2508.04037_SEA: Self-Evolution Agent with Step-wise Reward for Computer Use¶
引用: 0(2025-09-09)
组织:
Lenovo
China Agricultural University
总结¶
三种方法
可验证任务轨迹生成流水线
用于生成可验证任务的闭环轨迹,从而训练智能体的推理能力,解决了模型从数据中自我进化的挑战
使用两个智能体分别生成任务指令和验证程序。生成的可验证任务随后被用于轨迹提取与评估。
这一过程周期性地用最新训练好的模型替代旧的生成模型,并产生高质量数据。
之后,筛选模型将从这些数据中选择合适的数据用于训练,这是整个流程中的关键步骤,确保了训练数据的质量和有效性。
分步强化学习的轨迹推理
替代传统的长周期训练方式
这种方法突破了计算资源的限制,使模型能够更高效地自我进化。
基于基础能力的泛化增强方法
帮助模型在任务执行过程中具备更强的基础能力与规划能力
Abstract¶
计算机使用代理是人工智能领域的一个新兴方向,旨在通过操作计算机来完成用户的任务,已经引起了学术界和工业界的广泛关注。然而,当前代理的性能还远未达到实际应用的要求。
在本文中,作者提出了自我进化代理(Self-Evolution Agent,SEA),用于计算机使用任务。为了开发这一代理,作者提出了一系列创新方法,分别涉及数据生成、强化学习和模型增强。
具体来说,作者首先提出了一种自动化的轨迹生成管道,用于生成可用于训练的可验证轨迹。这是数据生成阶段的重点,旨在为训练提供高质量的数据。
其次,作者提出了高效的逐步强化学习方法,以缓解长期训练所带来的显著计算需求。这是训练策略上的关键创新,有助于提升训练效率。
最后,作者提出了一种模型增强方法,能够将语义理解和规划能力融合到一个模型中,而且无需额外的训练。这一步是实现SEA综合能力的关键。
通过上述在数据生成、训练策略和模型增强方面的创新,作者开发了一个仅包含7B参数的SEA模型,其性能优于同参数规模的其他模型,且与更大参数模型相当。此外,作者表示将在未来开源相关模型权重和代码。
I Introduction¶
以下是对该论文章节内容的总结,按照原文结构进行整理,并对重点内容进行强调说明:
I 引言¶
研究背景与意义:
计算机使用代理(computer use agent)是一种能够根据用户指令操作计算机、实现用户目标的技术,被认为是迈向通用人工智能的一个重要里程碑。要实现这一目标,代理需要理解计算机环境、基于指令制定计划,并最终执行操作。当前,研究人员通常以屏幕截图作为计算机环境的表示方式。随着多模态大语言模型(MLLMs)的发展,其在感知和推理方面的能力显著提升,能够较好地满足计算机使用代理的需求。
研究挑战:
尽管智能代理领域取得了显著进展,但构建适用于真实世界部署的鲁棒代理仍然极具挑战性,尤其是在需要复杂多模态推理和动态、不确定环境的场景中。其中一个关键挑战是高质量数据的获取。
当前主流的数据构建方法主要依赖于人工设计的任务模板和标注,这种方式不仅成本高、难以扩展,而且在复杂任务的语义覆盖和多样性方面往往不足。此外,真实世界任务通常涉及多步骤、长时序的交互,而稀疏奖励(sparse reward)使得代理难以建立动作与结果之间的明确联系,导致任务执行效果不佳。
另外,处理复杂的图形用户界面(GUI)任务时,图像数据的编码通常需要处理大量token,其中许多token对任务执行和推理贡献较小,但计算成本较高。此外,现有推理机制频繁依赖外部模型进行轨迹评估和选择,这增加了计算负担和系统复杂性,限制了代理的效率和可扩展性。
