2311.08719_Think-in-Memory: Recalling and Post-thinking Enable LLMs with Long-Term Memory¶
引用: 57(2025-08-10)
组织:
CUHK-Shenzhen, 香港中文大学(深圳)
Ant Group, 蚂蚁集团
总结¶
总结
有几个图,看明白就明白地了
TiM框架
两个关键阶段:
生成回复前:LLM从记忆中召回相关的思考内容;
生成回复后:LLM进行“后思考”(post-thinking),将历史与新的思考整合,以更新记忆。
工作流程
Stage 1: Recall & Generation
接收新问题 → 从记忆中检索相关想法 → 用于生成回答(无需重读原始对话)。
Stage 2: Post-think & Update
回答后 → LLM 对 Q-R 进行后思考 → 将新想法写入记忆 M。
背景
现有记忆方法
内部记忆方法(Internal memory based)
局限:多需要模型结构改造,适配性差
外部记忆方法(External memory based / Long-term memory)(本文属于此类🌼)
优势:通常优于内部记忆方法,且无需对 LLM 结构进行大规模改动
现在外部记忆的问题:
只存原始对话文本,导致每次调用历史都要重复推理,效率低。
检索相关信息需计算成对相似度,在长期交互中耗时严重。
From Deepseek¶
论文简介¶
核心问题:如何赋予大语言模型(LLMs)真正有效的长期记忆能力,使其在跨会话(multi-session)交互中保持上下文一致性并实现动态知识更新?
1. 研究背景¶
现有LLMs的上下文窗口受限于单次会话,无法像人类一样长期积累和调用历史信息。
传统扩展上下文窗口的方法(如增大token限制)成本高且效率低,而外部数据库(如向量检索)可能导致信息碎片化或无关召回。
关键挑战:如何平衡记忆的高效存储、精准检索与逻辑推理的结合?
2. 核心方法¶
论文提出 “Think-in-Memory (TiM)” 框架,包含两阶段机制:
动态记忆存储与结构化召回(Recalling)
将历史交互信息压缩为结构化记忆单元(如关键实体、事件、用户偏好),并分层存储(短期/长期记忆)。
通过基于语义的触发机制动态激活相关记忆,而非全量检索,减少噪声。
后置反思与记忆优化(Post-thinking)
在每次交互后,模型自动对当前对话进行反思,提取潜在长期价值的信息(如用户习惯、任务状态)更新记忆库。
引入记忆重要性评分,优先保留高频或高权重内容,避免信息过载。
3. 技术亮点¶
轻量化记忆网络:与模型参数解耦,支持动态编辑(新增/遗忘)而无需重新训练。
双通道注意力:在生成响应时,同时关注当前输入和召回的记忆,通过门控机制融合信息。
用户可控性:允许用户显式指定记忆的保存或删除(如隐私需求)。
4. 实验结果¶
在个性化对话、长周期任务跟踪(如项目管理助手)等场景中,TiM显著优于纯检索增强方法(+32%任务完成率)。
相比传统上下文窗口扩展,TiM降低50%的计算开销,同时支持跨会话数千轮次的记忆保持。
5. 意义与未来方向¶
理论贡献:提出“记忆-推理”协同的LLM架构设计范式。
