2509.11914_EgoMem: Lifelong Memory Agent for Full-duplex Omnimodal Models¶
引用: 1
组织:
1Beijing Academy of Artificial Intelligence, Beijing, China
2Spin Matrix, China
3Institute of Computing Technology, Chinese Academy of Sciences, Beijing, China
4Harbin Institute of Technology, Shenzhen, China
5Nanyang Technological University, Singapore
总结¶
背景
类人机器人需要的能力
多模态感知(omnimodality)
实时响应(real-time responsiveness)
时分复用(如 Full-Dup)或原生双工(如 Moshi)
类人认知(humanoid cognition)
终身记忆能力
相关依赖
RoboEgo: 全双工多模态模型(2506.01934)
EgoMem
首个面向 实时、多模态、全双工交互 的记忆系统
核心功能
实时识别多个用户:直接从原始音视频流中识别人脸和声音;
个性化响应:基于用户历史信息生成定制化对话;
长期记忆管理:持续存储并更新用户的事实信息、偏好和社交关系。
三个异步处理模块
检索模块(Retrieval):
动态识别用户(通过人脸和声音);
从长期记忆中提取相关上下文信息。
多模态对话模块(Omnimodal Dialog):
基于检索到的上下文生成个性化的语音回应。
参考上下文包括单用户档案(Level-1)和多用户社交图谱(Level-2)
记忆管理模块(Memory Management):
自动检测对话边界;
提取关键信息用于更新长期记忆。
两个层级:
Level-1(Profile-only):支持基于用户个人资料的多用户个性化;
Level-2(Content-driven):在 Level-1 基础上,进一步支持基于社交网络等内容驱动的个性化对话。
Level-1(Profile-only)
存储结构(键值对):
键为视觉(人脸)和音频(语音)嵌入向量;
值为用户信息(姓名、事实、对话摘要、偏好)。
总结
专注于基于用户资料的个性化对话,通过异步检索机制实现主动识别与响应
三大组件流程
检索流程(Retrieval Process):
每隔2秒主动提取音视频信号,生成查询向量
进行人脸识别和语音识别
若识别到用户,则将其个人信息推入 Level-1 MemChunk
MemChunk 内容随用户切换而更新
每次切换用户触发主对话模型的一次前向计算,更新KV缓存
全模态对话流程(Omnimodal Dialog Process):
主流程运行 RoboEgo 对话服务;
基于 Level-1 MemChunk 生成个性化响应;
使用流式数据格式进行微调(参见第4章)。
记忆管理流程(Memory Management Process):
定期从对话流中提取记忆内容;
利用外部 LLM 提取事件、用户事实、偏好;
若为新用户则创建新资料,否则更新已有资料;
使用 Memory Update Agent 解决冲突。
子模块
人脸识别(Face Verification)
语音识别(Speaker Verification)
对话片段识别(Episodic Trigger)
0: 无对话;1: 新对话开始;2: 对话中;3: 结束
记忆提取器(Memory Extractor)
记忆更新代理(Memory Update Agent)
主对话模型(Main Dialog Model)
Level-2(Content-driven)
存储结构:
每个用户新增社交关系三元组字段;
可扩展添加其他辅助信息。
总结
在 Level-1 基础上引入社交图谱和内容驱动的主动检索机制,实现更复杂的个性化对话;
更强调主模型对内容的理解与主动检索能力,提升了对话的上下文相关性和个性化程度。
三大流程
检索流程(Retrieval Process):
新增 Level-2 MemChunk(最大256步),由主模型根据对话内容主动触发
Level-2 内容基于主模型生成的文本查询,检索社交图谱和外部知识库。
全模态对话流程(Omnimodal Dialog Process):
