2510.11639_OneRec-Think: In-Text Reasoning for Generative Recommendation¶
组织:
Kuaishou Inc
总结¶
总结
🤖 现有的生成式推荐模型缺乏大型语言模型(LLM)特有的显式推理能力,为此,OneRec-Think提出了一个统一框架,旨在将对话、推理和个性化推荐无缝集成,以弥补这一关键差距。
💡 该框架包含三个核心阶段:
通过多任务预训练实现物品与文本的语义对齐;
通过推理支架激活LLM在推荐场景中的显式推理能力;
设计推荐专用奖励函数进行强化学习以优化推理路径。
🚀 实验证明,OneRec-Think在公共基准测试中取得了最先进的性能,并在快手平台的工业部署中实现了0.159%的APP停留时长增长,有效验证了其显式推理能力和实际应用价值。
OneRec-Think
一个将对话、推理与个性化生成推荐集成于单一模型中的新框架
特点包括:
能够生成高质量、可解释的文本推理路径
提升推荐准确性和用户信任度
支持根据用户具体约束动态调整推荐
三个阶段
Itemic Alignment(项目语义对齐):将推荐项目映射到 LLM 的文本嵌入空间,构建统一的表示空间,为推理能力打下基础。
Reasoning Activation(推理激活):在推荐系统上下文中激发 LLM 的推理能力。
Reasoning Enhancement(推理增强):使用专门设计的推荐奖励函数,捕捉用户偏好多样性(multi-validity)。
Abstract¶
本节为论文的摘要部分,简明扼要地介绍了研究背景、问题、提出的方法(OneRec-Think)以及实验结果。
研究背景与问题:¶
大型语言模型(LLMs)在推荐系统领域展现出强大的生成能力,带来了范式转变。
然而,现有的生成式推荐模型(如 OneRec)主要作为隐式预测器运行,缺乏显式、可控的推理能力,而这正是LLMs的重要优势。
提出方法:OneRec-Think¶
OneRec-Think 是一个统一框架,将对话、推理与个性化推荐无缝结合,包含三个核心模块:
Itemic Alignment(项目-文本对齐):
实现跨模态的项目与文本语义对齐,为推荐提供语义基础。
Reasoning Activation(推理激活):
引入“推理支架”机制,激活LLM在推荐场景中的推理能力。
Reasoning Enhancement(推理增强):
设计面向推荐的奖励函数,考虑用户偏好具有“多有效性”的特点,提升推理质量。
实验与应用效果:¶
在多个公开基准数据集上表现优异,达到最先进水平(SOTA)。
提出的“前瞻思考”(Think-Ahead)架构在快手工业场景中成功部署,带来APP停留时长提升0.159%,验证了模型的实用价值和显式推理能力的有效性。
重点内容强调:
OneRec-Think 的核心创新在于激活LLM在推荐系统中的显式推理能力,弥补了现有模型的不足。
该模型不仅在学术数据集上表现突出,还在工业场景中取得实际收益,具有良好的应用前景。
1 Introduction¶
本节介绍了推荐系统在大语言模型(LLMs)推动下的范式转变,以及作者提出的新框架 OneRec-Think 的核心思想和贡献。
1.1 背景与现状¶
生成式检索(Generative Retrieval, GR)的兴起:随着大语言模型的发展,推荐系统正从传统的“查询-候选匹配”方式转向生成式检索。GR 利用基于 Transformer 的序列到序列模型,通过自回归方式生成目标候选的标识符。
统一生成式框架的发展:当前研究热点是构建端到端的生成式推荐框架,如 OneRec、OneLoc、OneSug 和 OneSearch 等。这些模型取代了传统的多阶段推荐流程(如召回和排序),实现了对最终目标的整体优化,提升了工业场景下的性能与扩展性。
