2504.15965_❇️From Human Memory to AI Memory: A Survey on Memory Mechanisms in the Era of LLMs¶
引用: 11(2025-08-30)
组织:
Huawei Noah’s Ark Lab
总结¶
总结
总结
综述❇️
贡献
提出一种基于三个维度(对象、形式和时间)及与之对应的八象限的分类方法
核心要点
人类记忆主要分为
短期记忆
感觉记忆(Sensory Memory):
保存外部感官输入的原始信息(如视觉、听觉),持续时间极短(毫秒到几秒)。
including
iconic memory (visual),
echoic memory (auditory),
haptic memory (touch),
other sensory data
一些感觉记忆被转移到工作记忆中,而另一些则最终存储在长期记忆中(例如情景记忆)
工作记忆(Working Memory):
用于临时存储和处理信息,支持当前的认知活动(如解决问题、学习)。
工作记忆在信息处理、决策和任务执行中起关键作用。
长期记忆
显性记忆(Explicit Memory):
可以被有意识回忆的记忆
也称为陈述性记忆,是指我们可以轻松地用语言表达或声明的记忆
包括:
情景记忆:
个人经历和事件的记忆(如午餐内容)
这种类型的记忆通常分为编码、存储和检索等阶段
语义记忆:
事实和知识的记忆(如地球绕太阳转的事实)
隐性记忆(Implicit Memory):
无需意识回忆的记忆
内隐记忆,又称非陈述性记忆,是指难以用语言描述的记忆。它与习惯、技能和程序有关,不需要有意识地回忆
包括:
程序性记忆(肌肉记忆,如骑车技能或弹钢琴)
条件反射
三个维度:
对象(Object):
个人记忆(Personal Memory):用户输入的信息,帮助系统理解用户偏好。
系统记忆(System Memory):任务过程中的中间输出,如CoT、ReAct等方法生成的思考链。
形式(Form):
参数化记忆(Parametric Memory):嵌入在模型参数中(如知识预训练),如语义记忆。
非参数化记忆(Non-Parametric Memory):存储在外部数据库中,如RAG(检索增强生成)。
时间(Time):
短期记忆(Short-Term Memory):当前任务中的上下文信息。
长期记忆(Long-Term Memory):跨会话存储的用户个性化数据。
八象限
Personal Memory
Non-Parametric
Short-Term: Loading Multi-Turn Dialogue, 象限I
Long-Term: Memory Retrieval-Augmented Generation, 象限II
Parametric
Short-Term: Memory Caching For Acceleration, 象限III
Long-Term: Personalized Knowledge Editing, 象限IV
System Memory
Non-Parametric
Short-Term: Reasoning & Planning Enhancement, Quadrant-V
Long-Term: Reflection & Refinement, Quadrant-VI
Parametric
Short-Term: KV Management & Reuse, Quadrant-VII
Long-Term: Parametric Memory Structures, Quadrant-VIII
记忆机制(Memory Mechanisms)
编码(Encoding):
将感官信息转化为大脑可处理的格式,包括视觉、听觉、语义等多种方式。
在信息处理方式方面有不同类型的编码,
如视觉编码,它涉及根据颜色、形状或纹理等视觉特征处理信息;
声学编码,关注信息的听觉特征,例如音高、音调或节奏;
语义编码,基于信息的含义,使其更易于构建和记忆。
记忆编码策略(如联想记忆、记忆术)有助于提高记忆效率。
如助记符,它涉及使用首字母缩略词或钉字系统来帮助回忆,
分块,其中信息被分解成更小的、有意义的单元以增强记忆力,
想象力,通过将图像链接到单词来加强编码,
关联,将新信息与先验知识联系起来,以提高理解和长期记忆存储。
存储(Storage):
信息储存在不同脑区,
包括前额叶皮层(工作记忆)、海马体(情景记忆)、大脑皮层(语义记忆)、小脑(程序性记忆)。
提取(Retrieval):
从记忆中调取信息,包括识别、回忆和再学习等形式。
巩固(Consolidation):
将短期记忆转化为稳定的长期记忆,依赖海马体和神经可塑性。
再巩固(Reconsolidation):
记忆被激活后再次进入不稳定状态,可能更新或修改。
反思(Reflection):
主动回顾和评估记忆内容,增强自我认知和学习策略。
遗忘(Forgetting):
自然过程,可通过多种机制(如干扰、记忆衰退)发生。
遗忘有助于大脑筛选重要信息。
