2410.03859_SWE-bench-Multimodal: Do AI Systems Generalize to Visual Software Domains?¶
统计: 47(2025-07-19)
组织
1.Stanford University
2.Princeton Language & Intelligence, Princeton University
3.Cornell University
4.Tubingen AI Center, University of Tubingen
5.Meta AI
huggingface: https://huggingface.co/datasets/SWE-bench/SWE-bench_Multilingual
总结¶
数据集
SWE-bench Multimodal(SWE-bench M)
专门评估系统在处理包含图像的 JavaScript 软件问题上的能力
数据收集方法
挑选用户界面相关的 JavaScript 项目:
通过 GitHub 搜索选择 17 个高星 JavaScript 项目,
重点关注有视觉输出的库(如地图、图表、语法高亮等)。
筛选包含视觉内容的任务:
从 13.5k 个 PR 中筛选出包含图像或视频链接的任务,最终获得 1478 个候选任务。
剔除不一致测试:
对测试运行 10 次,剔除结果不一致的测试,最终保留 643 个任务。
人工验证:
人工检查每个任务的可行性与图像必要性,剔除 24 个不可行任务,最终保留 619 个任务。
Abstract¶
该文章主要探讨了当前用于软件工程的自主系统在多模态和跨语言环境下的性能表现。现有系统通常在 SWE-bench 数据集上进行评估,该数据集主要针对 Python 项目,以文本形式描述问题,缺乏视觉元素。作者指出,这种方法无法全面反映系统在前端、游戏开发、DevOps 等不同软件工程领域中的真实能力,尤其是那些使用 JavaScript 等不同语言和视觉化编程任务的场景。
为此,作者提出了 SWE-bench Multimodal(SWE-bench M),这是一个新的基准数据集,专门评估系统在处理包含图像的 JavaScript 软件问题上的能力。SWE-bench M 包含 617 个任务实例,覆盖了 17 个用于网页界面设计、图表绘制、数据可视化、语法高亮和交互地图的 JavaScript 库,每个任务实例中都至少包含一张图像。
分析结果显示,目前在 SWE-bench 上表现优异的系统在 SWE-bench M 上表现不佳,暴露出其在视觉问题解决和跨语言泛化能力上的不足。相比之下,SWE-agent 因其语言无关的灵活性,在 SWE-bench M 上表现突出,解决了 12% 的任务实例,远超次优系统 6% 的表现。
文章最后提供了数据、代码和排行榜的访问链接,以促进该领域的进一步研究与比较。
1 Introduction¶
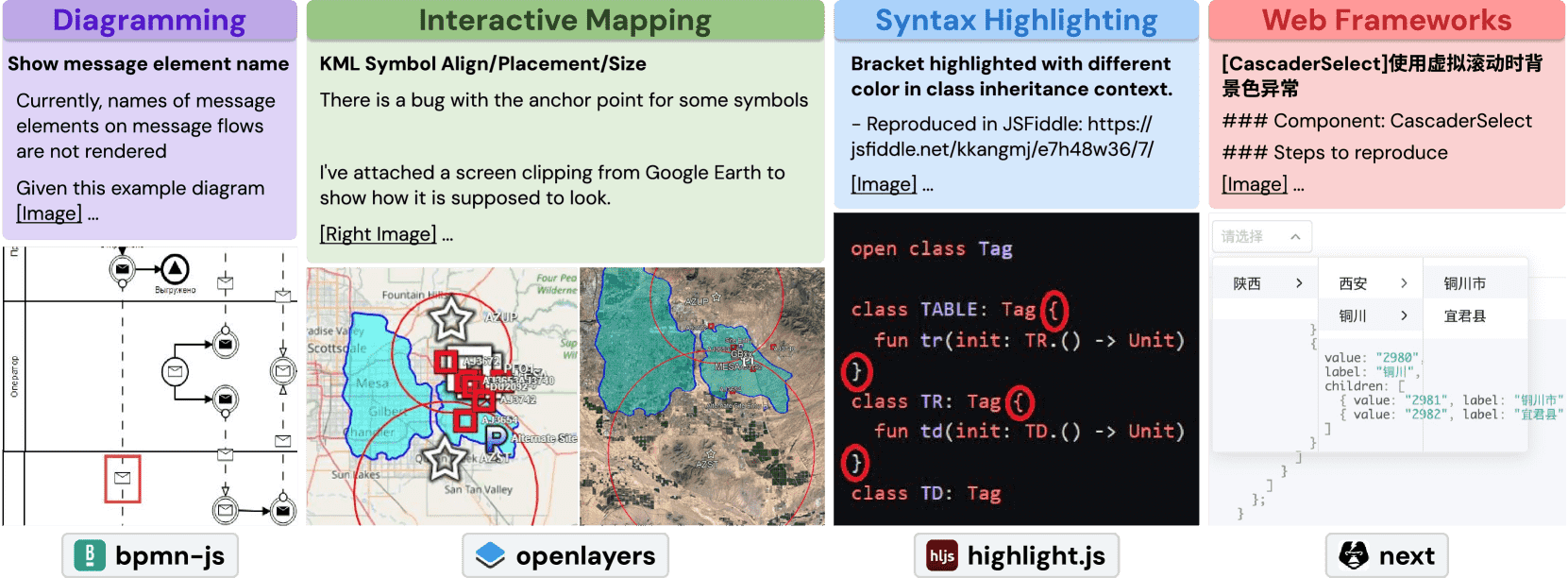
Figure 1: Four task instances from SWE-bench Multimodal.