1.2 现有方法的局限性¶
尽管这些统一模型能够利用 LLM 的生成能力进行推荐,但它们缺乏明确、可验证的推理路径,而这种能力是现代 LLM 在其他任务中取得突破的关键(如基于文本的思维链 CoT)。
1.3 提出的方法:OneRec-Think¶
为弥补这一差距,作者提出 OneRec-Think,一个将对话、推理与个性化生成推荐集成于单一模型中的新框架。其特点包括:
能够生成高质量、可解释的文本推理路径;
提升推荐准确性和用户信任度;
支持根据用户具体约束动态调整推荐(见图1)。
1.4 框架结构¶
OneRec-Think 通过三个阶段实现:
Itemic Alignment(项目语义对齐):将推荐项目映射到 LLM 的文本嵌入空间,构建统一的表示空间,为推理能力打下基础。
Reasoning Activation(推理激活):在推荐系统上下文中激发 LLM 的推理能力。
Reasoning Enhancement(推理增强):使用专门设计的推荐奖励函数,捕捉用户偏好多样性(multi-validity)。
此外,作者还提出了 OneRec-Think Inference Architecture,以支持工业级高效部署和实时响应。
1.5 主要贡献(总结)¶
提出一个统一框架,弥合离散推荐项与连续推理空间之间的语义鸿沟,实现推荐与语言理解的融合;
设计一种新的推理范式,将多步推理与推荐优化协同训练,实现可解释且注重准确性的个性化推荐;
在多个公开基准上达到 SOTA 表现,提出的“Think-Ahead”架构在工业部署中显著提升了用户停留时间(APP Stay Time 提升 0.159%)。
2 Related Work¶
2.1 大语言模型中的推理¶
本节回顾了大语言模型在实现复杂推理方面的主要方法。思维链(Chain-of-Thought, CoT)提示是基础方法,它通过将问题分解为多个中间推理步骤来提升模型的推理能力(Wei et al., 2022)。在此基础上,研究者提出了多种扩展方法,如零样本CoT、自洽解码和**思维树(Tree-of-Thoughts)**等,这些方法在推理阶段通过增加计算资源提升性能,体现了“测试时扩展”的趋势(Snell et al., 2024)。
近年来,研究重点从提示工程转向了通过强化学习等技术进行推理能力的后训练优化。例如,DeepSeek-R1 和 Seed-1.5 等模型通过 GRPO、DAPO 和 VAPO 等强化学习算法优化推理行为,取得了显著进展(Guo et al., 2025a; Shao et al., 2024; Yu et al., 2025; Yue et al., 2025)。
重点内容:CoT 是推理能力提升的起点;强化学习在后训练阶段显著增强了模型的推理表现。
2.2 基于推理的推荐系统¶
尽管已有如 TIGER、HSTU 和 OneRec 等生成式推荐模型展现出良好的推荐效果,但它们缺乏明确的推理机制。为解决这一问题,近年来研究者提出了基于推理的推荐系统,旨在通过多步推理提高推荐的准确性和可解释性。
现有方法主要分为两类:
显式推理方法:生成可读性强的推理路径,但多用于判别式任务(Tsai et al., 2024; Bismay et al., 2024; Fang et al., 2025; Kim et al., 2025)。
隐式推理方法:在无文本解释的情况下进行潜在推理(Zhang et al., 2025a; Tang et al., 2025)。
本文贡献:提出 OneRec-Think 框架,将显式推理引入生成式推荐系统,兼顾推荐的可解释性与物品生成能力。
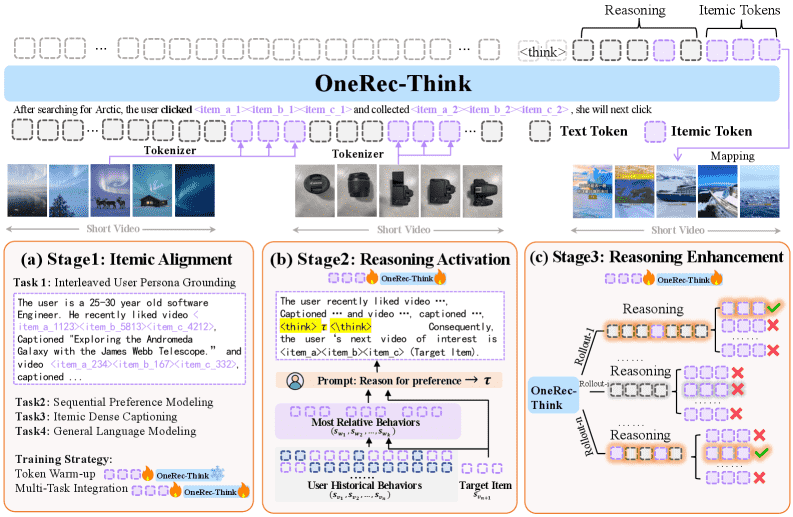
Figure 2:The framework of the OneRec-Think.
