2108.00941_Human-in-the-loop: A Survey of Human-in-the-loop for Machine Learning¶
引用: 833(2025-08-27)
组织:
1 Shanghai Key Laboratory of Multidimensional Information Processing, East China Normal University, Shanghai, China(华东师范大学)
2 School of Computer Science and Technology, East China Normal University, Shanghai, China(华东师范大学)
3 Fudan University, Shanghai, China(复旦大学)
总结¶
总结
Human-in-the-loop:人机交互
背景
传统机器学习通常包括三个部分:
数据预处理
模型建模
开发者手动调优
背景与挑战
深度学习的成功依赖于大规模模型和大量标注数据,但标注数据成本高昂且难以跟上模型复杂度的增长。
未标注数据的使用成为研究热点,但其中可能存在错误样本(如干扰图像、违规内容等),若处理不当可能导致严重误差。
关键问题:如何识别关键样本,并更高效地标注这些关键样本?
Data Processing
数据预处理(Data Preprocessing)
数据标注(Data Annotation)
迭代标注(Iterative Labeling)
贡献
本文是首篇系统分析人机协同在机器学习中应用的综述
是对人机协同在机器学习中应用的系统性总结与分析
本文的贡献
全面总结已有研究
方法分类与比较
Abstract¶
机器学习已成为计算机视觉、自然语言处理、语音处理等许多任务中的尖端技术。然而,机器学习所面临的独特挑战表明,将用户知识整合到系统中是有益的。整合人类领域知识的目的,也是为了推动机器学习的自动化。
重点强调:随着机器学习所学知识无法超越人类领域知识,Human-in-the-loop(人在回路)这一领域在未来研究中变得日益重要。Human-in-the-loop的目标是通过整合人类知识和经验,以最低的成本训练出准确的预测模型。
人类可以为机器学习应用提供训练数据,并通过基于机器的方法,在流程中直接完成对计算机来说困难的任务。
在本文中,我们从数据的角度对现有的Human-in-the-loop相关工作进行了综述,并将其分为三个具有递进关系的类别:
从数据处理方面提升模型性能的工作(改进模型性能的数据处理方法)。
通过介入式模型训练来提升模型性能的工作(介入式模型训练方法)。
设计独立的Human-in-the-loop系统(系统级别的设计方法)。
重点总结:通过上述分类,我们总结了该领域的主要方法,并结合它们的技术优缺点,对自然语言处理、计算机视觉及其他领域进行了简单分类和讨论。此外,我们还提供了该领域中的开放性挑战和机遇。
文章目的总结:本文旨在为Human-in-the-loop提供一个高层次的综述,并激励感兴趣的读者考虑设计高效的Human-in-the-loop解决方案的途径。
关键词(Index Terms)
Human-in-the-loop(人在回路)
机器学习(Machine Learning)
深度学习(Deep Learning)
1 Introduction¶
深度学习的现状与发展¶
深度学习作为人工智能的前沿领域,正不断向实现“通用人工智能”的目标靠近。它在自然语言处理、语音识别、医疗应用、计算机视觉、智能交通系统等多个领域取得了巨大成功。这些成功主要归功于模型规模的扩大,现代深度学习模型通常包含数亿个参数,赋予了模型更强大的描述能力。
然而,大规模参数也带来了挑战:
数据需求激增:模型参数的增长远超数据的增长速度,限制了模型的发展。
新任务的数据更新困难:标注数据耗时且成本高,尤其是面对不断出现的新任务时。
为解决这些问题,研究者提出了多种方法:
生成数据:通过生成样本来加速模型迭代,降低标注成本。
预训练与迁移学习:如Transformer、BERT、GPT等模型,通过迁移学习显著提高了模型表现。
弱监督与少样本学习:在数据有限的情况下提升模型性能。
1.1 Significance of Human-in-the-loop(人机协同的重要性)¶
人机协同的背景与价值¶
在数据稀疏的情况下,将先验知识(特别是人类知识)整合到模型中,成为提升模型性能的重要手段。人类作为特例,拥有丰富的先验知识,在医疗诊断等数据稀缺领域尤其有价值。
近年来,越来越多的研究者尝试将预训练知识与人类知识融合到学习框架中。此外,认知科学和人机交互的研究表明,人类的情感状态和实践能力等也会影响教学效果和模型学习结果。
为应对上述挑战,研究者提出了“人机协同(Human-in-the-loop)”这一概念,强调在建模过程中引入人类的参与。人机协同是一个涵盖计算机科学、认知科学和心理学的广泛研究领域。
人机协同的基本框架¶
传统机器学习通常包括三个部分:
数据预处理
模型建模
开发者手动调优
模型性能的不确定性使得在哪个环节引入人类干预最有效尚不明确。不同研究者聚焦于不同的干预部分。本文从数据处理、模型训练与推理、系统构建与应用三个视角出发,探讨人机协同的多种实现方式及其对学习效果的影响。
本文关注的研究问题¶
本文围绕人机协同在机器学习中的应用,探讨以下几个问题:
人机协同在机器学习中面临哪些挑战?可能的解决方案是什么?
