2309.02427_❇️CoALA: Cognitive Architectures for Language Agents¶
引用: 347(2025-08-10)
组织: Princeton University
引用链接
memory 定义与运作机制: https://zhuanlan.zhihu.com/p/21982477056
总结¶
产生式系统(具体看第2章,重新整理了❇️)
用于字符串操作
控制流(算法)
认知架构(符号AI的巅峰)
LLM与智能体
From Deepseek¶
论文背景与目标¶
该论文探讨了如何将认知架构(Cognitive Architectures)与语言智能体(Language Agents)相结合,以构建更高效、灵活且具备人类-like推理能力的AI系统。传统语言模型(如LLMs)虽在文本生成上表现优异,但在复杂任务中常缺乏系统性、可解释性和长期推理能力。作者提出,通过借鉴认知科学中的架构设计(如SOAR、ACT-R),可以增强语言智能体的认知能力,使其更好地模拟人类思维过程。
定义:认知架构是对人类认知过程的计算建模框架,旨在模拟人类思维、学习、记忆、决策和问题解决等核心能力。它提供了一种结构化的方式,将感知、推理、记忆和行动等模块整合到一个统一的系统中,使AI或计算模型能够像人类一样处理复杂任务。
核心内容¶
认知架构的整合:
论文分析了经典认知架构(如基于规则的推理、记忆系统、注意力机制)如何为语言智能体提供结构化框架,弥补纯数据驱动方法的局限性。
提出将符号逻辑、子目标分解、工作记忆等模块与LLMs结合,实现更可控的推理流程。
关键设计原则:
模块化:分离记忆、推理、学习等组件,提升透明性和可扩展性。
迭代优化:通过反馈循环(如自我监控或外部反馈)动态调整决策。
情境感知:利用长期记忆和上下文管理增强智能体的环境适应性。
应用场景:
复杂问题求解(如数学推理、规划任务)
交互式环境(如虚拟助手、游戏NPC)
持续学习场景(如动态知识更新)
实验与验证:
通过对比实验,展示了融合认知架构的语言智能体在任务完成率、推理步骤可解释性等方面的优势。
意义与贡献¶
理论层面:为语言智能体的设计提供了认知科学视角的框架, bridging AI与认知心理学。
实践层面:提出可实现的架构设计方案,推动语言智能体向更可靠、可解释的方向发展。
Abstract¶
本节主要介绍了研究的背景、动机和贡献。
背景与动机:近年来,研究人员通过引入外部资源(如互联网)或内部控制流程(如提示链)来增强大语言模型(LLMs),以处理需要事实依据或推理能力的任务,从而催生出一类新型系统——语言智能体(language agents)。这些智能体在实际应用中取得了显著成果,但目前缺乏一个系统性的框架来组织现有研究并指导未来的发展。
贡献与核心思想:针对这一问题,本文借鉴认知科学和符号主义人工智能的丰富历史,提出了 CoALA(Cognitive Architectures for Language Agents) 这一框架。CoALA 描述了一个语言智能体的结构,包括模块化的记忆组件、用于与内部记忆和外部环境交互的结构化动作空间,以及用于选择动作的通用决策过程。
研究方法与目的:作者利用 CoALA 对近期大量相关工作进行了回顾性的整理和分析,并通过这一框架前瞻性地识别出提升语言智能体能力的可行方向。
结论与意义:综合来看,CoALA 将当前的语言智能体放置在人工智能发展史的更广阔背景中,并为迈向基于语言的一般智能(general intelligence)指明了路径。
1 Introduction¶
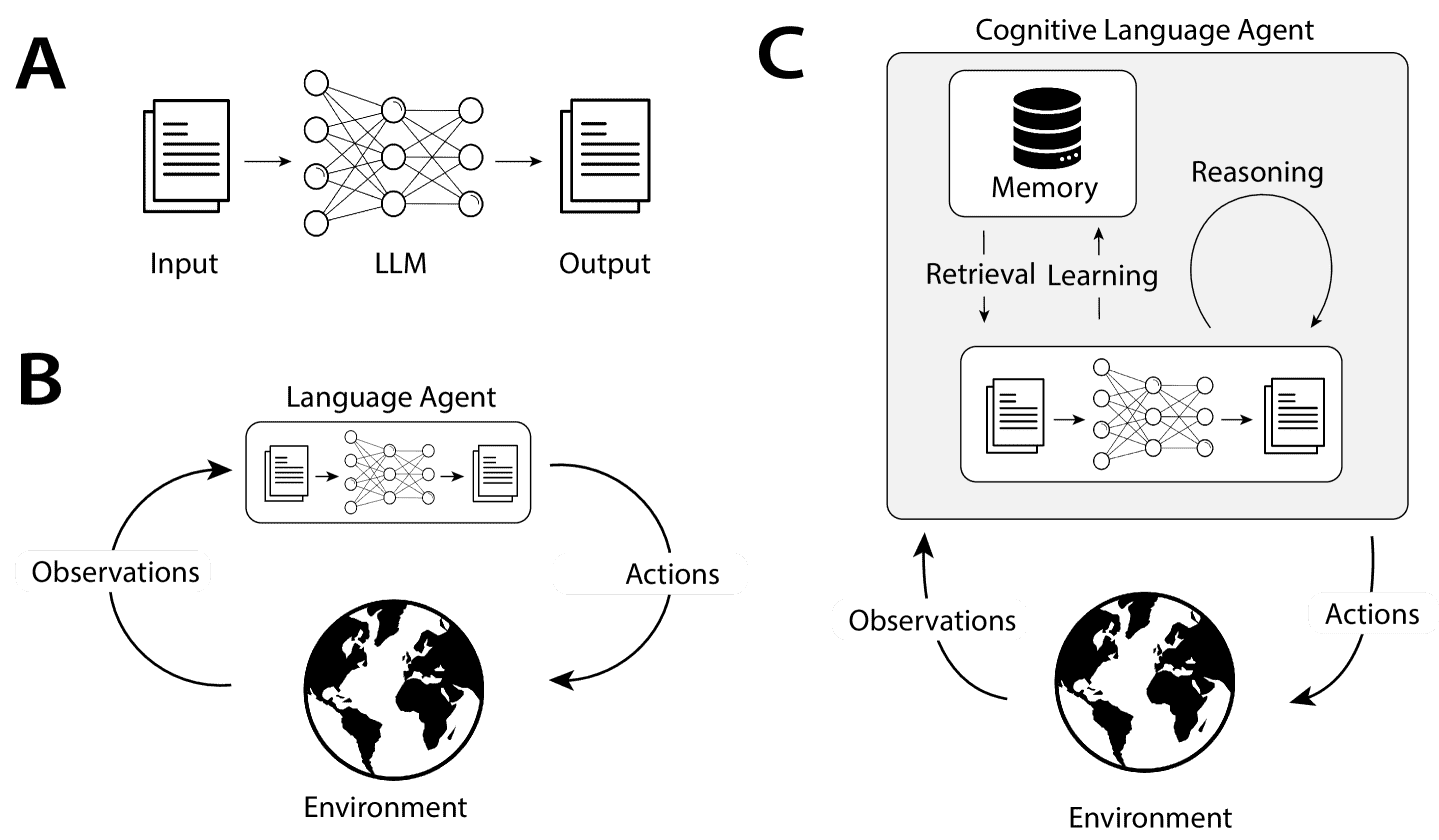
Figure 1:Different uses of large language models (LLMs).
