2401.15391_MultiHop-RAG: Benchmarking Retrieval-Augmented Generation for Multi-Hop Queries¶
引用: 139(2025-08-02)
组织: Hong Kong University of Science and Technology
Huggingface: https://huggingface.co/datasets/yixuantt/MultiHopRAG
总结¶
数据集
包含多个来源的多跳问答数据集(如HotpotQA、2WikiMultiHopQA等)
一个知识库、大量多跳查询、真实答案及其对应的支撑证据
数据集构建
Dataset Collection数据集收集
Evidence Extraction证据提取
提取事实性句子作为证据
保留那些与其他文章存在关键词重叠的新闻,以便后续生成跨文档的多跳查询
Claim, Bridge-Entity, Bridge-Topic Generation主张、桥接实体、桥接主题生成
跨证据的共享实体或主题称为桥接实体或桥接主题
这些桥接实体或桥接主题可用于链接不同的证据,从中得出多跳查询的答案(参见图2, prompt 参见附录A)
Query and Answer Generation
利用桥接实体或桥接主题生成多跳查询
首先将具有相同桥接实体或桥接主题的声明分组为一个声明集
将声明集限制为至少包含两个声明但不超过四个声明(prompt 参见附录A)
四种类型的多跳问题
推断问题(Inference Query):综合多个声明,最终答案为实体本身
对比问题(Comparison Query):比较桥梁实体或主题的异同,答案通常为“是”或“否”
时间问题(Temporal Query):涉及事件的时间顺序,答案为“之前”或“之后”等时间词
空问题(Null Query):答案无法从知识库中获取,答案为“信息不足”
多跳查询
定义
多跳查询是指需要从多个证据片段中推理得出答案的复杂查询。
分类
推断查询(Inference query):需要从多个文档中推断关系。
比较查询(Comparison query):比较多个数据点。
时间序列查询(Temporal query):分析事件的时间顺序。
空查询(Null query):查询无法从知识库中得出答案,用于评估模型是否会在信息不足时产生幻觉。
评估指标
检索评估(Retrieval Evaluation):
Mean Average Precision at K (MAP@K):衡量 top-K 结果的平均精确率。
Mean Reciprocal Rank at K (MRR@K):衡量首个相关块的倒数排名平均值。
Hit Rate at K (Hit@K):衡量 top-K 内包含相关证据的比例。
除空值查询外,所有查询都应与真实证据进行对比评估。
生成评估(Response Evaluation):
通过比较 LLM 生成的答案与真实答案,评估模型的推理能力。
Figure 1:RAG with multi-hop query.
LLM总结¶
背景与动机¶
传统的RAG方法在处理需要多步推理的问题时表现不佳。多跳查询通常需要从多个文档中提取信息,并进行跨文档的推理,这对检索和生成系统提出了更高的要求。然而,现有的RAG研究主要关注单跳问答(single-hop QA),缺乏对多跳问题的系统评估。
贡献¶
提出MultiHop-RAG基准测试框架:
该框架专门设计用于评估RAG系统在处理多跳查询时的表现。
包含多个来源的多跳问答数据集(如HotpotQA、2WikiMultiHopQA等)。
分析现有RAG方法的局限性:
在多跳任务中,现有模型在检索相关文档、信息整合和跨文档推理方面存在显著不足。
例如,模型可能忽略关键中间步骤或错误地依赖不相关的信息。
实验分析与比较:
对多个RAG方法(如Dense Retrieval、Sparse Retrieval、Hybrid Retrieval等)在多跳任务上的性能进行了系统评估。
发现检索结果的质量和相关性对最终答案的准确性有显著影响。
提出改进建议:
建议改进检索策略,例如在检索阶段引入多跳推理机制。
推荐在生成阶段使用更复杂的推理链模型,以更好地整合多跳信息。
方法概览¶
检索模块:从多个文档中检索相关信息。
生成模块:基于检索到的信息生成最终答案。