应用价值:适用于医疗助手、教育机器人等需长期记忆的场景。
开放问题:记忆的因果性验证、多模态记忆扩展等。
备注¶
若该论文为假设性工作,上述简介基于以下相关研究的共性提炼:
记忆增强LLM(如MemGPT、Longformer)
检索与生成结合(如RETRO、FAISS+LLM)
持续学习与动态更新(如Lifelong Learning for LLMs)
Abstract¶
Memory-augmented LLMs 与问题背景¶
记忆增强型大语言模型(Memory-augmented LLMs)在长期人机交互中表现突出,其关键依赖于反复回忆(recall)和推理(reasoning)历史对话来生成高质量回复。
问题:这种反复的“回忆-推理”会引入偏置思维——即在面对不同问题时,对同一历史可能得出不一致的推理结果。
对比:人类通常能一次性形成想法并将其存储,之后直接调用,而不必重新推理。

figure 1. 以前的记忆机制与我们提出的 TiM 之间的比较。(左): 现有的记忆机制主要保存前几轮的原始文本,这需要对同一历史记录进行重复推理。这很容易导致推理路径不一致( 即左侧的红色部分 )和错误的响应。(右): 所提出的 TiM 存储了 LLM 在前一轮的思想,这可以避免这种不一致,而无需重复推理(即右侧的红色部分 )。
TiM(Think-in-Memory)机制¶
动机:模仿人类的“保留并调用想法”的能力。 核心目标:让 LLM 在对话流中维护一个不断进化的记忆,用来存储历史推理结果(thoughts)。
两个关键阶段¶
生成前阶段(Recall)
LLM 先从记忆中检索相关的历史想法(thoughts),作为生成参考。
生成后阶段(Post-think)
在完成回答后,LLM 进行后思考(post-thinking),结合历史想法与新产生的想法更新记忆。
这样,TiM 通过保存后思考结果作为历史,避免了反复推理带来的偏差。
思想组织原则¶
TiM 基于三类经典操作来组织和演化记忆中的想法:
插入(Insert):新增想法。
遗忘(Forget):丢弃不重要或过时的想法。
合并(Merge):将相关想法融合为更高层次的抽象。
高效检索策略¶
引入 Locality-Sensitive Hashing(LSH)
适配长对话场景
在海量历史中快速找到相关想法,提高检索效率。
实验与结果¶
在真实场景与模拟对话(涵盖多主题)中进行定性与定量实验。
结果:在现有 LLM 中引入 TiM,可以显著提升长期交互中的回复质量。
1 INTRODUCTION¶
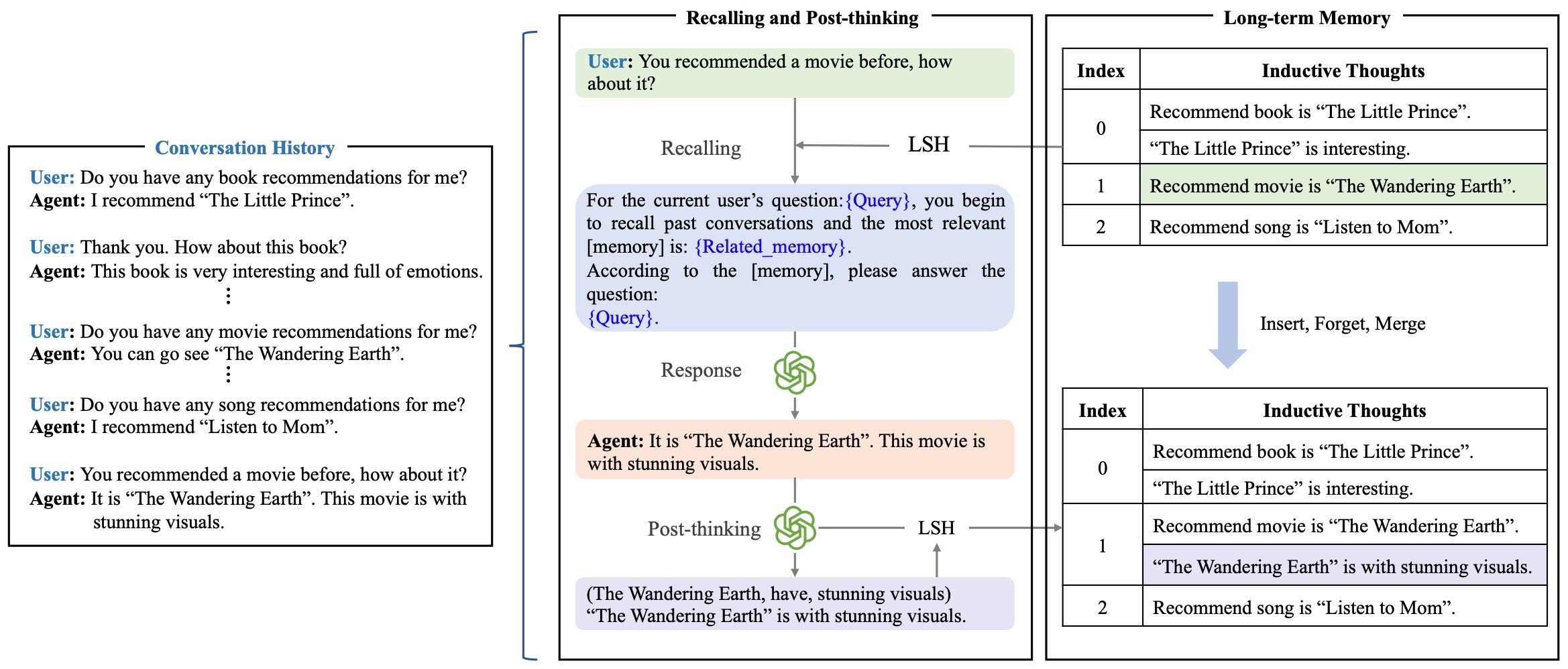
Figure 2: The overview of TiM framework. LLMs firstly recall history and give response for the question. Then new thoughts can be generated via the post-thinking step. These thoughts are saved as the memory to avoid repeated reasoning on the history.
