2511.11255_Align3GR: Unified Multi-Level Alignment for LLM-based Generative Recommendation¶
引用: 0(2025-12-06)
组织:
Kuaishou Technology
总结¶
From Web¶
https://mp.weixin.qq.com/s/WPPBqI0g-3XkHF4VC9fWVw
From Moonlight¶
关键词¶
Recommender Systems (RS):
Generative Recommendation (GR):
Semantic-Collaborative ID (SCID):
Dual SCID Tokenization:
Progressive DPO Strategy:
Self-Play DPO (SP-DPO):
Real-world Feedback DPO (RF-DPO):
Residual Quantization Variational Autoencoder (RQ-VAE):
三句摘要¶
💡 Align3GR 提出一个统一的多层对齐框架,旨在弥合大型语言模型 (LLM) 与推荐系统 (RS) 之间的语义和行为差距,从而将 LLM 有效地转换为生成式推荐器。
⚙️ 该框架通过 Dual SCID Tokenization 实现用户和物品的语义与协同信号融合,并通过增强型多任务 SFT (Supervised Fine-Tuning) 进一步提升行为建模,引入用户 SCID 和双向语义对齐任务。
🚀 为实现偏好对齐,Align3GR 采用渐进式 DPO (Direct Preference Optimization) 策略,结合 Self-Play (SP-DPO) 和 Real-world Feedback (RF-DPO) 以适应动态用户偏好,并在离线和在线实验中均实现了显著的性能提升。
摘要¶
Align3GR是一项针对基于Large Language Models (LLMs) 的生成式推荐系统 (Generative Recommendation, GR) 提出的统一多级对齐框架,旨在解决LLMs在转化为真实世界推荐系统时面临的语义和行为错位等根本性挑战。该框架通过整合Token-level、Behavior Modeling-level和Preference-level的对齐,显著提升了LLMs在推荐任务上的表现。
核心思想与挑战应对 传统的LLMs主要关注语义信息和next-token prediction (NTP),而推荐系统则侧重于基于用户交互行为来建模隐式偏好。这种根本性的差异导致了LLMs在推荐场景中的性能局限性。Align3GR通过三个关键层次的对齐来弥合这一差距:
Token-level Alignment: 引入Dual tokenization,融合用户-物品的语义和协同信号,生成紧凑且富有表达力的Semantic-Collaborative ID (SCID)。
Behavior Modeling-level Alignment: 增强了行为建模,通过双向语义对齐强化LLM理解推荐任务数据结构和用户行为模式的能力。
Preference-level Alignment: 提出Progressive DPO策略,结合self-play (SP-DPO) 和real-world feedback (RF-DPO),实现动态偏好适应。
方法论
1. Token-level Alignment: Dual SCID Tokenization Align3GR的Token-level对齐通过Dual SCID Tokenization实现,旨在共同编码用户和物品,并融合它们的语义和协同特征。
特征提取: 首先提取用户和物品的语义特征(如profile或description)和协同特征(如行为模式)。
Encoder处理: 语义特征由冻结的Semantic Encoder (例如T5初始化) 处理;协同特征由冻结的Collaborative Encoder (例如DIN) 建模。
SC Encoder: 将语义和协同嵌入concatenate,通过Hybrid Semantic-Collaborative (SC) Encoder (例如MLP) 生成统一的SC embeddings (\(SC_u\), \(SC_i\))。
量化: 使用RQ-VAE (Residual Quantization VAE) 将这些统一的嵌入量化为离散的SCID。RQ-VAE的Hierarchical结构帮助在保持紧凑Token空间的同时捕获多层次信息。
训练目标:
User-Item Behavior Loss (\(\mathcal{L}_{U2I}\)): 在embedding层面,优化采样softmax用户-物品行为损失,以增强用户和物品SC embeddings之间的对齐。 \(\mathcal{L}_{U2I} = - \frac{1}{|\mathcal{B}|} \sum_{(u, i^+) \in \mathcal{B}} \log \frac{\exp(u^\top v_{i^+})}{\exp(u^\top v_{i^+}) + \sum_{j \in \mathcal{N}_u} \exp(u^\top v_j)}\) 其中,\(\mathcal{B}\) 是batch size,\(u\) 和 \(v\) 分别代表 \(SC_u\) 和 \(SC_i\),\((u, i^+)\) 是正向用户-物品交互对,\(\mathcal{N}_u\) 是负样本集。