RoboEgo 可基于 Level-1 和 Level-2 MemChunk 生成响应;
记忆管理流程(Memory Management Process):
与 Level-1 类似,但增加了社交关系的处理
子模块
同 Level-1
文本检索(Textual Retrieval):
使用 BM25 和 BGE-small 模型进行检索
先用关系查询匹配用户文档,再用关键词重排序
返回 Top-K 结果至 Level-2 MemChunk
性能评估
检索评估
人脸验证:
LFW 数据集
准确率达到 98.4%, 单个 H100 GPU 上每次查询耗时 0.2 秒
说话人识别
VoxCeleb 数据集
pass@1: 95.8%, 0.1 秒内完成超过 1000 个候选条目的检索
文本检索
Level-2 EgoMem
pass@5: 96%, 单个 H100 GPU 上每次检索耗时小于 0.1 秒
情节触发器评估
评估标准
Jaccard 分数
span_match@N
每秒有 12.5 个时间步(可能是以 80ms 为一个 step)
个性化对话评估
LLM 评估
输入内容
the user instruction (textual transcript),
the ground-truth textual response,
the contents of the MemChunks,
the textual monologue response generated by RoboEgo
两个评分指标
事实评分(Fact Score):二值指标,判断响应是否个性化且无事实错误。
回答质量(Answer Quality):0-10 分,评估响应的有用性和整体质量,与个性化无关。
span_match@N
span_match@N 是一个用于评估预测的对话边界与真实边界是否匹配的指标。
具体:如果模型预测的对话边界与真实标注的边界之间的偏差不超过 ±N 个时间步(steps),就认为是一次“正确匹配(match)”。
示例
假设真实边界(ground truth)在时间步:[100, 250, 400]
模型预测:[98, 255, 395]
结论:
当 N=0 时:只有完全相同的位置算匹配 → 没有匹配成功。
当 N=5 时:偏差在 ±5 步内都算对 → 这三次预测都算对。
未来
扩展检索增强生成(RAG):不仅限于用户画像与社交网络,还可涵盖程序性记忆及多模态(视觉/音频)记忆内容。
参数化:探索是否可用可训练参数替代部分复杂的代理模块与记忆单元,以提升系统灵活性与效率。
Abstract¶
本论文提出了 EgoMem,这是首个专为全双工模型设计的终身记忆智能体,能够处理实时的多模态流数据(如音视频)。EgoMem 的核心功能包括:
实时识别多个用户:直接从原始音视频流中识别人脸和声音;
个性化响应:基于用户历史信息生成定制化对话;
长期记忆管理:持续存储并更新用户的事实信息、偏好和社交关系。
EgoMem 通过三个异步处理模块协同工作:
检索模块(Retrieval):
动态识别用户(通过人脸和声音);
从长期记忆中提取相关上下文信息。
多模态对话模块(Omnimodal Dialog):
基于检索到的上下文生成个性化的语音回应。
记忆管理模块(Memory Management):
自动检测对话边界;
提取关键信息用于更新长期记忆。
与以往面向大语言模型(LLMs)的记忆系统不同,EgoMem 完全依赖原始音视频流,因此更适用于真实、持续、具身化(embodied)场景。
实验结果显示:
EgoMem 的检索与记忆管理模块在测试集上准确率超过 95%;
与微调后的 RoboEgo 多模态聊天机器人结合后,在实时个性化对话中实现了 87% 以上的事实一致性得分;
为未来相关研究建立了坚实的基线。
重点强调:
EgoMem 是首个面向实时、多模态、全双工交互的记忆系统;
它实现了端到端的用户识别、个性化对话与记忆更新;
在真实场景中表现出色,具有很高的应用潜力。
1 Introduction¶
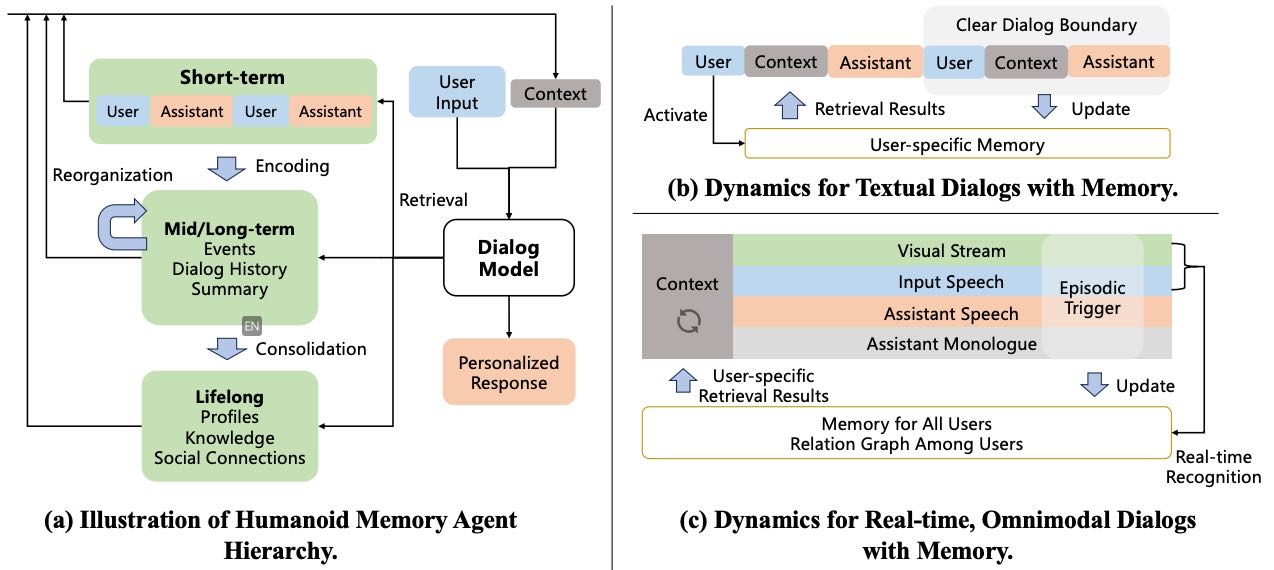
Figure 1:Different dialog dynamics for textual memory agents and full-duplex omnimodal memory agent (ours).