研究背景¶
LLMs 进展:大型语言模型(如 ChatGPT、GPT-4)在金融、医疗、商务、客服等领域表现出强大的问答与生成能力。
规模驱动能力:数百亿到千亿级参数规模促成了类人对话能力的涌现。
长期交互的限制
问题:当前 LLM 在长期场景下仍有输入长度限制,无法处理极长的历史对话。
影响:例如医疗场景中,AI 助手需要保留之前的症状信息,否则可能影响诊断准确性。
需求:需要具有长期记忆能力的 AI 系统,以实现更准确、可靠的交互。
现有方法分类¶
内部记忆方法(Internal memory based)
目标:减少自注意力计算成本,扩展可处理序列长度。
手段:使用特殊位置编码(positional encoding)学习相对位置,或局部-全局混合 Transformer 结构。
局限:多需要模型结构改造,适配性差。
外部记忆方法(External memory based / Long-term memory)
目标:用独立物理存储(memory cache)保存历史信息,按需读取补充 LLM。
数据形式:Token 或原始文本。
示例:BERT embedding 辅助的万亿 token 外部缓存显著提升性能。
优势:通常优于内部记忆方法,且无需对 LLM 结构进行大规模改动。
本研究方向:设计**LLM-无关(LLM-agnostic)**的外部记忆机制来增强 LLM 记忆力。
现有外部记忆机制的问题¶
反复推理(Iterative reasoning):
对第 n 轮对话,LLM 需要从第 0 轮到 n-1 轮重新理解并推理,多次重复同一历史的推理。
可能导致推理路径不一致(同一上下文得出不同结论)。
检索成本高:
需要逐一计算问题与每条历史对话的相似度,长对话下非常耗时。
TiM(Think-in-Memory)的提出¶
灵感:类比**元认知(metacognition)**过程——人脑储存的是“想法(thoughts)”,而非事件全部细节。
目标:让 LLM 记住并有选择地回忆历史想法,减少重复推理。
TiM 两阶段流程
Recall 阶段:检索记忆中与新问题相关的想法,用于生成回复。
Post-thinking 阶段:在生成回复后,基于历史与新想法推理,并将新想法保存到外部记忆。
思想组织原则
插入(Insert):加入新想法。
遗忘(Forget):丢弃无关或过时想法。
合并(Merge):融合相关想法,形成更高层次抽象。
检索优化
使用 Locality-Sensitive Hashing (LSH) 提升长对话场景下的检索效率(快速插入和取出想法)。
设计为 LLM-无关,可支持闭源(如 ChatGPT)与开源模型(如 ChatGLM)。
主要贡献¶
提出 TiM:一种类人长期记忆机制,让 LLM 在记忆中思考,无需反复推理整个历史。
提出思想组织原则(Insert / Forget / Merge)+ 哈希检索机制,实现动态更新与高效利用。
在多轮对话数据集上大量实验,结果显示 TiM:
适用于从开放域到特定领域的多主题对话。
支持中英文双语。
显著提升回复的正确性与连贯性。
3 METHODOLOGY¶
3.1 Framework Overview¶
目标:在多轮对话中生成更准确、连贯的回复,同时保留长期历史信息。
主要组件(见 Figure 2)¶
Agent A:预训练 LLM(如 ChatGPT、ChatGLM),执行对话与推理。
Memory Cache M:哈希表结构,存储思考(thoughts),key 为哈希索引,value 为单条想法。
Hash-based Mapping F(·):基于 LSH(Locality-Sensitive Hashing)的映射,用于快速保存和检索相关想法。
工作流程¶
Stage 1: Recall & Generation
接收新问题 → 从记忆中检索相关想法 → 用于生成回答(无需重读原始对话)。
Stage 2: Post-think & Update
回答后 → LLM 对 Q-R 进行后思考 → 将新想法写入记忆 M。
3.2 Storage for Memory Cache¶
3.2.1 Thoughts-based System¶

Figure 3.An example of prompts for generating thoughts.
