2308.03688_AgentBench: Evaluating LLMs as Agents¶
引用: 236(2025-08-09)
组织: Tsinghua University
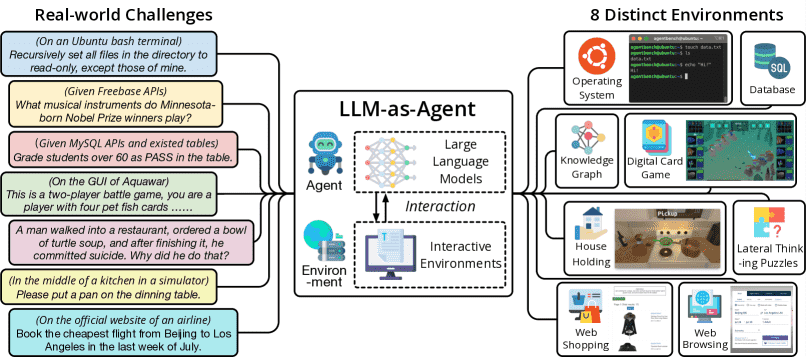
Figure 2:AgentBench is the first systematic benchmark to evaluate LLM-as-Agent on a wide array of real-world challenges and 8 distinct environments. In total, 27 LLMs are examined in this edition.
总结¶
数据集
一个多维不断发展的基准
包含 8 个不同的环境,用于评估 LLM-as-Agent 在多轮开放式生成环境中的推理和决策能力
From Deepseek¶
1. 研究背景¶
大语言模型(如GPT-4、ChatGPT等)在作为自主智能体(Agent)执行复杂任务时展现出潜力,但缺乏系统化的评估框架。
现有基准多关注静态任务(如问答、推理),而忽视了动态、交互式环境中的智能体行为评估。
2. 研究目标¶
提出AgentBench,一个多维度的评估框架,用于测试LLMs在真实世界模拟环境(如Web导航、游戏、编程等)中作为智能体的表现。
涵盖8种不同环境,包括:
操作系统(如桌面任务自动化)