1.1 背景与挑战¶
本节介绍了人工智能在终身多模态实时流场景中的应用,例如家庭和公共场所中的机器人(如 Agibot)。这类系统需要具备快速响应指令、识别用户、记忆历史、理解社交关系并提供个性化服务的能力。技术上,这些能力可归纳为三点:多模态感知(omnimodality)、实时响应(real-time responsiveness) 和 类人认知(humanoid cognition)。
多模态感知:近年来,随着基础模型(如 GPT-4、o1)的发展,音频、视觉和动作信号的融合取得了显著进展(如 Kimi-Audio、LLaVA、RT-2 等)。
实时响应:已有研究通过时分复用(如 Full-Dup)或原生双工(如 Moshi)实现全双工交互。
类人认知:目前仍是一个未充分探索的领域,尤其是在多模态、全双工系统中(如 MiniCPM-O、RoboEgo)。
作者指出,终身记忆能力是实现类人认知的关键第一步,因为记忆系统是人类与人工智能通用智能的基础。
1.2 现有方法与局限性¶
文献中主要有两种为大语言模型(LLMs)赋予长期记忆的方法:
扩展上下文窗口(如 RoPE、XPos):
可以保留长序列的特征表示,适用于多模态信息编码。
但在终身场景中,音频和视频流长度无限增长,百万级 token 上下文也难以满足需求,导致信息丢失(如用户身份)。
记忆代理方法(Memory Agents):
更适合终身操作(如 Gist-Memory、Mem0)。
但通常依赖几个强假设:
用户身份已知;
对话有明确边界;
所有输入为文本。
这些假设在全双工多模态应用中不成立(如 Moshi、RoboEgo):
用户身份隐含在音视频流中;
对话无明确边界;
输入为多模态;
忽略了多用户社交关系图(如 Person-Graph)。
1.3 应用示例:个性化对话¶
文章通过一个具体例子说明多模态终身记忆代理在个性化对话中的作用:
用户 Emily 出现,系统从音视频流中识别其身份;
Emily 的档案被编码并加入对话上下文;
Emily 问:“我的同事中有人喜欢网球吗?”系统生成查询,检索其社交图谱,返回相关信息;
系统回答:“是的,你的同事 John 喜欢网球。”
系统从对话中提取新信息(如 Emily 对网球感兴趣),更新其档案;
下次 Emily 出现时,系统可主动问候:“Emily,你和 John 聊过网球了吗?”
1.4 提出方法:EgoMem¶
为解决上述问题,作者提出 EgoMem,这是首个专为多模态场景设计的终身记忆系统,支持全双工个性化对话。其核心由三个异步过程组成:
检索过程(Retrieval Process):
实时识别用户身份(音视频检索);
内容驱动的文本检索模块,用于获取相关记忆;
支持将用户特定信息与 RAG 风格信息高效整合进对话流程。
多模态对话过程(Omnimodal Dialog Process):
使用微调后的对话模型,基于检索上下文,提供全双工、个性化的实时回复。
记忆管理过程(Memory Management Process):
处理实时音视频流,检测对话边界、提取信息并更新记忆;
实现低成本、持续的信息收集与记忆更新。
1.5 实验与实现¶
虽然 EgoMem 可适配任何多模态主干模型,但作者将其集成到 RoboEgo 中,这是一个原生支持全双工交互的模型,与目标场景高度契合。作者扩展了 RoboEgo,加入完整的 EgoMem 模块,并训练对话模型及相关子模块,以实现对任意用户的实时、终身、个性化响应。
评估涵盖音频、文本、视觉检索模块、记忆管理模块及系统的个性化能力,参考上下文包括单用户档案(Level-1)和多用户社交图谱(Level-2)。结果表明,这些模块具有高准确率和鲁棒性,且 EgoMem 的引入未影响 RoboEgo 原有的对话能力。
1.6 贡献总结¶
框架贡献:提出首个面向全双工、多模态交互的终身记忆代理系统 EgoMem。
实现贡献:基于 RoboEgo 提供了 EgoMem 的具体实现方案,包括模块设计、数据构建流程和训练配置。
评估贡献:在终身多模态场景下的个性化任务中验证了 EgoMem 的鲁棒性,为未来研究建立了坚实基线。
2 Task Definition and Preliminaries¶