图片说明
A: In natural language processing (NLP), an LLM takes text as input and outputs text.
B: Language agents (Ahn et al., 2022; Huang et al., 2022c) place the LLM in a direct feedback loop with the external environment by transforming observations into text and using the LLM to choose actions.
C: Cognitive language agents (Yao et al., 2022b; Shinn et al., 2023; Wang et al., 2023a) additionally use the LLM to manage the agent’s internal state via processes such as learning and reasoning. In this work, we propose a blueprint to structure such agents.
语言代理概述(Language agents)¶
语言代理是一种新兴的人工智能(AI)系统,它们利用大语言模型(LLMs)与外界进行交互。这种系统结合了LLM的最新进展和传统智能体设计,具有双向促进效果:一方面,LLM本身知识和推理能力有限,而语言代理通过连接内部记忆和环境,解决了这一问题;另一方面,传统代理通常依赖人工规则或强化学习,难以适应新环境,而语言代理通过LLM中的常识先验知识来提高适应性。
语言代理的发展¶
最初的语言代理直接利用LLM来选择或生成动作,但近年来,代理也开始利用LLM进行推理、规划和长期记忆管理,以提升决策能力。新一代“认知型”语言代理内部结构复杂,但当前研究中术语不统一,导致难以比较和演进。
提出概念框架:CoALA¶
为了解决术语混乱的问题,作者借鉴了计算机科学和AI历史中的两个概念:生产系统(production systems)和认知架构(cognitive architectures)。这些系统通过规则迭代生成结果,能实现复杂行为。作者提出,LLM与生产系统有相似之处,都可以看作是对文本进行变换,因此可以借鉴认知架构中的控制机制来构建语言代理。
CoALA 框架简介¶
作者提出了 CoALA(Cognitive Architectures for Language Agents),这是一个用于描述和设计通用语言代理的概念框架。该框架基于三个核心维度:
信息存储(Memory):包括工作记忆和长期记忆;
动作空间(Action):分为内部动作和外部动作;
决策过程(Decision-making):结构化为交互循环,包含规划与执行。
通过这三个维度,CoALA 能清晰地表达现有代理系统,并帮助识别未来发展方向。相比已有研究,本文不仅提出了理论框架,还将其应用于组织大量实证工作,既理论扎实,又具有指导意义。
2 Background: From Strings to Symbolic AGI¶
本节首先介绍产生式系统和认知架构,并从逻辑与计算理论的历史视角出发,介绍认知科学与人工智能的发展历程,从早期的逻辑与计算理论(Post, [1943])一直延伸到构建符号通用人工智能(Newell et al., [1989])的努力。随后,简要介绍语言模型与语言智能体。第3节将连接这些概念,探讨产生式系统与语言模型之间的类比关系。
2.1 用于字符串操作的产生式系统¶
在20世纪上半叶,数学与计算被形式化为符号操作的领域(Whitehead & Russell, [1997]; Church, [1932]; Turing et al., [1936])。
产生式系统是一种形式化方法,其核心思想是:由一组规则构成,每条规则由前提条件和动作组成。当前提条件满足时,执行相应动作。Post([1943])提出,任意逻辑系统可以形式化为字符串的生成规则,例如规则形式为:
这表明字符串 XYZ 可以被重写为 XWZ。这种字符串重写在形式语言理论中发挥重要作用,特别是乔姆斯基短语结构语法(Chomsky, [1956]),它进一步发展了语言结构的形式化描述。
产生式系统(Production Systems)的定义
基本组成:一组规则(Rules),每条规则包含:
前提(Precondition):当前状态或字符串的匹配条件。
动作(Action):若前提满足,则执行动作(通常是字符串的改写)。
直观理解:类似于“如果……那么……”的规则,例如:
如果 字符串是
XYZ,那么 可将其改写为XWZ。
2.2 控制流:从字符串到算法¶
核心概念解析
基本产生式系统的局限性
单纯的产生式系统只能生成字符串(如通过重写规则从初始字符串派生新字符串),但无法体现算法的步骤性。例如,它无法决定“先应用哪条规则”或“何时停止”。引入控制流(Control Flow)
通过为产生式规则添加执行顺序和优先级,可将字符串重写升级为完整的算法。关键机制:
