2312.07104_SGLang❇️: Efficient Execution of Structured Language Model Programs¶
引用: 182(2025-08-16)
组织:
1 Stanford University
2 UC Berkeley
3 Shanghai Jiao Tong University
4 Texas A&M University
5 Independent Researcher
SGLang: Structured Generation Language
总结¶
RadixAttention
核心思想
在运行时自动保留并复用KV缓存,而不是像传统方式那样在请求完成后丢弃缓存
数据结构
使用 radix tree(基数树) 来管理KV缓存
速度高效的原因
KV 缓存复用
调度优化
解码加速
贡献
首次提出将KV缓存(Key-Value Cache)视为基于树结构的LRU缓存(Least Recently Used Cache),是支持多级共享、缓存感知调度、前端与运行时协同调度、以及分布式场景的首个解决方案。
OpenAI GPT-4总结¶
1. 论文速览(20秒内可理解)¶
📌 研究类型: - 领域标签:NLP/机器学习 - 任务类型:模型优化/实验分析 🌍 现实意义:该研究提出了一种新的系统SGLang,能够有效执行复杂的语言模型程序,对于提高大型语言模型的执行效率具有重要价值。
2. 核心创新(对比现有方法)¶
✨ 技术突破: - 方法创新点:SGLang系统包括一个前端语言和一个运行时,前端简化了编程过程,运行时通过RadixAttention和压缩有限状态机等优化技术加速了执行过程。 - 数据/实验设计的独特性:实验表明,SGLang在各种大型语言和多模态模型的任务上,与最先进的推理系统相比,吞吐量提高了高达6.4倍。 ⚠️ 作者自述局限:论文并未明确提到任何限制。
3. 核心价值:¶
解决了什么问题?对谁有用?
SGLang解决了大型语言模型执行效率低下的问题,对于需要使用大型语言模型进行复杂任务的研究者和开发者有用。方法论的新颖性
SGLang的新颖之处在于它将语言模型的执行过程视为一个程序,通过引入新的优化技术,提高了执行效率。
4. 精读决策指南¶
🔍 推荐指数:★★★★☆
如果你在研究大型语言模型的执行优化,或者你的工作需要使用大型语言模型进行复杂任务,那么这篇论文值得你仔细阅读。
Qwen-Plus总结¶
1. 论文速览(20秒内可理解)¶
📌 研究类型:
领域标签:NLP / 机器学习系统
任务类型:模型优化 / 系统设计 / 实验分析
🌍 现实意义:
SGLang 提供了一种高效执行复杂语言模型程序的系统,显著提升多轮生成任务的吞吐量,对构建智能代理、多模态应用和结构化输出任务具有重要工业价值。
2. 核心创新(对比现有方法)¶
✨ 技术突破:
方法创新点:
引入 RadixAttention 机制,实现 KV 缓存的高效复用,减少重复计算。
提出 压缩有限状态机(Compressed FSM),实现结构化输出(如 JSON)的快速解码。
支持 API-only 模型的 推测执行(Speculative Execution),优化多调用流程。
数据/实验设计的独特性:
在多种大语言模型(Llama-7B/70B、Mistral、LLaVA 等)和多模态任务上进行了广泛实验。
对比了多个当前主流系统(如 vLLM、LMQL),展示了显著性能提升(最高 6.4 倍吞吐量)。
⚠️ 作者自述局限:
当前系统主要面向结构化语言模型程序(LM Programs)优化,对非结构化任务的优化效果未明确评估。
依赖 Python 嵌入式语言,可能对非 Python 用户不够友好。
3. 核心价值:¶
解决了什么问题?对谁有用?
SGLang 解决了当前语言模型程序执行效率低、开发复杂的问题,适用于需要多轮生成、结构化输出、多模态处理的场景,如智能代理、多模态推理、结构化输出生成等。方法论的新颖性
通过系统性地利用 LM Programs 的多调用结构,提出前端语言 + 后端优化的双层架构,并引入 RadixAttention 和 FSM 解码等创新技术,实现了性能与开发效率的双重提升。
4. 精读决策指南¶
🔍 推荐指数:★★★★☆
如果你是 NLP 系统工程师 / 大模型部署者 / 智能代理开发者,这篇论文值得精读,尤其是你关注 多调用语言模型程序的执行效率。
如果你主要研究 模型架构 / 理论分析 / 单模型推理,则可略读或仅关注实验部分。
Abstract¶
Abstract 部分介绍了当前大语言模型(LLMs)在处理复杂任务时所面临的问题和 SGLang 系统的解决方案。
问题背景:
大语言模型越来越多地被用于需要多次生成调用、高级提示技术、控制流和结构化输入/输出的复杂任务。然而,目前缺乏高效的系统来编程和执行这些应用。
解决方案:
为此,作者提出了 SGLang,一个高效的复杂语言模型程序执行系统。SGLang 包括两个主要部分:
前端语言:
通过提供生成和并行控制的基本操作(primitives),简化编程过程。这部分强调了前端对开发者的友好性。运行时系统(Runtime):
这是 SGLang 的核心部分,通过一些创新优化来加速执行,重点包括:RadixAttention:用于 KV 缓存的重用,提高效率。
压缩有限状态机:用于更快速的结构化输出解码。
实验结果:
实验表明,SGLang 在各种大型语言和多模态模型上,相比最先进的推理系统,在多个任务中实现了高达 6.4 倍的吞吐量提升。这些任务包括:
Agent 控制
逻辑推理
少样本学习基准
JSON 解码
检索增强生成(RAG)流程
多轮对话等
重点强调:
SGLang 的创新点主要在于其高效的运行时优化(如 RadixAttention 和压缩有限状态机),以及在多种复杂任务上的显著性能提升,是本文的核心贡献。