从数据、模型训练和应用三个角度,其研究现状、挑战和未来方向如何?
这些问题旨在系统性地评估人机协同在不同阶段的作用机制及其对智能系统学习结果的影响。
1.2 Importance of this survey(本文综述的重要性)¶
本文的贡献¶
本文是对人机协同在机器学习中应用的系统性总结与分析,主要贡献如下:
全面总结已有研究:将相关论文按CV、NLP等应用领域分类,并根据数据流(数据预处理、标注、模型训练与推理)进行串联,最终聚焦于人机协同的应用研究。
方法分类与比较:对各种人机协同方法进行分类与比较,总结当前面临的挑战,并提出解决思路。
定性评估:对不同方法进行一致性评估,帮助读者选择适合其问题的解决方案。
重要里程碑梳理:识别此领域的重要进展。
系统构建与应用分析:不仅分析方法,还探讨系统构建和应用中的工程需求,从系统组成和实际应用场景进行分类讨论。
与已有工作的区别¶
尽管已有少量关于人机协同的综述(如从机器人和硬件角度),但本文是首篇系统分析人机协同在机器学习中应用的综述。我们结合前人的经验和思路,以更加全面和系统的方式进行分析。
尽管无法覆盖该领域的所有方法,但通过大量文献调研、多种分类方式的尝试,最终以数据流为切入点,构建了完整的内容体系。
1.3 Organization of contents(内容组织)¶
文章结构安排¶
由于此前没有类似综述,本文首先通过Google Scholar检索包含关键词“human-in-the-loop”和“machine learning”的论文(自1990年起),并按照以下步骤进行整理:
筛选:通过标题和摘要筛选相关论文;
分类:初步分类所选论文;
深入阅读与调整分类:详细阅读并不断优化分类方式;
总结:根据最终分类形成综述内容。
各章节内容概览:¶
第2章(Data Processing):探讨数据处理中的人机协同方式,包括数据预处理、数据标注与迭代标注。
第3章(Model Training and Inference):总结和分析基于人机协同的模型训练与推理方法,分别从NLP和CV角度进行讨论。
第4章(System construction and Application):从系统构建和应用角度,分析人机协同在软件与硬件集成中的应用。
第5章(Discussion and Future Directions):基于综述结果,提出当前挑战与未来研究方向。
第6章(Conclusion):总结全文研究内容与贡献。
总结¶
本节介绍了深度学习的发展现状、所面临的数据与模型挑战,以及人机协同作为重要解决方案的研究背景。本文通过系统综述的方式,从数据处理、模型训练、系统构建与应用三个维度出发,全面分析了人机协同在机器学习中的研究进展与挑战,并提出了未来研究方向。文章结构清晰,内容详实,具有较强的参考价值。
2 Data Processing¶
背景与挑战¶
深度学习的成功依赖于大规模模型和大量标注数据,但标注数据成本高昂且难以跟上模型复杂度的增长。
未标注数据的使用成为研究热点,但其中可能存在错误样本(如干扰图像、违规内容等),若处理不当可能导致严重误差。
关键问题:如何识别关键样本,并更高效地标注这些关键样本?
