2107.03374_HumanEval: Evaluating Large Language Models Trained on Code¶
引用: 5265(2025-07-03)
HumanEval数据集GitHub: https://github.com/openai/human-eval
组织: OpenAI
总结¶
简介
随着 Codex 一起发布
专注于 Python 代码
英文版
评估指标:pass@k
评估集
包含 164 道手工编写的编程题,每题配有函数签名、注释、函数体和平均 7.7 个测试用例
其他变体
HumanEval-XL
Abstract¶
我们发布了 Codex,这是一个在 GitHub 上公开代码上微调过的 GPT 模型,专注于写 Python 代码。Codex 的一个版本被用在 GitHub Copilot 中。
我们还发布了一个新测试集 HumanEval,用来评估模型根据注释生成代码的准确性。Codex 能解决 28.8% 的问题,而 GPT-3 是 0%,GPT-J 是 11.4%。
我们发现,多次从模型采样可以提高成功率——对每个问题采样 100 次,能解决 70.2% 的问题。
不过,Codex 也有局限,比如处理包含多步操作的注释,以及变量绑定方面有困难。
最后,我们也探讨了代码生成技术在安全、隐私和经济方面可能带来的影响。
1.Introduction¶
大规模的序列预测模型(如 Transformer)已经广泛应用于自然语言、视觉、语音、生物等多个领域。近年,随着大量公开代码的出现,这类模型也在**程序生成(代码生成)**上取得进展。
研究人员发现,GPT-3 虽然没专门学代码,却已经能根据 Python 的注释写出简单函数。这启发他们训练了专门学代码的模型——Codex,它是 GPT 的衍生模型,并成为 GitHub Copilot 的核心。
他们创建了一个名为 HumanEval 的数据集,用于评估模型是否能根据函数注释生成正确的 Python 函数(通过单元测试验证)。
评测发现:
普通 GPT 模型几乎无法解题;
Codex(12B参数)单次生成能解出约 28.8% 的题;
进一步微调后的 Codex-S,能达到 37.7%;
如果多生成100个版本并选出最好的一个,准确率可达 77.5%。
这说明:大语言模型在代码生成任务中非常有潜力,尤其在多样尝试+自动测试+概率评分的策略下,能解决大部分编程问题。
2.Evaluation Framework¶
2.1 Functional Correctness¶
评估指标:pass@k
用传统的“代码匹配评分”(如 BLEU)来评估代码正确性存在问题,因为:
同样功能的代码可能写法不同,但匹配度低;
BLEU 无法捕捉代码语义;
所以作者用 功能正确性(Functional Correctness) 来衡量:模型生成的代码能否通过一组 单元测试。
指标 pass@k:每道题生成 k 个代码版本,只要有一个通过测试就算成功。
2.2 HumanEval: Hand-Written Evaluation Set¶
评估集包含 164 道手工编写的编程题,每题配有函数签名、注释、函数体和平均 7.7 个测试用例;
手写的原因是:自动收集的数据(比如 GitHub)可能已在训练集中出现;
数据集重点考查理解、算法和数学等综合能力;
2.3 Sandbox for Executing Generated Programs¶
执行模型生成的代码存在安全风险(例如运行恶意代码);
OpenAI 用了 gVisor 沙箱系统,防止生成代码:
修改主机系统;
保持后台运行;
访问敏感信息;
与外部网络通信(除实验控制外);
网络安全由 eBPF 防火墙保护。
3.Code Fine-Tuning¶
Codex 是在 GPT 模型(最多 120 亿参数)基础上,用大量 GitHub 上的 Python 代码微调得到的。
微调后,Codex 在代码评测集 HumanEval 上表现远超 GPT,能通过大多数编程题的单元测试(尤其是在多采样、多评估条件下)。
📊 数据与训练方法:¶
数据来源: 2020 年 GitHub 上 5400 万个开源项目,共 159 GB 高质量 Python 代码(过滤掉了自动生成、格式异常的代码)。
微调方法:
使用 GPT-3 作为初始模型(虽然效果提升不大,但收敛更快)。
学习率策略:线性 warmup + 余弦衰减。