评估指标:采用EM(Exact Match)和F1分数等标准指标进行评估,并特别关注推理链的完整性。
实验结果¶
现有RAG方法在多跳任务上的表现显著低于单跳任务。
检索阶段的改进(如使用DPR、BM25等)能够提升性能,但仍存在较大优化空间。
多跳任务的成功依赖于多个因素,包括文档相关性、信息整合能力和推理能力。
总结¶
《MultiHop-RAG》为RAG系统在多跳问题上的评估与改进提供了重要的基准和分析。该研究揭示了当前RAG方法在多跳推理任务中的挑战,并为未来的研究指明了方向,例如改进检索策略、引入更强的推理模型等。
这篇论文有助于推动检索增强生成技术在复杂推理任务中的发展,特别是在需要跨文档推理的现实场景中。
Abstract¶
本文提出了一种新的用于评估检索增强生成(RAG)系统在多跳查询(multi-hop queries)任务中表现的数据集 MultiHop-RAG。当前,尽管RAG在减少大语言模型(LLM)幻觉和提升回答质量方面表现出潜力,但其在处理需要多步推理和多源证据支持的复杂查询方面仍存在明显不足。此外,现有的RAG评估数据集尚未专注于多跳查询任务。
为解决这一问题,作者构建了 MultiHop-RAG,其中包括一个知识库、大量多跳查询、真实答案及其对应的支撑证据。数据集构建基于英文新闻数据,具有现实意义和代表性。文章通过两个实验验证了该数据集的评估价值:
实验一:比较不同嵌入模型在多跳查询中的证据检索效果;
实验二:评估多个先进LLM(如GPT-4、PaLM、Llama2-70B)在给定证据的情况下处理多跳查询的能力。
实验结果表明,现有RAG方法在处理多跳查询时表现不佳,揭示了当前系统的局限性。作者希望 MultiHop-RAG 能够成为社区开发更高效RAG系统的重要资源,推动大语言模型在实际应用中的更广泛使用。该数据集和实现的RAG系统已开源,可供研究者使用。
1 Introduction¶
本文介绍了MultiHop-RAG,这是一个专注于多跳查询(multi-hop queries)的RAG(检索增强生成)数据集,旨在解决当前RAG基准测试中缺乏对复杂、多文档推理能力评估的问题。
主要内容总结如下:¶
背景与动机
随着大型语言模型(LLMs)的兴起,RAG技术在提升模型输出质量与减少幻觉方面展现出优势。然而,现有的RAG基准(如RGB和RECALL)主要评估基于单条证据的查询,无法反映现实世界中需要检索和推理多个文档的复杂查询场景。MultiHop-RAG的提出
为填补这一空白,作者提出了MultiHop-RAG,这是首个专门针对多跳查询设计的RAG数据集。作者认为,多跳查询在金融分析、新闻解读等实际应用中非常常见,例如比较多个公司财务表现或分析时间序列数据。多跳查询的分类
作者将多跳查询分为四类:推断查询(Inference query):需要从多个文档中推断关系。
比较查询(Comparison query):比较多个数据点。
时间序列查询(Temporal query):分析事件的时间顺序。
空查询(Null query):查询无法从知识库中得出答案,用于评估模型是否会在信息不足时产生幻觉。
数据构建方法
使用新闻文章作为知识库,通过GPT-4提取事实句子作为证据,再将其转化为明确的声明(claim),并提取出主题和实体(桥接主题和桥接实体)用于构建多跳查询。通过这种方式生成了结构化的多跳查询和答案。实验与评估
作者使用LlamaIndex构建RAG系统,并进行了两组实验:embedding模型比较:评估不同嵌入模型在多跳查询中的检索性能。
LLM推理能力评估:测试包括GPT-4、GPT-3.5、PaLM、Claude-2、Llama2-70B等在内的多种SOTA模型在多跳查询上的表现。
实验结果表明,当前的RAG系统在处理多跳查询时仍然存在显著不足。
公开与贡献
作者公开了MultiHop-RAG数据集,希望其能成为研究和评估RAG系统的重要资源,推动生成式AI在实际应用中的发展。

Table 1:An example of a multi-hop query, including supporting evidence from two news articles, the paraphrased claim, the bridge-topic and bridge-entity, and the corresponding answer.