方法概述¶
提出一个三步方法:选择模型难以识别的样本 → 使用特定方法标注 → 让模型学习新标注数据,以最低成本最大化数据利用。
多数研究采用人机协同(Human-in-the-loop)方法优化模型,研究表明科学家约 80%的时间花在数据处理 上。
文章总结了代表性工作(见表格 1),分类为数据预处理(DP)、数据标注(DA)和迭代标注(IL),并按任务和领域(CV、NLP、语音等)进行归纳。
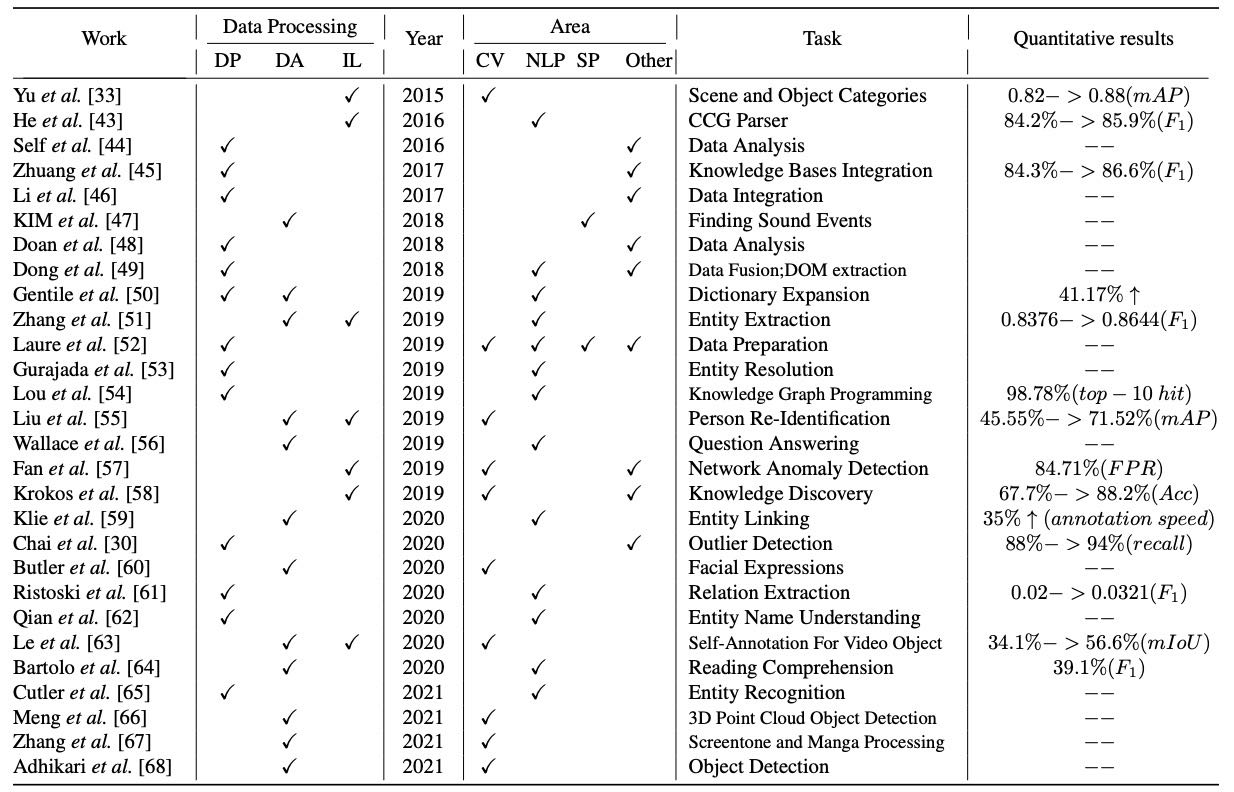
Table 1: A overview of representative works in data processing. DP: data preprocessing; DA: data Annotation; IL: iterative labeling; CV: Computer Vision; NLP: Natural Language Processing; SP: Speech Processing.
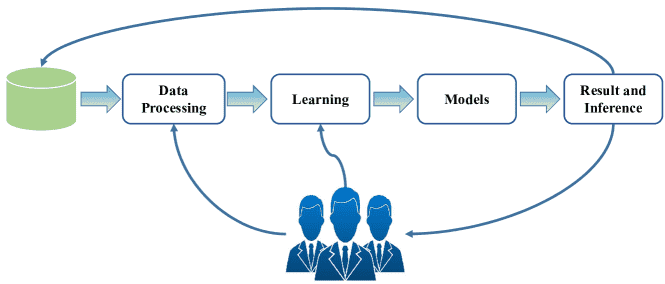
Fig. 1:The development cycle of model.
