2409.19256_❇️HybridFlow: A Flexible and Efficient RLHF Framework¶
引用: 944(2026-01-31)
组织:
The University of Hong Kong
ByteDance
简介
2024 年 10 月首次开源,2026 年 1 月仓库迁移至verl-project组织,由字节 Seed 团队主导
2024 年 8 月 HybridFlow 论文被 EuroSys 2025 接收
总结¶
图解¶
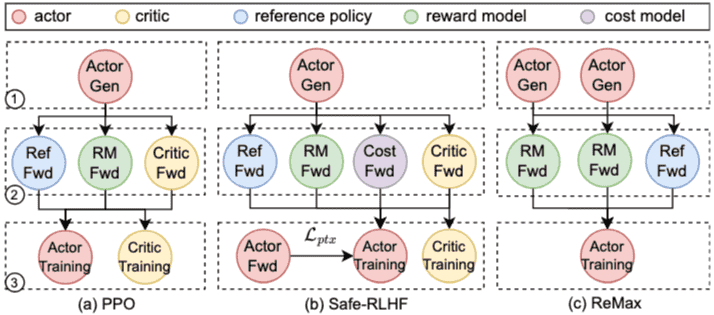
Figure 1. Dataflow graph of 3 RLHF algorithms. Stage 1, 2, 3 represent Generation, Preparation, andTraining, respectively.
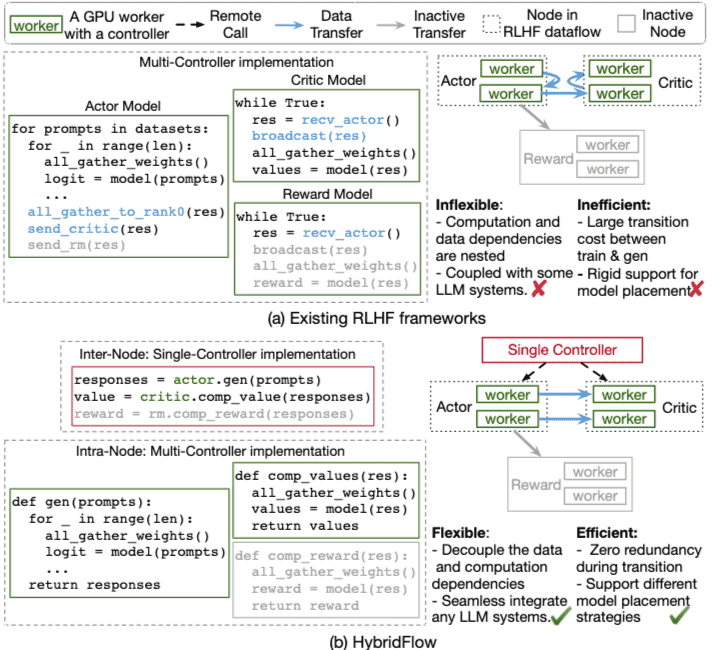
Figure 2. Programming model used in RLHF systems.
(a)Existing RLHF systems adopt the multi-controller paradigm.
(b)HybridFlow utilizes a hybrid programming model:
the single-controller coordinates models;
each model uses multi-controller paradigm in distributed computation.
Inactive node in grey represents operation not executed at this time
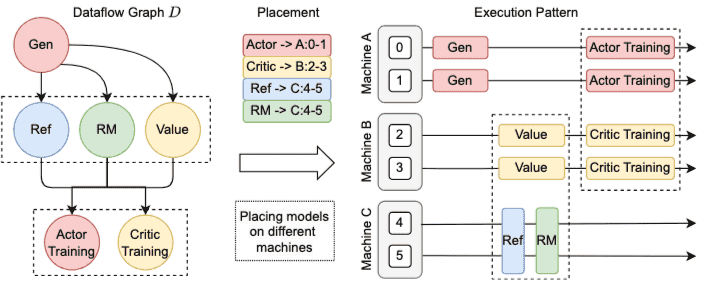
Figure 3. Dataflow execution given a model placement plan
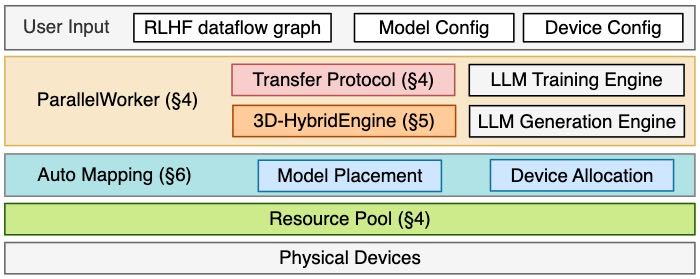
Figure 4. Architecture of HybridFlow.
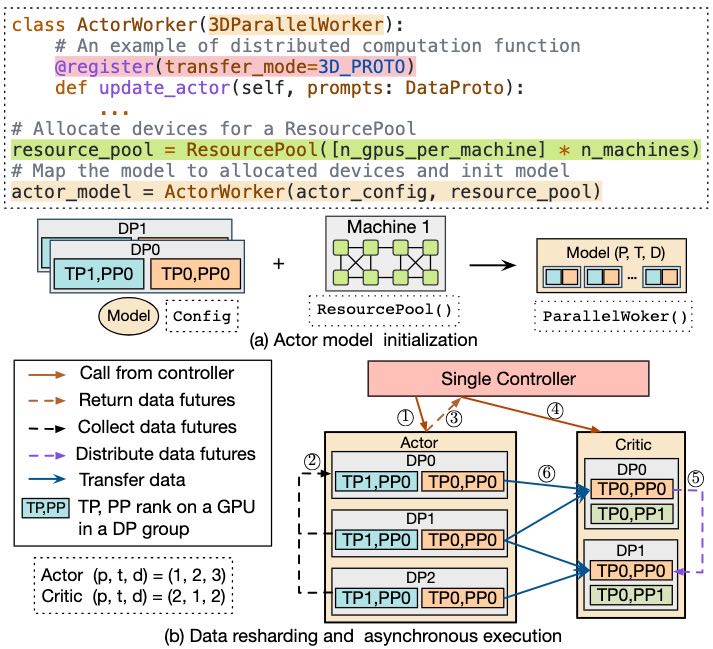
Figure 5. An illustration of hierarchical APIs. (a) Model with 3D parallel configuration, resource allocation, and 3DParallelWorker initialization. (b) Asynchronous data re-sharding between two models with collect and distribute functions in 3D_PROTO.