Future Directions
从单模态记忆到多模态记忆(From Unimodal Memory to Multimodal Memory)
从静态记忆到流式记忆(From Static Memory to Stream Memory)
从特定记忆到综合记忆(From Specific Memory to Comprehensive Memory)
从独占记忆到共享记忆(From Exclusive Memory to Shared Memory)
从个体隐私到集体隐私(From Individual Privacy to Collective Privacy)
从基于规则的记忆进化到自动进化(From Rule-Based Evolution to Automated Evolution)
Abstract¶
记忆是信息编码、存储和提取的过程,使人类能够在时间上保留经验、知识、技能和事实,并作为成长和有效与世界互动的基础。 它在塑造我们的身份、做决策、从过去经历中学习、建立关系以及适应变化中起着关键作用。
在大型语言模型(LLMs)时代,记忆指的是AI系统保留、回忆和使用过去交互中的信息,以改善未来响应和互动的能力。 尽管先前的研究和综述已经详细描述了记忆机制,但仍缺乏一个系统的综述,来总结和分析LLM驱动的AI系统记忆与人类记忆之间的关系,以及如何从人类记忆中获得启发以构建更强大的记忆系统。
为此,本文提出了一项关于LLM驱动AI系统记忆的全面综述。 首先,我们对人类记忆的类别进行了详细分析,并将其与AI系统的记忆联系起来。 这部分是全文的重点之一,强调人类记忆结构如何为AI系统设计提供借鉴。
其次,我们系统地整理了现有的与记忆相关的工作,并提出了一种基于三个维度(对象、形式和时间)和八个象限的分类方法。 这一部分对现有研究成果进行了系统总结,分类清晰,是本文的核心贡献之一。
最后,我们阐明了当前AI系统在记忆方面的一些开放性问题,并概述了在大型语言模型时代记忆发展的可能未来方向。 这一部分指出了当前研究的不足,并展望了未来研究的发展趋势,为读者提供了研究方向的参考。
1 Introduction¶
1.1 大型语言模型(LLMs)在AI系统中的地位¶
近年来,大型语言模型(LLMs)因其强大的语言理解和生成能力,已成为AI系统的核心组成部分,并被广泛应用于智能客服、自动写作、机器翻译、信息检索和情感分析等领域。与传统依赖预定义规则和人工标注特征的AI系统不同,基于LLM的AI系统更具灵活性,能够适应多种任务并具备更强的上下文感知能力。
此外,引入记忆机制使LLM能够存储用户交互历史和上下文信息,从而在未来交互中提供更个性化、连贯和上下文感知的响应。具备记忆功能的LLM驱动的AI系统不仅提升了用户体验,也为更复杂和动态的应用场景提供了支持,推动AI技术向更智能化和以人类为中心的方向发展。
1.2 人类记忆的分类与机制¶
从神经科学的角度来看,人类记忆是指大脑存储、保留并回忆信息的能力,是理解世界、学习新知识、适应环境和做出决策的基础。人类记忆主要分为短期记忆(包括感觉记忆和工作记忆)和长期记忆(包括显性记忆如情景记忆和语义记忆,以及隐性记忆如条件反射和程序性记忆)。
记忆是一个复杂且动态的过程,依赖于不同的记忆系统来处理信息,影响我们如何理解和回应世界。人类记忆的类型及其工作机制为设计更具科学性和合理性的记忆增强型AI系统提供了重要启发。
1.3 LLM驱动的记忆增强型AI系统¶
在LLM时代,最常见的记忆增强型AI系统是LLM驱动的自主代理系统。这些系统能够通过自然语言执行复杂任务,具备规划、工具使用、记忆和多步骤推理等功能,以增强交互与问题解决能力。记忆作为LLM代理系统的关键组成部分,使LLM能够克服其上下文窗口的限制,从而在交互中记住历史信息并做出更准确的决策。例如,MemoryBank 提出了一种长期记忆机制,帮助LLM通过持续更新和整合历史交互信息来理解并适应用户的个性。此外,诸如 OpenAI ChatGPT Memory、Apple Personal Context、mem0 和 MemoryScope 等系统也引入了记忆机制以提升个性化能力。
1.4 现有研究的局限与本文动机¶
尽管已有研究对记忆机制进行了详细分析,但大多数研究主要从时间维度(短期和长期记忆)进行分类,忽略了记忆的其他维度,如对象维度(个人与系统)和形式维度(参数化与非参数化记忆)。
例如,从对象维度来看,AI系统需要处理与用户相关的个人记忆和系统执行复杂任务时产生的系统记忆;从形式维度来看,AI系统可通过模型参数内的参数化记忆和模型外部的非参数化记忆文档存储信息。因此,当前LLM驱动的AI系统中,从对象(个人与系统)、形式(参数与非参数)和时间(短期与长期)三个维度全面理解记忆的视角仍缺乏,尚无系统性地分析AI系统记忆与人类记忆之间的关系及如何借鉴人类记忆机制构建更高效的AI记忆系统。
1.5 本文贡献¶
为弥补这一研究空白,本文提出了一种对LLM驱动AI系统中记忆机制的全面综述,主要贡献包括:
系统定义并建立LLM驱动AI系统与人类记忆之间的对应关系。