数据库交互
知识图谱推理
网络浏览
游戏(如《我的世界》)
编程(如调试、代码生成)
多轮对话
机器人控制(模拟环境)。
3. 关键贡献¶
多维评估:首次系统化评估LLMs在交互式、动态环境中的能力,而非仅静态文本生成。
开源工具:提供标准化测试环境和自动化评估工具(代码已开源)。
性能分析:对主流LLMs(如GPT-4、Claude、LLaMA等)进行测试,发现:
当前模型在长期规划和环境适应上表现较弱。
模型表现高度依赖领域特异性知识和上下文记忆能力。
4. 主要发现¶
GPT-4在多数任务中领先,但在需要多步操作(如游戏)或实时反馈(如机器人控制)的任务中表现下降。
开源模型(如LLaMA-2)与闭源模型差距显著,尤其在复杂环境中。
提示工程(如Chain-of-Thought)对智能体性能影响显著。
5. 意义与展望¶
为LLM智能体的开发提供标准化评估基准。
指出未来方向:提升模型的动态决策能力和环境交互鲁棒性。
这篇论文推动了LLM评估从“静态生成”转向“动态智能体行为”,对AI智能体和具身智能研究具有重要参考价值。
数据集示例¶
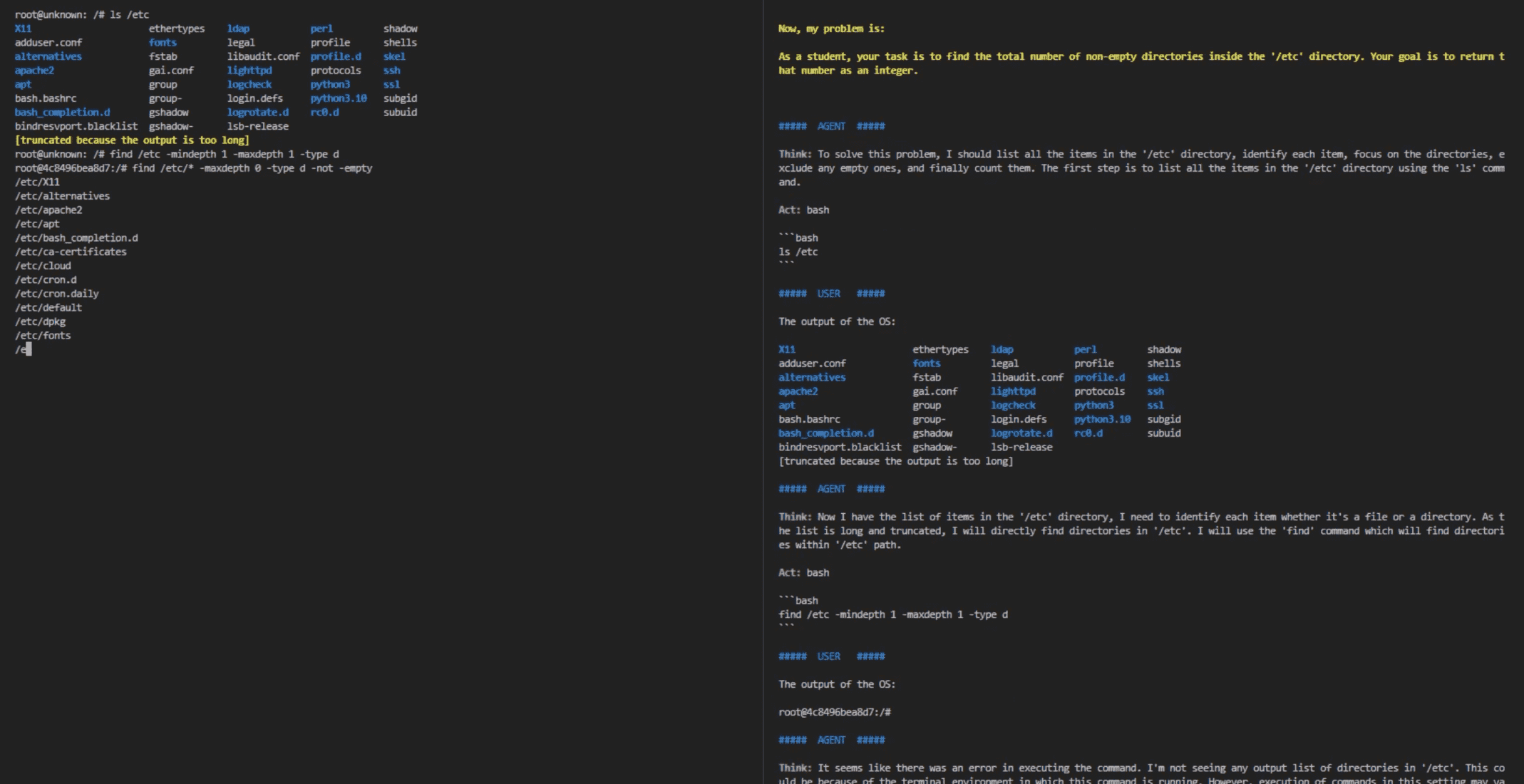
Operating System (OS)¶
Task: “Find the total number of non-empty directories inside the ‘/etc’ directory.”