该文章的引言部分主要围绕语言模型(LMs)在软件工程领域中的应用展开,尤其是其在代码维护和复杂开发任务中的潜力。随着LMs的发展,研究重点已从基于代码行或函数的辅助工具,扩展到能够管理大型代码库的自主系统。这些系统通过多步骤交互来解决复杂的开发问题。
文章介绍了SWE-bench,这是目前评估这些系统性能的主流基准。SWE-bench通过GitHub的问题和拉取请求构建任务实例,使用单元测试验证解决方案的有效性。然而,SWE-bench存在局限性,例如:数据集主要基于Python语言、代码库结构相似、缺乏对视觉元素(如图像)的支持,因此不能全面代表现实中的软件开发场景。
为了解决这一问题,作者提出了研究问题:“AI系统是否能泛化到视觉化软件开发领域?”,并聚焦于前端开发,尤其是JavaScript生态中的问题。前端开发涉及大量视觉和交互元素,是软件工程中探索较少的领域。
为此,文章引入了SWE-bench Multimodal(SWE-bench M),一个专注于视觉化JavaScript问题的数据集。该数据集包含619个任务实例,选自GitHub上的实际问题,并筛选出包含图像或视频的任务。通过人工验证,发现有83.5%的任务需要图像才能正确解决。
研究发现,现有系统在SWE-bench M上的表现明显低于SWE-bench,主要原因包括视觉问题的复杂性和JavaScript开发实践的多样性。不同的视觉元素(如代码截图、网站界面、图表)需要不同的理解能力,而JavaScript支持多种编程范式,增加了代码结构的复杂性。
最后,文章指出,现有系统在处理非Python语言和视觉内容方面存在明显不足,建议在构建LM系统时考虑多语言支持和视觉内容的处理能力,以提高系统的泛化性。
2 SWE-bench Multimodal¶
本文第二部分主要介绍了 SWE-bench Multimodal(简称 SWE-bench M)这一多模态软件工程基准数据集的构建过程与核心特征。SWE-bench M 是在 SWE-bench 基础上扩展而来的,旨在评估 AI 系统在视觉软件开发场景下的泛化能力。以下是各部分的总结:
2.1 基础回顾与限制¶
SWE-bench 概述:
SWE-bench 是一个流行的基于大型语言模型(LLM)评估的软件开发基准。
任务来源于真实的 GitHub Pull Request(PR),反映实际的开发问题。
每个任务包括问题描述、解决方案代码和验证单元测试。
测试类型包括“失败到通过”(F2P)和“通过到通过”(P2P)测试,确保代码修复正确且不破坏原有功能。
当前 SWE-bench 主要关注文本任务,使用 Python 编写,缺乏对视觉元素和多语言支持的探索。
SWE-bench 的局限性:
视觉元素缺失:尽管 SWE-bench 有 5.6% 的任务包含图像,但图像的作用和必要性未被明确分析。
语言单一:仅支持 Python,忽略了其他语言(如 JavaScript)带来的复杂性(如 Web 开发、异步编程、DOM 操作等)。
2.2 数据收集方法¶
SWE-bench M 在 SWE-bench 基础上进行了以下改进以引入视觉元素和 JavaScript 支持:
挑选用户界面相关的 JavaScript 项目:
通过 GitHub 搜索选择 17 个高星 JavaScript 项目,重点关注有视觉输出的库(如地图、图表、语法高亮等)。
这些项目以 JavaScript/TypeScript 为主,HTML 和 CSS 为辅,无 Python 代码。