总结:¶
本文提出并构建了MultiHop-RAG数据集,填补了现有RAG基准在多跳查询评估方面的空白。通过对多跳查询的分类和系统实验,展示了当前LLMs和RAG系统在多文档推理能力上的挑战,并为未来研究提供了有价值的基准和工具。
2 RAG with multi-Hop queries¶
本章节主要探讨了在 RAG(Retrieval-Augmented Generation)框架中处理多跳(Multi-Hop)查询的方法及其评估方式,内容总结如下:
2.1 RAG(检索增强生成)概述¶
RAG 系统通过一个外部知识库(文档集合 𝒟)来增强生成模型的能力。
每个文档被分割为多个块(chunks),并通过嵌入模型转化为向量,存储在嵌入数据库中。
给定用户查询 q,系统会检索与之最相关的 top-K 个块,形成检索集 ℛq。
最终,检索集 ℛq 与原始查询和提示信息一起输入 LLM,生成最终答案。
2.2 多跳查询(Multi-Hop Queries)¶
多跳查询是指需要从多个证据片段中推理得出答案的复杂查询。
与单跳查询(仅需一个证据)不同,多跳查询需要结合多个证据进行比较、推理。
常见的多跳查询类型包括:
推理查询(Inference query):从多个证据中推断答案。例如,判断某份年报是否涉及特定内容。
比较查询(Comparison query):对多个证据进行比较。例如,对比两家公司的收入。
时间顺序查询(Temporal query):分析时间信息。例如,判断某产品是否在另一个产品发布之前推出。
空值查询(Null query):用于测试生成模型是否能在无有效证据时生成“无答案”响应,而非幻觉(hallucination)。
2.3 评估指标¶
多跳查询的 RAG 系统可以从两个方面进行评估:
检索评估(Retrieval Evaluation):
评估检索集 ℛq 的质量,使用指标包括:
Mean Average Precision at K (MAP@K):衡量 top-K 结果的平均精确率。
Mean Reciprocal Rank at K (MRR@K):衡量首个相关块的倒数排名平均值。
Hit Rate at K (Hit@K):衡量 top-K 内包含相关证据的比例。
除空值查询外,所有查询都应与真实证据进行对比评估。
生成评估(Response Evaluation):
通过比较 LLM 生成的答案与真实答案,评估模型的推理能力。
总结¶
本章系统介绍了 RAG 系统在处理多跳查询时的结构和关键挑战,定义了多跳查询的类型,并提出了相应的评估方法,为后续研究和优化 RAG 模型提供了理论基础和实践指导。
3 A Benchmarking Dataset: MultiHop-RAG¶
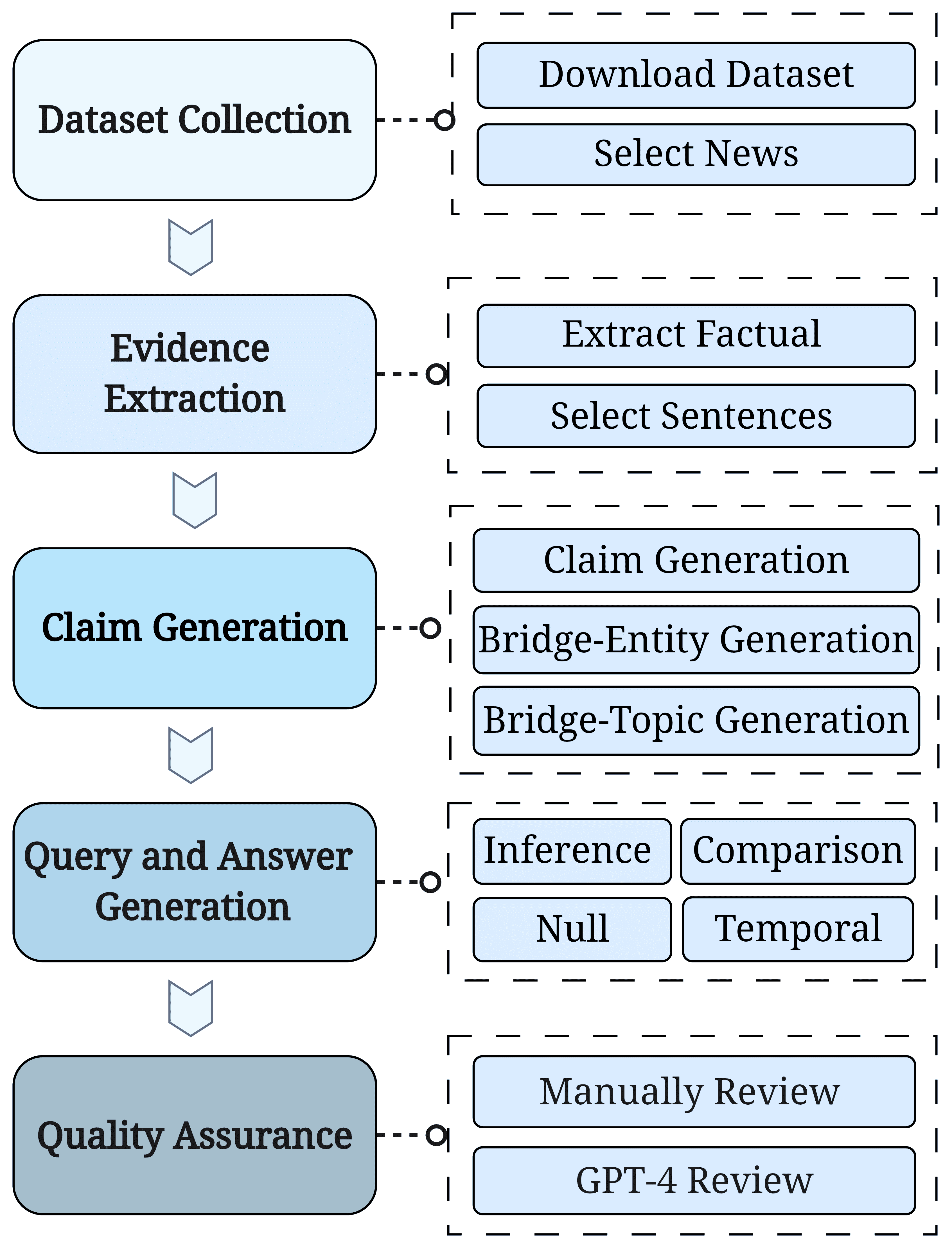
Figure 2:MultiHop-RAG Construction Pipeline.
一、MultiHop-RAG 数据集构建流程¶
步骤1:数据集收集
使用 Mediastack API 收集了2023年9月26日至12月26日间的英文新闻数据,涵盖娱乐、商业、体育、科技、健康和科学六大类。
选择该时间段是为了确保数据在许多常用大语言模型(如ChatGPT、LLaMA)的训练时间之后,从而避免模型已预先训练过这些新闻内容。