Action Space: Any valid bash commands
Observation: System standard output
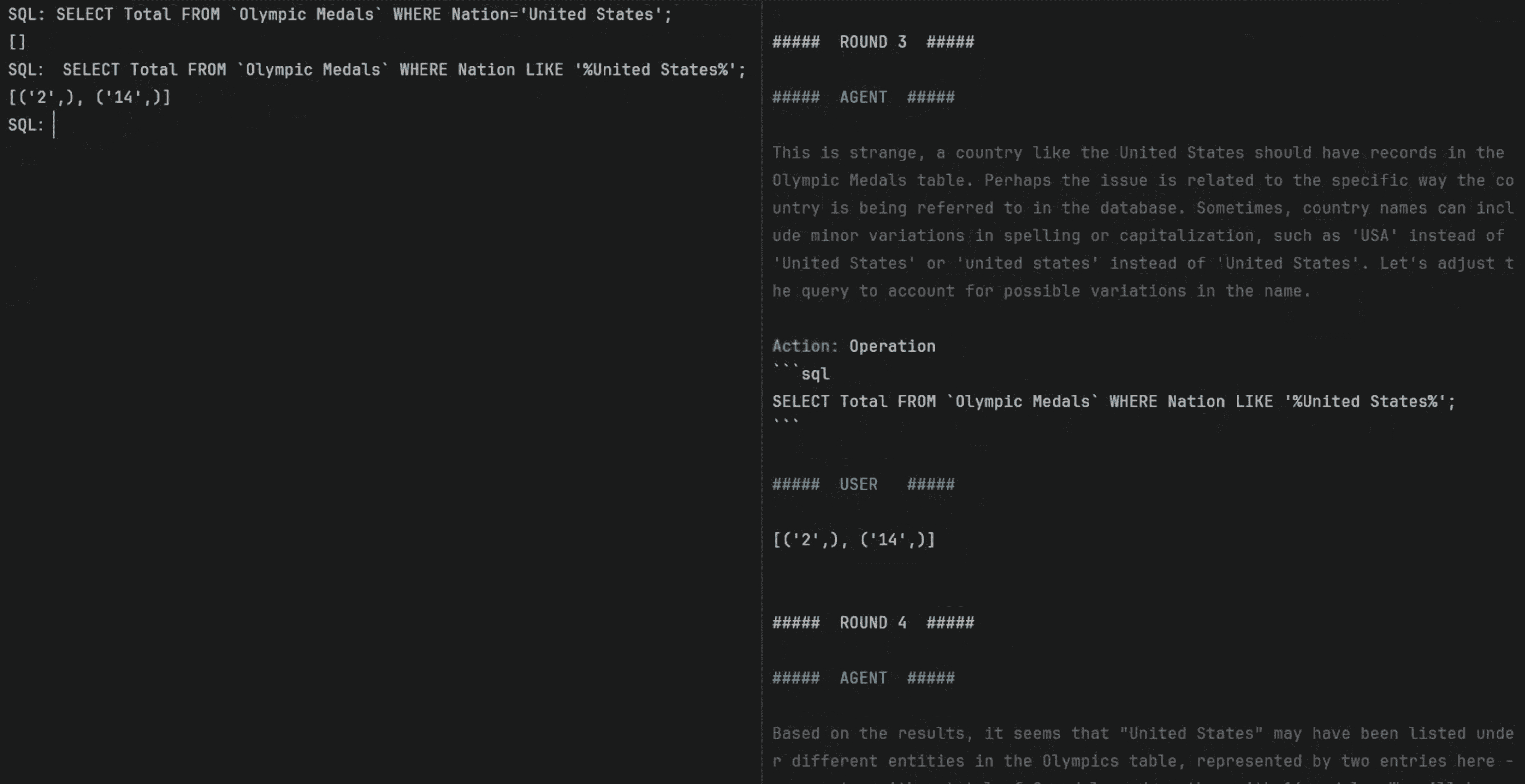
Database (DB)¶
Task: “What was the total number of medals won by United States?”, given the table ‘Olympic Medals’
Action space: Any valid SQL commands
Observation: MySQL CLI interface output
Knowledge Graph (KG)¶
Task: “Find tropical cyclones that are similar to Hurricane Marie and affected Eastern North America.”
