2502.00592_M+: Extending MemoryLLM with Scalable Long-Term Memory¶
引用: 2(2025-08-17)
组织:
1UC, San Diego
2MIT-IBM Waston Lab
3IBM Research
4Amazon
5OPPO.
总结¶
【定义】记忆模块分类
Token-level Memory(token级记忆):
将记忆表示为结构化文本,便于在token级别进行检索与操作
Latent-space Memory(潜在空间记忆)❇️:
以高维向量形式在隐藏空间中存储信息,更加抽象、紧凑。
潜在空间记忆在压缩性、训练端到端性和人类记忆机制模拟性上更优。
关键创新
结合MemoryLLM,并引入了长期记忆机制;
采用了一个共训练的检索器(co-trained retriever),在文本生成过程中动态检索相关信息,从而增强对长期上下文的利用。
M+
MemoryLLM
它是 M+ 的基础结构
由两部分组成
θ(记忆池)
ϕ(基于 Transformer 的解码器语言模型)
训练分为三个阶段:
MemoryLLM 的持续训练(阶段 1)
长文档建模(阶段 2)
引入长期记忆(阶段 3)
未来的工作重点
减少 CPU 与 GPU 之间的通信开销,从而提升 M+ 在实际应用中的生成效率
Abstract¶
本文的研究主题是为大语言模型(LLMs)增强潜在空间记忆能力(latent-space memory),以扩展其上下文窗口,从而更好地处理长文本任务。
研究背景:
当前大语言模型的上下文窗口有限,难以处理较长的输入序列。MemoryLLM 是一个具有潜在空间记忆能力的代表性工作,它通过将过去的信息压缩到所有层的隐藏状态中,形成一个包含 10 亿参数的记忆池。该方法在处理 16k token 以内的序列时表现良好,但在超过 20k token 后信息保留能力显著下降,这是现有方法面临的一个挑战。本文贡献:
本文提出M+,这是一个基于 MemoryLLM 的增强模型,在长时记忆能力上取得了显著提升。M+ 的关键创新在于:引入了长期记忆机制;
采用了一个共训练的检索器(co-trained retriever),在文本生成过程中动态检索相关信息,从而增强对长期上下文的利用。
实验与结果:
M+ 在多个基准任务上进行了评估,包括长文本理解和知识保留等任务。实验结果表明:M+ 显著优于 MemoryLLM 和最新的强基线模型;
将知识保留能力从 20k token 扩展到了 160k token,且在 GPU 内存消耗方面与 MemoryLLM 相当。
关键词:
混合专家(mixtural-of-expert)、记忆机制(memory)、大语言模型(large language model)。
1 Introduction¶