本文贡献与方法概述:
为解决上述问题,本文提出了一套新颖的代理训练方法,旨在实现高效且可扩展的任务学习与执行。
1. 数据生成阶段:¶
提出一个闭环任务生成管道,通过任务生成代理与代码生成代理的协同工作,自动生成包含任务指令、执行程序和验证程序的可验证任务。
该双代码生成策略确保了每个任务都有明确的成功标准和程序化验证方法,形成了闭环监督结构,显著提升了生成数据的有效性和可用性。
使用虚拟环境运行任务,并通过验证程序筛选成功完成的任务。
提出GATE方法(Generation and Assessment for Trajectory Extraction),用于构建高质量且具有代表性的训练轨迹,提升代理的学习效率:
对每个验证通过的任务进行多轮推理,生成多样化的候选轨迹;
随着训练推进,逐渐用代理模型替换推理模型;
通过验证代码再次筛选轨迹,确保成功完成任务;
优先选择步骤最少的轨迹,并训练步骤过滤模型以消除冗余或错误步骤,从而获得高质量、简洁的训练数据。
2. 训练阶段:¶
提出TR-SRL(Trajectory Reasoning by Step-wise Reinforcement Learning)方法:
通过对比代理执行结果与真实结果,评估每一步;
同时评估代理生成的“思考”与执行行为之间的一致性,确保内部推理与外部行为的一致性。
3. 模型增强阶段:¶
提出基于Grounding的泛化增强方法,将规划能力与Grounding能力整合到统一模型中,提升模型的整体性能;
引入时间压缩感知机制(Temporal Compressed Sensing Mechanism),通过建模输入图像token在时间上的重要性,仅保留关键token,从而显著降低训练成本,同时保留关键语义内容,提高推理效率。
主要贡献总结:¶
提出闭环可验证任务生成管道:通过任务生成代理和代码生成代理的协同,生成包含指令、执行和验证程序的任务轨迹。引入GATE方法,通过轨迹采样和评估筛选最优训练步骤。
提出TR-SRL方法:采用分步强化学习的方式,替代传统的长时序训练,提高训练效率和任务执行的准确性。
提出基于Grounding的泛化增强方法:将规划和Grounding能力统一,不仅保持原有模型性能,还能进一步提升性能。
总结:¶
基于上述方法(可验证数据生成、高效强化学习和模型增强),作者提出了SEA(Self-Evolution Agent),即一种面向计算机使用的自进化代理。实验结果显示,该代理在性能上优于7B参数模型,且在更大参数规模下具有可比性,展示了该方法的有效性和扩展性。
如需进一步分析方法细节或实验结果部分,也可以继续提供相应章节内容。
II Related Works¶
II-A High-quality Training Data¶
高质量的训练数据是连接“符号世界”与“数字世界”的关键,对于智能代理的发展具有重要意义。
早期工作:如 Rico 和 Mini-Wob 提供了序列化的 GUI 数据和低级别的键盘/鼠标交互数据,分别应用于移动应用和网页任务。
后续研究:扩展了数据资源,覆盖了移动、网页和桌面应用场景。
轨迹数据:研究者常用轨迹数据(包含 GUI 信息、高低级别指令和操作序列)来训练代理。
演示数据与自收集数据:通过演示数据、模仿学习和自收集数据来微调视觉语言模型(VLMs),如 AutoUI 和 CogAgent。
自动任务生成:PAE 可以自动生成任务,提供多样化的训练数据。
🔍 主要挑战:
依赖代价高昂的手动标注任务模板;
静态数据无法适应真实世界的动态变化;
任务轨迹质量不一致。