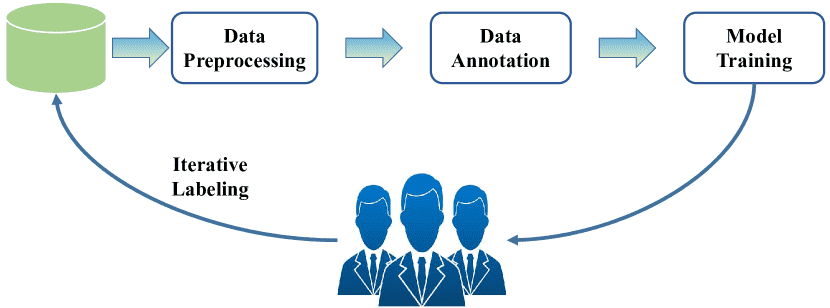
Fig. 3: A human-in-the-loop data processing pipeline.
2.1 数据预处理¶
数据预处理是构建有效模型的基础,但高维数据的复杂性使得模型难以自动发现数据结构。
研究趋势包括:
引入专家经验优化参数(如 Self et al. 的交互式参数调整)。
自动化参数分析与基准建立(如 Doan et al. 和 Laure 的 AutoML 方法)。
构建知识库或图谱以获取信息(如 Ristoski et al. 的网络实例提取方法)。
NLP 领域更常使用人机协同,如 Qian et al. 提出基于主动学习和弱监督的实体理解系统(PARTNER)。
CV 领域的人机协同预处理仍较少,主要原因是缺乏成熟的图像处理模式(将在第 5 章详细讨论)。
2.2 数据标注¶
数据标注是实现 AI 的关键步骤,尤其在 NLP 和 CV 领域。
NLP 标注任务包括实体提取、实体链接、问答任务、阅读理解等:
Zhang et al. 提出基于人机协同的实体抽取方法,提高效率和准确性。
Wallance et al. 构建一个交互系统,通过用户与模型对话生成更多问答数据。
Bartolo et al. 通过三阶段标注法构建强壮模型,但也发现模型性能随循环增强而下降。
CV 标注任务如人脸表情识别、3D 点云目标检测、视频目标检测等,也广泛采用人机协同:
Liu et al. 提出基于强化学习的 Re-ID 模型,减少人工标注需求。
Butler et al. 构建微表情识别系统,允许用户校正自动标注。
Le et al. 使用自监督学习构建视频标注框架,大幅减少标注时间。
Zhang et al. 将人类绘画技能引入模型训练,提升模型在漫画生成任务中的表现。
2.3 迭代标注¶
迭代标注强调与用户的交互,不仅限于直接标注数据,更注重 知识注入 和 用户体验优化。
与数据标注不同,迭代标注的核心在于:
算法与界面的紧密结合(如 Fan et al. 的网络异常检测系统)。
最小化人工标注量,最大化模型性能(如 Liu et al. 基于强化学习的 Re-ID 模型)。
代表方法:
Yu et al. 提出部分自动化标注方案,是迭代标注的基本原型。
Liu et al. 将强化学习引入迭代标注,扩展了人机协同的应用边界。
Fan et al. 结合主动学习与视觉交互,提高网络异常检测的标注效率。
总结¶
数据处理是深度学习成功的关键,但高质量标注数据难以为继,推动了人机协同方法的发展。
NLP 领域在人机协同数据处理方面研究较为成熟,CV 领域仍有待探索。
数据预处理依赖专家经验和自动化策略;数据标注强调任务定制与用户交互;迭代标注更关注知识注入与用户体验。
未来方向应进一步优化人机交互方式,提升模型对未标注数据的利用效率,并推动人机协同技术在更多领域的应用。
3 Model Training and Inference¶
在人工智能的多个领域,如自然语言处理(NLP)和计算机视觉(CV)中,都有大量研究利用人类智能来训练模型并进行推理,以提升实验结果的质量。
对于NLP和CV,相关研究涵盖了深度学习技术以及人机混合方法。这些启发式方法充分考虑了人类创造力的多样性,以实现高质量的结果。图6展示了NLP中人机协作的模型训练与推理流程。在这个流程中,人类参与者在模型训练和推理的不同阶段提供反馈,以提升NLP模型的性能。这种持续的协作机制有助于构建更可靠的人机协同系统,从而提高NLP系统的准确性和鲁棒性。
3.1 自然语言处理(NLP)¶
3.1.1 文本分类(Text Classification)¶
文本分类是NLP中的基础任务,用于将句子或文本归类到相应的类别。Karmakharm等人提出了一种谣言分类系统,通过记者的反馈重新训练模型,提升模型的准确性。Arous等人则提出了一种人机混合框架MARTA,通过贝叶斯学习联合更新模型参数与人类可靠性,提升模型的可解释性与性能。
3.1.2 语法与语义解析(Syntactic and Semantic Parsing)¶
