2412.09764_Memory+: Memory Layers at Scale¶
引用:
19(2026-01-19)
组织:
Meta FAIR
链接
总结¶
图解¶
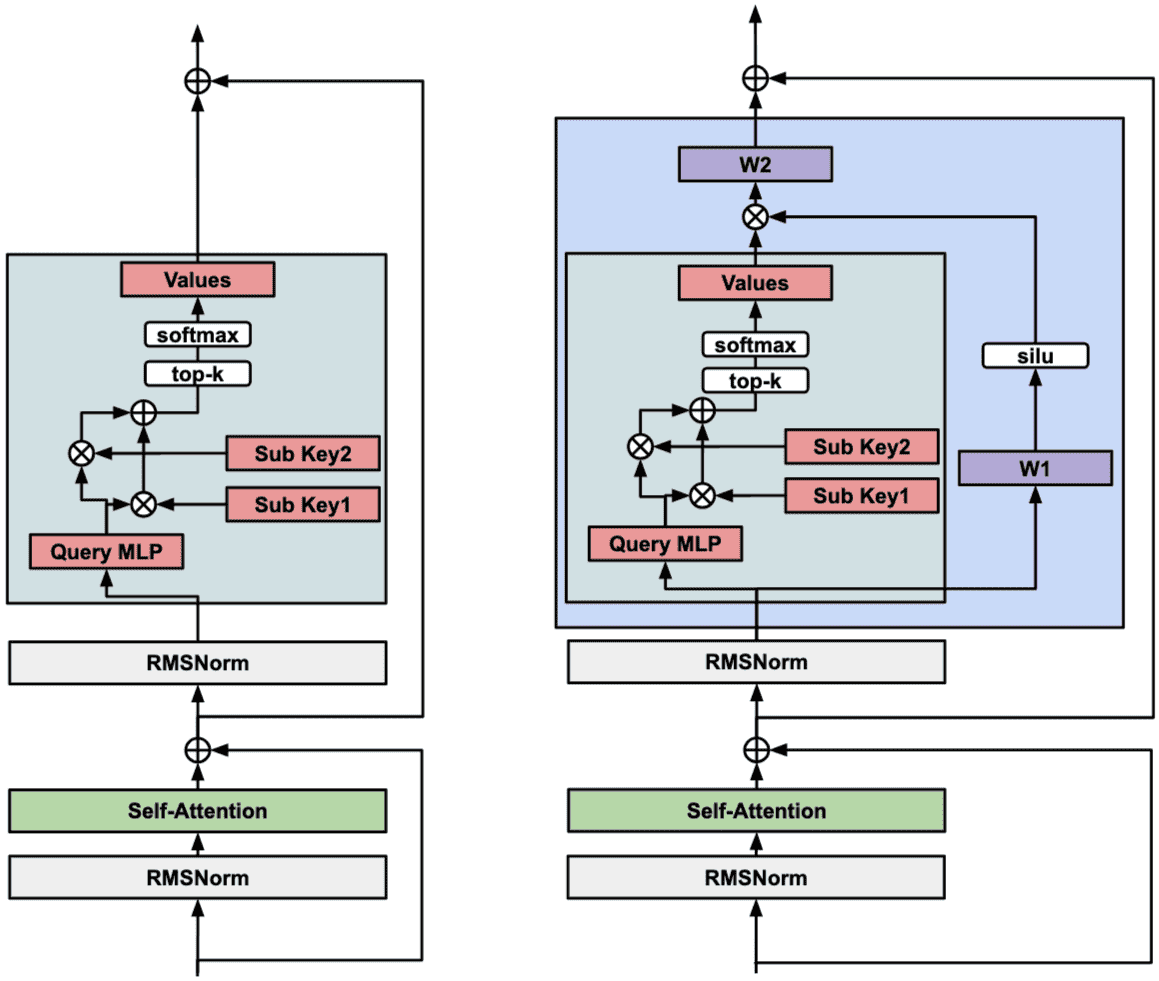
Figure 3 On the left the regular memory layer. On the right, the Memory+ block, with the added projection, gating and silu non-linearity
From Moonlight¶
三句摘要¶
💡 本文将 Memory layers 扩展到当代规模,证明其能有效增强大型语言模型,在不显著增加 FLOPs 的前提下提供额外参数,尤其在事实性任务上表现突出。
⚙️ 作者通过 Product-key lookup、并行内存、共享内存池以及优化的 CUDA 内核等技术改进,实现了 Memory layers 的大规模部署,参数量最高可达 128B。
📈 实验结果显示,使用 Memory layers 增强的模型在事实性 QA 任务上准确率提升超过 100%,性能优于计算预算多两倍的 dense 模型以及参数和计算匹配的 Mixture-of-Experts 模型。
关键词¶
Memory Layers: 记忆层是一种可训练的键值(Key-Value)查找机制,旨在为模型添加额外的参数,而不会显著增加计算量(FLOPs)。它们在概念上可以看作是计算密集型密集前馈层(dense feed-forward layers)的补充,提供专门的能力来廉价地存储和检索信息。本文作者将记忆层从概念验证阶段推向了实际应用,证明了它们在当前规模下(scale)的效用。通过用作者改进的记忆层替换一个或多个 Transformer 层中的前馈网络(FFN)部分,可以增强语言模型。
Key-Value Lookup: 键值查找是一种机制,其中信息被存储为“值”(values),并通过与“键”(keys)的匹配来检索。“键”和“值”通常都表示为嵌入向量(embeddings)。在记忆层中,输入查询(query)与一组可训练的键进行比较,以确定哪些键最匹配。然后,根据匹配的程度,对相应的“值」进行加权求和,生成输出。这种机制模仿了人类的联想记忆,允许模型快速找到并利用存储的信息。
Sparse Activation: 稀疏激活是指在模型计算过程中,只有一部分神经元或参数被激活(即参与计算)。与密集层(dense layers)不同,密集层通常会激活所有参数,记忆层通过仅激活与查询最相关的“k”个键值对来实现稀疏激活。这种稀疏性使得记忆层在计算上非常高效,即使拥有大量的潜在存储容量,也只需要很少的计算资源。
FLOPs: FLOPs(Floating Point Operations,浮点运算次数)是衡量计算量的一个常用指标,表示模型在处理输入时执行的浮点运算数量。论文中,作者将记忆层的计算成本(主要受内存带宽限制)与传统密集层的计算成本(主要受FLOPs限制)进行对比。记忆层通过其稀疏激活特性,在不显著增加FLOPs的情况下,大大增加了模型的参数数量和信息存储能力,与计算密集型的密集层形成互补。
Memory Bandwidth: 内存带宽是指数据在内存和处理器之间传输的速度,通常以 GB/s 或 TB/s 为单位。与主要受计算能力(FLOPs)限制的密集层不同,记忆层由于其需要从大量存储的键值对中读取数据,因此其性能瓶颈往往在于内存带宽。论文中提到,作者通过优化 CUDA 核函数,显著提高了记忆层的内存访问效率,使其接近硬件的最大内存带宽。
Feed-Forward Network (FFN): 前馈网络(FFN)是 Transformer 模型中每层的一个组成部分,通常包含两个线性变换和一个非线性激活函数。它负责在注意力机制之后处理序列中每个位置的表示。在本文中,作者提出用记忆层来替换 Transformer 层中的 FFN 部分,认为记忆层比标准的 FFN 在存储和检索信息方面更高效,尤其对于事实性任务。
Mixture-of-Experts (MoE): 混合专家(MoE)模型是一种通过使用多个“专家”网络(通常是 FFN)并仅激活其中一部分来增加模型参数量而不显著增加计算量(FLOPs)的架构。它被认为是与记忆层类似的参数扩展技术。论文中,MoE 被用作与记忆层进行对比的基线模型,尤其是在参数数量和计算量相当的情况下进行比较。研究发现,在事实性任务上,作者的记忆层模型通常优于 MoE 模型。