✅ 本文贡献:提出了一种生成高质量且可验证任务的流水线方法,确保轨迹正确性,从而提升代理在不同环境中的适应性和有效性。
II-B Compute Use Agent¶
随着多模态大语言模型(MLLMs)的发展,代理能够执行更复杂的 GUI 任务。
模型案例:
SeeClick、ScreenAgent:利用视觉语言模型(VLMs)进行界面理解和任务执行;
GUI-R1:引入强化学习机制提升 UI grounding;
Song:提出基于 API 的网络代理框架;
AgentWorkflow Memory(AWM):优化代理的记忆管理,提升后续决策效率;
PresentAgent:专注于生成演示文稿。
🔍 关键问题:
长周期任务奖励稀疏;
训练计算成本高;
缺乏思维与行为一致性建模。
✅ 本文解决方案:提出使用逐步强化学习(step-wise RL),通过设计专用奖励机制和先进的强化学习策略,替代传统长周期训练,提升任务执行效率与一致性。
II-C Reinforcement Learning¶
强化学习在提升语言模型性能方面发挥了重要作用,尤其是在复杂任务中的表现。
代表性模型:
DeepSeek-R1:通过后训练显著提升模型性能;
OpenAI 的 o1:在数学推理、代码生成和多模态推理任务中表现出色;
Sweet-RL:引入多轮 DPO 框架提升长周期行为;
ARPO:结合经验回放和任务选择策略,提升 GUI 多轮任务成功率;
DISTRL:通过异步分布式强化学习框架和 A-RIDE 算法,提升 GUI 代理的训练效率;
UI-TARS:通过增强感知、统一动作建模和双阶段推理,显著提升复杂 GUI 任务性能;
交互式优化方法:使用自评估反馈优化 LLM/VLMs 和 Web/GUI 代理。
🔍 核心思想:通过结构化奖励信号、经验回放、任务选择等机制,解决强化学习中训练效率低、奖励稀疏等问题。
✅ 本文方向:借鉴这些先进强化学习方法,结合任务导向的奖励机制,提升代理的训练效率与泛化能力。
总结¶
本节从三个关键方面系统回顾了相关研究:
II-A High-quality Training Data:强调高质量训练数据对智能代理的重要性,指出现有方法的局限性,并提出生成可验证任务的改进方案;
II-B Compute Use Agent:总结了当前 GUI 代理的研究进展,聚焦于 MLLMs 的应用与挑战,并提出采用逐步强化学习来优化任务训练;
II-C Reinforcement Learning:回顾了强化学习在提升代理能力中的关键作用,指出各种策略和框架,并作为本文方法设计的参考基础。
整体来看,本文的研究在数据生成与强化学习训练两个方面进行了创新,旨在提升智能代理在复杂 GUI 任务中的性能与适应性。
III Method¶
本文的方法部分详细介绍了提出的SEA(Self-Evolution Agent)模型的设计与实现,整体方法围绕三个核心技术展开:自动数据收集、基于多奖励的强化学习和基于定位模型的泛化增强。以下是对该章节的结构化总结:
III-A Data Engine for Self-evolution(自进化数据引擎)¶
为实现模型的持续进化,提出了一种自动数据生成引擎,用于生成计算机软件交互的轨迹数据,以解决人工操作产生的数据量不足的问题。
III-A1 生成闭合验证任务(Generation of closed-loop verifiable tasks)¶
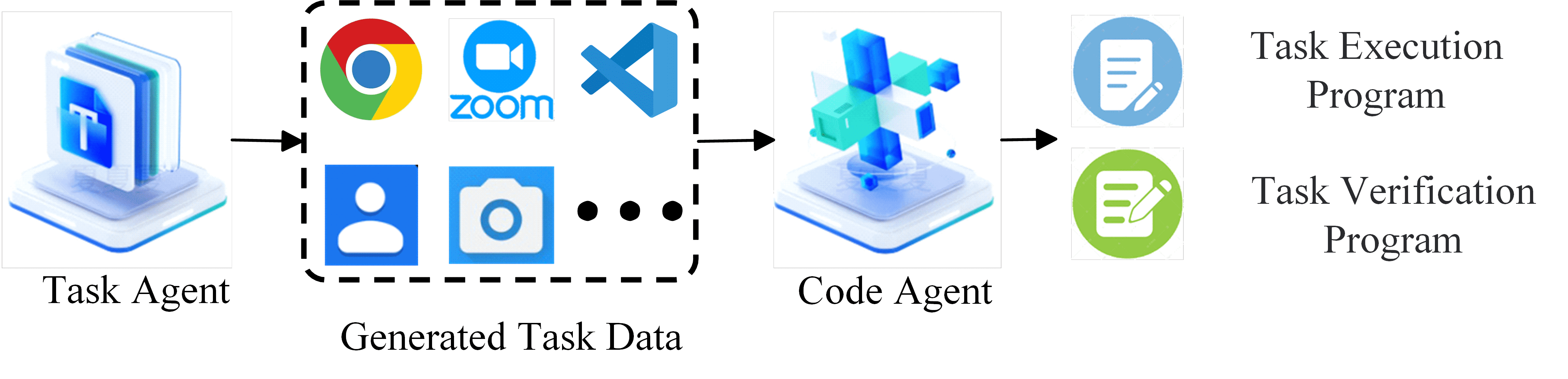
Figure 2:Illustration of Generating Closed-loop Task Data.
