2402.04624_MemoryLLM: Towards Self-Updatable Large Language Models¶
引用: 36(2025-08-17)
组织:
1UC, San Diego
2Amazon
3UC, Los Angeles
总结¶
方法创新点
引入了一个固定大小的内存池,嵌入在transformer的潜在空间中,使模型能够自我更新并记忆早期注入的知识。
在模型编辑和长期记忆方面的优势
MemoryLLM
使LLM具备自我更新的能力
能够通过内部的“记忆”机制,动态地存储和使用新信息,而无需完全重新训练模型。
规模
在 7B 参数模型上增加了包含 1B 参数的记忆池
Structure Design
Memory Pool
每个Transformer层都有一个对应的记忆池
Self-Update Process
Analysis of Forgetting
艾宾浩斯遗忘曲线
Training Strategy
New knowledge incorporation(新知识注入)
Enhancing continuous contexts understanding(增强连续上下文理解)
Mitigating forgetting problems(缓解遗忘问题)
贡献
首次将固定大小的内存池集成到大型语言模型的潜在空间中,实现了有效的新知识整合和长期知识保留。
论文重点
重新整理了第3章和附录 A
Abstract¶
当前的大型语言模型(LLMs)在部署后通常保持不变,这使得模型难以注入新知识。本文旨在构建一种包含大量可自我更新参数的模型,从而高效有效地融合新知识。
为此,作者提出了MemoryLLM,该模型由一个Transformer和一个位于其潜空间中的固定大小记忆池组成。MemoryLLM能够自我更新文本知识,并记住之前注入的知识。
评估结果显示,MemoryLLM在模型编辑基准测试中表现出色,证明其能够有效整合新知识。同时,该模型在长期信息保持能力方面表现良好,这一能力通过自定义评估和长上下文基准测试得到了验证。
此外,MemoryLLM在接近一百万次记忆更新后依然保持操作完整性,性能无明显下降。
关键词:memory,large language model
总结说明:
重点强调了MemoryLLM的核心创新点:固定大小记忆池与自我更新能力,以及其在模型编辑和长期记忆方面的优势。
次要内容如代码开源地址、关键词等进行了简洁呈现。
1 Introduction¶
本节主要介绍了当前大语言模型(LLMs)在更新最新知识方面所面临的核心问题:“我们该如何用最新的知识更新模型?”,并回顾了现有的三种主流解决方案及其局限性,随后提出了本文提出的 MemoryLLM 模型,并概述了其创新点和实验成果。
1. 当前方法的分类与局限¶
(1)基于检索的方法(Retrieval-Based Methods)¶
核心思想:利用知识库进行信息检索,辅助模型生成。
优点:效果较强。
缺点:
面临知识库冗余问题;
在多模态场景中,需要存储大量图像数据(如每秒24张图像),造成存储压力。
重点问题:知识库管理复杂,扩展性差。
(2)模型编辑方法(Model Editing)¶
核心思想:通过针对性修改模型参数,使其适应新事实,同时保留原有能力。
当前局限:
多聚焦于单句级别的事实编辑;
对长文本或复杂上下文的处理能力较差。
重点问题:无法有效处理复杂的、多句的知识注入。
(3)长上下文方法(Long Context Methods)¶
核心思想:将所有知识直接纳入模型的上下文中,作为推理依据。
技术手段:
优化注意力机制(如降低复杂度);
修改位置编码以支持更长的上下文。
缺点:
上下文长度有限;
在需要大量知识的复杂推理任务中,上下文过载问题严重。
重点问题:无法无限扩展,存在实际使用瓶颈。
2 MemoryLLM 的提出与设计¶
为解决上述问题,作者提出 MemoryLLM,其核心创新是:
设计了一个固定大小的、可自我更新的“记忆池”,嵌入在模型的潜在空间中。
具体实现:
在每个 Transformer 层中设置记忆向量(memory tokens),用于表示压缩后的知识。
