形成一个核心摘要(句子嵌入)。
解码(学生根据摘要和少量提示复述文章):学生拿到老师的摘要,但看到的文章版本被涂掉了大部分词语(50-70%)。他必须结合摘要和剩下的少数词语,猜出所有被涂掉的内容。这个过程非常困难,迫使学生必须极度依赖和信任老师的摘要,从而证明摘要的质量非常高。
增强解码(进阶训练):为了让学生学得更好,我们让他做更复杂的练习。这次他需要复述每一个词,但每次能看到的提示(上下文)都不同且是随机挑选的。这确保他对整个摘要和句子的理解非常全面和灵活。
1. 编码 (Encoding) - 见图2(A)¶
目的:生成句子的表示(句子嵌入
h_{X~})。过程:
输入:原始句子
X。轻度掩码:随机将其中 15% - 30% 的单词替换为
[MASK]标记,得到X~enc。这个比例不高,意味着大部分原始信息都得以保留。编码:将一个 12层的BERT模型 (
Φ_enc) 作为编码器,处理X~enc。输出:取编码器输出的
[CLS]标记对应的向量作为整个句子的嵌入表示h_{X~}。这个向量旨在捕获整个句子的深度语义。
2. 解码 (Decoding) - 见图2(B)¶
目的:检验句子嵌入
h_{X~}的质量。如果能用它和极少的信息重建原句,说明它很好。过程:
重度掩码:对同一个原始句子
X进行第二次掩码,但这次更狠,50% - 70% 的单词被掩码,得到X~dec。这使得重建任务变得极具挑战性。组合输入:将句子嵌入
h_{X~}和X~dec中各个单词的(嵌入+位置编码)拼接起来,形成一个序列H_{X~dec}(公式2)。重建:一个仅有一层的简单Transformer解码器 (
Φ_dec) 接收这个序列,并尝试预测所有被掩码的单词(公式3,使用交叉熵损失)。
设计精髓:
高掩码率 + 弱解码器:这是关键。解码器本身能力很弱(只有一层),输入信息又极度缺失(一半以上的词没了)。它想成功重建,就必须极度依赖那个唯一的“救命稻草”——句子嵌入
h_{X~}。这就倒逼编码器必须生成包含足够多信息的、高质量的句子嵌入。
3. 增强解码 (Enhanced Decoding) - 见图2(C)¶
增强解码的核心目标¶
普通解码的两个缺陷:
训练信号有限:只有被掩码的词(占30-50%)参与损失计算,其他词没有被直接用来训练模型。
上下文单一:所有被掩码的词在重建时,依赖的是完全相同的上下文信息
H_{X~dec}(即句子嵌入+未被掩码的词)。这限制了模型学习多样化的推理模式。
增强解码的目的就是解决这两个问题:
目标1:让输入句子的每一个token都产生训练信号。
目标2:让每个token在重建时,都基于一个独一无二、随机生成的上下文环境。
工作机制详解(三步走)¶
第1步:准备双流输入 (Two-Stream Input)¶
模型创建了两个并行输入序列:查询流 (Query Stream) 和 上下文流 (Context Stream)。
上下文流 (
H2) - “知识库”:H2 = [h_{X~}, e_x1+p1, e_x2+p2, ..., e_xN+pN]h_{X~}:编码器产生的句子嵌入,是整个句子的概要。e_xi + pi:这是原始完整句子X的嵌入,没有任何一个词被掩码!每个词都以其正常的嵌入向量加上位置编码出现。作用:
H2包含了重建所需的所有“知识”或“事实”,但它是一个混乱的集合。模型需要学会从中挑选正确的信息。
查询流 (
H1) - “问题列表”:H1 = [h_{X~}+p0, h_{X~}+p1, h_{X~}+p2, ..., h_{X~}+pN]这个序列全是句子嵌入
h_{X~}的复制品,只是在每个位置i加上了对应位置的位置编码pi。作用:序列中第
i个位置的向量(h_{X~} + pi)可以理解为模型提出的一个特定问题:“在位置i上,原本的词是什么?” 或者 “根据整个句子的概要h_{X~}和位置信息pi,我应该输出哪个词?”