筛选包含视觉内容的任务:
从 13.5k 个 PR 中筛选出包含图像或视频链接的任务,最终获得 1478 个候选任务。
构建执行环境:
SWE-bench 原生不支持 JavaScript,因此需手动配置 Node.js 和 Chrome 支持。
为每个项目编写安装和测试脚本,平均每个项目耗时约 10 小时。
剔除不一致测试:
对测试运行 10 次,剔除结果不一致的测试,最终保留 643 个任务。
人工验证:
人工检查每个任务的可行性与图像必要性,剔除 24 个不可行任务,最终保留 619 个任务。
评估图像对问题解决的必要性,发现 80% 的图像提供了比文字更关键的视觉信息,83.5% 的任务需要图像来解决问题。
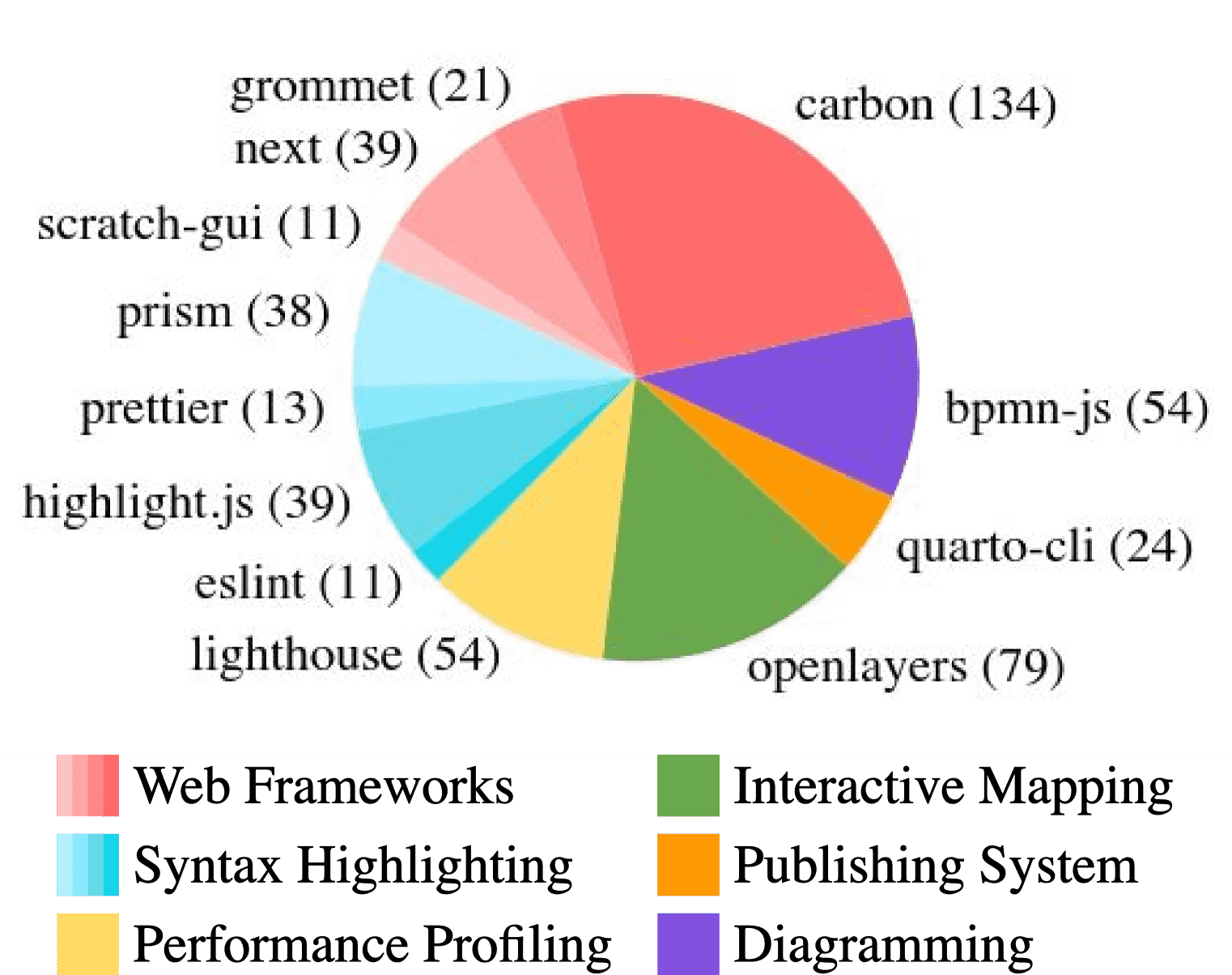
Figure 2: SWE-bench M Test Split Distribution of 517 task instances from 12 open source GitHub repositories written mainly in JavaScript.
2.3 SWE-bench M 的核心特征¶
数据规模与多样性:
SWE-bench M 包含 619 个 JavaScript 多模态任务,来自 17 个开源 GitHub 项目。
测试集包含 517 个任务,开发集为 102 个任务。
包含多种视觉内容,如图表、地图、UI 截图、错误画面等。
视觉内容的类型:
问题描述图像:包括 UI 截图、错误截图、图表、地图等。
视频和参考图像:用于展示交互行为(如拖拽、缩放)和“实际 vs 预期”的对比图。
像素级视觉测试:部分任务通过对比截图像素来验证视觉功能的正确性。
任务难度分布:
任务难度涵盖从 15 分钟到 4 小时不等,平均难度高于 SWE-bench。
SWE-bench M 的参考解决方案涉及更多文件、函数和代码行的修改。
图像的重要性:
图像在大多数任务中是解决问题的关键,特别是 UI 问题和视觉效果验证。
80% 的图像提供了比文字更关键的视觉信息,83.5% 的任务需要图像才能正确解决。
总结¶
SWE-bench Multimodal 是一个专为评估 AI 系统在视觉软件开发任务中表现而设计的数据集。它通过引入 JavaScript 支持和视觉元素,弥补了原 SWE-bench 的不足,提出了新的挑战,如多模态推理、跨语言开发、视觉测试等。该数据集为研究 AI 在视觉密集型软件开发中的泛化能力提供了坚实的基础。
3 Evaluating on SWE-bench M¶
该章节主要围绕 SWE-bench M 评估基准,探讨现有开源系统在多模态、跨语言(如从 Python 到 JavaScript)以及处理图像相关 bug 时的泛化能力问题,并介绍实验设置和所选系统、模型以及评估指标。
3.1 Do Existing Systems Generalize?(现有系统是否具备泛化能力?)¶
本节评估了当前在 SWE-bench 中表现良好的几种开源系统在 SWE-bench M 上的泛化能力。发现多数系统由于过于依赖 Python 或特定工作流,难以适应 JavaScript 项目或处理图像相关的问题。
主要结论如下:
泛化能力不足:现有系统大多为 Python 量身定制,缺乏对多语言(如 JavaScript)和图像模态的支持。
