2306.03901_ChatDB: Augmenting LLMs with Databases as Their Symbolic Memory¶
引用: 106(2025-08-10)
组织:
1Tsinghua University
2Beijing Academy of Artificial Intelligence
3Zhejiang University
总结¶
ChatDB
一种将数据库作为 LLM 的外部符号记忆的新方法
具体实现形式
一个LLM与一组SQL数据库的结合,其中LLM生成SQL指令来操作数据库
优势:
数据库支持结构化存储与符号化操作(如 SQL),适合需要精确记录、修改、查询和分析历史信息的场景。
链式记忆(Chain-of-Memory,CoM)
将用户输入转换为多个中间记忆操作步骤,每个步骤包含一个或多个 SQL 语句
通过将复杂问题拆解为多个步骤,显著降低了问题解决的复杂度
该方法增强了 LLM 的多步骤推理能力,提高了处理多表数据库交互任务的准确性与稳定性
Abstract¶
本文探讨了具有记忆能力的大语言模型(LLM)在计算上是通用的(Schuurmans, 2023),即它们理论上能够模拟任何计算过程。然而,主流的LLM并未充分发挥记忆的潜力,其设计在很大程度上受到生物大脑的启发。由于传统神经记忆机制的近似性和误差累积问题,它们难以支持LLM进行复杂的推理过程。
为了解决这一问题,本文从现代计算机架构中汲取灵感,提出了一种增强LLM的方法:通过引入符号记忆来支持多跳复杂推理。具体实现形式是一个LLM与一组SQL数据库的结合,其中LLM生成SQL指令来操作数据库。
作者在合成数据集上验证了该记忆框架的有效性,证明其在处理复杂推理任务中的优势。项目网站为:https://chatdatabase.github.io/。
1 Introduction¶
大型语言模型的重要性与局限性¶
大型语言模型(LLMs),如 GPT-4 和 PaLM 2,已成为现代人工智能系统的重要组成部分,推动了自然语言处理(NLP)的发展,并在多个领域产生了深远影响。虽然这些模型在理解和生成上下文相关的回复方面取得了显著进展,但仍存在一些关键性局限。
重点问题是:在多轮对话中,模型需要处理不断增加的上下文信息,而这些信息在拼接后很容易超过模型的输入长度限制(例如 GPT-4 的 32,000 tokens 限制),从而导致模型无法准确跟踪对话,降低回复质量。
传统神经记忆机制的不足¶
为了解决输入长度限制问题,研究者尝试引入神经记忆机制(如 Wu et al., 2022a 等)。这类机制通过存储和检索历史信息来辅助模型处理长上下文问题。然而,传统神经记忆机制存在两个主要问题:
存储信息缺乏结构化:信息以非结构化的方式存储,不利于复杂推理任务。
操作依赖向量相似度计算:信息检索和操作是基于向量相似性,缺乏符号操作的精确性,容易积累误差,从而影响模型性能。
ChatDB:将数据库作为符号记忆¶
为了解决上述问题,作者提出了 ChatDB,这是一种将数据库作为 LLM 的外部符号记忆的新方法。
ChatDB 的结构:
LLM 控制器:负责控制对数据库的读写操作,可以是任意常用 LLM。
数据库(符号记忆):用于结构化存储历史信息,并通过 SQL 语句进行精确的增删查改操作。
优势:
数据库支持结构化存储与符号化操作(如 SQL),适合需要精确记录、修改、查询和分析历史信息的场景。
与传统的文本或矩阵式记忆相比,数据库更适合处理长期、多轮、需要复杂操作的数据,如商店销售记录管理。
链式记忆(Chain-of-Memory,CoM)方法¶
为更有效地操作数据库,ChatDB 提出了 链式记忆(CoM)方法:
CoM 将用户输入转换为多个中间记忆操作步骤,每个步骤包含一个或多个 SQL 语句。