提出一个基于对象(个人与系统)、形式(参数与非参数)和时间(短期与长期)三个维度的分类方法,形成八象限模型,有助于更系统性地研究LLM时代的记忆机制。
从个性化能力提升的角度,分析并总结了与个人记忆相关的研究。
从AI系统执行复杂任务的能力角度,分析并总结了与系统记忆相关的研究。
识别当前记忆研究中存在的问题与挑战,并指出未来发展的潜在方向。
1.6 论文结构¶
本文其余部分安排如下:
第2节:详细介绍人类记忆与AI系统记忆的差异与联系,引入基于三个维度和八象限的记忆分类方法。
第3节:总结与个人记忆相关的研究,旨在提升AI系统的个性化响应能力。
第4节:总结与系统记忆相关的研究,旨在提升AI系统执行复杂任务的能力。
第5节:分析当前记忆相关的开放性问题,并指出未来可能的发展方向。
第6节:总结全文。
2 Overview¶
总体内容概述¶
本章从人类记忆机制出发,探讨其在AI系统设计中的借鉴意义,特别是基于**大语言模型(LLM)**的AI系统。内容分为三个主要部分:
人类记忆系统:介绍人类记忆的分类、机制和运作过程。
LLM驱动的AI系统的记忆:分析AI系统中与人类记忆相对应的记忆机制,并提出一个三维分类方法。
对现有研究的分类与回顾:基于提出的三维分类框架,系统性地总结当前AI记忆相关的研究工作。
2.1 Human Memory¶
2.1.1 短期与长期记忆(Short-Term and Long-Term Memory)¶
人类记忆根据存储时间可分为短期记忆和长期记忆(基于Atkinson-Shiffrin模型)。
短期记忆(Short-Term Memory)¶
感官记忆(Sensory Memory):保存外部感官输入的原始信息(如视觉、听觉),持续时间极短(毫秒到几秒)。
工作记忆(Working Memory):用于临时存储和处理信息,支持当前的认知活动(如解决问题、学习)。工作记忆在信息处理、决策和任务执行中起关键作用。
长期记忆(Long-Term Memory)¶
显性记忆(Explicit Memory):可以被有意识回忆的记忆,包括:
情景记忆:个人经历和事件的记忆(如午餐内容)。
语义记忆:事实和知识的记忆(如地球绕太阳转的事实)。
隐性记忆(Implicit Memory):无需意识回忆的记忆,例如程序性记忆(如骑车技能)。
✅ 重点总结:短期记忆处理即时信息,长期记忆负责长期存储,两者相互作用,是人类记忆系统的核心结构。
2.1.2 记忆机制(Memory Mechanisms)¶
人类记忆包含以下几个关键过程:
编码(Encoding):将感官信息转化为大脑可处理的格式,包括视觉、听觉、语义等多种方式。记忆编码策略(如联想记忆、记忆术)有助于提高记忆效率。
存储(Storage):信息储存在不同脑区,包括前额叶皮层(工作记忆)、海马体(情景记忆)、大脑皮层(语义记忆)、小脑(程序性记忆)。
提取(Retrieval):从记忆中调取信息,包括识别、回忆和再学习等形式。
巩固(Consolidation):将短期记忆转化为稳定的长期记忆,依赖海马体和神经可塑性。
再巩固(Reconsolidation):记忆被激活后再次进入不稳定状态,可能更新或修改。
反思(Reflection):主动回顾和评估记忆内容,增强自我认知和学习策略。
遗忘(Forgetting):自然过程,可通过多种机制(如干扰、记忆衰退)发生。遗忘有助于大脑筛选重要信息。
✅ 重点总结:记忆机制是人类记忆系统高效运作的关键,包括编码、存储、提取、巩固等多个阶段,其中记忆巩固和再巩固是记忆长期化的关键环节。
2.2 Memory of LLM-Driven AI Systems¶
2.2.1 AI记忆的基本维度(Fundamental Dimensions of AI Memory)¶
LLM驱动的AI系统也具有类似人类的记忆机制,其记忆可从三个核心维度进行分类:
对象维度(Object):
个人记忆(Personal Memory):用户输入的信息,帮助系统理解用户偏好。
系统记忆(System Memory):任务过程中的中间输出,如CoT、ReAct等方法生成的思考链。
形式维度(Form):
参数化记忆(Parametric Memory):嵌入在模型参数中(如知识预训练),如语义记忆。
非参数化记忆(Non-Parametric Memory):存储在外部数据库中,如RAG(检索增强生成)。
时间维度(Time):
短期记忆(Short-Term Memory):当前任务中的上下文信息。
长期记忆(Long-Term Memory):跨会话存储的用户个性化数据。
✅ 重点总结:AI系统的记忆可从“对象、形式、时间”三个维度进行系统分类,这与人类记忆结构具有相似性。
2.2.2 人类与AI记忆的类比(Parallels Between Human and AI Memory)¶
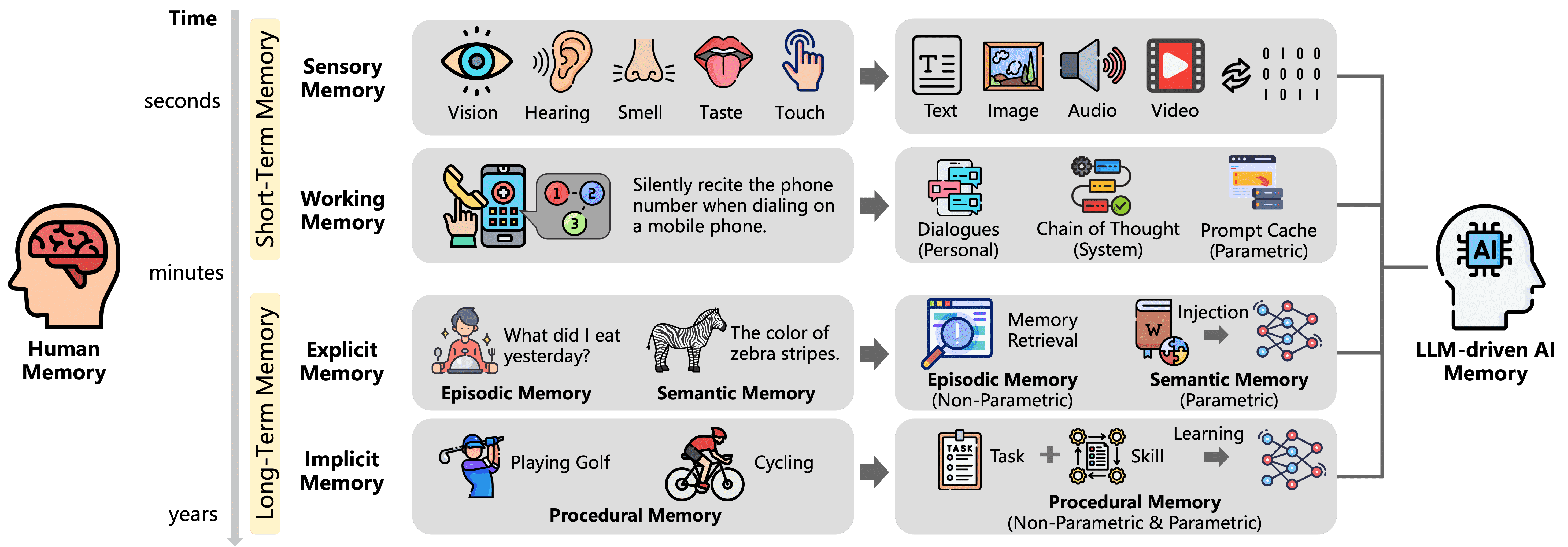
Figure 1:Illustrating the parallels between human and AI memory.