【图解】OneRec-Think 框架分为三个阶段:
多任务预训练阶段:实现物品级别的语义对齐;
显式推理激活阶段:通过提示引导模型生成偏好推理路径;
强化学习优化阶段:基于定制推荐奖励对推理路径进行优化。
重点内容:该框架结合了显式推理与强化学习,提升了推荐系统的可解释性与生成能力。
3 Preliminary¶
Itemic Token(物品标记)¶
重点内容:
定义:Itemic Token 是一种离散的、语义丰富的物品表示单位,类似于自然语言中的词(word token)。
生成方式:每个物品 \( v \) 被映射为一个 Itemic Token 序列 \( \mathbf{s}_v = (s_v^1, \dots, s_v^L) \),这些标记是从物品的多模态信息(如文本、图像等)和协同信息(如用户-物品交互)中生成的。
引用方法:该表示方式借鉴了 OneRec(Zhou et al., 2025a; Rajput et al., 2023)。
总结:Itemic Token 是将物品转化为可被模型处理的语义单元,是后续建模的基础。
Problem Definition(问题定义)¶
重点内容:
用户与物品集合:设 \( \mathcal{U} \) 为用户集合,\( \mathcal{V} \) 为物品集合。
用户历史:每个用户 \( u \in \mathcal{U} \) 有按时间顺序排列的交互历史 \( V_u = (v_1^u, v_2^u, \dots, v_{n_u}^u) \)。
简化表示:省略用户索引后,历史表示为 \( V = (v_1, v_2, \dots, v_n) \)。
基于 Itemic Token 的表示:用户历史可进一步表示为 Token 序列 \( S_u = (\mathbf{s}_{v_1}, \dots, \mathbf{s}_{v_n}) \)。
传统方法的建模方式:
传统生成式推荐模型(如 OneRec)将任务定义为:根据历史 Token 序列,生成下一个物品的 Token: $\( \mathbf{s}_{v_{n+1}} \sim P(\cdot | \mathbf{s}_{v_1}, \dots, \mathbf{s}_{v_n}; \theta) \)$
本文的建模方式(重点):
创新点:将推理过程与推荐过程统一在一个自回归生成过程中。
具体方式:
给定构造好的用户历史提示(prompted user history),模型先生成推理序列 \( \mathbf{\tau} = (r_1, \dots, r_M) \),
然后生成下一个物品的 Token \( \mathbf{s}_{v_{n+1}} \)。
数学表达: $\( \mathbf{\tau} \sim P(\cdot \mid \mathcal{P}(\mathbf{s}_{v_1}, \dots, \mathbf{s}_{v_n}); \theta) \)\( \)\( \mathbf{s}_{v_{n+1}} \sim P(\cdot \mid \mathcal{P}(\mathbf{s}_{v_1}, \dots, \mathbf{s}_{v_n}), \mathbf{\tau}; \theta) \)$
其中 \( \mathcal{P}(\cdot) \) 表示为推荐任务构建的有效提示(prompt)。
总结:本节重新定义了推荐任务,使其在生成下一个物品的同时,也输出推理过程(如推荐理由),实现推理与推荐的统一建模。
如需继续总结后续章节,请继续提供内容。
4 Methodolody¶
本节介绍了 OneRec-Think,一个可扩展的端到端生成式推理推荐框架。该方法包含三个核心组件:Itemic Alignment(项目对齐)阶段、Reasoning Activation(推理激活)阶段,以及用于工业部署的“Think Ahead(前瞻思考)”架构。整体结构如图2所示。
4.1 通过多任务预训练实现 Itemic Alignment¶
为了将推荐知识与大语言模型(LLM)的语言空间对齐,作者设计了一种多任务预训练策略,通过四种互补任务在“下一个词预测”框架下实现自然语言与 itemic token(项目表示)的无缝处理。
重点任务:¶
Interleaved User Persona Grounding(交错用户画像建模)
