2508.09736_M3-Agent❇️: Seeing, Listening, Remembering, and Reasoning: A Multimodal Agent with Long-Term Memory¶
引用: 0(2025-08-18)
组织:
1ByteDance Seed,
2Zhejiang University,
3Shanghai Jiao Tong University
总结¶
标签
tag: prompt
tag: 多模态智能体
tag: 记忆memory
M3-Agent
简介
【定义】一个具备长期记忆的多模态智能体框架,能够持续感知、构建记忆并推理执行复杂任务。
能够自主进行多轮、迭代式的推理,并从记忆中检索相关信息以完成任务
能够像人类一样处理实时视觉和听觉输入,并据此构建和更新长期记忆
记忆以以实体为中心、多模态格式组织
架构包含两个并行过程:
记忆(Memorization):实时处理多模态输入(视频和音频),构建和更新长期记忆中的事件(episodic memory)和概念知识(semantic memory)。
控制(Control):通过推理和检索长期记忆,执行用户指令,完成任务。
两大挑战:
无限信息处理:
传统方法处理的是有限时长的离线视频,而 M3-Agent 能够在线处理任意长时间的多模态流媒体输入,更接近人类长期记忆的形成方式。
世界知识构建:
传统视频描述侧重于低级视觉细节,忽视高级世界知识(如人物身份、实体属性)。
M3-Agent 通过实体中心的记忆结构,逐步构建丰富的多模态实体表示,从而实现上下文一致的记忆和推理。
长视频问答基准测试集 M3-Bench
首个用于评估记忆与推理能力的长视频问答基准
该基准包含两个数据集:
M3-Bench-robot:100 个从机器人视角录制的现实世界视频;
M3-Bench-web:929 个来自网络的多样化场景视频。
多模态智能体需要具备三种核心能力:
通过多模态传感器持续感知世界
将经验存储在长期记忆中,并逐步构建环境知识
基于积累的记忆进行推理,指导其行动
评估 M3-Agent 性能的三类基线方法
Socratic Models(苏格拉底模型)
在线视频理解方法(Online Video Understanding Methods)
基于代理的方法(Agent Methods)
应用前景:
智能助手:能够记住用户的偏好和习惯,提供更加个性化的服务。
智能监控:能够持续观察环境,识别异常事件,并进行长期跟踪。
教育辅助:能够记住学生的学习情况,提供个性化的学习建议。
医疗诊断:能够记住患者的病史和症状,辅助医生进行诊断。
自动驾驶:能够记住道路环境和交通规则,提高驾驶安全性。
机器人控制:能够记住环境布局和任务要求,提高机器人的自主性。
关键技术:
双线程认知架构
由记忆化工作流和控制工作流组成,实现持续学习和及时响应的平衡。
双重记忆系统
包括情节记忆和语义记忆,能够同时记住具体事件和提炼抽象知识。
实体中心的记忆组织
为每个实体建立专门的”档案夹”,确保认知的一致性和完整性。
多轮深度推理机制
通过多轮搜索和推理,解决复杂问题。
实体中心的多模态记忆图谱
以图谱的形式组织多模态信息,支持高效的记忆检索和推理。
未来发展方向
多模态信息处理能力的扩展
除了视觉和听觉外,还可以考虑加入触觉、嗅觉等更多模态的信息处理能力。
记忆系统的效率优化
进一步优化记忆的存储和检索效率,提高系统的实时性能。
推理能力的增强
增强复杂推理能力,支持更加抽象和复杂的问题解决。
多智能体协作
研究多个M3-Agent之间的协作机制,实现更加复杂的任务。
自主学习能力
增强系统的自主学习能力,减少对人工干预的依赖。
Abstract¶
本文提出了一种新颖的多模态智能体框架 M3-Agent,具备长期记忆能力。M3-Agent 能够像人类一样处理实时视觉和听觉输入,并据此构建和更新长期记忆。除了情景记忆(episodic memory),它还具备语义记忆(semantic memory),能够随时间积累世界知识。其记忆以以实体为中心、多模态格式组织,有助于对环境进行更深入、一致的理解。
在给定任务指令时,M3-Agent 能够自主进行多轮、迭代式的推理,并从记忆中检索相关信息以完成任务。为评估多模态智能体在记忆有效性和基于记忆的推理能力方面的表现,作者提出了一个新的长视频问答基准测试集 M3-Bench。该基准包含两个数据集:
M3-Bench-robot:100 个从机器人视角录制的现实世界视频;
M3-Bench-web:929 个来自网络的多样化场景视频。
研究者对这些视频进行了问答对标注,用于测试智能体在人类理解、通用知识提取和跨模态推理等关键能力上的表现。
实验结果显示,M3-Agent 通过强化学习训练,在 M3-Bench-robot、M3-Bench-web 和 VideoMME-long 三个基准上,分别比最强的基线模型(使用 Gemini-1.5-pro 和 GPT-4o 的提示式智能体)高出 6.7%、7.7% 和 5.3% 的准确率。
本研究推动了多模态智能体向更接近人类的长期记忆能力发展,并提供了其实际设计的重要见解。
总结重点:
M3-Agent 是首个具备长期记忆的多模态智能体;
引入了语义记忆与情景记忆的结合;
M3-Bench 是首个用于评估记忆与推理能力的长视频问答基准;
M3-Agent 在多个基准上显著优于现有方法;
研究具有实际应用价值,推动多模态智能体的发展方向。
1 Introduction¶
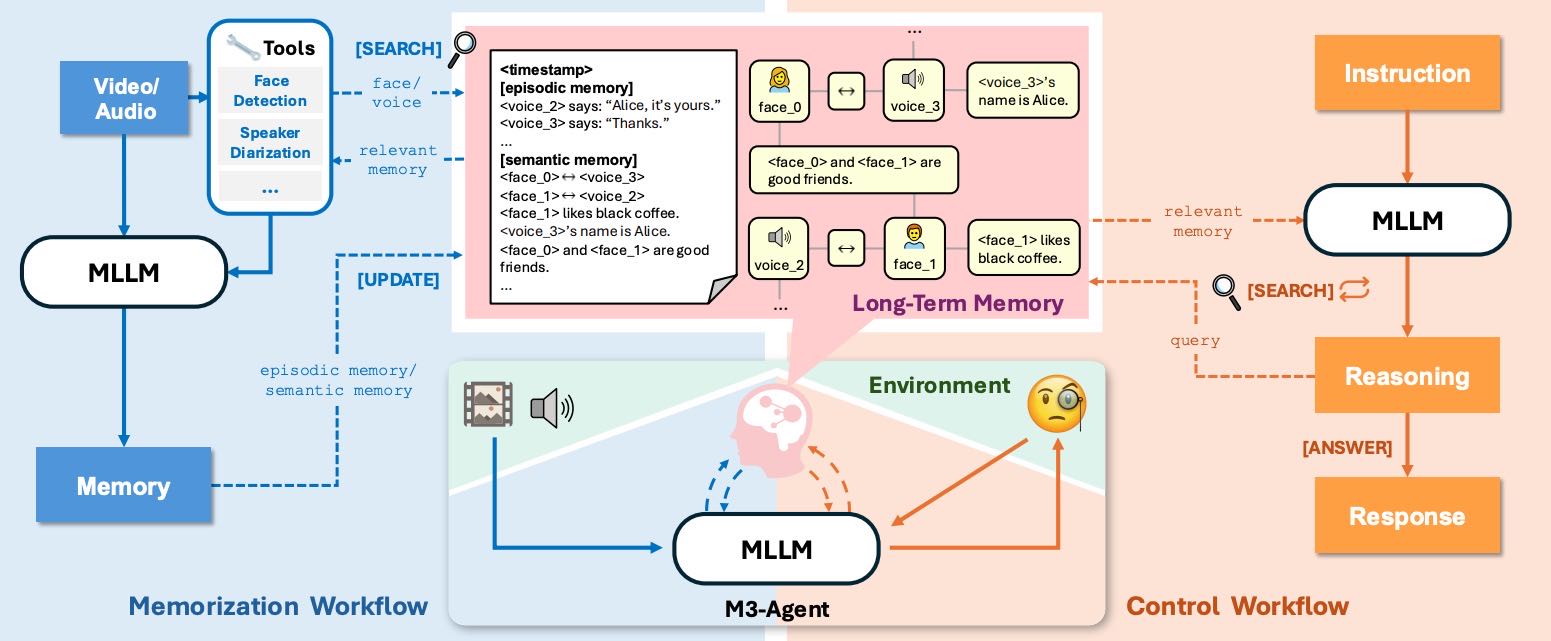
Figure 1:Architecture of M3-Agent, comprising a multimodal large language model (MLLM) and a multimodal long-term memory. The system consists of two parallel processes: memorization and control. During memorization, M3-Agent processes video and audio streams online to generate episodic and semantic memory. During control, it executes instructions by iteratively reasoning and retrieving from long-term memory. The long-term memory is structured as a multimodal graph.