语法解析旨在获取句子的语法结构,而语义解析则是将自然语言映射到形式化的语义表示。Yao等人提出了一种结合人类反馈的交互式语义解析方法,通过用户澄清问题来提升解析准确性。尽管该方法在特定形式语言中有效,但普遍性仍受限。他们还提出了MISP(Model-Based Interactive Semantic Parsing),作为通用的交互式语义解析原则。
3.1.3 文本摘要(Text Summarization)¶
文本摘要任务旨在生成保留原意的简短版本。Ziegler等人使用强化学习结合人类偏好进行模型微调,提升了摘要质量。Stiennon等人则通过构建人类偏好的数据集,训练奖励模型并使用强化学习优化策略,提高了摘要生成的准确性与一致性。
3.1.4 问答(Question Answering)¶
问答系统通过在线或离线的反馈机制提升性能。Hancock等人提出了一种“终身学习”框架,通过用户对话生成新样本用于模型再训练。Wallace等人则利用“问答爱好者”生成对抗性样本来提升模型的鲁棒性。
3.1.5 情感分析(Sentiment Analysis)¶
情感分析涉及对文本中提及的实体进行情感判断。Liu等人提出了一种可解释的人机协同框架,通过分析局部与全局特征贡献,帮助用户理解模型的预测依据并修正错误预测。
3.1.6 NLP中人机协同的总结¶
表2总结了NLP中代表性的人机协同研究,涵盖文本分类、解析、摘要、问答和情感分析任务。研究表明,即使是少量的人类反馈也能显著提升模型性能。此外,这类方法在提升模型性能的同时,也增强了模型的可解释性和可用性。
3.2 计算机视觉(CV)¶
在CV中,神经网络和深度学习已成为主流方法。为了进一步提升性能,研究者将人类反馈集成到模型中,构建更智能的系统。图7展示了CV中人机协同框架的典型流程。
3.2.1 目标检测(Object Detection)¶
目标检测是CV中的基础任务,旨在识别图像中的特定对象。Yao等人提出一种交互式目标检测框架,通过人类注释提高检测精度。Madono等人则使用深度SORT与交互式注释方法,减少人工标注负担,提升模型性能。
3.2.2 图像修复(Image Restoration)¶
图像修复旨在恢复损坏图像的原始版本。Weber等人提出一种基于Deep Image Prior的交互式修复系统,允许用户通过界面参与修复过程,提升图像质量。Roels等人则在电子显微镜图像中引入专家知识,提升图像的清晰度。
3.2.3 图像分割(Image Segmentation)¶
图像分割是为图像的每个像素分配类别标签的任务。Wang等人提出一种两阶段混合系统,利用人类反馈挖掘模型弱点并进行修正。Ravanbakhsh等人则结合生成对抗网络与专家标注,提升医学图像的分割准确性。
3.2.4 图像增强(Image Enhancement)¶
图像增强旨在生成更符合用户需求的图像。Murata等人通过用户评分学习偏好,优化增强参数。Fischer等人提出NICER系统,通过质量评估模块优化图像增强效果,同时允许用户参与调整参数。
3.2.5 视频对象分割(Video Object Segmentation)¶
视频对象分割是为视频中的对象逐帧生成掩码。Benard等人提出一种交互式分割方法,Oh等人提出IPN(交互与传播网络),允许用户在多帧提供反馈以优化分割结果。
3.2.6 CV中人机协同的总结¶
表3总结了CV中代表性的人机协同研究,涵盖目标检测、图像修复、分割、增强和视频分割任务。结果显示,人机协同显著提升了模型性能,尤其在目标检测和图像分割方面效果显著。此外,部分研究还提升了模型的可用性与可解释性。
总结¶
本章总结了NLP和CV领域中人机协同在模型训练与推理中的应用。研究表明,通过引入人类反馈,可以有效提升模型的准确性、鲁棒性和可解释性。尽管研究重点不同,但NLP和CV领域在提升模型性能方面表现出相似的趋势。未来的研究可以进一步探索如何更好地结合人类智慧与机器学习,实现更高效的协同系统。
4 System construction and Application¶