关键点:H2 包含了所有答案,但需要正确的问题来检索。H1 就是一系列定位精准的问题。
第2步:构建位置特定注意力掩码矩阵 (M) - “游戏规则”¶
这是实现“多样化上下文”的核心。矩阵 M 的尺寸是 (L x L),其中 L = N+1(H1 或 H2 的长度)。
M的规则 (公式7): 对于矩阵M的第i行(对应H1中第i个“问题”),其在第j列的值M[i][j]决定了在回答第i个问题时,能否查看H2中第j个“知识”项。M[i][j] = 0:允许关注(softmax时正常计算)。M[i][j] = -∞:禁止关注(softmax后权重为0)。
如何为第
i行设置规则?永远禁止自我关注:
M[i][i] = -∞。这是最重要的规则。在重建位置i的词时,绝不允许直接看到H2中位置i的答案(即e_xi+pi)。否则任务就变成了简单的复制,失去了训练意义。永远允许关注句子概要:
M[i][0] = 0。第0位是句子嵌入h_{X~},这是重建的根本依据,永远可用。随机采样一部分其他token作为上下文:从除第
i个token以外的所有token中,随机采样一小部分(例如15%),将这些token对应的位置j设置为M[i][j] = 0。其余全部禁止:其他所有位置都设为
-∞。
结果:每一行 i 的掩码模式都是随机且独特的。这意味着:
重建
word1时,能看到的上下文是[概要] + [随机一组词,比如 word3, word5]。重建
word2时,能看到的上下文是[概要] + [另一组随机词,比如 word1, word4, word7]。…
这样就完美实现了 “基于多样化上下文进行重建” 的目标。
第3步:执行注意力与计算损失¶
注意力计算:
将 查询流
H1作为 Query (Q)。将 上下文流
H2作为 Key (K) 和 Value (V)。使用上面生成的位置特定掩码矩阵
M。执行标准的掩码自注意力计算(公式5):
A = softmax((QK^T)/√d + M) * V
输出与损失:
注意力输出的序列
A与H1(通过残差连接) 一起,送入一个前馈网络(FFN),最终产生一个概率分布,用来预测每个位置的词。最关键的变化:损失函数(公式6)不再是只计算被掩码的词,而是计算整个原始句子
X的所有位置上的交叉熵损失。ℒ_dec = Σ_{每一个xi in X} CE(xi | A, H1)
这意味着每一个词,无论它最初有没有被掩码,现在都成为了一个训练样本,为模型提供训练信号。
比喻与总结¶
想象一个极端严格的考试:
普通解码:考官给你一篇文章(
X~dec),其中很多句子被挖空,再给你一个摘要(h_{X~})。让你填所有空。所有考生看到的题目和提示都一样。增强解码:
考官给你一本完整的、未删减的百科全书(
H2),里面包含所有答案。但发给你一张独一无二的“答题卡”(
M)。这张卡上对于每一道题“第i个词是什么?”,只允许你查阅百科全书里的特定几页(比如摘要页、第3页、第5页)。你(模型)必须根据这张答题卡的规则,从允许你查阅的页面中,整合信息,推理出答案。
最后,考官会检查你答对了所有题目(所有词),而不仅仅是填空题。
这种方法迫使模型不能死记硬背,必须对句子嵌入 h_{X~} 和 token 之间的语义关系有极其深刻和灵活的理解,从而学习到无比强大的句子表示能力。这正是其为“检索 oriented”而设计的原因——检索需要模型对语义的细微差别有精准的把握。
总结与优势¶
总损失:最终目标是同时最小化编码器的MLM损失
ℒ_enc和解码器的重建损失ℒ_dec。** RetroMAE 的优势**:
高效:解码器只有一层,计算成本低。
有效:艰巨的重建任务确保了句子嵌入的高质量。
信号丰富:增强解码机制充分利用了每一个输入词作为训练信号。
简单:不需要复杂的数据增强或负样本采样策略。
总而言之,RetroMAE 通过设计一个“难题”(用极其简化的解码器和高度残缺的输入来重建句子),巧妙地创造了一个强大的自监督信号,从而训练出一个能为检索任务生成卓越句子表示的编码器。
4 Experimental Studies¶
本节主要评估了 RetroMAE 预训练编码器在句子嵌入检索任务中的性能,从两个关键方面进行了探索:一是 RetroMAE 在零样本和监督检索任务中的表现,并与通用预训练模型和检索专用预训练模型进行对比;二是 RetroMAE 中四个技术因素的影响,分别为增强解码、解码器尺寸、解码器掩码比例和编码器掩码比例。
4.1 实验设置总结¶
数据集¶
预训练数据:使用了 BERT 常用的英文维基百科和 BookCorpus,并在 MS MARCO 上进行了在域预训练(对 MS MARCO 的表现影响显著)。
评估数据:
监督检索:MS MARCO 和 Natural Questions,用于评估模型在检索任务中的性能。
零样本检索:使用 BEIR 基准,在 18 个跨领域任务中评估模型的迁移到能力。
基线模型¶
通用预训练模型:BERT、RoBERTa、DeBERTa。
检索专用模型:
自对比学习类:SimCSE、LaPraDoR、DiffCSE。
自编码类:SEED、Condenser。
RetroMAE 实现细节:使用双向 Transformer 编码器(12 层,768 维),单层 Transformer 解码器,默认掩码比例编码器 0.3,解码器 0.5,使用 AdamW 优化器和 8×A100 GPU 训练。