1 Introduction¶
随着大语言模型(LLM)能力的提升,其应用场景也得到了扩展,能够处理更广泛的一般任务,并作为自主代理(autonomous agents)运行。这类应用中,LLMs需要进行多轮的规划、推理和与外部环境的交互。实现这一目标的关键方法包括:
工具使用(tool usage):如 ToolFormer 和 Gorilla,通过调用外部工具完成任务;
多模态输入(multiple input modalities):如 Gemini 和 Flamingo,支持图像、文本等多种输入形式;
多种提示技术(prompting techniques):如 Few-Shot Learning、Self-Consistency、Skeleton-of-Thought、Tree-of-Thought 等,以提高推理能力。
这些新用例通常需要多次、依赖性强的 LLM 生成调用,体现出一种使用多调用结构(multi-call structures)来完成复杂任务的趋势,例如 REACT 和 LLM-Driven Workflows。
语言模型程序(LM Programs)¶
这些多调用结构的应用,标志着我们与 LLM 的交互方式从简单的聊天转变为一种程序化的方式,即通过程序来调度和控制 LLM 的生成过程。这种程序被称为“Language Model Programs(LM Programs)”,相关技术包括 LMQL 和 DSPy。
LM Programs 的两个主要特点:
包含多个 LLM 调用,并结合控制流(如循环、条件判断),用于完成复杂任务并提高整体质量;
输入和输出结构化,便于程序组合和系统集成。
当前挑战(Challenges)¶
尽管 LM Programs 被广泛使用,但目前的系统在表达与执行上仍存在效率问题,主要体现在两个方面:
1. 开发难度大¶
LLM 的输出具有非确定性,编写 LM Programs 需要进行大量的字符串处理、提示调优、输出解析;
支持多模态输入和并行机制,增加了程序复杂性;
使得即使是简单的程序也难以被清晰表达和维护。
2. 执行效率低¶
当前主流的 LLM 推理引擎(如 vLLM、TGI、TensorRT-LLM)虽然优化了延迟和吞吐量,但它们缺乏对工作负载结构的了解,导致执行效率低下。具体表现如下:
KV 缓存(KV Cache)无法复用:多个 LLM 调用之间可能共享前缀,但当前系统无法有效复用缓存,导致重复计算和内存浪费;
约束解码效率低:在生成结构化输出(如 JSON)时,只能逐个解码 tokens,效率低下。
SGLang:解决方案¶
为解决上述问题,本文提出了 SGLang(Structured Generation Language),一种用于 LLM 的结构化生成语言。SGLang 的核心思想是系统化地利用 LM Programs 中的多调用结构来提高执行效率。
SGLang 包括两个部分:
前端语言:简化 LM Programs 的编程;
后端运行时:加速其执行。
这两部分可协同工作,也可独立使用。
前端语言(Front-end)¶
SGLang 是一种嵌入在 Python 中的领域特定语言(DSL),提供以下关键操作:
生成原语(如
extend、gen、select);并行控制(如
fork、join);支持 Python 的控制流和库,便于开发复杂提示流程。
SGLang 提供了解释器与编译器,其中解释器通过异步执行原语操作,管理程序的同步和并行。
后端运行时优化(Runtime Optimizations)¶
SGLang 在运行时引入了三种关键优化技术:
RadixAttention(基数注意力):
解决 KV 缓存复用问题;
通过基数树(radix tree)管理缓存,支持高效匹配、插入和驱逐;
可自动识别并复用多个调用中共享的缓存,提升执行效率。
压缩有限状态机(Compressed Finite State Machine):
用于结构化输出的解码加速(如 JSON);
传统系统只能逐个 token 解码,而 SGLang 通过构建压缩状态机,将多个 token 解码路径压缩为一步,实现并行解码。
API 推测执行(API Speculative Execution):
为仅提供 API 接口的模型(如 GPT-4)优化多调用程序执行。
应用与实验结果(Applications and Evaluation)¶
SGLang 已被应用于多个 LLM 场景,包括:
代理控制、逻辑推理、few-shot 学习基准、JSON 解码、检索增强生成、多轮对话、多模态处理等。
在多个模型(如 Llama-7B/70B、Mistral-8x7B、LLaVA 系列)和 GPU 硬件(A10G/A100)上测试,SGLang 相比现有系统(Guidance、vLLM、LMQL)的吞吐量最高提升了 6.4 倍。
总结(重点)¶
LLMs 正从聊天工具演进为程序化工具,通过 LM Programs 实现复杂任务的自动化处理;
当前的 LM Programs 开发复杂、执行效率低,主要问题包括 KV 缓存复用和结构化解码效率;
SGLang 通过结构化语言 + 高效运行时优化,解决了上述问题,显著提升了执行效率;
实验表明,SGLang 在多模型、多任务、多硬件环境下的性能优势显著。
2 Programming Model¶

Figure 2:The implementation of a multi-dimensional essay judge in SGLang utilizes the branch-solve-merge prompting technique saha2023branch. Primitives provided by SGLang are shown in red.