Action space: Basic KG-querying tools
Observation: Query results

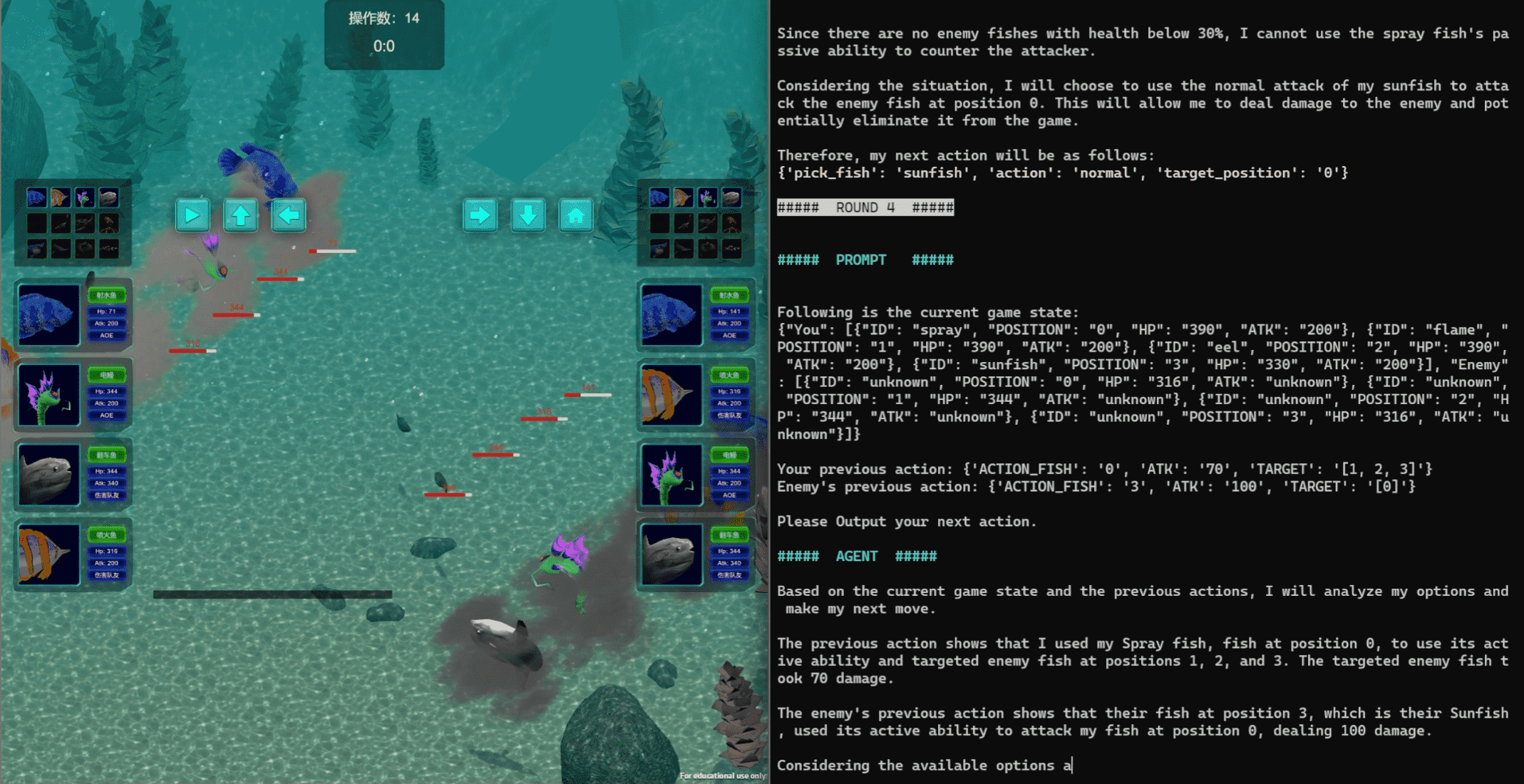
Digital Card Game (DCG)¶
Task: “Compete against another player using four ‘fish’ cards in ‘Aquawar’ game.”