2 任务定义与预备知识¶
2.1 任务描述¶
EgoMem 是为全双工、个性化聊天设计的,适用于终身部署的全模态模型。目前研究聚焦于单用户发言的场景,复杂场景(如鸡尾酒会问题)留待未来研究。
在每个时间步 \( t \),对话模型 \( F \) 接收以下输入:
音频 \( a_t \)
视频 \( v_t \)
可选文本输入 \( l_t \)
用户画像 \( p_t \)
参考信息 \( c_t \)
输出为个性化响应 \( r_t \),公式如下:
其中:
\( p_t \) 和 \( c_t \) 被称为上下文或短期记忆,通常通过输入序列或 Transformer 的 KV-cache 传递。
EgoMem 管理一个外部记忆单元 \( M \),具备三个核心功能:
检索(Retrieval):
根据当前对话内容从记忆中检索相关信息,提供 \( p_t \) 和 \( c_t \)。
公式:
$\( p_t, c_t = \text{EgoMem.retr}(a_t, v_t, M) \)$与传统 RAG 系统不同,EgoMem 能从原始音视频流中自动识别用户身份和对话边界。
写入(Writing):
从终身多模态流中提取重要事件并写入记忆。
公式: $\( \text{Episode} = \text{EgoMem.extract}(a_{0\sim t}, v_{0\sim t}, l_{0\sim t}) \)\( \)\( M \leftarrow \text{EgoMem.write}(M, \text{Episode}) \)$
EgoMem 异步于主对话流程,从对话历史中提取事件描述、用户画像等信息。
更新(Updating):
定期整合记忆,生成更紧凑的表示并解决冲突。
公式: $\( M \leftarrow \text{EgoMem.update}(M) \)$
2.2 预备知识¶
本节介绍 EgoMem 的实现基础,但其框架适用于任意全双工全模态对话模型。
模型选择¶
使用 RoboEgo 作为主对话模型,因其支持原生全双工音频处理,具有低延迟、高扩展性。
在对话质量和用户体验方面,RoboEgo 与当前最先进的系统(如 Qwen-2.5-Omni)相当。
全模态流处理¶
音频处理:
使用 Mimi tokenizer 提取音频特征,每秒 12.5 帧。
每帧包含 1 个语义 token 和 7 个声学 token。
输入包括听觉、说话和文本三个通道,每步共 17 个 token。
模型结构:
使用 7B 参数的 LLM 处理历史输入,生成当前隐藏状态。
采用 RQ-Transformer 架构,先生成文本 token,再自回归生成 8 个说话 token。
视觉处理:
视频信号通过 Vision Transformer 编码,以 2–4 秒间隔通过时分复用(TDM)方式加入上下文。
该流程在终身部署中持续运行,形成主对话流。
总结¶
EgoMem 是一个面向全双工、全模态对话系统的终身记忆代理,具备检索、写入、更新三大核心功能。
它能从原始音视频流中自动识别用户身份和对话边界,实现更自然的个性化交互。
基于 RoboEgo 模型,结合多模态流处理机制,EgoMem 支持实时、低延迟的对话体验。
整体架构灵活,适用于不同模型和输入流组织方式。
3 EgoMem¶
以下是对论文章节 “3 EgoMem” 的总结,按照原文结构进行讲解,重点内容详细说明,非重点内容适当精简:
EgoMem 的设计分为两个层级:
Level-1(Profile-only):支持基于用户个人资料的多用户个性化;
Level-2(Content-driven):在 Level-1 基础上,进一步支持基于社交网络等内容驱动的个性化对话。
Level-2 更适合用户之间联系紧密的场景,如家庭机器人。每个层级都包括整体记忆系统设计和子模块实现细节。
3.1 Level-1: Profile-only¶
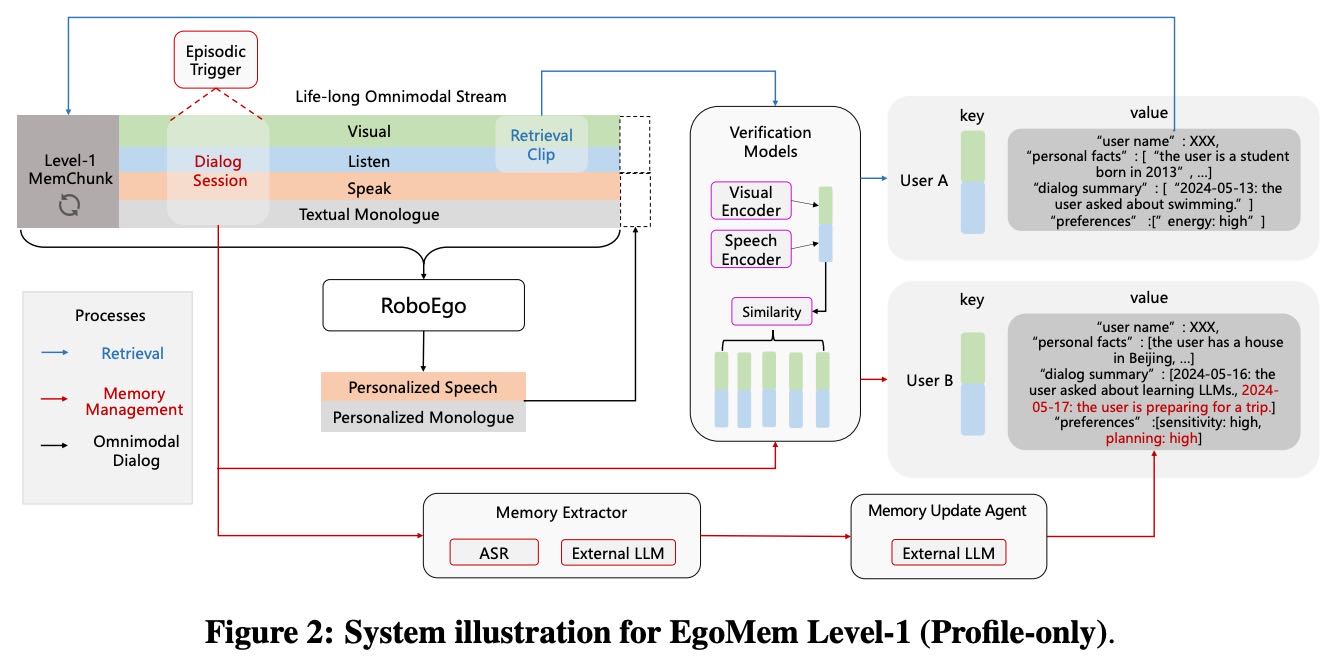
Figure 2: System illustration for EgoMem Level-1 (Profile-only).