本节介绍了 SGLang 编程模型,通过运行示例展示了其语言原语与执行模式,并概述了运行时优化的潜力。该编程模型通过提供灵活且可组合的原语,简化了多轮调用工作流中的繁琐操作(例如字符串操作、API 调用、约束定义、并行化等)。
一个运行示例¶
SGLang 是一个嵌入在 Python 中的领域特定语言(DSL)。图 2 展示了一个使用 branch-solve-merge 提示技术 的多维作文评分程序。
函数 multi_dimensional_judge 有三个参数:s(提示状态)、path(图像路径)和 essay(作文文本)。通过 += 操作符,可以将字符串和 SGLang 原语添加到状态 s 中以执行。
程序的执行流程如下:
将图像和作文添加到提示中;
使用
select判断作文是否与图像相关,结果存储在s["related"];如果相关,提示被“分支”为三个副本,并行评估不同维度,使用
gen存储结果到f["judgment"];合并判断结果,生成摘要并给出字母等级;
最终返回符合正则表达式约束的 JSON 格式结果。
重点:SGLang 显著简化了这类程序的编写。若使用 OpenAI API 类接口实现相同功能,需要 2.1 倍的代码行数,因为需要手动处理字符串和并行控制。
语言原语¶
SGLang 提供了控制提示状态、生成和并行化的原语,并可与 Python 语法和库结合使用。主要原语包括:
gen: 调用模型生成内容,并将结果存储在指定变量中。支持通过
regex参数对输出施加约束(如 JSON Schema)。select: 调用模型从选项列表中选择概率最高的选项。
+= / extend: 将字符串追加到提示中。
[variable_name]: 获取生成结果。
fork / join: 创建并重新合并提示状态的并行分支。
image / video: 接收图像和视频输入。
重点:这些原语提供了对提示状态的细粒度控制,是 SGLang 的核心能力之一。
执行模式¶
SGLang 程序可以通过两种方式执行:
解释器模式:将提示视为异步流,
extend、gen、select等原语提交到流中异步执行。非阻塞调用允许 Python 代码继续运行。每个提示由后台线程中的流执行器管理,支持程序内的并行性。获取生成结果将阻塞,直到结果就绪。类比:这种方式类似于异步启动 CUDA 内核。
编译模式:程序可编译为计算图,通过图执行器运行,从而实现更多优化。本文默认使用解释器模式,编译模式的评估结果见附录 D。
此外,SGLang 支持开源模型(通过其自研运行时 SRT)和 API 模型(如 OpenAI 和 Anthropic)。
与其他系统的比较¶
LLM 编程系统可分为两类:
高层系统:如 LangChain、DSPy,提供预定义或自动生成的提示。例如,DSPy 有提示优化器。
低层系统:如 LMQL、Guidance、SGLang,不改变提示,允许直接操作提示和原语。
SGLang 属于低层系统,更多关注运行时效率,并配有专门设计的运行时,支持本文后续介绍的新颖优化。高层语言(如 DSPy)可以编译为低层语言(如 SGLang)。第 6 节展示了将 SGLang 作为 DSPy 后端的例子。
表 1 对比了 LMQL、Guidance 和 SGLang 的特性:
系统 |
语法 |
语言原语 |
运行时后端 |
|---|---|---|---|
LMQL |
自定义 |
extend, gen, select |
HF Transformers, llama.cpp, OpenAI |
Guidance |
Python |
extend, gen, select, image |
HF Transformers, llama.cpp, OpenAI |
SGLang |
Python |
extend, gen, select, image, video, fork, join |
SGLang Runtime (SRT), OpenAI |
重点:SGLang 提供了更丰富的并行控制能力(如 fork/join),并有自己的高效运行时。
运行时优化¶
图 2 中展示了三个运行时优化机会:
KV 缓存重用
快速约束解码
API 推测执行
这些优化将在后续章节中详细讨论。
3 Efficient KV Cache Reuse with RadixAttention¶
本节介绍了 RadixAttention,这是一种用于在运行时自动、系统性地复用KV缓存(Key-Value Cache)的新技术。该方法旨在优化SGLang程序中多个生成调用和实例之间的KV缓存复用,从而减少重复计算和内存占用。
KV缓存复用的背景与挑战¶
在大型语言模型(LLM)的推理过程中,KV缓存存储了前向传播过程中的中间张量,并用于解码后续的token。由于KV缓存的计算仅依赖于前缀token,因此具有相同前缀提示的不同请求可以共享KV缓存。这一特性带来了很多缓存复用的机会。
然而,现有系统在处理KV缓存复用时存在局限性。例如,它们通常需要手动配置,且难以处理动态树结构等复杂模式。因此,大多数系统选择重新计算KV缓存,而不是复用,这导致了性能和资源的浪费。
RadixAttention 的核心思想与实现¶
RadixAttention 的核心思想是:在运行时自动保留并复用KV缓存,而不是像传统方式那样在请求完成后丢弃缓存。
数据结构:系统使用 radix tree(基数树) 来管理KV缓存。这是一种高效的空间压缩树结构,支持快速的前缀匹配、插入和复用。
缓存存储方式:KV缓存以“分页”方式存储,每页对应一个token。这样可以灵活管理GPU内存。
内存管理策略:
采用 LRU(Least Recently Used) 策略进行缓存淘汰,优先淘汰最近最少使用的叶节点。
节点维护引用计数器,只有当引用计数为0时才可被回收。
系统不预先分配固定大小的缓存池,而是与正在运行的请求共享同一块内存池,实现动态内存分配。
前端提示机制(Frontend Hint):前端在执行
fork操作时,会先发送前缀提示,帮助运行时快速建立树结构,从而提升匹配效率。图示说明(见图3):演示了多个请求在不同时刻的radix树演化过程,包括插入、复用、分裂和淘汰等操作。

Figure 3: Examples of RadixAttention operations with an LRU eviction policy, illustrated across nine time points.
图解
每条树边都带有一个标签,
表示一个子字符串或一个标记序列
节点采用颜色编码以反映不同的状态:
绿色表示新添加的节点,
蓝色表示在该时间点访问过的缓存节点,
红色表示已被驱逐的节点。
步骤详解
在步骤 (1) 中,基数树最初为空。
在步骤 (2) 中,服务器处理传入的用户消息“Hello”,并以 LLM 输出“Hi”进行响应。系统提示“You are a helpful assistance”(您是一位乐于助人的助手)、用户消息“Hello!”和 LLM 回复“Hi!”被合并到树中,作为一条指向新节点的边。
在步骤 (3) 中,一个新的提示到达,服务器在基数树中找到该提示的前缀(即对话的第一个轮次),并重用其键值缓存。新的轮次将作为新节点附加到基数树中。
在步骤 (4) 中,开始一个新的聊天会话。步骤 (3) 中的节点“b”被拆分为两个节点,以允许两个聊天会话共享系统提示。
在步骤 (5) 中,第二个聊天会话继续进行。但是,由于内存限制,步骤 (4) 中的节点“c”必须被移除。新的轮次将附加到步骤 (4) 中的节点“d”之后。
在步骤 (6) 中,服务器接收一个少样本学习查询,对其进行处理,并将其插入到树中。由于新查询与现有节点不共享任何前缀,因此根节点被拆分。
在步骤 (7) 中,服务器接收一批额外的少样本学习查询。 这些查询共享同一组小样本示例,因此我们将节点“e”从 (6) 中拆分出来以实现共享。