LLM总结¶
核心问题¶
现有 RLHF 系统存在两个主要问题:
单控制器范式(如 Ray、RLlib):控制开销过大,因为每个节点都是分布式 LLM 程序
多控制器范式(如 DeepSpeed-Chat、OpenRLHF):计算与通信深度耦合,缺乏灵活性
💡 HybridFlow 核心思想¶
混合控制器架构:
节点间:单控制器 —— 灵活管理数据依赖和跨节点通信
节点内:多控制器 —— 高效执行分布式计算
┌─────────────────────────────────────────────┐
│ 单控制器(全局调度) │
│ 管理模型间的数据重分片和执行顺序 │
└─────────────────────────────────────────────┘
│
┌───────────┼───────────┐
▼ ▼ ▼
[Actor] [Critic] [Reward]
多控制器 多控制器 多控制器
(内部计算) (内部计算) (内部计算)
HybridFlow 解决方案¶
1. 混合编程模型¶
跨节点层:单控制器 — 灵活管理数据依赖和跨节点通信
节点内层:多控制器 — 高效执行分布式计算
分层 API:
节点内:封装
3DParallelWorker、FSDPWorker、ZeROWorker基类节点间:通过 传输协议(Transfer Protocols)统一数据重分片(collect/distribute 函数)
2. 3D-HybridEngine¶
解决 Actor 模型训练与生成阶段的参数重分片问题:
特性 |
DeepSpeed-Chat |
OpenRLHF |
HybridFlow |
|---|---|---|---|
通信量 |
\(\frac{tpd-1}{tpd}M\) |
\(\frac{tp-1}{tp}M\) |
\(\frac{tp-t_gp_g}{t_gp_gtp}M\) |
峰值内存 |
M |
M |
\(\frac{1}{t_gp_g}M\) |
冗余内存 |
\(\frac{1}{tpd}M\) |
\(\frac{1}{tp}M\) |
0 |
关键设计:
训练和生成使用不同的 3D 并行配置(\(p\)-\(t\)-\(d\) vs \(p_g\)-\(t_g\)-\(d_g\)-\(d\))
通过巧妙选择并行组,使训练和生成权重在每个 GPU 上重叠
零内存冗余,显著降低通信开销
3. 自动设备映射算法¶
目标:找到最优的模型放置和并行策略,最小化端到端延迟
流程:
枚举所有可能的设备放置方案
为每个共置集计算最小 GPU 数量
枚举可行的设备分配
使用
auto_parallel子模块选择最优并行策略计算端到端成本,选择最优映射
核心贡献¶
提出 混合编程模型,结合单/多控制器优势
设计 3D-HybridEngine,实现零冗余参数重分片
提供 自动设备映射算法,优化资源分配
在多种 RLHF 算法(PPO、ReMax、Safe-RLHF)上实现 1.53× ~ 20.57× 吞吐量提升
From Moonlight¶
三行摘要¶
🌐 HybridFlow提出了一种混合编程模型,结合了单控制器和多控制器范式,旨在解决RLHF中大型LLM对齐的复杂数据流表示和高效执行问题。
🛠️ 为实现这一目标,HybridFlow设计了分层API以解耦计算与数据依赖,并引入3D-HybridEngine来高效处理Actor模型在训练和生成阶段间的参数重分片,实现零内存冗余。
🚀 此外,通过自动映射算法优化GPU分配和模型放置,HybridFlow在各种RLHF算法、模型规模和集群规模的实验中,相比现有最先进的基线,吞吐量实现了1.53倍至20.57倍的提升。
关键词¶
Reinforcement Learning from Human Feedback (RLHF):
Large Language Models (LLMs):
HybridFlow: HybridFlow 是本文提出的一个灵活且高效的 RLHF 框架。它结合了单控制器和多控制器的范式,旨在解决传统 RLHF 系统在表达 RLHF 数据流的灵活性和执行效率方面的不足。HybridFlow 通过设计一套分层 API 来解耦计算和数据依赖,从而能够高效地编排 RLHF 算法,并将计算灵活地映射到各种设备上。其核心组件包括混合编程模型、3D-HybridEngine 和自动映射算法。
Dataflow: 在此论文中,数据流 (Dataflow) 用于表示 RLHF 算法的计算图,它是一个有向无环图 (DAG)。图中的每个节点代表一个神经网络 (NN) 的计算(例如 actor、critic 的前向或后向传播),而图中的每条边则表示 NN 计算之间的数据依赖关系。对于 RLHF 这样复杂的场景,每个节点通常对应一个分布式 LLM 的训练或生成程序,边则代表可能的多对多数据组播 (multicast)。
Single-Controller Paradigm: 单控制器范式 (Single-Controller Paradigm) 是一种分布式计算的控制方式。在这种模式下,一个集中的控制器负责管理整个分布式程序的执行流程。控制器会为数据流中的节点分配到不同的进程,并协调它们的执行顺序。虽然单控制器能够灵活地进行资源映射和执行顺序协调,但当数据流图庞大且节点数量多时,控制器与各个工作进程之间的通信会产生显著的调度开销。
Multi-Controller Paradigm: 多控制器范式 (Multi-Controller Paradigm) 是一种分布式计算的控制方式。在这种模式下,每个设备(工作进程)都有自己的控制器,独立管理其计算任务。这种方式在 LLM 的分布式训练和推理系统中被广泛采用,因为它能够提供较低的调度开销,特别是在设备间通信速度快的情况下。然而,多控制器在实现复杂的 RLHF 数据流时可能不够灵活,因为修改一个节点的实现可能需要改变所有依赖节点的代码,这会阻碍代码重用。
3D Parallelism: 3D 并行 (3D Parallelism) 是一种用于训练大型深度学习模型(尤其是 LLM)的分布式并行策略,它结合了三种并行方式:数据并行 (DP)、流水线并行 (PP) 和张量并行 (TP)。PP 将模型按层划分到不同设备上,TP 将模型的张量(权重矩阵)按列或行划分到不同设备上,DP 则将输入数据分发到多个模型副本上。3D 并行通过组合这三种并行方式(表示为 (P, T, D) 或 (p, t, d) 元组),能够有效地在大量 GPU 上训练和部署参数量巨大的模型。
3D-HybridEngine: 3D-HybridEngine 是 HybridFlow 框架中为高效执行 actor 模型训练和生成阶段而设计的核心组件。它特别关注 actor 模型在训练和生成这两个阶段之间进行参数重组 (resharding) 时,如何实现零内存冗余和显著降低通信开销。通过设计优化的并行组 (parallel groups) 方法,3D-HybridEngine 能够使得训练和生成阶段在同一组 GPU 上运行,并高效地转换模型状态,从而大幅提升 RLHF 的整体吞吐量。
Model Placement: 模型放置 (Model Placement) 指的是在分布式系统中,如何将 RLHF 数据流图中的不同模型(如 actor, critic, reward model 等)分配到具体的计算设备(如 GPU)上。这包括决定哪些模型可以被放置在同一组 GPU 上(共址/colocation),哪些模型需要放置在不同的 GPU 集上,以及为每个模型分配多少 GPU 资源。优化的模型放置策略对于最大化 RLHF 整体吞吐量、避免资源争用和减少通信开销至关重要。
Throughput: 吞吐量 (Throughput) 是衡量一个计算系统性能的关键指标,通常表示单位时间内系统能够处理的数据量。在 RLHF 框架的评估中,吞吐量常以“tokens/秒”来衡量,即在一个 RLHF 迭代周期内,系统能够处理的总 token 数(包括输入提示和生成的响应)除以完成该迭代所需的时间。HybridFlow 的实验结果显示,其在 RLHF 吞吐量上相比现有方法有显著提升。
摘要¶
HybridFlow是一个灵活高效的RLHF(Reinforcement Learning from Human Feedback)框架,旨在解决大型语言模型(LLM)对齐中RLHF数据流的复杂性和效率挑战。传统的RL框架采用单控制器范式,在RLHF中效率低下,因为每个节点都是一个分布式LLM程序,导致控制分派开销巨大。现有RLHF系统采用多控制器范式,虽然分派开销小,但因计算与数据通信深度耦合而缺乏灵活性。HybridFlow创新性地结合了这两种范式,在跨节点层面采用单控制器,在节点内部(即模型内部)采用多控制器,从而实现灵活表示和高效执行RLHF数据流。