本章节总结了基于“人在回路”(Human-in-the-loop)的系统在不同应用场景中的研究与实践成果,重点介绍了四个主要应用领域:安全系统(Security Systems)、代码生成工具(Code Production Tools)、仿真系统(Simulation Systems)、搜索引擎(Search Engines),同时提及其他应用方向。通过表格和具体案例展示了“人在回路”在实际系统中的设计、作用与效果。
表 4:代表性“人在回路”软件系统的应用场景概述¶
表格总结了多个代表性研究的系统应用、年份、人在回路中所扮演的角色(如监督者、执行者、协作者、用户)以及取得的定量结果。研究案例包括:
安全系统:如 Brostoff & Sasse (2001) 和 Singh et al. (2020) 的研究,通过人在回路提升安全任务的准确性。
代码生成:如 MacHiry et al. (2013) 和 Bohme et al. (2020) 的系统,实现了自动化测试与修复。
仿真系统:如 Davidson et al. (2021) 的决策支持系统与 Demirel (2020) 的人体仿真系统。
搜索引擎:如 Kovashka et al. (2015) 和 Plummer et al. (2019) 的图像搜索系统,引入用户反馈提升搜索质量。
4.1 安全系统¶
安全系统是“人在回路”应用最广泛且最紧密的领域之一。随着深度学习的发展,研究人员尝试构建更有效的“人机协作”模式,以取代传统的人工干预流程。
Cranor (2008) 提出了一种基于“人在回路”的推理框架,帮助系统设计者识别潜在的人类操作失误原因。
Singh et al. (2020) 将人机界面(HMI)状态预测转化为语言翻译任务,用“人在回路”方式建模,提高操作安全性。
Demartini et al. (2020) 和 ODEKERKEN et al. (2020) 提出结合机器学习、专家与用户反馈的系统,提升在线信息审核与分类的效率与可信度。
重点:“人在回路”在安全系统中的核心作用是通过融合人类经验与机器的计算能力,降低错误率、提升人机协作效率,已在病毒检测、虚假信息过滤、隐私保护等多个领域取得良好效果。
4.2 代码生成工具¶
代码编写和模型训练是人工智能领域的重要任务,也是“人在回路”系统的典型应用场景。
MacHiry et al. (2013) 提出了 Dynodroid 系统,通过事件驱动方式对 Android 应用进行模糊测试,并在必要时引入人工干预。
Yan et al. (2017) 设计了以“人为主”的漏洞分析系统,提升代码测试效率。
Bohme et al. (2020) 提出 LEARN2FIX 框架,通过人机协作实现半自动程序修复,显著降低了标注工作量。
重点:代码生成工具的“人在回路”系统通过整合已有代码资源、自动化生成与人工反馈,有效提高了编程效率。未来,随着预训练模型(如 BERT、GPT)的发展,人机协作编程将成为研究热点。
4.3 仿真系统¶
仿真系统通过虚拟环境模拟对象或流程,广泛应用于决策支持、流程预测与安全控制等领域。
Davidson et al. (2021) 通过半结构化访谈方法总结了提升“人在回路”仿真的八大需求,增强其在军事设计早期阶段的可用性。
Demirel (2020) 提出了基于数字人建模的交互方法,用于评估人机互动的安全性与效能。
Metzner et al. (2020) 结合虚拟现实与运动追踪技术,模拟人机协作流程,提升工业机器人系统的安全性。
重点:仿真系统中“人在回路”的核心是通过数字建模与虚拟交互,实现流程预演与优化,尤其在工业自动化、军事训练等领域具有重要应用价值。
4.4 搜索引擎¶
搜索引擎的智能化与自动化是当前研究重点。通过引入“人在回路”,系统能更精准地理解用户意图,提升搜索质量。
Polisetty et al. (2020) 提出了一个具备反馈机制的推荐系统,通过用户交互不断优化推荐结果。
Kovashka et al. (2015) 和 Plummer et al. (2019) 设计了图像搜索系统,利用用户反馈迭代优化搜索结果,并引入深度强化学习提升模型性能。
重点:图像搜索与推荐系统通过“人在回路”机制,可实现更自然、准确的搜索体验。未来,随着语义匹配技术的发展,搜索系统将更具个性化与智能化。