通过将复杂问题拆解为多个步骤,显著降低了问题解决的复杂度。
该方法增强了 LLM 的多步骤推理能力,提高了处理多表数据库交互任务的准确性与稳定性。
主要贡献¶
ChatDB 的主要贡献包括:
引入数据库作为结构化的外部符号记忆,支持精确的 SQL 操作,为 LLM 提供更强大的历史信息管理能力。
提出链式记忆(CoM)方法,通过多步骤的数据库操作增强 LLM 的复杂推理能力。
实验验证:ChatDB 在合成数据集上表现出优于 ChatGPT 的性能,特别是在多跳推理和错误积累控制方面具有明显优势。
总结:ChatDB 通过将数据库作为 LLM 的符号记忆单元,并结合链式记忆方法,有效解决了 LLM 在多轮对话中面临的上下文管理难题,为提升模型在复杂任务中的推理能力和稳定性提供了新的思路。
3 ChatDB¶
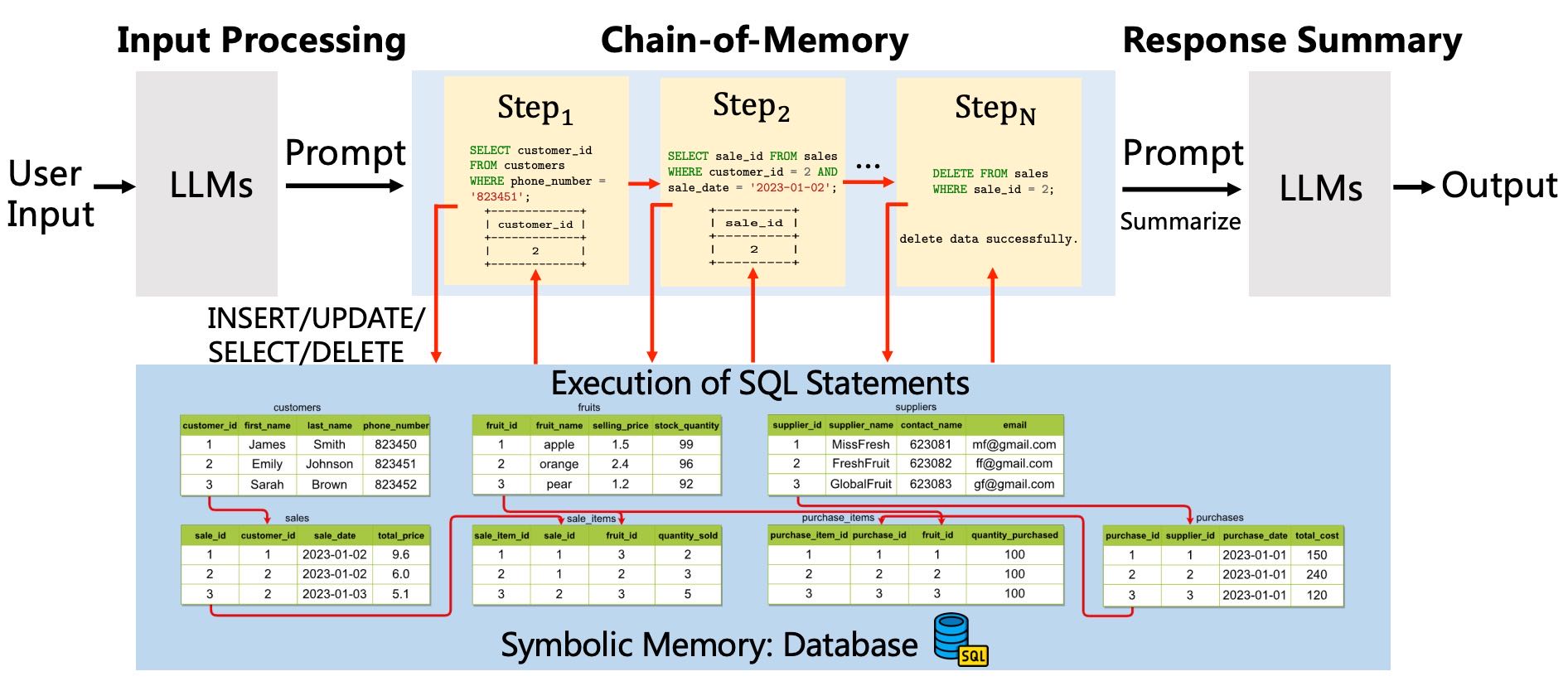
本节首先简要介绍任务定义与设置,接着描述了 ChatDB 的整体框架,最后深入讲解了其核心组成部分——**chain-of-memory(链式记忆)**的细节。
3.1 任务定义¶
任务目标:
给定用户以自然语言输入的请求以及数据库中已有表的结构(如果有的话),目标是通过操作外部数据库(即“符号记忆”)来完成用户的请求。
示例:
如果用户是商店经理,请求包括记录、修改、查询和删除特定数据,则对应的 SQL 操作应分别为插入(insert)、更新(update)、选择(select)和删除(delete)相关表中的数据。这些操作通常涉及数据库中的多个表。
重点:
数据库作为外部符号记忆,用于支持用户对数据的操作。操作可能涉及多个表,体现出数据操作的复杂性。
3.2 框架概述¶
ChatDB 的框架由三个主要阶段组成:
输入处理(Input Processing)
如果用户请求需要操作数据库,则利用 LLM 生成一系列中间操作步骤。
如果不需要操作数据库,则直接使用 LLM 生成回复。
链式记忆(Chain-of-Memory)
根据生成的 SQL 语句,ChatDB 依次执行操作(insert、update、select、delete 等)。
在执行每一步之前,ChatDB 会根据前一步的结果决定是否更新当前操作步骤。
整个过程在数据库中执行,最终返回结果。
响应总结(Response Summary)
基于链式记忆的执行结果,ChatDB 最终生成用户能够理解的自然语言回复。
重点:
整个流程由算法 Algorithm 1 描述。
Chain-of-Memory 是核心环节,决定了 ChatDB 如何与数据库交互并执行多步骤操作。
3.3 链式记忆(Chain-of-Memory)¶
概念来源:
Chain-of-Memory(CoM)是 Chain-of-Thought(CoT)的扩展,它将中间推理步骤与符号存储(数据库)结合,增强了 LLM 在操作数据库时的推理能力。
核心思想:
将用户请求转换为一系列数据库操作步骤,使 LLM 能以符号化方式更准确地操作数据库。
特别适用于需要多表交互的复杂场景,比如记录、数据分析等。
技术手段:
使用 in-context learning,通过提供多个示例步骤,帮助 LLM 更好地生成和更新操作序列。
通过分步执行,提高系统处理复杂和边缘情况的能力。
优势:
提升多跳推理能力:通过分步操作数据库,提高了 LLM 在多表、多步骤交互中的准确性。
增强复杂场景处理能力:分步执行和回滚机制,使得 LLM 更容易处理异常和未知情况。
重点:
Chain-of-Memory 是 ChatDB 的核心机制,是其区别于其他方法的重要创新点。
通过引入结构化数据库作为记忆系统,使得 LLM 在处理符号化数据时更加稳定和准确。
3.4 与已有记忆增强 LLM 的比较¶