在步骤 (8) 中,服务器从第一个聊天会话收到一条新消息。它会驱逐第二个聊天会话中的所有节点(节点“g”和“h”),因为它们是最近最少使用的。
在步骤 (9) 中,服务器收到一个请求,要求从 (8) 中为节点“j”中的问题采样更多答案,这可能是为了实现自洽性提示。为了给这些请求腾出空间,我们驱逐了 (8) 中的节点“i”、“k”和“l”。
缓存感知调度策略(Cache-aware Scheduling)¶
为了最大化KV缓存的命中率,系统引入了缓存感知调度算法。
定义:缓存命中率 = 已缓存的提示token数 / 总提示token数。
(number of cached prompt tokens)/(number of prompt tokens)
调度原则:
在批处理场景中,按最长共享前缀优先(longest-shared-prefix-first)排序请求,而不是采用先到先服务(FIFO)。
该策略与深度优先搜索(DFS)顺序等价,从而在离线情况下可实现最优缓存命中率(定理3.1)。
定理3.1(Theorem 3.1):
对于一批请求,当缓存大小 ≥ 最长请求长度时,按照radix树的DFS(depth-first search)顺序执行请求可实现最优缓存命中率。最长共享前缀优先顺序等同于深度优先搜索顺序。
在线场景:系统在实际运行中无法完全遵循DFS顺序,但通过调度策略模拟DFS行为,仍能保持较高的缓存命中率。
局限性:贪心式调度可能导致饥饿问题(某些请求长期得不到执行),未来将结合公平调度算法优化。
分布式扩展(Distributed Cases)¶
RadixAttention 可扩展到多GPU和分布式环境:
Tensor 并行:每个GPU维护自己的KV缓存分片,无需额外同步,结构操作一致。
数据并行:多个工作节点的RadixAttention实现可参考附录A.4部分。
总结(重点内容强调)¶
核心贡献:RadixAttention 实现了KV缓存的自动复用,通过 radix tree 结构和缓存感知调度策略,显著提升了LLM推理效率。
关键技术点:
radix tree 用于高效组织和复用KV缓存;
LRU + 引用计数 实现内存管理;
缓存感知调度 提升缓存命中率;
分布式支持 保证系统可扩展。
优势:相比现有系统无需手动配置、支持复杂结构、内存开销低。
不重要内容精简说明¶
附录A中关于KV缓存背景和定理的证明,仅在需要时参考,正文重点在于实现机制和调度策略。
图3的具体示例流程仅为辅助理解,重点在于radix tree的动态维护机制和缓存复用的逻辑。
4 Efficient Constrained Decoding with Compressed Finite State Machine¶
4 高效的有限状态机压缩约束解码¶
在语言模型(LM)程序中,用户常常希望限制模型的输出遵循特定格式,例如 JSON Schema。这种限制可以提高输出的可控性和鲁棒性,并使其更易于解析。SGLang 提供了一个 regex 参数,通过正则表达式来强制这些限制,正则表达式在许多实际场景中已经足够表达。
现有系统的约束解码方法¶
现有系统通常通过将正则表达式转换为有限状态机(FSM) 来实现这种约束。在解码过程中,系统会维护当前的 FSM 状态,从下一状态中获取允许的 token,并将不符合约束的 token 的概率设为零,逐 token 解码。然而,这种逐 token 解码的方式在某些情况下效率不高,尤其是当多个 token 可以同时解码时。
例如,在 "summary": " 这样的固定序列中,虽然在常规解码过程中需要多个步骤,但实际上每一步只有一个有效 token,因此整个序列可以一次性解码完成(即一次前向传播)。但现有系统由于 FSM 和模型运行器之间缺乏集成,无法进行多 token 并行处理,导致解码速度较慢。
SGLang 的高效解码方法¶

Figure 4:The decoding process of normal and compressed FSMs (the underscore _ means a space).
SGLang 通过构建一个快速的约束解码运行时,利用压缩有限状态机(Compressed FSM) 克服了这一限制。该运行时会对 FSM 进行分析,并将连续的单 token 转移边压缩为单个边,如图 4(b) 所示。这种方式使得系统能够识别哪些 token 可以一起解码。
如图 4(d) 所示,多个 token 可以在一个前向传播步骤中完成解码,从而显著提高了解码效率。该方法具有通用性,适用于所有的正则表达式。有关背景和实现细节,详见附录 B。
5 Efficient Endpoint Calling with API Speculative Execution¶
5 利用 API 推测执行高效调用端点¶
本节在前文基础上,介绍了针对仅可通过 API 调用的模型(如 OpenAI 的 GPT-4)的优化方法。由于这类模型是黑盒,无法对推理过程进行修改,因此需要通过其他方式提升性能和降低调用成本。
核心内容是提出了一种新的优化方法:API 推测执行(speculative execution),用于加速多调用 SGLang 程序的执行,并降低 API 成本。
优化动机¶
一个典型的 SGLang 程序可能会包含多个 gen 调用,如:
s += context + "name:" + gen("name", stop="\n") + "job:" + gen("job", stop="\n")
如果没有优化,每个 gen 都会触发一次 API 调用,这样会导致:
输入 token 费用重复计算:
context部分会被多次传入,导致费用增加;调用延迟叠加:多次 API 请求会增加整体响应时间。
推测执行的原理¶
SGLang 提出的优化方法是在第一次调用时启用推测执行。具体做法是:
忽略第一次调用中的
stop条件;让模型继续生成比所需更多的 token;
将这些额外的生成结果缓存起来;
在后续的
gen调用中匹配并复用这些缓存的输出。
优势¶
如果提示词设计得当,模型能够高准确率地匹配模板结构,从而实现:
减少一次 API 调用:节省调用延迟;
降低输入费用:避免重复传入相同的
context部分。
总结¶
本节的重点是通过API 推测执行优化黑盒模型的多调用场景,其关键在于通过一次调用生成更多 token,后续通过缓存和复用来减少 API 调用次数,从而提升性能和降低成本。
6 Evaluation¶
本节评估了 SGLang 在多种大型语言模型(LLM)工作负载中的性能,并通过消融实验和案例研究展示了其组件的有效性。SGLang 基于 PyTorch 实现,并使用了 FlashInfer 和 Triton 提供的定制 CUDA 内核。
6.1 实验设置(Setup)¶
模型(Models)¶
测试了多种模型,包括:
稠密模型:Llama-2(参数量 7B-70B)
稀疏模型:Mixtral
多模态模型:LLaVA(图像、视频)
API 模型:OpenAI 的 GPT-3.5
所有模型均采用 float16 精度进行运算。
硬件(Hardware)¶
主要实验平台:AWS EC2 G5 实例,配备 NVIDIA A10G GPU(24GB)
大模型实验:使用多张 A10G GPU 并启用张量并行(Tensor Parallelism)
部分补充实验:在 A100G(80GB)GPU 上进行
基线(Baselines)¶
与以下系统进行对比:
Guidance:用于控制 LLM 的语言,使用 llama.cpp 后端
vLLM:高吞吐量的推理引擎
LMQL:查询语言,使用 Hugging Face Transformers 后端
除非特别说明,所有系统使用默认设置以保证计算结果一致。
工作负载(Workloads)¶
测试了多种任务,包括:
MMLU(5-shot)
HellaSwag(20-shot)
ReAct 代理与生成式代理
Tree-of-thought(GSM-8K)
Skeleton-of-thought(生成提示)