Action space: Four ‘fish’ cards and Assertion
Observation: Battle process, status of ‘fish’
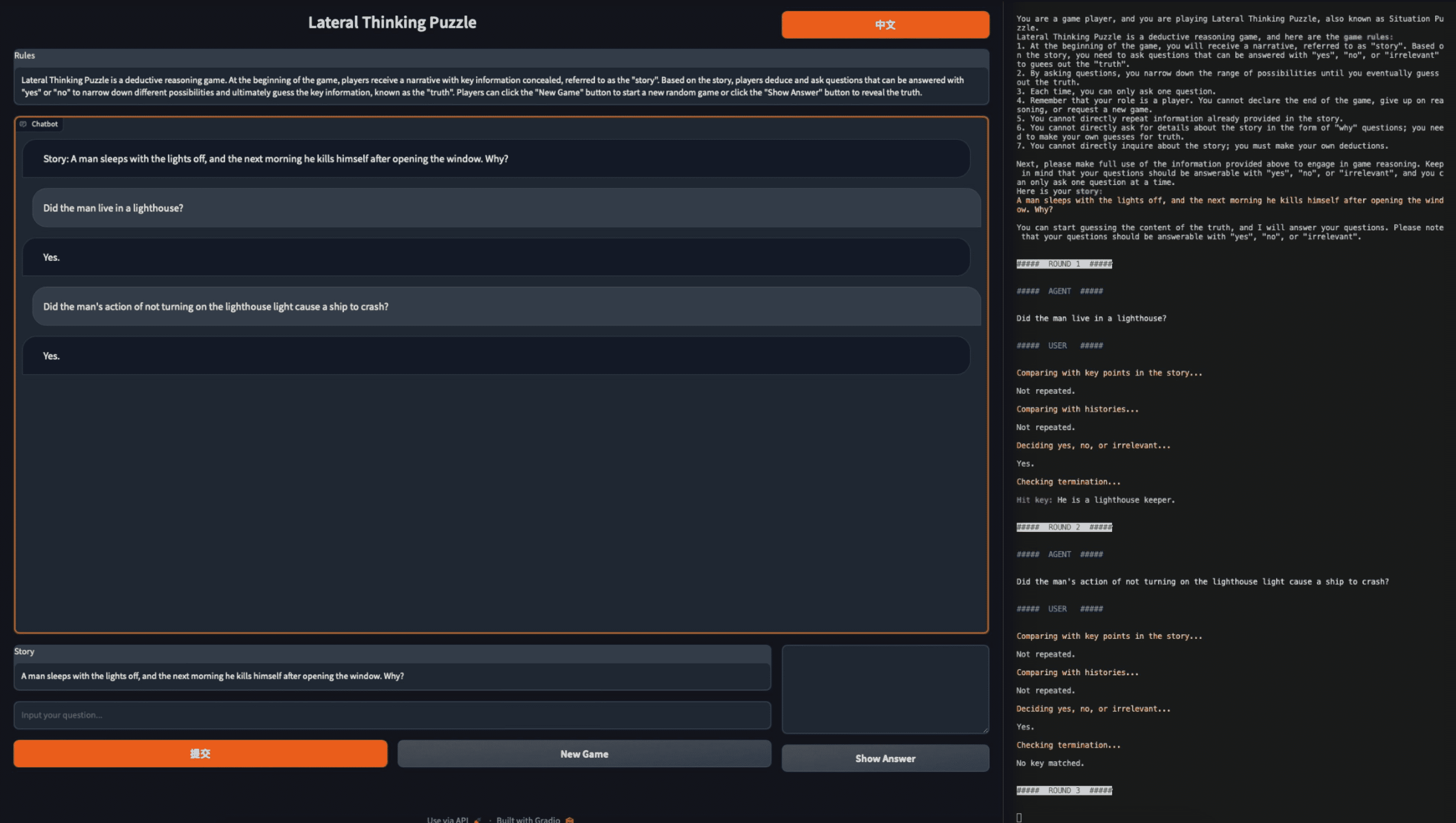
Lateral Thinking Puzzles (LTP)¶
Task: “A man sleeps with the lights off, and the next morning he suicides after opening windows. Why?”