本节将 ChatDB 与基于 Prompt-based 和 Matrix-based 的记忆增强方法进行比较,从以下几个维度进行分析:
维度 |
ChatDB |
Prompt-based(如 Auto-GPT) |
Matrix-based(如 RMT) |
|---|---|---|---|
记忆格式 |
符号化(结构化数据库) |
半结构化(内容/向量) |
半结构化(矩阵/标记) |
支持操作 |
插入、更新、删除、查询 |
主要支持插入和查询 |
支持读写(由网络控制) |
存储形式 |
结构化 |
半结构化 |
半结构化 |
执行方式 |
符号化(SQL) |
非符号化(向量相似度) |
非符号化(神经网络) |
可解释性 |
高(结构清晰) |
低(向量难以解释) |
低(依赖网络) |
状态跟踪 |
可有效跟踪当前状态并回滚 |
仅存储历史,无法跟踪当前状态 |
自动更新状态,但不透明 |
重点:
ChatDB 在结构化存储、符号化执行、高可解释性和状态跟踪能力等方面具有显著优势。
通过使用数据库作为符号记忆,ChatDB 提供了更高的透明度和可控性,适合实际应用中对数据管理和操作有高要求的场景。
总结:
ChatDB 的优势在于其使用了结构化的数据库作为记忆机制,使得 LLM 能够以符号化、可解释的方式操作记忆,从而在复杂数据交互中表现出更高的稳定性和准确性。
总体结构回顾¶
章节 |
内容 |
重点 |
|---|---|---|
3.1 任务定义 |
定义 ChatDB 的目标和应用场景 |
数据库作为符号记忆,操作可能涉及多表 |
3.2 框架概述 |
三个阶段:输入处理、链式记忆、响应总结 |
链式记忆是核心,通过 SQL 操作数据库 |
3.3 链式记忆 |
基于 CoT 的扩展,结合结构化数据库 |
提高 LLM 的多表、多步骤推理能力 |
3.4 与现有方法比较 |
与 Prompt-based 和 Matrix-based 方法对比 |
ChatDB 在结构化、符号化和可解释性上占优 |
该章节清晰地展示了 ChatDB 的核心思想与实现方式,并通过与其他方法的对比,突出了其使用数据库作为符号记忆机制的独特优势。
4 Evaluation¶
4 评估¶
本节通过实验评估了将数据库作为大语言模型(LLM)的符号记忆进行扩展的有效性。实验结果表明,ChatDB 显著优于基线模型 ChatGPT,凸显了符号记忆整合的优势。
4.1 实验设置¶
正如前面所述,数据库作为符号记忆尤其适合需要精确记录和处理历史信息的场景,如各种数据管理情况。为了适应 ChatDB 的使用场景并实现与其他模型的定量比较,我们构建了一个模拟水果店管理的合成数据集。
此外,为了评估模型性能,我们收集了 50 个带有标注标准答案的问题。这些问题难度不一,从需要多跳推理的难题到只需从历史数据中检索信息的简单问题不等。其中,简单问题有 15 个,困难问题有 35 个。每个问题由模型独立回答。
4.1.1 模型配置¶
ChatDB:使用的 LLM 是 ChatGPT(GPT-3.5 Turbo),温度参数设为 00。使用 MySQL 数据库作为外部符号记忆。
基线模型(ChatGPT):使用 ChatGPT(GPT-3.5 Turbo),最大 token 长度为 4096。与 ChatDB 一样,温度参数设为 00。
文中还详细描述了 ChatDB 处理四种常见操作(进货、销售、退货、调价)的数据库操作流程,展示了其与数据库交互的步骤。
4.1.2 数据集¶
我们合成一个名为“Fruit Shop Dataset”的水果店管理记录数据集,模拟四种常见操作:进货、销售、调价和退货。所有历史记录有效,避免了如负库存等问题。数据集共生成 70 条记录,按时间顺序排列,总 token 数约为 3.3k,未超过 ChatGPT 的最大 token 长度限制。
为什么限制数据集的 token 长度?