本节介绍了 M3-Agent——一种具备长期记忆能力的多模态智能体框架。设想一个未来场景:家庭机器人通过日常经验自动学习家庭规则,无需用户明确指令,而是通过长期交互了解用户习惯并做出个性化响应。例如,它能记住你早上喜欢喝咖啡,并在不询问的情况下为你准备一杯。
要实现这一目标,多模态智能体需要具备三种核心能力:
通过多模态传感器持续感知世界
将经验存储在长期记忆中,并逐步构建环境知识
基于积累的记忆进行推理,指导其行动
为实现这些能力,作者提出了 M3-Agent,其架构包含两个并行过程:
记忆(Memorization):实时处理多模态输入(视频和音频),构建和更新长期记忆中的事件(episodic memory)和概念知识(semantic memory)。
控制(Control):通过推理和检索长期记忆,执行用户指令,完成任务。
记忆结构解析¶
M3-Agent 生成两种类型的记忆,类比人类认知系统:
Episodic Memory(情节记忆):记录具体的事件,如“Alice 早上拿咖啡说她离不开它”,“Alice 把空瓶子扔进绿色垃圾桶”。
Semantic Memory(语义记忆):提取一般性知识,如“Alice 早上喜欢喝咖啡”,“绿色垃圾桶用于回收”。
这些记忆存储于多模态长期记忆中,支持图像、语音和文本信息。记忆以实体为中心组织,例如一个人的面部、声音和相关知识通过图结构连接,便于信息整合与推理。
控制过程¶
在控制阶段,M3-Agent 不采用传统的单次检索增强生成(RAG),而是通过强化学习实现多轮推理和迭代记忆检索,从而提升任务完成率。这使得智能体能更灵活地处理复杂指令。
关键挑战¶
M3-Agent 面临两大挑战:
无限信息处理:传统方法处理的是有限时长的离线视频,而 M3-Agent 能够在线处理任意长时间的多模态流媒体输入,更接近人类长期记忆的形成方式。
世界知识构建:传统视频描述侧重于低级视觉细节,忽视高级世界知识(如人物身份、实体属性)。M3-Agent 通过实体中心的记忆结构,逐步构建丰富的多模态实体表示,从而实现上下文一致的记忆和推理。
M3-Bench 评估基准¶
为了评估 M3-Agent 的记忆与推理能力,作者提出了一个新的长视频问答(LVQA)基准 M3-Bench。当前的 LVQA 基准主要关注视觉理解(如动作识别和时空感知),而 M3-Bench 更关注依赖长期记忆的高级认知能力,如理解人类行为、提取通用知识、跨模态推理等。
M3-Bench 包括两个数据集来源:
M3-Bench-robot:100 个从机器人视角录制的真实世界视频
M3-Bench-web:929 个来自 YouTube 的广泛内容视频
定义了五种问题类型(见表 1),共标注了 1,344 对问答(robot)和 5,037 对问答(web)。
实验与结果¶
实验在 M3-Bench-robot、M3-Bench-web 和 VideoMME-long 上进行。结果显示:
M3-Agent(使用强化学习训练)在所有三个基准上均优于所有基线模型。
相比最强大的基线模型 Gemini-GPT4o-Hybrid,M3-Agent 的准确率分别提升了 6.7%、7.7% 和 5.3%。
语义记忆对性能影响显著:移除后准确率分别下降 17.1%、19.2% 和 13.1%。
强化学习训练、多轮指令和推理模式对控制性能至关重要,对准确率提升分别为 10.0%、5.8% ~ 10.5% 和 8.8% ~ 11.7%。
主要贡献¶
本节总结了论文的主要贡献如下:
提出 M3-Agent:一个具备长期记忆的多模态智能体框架,能够持续感知、构建记忆并推理执行复杂任务。
构建 M3-Bench:一个评估多模态智能体记忆与推理能力的新型长视频问答基准。
实验证明:M3-Agent 在多个基准上优于基于商业模型提示的智能体,展示了其优越性。
3 Datasets¶
本节介绍了 M3-Bench,这是一个用于评估多模态智能体在长期记忆背景下进行推理能力的长视频问答(LVQA)数据集。每个数据样本包含一个模拟智能体感知输入的长视频,以及一组与之相关的开放式问答对。该数据集分为两个子集:
M3-Bench-robot:包含100个真实世界视频,从机器人的第一视角录制。
M3-Bench-web:包含929个从网络来源获取的视频,覆盖更广泛的内容和场景。
M3-Bench 的特点包括:
长时长、真实世界视频:涵盖与多模态智能体部署相关的多样化场景;
具有挑战性的问答:问题并非仅基于浅层感知理解,而是要求在长期上下文中进行复杂推理。
表1:M3-Bench中不同问题类型的解释及其对应的示例
多细节推理(Multi-detail Reasoning)
需要从视频中多个片段中提取并整合多个信息。
例如:视频中展示的五个物品中,哪个集合的起始价格最高?代理需要识别并回忆五个片段中的起始价格,然后比较以确定最高价格。
多跳推理(Multi-hop Reasoning)
需要跨不同片段逐步推理得出结论。
例如:在访问“定茶”之后,他们去了哪家珍珠奶茶店?代理需要先找到“定茶”的访问片段,然后跟踪后续片段以确定下一家奶茶店。
跨模态推理(Cross-modal Reasoning)
需要结合多种模态(如视觉和音频)进行推理。
例如:(Bob向机器人展示一个红色文件夹并说“机密文件应该放在这里”,然后展示一个白色文件夹并说“普通文件应该放在这里”)
机密文件应放在哪个文件夹?代理需结合视觉线索(文件夹颜色)与对话内容推断正确答案。
人类理解(Human Understanding)
涉及对人类相关属性(如身份、情绪、个性或关系)的推理。
例如:Lucas擅长烹饪吗?虽然视频中没有直接说明,但代理需通过多个烹饪场景中Lucas的行为整合信息,以推断其技能水平。
通用知识提取(General Knowledge Extraction)
评估代理是否可以从特定事件中提取通用知识。
例如:(视频中有人将不同杂货分类并放入冰箱的不同层)哪一层适合存放蔬菜?代理需从观察中识别典型存储规则,从而正确回答。
3.1 M3-Bench-robot¶
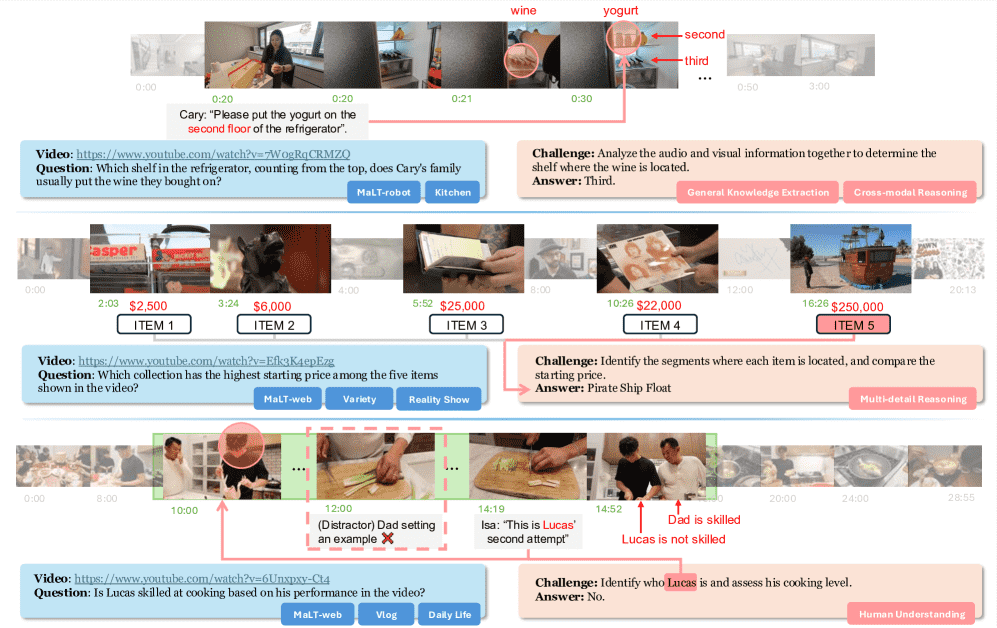
Figure 2 presents examples from M3-Bench. The overall statistics of M3-Bench is shown in Figure 3. Table 2 provides a comparative analysis with existing LVQA benchmarks. The remainder of this section elaborates on the data collection and annotation procedures for M3-Bench-robot and M3-Bench-web, respectively.
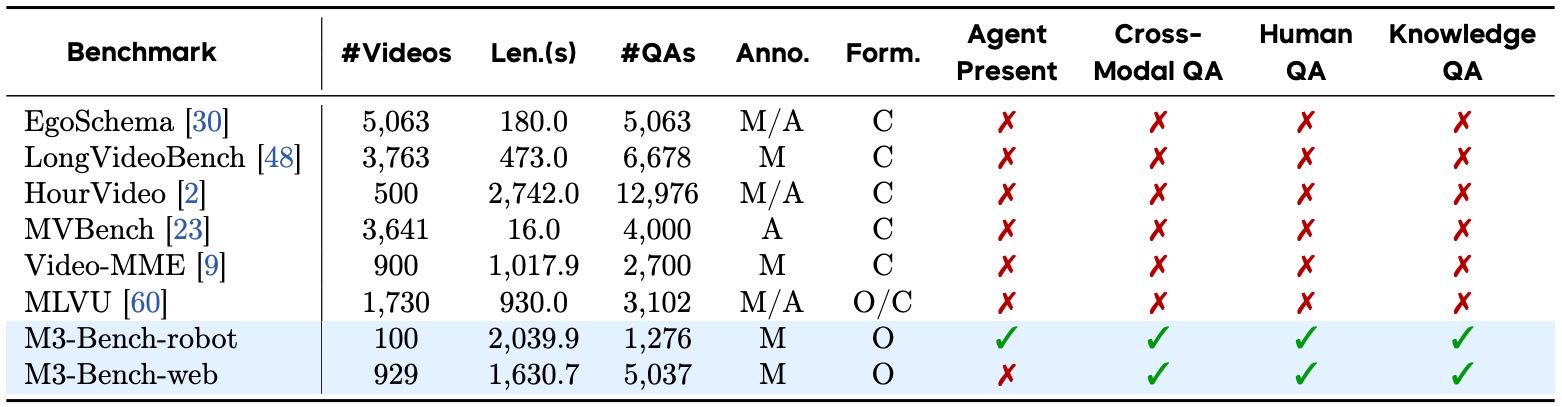
Table 2:Comparison of M3-Bench with existing long-video question answering benchmarks across key dimensions: number of videos (#Videos), average video length in seconds (Len.), number of QA pairs (#QAs), annotation method (Anno., M/A denote manually/automatic), question format (Form., O/C indicate open-ended/close-ended), presence of an agent in the video (Agent Present), inclusion of cross-modal reasoning questions (Cross-Modal QA), human understanding questions (Human QA), and questions about general knowledge (Knowledge QA).
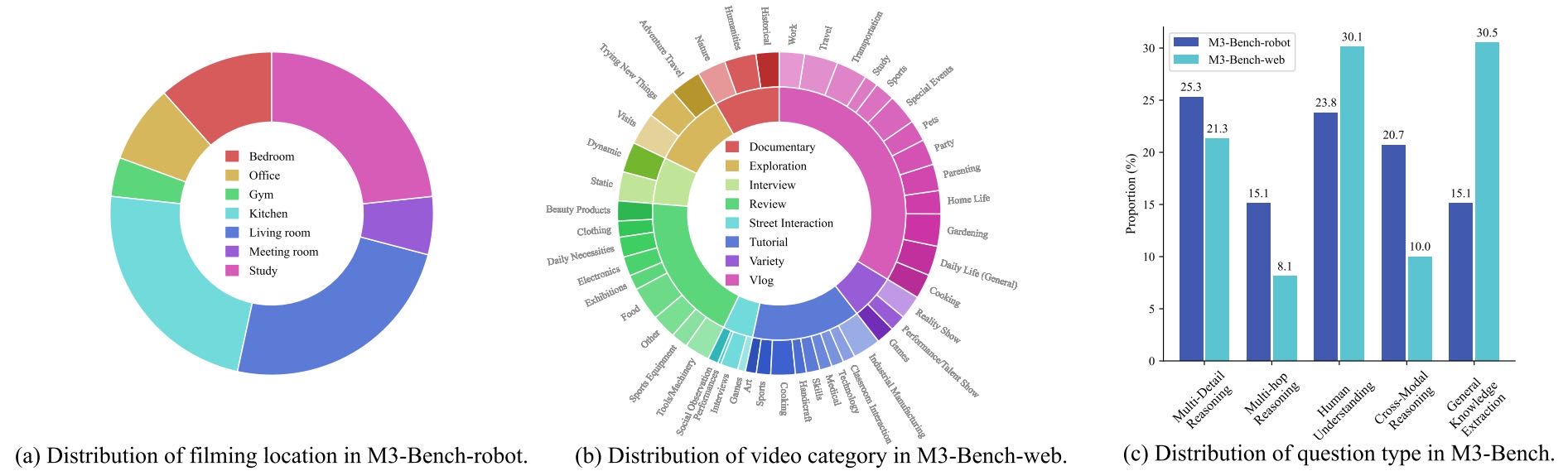
Figure 3 Statistical overview of M3-Bench benchmark. Each question may correspond to multiple question types.