在训练时引入自我更新机制,通过逐层更新部分记忆,实现新知识的吸收与旧知识的缓慢遗忘。
优势:
相比传统方法,记忆池更加紧凑、冗余度低;
固定大小避免了知识库无限增长的问题;
通过“自我更新”,模型可以持续保持最新状态。
训练成果:
MemoryLLM 在接近 一百万次更新 后,性能未出现下降。
3 评估与实验结果¶
作者从三个方面对 MemoryLLM 进行了系统评估:
(1)新知识整合能力(Integration of New Knowledge)¶
在模型编辑基准和长上下文问答任务中表现优异,显著优于现有方法。
(2)知识保留能力(Knowledge Retention Ability)¶
通过长上下文任务和自定义的知识保留实验验证,MemoryLLM 展现出良好的记忆保持能力。
(3)鲁棒性(Robustness)¶
在近乎 一百万次更新操作 下,模型仍能正常运行,稳定性高。
4 主要贡献总结¶
提出 MemoryLLM:首次在 LLM 中引入固定大小的“记忆池”,实现新知识整合与旧知识缓慢遗忘。
扩展模型规模:在 7B 参数模型上增加了包含 1B 参数的记忆池。
实验验证有效性:在多个任务(模型编辑、长上下文、知识保持)中表现优异,验证了模型的通用性与高效性。
综上,MemoryLLM 提供了一种解决 LLM 知识更新问题的创新方法,在控制模型规模与更新效率之间取得了良好的平衡,具有较高的研究与应用价值。
2 Preliminaries¶
2.1 Problem Statement(问题陈述)¶
本节提出的核心问题是:如何设计一种大语言模型,使其能够高效地引入新知识,同时最大程度地保留已学知识? 为明确该挑战,作者提出了模型应具备的五个关键属性:
效率(Efficiency):知识注入过程应高效,理想情况下无需反向传播,以减少计算开销。
有效性(Efficacy):新知识需有效融入模型,并对其性能产生积极影响。
知识保留(Knowledge Retention):模型的记忆池大小固定,因此需要一种机制逐步淘汰旧知识以腾出空间。
完整性(Integrity):无论对记忆池进行多少次更新,模型始终应保持完整功能。
非冗余性(Non-redundancy):追求更紧凑的知识存储方式,减少冗余,提升存储效率。
这是设计模型的指导原则,也是后续方案设计的出发点。
2.2 Sketch of MemoryLLM(MemoryLLM 的初步构想)¶
为解决上述问题,作者提出了一个初步模型构架:MemoryLLM,记作 ℳθ,ϕ,包含两组参数:
ϕ:静态参数,用于表示持久不变的通用知识,例如常识或长期不变的事实。
θ:动态参数,表示可更新的“记忆池”,用于存储新知识,并随新知识的引入而更新。
具体来说:
ϕ 由现有大语言模型(如 Llama2)提供,这部分参数固定不变。
θ 是模型的核心创新点之一,需要设计其结构以及与 ϕ 的交互方式,使得模型在生成过程中能够有效利用 θ 中的新知识。
接下来,作者提出了自更新机制的概念:当模型遇到新知识 x(一段文本)时,它应通过一个更新函数 U 来更新 θ,生成新的 θ′:
这表示 θ 在不破坏模型原有能力的前提下,将新知识 x 注入其中。
对于多步更新的情况,例如多个对话历史或持续上下文,作者将更新过程定义为:
模型需要在这一过程中逐步整合所有新知识。
作者指出,这一设计面临两个关键挑战:
参数与交互设计:需确定 θ 的结构以及它与 ϕ 的交互方式,确保 LLM 能够在生成过程中有效利用 θ 中的知识。
更新函数设计:更新函数 U 的设计至关重要,必须确保 θ 更新时不破坏旧知识,且不损害模型整体能力。
总结:本节为后续的模型设计奠定了基础,明确了设计目标与关键挑战。其中,MemoryLLM 的双参数结构(ϕ 与 θ)和自更新机制是整个方案的核心,而如何高效、有效地实现 θ 的更新则是后续工作的重点。
3 MemoryLLM¶
3.1 Structure Design¶
MemoryLLM通过**记忆池(Memory Pool)和自更新机制(Self-Update)**实现模型的持续学习。模型整体结构如下:
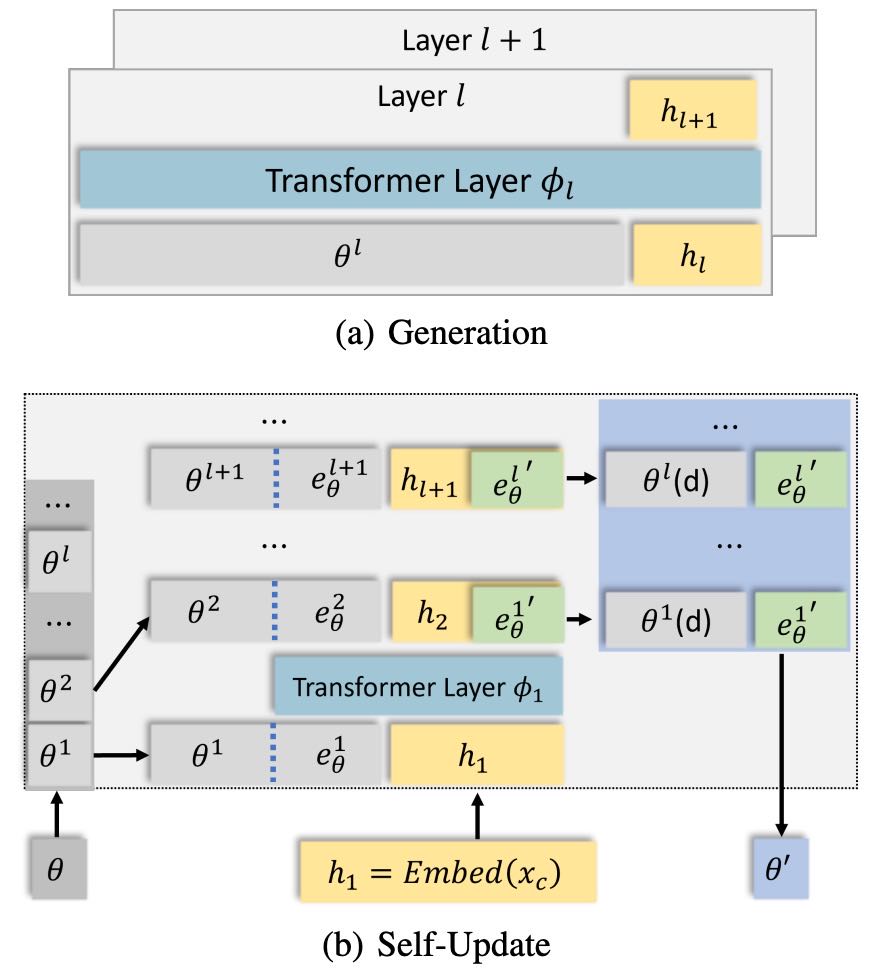