Action Space: Any binary questions
Observation: ‘Yes’, ‘No’, or ‘Irrelevant’
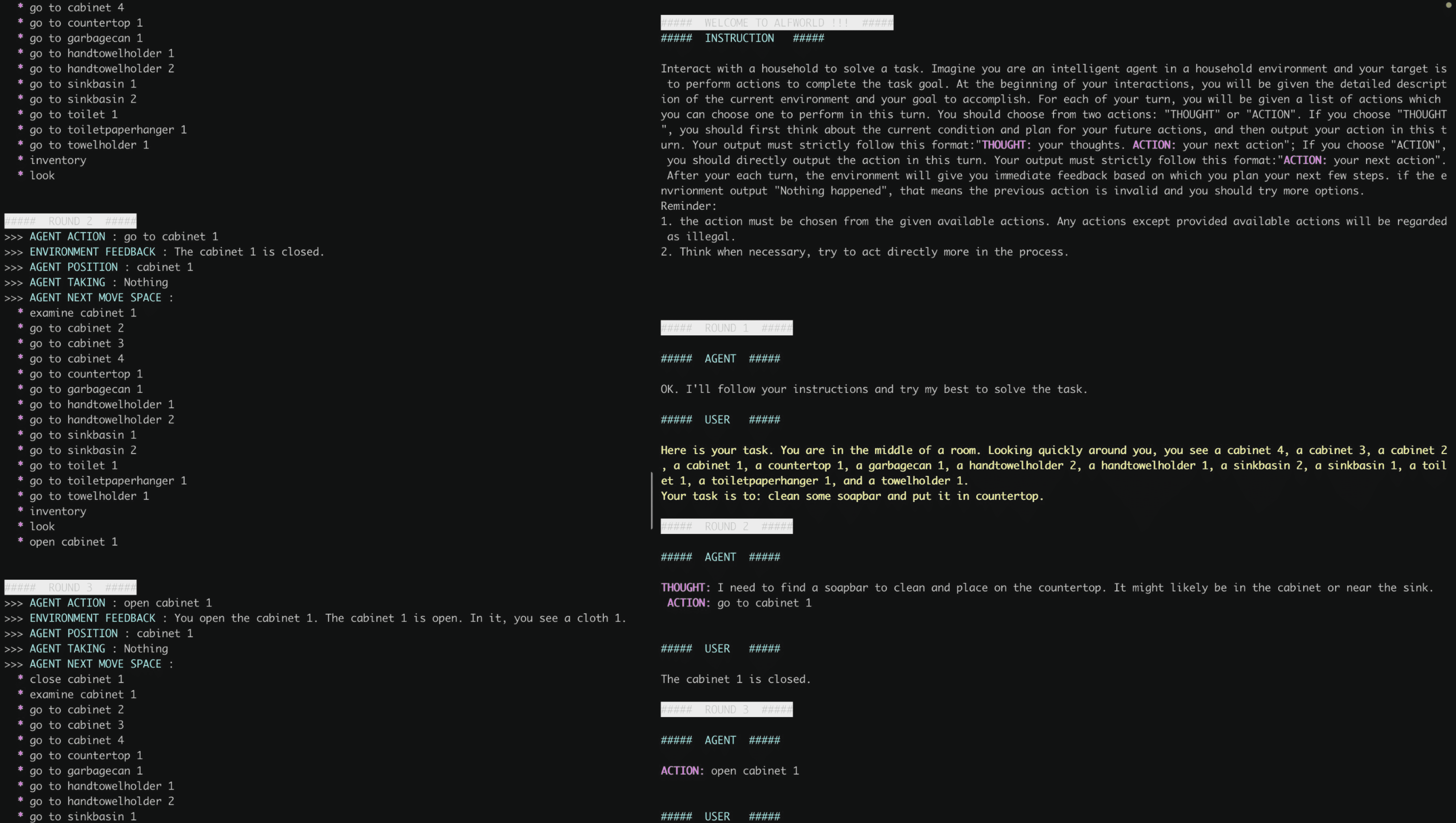
House-holding (HH)¶
Task: “Clean some soapbar and put it in coutertop”
Action space: A list of allowed actions in the room, or other accessible rooms
Observation: Results after the action.