M3-Bench-robot 的设计目的是通过机器人视角的视频,评估多模态智能体在长期记忆维护与推理方面的能力。
脚本设计(Scripts Design)¶
视频脚本设计涵盖七个日常场景:客厅、厨房、卧室、书房、办公室、会议室和健身房;
每个脚本包括 1~4 个“人机互动”事件,且每个剧本需至少包含 70 个事件,确保视频时长不少于 30 分钟;
问题可以出现在事件序列中的任意位置,或在剧终,部分问题依赖后续事件来回答;
每个问题必须与表 1 中列出的至少一种问题类型对应。
视频拍摄(Video Filming)¶
由于实际机器人拍摄成本高、硬件限制多,采用人类演员模拟机器人行为;
使用头戴式设备模拟机器人视角拍摄视频;
拍摄涉及 67 名演员和 51 个不同地点,以提升多样性;
每个视频录制两种音频:一种为头戴设备录制的环境音,一种为演员佩戴的领夹麦克风录制的高质量语音。
标注(Annotations)¶
由标注人员从脚本中提取问答对;
根据实际拍摄内容,对脚本问题进行筛选、修改或删除;
每个问题必须指定提问时间戳,且不能早于机器人响应的时刻;
每个视频至少包含 12 个问答对;
标注人员还需添加新问题,以覆盖表 1 中的所有问题类型;
另外,生成字幕,包括对话的开始和结束时间、说话人身份及转录内容。
3.2 M3-Bench-web¶
为提升视频多样性,M3-Bench-web 通过从 YouTube 等平台收集视频构建。
视频收集(Video Collection)¶
采用问题驱动方式选取视频,要求视频能支持至少 5 个与表 1 中问题类型相关的问题;
提供视频类别列表,要求标注人员从每个类别中最多提交 20 个视频;
最终共涵盖 46 种视频类型,如图 3 所示。
问答标注(QA Annotations)¶
由视频收集者生成至少 5 个问答对;
每个问题必须对应表 1 中至少一种问题类型;
所有问题设置在视频结尾时间戳;
要求问题具体、客观、答案唯一,避免歧义或基于主观理解的提问。
3.3 自动评估(Automatic Evaluation)¶
使用 GPT-4o 作为 M3-Bench 的自动评估器,通过比较生成答案与参考答案的匹配度判断是否正确;
构建一个由 100 个样本组成的测试集,每个样本包含一个问题、参考答案和模型生成答案;
三位作者独立评估生成答案的正确性,与 GPT-4o 的判断进行对比;
结果显示,GPT-4o 与人类标注者的一致性达到 96%,验证了其作为自动评估工具的有效性。
总结¶
M3-Bench 是一个面向多模态智能体的长视频问答数据集,强调长期记忆建模与推理能力。它通过 M3-Bench-robot 和 M3-Bench-web 两个子集,覆盖了从机器人视角到网络来源视频的多种场景。数据集在视频多样性、问题挑战性和评估可靠性方面具有显著优势,为研究多模态智能体的长期推理能力提供了坚实基础。
4 Approach¶
4.1 长期记忆¶

Table 3 Attributes and their descriptions for a memory node.
M3-Agent 的长期记忆模块以一个外部数据库的形式实现,用于以结构化、多模态的形式(文本、图像、音频)存储信息。具体来说,记忆条目被组织为一个记忆图(memory graph),其中每个节点代表一个独立的记忆项。每个节点包含以下内容:
id:节点的唯一标识符。
type:节点的模态类型(如文本、图像、音频)。
content:节点的原始内容(如纯文本、base64图像、base64音频)。
embedding:节点内容的向量表示,用于相似性检索。
weight:表示该节点信心程度的数值。
extra_data:包含其他元数据(如时间戳)的 JSON 对象。
节点通过无向边连接,表示记忆项之间的逻辑关系。这些边有助于在检索时找到相关记忆。
在构建记忆时,M3-Agent通过增量方式添加新的文本、图像或音频节点,并连接它们,或更新现有节点的内容和权重。为了避免冲突,M3-Agent采用基于权重的投票机制:被频繁强化的记忆条目权重更高,能够覆盖权重较低的冲突条目。这种机制确保了记忆图的稳健性和一致性。
此外,M3-Agent 提供了一套搜索工具,用于根据具体需求检索相关记忆。目前,支持两种级别的搜索机制:
search_node:接受查询并返回最相关的前k个节点,支持多模态查询,支持指定模态的查询。search_clip:针对文本查询检索前k个相关视频片段,涵盖 情景记忆 和 语义记忆
4.2 记忆(Memorization)¶
M3-Agent 通过以片段为单位处理输入的视频流,生成两种类型的记忆:
情景记忆(Episodic Memory):捕捉视频中的视觉和听觉内容。
语义记忆(Semantic Memory):提取一般知识(如角色身份、属性、关系和世界知识),以丰富记忆内容并增强控制过程的检索效果。
一个关键挑战是在长时间跨度内保持核心概念(如主要角色和物体)的一致表示。为了解决这一问题,M3-Agent 使用外部工具(如人脸识别和说话人识别)从视频片段中提取角色的面部和声音,并将其与长期记忆中的节点进行关联或创建新节点。返回的标识符(如 face_id 或 voice_id)作为角色的持久引用。
此外,M3-Agent 通过构建跨模态关系(例如将同一角色的面部和声音节点连接起来),进一步提升记忆的一致性。这些关系以图中的边的形式存储。
在生成记忆时,M3-Agent 输出文本形式的条目,每个条目作为图中的一个文本节点存储。节点之间的语义关系则以边的形式表示。对于冲突信息,M3-Agent 通过权重投票机制自动解决,确保最终记忆的准确性。
4.3 控制(Control)¶
当接收到指令时,M3-Agent 启动控制过程。该过程通过多轮推理和调用搜索函数从长期记忆中检索相关信息,最多持续 H 轮。
控制过程的核心是一个策略模型 πθ,根据当前问题 q 和长期记忆 ℳ 执行多轮推理。整个过程通过一个算法(Algorithm 1)实现,包括:
系统提示(System Prompt):在每个对话的开始定义任务目标。
指令提示(Instruction Prompt):在每轮(最后一轮除外)提供问题和详细指导。
最后一轮提示(Last-Round Prompt):在最终一轮提示模型提供最终答案。
算法流程包括:
初始化轨迹,包含系统提示和指令提示。
每轮迭代中,模型生成一个动作(如搜索或回答)。
如果动作是“搜索”,模型会调用相应的搜索函数(如
search_node或search_clip)。将搜索结果和新的提示添加到轨迹中,继续下一轮推理。
最终返回完整的轨迹和答案。
4.4 训练¶
M3-Agent 通过 强化学习(Reinforcement Learning) 进行训练。虽然记忆和控制由同一个模型处理,但为了性能优化,实际使用两个独立模型进行训练:
记忆模型:基于 Qwen2.5-Omni,具备强大的多模态理解能力。
控制模型:基于 Qwen3,具备强大的推理能力。
训练数据来源于作者内部的视频数据集,包含 500 个长视频,总计 26,943 个 30 秒片段和 2,736 个问答对。
记忆训练¶
采用**模仿学习(Imitation Learning)**训练记忆模型。
通过一个三阶段的合成标注过程生成高质量的记忆注释:
情景记忆合成:结合 Gemini-1.5-Pro 和 GPT-4o 进行混合标注。
身份等价检测:自动构建面部与声音的全局映射关系。
语义记忆合成:通过模板提取语义信息。
最终合成 10,952 个样本,其中 10,752 用于训练,200 用于验证。
控制训练¶
使用 DAPO(Decentralized Advantage Policy Optimization) 算法训练策略模型 πθ。
每个视频生成对应的长期记忆,用于问答任务。
通过 GPT-4o 评估器评估模型生成的答案质量。
计算奖励和优势函数,通过策略梯度优化模型参数。
总结:
M3-Agent 通过长期记忆图、多模态记忆生成机制和基于强化学习的控制策略,实现了一个能够观看、聆听、记忆和推理的多模态智能代理。该方法在长期记忆的一致性、多模态信息融合和控制逻辑的优化方面具有显著优势。
5 Experiments¶
5.1 基线方法(Baselines)¶
本节介绍了用于评估 M3-Agent 性能的三类基线方法:
Socratic Models(苏格拉底模型)
该基线采用 Socratic Models 框架,通过多模态模型对 30 秒视频片段进行描述,作为长期记忆存储。
使用 LLM 进行 检索增强生成(RAG):首先调用
search_clip函数检索与问题相关的记忆,然后基于检索内容生成回答。重点模型:
Gemini-1.5-Pro:处理完整的 30 秒视频。
GPT-4o:由于不支持音频,使用 0.5 fps 的视频帧和 ASR 文本。
Qwen2.5-Omni-7b:开源多模态模型,支持视觉和音频输入。
Qwen2.5-VL-7b:在视觉语言任务中表现优秀,使用视频帧(0.5 fps)和 ASR 文本。
所有方法使用 GPT-4o 作为 RAG 的 LLM,并通过提示工程优化性能。
在线视频理解方法(Online Video Understanding Methods)
比较了以下三种框架:
MovieChat:使用滑动窗口提取帧特征,存储在混合记忆中,LLM 基于此记忆进行问答。
MA-LMM:在线处理视频帧,包含特征提取(1 fps)、时间建模(100 帧输入)和 LLM 解码。
Flash-VStream:采用异步两阶段流水线:视频帧压缩(1 fps),压缩特征上进行 LLM 问答。
使用其官方预训练权重和默认配置。
基于代理的方法(Agent Methods)
比较了两种基于 Gemini 的代理方法:
Gemini-Agent:Gemini-1.5-Pro 负责记忆访问和控制过程。
Gemini-GPT4o-Hybrid:Gemini 负责记忆访问,GPT-4o 负责控制过程。
所有代理方法设置最大交互轮次为 5,
search_clip返回最多 2 个相关记忆片段。
5.2 数据集与评估(Dataset and Evaluation)¶
评估模型在以下数据集上的表现:
M3-Bench-robot:机器人相关问答任务。
M3-Bench-web:网页视频理解任务。
VideoMME-long:长视频理解基准,用于测试方法的通用性。
评估指标包括多种问答类型:
多细节推理(MD)、多跳推理(MH)、跨模态推理(CM)、人类理解(HU)、常识知识提取(GK)。
5.3 主要结果(Main Results)¶
M3-Agent 在所有基准任务上均优于所有基线方法。
性能对比:
M3-Bench-robot:M3-Agent 比最强基线 MA-LMM 提高 6.3%。
M3-Bench-web:比最强基线 Gemini-GPT4o-Hybrid 提高 7.7%。
VideoMME-long:提高 5.3%。
在特定任务上的优势:
人类理解(HU) 和 跨模态推理(CM) 表现尤其突出。
M3-Agent 在这些任务上分别比最强基线提高 4.2% 和 8.5%(M3-Bench-robot),以及 15.5% 和 6.7%(M3-Bench-web)。
总结:M3-Agent 在跨模态信息整合、角色一致性维护、人类理解能力方面表现优异。
5.4 消融实验(Ablation Study)¶
记忆生成部分(Memorization)¶
memory-7b-sft(M3-Agent) 在所有任务中表现最佳。
消融实验表明:
使用 Gemini 生成记忆(memory-gemini-prompt)性能下降 2.0%~9.1%。
仅用提示生成记忆(memory-7b-prompt)性能更差,下降 5.4%~11.0%。
关键组件(如角色等价性、语义记忆)缺失会显著降低性能。
控制过程部分(Control)¶
控制模型的训练方式(DAPO vs GRPO)对性能有明显影响:DAPO 优于 GRPO。
模型规模:随着模型增大,性能提升显著。
关键设计:
跨轮次指令(inter-turn instruction) 对性能影响显著,移除后准确率下降 5.8%~10.5%。
推理能力 也是关键,移除后性能下降 8.8%~11.7%。
结论:M3-Agent 的控制模型(control-32b-rl)在多任务中表现最优。
5.5 案例研究(Case Study)¶
记忆生成示例¶
memory-7b-sft 生成的Episodic & Semantic memories 比 memory-gemini-prompt 更详细、更准确。
优势体现在:
更丰富的场景描述、角色行为与对话。
更好的角色身份一致性识别。
主动提取语义知识。
控制过程示例¶
展示了 M3-Agent 如何通过多轮交互完成一个复杂推理问题:”Tomasz 是一个有丰富想象力的人,还是缺乏想象力?”