如果数据集 token 长度超过 ChatGPT 的最大限制,就需要引入记忆机制。但基于向量嵌入的记忆检索方法容易出错,从而导致性能下降。因此,我们特意将数据集的 token 长度控制在 ChatGPT 的限制内,以最大化模型性能。而 ChatDB 的性能不受数据集 token 长度的影响,因此在小数据集上表现优异时,也预示其在大数据集上也优于带记忆的 ChatGPT。
4.1.3 处理记录¶
对于 ChatDB,第一步是初始化数据库,生成合理的数据库模式。随后,ChatDB 逐条处理数据集中的记录,通过 SQL 语句与数据库进行交互。ChatDB 处理记录的方式具有容错性,每一步操作都基于符号化数据库操作,因此理论上可处理无限量的历史记录而不影响性能。
ChatGPT 则简单地将记录作为提示的一部分进行处理。
4.1.4 回答问题¶
在回答问题时,ChatDB 不需要将历史记录包含在提示中,因为信息已经被存储在数据库中。ChatDB 通过生成 SQL 语句执行数据库查询(包括计算)来回答问题。而 ChatGPT 将记录和问题一并作为提示,提示模板如图所示。
4.2 结果¶
实验结果如表 2 所示,ChatDB 明显优于 ChatGPT,尤其是在处理难以问题时。ChatGPT 虽然能回答简单问题,但在需要多跳推理和精确计算的问题上表现不佳,准确率很低。而 ChatDB 准确率高达 82%,凸显了数据库作为符号记忆的优势。这种方法不仅防止了误差累积,还增强了 LLM 的多跳推理和精确计算能力。
模型 |
简单问题 |
困难问题 |
总问题 |
准确率 |
|---|---|---|---|---|
ChatGPT |
10/15 |
1/35 |
11/50 |
22% |
ChatDB |
13/15 |
28/35 |
41/50 |
82% |
文中还展示了几个问答示例,ChatDB 成功回答了所有问题,而 ChatGPT 存在大量计算和推理错误。ChatDB 的优势体现在两个方面:
通过“记忆链”方式,将复杂问题分解为多个步骤,每个步骤的中间结果准确存储并用于后续步骤,大大简化了问题的复杂度。
符号记忆支持精确操作和计算。通过执行 SQL 语句,ChatDB 将许多计算任务委托给数据库,确保每一步的准确性,避免误差的积累。
综上所述,通过将外部数据库作为符号记忆,ChatDB 在实验中显著优于 ChatGPT。
5 Conclusion¶
5 结论¶
在本文中,作者介绍了 ChatDB,这是一个通过以数据库形式加入符号化记忆来增强大语言模型(LLM)的框架。这是本节的重点内容,ChatDB 的设计目标是提升模型在复杂任务中的推理能力和准确性。
作者展示了符号化记忆和记忆链(chain-of-memory)方法在增强复杂推理和防止错误累积方面的优势和能力。这部分是研究的核心贡献之一,强调了符号化记忆在处理多步骤推理中的重要作用。
通过提供一种精确的中间结果存储机制,符号化记忆使得模型能够执行准确且可靠的操作。这是 ChatDB 的关键设计之一,有效解决了传统模型在中间结果处理时的不确定性和误差问题。
此外,符号化语言(如 SQL)的使用允许对存储的信息进行符号计算和操作。这也是本研究的一个重点,展示了符号语言如何增强模型的数据处理和查询能力。
在实验评估中,作者发现与 ChatGPT 相比,ChatDB 的性能有显著提升。这一部分通过实验数据验证了 ChatDB 的有效性。
ChatDB 中符号化记忆的集成,大幅提升了模型在管理场景中处理各种查询和推理任务的能力。这进一步证明了在大语言模型中利用符号化记忆的优势和有效性,是本研究的重要结论。