优先级排序:规则按固定顺序尝试匹配(如从上到下)。
匹配方向:通常从左到右扫描字符串,选择第一个匹配的子串。
终止条件:某些规则触发后停止算法(如标记
→∙)。
示例:马尔可夫算法(Markov Algorithm)
论文中的例子是一个表示数字的除法的算法
输入:
|||||||||||(11条竖线,表示数字11)。输出:
||*|(表示11 ÷ 5 = 2余1)。
规则解析
规则 |
作用 |
优先级 |
示例步骤 |
|---|---|---|---|
|
每匹配5条竖线,替换为1个 |
最高 |
|
|
若无法继续匹配5条竖线,剩余竖线为余数,终止计算 |
中 |
|
|
处理空输入(边界情况) |
最低 |
无 |
执行过程
初始字符串:
*|||||||||||(注:初始需补*以标记起始)。第一步:应用最高优先级规则
*||||| → |*,匹配最左边的5条竖线:替换后:
|*||||||(表示已减5,商+1)。
第二步:重复同一规则,再次匹配5条竖线:
替换后:
||*|(商变为2,剩余1条竖线)。
第三步:无法继续匹配
*|||||,触发终止规则→∙ *,输出||*|(即2余1)。
2.3 认知架构:从算法到智能体¶
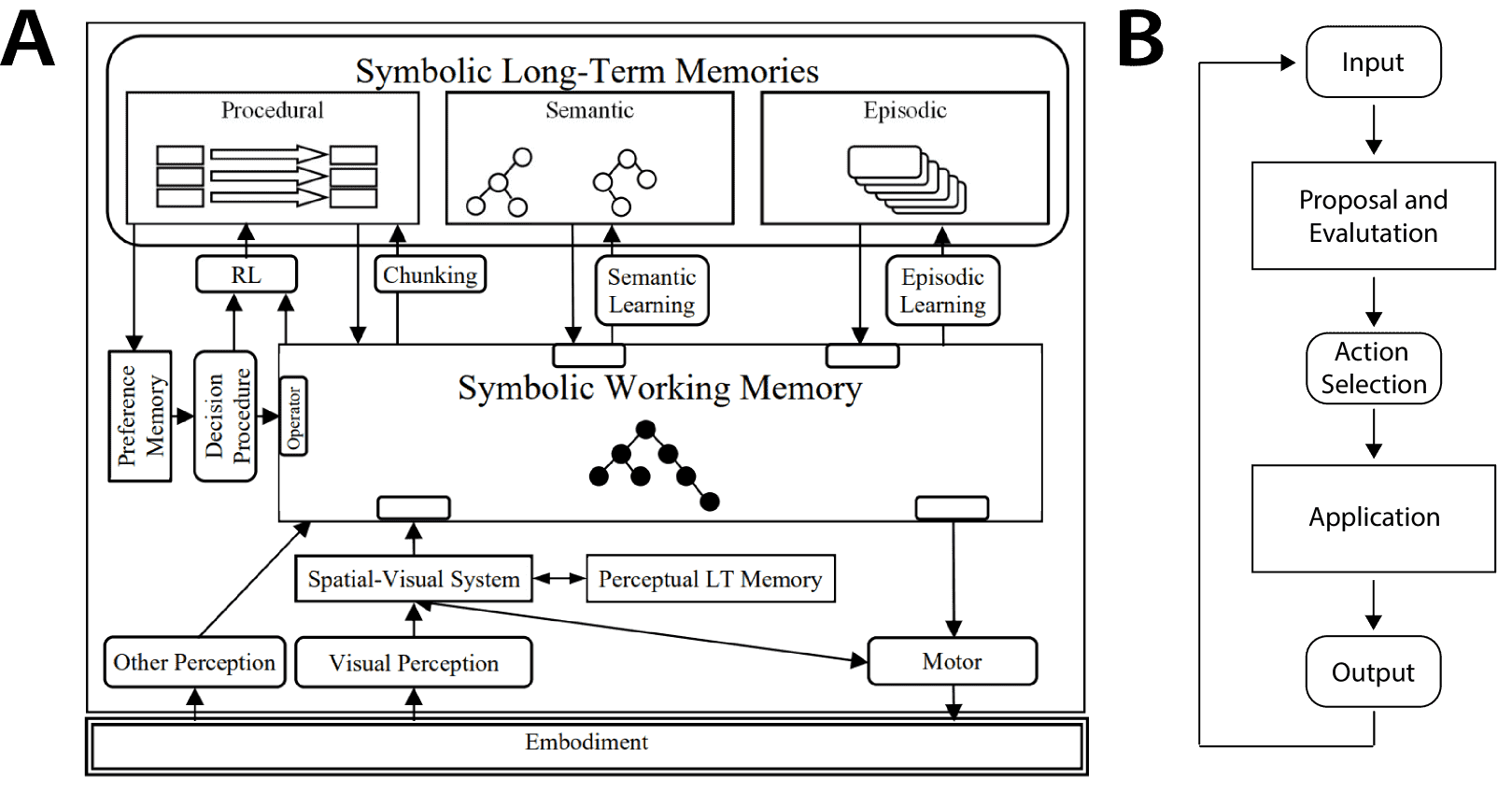
Figure 2:Cognitive architectures augment a production system with sensory groundings, long-term memory, and a decision procedure for selecting actions. A: The Soar architecture, reproduced with permission from Laird (2022). B: Soar’s decision procedure uses productions to select and implement actions. These actions may be internal (such as modifying the agent’s memory) or external (such as a motor command).
1. 产生式系统的进化:从字符串到逻辑规则
早期产生式系统:仅支持字符串重写(如2.1节所述)。
Newell和Simon的贡献:
将产生式规则泛化为逻辑操作,规则形式变为:
IF (前提条件) THEN (动作)示例(恒温器智能体):
IF (温度>70° ∧ 温度<72°) THEN 停止加热 IF (温度<32°) THEN 呼叫维修并开启电暖器 IF (温度<70° ∧ 炉子关闭) THEN 开启炉子
意义:规则不再局限于字符串,而是能直接操作智能体的目标、环境状态和行动。
认知架构的诞生
产生式系统与感知、记忆、规划等模块结合,形成认知架构(Cognitive Architectures),目标是模拟人类认知的灵活性。
核心组件(以Soar为例)
记忆系统(仿照心理学理论)
工作记忆(Working Memory):存储当前感知、目标和中间推理结果(类似人类短期记忆)。
长时记忆(Long-Term Memory):分为三类:
程序性记忆:存储产生式规则(即“技能”)。
语义记忆:存储世界知识(如“鸟会飞”)。
情景记忆:存储过去行为序列(如“昨天我打开了炉子”)。
决策循环
步骤:
匹配:检查工作记忆内容是否匹配某条产生式规则的前提。
提议:生成候选动作(如“开启炉子”)。
评估:选择最优动作(若冲突则触发子目标分解)。
执行:修改记忆或触发外部动作(如发送指令给机器人)。
学习能力
强化学习:根据结果调整规则权重。
自动编写新规则:动态更新程序性记忆(类似“自我编程”)。
认知架构的局限性
依赖逻辑谓词:仅适用于可符号化的领域(难以处理模糊信息)。
规则需人工设计:大规模系统需大量专家知识(难以扩展)。
总结
认知架构是符号AI的巅峰,通过模块化设计实现类人推理,但受限于人工规则。
LLM为认知架构注入新活力:
弥补其灵活性不足和知识获取成本高的缺陷。
未来方向可能是神经符号融合的智能体架构。
2.4 语言模型与智能体¶
语言模型的基础
定义:语言模型(Language Model, LM)的核心是学习一个条件概率分布 \( P(w_i | w_{<i}) \),即根据历史词序列 \( w_{<i} \) 预测下一个词 \( w_i \)。
示例:输入“I went to the”,模型可能输出“market”(概率0.4)、“beach”(概率0.3)等。
发展历程:
早期方法(如n-gram):依赖统计共现,泛化能力有限。
现代LLMs(如GPT-4):基于Transformer架构,通过海量参数(数十亿级)和智能分词技术,从互联网规模数据中学习,生成类人文本。
语言智能体的崛起
核心思想:将LLM作为“大脑”,赋予其推理、规划和行动能力。
语言智能体的潜力与挑战
优势:
自然语言接口:无需预定义符号规则,直接理解人类指令。
隐式知识库:预训练中学习的常识和领域知识可直接调用。
关键挑战:
长期规划:如何将复杂任务分解为可执行的子步骤?