流程限制:虽然当前大语言模型(LLM)在多语言上表现良好,但某些系统的工作流程(如预处理、AST 解析)过于刚性,限制了模型的灵活性和泛化能力。
系统适配情况:
SWE-agent:进行了三种配置的测试:
Base:原配置。
JS:适配 JavaScript 语法校验。
M:增加了图像查看和截图功能,以处理图像问题。
Agentless:将原有的 Python AST 模块替换为自定义的 JavaScript 解析器,并调整提示词,最终版本命名为 Agentless JS。
AutoCodeRover:由于高度依赖 Python 特定的分析工具和 SWE-bench 专属知识,未进行适配。
Moatless:尽管其方法本身语言无关,但其 Python AST 输入格式难以迁移到 JavaScript,未进行基准测试。
RAG(检索增强生成):使用 BM25 方法,调整提示词为 JavaScript 示例,并新增图像复现代码插入部分。
3.2 Experiment Setup(实验设置)¶
本节介绍了实验所选用的模型、基线系统和评估指标。
模型选择:
GPT-4o 和 Claude 3.5 Sonnet:这两者是目前支持长上下文、多模态处理和结构化预测的最佳模型,因此被选为实验模型。
基线系统:
共评估 5 个系统:Retrieval Augmented Generation (RAG)、SWE-agent 的三种配置(Base, JS, M)、以及 Agentless JS。
所有系统均基于 SWE-bench M 的开发集进行调整和训练。
评估指标:
% Resolved:主要性能指标,表示成功解决任务的比例。
Avg. $ Cost:平均每个任务的推理成本,用于衡量经济效率。
总结¶
该章节重点探讨了当前自动化软件工程系统在 SWE-bench M(多模态、多语言)场景下的泛化能力问题。通过适配几种主流系统并进行实验,揭示了现有方法在语言迁移、图像处理和工作流程灵活性方面的局限性,并提出了评估基准和实验设置,为后续性能比较提供了基础。
4 Results¶
本研究对多种基线系统在SWE-bench M数据集上的性能进行了比较,并分析了视觉信息、多模态工具和语言模型(LM)选择对系统表现的影响。以下是主要结论的总结:
一、基线系统性能对比¶
在SWE-bench M上,所有系统的性能普遍较低,但交互式SWE-agent系统(平均解决率为11.5%)明显优于无代理系统(Agentless,3.9%)和基于RAG的系统(5.5%)。
SWE-agent的不同变体(如SWE-agent M、JS、Base)之间性能差异不大,表明JavaScript特定的定制化影响有限。
使用不同的语言模型(如GPT-4o和Claude 3.5 Sonnet)对性能影响也较小。
尽管如此,多模态工具在某些情况下能提高系统性能,但整体效果仍不明确。
二、任务解决时间与系统性能¶
检查任务解决时间与模型训练数据的关系,未发现测试集数据泄露的证据。例如,SWE-agent M使用GPT-4o在解决日期晚于其知识截止日期的实例上表现更好,说明模型并未依赖训练数据中的解决方案。
三、图像对系统性能的影响¶
图像信息显著影响系统表现:当图像包含非文本内容时,SWE-agent JS的性能从13%下降到8.7%;而如果图像主要是文本,性能下降较小。
在人类验证中,当图像对任务解决“必要”时,缺少图像输入会导致性能大幅下降。
在RAG和SWE-agent JS中,图像的引入普遍提升了成功率,尤其在复杂任务中,视觉推理能力变得关键。