其他应用场景¶
“人在回路”系统还被应用于以下领域:
生物信息学:如 Fredrik Wrede 等人(2019)利用“人在回路”机制优化基因调控。
医疗健康:如 Zhu et al. (2020) 在肾病理分析中的应用。
众包任务:如 Louis Rosenberg 等人(2016)设计的人工智能调度系统。
总结:随着人机交互技术的发展,“人在回路”系统在更多领域展现出巨大潜力,未来将在更多复杂任务中实现人机协同与智能决策。
5 Discussion and Future Directions¶
该节首先讨论了人机协同在机器学习中的一些现存挑战和关键问题,随后在计算机视觉(CV)、自然语言处理(NLP)和实际应用三大领域提出了未来的研究方向。
5.1 挑战与讨论¶
如何将人类经验与知识融入计算机视觉任务中?¶
当前,人机协同的研究主要集中在自然语言处理领域,而在计算机视觉中进展较慢。主要障碍在于,除了直接标注图片外,难以让人类有效地与图像进行交互,从而在整个模型训练过程中融入人类经验。随着多模态技术的发展,利用多模态表示图像成为一种有效方法。例如,Holzinger 等人使用图神经网络(GNN)进行多模态信息融合,是一个重要的里程碑。此外,逆强化学习也被认为是可行的解决方案之一。
重点内容:图像任务中人类参与度低、多模态技术与图神经网络的引入是当前研究的热点和难点。
如何从更高维度学习人类知识与经验?¶
人机协同的目标是让机器在模型循环中学习人类的知识与经验。当前大多数方法依赖于人工标注,这只是一个基础手段。研究者应探索如何帮助模型“学会学习”,比如通过对话机制让模型从交互中逐步学习。图像质量评估、设计任务等较高级别的任务,也依赖于人类经验和审美,若能有效整合,模型性能将显著提升。
重点内容:需突破“仅标注”的局限,探索交互式、对话式的人类知识学习机制。
如何选择关键样本?¶
人机协同的关键技术是通过人类参与来获取关键样本。当前主要使用基于模型置信度的方法,适用于分类任务。但对于语义分割、目标检测等任务,置信度评估不够有效。主动学习(active learning)提供了一种更通用的样本选择策略,值得进一步借鉴和研究。
重点内容:主动学习在非分类任务中的应用潜力值得进一步探索。
如何构建评估基准?¶
目前缺乏统一的人机协同研究基准,这对领域发展极为不利。建立有效的评测方法和标准,不仅有助于研究的规范化,也有利于技术的进一步细化和比对。
重点内容:统一评估基准对推动人机协同研究至关重要。
如何构建通用多任务框架?¶
现实任务复杂多样,难以通过单一模型完全解决。但随着大模型(如预训练模型)的出现,通过人机协同进行微调,实现通用模型成为可能。未来的研究方向之一是探索如何将人类知识有效引入大模型,以提升其智能水平。
重点内容:大模型与人机协同的结合是未来发展的关键方向之一。
5.2 未来方向¶
为了推动更先进的人机协同系统的发展,论文从 NLP、CV 和现实应用三个方向提出了具体的未来研究方向。
5.2.1 人机协同 NLP 系统的未来方向¶
在对话系统(如聊天机器人、自动摘要、机器翻译)中,用户只能对输出结果进行稀疏反馈,限制了模型的学习效率。
在句法解析任务中,应探索基于人机协同的不确定解析方法,并扩展到大规模语料库和多语言。
在主题建模任务中,信任与置信度是用户中心设计的关键。
在 AI 安全方面,需警惕人类反馈可能被恶意利用,用于训练有潜在危害的模型。
重点内容:用户反馈稀疏性、恶意利用风险、信任建模等是 NLP 领域的关键挑战。
5.2.2 人机协同 CV 系统的未来方向¶
在图像恢复任务中,应结合监督回归模型优化预测参数,并分析不同算法参数之间的相关性。
在图像增强任务中,使用主动学习减少用户干预次数,提高效率。
重点内容:优化参数、减少用户负担是 CV 领域的重要研究方向。
5.2.3 通用人机协同系统(NLP + CV)的未来方向¶
人类监督在不同任务中具有不同权重,需考虑专业性和工作负载带来的错误风险。
收集和共享更多的人类反馈数据集,有助于模型训练和跨领域研究。
应评估用户反馈质量,考虑其可信度对模型的影响。
应设计更深入的用户研究,评估人机协同框架的效果和鲁棒性。