Branch-solve-merge(LLM 判定)
JSON 解码(带正则表达式约束)
多轮对话(短输出和长输出)
DSPy RAG 管道
指标(Metrics)¶
吞吐量(Throughput):运行足够大的程序实例,计算每秒执行的程序数(p/s)
延迟(Latency):单程序运行,计算平均延迟
6.2 端到端性能(End-to-End Performance)¶
开源模型结果¶
图5和图6 展示了 SGLang 在 Llama-7B 上的吞吐量和延迟。SGLang 相较于基线模型,吞吐量提升最高达 6.4 倍,延迟降低最高达 3.7 倍。
性能提升原因:
KV 缓存复用:如 RadixAttention,有效减少内存使用和预填充计算
单程序内并行:利用程序结构进行更高效的调度
受限解码加速:如 JSON 解码中使用压缩有限状态机(CFSM)一次解码多个 token
多模态模型支持¶
SGLang 支持图像和视频原语,可原生运行多模态模型(如 LLaVA)
对于相同图像的多问题处理,SGLang 复用 KV 缓存,提升吞吐量
表2 中比较了 SGLang 与原始实现的吞吐量,SGLang 吞吐量最高提升 6 倍
生产部署¶
SGLang 部署在 Chatbot Arena,用于服务开源模型
在 LLaVA-Next-34B 和 Vicuna-33B 上观察到 52.4% 和 74.1% 的 KV 缓存命中率
缓存命中主要来自系统消息、常见图像和多轮对话历史,显著降低首 token 生成延迟(平均降低 1.7 倍)
API 模型结果¶
使用 OpenAI 的 GPT-3.5 进行维基页面字段提取
通过少样本提示,提升了推测执行的准确性,并将输入 token 成本降低约三倍
6.3 消融实验(Ablation Study)¶
缓存命中率与性能的关系¶
图8(a)(b) 显示:缓存命中率越高,吞吐量越高,延迟越低,批次大小也越大
通过部分禁用匹配 token 验证了缓存系统对性能的影响
RadixAttention 的有效性¶
图8(c) 展示了不同组件的消融实验结果,包括:
不使用缓存
不使用树结构缓存
不使用缓存感知调度策略
不使用前端并行
不发送前端提示
实验结果表明:所有组件对性能均有显著影响,特别是前端提示与并行机制对运行时性能非常重要
RadixAttention 的开销¶
在无缓存复用机会的基准测试中,RadixAttention 数据结构管理仅占 0.3% 的开销
因树操作复杂度低,RadixAttention 可以默认启用
压缩有限状态机(CFSM)有效性¶
在 JSON 解码任务中,CFSM 将吞吐量提升 1.6 倍
预处理后复用状态机是关键,否则每请求预处理会使吞吐量降低 2.4 倍
总结¶
本节通过多个实验验证了 SGLang 在 LLM 执行中的高效性,特别是在 KV 缓存复用、调度优化和解码加速方面表现突出。无论是在稠密模型、稀疏模型、多模态模型还是生产部署中,SGLang 都展现出显著性能优势。消融实验进一步验证了关键组件对性能的贡献,证明了 SGLang 前端语言与运行时协同设计的重要性。
8 Future Directions and Conclusion¶
未来方向¶
尽管 SGLang 在提升语言模型程序效率方面已取得一定进展,但仍存在一些局限性,这些局限性指出了未来研究的潜在方向:
扩展 SGLang 的输出模态:当前 SGLang 主要面向语言类输出,未来可以扩展其支持更多的输出模态(如图像、音频等),以增强其多功能性。
适配不同内存层次的 RadixAttention:将 RadixAttention 优化为能够在多种内存层次(如 DRAM 和磁盘)上运行,参考了 FlexGen 的研究[sheng2023flexgen],这有助于提升大规模模型的执行效率。
实现模糊语义匹配:在 RadixAttention 中引入模糊语义匹配能力,以提高模型对上下文相似但表达不同的内容的识别能力。
提供更高层的编程原语:在 SGLang 基础上提供更高层次的抽象和编程接口,使开发者能够更便捷地构建和调度复杂语言模型程序。
解决缓存感知调度中的饥饿问题:当前缓存感知调度存在某些请求长期得不到响应的问题(即“饥饿”),参考了相关公平性研究[sheng2023fairness],未来需改进调度策略以提高公平性和资源利用率。
增强编译器的静态优化能力:优化 SGLang 编译器,使其能够进行更高级的静态优化,包括任务调度和内存规划,从而提升执行效率。
结论¶
本文介绍了 SGLang,这是一个用于高效编程和执行结构化语言模型程序的框架。SGLang 通过引入创新的优化技术(如 RadixAttention、压缩有限状态机和语言解释器)显著提升了复杂语言模型程序的吞吐量与延迟表现。它为高级提示技术和智能代理工作流的开发提供了有力工具。目前,SGLang 的源码已公开,可供研究和应用。
Acknowledgement¶
该章节主要对项目的支持单位和个人表示感谢。
项目资助:本项目得到了 斯坦福大学自动推理中心(Stanford Center for Automated Reasoning)以及多家企业的资助,包括 Astronomer、Google、IBM、Intel、Lacework、Microsoft、Mohamed Bin Zayed人工智能大学、Nexla、Samsung SDS、Uber 和 VMware。这些支持为项目的开展提供了重要的资源。
个人资助:其中,Lianmin Zheng 的研究得到了 Meta 公司的博士奖学金(Meta Ph.D. Fellowship)的支持,体现了其个人研究的重要价值。
技术支持:作者特别感谢 Yuanhan Zhang 和 Bo Li 提供了对 LLaVA-NeXT(视频) 的支持,这对项目的某些技术实现具有关键作用。
整体来看,该章节虽然简短,但详细列出了项目的重要支持来源,突出了合作与资助的重要性。
Appendix A Additional Details on RadixAttention¶
A.1 Background on the KV Cache¶
本节介绍了KV Cache(键值缓存)在大语言模型(LLM)中的背景和作用。
KV Cache的作用:
LLM在推理过程中分为两个阶段:prefill(预填充)和decoding(解码)。Prefill阶段处理输入序列,decoding阶段逐字生成输出。
每个token的处理会生成中间张量(即KV Cache),用于后续token的自注意力计算。
KV Cache的计算只依赖于前面的token,因此相同前缀的多个请求可以复用KV Cache,从而减少冗余计算。
KV Cache重用的挑战:
在实际的LLM程序中,常常需要处理多个请求或者生成多个输出,这些请求可能共享部分前缀。
现有的系统无法完全自动处理复杂的KV Cache共享模式,例如树状结构共享(tree-structured sharing)。
图9展示了四种KV Cache共享模式,包括few-shot学习示例、多轮对话的聊天历史、多输出自一致性(self-consistency)和思维树(tree-of-thought)中的搜索历史。

Figure 9:KV cache sharing examples. Blue boxes represent shareable prompt parts, green boxes indicate non-shareable parts and yellow boxes mark non-shareable model outputs. Shareable elements include few-shot learning examples, questions in self-consistency [53], chat history in multi-turn chat, and search history in tree-of-thought [56].