关键步骤:
第一轮:搜索角色 ID。
第二轮:直接查询角色想象力相关记忆。
第三轮:根据角色身份推理出更具体的查询。
第四轮:结合语义记忆生成最终答案。
M3-Bench 难点分析¶
两大挑战:
细粒度推理:需要从记忆中提取精确信息(如“Emma 的帽子应该挂在哪一个衣帽架上?”)。
需要引入注意力机制,进行选择性记忆。
空间推理:理解空间布局与变化(如“机器人在哪里拿零食?”)。
文本记忆在空间信息存储上较弱,建议加入视觉记忆(如截图)。
总结¶
本章通过多种基线对比、多个数据集的评估、消融实验及案例研究,全面验证了 M3-Agent 在多模态长期记忆建模与推理方面的优越性。实验结果表明,M3-Agent 在跨模态理解、角色一致性、复杂推理任务中表现显著优于现有方法,尤其在人类理解和空间推理等挑战性任务中展现出强大的适应能力。
6 Conclusion and Future Work¶
本文介绍了M3-Agent,这是一个配备了长期记忆的多模态智能体框架。M3-Agent 能够实时感知视频和音频流,构建情景记忆和语义记忆,从而实现世界知识的积累,并在长时间内保持丰富上下文信息的记忆一致性。在执行任务时,M3-Agent 能够自主推理并从记忆中检索相关信息,从而提高任务完成的效率。
为了评估记忆效果和推理能力,作者开发了M3-Bench,这是一个LVQA(长视频问答)基准测试,其特点是包含真实环境中从机器人视角拍摄的视频,并提出具有挑战性的问题,这些问题围绕人类理解、知识提取和跨模态推理,紧密贴合现实需求。
我们对 M3-Agent 与多种基线方法进行了比较评估,包括苏格拉底模型(Socratic models)、在线视频理解方法,以及通过提示方式实现 M3-Agent 的闭源模型。实验结果表明,在 M3-Bench-robot、M3-Bench-web 和 VideoMME-long 等数据集上,M3-Agent 稳定地优于所有基线方法,展示了其在记忆和推理能力上的优越性。
此外,通过详细的案例研究,我们识别出 M3-Agent 的一些关键局限性,这些发现为未来的研究指明了方向。主要包括:
增强注意力机制,以提升语义记忆的构建能力;
开发更丰富且高效的视觉记忆方法。
这些方向将有助于进一步提升多模态智能体的记忆与推理性能。
7 Acknowledgment¶
本节对在研究过程中提供帮助的人员表示感谢。重点提到了 Xiran Suo、Wanjun Wang 和 Liu Ding,他们来自 ByteDance,在 数据标注 方面提供了重要支持。此外,Peng Lin 负责制作了图示(illustration),对论文的视觉呈现也起到了积极作用。这些贡献虽非研究的核心内容,但对论文的完成具有实际帮助。
8 M3-Bench-robot¶
8.1 Script Annotation Guidelines(脚本标注指南)¶
Actor Setup(演员设置)
四到五名演员参与录制,其中一名扮演“机器人”,佩戴头戴式摄像头(如iPhone 16 Pro、Xiaomi 14 Ultra 或 GoPro HERO13),从机器人视角录制视频。这是核心设备,用于构建视频数据集。
Definitions(定义)
重点定义如下几个关键概念:
Script(脚本):包含事件和问题,为演员提供对话和舞台指示。
Robot(机器人):由真人扮演,是一个具备类人推理和记忆能力的“理想化高智能机器人”。
Scenario(场景):包括客厅、厨房、卧室、书房、办公室、会议室和健身房等7个常见室内场景。
Event(事件):脚本中独立的小情节,包含未来问题相关的参考信息。
Question(问题):用于评估机器人记忆,必须与表1中的问题类型之一对应。
Requirements(要求)
标注要求如下:
每个脚本至少标注15个问题,每个问题需标注对应的参考事件。
每个脚本至少包含70个事件,确保视频时长不少于30分钟。
问题不能仅依赖常识回答、不能无法回答、不能仅通过对话回答、不能与参考事件弱相关、答案必须清晰可验证。
8.2 QA Annotation Guidelines(问答标注指南)¶
Background(背景)
机器人未来将在室内环境(如家庭)中帮助人类完成任务。因此,视频从机器人视角录制,问题设置在不同时间戳处,用于评估模型能力。部分问题需要人工审核或额外标注,确保每段视频至少包含10个问题。
Task(任务)
提供30-45分钟的视频和对应脚本,脚本内容可能因实际拍摄进行微调:
Review existing questions(审核已有问题)
为每个问题标注视频中的时间戳。
判断问题是否可被视频内容回答,若不能回答则考虑修改问题。
每个问答对需标注推理过程和问题类型(对应表1)。
Annotate additional questions(标注额外问题)
若脚本问题不足10个,需新增问题,且必须符合表1中指定的类型。
8.3 Quality Control(质量控制)¶
标注过程分为两轮:
第一轮
确保标注员理解标注指南。
每位标注员标注三个视频,作者审核并反馈,标注员据此修改。
根据初步标注质量决定是否进入正式标注阶段。
第二轮
每次标注五个视频,作者随机抽检其中一个视频。
若发现超过一个无效问答对,整批需重新标注;否则视为通过。
全流程有两位作者参与质量控制。
此外,为保证问题质量,每个问题由五名标注员独立回答,标注员可多次观看视频,最终人工准确率为90.7%。错误分析显示,最常见问题为计数类错误。
8.4 Annotator Information(标注员信息)¶
所有标注员来自商业标注公司,合同签订、按市场价支付薪酬。标注员均为本科以上学历,英语水平良好:
脚本标注:11名标注员
视频拍摄:67名演员
QA标注:5名标注员
8.5 Data Examples(数据示例)¶
提供了一个M3-Bench-robot脚本的标注示例(表8),展示了事件和问题的对应关系。例如:
Event 1:Rose打电话感谢Amy送花,并拍照分享。此事件为后续问题提供信息。
Event 2 & 5:Rose交代机器人将礼物放在衣柜底层。
Question:Rachel的礼物在衣柜哪一层?
Reference:event-2和event-5(重要参考事件)
Event 1 中的信息用于回答“谁送的花”。
通过这类示例,展示了事件与问题之间的逻辑关联,以及如何通过机器人视角的记忆和推理能力进行评估。
总结:
本章节详细介绍了M3-Bench-robot的数据构建过程,包括脚本与问题的标注要求、质量控制流程、标注员信息及数据样例。核心目标是构建一个高质量的视频与问答数据集,用于评估机器人在真实环境中的记忆、推理与任务完成能力。
9 M3-Bench-web¶
本章节介绍了 M3-Bench-web 数据集的标注指南、质量控制流程以及标注人员信息。目的是确保数据集的高质量、安全性和有效性,以便用于视频理解模型的评估。
9.1 Annotation Guidelines(标注指南)¶
标注指南详细说明了标注任务的要求和规范,以确保答案的可验证性和客观性。重点内容如下:
问题需可验证且答案客观:避免开放式、复合型或多答案的问题,确保答案有明确标准。
每段视频必须包含两个角色属性建模问题与两个常识推理问题:这是为了全面评估模型在不同任务上的表现。
视频应保证在低分辨率(≤720p)下仍可识别必要的视觉信息:确保问题在低质量视频中仍然可解。
视频时长与问题数量对应:20-40分钟的视频需5个问题,40分钟以上的视频需10个问题,标注报酬也与此挂钩。
常识推理问题需标注所考察的常识知识:帮助评估模型是否真正理解了常识背景。
必须包含视觉中心的问题:不能仅通过音频回答,需结合视频内容。
禁止重复问题:例如分别描述不同人物的外貌视为重复。
问题需涵盖较长的视频内容(超过10秒):避免仅依赖瞬间片段。
视频内容必须安全、无敏感或不当内容。
避免仅依赖常识的问题:不能脱离视频内容,否则无法测试真实理解能力。
避免因语言偏见或社会常识而易于猜测的问题:例如基于文化预设的问题会削弱评估效果。
避免直接将人物台词转为问题:这类问题可通过关键词匹配回答,不能检验视频理解。
答案为“是/否”的问题要保持平衡:避免答案分布偏向某一方。
9.2 Quality Control(质量控制)¶
为了保证标注质量,设置了三阶段的质量控制流程:
阶段1:试标任务
候选标注者完成一个视频的标注任务,作者进行审核并给予反馈。只有通过审核者才能进入正式标注。阶段2:批量提交与审核
标注者提交10个视频及对应问题答案对,作者随机抽查2个并提供反馈。标注者根据反馈修改整批。若合格率低于90%,需再次抽检。合格率达标则进入下一阶段。阶段3:大规模提交与最终审核
标注者提交30个视频及问题答案对,作者随机抽查5个。若合格率低于90%,需再次修改;否则视为通过。
整个质量控制过程由两位作者共同参与,确保标注的准确性和一致性。
9.3 Annotator Information(标注人员信息)¶
所有标注人员来自一家商业数据标注公司,作者与其有合同关系。
标注人员为本科学历,英语能力强,确保能准确理解任务要求。
一共有10名标注人员参与了 M3-Bench-web 数据集的构建工作。
总结¶
本章通过严格的标注指南、多阶段的质量控制流程,以及专业标注人员的参与,确保了 M3-Bench-web 数据集的高质量。该数据集的设计重点在于评估模型的视频理解能力,特别是涉及角色属性建模和常识推理的能力。
10 Implementation Details of Tools¶
本节总结了用于表示提取的工具的实现细节,主要涵盖面部识别、语音识别及基于记忆的检索系统。
Facial Recognition(面部识别)¶
视频采样:以每秒5帧的速率均匀采样视频帧。
模型使用:使用来自 InsightFace 库中的
buffalo_l模型,提取面部属性,包括边界框坐标、身份嵌入和检测/质量评分。质量过滤:剔除低质量检测(如异常的宽高比或极低置信度)。
聚类处理:对高质量的面部嵌入使用 HDBSCAN 进行聚类,按角色身份分组,生成一组可靠的面部表示。
重点:通过模型提取面部特征并进行聚类,实现角色的面部识别。
Voice Identification(语音识别)¶
分割与识别:使用 Gemini-1.5-Pro 提取不同说话人的音频片段,并进行自动语音识别(ASR)。
片段过滤:过滤掉时长少于2秒的片段,确保识别可靠性。
语音嵌入:使用 ERes2NetV2 模型将每个片段编码为说话人特定的表示。
聚类合并:对相似语音特征进行聚类和合并,生成高质量的说话人表示,按角色分组。
重点:结合语音分割、ASR 和语音嵌入模型,实现说话人的准确识别和分组。
提示模板:提供了一个详细的提示模板,用于指导语音处理系统生成特定格式的 JSON 输出,包含时间戳与识别文本。
Search(检索)¶
基于记忆的检索:所有检索通过最大内积搜索(MIPS)实现,并针对不同模态进行适配。
特征存储:每个面部和语音节点维护一组代表性的特征快照。
匹配逻辑:
计算新特征与存储快照之间的平均余弦相似度。
若相似度超过预设阈值(图像 0.3,语音 0.6),则视为匹配;否则创建新节点。
匹配节点会更新新特征,逐步优化表示。
文本检索:使用 OpenAI 的
text-embedding-3-large模型,将查询与所有文本节点进行 MIPS 检索。多结果检索:结合 top-k 和相似度阈值进行多条目检索(k=2, t=0.5),以减少检索随机性,提高一致性。
片段级检索:每个片段按其最高相似度评分排序,返回前几个片段。
重点:基于 MIPS 的多模态检索系统,结合阈值和参数控制,确保检索的稳定性和准确性。
总结¶
本节详细介绍了用于多模态记忆系统中的面部识别、语音识别和记忆检索的实现细节,强调了模型选择、质量控制、聚类与检索策略等方面的实现方法。这些技术共同支持了系统在长期记忆、角色识别和信息检索方面的能力。
11 Demonstration Data Synthesis for Memorization¶
本节讨论了如何合成用于训练多模态模型的记忆数据,主要分为情景记忆(Episodic Memory)和语义记忆(Semantic Memory)两大类。输入包括视频、音频、面部识别结果和语音身份识别结果,系统通过数据分割与合成策略,共生成了10,752个训练样本和200个验证样本。
11.1 情景记忆合成(Episodic Memory Synthesis)¶
情景记忆用于记录具体事件,包含时间、地点、人物、行为和环境等细节。为提高合成质量,采用混合策略,结合了Gemini-1.5-Pro(擅长生成事件性描述)和GPT-4o(擅长生成视觉细节)的优势:
GPT-4o基于视频帧(0.5fps采样)生成详细的视觉描述,作为上下文;
Gemini-1.5-Pro在该上下文中生成最终的情景记忆,补充音频、对话和人物交互等信息;
模型输出为Python列表,包含多个简洁的英文句子,每个句子描述一个细节。
重点提示:GPT-4o的视觉输出显著提升了最终记忆的丰富性。
11.2 实体ID关系检测(Entity ID Relationship Detection)¶