本节主要介绍了将 记忆模块(memory modules) 集成到 大语言模型(LLMs) 中的研究背景与现状,并重点探讨了 潜在空间记忆(Latent-Space Memory) 方法的优势及其在当前模型中的应用,最终引出了本文提出的新模型 M+。
1.1 当前记忆模块分类¶
当前构建记忆模块的方法可以分为两类:
Token-level Memory(token级记忆):
特点:将记忆表示为结构化文本,便于在token级别进行检索与操作。
优点:模型可替换性强、可解释性好(文本形式易于人类理解)。
缺点:文本形式可能冗余,压缩性差;当存在冲突信息时,处理难度大。
Latent-space Memory(潜在空间记忆):
特点:以高维向量形式在隐藏空间中存储信息,更加抽象、紧凑。
优点:
高效压缩:信息被压缩成隐藏状态或嵌入到模型参数中,减少存储开销。
端到端训练:记忆模块可参与梯度优化,使记忆在训练过程中动态更新。
接近人类记忆机制:人类推理依赖于整合的表示,而非离散token,潜在空间的记忆方式更接近这一机制。
1.2 本文重点:潜在空间记忆¶
本文聚焦于潜在空间记忆方法。代表性工作如 MemoryLLM,它通过在每层中加入大量记忆tokens,构建了一个包含10亿参数的记忆池,通过精心设计的更新与生成机制,在Llama-2-7B及其它长上下文模型中表现出色。
MemoryLLM的局限性:
对于超过20k token的信息,记忆模型的召回能力受限,长期记忆能力不足。
1.3 提出模型 M+¶
为解决上述问题,本文提出了**M+**模型,其主要贡献如下:
引入长期记忆机制并结合MemoryLLM:
M+引入了一个长期记忆机制,并加入了一个共训练的检索器(co-trained retriever),实现高效且有效的记忆检索。
设计长上下文训练数据课程(data curriculum):
通过专门的数据训练策略,增强模型对长上下文的理解能力。
实验验证 M+ 的优势:
在多个基准测试(包括长书理解、知识保留、文档问答等)中,M+ 显著优于现有方法。
同时,M+ 的GPU内存占用与现有方法相当或更低,实现了性能与效率的平衡。
重点总结¶
重点1:当前记忆模块分为token级和潜在空间两种,潜在空间记忆在压缩性、训练端到端性和人类记忆机制模拟性上更优。
重点2:MemoryLLM 是潜在空间记忆的代表作,但存在长上下文记忆能力不足的问题。
重点3:本文提出的 M+ 通过共训练检索器和长期记忆机制,解决了MemoryLLM的局限,并通过实验验证了其在多种任务上的优越性能。
3 Methodology¶
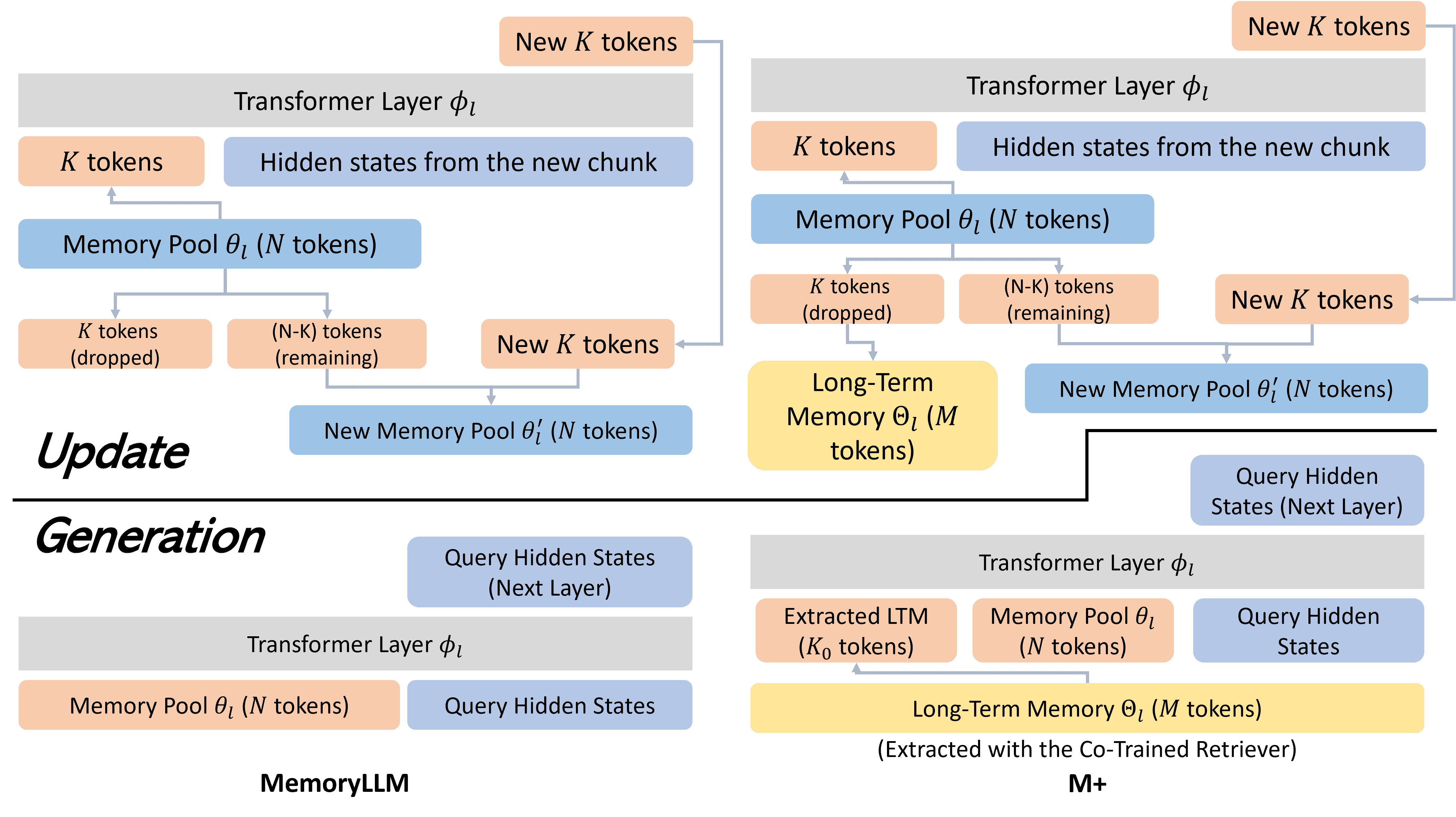
Figure 1:The left side shows the Update and Generation Process of MemoryLLM. The right side shows the Update and Generation Process of M+.