Figure 1: The framework of MemoryLLM
图片理解¶
整体架构:MemoryLLM 由两部分组成:
主 Transformer 模型:负责常规的文本生成和上下文理解。
分层记忆池(Memory Pool):嵌入在每一层 Transformer 中,存储压缩后的隐空间记忆(Memory Tokens),通过注意力机制与模型交互。
记忆池的初始化与结构
记忆容量:每层记忆池固定包含 N 个 Memory Tokens(如实验中 N=12,800),每个 Token 是 4096 维的隐向量(与 Llama3-8B 的隐藏层维度一致)。
存储形式:记忆池本质是一个环形缓冲区,新记忆覆盖旧记忆,避免无限扩容。
a) Generation Phase(读记忆)
跨层注意力注入:
每一层的隐藏状态 \( h_l \) 会与当前层的记忆池 \( \theta^l \) 进行 Cross-Attention,将记忆作为前缀(Prefix)注入后续层的计算中,使模型能参考历史信息。例如:第 \( l \) 层的输出会同时依赖当前输入和 \( \theta^l \) 中的记忆。
b) Self-Update Phase(写记忆)
取材:从当前层记忆池 \( \theta^l \) 中取出最后 K 个 Token(如 K=256),与当前隐藏状态 \( h_l \) 拼接。
压缩写入:通过一个小型网络 \( \phi_l \)(通常是线性层或轻量 Transformer)生成 K 个新 Memory Tokens \( e_{\theta^l}' \)。
淘汰旧记忆:随机丢弃 \( \theta^l \) 中的 K 个旧 Token,将新 Token 追加到记忆池尾部。
目的:保持记忆池大小固定,同时动态更新内容。
3.1.1 Memory Pool(记忆池)¶
记忆池结构:每个Transformer层都有一个对应的记忆池,表示为 θ = {θ₁, θ₂, …, θₗ},其中 θₗ 是第 l 层的记忆池。
记忆表示:每个 θₗ 是 N×d 的矩阵,其中 N 是记忆长度,d 是词向量维度。每一行对应一个“记忆标记(memory token)”。
目标:最大化记忆池的大小,使得模型在生成时能够访问大量历史知识,提高模型的上下文理解能力。
生成过程:在生成阶段,模型会将当前输入的隐藏状态 hₗ 与所有记忆池中的记忆标记 θₗ 进行注意力交互,获取更丰富的上下文信息。
3.1.2 Self-Update Process(自更新过程)¶
更新目标:模型在学习新知识时,将新知识压缩成 K 个记忆标记(eθₗ),并将其加入记忆池中,同时随机删除 K 个旧的记忆标记。
更新方式:在第 l 层中,将当前隐藏状态 hₗ 与最后 K 个记忆标记 eθₗ 拼接后,输入到 ϕₗ(基于 Llama2 的 Transformer 层)中,生成新的隐藏状态 hₗ₊₁。取 hₗ₊₁ 的最后 K 个标记作为 eθₗ′,并更新记忆池。
效率考虑:为避免将整个记忆池输入 ϕₗ 所带来的计算开销,只使用最后 K 个记忆标记,K 小于 N,从而降低了计算复杂度。
3.1.3 Analysis of Forgetting(遗忘分析)¶
遗忘机制:MemoryLLM 的更新机制类似人脑的艾宾浩斯遗忘曲线,即知识会以指数级衰减的方式遗忘。
理论分析:在每次更新中,K/N 的比例决定了知识遗忘的速度。通过公式 (1 - K/N)^(N/K),可以估算记忆池中知识的保留比例。当 N/K 趋近于无穷大时,保留比例趋近于 1/e(自然常数的倒数),即 36.8%。
减少遗忘的策略:减少 K(压缩比)和增加 N(记忆池大小)可以有效减缓遗忘,从而提高模型的记忆能力。
3.2 Training Strategy(训练策略)¶
MemoryLLM 的训练目标包括三个核心方向:
3.2.1 New knowledge incorporation(新知识注入)¶
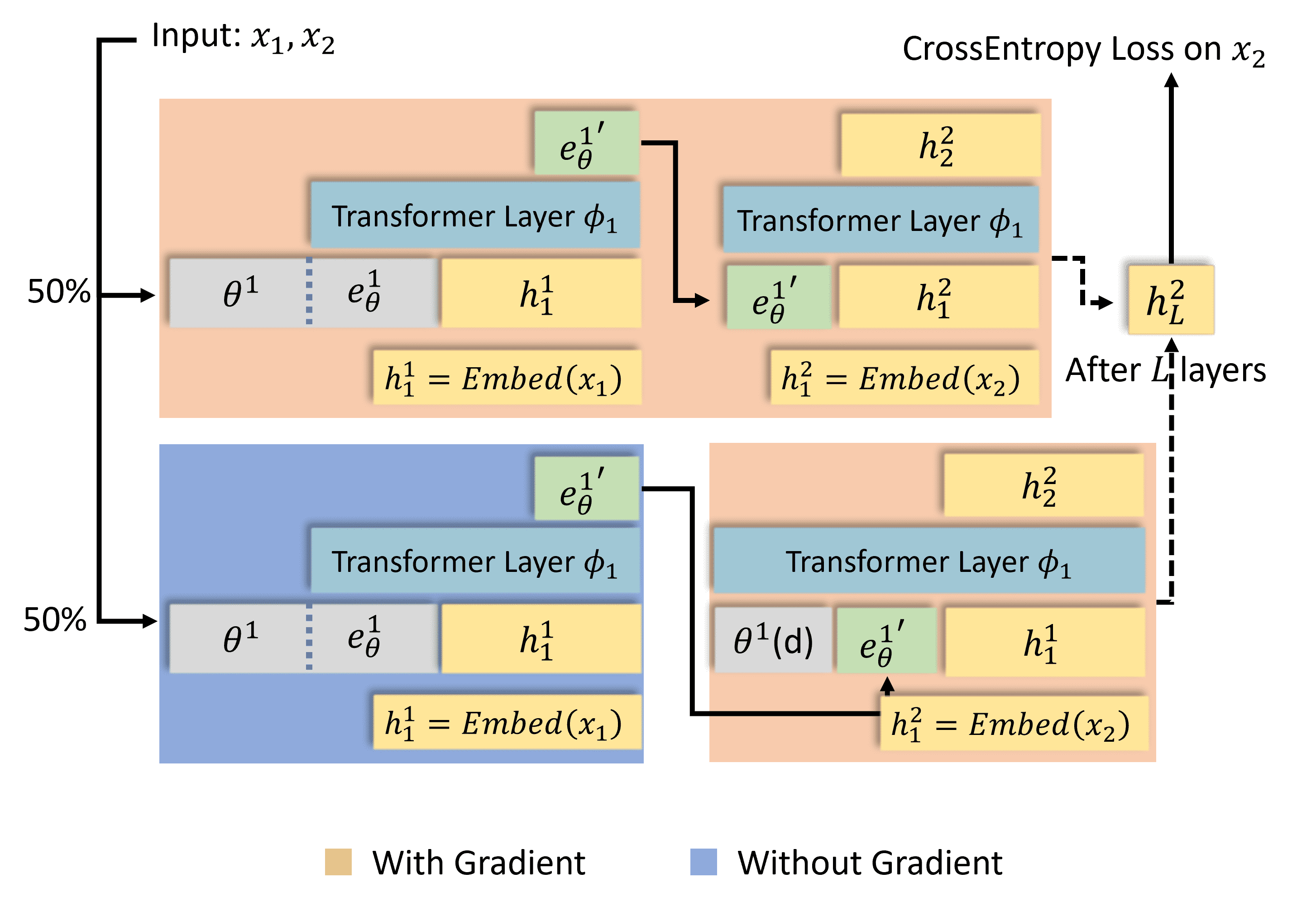
Figure 2:Training Process for new knowledge incorporation.