环境交互:如何将文本输出映射为具体动作(如机器人控制)?
可解释性:黑箱模型如何提供可信的决策依据?
与认知架构的联系
互补性:
LLMs:提供灵活的自然语言处理和隐式知识。
认知架构(如Soar):提供结构化推理、记忆管理和控制流。
融合方向:
用LLM替代传统符号系统的规则引擎(如生成动态产生式规则)。
为LLM添加工作记忆和子目标管理模块,增强可控性。
总结
语言模型从“文本生成工具”发展为通用任务求解器,是语言智能体的核心驱动力。
未来方向可能是神经-符号结合的智能体架构,兼具LLM的灵活性和认知架构的系统性。
当前研究重点:如何将LLM的概率生成能力与理性决策、可解释性需求相结合。
3 Connections between Language Models and Production Systems¶
本节从语言模型和生产系统在处理字符串方面的共性出发,提出二者之间存在类比关系。语言模型通过概率方式模拟生产系统的字符串重写操作,并且提示工程可以看作是控制流程的实现。这种类比为设计基于认知架构的语言代理(Cognitive Architectures for Language Agents)提供了理论依据。
3.1 Language models as probabilistic production systems¶
语言模型可以看作是概率性生产系统(Probabilistic Production Systems)。生产系统通过一系列离散的字符串重写操作生成目标字符串,而语言模型则通过概率方式定义可能的字符串扩展方式。例如,给定一个提示字符串 \(X\) 和它的扩展 \(Y\),语言模型可以在概率上定义 \(X \rightarrow X Y\) 的重写过程。
与传统生产系统相比,语言模型的优势在于其大规模预训练带来的强大先验知识,能够直接处理多种任务。但劣势在于其黑箱性和随机性,导致难以解释和控制其行为。
3.2 Prompt engineering as control flow¶
提示工程(Prompt Engineering)可以看作是控制流程(Control Flow)的一种实现。通过设计不同的提示方式,可以引导语言模型生成特定任务的输出。例如:
Zero-shot:直接输入问题 \(Q\),语言模型输出答案 \(A\);
Few-shot:在提示中加入多个示例 \(Q_1A_1, Q_2A_2\),引导模型输出答案;
Retrieval Augmented Generation:结合外部知识库(如维基百科)生成答案;
Socratic Models:结合视觉模型(VLM)生成中间观察 \(O\),再由语言模型生成答案;
Self-Critique:语言模型先生成答案 \(A\),再自我批评生成 \(C\),最后生成改进后的答案 \(A\)。
这些方法本质上定义了一个生产序列(Production Sequence),即语言模型在不同阶段根据输入生成不同的输出。通过链式调用语言模型,可以实现更复杂的行为(如多步推理)。
3.3 Towards cognitive language agents¶
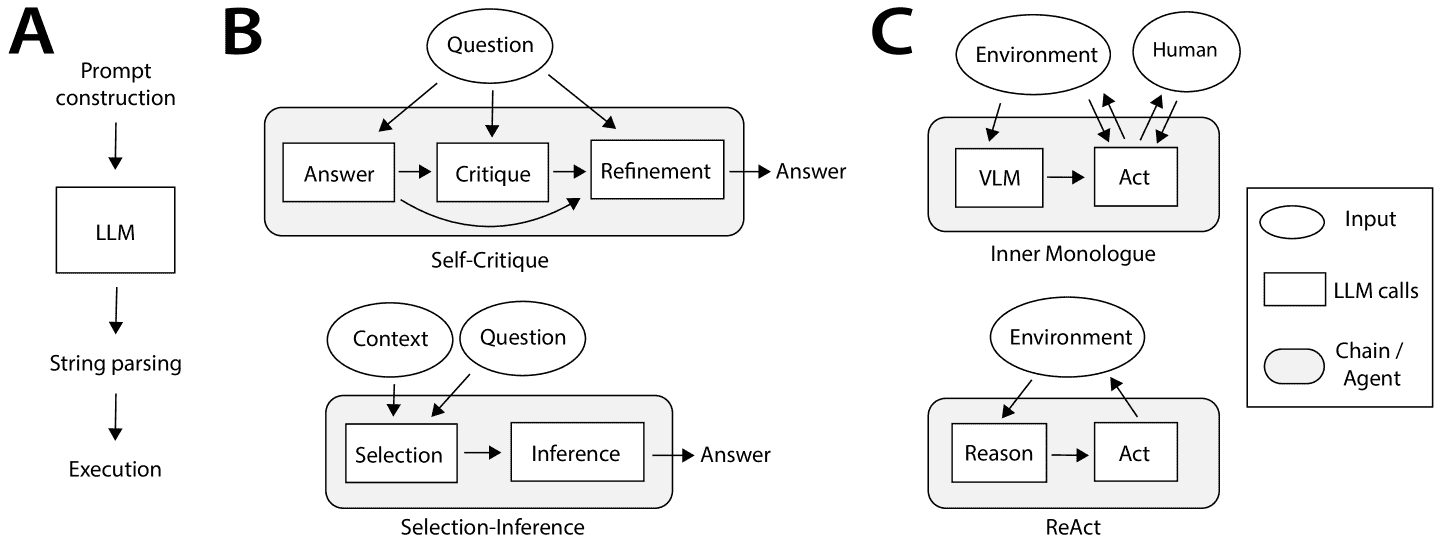
Figure 3:From language models to language agents. A: Basic structure of an LLM call. Prompt construction selects a template and populates it with variables from working memory. After calling the LLM, the string output is parsed into an action space and executed. An LLM call may result in one or more actions – for example, returning an answer, calling a function, or issuing motor commands. B: Prompt chaining techniques such as Self-Critique (Wang et al., 2022b) or Selection-Inference (Creswell et al., 2023) use a pre-defined sequence of LLM calls to generate an output. C: Language agents such as Inner Monologue (Huang et al., 2022c) and ReAct (Yao et al., 2022b) instead use an interactive feedback loop with the external environment. Vision-language models (VLMs) can be used to translate perceptual data into text for the LLM to process.