文中通过类比指出AI记忆与人类记忆在功能上的相似性:
感官记忆:AI对外部输入(如文本、图像)的初次处理。
工作记忆:AI的上下文存储与处理机制。
显性记忆:分为非参数化(用户交互)和参数化(语义知识)。
隐性记忆:AI通过模型参数内化任务执行模式,类似程序性记忆。
✅ 重点总结:类比帮助我们理解AI系统如何模拟人类记忆,在结构和功能上实现更高效的信息处理和学习。
2.2.3 三维八象限(3D-8Q)分类法(3D-8Q Memory Taxonomy)¶
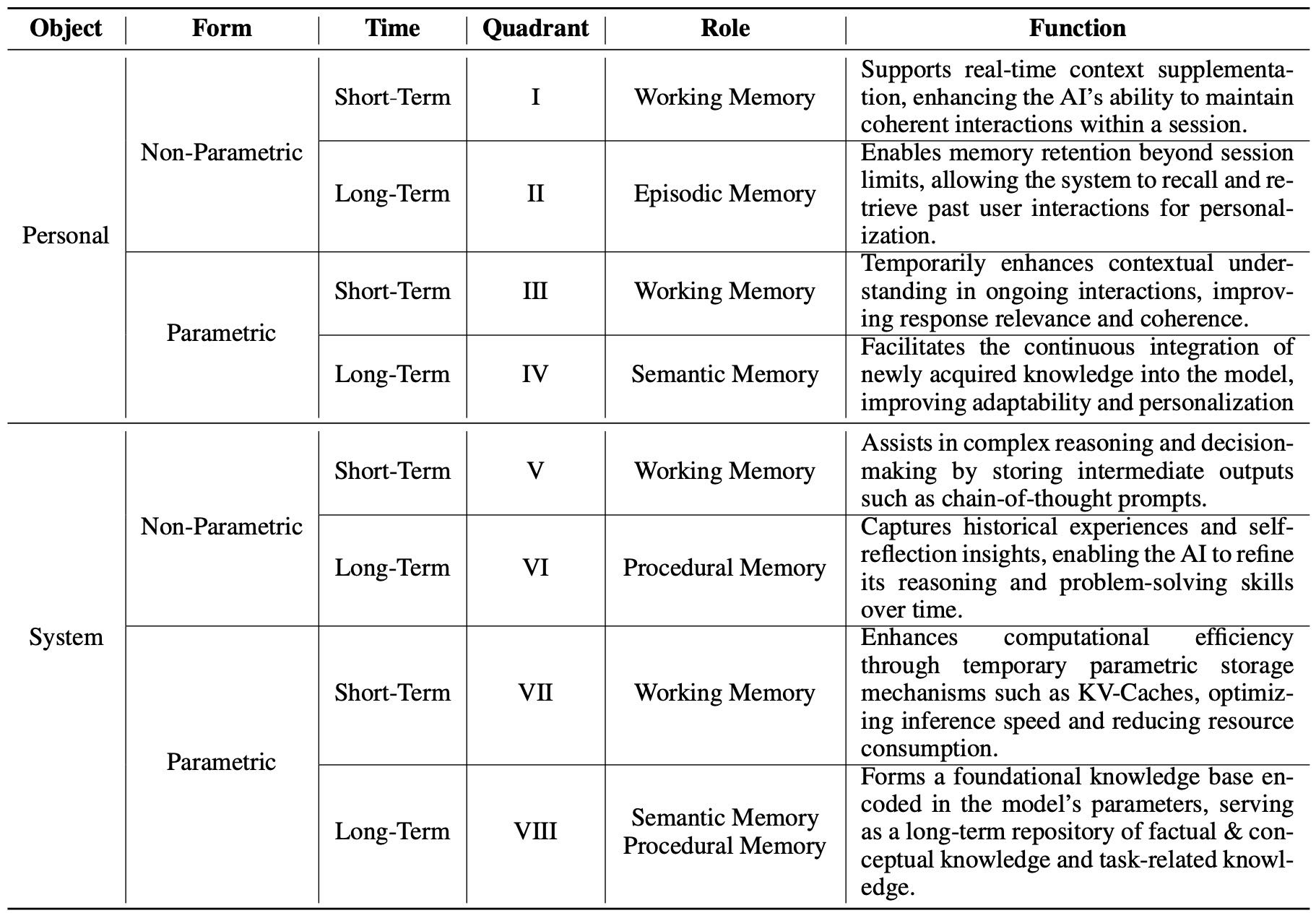
Table 1: Three-dimensional, eight-quadrant (3D-8Q) memory taxonomy for LLM-driven AI systems.