Parameters: 参数是模型中可训练的权重,它们存储了模型从训练数据中学到的信息。增加模型的参数量通常会提升其性能,但也会增加计算和内存需求。记忆层的主要优势在于,它能够在不显著增加 FLOPs 的前提下,通过增加大量的键值对来极大地扩展模型的参数量,从而增强其知识存储和检索能力。
Product-Key Lookup: 产品键查找(Product-Key Lookup)是一种优化记忆层中查询-键检索效率的技术,由 Lample et al. (2019) 提出。它通过将原始的 N 个键拆分成两个更小的集合(每个集合有 √N 个“半键”),并计算它们的“乘积”来表示完整的键集。这样,在进行 top-k 查找时,只需先在较小的半键集合上进行搜索,大大降低了计算复杂度,尤其适用于大规模记忆。
Parallel Memory: 并行内存(Parallel Memory)是指将记忆层的计算和存储分布到多个设备(如 GPU)上,以处理大规模的记忆参数。由于记忆层需要存储大量的键值对(可达数百万甚至数亿),其参数量和优化器状态可能会非常大。论文中采用了类似于 PyTorch 的
EmbeddingBag操作的并行化策略,将内存值分片(sharded)到不同的 GPU 上,每个 GPU 处理一部分键值对的查找和聚合,然后将结果汇集。Shared Memory: 共享记忆(Shared Memory)是指在模型中,多个记忆层共享同一个大的键值参数池。这意味着,即使模型中集成了多个记忆层(如 Memory+ 模型中的 3 个),实际的内存参数量也只相当于一个单层的内存参数量。这种参数共享策略有助于控制模型总参数量,并被发现能带来性能上的显著提升,说明了信息在不同抽象层级的记忆使用和共享的有效性。
Memory+: Memory+ 是本文提出的改进型记忆层架构。它在基础记忆层的基础上,引入了几项关键改进,包括:使用输入相关的门控(gating)和 SiLU 非线性激活函数(见图 3),采用了更高效的 CUDA 核函数实现,以及使用共享内存池(Shared Memory)。Memory+ 模型在多种下游任务上展现出超越原始记忆层和同期其他先进模型(如 MoE、PEER)的性能。
Factuality: 事实性(Factuality)是指语言模型在生成内容时,其输出内容与真实世界事实的符合程度。论文指出,增加模型规模可以提高其事实性,但即使是现代大型语言模型也可能产生幻觉。记忆层因其能够存储和精确检索大量事实性知识,在事实性问答(Factual QA)等基准测试上取得了显著的性能提升,表明它们是提高模型事实性的有效手段。
SiLU: SiLU(Sigmoid-weighted Linear Unit,Sigmoid 加权线性单元)是一种激活函数,其公式为
silu(x) = x * sigmoid(x)。在本文中,作者在 Memory+ 模型中引入了一种自定义的 SiLU 变体(swilu),并将其应用于门控机制之后,用于增强记忆层的输出。这种非线性变换被发现能够提升训练性能和模型表现,尤其是在处理大规模记忆时。PEER: PEER 是该论文中提到的一个近期模型架构,被用作与本文提出的记忆层进行对比的基线模型之一。PEER 模型在概念上类似于记忆层,但它不是检索单个值嵌入,而是检索一对嵌入,这些嵌入组合成一个秩一矩阵(rank-one matrix)。多个这样的结构被组合起来形成一个动态前馈层。PEER 的工作方式与记忆层相似,但为了达到相同的键的数量,它通常需要更多的参数。
摘要¶
该论文提出了将Memory Layers扩展到现代规模的方法,以增强大型语言模型 (LLM) 的能力,特别是在事实性任务上,同时避免显著增加计算量(FLOPs)。传统上,LLMs主要通过增加密集参数来存储信息,这导致计算和能源需求随之增加。Memory Layers提供了一种稀疏激活的机制,通过可训练的键值查找 (key-value lookup) 来专门存储和检索信息,被认为是一种更高效、更自然的关联记忆方式。