任务生成管道由三部分组成:
任务代理(Task Agent)生成任务指令,并利用少量样本激活模型的上下文学习能力。
代码生成代理(Code Generation Agent)生成执行程序和验证程序。
执行程序:使用 Python 完成任务。
验证程序:判断执行结果是否满足任务需求。
验证任务对:通过执行与验证程序的配对运行,筛选出可验证的完整任务。
该过程生成的是可验证的闭环任务,确保生成的轨迹能完成任务目标。
III-A2 轨迹提取与多阶段过滤(Generation and Assessment for Trajectory Extraction)¶
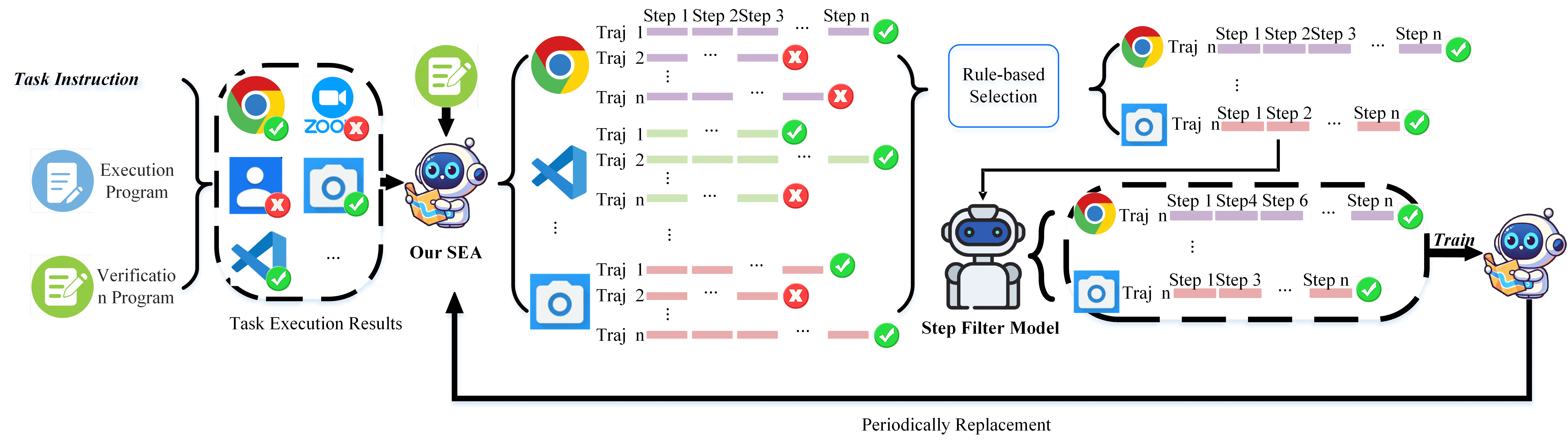
Figure 3:Illustration of the data generation and multi-stage trajectory filtering strategy.