四、系统设计对语言支持的局限性¶
当前大多数系统(如Agentless、Moatless、AutoCodeRover)基于Python的AST解析模块,对其他语言(如JavaScript)的支持较差。
为Agentless实现JavaScript支持需重新编写解析器,耗费大量人力,且其性能依然较低(4.6%)。
语言特定的设计限制了系统的泛化能力,尤其是在SWE-bench M中,30%的解决方案涉及多种文件类型(如TS、HTML、CSS等),需要为每种语言编写专门的AST处理模块。
五、多模态工具的使用与挑战¶
SWE-agent M引入的网页专用工具(如截图)虽然提高了图像相关任务的解决成功率,但也显著增加了任务复杂性和成本。
在GPT-4o上,SWE-agent M的截图使用频率高达38.3%,平均每个实例生成7.5张截图,说明多模态工具被用于迭代式问题解决。
但这些工具的使用也导致超成本限制终止的任务比例大幅上升(增加近3倍),尤其在使用Claude 3.5 Sonnet时性能下降。
剔除因成本过高而终止的任务后,多模态工具在GPT-4o上显著提升了正确提交率(从10.4%提升到19.6%),但在Claude 3.5 Sonnet上未见类似效果。
六、研究结论与未来方向¶
多模态交互系统优于传统流程式系统:SWE-agent的性能优于Agentless,说明将问题解决负担放在语言模型上,而非手动设计的流程中,是更有效的策略。
未来的软件工程系统应强调语言模型与环境的交互,而不仅仅是将其嵌入固定流程中。
图像和多模态工具在某些任务中能显著提升性能,但目前系统尚难以充分驾驭其复杂性,整体效果仍不明确。
总体观点¶
本研究指出,当前AI系统在处理视觉软件工程任务时仍存在较大挑战,图像信息的利用、语言模型的泛化能力、以及多模态工具的合理使用是提升系统性能的关键方向。
6 Conclusion¶
本文总结如下:
该研究介绍了 SWE-bench Multimodal (SWE-bench M),这是第一个用于评估代码智能体在涉及视觉元素的真实软件工程任务中的表现的基准测试。该基准包含来自17个面向用户JavaScript项目的619个任务实例,涵盖网页用户界面设计、数据可视化、艺术和地图等领域。
分析表明,SWE-bench M 包含多样的视觉挑战,并且相比 SWE-bench 提高了任务的复杂性。现有系统在该基准上的表现较差,最高解决率仅为12.2%。SWE-bench M 提供了对先进语言模型系统也具有挑战性的仓库级编程任务。
引入多模态的 SWE-bench M 不仅扩展了软件工程中有趣且实用挑战的覆盖范围,也鼓励研究人员开发更通用、语言无关的解决方案,以避免对特定基准或Python项目过度拟合。
Appendix A Dataset¶
本节总结了 SWE-bench M 数据集的附录内容,主要包括数据集的开发集(Development Split)、附加特征分析以及数据集的进一步统计和分析。以下是各个部分的要点总结:
A.1 开发集(Development Split)¶
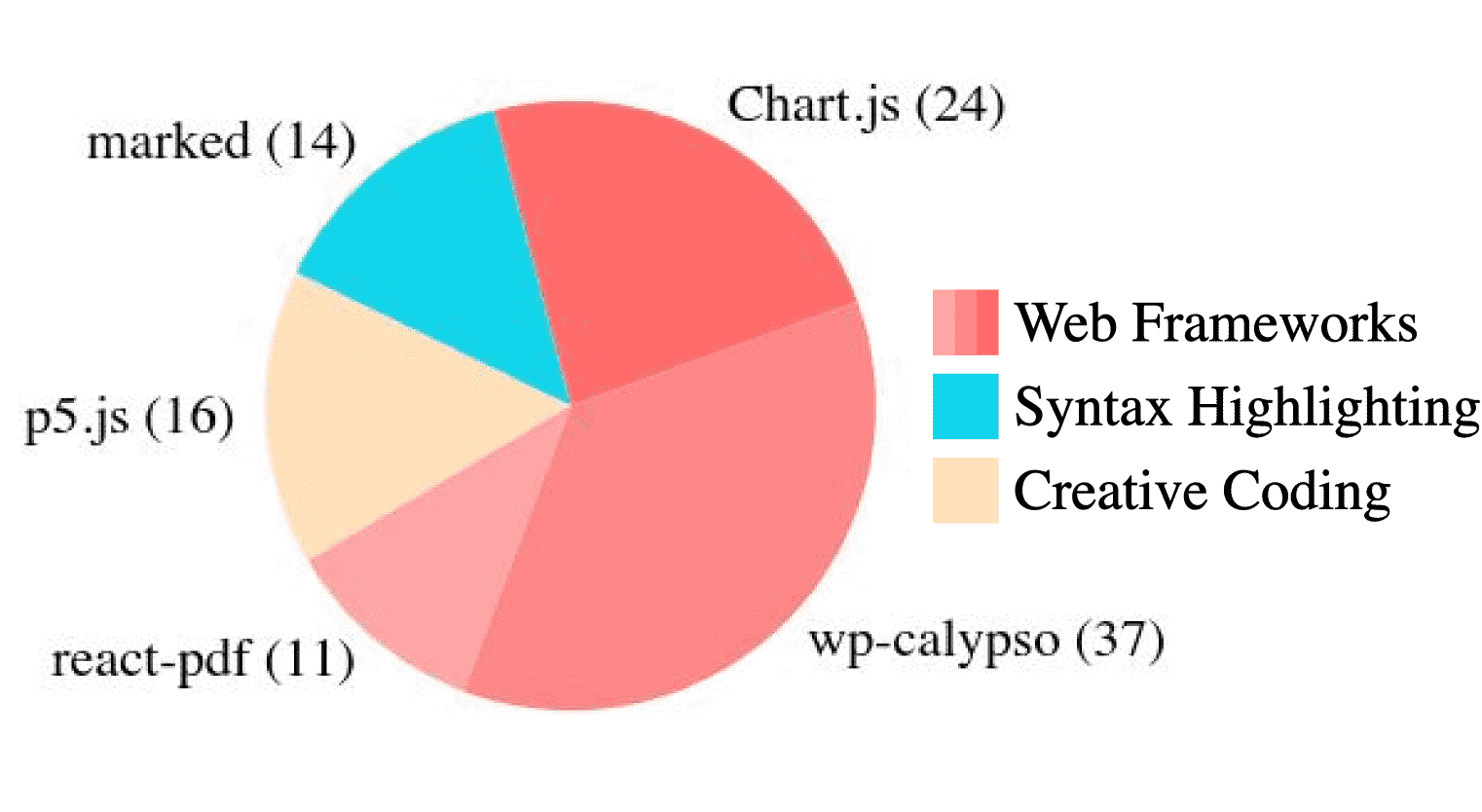
Figure 4: Distribution of SWE-bench M development set tasks (in parenthesis) across 5 open source GitHub repositories.