基于上述三个维度(对象、形式、时间),文章提出一个三维八象限(3D-8Q)分类法,对AI记忆系统进行系统性分类。每个象限对应一种记忆类型和其功能(如工作记忆、情景记忆、程序性记忆等)。
对象 |
形式 |
时间 |
象限 |
角色 |
功能 |
|---|---|---|---|---|---|
个人 |
非参数 |
短期 |
I |
工作记忆 |
支持会话中的上下文补充 |
个人 |
非参数 |
长期 |
II |
情景记忆 |
个性化记忆 |
个人 |
参数 |
短期 |
III |
工作记忆 |
提升推理 |
个人 |
参数 |
长期 |
IV |
语义记忆 |
知识集成 |
系统 |
非参数 |
短期 |
V |
工作记忆 |
支持复杂推理 |
系统 |
非参数 |
长期 |
VI |
程序性记忆 |
自我优化 |
系统 |
参数 |
短期 |
VII |
工作记忆 |
提高推理效率 |
系统 |
参数 |
长期 |
VIII |
语义记忆 |
知识存储 |
✅ 重点总结:3D-8Q分类法为AI记忆系统提供了一个系统框架,有助于未来研究的设计和优化。
总结¶
本章结构清晰,从人类记忆出发,逐步过渡到AI记忆系统的分析,提出一个系统化的三维分类框架。
核心重点在于类比与结构化:通过类比人类记忆机制,构建适用于LLM驱动AI系统的记忆模型;通过三维分类法(3D-8Q)实现对AI记忆的系统性分类。
为后续章节奠定基础:下一章将基于个人记忆和系统记忆两大方向,分别展开对现有研究的综述。
3 Personal Memory¶
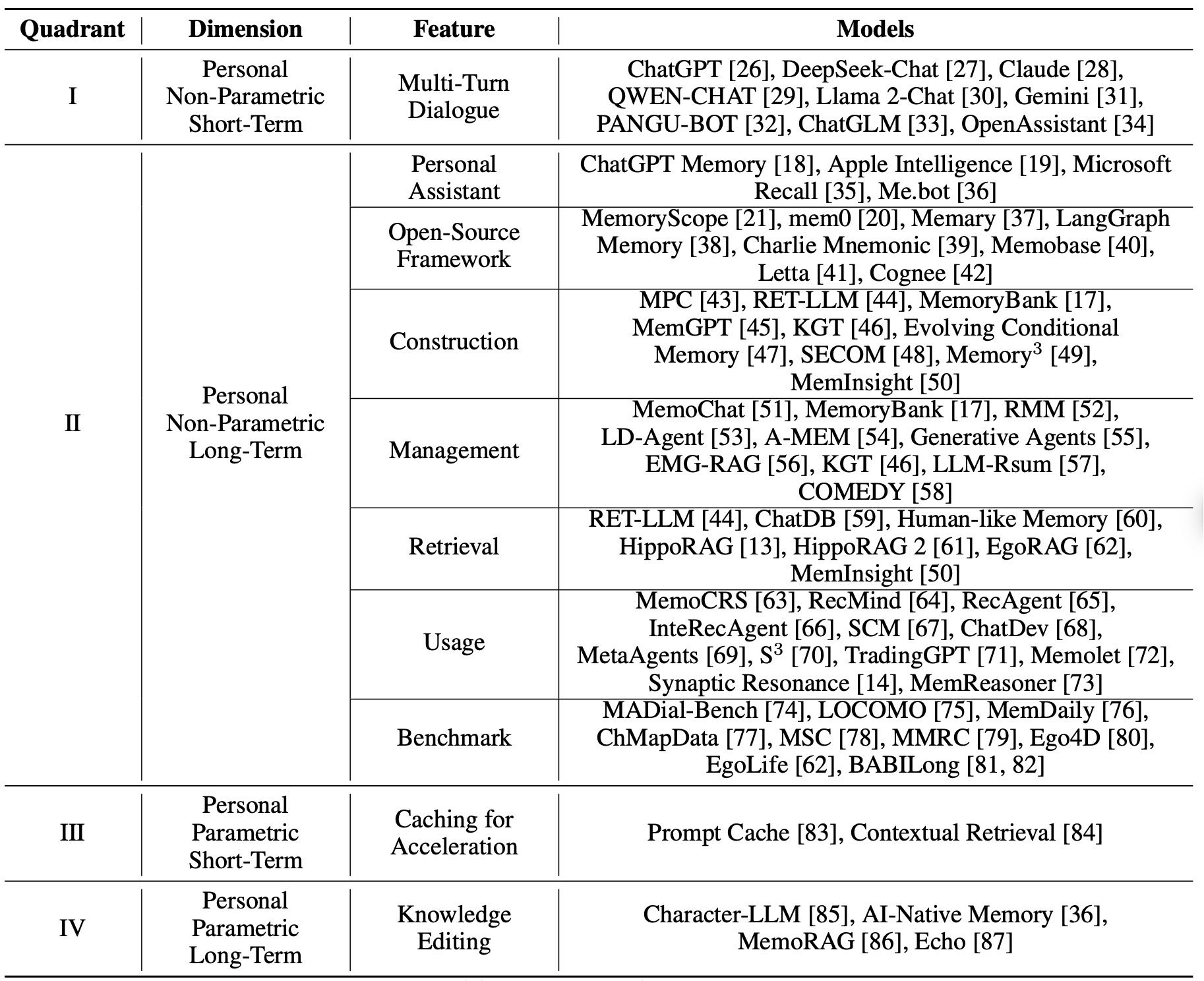
Table 2: Personal Memory
3.1 上文记忆(非参数化)¶
个人记忆是指在与基于大语言模型(LLM)的AI系统交互过程中,对用户输入和响应数据的存储与利用。其发展和应用对增强AI系统的个性化能力、提升用户体验具有重要意义。
该部分内容分为两类:**短期(当前会话)和长期(跨会话)**上下文记忆。
3.1.1 多轮对话记忆加载(Loading Multi-Turn Dialogue, 象限I)¶
在多轮对话中,当前会话的对话历史可作为短期记忆,帮助系统理解用户的实时意图。代表性系统包括ChatGPT、Claude、Llama 2-Chat等,它们通过角色-内容格式(如“用户”、“助手”)编码对话内容,实现对话状态的追踪与管理。通过限制输入长度、截断对话轮次,系统在不超出模型上下文窗口限制的前提下,保持对话连贯性与一致性。
3.1.2 记忆增强生成(Memory Retrieval-Augmented Generation, 象限II)¶
在跨会话的场景中,长期记忆指的是用户的历史对话、行为偏好、与AI的交互记录等。通过检索增强生成(RAG),系统可快速获取用户长期记忆中的相关信息,以弥补当前对话中缺失的信息。
构建阶段:从原始数据(如对话历史)中提取关键信息,构建结构化(如键值对、图、向量)的长期记忆。如MemoryBank、RET-LLM通过不同格式对记忆进行存储。
管理阶段:通过去重、合并、冲突解决等方式优化记忆。如RMM结合强化学习优化检索机制;LD-Agent通过动态人格建模提升对话个性化。
检索阶段:根据记忆存储方式选择检索方法。例如,ChatDB使用SQL检索结构化数据,HippoRAG结合图结构增强检索的丰富性,MemoryBank使用向量检索相似记忆片段。
使用阶段:将检索到的记忆用于个性化推荐、对话、开发、金融交易等任务。如MemoCRS、RecMind等系统在对话推荐中使用记忆增强,提升用户体验。
此外,研究者已提出多个记忆相关基准,用于评估长期对话记忆、生活记忆、多模态记忆等能力,如MADial-Bench、MemDaily、EgoLife等。
3.2 参数化个人记忆¶
除了非参数化记忆(如对话历史存储),还可以通过参数化方式存储用户记忆,即将用户数据用于微调LLM,将记忆嵌入模型参数中,从而实现个性化模型。