多阶段轨迹过滤策略用于提取高质量的交互轨迹:
冷启动模型(UI-TARS-1.5-7B)生成多种轨迹。
验证程序筛选出任务成功完成的轨迹。
优先选择步数最少的轨迹,保证效率。
引入步模型(Step Model)进一步过滤冗余或错误的步骤。
逐步进化策略:训练过程中逐步替换冷启动模型,使模型在训练过程中持续进化。
III-B Filtering data with step model(基于步模型的数据过滤)¶
步模型用于判断每个步骤是否成功执行。
通过手动标注数据 + 提示调整 + 多次推理投票的方式训练出轻量级的步模型。
使用 QWen2.5-VL-72B 模型进行推理,并通过数据蒸馏方式将大模型能力转移到小模型中,实现性能和效率的兼顾。
III-C Step-wise Reinforcement Learning(基于步骤的强化学习)¶
提出基于步骤的强化学习方法(Trajectory Reasoning by Step-wise RL),提升模型在多步骤任务中的决策能力。
III-C1 GRPO 预备知识(Preliminary of GRPO)¶
使用 Group Relative Policy Optimization (GRPO) 作为强化学习框架:
GRPO 无需显式价值函数,适合大型语言模型的微调。
目标函数结合了优势估计(Advantage Estimation)和KL 散度约束,优化模型策略。
III-C2 步骤式 RL 训练(Step-wise RL training)¶
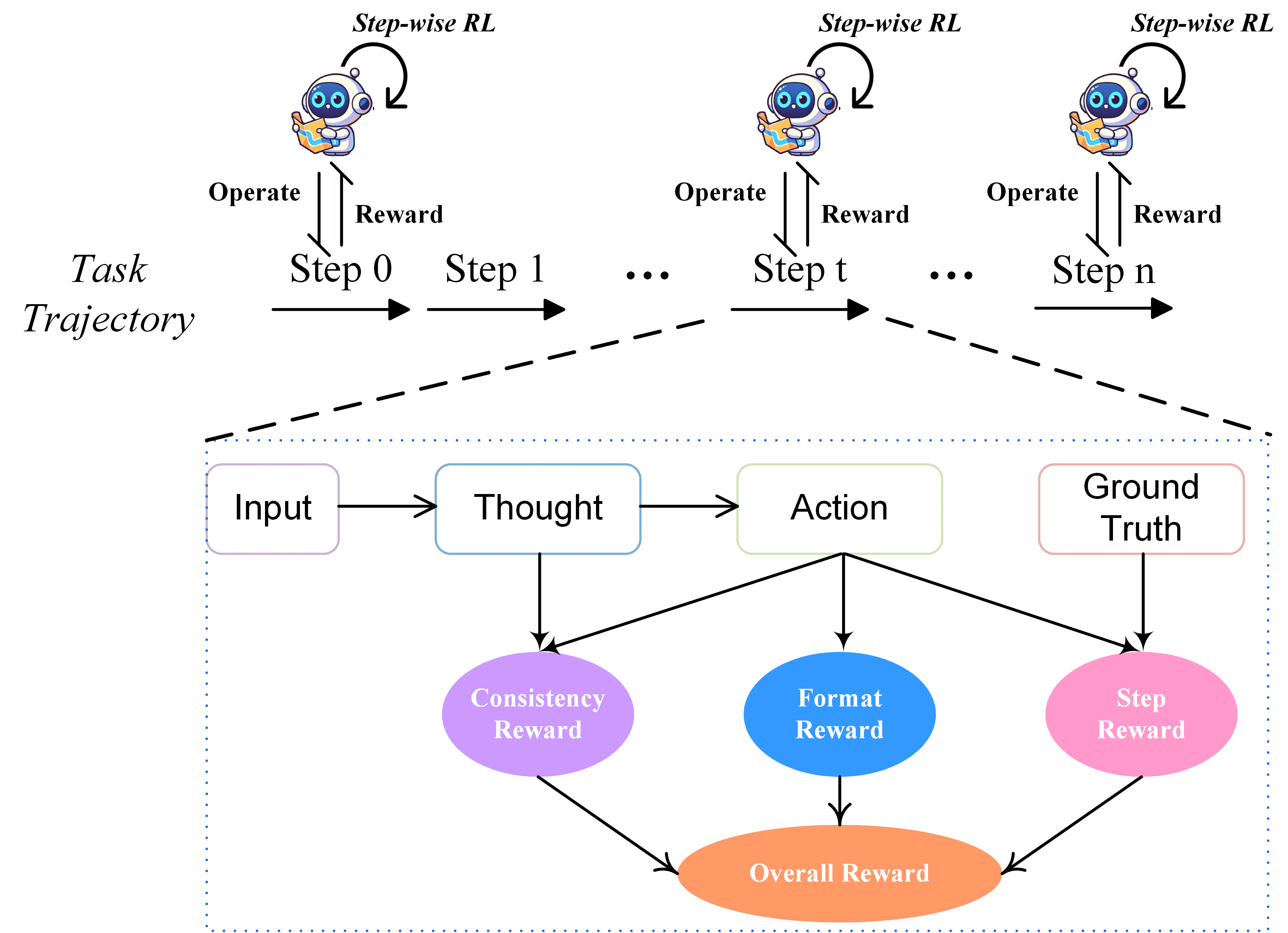
Figure 4:Illustration of Trajectory Reasoning by Step-wise Reinforcement Learning.