语言代理(Language Agents)不再依赖固定的提示链,而是将语言模型置于一个与外部环境交互的反馈循环中。例如:
基于感知输入(如视觉)生成文本,再由语言模型推导行为;
通过链式调用语言模型生成中间推理步骤,再执行动作;
使用认知策略(如反思、修改程序代码)来增强代理的适应能力。
本节最后提出,认知架构(Cognitive Architectures)可以用来组织语言代理中的模块(如记忆、推理、外部交互等),从而构建更具认知能力的语言代理系统。这一思路将在后续章节中进一步展开。
总结¶
本节核心观点是:语言模型本质上是带有概率性决策的生产系统,而通过设计合适的提示工程和反馈机制,可以构建出具有复杂认知能力的语言代理。该思路为后续研究提供了一个理论框架(CoALA),即将语言模型与认知架构结合,以实现更智能的自主系统。
4 Cognitive Architectures for Language Agents (CoALA): A Conceptual Framework¶
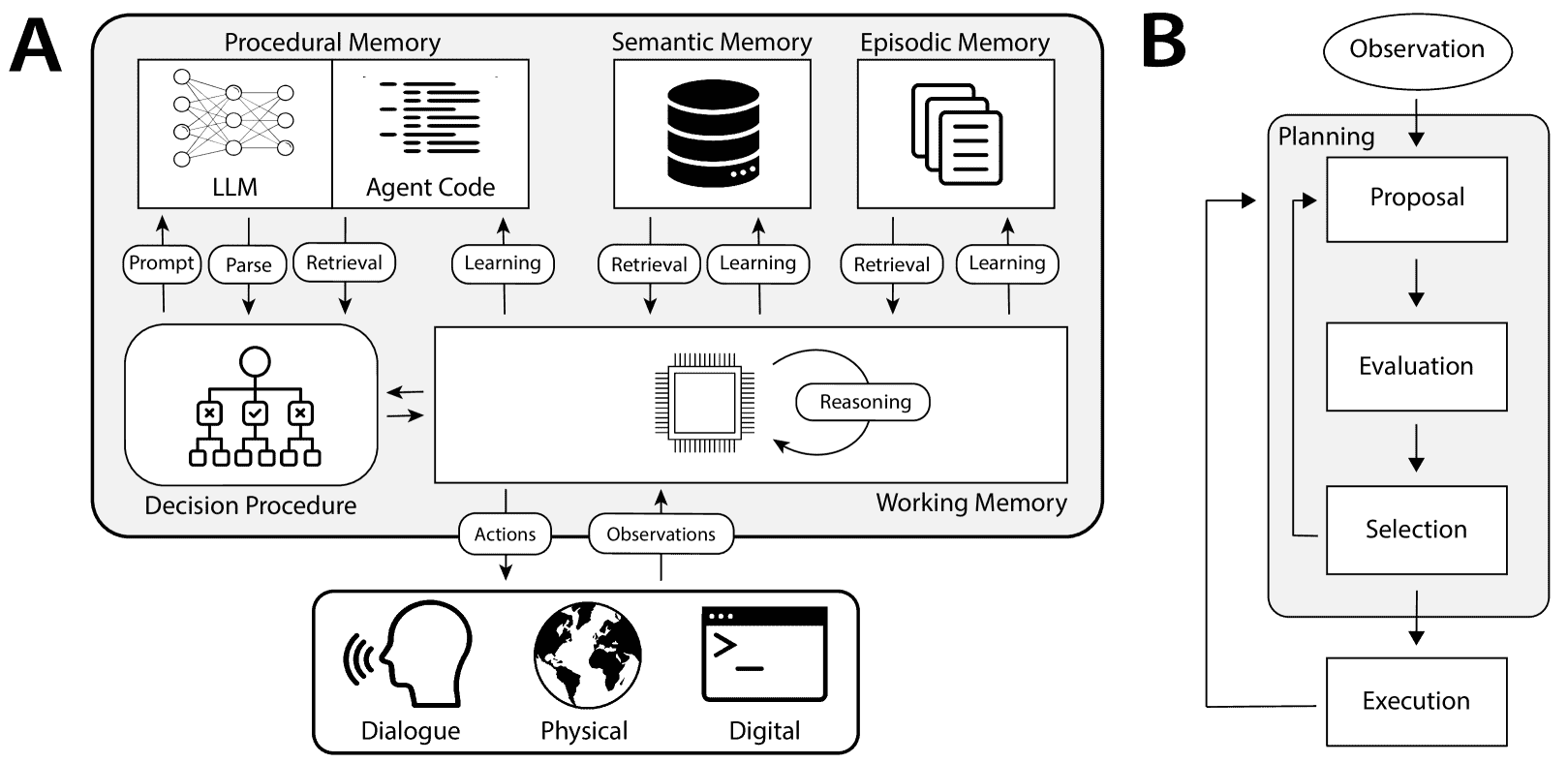
Figure 4:Cognitive architectures for language agents (CoALA). A: CoALA defines a set of interacting modules and processes. The decision procedure executes the agent’s source code. This source code consists of procedures to interact with the LLM (prompt templates and parsers), internal memories (retrieval and learning), and the external environment (grounding). B: Temporally, the agent’s decision procedure executes a decision cycle in a loop with the external environment. During each cycle, the agent uses retrieval and reasoning to plan by proposing and evaluating candidate learning or grounding actions. The best action is then selected and executed. An observation may be made, and the cycle begins again.