整体损失: 结合U2I行为损失和来自用户-特定及物品-特定RQ-VAE的量化损失。 \(\mathcal{L} = \alpha \cdot \mathcal{L}_{U2I} + \gamma \cdot (\mathcal{L}_{\text{User RQ}} + \mathcal{L}_{\text{Item RQ}})\) 其中,\(\mathcal{L}_{\text{User RQ}}\) 和 \(\mathcal{L}_{\text{Item RQ}}\) 是用户和物品嵌入的重建和量化损失,\(\alpha, \gamma\) 是超参数。实践中,首先设置 \(\alpha=1, \gamma=0\) 优化 \(\mathcal{L}_{U2I}\),然后切换到 \(\alpha=0.1, \gamma=1\) 专注于量化损失。 这种设计不仅压缩了Token空间,还在模型管道中保留了协同关系,为后续SFT和Preference-based RL奠定基础。
2. Behavior Modeling-level Alignment: Multi-task SFT 在获得量化的SCID后,Align3GR通过多任务Supervised Fine-Tuning (SFT) 进一步增强LLM的生成和语义对齐能力。
词汇扩展: 将用户和物品的SCID Token纳入LLM的词汇表,避免OOD (out-of-vocabulary) 问题。
多任务框架: 基于LC-Rec,包含以下任务:
Sequential Item Prediction: 根据用户历史交互序列预测下一个物品。
Asymmetric Item Prediction: 基于用户SCID和历史物品标题序列推荐下一个物品。
Item Prediction Based on User Intention: 假设LLM是搜索引擎,根据用户SCID和搜索查询选择物品响应。
Personalized Preference Inference: 根据用户SCID和历史交互物品,推断用户偏好。
关键增强:
User SCID注入: 将用户的SCID Token注入所有任务的prompt中,提供更丰富的上下文对齐。
双向对齐目标 (B.2): 引入用户侧双向对齐,一个任务是从用户profile文本预测其SCID Token (text \(\to\) SCID),另一个任务是从给定的SCID Token重建用户profile文本 (SCID \(\to\) text)。这明确地将SCID Token与其真实世界的语义含义联系起来。 这些增强通过直接整合SCID Token并明确对齐结构化和语义信息,为后续偏好优化提供了更强的基础。
3. Preference-level Alignment: Progressive DPO with Self-Play and Real-world Feedback 尽管SFT阶段赋予模型初步推荐能力,但仅依赖标注偏好数据进行简单偏好优化不足以实现持续改进或鲁棒的业务对齐。Align3GR引入了Progressive DPO,结合self-play (SP-DPO) 和real-world feedback (RF-DPO)。
Progressive DPO: 基于Softmax-DPO构建,通过构建包含多个拒绝响应的训练样本,并采用逐步学习(easy to hard)的策略。
训练目标: \(\mathcal{L}(\pi_i^\theta, \pi_i^{ref}) = -E_{(x, y_i^w, Y_i^l) \sim D_i} \left[ \log \sigma \left( \beta \log \frac{\pi_i^\theta(y_i^w | x)}{\pi_i^{ref}(y_i^w | x)} - \beta \log \sum_{y_i^l \in Y_i^l} \frac{\pi_i^\theta(y_i^l | x)}{\pi_i^{ref}(y_i^l | x)} \right) \right]\) 其中,\(\pi_i^\theta\) 是当前阶段 \(i\) 的策略,\(\pi_i^{ref}\) 是参考策略,\(x\) 是prompt,\(y_i^w\) 是选择的响应,\(Y_i^l\) 是拒绝响应的集合,\(D_i\) 是阶段 \(i\) 的渐进训练集,\(\beta\) 是超参数,\(\sigma(\cdot)\) 是sigmoid函数。每个阶段微调后的模型成为下一阶段的参考模型 (\(\pi_i^\theta \to \pi_{i+1}^{ref}\))。
Progressive SP-DPO: 利用self-play机制增强模型的生成能力。将学习分为Easy、Medium和Hard三个阶段,使用prefix-ngram match metric(相同prefix表示相似语义和协同信息)来区分 chosen 和 rejected SCID响应。
Easy阶段: Chosen和rejected SCID响应完全不同,没有共享prefix-ngram。
Medium/Hard阶段: Chosen和rejected SCID响应之间的prefix-ngram重叠逐渐增加,增加判别难度。 这些阶段性偏好数据结合真实用户行为序列,逐步作为DPO的训练数据。