存储目标:保存 AI 与用户交互中由 LLM 自行生成的归纳型想法(Inductive Thought)。
定义(Definition 3.1):一个包含实体关系的文本,符合三元组 (Eh, ri, Et) 结构(头实体、关系、尾实体)。
生成方法:
预训练模型进行开放信息抽取(如 OpenIE)。
基于 LLM 的 few-shot 提示生成(本文采用此法)。
3.2.2 Hash-based Storage¶
设计原则:相似想法放在同一哈希组中,提高检索与更新效率。
方法:
将想法嵌入向量映射到哈希索引 F(x)。
LSH 属性:相似向量高概率分到同一索引组。
公式:
\[ F(x) = \arg\max([xR; -xR]) \]其中 R 为随机矩阵,b 为哈希组数。
3.3 Retrieval for Memory Recalling¶
两阶段检索流程:
Stage 1: LSH-based Retrieval
对新问题 Q → 计算嵌入 → 用 LSH 得到哈希组索引。
Stage 2: Similarity-based Retrieval
在该组中计算 Q 与每条想法的相似度 → 选取 top-k 作为回答参考。
优势:只在组内做相似度计算,比全局检索更高效。
3.4 Organization for Memory Updating¶

Figure 4.An example of prompts for forgetting thoughts.

Figure 5.An example of prompts for merging thoughts.
TiM 模仿人类记忆机制,支持以下三种操作:
插入(Insert):将新生成的“思考”插入到记忆中;
遗忘(Forget):删除不相关或矛盾的“思考”;
合并(Merge):将相同头实体的“思考”合并,提升记忆的组织性。
3.5 Parameter-efficient Tuning¶
方法:使用 LoRA(Low-Rank Adaptation)进行高效微调,冻结原权重,仅优化低秩分解矩阵 A、B。
效果:降低可训练参数量,适配多轮对话生成。
实验设置:LoRA rank = 16,训练 10 个 epoch。
3.6 Insightful Discussion(与现有方法对比)¶
作者将 TiM 与已有记忆机制进行了比较,如表 1 所示。主要差异如下:
方法 |
内容 |
LLM 无关 |
插入 |
遗忘 |
合并 |
|---|---|---|---|---|---|
SCM |
Q-R |
✅ |
✅ |
❌ |
❌ |
RelationLM |
知识图谱 |
❌ |
✅ |
❌ |
❌ |
LongMem |
Token |
❌ |
✅ |
❌ |
❌ |
MemoryBank |
Q-R |
✅ |
✅ |
✅ |
❌ |
TiM(本文) |
思考 |
✅ |
✅ |
✅ |
✅ |
关键优势:
TiM 存储的是“思考”,而非原始对话或知识图谱,无需重复推理;
支持多种记忆操作(插入、遗忘、合并),比传统方法更灵活;
LLM-无关,可灵活应用于多种模型。
4. Experiment¶
4.1. Experimental Settings¶
4.1.1. Dataset¶
本研究使用了三个数据集来验证所提出方法的有效性:
KdConv:一个中文多领域的知识驱动对话数据集,包含4.5K次对话和86K条语句,话题涉及电影、音乐和旅游。平均对话轮次为19次。
Generated Virtual Dataset (GVD):一个合成的长期对话数据集,由15个虚拟用户(基于ChatGPT)在10天内生成,包含中英文对话。测试集包含194个手动构建的问题,用于评估模型的长期记忆能力。
Real-world Medical Dataset (RMD):一个手动构建的真实医疗对话数据集,包含1800次医患对话,其中80次用于测试模型的诊断准确性。
重点:数据集覆盖了多样化的应用场景(虚拟对话、知识对话和医疗对话),能够全面验证TiM机制的有效性。
4.1.2. LLM¶
本研究基于两个大语言模型(LLM)进行实验,这两个模型本身不具备长期记忆能力:
ChatGLM:一个开源的双语模型,参数规模为62亿,经过监督微调、反馈引导和人类反馈强化学习优化。
Baichuan2:一个开源的多语言模型,参数规模为130亿,训练数据量达2.6万亿token,擅长对话和上下文理解。
重点:选用这些模型是为了验证TiM机制是否能有效增强LLM的长期记忆能力,而不依赖模型本身特性。