将 itemic token 与用户画像的文本 token 交错输入,构建双模态训练样本。
包含用户静态属性、搜索行为、交互序列和兴趣摘要,增强语义上下文理解。
Sequential Preference Modeling(序列偏好建模)
核心推荐任务,训练模型根据用户历史行为预测下一个交互项目。
Itemic Dense Captioning(项目密集描述生成)
要求模型从 itemic token 生成详细描述,帮助理解项目组合的语义特征。
General Language Modeling(通用语言建模)
在通用文本语料上继续预训练,保持模型的语言理解能力。
训练策略:¶
Token Warm-up:冻结 LLM,仅训练 itemic token 的嵌入。
Multi-Task Integration:联合优化所有参数,使用特定比例进行多任务学习。
4.2 Reasoning Activation(推理激活)¶
尽管完成了 itemic 对齐,但直接在工业场景中应用仍难以生成有效的思维链(CoT),因为真实用户行为序列通常噪声大且长度长。
解决方案:¶
提出一种监督微调框架,从剪枝后的用户上下文中提取连贯的推理路径,并利用这些路径指导在原始行为数据上生成推理依据(rationale),从而实现对噪声环境的上下文蒸馏。
两个关键步骤:¶
Bootstrapping with Pruned Contexts(剪枝上下文引导)
构建逻辑关系保留的简短上下文对 <(历史项目), 目标项目>。
使用相似度函数 g(·,·) 检索 top-k 相关项目。
利用预训练模型生成解释目标交互的 rationale。
Learning to Reason from Noisy Sequences(从噪声序列中学习推理)
使用蒸馏出的 rationale 作为监督信号。
最小化生成 rationale 和目标项目 token 的负对数似然损失(ℒRA)。
使模型学会从噪声中提取相关信息并生成连贯推理路径。
4.3 Reasoning Enhancement(推理增强)¶
在推理激活的基础上,进一步通过强化学习提升推理质量,确保推理过程的稳定性与推荐准确性。
核心方法:¶
引入 Rollout-Beam Reward(滚动-束搜索奖励),解决传统奖励稀疏问题。
使用束搜索(beam search)生成多个候选推理路径,选择与目标项目最匹配的路径作为奖励信号:
\[ \mathcal{R}_{\text{Rollout-Beam}} = \max_{\hat{s}_{v_{n+1}} \in \mathcal{B}} \sum_{l=1}^{L} \mathbb{I}(\hat{s}_{v_{n+1}}^{l} = s_{v_{n+1}}^{l}) \]基于 GRPO 算法优化模型,利用多路径评估提供更密集的学习信号。
优势:¶
实现训练与推理阶段的一致性(均基于束搜索)。
提升模型在复杂推荐场景下的推理能力。
4.4 工业部署:一种“Think-Ahead”架构¶
在工业推荐系统中部署 OneRec-Think 的关键挑战是:如何在多步推理的计算开销与实时交互的低延迟要求之间取得平衡。
解决方案:“Think-Ahead”推理架构¶
第一阶段(离线):
使用完整 OneRec-Think 模型生成推理路径和前两个 itemic token。
这些 token 捕捉用户整体意图或偏好。
第二阶段(在线):
使用轻量级 OneRec 模型(Zhou et al., 2025a)进行实时推荐。
利用预生成的 token 作为前缀,快速生成最终推荐结果。
优势:¶
保证实时响应能力。
利用当前上下文数据,实现生产级性能。
总结¶
OneRec-Think 通过以下三阶段实现生成式推荐:
Itemic Alignment:通过多任务预训练对齐项目与语言空间。
Reasoning Activation:从剪枝上下文中提取推理路径,指导模型在噪声数据中生成连贯推理。
Reasoning Enhancement:引入强化学习机制,提升推理质量与推荐准确性。
最终,通过“Think-Ahead”架构实现工业部署,兼顾推理能力与实时性要求,在多个数据集上表现优于现有方法(见表1)。
5 Experiments¶
5.1 实验设置¶
数据集与基线模型:
作者使用了三个来自Amazon评论基准的真实推荐数据集:Beauty、Toys 和 Sports。对比的基线模型分为两类:
经典的序列推荐模型,如 BERT4Rec、HGN、GRU4Rec 和 SASRec;
生成式推荐模型,如 TIGER、HSTU 和 ReaRec。
评估指标:
采用 Top-K Recall (R@K) 和 NDCG (N@K),其中 K=5 和 10。
实现细节:
代码和数据已公开,详见附录 A.1。
5.2 总体性能¶
实验结果见表1。
结果显示,基于推理能力的模型(如 ReaRec 和 OneRec-Think)在所有指标上均优于传统序列模型和生成式模型。
OneRec-Think 表现最优,说明其基于文本的显式推理能力在推荐生成中具有显著优势,优于以往模型的隐式生成机制。
5.3 消融实验¶
实验设计:
在 Beauty 数据集上比较三种配置:
Base(仅使用原始 itemic token 序列)
Base+IA(加入 Itemic Alignment)
Base+IA+R(完整模型,加入推理机制)
结果:
模型 |
R@5 |
R@10 |
N@5 |
N@10 |
|---|---|---|---|---|
Base |
0.0460 |
0.0654 |
0.0314 |
0.0377 |
Base+IA |
0.0532 |
0.0735 |
0.0342 |
0.0402 |
Base+IA+R |
0.0563 |
0.0791 |
0.0398 |
0.0471 |
结论:
Itemic Alignment 提供了语义一致性基础,而推理机制进一步显著提升性能,说明两者协同作用有效解决了序列推荐中的核心问题。
5.4 工业实验¶
5.4.1 训练设置¶
使用 Qwen-8B 作为主干模型,扩展了 24,576 个 itemic token(三级结构)和两个特殊标记。
实施每日增量训练,使用 80 块 GPU,每天处理约 200 亿 token。
5.4.2 结果¶
在线 A/B 测试结果(表3):¶
部署在快手短视频平台,实验组流量占比 1.29%,测试一周后结果如下:
指标 |
提升幅度 |
|---|---|
App 停留时间 |
+0.159% |
观看时长 |
+0.169% |
视频播放量 |
+0.150% |
关注 |
+0.431% |
转发 |
+0.758% |
点赞 |
+0.019% |
收藏 |
+0.098% |
结论:
主要指标 App 停留时间提升显著,说明模型有效提升了用户参与度。
Itemic Alignment 的消融实验(表4):¶
使用 BertScore 评估 Token Warm-up (TW) 和 Multi-Task Integration (MI) 的效果:
模型 |
用户理解 |
短视频理解 |
|---|---|---|
Qwen3 |
0.6588 |
0.6031 |
Qwen3 + TW |
0.6492 |
0.6443 |
Qwen3 + TW + MI |
0.7053 |
0.7300 |
结论:
在文本密集的用户理解任务中,MI 提升显著;
在纯 itemic token 的短视频理解任务中,TW 和 MI 均有提升,说明两者对非文本信息理解至关重要。
推理过程可视化(图5):¶
展示了从广义兴趣匹配(左)到细粒度主题指定(中)的推理过程,推荐结果(右)与推理步骤保持语义一致性。
itemic-文本交错推理(图6):¶
通过 itemic token 锚定内容,文本 token 进行因果推理,实现了更准确的推荐和可解释性。
5.5 案例研究¶

Figure 3: Demonstration of context-aware recommendation adaptation: our model dynamically shifts recommenda- tions to relaxing content based on the user’s command.
情境一:用户情绪感知推荐(图3)
当用户表达负面情绪时,模型能识别并主动推荐放松、积极内容,优化观看体验。

Figure 4: Demonstration of fine-grained interest reasoning, which shows the end-to-end process from user behavior analysis to interpretable recommendations.