核心
如何通过训练让模型学会将新知识(如文档片段)存入记忆池,并利用记忆池辅助预测后续内容。
通过两种路径的交替训练,让 MemoryLLM 同时掌握“记忆写入”和“记忆读取”能力,同时避免显存过载。
训练流程概览
输入数据:从数据集中采样一个文档 \( d \),将其分成两部分 \( (x_1, x_2) \)。
\( x_1 \):用于更新记忆池(写入新知识)。
\( x_2 \):用于验证模型是否能利用更新后的记忆池正确预测(读取知识)。
两种训练路径:
每次训练随机选择以下两种路径之一(各50%概率):带梯度的路径(Upper Process):优化知识压缩(如何将 \( x_1 \) 存入记忆)。
无梯度的路径(Lower Process):模拟推理时的自更新过程(仅用记忆池预测 \( x_2 \))。
两种路径的详细对比
(1) 带梯度的路径(Upper Process)
目标:训练模型如何压缩新知识到记忆池中。
步骤:
用 \( x_1 \) 更新记忆池:
通过自更新机制(Self-update)生成新记忆 token \( e_{\theta^l}' \)(第 \( l \) 层)。
保留梯度:反向传播会优化 \( e_{\theta^l}' \) 的生成过程,确保 \( x_1 \) 的信息被有效压缩到记忆中。
预测 \( x_2 \):
仅用 \( e_{\theta^l}' \)(而非整个更新后的记忆池 \( \theta_l' \))参与预测。
为什么? 减少显存占用(避免存储整个记忆池的梯度)。
效果:模型学会“如何将 \( x_1 \) 的信息高效存入记忆”。
(2) 无梯度的路径(Lower Process)
目标:训练模型如何利用记忆池中的知识进行预测。
步骤:
用 \( x_1 \) 更新记忆池:
执行自更新生成 \( \theta_l' \),但不计算梯度(类似推理时的冻结状态)。
预测 \( x_2 \):
使用完整的更新后记忆池 \( \theta_l' \) 辅助预测。
效果:模型学会“如何依赖记忆池中的知识生成答案”。
设计动机与解决的核心问题
显存优化:
如果全程保留梯度(如理想情况),需存储整个记忆池的中间状态,显存爆炸。
折中方案:仅在生成新记忆 \( e_{\theta^l}' \) 时保留梯度,其余部分冻结。
功能分工:
带梯度路径 → 优化记忆写入能力。
无梯度路径 → 优化记忆读取能力。
随机切换:
通过交替训练,模型既能学会存储知识,又能学会调用知识。
3.2.2 Enhancing continuous contexts understanding(增强连续上下文理解)¶
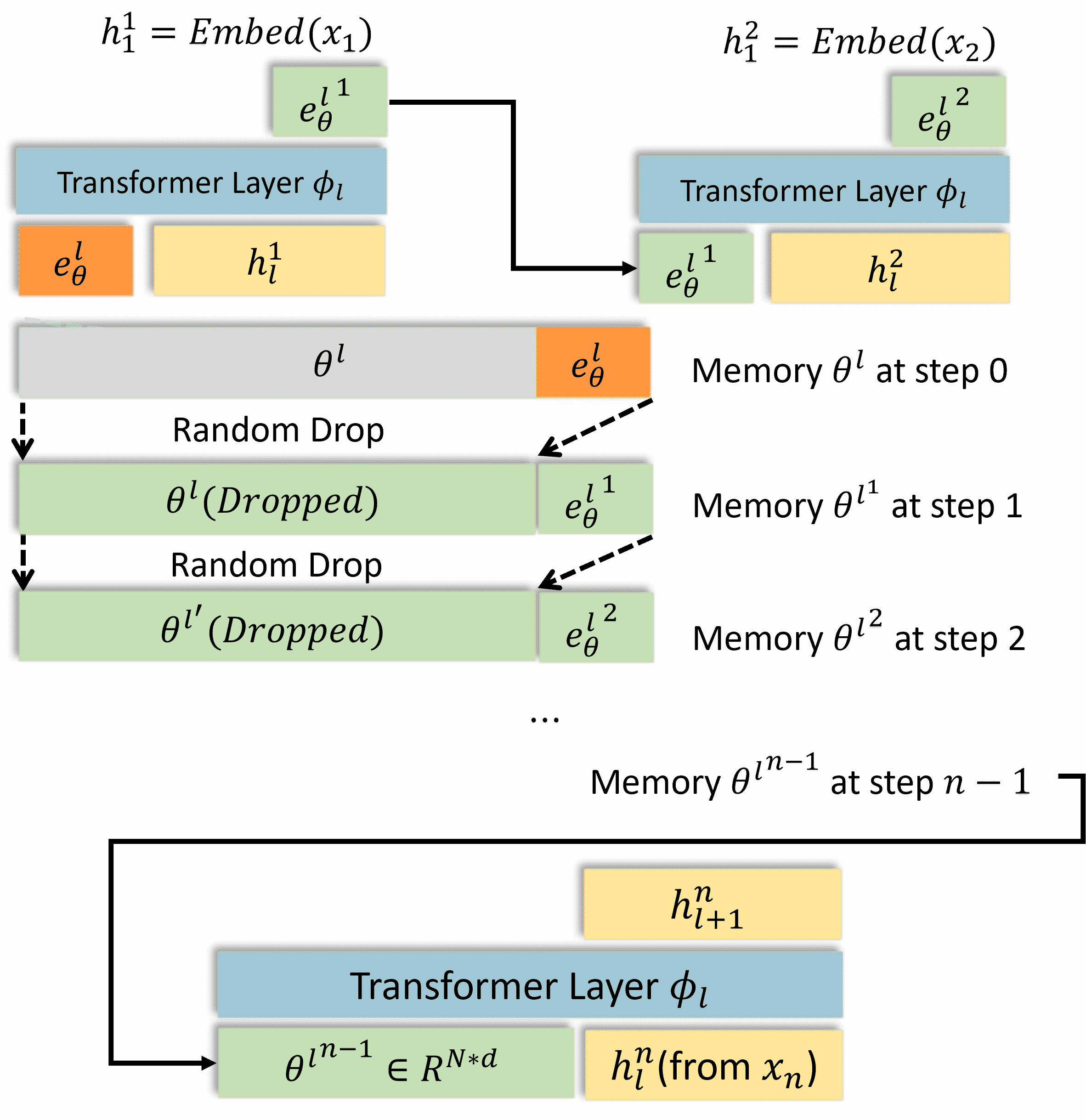
Figure 3:Training process for continuous contexts understanding.