3.1.1 系统设计¶
Level-1 仅维护每个用户的个人资料信息,不记录用户之间的社交关系或其他参考材料。在公式中,Level-1 设置 ct=None。
存储结构:
每个用户以键值对形式存储;
键为视觉(人脸)和音频(语音)嵌入向量;
值为用户信息(姓名、事实、对话摘要、偏好)。
三大组件流程(异步运行):
检索流程(Retrieval Process):
每隔2秒主动提取音视频信号,生成查询向量;
使用距离和阈值进行人脸识别和语音识别;
若识别到用户,则将其资料推入 Level-1 MemChunk;
MemChunk 占用512时间步,文本内容随用户切换而更新;
每次更新触发主对话模型的一次前向计算,更新KV缓存;
无用户识别时填充
<pad>。
全模态对话流程(Omnimodal Dialog Process):
主流程运行 RoboEgo 对话服务;
基于 Level-1 MemChunk 生成个性化响应;
使用流式数据格式进行微调。
记忆管理流程(Memory Management Process):
定期从对话流中提取记忆内容;
使用序列标注模型(Episodic Trigger)识别对话片段;
利用外部 LLM 提取事件、用户事实、偏好;
若为新用户则创建新资料,否则更新已有资料;
使用 Memory Update Agent 解决冲突。
3.1.2 子模块实现¶
人脸识别(Face Verification):
使用 DeepFace、RetinaFace、Facenet512 提取人脸特征;
使用余弦距离和阈值(0.3)进行匹配。
语音识别(Speaker Verification):
使用 fine-tuned WavLM 模型;
使用 s-norm 标准化提升识别效果;
阈值基于 EER 调整。
对话片段识别(Episodic Trigger):
基于 RQ-Transformer 的序列标注模型;
输入为17通道音视频流;
输出为标签:{0: 无对话;1: 新对话开始;2: 对话中;3: 结束};
使用 BERT 式注意力掩码。
记忆提取器(Memory Extractor):
基于 DeepSeek-V3 API;
提取对话内容、用户事实、90维用户特征;
包括 ASR 和对话内容分析。
记忆更新代理(Memory Update Agent):
同样基于 DeepSeek-V3;
解决用户资料冲突,格式化更新内容。
主对话模型(Main Dialog Model):
微调 RoboEgo 模型,使其能关注 Level-1 MemChunk;
生成个性化响应。
3.2 Level-2: Content-driven¶
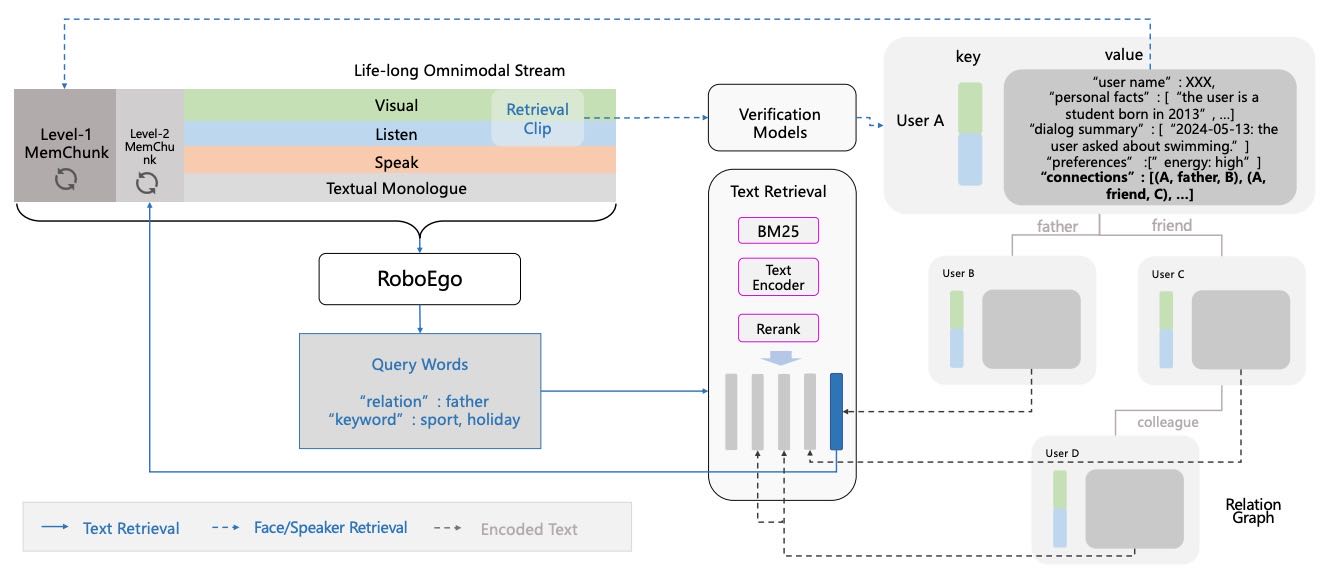
Figure 3: System illustration for EgoMem Level-2 (Profile-only). We focus on showing the differences in retrieval process and hide the details for other processes like memory management.