任务组成:
开发集包含 100 个任务实例,来自 5 个开源仓库,主要使用 JavaScript 及其衍生语言(如
.js,.jsx,.ts,.tsx)编写。每个开发集仓库在测试集中都有一个“等效”仓库,以促进开发集解决方案在测试集上的泛化能力。
任务实例特征:
问题文本的中位数长度为 145 个词。
代码库的中位数行数为 228K,文件数为 1324 个。
修复操作中涉及修改的中位数行为 35 行,修改文件数为 2 个,修改函数数为 3 个。
测试方面,中位数“Fail-to-Pass”测试为 2 项,“Pass-to-Pass”测试为 7 项。
与测试集对比:
问题文本稍长,但代码库规模较小。
修改行数略多,测试项略多。
A.2 数据集附加特征¶
视觉测试(Visual Testing):
69 个任务实例来自 Chart.js 和 openlayers 两个可视化库,使用像素级视觉测试验证功能正确性。
使用 Puppeteer 和 Pixelmatch 等工具允许对特定区域进行视觉差异比较,忽略动态内容(如时间戳、广告)。
任务实例按年份分布:
大部分任务集中在 2019 到 2022 年之间。
例如,lighthouse 和 wp-calypso 等仓库包含较多早期任务。
多语言问题描述:
有 55 个任务的问题描述或图像中包含非英语语言(如中文)。
来自阿里巴巴设计团队的仓库(如 next)是多语言任务的主要来源。
参考解决方案涉及多文件类型:
SWE-bench M 有 174 个任务的修复方案涉及修改多种文件类型(如
js、scss、jsx等)。与 SWE-bench 仅修改 Python 文件相比,SWE-bench M 更具多样性。
A.3 附加分析¶
仓库统计:
提供了每个仓库的任务实例的中位数统计,包括问题文本长度、代码库规模、修改行数、测试数量等。
不同仓库的测试数量差异较大,主要受测试定义和日志颗粒度影响。
任务修改分布:
大部分修改是局部的(1 个文件或函数),但有一定的长尾分布(修改多个文件和函数)。
与 SWE-bench 相比,SWE-bench M 的修改幅度更大,且多文件修改更常见。
GitHub 问题标签(Issue Tags):
提供了测试集与开发集中问题的标签分类统计,如 Bug、Feature、Other。
“Bug” 类占 25%,但大部分标签属于仓库特定的“Other”类别,如可访问性(a11y)、语言定义(language)、WebGL 使用问题等。
这些标签反映了任务实例的多样性和对视觉推理能力的要求。
小结¶
本附录详细描述了 SWE-bench M 数据集的开发集构成、视觉测试机制、多语言支持、多文件修改特征,以及从 GitHub 收集的标签信息。这些信息展示了该数据集在视觉软件调试任务上的复杂性与多样性,为研究人员提供了全面的背景和分析依据。
Appendix B Collection¶
本附录主要介绍了 SWE-bench M 数据集的构建过程及相关挑战,内容涵盖数据筛选流程、不一致性测试方法以及数字资源的收集方式。
1. 数据统计(B.1 Statistics)¶
附表13展示了从原始拉取请求(Pull Requests, PRs)中经过多阶段筛选流程后,最终生成可用 SWE-bench M 任务实例的数量。筛选阶段包括:
Crawled PRs:爬取的原始PR数量;
Conversion:初步转换为任务实例的PR数量;
Validation:通过验证的实例数量;
Inconsistent Test:通过不一致性测试的实例数量;
Manual Filter:人工过滤后保留的最终任务实例数量。
从各个仓库的数据来看,大多数PR在转换阶段就被大量过滤,主要原因包括转换失败或测试不一致。最终保留的任务实例数量相对较少,例如在 Automattic/wp-calypso 仓库中,从6亿多个PR中仅保留了37个最终任务实例。
2. 不一致性测试(B.2 Inconsistency Testing)¶
为了确保任务实例的可靠性,所有实例需通过一致性测试。具体方法是:
对每个任务实例运行测试用例 五次;
检查 测试用例是否一致(所有运行中的用例相同);
检查 测试结果是否一致(每次运行中通过和失败的用例相同)。
如果任一条件不满足,则该任务实例将被过滤掉。此步骤有效剔除了由于测试环境变化或测试用例不稳定导致的结果不一致问题。
3. 资源收集(B.3 Resource Collection)¶
SWE-bench M 不仅包含文本信息,还涉及多种数字资源,主要包括:
图片:用于展示 UI 问题或新功能说明,包括静态截图和动态图(GIF);
在线 IDE 链接:用于测试和展示 HTML、CSS、JavaScript 代码片段。17% 的任务实例包含至少一个 IDE 链接,15% 包含多个。
支持的 IDE 平台包括 codesandbox.io, jsfiddle.net, codepen.io, stackblitz.com, editor.p5js.org,共收集了114个链接。为获取这些资源,研究人员编写了自动化脚本或使用浏览器工具下载代码内容,并进行了后处理以确保代码能够直接运行,包括:
补充缺失的标签;