核心问题
背景:MemoryLLM 通过记忆池(Memory Pool)存储信息,但默认只保留最近注入的 K 个 Token(即 \( e_{\theta^l}' \))。
问题:
如果模型需要基于多个历史片段(如长文档的不同部分)进行预测,仅依赖最后 K 个 Token 可能丢失早期关键信息。
这本质上是长上下文建模问题(类似传统模型的上下文窗口限制)。
解决方案:分段训练
(1) 数据准备
将一个长文档分割为 n 个片段:\( x_1, x_2, \cdots, x_n \)。
每个片段长度小于预设最大值(避免单次输入过长)。
(2) 记忆注入(无梯度更新)
顺序注入前 n-1 个片段:
依次将 \( x_1, x_2, \cdots, x_{n-1} \) 通过模型,并更新记忆池 \( \theta \)(使用公式2的自更新机制)。
关键细节:
此过程禁用梯度计算(即
with torch.no_grad()),仅更新记忆池,不调整模型参数。最终得到更新后的记忆池 \( \theta_{n-1} \),它压缩了前 n-1 个片段的知识。
(3) 目标预测(带梯度训练)
使用记忆池 \( \theta_{n-1} \) 预测第 n 个片段 \( x_n \):
计算 \( x_n \) 的交叉熵损失(Cross-Entropy Loss)。
反向传播:通过损失更新模型参数,迫使模型学会利用记忆池中的长期信息。
设计动机
模拟长上下文学习:
前 n-1 个片段相当于“历史背景”,模型需从中提取关键信息存入记忆池。
第 n 个片段是“当前任务”,模型需结合记忆池中的压缩知识进行预测。
避免遗忘:
传统模型可能因上下文窗口限制而遗忘早期信息,而 MemoryLLM 通过记忆池保留压缩后的长期记忆。
技术细节
记忆池的压缩能力:
记忆池 \( \theta_{n-1} \) 本质是前 n-1 个片段的隐空间摘要(latent summary),而非原始文本。
模型需学会选择性保留重要信息(如主题、实体关系等)。
梯度控制:
记忆注入阶段禁用梯度,确保模型专注于学习如何利用记忆,而非直接记忆输入片段。
3.2.3 Mitigating forgetting problems(缓解遗忘问题)¶
解决遗忘问题(Mitigating Forgetting)¶
核心思想
强迫模型在预测时依赖 很早之前注入的信息,而非仅依赖近期上下文。
具体方法
构造跨文档任务:
选取两类文档:
主文档(Main Document) \( d \):分段为 \( (x_1, \cdots, x_n) \)
辅助文档(Side Document) \( d' \):分段为 \( (x'_1, \cdots, x'_n) \)
示例:
主文档:一篇关于“量子力学”的文章(分5段)。
辅助文档:一篇关于“爱因斯坦”的传记(分5段)。
分阶段注入信息:
第一步:将主文档的前 \( n-1 \) 段 \( (x_1, \cdots, x_{n-1}) \) 和辅助文档的全部内容 \( (x'_1, \cdots, x'_n) \) 顺序输入模型(梯度计算禁用,仅存储到记忆池)。
第二步:要求模型仅根据记忆池预测主文档的最后一段 \( x_n \)。
设计动机:
主文档的 \( x_n \) 需要结合辅助文档的知识才能准确预测(例如 \( x_n \) 提到“爱因斯坦对量子力学的贡献”)。
由于辅助文档的信息是早期注入的,模型必须从长期记忆中提取信息,而非依赖短期上下文。
效果
通过这种训练,模型学会主动利用记忆池中的历史信息,减少遗忘。
解决模型完整性破坏(Maintaining Integrity)¶
问题背景
如果记忆池 \( \theta \) 被频繁更新(例如每次对话都修改),可能导致记忆分布漂移,最终使模型行为异常。
解决方案:在训练时对记忆池更新进行正则化约束:
延迟更新策略:
在训练迭代结束时,才更新记忆池 \( \theta \)(而非实时更新)。
具体更新内容:
对于单文档任务(3.2.1节):用 \( x_1 \) 更新 \( \theta \)。
对于多文档任务(3.2.2节):用 \( \{x_1, \cdots, x_{n-1}\} \) 更新 \( \theta \)。
分布一致性约束:
确保新记忆 \( e_{\theta^l}' \) 的分布与旧记忆 \( \theta^l \) 的分布一致。
实现方式:
通过损失函数约束 \( e_{\theta^l}' \) 和 \( \theta^l \) 的统计特性(如均值、方差)。
类似“知识蒸馏”,防止新记忆偏离原始语义空间。
3.3 Model Instantiation(模型实例化)¶
基础模型:MemoryLLM 使用 Llama2-7b 作为 ϕ,共有 32 层,隐藏维度为 4096。
记忆池规模:每层设有 7,680 个记忆标记,总参数量为 1.066B。
结构表示:θ ∈ ℝ³²×⁷⁶⁸⁰×⁴⁰⁹⁶,表示 32 层 × 7680 记忆标记 × 4096 维。
3.4 Discussions(讨论)¶
可扩展性¶
记忆池大小可扩展:当前实验中记忆池参数规模约为 10 亿。由于自更新过程只使用最新的 K 个记忆标记,因此记忆池的扩展不会显著影响计算效率。
生成阶段的限制:生成过程中注意力机制的复杂度与记忆池大小线性增长,但可通过分布式训练扩展。
随机删除策略¶
随机删除 vs 指数衰减:为了保持记忆池大小不变,采用随机删除 K 个旧记忆标记的方式。虽然有遗忘风险,但能保证最新知识的完整保留。
与聚合策略的对比:尝试将新旧知识聚合的方式,但发现会破坏原始知识结构,导致新旧知识混合不理想。
其他模型的适配性¶
模型通用性:MemoryLLM 的结构适用于具有完整注意力机制的 Transformer 模型,不仅限于 Llama2。