图解:M+ 的改进
(1) 更新过程(Update)
分拆记忆池:将 \( \theta_l \) 分成两部分:
丢弃的 \( K \) 个 Token:存入长期记忆池 \( \Theta_l \)(类似“存档”)。
保留的 \( N-K \) 个 Token:继续留在短期记忆池。
合并新记忆:将保留的 \( N-K \) 个 Token 和新生成的 \( K \) 个 Token 拼接,得到 \( \theta_l' \)。
(2) 生成过程(Generation)
检索长期记忆:
通过一个协同训练的检索器(Co-trained Retriever),从长期记忆池 \( \Theta_l \) 中召回与当前查询相关的 Token。
综合记忆输入:
将检索到的长期记忆 + 短期记忆 \( \theta_l \) + 当前隐藏状态 \( h_l \) 一起输入到 \( \phi_l \) 中生成输出。
MemoryLLM vs. M+ 的关键区别
特性 |
MemoryLLM |
M+ |
|---|---|---|
记忆类型 |
仅短期记忆 \( \theta_l \) |
短期记忆 \( \theta_l \) + 长期记忆 \( \Theta_l \) |
旧记忆处理 |
直接丢弃 |
存入长期记忆池,可后续检索 |
生成时的记忆来源 |
仅当前 \( \theta_l \) |
\( \theta_l \) + 检索到的 \( \Theta_l \) |
记忆跨度 |
受限于 \( N \)(如 50k Tokens) |
理论上无限(依赖检索效率) |
3.1 基础概念¶
本节介绍了 MemoryLLM 的结构,它是 M+ 的基础结构。MemoryLLM 由两部分组成:
θ(记忆池):这是一个包含 L 层的模块,每一层有 N 个记忆 token,每个 token 是一个 ℝ^d 维的向量。d 表示语言模型的隐藏层维度。
ϕ(基于 Transformer 的解码器语言模型):这是标准的语言模型部分。
在更新过程中,每层会从记忆池中提取最后 K 个 token,并与新注入的 chunk 结合,生成新的 K 个 token。然后通过随机丢弃 K 个旧 token,将新 token 添加到记忆池的末尾,完成更新。
生成时,模型通过交叉注意力机制访问记忆池中的内容,以获取相关信息。
3.2 为 MemoryLLM 赋予长期记忆¶
本节描述了如何为 MemoryLLM 添加长期记忆模块,并与原有的短期记忆(θ)进行整合。新增的长期记忆称为 Θ,与短期记忆类似,也有 L 层,每层的大小可扩展,最大容量设为 150k 个 token。
3.2.1 记忆结构¶
长期记忆的更新过程:在更新时,原本被丢弃的 K 个 token 会被保存到 Θ 中,而不是直接删除。每个 token 会记录“年龄”信息,以便在需要时按时间排序。当长期记忆达到容量上限时,会丢弃“年龄”最大的 token。
生成过程:在生成时,每层会从 Θ 中提取 K₀ 个 token(按年龄排序),并与短期记忆合并,通过交叉注意力机制供模型查询使用。
多 LoRA 设计:使用两个 LoRA 权重集,分别用于更新和生成过程。这种设计类似于 T5 中的编码器与解码器权重不共享,有助于模型更高效地学习“写入”与“读取”过程。
3.2.2 检索器设计与训练¶
检索器结构:包含两个投影器(query projector 和 key projector),二者均为两层感知器。输出维度为 d_proj,设置为 d/20,以减少额外内存消耗。
训练目标:在训练时,将文档划分为多个 chunk,前 n-1 个 chunk 注入到短期记忆中,第 n 个 chunk 用于训练。目标是最大化查询与无关记忆(θ⁻)之间的距离,最小化与相关记忆(θ⁺)之间的距离。
3.2.3 训练细节¶
配置设置:M+ 基于 Llama-3.1-8B 模型,在 8 张 A100 GPU 上训练。选择使用 DeepSpeed-stage-2 优化器。每层短期记忆大小为 12,800 token,生成窗口为 2,048。
模型能力上限:由于硬件限制,当前模型处理的上下文长度为 14,848 token。若资源允许,可扩展至 128k token。
3.2.4 数据课程¶
训练分为三个阶段:
MemoryLLM 的持续训练(阶段 1):使用 Llama-3.1-8B 作为基础模型,训练 120 万步,目标是处理短文档。
长文档建模(阶段 2):为增强模型处理长上下文的能力,使用 4k-64k token 的文档进行训练,并对长文档进行过采样。