3.2.1 系统设计¶
Level-2 在 Level-1 基础上,增加了用户之间的社交关系图谱和其他辅助信息。在公式中,Level-2 同时提供 pt 和 ct。
存储结构:
每个用户新增社交关系三元组字段;
可扩展添加其他辅助信息。
三大流程的差异:
检索流程(Retrieval Process):
Level-1 MemChunk 仍由外部轮询驱动;
新增 Level-2 MemChunk(最大256步),由主模型根据对话内容主动触发;
Level-2 内容基于主模型生成的文本查询,检索社交图谱和外部知识库。
全模态对话流程(Omnimodal Dialog Process):
RoboEgo 可基于 Level-1 和 Level-2 MemChunk 生成响应;
可在任意时间步生成特殊标记的查询词,触发 Level-2 检索。
记忆管理流程(Memory Management Process):
与 Level-1 类似,但 Memory Extractor 还提取社交关系;
Memory Update Agent 更新社交图谱。
3.2.2 子模块实现¶
人脸识别、语音识别、对话片段识别:
与 Level-1 相同。
记忆提取器与更新代理:
与 Level-1 类似,但提示词不同,用于提取社交关系。
主对话模型(Main Dialog Model):
微调 RoboEgo,使其能生成两类查询词:
<retr>:\n<group1>\n<group2><answer>;group1 为关系查询,group2 为关键词查询;
使用新旧 MemChunk 和查询词组合进行训练。
文本检索(Textual Retrieval):
使用 BM25 和 BGE-small 模型进行检索;
先用关系查询匹配用户文档,再用关键词重排序;
返回 Top-K 结果至 Level-2 MemChunk。
总结¶
Level-1 专注于基于用户资料的个性化对话,通过异步检索机制实现主动识别与响应;
Level-2 在此基础上引入社交图谱和内容驱动的主动检索机制,实现更复杂的个性化对话;
两个层级均依赖于多个子模块(如人脸识别、语音识别、对话片段识别、记忆提取等)协同工作;
Level-2 更强调主模型对内容的理解与主动检索能力,提升了对话的上下文相关性和个性化程度。
如需进一步精简或扩展某部分内容,请告知。
4 Training Details¶
本章节详细介绍了 RoboEgo 模型的训练过程,包括数据收集、监督掩码设计以及训练配置。整体结构如下:
4.1 数据收集¶
4.1.1 文本对话收集(Transcript Collection)¶
Level-1 EgoMem 数据生成:
使用 DeepSeek-V3 合成 500 个用户画像(包括姓名、对话历史、90 维人格特征)。
基于开源指令数据集(如 Infinity-Instruct、WizardLM、视觉问答数据集)生成 10k 条对话,用户指令保留,AI 回答由 DeepSeek-V3 或 Gemini-2.5-Pro 生成,更具个性化。
进一步引导模型生成涉及用户历史和画像的问题,每段对话通常包含 3–5 轮。
Level-2 EgoMem 数据生成:
合成 500 种人际关系(如“父亲”、“同事”),构建包含 1 个主用户和 3–5 个关联用户的社交图。
引导模型生成需要关系推理的问题(如“我妈妈喜欢运动吗?”),混合通用指令生成 5k 条对话。
每个问题需标注有效查询词(关系词和关键词),并提供个性化回答用于训练。
4.1.2 TTS 与数据增强¶
使用 Fishaudio TTS 将文本对话转为语音,用户使用随机人声,AI 使用固定人声。
在“听”通道中加入噪声(如 DNS Challenge、RNNoise)和随机语音片段。
模拟麦克风回声(概率 0.3,增益 0–0.2x,延迟 0.1–0.5s)。
4.1.3 音频流组织(Token Stream Organization)¶
多段对话波形拼接成完整音频流,部分样本模拟全双工场景(用户打断 AI 回答)。
使用 Mimi tokenizer 编码音频,文本响应提前 2 步开始。
Level-1 MemChunk 占前 512 个 token,Level-2 MemChunk 占 512–768,对话从 768 之后开始。
4.1.4 监督掩码(Supervision Masks)¶
Level-1 EgoMem:
每个对话的用户画像放入 Level-1 MemChunk,仅在当前对话时间段内设置监督掩码为 1,其余为 0,生成 N 个样本。