该研究将Memory Layers集成到Transformer架构中,取代了一个或多个Feed-Forward Network (FFN) 层。与典型的attention机制不同,Memory Layers的键 (keys) 和值 (values) 是可训练参数,并且通常具有更大的规模,这使得稀疏查找和更新成为必要。一个简单的Memory Layer操作可描述为:首先,根据查询 \(q\) 与键 \(K\) 的相似性选择前 \(k\) 个最近的键的索引 \(I\),然后计算这些选定键的softmax分数 \(s\),最后输出是对应值 \(V_I\) 的加权和 \(y\),即: $\(I = \text{SelectTopkIndices}(Kq)\)\( \)\(s = \text{Softmax}(K_Iq)\)\( \)\(y = sV_I\)\( 其中 \)K_I, V_I \in \mathbb{R}^{k \times n}$。
为了实现Memory Layers的大规模应用,论文解决了以下几个关键挑战并提出了相应的改进措施:
Product-key Lookup (乘积键查找):为解决大规模Memory Layer中查询-键检索的瓶颈,论文采用了Product-key Networks (Lample et al., 2019) 的思想。它将一个大型键集分解为两个更小的半键集 \(K_1, K_2 \in \mathbb{R}^{\sqrt{N} \times \frac{n}{2}}\)。查询 \(q\) 也被分割为 \(q_1, q_2 \in \mathbb{R}^{\frac{n}{2}}\)。通过首先在这些较小的半键集上执行高效的top-k查找(获取索引 \(I_1, I_2\) 和分数 \(s_1, s_2\)),然后组合这些结果,可以在不实例化整个大键集的情况下高效地执行全局top-k查找。
Parallel Memory (并行存储):Memory Layers天生是内存密集型组件,尤其是在参数和优化器状态方面。为了扩展到数百万个键,论文实现了跨多个GPU的并行化。Memory Values被分片 (sharded) 存储在嵌入维度 (embedding dimension) 上。在每个步骤中,索引从进程组中收集,每个工作单元在其拥有的嵌入分片上执行
EmbeddingBag操作,然后将部分嵌入结果聚合。这种实现方式独立于其他模型并行化方案,并且管理激活内存效率高。Shared Memory (共享存储):论文发现,在多个Transformer层中共享一个单一的Memory参数池,可以在不增加总参数量的情况下显著提升性能。与以前的工作不同,这种方法最大化了参数共享。实验表明,增加Memory Layers的数量起初能提升性能(最佳为3个Memory Layers),但超过某个点后,由于移除了过多密集参数,性能反而会下降,这表明稀疏和密集层是互补的。
性能和稳定性改进:
优化的CUDA kernels:Memory Layer的核心操作是加权求和,这在PyTorch中通常通过
EmbeddingBag实现。鉴于FLOPs可忽略不计,该操作主要受限于GPU内存带宽。论文开发了新的、更高效的CUDA核函数,将Memory Layer的前向传播的内存访问优化到接近H100硬件规格(3TB/s),相比PyTorch的实现提高了6倍。反向传播也通过atomics、lock和reverse_indices等策略进行了优化。输入依赖的门控和silu非线性:为提升训练性能和稳定性,Memory Layer的输出增加了输入依赖的门控机制和
silu非线性激活函数 (Hendrycks and Gimpel, 2023)。修改后的输出计算为: $\(\text{output} = (y \odot \text{silu}(x^T W_1))^T W_2\)\( 其中 \)x\( 是输入, \)W_1, W_2\( 是可训练权重,\)\odot$ 表示元素级乘法。这使得模型能更好地控制Memory Layer的贡献。qk-normalization:对于大型Memory Layers,特别是对于小型基座模型,训练可能会不稳定。论文采用了qk-normalization (Team, 2024) 来缓解这一问题。