引入长期记忆(阶段 3):在阶段 2 的基础上引入长期记忆模块,调整短期记忆大小,并从新的长文档数据集中进行训练,以适应长期记忆的结构。
总结结构:
本章详细介绍了 M+ 的方法设计,包括短期记忆与长期记忆的结构、更新与生成机制、检索器的设计与训练、以及训练过程中的具体配置与数据策略。重点内容包括长期记忆模块的实现细节、多 LoRA 权重的设计、以及针对长文档的训练策略。这些组成部分共同构建了 M+ 模型在处理大规模上下文任务时的能力。
4 Experiments¶
本章主要围绕 M+ 模型在多种任务和数据集上的性能表现、GPU 消耗、知识保留能力、内存机制有效性、以及对比实验展开,验证了 M+ 在长文本处理和长时记忆建模方面的优势。
4.1 Long Book QA and Event QA(长书问答与事件问答)¶
4.1.1 Experimental Settings(实验设置)¶
本节评估 M+ 在长文本理解与长时记忆能力方面的表现,使用了两个数据集:
LongBook-QA:
来自 ∞-Bench,包含 351 个 (book, question, answer) 元组。
每本书平均长度为 192k tokens,需从整本书中回答问题。
评估指标为 QA-F1。
LongBook Event QA(本文提出的新基准):
评估模型对事件的顺序记忆与推理能力。
使用 SpaCy 提取每本书前五本书中最常出现的十个角色。
将书分成 4096-token 的块,利用 GPT-4o 提取事件,构建多选问答任务。
评估指标为准确率(accuracy)。
基线模型包括:
Llama-3.1-8B-16k:固定 16k 上下文窗口。
Llama-3.1-8B-SnapKV:使用 SnapKV 技术选择 16k key-value 缓存,但内存开销高。
Llama-3.1-3B-128k:小参数版本,128k 上下文窗口,GPU 内存消耗接近 M+。
Llama-3.1-8B-BM25:使用 BM25 检索器,从全书中检索相关 chunk。
补充实验(见附录):
与基于注意力的检索方法的相似性。
长时记忆的结构(隐藏状态 vs. KV)。
扩展规模时的延迟与内存消耗。
FLOPs 比较。
记忆向量的可解释性。
4.1.2 Experimental Results(实验结果)¶
M+ 在两个数据集上均优于所有基线模型,在使用更少 tokens 的情况下(12,800 + 2,048)实现了更高的 QA-F1 和事件识别准确率。
Llama-3.1-3B-128k 在 LongBook-Event-QA 上表现较差,说明大模型结构对任务表现更关键。
SnapKV 在 LongBook-QA 上表现不如 M+,说明仅依赖注意力得分选择 tokens 的方式效果有限。
BM25 检索器在 LongBook-Event-QA 上表现不及 M+,说明 chunk-level 检索在全局理解任务中存在局限。
M+ 在内存效率方面表现优异,详细对比见 4.2 节。
4.2 GPU Cost Comparison(GPU 开销对比)¶
M+ 的 GPU 内存消耗低于 SnapKV 和 Llama-3.1-3B-128k,仅次于 Llama-3.1-8B-16k。
原因:M+ 在每一层使用 12,800 tokens,而 Llama-3.1-8B-16k 仅在顶层使用 16k tokens。
为降低 GPU 开销,M+ 采用 CPU offloading 机制,将长时记忆 token 存储在 CPU 上,仅在需要时加载回 GPU。
M+ (offload) 在 GPU 消耗上达到最低值(17973.34 MB)。
未引入长时记忆的 MemoryLLM-8B 与 M+ 消耗相近,说明长时记忆并未增加 GPU 开销。
4.3 Knowledge Retention Experiments(知识保留实验)¶
4.3.1 Experimental Settings(实验设置)¶
使用 SQuAD 和 NaturalQA 评估模型对长期知识的保留能力。
插入 干扰上下文(distracting contexts)模拟知识遗忘场景。
从 SQuAD 训练集采样干扰上下文。
基线模型包括 MemoryLLM-7B 和 Llama-3.1-8B-SnapKV(48k 上下文窗口)。
4.3.2 Experimental Results(实验结果)¶
M+ 显著优于 MemoryLLM-7B,说明其改进的长时记忆机制有效。