情境二:细粒度兴趣推理(图4)
模型能生成多样化的推理路径,捕捉用户对游戏机制、叙事风格等细节偏好,实现超越粗粒度主题匹配的精准推荐。

Figure 5: The model’s reasoning process evolves from broad interest matching (left) to fine-grained theme specification (middle), with recommendations (right) showing semantic consistency with each reasoning step.
情境三:推理与推荐一致性分析(图5)
通过 beam search 分析推理过程,验证了推理文本与推荐结果之间的一致性,说明推理过程真实引导了推荐生成。

Figure 6: Demonstration of itemic-textual interleaved reasoning.
情境四:itemic-文本交错推理(图6)
模型实现了 itemic token 与文本 token 的交替推理,提升了推荐准确性和可解释性。
总结¶
本章通过多个实验验证了 OneRec-Think 在推荐任务中的优越性:
总体性能优于现有模型,尤其在推理能力方面表现突出;
消融实验验证了 Itemic Alignment 和推理机制的有效性;
工业实验展示了模型在真实场景中的显著提升,特别是在用户参与度指标上;
案例研究展示了模型在情绪感知、细粒度兴趣建模、多模态推理等方面的能力,证明其具备多维度的真实推理能力。
6 Conclusion¶
本节对提出的 OneRec-Think 框架进行了总结,强调其通过三项关键技术将推理能力与生成式推荐相结合:
分层项目化 token 对齐
该技术实现了推荐系统中多源信息的统一表示,是构建推理能力的基础。基于思维链(CoT)监督微调的推理激活
通过引入类似人类思考的推理过程,使模型不仅能预测推荐结果,还能生成可解释的推理依据。基于强化学习的推理优化
利用强化学习进一步优化推理过程,提升推荐质量与合理性。
这些创新使推荐系统从传统的“物品预测器”转变为具备推理能力、可解释性强的智能模型。实验表明,OneRec-Think 在多个基准测试中达到最先进的性能,并在工业场景中带来了实际提升(如 APP 停留时间提升 0.15%)。
未来研究方向包括:
用户长序列行为建模
基于密集强化学习的奖励机制
旨在进一步提升用户偏好建模的精细度,更好地融合大语言模型的推理能力与工业级推荐系统的需求。
Limitations¶
本节指出了当前研究中存在的数据质量问题及其对模型推理能力的影响,结构清晰,重点突出。以下是详细总结:
数据质量限制¶
当前公开的数据集存在行为序列长度有限和物品空间受限的问题,这直接影响了模型推理能力的提升。这些局限性使得模型难以学习到高质量的推理能力。
对模型的影响¶
由于上述数据问题,Reasoning Activation 和 Reasoning Enhancement 模块无法获得与工业级数据相当的推理能力。这成为模型性能提升的主要障碍。
应对策略¶
为了解决这些问题,作者对方法进行了简化和适应性调整,以在现有公开数据集上实现稳定但简化的推理能力。尽管有所简化,模型仍能保持一定的鲁棒性。
未来工作方向¶
为了更全面地评估基于推理的推荐模型,作者正在积极构建一个大规模基准测试平台。该平台将包含更长的行为轨迹和多样化的物品目录,旨在支持更深入的推理能力研究。
重点内容:
数据集的局限性(行为序列短、物品空间小)是本节核心问题。
对模型推理模块的影响是关键分析点。
未来构建大规模基准测试平台是作者的重点改进方向。
Ethics Statement¶
本节内容主要阐述了作者在进行实验过程中所遵循的伦理原则,分为两个实验场景进行说明:
1. 开源基准数据集实验¶
所使用的数据集均来自已有研究或公开API,且数据已公开并保持匿名化处理。
2. 工业场景实验¶
使用的是平台上的用户交互数据,用于训练推荐模型。
数据的收集和使用严格遵守平台的隐私政策和服务条款,用户在使用平台时已明确同意这些条款。