总结¶
MemoryLLM 通过引入记忆池结构和自更新机制,实现了语言模型的持续学习与知识更新。模型在生成时可访问大量历史知识,同时通过指数式遗忘机制有效平衡新旧知识。训练方面,模型通过分段注入、多文档预测等方式增强上下文理解和缓解遗忘问题。未来,该模型可通过扩展记忆池规模和优化注意力机制进一步提升性能。
4 Experiments¶
4.1 评估协议(Evaluation Protocols)¶
本论文从三个方面评估了 MemoryLLM 的性能:
新知识的整合能力(Integration of New Knowledge)
通过模型编辑任务(Section 4.3)和长上下文问答任务(Section 4.4)进行评估。知识保持能力(Knowledge Retention Ability)
通过长上下文问答任务(Section 4.4)和专门设计的知识保持实验(Section 4.5)评估。鲁棒性(Robustness)
对模型进行了近一百万次更新,测试其功能是否依然稳定(Section 4.6)。
4.2 实现细节(Implementation Details)¶
模型基于 Llama2-7B 架构,使用 Red-Pajama 数据集中处理后的 C4 数据集进行训练。
训练分为三个部分:
新知识整合训练: 从整个 C4 数据集中采样。
长上下文理解训练: 基于 C4 的子集(文档长度大于 2048)。
遗忘问题缓解训练: 随机从原始 C4 和长上下文子集中采样。
训练使用 8 块 A100-80GB GPU,持续三天。
4.3 模型编辑(Model Editing)¶
4.3.1 实验设置(Experimental Setup)¶
基准数据集:
zsRE(Zero-Shot Relation Extraction): 用于评估模型编辑任务。
CounterFactual: 包含虚假事实的问答数据集,评估模型是否能更新并保留新知识。
评估指标:
Efficacy(效率): 编辑后的准确率。
Generalization(泛化): 对事实语句的改写版本的准确率。
Specificity(特异性): 对不相关事实的准确率。
综合 Score: 上述三项的调和平均值。
对比基线模型:
包括 FT、FT-L、IKE、ROME 等。
省略 MEND,因其对 Llama2 缺乏支持且效果不佳。
4.3.2 综合性能比较(Overall Performance Comparison)¶
MemoryLLM-7B(w/ EF) 在两个数据集上的综合性能显著优于所有基线模型。
FT 在 Efficacy 和 Generalization 上表现良好,但 Specificity 较差,说明其知识更新会影响原有知识。
FT-L Specificity 提高,但 Efficacy 下降,说明知识吸收不充分。
ROME 在综合性能上较为均衡,但整体不如 MemoryLLM。
IKE 与 MemoryLLM 思路相似,但因提示复杂,导致 Specificity 有限。
4.4 长上下文评估(Long Context Evaluation)¶
4.4.1 实验设置(Experimental Setup)¶
使用 LongBench 基准评估模型的长上下文处理能力。
对比的基线包括:
Llama2-7B(本模型的基座)
LongLLaMA、OpenLLaMA-V2、Llama2-LongLora
由于显存限制,部分模型(如 16k 上下文模型)无法运行,而 MemoryLLM 仅需 48GB 或 2 个 40GB GPU 即可推理,显示出其优势。
4.4.2 综合性能比较(Overall Performance Comparison)¶
MemoryLLM 在六组数据中的四组中优于基线模型。
Qasper 数据集 表现出色不足,可能因未使用 arXiv 数据集所致。
上下文长度越长,性能越佳,表明 MemoryLLM 具有良好的知识保持能力。
当上下文长度小于 4k 时,MemoryLLM 表现略弱于 Llama2-7B,因训练数据子集存在分布偏移。
4.4.3 与 RAG 方法的比较(Comparison with RAG methods)¶
RAG 与 MemoryLLM 的关系: 互补,RAG 用于粗粒度检索,MemoryLLM 用于处理检索出的上下文。
使用 BM25 检索器提取 4k 词,再由 MemoryLLM 处理。
效果分析: 在部分数据集上提升明显,如 MultiFieldQA,但在 NarrativeQA 上效果下降。
4.5 知识保持实验(Knowledge Retention Experiments)¶
4.5.1 实验设置(Experimental Setup)¶
使用 SQuAD 和 NaturalQA 数据集评估模型在多次更新后是否遗忘知识。
构建二分类数组记录模型是否能回忆最近更新的知识。
计算模型在不同更新次数下的准确率。
4.5.2 实验结果(Results)¶
MemoryLLM 在 20 次更新后仍能保持良好知识记忆能力。
与理论上限相比,性能存在差距,可能因知识部分被干扰。
SQuAD 数据集在第二次更新中出现了短暂性能上升,推测与推理波动有关。
4.6 模型完整性分析(Model Integrity Analysis)¶
模型持续进行 65 万次更新,每次更新后评估其对最新知识的回答准确率。
结果: 准确率没有下降趋势,说明模型具备 “无限更新”能力,不影响其功能。
4.7 消融实验(Ablation Study)¶
4.7.1 不同 K 和 N 的影响(Effect of different K and N)¶
K: 每次更新存储的 token 数量。