实验部分,论文在Llama系列的基座模型(从134M到8B参数)上进行了广泛的测试,Memory Layers的容量最高达到128B参数,预训练数据量达到1万亿 (1T) token。结果表明,与具有两倍以上计算预算的密集模型相比,Memory Augmented模型在下游任务(特别是事实问答,如NaturalQuestions和TriviaQA)上表现更优。与相同计算和参数规模的Mixture-of-Experts (MoE) 模型相比,Memory Layers也表现出优越性。此外,在8B规模的实验中,Memory+模型在训练200B token时就表现出显著提升,在1T token时接近甚至超过了Llama3.1 8B模型在15T token上的性能,尤其是在事实性任务、常识推理和代码生成任务上。
论文认为,Memory Layers能够有效地增加模型的知识获取能力,同时保持较低的计算成本,为LLM的未来架构提供了新的方向。尽管工程上仍需进一步优化以使其在生产环境中高效运行,但其在模型能力提升上的潜力是巨大的。
Abstract¶
本论文研究了记忆层(memory layers)在大规模语言模型中的应用。记忆层通过一种可训练的键值查找机制,在不增加计算量(FLOPs)的前提下为模型引入额外参数,从而增强模型的信息存储与检索能力。
核心观点与贡献:¶
记忆层的结构优势:
记忆层是一种稀疏激活(sparsely activated)的模块,与计算密集型的全连接前馈层(dense feed-forward layers)形成互补。
它以较低的计算成本提供额外的容量,用于存储和检索信息。
实际应用验证:
本文首次将记忆层应用于大规模模型,而不仅仅是概念验证阶段。
实验表明,在下游任务中,使用改进记忆层的语言模型在性能上优于计算预算两倍的密集模型,以及在计算和参数数量相同时的混合专家模型(MoE)。
任务表现亮点:
在事实性任务(factual tasks)中,记忆层带来的性能提升尤为显著,说明其在知识密集型任务中具有优势。
实现与扩展性:
提供了一个完全可并行化的记忆层实现,支持大规模部署。
实验展示了记忆层可以扩展到1280亿(128B)个记忆参数,预训练数据达到1万亿个token。
对比的基线模型最大为80亿(8B)参数。
总结:¶
这篇论文证明了记忆层不仅在理论上具有优势,在实际大规模应用中也能显著提升模型性能,尤其是在知识密集型任务中。其低计算成本、高扩展性,使其成为未来模型架构设计的重要方向之一。
1 Introduction¶
1 引言(Introduction)¶
核心内容概述:¶
本节介绍了语言模型中使用**记忆层(memory layers)**的动机、挑战以及本文的主要贡献。作者指出,虽然当前语言模型通过增加参数量来提升性能,但这种方式在计算和能耗方面代价高昂。而记忆层作为一种替代方案,可以更高效地处理信息存储,尤其是对于需要记忆事实性知识的任务。
1.1 问题背景与动机¶
语言模型的信息存储:预训练语言模型(LLMs)通过参数存储大量信息,且模型规模越大,信息回忆和使用能力越强。
传统方法的局限性:当前模型主要依赖密集矩阵变换(dense linear transforms)来存储信息,参数规模的增加直接导致计算和能耗上升。
记忆层的优势:某些任务(如事实性知识关联)更适合使用**键值查找机制(key-value lookup)**实现的记忆层,这种方式更自然、更高效。
1.2 记忆层的实现与挑战¶
记忆层的实现方式:基于嵌入(embedding)的键值对查找机制(Weston et al., 2015),并可端到端训练(Sukhbaatar et al., 2015)。
当前挑战:
硬件适配问题:记忆层是内存带宽受限(memory bandwidth bound)的,与传统密集层(FLOP-bound)不同,难以在现代硬件上高效运行。
研究投入不足:由于上述限制,记忆层在现代AI架构中未被广泛研究和应用。
替代方案兴起:如MoE(Mixture-of-Experts)因其更接近密集网络结构,更容易扩展,因此成为主流。
1.3 本文贡献与实验结果概览¶
主要贡献:
提出并实现了大规模记忆增强架构(Memory-Augmented Architectures),将Transformer中的FFN层替换为记忆层。
实验覆盖了从134M到8B的模型规模,记忆容量高达1280亿参数,比以往研究提升两个数量级。
实验结果亮点:
事实性问答准确率提升超过100%(在NaturalQuestions和TriviaQA上)。
在代码生成(HumanEval、MBPP)和通用知识任务(Hellaswag、MMLU)上也有显著提升。
记忆增强模型在许多任务上表现接近或超过训练资源多4倍的密集模型。