重点强调:训练过程仅基于聚合的行为序列、文本内容和用户基础信息,不涉及任何个人身份识别信息(PII)的访问或处理。
✅ 核心重点:研究在数据隐私和用户同意方面有明确合规措施,尤其强调不处理敏感个人信息,保障用户隐私。
Appendix A Appendix¶
A.1 实验设置¶
基线模型细节¶
本文将 OneRec-Think 与两类推荐模型进行比较:传统推荐模型和生成式推荐模型。具体包括:
BERT4Rec:利用 BERT 的预训练语言表示来捕捉用户-物品的语义关系。
HGN:使用图神经网络学习用户和物品的表示,以预测用户-物品交互。
GRU4Rec:一种轻量级的图卷积网络模型,关注用户和物品之间的高阶连接。
SASRec:采用自注意力机制捕捉用户交互历史中的长期依赖关系。
TIGER:通过 RQ-VAE 引入基于码本的标识符,将语义信息量化为代码序列,用于基于 LLM 的生成式推荐。
HSTU:将推荐问题重新表述为顺序转换任务,并提出了一种适用于流数据的新架构。
ReaRec:在推理时计算框架中通过隐式多步推理增强用户表示。
评估指标¶
使用两个指标:Top-K Recall (R@K) 和 NDCG (N@K),其中 K = 5 和 10。
开源数据集实验细节¶
使用 Qwen3-1.7B 作为主干模型。
模型词汇表扩展了 1,024 个新标记,表示四级层次语义 ID(每级 256 个标记),并添加了两个特殊边界标记。
所有模型在配备旗舰 GPU 的服务器上训练。
评估时使用 beam search 策略生成 top-K 推荐,beam 宽度为 10。
由于公共基准数据集中物品序列较短且稀疏,采用手动构建的基于类别的 CoT 作为 Reasoning Activation 的剪枝内容。
数据预处理技术来自之前的工作,丢弃交互次数少于 5 的稀疏用户和物品。
使用 leave-one-out 策略划分数据集。
训练时限制用户历史中的物品数量为 50。
A.2 模型演示¶
短视频推荐的推理案例¶
展示了 OneRec-Think 在短视频推荐中的两个推理路径:
游戏偏好与硬件比较行为:模型将用户的兴趣与硬件比较行为联系起来,推断出对性能优化的需求,最终推荐显示器分析视频。
体育/军事观看历史与青少年叛逆搜索:模型通过关联观看历史与搜索行为,识别出育儿挑战为核心关注点。
语义理解验证¶
模型在语义对齐后能够通过自然语言理解和描述物品标记的语义。通过生成描述性标题验证模型能力,模型能够生成准确描述物品特征的文本,表明对齐过程成功建立了真正的语义理解。
A.3 实现细节¶
A.3.1 物品语义对齐¶
任务细节¶
交错用户画像基础:将物品标记与用户画像中的自然语言文本交错,迫使模型创建物品标记与现实世界含义之间的映射。
顺序偏好建模:给定用户最近的交互序列(最多 256 个物品),预测下一个物品。
物品密集描述生成:要求模型生成给定物品标记的文本描述,确保物品标记与自然语言之间的稳健映射。
通用语言建模:包含预训练和指令微调数据,以保持语言模型的基本能力。
两阶段训练¶
标记预热:冻结 LLM 主干参数,仅训练新引入的物品标记嵌入,使用较高的学习率(5×10^-4)。
多任务整合:开发模型的核心推荐能力,使用多任务整合策略,防止模型将物品标记视为传统标识符。
A.3.2 推理激活¶
剪枝上下文引导:构建高质量的推理数据集,保留最相关的交互,使用语义相似性函数提取 top-k 个最相关的物品。
从噪声序列中学习推理:训练模型从完整的用户行为序列中生成推理路径,并生成准确的目标物品预测。
A.3.3 推理增强¶
使用强化学习进一步优化推理连贯性和推荐准确性,采用 VERL 框架和 GRPO 算法,进行分布式训练和可扩展奖励计算。
A.3.4 系统部署:”前瞻”架构¶
推理引导前缀生成:离线阶段生成推理路径和初始物品标记,捕捉广泛的用户意图。
前缀约束最终化:在线阶段利用离线生成的前缀进行实时最终化,确保生产级延迟。
总结¶
附录详细描述了 OneRec-Think 的实验设置、模型演示、实现细节和系统部署。通过多阶段训练和推理策略,OneRec-Think 在生成式推荐中实现了高效的语义理解和推理能力。