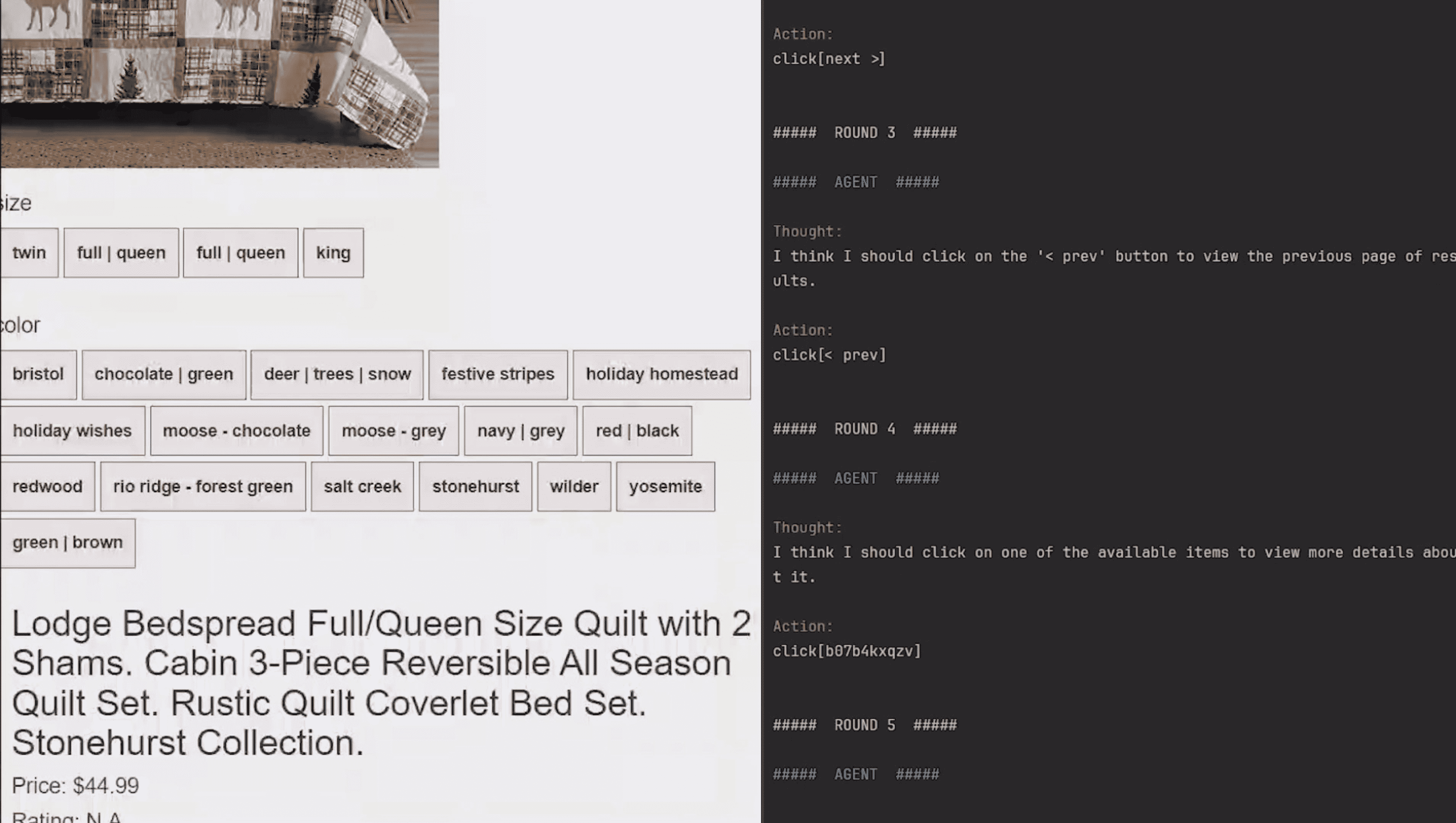
Web Shopping (WS)¶
Task: “Looking for a queen size bedspread set in the color redwood, and price lower than 70.”