在生成任务中,明确用户反馈功能,用于评估生成内容。
需要高效地动态挑选最具代表性和价值的反馈。
应提供更友好的可视化,展示模型从反馈中学习的内容和变化过程。
重点内容:跨领域共享数据、用户可信度建模、反馈可视化等是通用系统的重点研究方向。
5.2.4 实际应用中的未来方向¶
在高可靠性任务中,应合理选择人工干预时机,以确保系统安全。
用户体验优先于性能,特别是在交互式系统中。
人类与计算机之间的信号建模与信息编解码是人机交互的核心问题。
当前的人类反馈多为表层判断,未来需探索更复杂的反馈形式。
人机协同系统应具备高鲁棒性和泛化能力,以应对领域变化、干扰和“超出范围”样本。
重点内容:安全、用户体验、复杂反馈机制、鲁棒性是实际应用中的关键问题。
总结¶
本节全面总结了人机协同在机器学习中的关键挑战与未来发展路径。从模型学习机制、样本选择、评估基准到实际部署,论文提出了多个亟需深入研究的问题,并结合 NLP、CV 和实际应用场景,为后续研究提供了清晰的方向和重点。
6 Conclusion¶
在本文中,作者回顾了当前关于“人机协同”(Human-in-the-loop)在机器学习中的研究现状,并从三个方面进行了系统性梳理与总结:数据处理、模型训练以及系统设计。
1. 从数据处理提升模型性能的研究(Data Processing)¶
作者首先探讨了通过数据处理提升模型性能的研究。这部分根据“人机协同”的数据处理流程,分为三个子部分:
数据预处理(Data Preprocessing)
数据标注(Data Annotation)
迭代标注(Iterative Labeling)
核心问题是如何从数据角度出发,以更少的样本实现更显著的模型性能提升。
研究发现,当前的研究主要集中在半监督方法在数据采集和标注中的应用,而对于如何识别和选择关键样本的关注较少。这是一个值得进一步探索的方向。
2. 从模型训练提升模型性能的研究(Interventional Model Training)¶
接着,作者讨论了通过人机协同干预模型训练来提升模型性能的研究。
这部分按照任务类型分为**自然语言处理(NLP)和计算机视觉(CV)**两个子模块。
核心问题是如何通过引入人类的高维知识,帮助模型突破关键问题。
研究发现,当前“人机协同”在模型训练中的主要方式是简单的数据增量,而缺乏对人类知识如何有效融入模型训练机制的深入探索。
作者指出,**逆强化学习(Inverse Reinforcement Learning)和多模态学习(Multimodal Learning)**是两个有潜力的解决方案。
3. 独立系统层面的“人机协同”设计(System-level Human-in-the-loop Design)¶
最后,作者探讨了系统层面的“人机协同”设计。
这部分介绍了一些实际应用场景,并按照任务类型分为:
安全系统(Security Systems)
代码生成工具(Code Production Tools)
模拟系统(Simulation Systems)
搜索引擎(Search Engines)
研究发现,实际应用中需要协调的变量远比学术研究中复杂得多。尽管“人机协同”系统在实践中具有一定优势,但如何快速整合高质量的人类知识并维持系统的鲁棒性,仍是亟待解决的问题。
开放挑战与未来方向(Open Challenges and Opportunities)¶
作者还提出了当前“人机协同”在机器学习中的挑战与机遇,并在此基础上明确了未来的研究方向:
在CV和NLP领域,探索如何更好地融合人类知识。
在应用层面,推动“人机协同”在实际系统中的落地。
随着大规模预训练模型的发展,基于少样本的人机混合方法具有广阔前景。
致谢(Acknowledgment)¶
最后,作者对支持本研究的项目和机构表示感谢,包括:
2020年华东师范大学优秀博士生学术创新能力提升项目(YBNLTS2020-042)
上海市科学技术委员会(19511120200)
总结重点:
本文通过对“人机协同”在数据处理、模型训练和系统设计三个层面的系统性梳理,揭示了当前研究的重点与不足,并指出未来研究的方向在于如何更高效地整合人类知识,尤其是在大规模模型和实际系统中的应用。