3.2.1 参数化短期记忆:缓存加速(Memory Caching For Acceleration, 象限III)¶
参数化短期记忆通常指注意力状态缓存,用于加速推理。例如,Prompt Caching技术在多轮对话中缓存用户历史信息,避免重复计算,提升系统响应速度。大型平台如DeepSeek、Google、Anthropic均采用该技术,以降低成本和提升效率。此外,Contextual Retrieval也可利用缓存降低检索生成开销。
3.2.2 参数化长期记忆:个性化知识编辑(Personalized Knowledge Editing, 象限IV)¶
参数化长期记忆通过知识编辑技术(如PEFT)将用户信息嵌入模型参数,例如:
Character-LLM:训练模型记住特定角色(如贝多芬、凯撒)并模拟其行为。
AI-Native Memory:通过持续交互参数化、压缩和更新用户记忆。
MemoRAG:将用户偏好和对话历史作为个性化全局记忆。
Echo:增强模型在复杂多轮对话中的表现。
尽管参数化记忆能实现更全局、更压缩的用户表示,但其面临高计算成本和难以扩展的挑战,限制了实际部署。
3.3 讨论¶
本节从非参数化和参数化两个角度综述了个人记忆的研究进展。
非参数化记忆关注对话历史、行为记录等外部信息的存储与使用,强调构建、管理、检索和使用机制。
参数化记忆则通过模型微调或缓存技术将用户信息内化到模型中,提升个性化和效率。
趋势表明,越来越多研究尝试结合短期与长期记忆机制,并通过参数化与非参数化组件的互补,提升系统整体性能。
下一节将重点介绍系统层面的记忆机制及其研究进展。
4 System Memory¶
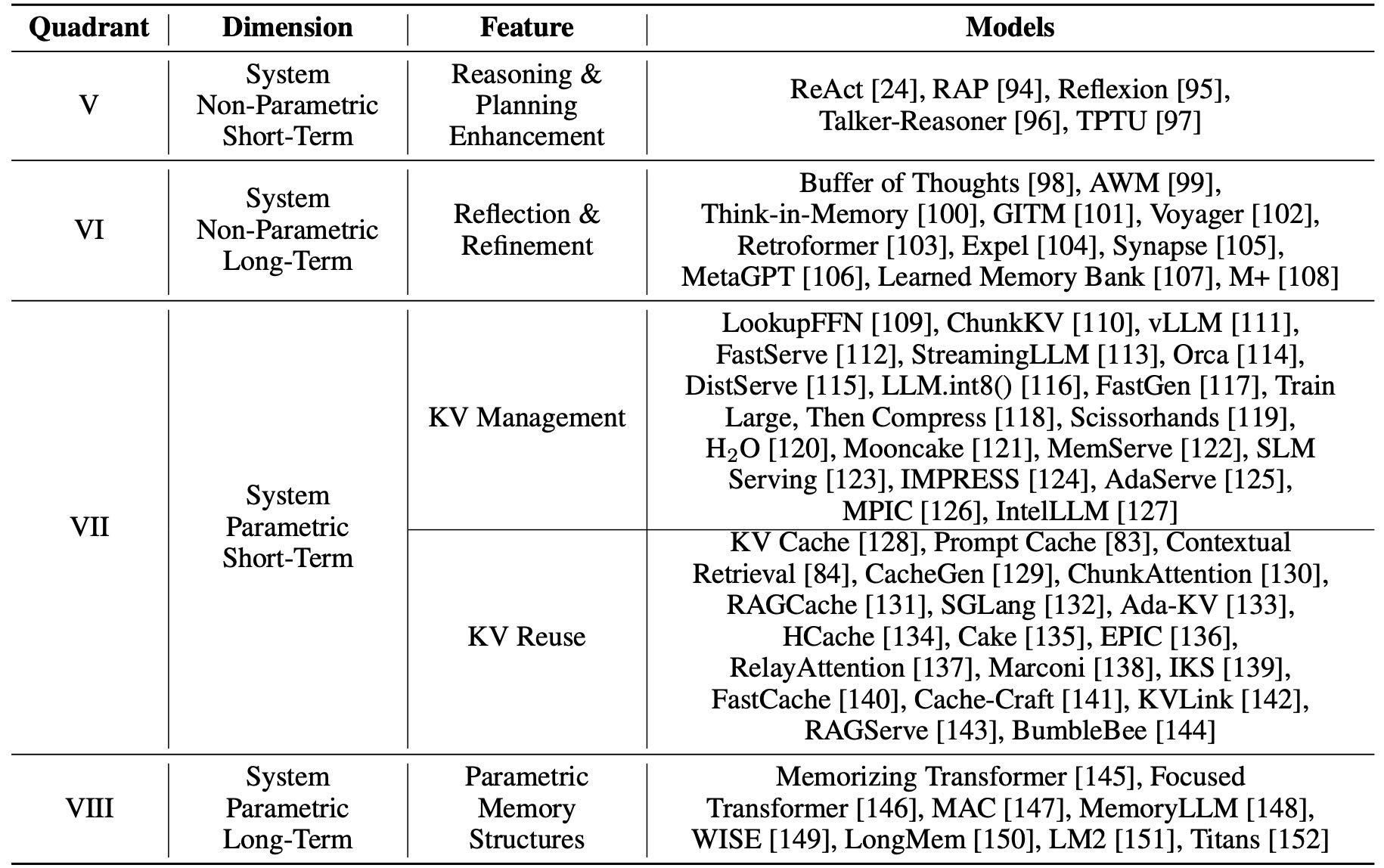
Table 3: System Memory
系统记忆是LLM驱动AI系统中的关键组成部分。它包括在任务执行过程中生成的一系列中间表示或结果。通过利用系统记忆,LLM驱动系统可以增强其推理、规划等高阶认知功能。此外,系统记忆的有效使用也有助于系统的自我进化与持续改进。本节将从非参数和参数两个视角,探讨系统记忆及其相关研究。
4.1 上下文系统记忆¶
从时间维度来看,非参数短期系统记忆指的是在任务执行过程中,LLM生成的一系列推理和动作结果。这种短期记忆支持模型在当前任务上下文中提升推理和规划能力,从而提高任务的准确率、效率和完成率。
相比之下,非参数长期系统记忆更加抽象和泛化。它包括对以往成功经验的整合以及基于历史交互的自我反思机制,帮助L驱动AI系统实现持续演化和自适应提升。
4.1.1 推理与规划增强(Reasoning & Planning Enhancement, Quadrant-V)¶
在推理和规划过程中,LLM生成一系列短期中间输出。这些输出可以反映任务的尝试,无论是否正确,都能作为指导后续任务的参考。这种非参数短期系统记忆对LLM驱动AI系统至关重要。实证研究表明,利用该结构显著增强LLM的推理和规划能力。
例如:
ReAct 将推理与动作结合,生成推理步骤和动作,使模型在复杂问题中实现智能规划与自适应决策。
Reflexion 引入动态记忆和自我反思机制,通过过往错误优化行为,实现类似连续学习的过程。
4.1.2 自我反思与优化(Reflection & Refinement, Quadrant-VI)¶
非参数长期系统记忆的构建类似于人类从成功与失败中学习的过程。它通过反思和优化短期记忆痕迹,帮助系统不仅复制过去的成功策略,还从失败中总结教训,避免重复错误。
例如:
BoT(Buffer of Thoughts) 将历史任务的思维链精炼成模板,存储于记忆库中,指导未来推理。
AWM(Agent Workflow Memory) 通过可重用路径(Workflow)指导后续任务生成。
Voyager 基于环境反馈优化技能,并将技能存储在记忆中,形成技能库。
ExpeL 利用成功案例,并通过比较分析抽象出经验教训,提升任务解决能力。
4.2 参数系统记忆¶