在事实性任务上优于参数和计算量相当的MoE模型。
1.4 图表分析(Figure 1)¶
图1说明:
横轴:记忆参数数量(单位为2048×2048),即不同记忆容量。
纵轴分别为:
左图:事实性问答准确率(NaturalQuestions的Exact Match和TriviaQA的F1)。
右图:任务负对数似然(NLL,越小越好)。
虚线表示一个70亿参数模型在2万亿token上训练的结果(计算量是当前模型的10倍)。
关键观察:
随着记忆容量增加,准确率提升,NLL下降。
即使在更少训练资源下,记忆增强模型也能接近甚至超过更大模型的表现。
总结:¶
本节通过理论分析与实验验证,提出记忆层是一种高效的信息存储机制,尤其适合处理事实性知识任务。作者通过大规模实现和优化,展示了记忆增强架构在性能和效率上的显著优势,并呼吁将其纳入下一代AI架构设计中。
2 相关工作(Related Work)¶
语言模型的扩展规律(Language Model Scaling Laws)¶
核心观点:Kaplan 等人(2020)提出了语言模型在计算资源、数据量和参数规模扩展时的经验性性能规律,通常以训练/测试的对数似然(log-likelihood)作为衡量指标,认为其与下游任务性能高度相关。
扩展行为:大多数任务在使用良好行为的指标(如任务似然损失)时,随着模型规模扩大,性能呈现平滑提升(Schaeffer 等人,2023)。
非线性行为:但在某些下游任务中也观察到非线性行为和相变现象(Wei 等人,2022;Ganguli 等人,2022),说明扩展规律并非总是线性。
混合专家模型(Mixture-of-Experts, MOE)¶
特点:MOE 是一种在不增加计算预算的前提下增加模型参数的方法(Shazeer 等人,2017;Lepikhin 等人,2020)。
扩展规律:虽然 MOE 的扩展规律也主要关注训练困惑度(perplexity),但其性能提升在实际应用中表现良好,因此被广泛采用(Jiang 等人,2024;OpenAI 等人,2024;Team 等人,2024)。
研究空白:目前对特定任务(如事实性生成)的扩展规律研究仍较少。
增强记忆模型(Memory Augmented Models)¶
发展历程:
早期模型:Weston 等人(2015)提出记忆网络,Sukhbaatar 等人(2015)实现端到端训练。
神经图灵机:Graves 等人(2014, 2016)提出结合外部可训练记忆的神经图灵机。
高效记忆查找:Lample 等人(2019)提出 Product-key Networks 提高记忆查找效率。
最新进展:He(2024)提出的 PEER 模型将向量值替换为秩一矩阵,连接了记忆架构与 MOE。
事实性文本生成(Factual Text Generation)¶
重要性:事实性生成是生成模型的核心能力之一,通常通过开放域问答(Chen 等人,2017;Chen & Yih,2020)等知识密集型任务进行评估(Petroni 等人,2021)。
模型规模与事实性:更大的模型通常更具备事实性(Roberts 等人,2020;Brown 等人,2020),但现代大模型仍存在幻觉问题(hallucination)(Ji 等人,2023)。
缓解幻觉的方法:
检索增强生成(Retrieval-Augmented Generation, RAG)被广泛验证有效(Lewis 等人,2021;Karpukhin 等人,2020;Lee 等人,2019;Guu 等人,2020;Khandelwal 等人,2020)。
其他方法:包括数据优化、架构改进、预训练与推理阶段优化等。详见 Ji 等人(2023)第五节综述。
本文研究重点¶
使用短格式问答任务验证记忆层的有效性。
长格式生成任务留作未来研究方向。
3 Memory Augmented Architectures¶
以下是论文第3章 Memory Augmented Architectures 的结构化总结,按照原文标题组织,重点内容详细讲解,非重点内容精简处理,并保留了数学公式、算法步骤和表格数据的要点。
3 Memory Augmented Architectures¶
本章介绍了一种可训练记忆层(memory layer)的结构,其工作原理类似于注意力机制(attention),但有两点关键区别:
记忆层的 keys 和 values 是可训练参数,而非注意力机制中的激活值(activations)。
记忆层的 key-value 对数量极大(可达数百万),因此需要稀疏查找和更新机制。
记忆层的基本操作如下:
给定查询 \( q \in \mathbb{R}^n \)
从 key 集合 \( K \in \mathbb{R}^{N \times n} \) 中选出 top-k 最相似的 key 索引 \( I \)
计算 softmax 权重 \( s = \text{Softmax}(K_I q) \)
输出为加权值:\( y = s V_I \)
其中:
\( I \) 是索引集合
\( K_I, V_I \in \mathbb{R}^{k \times n} \) 是选出的 top-k key 和 value
\( y \in \mathbb{R}^n \) 是输出
每个 token embedding(即前一层注意力的输出)独立进行记忆查找,类似于 FFN 操作。
3.1 Scaling memory layers¶
由于记忆层是内存密集型操作,其扩展面临独特挑战。本节讨论了几个关键的扩展策略。
3.1.1 Product-key lookup(乘积键查找)¶
问题:当 memory 规模很大时,传统的最近邻搜索效率低,且难以在 keys 被持续训练和重新索引时使用近似向量相似度技术。
解决方案:采用 可训练的乘积量化键(product-quantized keys):
使用两个 key 集合 \( K_1, K_2 \in \mathbb{R}^{\sqrt{N} \times \frac{n}{2}} \)
完整的 key 集合是这两个集合的笛卡尔积,不实际存储
查询 \( q \) 被拆分为 \( q_1, q_2 \in \mathbb{R}^{\frac{n}{2}} \)
分别在两个 key 集合中查找 top-k,再组合得到最终 top-k
该方法显著减少了计算和内存开销。
3.1.2 Parallel memory(并行记忆)¶
挑战:大规模 memory 层的参数和优化器状态占用大量内存。
解决方案:跨多个 GPU 并行实现 embedding lookup 和聚合:
memory values 按 embedding 维度分片
每个 GPU 只处理其分片部分的 embedding
最终通过 gather 操作组合结果
该实现独立于其他模型并行策略(如 tensor、context、pipeline 并行),并运行在自己的进程组中。
3.1.4 Performance and stability improvements(性能与稳定性优化)¶
核心操作:top-k embedding 的加权和,使用 PyTorch 的 EmbeddingBag 实现。
问题:PyTorch 实现效率低,远低于 GPU 内存带宽上限。
优化方案:
实现了新的 CUDA 内核,前向达到 3TB/s 内存带宽(接近 H100 的 3.35TB/s)
后向传播优化策略包括:
原子加法(atomics)
行级锁(lock)
无原子操作(reverse_indices)
性能对比:
atomics 比 PyTorch 快 5 倍
reverse_indices 和 lock 在 embedding 维度 > 128 时更快(需 embedding 分布均衡)
端到端性能提升:自定义内核比 PyTorch 快 6 倍。
训练稳定性优化:
引入输入依赖的门控机制(gating)和 silu 非线性激活函数:
其中:
\( \text{silu}(x) = x \cdot \text{sigmoid}(x) \)
\( \odot \) 表示逐元素乘法
作用:提升训练稳定性,尤其对小模型。
额外措施:在需要时使用 qk-normalization(Team, 2024)缓解训练不稳定问题。
总结¶
本章系统介绍了大规模 memory 层的设计与优化方法,包括:
基本结构与数学公式
乘积键查找(product-key lookup)提升效率
多 GPU 并行实现
参数共享机制
自定义 CUDA 内核提升性能
门控机制与 silu 激活提升训练稳定性
这些技术共同支持了 memory 层在数百万 key-value 对规模下的高效训练与部署。
4 Experimental setup¶
4 实验设置(Experimental setup)¶