Progressive RF-DPO: 捕获真实用户反馈作为对齐的偏好数据,通过向用户推荐模型生成的项目。反馈分为disliked、neutral和liked三个级别。训练也分阶段进行:
Easy阶段: 将 strongly disliked 项目作为负样本(liked 作为正样本)。
Hard阶段: 将 neutral 项目作为更难的负样本(liked 仍为正样本)。 在工业推荐场景中,反馈级别由用户行为定义(dislike、impression without click、like/purchase)。在公开数据集上,使用LLM-based sentiment model(如ecomGPT)对评论进行评分并映射到相应级别。
这种渐进式DPO框架通过从易到难的策略,结合self-play和真实世界反馈,使模型能够持续增强其识别和泛化用户偏好的能力,克服了静态数据的“偏好天花板”。
实验结果 Align3GR在Instruments、Beauty和Yelp三个公开数据集上与多种基线模型(包括传统推荐系统、序列推荐方法和基于LLM的生成式推荐方法,如TIGER、LC-Rec、EAGER-LLM等)进行比较,并在工业广告推荐平台上进行了在线A/B测试。
离线性能: Align3GR在所有数据集和评估指标(Recall@K, NDCG@K)上均取得最佳或具有竞争力的结果。例如,在Instruments数据集上,Align3GR在Recall@10和NDCG@10上分别超越SOTA基线EAGER-LLM 17.8%和20.2%。
增量对齐效果: 实验证明Token-level对齐(尤其是引入dual learning-based item-side SCID)带来了显著性能提升。Preference-level对齐阶段(Progressive DPO)带来了最实质性的改进。
在线A/B测试: 在工业广告推荐平台上,Align3GR分配了10%的流量(约4000万用户)进行A/B测试,结果显示其在online retrieval performance (recall@100) 上超越了工业两塔检索基线和生成式TIGER模型,并实现了 statistically significant 的+1.432% 收入提升。
消融研究:
Dual SCID Tokenization: 结果表明,从单边(仅物品)到双边Tokenization,以及整合协同特征(CF)和User-Item对齐(U-I Alignment),都持续提升了性能,证明了Dual SCID Tokenization所有组件的有效性。
Behavior Modeling-level Alignment Tasks: 在SFT中引入用户SCID和用户侧双向对齐任务(B.2)带来了显著性能提升,特别是B.2任务,强调了将LLM暴露给结构化用户语义的关键作用。
Preference-Level Alignment Tasks: SP-DPO和RF-DPO的逐步引入和渐进式学习策略都带来了持续的性能提升,证实了渐进式优化和真实反馈整合在对齐LLM与用户偏好信号方面的互补优势。
结论 Align3GR通过其统一的多级对齐框架,有效地弥合了LLMs与个性化推荐系统之间的差距。该框架通过Dual SCID Tokenization、多任务行为建模和Progressive DPO,实现了对用户和物品表示的联合优化。实验结果表明,该方法在离线和在线场景中均显著优于现有SOTA基线,突出了分层对齐对于基于LLM的GRs实现更稳健和自适应个性化的重要性。
Abstract¶
本论文指出,尽管大语言模型(LLMs)在利用结构化世界知识和多步推理能力方面具有显著优势,但在将其应用于实际推荐系统时,仍面临语义和行为层面的不匹配问题。
为了解决这一问题,作者提出了 Align3GR 框架,该框架从三个层面实现对齐:
词元级对齐(Token-level Alignment):采用双词元化方法,融合用户-物品的语义信息与协同信号,提升输入表示的丰富性。
行为建模级对齐(Behavior Modeling-level Alignment):引入双向语义对齐机制,增强用户行为序列建模的准确性。
偏好级对齐(Preference-level Alignment):提出一种渐进式 DPO 策略,结合自博弈(SP-DPO)与真实反馈(RF-DPO),实现对用户偏好的动态适应。
实验结果显示,Align3GR 在公开数据集上的 Recall@10 和 NDCG@10 分别优于当前 SOTA 基线模型 17.8% 和 20.2%,并在工业级推荐平台的在线 A/B 测试和全量部署中表现出显著提升效果。
重点内容:Align3GR 的三重对齐机制(尤其是渐进式 DPO 策略)是模型性能提升的关键。
Introduction¶
推荐系统与大语言模型的结合¶
推荐系统(Recommender Systems, RS)是现代电商平台、视频流媒体和社会化媒体等数字平台的核心基础设施。随着**大语言模型(LLMs)**的快速发展,研究者探索了两种主要方式将其应用于推荐系统:
增强传统推荐系统:如通过语义理解、用户建模、查询重写和推理等手段提升推荐效果;
构建端到端生成式推荐系统:LLM直接输出推荐结果,成为独立的推荐器。
这种从“辅助增强”到“完全替代”的转变,提出了一个核心问题:如何真正将LLM转化为推荐系统?