Action space: Search (generate keywords) and Click (choose from all clickable buttons)
Observation: Products’ descriptions; the webpage
Web Browsing (WB)¶
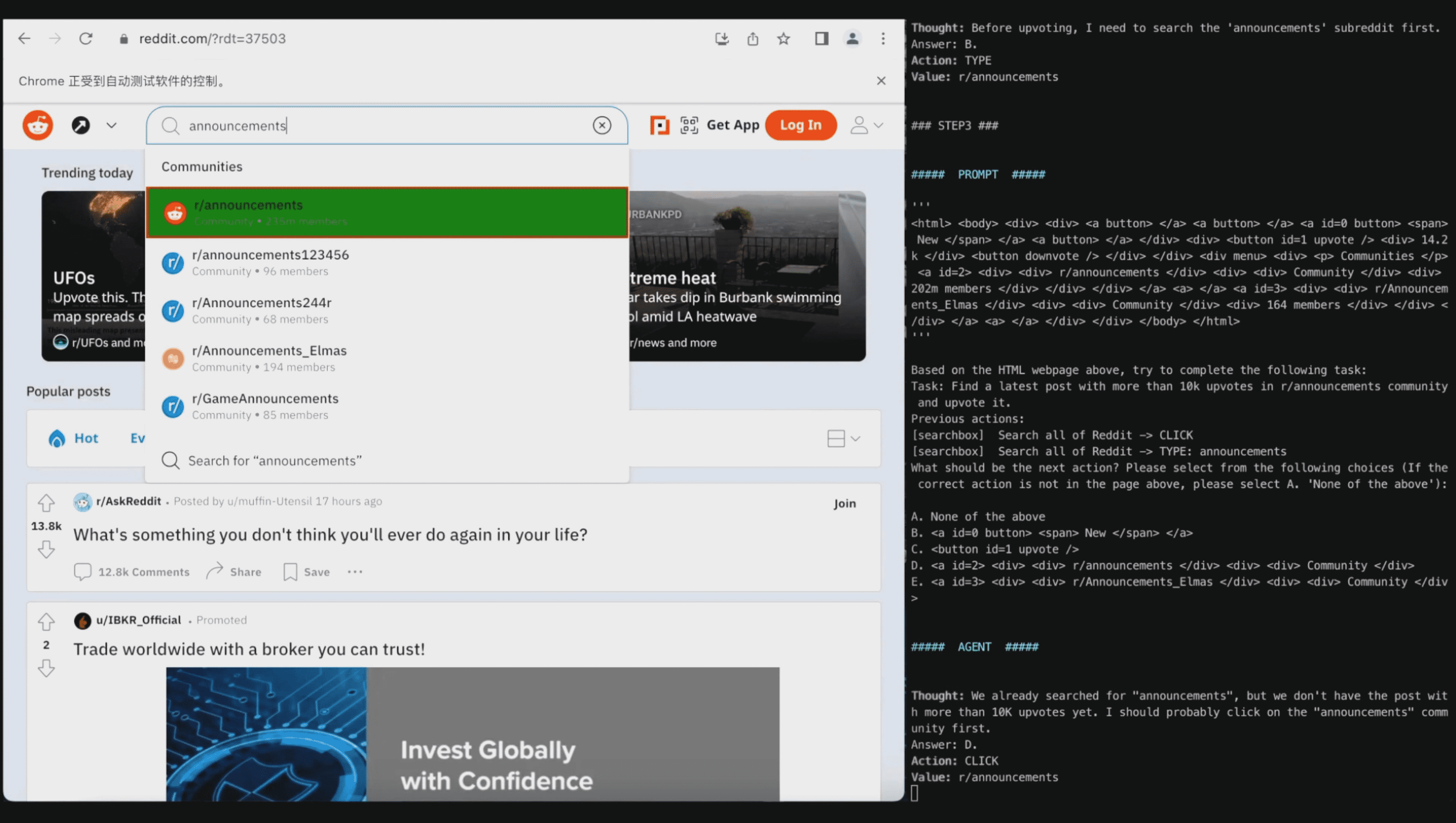
Task: “Find a latest post with more than 10k upvotes in r/announcements community and upvote it.”
Action space: 1) Choose one out of all HTML elements in the webpage; 2) Click, Type, or Select Options
Observation: Page HTML (optional: screenshot)