优化器:Adam(含权重衰减)。
编码优化: 为减少 token 数量,Codex 添加了表示不同空格长度的新 token,比原 GPT-3 tokenizer 更适合代码。
✅ 评估方式与结果:¶
HumanEval 测试:
评估指标:
pass@k(k 个生成结果中至少一个通过测试的概率)。采样策略:nucleus sampling(top-p=0.95),并设置 stop token 避免生成过多无关内容。
结果:更大模型、更高采样数量、更高温度能带来更好结果。
选样技巧:
在无测试用例时(如代码自动补全),选“平均 token log 概率最高”的结果,优于随机挑选。
BLEU 分数局限: 正确和错误代码的 BLEU 得分分布重叠严重,说明 BLEU 不能很好衡量代码正确性。
🔍 与其他模型对比:¶
GPT-Neo 和 GPT-J(训练数据含 8% 代码)性能优于 GPT,但仍远不如 Codex。
GPT-Neo 性能大致相当于 Codex-85M(参数少 30× )
GPT-J-6B 性能与 Codex-300M(少 20 倍参数)相同
但两者都比原版的 GPT 模型要好
Codex 远超 Tabnine(领先自动补全系统),12M 模型就能打平 Tabnine。
🧪 在 APPS 编程测试集上的表现:¶
Codex 没有专门为 APPS 微调,但添加“一组输入输出例子”提示后(1-shot),表现与专门微调过的 GPT-Neo 相当。
优化技巧:
从 1000 个生成中筛选通过公开测试用例的(filtered pass@k)。
排除运行超时的方案(>3秒)。
结论: 即使在更复杂的编程任务上,Codex-12B 在生成数量足够多的前提下也有较好表现。
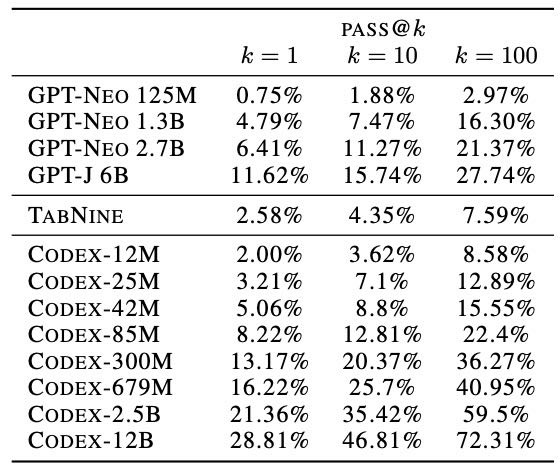
Table 1. Codex, GPT-Neo, & TabNine evaluations for HumanEval.
4.Supervised Fine-Tuning¶
这段内容主要讲了作者如何通过监督微调(Supervised Fine-Tuning)来提升 Codex 模型的代码生成能力
📌 背景问题¶
GitHub 上的代码内容太杂,很多不是函数实现,比如配置文件、脚本等。
这导致 Codex 模型训练数据分布与目标任务(如 HumanEval)不匹配,从而影响性能。
✅ 解决方法:构造高质量函数训练集,进行监督微调¶
作者创建了两个数据来源:
1️⃣ 编程竞赛题(4.1)¶
来自算法竞赛或面试网站(题目自包含、说明清晰、覆盖面广)。
用题目描述做 docstring,构造了约 1 万道题目。
2️⃣ 持续集成测试中的函数(4.2)¶
从开源项目的集成测试中追踪函数输入输出(用
sys.setprofile工具)。主要来自使用 Travis 和 Tox 的 GitHub 仓库及 PyPI 包,共提取了约 4 万个函数。
这些函数偏向真实项目中的实用功能(如命令行工具),与竞赛题互补。
🔍 质量控制(4.3)¶
用 Codex-12B 对每道题生成 100 个样例。
如果没有样例通过单元测试,认为题目模糊或太难,予以剔除。
多次运行排除有状态或非确定性题目。
🧪 微调方法(4.4)¶
针对这些训练问题对 Codex 进行微调,生成一组“监督微调”模型,我们称之为 Codex-S
将题目整理成统一格式(docstring + 函数签名)。
训练时掩盖 prompt 的损失,只优化函数实现部分。
使用比原始 Codex 更小的学习率,训练到验证损失稳定。
📈 实验结果(4.5)¶
Codex-S 相比原始 Codex:
在 pass@1 上平均提升 6.5 个百分点
在 pass@100 上平均提升 15.1 个百分点
Codex-S 更适合用稍高的采样温度,可能因为它建模了更“集中”的分布。
使用平均 log 概率筛样例,Codex-S 的效果也比 Codex 更好。
5.Docstring Generation¶
Codex 通常可以根据注释(docstring)生成代码,但反过来、从代码生成注释比较难。
不过,为了安全考虑,团队还是训练了一个叫 Codex-D 的模型,专门用来生成代码的注释,帮助描述代码的意图。
训练方式是把函数签名 + 正确代码 + 注释组合起来,让模型学着写注释,目标是最小化预测的注释和真实注释之间的差距。