M+ 超过 Llama-3.1-8B-SnapKV,说明直接存储记忆比依赖 key-value cache 更有效。
SnapKV 在 30k+ tokens 后丢失记忆,说明其机制对长时知识保留存在局限。
附录中 NaturalQA 的结果趋势与 SQuAD 一致。
4.4 Experimental Results on (Relatively) Short Documents(相对短文档实验)¶
使用 LongBench 基准评估 M+ 和 Llama-3.1-8B 在 8k 和 16k 上下文窗口下的表现。
评估指标为 QA-F1。
M+ 在 4 个数据集上表现接近 Llama-3.1-8B,仅在 HotpotQA 和 Musique 上稍差。
性能差异原因:
随机丢弃机制导致部分信息损失。
M+ 使用固定长度的 chunk 限制了跨 chunk 注意力,而 Llama-3.1-8B 能访问所有前缀。
4.5 Ablation Study(消融实验)¶
4.5.1 Ablation Study on Long-term Memory(长时记忆消融)¶
模型训练阶段:
Stage 1:仅训练短时记忆。
Stage 2:引入长时记忆。
Stage 3:最终的 M+。
实验结果:
M+ 在 Slim-Pajama 数据集上达到最低验证损失,说明长上下文建模能力随阶段提升。
长时记忆显著提升知识保留能力:Stage 3 在 SQuAD 和 NaturalQA 上的保留范围分别达到 160k 和 30k tokens。
长时记忆不影响短文档性能:M+ 在 8k 上下文窗口下的 LongBench 表现与 MemoryLLM-8B-Long 相似。
4.5.2 Ablation Study on Retriever(检索器消融)¶
对比 M+ 使用的训练检索器与基于注意力的检索(M+-Attn)。
M+ 明显优于 M+-Attn,说明训练检索器在知识保留与检索效率上更优。
4.6 Analysis(分析)¶
4.6.1 Model Quality within Context Window(上下文窗口内的模型质量)¶
M+ 在 2,048-token 上下文窗口内的 perplexity 与 Llama-3.1-8B 接近,说明其在短文档上质量保持。
4.6.2 Retrieval Quality(检索质量)¶
在长时记忆中,约 30% 的 ground-truth tokens 被成功检索回来,远高于随机检索(3%)。
4.6.3 Latency Analysis(延迟分析)¶
M+ 的延迟主要来源于检索过程。
使用 CPU offloading 后,延迟增加约 1 秒(128k 输入),但总体影响较小。
总结¶
本章通过多个实验验证了 M+ 模型在长文本理解、知识保留、GPU 效率等方面的优越性。M+ 通过引入 可扩展的长时记忆机制 和 高效检索器,在多个数据集上表现优于现有基线模型。虽然其在短文档上略有性能损失,但整体性能与内存效率达到了良好平衡。
5 Conclusion and Future Work¶
本章总结了研究的主要成果,并提出了未来的研究方向。
主要成果:
本文提出了 M+,这是一种增强型的记忆增强语言模型,扩展了 MemoryLLM 的长期记忆能力。通过将长期记忆机制(LTM)与共训练的检索器相结合,M+ 能够有效地检索和利用过去的信息,显著提升了模型的知识保留能力。在给定相似 GPU 内存预算的前提下,M+ 在长上下文理解任务中表现优于近期的基线模型。
未来工作:
未来的工作重点是减少 CPU 与 GPU 之间的通信开销,从而提升 M+ 在实际应用中的生成效率。这一步将有助于进一步优化模型的性能与实用性。
Impact Statement¶
本节主要阐述了该研究工作的影响与潜在问题。
重点内容:
研究贡献:该工作提出了一种增强记忆能力的方法,用于大语言模型(LLMs),使其能够更有效地保留和检索长期信息。这种方法在教育、研究和工业等领域具有潜在的应用价值。
潜在社会影响:由于模型记忆容量的增强,可能会引发关于AI安全性、可靠性和公平性的担忧。例如,如果管理不当,这类模型可能在长文本中传播偏见内容,或存储敏感信息的时间超出预期,带来潜在风险。
应对措施:作者强调,必须采取强有力的保护措施,包括偏见缓解策略和持续监督机制,以防止模型被滥用或加剧有害内容的传播。
次要内容:
除了LLMs本身已有的社会影响外,作者认为该研究不会引发其他重大社会问题。
Appendix A Justifications of using deepspeed-stage-2¶