LLM与推荐系统的对齐挑战¶
LLM与推荐系统之间存在根本性差异:
语言模型:以语义信息为核心,目标是预测下一个词(Next Token Prediction, NTP);
推荐系统:关注用户行为数据,建模其隐性偏好。
为解决这一问题,研究者提出了一个统一的对齐流程,包括三个关键层次:
Token级对齐(Tokenization)
行为建模级对齐(Multi-task Supervised Fine-tuning, SFT)
偏好级对齐(Preference-based Reinforcement Learning, RL)
现有方法的局限性¶
尽管已有研究尝试在上述三个层次进行对齐,但仍存在以下问题:
Token级:用户与物品信息被独立建模,忽略了语义与协同关系,影响推荐效果;
偏好级:现有基于偏好的RL方法(如DPO)依赖离线数据,缺乏渐进式学习机制,难以捕捉真实用户复杂、模糊的偏好。
本文提出的方法:Align3GR¶
为解决上述问题,本文提出Align3GR,一个统一的多级对齐框架,系统性整合了:
层级式双SCID(Semantic-Collaborative ID)编码:实现用户与物品的语义与协同融合;
多任务SFT:增强模型对推荐任务的理解;
渐进式DPO策略(包括SP-DPO与RF-DPO):实现从简单到复杂、从自我生成到真实反馈的偏好对齐。
实验与效果¶
在公开数据集(如Instruments)和工业数据集上进行了全面实验,结果表明:
Align3GR在Recall@10和NDCG@10指标上分别优于SOTA基线17.8%和20.2%;
在工业场景中,线上A/B测试也验证了其显著的业务提升效果。
核心贡献¶
提出Align3GR统一对齐框架,实现LLM与RS在token、行为建模和偏好三个层次的联合优化;
设计双语义-协同编码机制,并在偏好对齐中引入渐进式DPO策略(SP-DPO + RF-DPO);
在多个基准和工业数据集中验证了方法的有效性与泛化能力。
如需进一步总结后续章节内容,请继续提供。
Methodology¶
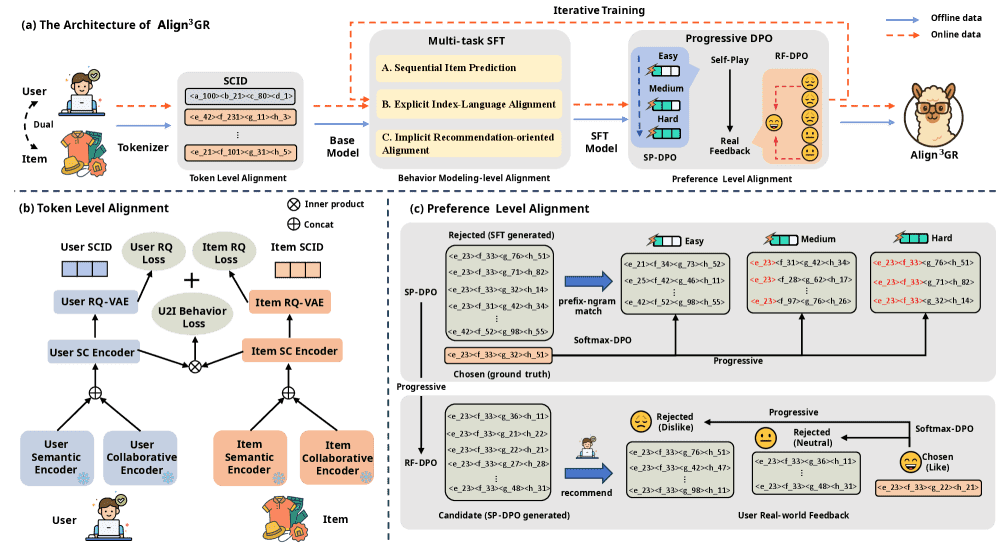
Figure 2:(a) The architecture of Align3GR, a unified multi-level alignment framework for generative recommendation, which integrates hierarchical dual SCID, multi-task SFT, and progressive DPO. (b) Token-level alignment is achieved through user-item dual SC encoders and RQ-VAEs. (c) Preference-level alignment is accomplished via progressive SP-DPO and RF-DPO.