添加外部依赖资源;
按 HTML、CSS、JavaScript 三部分提取并整合。
总结¶
本附录详细介绍了 SWE-bench M 数据集的构建过程,包括从原始数据中筛选出高质量任务实例的步骤、不一致性测试的机制以及如何收集和处理非文本资源。这些努力提升了数据集的准确性和实用性,为视觉软件工程领域的 AI 模型评估提供了坚实基础。
Appendix C Experiments¶
本章节总结了论文中关于SWE-bench M实验的附加细节和基线模型的调整过程,主要包括以下几个方面:
1. 实验与消融研究的额外细节¶
提供了关于检索增强生成(RAG)中最优上下文窗口选择的方法。
描述了为了使软件开发代理框架(如Agentless、Aider、AutoCodeRover等)兼容SWE-bench M任务实例所做的重构工作。
展示了更详细的实验结果分析,例如按仓库和年份划分的解决率(solve rates)。
2. 基线模型的调整方法¶
a. Agentless¶
原本依赖Python的
ast模块进行代码定位,但该方法无法支持JavaScript/TypeScript。使用Tree-sitter解析器替代,并增加了额外的解析步骤以适应JavaScript的函数变体(如箭头函数)。
替换了所有Python代码片段为JavaScript版本。
由于JavaScript版本间的语法差异,无法使用原有的语法检查机制,因此去除了手动验证步骤,转向完全自动化的实现。
添加了对Claude模型的支持功能。
b. Aider¶
使用Tree-sitter解析AST,支持更多语言。
与Agentless不同,它通过迭代语法检查和代码格式化生成合理代码。
由于JavaScript版本差异导致解析器误判,放弃使用该基线。
c. AutoCodeRover¶
原设计基于
ast模块,难以适应JavaScript。使用Tree-sitter替代并重写了接口API。
发现其API过于依赖
ast结构,导致在JavaScript AST中定位失败,需完全重构才能适配。
d. Moatless¶
虽然设计为语言无关,但其Python到代码图的转换未充分覆盖JavaScript的结构(如箭头函数),因此放弃使用。
e. SWE-agent¶
对原始SWE-bench任务使用本地环境测试,适配JavaScript时同样安装依赖并构建本地项目。
引入**“复现代码”**(reproduction code),将其存入对应目录并初始化为npm包,供模型使用。
SWE-agent JS:适配JavaScript的编辑命令,使用ESLint进行语法检查。
SWE-agent M:引入新命令支持Web交互和图像处理,如打开网页、截图等,使用Xvfb模拟显示环境。
3. 基线配置的实验参数搜索¶
SWE-agent:通过在开发集上测试不同历史观察长度(5或9)的配置,选择性能最佳的设置。
RAG系统:通过网格搜索测试不同上下文长度(32K、64K、100K)以及是否包含图像,选择最优配置进行评估。
4. 实验结果¶
提供了表格和图表,展示不同配置下的解决率(% Resolved)和成功与退出状态的频率。
不同模型(如Claude 3.5 Sonnet和GPT-4o)在不同配置下的表现差异。
总结¶
本章节详细描述了为了在SWE-bench M上评估不同软件开发代理和RAG系统所做的技术适应与实验配置,涵盖了从代码解析器更换到环境模拟、从语法检查到图像处理等多个方面。同时通过参数搜索和实验结果分析,优化了各基线系统的性能表现。
C.3 Further Analyses¶
该节内容主要对SWE-bench M数据集上不同基线方法的性能进行了进一步的分析,重点包括以下几部分:
按仓库的解决率分析(Table 17)
展示了不同基线方法(SWE-agent M、Agentless JS、RAG)在各个仓库上解决任务的比例。
所有性能数据基于GPT-4o模型,测试集(test split)使用的是pass@1指标,而开发集(development split)则采用超参数搜索的最佳结果。
多数仓库的解决率较低,但某些仓库(如
openlayers/openlayers)在SWE-agent M和Agentless JS上表现较好。有些仓库(如
PrismJS/prism、eslint/eslint)的解决率几乎为零,说明这些仓库的任务对模型来说较为困难。
时间维度的分析(Table 18)
展示了不同年份任务的解决率。
除Agentless JS在早期任务上表现稍好外,其他系统在2024年的任务上表现最佳,尤其是SWE-agent M在2024年的解决率达到53.8%。
由于各仓库的任务分布和解决率不均衡(如2024年的13个任务中有8个来自
openlayers/openlayers),因此年份间的解决率难以直接比较。
训练截止时间前后的比较(Table 19)
为了消除仓库分布变化的影响,作者对GPT-4o训练截止时间(2023年10月)前后任务的解决率进行了重新加权比较。
结果显示,所有系统在训练截止时间之后的表现均优于之前,说明模型在新数据上的泛化能力有所提升。