筛选出长度不少于1024个token的新闻,并保留标题、发布时间、作者、类别、网址和新闻来源等元数据。
步骤2:证据提取
使用训练好的语言模型(lighteternal/fact-or-opinion-xlmr-el)从每篇新闻中提取事实性句子作为证据。
保留那些与其他文章存在关键词重叠的新闻,以便后续生成跨文档的多跳查询。
步骤3:声明、桥梁实体和桥梁主题生成
使用 GPT-4 对提取的原始证据进行重写,生成更一致的“声明”(claim),并通过UniEval框架进行事实核查,确保声明与原文一致。
提取“桥梁实体”和“桥梁主题”(bridge-entity 和 bridge-topic),用于连接多个证据,作为生成多跳问题的依据。例如,“Google”是桥梁实体,“利润”是桥梁主题。
步骤4:查询和答案生成
根据桥梁实体或桥梁主题,将包含相同主题的声明分组,形成每个组内包含2到4个声明的声明集。
使用GPT-4根据声明集生成四种类型的多跳问题:
推断问题(Inference Query):综合多个声明,最终答案为实体本身。
对比问题(Comparison Query):比较桥梁实体或主题的异同,答案通常为“是”或“否”。
时间问题(Temporal Query):涉及事件的时间顺序,答案为“之前”或“之后”等时间词。
空问题(Null Query):答案无法从知识库中获取,答案为“信息不足”。
步骤5:质量保证
人工抽查部分生成的查询、证据和答案,评估数据质量。
使用GPT-4对数据集条目进行评估,确保查询满足以下标准:
回答必须使用所有提供的证据;
仅能基于提供的证据回答;
回答应为单个单词或具体实体;
查询应符合其指定类型。
二、MultiHop-RAG 数据集统计信息¶
新闻文章统计:
总共包含609篇新闻,平均每篇2,046个token。
按类别分布:科技最多(172篇),健康最少(10篇)。
查询类型分布:
推断问题(31.92%)、对比问题(33.49%)、时间问题(22.81%)、空问题(11.78%),共计2,556个问题。
约88%为非空问题(答案可由知识库推导)。
证据数量分布:
42%的问题需要2个证据;
30%需要3个证据;
15%需要4个证据;
11.78%的问题无可用证据(空问题)。
问题形式多样化:
问题常用问词包括“does”(27%)、“what”(15%)、“which”(15%)、“who”(14%)等。
总结¶
本节详细介绍了MultiHop-RAG数据集的构建过程,包括数据收集、证据提取、桥梁实体与主题生成、查询生成及质量控制等环节,并提供了数据集的统计信息。该数据集聚焦于多跳查询的评估,适用于检索增强生成(RAG)系统的基准测试,具有多样性、真实性和高质量的特点。
4 Benchmarking RAG system using MultiHop-RAG¶
本章节主要探讨了如何利用 MultiHop-RAG 数据集对 RAG(Retrieval-Augmented Generation) 系统进行基准测试,重点分析了两类任务:检索相关任务和生成相关任务,并提出了一些可能的改进方向。
三、其他潜在改进方向(Other Use Cases)¶