4.1 概述¶
CoALA(Cognitive Architectures for Language Agents)是一个用于组织现有语言智能体并指导新智能体开发的概念框架。在CoALA框架中,大型语言模型(LLM)被定位为一个更大的认知架构的核心组件。该架构包括记忆模块和动作空间,分为外部动作和内部动作。外部动作通过接地(grounding)与外部环境进行交互,如控制机器人、与人类通信或导航网站。内部动作则通过访问不同的记忆模块,分为检索(从长期记忆读取)、推理(更新短期记忆)和学习(写入长期记忆)。
语言智能体通过决策机制在这些动作中循环选择,这一循环类似于程序中的“主过程”,持续运行、接受感知输入并调用相应的动作过程。
CoALA受多年来认知架构研究的启发,引入了记忆、接地、学习和决策等核心概念。通过LLM的加入,新增了“推理”动作,能够灵活生成新的知识和启发式方法,替代传统架构中的手写规则。此外,文本被作为内部表示,简化了记忆模块;多模态模型的进展也简化了接地过程,将感知数据翻译为文本。
4.2 记忆¶
语言模型本身是无状态的,不能跨调用保留信息。CoALA框架中,语言智能体通过多个记忆模块组织信息,主要包括:
工作记忆:用于当前决策周期中的活跃信息,包括感知输入、知识、目标等。工作记忆是LLM调用之间的持久数据结构,输入由其合成,输出解析后写回工作记忆,用于执行相应动作。
情景记忆:存储以前决策周期的经验,例如训练输入输出对、事件流程、游戏轨迹等。这些经验可在规划阶段被检索,并用于学习。
语义记忆:存储关于世界和智能体自身的知识。传统方法从中检索信息支持推理和决策,语言智能体可将LLM推理结果写入语义记忆。
程序记忆:分为隐式和显式知识。隐式知识存储在LLM权重中,显式知识写在智能体代码中,包括执行动作和决策的程序。程序记忆由设计者初始化,更新时需谨慎。
4.3 接地动作¶
接地动作使智能体能够与外部环境交互,并将反馈转化为文本。主要分为三类:
物理环境:通过视觉、听觉等感知输入,结合预训练模型转换为文本,控制机器人等。
人类或其他智能体的对话:智能体接受指令、学习、帮助人类,或与其他智能体进行辩论、协作等。
数字环境:与游戏、API、网站或代码执行交互,较物理或人际交互更便宜、更快,是语言智能体的测试平台。
4.4 检索动作¶
检索动作从长期记忆读取信息到工作记忆,实现方式包括基于规则、稀疏或密集检索。例如,Voyager通过密集检索从技能库加载技能,Generative Agents通过时间、重要性和相关性评分检索事件,DocPrompting利用语义记忆辅助代码生成。当前研究在自适应检索方面仍有不足。
4.5 推理动作¶
推理动作允许智能体处理工作记忆中的信息,生成新信息。不同于检索仅读取,推理可读写工作记忆。例如,总结最近观察或轨迹,或基于长期记忆提取信息。推理可用于支持学习(将结果写入长期记忆)或决策(作为后续LLM调用的上下文)。
4.6 学习动作¶
学习通过将信息写入长期记忆实现,包括:
情景记忆更新:存储经验用于后续推理或决策。
语义记忆更新:LLM推理结果可写入语义记忆,如生成环境语义地图。
LLM参数更新:通过微调调整LLM权重,适应智能体领域。
智能体代码更新:修改智能体的代码实现,如推理模板、接地代码等。当前方法多集中于创建新代码技能,如何更新检索或决策机制仍需探索。
语言智能体相比强化学习智能体,具有更多样化的学习方式,可快速存储任务相关语言,利用多种学习方式实现自我提升。
4.7 决策机制¶
语言智能体通过决策机制选择动作,该机制是智能体的“主程序”,由决策周期组成。每个周期包括规划阶段和执行阶段。
规划阶段:
提案:生成一个或多个动作候选,通常通过LLM推理加检索。
评估:若存在多个动作,评估其价值,可使用启发式规则、LLM推理等。
选择:根据评估结果选择一个动作执行,或返回提案阶段。
执行阶段:执行所选动作,可能是外部接地动作(如API调用)或内部学习动作(如写入情景记忆)。执行后,通过环境反馈进入下一轮决策周期。
早期语言智能体通常仅用LLM提案动作。后续研究引入了中间推理和检索,支持更复杂的规划。近年来,研究开始探索迭代提案与评估机制,如Tree of Thoughts和RAP,分别采用BFS/DFS和MCTS,模拟动作并评估其效果,提升决策质量。
5 Case Studies¶
本节通过CoALA框架展示了语言智能体(Language Agents)在记忆模块、动作空间和决策过程中的多种变体和消融实验。CoALA能够统一表达不同类型的智能体,揭示它们内部机制的异同。表2总结了多个近期流行的智能体,涵盖Minecraft、机器人、纯推理和社会模拟等不同领域。
SayCan(Ahn et al., 2022)¶
SayCan是一个将语言模型与厨房机器人交互结合的智能体,旨在满足用户指令(如“我刚锻炼完,能给我带一杯饮料和点零食来恢复吗?”)。其长期记忆仅包含过程性记忆(LLM权重和学习的价值函数),动作空间仅包含外部动作 —— 一组固定的551个基本技能(如“找到苹果”、“走到桌子旁边”),没有内部动作(如推理、检索、学习)。在决策阶段,SayCan通过LLM与价值函数结合,评估每个动作的实用性与接地性。因此,SayCan使用LLM(结合价值函数)作为一个单步规划器。
ReAct(Yao et al., 2022)¶
ReAct是一个基于数字环境(如Wikipedia API、文字游戏、网页)的语言智能体。它没有语义或情景记忆,因此不支持检索或学习动作。其动作空间包含两个部分:内部推理动作和外部接地动作。其决策流程是:先推理分析当前状况,再制定或更新行动计划,最后生成一个接地动作,但不再进行评估或选择阶段。ReAct是最早展示内部与外部动作协同效果的研究之一:推理引导动作,动作又提供环境反馈以支持推理。
Voyager(Wang et al., 2023)¶