本节主要说明作者在模型训练中选择使用 deepspeed-stage-2 配置的原因,并对比了三种在 8 张 A100 GPU 上的训练配置:
使用 FSDP(Fully Sharded Data Parallel)进行全量微调,上下文窗口为 8k
使用 FSDP 可以实现高内存利用率和分布式训练,适用于 8k 上下文窗口的模型训练。
但 FSDP 的配置和调试较为复杂。
使用 deepspeed-stage-2,上下文窗口为 6k,且采用全注意力机制
这是作者最终选定的配置。
虽然上下文窗口略低于 FSDP,但 deepspeed-stage-2 提供了良好的平衡,兼顾训练效率和内存使用。
全注意力机制可以更精确地建模长距离依赖关系。
使用 accelerate 和 deepspeed-stage-3-offload 实现 32k 上下文窗口的全注意力机制
此配置理论上可以支持更长的上下文窗口,但作者指出在保存模型时遇到了版本兼容性问题。
至今未找到有效解决方案,因此作者未采用此方法。
重点总结:¶
作者放弃了 FSDP 和 deepspeed-stage-3-offload,因为它们要么调试复杂,要么存在未解决的兼容问题。
综合考虑训练效果与可行性,作者最终选择了 deepspeed-stage-2。
为了提升模型性能,作者将 cross-attention 的形状设置为 2048 × 14848,这是在可用资源下进行的优化配置。
Appendix B Experiments on datasets NaturalQA¶
B.1 NaturalQA 上的知识保持实验(Knowledge Retention Experiments on NaturalQA)¶
本节展示了模型在 NaturalQA 数据集上的知识保持实验结果,如 图8 所示。通过这些实验,作者评估了模型在长时间运行或更新后是否能保留之前学习到的知识。这是衡量模型长期记忆能力的重要指标。
重点内容:图8直观地展示了模型在不同条件下对知识的保留能力,是验证模型长期记忆机制是否有效的关键实验结果。
精简说明:具体的数据和对比分析未在文本中给出,但引用了图8供进一步参考。
B.2 NaturalQA 上的消融实验(Ablation Study on NaturalQA)¶
本节展示了在 NaturalQA 数据集上的消融实验结果,如 图9 所示。消融实验用于评估模型中不同组件或设计选择对整体性能的影响。
重点内容:图9提供了模型不同模块或配置下的性能对比,帮助理解各个设计决策对模型效果的贡献。
精简说明:该部分未提供具体实验设置和数值结果,但对理解模型结构优化至关重要。
总结:
本附录通过图8和图9分别展示了模型在 NaturalQA 数据集上的知识保持能力和不同模块的消融实验结果,重点在于验证模型的长期记忆机制及其关键组件的有效性。
Appendix C Statistics of the Dataset of Long Documents¶
在本节中,我们对整个 SlimPajama-627B 数据集进行了处理,提取出使用 Llama-3.1-8B tokenizer 后长度超过 4k token 的数据部分。统计结果如 表 4 所示。
为了便于分析,我们按长度范围划分为六类(4k-8k,8k-16k,16k-32k,32k-64k,64k-128k,128k+),但我们在实际使用中仅使用了前四类(4k-8k,8k-16k,16k-32k,32k-64k)。这是因为长度超过 64k token 的例子主要来自“Book”类别,并且缺乏多样性,因此不适用于我们的训练和实验。
表 4:各个长度区间的样本数及其来源(数量和百分比)¶
范围(token数) |
总数 |
CommonCrawl |
GitHub |
ArXiv |
C4 |
StackExch. |
Wikipedia |
Book |
|---|---|---|---|---|---|---|---|---|
4k–8k |
11,189,999 |
7,759,741 (69.35%) |
692,224 (6.19%) |
286,537 (2.56%) |
1,825,018 (16.31%) |
142,457 (1.27%) |
481,854 (4.31%) |
2,168 (0.02%) |
8k–16k |
4,706,687 |
3,273,619 (69.55%) |
270,369 (5.74%) |
550,192 (11.69%) |
439,143 (9.33%) |
20,284 (0.43%) |