该部分目标是检测跨模态身份等价关系(如某人脸ID与语音ID是否属于同一人)。难点在于多个面孔和语音并存的场景,因此提出渐进式标注算法(Progressive Annotation Algorithm):
Meta-Clip提取:将视频分割为小于5秒的短片段,筛选出仅包含一个脸部和一个语音身份的片段(称为meta-clip),用于建立身份映射;
Meta-Dictionary构建:通过投票机制,将多个meta-clip中出现的关联关系整合为映射字典;
New-Clip标注:利用字典对30秒视频片段进行标注,生成如“<face_1> 和 <voice_2> 等价”类的语义记忆。
实验显示,手动评估48个映射关系时准确率达到95.83%。
11.3 语义记忆合成(Semantic Memory Synthesis)¶
语义记忆关注抽象属性、人物关系、场景理解与常识知识。同样采用混合策略,由GPT-4o生成初步语义内容,Gemini-1.5-Pro进行整合与优化:
GPT-4o基于视频帧和情景记忆生成初步语义内容;
Gemini-1.5-Pro在整合视频、情景记忆和初步语义后,生成最终的语义记忆;
输出形式为Python列表,强调高阶推理结论,如人物性格、社会角色、情绪互动等。
重点提示:输出需避免重复原始输入内容,需体现深层推理,并严格遵循ID使用规则。
11.4 合成数据质量(Quality of the Synthetic Data)¶
尽管合成数据为人工生成,但质量较高:
长度对比:合成情景记忆平均245.7词,语义记忆276.2词,均高于Gemini-1.5-Pro的输出(151.3和81.4词),说明合成数据更细致;
准确性测试:随机抽样353项进行人工审核,整体准确率为95.5%;
主要错误来源:语音识别工具在噪声或重叠说话时表现不佳,导致部分对话遗漏或识别错误。
总结:本章系统性地构建了多模态记忆训练数据,包括情景记忆和语义记忆,结合多模型优势提升合成质量,并通过算法和手动评估确保数据质量与准确性。
12 Evaluation of Memorization¶
本节评估模型在训练过程中的记忆能力。评估基于一个独立的验证集,包含 200 个样本,并选择性能最好的模型检查点(checkpoint)。使用两个评估指标:
AutoDQ:评估生成输出与参考描述的匹配质量,衡量模型在情景记忆和语义记忆方面的表现,但不包括身份等价性。
身份等价性(Equivalence):通过与验证集中真实数据的对比,计算精确率(Precision)、召回率(Recall)和F1 分数。
根据表 13 的结果,作者选择在训练3 个 epoch后取得的模型检查点。为了进一步比较,作者还报告了两种基线模型(baseline)在相同验证集上的结果:memory-gemini-prompt 和 memory-7b-prompt。评估结果显示,本文提出的模型 memory-7b-sft 显著优于这两个基线模型。
表 13:记忆模型评估结果(AutoDQ 和 Equivalence 指标)¶
模型 |
AutoDQ-P |
AutoDQ-R |
AutoDQ-F1 |
Eq.-P |
Eq.-R |
Eq.-F1 |
|---|---|---|---|---|---|---|
memory-gemini-prompt |
0.692 |
0.539 |
0.606 |
0.472 |
0.805 |
0.595 |
memory-7b-prompt |
0.495 |
0.355 |
0.414 |
0.117 |
0.192 |
0.145 |
memory-7b-sft (1 epoch) |
0.634 |
0.596 |
0.616 |
0.742 |
0.817 |
0.778 |
memory-7b-sft (2 epoch) |
0.628 |
0.610 |
0.619 |
0.845 |
0.810 |
0.827 |
memory-7b-sft (3 epoch) |
0.635 |
0.620 |
0.627 |
0.836 |
0.856 |
0.846 |
memory-7b-sft (4 epoch) |
0.616 |
0.618 |
0.617 |
0.825 |
0.839 |
0.832 |
memory-7b-sft (5 epoch) |
0.609 |
0.621 |
0.615 |
0.813 |
0.840 |
0.827 |
重点内容:
AutoDQ-F1 表示模型在记忆描述质量上的综合表现。
Equivalence-F1 表示模型在判断是否完全匹配原始输入时的综合表现,数值越高越好。
memory-7b-sft 在训练到第 3 个 epoch 时达到最佳性能(AutoDQ-F1 为 0.627,Equivalence-F1 为 0.846)。
对比基线模型:
memory-gemini-prompt 在 AutoDQ-F1 表现较好(0.606),但在 Equivalence-F1 表现一般(0.595)。
memory-7b-prompt 表现最差,无论是 AutoDQ 还是 Equivalence 指标都明显落后。
memory-7b-sft 明显优于两个基线模型,尤其是在 Equivalence-F1 上高出许多。
简要总结:
本节通过两个关键指标对模型的记忆能力进行了系统评估。结果显示,经过微调的 memory-7b-sft 模型在多个指标上均优于基线模型,尤其是在身份等价性上表现突出。最终选择训练 3 个 epoch 后的模型进行后续实验。
13 RL Training Details¶
13.1 Details of DAPO Training¶
本节主要介绍DAPO训练过程中的超参数和训练曲线。
超参数设置¶
表14列出了DAPO训练所使用的不同模型规模(8B、14B、32B)的超参数设置。重点关注以下内容:
参数名称 |
8B |
14B |
32B |
|---|---|---|---|
Batch Size |
32 |
32 |
32 |
GPU(80GB内存)数量 |
16 |
16 |
32 |
Rollout模型并行大小 |
1 |
1 |
2 |
学习率 |
1e-6 |
1e-6 |
1e-6 |
最大轮次(HH) |
5 |
5 |
5 |
每组样本数量(GG) |
4 |
4 |
4 |
总训练步数 |
180 |
180 |
180 |
ϵlow |
0.2 |
0.2 |
0.2 |
ϵhigh |
0.28 |
0.28 |
0.28 |
从表中可以看出,不同模型规模的设置基本一致,仅在GPU数量和Rollout模型并行大小上略有不同,32B模型需要更多的硬件资源。
训练曲线¶
图4展示了DAPO训练过程中的平均分数(训练集)和准确率(验证集)。曲线显示随着训练步数的增加,模型表现稳步提升。图中的曲线使用了指数移动平均(EMA)平滑方法,权重为0.9,与WandB中的一致。
13.2 GRPO Training¶
本节介绍了在消融实验中使用的Group Relative Policy Optimization(GRPO)方法。GRPO通过最大化以下目标函数来优化策略模型πθ:
其中包含两个关键部分:
最小化与剪切机制:使用了类似PPO的clip机制(clip ratio为1-0.2到1+0.2),避免更新过大导致策略不稳定。
KL散度惩罚项:通过对比当前策略和参考策略的KL散度,防止策略偏离过多。KL散度的计算公式为:
超参数设置¶
GRPO的主要超参数为:
ϵ = 0.2
β = 0.01
其他超参数与DAPO训练中相同。
总结¶
本章节详细介绍了DAPO和GRPO两种政策优化方法的训练细节。重点在于:
DAPO的超参数设置和训练曲线表现;
GRPO的目标函数结构、clip机制和KL散度惩罚;
GRPO用于策略优化的消融实验中。
14 Case Study¶
案例研究一:M3-Bench-web¶

对话内容
<voice_1>(00:03-00:12): “每个兄弟姐妹的关系都不一样。我是最小的那个,所以我总是忍让。我就那么接受了,没有那种反抗的冲动……”
<voice_2>(00:00-00:02): “通过我的孩子们重新体验这些经历……” (00:11-00:16): “他们俩势均力敌,真的,总是互相较劲。” (00:24-00:29): “我们要让鱼来吃饲料,鸭子也会过来。到时候会变成一场……”
<voice_812>(00:17-00:23):
“哇!我们要去池塘钓鱼了!我要买个鱼饲料机,然后我们就能看到……”
memory-gemini-prompt版输出¶
情景记忆(Episodic Memory)
人物与场景
<face_1412>(疑似父亲):
穿着浅蓝色带图案的T恤、黑色棒球帽和反光墨镜。
站在后院,背景有砖房、木制露台、围栏和树木。
一名女性(可能是妻子)从背景走过,手里拿着东西。
事件片段
<voice_2>提到通过孩子重温自己的童年经历。
<voice_1>谈论兄弟姐妹间的动态,提到自己作为老幺的忍让。
<voice_2>说孩子们“势均力敌,经常打闹”。
家庭活动:
<face_1412>和妻子手里拿着小黄鸭。
两个孩子在后院用水枪玩耍。
<voice_812>计划去池塘钓鱼,提到要买鱼饲料机,吸引鱼和鸭子过来。
语义记忆(Semantic Memory)
人物关系
<face_1412>:
热爱家庭生活的父亲,喜欢户外活动(如钓鱼)。
与妻子(<face_1413>)关系轻松融洽。
环境与主题
场景位于郊外或乡村住宅,有大后院和池塘。
视频内容:
家庭准备钓鱼活动。
讨论孩子们的兄弟姐妹竞争关系。
memory-7b-sft (Ours)版输出¶
情景记忆(Episodic Memory)
人物外貌与环境
<face_1412>(男):
穿着 白色T恤,印有绿黄图案,戴黑色棒球帽和绿色反光墨镜。
在阳光明媚的户外草地,背景有砖房和木栅栏。
对镜头说:“这些通过孩子们的经历,就是……”
<face_1413>(女):
加入时穿白色背心和牛仔短裤。
与<face_1412>一起手捧两只黄色小鸭。
对话内容
<voice_1>(可能是<face_1413>的声音):
谈论兄弟姐妹关系:“每个 sibling 动态都不同,我是最小的,只能忍受……没有攻击性去反抗。”
<voice_2>(可能是<face_1412>的声音):
兴奋提到:“我们要去池塘钓鱼!准备鱼饲料,吸引鱼和鸭子过来。”
互动细节
两人将小鸭放在草地上,旁边有一个黑色宠物箱。
<face_1413>跪在宠物箱旁,手捧一只小鸭。
背景中出现一个穿蓝色衣服的孩子。
语义记忆(Semantic Memory)
人物特征
<face_1412>:
性格随性,喜欢户外活动和家庭时光。
可能擅长宠物养护(如养鸭)和钓鱼。
<face_1413>:
温柔细心,表现出照顾小动物的母性。
<voice_1>:
善于反思,分析个人经历(如家庭关系)。
关系推测
<face_1412>和<face_1413>可能是夫妻或亲密家人,互动自然。
<voice_1>(可能是他们的孩子)与<face_1412>关系亲密,常分享经历。
视频主题与风格
类型:家庭生活Vlog,记录日常休闲活动。
基调:轻松温馨,强调家庭互动与自然乐趣。
场景:郊区或农村,结合室内外环境(房屋、草地、池塘)。
文化与社会惯例
养鸭需专业知识(如饲料、住所)。
钓鱼和投喂鱼饲料是常见的户外娱乐方式。
家庭成员共同参与活动是普遍的文化习惯。
对比评价¶
memory-gemini-prompt 提供了较丰富的场景描述,但在细节精确性和人物互动生成方面相对略显模糊。
memory-7b-sft (Ours) 在人物性格分析、对话理解、动作细节方面表现出更强的记忆生成能力,尤其在语义记忆的结构化和深入分析方面具有优势。
14.3 案例研究二:M3-Bench-robot¶
略……
14.4 完整生成轨迹案例(控制过程)¶
略……
14.5 总结¶
作者模型(memory-7b-sft) 在情景记忆和语义记忆的生成中表现出更强的细节描述能力、人物性格分析能力与互动理解能力。
相比之下,memory-gemini-prompt 更注重宏观场景描述,但在人物行为分析与语义推理方面稍逊。
通过多个案例研究可以看出,作者模型在真实场景理解、人物关系建模和信息整合方面具有明显优势,尤其是在视频内容复杂、人物互动多变的情况下表现更佳。
15 Prompt Templates¶
15.1 Prompt for Automatic Evaluator of M3-Bench¶
You are provided with a question, a ground truth answer, and an answer from an agent model. Your task is to determine whether the ground truth answer can be logically inferred from the agent’s answer, in the context of the question.