评估方法¶
零样本检索:使用 BEIR 基准,采用 NDCG@10 指标。
监督检索:使用 DPR 和 ANCE 进行微调,并结合知识蒸馏(distillation)方法进行评估。
4.2 主要实验结果总结¶
零样本检索¶
RetroMAE 的优势显著:在 BEIR 基准的 18 个任务中,RetroMAE 的平均 NDCG@10 指标为 0.452,比最强基线模型高 4.5%。
提升来源:性能提升主要来自预训练算法的改进,而非模型规模或训练数据的增加。
监督检索¶
RetroMAE 在 DPR 和 ANCE 微调后均表现优异:
在 MS MARCO 和 Natural Questions 两个任务中,均优于其他模型,提升幅度显著(+1.4% 到 +2.8%)。
与最新模型对比:
在 MS MARCO 上,RetroMAE 超过 coCondenser、AR2、ColBERTv2、RocketQAv2、ERNIE-Search 等模型,MRR@10 提升最高达 2.8%。
实验观察¶
通用模型(如 RoBERTa、DeBERTa)在检索任务中不如 BERT,这说明通用预训练未必适合检索任务。
自编码预训练模型(如 SEED、Condenser、RetroMAE)在检索任务中表现更优。
自对比学习模型在微调后提升有限,说明其在检索任务中对微调的依赖较大。
4.3 消融实验总结¶
RetroMAE 的性能受以下四个技术因素的影响:
1. 增强解码 vs. 基本解码¶
增强解码效果更好:通过更充分和多样化的训练信号,显著提升检索性能。
2. 解码器层数¶
单层解码器表现最优:增加解码器层数并未带来性能提升,且无法使用增强解码。
3. 解码器掩码比例¶
掩码比例影响显著:
在使用增强解码时,最优掩码比例为 0.5。
未使用增强解码时,最优比例为 0.7。
高掩码比例能提升训练信号的多样性,从而改善检索性能。
4. 编码器掩码比例¶
中等掩码比例(0.3)表现最佳:掩码比例过高(如 0.9)会破坏句子嵌入质量,导致性能下降。
总结¶
增强解码是提升性能的关键。
单层解码器结构最优。
解码器高掩码比例、编码器适度掩码比例有助于提升检索效果。
总体结论¶
RetroMAE 作为一种基于掩码自编码的检索专用预训练模型,表现出以下优势:
零样本能力强:在跨领域任务中表现优于其他模型。
监督微调后效果好:在 MS MARCO 和 Natural Questions 任务中均达到 SOTA。
结构设计合理:增强解码、单层解码器、掩码比例等关键因素对其性能有显著影响。
这些实验结果证明了 RetroMAE 在预训练模型设计方面的有效性,特别是在提升检索性能方面具有显著优势。
5 Conclusion¶
本文提出了 RetroMAE,这是一种用于预训练面向检索的语言模型的新型掩码自编码框架。其核心机制是:对输入句子在编码器和解码器中进行随机掩码处理,并将句子嵌入与解码器的掩码输入结合,以重建原始输入。这一设计旨在提高模型对语义信息的捕捉能力。
重点内容讲解:¶
模型结构的非对称性
采用不对称模型架构:使用全规模编码器(full-scale encoder)和单层解码器(single-layer decoder)。这种结构设计有助于在计算效率与性能之间取得平衡。
掩码比例不对称:对编码器采用中等掩码比例,而对解码器使用较高掩码比例。这种设计增加了重建任务的难度,从而提升了模型学习的深度。
改进的解码机制
引入了增强解码(enhanced decoding)技术,充分利用预训练数据。这有助于提升模型在实际任务中的泛化能力。
实验验证
在 BEIR、MS MARCO 和 Natural Question 等主流检索数据集上的实验结果表明,RetroMAE 在零样本(zero-shot)和监督(supervised)评估中均表现出显著优于现有方法的性能。
精简内容讲解:¶
所有设计目标都是为了提升语言模型在信息检索任务中的表现,特别是在输入不完整或需要进行密集语义匹配的场景下。
实验部分验证方法的有效性,强调了在多个基准任务中的优越性。
总结而言,RetroMAE 通过创新的掩码策略、非对称结构和增强解码机制,为预训练语言模型在检索任务中的应用提供了新的有效路径。
6 Limitations¶
本节主要探讨了当前研究中存在的几个限制因素。
首先,研究基于 BERT base 规模的 Transformer 模型进行。虽然 BERT base 已经在许多任务中表现出色,但更大型的网络(如 BERT large 或更大)可能会带来性能的进一步提升。这一点在近期的工作中(如 Ni 等人,2021)也得到了验证,网络规模的扩大通常对模型效果有积极影响。因此,扩大网络规模的影响仍有待探索。
其次,预训练数据量仅达到中等水平,这主要是由于计算资源的限制。尽管当前的实验结果已经显示出模型的有效性,但已有研究表明,增加预训练数据量对模型性能有显著提升作用。因此,预训练数据量增加对模型的影响也值得进一步研究。
重点总结:¶
模型规模受限:目前仅使用 BERT base 模型,未来可尝试更大规模的网络。
数据量有限:由于计算资源限制,预训练数据量较少,需探索更大规模数据对性能的影响。
研究意义:尽管当前结果有效,但扩大模型和数据规模可能是未来提升性能的关键方向。