核心方法论与技术细节:
分层混合编程模型(Hierarchical Hybrid Programming Model) HybridFlow通过一套分层API实现了这一混合范式:
节点内部(Intra-node)封装分布式计算:HybridFlow提供了一系列基础类,如
3DParallelWorker、FSDPWorker和ZeROWorker。这些类封装了LLM在RLHF不同阶段的分布式计算逻辑(训练、推理和生成),解耦了分布式计算代码与模型间的数据依赖。用户可以通过继承这些类来定义Actor、Critic、Reference和Reward等模型,并使用其提供的API(如generate_sequence、compute_values、update_actor等)来实现各自的分布式前向、后向计算、自回归生成和优化器更新。这些API能够无缝支持现有LLM框架的并行策略,包括Megatron-LM的3D并行(Pipeline, Tensor, Data Parallelism)、PyTorch FSDP和ZeRO。模型计算在多控制器范式下执行,确保低分派开销。跨节点(Inter-node)统一数据重分片:模型间的数据传输(通常是不同并行策略下的多对多组播)通过统一的“传输协议”(transfer protocols)实现。每个模型操作都与一个特定的传输协议关联(通过
@register装饰器)。每个协议包含一个collect函数(聚合源模型的输出数据)和一个distribute函数(根据目标模型的并行策略分发输入数据)。例如,3D_PROTO协议用于处理3D并行下的数据重分片,其collect函数从每个DP组的最后流水线阶段收集数据,distribute函数将数据分散到目标DP组。这种机制使得用户无需手动管理复杂的通信细节,实现远程过程调用(RPC)和数据的异步传输。当模型部署在不同的设备集上时,执行是异步的;当模型共享设备时,执行是顺序的。ResourcePool类提供了GPU设备的虚拟化和分配机制,使得用户能够灵活地配置模型放置策略。
3D-HybridEngine 这是HybridFlow为优化Actor模型训练和生成阶段设计的关键组件,解决了两者对并行策略不同需求导致的效率问题。
并行组(Parallel Groups):Actor训练通常是计算密集型,可能需要更大的模型并行(MP)规模(例如 \(P \times T\))。而自回归生成是内存密集型,更适合较小的MP规模但更大的数据并行(DP)规模。3D-HybridEngine为Actor训练和生成构建了不同的并行组配置。对于训练,并行组表示为 \(p-t-d\)(流水线并行大小-张量并行大小-数据并行大小)。对于生成,为了实现更大的DP规模,引入了微数据并行(micro DP)组,表示为 \(pg-tg-dg-d\),其中 \(d_g = \frac{p \times t}{p_g \times t_g}\),表示每个训练DP副本在生成阶段被分解为 \(d_g\) 个微DP副本。整个Actor模型始终部署在同一组设备 \(N_a\) 上,即 \(N_a = p \times t \times d = p_g \times t_g \times d_g \times d\)。
零冗余模型重分片(Zero Redundancy Model Resharding):为了避免在训练和生成阶段之间Actor模型参数重分片时产生内存冗余和高通信开销,HybridFlow设计了一种优化的并行分组方法。传统的重分片可能导致部分GPU上的训练权重与生成权重不重叠,需要额外内存来维护两份权重。HybridFlow的优化方法通过巧妙地构建生成阶段的TP和PP组(例如,通过以固定间隔选择秩),使得训练和生成阶段的模型权重在每个设备上都能重叠。这样,生成阶段可以直接复用训练权重,实现零内存冗余。此外,通过在每个微DP组内并发执行All-Gather操作,显著降低了通信开销。与DeepSpeed-Chat和OpenRLHF相比,HybridFlow在模型转换时的通信量和峰值内存占用均大幅降低,例如,通信量从 \( \frac{tpd-1}{tpd}M \) 或 \( \frac{tp-1}{tp}M \) 降至 \( \frac{tp-t_g p_g}{t_g p_g tp}M \),峰值内存占用从 \(M\) 降至 \( \frac{1}{t_g p_g}M \),且冗余内存为0。
自动设备映射(Auto Device Mapping)算法 HybridFlow提供了一种自动映射算法(Algorithm 1)来寻找RLHF数据流在给定GPU集群上的最优设备放置和并行策略,以最小化每次RLHF迭代的端到端延迟。
流程:
探索放置方案:遍历RLHF数据流中模型的所有可能放置方案(即将哪些模型共置于同一组设备上)。
最小GPU分配:确定每个共置模型集所需的最小GPU数量,以避免内存溢出(OOM)。
枚举可行分配:在最小分配的基础上,枚举所有可行的设备分配方案。
自动并行化:对于每种设备分配,调用
auto_parallel子模块(Algorithm 2),该模块利用仿真器(simu)来估算不同并行策略下的模型执行延迟。它会遍历所有可行的张量并行(TP)和流水线并行(PP)组合,找到在给定GPU数量下延迟最低的并行策略。计算端到端成本:
d_cost函数计算整个RLHF数据流的端到端延迟。如果模型在同一共置集内且属于同一阶段,它们的执行时间相加;如果模型在不同的共置集内,且可以并行执行,则取它们执行时间的最大值作为该阶段的延迟。选择最优映射:最终选择总延迟最低的设备放置和并行策略。
复杂度与优化:算法复杂度取决于模型数量和设备总数。为提高效率,HybridFlow会缓存已确定的模型并行策略,避免重复搜索。
实验结果 HybridFlow在PPO、ReMax和Safe-RLHF等多种RLHF算法、不同模型规模(7B-70B)和集群规模(8-128 GPUs)下进行了广泛实验。结果显示,HybridFlow相较于DeepSpeed-Chat、OpenRLHF和NeMo-Aligner等SOTA基线,实现了1.53倍至20.57倍的吞吐量提升。尤其在大规模模型和集群上,性能提升更为显著,主要得益于其高效的Actor模型训练/生成转换(减少高达89.1%的转换开销)和优化的设备映射能力。HybridFlow的自动映射算法也能根据集群规模动态调整最优放置策略,例如,在小规模集群上倾向于共置所有模型以最大化GPU利用率,而在大规模集群上则可能将Actor和Critic模型放置在不同设备上以实现并行执行。
Abstract¶
核心内容:
本文介绍了 HybridFlow,一种用于强化学习与人类反馈(Reinforcement Learning from Human Feedback, RLHF)的分布式系统框架。HybridFlow 结合单控制器和多控制器的执行模式,旨在解决传统 RLHF 系统中存在的控制开销大和执行灵活性不足的问题。
背景与问题:
传统强化学习(RL)可建模为数据流(dataflow),其中节点表示神经网络计算,边表示数据依赖关系。RLHF 将每个节点扩展为分布式语言模型训练或生成程序,边则变为多对多的广播通信。
传统的 RL 框架使用单控制器来管理计算和通信,但在 RLHF 中由于节点内存在大量分布式计算,导致控制开销过高。已有 RLHF 系统采用多控制器模式,但由于计算与通信层次嵌套复杂,执行效率和灵活性受限。
解决方案:
HybridFlow 提出一种混合控制器架构,结合单控制器和多控制器的优势,以实现 RLHF 数据流的灵活表示和高效执行。
具体实现包括:
分层 API 设计:将 RLHF 中的计算与数据依赖解耦并封装,支持高效的算法实现和灵活的设备映射。
3D-HybridEngine:用于在训练和生成阶段之间高效地进行Actor模型的重组(resharding),实现零内存冗余和显著减少通信开销。
实验结果:
HybridFlow 在运行多种 RLHF 算法时,相较于最先进的基线系统,吞吐量提高了 1.53× 到 20.57×,显著提升了性能。
开源:
HybridFlow 的源代码将开源,可在 https://github.com/volcengine/verl 获取。
关键词(Keywords)¶
Distributed systems(分布式系统)
Reinforcement Learning from Human Feedback(人类反馈强化学习)
总结:本文围绕 RLHF 中的系统执行效率问题,提出 HybridFlow 框架,通过混合控制架构与高效通信机制,实现性能的显著提升,是一篇聚焦大模型训练与部署优化的前沿研究论文。
1. Introduction¶
1.1 大型语言模型(LLM)的应用¶