Overview of the Proposed Framework(框架概述)¶
本节介绍了提出的统一多级对齐框架 Align3GR,旨在系统性地弥合大语言模型(LLM)与推荐系统之间的差距。该框架包含三个紧密对齐的阶段:
Token-level Alignment(Token级对齐):提出了一种基于用户-物品双学习策略的新型分词方案,融合用户和物品的语义与协同特征,生成分层离散的 SCID(Semantic-Collaborative ID),同时保持低计算开销。
Behavior Modeling-level Alignment(行为建模级对齐):在 LC-Rec 的基础上设计增强的多任务 SFT(监督微调),通过用户对齐任务将 SCID 与语义信息显式对齐。
Preference Alignment-level Alignment(偏好对齐级):受课程学习启发,提出渐进式 DPO 策略(从易到难),结合自玩 DPO(SP-DPO)和真实反馈 DPO(RF-DPO),从生成性能和用户反馈两个角度进行偏好学习。
这三个层级形成一个连贯的对齐流程,使基于 LLM 的生成式推荐模型在大规模动态推荐中实现高质量个性化和稳健适应。
Token-level Alignment: Dual SCID Tokenization(Token级对齐:双 SCID 分词)¶
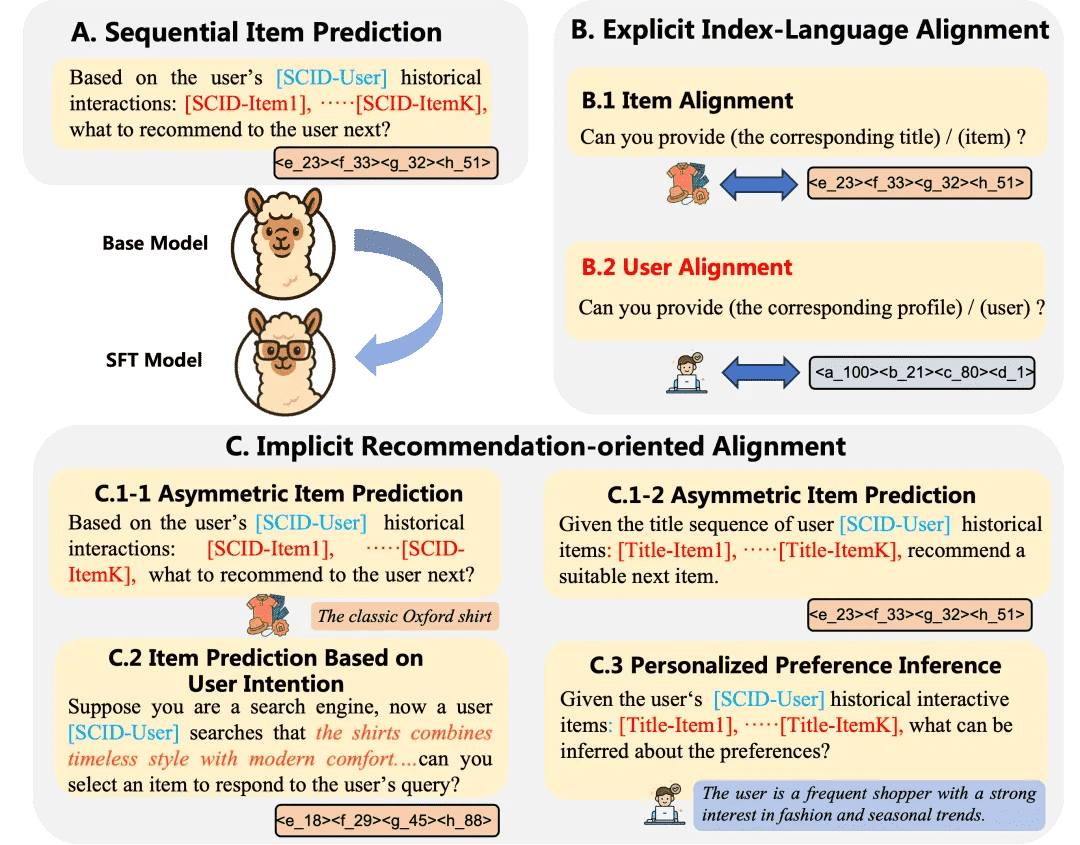
Figure 3:Behavior Modeling-level Alignment.