Level-2 EgoMem:
每轮对话分别监督“查询词生成”和“个性化回答生成”:
查询词生成:监督从当前对话开始到查询词结束。
个性化回答生成:基于查询词检索相关信息填充 Level-2 MemChunk,监督从查询词结束到对话结束。
每轮生成两个样本,总样本数为 2×∑Tj。
Episodic Trigger:
对音频流中的每个时间步进行标注,标记对话边界,用于后续记忆提取。
4.2 训练配置¶
Level-1 EgoMem 训练¶
数据集:158K 样本,包含不同 MemChunk、上下文和监督掩码组合。
数据增强:使用原始和加噪的“听”通道数据。
训练设置:
从 RoboEgo 的 SFT 检查点开始。
训练 5 轮,batch size 64。
学习率从 1e-5 到 1.5e-6 的余弦衰减。
Level-2 EgoMem 训练¶
数据集:54K 包含有效 Level-2 MemChunk 的样本,混合 50% 的 Level-1 数据(Level-2 部分为空)。
数据增强:同样使用原始和加噪“听”通道。
训练设置:
从 Level-1 的检查点继续训练。
训练 1 轮,batch size 64。
学习率同样使用余弦衰减(1e-5 到 1.5e-6)。
Episodic Trigger 训练¶
模型初始化:随机初始化。
数据集:100K 干净样本 + 100K 加噪样本。
训练设置:
训练 45 轮,batch size 64。
学习率从 1e-4 到 1e-6 的余弦衰减。
总结¶
本章详细描述了 RoboEgo 模型的训练流程,重点包括:
数据生成:通过合成用户画像和社交关系,构建个性化对话数据。
多任务统一训练:利用监督掩码机制,将 Level-1、Level-2 EgoMem 和 Episodic Trigger 的训练统一在一个框架下。
训练策略:采用数据增强、分阶段训练和余弦学习率衰减,提升模型在全双工、多模态环境下的个性化响应能力。
其中,监督掩码的设计是核心创新点,使得模型能够在不同上下文中分别学习记忆提取与个性化生成。
5 Experiments¶
本节围绕三个核心研究问题展开实验评估:(1) 检索子模块是否能正确识别用户并召回相关内容?(2) 情节触发器是否能准确检测全模态对话的边界?(3) 微调后的 RoboEgo 模型是否能有效利用 Level-1 和 Level-2 EgoMem 提供终身个性化响应?作者通过在专用基准上的定量结果来回答这些问题,并计划公开部分测试集以推动后续研究。
5.1 检索评估¶
作者构建了多个基准任务来评估 EgoMem 的检索能力,结果汇总在表1中。
表1:EgoMem 子模块的人脸验证、说话人识别与文本检索结果¶
任务 |
人脸验证 |
说话人识别 |
文本检索 |
||
|---|---|---|---|---|---|
指标 |
准确率 |
pass@1 |
EER |
pass@5 |
|
结果 |
0.984 |
0.958 |
0.965 / 0.00892 |
0.960 |
|
耗时(秒) |
0.2 |
0.1 |
0.1 |
人脸验证¶
在 LFW 数据集上测试人脸检索模块,准确率达到 98.4%,与公开结果一致。由于开源方案在姿态和角度变化下表现良好,系统未进行额外微调。单个 H100 GPU 上每次查询耗时 0.2 秒。
说话人识别¶
使用 VoxCeleb 数据集构建测试基准,并引入自适应 s-norm 技术提升稳定性。实验显示,使用 s-norm 后 pass@1 从 95.8% 提升至 96.5%。
在更具挑战性的不平衡测试集(正负样本比 1:119)上,EER 达到 0.89%。部署时根据人工案例调整阈值至 6,以平衡精度与召回率。系统在 0.1 秒内完成超过 1000 个候选条目的检索。
文本检索¶
针对 Level-2 EgoMem,使用 pass@5 指标评估在 256 token 窗口内的检索能力。基于 200 个个性化对话查询和 500 个候选事实,系统达到 96% 的 pass@5。单个 H100 GPU 上每次检索耗时小于 0.1 秒。
5.2 情节触发器评估¶
从收集的 token 流中保留 1000 个样本用于评估情节触发器的对话边界检测能力。使用 Jaccard 分数和 span_match@N(允许 ±N 步偏差)作为评估指标。
表2:情节触发器评估结果¶
指标 |
Jaccard |
P/R/F1@0 |
P/R/F1@5 |
P/R/F1@10 |
耗时(秒) |
