2305.07001_InstructRec: Recommendation as Instruction Following: A Large Language Model Empowered Recommendation Approach¶
引用: 305(2025-09-10)
组织:
1Gaoling School of Artificial Intelligence Renmin University of China
2WeChat, Tencent China
总结¶
总结
长期偏好(历史行为)和短期意图(当前搜索/购买)
InstructRec
核心思想是:将推荐任务视为LLM的指令遵循任务,允许用户通过自然语言自由表达其信息需求(称为“指令”)。这一设计重点在于提升推荐系统的个性化和交互灵活性。
将推荐任务视为指令遵循(instruction following),允许用户通过自然语言指令表达其具体需求,系统则根据指令生成推荐结果
具体步骤:
设计指令模板:他们创建了一个通用的模板,将用户的偏好、意图、任务形式(如评分、排名)和上下文信息整合成一段自然语言文本。
自动生成数据:利用上述模板,自动生成了 25万2千条 细粒度的、个性化的用户指令数据。
微调模型:使用这些生成的指令数据,对一个开源的LLM(Flan-T5-XXL,30亿参数)进行指令微调。微调后,这个通用的LLM就变成了一个擅长理解和执行推荐指令的专家模型。
推荐问题的三个维度
1. 偏好(P):用户的长期、固有的品味和喜好。
P₀(无偏好):适用于冷启动或隐私保护场景,没有任何用户信息。
P₁(隐性偏好):通过用户的行为数据推断,如历史购买、点击记录等。但这里强调使用物品的标题文本(如“黑色耐克运动鞋”),而不是单纯的ID号。
P₂(显性偏好):用户直接用语言表达的喜好,例如评论“这双鞋很轻便,透气性好”。
2. 意图(I):用户当下、即时的、更具体的需求。
I₀(无意图):用户没有明确目标,只是随便浏览,比如抖音首页推荐。
I₁(模糊意图):用户有大致方向,但不够具体,比如“送给儿子的礼物”。
I₂(具体意图):用户的需求非常明确,比如“蓝色、便宜、iPhone 13”。
3. 任务形式(T):要求LLM具体怎么做推荐。
T₀(点对点):判断某个物品是否适合用户,例如“用户可能会喜欢《三体》吗?”
T₁(配对):在两个物品中选择更合适的,例如“《三体》和《流浪地球》,哪本更适合用户?”
T₂(匹配/生成):从整个物品库中直接生成或匹配候选物品,这是最困难的任务。
T₃(重排序):对一批已筛选出的候选物品(如20个)进行排序,把最合适的排在前面。这是目前LLM最擅长、成本也相对较低的方式。
增加指令的多样性
任务反转 (Turn the task around): * 不仅让模型“根据查询推荐商品”,也让它“根据买的商品反推用户可能用了什么查询词”。 * 这能帮助模型理解用户行为和信息需求之间的深层关系。
强化偏好与意图的关联 (Enforcing relatedness):
创建一些指令,让模型在用户的长期偏好(历史行为)和短期意图(当前搜索/购买)之间进行推理。
例如,“根据他的搜索词和选择,推断他可能还喜欢什么别的(历史行为)”。
链式推理 (Chain-of-thought):
让模型在给出最终推荐时,展示出推理过程。
例如,指令是“根据历史交互推荐商品”,理想的回答是:“根据历史交互,我们推断出用户偏好是XXX,因此我们推荐YYY商品。”
Abstract¶
在过去的几十年中,推荐系统在研究和工业界都受到了广泛关注,大量研究致力于开发有效的推荐模型。这些模型通常通过从用户的历史行为数据(如项目ID)中学习潜在的用户偏好,从而估计用户与项目之间的匹配关系以进行推荐。
受大型语言模型(LLMs)最新进展的启发,本文提出了一种不同的方法:将推荐任务视为LLMs的“指令跟随”(instruction following)。其核心思想是将用户的偏好或需求以自然语言的形式(称为“指令”)表达出来,使LLMs能够理解并执行这些指令以完成推荐任务。为了更好地将LLMs应用于推荐系统,本文选择对一个开源的LLM(3B Flan-T5-XL)进行指令微调,而不是使用LLMs的公开API。为此,作者设计了一个通用的指令格式,用以自然语言描述用户的偏好、意图、任务形式和上下文。
然后,作者手动设计了39个指令模板,并通过自动方法生成了大量个性化的用户指令数据(共252K条指令),涵盖多种偏好和意图类型。为了验证该方法的有效性,作者将这些指令模板实例化为多个广泛研究的推荐(或搜索)任务,并在真实数据集上进行了大量实验。实验结果表明,该方法在这些任务上的表现优于多个竞争性基线,包括功能强大的GPT-3.5。
该方法为开发更加用户友好的推荐系统提供了新思路,使用户能够通过自然语言指令自由地与系统交互,从而获得更准确的推荐结果。
关键词(Keywords)
大型语言模型(Large language models),指令微调(Instruction tuning),推荐系统(Recommender systems)
总结重点:
核心创新点:将推荐系统与指令跟随相结合,利用自然语言指令驱动推荐任务。
方法优势:通过指令微调LLM,提升其在推荐任务中的性能,优于当前主流模型(如GPT-3.5)。
数据构建:手动+ 自动生成252K指令数据,支持多种用户意图和偏好的表达。
实验验证:在多个真实任务中验证方法有效性,展示其广泛应用潜力。
1. Introduction¶
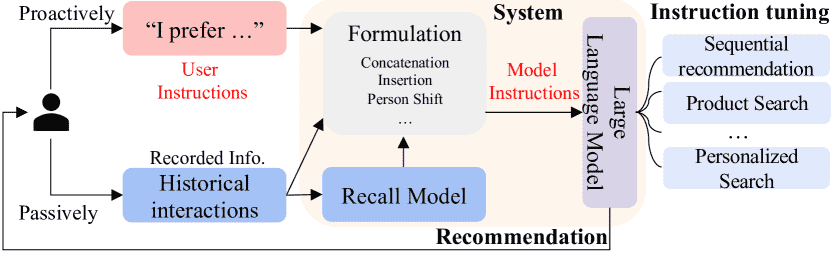
Figure 1.A framework of our proposed InstructRec.
1.1 推荐系统的发展与挑战¶
推荐系统已被广泛部署在各类应用平台中,其目标是满足用户需求并促进资源的使用或销售。早期的推荐系统主要依赖协同过滤算法,通过用户间或物品间的相似性进行推荐。随后,矩阵分解和神经网络方法被引入,以捕捉更复杂的用户偏好并建立更精确的用户-物品关系。
尽管取得显著进展,现有推荐算法仍面临两个主要问题:
泛化能力差:大多数算法依赖于用户-物品交互数据进行训练,在面对新用户或新任务等未见过的场景时表现不佳;
用户参与度低:用户在传统推荐系统中处于被动地位,无法灵活表达其真实需求。
1.2 大型语言模型(LLM)的潜力与挑战¶
近年来,预训练的大型语言模型(如 T5 和 GPT-3)在各类自然语言任务中表现出色,为推荐系统的发展提供了新的思路。已有研究表明,语言模型可以提升推荐系统的迁移能力(transferability)和用户-系统交互能力。
然而,语言模型主要基于文本数据,而推荐系统需要处理的是行为数据,因此直接应用语言模型存在挑战。一个可行的解决方案是将行为建模视为语言建模,即将推荐任务转化为自然语言处理任务进行处理。这引发了两个关键问题:
如何将推荐任务自然语言化(即“verbalize”)?
必须设计一种形式,能够全面描述用户的偏好、行为历史、任务意图等信息。如何将语言模型适配到推荐任务?
虽然语言模型擅长语言生成与理解,但对特定任务仍需针对性的微调策略,以提升其在推荐任务中的性能。
1.3 本文的贡献与方法¶
本文提出了一种新的基于语言模型的推荐范式——InstructRec,将推荐任务视为指令遵循(instruction following),允许用户通过自然语言指令表达其具体需求,系统则根据指令生成推荐结果。主要贡献如下:
贡献一:引入“指令”概念到推荐系统中¶
本文首次将“指令”(instruction)这一概念正式引入推荐系统中,将其视为一种用户需求表达方式,并将推荐问题建模为指令执行任务。与以往方法相比,本文讨论了在 LLM 框架下用户需求的表达形式,并提出了针对不同推荐任务的具体指令设计方法。
贡献二:设计指令微调的语言模型¶
为适配推荐任务,本文提出通过“指令微调”(instruction tuning)优化语言模型。为此,自动生成了大量与推荐相关的指令数据,包括粗粒度指令模板(39 种)和细粒度个性化指令数据(252K 条),涵盖用户的不同偏好与意图。通过 GPT-3.5 生成高质量数据,并采用多种策略提升指令的多样性,从而提升模型的泛化能力。
1.4 实验与效果¶
实验部分基于真实世界数据集构建了多种交互场景,结果表明:
InstructRec 在多种任务中表现优于多个竞争基线;
具备较强的适应能力,能够有效应对多样化的用户需求;
在未见过的指令和领域上也表现出良好的泛化性能。
1.5 总结¶
本文的核心创新点在于:
将推荐系统建模为“指令跟随”问题,提升用户参与度;
设计灵活通用的指令格式并自动生成高质量数据;
基于 3B 参数的 Flan-T5-XL 模型进行指令微调,构建适用于推荐系统的语言模型;
实验验证了该方法在多样任务场景下的有效性与泛化能力。
附加说明¶
虽然目前仅考虑单轮指令交互,但未来可拓展为多轮对话式推荐,进一步提升用户体验。这种任务导向的 LLM 适配方法,有助于增强推荐系统的泛化能力与用户满意度。
2. Methodology¶
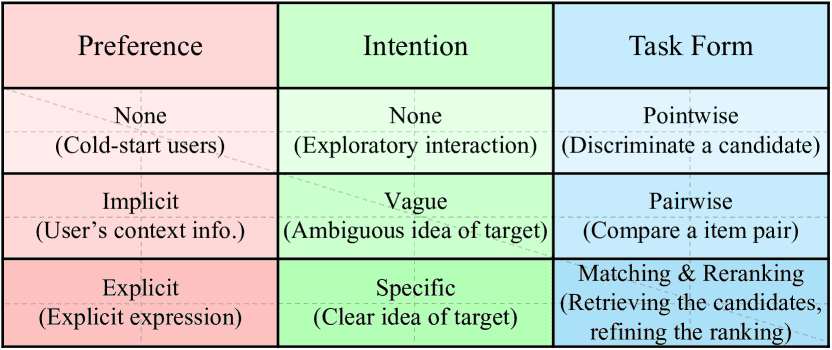
Figure 2.Various types of key aspects in instructions.
在本节中,作者提出了一种名为 InstructRec 的指令微调方法,用于推荐系统。该方法允许用户通过自然语言指令与推荐系统进行交互,自由表达其信息需求。整体方法分为三个主要部分:指令格式设计(2.1)、指令数据生成(2.2)以及指令微调过程(2.3)。
2.1. 推荐的指令格式(Instruction Format for Recommendation)¶
核心摘要¶
这段文字的核心是:为了让大型语言模型(LLM)能像人类一样理解和执行个性化推荐任务,研究者设计了一套标准化的“指令格式”。这套格式就像给LLM下的“命令模板”,通过组合不同的模块(用户偏好、用户意图、任务形式),可以灵活地应对各种真实的推荐场景(如猜你喜欢、搜索、个性化搜索等)。
1. 目标¶
目标:让LLM具备个性化推荐的能力。
方法:设计一种合适的“指令格式”。
指令格式的作用:
揭示用户的模糊/具体意图 (Intention)
提供用户的隐性/显性偏好 (Preference)
阐明任务的具体设置 (Task Form)
2. 指令的三个关键方面 (Key Aspects)¶
推荐问题可以从三个维度来划分:偏好(Preference - P)、意图(Intention - I) 和 任务形式(Task Form - T)。
1. 偏好(P):用户的长期、固有的品味和喜好。
P₀(无偏好):适用于冷启动或隐私保护场景,没有任何用户信息。
P₁(隐性偏好):通过用户的行为数据推断,如历史购买、点击记录等。但这里强调使用物品的标题文本(如“黑色耐克运动鞋”),而不是单纯的ID号。
P₂(显性偏好):用户直接用语言表达的喜好,例如评论“这双鞋很轻便,透气性好”。
2. 意图(I):用户当下、即时的、更具体的需求。
I₀(无意图):用户没有明确目标,只是随便浏览,比如抖音首页推荐。
I₁(模糊意图):用户有大致方向,但不够具体,比如“送给儿子的礼物”。
I₂(具体意图):用户的需求非常明确,比如“蓝色、便宜、iPhone 13”。
3. 任务形式(T):要求LLM具体怎么做推荐。
T₀(点对点):判断某个物品是否适合用户,例如“用户可能会喜欢《三体》吗?”
T₁(配对):在两个物品中选择更合适的,例如“《三体》和《流浪地球》,哪本更适合用户?”
T₂(匹配/生成):从整个物品库中直接生成或匹配候选物品,这是最困难的任务。
T₃(重排序):对一批已筛选出的候选物品(如20个)进行排序,把最合适的排在前面。这是目前LLM最擅长、成本也相对较低的方式。
此外,指令中还可以加入其他上下文(Context),如时间、地点等。
3. 指令实例化 (Instantiation for Various Interaction Scenarios)¶

Table 1: Example instructions with various types of user preferences , intentions , and task forms . To enhance the readability, we make some modifications to the original instructions that are used in our experiments.
这一部分解释了如何将上述三个维度组合起来,对应到真实的互联网应用场景中。表1提供了多个组合的例子。
⟨P₁, I₀, T₀⟩:传统推荐系统(如“猜你喜欢”)场景:用户没有主动输入任何意图(I₀),但系统知道他的历史行为(P₁)。任务形式是判断一个特定商品(Target Item)他是否喜欢(T₀)。
指令示例:“该用户购买过:[历史商品]。基于此信息,用户接下来是否可能对[目标商品]感兴趣?”
⟨P₀, I₁/I₂, T₃⟩:传统搜索引擎场景:用户有一个明确的搜索 query(I₁ 或 I₂),但系统不了解这个用户是谁(P₀)。任务形式是对搜索结果进行排序(T₃)。
指令示例:“你是一个搜索引擎,收到用户查询:[具体意图]。请从这些候选:[候选物品] 中挑选物品来回复用户。”
⟨P₁/P₂, I₁/I₂, T₃⟩:个性化搜索(如淘宝/京东的搜索框)场景:这是推荐和搜索的融合。用户既有主动意图(I),系统又了解他的个人偏好(P)。任务形式是对结果进行重排序(T₃)。
指令示例:“用户最近购买过:[历史商品]。用户表示想要:[具体意图]。请提供推荐。”
这是最强大的模式,因为它同时利用了用户的长期兴趣和即时需求。
4. 重要说明¶
模糊的边界:在
⟨P, I, T⟩的框架下,推荐(无意图,有偏好)和搜索(有意图,无偏好)的边界变得模糊,它们可以被统一到同一个指令框架下处理。其混合形态就是个性化搜索。为什么多用T₃(重排序):因为让LLM直接从海量商品中生成(T₂)成本极高、速度慢。目前更实用的做法是先用传统检索模型快速找出一个候选集,再用LLM这个“智能大脑”对这个候选集进行精细的重排序(T₃)。
总结与类比¶
你可以把这一切想象成给一个非常聪明但需要明确指示的实习生(LLM)下达工作指令:
了解客户(Preference):
“这是个新客户,我们什么都不了解。”(P₀)
“这个老客户过去买过A、B、C产品。”(P₁)
“这个客户上次评论说喜欢复古风格的东西。”(P₂)
明确客户本次需求(Intention):
“客户今天就来随便看看。”(I₀)
“客户想买‘一套喝茶的器具’。”(I₁)
“客户明确要‘一个300元以内的白色陶瓷茶杯’。”(I₂)
交代你的工作任务(Task Form):
“你看看这个‘XX茶杯’他会不会喜欢?”(T₀)
“这两个茶杯,哪个更适合他?”(T₁)
“你帮我想10个可能适合他的茶杯。”(T₂)
“我已经找了20个茶杯,你帮我把最好的5个排出来。”(T₃)
研究者设计的这套“指令格式”,就是教我们如何把这三个方面的信息组合成一句清晰的“人话”(自然语言指令),让LLM实习生能够准确无误地执行推荐任务。
2.2. 指令生成(Instruction Generation)¶
这段文字的核心是:研究人员如何利用大型语言模型(LLM)来自动生成大量、多样且高质量的“指令数据”,用于训练一个能做推荐系统的AI模型。
整体概括¶
简单来说,这部分描述了一个数据制造流水线:
目标:获得大量格式规范、包含用户偏好和意图的指令数据。
挑战:真实数据中很难直接获得用户明确的偏好和意图。
解决方案:请一个非常强大的“老师LLM”(即GPT-3.5)来帮忙,根据用户的历史行为(如购买记录、评论)来“模拟”或“推断”出用户的偏好和意图,并填充到预先设计好的指令模板中。
增强:使用一些策略(如反转任务、链式推理)来增加生成指令的多样性,从而让最终训练的模型更强大。
核心思想:由于很难获得用户直接说出的“我喜欢恐怖游戏”这样的数据,所以他们用GPT-3.5这个“老师”来根据用户的行为(比如他买了《生化危机4》和《生化危机:启示录2》)来“猜”出他的偏好(“他喜欢有强叙事的恐怖游戏”)。
流程:先手动创建一些粗糙的模板,然后用具体的用户信息(由GPT-3.5生成或从数据中提取)来填充这些模板,形成最终的、精细的指令数据。
2.2.1. Annotating the Aspects in Instructions (标注指令中的各个方面)¶
这部分详细说明了如何生成指令中的三个核心部分:偏好 (Preference)、意图 (Intention) 和 任务形式 (Task Form)。
偏好标注 (Preference annotation)
隐式偏好 (P₁): 直接来自数据。例如,把用户买过的东西的标题列出来。指令类似:“该用户之前购买过以下商品:{[游戏A, 游戏B]}”。
显式偏好 (P₂): 让GPT-3.5根据用户的历史行为总结和推断出用户的偏好。这是关键创新。
例子:输入是用户购买的两个游戏名,GPT-3.5输出:“他偏好具有强叙事的恐怖游戏。” 这比单纯罗列游戏名包含了更多信息。
意图标注 (Intention annotation)
模糊意图 (I₁): 让GPT-3.5从用户对目标商品的评论中提取购买意图。评论能反映用户的动机和感受。
例子:从评论“我儿子很喜欢…我很高兴给他买了这个”中,GPT-3.5提取出:“我喜欢给我儿子买他喜欢的游戏。”
具体意图 (I₂): 直接从目标商品的类别信息中获取。这反映了用户非常明确的需求。
例子:用户想买一个游戏鼠标,意图就是:“视频游戏,电脑,配件,游戏鼠标”。
任务形式标注 (Task Form annotation)
说明了指令可以对应不同的推荐任务:
T₀ (点对点推荐): 问模型“用户会不会喜欢这个商品?”,回答是/否。
T₂ (匹配): 让模型“预测下一个可能是什么商品”。
T₃ (重排序): 给模型一个候选列表,让它“从里面选一个最合适的”。
2.2.2. Increasing the Diversity of Instructions (增加指令的多样性)¶
为了训练出更强大的模型,需要数据更多样。这里提出了三种策略:
任务反转 (Turn the task around): 不仅让模型“根据查询推荐商品”,也让它“根据买的商品反推用户可能用了什么查询词”。这能帮助模型理解用户行为和信息需求之间的深层关系。
强化偏好与意图的关联 (Enforcing relatedness): 创建一些指令,让模型在用户的长期偏好(历史行为)和短期意图(当前搜索/购买)之间进行推理。例如,“根据他的搜索词和选择,推断他可能还喜欢什么别的(历史行为)”。
链式推理 (Chain-of-thought): 让模型在给出最终推荐时,展示出推理过程。例如,指令是“根据历史交互推荐商品”,理想的回答是:“根据历史交互,我们推断出用户偏好是XXX,因此我们推荐YYY商品。”
2.2.3. Statistics and Quality of Instruction Data (指令数据的统计与质量)¶
这部分是“成果验收”:
规模:他们最终生成了一个巨大的数据集——252,730 条精细指令,来源于39个粗糙模板。
质量评估:他们人工检查了生成指令的质量,发现:
大部分指令 (90%+) 确实是从用户信息中生成的。
老师LLM (GPT-3.5) 经常能提供相关的世界知识来丰富指令(尤其在偏好生成上,87%)。
主要问题在于:生成的意图与目标商品完全对齐的比例只有69%。作者认为这是因为用户评论本身可能有噪音(比如评论跑题了)。
核心要点总结¶
自动化与 scalability (可扩展性):该方法的核心优势是利用GPT-3.5自动从现有数据中生成海量的高质量指令,避免了昂贵且缓慢的人工标注。
富化信息:GPT-3.5不仅能提取信息,还能推断和总结,将简单的用户行为(购买记录)转化为富含语义的偏好描述,为模型提供了更丰富的学习信号。
多样性设计:通过精心设计的不同策略(反转、关联、推理链),极大地增加了数据的多样性,这有助于训练出的模型更加通用和鲁棒。
依赖强大教师模型:整个流程的成功高度依赖于“老师-LLM”(此处是GPT-3.5)的强大能力(文本理解、推理和生成)。
2.3. 推荐任务的指令微调(Instruction Tuning for Recommendations)¶
核心思想总结¶
这篇文章的核心想法是:把“给用户做推荐”这件事,变成让大型语言模型“遵循用户指令”来完成的一项任务。
就像你让ChatGPT写一首诗或翻译一段话一样,这里是你让LLM“根据我的历史行为,推荐我可能喜欢的下一部电影”。为了实现这个目标,需要用一个包含大量“指令-反馈”对的数据集来专门训练(微调)LLM,让它学会如何正确响应推荐类的指令。这个训练过程就叫做指令微调。
2.3.1. The Backbone LLM (骨干大型语言模型)¶
这一部分解释了为什么选择LLM以及选择哪个具体的LLM作为基础。
为什么用LLM?
LLM(如GPT系列、LLaMA等)已经被证明非常擅长理解和遵循人类用自然语言发出的指令,完成各种任务。
作者希望利用LLM的这个强大能力,让它来遵循“用户-centric的指令”(即用户表达自己需求的指令),从而完成推荐任务。
指令微调可以让LLM泛化到它没见过的、但用自然语言描述的新任务上。这意味着,未来可以很容易地让这个推荐系统完成更多样化的任务(例如,不仅推荐“下一个商品”,还可以推荐“为什么喜欢这个商品”的理由)。
选择了哪个模型?为什么?
模型选择:他们选择了 Flan-T5-XL(一个参数量为30亿的模型)。
选择理由:
已经过指令微调:Flan-T5本身就是在T5基础上,用了大量各种任务的指令数据进行过微调的模型。因此,它“天生”就比原始模型更懂得如何遵循指令,这是一个很好的起点。
encoder-decoder架构:T5是编码器-解码器架构,这种结构非常适合于“序列到序列”的任务,比如根据一段输入文本来生成一段输出文本,这和“根据用户指令生成推荐结果”的模式很匹配。
存在什么挑战?
输入长度限制:Flan-T5最大只能处理512个token的输入。在推荐系统中,我们需要把用户的历史行为(例如看过的几十个电影标题、买过的上百个商品名)都塞进输入里,很容易就超过这个限制。
解决方案:只能对过长的用户行为序列进行截断,但这可能会丢失重要信息,导致效果不是最优。作者提到,其他研究者可以选择上下文长度更长的LLM(如LLaMA)来解决这个问题。
2.3.2. Training and Inference (训练与推理)¶
这一部分讲解了如何用指令数据训练模型,以及训练好后如何使用它进行推荐。
训练(优化)过程 - Instruction Tuning
本质:这是一种有监督的微调。你需要准备一个数据集,里面每一条数据都包含:
(指令, 期望的输出)。如何准备数据?
指令:就是前面提到的各种推荐指令模板。
目标输出:根据指令类型不同,输出也不同。
对于“预测下一个商品”的指令,输出就是目标商品的名字。
对于“思维链”推理的指令,输出就是用户做出这个选择的一系列推理过程(例如:“因为我喜欢A,而B和A类似,所以我也可能喜欢B”)。
如何训练?
将所有指令和期望输出都用自然语言格式化,统一成一个“序列到序列”的任务:模型读入指令序列,生成目标输出序列。
训练目标是最大化目标输出序列的似然概率。简单说,就是让模型输出的文字和我们期望它输出的文字尽可能一样。
公式(1)
ℒ= ...就是这个损失函数的数学表达,计算的是模型生成的每一个词的概率的对数之和。
推理(应用)过程
角色:由于计算效率和模型能力的考虑,他们不直接用LLM从海量商品中生成答案,而是把它作为一个重排序器。
第一步:先用其他更高效的方法(例如传统推荐模型)从全量商品中快速筛选出一个较小的候选商品集合。
第二步:让LLM对这个小的候选集合进行精细排序,产生最终推荐列表。
工作流程:
理解用户指令:系统根据用户当前发出的指令和历史行为,选择一个合适的指令模板。
构建模型指令:通过拼接、插入信息(如用户历史)、角色转换等操作,将模板填充成完整的、模型能理解的指令。
执行推荐:将指令喂给LLM,让它执行。
一个关键问题与解决方案:
问题:LLM是生成式模型,它可能会天马行空地生成一些不在候选集合里的商品名,这显然不行。
解决方案:他们不让LLM“自由生成”商品名,而是把候选商品列表直接作为输入的一部分喂给模型,让模型为列表中的每一个候选商品计算一个“得分”(即模型认为该商品是正确答案的 likelihood/概率)。最后,根据这个得分对所有候选商品进行排序,得分最高的就是最推荐的。这样就完美地将LLM的生成能力约束在了候选集之内,用于排序。
3. Table 4. 方法对比¶

Table 4: Comparison between the proposed InstructRec and two related studies. “IT” denotes instruction tuning.
这个表格将他们提出的 InstructRec 方法与另两个相关研究做了对比,突出了自己的创新点。
M6-Rec:
也用了LLM(M6),没有用指令微调。
核心是把用户行为当成普通文本处理。
它可能只是用LLM来学习用户历史序列的表示,而不是直接遵循指令。
P5:
用了指令微调(IT)。
但它将所有数据(用户、商品)都转换成了匿名ID(Non-ID? 这里表格标题可能是笔误,应为ID),而不是用商品本身的文本信息(如标题)。
它的指令更像是“任务描述”。
InstructRec (本文方法):
既用了指令微调(IT),也利用了商品的非ID文本信息(如标题,即Non-ID)。
最关键的不同:它的核心思想是让LLM与用户需求对齐,指令是直接来源于或模拟用户的真实需求,而不仅仅是冷冰冰的任务描述。
一句话概括¶
这篇文章研究的是,如何通过“指令微调”的方式,把一个现成的大型语言模型(Flan-T5)训练成一个能听懂用户话、并据此进行个性化推荐的智能推荐系统。
2.4. 讨论(Discussion)¶
作者将 InstructRec 与传统推荐方法(如 SASRec、LightGCN)和基于 LLM 的推荐方法(如 P5、M6-Rec)进行了对比。主要优势包括:
更灵活的指令格式:支持多种偏好、意图和任务形式
更强的泛化能力:利用 LLM 的通用知识,提升冷启动和复杂需求下的表现
用户中心化设计:通过自然语言指令,更贴近用户真实需求
总结¶
本节系统性地介绍了 InstructRec 方法的三大核心模块:指令格式设计、指令数据生成 和 指令微调训练。作者通过设计灵活的指令模板,并结合教师模型生成高质量指令,最终实现用户中心化的推荐任务。相比于传统方法和现有 LLM 推荐方法,InstructRec 在多样性、泛化性和个性化方面具有明显优势,为未来推荐系统的自然语言交互提供了新思路。
3. Experiments¶
3.1. 实验设置¶
3.1.1. 数据集¶
我们使用了 Amazon 数据集中的两个子集进行评估:“Video Games” 用于评估模型对用户为中心指令的适应能力,“CDs & Vinyl” 用于评估模型对未见数据的泛化能力。根据先前研究(Hou 等,2022),我们过滤掉了交互次数少于5次的用户和物品。由于 Flan-T5(模型的主干)的上下文长度限制为512个token,我们将生成的行为序列截断为最多20个物品。预处理后的数据集统计信息见表5。
表5 数据集预处理后的统计信息:
Games:50,546 个用户,16,859 个物品,410,907 次交互,平均行为序列长度为 8.13
CDs:93,652 个用户,63,929 个物品,871,883 次交互,平均行为序列长度为 9.31
3.1.2. 评估指标¶
我们采用 Top-K Hit Ratio(HR) 和 Top-K Normalized Discounted Cumulative Gain(NDCG) 作为评估指标,分别在 K=1、3、5 的情况下进行评估。对于序列推荐和个性化搜索等交互场景,我们使用 leave-one-out 策略进行评估,将最后一个交互项作为测试数据。对于商品搜索场景,我们将数据划分为训练集(80%)、验证集(10%)和测试集(10%),测试集中的样本在训练阶段是未见过的,增加了推理难度。我们使用了开源推荐库 RecBole 实现一些基线模型。此外,我们对不同粒度的指令类型,使用验证集选择表现最好的指令进行测试,并通过与九个随机负样本进行对比排序,计算最终的测试集得分。
3.2. 各种用户信息需求的总体性能¶
我们通过不同交互场景下的指令实例化来验证模型在满足多样化用户需求方面的有效性。这些指令包括隐式偏好、显式偏好、含糊意图和明确意图等。
3.2.1. 序列推荐 ⟨P1,I0,T3⟩¶
我们首先在序列推荐任务中测试了模型的性能,使用用户隐式偏好(如行为序列)构建指令。
基线模型:SASRec(基于Transformer结构)、BERT4Rec(双向注意力机制)
GPT-3.5 表现不佳,说明通用大语言模型在行为序列建模上存在不足。相比之下,InstructRec 在所有指标上均优于其他基线模型(见表6)。
表6 序列推荐性能对比:
InstructRec 在 HR@1、HR@3、HR@5 和 NDCG 指标上分别比 SASRec 提升了 4.26%、0.59%、0.43%、1.85% 和 1.72%
3.2.2. 商品搜索 ⟨P0,I2,T3⟩¶
在商品搜索场景中,我们使用目标物品的元数据(如分类)模拟用户意图,构建搜索查询。
基线模型:DSSM(双塔结构检索模型)
InstructRec 在 HR@1 和 NDCG@1 等关键指标上显著优于 DSSM 和 GPT-3.5(见表8)。
表8 商品搜索性能对比:
InstructRec 相比 DSSM 提升了 13.52%(HR@1)、4.16%(NDCG@3)和 3.60%(NDCG@5)
3.2.3. 个性化搜索 ⟨P1,P2/I1/I2,T3⟩¶
个性化搜索是推荐与搜索的结合。我们引入了历史行为序列(P1)来表示“个性化”部分,并将 LLM 生成的显式偏好(P2)、含糊意图(I1)和明确意图(I2)分别作为查询。
基线模型:TEM(基于Transformer的个性化搜索引擎)
InstructRec 在几乎所有的测试指标上均显著优于 TEM 和 GPT-3.5,尤其在面对模糊指令时表现出更强的泛化能力(见表7)。
表7 个性化搜索性能对比:
InstructRec 在 HR@1、HR@3、HR@5 等指标上提升幅度在 6.97% 到 44.64% 之间
总结:通过指令微调,InstructRec 有效整合了用户行为数据与通用知识,在多种推荐场景中表现出色。
3.3. 进一步分析¶
3.3.1. 区分困难负样本¶
我们进一步测试了模型在重排序(reranking)阶段区分困难负样本的能力。我们构建了一个“匹配-重排序”管道,首先使用双塔模型进行匹配,再使用 InstructRec 重排序候选列表。
表9 硬负样本重排序性能对比:
InstructRec 在 HR@1 指标上比 SASRec 提升了 67.36%,在 NDCG@3 上提升了 43.41%
3.3.2. 区分更多候选物品¶
我们测试了模型在面对 100 个候选物品时的性能。由于上下文长度限制,我们采用分组评估策略。结果表明,InstructRec 显著优于 TEM(见表10)。
表10 100 个候选物品重排序性能对比:
InstructRec 在 HR@3、HR@5、NDCG@3 和 NDCG@5 上分别提升了 71.59%、57.72%、56.29% 和 50.10%
3.3.3. 指令对模型性能的影响¶
我们通过增加不同类型的指令,测试了指令多样性对模型泛化性能的影响。结果表明,随着指令数量的增加,模型在未见交互场景中的性能稳步提升,特别是引入模糊意图(vague intention)后效果提升显著。
3.3.4. 跨数据集泛化¶
我们评估了模型从“Games”数据集迁移到“CDs”数据集的能力。虽然零样本性能不如在域内训练的模型(如 SASRec 和 BERT4Rec),但 InstructRec 仍显著优于其他大型语言模型(如 GPT-3.5 和 Flan-T5-XL),表明指令微调有效提升了跨域泛化能力(见表11)。
总结:
InstructRec 通过指令微调,成功将用户行为与通用知识结合,表现优于现有主流推荐模型。
在序列推荐、商品搜索、个性化搜索等常见推荐任务中,InstructRec 均表现出色。
模型在区分困难负样本和处理模糊指令方面具有优势。
指令多样性和微调策略显著提升了模型的泛化能力。
在跨数据集迁移任务中,InstructRec 也展现出良好的适应性。
4. Conclusion and Future Work¶
在本论文中,我们提出了一种面向推荐系统的大型语言模型(LLM)指令微调方法,命名为 InstructRec。与现有将LLM应用于推荐的研究所不同,我们的核心思想是:将推荐任务视为LLM的指令遵循任务,允许用户通过自然语言自由表达其信息需求(称为“指令”)。这一设计重点在于提升推荐系统的个性化和交互灵活性。
具体而言,我们首先设计了一种通用的指令模板格式,该模板整合了用户在自然语言文本中表达的偏好、意图、任务形式以及上下文信息。然后,我们自动生成了252,000条细粒度的个性化用户指令,用于描述用户的偏好和意图。通过将开源的LLM(3B Flan-T5-XXL)在这些指令数据上进行微调,使得基础模型能够很好地适应推荐系统场景,并根据用户的自然语言指令进行个性化推荐。大量实验验证了该方法在不同场景下的有效性与泛化能力。
未来工作¶
在未来的方向中,我们计划扩大LLM的规模,以进一步提升指令微调的效果。同时,我们也将考虑扩展上下文长度,以更好地建模用户长期的行为序列。
此外,我们还计划将该方法应用于多轮交互场景,即用户可以以聊天对话的方式与系统进行交流,从而实现更自然、更灵活的个性化推荐体验。这也是本文方法的一个重要扩展方向。
Appendix A Instruction Templates for Traditional Recommendation¶
⟨P1,I0,T2⟩¶
目标:基于用户的历史交互,预测用户最可能交互的下一个产品。
输入:用户的历史交互记录
{historical interactions}。任务:直接根据用户行为数据进行推荐,不涉及用户画像或其他信息。
⟨P1,P2,I0,T2⟩¶
目标:基于用户个人资料(包括显式偏好)和历史交互,推荐下一个潜在产品。
输入:用户偏好
{explicit preference}和历史交互{historical interactions}。重点:将用户画像与行为数据结合,提升推荐的个性化程度。
Chain-of-thought (CoT)¶
目标:使用推理链的方式进行推荐。
方法:首先根据历史交互推断用户偏好,再据此推荐产品。
重点:强调逻辑推理过程,模拟人类思维路径,提高推荐的可解释性。
⟨P1,(P2),I0,T2⟩(多个变体)¶
目标:基于用户的历史交互和显式偏好,推荐下一个可能的产品。
输入:历史交互
{historical interactions}和显式偏好{explicit preference}。重点:强调通过分析用户行为和偏好共同推导出推荐结果。
⟨P1,(P2),I0,T3⟩(多个变体)¶
目标:从给定的候选集中选择一个最符合用户偏好的产品。
输入:用户历史交互和显式偏好,以及候选产品集合
{candidate items}。重点:
强调在多个选项中进行比较和选择。
任务更偏向于列表推荐或Top-K 推荐。
需要比较候选项与用户偏好的相似性。
⟨P1,(P2),I0,T1⟩(多个变体)¶
目标:判断用户是否有可能与某个候选产品交互(例如点击或购买)。
输入:用户历史交互、偏好和候选产品
{candidate item}。任务:是一个二分类预测任务(是/否),重点在于判断交互的概率。
Turn the task around(多个变体)¶
目标:从用户历史交互中推断其总体偏好。
输入:用户历史交互
{historical interactions}。重点:不直接进行推荐,而是通过行为数据提取用户的偏好特征。
用途:可作为后续推荐任务的输入,强调偏好建模能力。
⟨P2,I0,T2⟩(多个变体)¶
目标:根据用户显式偏好直接推荐产品。
输入:用户偏好
{explicit preference}。重点:不依赖历史交互,仅基于用户明确提供的偏好进行推荐,适用于偏好明确的场景。
总结¶
整体结构:该章节共提供了多种推荐任务的指令模板,涵盖了从纯行为数据推荐到结合用户画像与候选选项推荐的多个变体。
任务类型包括:
下一产品预测(T2)
候选列表中选择推荐(T3)
预测用户是否交互(T1)
从行为中推断偏好(Turn the task around)
重点内容:
用户显式偏好和历史交互结合使用提升推荐质量;
推理过程(如CoT)增强推荐的可解释性;
多任务形式(如二分类预测、Top-K 选择)适应不同推荐场景;
偏好建模是所有任务的核心基础。
这些模板为传统推荐系统的指令式方法提供了全面的示例和结构指导,适用于构建基于语言模型的推荐系统。
Appendix B Instruction Templates for Traditional Product search¶
⟨P₀, P₂/I₁/I₂, T₂⟩¶
结构说明:该模板用于模拟一个搜索引擎的反应,用户提出的查询可能是明确偏好、模糊意图或具体意图。任务要求根据查询生成一个相关的**项目(item)**作为回应。
重点内容:
假设你是搜索引擎,用户输入了某种查询(如“喜欢红色的衣服”、“想找一个适合旅行的包”或“小米13手机”)。
你的任务是根据用户输入,生成一个相关的商品或项目来回应。
适用于需要生成式回答的任务,而不是从候选列表中选择。
⟨P₀, I₂, T₂⟩¶
结构说明:与上一个模板类似,但输入被明确为“具体意图”(specific intention),强调用户的需求非常明确。
重点内容:
用户的查询是明确的,如“我要买一双耐克运动鞋”。
你的任务是根据这个明确的意图,推荐一个相关项目作为回答。
与上一条不同,该模板更适用于推荐系统任务,强调“推荐”而非生成描述。
⟨P₀, I₂, T₂⟩(推荐系统版本)¶
结构说明:该模板从“推荐系统”角度出发,用户给出具体意图,要求系统推荐一个相关项目。
重点内容:
用户的请求是“具体意图”,如“我想要一副降噪耳机”。
作为推荐系统,你需要根据这个具体意图推荐一个商品。
强调从用户意图出发进行推荐,适用于个性化推荐场景。
⟨P₀, P₂/I₁/I₂, T₂⟩(回答用户问题版本)¶
结构说明:该模板仍然要求根据用户查询生成一个回答,但更强调“回答用户问题”这一任务性质。
重点内容:
用户的问题可能是模糊或明确的。
你需要生成一个相关答案来帮助用户,例如推荐商品或解释查询结果。
适用于问答型或解释型的搜索场景。
Turn the task around¶
结构说明:这部分是任务反转,即用户不知道如何准确表达搜索意图,需要系统帮助生成合适的搜索查询。
重点内容:
如果用户想搜索某个商品(如“无线蓝牙耳机”),但不知道如何表达。
你作为搜索引擎,可以根据目标商品的特征(如品牌、类型等)生成合适的搜索关键词。
例如:用户想搜索“无线蓝牙耳机”,你可以生成查询“蓝牙无线耳机推荐”或“高性价比无线耳机”。
⟨P₀, P₂/I₁/I₂, T₃⟩(从候选列表中选最优项)¶
结构说明:该模板要求从多个候选项目中,选择一个最符合用户查询的项目,适用于搜索结果排序或推荐场景。
重点内容:
用户输入查询可能是明确、模糊或具体意图。
系统需要从给定的候选项目列表中,选择最匹配用户查询的项目。
适用于搜索结果匹配、推荐系统排序等任务。
⟨P₀, P₂/I₁/I₂, T₃⟩(多个版本)¶
结构说明:该模板在不同版本中略有不同,但核心任务一致,即从候选列表中选择最优匹配项。
重点内容:
用户输入查询,系统获得候选项目列表。
任务是比较候选项目的相关性,选出最符合用户意图的项目。
不同版本强调了“匹配用户查询”或“比较相关性”的不同侧重点。
总结¶
附录B 中的模板主要围绕传统产品搜索任务,涵盖以下几种类型:
生成式任务:根据用户意图生成相关商品项目(T₂)。
推荐任务:根据用户意图推荐最合适的商品(T₂)。
任务反转:帮助用户生成搜索查询(T₂)。
选择任务:从候选列表中选择最匹配用户意图的项目(T₃)。
这些模板可用于训练或评估搜索引擎、推荐系统等模型在不同搜索和推荐场景下的表现。重点在于理解用户意图,生成或选出最相关的结果。
Appendix C Instruction Templates for Personalized Search¶
本附录(Appendix C: Instruction Templates for Personalized Search)总结了用于个性化搜索任务的一组指令模板。这些模板结合了用户历史交互、用户偏好(显式或隐式)、当前意图(具体或模糊)以及目标项或候选项推荐,用于构建更加个性化和精准的搜索系统。以下是按照原始结构的总结,重点内容已作强调说明。
指令模板分类¶
1. ⟨P1,P2,T2⟩¶
目标:根据用户的历史交互和显式偏好,生成与其偏好一致的新产品。
P1:用户历史交互(Historical interactions)
P2:用户显式偏好(Explicit preference)
T2:生成新产品(Generate new product)
重点:显式偏好驱动生成逻辑,系统需完全符合用户已表达的偏好。
2. ⟨P1,I1,T2⟩¶
目标:根据用户历史交互和模糊意图(vague intention),生成匹配当前意图的产品。
P1:用户历史交互
I1:模糊意图
T2:生成匹配当前意图的产品
重点:系统需从历史交互中推测用户当前意图,生成符合该意图的产品。
3. ⟨P1,I1,T2⟩(重复项)¶
目标:作为购物助手,根据用户最近购买的物品和模糊意图,推荐符合其意图的新产品。
P1:最近购买的物品
I1:模糊意图
T2:推荐新物品
重点:与前一个模板类似,但强调用户为购物者,需提供购物指南类推荐。
4. ⟨P1,I2,T2⟩¶
目标:根据用户当前的具体查询(specific intention)和历史交互,推荐匹配的产品。
P1:用户历史交互
I2:具体查询
T2:推荐匹配产品
重点:强调用户有明确搜索意图,系统需结合历史和意图进行推荐。
任务反转类模板(Task Reversal)¶
5. Turn the task around(第1类)¶
目标:用户对某个目标物品感兴趣,但不知道如何撰写查询。需帮助其生成一个符合其偏好的查询。
输入:历史交互 + 目标物品
输出:生成查询语句
重点:强调从用户行为中提取偏好,构建个性化查询。
6. Turn the task around(第2类)¶
目标:分析用户历史交互,反推出用户偏好,并解释这些偏好如何引导其与目标物品互动。
输入:历史交互 + 目标物品
输出:识别偏好并解释
重点:用于偏好建模,有助于个性化推荐系统理解用户行为动机。
强调偏好与意图一致性(Preference-Intention Consistency)¶
9. Turn the task around(第3类)¶
目标:分析用户的查询,推测其过去购买和未来购买的物品。
输入:用户查询(显式偏好 / 模糊意图 / 具体意图)
输出:推测历史购买 + 预测未来购买
重点:强调查询分析在个性化推荐中的作用。
三元组合模板(Triple Combinations)¶
10. ⟨P1,(P2),P2/I1/I2,T3⟩¶
目标:根据用户当前查询(显式/模糊/具体)和历史交互,推断其偏好,并从候选物品中选择最佳匹配。
P1:当前查询
P2:潜在偏好(可显式或隐式)
I1/I2:用户意图
T3:从候选物品中选择匹配项
重点:结合多源信息(查询、意图、交互)实现高精度匹配。
11. ⟨P1,(P2),I1/I2,T3⟩(第1类)¶
目标:根据用户搜索词和历史购买行为,推断其偏好,并推荐匹配的候选物品。
输入:搜索词 + 历史购买
输出:推荐匹配项
重点:强调搜索词与历史行为的结合推荐。
12. ⟨P1,(P2),I1/I2,T3⟩(第2类)¶
目标:对于一个购物热情高、历史购买丰富的用户,推荐匹配其当前需求和偏好的物品。
输入:历史购买 + 显式/模糊/具体意图
输出:推荐匹配项
重点:适用于高活跃用户,推荐需兼顾多样性和个性化。
13. ⟨P1,(P2),I1/I2,T3⟩(第3类)¶
目标:从用户历史交互中推断其偏好,再根据其当前查询推荐匹配物品。
输入:历史交互 + 查询
输出:推荐匹配项
重点:强调历史行为与当前意图的结合,精准推荐。
总结¶
本附录提供了一套完整的个性化搜索指令模板,涵盖从用户行为建模到意图理解,再到匹配推荐的全流程。这些模板强调:
个性化偏好(P)的识别与建模
意图(I)的区分(显式/模糊/具体)
任务目标(T)的多样性(生成、推荐、预测、查询构建等)
任务反转与偏好-意图一致性的强化
这些模板为构建更智能、更精准的个性化搜索系统提供了理论支持和实践指导。