重点内容:
当前的生成式推荐分词方法主要关注物品编码,忽视用户结构建模,且用户与物品表示未联合优化,导致对齐效果不佳。
提出 Dual SCID Tokenization 方法,通过统一的双学习框架,联合编码用户与物品的语义与协同特征,提升表示能力。
框架流程:
提取用户与物品的语义特征(如描述)和协同特征(如行为模式)。
使用冻结的语义编码器(如 T5)和协同编码器(如 DIN)分别处理两类特征。
将特征拼接后通过 SC Encoder(如 MLP)整合,生成统一的 SC 嵌入。
使用 RQ-VAE 对嵌入进行量化,生成 SCID。
训练目标:
嵌入层优化用户-物品行为损失(ℒU2I),增强用户与物品 SC 嵌入的对齐。
总体损失还包括用户与物品的 RQ-VAE 量化损失(ℒUser RQ + ℒItem RQ)。
训练分为两个阶段:先优化行为对齐,再优化量化损失。
精简内容:
推理阶段用户与物品模块可独立部署,各自生成 SCID 用于下游任务。
该设计不仅压缩了 token 空间,还提升了后续多任务 SFT 和基于偏好的强化学习效果。
Behavior Modeling-level Alignment: Multi-task SFT(行为建模级对齐:多任务 SFT)¶
重点内容:
在获得 SCID 后,继续增强 LLM 在新 token 空间中的生成与语义对齐能力。
基于 LC-Rec 构建多任务 SFT 框架,包括:
序列物品预测
非对称物品预测
基于用户意图的物品预测
个性化偏好推理
提出两项关键增强:
在所有任务提示中注入用户的 SCID token,增强上下文对齐。
引入双向对齐目标:
文本 → SCID(根据用户描述预测 SCID)
SCID → 文本(根据 SCID 重建用户描述)
精简内容:
与以往方法相比,该 SFT 设计通过引入 SCID 和双向任务,显著增强了用户建模与信息对齐能力,为后续偏好优化打下基础。
Preference-level Alignment: Progressive DPO with Self-Play and Real-world Feedback(偏好级对齐:结合自玩与真实反馈的渐进式 DPO)¶
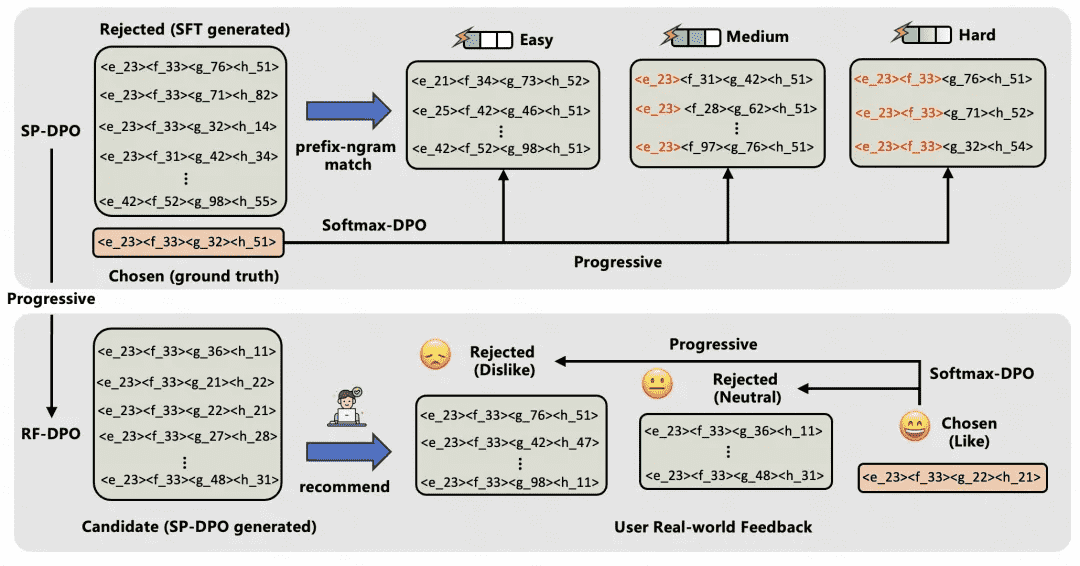
重点内容:
提出 渐进式 DPO 策略,结合自玩(SP-DPO)与真实反馈(RF-DPO),解决偏好数据覆盖有限的问题。
SP-DPO 分为三个阶段(Easy、Medium、Hard),通过前缀 n-gram 匹配机制逐步提升模型生成能力。
RF-DPO 利用真实用户反馈数据,按反馈强度分阶段训练,提升推荐相关性。
每阶段训练目标基于 Softmax-DPO,使用多个拒绝响应构建训练样本,逐步提升模型对用户偏好的理解能力。
模型在每个阶段的微调结果作为下一阶段的参考模型,实现渐进式学习。
精简内容:
在工业场景中,用户反馈分为“不喜欢”、“中性”、“喜欢”三类;在公开数据集上使用 LLM 情感模型进行评分映射。
该框架通过从易到难的渐进学习,结合自生成与真实反馈数据,有效突破静态数据带来的“偏好天花板”。
实验结果(表格 1)¶
重点内容:
Align3GR 在多个公开数据集(Instruments、Beauty、Yelp)上的推荐性能显著优于传统推荐、序列推荐、生成式与 LLM-based 推荐方法。
主要指标包括 Recall@K 和 NDCG@K。
与当前最优模型 EAGER-LLM 相比,Align3GR 平均提升 11.3%~27.9%。
精简内容:
表格展示了 Align3GR 在各项指标上的领先优势,验证了其在生成式推荐中的有效性。
综上,Align3GR 通过 Token级、行为建模级、偏好级 的三重对齐机制,构建了一个统一、高效的 LLM-based 生成式推荐框架,显著提升了推荐的个性化与适应能力。
Experiments¶
实验设置¶
数据集¶
本研究在三个真实世界序列推荐数据集上进行实验,涵盖不同领域:
Instruments:来自亚马逊评论数据集,聚焦用户与乐器的交互;
Beauty:同样来自亚马逊,涉及用户与美妆产品的行为;
Yelp:来自Yelp挑战数据集,记录用户与商家的互动。
预处理遵循标准协议,过滤交互次数少于5次的用户和物品,并采用留一法划分训练集、验证集和测试集。所有序列模型限制用户历史长度为20。此外,还在工业广告推荐平台部署Align3GR进行A/B测试。
基线方法¶
与多种传统和生成式推荐系统方法进行对比,涵盖不同token化和对齐策略,包括:
传统方法:MF、Caser、HGN、BERT4Rec、LightGCN、SASRec;
LLM-based生成式方法:BIGRec、P5-SemID、P5-CID、TIGER、LC-Rec、LETTER、EAGER-LLM。
所有基线方法尽可能使用开源代码实现或调整。
评估指标¶
采用标准Top-K指标:Recall@K 和 NDCG@K(K=5,10),训练时限制用户历史为最近20个物品。对于使用beam search的生成方法,beam width设为20。
实现细节¶
模型基于Llama2-7B,使用LoRA进行参数高效微调;
使用3级RQ-VAE进行item token化,每级codebook包含256个32维嵌入;
用户和物品的SCID表示加入模型词汇表以避免OOV;
训练20,000步,AdamW优化器,batch size=1024,学习率从1e-3、5e-4、1e-4中选择;
α和β等超参数在验证集上调优;
Softmax-DPO中,每个样本选择1个正例,拒绝20个负例;
所有结果取5次不同随机种子的平均。
离线性能¶
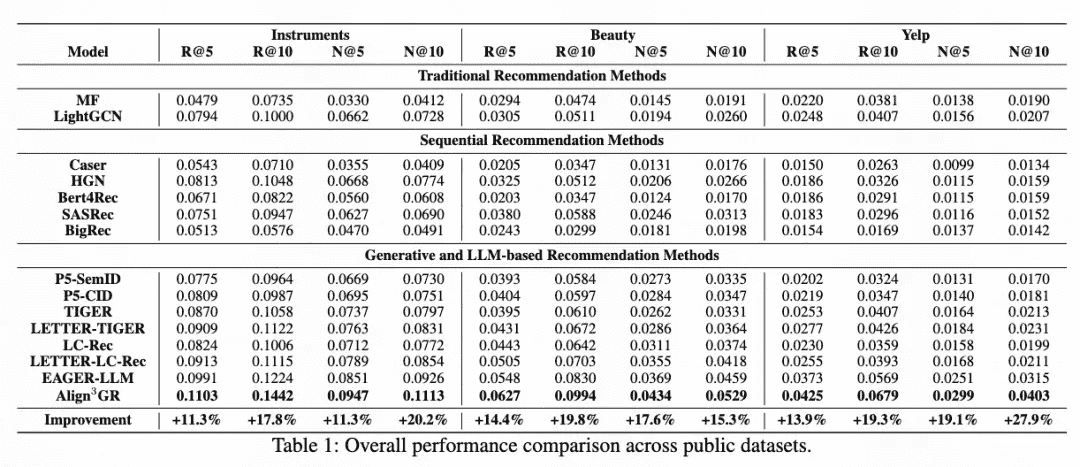
Table 1:Overall performance comparison across public datasets.