Voyager是一个基于Minecraft API的语言智能体,其接地方式不同于SayCan,仅基于文本信息。它拥有一个长期过程性记忆,存储基于代码的接地过程(称为“技能”),例如“combatZombie”、“craftStoneSword”。该技能库具有层次结构:复杂技能可以调用简单技能作为子程序。其动作空间包含四种动作:接地、推理、检索和学习(通过添加新的接地过程)。在决策周期中,Voyager首先通过推理生成任务目标,然后推理生成接地技能来执行任务。在下一步,其通过环境反馈判断任务是否完成。如果成功,则通过学习动作将技能写入长时记忆;否则,通过推理优化代码并重新执行。通过与ReAct、AutoGPT等基线的比较以及缺少过程性记忆的消融实验,验证了长期记忆与过程性学习的重要性。Voyager在环境探索、技术树掌握、以及零样本任务泛化方面表现更优。
Generative Agents(Park et al., 2023)¶
Generative Agents是一个基于沙盒游戏的语言智能体,可以与环境和其他智能体互动。其动作空间包含四种动作:接地、推理、检索和学习。每个智能体拥有一个长期情景记忆,存储事件列表。它们通过检索和推理生成关于自身经历的反思(如“我现在喜欢滑雪。”),并将这些反思写入长期语义记忆。在决策阶段,智能体检索相关反思,再推理生成当天的高层计划。在执行计划过程中,智能体接收接地观察流,通过推理进行计划的维持或调整。
Tree of Thoughts(ToT, Yao et al., 2023)¶
Tree of Thoughts(ToT)可以看作是一种特殊的语言智能体,其唯一的外部动作是提交最终解决方案(如24点游戏、创意写作、填字游戏等)。它没有长期记忆,内部动作仅包含推理。其与之前智能体的主要不同在于决策过程的刻意性。在规划阶段,ToT通过LLM推理迭代地提出、评估和选择“思想”(推理动作),并通过树搜索算法维护这些“思想”,从而实现全局探索、局部回溯和前瞻性规划。
总结¶
本节通过CoALA框架系统地分析了多个语言智能体的内部机制,强调了记忆模块、动作空间和决策流程这三个维度的设计差异。不同的智能体在这些维度上表现出不同的能力组合:如SayCan专注于外部动作与LLM结合的单步规划,Voyager则体现了过程性记忆与学习的结合,而Generative Agents展示了复杂反思和长期记忆的协同。ToT则通过树搜索实现更高级的推理规划。这些案例展示了语言智能体在不同任务和环境中的多样化设计。
6 Actionable Insights¶
本章节提出了 CoALA(面向语言代理的认知架构)所带来的实用见解与未来研究方向。这些见解不仅基于理论框架,还结合了实际应用和行业经验,旨在为语言代理的设计、开发和优化提供指导。
Modular Agents: Thinking Beyond Monoliths(模块化代理:超越单体架构)¶
重点内容:
作者指出,语言代理应采用模块化结构,而不是单体式设计。这一思想借鉴了机器人平台中模块化软件的标准化实践。
学术研究方面:标准化术语和开源实现有助于模块化复用和比较不同研究。例如,强化学习中的 Markov Decision Process(MDP)提供了标准化概念(状态、动作、奖励等),而 OpenAI Gym 提供了标准化抽象。类似地,CoALA 建议为语言代理实现可复用的模块化类(如 Memory、Action、Agent),并提供一个通用框架来构建更复杂的代理。
工业应用方面:建立统一的“语言代理库”可以减少技术债务,提升测试与组件复用性,同时统一用户体验。
LLM 与代码的关系:代理的“过程性记忆”包括 LLM 参数(灵活但难以解释)和代码(可解释但脆弱)。建议用代码补充 LLM 的不足,例如使用树搜索缓解 LLM 的短视问题。
Agent Design: Thinking Beyond Simple Reasoning(代理设计:超越简单推理)¶
重点内容:CoALA 代理由三部分组成:内部记忆、动作空间、决策机制。
内部记忆模块:决定了代理所需的记忆类型。例如,个性化零售助理需要语义记忆(商品)、情景记忆(用户历史)和程序记忆(搜索函数)。
动作空间定义:包括对各类记忆的读写权限。例如,零售助理应能读写情景记忆,但只能读取语义和程序记忆。
决策机制:需要在性能与通用性之间权衡。复杂的机制如 Voyager 更适合特定任务,而通用机制如 ReAct 更具扩展性。决策机制还可以通过延迟学习、对话摘要等方式简化。
Structured Reasoning: Thinking Beyond Prompt Engineering(结构化推理:超越提示工程)¶
重点内容:传统的提示工程依赖字符串操作,而 CoALA 提出更结构化的推理方式,以更新工作记忆。
工具与框架:如 LangChain 和 LlamaIndex 可定义推理步骤序列,减少每次推理负担;Guidance 和 OpenAI Function 可用于更新工作记忆变量。
推理与训练方向:代理中的推理任务可反向影响 LLM 训练,如自我评价、反思、动作生成等。未来 LLM 可能更多地围绕这些任务进行训练或微调。
Long-term Memory: Thinking Beyond Retrieval Augmentation(长期记忆:超越检索增强)¶
重点内容:与传统检索增强模型不同,CoALA 代理支持自主读写生成内容,实现终身学习。
知识与经验结合:代理可以利用语义知识(如编程手册)生成经验知识,并通过反思生成新知识,最终形成程序知识(如代码库)。
推理与检索结合:记忆检索与决策过程的结合可提升规划能力。例如,计算心理学模型表明,记忆与决策的交互有助于更有效的决策。
Learning: Thinking Beyond In-Context Learning or Finetuning(学习:超越上下文学习或微调)¶
重点内容:CoALA 扩展了“学习”的定义,包括存储新经验、知识及代码。
元学习修改代理代码:可以提升学习效率。例如,通过学习更好的检索策略,优化记忆使用。
新学习形式:包括微调子模型、删除无用记忆(“遗忘”)、研究多种学习方式(如元学习、迁移学习)之间的交互效应。
Action Space: Thinking Beyond External Tools or Actions(动作空间:超越外部工具)¶