本节介绍了论文中实验的设计与配置,主要包括模型架构、基线模型以及评估基准。
4.1 基线模型(Baselines)¶
密集模型基线(Dense Baselines):作者基于Llama系列的密集Transformer模型构建基础架构,包括Llama2和Llama3。这些模型作为对比实验中的基线。
增强模型设计:在基础模型上,作者将一个或多个前馈网络(FFN)层替换为共享记忆层(shared memory layer),以增加模型参数量而不显著增加计算量(FLOPs)。
模型规模选择:
在探索缩放规律(scaling law)的实验中,选择了参数量分别为134M、373M、720M和1.3B的模型。
在8B级别的实验中,使用Llama3的配置和更大的词表(128k tokens)。
训练设置:使用Llama2或Llama3的tokenizer,训练到1T token,预训练数据混合策略与Llama2或Llama3相似。
对比的其他参数扩展方法:¶
MoE(Mixture-of-Experts):
每个FFN层由多个“专家”组成,每次只激活部分专家。
使用**专家选择(expert choice)**方法训练,推理时使用top-1路由。
与记忆层类似,MoE在不显著增加FLOPs的情况下提升参数量。
PEER模型:
与记忆层类似,但每次检索两个嵌入向量,组合成一个秩1矩阵。
多个这样的矩阵组合成动态的FFN层。
PEER在参数数量上是记忆层的两倍。
使用与记忆层相同的超参数配置。
重点说明:所有对比模型(MoE、PEER)的参数量尽可能与记忆增强模型匹配,以便公平比较。
4.2 评估基准(Evaluation benchmarks)¶
本节列出了用于评估模型性能的多个任务和数据集,涵盖以下几类:
1. 事实性问答(Factual QA):¶
NaturalQuestions
TriviaQA
2. 多跳问答(Multi-hop QA):¶
HotpotQA
3. 知识类任务(Knowledge-based):¶
MMLU(涵盖科学与常识)
HellaSwag(常识推理)
OBQA(开放域常识问答)
PIQA(物理常识推理)
4. 编程能力(Code Generation):¶
HumanEval
MBPP
评估指标:¶
主要使用常见的准确率指标:
QA任务:Exact Match 或 F1 Score
编程任务:Pass@1
对于小模型表现较差的任务,使用**正确答案的负对数似然(Negative Log-Likelihood, NLL)**进行模型消融分析。
重点说明:NLL被用于小模型的性能评估,因为其准确率可能不稳定或噪声较大。
5 Scaling results¶
5 扩展结果总结¶
本章节主要探讨了在计算资源受限的情况下,Memory模型与多种基线模型(如Dense、MOE、PEER)的性能对比,以及Memory模型在不同参数规模和内存规模下的扩展表现。以下是对各小节的结构化总结:
5.1 固定内存大小下的比较¶
实验设置:
固定内存大小(即额外参数数量),比较Memory模型与Dense、MOE、PEER模型。
Memory模型的“半键”数量固定为 \(2^{10} = 1024\),对应“值”数量为 \(2^{20} \approx 100\) 万。
PEER模型使用768个半键,参数略多于Memory。
MOE模型选择最少专家数,使得参数略超Memory,具体为16、8、6、4个专家,对应134m、373m、720m、1.3b的模型大小。
模型结构改进:
Memory:仅使用1个内存层,替换Transformer中间的FFN层。
Memory+:使用3个内存层,间隔分布(134m模型间隔4,其他间隔8),并引入swilu非线性激活函数,优化键维度(设为值维度的一半)。
内存层共享参数,因此内存占用与单层相当。
性能表现:
Memory模型显著优于Dense基线,在QA任务上接近参数量两倍的Dense模型。
Memory+进一步提升性能,表现介于2x~4x计算量的Dense模型之间。
PEER表现与Memory相近,但弱于Memory+。
MOE模型表现明显落后于Memory系列模型。
图表支持:
图4展示了不同模型在NaturalQuestions和TriviaQA任务上的准确率与基础参数的关系,Memory+在相同参数下表现最优。
5.2 固定基础模型下的内存扩展¶
实验设置:
固定基础模型大小(如1.3b),扩展内存大小(即键值对数量)。
关键发现:
Memory+模型在增加内存大小时,QA性能持续提升。
当内存达到6400万键(1280亿参数)时,1.3b Memory模型接近Llama2 7B的性能,而后者训练使用了2倍token和10倍FLOPs。
表格支持:
表1详细对比了不同模型配置在多个QA任务上的表现(NQ、TQA、PIQA、OBQA、HotPot)。
Memory+在多个任务上显著优于Dense、MOE和PEER。
Memory+在1.3b模型下达到13.68的NQ准确率,接近Llama2 7B的25.10。
5.3 8B模型规模下的结果¶
实验设置:
使用Llama3 8B架构,内存值数量为 \(4096^2 = 16\) 万,对应640亿额外参数。
训练数据与Llama3相似,训练了2000亿和1万亿token。
关键发现:
Memory+在多个任务(包括科学知识、世界知识、编程)上显著优于Dense模型。
在训练早期(2000亿token)表现提升更明显,说明Memory有助于更快学习事实。
在1万亿token训练下,Memory+接近Llama3.1 8B的表现(后者训练了15万亿token)。
表格支持:
表2展示了Memory+与Dense模型在多个基准任务上的对比。
Memory+在1万亿token训练下,在MMLU、NQ、TQA等任务上接近Llama3.1 8B。
5.4 模型消融实验¶
1. 内存层放置¶
增加内存层数可提升性能,但超过一定数量后性能下降,最佳为3层。
中心化放置、较大间隔效果更好,被用于Memory+。
2. 内存层变体¶
swilu非线性:显著提升性能,被采用。
输入门控:仅在部分情况下有效,swilu已部分覆盖其效果,未采用。
随机键值对/固定键(softmax sink):有轻微提升,但影响训练速度,未采用。
表格支持:
表3展示了不同内存层数和结构变体对NLL的影响,swilu和合理层数配置最优。
3. 键与值维度分析¶
值维度 vs 值数量:保持总参数不变,值维度越大效果越好,最终选择1024维(对应100万值)。
键维度:增加键维度有助于性能,但会增加密集参数,最终选择为基模型维度的一半(512维)。
表格支持:
表4展示了不同键值维度配置对NLL的影响,验证了上述结论。
总结¶
本章系统评估了Memory模型在不同参数规模和内存配置下的表现,证明其在QA任务上显著优于传统Dense、MOE和PEER模型。Memory+通过结构优化(多层、swilu、键维度优化)进一步提升性能,尤其在训练早期表现出更强的事实学习能力。消融实验验证了模型设计选择的有效性,为后续研究提供了明确方向。
6 Implications and shortcomings of the work¶
6 工作的意义与不足¶
意义:记忆层为模型扩展提供新方向¶
本节首先指出,过去6年中,AI领域的发展主要依赖于对密集Transformer模型的不断扩展。然而,随着计算和能源成本接近物理极限,寻找更高效的替代架构变得尤为重要。记忆层(memory layers) 由于其稀疏激活特性,能够在计算资源较少的情况下提供更强的知识获取能力,是对传统密集网络的有效补充。它们不仅具有良好的可扩展性,还为在内存与计算之间进行权衡提供了新的方向。
不足:工程实现仍需优化¶
尽管本文提出的方法在可扩展性上比以往工作提升了几个数量级,但在大规模生产环境中仍需大量工程优化。目前的密集架构已经与现代GPU硬件协同进化了几十年,优化程度非常高。虽然作者相信在现有硬件上,记忆层理论上可以做到与传统FFN层一样快、甚至更快,但实现这一点需要非 trivial 的工程努力。
潜在影响:对模型学习机制的深远意义¶
目前作者仅提供了高层次的实验证据表明记忆层可以提升模型的事实性(factuality)。但更深层次地,记忆层所支持的稀疏更新机制可能会影响模型学习与存储信息的方式。作者希望未来可以开发新的学习方法,进一步提升这些层的性能,从而实现:
更少的遗忘(less forgetting)
更少的幻觉(fewer hallucinations)
更好的持续学习能力(continual learning)
致谢(略)¶
本节最后对多位研究人员和工程师在资源支持与实现优化方面提供的帮助表示感谢。
总结:本章强调了记忆层在模型扩展中的潜力,同时指出了其实现效率仍需提升,并展望了其在模型学习机制上的深远影响。