主要发现¶
Align3GR表现最优:在所有数据集和指标上均取得最佳或接近最佳结果,尤其在Instruments数据集上,Recall@10和NDCG@10分别比EAGER-LLM提升17.8%和20.2%,p值显著(p << 0.05);
多级对齐效果显著:图4显示逐步加入对齐模块后性能持续提升,其中:
使用基于双学习的SCID替代语义ID显著提升token级对齐;
偏好级对齐(特别是结合自玩和真实反馈的DPO)带来最大提升;
整体优于SOTA方法EAGER-LLM,验证了多级对齐的有效性;
综合优化优势:通过token、行为、偏好三级联合优化,Align3GR能更全面捕捉用户意图和协同信号,显著提升推荐性能。
在线A/B测试¶
在工业广告推荐平台进行A/B测试,覆盖约4000万用户。结果表明:
Align3GR在recall@100上优于工业双塔基线和TIGER;
在全量部署下,广告收入提升+1.432%,显著优于TIGER的+0.555%;
验证了Align3GR在实际生产环境中的商业价值。
消融实验¶
Dual SCID Tokenization¶
在Instruments数据集上进行消融实验,验证Dual SCID各组件效果:
Dual Tokenization:相比单侧token化(仅item),双侧(user+item)显著提升性能;
CF(协同过滤):在语义输入基础上加入CF特征进一步提升;
U-I对齐:通过U2I行为损失联合优化用户和物品嵌入,带来持续增益;
综合效果:三者互补,联合使用效果最佳(Recall@10=0.1442,NDCG@10=0.1113)。
行为级对齐任务¶
在Instruments数据集上测试不同语义对齐任务的影响:
SEQ任务:作为基础,Recall@10=0.1329;
加入C1-C3任务:小幅提升;
加入B1任务(用户行为建模):显著提升至Recall@10=0.1399;
加入User SCID:进一步提升至0.1417;
加入B2任务(用户侧对齐):达到最佳性能(Recall@10=0.1442,NDCG@10=0.1113);
结论:结构化用户语义建模对LLM理解推荐信号至关重要。
偏好级对齐策略¶
测试不同DPO变体对偏好级对齐的影响:
Softmax-DPO:Recall@10=0.1295;
SP-DPO(自玩):提升至0.1356;
SP-DPO + Progressive:进一步提升至0.1396;
RF-DPO(真实反馈):优于SP-DPO,Recall@10=0.1414;
RF-DPO + Progressive:最终达到最佳性能(Recall@10=0.1442,NDCG@10=0.1113);
结论:渐进式训练与真实反馈结合,显著提升模型对用户偏好的建模能力。
总结:Align3GR通过token、行为、偏好三级对齐策略,结合Dual SCID tokenization、多任务SFT和渐进式DPO优化,在离线和在线实验中均显著优于现有方法,验证了其在生成式推荐系统中的优越性。
Conclusion¶
本节标题保持不变:Conclusion
作者提出了一个统一的多层级对齐框架 Align3GR,旨在通过以下三个关键技术,弥合大语言模型(LLMs)与个性化推荐之间的差距:
双SCID分词(Dual SCID Tokenization)
通过为用户行为和物品信息分别设计结构化分词策略,提升模型对用户意图和物品特征的表达能力。多任务行为建模(Multi-task Behavior Modeling)
利用多任务学习方式建模用户的行为序列,增强模型对用户兴趣的全面理解。渐进式偏好优化(Progressive Preference Optimization)
通过逐步优化策略,使模型能够更精准地捕捉用户的长期和短期偏好。
在真实数据集上的实验表明,Align3GR 明显优于多个强基线模型。研究结果强调了层级对齐机制在基于LLM的推荐系统中的重要性,使得个性化推荐更加稳健和灵活。
重点总结:
Align3GR 的核心贡献在于将语言模型与推荐系统深度融合,并通过多层次的对齐机制实现更高效、个性化的推荐效果。