146,545 (3.11%) |
6,535 (0.14%) |
16k–32k |
1,607,064 |
968,714 (60.28%) |
95,445 (5.94%) |
423,401 (26.35%) |
70,223 (4.37%) |
1,510 (0.09%) |
34,323 (2.14%) |
13,448 (0.84%) |
32k–64k |
443,438 |
224,168 (50.55%) |
32,653 (7.36%) |
146,582 (33.06%) |
3,413 (0.77%) |
102 (0.02%) |
5,940 (1.34%) |
30,580 (6.90%) |
64k–128k |
192,515 |
72,583 (37.70%) |
11,753 (6.10%) |
27,942 (14.51%) |
38 (0.02%) |
5 (0.00%) |
507 (0.26%) |
79,687 (41.39%) |
128k+ |
98,097 |
23,721 (24.18%) |
4,523 (4.61%) |
5,167 (5.27%) |
0 (0.00%) |
2 (0.00%) |
49 (0.05%) |
64,635 (65.89%) |
重点内容讲解:¶
4k–8k token 的数据量最大,总数达 11,189,999 个样本,占所有长文本数据的大部分。
CommonCrawl 是主要的数据来源,在所有长度范围内占比普遍最高,表明其在数据集中占据主导地位。
ArXiv 和 Book 在长度越大的区间中占比越高,例如在 32k–64k token 范围内,ArXiv 占 33.06%,Book 占 6.90%。
64k–128k 和 128k+ 的数据主要来自 Book 类别,且 Book 在 128k+ 范围中占比高达 65.89%。这类数据虽然长度很长,但类别单一,因此在本研究中被排除。
StackExch. 和 Wikipedia 在各长度范围内占比都相对较小,说明它们在长文档中的代表性较低。
总结:¶
本节对 SlimPajama-627B 中的长文档进行了统计,发现大部分长文档集中在 4k–64k token 的范围,且主要来自 CommonCrawl 和 ArXiv。长度超过 64k 的文档主要来自 Book 类别,但由于类别单一,未被实际使用。
Appendix D Additional Training Details¶
在本节中,作者详细介绍了在训练过程中设计的三种子任务,这些子任务基于 MemoryLLM(Wang 等,2024a)的思路,用于更好地模拟和训练模型的记忆能力。整体目标是通过不同方式将文档分块注入到模型内存中,并利用这些信息来训练模型参数 ϕ。
1. Two-Chunk Training(双块训练)¶
重点内容:
这是最基础的训练方式。文档被分为两个块,记为 (x₁, x₂)。训练时,将第一个块 x₁ 注入到模型的“记忆”中,然后使用第二个块 x₂ 来计算损失,并基于该损失更新模型参数 ϕ。
关键点:
使用了两个前向传播过程,并且在两个过程中保留梯度,以确保 x₁ 对模型学习的影响能够传递到 x₂ 的预测中。
这种方式强调模型能够基于前一信息进行后续推理。
2. Multi-Chunk Training(多块训练)¶
重点内容:
对于由多个块组成的文档(x₁, x₂, …, xₙ),训练方式扩展为将前 n-1 个块 (x₁, …, xₙ₋₁) 注入到记忆中,并不计算这些块的梯度,仅使用最后一个块 xₙ 来计算损失并更新模型参数 ϕ。
关键点:
前 n-1 个块在注入时不计算梯度,这种设计减少了计算负担,同时也模拟了模型在面对长文档时,仅关注最新块的场景。
最后一个块 xₙ 负责驱动模型参数的更新。
3. Revisiting Cached Chunks(缓存块的回访)¶
重点内容:
由于训练过程中内存是持续更新的,为了防止模型遗忘之前的信息,作者引入了一个“缓存”机制,将之前文档的最后一个块 xₙ 缓存起来,并定期回访。
关键点:
在回访时,xₙ 前面通常已经注入了多个块(x₁, …, xₙ₋₁),这些块与 xₙ 之间的距离被称为“回访距离”。
作者通过调节缓存中块的删除和更新概率,在不同训练阶段控制平均回访距离:
Stage 1 和 Stage 2:平均回访距离约为 60;
Stage 3:平均回访距离约为 200。
这种机制有助于模型在长期训练中保持对历史信息的记忆能力,防止遗忘。
总结¶