RadixAttention的优势:
与现有系统不同,RadixAttention可以在运行时自动处理所有共享模式,无需手动干预。
A.2 Pseudocode for Cache-Aware Scheduling¶
本节给出了RadixAttention的缓存感知调度算法的伪代码。
核心思想:
通过前缀匹配(prefix matching)和缓存状态管理(通过radix树和内存池)来高效调度多个请求。
关键步骤包括:
从等待队列中获取所有请求。
对每个请求进行前缀匹配,找到radix树中对应的节点。
根据匹配长度对请求排序,优先处理匹配较长的请求。
组合请求为一个批次,同时确保内存充足或进行缓存驱逐。
运行该批次的处理,并在完成后更新缓存状态。
重点数据结构:
Radix树(T):用于组织和匹配请求的前缀。
内存池(P):用于管理缓存的KV Cache。
运行批(B):当前正在运行的请求组。
等待队列(Q):等待处理的请求队列。
总结:
该算法通过动态调度和缓存优化,使得多个共享前缀的请求可以高效运行,显著减少冗余计算。
A.3 Proof of [Theorem 3.1]¶
本节证明了深度优先搜索(DFS)顺序在缓存命中率上的最优性。
定理核心:
假设一个请求批R,构建的radix树为T。
对于T的每条边e,对应的KV Cache需要至少计算一次,其总计算复杂度为C。
证明了DFS顺序可以最小化C,从而最大化缓存命中率(cache hit rate)。
关键结论:
DFS顺序下,每条边的KV Cache只计算一次。
缓存命中率公式为: $\( \text{cache hit rate} = 1 - \frac{C}{\sum_{r \in R} \text{number of prefill tokens in } r} \)$
当C最小化时,缓存命中率最大,达到最优。
扩展:在线场景下的DFS行为:
在新增请求的情况下,虽然DFS顺序会被打断,但最长共享前缀优先调度(longest-shared-prefix-first)仍能近似DFS行为。
通过维护缓存状态和逐步处理子树,仍可达到良好的缓存效率。
A.4 Data-Parallel Distributed RadixAttention¶
本节探讨了如何将RadixAttention扩展到数据并行(data-parallel)的分布式设置中。
分布式设计:
每个worker维护一个局部的子树(sub-tree)。
路由器(router)维护一个元树(meta-tree),记录所有子树及其所在的设备。
新请求到达时,路由器在元树上执行前缀匹配,并根据请求与worker的亲和性(affinity)决定调度到哪个worker。
更新与缓存一致性:
各worker在处理新请求时,独立更新自己的子树。
如果发生缓存驱逐(eviction),worker将驱逐记录提交到队列,由路由器在低峰时段更新元树。
设计为弱一致性缓存,在保证效率的同时牺牲部分一致性。
实验与效果:
使用四个worker和MMLU数据集进行测试,结果显示:
线性扩展:随着worker数量增加,性能线性提升。
高缓存命中率:几乎接近最优。
低开销:由于弱一致性的设计,分布式缓存的额外开销较小。
未来方向:
调度策略优化:探索更高级的调度策略,以平衡数据本地性和并行效率之间的权衡。
相关研究:Preble的工作基于SGLang的早期版本,研究了数据并行调度。
总结¶
本附录详细介绍了RadixAttention在KV Cache管理和调度方面的核心技术,包括:
KV Cache共享与优化:通过radix树结构实现高效共享,减少冗余计算。
缓存感知调度算法:实现了连续批处理与动态调度,支持复杂请求模式。
理论证明:DFS顺序最优,最长共享前缀调度可近似DFS行为。
分布式扩展:支持数据并行,通过元树和子树结构实现弱一致性缓存管理。
这些技术共同提升了大语言模型在并发、复杂请求场景下的运行效率和资源利用率。
Appendix B Additional Details on Compressed Finite State Machine¶

Figure 10:Example of how regex is converted into FSM and how FSM guides the decoding process.
本节主要介绍压缩有限状态机的背景及其在加速约束解码中的实现细节。目标是使语言模型(LLM)输出的内容遵循正则表达式(regex)的约束,从而可以用于生成结构化数据(如 JSON 格式)。为此,作者将正则表达式转换为有限状态机(FSM),并在解码过程中使用该状态机来指导生成过程 [54]。
FSM 的基本原理¶
FSM 是一种由状态节点和带字符串的转移边构成的图结构。解码过程从初始状态出发,通过选择边上的字符串逐步转移状态,直到到达终止状态。这个机制可以过滤掉不符合 regex 的 token,从而实现结构化输出。如图 10 所示,LLM 在解码过程中会根据当前 FSM 所处的状态,限制下一步可能生成的 token。
图 10 展示了 regex 转换为 FSM 的过程,并说明 FSM 如何引导解码流程。
挑战:字符串与 token 的映射问题¶
正则表达式是基于字符串的,而 LLM 是基于 token 的,因此存在字符串与 token 之间缺乏一一对应的问题,导致约束解码复杂化。这也是压缩有限状态机设计的一个核心挑战。
本节内容改编自一篇早期博客[333],建议读者阅读以获得更深入的背景知识。
B.1 压缩有限状态机的实现细节¶
为了简化压缩 FSM 的构建,作者首先基于字符/字符串构建原始 FSM,而非直接基于 token。这一步骤为后续的压缩奠定了基础。
关键概念定义:¶
Singular transition edge(单向转移边):如果一个边的起点节点只有一个后续节点,并且该边只接受一个特定的字符/字符串,则称为单向边。
Compressed edge(压缩边):当多个连续的单向边可以被压缩为一个边时,其文本为这些边文本的拼接。压缩直到无法进一步压缩为止。
通过递归地将单向边合并到其前边中,最终获得一个压缩后的 FSM。这种方式能显著提升解码效率,如图 11 所示,展示了压缩 FSM 相比于普通 FSM 在运行效率上的提升。
图 11 对比了压缩 FSM 与普通 FSM 的解码过程,左侧显示每个前向传播的解码过程,右侧解释了结果的构成来源。

Figure 11:Comparison of decoding using Compressed FSM versus normal FSM: The left subfigure depicts the decoding process per forward pass, while the right subfigure explains the origins of various result components.
B.2 通过重分词处理 token 化伪影(Retokenization)¶
在生成一个新 token 后,系统会获取其对应的字符串,并在当前状态的所有出边中查找匹配的边。若该边是压缩边(包含较长的字符串),则可以提前预测后续的 token 内容,这种机制称为Jump Forward(跳跃前进),从而加速解码。
但由于 LLM 的 token 化方式与直接字符串分割不同,直接分割字符串可能会破坏语义。例如,压缩字符串 {"summary": 可能被正确 token 化为 {", summary, ":,而非错误地拆分为 {", summa, ry, ...。
为解决这个问题,系统在处理压缩边时,使用原始 tokenizer 对整个压缩边文本进行重分词,确保与 LLM 的输入格式一致。该步骤带来的额外开销较小。
B.3 未来扩展:处理概率分布失真问题¶
由于字符串与 token 之间的映射问题,可能导致概率分布的扭曲 [50]。例如,一个压缩边可能将多个可能的 token 序列映射到同一个选项,而模型可能会错误地选择概率最高的那个,从而导致语义不一致。
例如,正则表达式 [ABCD][+-]? 用于表示 A+ 到 D- 的成绩,但若将其替换为 Excellent|Above Average|Fair|Below Average,模型可能错误地将 “A” 映射为 “Above Average”,因为后者在压缩边中出现,导致等级排序混乱。
解决方法之一是在预填充提示(prefill prompt)中加入选项或 regex,引导模型生成正确的 token 序列。但这种方法仅是表面解决,无法从根本上解决概率失真问题。因此,作者指出这一方向仍需进一步研究,以提升压缩 FSM 的准确性。
总结¶
本节详细介绍了压缩有限状态机(Compressed FSM)在约束解码中的实现机制,包括:
将 regex 转换为 FSM,并用于控制解码流程;
通过压缩 FSM 提升解码效率;
通过重分词处理 token 化的不一致性;
指出未来需要解决的概率分布扭曲问题。
整体来看,压缩 FSM 是实现结构化输出的一个关键技术,但其在 token 化和概率建模方面仍面临挑战,需要进一步研究与优化。
Appendix C Additional Experimental Setups and Results¶
其他实验设置¶
本部分介绍了一些额外实验的硬件配置与模型运行情况:
图5 和 图6 的实验是在单块 A10G(24GB)GPU 上运行 Llama-7B 模型获得的。
图7 的实验是在 8 块 A10G(24GB)GPU 上使用 张量并行(Tensor Parallelism) 技术运行 Mixtral-8x7B 模型获得的。