参数系统记忆是指在推理过程中以参数形式临时存储知识信息(如KV缓存),或在模型参数中长期编辑和存储知识信息。前者对应人类的工作记忆,能降低L模型的推理成本并提升效率;后者对应人类的语义记忆,有助于高效整合新知识。
4.2.1 KV管理与复用(KV Management & Reuse, Quadrant-VII)¶
参数短期系统记忆主要关注LLM中注意力机制中的键(Key)和值(Value)的管理与复用,解决推理过程中的高成本和延迟问题。主要技术包括:
KV缓存组织、压缩与量化(如ChunkKV、vLLM、LLM.int8()等)。
KV复用通过KV缓存和Prompt缓存减少计算量,提升推理效率。
KV缓存:存储注意力键值对,避免重复计算,提升长文本生成效率。
Prompt缓存:缓存输入提示及其输出结果,遇到相似提示时直接返回缓存响应。
此外,RAGCache等方法进一步优化了RAG(检索增强生成)系统的缓存机制,降低了延迟并提升了吞吐量。
4.2.2 参数记忆结构(Parametric Memory Structures, Quadrant-VIII)¶
从长期来看,LLM可作为 参数化长期记忆,存储和整合信息,形成不断演进的知识系统。Transformer架构的自注意力机制和大规模参数训练使其具有强大的记忆能力。
例如:
MemoryLLM 能够自我更新并注入新知识,表现出良好的模型编辑能力和长期记忆能力。
WISE 采用双参数记忆设计,主记忆保存预训练知识,侧记忆存储编辑内容,通过路由机制动态访问,确保更新的可靠性和通用性。
参数化知识编辑的核心在于赋予LLM动态更新的能力,使其能适应不断变化的任务需求和新信息,从而在多种应用场景中保持高效和准确。
4.3 讨论¶
本节从非参数和参数两个角度讨论了系统记忆及其相关研究。
非参数短期系统记忆增强当前任务的推理与规划能力;
非参数长期系统记忆实现经验的复用与自我反思,推动系统持续进化;
参数短期系统记忆降低推理成本,提升效率;
参数长期系统记忆存储整合信息,构建持续演进的知识体系。
下一节将总结大语言模型时代下的记忆研究问题与挑战,并指出未来发展的潜在方向。
5 Open Problems and Future Directions¶
在当前的记忆研究中,尽管在三个维度(对象、形式、时间)及八个相应象限中取得了显著进展,但仍有许多未解问题与挑战。
基于近期的技术进步并认识到现有局限,本文提出了以下具有前景的未来研究方向:
从单模态记忆到多模态记忆(From Unimodal Memory to Multimodal Memory)¶
在大语言模型(LLM)时代,AI系统正逐步从处理单一类型数据(如文本)扩展到同时处理多种类型的数据(如文本、图像、音频、视频,甚至传感器数据)。这种转变增强了系统的感知能力,并在复杂现实任务中表现出更强大的性能。
例如,在医疗领域,结合文本(病历)、图像(医学影像)和语音(医患对话)的信息,AI可以更准确地理解和诊断病情。多模态记忆系统能够整合来自不同感知通道的信息,形成统一的理解,从而更加贴近人类的认知过程。
此外,多模态记忆的发展也为更个性化和互动的AI应用提供了可能。例如,个人AI助手不仅可以与用户通过文本交流,还能通过识别用户面部表情、语音语调或肢体语言来理解情绪,从而提供更具个性和共情能力的回应。
重点:多模态记忆是提升AI感知和交互能力的关键,未来应致力于构建统一、高效、跨模态的信息整合机制。
从静态记忆到流式记忆(From Static Memory to Stream Memory)¶
静态记忆可视为一种批处理式的记忆存储方式,它以离散批次的形式积累信息或经验,通常在特定的时间点进行处理、存储和检索。作为一种离线记忆模型,静态记忆强调信息的系统组织和长期留存,适合用于长期知识积累和结构化学习。
相比之下,流式记忆以连续、实时的方式运行,类似于数据流处理。它优先处理实时到达的信息,强调即时性和适应性。作为一种在线或实时记忆模型,流式记忆更关注信息的动态更新和对变化环境的快速响应。