本节首先介绍了大型语言模型(LLMs),如 GPT、Llama 和 Claude,它们在诸如写作、搜索和编程等 AI 应用中起到了革命性的作用。这些模型通过大规模预训练(pre-training)和监督微调(supervised fine-tuning, SFT)积累了广泛的知识,并能够遵循人类指令。然而,训练数据中可能包含有害或偏见内容,这可能导致 LLM 生成有毒或不适当的内容。
为了解决这一问题,引入了基于人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF),通过 RLHF 可以使 LLM 更好地对齐人类价值观,从而生成更有益、无害的内容。
1.2 RLHF 的基本结构与流程¶
RLHF 基于传统的强化学习算法(如 PPO、REINFORCE)构建。一个典型的 PPO-based RLHF 系统通常包含四个模型:Actor(执行动作)、Critic(评估动作)、Reference Policy(参考策略)和Reward Model(奖励模型)。
RLHF 的训练过程通常分为三个阶段:
生成响应:使用 Actor 模型对一批提示(prompts)生成响应;
准备训练数据:通过 Critic、Reference 和 Reward 模型的前向传播,对响应进行评分;
学习人类偏好:通过前向与反向计算更新 Actor 和 Critic。
其他 RLHF 的变体虽然流程类似,但使用的模型数量和数据依赖有所不同。
1.3 RLHF 数据流的复杂性¶
传统的强化学习可以通过数据流图(dataflow)建模,其中节点表示神经网络计算(如 Actor 或 Critic),边表示数据依赖关系。RLHF 的数据流更为复杂,因为:
涉及多个 LLM 模型(如 Actor/Critic/Reference/Reward);
每个模型计算不同,且数据依赖多样(如分布式模型分区之间的多播通信);
模型训练与生成需要分布式计算(如 tensor、pipeline、data parallelism);
每个节点对应的是一个复杂的分布式程序,且不同节点的并行策略可能不同;
边表示数据重分片(data resharding),通常为多对多通信;
因此,灵活表示与高效执行 RLHF 数据流成为关键挑战。
1.4 传统 RL 框架的局限性¶
传统强化学习框架(如 RLLib、RLLib Flow)使用单控制器(single-controller)架构来执行数据流:
中央控制器负责节点分配与执行顺序;
支持数据并行训练,但仅适用于小型网络(最大几百 MB);
无法处理 RLHF 中的大规模 LLM 模型(含数十亿参数);
在分布式设备上调度操作时,存在显著开销。
1.5 现有 RLHF 系统的解决方案¶
现有 RLHF 系统采用多控制器(multi-controller)架构:
每个控制器管理一个设备的计算;
使用点对点通信协调不同节点之间的数据依赖;
虽然调度开销小,但缺乏中央控制,导致在实现不同数据流时灵活性差,修改一个节点会影响所有依赖节点,不利于代码复用。
1.6 HybridFlow 的提出¶
为解决上述问题,本文提出了HybridFlow,一个灵活且高效的 RLHF 框架,具备以下特点:
核心思想:¶
在节点间使用单控制器(single-controller):实现灵活的数据依赖性和低开销的跨节点通信;
在节点内使用多控制器(multi-controller):提升计算效率。
程序模型设计:¶
提供一系列分布式计算模型类(intra-node model classes):封装 LLM 的训练、推理和生成操作;
支持多种并行方式(如 3D 并行、ZeRO、FSDP);
跨节点通信由单控制器协调,设计数据转移协议(transfer protocols),隐藏数据重分片的复杂性;
用户只需少量代码即可构建 RLHF 数据流,实现计算与通信的解耦,便于独立优化每个模型。
3D-HybridEngine:¶
专门用于Actor 模型的训练和生成;
实现零内存冗余和低通信开销;
提升训练与生成阶段之间的切换效率。
GPU 自动映射算法:¶
支持灵活模型部署,可将多个模型部署在相同或不同 GPU 上;
提供自动 GPU 分配算法,优化大规模部署下的计算资源利用率。
贡献总结:¶
提出层次化混合编程模型,便于构建灵活的 RLHF 数据流;
设计3D-HybridEngine,高效执行 Actor 模型的训练与生成;
提出GPU 自动映射算法,优化模型部署;
实验表明,HybridFlow 在多种 RLHF 算法、模型规模和集群规模下,较现有系统提升了 1.53× 到 20.57× 的吞吐量。
1.7 开源与展望¶
作者已将 HybridFlow 开源,认为该框架可加速未来 RLHF 研究与开发。图 1 展示了三种 RLHF 算法的数据流图,包括生成、准备和训练三个阶段。
2. Background and Motivation¶
2.1. 从人类反馈中学习的强化学习(Reinforcement Learning from Human Feedback, RLHF)¶
RLHF 工作流程:
RLHF 通过人类偏好对齐大语言模型(LLMs)的语言空间,以更符合人类价值。一个典型的 RLHF 系统通常包含多个模型,例如演员(actor)、评论器(critic)、参考策略(reference policy)和一个或多个奖励模型(reward models)。其中,演员和参考策略通常为经过预训练或微调的 LLM;评论器和奖励模型则是基于人类偏好数据进行微调的 LLM,其语言建模头被替换为标量输出头。
RLHF 的工作流程可以分为三个阶段(以 PPO 为例):
阶段一(生成): 演员基于一批提示生成响应。
阶段二(准备): 评论器计算价值,参考策略计算参考对数概率,奖励模型计算奖励,各模型通过前向计算完成。
阶段三(学习/训练): 演员和评论器使用 Adam 优化器进行更新。
其他 RLHF 算法(如 Safe-RLHF、ReMax)也基本遵循这三阶段流程,但引入了额外的模块(如成本模型、辅助预训练损失)或优化策略(如减少方差生成、去除评论器模型)。
并行策略:
为提高训练和推理效率,LLMs 常采用数据并行(DP)、管道并行(PP)和张量并行(TP)等策略。
数据并行(DP):将输入数据划分,每个设备处理一部分。
管道并行(PP) 和 张量并行(TP):将模型参数分布到多个 GPU 上。
3D 并行(PP + TP + DP) 被广泛用于现代训练和推理系统。
不同模型在 RLHF 中执行不同计算(训练、推理、生成),因此需要不同的并行策略以优化吞吐量。
2.2. 分布式机器学习的编程模型¶
单控制器(Single-Controller)模型:
采用集中式控制器管理整个分布式程序的执行流程。
控制器全局掌握硬件和数据流图,可灵活调度资源和执行顺序。
但在大规模集群中,调度开销较高,可能影响性能。
多控制器(Multi-Controller)模型:
每个设备(worker)拥有独立控制器,适合大规模分布式系统。
每个模型独立运行程序,需通过点对点通信协调执行顺序。
虽然可扩展性和调度开销低,但代码嵌套复杂,难以维护和优化。
2.3. RLHF 的特性¶
模型工作负载的异质性:
不同模型(actor、critic、reference、reward)在不同阶段执行不同任务,内存占用和计算需求差异大。例如:
参考策略和奖励模型仅进行前向计算,只需存储模型参数。
演员和评论器需保存参数、梯度和优化器状态。
不同模型可能大小差异很大(如 7B 与 70B),需不同并行策略。
演员训练与生成的不平衡性:
演员训练通常计算密集,需较大模型并行规模(MP size)和更多 GPU。
生成阶段为内存密集型,采用较小 MP 和较大 DP 更高效。
但切换训练与生成的并行策略会带来模型参数重组的高开销(如 70B 模型重组需 36.4% 的迭代时间)。
模型放置的多样性需求:
根据模型间的数据依赖和计算负载,需合理分配模型到不同设备。
并行模型可在无依赖时并行执行,共用 GPU 的模型需时分复用执行以避免内存溢出(OOM)。
需支持多种模型放置策略以最大化 GPU 利用率。
2.4. 现有 RLHF 系统的局限性¶
缺乏对多样 RLHF 数据流图的支持:
多控制器架构下,用户需手动管理通信、计算和数据传输的混合代码,难以模块化,耦合度高。
各系统仅支持特定算法(如 PPO),扩展性强差。
3D 并行等策略难以兼容,系统重构成本高。
RLHF 执行效率低下:
DeepSpeed-Chat 和 OpenRLHF 等系统在训练与生成阶段采用不同设备存储演员模型,带来冗余内存和同步开销。
NeMo-Aligner 使用相同并行策略,但生成吞吐率低。
现有系统仅支持单一模型放置策略,无法充分利用硬件资源。
2.5. 设计考虑¶
核心问题:
如何设计一种 灵活且高效 的编程模型,以实现多样化的 RLHF 数据流?