除了嵌入模型和生成模型的性能评估,作者还提出了一些可能的改进方向,包括:
查询分解(Query Decomposition):将复杂查询拆分为多个子查询,分别检索再整合,有助于提升准确性。
基于 LLM 的智能代理(LLM-based Agents):如 AutoGPT,可通过自动规划和执行多跳查询来提升 RAG 系统的复杂任务处理能力。
混合检索方法(Hybrid Retrieval):结合关键词匹配和嵌入匹配,提升检索的全面性和准确性。
总结¶
该章节通过 MultiHop-RAG 数据集,系统性地评估了 RAG 系统在多跳查询任务中的性能瓶颈,包括:
检索阶段:嵌入模型和重排序模块的性能仍有限,难以准确匹配多跳查询。
生成阶段:即使是最先进的 LLM(如 GPT-4)在使用检索信息时表现也欠佳,而开源模型在复杂任务上存在明显不足。
作者认为,MultiHop-RAG 可作为 RAG 系统的基准数据集,推动未来在检索增强生成技术上的研究与优化。
6 Conclusion¶
本章节总结如下:
本文介绍了 MultiHop-RAG,这是一个专为需要从多个证据中进行检索与推理的复杂查询设计的全新且独特的数据集。这类多跳查询在现实场景中非常常见。MultiHop-RAG 包括知识库、大量多跳查询、其标准答案以及相关支持证据。文中详细描述了 MultiHop-RAG 的构建过程,采用了一种结合人工与 GPT-4 的混合方法。此外,作者还探讨了 MultiHop-RAG 在 RAG 系统基准测试中的两个应用案例,展示了该数据集的潜在价值。通过公开发布 MultiHop-RAG,研究者希望为社区提供一个宝贵资源,推动 RAG 系统的发展与评估。
Limitations¶
本章节总结了当前工作的局限性,并提出了未来研究的改进方向:
答案形式受限:当前的基准答案仅限于“是”、“否”、实体名称或时间指示词(如“之前”、“之后”),以便使用简单的准确率指标评估生成效果。未来可考虑允许自由文本作为答案,并采用更复杂的质量评估指标。
支持证据数量有限:当前数据集中每个问题最多只包含四条支持证据。未来可扩展数据集,纳入需要从更多证据中检索并进行推理的问题。
框架较为基础:当前实验使用了基于 LlamaIndex 的基本 RAG 框架。未来可尝试使用更先进的 RAG 或 LLM-agent 框架,评估对多跳问题的回答能力。
Appendix A Appendix A: GPT-4 Prompts Used for Data Generation¶
Table 7:Claim Generation Prompting¶
**说明**
"主张"(claim)指文本中表达信念、观点或事实的陈述。请根据原文证据提取一个主张及其相关主题。
**要求**:
1. 主张中不得包含模糊指代(如"他/她/它"),需使用完整名称。
2. 若存在多个主题,提供最核心的一个。
3. **主张目标**(Claim Target):主张针对的具体实体(个人、团体或组织)。
4. **主张主题**(Claim Topic):用简单短语概括主张的核心论点概念。
5. 若无主张,则留空。
6. 必须基于给定证据生成主张,不可自行编造证据。
**回答格式**:
```
证据: [原文内容]
主张: [提取的主张]
主张目标: [目标实体]