每个任务轨迹由多个步骤组成,每个步骤包含:
屏幕状态(State)
操作(Action)
奖励(Reward)
III-C3 奖励机制(Rewards)¶
步骤奖励(Step Reward):基于步骤是否成功完成。
推理与动作一致性奖励(Reasoning and Action Consistency Reward):若生成动作与推理逻辑一致,则奖励为 1,否则为 0。
动作格式奖励(Action Format Reward):若输出格式正确,奖励为 1,否则为 0。
III-C4 训练目标(Training Objective)¶
目标函数为最大化三类奖励的期望值(步骤奖励 + 推理一致性 + 格式奖励),公式如下:
\[ \max_{\theta} \mathbb{E}_{x_i \sim D, \tau_i \sim \pi_\theta} [r_i(x_i, \tau_i) + r_c(x_i, \tau_i) + r_f(x_i, \tau_i)] \]使用 GRPO 框架进行优化,无需显式价值函数,训练效率高。
III-D Inference Stage(推理阶段)¶
在推理阶段,SEA 模型替代传统模型(如 GTA1),自主完成候选轨迹的生成与选择。
不依赖外部评分模型,显著降低计算开销,提升推理效率。
III-E Grounding-Based Generalization Enhancement(基于定位的泛化增强)¶
在训练出具备规划能力的模型后,进一步增强其对屏幕元素的定位能力(Grounding)。
III-E1 定位模型训练(Train Grounding Model)¶
使用**监督微调(SFT)**训练定位模型。
数据来源包括 Aguvis 和 OS-Atlas 等高质量公开数据集。
通过数据增强(如图像缩放、颜色反转)提升模型鲁棒性。
引入改进的样本构造方法,保留复杂任务样本,提升模型对复杂任务的理解。
使用IoU(交并比)奖励函数作为训练目标:
\[ \text{Reward} = \min\left(1, \frac{\text{IoU}(B_p, B_{gt})}{\mathbb{I}[\text{IoU}(B_p, B_{gt}) \leq 0.7] + \varepsilon} \right) \]
III-E2 模型融合(Model Merge)¶
使用 DARE(Difference-based Adapter Replacement) 方法将规划模型和定位模型合并。
通过保留两个模型的参数差异,保留原有性能的同时实现模型融合。
III-F Temporal Compressed Sensing Mechanism(时间压缩感知机制)¶
提出 TCSM 机制提升训练效率、减少计算成本。
核心思想是:根据时间近度对图像帧进行优先级划分。
保留最近的 \(k\) 帧,其余压缩处理,保留关键时序信息。
公式如下:
\[ \mathcal{I}_{\text{TCSM}} = \left\{ \text{Pad}\left(\text{Resize}(I_i)\right) \mid i \in \mathcal{H},\ i \geq n - k + 1 \right\} \]
总结¶
本文的方法部分完整地构建了一个自进化、多奖励强化学习、定位增强的智能代理系统(SEA)。其核心突破包括:
自动化闭环任务生成与数据过滤:解决训练数据不足问题,构建高质量轨迹数据集。
多奖励强化学习训练策略:提升模型在复杂任务中的决策与推理能力。
定位模型与规划模型融合:增强模型对复杂界面的感知与操作能力。
TCSM 机制:提升训练效率,减少计算资源消耗。
整体方法在多个任务类别中表现出优越性能,尤其在复杂、多步骤的计算机交互任务中具有显著优势。
IV Experiments¶
以下是对该章节内容的总结,按照原文结构进行组织,重点内容进行了强调,非重点内容做了精简处理:
IV 实验¶
在本节中,作者进行了大量实验,对比了所提出的智能体与其他最先进的方法,并对方法进行了相关分析。
IV-A 实验设置¶
实现细节¶
训练阶段:使用 LLaMa-Factory 训练用于模型集成的 grounding 模型;整个模型使用 Easy-R1 通过 GRPO(Gradient-based Reinforcement Policy Optimization) 进行训练。