N: 总共的 token 缓存容量。
实验结果表明:
固定 K,增加 N 可提升知识保持能力。
固定 N,减少 K 也有助于提升保持能力。
N/K 比值越大,模型记忆能力越强。
4.7.2 模型结构的消融研究(Ablation of Model Structures)¶
实验了不同层次添加 memory token 的效果:
仅在一层添加 memory token: 几乎无提升。
仅在后半层添加 memory token: 性能仍低于全文本添加。
结论: Memory token 需要分布在整个模型中,才能发挥最佳性能。
小结¶
本章通过一系列实验验证了 MemoryLLM 在新知识整合、长上下文理解、知识保持以及模型稳定性方面的卓越表现。尤其在与多种基线模型和 RAG 方法的对比中,MemoryLLM 表现出更高的综合性能和鲁棒性。消融实验进一步证明了其设计的有效性,为自更新大语言模型的研究提供了坚实基础。
6 Conclusion and Future Work¶
结论部分¶
本论文提出了 MemoryLLM,这是一种语言模型,由 transformer 和一个位于其潜在空间中的 巨大记忆池 组成。这个记忆池是模型中可以自我更新的参数。MemoryLLM 能够通过记忆池对新知识进行自我更新,实现 有效吸收新知识 的能力,并具有 缓慢遗忘旧知识 的特性。
作者通过与基线模型在 模型编辑 和 长上下文处理 方面的对比,以及专门设计的 知识保留评估,验证了 MemoryLLM 在知识吸收和知识保留方面的 优越性能。这是本研究的重点部分,突出了模型的核心优势。
未来工作部分¶
未来的研究方向包括:
扩展记忆容量:增加模型的记忆空间,使其能够存储更多知识。
提高压缩率:在自我更新过程中使用 更少的记忆 token 来存储新知识,从而提升模型的效率。
扩展为多模态模型:由于 MemoryLLM 的记忆 token 具有存储多种模态知识的潜力,未来计划将其拓展到 多模态场景,例如文本、图像、音频等的联合处理。
这部分内容较为概括,属于未来研究方向的展望,没有过多展开具体实现方式。
Impact Statement¶
本节主要阐述了论文的研究意义及其潜在的社会影响。论文的目标是推动自然语言处理(NLP)领域的发展,尤其专注于大型语言模型(LLMs)的研究。这是本文的核心贡献所在,具有重要的学术与应用价值。
论文强调,与大型语言模型相关的社会影响是值得关注的,例如AI的安全性和可靠性问题。这些是当前LLM研究中极为重要的议题,也是社会和学术界持续关注的焦点。作者明确指出,除了LLMs之外,其他方面的潜在影响在此无需特别强调。
Appendix A Details in Methodology¶
A.1 自我更新过程¶
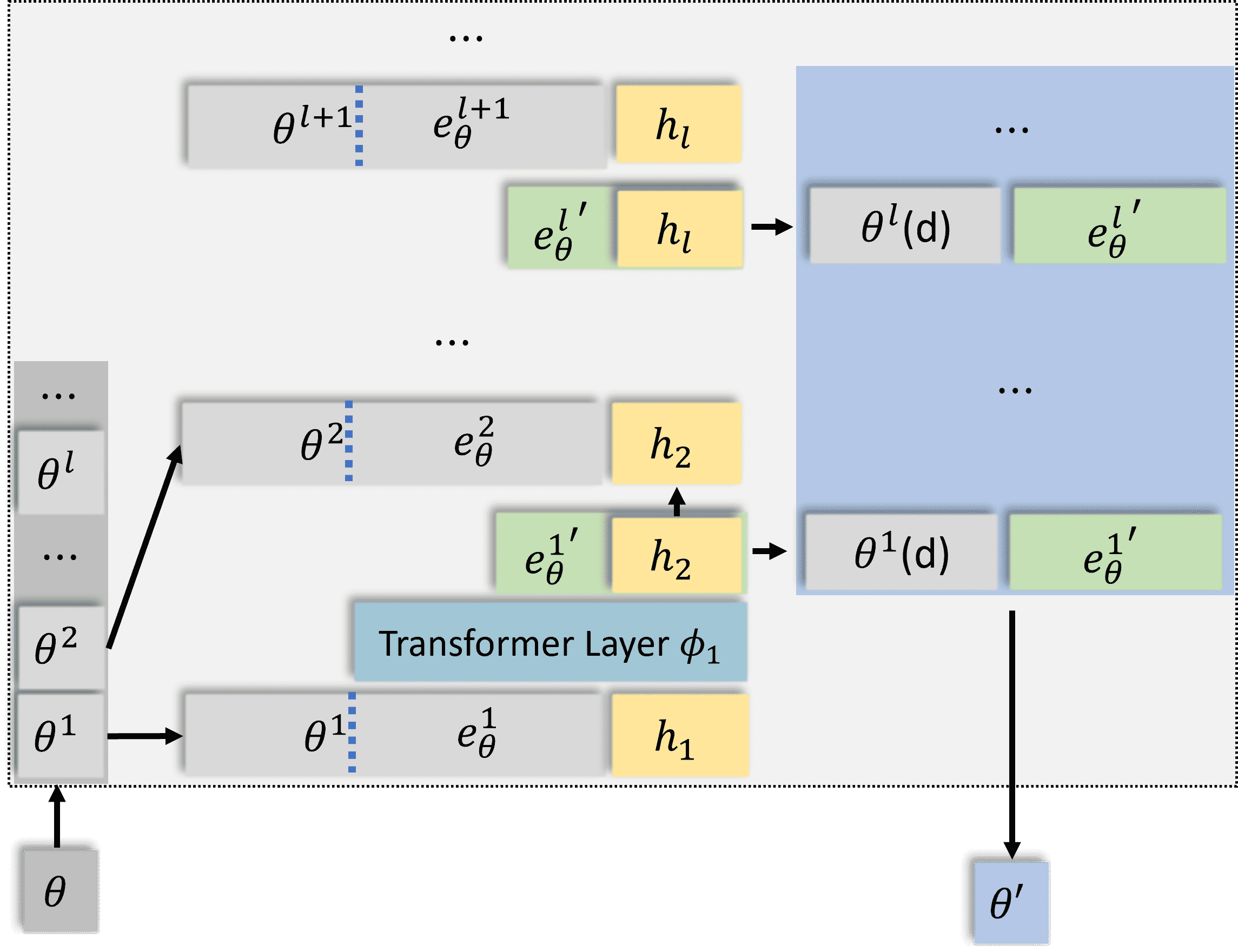
Figure 8:Self-Update process when the number of tokens is smaller than the number of memory tokens needed.
问题背景
正常情况:当输入上下文 \( x_c \) 的 token 数 ≥ \( K \)(记忆池每次更新的 token 数)时,直接取最后 \( K \) 个 token 用于更新记忆(如正文所述)。
特殊情况:如果输入 \( x_c \) 的 token 数 \( n_{x_c} < K \),此时无法直接截取 \( K \) 个 token,需要特殊处理(即图8描述的场景)。
设计意图
动态适配:无论输入长短,记忆池总能稳定更新(短输入少更新,长输入多更新)。
避免信息稀释:短输入生成的新记忆较少,防止无关信息过度写入。
计算一致性:拼接后的输入长度始终为 \( K + n_{x_c} \),确保 \( \phi_l \) 层计算稳定。
举例说明
假设:
记忆池每层容量 \( N=1000 \),每次更新需 \( K=256 \) 个 token。
当前输入 \( x_c \) 只有 100 个 token(即 \( n_{x_c}=100 \))。
步骤:
从记忆池 \( \theta^l \) 取最后 256 个 token(\( e_{\theta}^l \))。
将 \( e_{\theta}^l \)(256)与 \( h_l \)(100)拼接,输入 \( \phi_l \)。
\( \phi_l \) 输出 \( h_{l+1} \),取最后 100 个 token 作为新记忆 \( {e_{\theta}^l}' \)。
从记忆池随机丢弃 100 个旧 token,加入这 100 个新 token。
关键点总结
记忆池是主导:即使输入很短,记忆池也能提供足够的 token(\( e_{\theta}^l \))参与计算。
对称更新:新增记忆数 = 丢弃记忆数 = 输入 token 数 \( n_{x_c} \)(短输入时)。
稳定性:通过固定拼接长度(\( K + n_{x_c} \)),避免因输入长度波动导致计算异常。
A.2 新知识融合的训练策略¶
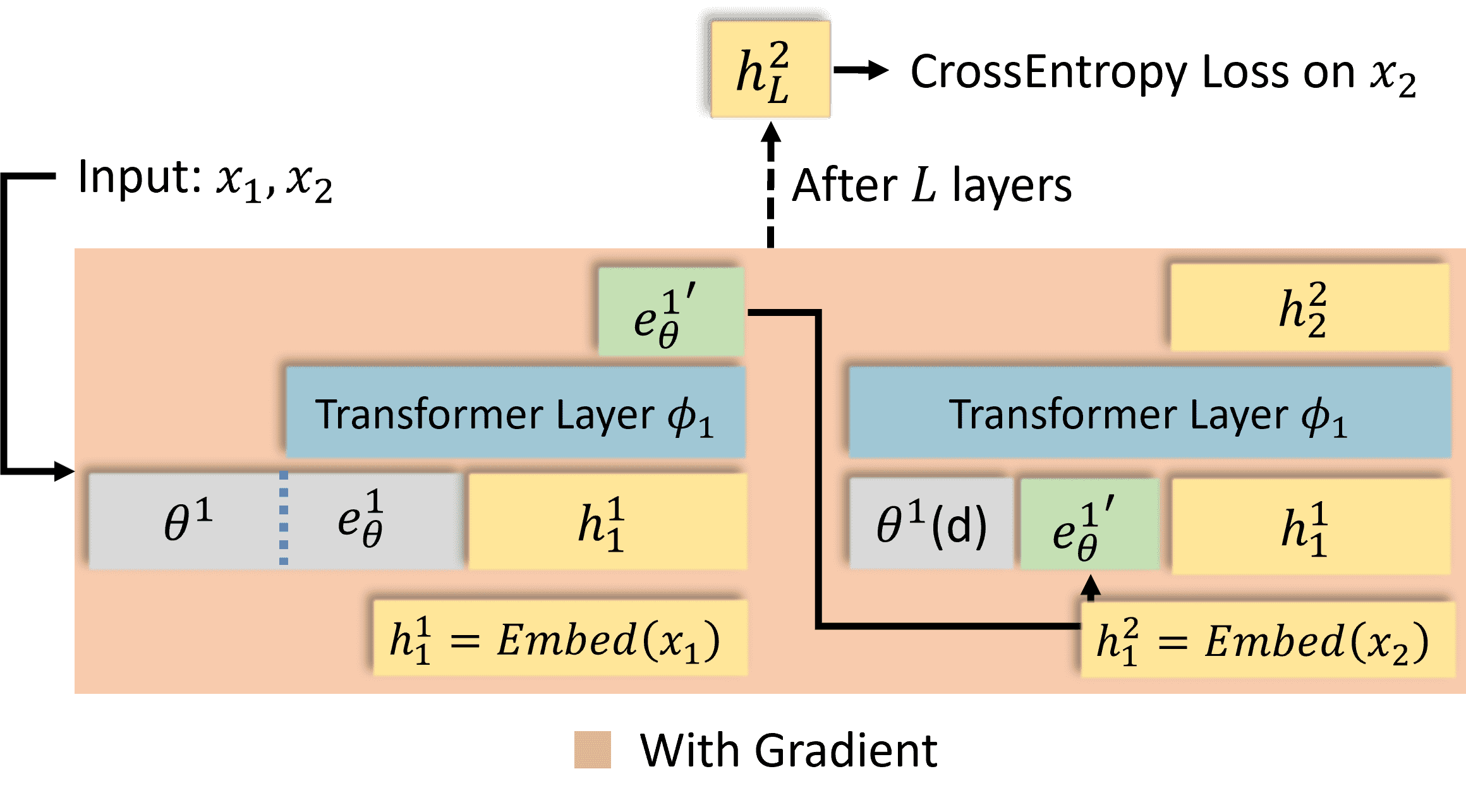
Figure 9:Ideal Training Routine for Latest Knowledge Incorporation
背景目标
MemoryLLM 的核心功能之一是动态吸收新知识(New Knowledge Incorporation)。
理想情况下,模型应该能:
通过
self-update机制将新知识(如输入x₁)写入记忆池。后续遇到相关问题时(如输入
x₂),能利用记忆池中的x₁信息正确回答。
但这里存在一个训练效率问题:如何设计梯度回传路径,使得模型能学会“该记住什么”?