4.1.3. Baseline¶
设置了两组基线:
无记忆机制:直接回答问题,不使用任何记忆。
SiliconFriend:一个经典记忆机制,支持将原始文本存储并读取。
重点:基线设计用于对比TiM机制的优势。
4.1.4. Evaluation Protocol¶
采用三类评估指标进行性能评估,所有评估均由人工完成,并对预测结果进行洗牌以确保公平性:
Retrieval Accuracy:评估是否成功检索到相关记忆(标签:{0: 否, 1: 是})。
Response Correctness:评估对问题的回答是否正确(标签:{0: 错误, 0.5: 部分正确, 1: 正确})。
Contextual Coherence:评估生成的回答是否与上下文和记忆一致(标签:{0: 不连贯, 0.5: 部分连贯, 1: 连贯})。
重点:这三项指标从不同角度衡量了TiM机制在长期对话中的性能表现。
4.2. Comparison Results¶
4.2.1. Results on GVD dataset¶
在GVD数据集的英中文测试集中,TiM机制在所有指标上都优于SiliconFriend基线,特别是在上下文连贯性方面表现突出。中文表现提升更显著,可能与模型的语言能力有关。
重点:TiM在多语言任务中均表现出色,尤其在中文场景下提升更明显。
4.2.2. Results on KdConv dataset¶
在KdConv数据集上,TiM机制在电影、音乐和旅游三个主题中均取得最佳表现。使用TiM后,LLM能够更好地进行记忆检索,从而提升响应正确性和上下文连贯性。
重点:TiM显著提升了LLM在知识驱动对话中的表现,解决了LLM缺乏长期记忆的问题。
4.2.3. Results on RMD dataset¶
在真实医疗对话数据集RMD上,TiM显著提升了ChatGLM和Baichuan2的响应性能,尤其是在响应正确性和上下文连贯性方面。TiM机制更接近人类记忆工作流程,使得LLM生成的回答更接近人类行为。
重点:在现实医疗场景中,TiM机制表现出良好的实用性和准确性。
4.3. More Analysis¶
4.3.1. Retrieval Time¶
TiM机制的检索时间(0.5305 ms)比基线(0.6287 ms)减少了约0.1 ms,表明TiM在效率方面也有优势。
重点:TiM不仅在效果上优于基线,在效率上也有所提升。
4.3.2. Top-k Recall¶
在KdConv(旅游主题)数据集上,Top-k检索准确率随着k值增加而提升,Top-10准确率可达0.973。Top-5检索可显著提升LLM在长期对话中的性能。
重点:Top-k检索是提升记忆效果的重要手段,TiM通过优化检索策略提升了整体表现。
4.4. Industry Application¶
基于ChatGLM和TiM机制,开发了一个医疗助手TiM-LLM,用于辅助医生进行患者诊疗(如图7所示)。结果显示,使用TiM后,医疗助手能够更准确地回忆患者症状,给出更全面的诊断和治疗建议。
重点:TiM机制在实际医疗场景中取得了良好应用效果,提升了LLM在长期对话任务中的实用性。
总结¶
本章通过实验验证了TiM机制在多个数据集和实际场景中的有效性。TiM机制在检索准确性、响应正确性和上下文连贯性方面显著优于基线方法,尤其在医疗场景中展现出良好的实用前景。此外,TiM机制在效率方面也优于传统方法,具备推广和应用的潜力。
5. Conclusion¶
在本文中,作者提出了一种新的记忆机制 TiM,用于解决 记忆增强型大语言模型(Memory-augmented LLMs) 中偏见性思维的问题。TiM 通过在进化后的记忆中存储历史思维内容,使 LLM 能够在对话中回忆相关思维并加以利用,从而避免重复推理。
TiM 的核心包含两个关键阶段:
生成前的思维回忆(recalling thoughts before generation)
生成后的思考更新(post-thinking after generation)
此外,TiM 依赖于一些基本的原则来组织记忆中的思维内容,从而实现记忆的动态更新。为了提升长期对话中的检索效率,作者将局部敏感哈希(Locality-Sensitive Hashing, LSH) 引入 TiM,以实现高效检索。
通过在真实和模拟对话中进行的定性和定量实验,结果表明,为 LLM 配备 TiM 机制具有显著的优势。总的来说,TiM 被设计为一种方法,用于提升长期人机交互中响应的质量和一致性。