主张主题: [核心主题]
```
**示例**:
*<示例>*
现在请根据以下内容提取主张:
*<待分析文本>*
*<证据>*
Table 8:Inference Query Generation Prompting¶
**多跳问题**是指需要通过多次推理或从不同来源获取多个信息片段才能回答的查询。以下是新闻文章的元数据及其相关主张(claims),这些主张均围绕同一目标(target)。你的任务是基于这些主张生成一个多跳推理问题。具体步骤如下:
---
1. **寻找关联**:
- 主张之间的关联是**<target>**,即这些关键信息如何相互关联,或如何组合成一个更复杂的观点。
2. **构建问题**:
- 设计一个**无法通过单一主张回答**的问题,必须结合所有来源的信息才能解答。
- 问题的答案应为**<target>**。
3. **确保逻辑性**:
- 问题需从组合信息中自然衍生,且清晰、无歧义。
4. **使用关键词**:
- 在问题中融入**<key set>**中的词汇。
5. **示例参考**(可选):
- *<examples>*
---
**上下文**:
*<Context>*
Table 9:Comparison Query Generation Prompting¶
**<上下文>**
以上是新闻文章的元数据及其相关声明(claims),所有声明都围绕一个相似的主题。你的任务是根据不同来源的声明,生成一个**对比性问题**。该问题需通过对比声明中明确陈述的事实性内容,找出它们的一致或差异之处。问题的正确答案需以以下形式呈现:
- 比较级形容词(如“更多”“更早”)
- 一致性声明(如“两者均提到…”)
- 简单的是/否
生成对比性问题时,需使用以下关键词:**<关键词集>**
**优质对比问题的特点**:
**<示例>**
**你生成的对比问题**:
Table 10:Temporal Query Generation Prompting¶
### 背景说明
请利用多篇新闻文章的元数据和摘录内容,创建一个具有时效性的对比问题。问题需用于比较以下两种情形:
1. **一致性对比**:比较不同时间点对相似主题报道的一致性。需在问题中明确标注*<时间范围>*和新闻来源。
2. **序列对比**:比较不同新闻来源对同一事件的报道顺序。仅需标注新闻来源,无需提及时间线。
请使用*<关键词集>*中提供的关键词构建问题。正确答案需基于事实摘录,且仅为单个单词。
### 示例模板
"对比*<新闻来源A>*和*<新闻来源B>*在*<时间范围>*内关于X事件的报道,双方对Y结论的描述是否一致?"
(正确答案:是/否)
### 注意事项
- 时间敏感性:若涉及时效对比,需清晰标注时间范围。
- 答案形式:必须为单个单词(如“一致”“矛盾”“增加”等)。
- 关键词集成:问题需包含*<关键词集>*中的指定术语。
Table 11:Null Query Generation Prompting¶
一个多跳问题是指需要通过多次推理或从不同来源获取多个信息片段才能得出答案的查询。假设你已经阅读了至少两篇关于*<实体>*的新闻文章,请构建一个包含所有新闻来源的多跳问题。问题中需注明新闻来源,并确保答案是一个单词/实体。不要直接回答这个问题,只需提供你构建的问题: