2407.11963_NeedleBench: Can LLMs Do Retrieval and Reasoning in Information-Dense Context¶
组织: Tsinghua University, Shanghai AI Laboratory
引用: 32(2025-07-09)
总结¶
简介
NeedBench 是一个评测框架
英文数据集: 通过 PaulGrahamEssays数据集构建
中文数据集: 通过 ChineseDomainModelingEval 数据集构建
长文本
主要贡献**
NeedleBench:双语长上下文评估框架,支持多种长度,覆盖信息稀疏和密集任务。
Ancestral Trace Challenge:设计了一个新的信息密集型任务,模拟现实中的复杂推理场景。
细致的评估与分析:对主流模型在不同上下文条件下的检索和推理性能进行全面评估。
说明:
解决现有评测集的2个问题
1.使用真实数据集进行评测,不能确定是不是 LLM 本来就有的知识
2.人为添加大量无关内容,信息过于“稀疏”,模型只需关注少数关键点即可成功
任务分类
信息稀疏型任务(如 Single-Needle、Multi-Needle Retrieval 和 Reasoning)
信息密集型任务(如 Ancestral Trace Challenge)
数据集
GitHub: https://github.com/open-compass/opencompass
这是一个评测项目的框架,感觉需要重点研究一下
GitHub: https://github.com/open-compass/CompassBench
这个是 opencompass 的评测数据集示例
包含语言、推理、知识、数学、代码、指令跟随、智能体等几个方面
介绍: https://opencompass.readthedocs.io/zh-cn/latest/advanced_guides/compassbench_intro.html
介绍2: https://opencompass.readthedocs.io/zh-cn/latest/advanced_guides/compassbench_v2_0.html
Abstract¶
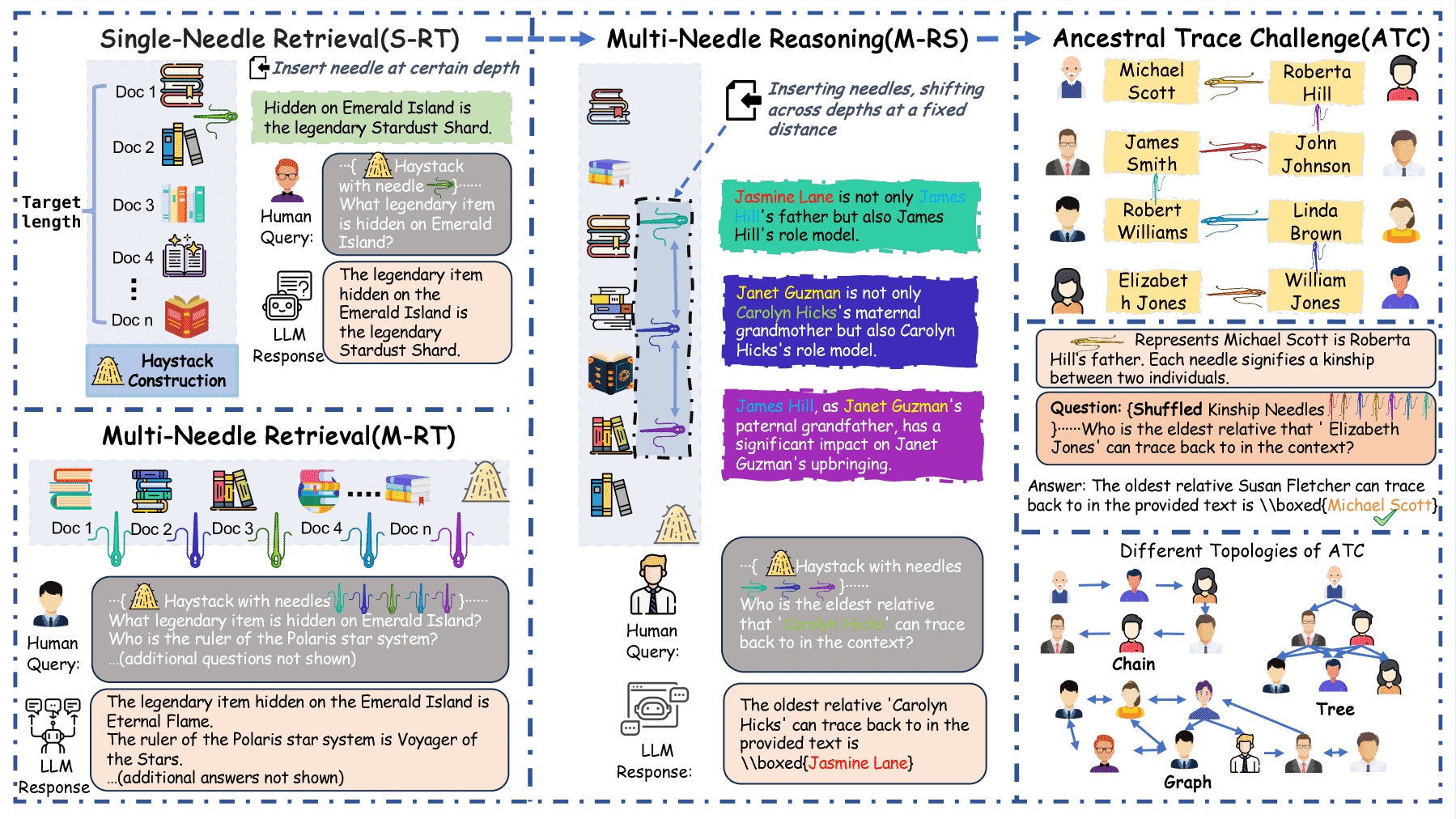
Figure 1:NeedleBench Framework. Our benchmark consists of two main categories: Information-Sparse Tasks (left two columns), which include Single-Needle Retrieval, Multi-Needle Retrieval, and Multi-Needle Reasoning with irrelevant filler content; and Information-Dense Tasks (rightmost column), specifically the Ancestral Trace Challenge, designed to eliminate irrelevant filler and require comprehensive understanding of all content.
大语言模型在处理长文本上下文时的能力,在很多实际应用中非常重要。但目前的评估方法有两个问题:
使用真实长文本会掺杂模型本身已有的知识,影响评估结果;
所以要使用真实环境中不存在的人、物等
人为添加大量无关内容来凑长度,会削弱评估的有效性。
人为添加无关内容与真实且相关的长文本是不一样的
真实的百科文章堆起来,里面的信息彼此相关,语言也通顺
只取一小段关键内容,其余大部分都用“随机维基段落”或者“Lorem ipsum”来填充
人为加入无关内容来增加上下文长度,会让评估变得“人为简单”或“不真实”,从而影响我们对模型真实长文本理解能力的判断。
为了解决这些问题,作者提出了一个新的评估框架 NeedleBench,它是一个合成(人工生成)测试集,用于测试模型在多语言长文本任务中的检索和推理能力,长度可变(比如32k、128k等)。
NeedleBench设计了两种测试场景:
信息稀疏型:大部分是干扰内容,只有少量有效信息,用来模拟简单的检索任务。
信息密集型(祖先追踪挑战):有用信息分布在整个文本中,更像复杂的推理任务。
实验发现:
一些在数学推理方面表现不错的模型(如 Deepseek-R1、OpenAI 的 o3),在这类信息密集型任务上表现不佳,哪怕上下文长度不长也会出错。
作者还发现一种叫做“思考不足(under-thinking)”的现象:模型还没找到所有关键信息就草率做出结论。
最终,NeedleBench 提供了一个更精准评估 LLM 长文本能力的工具。
1 Introduction¶
这篇论文的 1. Introduction 部分主要介绍了长文本处理能力在大语言模型(LLMs)中的重要性,以及现有评估方法的不足,并提出了一个新的评估框架 NeedleBench 来更全面地测试 LLMs 在长文本理解方面的性能。以下是该章节的关键内容总结:
1. 长文本处理能力的重要性¶
LLMs 在处理长文本方面具有广泛应用,如法律文件检索、学术研究、商业情报分析等。
为满足这些需求,现代闭源模型支持更长的上下文窗口(例如 OpenAI、Anthropic、Google 等公司的模型)。
当模型可以处理更长的文本时,评估其对文本细节的理解能力变得尤为重要。
2. 现有评估方法的局限性¶
早期方法如 Passkey 和 Needle In A Haystack (NIAH) 通过在重复结构或非重复文本中嵌入关键信息来测试长序列的信息检索能力。
但这些方法存在一定局限:
NIAH 使用个人散文填充,虽然更贴近现实但仍不足够复杂。
LongBench v2 提供了多样化的任务,但长度固定,缺乏灵活性。
Ruler 通过插入无关文本实现长度自适应,但可能导致模型只需关注少数关键点,无法真正评估其完整上下文处理能力。
模型可能依赖预训练知识,而非真正理解上下文内容。
3. NeedleBench 的提出与特点¶
NeedleBench 是一个综合性长上下文评估框架,旨在弥补现有方法的不足。
它包含两类任务:
信息稀疏型任务(如 Single-Needle、Multi-Needle Retrieval 和 Reasoning),用于评估模型在长文本中提取关键信息的能力。
信息密集型任务(如 Ancestral Trace Challenge),要求模型在整个上下文中进行持续的逻辑推理,模拟更复杂的现实场景。
支持多种上下文长度(4k 到 1000k 以上),并允许灵活插入关键信息点,以测试不同深度的检索和推理能力。
合成数据的使用减少了模型对预训练知识的依赖,迫使模型真正处理当前输入。
4. 研究发现¶
近期表现优秀的模型(如 o3 和 DeepSeek-R1)在数学基准测试中表现优异,但在 NeedleBench 的信息密集型任务中表现不佳。
这表明当前 LLMs 在处理长文本时,难以泛化其推理能力,尤其是在需要整合多部分信息的复杂任务中。
5. 论文的主要贡献¶
NeedleBench:双语长上下文评估框架,支持多种长度,覆盖信息稀疏和密集任务。
Ancestral Trace Challenge:设计了一个新的信息密集型任务,模拟现实中的复杂推理场景。
细致的评估与分析:对主流模型在不同上下文条件下的检索和推理性能进行全面评估。所有代码和数据将在发表时公开。
总结¶
本章深入分析了长文本处理能力的重要性与评估挑战,指出当前方法的不足,并提出了 NeedleBench 框架,旨在提供一个更全面、灵活、贴近现实任务的评估体系,以更准确地衡量 LLMs 在处理长文本时的真实能力。
3 Tasks and Datasets¶
本文第3章对 NeedleBench 的任务与数据集进行了详细分类和描述,主要分为信息稀疏任务和信息密集任务。以下是对该章节内容的总结:
3.1 NeedleBench 信息稀疏任务(Information-Sparse Tasks)¶
这一部分介绍了三种任务,重点测试模型在长文本中处理少量关键信息的能力:
单针检索任务(S-RT)
评估模型在长文本中查找单一关键信息的能力。
针头(needle)嵌入在文本的不同位置,测试模型是否能精准提取。
多针检索任务(M-RT)
测试模型在长文本中提取多个相关针头的能力。
模拟需要从复杂文档中提取多个数据点的现实场景。
多针推理任务(M-RS)
要求模型在提取多个信息后进行逻辑推理,综合多个片段内容来回答问题。
数据集构建¶
针头:合成的、无现实世界重叠的虚构信息(如“Emerald Island 隐藏了 Stardust Shard”)。
背景内容(haystack):
英文任务使用 PaulGrahamEssays 数据集。
中文任务使用 ChineseDomainModelingEval 数据集。
设计目的:避免模型依赖已有知识,迫使模型真正处理输入文本。
评估指标¶
使用**关键词感知的精确匹配(EM)**指标(见公式 1、2、3)。
评分机制:若模型输出中包含至少一个关键词则得满分(100分),否则得0分。
最终评分是任务类型、上下文长度、针头位置和重复次数的平均值。
3.2 NeedleBench 信息密集任务(Information-Dense Tasks)¶
这一部分提出了 Ancestral Trace Challenge(ATC),这是一种完全信息密集的任务,其中每句话都包含关键信息,模型必须完整理解和整合才能正确作答。
任务特点¶
无冗余信息:每句话都与问题相关。
针头嵌入方式:多组互相关联的事实被嵌入文档中,模型需准确追踪所有信息,才能填空。
多样性设计:
名称多样化:关键信息的名称随机化,防止记忆。
关系多样化:包括父-子、祖先-后代、双重角色等复杂关系。
任务多样化:包括寻找祖先、后代、计算关系距离等。
逻辑复杂度和上下文长度:针头数量从2到512,任务难度逐渐提高。
语言多样性:支持中英文双语评估。
评估指标¶
使用**精确匹配(EM)**指标,要求模型输出正确答案并使用指定格式(如 \boxed{…})。
采用加权平均精确率(见公式 4),权重与针头数量成正比。
引入ENL-50(Effective Needle Length),衡量模型在准确率至少为50%时的最大针头数量,反映模型的有效推理深度。
总结¶
本章全面介绍了 NeedleBench 框架下的两类任务:
信息稀疏任务:测试模型在长文本中提取少量关键信息的能力,包括单针、多针检索和推理。
信息密集任务(ATC):测试模型在完全信息密集的上下文中进行推理和追踪信息的能力,强调全面理解和逻辑整合。
评估方法强调真实信息处理能力而非记忆或预训练知识,涵盖多语言、多任务、多难度维度,为评估大语言模型的长上下文过程能力提供了系统化的基准。
4 Experiments¶
这篇论文的 第4章实验 部分主要探讨了在 信息稀疏任务(Information-Sparse Tasks) 和 信息密集任务(Information-Dense Tasks) 中,不同规模和架构的大型语言模型(LLMs)在长上下文设置下的表现。以下是该章节内容的总结:
1. 实验设计与评估范围¶
目标:评估主流开源语言模型在信息稀疏任务中的表现。
设置:
两种上下文长度:32K 和 128K tokens。
每个模型在它官方支持的最大上下文长度上进行测试。
为了公平比较,所有模型均为指令微调模型(Instruction-Tuned Models),而非基础模型。
由于计算成本较高,仅评估开源模型。例外的是,信息密集任务(ATC任务)中还包括了如 GPT-4.1、Claude-3.7、DeepSeek R1 等闭源模型。
2. 信息稀疏任务的主要结果¶
模型表现差异:
小型模型(<7B参数)在信息稀疏任务中表现较差,尤其在多点推理任务中几乎无法完成。
中型模型(7B-20B参数)在检索任务中表现尚可,但在推理任务中仍存在较大差距。
大型模型(>20B参数)如 Qwen-2.5-72B 和 Qwen-2.5-32B 表现出较强的多点推理能力,尽管最高得分仍低于50%。
Qwen-2.5 系列表现突出:
尽管模型规模小(如1.5B),但 Qwen-2.5 在信息检索任务中接近完美表现,归功于其先进的长上下文建模技术(如 Dual Chunk Attention, YaRN)。
Qwen-2.5-72B 在 Multi-Needle Reasoning 中得分最高(45.93%),但仍与理想性能有差距。
3. 多点推理任务的难点分析(4.1.2)¶
任务特点:
需要模型从上下文多个位置提取关键信息,并进行复杂的多点整合推理。
相比于简单的检索任务,推理任务对模型提出了更高要求,尤其是对长序列中信息的逻辑整合能力。
模型能力差异显著:
小模型(<20B)几乎无法完成推理任务。
大模型中,Qwen-2.5-72B 和 Gemma-3-27B 表现较好,但在128K上下文中,最高得分仍低于50%。
尽管模型规模增加有助于提升推理能力,但模型结构、训练策略和微调方法对性能也有显著影响。
4. 模型规模对推理性能的影响(4.1.3)¶
总体趋势:
模型参数规模与推理性能呈正相关,尤其是在10B-20B参数区间内提升显著。
例如,Gemma-3 系列中,27B参数模型明显优于4B和12B版本。
例外情况:
某些小模型(如 InternLM3-8B)在推理任务中表现优于部分大模型(如 Qwen-2.5-14B),说明模型结构、训练数据和微调方法对性能有重要影响。
LLaMA-3.1 系列在参数从8B增加到70B时,推理性能提升有限,表明仅靠参数规模不足以显著提升性能,还需其他优化手段。
语言差异:
英语任务普遍优于中文任务,说明大多数模型在英语语言任务上表现更好。
5. 推理任务复杂度的影响(4.1.4)¶
任务复杂度与性能负相关:
随着“针”(关键信息点)数量从2增加到5,模型性能逐步下降。
即使是强大的 Gemma-3-27B 模型,在5-Needle任务中也表现出明显性能下降。
关键挑战:
当模型需要整合的信息点越多、越分散,正确推理的难度呈指数级增长。
当前模型在整合多点信息、构建逻辑链条方面仍存在瓶颈,表明该任务仍是研究重点和难点。
总结¶
检索任务已基本解决,尤其在使用较新技术(如 DCA, YaRN)的模型中表现优异。
多点推理任务仍具挑战性,尤其在长上下文中整合多个分散信息点的能力有限。
模型规模有助于提升推理性能,但并非唯一决定因素。模型架构、数据质量和训练策略同样起着关键作用。
英语任务表现优于中文任务,提示当前模型在多语言推理能力方面仍有提升空间。
如需进一步分析特定模型或技术点(如 DCA 或 YaRN),也可以继续深入探讨。
4.1.5 Impact of Language_ Which Model Performs Better under the Bilingual Scenario_¶
这段内容主要研究了大型语言模型(LLMs)在双语和信息密集型任务中的性能表现。以下是该章节的总结:
4.1.5 语言对模型性能的影响:哪种模型在双语场景中表现更好?¶
Qwen2.5-72B 在英语和中文的 NeedleBench 128K 任务中得分最高,显示出最强的双语能力。
大多数模型在英语上的表现优于中文,这可能与数据分布、分词策略和语言建模方法有关。
例外情况包括 Qwen2.5-14B 和 GLM4-9B,它们在中文上的表现略好于英语。
此现象表明,跨语言泛化能力和多语言长上下文建模仍需进一步研究。
4.2 NeedleBench 信息密集任务¶
ATC 任务评估了模型在不同上下文长度(由“针”即事实单元数量决定)下的表现。
“推理模型”指的是那些在输出最终答案前会明确展示“思考”或中间推理过程的模型。
随着针数增加,输入上下文变长,对模型的持续检索与推理能力要求更高。
DeepSeek-R1 在整体表现上最好(总分 44.01),其次是 Claude-3.7-Sonnet 和 GPT-4.1。
小型模型(如 Qwen1.5-1.8B)得分很低,常仅个位数。
模型规模对性能有显著影响:Gemma 系列随着参数量从 4B 增加到 27B,性能稳步提升。
Gemma-3 系列在短上下文(≤2K tokens)下表现较强,不同规模模型在各自类别中取得最佳成绩。
4.2.1 高级推理模型是否能泛化到长链推理?¶
使用 ENL-50 指标衡量模型的推理深度(即模型能可靠处理的复合推理步骤数)。
小模型(≤7B)只能泛化到 2 步,中型模型(7–20B)最多 4 步,大型模型(>20B)可达到 8 步。
DeepSeek-R1 和 GPT-4.1 表现突出,分别达到 256 和 64 步。
DeepSeek-R1-Qwen 系列(通过 Distillation 得到的模型)虽然继承了 DeepSeek-R1 的推理数据,但其泛化能力较差,甚至低于小型模型,说明单纯模仿推理模式并不能实现真正泛化。
4.2.2 信息密集型长上下文任务中的“浅思考”瓶颈¶
通过人工标注 ATC 任务的错误,发现 “Under-thinking” 是最强模型的主要失败模式。
“Under-thinking” 指模型在仍有可用信息时提前终止推理,误以为无法进一步推断。
其他常见错误类型包括:
Partially Understanding:只理解了部分关键信息。
Instruction Following Errors:不遵循输出格式(常见于小模型)。
Repetitive Output:重复推理过程或输出无意义内容。
Hallucination:引入原文中没有的信息。
强模型(如 DeepSeek-R1、o3-mini)主要犯“Under-thinking”错误,弱模型则更易出现格式或逻辑错误。
表明当前 LLM 在信息密集、长上下文任务中仍面临推理深度不足和错误泛化能力弱等挑战。
总结¶
双语任务中,Qwen2.5-72B 表现最佳,但大多数模型在中文表现上仍落后。
信息密集任务中,模型性能随上下文长度增加而下降,大型模型(如 DeepSeek-R1)更具抗性。
推理深度与模型规模正相关,但仅靠 Distillation 并不能复制推理能力。
“Under-thinking” 是强模型在信息密集任务中的关键瓶颈,表明当前 LLM 仍难以有效利用长上下文中的所有信息。
这段内容揭示了当前 LLM 在信息密集型长上下文任务中的性能上限和主要挑战,为未来研究方向提供了重要线索。
5 Conclusion and Future Work¶
这一章节是论文的结论与未来工作部分,主要内容总结如下:
研究总结:作者对大语言模型(LLMs)在长文本情境下的检索与推理任务进行了全面评估。结果显示,即使是当前最先进的模型(如 Claude 3.7 Sonnet-Thinking、o3-mini 和 DeepSeek R1),在处理信息密集、多步骤的长文本任务(如 Ancestral Trace Challenge)时仍存在明显不足。
主要发现:
尽管一些长上下文模型在信息检索方面有所进步,但在需要持续多步骤推理和检索的复杂任务中表现不佳。
模型在面对信息密集且交织的文本时,常常表现出“under-thinking”现象,即过早结束任务,未能充分挖掘可用证据。
研究意义:强调了通过针对性评估来识别和弥补模型在处理复杂信息时的短板的重要性。
未来方向:
探索使用强化学习来增强模型的推理能力,减少“under-thinking”现象。
扩展 NeedleBench 基准,使其涵盖更多元化和贴近现实的信息密集场景,以更真实地反映实际任务的复杂性。
总体而言,本章总结了研究发现,指出了当前大语言模型在长上下文信息处理中的局限性,并为未来的研究和改进提供了清晰的方向。
Appendix A Evaluated Models¶
章节总结:Appendix A Evaluated Models
本附录列出了在研究中评估的一系列大型语言模型(LLMs)及其各自的最大上下文长度。评估覆盖了多个模型系列,包括 Qwen、ChatGLM、InternLM、LLaMA、Mistral、Zephyr、Gemma、DeepSeek、OpenAI(如 GPT-4o)以及 Claude 等主流模型。不同模型的上下文窗口长度从 32K 到 1M tokens 不等。
研究使用 LMDeploy 和 vLLM 作为推理加速工具,并在所有模型中默认采用 温度为 0 的贪婪解码(greedy decoding),除非另有说明。
核心信息总结:
涉及多个主流模型系列;
上下文长度范围广泛,从 32K 到 1M tokens;
使用工具:LMDeploy 和 vLLM;
默认解码方式:温度为 0 的贪婪解码。
Appendix B NeedleBench Prompt Examples¶
本节总结了《NeedleBench》论文附录B中关于不同任务的提示(Prompt)示例,这些示例展示了如何评估大型语言模型(LLMs)在信息密集型上下文中的检索和推理能力。具体包括以下四类任务的示例总结:
B.1 Single-Needle Retrieval(单目标检索)¶
任务描述:在一段长文本中定位一个关键信息(即“needle”),并根据该信息回答问题。
示例结构:
** Needle 在开头**:关键信息出现在文本开头,例如“隐藏在翡翠岛上的传奇物品是星尘碎片”。
** Needle 在中间**:关键信息出现在文本中间,其他部分由重复内容(如Paul Graham的散文)填充。
** Needle 在结尾**:关键信息出现在文本末尾,测试模型对长文本末尾信息的检索能力。
目的:评估模型在不同位置(开始、中间、结尾)检索关键信息的能力。
B.2 Multi-Needle Retrieval(多目标检索)¶
任务描述:从长文本中检索多个目标信息(“needles”)。
示例结构:提供多个分散在文本中的关键信息项,例如不同岛屿上的传奇物品和不同星系的统治者。
要求:依次回答多个问题,每个问题对应一个具体的“needle”。
目的:测试模型在信息密集环境中提取和组织多个关键点的能力。
B.3 Multi-Needle Reasoning(多目标推理)¶
任务描述:在多个分散的关键信息基础上进行逻辑推理,找出最年长的祖先。
示例结构:给出多个亲属关系的描述,例如“Jasmine是James的父亲和榜样”,“Janet是Carolyn的祖母和榜样”等,模型需推断出Carolyn最年长的亲属。
要求:结合多个信息片段进行逻辑推理,最终输出一个经过推理的答案。
目的:测试模型在信息密集型文本中进行复杂推理的能力,例如家庭关系推理。
B.4 Ancestral Trace Challenge(祖先追溯挑战)¶
任务描述:进行多步骤推理,追踪家族关系,找出最年长的祖先。
示例结构:给出混杂的家族关系描述(如“Wyatt是Maria的孩子”,“Emily是Maria的祖父”,“Joseph是Emily的祖父”),模型需通过多步推理确定Wyatt的最年长祖先。
示例输出:展示了正确推理过程和最终答案(Joseph Taylor)。
目的:测试模型在多步逻辑推理和复杂关系链中的表现。
总结¶
本节展示了NeedleBench框架中四种核心任务的提示示例,分别测试了LLMs在单目标检索、多目标检索、多目标推理和多步家族关系推理中的能力。这些任务通过在信息密集文本中放置“needle”或“needles”的方式,评估模型对关键信息的提取、组织和推理能力,是评估LLM在复杂文本理解能力的重要方法。
Appendix C Error Analysis Examples¶
这篇论文的附录C“Error Analysis Examples”详细分析了在Ancestral Trace Challenge(ATC)任务中,大型语言模型(LLMs)出现的几种典型错误类型,并提供了具体的例子。总结如下:
C.1 Under-thinking Error(思考不足错误)¶
定义:模型在推理过程中过早停止,未能继续挖掘潜在的线索,因此未能找到最远的祖先。
例子:在GPT-4.1模型中,尽管还有信息可以继续推理,但模型在找到Eileen Green后就终止了推理,错误地认为没有更早的祖先。
影响:导致结果不完整或错误。
C.2 Instruction Following Error(指令遵循错误)¶
定义:模型的推理过程是正确的,但未遵循任务中要求的输出格式(如未使用\boxed{}格式)。
例子:Qwen1.5-1.8B-Chat模型正确地找到了最远祖先,但没有在答案周围加上\boxed{},导致答案格式错误。
影响:答案虽然逻辑正确,但不符合任务要求,被视为无效。
C.3 Partial Understanding Error(部分理解错误)¶
定义:模型只识别了部分信息,忽略了其他关键关系,导致答案不完整。
例子:InternLM3-8B模型在处理“Dan Newton is more than just a mother”这句话时,仅将其视为导师关系,忽略了其中的祖母关系,导致遗漏了更远的祖先。
影响:答案部分正确,但忽略了关键信息,仍不完整。
C.4 Repetitive Output Error(重复输出错误)¶
定义:模型陷入重复推理的循环,不断重复相同的结论,无法得出最终答案。
例子:Deepseek-R1-Distill-Qwen-7B模型在分析家族关系链时反复重述相同的内容,无法继续推理到最终祖先。
影响:推理过程停滞,无法完成任务。
C.5 Hallucination Error(幻觉错误)¶
定义:模型在推理中引入了原始文本中并不存在的关系或信息,导致错误的结论。
例子:Deepseek-R1-Distill-Qwen-7B模型将“Carol Barron is not only Kathy Marshall’s maternal grandfather”误读为“Carol是George Estes的母亲”,导致错误推断出Carol是Nancy的祖先。
影响:生成错误关系,答案完全错误。
总结¶
该附录通过多个实际案例,系统地展示了LLMs在进行多跳推理任务时可能表现出的五类典型错误,分别是:
思考不足:过早停止推理。
未遵循指令:答案格式错误。
部分理解:遗漏关键信息。
重复输出:陷入循环无法前进。
幻觉错误:生成不存在的关系。
这些错误分析有助于理解LLMs在信息密集型推理任务中的局限性,并为模型改进提供了方向。