但是,注释不像代码那样能用单元测试来自动评估,只能人工评分:判断注释是否准确描述了代码功能。团队用 Codex-D-12B 模型随机生成了1640个问题的注释,每题人工打10个样本。
发现问题包括:
模型经常输出无关的内容或把代码直接复制到注释中;
有时遗漏重要细节(比如“结果保留两位小数”);
有时受函数名误导,写了偏题的注释。
从结果上看,Codex-D 的准确率比代码生成模型 Codex-S 略低,但差不太多:
模型 |
pass@1 |
pass@10 |
|---|---|---|
Codex-S |
32.2% |
59.5% |
Codex-D |
20.3% |
46.5% |
最后,他们也尝试用“注释模型反推注释准确度”的方法来挑选生成结果(叫 back-translation),但效果不如用平均概率排序。
6.Limitations¶
训练效率低:
虽然用的是 GitHub 上海量的 Python 代码(上亿行)
但 Codex 学得不如人类学生,一个学完入门课程的学生能解决的问题比例更高。
容易出错的情况:
面对复杂或抽象的代码需求(如长 docstring 描述)时,Codex 的表现会急剧下降。
可能生成语法错误、用到未定义的函数或变量。
无法处理过长或系统级的指令说明。
性能下降示例:
用一组简单的字符串处理任务拼接成更复杂的问题后发现:
每增加一个处理步骤,Codex 的正确率大约降低 2-3 倍。
这不像人类程序员,能应对任意长度的任务链。
变量和操作绑定出错:
当指令中变量和操作太多时,Codex 容易搞混,犯错。
举的例子里,它没有正确处理变量 w,也没返回四个数的乘积。
结论:
Codex 在系统级代码合成方面能力有限,这也提醒我们它在实际应用中可能带来的风险和社会影响。
7.Broader Impacts and Hazard Analysis¶
这段内容是对 Codex(一个代码生成 AI)潜在影响与风险的深入分析。
🔍 总体观点:¶
Codex 有很多好处,比如帮助新手理解代码、提高开发效率、支持非程序员写代码等,但也存在安全性、误用、偏见、法律和环境等方面的重大风险,需要警惕。
⚠️ 核心风险简要说明:¶
过度依赖(Over-reliance)
用户容易盲目信任 Codex 生成的代码,尤其是新手。
Codex 可能生成看起来正确、实际有误的代码,甚至是不安全的代码。
需要人类审查和警示机制防止自动化偏见。
模型意图不对齐(Misalignment)
模型并非总是按用户真实意图行动。
它有能力写对的代码,但可能“选择”写错的,尤其当用户输入中有细微错误。
这种偏差可能随着模型能力增强而加剧。
偏见与歧视(Bias and Representation)
Codex 可能生成带有种族、性别、阶层等刻板印象的内容,甚至写入代码结构。
特别是在用户未充分思考设计时,这可能被无意识使用,带来风险。
对经济与就业的影响(Economic and Labor Market Impacts)
当前阶段 Codex 可能提升程序员效率,但对整体开发流程影响有限。
长远来看,模型推荐偏好某些库或作者,可能改变行业格局。
安全性风险(Security Implications)
Codex 可能生成漏洞代码,被滥用于网络攻击。
非确定性特性可能被利用开发变种恶意软件(多样化绕过检测)。
模型也可能记住或暴露训练数据中的敏感信息。
环境影响(Environmental Impacts)
训练和使用 Codex 耗费大量算力与能源。
如果大规模部署,其碳排放和资源消耗可能显著上升。
法律问题(Legal Implications)
模型训练基于开源代码,目前一般视为“合理使用”。
生成的代码通常不等同于抄袭,但仍需关注知识产权问题。
用户对最终代码负有责任,Codex 只是辅助。
风险缓解建议(Risk Mitigation)
加强文档说明、界面设计、代码审查、内容过滤。
限制高风险场景使用,启用用户审查、速率限制等 API 管控。
鼓励跨行业合作,共同研究与应对风险。
9.Conclusions¶
他们研究了能否训练大语言模型,让它根据自然语言的注释(docstring)生成功能正确的代码。结果发现,通过用 GitHub 上的代码微调 GPT 模型,模型在一些类似简单面试题的问题上表现不错。 如果用更接近测试集的数据来训练,或者让模型生成多个答案,效果还能更好。 他们还尝试了反过来从代码生成注释,发现也很容易训练,且表现相似。 最后,他们还讨论了代码生成模型可能带来的影响和存在的不足,目前还有很多改进空间。