设计原则:
单控制器 + 多控制器混合模型: 在节点间(inter-node)使用单控制器调度全局资源与数据流;在节点内(intra-node)使用多控制器实现高效并行计算。
该设计能灵活表达 RLHF 数据流,同时保持控制开销低。
通过解耦节点间通信与节点内计算,简化模型开发与维护。
总结¶
本章系统性地介绍了 RLHF 的工作流程、并行策略、模型特性及其面临的挑战。重点指出现有系统在灵活性、执行效率和模型放置策略等方面的局限性,并提出需设计一种灵活、高效且可扩展的混合编程模型以解决这些问题,为后续提出的 HybridFlow 框架奠定了基础。
3. HybridFlow Overview¶
HybridFlow 是一个灵活且高效的 RLHF(Reward Learning from Human Feedback)框架,其整体架构如图4所示,主要包括三个核心组件:
Hybrid Programming Model(混合编程模型)
3D-HybridEngine
Auto-Mapping 算法
1. Hybrid Programming Model(混合编程模型)¶
提供了一组分层的API,用于灵活表达RLHF的数据流,并支持模型在数据流中的高效计算。
该模型允许用户根据需要定义不同的模型结构和并行策略,增强了系统在不同场景下的灵活性和可扩展性。
更详细的实现方式在第4节中描述(§4)。
2. 3D-HybridEngine¶
是HybridFlow中专门设计用于高效训练和生成Actor模型的组件。
支持在RLHF的两个阶段(训练和生成)中使用不同的3D并行配置(PP:Pipeline并行,TP:Tensor并行,DP:Data并行)。
关键优势在于:
零内存冗余
最小通信开销,特别是在两个阶段之间的转换阶段。
更详细的技术细节在第5节中(§5)。
3. Auto-Mapping 算法¶
用于自动确定各模型在设备上的部署位置,目的是最大化RLHF的吞吐量。
根据给定的GPU集群配置,自动分配模型到合适的设备上,优化资源利用效率。
该算法在第6节中有详细说明(§6)。
HybridFlow 的工作流程¶
HybridFlow 的系统工作流程如下:
用户输入:
模型规格(包括Actor、Critic、Reference Policy、Reward Model的结构和大小)
模型在数据流中的设备部署方案(由Auto-Mapping算法确定)
每个模型在每个阶段的并行策略(如3D并行的(p, t, d)参数)
控制器程序处理:
接收输入,初始化模型和虚拟资源池。
根据部署计划,将操作或模型分配到对应设备。
调用多个控制器程序执行分布式计算。
Multi-Controller 实现(ParallelWorker类):
在分配的设备上构建模型的并行组。
调用3D-HybridEngine 进行Actor模型的训练与生成。
可以与现有的LLM引擎(如Megatron-LM、DeepSpeed等)无缝集成。
控制器间协调(数据传输协议):
单控制器负责协调不同模型之间的数据重分片(resharding),以支持不同并行策略之间的数据转换。
Actor模型在训练与生成阶段之间的数据重分片由3D-HybridEngine负责处理。
小结¶
HybridFlow 的核心设计目标是灵活性和高效性,通过混合编程模型、3D-HybridEngine 和 Auto-Mapping 算法,实现了对RLHF流程的全面优化。系统支持不同模型和并行配置的灵活组合,并通过高效的资源分配和数据传输策略,最大化整体吞吐量和训练效率。
4. Hybrid Programming Model¶
本节介绍了HybridFlow框架中用于支持RLHF(强化学习从人类反馈)算法的混合编程模型。该模型采用分层API设计,支持灵活的模型部署和高效的跨模型数据交换,同时兼容多种并行策略。
4.1. 分层API(Hierarchical APIs)¶
核心思想:
通过封装模型的分布式计算逻辑和数据交换机制,实现高效、灵活的RLHF训练流程。分层API设计分为节点内和节点间两个部分,分别处理模型的并行初始化和跨模型的数据重分布(resharding)。
节点内:封装分布式程序(Intra-node: encapsulating distributed program)¶
基础类
3DParallelWorker为每个RLHF阶段中的模型(如actor、critic等)提供基础类,用于初始化模型参数并建立3D并行组。
每个并行组对应模型的不同维度(如TP、DP、PP),以实现高效的分布式训练。
示例见图5(a):actor模型的初始化过程,其他模型的结构类似。
模型类封装计算逻辑
继承自
3DParallelWorker,提供actor、critic、reference、reward模型类。各类封装了模型的前向/反向传播、自回归生成(autoregressive generation)和优化器更新等API。
这些API与现有LLM训练框架(如Megatron-LM)中的脚本高度兼容,便于复用。
例如,actor模型的
update_actor函数与Megatron-LM的预训练脚本逻辑相似。
支持多种并行策略
除了3D并行,还支持PyTorch的FSDP和ZeRO并行策略,分别通过
FSDPWorker和ZeROWorker基类实现。图4中的
ParallelWorker指代这些不同策略的基类。
节点间:统一跨模型的数据重分布(Inter-node: unifying data resharding)¶
数据转移协议(Transfer Protocols)
每个模型类的操作通过
@register注册一个数据转移协议,例如3D_PROTO。每个协议包含两个函数:
collect函数:聚合输出数据;
distribute函数:将输入数据分发到并行组中。
示例见图5(b):actor和critic之间的数据转移。actor通过
3D_PROTO的collect函数聚合输出(优势值),critic通过distribute函数将这些数据分发到各并行组。
8种标准协议
提供了8种常用的数据转移协议,例如
3D_PROTO、DP_PROTO、ONE_TO_ALL等,覆盖大部分数据重分布场景。用户可自定义协议,扩展功能。
异步执行与GPU间直接传输
数据传输在GPU之间直接进行,避免中央控制器的瓶颈。
当模型输入就绪时,自动触发执行(类似于DAG调度),如图5(b)所示的异步执行流程。
灵活的模型部署(Facilitating flexible model placement)¶
提供
ResourcePool类,用于虚拟化一组GPU设备。不同模型可通过绑定不同的
ResourcePool实例,实现GPU资源的灵活分配。同一
ResourcePool实例内的模型部署在相同GPU上;不同实例则部署在不同GPU上。避免资源重叠,支持高效并行计算。
异步数据流执行(Asynchronous dataflow execution)¶
模型部署在不同设备上时,采用异步执行机制。
控制器在数据就绪后立即触发后续操作,减少等待时间。
如图5(b)所示,actor生成数据后,控制器立即返回结果并触发critic执行。
模型部署在相同设备上时,按调用顺序串行执行。
4.2. 不同RLHF算法的实现(Implementation of different RLHF algorithms)¶
核心思想:
通过封装好的API,用户可以快速实现多种RLHF算法,仅需少量代码即可完成从基础算法(如PPO)到复杂变体(如Safe-RLHF)的扩展。
算法实现示例
图6展示了PPO、ReMax和Safe-RLHF的实现。
PPO仅需8行代码,调用
compute_values和generate_sequences等API。Safe-RLHF在PPO基础上增加5行代码,用于集成额外的cost模型。
ReMax则需增加一次actor生成调用,删除critic相关代码。
灵活性与扩展性
用户只需调整数值计算逻辑(如GAE、KL散度),即可适配不同算法。
模块化API设计支持代码复用和现有LLM框架的直接集成。
算法逻辑与分布式计算解耦,便于优化每个模型的执行效率(如第5节3D-HybridEngine)。
自动设备映射(见第6节)
支持根据不同模型负载进行设备映射优化。
实现高效的数据流调度和资源分配。
总结:
本节详细介绍了HybridFlow框架中的混合编程模型。通过分层API设计和灵活的数据转移机制,实现了高效、可扩展的RLHF训练流程。用户可以快速实现和扩展各种RLHF算法,同时支持多种并行策略和模型部署方式,为研究和工业应用提供了强大的工具基础。
5. 3D-HybridEngine¶
本文提出 3D-HybridEngine,旨在支持演员模型(actor model)的高效训练与生成,目标是显著提升 RLHF(强化学习与人类反馈)的吞吐量。
图7 展示了在一次 RLHF 迭代中 3D-HybridEngine 的工作流程。4 个 GPU 用于演员训练和生成。训练阶段使用 1-2-2(p-t-d)并行组,生成阶段使用 1-1-2-2(pg-tg-dg-d)并行组。
5.1. 并行组(Parallel Groups)¶
核心思想:
作者主张将训练和生成阶段部署在同一组 GPU上,以消除冗余模型副本,并通过顺序执行在同一份模型权重上进行训练和生成。
不同阶段的并行策略差异:
训练阶段和生成阶段可能会采用不同的3D并行策略。例如,生成阶段通常需要较小的 TP(Tensor并行)和 PP(Pipeline并行),但需要较大的 DP(Data并行)。
3D-HybridEngine 的关键设计:
支持在相同设备集上,高效地在训练和生成阶段之间进行模型参数的重分片(resharding)。
用 p-t-d 表示训练阶段的并行组,分别对应管道阶段、张量分片和模型副本。
用 pg-tg-dg-d 表示生成阶段的并行组,其中:
pg:生成管道并行组大小
tg:生成张量并行组大小
dg:微数据并行组大小(micro DP)
d:模型副本数量
重要公式:
$\( N_a = p \times t \times d = p_g \times t_g \times d_g \times d \)\(
\)\( d_g = \frac{p \times t}{p_g \times t_g} \)$
微DP组的作用:
在生成阶段中,用于增加 DP 的大小,从而充分利用设备资源。
5.2. 3D-HybridEngine 工作流程(3D-HybridEngine Workflow)¶
在 RLHF 的第 i 次迭代训练(actor training)和第 i+1 次生成(actor generation)之间,需要完成:
模型参数重分片
提示数据的分布
具体流程如下:
步骤①(All-Gather): 在每个 micro DP 组内,收集迭代 i 更新的模型参数,用于生成(图7①)。
步骤②(加载提示): 每个模型副本加载一批提示数据(图7②)。
步骤③(生成响应): 生成阶段生成响应。
步骤④(再分片): 根据训练并行策略重新划分模型参数(图7④)。
步骤⑤(计算损失与更新模型): 计算损失并更新演员模型权重(图7⑤)。
5.3. 零冗余模型重分片(Zero Redundancy Model Resharding)¶
传统并行策略:
PP 和 TP 通常采用连续 GPU 分配。
DP 按固定间隔选取 GPU。
HybridFlow-V 的问题:
在训练与生成之间进行模型参数重分片时,有些 GPU 上的训练权重无法复用,需额外存储(如图8(a)中灰色区域),导致内存冗余和通信开销。
HybridFlow 的改进:
设计了一种新的并行组策略,在生成阶段中:
TP 和 PP 组按固定间隔选择 GPU。
DP 组按生成的 TP 或 PP 维度顺序分配。
每个 GPU 上的训练与生成权重重叠,实现零冗余,无需额外存储,同时并发执行多个 all-gather 操作,显著减少通信开销。
图8(b)示例:
使用 1-2-2-2 并行组。
生成 TP 组为 [G1, G3]、[G2, G4] 等。
微 DP 组为 [G1, G2]、[G3, G4] 等。
实现了训练与生成参数的内存复用,无冗余。
5.4. 转换开销(Transition Overhead)¶
比较表(表2):
项目 |
DeepSpeed-Chat |
HybridFlow-V |
HybridFlow |
|---|---|---|---|
通信量 |
\( \frac{tpd-1}{tpd}M \) |
\( \frac{tp-1}{tp}M \) |
\( \frac{tp - t_g p_g}{t_g p_g tp}M \) |
峰值内存 |
M |
M |
\( \frac{1}{t_g p_g}M \) |
冗余内存 |
\( \frac{1}{tpd}M \) |
\( \frac{1}{tp}M \) |
0 |
关键分析:
DeepSpeed-Chat 在转换阶段会在所有 GPU 上全量 all-gather,通信量和内存开销最大。
HybridFlow-V 仅在训练 TP 和 PP 组内进行 all-gather,有所优化,但仍有冗余。
HybridFlow(本文方法) 通过合理设计并行组,在每个 micro DP 组内局部 all-gather,完全消除冗余内存,显著降低通信量。
总结¶
3D-HybridEngine 通过:
统一设备部署训练与生成阶段
灵活支持不同并行策略
高效模型参数重分片
零冗余内存设计
显著提高了 RLHF 的训练与生成效率,降低了通信和内存开销,是 RLHF 系统中提升吞吐量的关键模块。
6. Auto Device Mapping¶
以下是对论文章节 6. Auto Device Mapping 的总结,按照原文结构进行讲解,并对重点内容进行强调,次要内容进行精简:
本节介绍了一个用于自动映射 RLHF 数据流 到给定设备的算法(见Algorithm 1)。其目的是 最小化每个 RLHF 迭代的端到端延迟,这是 HybridFlow 混合编程模型中的一个关键部分。
用户输入的配置¶
用户需要提供以下两种配置信息:
模型的设备放置(Device placement of models in the dataflow);
每个阶段中模型的并行策略(The corresponding parallelism strategy for each model in each stage)。
算法概览(Algorithm 1)¶
目标:在给定集群设备上,为 RLHF 数据流找到最优的设备映射方案,使得端到端延迟最小。
输入:
RLHF 数据流图 \( D \)
数据流中涉及的 LLM 模型集合 \( L = [l_1, l_2, ..., l_k] \)
每个模型的计算负载 \( W \)
总 GPU 数量 \( N \)
每个 GPU 的内存容量 \( Q \)
输出:
RLHF 数据流中模型的最优设备映射方案(device mapping)
算法步骤详解¶
1. 枚举所有可能的设备放置方案 \( \mathcal{P} \)¶
对于一个包含 \( k \) 个模型的 RLHF 数据流(例如 PPO 算法有 4 个模型),通过贝尔划分问题(Bell partition problem),可以计算出 15 种可能的设备放置方式。
例如,一种是将每个模型放在不同的 GPU 上(如 OpenRLHF 的方式),另一种是将所有模型放在同一个 GPU 集合上(如 DeepSpeed-Chat 的方式)。
重点:每个模型集合称为一个 colocated set,它们可以使用不同的并行策略。
2. 为每个 colocated set 计算最小 GPU 数量 \( A_{min} \)¶
根据模型的内存消耗,计算每个 colocated set 所需的最小 GPU 数量,以避免内存溢出。
重点:这是算法中保证资源不冲突的必要步骤。
3. 枚举所有可行的 GPU 分配方案 \( A \)¶
从 \( A_{min} \) 开始,逐步枚举所有可能的 GPU 分配方式(Lines 10–12)。
对每个模型,通过
auto_parallel模块选择最优的并行策略,以最小化模型执行延迟。重点:
auto_parallel模块使用了一个模拟器simu,根据模型的负载信息(输入输出形状、计算类型等)估计不同并行策略的执行时间(参考 Zhong et al. 等人的工作)。
4. 计算整个数据流的端到端延迟(d_cost 模块)¶
通过遍历数据流图的每一阶段,累加各阶段的延迟(Lines 17–25)。
关键逻辑:
如果多个模型属于同一个 colocated set 且在同一个阶段计算,它们的延迟相加(Line 32)。
如果模型属于不同的 colocated set,它们的执行可以并行,因此该阶段的延迟由最慢的模型决定(Line 33)。
最终,选择延迟最小的设备映射方案作为输出。
5. 返回最优映射方案¶
算法最终返回延迟最小的模型设备映射方案(
best_mapping)。
算法复杂度分析¶
算法的最坏情况复杂度为: $\( O\left(\frac{(N-1)!}{(k-1)!(N-k)!}\right) \)\( 其中 \) k \( 是模型数量,\) N $ 是总 GPU 数量。
该复杂度来源于对所有可能设备分配的枚举(整数划分问题)。
优化策略:通过缓存每个模型在不同 GPU 数量下的并行策略,避免重复搜索,从而提升算法效率。
扩展性¶
当前算法假设所有 GPU 是同构的。
重点:通过在
simu和auto_parallel模块中加入对异构设备的支持,该算法可以扩展为支持异构设备的映射优化(参考 Zhang et al., 2024a)。
小结¶
本节提出的 自动设备映射算法 是 HybridFlow 框架中的核心部分。它通过组合优化的方式,在满足资源限制的前提下,最小化 RLHF 数据流的端到端延迟。通过枚举所有可能的模型放置与 GPU 分配方案,并结合并行策略选择与延迟估计模块,最终输出最优的模型部署方案。算法设计兼顾了性能与可扩展性,并在保证正确性前提下实现了较高的效率。
7. Implementation¶
7. 实现(Implementation)¶
本节主要介绍了 HybridFlow 的具体实现细节,包括混合编程模型、3D-HybridEngine 以及自动映射算法的实现方式和关键组件。
Hybrid programming model¶
这部分的实现代码量约为 1.8k 行。HybridFlow 的层次化 API 构建在 Ray 框架之上,通过 Remote Process Calls (RPC) 协调不同模型的执行顺序,并根据数据流在模型之间传输数据。中间数据使用 TensorDict 进行存储。
在分布式计算的多控制器范式中,每个模型函数运行在不同设备的独立进程中,控制信息从每个控制器的 CPU 进程传递到对应的 GPU。HybridFlow 支持多种 LLM 训练与推理引擎,包括 Megatron-LM、PyTorch FSDP、DeepSpeed,以及用于自回归生成的 vLLM。在 vLLM 中,为了与多控制器范式保持一致,我们替换其集中式 KVCache 管理器为分布式管理器。
3D-HybridEngine¶
3D-HybridEngine 的主要逻辑基于 Megatron-LM 和 vLLM 实现,代码量约为 2.4k 行。该引擎的关键在于对模型权重和缓存的管理:
在训练和生成阶段,actor 模型权重存储在不同的内存缓冲区中。
在训练阶段,生成阶段的权重会被卸载到 CPU 内存。
在训练与生成切换时,权重会重新加载回 GPU 内存。