本节详细介绍了三种训练策略,旨在提升模型对长文档和历史信息的记忆能力:
Two-Chunk Training:训练模型基于前一块内容理解后续内容;
Multi-Chunk Training:扩展到多块场景,仅用最新块更新模型;
Revisiting Cached Chunks:通过缓存和回访机制,维持对历史信息的记忆。
这些策略在不同训练阶段中被精心调参,以确保模型在长文档处理和记忆保持方面表现出色。
Appendix E Discussions¶
E.1 与基于注意力的检索方法的相似性¶
在M+中,我们使用了一个共训练的检索器来检索隐藏状态。这种方法与使用注意力机制检索键值对的传统方法有一定相似之处,但有关键的区别:
效率:SnapKV等方法需要为每个注意力头维护和检索键值对,当模型规模扩大时(如32层,每层32个注意力头),需要进行1024次检索,显著增加延迟。而M+只在每层进行一次检索,总共32次,大幅降低了计算成本和延迟。
性能:实验结果(图6)显示,M+在性能上优于基于注意力的检索方法,如SnapKV,说明其在效率提升的同时也带来了性能提升。
设计:M+的训练过程中引入了相关和不相关的文档,适用于对比学习,使得检索器的训练更加自然和有效。
E.2 长期记忆的形式(隐藏状态 vs. 键值对)¶
我们选择使用隐藏状态作为长期记忆的潜空间形式,而不使用键值对(KV)缓存,主要基于以下两点考虑:
压缩效率:我们以无损方式将每512个token压缩为每层256个记忆向量,而KV方法通常需要下采样(如丢弃一半键值),导致信息丢失。
检索效率与性能:隐藏状态通过共训练的检索器进行检索,只需32次检索即可完成查询,而KV方法需要1024次检索,计算成本高。实验表明,隐藏状态的性能也优于KV缓存。
E.3 扩展时的延迟与内存消耗¶
我们分析了M+在扩展时的延迟和内存消耗,得出以下结论:
延迟分析:端到端检索延迟与三个变量线性相关:
检索器的隐藏维度 \(d\)(M+ 中为256,原模型为4096)
长期记忆大小 \(s\)(上限为150k)
Transformer层数 \(L\)(LLaMA-3-8B 为32层)
因此,总延迟 \(\text{latency} \propto d \times s \times L\)。由于 \(s\) 是固定值,延迟简化为 \(\text{latency} \propto d \times L\),而 \(d\) 和 \(L\) 与模型大小成正比,因此延迟与模型大小成线性关系。
具体示例:从 LLaMA-3-8B 扩展到 LLaMA-3-70B,延迟增加约5倍,而参数数量增加约8.75倍,显示延迟增长是线性的而非二次的。
内存消耗:额外的内存开销仅来自引入的记忆向量,其增长也与 \(d\) 和 \(L\) 成线性关系,与延迟增长一致。
E.4 FLOPs对比¶
我们比较了M+与LLaMA-3.1-8B在不同序列长度(从2k到128k)下的FLOPs消耗(使用H100 GPU进行推理):
序列长度 |
LLaMA-3.1-8B |
M+ |
|---|---|---|
2048 |
5.68×10¹³ |
6.92×10¹³ |
4096 |
1.13×10¹⁴ |
1.32×10¹⁴ |
8192 |
2.26×10¹⁴ |
2.55×10¹⁴ |
16384 |
4.48×10¹⁴ |
5.01×10¹⁴ |
32768 |
8.88×10¹⁴ |
9.86×10¹⁴ |
65536 |
1.75×10¹⁵ |
1.94×10¹⁵ |
131072 |
OOM |
3.78×10¹⁵ |
M+在所有长度上与LLaMA-3.1-8B的FLOPs基本相当。
重要的是,LLaMA-3.1-8B在128k时出现内存不足(OOM),而M+仍能正常运行,显示出其在长上下文推理中的可扩展性优势。
E.5 记忆向量的可解释性¶
我们的记忆向量本质上是Transformer各层中的隐藏状态,其关键区别在于它们可能存储了更压缩的信息,因为它们在多个序列中被持久化使用。
跨层模式:我们推测这些记忆向量在不同层中遵循类似于传统Transformer中观察到的表示模式:
低层捕捉表面特征;
高层捕捉语义或抽象信息。
长期与短期记忆:长期记忆由随机从短期记忆中丢弃的向量构成,与短期记忆结构相同,因此在任意时刻交换两者不会影响模型行为。长期记忆本质上是一个缓存,帮助记忆向量在时间上持久化,而不是被快速覆盖。
总结:本附录讨论了M+方法在检索效率、压缩性能、扩展性、计算消耗和记忆向量可解释性方面的关键特性,强调了其在大规模长上下文任务中的优势与创新性。