|---|---|---|---|---|---|
干净环境 |
0.992 |
0.857/0.857/0.857 |
0.986/0.986/0.986 |
0.986/0.986/0.986 |
0.08 |
噪声环境 |
0.989 |
0.790/0.788/0.789 |
0.983/0.981/0.982 |
0.984/0.982/0.983 |
在 N=5 时,情节触发器在干净和噪声环境下均达到超过 0.98 的 F1 分数,表明其在 ±0.4 秒内具有良好的对话边界检测能力。噪声环境对精细边界(<0.2s)检测影响较大,但整体表现仍稳健。处理 10 分钟音频(8192 步)仅需 0.08 秒。
5.3 个性化对话评估¶
从屏蔽 token 流中保留测试集,评估 RoboEgo 在集成 Level-1 和 Level-2 EgoMem 后的个性化响应质量。评估模型 DeepSeek-V3 API 提供两个评分指标:
事实评分(Fact Score):二值指标,判断响应是否个性化且无事实错误。
回答质量(Answer Quality):0-10 分,评估响应的有用性和整体质量,与个性化无关。
表3:个性化对话评估结果¶
模型 |
Level-1 |
Level-2 |
||||
|---|---|---|---|---|---|---|
指标 |
事实评分 |
回答质量 |
吞吐量(fps) |
事实评分 |
回答质量 |
吞吐量(fps) |
干净环境 |
0.959 |
9.170 |
21.73 |
0.895 |
8.970 |
20.56 |
噪声环境 |
0.931 |
9.020 |
- |
0.876 |
8.820 |
- |
结果显示,Level-1 和 Level-2 EgoMem 均能有效支持基于 MemChunk 的检索增强生成(RAG)能力。Level-2 的事实评分较低,主要由于 MemChunk 更新频繁和文本检索模块误差累积。但回答质量评分差距较小,说明 EgoMem 未显著影响 RoboEgo 的基础指令遵循能力。
Level-2 引入较长的 MemChunk 导致吞吐量略有下降,但在全双工实时聊天中影响可忽略(生成音频帧率仍超过 20 fps,远高于 12.5 fps 的最低要求)。
总结¶
本章通过三组实验系统评估了 EgoMem 的核心能力:
检索模块:在人脸、说话人和文本检索任务中均表现优异,具备高准确率和低延迟。
情节触发器:在干净和噪声环境下均能稳健检测对话边界,支持实时处理。
个性化对话能力:RoboEgo 在集成 EgoMem 后仍保持高质量响应,Level-2 虽有轻微性能下降,但整体效果良好,且不影响实时性。
实验结果验证了 EgoMem 在构建终身记忆代理系统中的有效性,为未来研究提供了公开测试集支持。
6 Conclusion and Future Challenges¶
主要内容总结:¶
本章节总结了本研究的核心成果与未来可探索的方向。
6.1 研究成果回顾¶
作者提出了一种面向全双工、全模态模型的终身记忆系统 EgoMem,并定义了其任务目标与核心功能。EgoMem 包含两个层级实现:
Level-1(基于用户画像):通过用户画像实现个性化记忆管理。
Level-2(内容驱动):基于对话内容进行更细粒度的记忆提取与整合。
该系统构建在全模态对话代理 RoboEgo 基础之上,实验结果表明,这是首次实现具备稳健终身个性化能力的全模态对话代理,为后续研究奠定了坚实基础。
6.2 限制与未来挑战¶
由于计算资源限制,研究中未尝试更大模型规模或更复杂的终身学习功能(如复杂工具使用)。未来可能的研究方向包括:
扩展检索增强生成(RAG):不仅限于用户画像与社交网络,还可涵盖程序性记忆及多模态(视觉/音频)记忆内容。
模块简化与参数化:探索是否可用可训练参数替代部分复杂的代理模块与记忆单元,以提升系统灵活性与效率。
总结¶
本章强调了 EgoMem 在实现全模态对话代理终身个性化方面的开创性意义,并指出未来在模型规模、功能扩展与系统优化方面的潜在研究路径。
Acknowledgments¶
本节简要说明了研究的资助来源和致谢对象。
本研究得到了国家科技重大专项(编号:2022ZD0116314)和国家自然科学基金(编号:62106249)的支持。
作者对北京智源人工智能研究院(BAAI)和Spin Matrix的同事在计算资源和实验设备方面提供的帮助表示感谢,并感谢其他所有对项目给予支持的同事。
(本节内容较为简短,主要为形式性的致谢信息,因此不做过多展开。)