理想训练流程(Figure 9)
流程描述
输入新知识
x₁:模型处理
x₁,通过self-update更新记忆池(生成新记忆 Token)。
输入相关查询
x₂:模型利用更新后的记忆池回答
x₂,计算预测结果的交叉熵损失(Cross-Entropy Loss)。
梯度回传:
损失梯度需要同时反向传播到
x₂和x₁的处理过程,从而优化:记忆写入机制(如何从
x₁提取有效记忆)。记忆读取机制(如何用记忆回答
x₂)。
为什么这是理想的?
端到端联合优化:记忆的“写”和“读”作为一个整体被训练,确保记忆池真正有用。
类比:像人类学习时,记住的知识(
x₁)和后续应用(x₂)是连贯的。
理想情况下的实际问题:内存爆炸
显存瓶颈:
若严格按上述流程,需在内存中同时保存x₁和x₂的完整计算图(尤其是长序列),显存占用会极高。传统方法限制:
普通 Transformer 的上下文窗口有限,无法直接处理超长序列(如x₁+x₂拼接)。
实际解决方案(分解训练,对应 Figure 2)
具体参见 Figure 2 中的方法。
关键对比
方案 |
梯度覆盖范围 |
显存占用 |
训练效果 |
|---|---|---|---|
理想端到端(Figure 9) |
|
极高 |
最优,但不可行 |
分解训练(Figure 2) |
仅 |
低 |
次优,但可实操 |
Appendix B Implementation Details¶
B.1 消除遗忘问题的细节¶
如第 3.2.3 节 所述,为了解决模型遗忘问题,我们需要从一个主文档 \(d = \{x_1, \cdots, x_n\}\) 中采样,同时注入多个辅助文档。在将 \(\{x_1, \cdots, x_{n-1}\}\) 注入内存后,再将 \(x_n\) 用于计算损失并更新模型。然而,为了避免每次训练步骤都采样多个文档,我们设计了一种更高效的训练策略,并在 算法 1 中给出了伪代码。
算法 1:缓解遗忘问题的训练策略¶
初始化参数:
r0 = 1:用于控制注入策略的初始标志;l = 0:用于控制更新频率的计数器;xcache = None:用于缓存上次的预测目标(即 \(x_n\));
训练流程:
遍历训练数据集中的每一个文档 \(d\),并提取其中的上下文数量 \(n\);
将 \(d\) 拆分成 \(\{x_1, \cdots, x_n\}\);
根据
r0和l的值,生成随机变量r:如果
r0 == 1或l == 0,则r = 0;否则,
r在 [0, 2) 范围内随机取值;
若
r == 0且r0 == 0:将 \(\{x_1, \cdots, x_{n-1}\}\) 注入内存;
用 \(x_n\) 计算损失并更新模型;
计数器
l += n;
若
r == 0且r0 == 1:将 \(\{x_1, \cdots, x_{n-1}\}\) 注入内存;
用 \(x_n\) 更新模型;
更新缓存
xcache = x_n;计数器
l += n;
若
r == 1:用
xcache更新模型;重置计数器
l = 0;
更新
r0 = r,用于下一步的策略判断。
重点说明:
每一步都会将部分上下文注入内存池,目的是在若干步之后,模型仍能从内存中提取关于
xcache的有用知识;通过这种方式,模型可以回顾过去注入的知识,防止遗忘;
当
r == 1时,模型会专门使用缓存的目标 (xcache) 来进行训练,从而强化模型对长期知识的记忆能力。
总结:
该策略的核心在于通过随机控制注入与更新的节奏,使模型在学习新知识的同时,有机会回顾和强化旧知识。这种方式在一定程度上缓解了连续训练过程中模型的遗忘问题,是实现“自更新语言模型”的关键实现细节之一。
Appendix C Additional Experiments¶
C.1 模型编辑的基线方法¶
本节介绍模型编辑实验中所使用的基线方法的细节:
FT(微调)¶
该方法使用 Adam 优化器,在一层网络上进行早停(early stopping)的微调,以在给定事实的基础上调整模型。这是最基本的一种模型编辑方法。
FT-L(受限微调)(Zhu 等,2020)¶
该方法在微调过程中对权重变化施加了参数空间中的 L∞ 范数约束,限制模型参数的变化范围,防止过大的调整。
IKE(上下文知识编辑)(Zheng 等,2023)¶
该方法通过将需要编辑的事实保存在上下文中,并在推理时将这些上下文输入模型,从而实现对模型的编辑。该方法仅在 CounterFactual 数据集上实现,因此作者在 CounterFactual 基准上与该方法进行了比较。
ROME(秩一模型编辑)(Meng 等,2022)¶
ROME 识别出大型语言模型(LLMs)中的多层感知机(MLPs)是存储知识的主要模块。该方法将 MLP 矩阵视为键值存储结构,并通过插入一个新的键值对来更新矩阵,从而将新的信息注入模型中。
重点总结:
本节重点介绍了四类模型编辑的基线方法,从简单的微调(FT)到复杂的结构修改(如 ROME)。
每个方法都有其特点:FT 是基础,FT-L 加入了约束,IKE 依赖于上下文,ROME 则通过修改 MLP 实现编辑。
这些方法旨在在不从头训练模型的前提下,调整模型知识,使其适应新的事实或任务需求。