重点内容:代理应定义清晰、任务适配的内外动作空间,包括推理、检索、学习等内部动作,以及与环境交互的外部动作。
动作空间规模与复杂性:更强大代理需要更大的动作空间,但也带来决策复杂性。因此,应根据任务需求最小化动作空间。
安全性问题:学习和接地动作(如删除文件、生成有害内容)可能带来风险,需制定任务特定的安全策略,并考虑最坏情况下的预测预防机制。
Decision Making: Thinking Beyond Action Generation(决策:超越动作生成)¶
重点内容:目前大多数代理仅能生成单个动作,未来应探索更复杂的决策机制,如“提议-评估-选择”流程。
结合语言与代码规划:将自然语言推理与代码规划结合,可能提升决策效率。例如,像 Soar 使用模拟器进行物理推理,代理可动态生成并执行代码模拟动作后果。
现实世界拓展:现有工作多基于简单任务(如游戏 24、积木),未来需拓展到复杂、有真实交互的任务,并结合长期记忆。
元推理提升效率:LLM 推理成本高,应开发机制动态评估推理价值,优化计算资源分配,如 ReAct 中提出的 CoT 与 ReAct 的切换。
校准与对齐问题:复杂决策面临如过度自信、偏差、幻觉和缺乏人类介入等问题,解决这些将提升 LLM 作为代理核心的实用性。
总结¶
本章从模块化设计、决策机制、推理结构、长期记忆、学习方式、动作空间和决策过程等多个维度,提出 CoALA 框架下的实际可行的代理设计建议与未来研究方向。强调结构化、模块化与系统性设计,并鼓励结合 LLM 灵活性与代码可解释性,以构建更智能、安全、通用的语言代理系统。
7 Discussion¶
LLMs vs VLMs:推理应是语言单一模态还是多模态?¶
目前大多数语言代理使用纯语言模型(LLM)进行决策,并依赖单独的图像描述模型(captioning model)将视觉信息转化为文本后再进行推理。然而,最新的语言模型已经具备多模态能力(如VLM),可以直接处理图像和文本的混合输入,从而避免图像到文本的损失性转换。
从高层次来看,这两种方法代表了不同的“非语言模态到语言域的编码方式”:一种是模块化设计(将图像转为文本),另一种是集成式设计(图像直接映射到语言模型空间)。集成式多模态推理可能更接近人类行为方式,但会使得推理和感知系统更加紧密耦合,从而更难更新和泛化。
重点:CoALA 提出的架构原则(如内部记忆、结构化动作空间、通用决策)仍然适用于这两种方式的设计。
内部 vs 外部:代理与其环境的边界在哪里?¶
数字语言代理与其环境的边界并不像人类或机器人那样明确。例如:
Wikipedia 是内部记忆还是外部环境?
代理在执行和优化代码前提交答案,这个过程是内部推理还是外部动作?
基于“提议-评估”机制的代理,是单个代理还是多个协作代理?
本文提出应从**可控制性(controllability)与耦合性(coupling)**两个维度来看待这一问题:
如果外部环境不可控(如他人可修改的在线数据库),则应视为外部。
如果是代理独占的、可控制的副本(如离线版数据库),则可以视为内部。
如果模块之间高度依赖、彼此设计,应视为同一代理的一部分;否则可视为多代理协作。
重点:这一概念框架有助于统一术语体系,并指导代理设计,尽管在实践中,研究者可以选择对自己最有益的框架,前提是保持一致性。
物理 vs 数字:环境差异如何影响行为?¶
数字环境(如互联网)具有可重置和并行试错的特点,与物理世界不同。这使得数字代理可以更自由地进行探索与并行任务处理(如打开百万个网页、并行执行多个任务路径)。
这种特性可能导致其决策方式与受人类认知启发的当前方法存在差异。数字代理的行为可能更加“激进”和“非人化”,但也更具效率。
重点:理解物理与数字环境的差异有助于设计出更适应数字世界的代理行为。
学习 vs 行动:代理应如何持续、自主地学习?¶
在 CoALA 框架中,学习被视为决策循环的一部分,与感知(grounding)一样,是代理主动选择的行动。与大多数代理仅通过预设学习计划进行训练不同,CoALA 强调代理在与环境交互中动态选择何时学习。
这种设计更接近生物代理的行为模式(生物必须在有限的生命周期中平衡学习与行动)。
重点:学习应与外部行为同等对待,成为代理的“可选动作”,从而实现更自主、更灵活的决策。
GPT-4 vs GPT-N:更强的 LLM 如何影响代理设计?¶
随着 LLM 能力的增长,代理设计也在不断演进。例如:
GPT-3 引入了“少样本”和“零样本”推理。
GPT-4 开始支持更可靠的自我评估和自我改进。
未来的 GPT-N 可能具备更强的“上下文模拟”能力,能够在内部模拟记忆、行动、评估等过程,甚至可能不再依赖外部推理组件。
重点:随着 LLM 能力的增强,CoALA 的部分组件(如长时记忆、评估机制等)可能会变得不那么重要。但即便如此,CoALA 仍可作为设计代理行为的理论框架,帮助理解和解释 LLM 内部的复杂行为。
总结¶
本节通过提出五个关键问题(LLM vs VLM、内部 vs 外部、物理 vs 数字、学习 vs 行动、GPT-4 vs GPT-N),探讨了语言代理设计的理论边界与未来发展方向。这些问题不仅具有概念意义,也对实际设计具有指导价值。即便未来 LLM 能力进一步增强,CoALA 提供的框架仍能作为代理设计的重要参考。
8 Conclusion¶
本节总结了作者提出的研究成果——认知语言代理架构(Cognitive Architectures for Language Agents, CoALA),这是一个用于描述和构建语言代理的概念性框架。作者强调,这一框架的灵感来源于符号主义人工智能和认知科学的悠久历史,并将这些经典洞见与当前大语言模型的前沿研究联系起来。这是本节的重点内容,体现了研究的创新性和跨学科融合的思路。
作者认为,这种结合传统与现代方法的架构为开发更加通用、更接近人类智能的人工智能提供了一条可行路径。这一观点是全文的主旨之一,也是对未来研究方向的重要展望。
整体而言,本节通过简洁有力的语言,重申了CoALA框架的价值,以及其在推动人工智能向更高级形态发展的潜力。