在生成阶段结束后,KVCache 会被卸载到 CPU 内存,并在下一轮迭代中重新加载到 GPU。
为了在训练与生成之间切换时同步参数,我们使用 NCCL 通信原语 收集和拼接每个微 DP 组的模型参数。
Auto-Mapping Algorithm¶
该算法的代码量约为 1.9k 行,并配套实现了三种模拟器,分别用于 训练、推理和生成 的工作负载。该算法在 CPU 上运行,在 RLHF 数据流启动前运行,用于生成:
设备映射策略
并行策略
这些策略用于初始化数据流,是 HybridFlow 高效调度和资源分配的关键部分。
总结:¶
HybridFlow 总共约 12k 行 Python 代码,分为三个主要模块:
混合编程模型:基于 Ray 与 TensorDict,实现多控制器与异构设备的协同;
3D-HybridEngine:核心引擎,管理模型权重的内存迁移和参数同步;
自动映射算法:用于生成优化的设备映射与并行策略,提升整体执行效率。
其中,RPC 通信、权重与缓存的内存管理、以及自动映射策略是实现中的关键技术点。
8. Evaluation¶
8.1. Experimental Setup(实验设置)¶
测试环境:
搭建了一个由 16台机器、共128块A100-80GB GPU 组成的集群。
每台机器内部通过 600GB/s NVLink 互联,机器之间带宽为 200Gbps。
使用的软件版本包括:CUDA 12.1、PyTorch 2.1.2、Megatron-core 0.6.0、NCCL 2.18.1、vLLM 0.3.1。
模型与RLHF算法:
测试了 PPO、ReMax、Safe-RLHF 三种主流RLHF算法。
模型均基于 Llama,参数量从 7B到70B。
Safe-RLHF 增加了一个与奖励模型相同的成本模型,ReMax 消除了批评模型。
训练时采用 混合精度(BF16参数 + FP32梯度和优化器),推理和生成使用 BF16。
默认实验结果基于 PPO。
基线系统:
对比了 DeepSpeed-Chat v0.14.0、OpenRLHF v0.2.5、NeMo-Aligner v0.2.0。
NeMo-Aligner 不支持 ReMax。
不比较其他如 Trlx、HuggingFaceDDP、Collosal-Chat,因为它们代表性和性能较差。
性能指标:
使用 RLHF吞吐量(tokens/sec) 作为指标,计算方式为:全局batch中prompt和response的总token数除以一个RLHF迭代时间。
所有结果基于 5次训练迭代的平均值,排除前10次预热迭代。
数据集与超参数:
使用 HuggingFace的“Dahoas/full-hh-rlhf” 数据集。
设置输入prompt长度和响应长度均为 1024 tokens,全局batch size为 1024。
PPO训练 1个epoch,每个epoch执行 8次更新,符合现有RLHF研究的标准。
8.2. End-to-End Performance(端到端性能)¶
性能对比:
HybridFlow 在所有模型规模下均显著优于基线系统。
相比 DeepSpeed-Chat、OpenRLHF、NeMo-Aligner,HybridFlow分别实现了 3.67×~7.84×、3.25×~5.93×、12.52×~20.57× 的吞吐量提升。
HybridFlow 的优势在于:
使用不同的并行策略对模型进行分片,适应不同计算负载;
有效降低 转换开销(transition overhead);
NeMo-Aligner 的瓶颈在于生成阶段,占RLHF迭代时间的 81.2%;
HybridFlow 在 70B模型 训练时平均提速 9.64×。
可扩展性(Scalability):
在 8块GPU 上,HybridFlow的加速比为 2.09×。
强扩展效率(Strong Scaling Efficiency)为 66.8%(基于Amdahl定律)。
在 128块GPU 上训练7B模型时,HybridFlow仍优于 OpenRLHF(1.53×~1.71×)。
HybridFlow 能根据模型和集群大小自适应调整放置策略,从而最小化RLHF时间。
8.3. Model Placement(模型放置策略)¶
实验设置:
在相同模型和集群配置下,比较以下几种模型放置策略:
colocate(DeepSpeed-Chat):所有模型放在同一设备集合;
standalone(OpenRLHF):各模型单独放置;
split(NeMo-Aligner):Actor和Reference Policy在一组设备,Critic和Reward Model在另一组;
hybridflow(HybridFlow默认):通过算法1优化得到的放置策略。
结果分析:
小集群(16~64 GPU):colocate 性能最优;
大集群(96~128 GPU):split 或 standalone 更优,因为可以并行执行不同模型;
HybridFlow的算法1 总是能找出最优放置策略,达到最高吞吐量;
KVCache的分配 对生成阶段性能影响显著,HybridFlow通过合理分配减少GPU空闲时间。
8.4. 3D-HybridEngine(HybridFlow核心机制)¶
过渡时间(Transition Time)对比:
HybridFlow 的过渡时间平均比 OpenRLHF 减少 55.2%(11.7秒);
对于 70B模型,过渡开销降低 89.1%(78.2秒);
关键机制是 新的并行分组方法,避免了层间多次收集参数,仅需一次all-gather即可完成模型转换;
基线方法因防止OOM需多次收集参数,过渡时间较长。
生成与训练阶段的并行差异:
HybridFlow在训练和生成阶段使用不同大小的TP(Tensor Parallelism)组;
例如,7B模型使用 TP=2,13B模型使用 TP=4,生成阶段延迟分别降低 60.3% 和 36.4%;
NeMo-Aligner 因使用与训练相同TP(如TP=8),导致GPU利用率低,生成延迟最大。
8.5. Algorithm Runtime(算法运行时间)¶
HybridFlow的设备映射算法(Algorithm 1)运行时间远小于实际训练时间(几天);
运行时间随模型和集群规模线性增长,显示良好的可扩展性;
主要时间花在 评估各种并行策略的延迟 上;
通过 缓存最优策略,搜索时间可控制在 最多半小时 内;
在图16中,模型规模和GPU数量同时增加时,算法运行时间呈线性上升。
小结(Summary)¶
本章通过一系列实验验证了 HybridFlow 在RLHF训练中的高效性:
HybridFlow 在不同模型规模、不同算法和不同集群配置下均表现优于现有系统;
通过 灵活的模型分片与放置策略、高效的3D-HybridEngine机制 和 自动化设备映射算法,HybridFlow显著提升了RLHF的端到端吞吐量;
HybridFlow 对超大模型(如70B)和大规模集群(如128 GPU)具有良好的扩展性和适应性,是目前RLHF训练中的高效框架。
如需进一步深入某一部分(如模型放置策略、HybridEngine机制等),可继续提出。
9. Discussions¶
Fault Tolerance(容错性)¶
HybridFlow 的容错机制与现有方法是正交的(orthogonal),并已经集成了 checkpointing(检查点机制)。系统通过 NCCL 错误检测节点故障,通过校验和(checksums)检测静默数据损坏(silent data corruption)。其编程模型通过 RPC 由单个控制器协调检查点操作,支持在每个 ParallWorker Group 内保存模型状态,包括:
演员/评论家模型(actor/critic models)的参数;
数据加载器 ID(dataloader IDs);
随机数生成器(RNG)状态;
这些机制确保了系统一致性。此外,当健康模型副本足够时,HybridFlow 也可以采用基于冗余的容错方法,如广播参数和 CPU 检查点,以实现快速恢复。
重点内容总结:HybridFlow 提供了多种容错机制,包括检查点和冗余恢复方案,确保在故障发生时能快速恢复并保持系统一致性。
Placement Insights(部署洞察)¶
对于 RLHF(Reinforcement Learning with Human Feedback)训练中的模型部署和 GPU 分配,本文总结了三个关键洞察:
增加 actor 模型的 GPU 分配,可以降低生成延迟(generation latency),因为该过程无法与其他模型并行化。
当各模型计算能充分利用 GPU 资源时,在小规模集群中将所有模型放在同一设备上训练最为有效。
当扩展到大规模集群(强扩展)时,将 actor 和 critic 模型部署在不同设备上并行执行,有助于提高训练吞吐量。
重点内容总结:HybridFlow 提出了在不同规模集群中优化 GPU 分配和模型部署策略的关键方法,以提高训练效率。
Resource Multiplexing(资源复用)¶
HybridFlow 通过 GPU 时间调度共享(time-sharing)实现在共享设备上部署多个模型。虽然 ResourcePool 支持并行执行,但 HybridFlow 通常采用 顺序执行,以避免 GPU 资源竞争或内存溢出(OOM)问题。
在 RLHF 训练中,GPU 共享和异构资源的使用面临特殊挑战,包括计算负载的平衡和复杂任务间数据依赖的管理。未来的研究方向包括:
细粒度自动映射算法,用于优化 GPU 共享;
模型卸载优化;
异构设备集成。
重点内容总结:HybridFlow 支持资源复用,但为避免资源竞争采用顺序执行。未来需探索更精细的资源管理策略。
From Alignment to Reasoning(从对齐到推理)¶