Do not directly compare the surface forms of the agent answer and the ground truth answer. Instead, assess whether the meaning expressed by the agent answer supports or implies the ground truth answer. If the ground truth can be reasonably derived from the agent answer, return "Yes". If it cannot, return "No".
Important notes:
• Do not require exact wording or matching structure.
• Semantic inference is sufficient, as long as the agent answer entails or implies the meaning of the ground truth answer, given the question.
• Only return "Yes" or "No", with no additional explanation or formatting.
Input fields:
• question: the question asked
• ground_truth_answer: the correct answer
• agent_answer: the model’s answer to be evaluated
Now evaluate the following input:
Input:
• question: {question}
• ground_truth_answer: {ground_truth_answer}
• agent_answer: {agent_answer}
Output (‘Yes’ or ‘No’):
中文版
你将得到一个问题、一个标准答案,以及一个来自代理模型的回答。你的任务是判断,在该问题的语境下,标准答案是否能够从代理模型的回答中逻辑推断出来。
不要直接比较代理模型回答和标准答案的表面形式。相反,应评估代理回答所表达的含义是否支持或蕴含标准答案。如果标准答案可以合理地从代理回答中得出,返回 **"Yes"**;如果不能,返回 **"No"**。
重要说明:
* 不需要完全相同的措辞或结构。
* 只要语义上可以推断或蕴含即可。
* 只返回 **"Yes"** 或 **"No"**,不要有其他解释或格式。
输入字段:
* question: 提出的问题
* ground_truth_answer: 正确答案
* agent_answer: 待评估的模型回答
输出("Yes" 或 "No"):
15.2 Prompts for Socratic Models: Caption Generation Prompt¶
Caption Generation Prompt¶
You are an advanced video description generator tasked with providing a detailed, cohesive description of a video clip.
**Follow these high-level principles to ensure your output is accurate and meaningful:**
1. Focus on Observable Content.
2. Provide Context for the Environment and Timing.
3. Incorporate Audio Dialogue Information.
You are provided with a current video clip. (GPT-4o, Qwen2.5-VL-7b Variant: You are provided with 15 key frames from a current video clip and audio text information <a list where each item represents a speech segment dict with the following fields: start time, end time, asr. The time information is the time in the current clip and not the global time>.)
**Your Task:**
Based on the video clip, generate a detailed and cohesive description of the video clip. The description should focus on the entire event, incorporating all relevant aspects of the characters, their actions, spoken dialogue, and interactions in a narrative format. The description should include (but is not limited to) the following categories:
1. **Characters’ Appearance**: Describe the characters’ appearance, including their clothing, facial features, body language, or any distinguishing characteristics that are noticeable in the frames.
2. **Characters’ Actions & Movements**: Describe specific gestures, movements, or interactions performed by the characters. Include both major and minor actions that contribute to the overall scene, emphasizing any transitions between different actions.
3. **Characters’ Spoken Dialogue**: Use the provided audio dialogue information to accurately transcribe or summarize the dialogue spoken by the characters. Include emotional tone, volume, or context if relevant (e.g., shouting, whispering, laughing).
4. **Characters’ Contextual Behavior and Attributes**: Describe the characters’ roles in the scene, their emotional states, motivations, or relationships with other characters. Highlight any conflict, bonding, or change in dynamics.
5. **Environmental Context**: Include relevant details about the environment where the scene takes place. Describe the physical location, setting, lighting, or any other environmental factors that affect the atmosphere or context of the video clip.
6. **Temporal Context**: Provide information about the timing of events within the scene. Describe the natural progression of time (e.g., morning, afternoon, evening) or any time-sensitive elements that contribute to the unfolding of the events.
**Strict Requirements:**
- Do not use generic descriptions, inferred names, or pronouns to refer to characters (e.g., "he," "they," "the man").
- The generated descriptions of the video clip should include every detail observable in the frames and mentioned in the audio dialogues. (GPT-4o, Qwen2.5-VL-7b Variant: • The generated descriptions of the video clip should include every detail observable in the frames and mentioned in the audio dialogues.)
- Pay close attention to any introduction of characters’ names, titles, or other identifiers provided in the frames or audio.
- Whenever possible, include natural time expressions and physical location cues in the descriptions to improve contextual understanding. These should be based on inferred situational context (e.g., "in the evening at the dinner table," "early morning outside the building").
- Include relevant background, common knowledge and environmental factors when needed (e.g., location, weather, setting) to provide a fuller understanding of the context.
- Maintain a natural, narrative flow in the description, ensuring that it reads like a coherent summary of the events in the video.
- Remember you are looking at key frames and audio dialogue information, not the full video, so focus on what can be observed from these specific materials. (GPT-4o, Qwen2.5-VL-7b Variant: • Remember you are looking at key frames and audio dialogue information, not the full video, so focus on what can be observed from these specific materials.)
**Example Output:**
"As Margaret returns with the teapot, Tom stands up to help her pour the tea, gesturing politely as she hands him a cup. Margaret sits back down. Margaret leans forward slightly, her hands resting on the table, and after a moment of silence, she speaks again, her voice steady but filled with a hint of urgency. Tom listens closely, his brow furrowing slightly as he takes in her words. He responds quietly, nodding slowly as he processes the information."
中文版
你是一个高级视频描述生成器,任务是为一个视频片段提供详细、连贯的描述。
**请遵循以下高层原则,确保输出准确且有意义:**
1. 聚焦可观察的内容。
2. 提供环境与时间的上下文。
3. 融合音频对话信息。
你将获得一个当前的视频片段。(GPT-4o, Qwen2.5-VL-7b 变体:你将获得该视频片段的 15 个关键帧,以及音频文本信息 <一个列表,每一项代表一个语音片段字典,字段包括:开始时间、结束时间、ASR 识别结果。时间信息是该视频片段中的局部时间,而不是全局时间>。)
**你的任务:**
基于该视频片段,生成一个详细且连贯的描述。描述应聚焦于整个事件,结合人物、他们的动作、口头对话和互动,以叙事的形式展开。描述应包括(但不限于)以下类别:
1. **人物外貌**:描述人物的外貌,包括服装、面部特征、肢体语言或任何显著特征。
2. **人物动作与移动**:描述人物的具体动作、手势或互动。包括主要与次要动作,这些动作如何推动场景发展,并强调动作之间的过渡。
3. **人物口头对话**:利用提供的音频对话信息,准确转写或总结人物的对话。若相关,请加入语气、音量或情绪(如:喊叫、低语、笑声)。
4. **人物行为与属性的上下文**:描述人物在场景中的角色、情绪状态、动机或与其他人物的关系。突出冲突、亲密或关系变化。
5. **环境上下文**:提供场景发生地点的相关细节。描述物理空间、布景、灯光或任何影响氛围与语境的环境因素。
6. **时间上下文**:提供场景中事件的时间信息。描述自然的时间进程(如:早晨、下午、晚上)或任何与事件发展相关的时间敏感要素。
**严格要求:**
* 不要使用泛泛的描述、推测的人名或代词来指代人物(例如:“他”、“他们”、“那个人”)。
* 视频片段的描述必须涵盖关键帧中可观察到的所有细节,以及音频对话中提到的内容。(GPT-4o, Qwen2.5-VL-7b 变体:• 必须涵盖关键帧中所有可观察到的细节和音频对话提到的内容。)
* 仔细注意人物名字、头衔或其他可识别信息的引入,确保在描述中正确引用。
* 尽可能加入自然的时间表达和地点提示,提升上下文理解。这些提示应基于场景推断(例如:“傍晚的餐桌前”、“清晨楼外”)。
* 在需要时加入相关的背景信息、常识或环境因素,以提供更完整的理解。
* 保持自然的叙事流畅度,确保描述读起来像对事件的连贯总结。
* 记住,你看到的是关键帧和音频信息,而不是完整视频,因此应仅关注这些材料所提供的内容。(GPT-4o, Qwen2.5-VL-7b 变体:• 仅关注关键帧和音频对话信息所呈现的内容。)
**示例输出:**
“当玛格丽特端着茶壶回来时,汤姆站起来帮她倒茶,他礼貌地做出手势,接过她递来的茶杯。玛格丽特重新坐下,微微前倾,把手放在桌上。沉默片刻后,她再次开口,声音平稳但带着一丝急切。汤姆认真聆听,眉头微微皱起,回应时语气平静,缓缓点头,似乎在消化她的话语。”
RAG Answer Prompt (GPT-4o)¶
Based on the following video description, answer the question as concisely as possible. Provide only the direct answer without explanations or reasoning.
**Question:** {question}
**Relevant Video Clip Captions:** {retrived_clips}
**Answer:**
中文版
基于以下视频描述,尽可能简洁地回答问题。只提供直接答案,不要给出解释或推理。
**问题:** {question}
**相关视频片段字幕:** {retrived_clips}
**答案:**
15.3 Prompts for M3-Agent¶
Memorization Prompt¶
You are given a video along with a set of character features. Each feature is either:
• Face: a single video frame with a bounding box, or
• Voice: one or more speech segments, each containing start_time (MM:SS), end_time (MM:SS) and asr (transcript).
Every feature has a unique ID enclosed in angle brackets (e.g. <face_1>, <voice_2>).
Your Tasks (produce both in the same response):
1. Episodic Memory (the ordered list of atomic captions)
• Using the provided feature IDs, generate a detailed and cohesive description of the current video clip. The description should capture the complete set of observable and inferable events in the clip. Your output should incorporate the following categories (but is not limited to them):
(a) Characters’ Appearance: Describe the characters’ appearance, such as their clothing, facial features, or any distinguishing characteristics.
(b) Characters’ Actions & Movements: Describe specific gesture, movement, or interaction performed by the characters.
(c) Characters’ Spoken Dialogue: Quote—or, if necessary, summarize—what are spoken by the characters.
(d) Characters’ Contextual Behavior: Describe the characters’ roles in the scene or their interaction with other characters, focusing on their behavior, emotional state, or relationships.
2. Semantic Memory (the ordered list of high-level thinking conclusions)
• Produce concise, high-level reasoning-based conclusions across five categories:
(a) Equivalence Identification – Identify which face and voice features refer to the same character. Use the exact format: Equivalence: <face_x>, <voice_y>. Include as many confident matches as possible.
(b) Character-level Attributes – Infer abstract attributes for each character, such as: Name (if explicitly stated), Personality (e.g., confident, nervous), Role/profession (e.g., host, newcomer), Interests or background (when inferable), Distinctive behaviors or traits (e.g., speaks formally, fidgets). Avoid restating visual facts—focus on identity construction.
(c) Interpersonal Relationships & Dynamics – Describe the relationships and interactions between characters: Roles (e.g., host-guest, leader-subordinate), Emotions or tone (e.g., respect, tension), Power dynamics (e.g., who leads), Evidence of cooperation, exclusion, conflict, etc.
(d) Video-level Plot Understanding – Summarize the scene-level narrative, such as: Main event or theme, Narrative arc or sequence (e.g., intro → discussion → reaction), Overall tone (e.g., formal, tense), Cause-effect or group dynamics.
(e) Contextual & General Knowledge – Include general knowledge that can be learned from the video, such as: Likely setting or genre (e.g., corporate meeting, game show), Cultural/procedural norms, Real-world knowledge (e.g., "Alice market is pet-friendly"), Common-sense or format conventions.
Strict Requirements (apply to both sections unless noted):
1. If a character has a provided feature ID, refer to that character only with the ID (e.g. <face_1>, <voice_2>).
2. If no ID exists, use a short descriptive phrase (e.g. "a man in a blue shirt").
3. Do not use "he," "she," "they," pronouns, or invented Names.
4. Keep face/voice IDs consistent throughout.
5. Describe only what is grounded in the video or obviously inferable.
6. Include natural Time & Location cues and setting hints when inferable.
7. Each Episodic Memory line must express one event/detail; split sentences if needed.
8. Output English only.
9. Output a Python list of sentences for each memory type.
Additional Rules for Episodic Memory:
1. Do not mix unrelated aspects in one memory sentence.
2. Focus on appearance, actions/movements, spoken dialogue (quote or summary), contextual behavior.
Additional Rules for Semantic Memory:
1. For Equivalence lines, use the exact format: Equivalence: <face_x>, <voice_y>.
2. Do not repeat simple surface observations already in the captions.
3. Provide only final conclusions, not reasoning steps.
Expected Output Format:
Return the result as a single Python dict containing exactly two keys:
{
"episodic_memory": [
"In the bright conference room, <face_1> enters confidently, giving a professional appearance as he approaches <face_2> to shake hands.",
"<face_1> wears a black suit with a white shirt and tie. He has short black hair and wears glasses.",
"<face_2>, dressed in a striking red dress with long brown hair.",
"<face_2> smiles warmly and greets <face_1>. She then sits down at the table beside him, glancing at her phone briefly while occasionally looking up.",
"<voice_1> speaks to the group, ’Good afternoon, everyone. Let’s begin the meeting.’ His voice commands attention as the room quiets, and all eyes turn to him.",
"<face_2> listens attentively to <voice_1>’s words, nodding in agreement while still occasionally checking her phone. The atmosphere is professional, with the participants settling into their roles for the meeting.",
"<face_1> adjusts his tie and begins discussing the agenda, engaging the participants in a productive conversation."
],
"semantic_memory": [
"Equivalence: <face_1>, <voice_1>",
"<face_1>’s name is David.",
"<face_1> holds a position of authority, likely as the meeting’s organizer or a senior executive.",
"<face_2> shows social awareness and diplomacy, possibly indicating experience in public or client-facing roles.",
"<face_1> demonstrates control and composure, suggesting a high level of professionalism and confidence under pressure.",
"The interaction between <face_1> and <face_2> suggests a working relationship built on mutual respect.",
"The overall tone of the meeting is structured and goal-oriented, indicating it is part of a larger organizational workflow."
]
}
Please only return the valid python dict (which starts with "{" and ends with "}") containing two string lists in "episodic_memory" and "semantic_memory", without any additional explanation or formatting.
中文版
你将获得一个视频以及一组角色特征。每个特征可以是:
• Face:视频中的单帧画面以及对应的人脸框,或
• Voice:一个或多个语音片段,每个片段包含 start_time (MM:SS)、end_time (MM:SS) 和 asr (转写文本)。
每个特征都有一个唯一的 ID,用尖括号包围(例如 <face_1>, <voice_2>)。
你的任务(在同一回答中生成):
1. 情景记忆(Episodic Memory,按顺序的原子化描述列表)
• 使用提供的特征 ID,生成一个详细且连贯的视频片段描述。描述需要完整涵盖该片段中可观察和可推断的事件。输出应包括以下类别(但不限于):
(a) 角色外貌:描述角色的穿着、面部特征或其他明显特征。
(b) 角色动作与移动:描述角色的具体手势、动作或交互行为。
(c) 角色对话:引用或必要时总结角色的讲话内容。
(d) 角色的情境行为:描述角色在场景中的身份或与他人的互动,强调其行为、情绪状态或关系。
2. 语义记忆(Semantic Memory,高层次思维结论的顺序列表)
• 针对以下五个类别,生成简洁的高层推理结论:
(a) 等价识别 – 识别哪些人脸和语音特征属于同一角色。使用严格格式:Equivalence: <face_x>, <voice_y>。尽可能多地输出有把握的匹配。
(b) 角色属性 – 推断每个角色的抽象属性,如:名字(若明确提到)、性格特征(如自信、紧张)、身份/职业(如主持人、新人)、兴趣或背景(可推断时)、独特行为或特点(如讲话正式、爱摆弄手指)。避免复述视觉事实——重点在于身份构建。
(c) 人际关系与动态 – 描述角色之间的关系和互动:角色关系(如主持-嘉宾、领导-下属)、情绪或语气(如尊重、紧张)、权力关系(如谁主导)、合作/排斥/冲突等证据。
(d) 视频剧情理解 – 总结场景层面的叙事,如:主要事件或主题、叙事顺序(如开场→讨论→反应)、整体氛围(如正式、紧张)、因果关系或群体动态。
(e) 背景与常识知识 – 包括从视频中可学到的常识或背景知识,如:可能的场景或类型(如公司会议、综艺节目)、文化/流程规范、现实知识(如“Alice 市场允许宠物进入”)、常识或格式惯例。
严格要求(适用于两个部分,除非特别说明):
1. 如果角色有特征 ID,只能用该 ID 指代(如 <face_1>, <voice_2>)。
2. 若没有 ID,用简短描述性短语代替(如“穿蓝衬衫的男人”)。
3. 不要使用“他”“她”“他们”之类的代词,也不要编造名字。
4. 始终保持人脸/语音 ID 的一致性。
5. 仅描述视频中能观察到或显然可推断的内容。
6. 包含可推断的时间、地点提示和环境线索。
7. 每条情景记忆必须表达一个事件/细节;必要时拆分句子。
8. 输出必须是英文。
9. 每个记忆类型的输出为 Python 列表,每个元素一条句子。
情景记忆附加规则:
1. 不要在一句中混合无关的方面。
2. 专注于外貌、动作/移动、对话(引用或总结)、情境行为。
语义记忆附加规则:
1. 等价识别必须使用严格格式:Equivalence: <face_x>, <voice_y>。
2. 不要重复在情景记忆中已描述的表面事实。
3. 只提供最终结论,不写推理过程。
期望输出格式:
返回一个 Python dict,包含两个键:
{
"episodic_memory": [
"In the bright conference room, <face_1> enters confidently, giving a professional appearance as he approaches <face_2> to shake hands.",
"<face_1> wears a black suit with a white shirt and tie. He has short black hair and wears glasses.",
"<face_2>, dressed in a striking red dress with long brown hair.",
"<face_2> smiles warmly and greets <face_1>. She then sits down at the table beside him, glancing at her phone briefly while occasionally looking up.",
"<voice_1> speaks to the group, ’Good afternoon, everyone. Let’s begin the meeting.’ His voice commands attention as the room quiets, and all eyes turn to him.",
"<face_2> listens attentively to <voice_1>’s words, nodding in agreement while still occasionally checking her phone. The atmosphere is professional, with the participants settling into their roles for the meeting.",
"<face_1> adjusts his tie and begins discussing the agenda, engaging the participants in a productive conversation."
],
"semantic_memory": [
"Equivalence: <face_1>, <voice_1>",
"<face_1>’s name is David.",
"<face_1> holds a position of authority, likely as the meeting’s organizer or a senior executive.",
"<face_2> shows social awareness and diplomacy, possibly indicating experience in public or client-facing roles.",
"<face_1> demonstrates control and composure, suggesting a high level of professionalism and confidence under pressure.",
"The interaction between <face_1> and <face_2> suggests a working relationship built on mutual respect.",
"The overall tone of the meeting is structured and goal-oriented, indicating it is part of a larger organizational workflow."
]
}
请只返回符合要求的 Python dict(以 "{" 开始,以 "}" 结束),其中 "episodic_memory" 和 "semantic_memory" 的值均为字符串列表,不要添加任何其他解释或格式。
Control Prompt¶
You are given a question and some relevant knowledge about a specific video. You are also provided with a retrieval plan, which outlines the types of information that should be retrieved from a memory bank in order to answer the question. Your task is to reason about whether the provided knowledge is sufficient to answer the question. If it is sufficient, output [ANSWER] followed by the answer. If it is not sufficient, output [SEARCH] and generate a query that will be encoded into embeddings for a vector similarity search. The query will help retrieve additional information from a memory bank that contains detailed descriptions and high-level abstractions of the video, considering the question, the provided knowledge, and the retrieval plan.
Your response should contain two parts:
1. Reasoning
• Analyze the question, the knowledge, and the retrieval plan.
• If the current information is sufficient, explain why and what conclusions you can draw.
• If not, clearly identify what is missing and why it is important.
2. Answer or Search
• [ANSWER]: If the answer can be derived from the provided knowledge, output [ANSWER] followed by a short, clear, and direct answer.
• When referring to a character, always use their specific name if available.
• Do not use ID tags like <character_{1}> or <face_{1}>.
• [SEARCH]: If the answer cannot be derived yet, output [SEARCH] followed by a single search query that would help retrieve the missing information.