硬件资源:训练过程中使用 1 台配备 8 张 80GB A100 GPU 的服务器。
推理阶段:参考了 GTA-1 的方法,但有所不同。作者使用自己的代理先生成 8 个可能结果(NN=8),然后使用另一个模型从中选择最优解,与 GTA-1 使用 GPT-o3 不同。
数据集与评估指标¶
训练数据:使用生成的 可验证任务(400 个任务),每条轨迹生成 8 个推理结果。
评估数据集:
ScreenSpot-V2 和 ScreenSpotPro:用于评估 grounding 模型的性能,使用 准确率 作为评估指标。
OSWorld 基准任务集:用于评估智能体在开放 GUI 任务上的表现,包含 369 个真实任务,评估指标为 任务成功率。
IV-B 实验结果¶
IV-B1 Grounding 性能¶
作者在 ScreenSpot-V2 和 ScreenSpotPro 上验证了改进后的 grounding 模型的性能。
在同等规模模型中,该 grounding 模型达到了 SOTA(State-of-the-Art) 水平。
IV-B2 OS-World 性能¶
在 OSWorld 基准 上,作者将方法与其他 SOTA 方法进行了对比。
尽管模型参数较少、训练成本更低,但作者的方法在任务成功率上仍优于 UI-TARS-72B-DPO(30.1% vs. 27.1%)。
与基准模型 UI-TARS-1.5-7B 相比,作者的方法(SEA)提高了 5.2% 的任务成功率,成为同规模模型中的最高水平。
表格(Table II)展示了各模型的性能:
模型 |
OSWorld 任务成功率(%) |
|---|---|
OpenCUA-3B |
18.8 |
OpenCUA-Qwen2-7B |
23.1 |
OpenCUA-7B |
26.6 |
UI-TARS-72B-DPO |
27.1 |
UI-TARS-1.5-7B |
27.4 (24.9) |
本文(无增强) |
28.1 |
本文(完整方法) |
30.1 |
重点强调:作者的方法在参数更少、成本更低的情况下仍取得 SOTA 性能,证明了 可验证任务的数据生成 和 逐步强化学习 的有效性。
IV-C 消融实验¶
规划的泛化增强¶
作者提出了一种增强方法,用于提升基于强化学习训练的模型的泛化能力。
在 OSWorld 上的实验中,任务完成率从 28.1% 提升到 30.1%,提升了 2.0%。
增强方法 包括:
不同任务模块的权重集成
自进化机制(self-evolution mechanism)
作者认为,这种增强方式使模型对 PC 截图的理解更深入,从而在面对新软件时也能生成更精确的规划。
重点强调:增强方法显著提升了模型在新任务场景中的泛化能力,验证了其在实际应用中的鲁棒性与适应性。
总结¶
本章通过实验验证了所提出的智能体(SEA)在 grounding 性能和开放任务处理能力上的优越性,特别是在资源有限的情况下仍能取得 SOTA 表现。同时,消融实验进一步证明了增强机制的有效性,提升了模型在真实场景中的泛化能力。
V Conclusion¶
V 结论¶
在本文中,我们提出了一系列创新方法,旨在实现计算机系统在用户指令下的自动自我进化。我们设计了一条创新的数据生成流水线,用于生成可验证任务的闭环轨迹,从而训练智能体的推理能力,解决了模型从数据中自我进化的挑战。
在该流水线中,我们使用两个智能体分别生成任务指令和验证程序。生成的可验证任务随后被用于轨迹提取与评估。这一过程周期性地用最新训练好的模型替代旧的生成模型,并产生高质量数据。之后,筛选模型将从这些数据中选择合适的数据用于训练,这是整个流程中的关键步骤,确保了训练数据的质量和有效性。
其次,我们提出了一种分步强化学习方法,替代传统的长周期训练方式。这种方法突破了计算资源的限制,使模型能够更高效地自我进化。
第三,我们提出了一种增强方法,帮助模型在任务执行过程中具备更强的基础能力与规划能力。虽然这部分内容技术细节相对较少,但它是确保模型具备良好泛化和执行能力的重要支撑。
实验部分在OSWorld基准上进行,结果表明,我们提出的智能体在性能上优于同规模模型,并达到了与更大模型相当的水平。我们相信,本文提出的三种方法——可验证任务轨迹生成流水线、分步强化学习的轨迹推理以及基于基础能力的泛化增强方法——为计算机使用智能体的研究方向提供了有前景的新路径。