在 LLM 对齐(alignment)中的 RLHF,奖励信号由奖励模型生成。除了对齐任务,PPO 和 GRPO 等强化学习算法(Shao et al., 2024)也可应用于其他领域,如代码生成和数学推理。对于这些任务,通常存在明确的“正确答案”,例如:
代码生成任务可通过测试用例验证输出是否正确;
数学推理任务可通过正确性验证结果是否准确。
因此,奖励模型可以被 非神经网络的奖励模块 替代,例如:
沙箱环境(Zhang et al., 2024b),用于评估生成代码;
奖励函数(Cobbe et al., 2021;Saxton, 2019),用于验证数学结果。
HybridFlow 可通过将这些奖励模块封装为远程函数,并在单进程脚本中协调执行,提供一个灵活且高效的强化学习框架,适用于多种任务场景。
重点内容总结:HybridFlow 不仅适用于对齐任务,还可扩展到代码生成和数学推理,支持多种非神经网络奖励模块的集成。
11. Conclusion¶
本节总结了 HybridFlow 的整体贡献与实验表现。
HybridFlow 框架概述:HybridFlow 是一个支持灵活表示和高效执行多种 RLHF 算法的强化学习人类反馈(RLHF)框架。这是全文的核心成果。
混合编程模型:作者提出了一种混合编程模型,用户可以通过封装不同大语言模型(LLMs)的分布式计算为原语 API,从而以少量代码构建 RLHF 数据流。该模型隐藏了节点间数据重分片的复杂性,是实现灵活与高效的关键。
3D-HybridEngine:作为执行引擎,3D-HybridEngine 负责高效训练与生成actor 模型。其优势在于实现了零内存冗余,并显著减少了模型参数重分片时的通信开销,是提升效率的核心组件。
有效映射算法:HybridFlow 还引入了一个优化算法,用于优化 RLHF 数据流中模型的GPU 分配与放置,从而进一步提升资源利用率和执行效率。
实验结果:大量实验表明,HybridFlow 在不同模型规模和集群规模下,相比最先进的 RLHF 系统,速度提升了 1.53 倍到 20.57 倍。这是验证 HybridFlow 高效性的重要依据,是全文的重点成果之一。
致谢部分(Acknowledgements)¶
在致谢部分,作者感谢了审稿人和项目合作者的建设性意见。具体包括:
感谢 shepherd Y. Charlie Hu 和匿名审稿人;
感谢 Xin Liu、Yangrui Chen 和 Ningxin Zheng 提供的宝贵反馈;
项目得到了来自 ByteDance 的研究合作项目以及香港 RGC 的资助(合同号:HKU 17204423 和 C7004-22G)。
这部分内容相对次要,主要是对支持人员和机构的感谢,不涉及技术重点。
Appendix A Primitive APIs in HybridFlow¶
Appendix A HybridFlow 中的基本 API¶
在 HybridFlow 中,每个模型的基本操作通过继承 3DParallelWorker、FSDP Worker 和 ZeROWorker 实现。这些模型类的设计目的是将分布式计算代码与用户操作解耦,并提供 RLHF 训练中的基础操作。
这些基本设计与现有的分布式推理和训练框架中的自回归生成、前向传播、反向传播和模型更新操作兼容。用户可以根据算法设计,通过适配这些函数中的数值计算,自定义 RLHF 的训练数据流,同时复用底层的分布式计算实现,从而提高开发效率和灵活性。
重点内容:
3DParallelWorker、FSDP Worker、ZeROWorker 是实现 RLHF 基本操作的基础类。
这些类的设计实现了分布式计算代码的解耦,便于用户使用和扩展。
用户可以通过自定义函数中的计算逻辑来自定义训练流程,同时复用底层实现,提高效率。
该设计兼容生成、前向、反向、更新等所有 RLHF 的核心操作。
精简内容:
表格 4 中详细说明了这些 API 的含义和实际计算过程,读者可参考以获取更具体的实现细节。
Appendix B Transfer Protocols¶
以下是对你提供的论文章节内容的总结,按照原文结构,使用中文进行讲解,突出重点内容并简化次要信息:
附录 B:数据传输协议(Transfer Protocols)¶
本部分介绍了用于RLHF数据流中模型间数据重新分片的传输协议。这些协议覆盖了RLHF数据流中的常见使用场景,用户可以通过预定义的传输协议生成各种RLHF数据流。此外,用户也可以通过定义两个函数——collect函数和distribute函数——来自定义传输协议。传输协议将复杂的数据重新分片与分布式训练解耦,简化了模型间的数据传输逻辑。
文中定义了三个参数:
p:pipeline并行组中的worker rankt:tensor并行组中的worker rankd:data并行组中的worker rank
预定义的传输协议详见表3(原文中未给出,感兴趣可查看引用文档)。
表4:各模型类提供的关键函数¶
表4总结了每种模型类中提供的关键函数,用户可基于这些函数快速构建各种RLHF算法,只需几行代码即可完成。
模型类型 |
接口(APIs) |
计算内容 |
功能说明 |
|---|---|---|---|
Actor |
generate_sequence |
自回归生成 |
基于一批提示(prompt),生成一批响应(response),并返回每个token的对数概率。 |
compute_log_prob |
前向传播 |
计算提示和响应中每个token的对数概率,用于后续训练(PPO中可选)。 |
|
compute_loss |
前向传播 |
基于预训练数据集计算预训练损失。 |
|
update_actor |
前向+反向传播+模型更新 |
根据优势(advantage)和预训练损失,计算训练损失并更新模型权重。支持多种RLHF算法(如PPO、Safe-RLHF、ReMax、GRPO等)。 |
|
Critic |
compute_values |
前向传播 |
计算每个提示和响应的值(value)。 |
update_critic |
前向+反向传播+模型更新 |
根据值和返回值计算平方误差损失并更新模型权重。也支持多种RLHF算法。 |
|
Reference Policy |
compute_ref_log_prob |
前向传播 |
计算提示和响应中token的参考对数概率,用于衡量策略与参考策略的差异。 |
Reward |
compute_reward |
前向传播 |
对给定提示和响应计算奖励分数,可为token级别或样本级别。 |
- |
compute_advantage |
数值计算 |
基于值模型和奖励模型计算优势,不涉及模型前向传播。 |
重点说明:
表4是整个RLHF系统的关键函数汇总,提供了模块化接口,便于用户快速构建不同算法。
所有模型类(actor、critic、reference、reward)都提供了接口与计算方式,说明系统高度结构化和模块化。
update_actor和update_critic支持多种算法变体,说明该框架的可扩展性较强。
算法 2:自动并行算法(Auto Parallelism Algorithm)¶
该算法用于根据设备分配、最小设备分配、模型并行规模和工作负载,自动生成最优的并行策略。
算法输入:¶
A:模型的设备分配Amin:每个模型的最小模型并行配置W:工作负载U:每台机器的GPU数量
算法输出:¶
为模型集合生成最优的并行策略
算法步骤概述:¶
遍历所有模型的设备分配和最小并行配置。
枚举可能的 tensor 并行度
t和 pipeline 并行度p。计算对应的 data 并行度
d。为每个
(p, t, d)配置调用模拟函数simu计算成本。保留成本最低的并行策略作为最优解返回。
重点说明:
该算法通过枚举所有可能的并行配置,选择性能最优的方案,体现了自动并行的灵活性和效率。
simu函数用于模拟不同并行策略的成本,是算法的核心部分(但未在文中展开)。适用于多模型、多设备的 RLHF 场景,能有效提升训练效率和资源利用率。
总结:¶
传输协议部分提供了模型间数据重新分片的方法,支持用户自定义。
表4详细列出了各模型类的关键函数,是构建RLHF算法的基础接口。
算法2实现了自动并行策略选择,是提升系统效率和灵活性的重要组件。
整体来看,附录 B 和表4 构成了RLHF框架的底层支持系统,强调模块化、灵活性与高效性。
Appendix C Auto-Parallelism Algorithm¶
附录C 自动并行算法¶
Algorithm 2 描述了每个模型最优并行策略的搜索过程。算法从每个模型的最小模型并行规模开始(用于防止在与多个工作器共置时发生OOM),基于GPU数量和每台机器上的GPU数 \(U\)(默认设为8),枚举所有可行的并行配置。系统使用一个名为 simu 的模块来估算每个模型的延迟,该模块包括训练、推理和生成三个工作负载的模拟器,均为分析模型,参考了相关研究工作(如 Yuan et al., 2024;Zhong et al., 2024;Li, 2023)。
训练和推理工作负载 是计算受限的;
生成工作负载 是内存受限的。
在actor模型中,首先为训练阶段确定并行策略,并记录训练阶段的内存使用情况。在actor生成阶段,根据批量大小和最大序列长度计算KVCache(键值缓存)需求。如果生成阶段的模型并行规模无法容纳参数和KVCache,就会增加该规模以满足需求。
最后,通过比较延迟估算值,选择最优的并行策略及对应的KVCache分配方案。
重点内容总结:
自动并行算法基于GPU资源和模型需求生成多个配置方案;
使用simu模块分析不同工作负载下的延迟表现;
actor模型的训练和生成阶段具有不同的资源瓶颈(计算 vs 内存);
KVCache需求在生成阶段是关键决策因素;
未来可引入更完善的自回归生成模拟器,提升在RLHF研究中的自动映射效率。