图8(c) 的实验同样是在单块 A10G(24GB)GPU 上运行 Llama-7B 模型。
图12 的实验是在 4 块 A100G(80GB)GPU 上运行 Llama-70B 模型,同样使用了张量并行。
表2 中的实验分别在单块 A10G(24GB)GPU 上运行 LLaVA-v1.5-7B 模型,以及在单块 A100G(80GB)GPU 上运行 LLaVA-Next-34B 模型。
⚠️ 注:每个基准测试图中的柱状图需要运行数分钟到一小时不等,说明实验耗时较长,对硬件设备要求较高。
其他实验结果¶
图13 展示了在不同基准测试中,实际缓存命中率 与 理想缓存命中率 的对比,用于评估缓存效率。
图12(如图 x12 所示) 展示了在使用张量并行技术运行 Llama-2-70B 模型时的吞吐量(throughput)。该图显示了不同配置下的性能表现,值越高越好。
✅ 重点内容:图12 和 图13 是关键的性能评估图。图12 用于评估大规模模型在并行计算下的吞吐性能,图13 用于评估缓存机制的优化效果。
SGLang 程序与数据流图(图14)¶
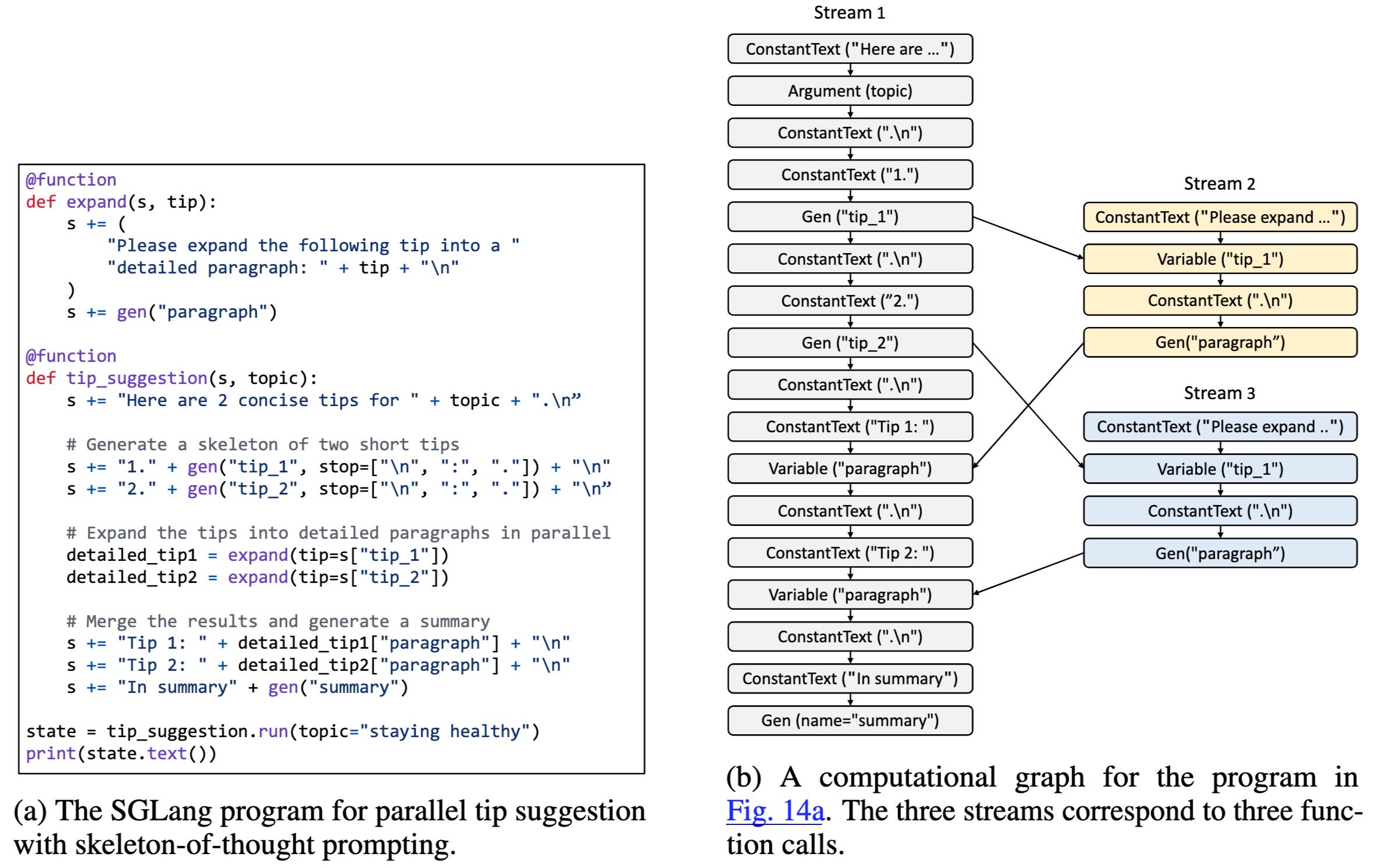
Figure 14: An SGLang program and its corresponding dataflow graph.
图14 包含两部分内容:
图14(a) 展示了一个 SGLang 程序,用于并行提示建议(tip suggestion)任务,使用了骨架思维提示(skeleton-of-thought prompting)的方法。
图14(b) 展示了上述程序的计算图(数据流图),其中三个流(stream)分别对应三个函数调用,体现了程序的结构化执行流程。
✅ 重点内容:这部分展示了 SGLang 的结构化执行特性,通过数据流图清晰展示了并行与函数调用之间的关系,是理解 SGLang 执行机制的重要部分。
Appendix D Compiler Mode¶
Appendix D 编译器模式¶
除了论文主体中使用的解释器模式,SGLang 程序还可以通过编译为计算图并在图执行器中运行。这种方式为更多的编译优化提供了可能,例如对图进行重写和进行更静态的规划。
D.1 设计与实现¶
本节介绍了为 SGLang 设计的中间表示(IR),它将 SGLang 程序的结构和操作表示为一个计算图。该图包括操作符节点和依赖关系边,用于表示程序中的结构和执行顺序。
节点类型包括:
ConstantText(常量文本)、Argument(参数)、Gen(生成)、Select(选择)、Variable(变量)、Fork(分叉)、GetForkItem(获取分叉项)、Join(合并)等。依赖关系分为两类:
流内依赖(intra-stream):同一流中通过
+=提交的操作必须按顺序执行。流间依赖(inter-stream):当一个流需要从另一个流获取变量值时,必须进行同步。
图生成方式通过追踪(tracing)运行程序,使用抽象参数动态构建图。这种方式不适用于包含数据依赖控制流的程序,这是未来需要解决的问题。
一旦图构建完成,即可通过图执行器运行,无需重新解释原始 Python 程序。这带来了图重写优化、运行时开销降低和程序序列化等优势。
执行时,为每个数据流启动一个流执行器,根据拓扑顺序将 IR 节点分发到流中。
D.2 编译优化案例研究:代码移动以提高前缀共享¶
本节探讨了一种针对 SGLang IR 的编译优化技术:通过代码移动来提高前缀共享。这种优化通过调整图中节点顺序,来延长可共享的文本前缀长度。这种优化属于激进类型,因为它不严格保持原计算顺序。
优化示例:将提示语从 “Here is a question + {question}. Please act as a math expert…” 重写为 “Please act as a math expert… Here is a question + {question}.”,从而使得前缀更长、共享更好。
优化实现方式:由于传统程序分析方法难以处理自然语言,我们使用 GPT-4 来对图节点进行重新排序。
实验设计:收集了 20 个提示模板,其中 5 个作为示例,其余 15 个作为测试用例。
优化效果:在 15 个测试模板中,GPT-4 成功对 12 个进行了无语义变化的重排序,平均前缀共享长度增加了 60 个 token。
失败原因:部分失败是由于 GPT-4 对图节点的语义理解不准确,导致错误地将所有常量前置,改变了原义。
研究意义:本案例探讨了使用 GPT-4 实现编译器优化的可行性,但指出未来仍需进一步提高这类优化的可靠性。
总结¶
编译器模式为 SGLang 提供了性能优化的新方向:通过图执行器执行程序,带来更高效、更灵活的执行方式。
**中间表示(IR)**的设计是关键,它支持节点依赖分析、图重写等高级编译优化。
代码移动优化展示了如何利用 LLM(如 GPT-4)实现自然语言控制流的优化,这是传统编译器难以处理的问题。
未来工作包括支持数据依赖控制流、提高 GPT 类模型在编译优化中的可靠性等。
以上是对 Appendix D 内容的结构化总结,重点强调了 IR 设计、图执行机制、代码移动优化方法及其实验结果。