这两种记忆模式并非相互排斥,而是互补的:静态记忆支持稳定的长期知识积累,而流式记忆则使系统能够灵活适应当前任务和实时信息需求。
重点:未来研究应探索静态与流式记忆的协同机制,以兼顾长期知识积累与实时响应需求。
从特定记忆到综合记忆(From Specific Memory to Comprehensive Memory)¶
人类的记忆系统包含多个相互关联的子系统(如感觉记忆、工作记忆、显性记忆和隐性记忆),各司其职,共同支持整体认知过程。
在当前的大语言模型中,记忆架构往往集中在狭窄或任务特定的组件上,例如用于即时推理的短期记忆或用于存储领域知识的特定记忆模块。虽然这些机制在特定场景下能提升性能,但其局限性也限制了系统的整体灵活性、泛化能力和适应性。
未来应致力于开发综合性且协同工作的记忆系统,整合多种记忆类型,并支持高效的交互、自组织和持续更新,从而使LLM能够应对日益复杂和动态的任务。通过更接近人类记忆的多层次、多维度和适应性特征,这类架构有望显著提升基于LLM的AI系统的通用智能和自主性。
重点:构建跨层次、多功能的综合记忆系统是实现AI通用智能的关键。
从个体隐私到集体隐私(From Individual Privacy to Collective Privacy)¶
在AI时代,随着数据共享的普及,隐私保护的焦点正从传统的“个体隐私”逐渐转向新兴的“集体隐私”概念。传统隐私框架主要关注保护个人数据,防止可识别信息的非法访问、泄露或滥用。
然而,在大语言模型的背景下,个体数据常被汇总为群体级别的数据集,用于大规模分析和预测。集体隐私关注的是这些群体或社区在数据被集体使用时的权利和利益,提出了如何防止群体层面的滥用、画像或过度监控等问题。
随着AI记忆系统变得更加先进和互联,确保集体隐私将成为一个关键挑战。解决这一问题需要创新技术,以有效平衡数据的可用性与隐私保护之间的权衡。
重点:未来需要发展兼顾数据效用与隐私保护的新技术,确保AI系统在共享与进化中不损害用户群体的隐私权益。
从基于规则的记忆进化到自动进化(From Rule-Based Evolution to Automated Evolution)¶
传统AI系统的进化依赖于对过去经验的反思(如复用成功策略),通常基于积累的知识和历史数据。然而,这种进化过程往往依赖于人工设计的规则和启发式调整,限制了系统的灵活性、可扩展性和效率。
未来,AI系统将朝向自动化进化方向发展,能够通过个人和系统级别的记忆,动态调整和优化自身,以适应不断变化的数据和环境。这类系统将能够自主识别性能瓶颈并启动自我改进,而不依赖明确的人工规则。
重点:自动化进化将极大提升系统的响应能力,减少人工干预,实现更智能、动态和持续自我进化的AI系统。
总结¶
未来AI记忆系统的演进方向包括:多模态整合、实时流式处理、综合性记忆架构、跨模型共享机制、集体隐私保护、以及自动进化能力。这些方向不仅有助于提升AI系统的智能水平和适应性,也将推动AI在更广泛和复杂的现实场景中发挥作用。
6 Conclusion¶
记忆在大语言模型(LLMs)时代的人工智能系统发展中起着关键作用。 它不仅决定了人工智能行为的个性化程度,还影响着适应能力、推理能力、规划能力和自我进化能力等关键能力。
本文系统地探讨了人类记忆与LLM驱动的人工智能系统中记忆机制之间的关系, 研究了人类认知原则如何启发设计更高效和灵活的记忆架构。
我们首先分析了人类记忆的多种类别,包括感知记忆、工作记忆和长期记忆,并将其与人工智能中现有的记忆模型进行比较。在此基础上,我们提出了一种基于三个维度(对象、形式和时间)的八象限分类框架, 为构建多层次和全面的记忆系统提供了理论基础。
此外,我们还从个人记忆和系统记忆两个角度回顾了人工智能记忆发展的现状。
最后,我们识别了当前人工智能记忆设计中的关键开放挑战, 并指出了未来研究在LLM时代中的有前景方向。
我们相信,随着技术的持续进步,人工智能系统将越来越多地采用更动态、自适应和智能化的记忆架构, 从而在复杂的现实任务中实现更强大的应用。