Instructions for [SEARCH] queries:
• Use the retrieval plan to inform what type of content should be searched for next. These contents should cover aspects that provide useful context or background to the question, such as character names, behaviors, relationships, personality traits, actions, and key events.
• Use keyword-based queries, not command sentences. Queries should be written as compact keyword phrases, not as full sentences or instructions. Avoid using directive language like "Retrieve", "Describe", or question forms such as "What", "When", "How".
• Keep each query short and focused on one point. Each query should target one specific type of information, without combining multiple ideas or aspects.
• Avoid over-complexity and unnecessary detail. Do not include too many qualifiers or conditions. Strip down to the most essential keywords needed to retrieve valuable content.
• The query should target information outside of the existing knowledge that might help answer the question.
• For time-sensitive or chronological information (e.g., events occurring in sequence, changes over time, or specific moments in a timeline), you can generate clip-based queries that reference specific clips or moments in time. These queries should include a reference to the clip number, indicating the index of the clip in the video (a number from 1 to N, where a smaller number indicates an earlier clip). Format these queries as "CLIP_x", where x should be an integer that indicates the clip index. Note only generate clip-based queries if the question is about a specific moment in time or a sequence of events.
• You can also generate queries that focus on specific characters or characters’ attributes using the id shown in the knowledge.
• Make sure your generated query focus on some aspects that are not retrieved or asked yet. Do not repeatedly generate queries that have high semantic similarity with those generated before.
Example 1:
Input:
Question: How did the argument between Alice and Bob influence their relationship in the story?
Knowledge:
[
{{
"query": "What happened during the argument between Alice and Bob?",
"related memories": {{
"CLIP_2": [
"<face_1> and <face_2> are seen arguing in the living room."
"<face_1> raises her voice, and <face_2> looks upset."
"<face_1> accuses <face_2> of not listening to her."
],
}}
}}
]
Output:
It seems that <face_1> and <face_2> are arguing about their relationship. I need to figure out the names of <face_1> and <face_2>.
[SEARCH] What are the names of <face_1> and <face_2>?
Example 2:
Input:
Question: How did the argument between Alice and Bob influence their relationship in the story?
Knowledge:
[
{{
"query": "What happened during the argument between Alice and Bob?",
"related memories": {{
"CLIP_2": [
"<face_1> and <face_2> are seen arguing in the living room."
"<face_1> raises her voice, and <face_2> looks upset."
"<face_1> accuses <face_2> of not listening to her."
],
}}
}},
{{
"query": "What are the names of <face_1> and <face_2>?",
"related memories": {{
"CLIP_1": [
"<face_1> says to <face_2>: ‘I am done with you Bob!’"
"<face_2> says to <face_1>: ‘What about now, Alice?’"
],
}}
}}
]
Output:
It seems that content in CLIP_2 shows exactly the argument between Alice and Bob. To figure out how did the argument between Alice and Bob influence their relationship, I need to see what happened next in CLIP_3.
[SEARCH] What happened in CLIP_3?
Now, generate your response for the following input:
Question: {question}
Knowledge: {search_results}
Output:
中文版
你将获得一个问题,以及关于某个特定视频的一些相关知识。同时,你还会得到一个检索计划,该计划概述了为了回答问题,需要从记忆库中检索的信息类型。你的任务是推理判断所提供的知识是否足以回答该问题。如果足够,输出 `[ANSWER]` 并给出答案;如果不够,输出 `[SEARCH]` 并生成一个查询,用于向记忆库检索额外信息。该查询将帮助从包含视频详细描述和高级抽象的记忆库中获取信息,同时结合问题、已有知识和检索计划。
你的回答应包含两个部分:
1. **推理**
* 分析问题、已有知识和检索计划。
* 如果当前信息足够,说明原因以及可以得出的结论。
* 如果信息不足,明确指出缺失的内容及其重要性。
2. **答案或搜索**
* `[ANSWER]`:如果可以从提供的知识中得出答案,输出 `[ANSWER]`,随后给出简明、直接的答案。
* 在提及角色时,始终使用其具体姓名(如果有)。
* 不要使用 ID 标签如 `<character_{1}>` 或 `<face_{1}>`。
* `[SEARCH]`:如果尚无法得出答案,输出 `[SEARCH]`,随后提供一个单一查询,以帮助检索缺失信息。
**[SEARCH] 查询说明:**
* 使用检索计划指导应搜索的内容类型。搜索内容应涵盖有助于理解问题的上下文或背景,如角色姓名、行为、关系、性格特征、动作和关键事件。
* 使用关键词查询,而非命令句。查询应简洁的关键词短语,不用完整句子或指令形式,如“检索”、“描述”或“What/When/How”等问题形式。
* 每个查询应聚焦一个具体信息点,不要混合多个想法或方面。
* 避免过度复杂或不必要的细节,只保留检索有价值信息的核心关键词。
* 查询应针对现有知识之外的信息,帮助回答问题。
* 对时间敏感或顺序性信息(例如事件发生顺序、变化或特定时间点),可以生成基于片段的查询,引用视频片段编号(从 1 到 N,数字越小表示越早的片段)。格式为 `"CLIP_x"`,其中 x 为片段索引。仅当问题涉及特定时间点或事件序列时使用。
* 也可以生成针对特定角色或角色属性的查询,使用知识中提供的 ID。
* 确保查询聚焦尚未检索或尚未提出的方面,避免生成与之前高度相似的查询。
示例 1:
输入:
问题:故事中,Alice 和 Bob 之间的争吵如何影响了他们的关系?
知识:
[
{
"query": "Alice 和 Bob 之间的争吵发生了什么?",
"related memories": {
"CLIP_2": [
"<face_1> 和 <face_2> 在客厅争吵。",
"<face_1> 提高了声音,<face_2> 看起来很沮丧。",
"<face_1> 指责 <face_2> 没有听她说话。"
]
}
}
]
输出:
看起来 <face_1> 和 <face_2> 正在为他们的关系争吵。我需要弄清楚 <face_1> 和 <face_2> 的名字。
[SEARCH] <face_1> 和 <face_2> 的名字是什么?
示例 2:
输入:
问题:故事中,Alice 和 Bob 之间的争吵如何影响了他们的关系?
知识:
[
{
"query": "Alice 和 Bob 之间的争吵发生了什么?",
"related memories": {
"CLIP_2": [
"<face_1> 和 <face_2> 在客厅争吵。",
"<face_1> 提高了声音,<face_2> 看起来很沮丧。",
"<face_1> 指责 <face_2> 没有听她说话。"
]
}
},
{
"query": "<face_1> 和 <face_2> 的名字是什么?",
"related memories": {
"CLIP_1": [
"<face_1> 对 <face_2> 说:‘我受够你了,Bob!’",
"<face_2> 对 <face_1> 说:‘那现在呢,Alice?’"
]
}
}
]
输出:
看起来 CLIP_2 中的内容正好显示了 Alice 和 Bob 之间的争吵。为了弄清楚这次争吵如何影响了他们的关系,我需要看看 CLIP_3 中接下来发生了什么。
[SEARCH] CLIP_3 中发生了什么?
现在,请针对以下输入生成你的回答:
问题:{question}
知识:{search_results}
输出:
Control Prompt (last round for Gemini-Agent and Gemini-GPT4o-Hybrid)¶
You are given a question about a specific video and a dictionary of some related information about the video. Each key in the dictionary is a clip ID (an integer), representing the index of a video clip. The corresponding value is a list of video descriptions from that clip.
Your task is to analyze the provided information, reason over it, and produce the most reasonable and well-supported answer to the question.
Output Requirements:
• Your response must begin with a brief reasoning process that explains how you arrive at the answer.
• Then, output [ANSWER] followed by your final answer.
• The format must be: Here is the reasoning… [ANSWER] Your final answer here.
• Your final answer must be definite and specific — even if the information is partial or ambiguous, you must infer and provide the most reasonable answer based on the given evidence.
• Do not refuse to answer or say that the answer is unknowable. Use reasoning to reach the best possible conclusion.
Additional Guidelines:
• When referring to a character, always use their specific name if it appears in the video information.
• Do not use placeholder tags like <character_1> or <face_1>.
• Avoid summarizing or repeating the video information. Focus on reasoning and answering.
• The final answer should be short, clear, and directly address the question.
Input:
• Question: {question}
• Video Information: {search_results}
Output:
中文版
你将获得关于特定视频的问题,以及一个包含视频相关信息的字典。字典中的每个键是一个剪辑 ID(整数),表示视频片段的索引。对应的值是该剪辑的描述列表。
你的任务是分析提供的信息,对其进行推理,并给出最合理、最有依据的答案。
输出要求:
* 回答必须以简短的推理过程开头,说明你是如何得出答案的。
* 然后输出 `[ANSWER]`,并给出最终答案。
* 格式必须为:Here is the reasoning… [ANSWER] 你的最终答案。
* 最终答案必须明确具体——即使信息不完整或存在歧义,也必须基于现有证据推理出最合理的答案。
* 不得拒绝回答或声称无法得出答案。
附加指导:
* 提到角色时,如果视频信息中出现了具体名字,必须使用具体名字。
* 不使用占位符标签,如 `<character_1>` 或 `<face_1>`。
* 避免总结或重复视频信息,重点放在推理和回答上。
* 最终答案应简短、清晰,直接回答问题。
输入:
* Question: {question}
* Video Information: {search_results}
输出:
Control Prompt (last round for M3-Agent)¶
# system_prompt
You are given a question and some relevant knowledge. Your task is to reason about whether the provided knowledge is sufficient to answer the question. If it is sufficient, output [Answer] followed by the answer. If it is not sufficient, output [Search] and generate a query that will be encoded into embeddings for a vector similarity search. The query will help retrieve additional information from a memory bank.
Question:{question}
# instruction_prompt
Output the answer in the format:
Action: [Answer] or [Search]
Content: {content}
If the answer cannot be derived yet, the {content} should be a single search query that would help retrieve the missing information. The search {content} needs to be different from the previous.
You can get the mapping relationship between character ID and name by using search query such as: "What is the name of <character_{i}>" or "What is the character id of {name}".
After obtaining the mapping, it is best to use character ID instead of name for searching.
If the answer can be derived from the provided knowledge, the {content} is the specific answer to the question. Only name can appear in the answer, not character ID like <character_{i}>.
# last_round_prompt
The Action of this round must be [Answer]. If there is insufficient information, you can make reasonable guesses.
中文版
# system_prompt
你将会得到一个问题以及一些相关知识。你的任务是推理判断所提供的知识是否足够回答该问题。如果足够,请输出 `[Answer]` 并给出答案;如果不够,请输出 `[Search]` 并生成一个查询,用于向量相似度搜索以从记忆库中检索更多信息。该查询将帮助获取额外的信息。
问题:
# instruction_prompt
请按以下格式输出答案:
Action: [Answer] 或 [Search]
Content: {content}
* 如果答案尚无法得出,`{content}` 应为一个单独的搜索查询,用于帮助检索缺失的信息。搜索的 `{content}` 需要与之前的不同。
* 你可以通过搜索查询获取角色 ID 与姓名的映射,例如:"What is the name of <character_{i}>" 或 "What is the character id of {name}"。
* 获得映射关系后,最好在搜索时使用角色 ID 而不是姓名。
* 如果答案可以从提供的知识中得出,`{content}` 应为问题的具体答案。答案中只能出现姓名,不可以出现类似 `<character_{i}>` 的角色 ID。
# last_round_prompt
本轮的 Action 必须为 `[Answer]`。如果信息不足,也可以进行合理的猜测。