尽管Claude 3.5 Sonnet的训练截止时间较晚(2024年4月),样本数量不足,但其表现趋势与GPT-4o类似,且在2024年的任务上性能提升更明显。
总结:
该章节通过多个维度(仓库、时间、训练时间)分析了SWE-agent M、Agentless JS 和 RAG 在 SWE-bench M 上的性能表现。SWE-agent M 整体表现优于其他方法,尤其在训练截止时间后和2024年任务上提升显著。然而,部分仓库任务难以解决,且任务分布差异较大,影响了年份间的直接比较。最终,通过加权调整后,所有系统的训练后表现均优于训练前,表明模型具有一定的泛化能力。
Appendix D Human Validation¶
本附录详细介绍了在 SWE-bench M 任务实例中进行的人类验证过程,尤其是对图像内容的分类及其是否能以文本形式表达的判断。
D.1 图像分类(Image Categorization)¶
该部分旨在对软件开源问题中常见的视觉内容进行分类,以分析开发者如何通过图像传达软件开发相关信息。
数据来源:从数据集中随机抽取了 50 张图像,并从中手动提取出 8 个类别。
分类任务:人类参与者将图像标记为以下 8 类之一:
代码截图
Web 界面(UI/UX 元素)
地图/地理空间可视化
图表/图示
数据可视化(如折线图、柱状图)
艺术/摄影
错误信息
其他
结果:
在 8.62 亿张问题描述图像中,代码截图和网页截图占绝对主导。
某些类别(如地图、数据图)仅在特定仓库中出现,说明图像的分布与仓库功能密切相关。
例如,图表多出现在 bpmn-js,数据可视化多在 Chart.js,艺术类图像多在 p5.js。
结论是:SWE-bench M 包含了多样化的图像,但多数为代码和网页截图,且图像类别与仓库功能密切相关。
D.2 图像是否能表示为文本(Is an image representable as text?)¶
该部分调查图像内容是否可以完全用文本表达,即是否可以通过 OCR 或文本描述完整保留图像信息。
判断标准:
如果图像仅包含文字,或文字为纯色、无重要图像细节,则可以表示为文本。
若图像包含颜色、布局、图形等非文本信息,则不能仅用文本表达。
标注方式:
人类标注者只能回答 “是”(Yes) 或 “否”(No)。
例如:
可以表示为文本:错误信息(如红色报错文本)。
不能表示为文本:代码高亮、网页排版、图表、艺术图像等。
结果:
在所有图像中,80% 被标记为“否”,即不能仅用文本表示。
20% 被标记为“是”,主要是错误信息类图像。
仓库之间差异明显:如 prettier 有较多文本可表示图像,而 bpmn-js、highlight.js 等几乎没有。
类别差异明显:代码截图和网页截图中,文本颜色和排版是关键信息,因此不能简单地用文本替代。
结论是:在 SWE-bench M 中,大多数图像不能仅用文本表示,尤其是涉及视觉细节(如高亮、排版、图形)的图像。图像的表示方式与其语义内容密切相关,不能简单降维处理。
总结¶
SWE-bench M 中的图像内容广泛,涵盖代码截图、网页界面、数据可视化等,其中图像在传达问题时往往不可替代,尤其在涉及颜色、排版、图形等视觉信息时。这些图像反映了开源项目中软件开发的视觉特性,也凸显了多模态模型在理解和处理视觉软件问题上的必要性。
D.3 Image Necessity.¶
本节研究了在解决 GitHub 问题时,图像在问题描述中的必要性。作者对包含图像的 557 个 SWE-bench M 任务实例进行了人工标注,以判断图像是否对理解并解决问题有帮助。
标注流程:¶
人类标注者首先仅根据问题描述、代码库、黄金补丁和测试补丁判断问题是否可解。
然后查看相关图像,再次判断问题是否可解。
根据两次判断结果,图像是否必要分为三种情况:
Yes:从“不可解”变为“可解”,图像必要。
No:始终“可解”,图像不必要。
Remove:始终“不可解”,任务实例被移除。
结果:¶
465 个任务实例中图像被认为是必要的(占 83.58%)。
只有 93 个任务实例图像被认为是不必要的。
影响因素:¶
如果问题描述中包含复现代码,图像可能被认为是冗余的。
有些仓库(如 bpmn-js、lighthouse)的贡献指南要求必须提供截图说明问题,因此这些仓库中没有“不必要图像”。
图像放在“附加信息”部分时,通常只作为辅助,而非关键。
D.4 任务难度总结¶
本节评估了任务的难度,即一个经验丰富的开发者解决该问题所需的大致时间。难度分为四个等级:
<15 分钟
15 分钟–1 小时
1–4 小时
>4 小时
标注方法:¶
从 SWE-bench M 中随机抽取 100100100100 个任务实例进行标注。
每个任务由三个标注者分别评分,最终采用多数投票决定难度等级。
Fleiss’ Kappa 为 0.78,说明标注者之间有高度一致性。
结果:¶
难度等级 |
SWE-bench M 比例 |
|---|---|
<15 分钟 |
13% |
15 分钟–1 小时 |
43% |
1–4 小时 |
38% |
>4 小时 |
6% |
影响难度的关键因素:¶
补丁大小:补丁越小越容易解决。
问题描述的清晰度:描述越详细,任务越容易。
图像的作用:截图能帮助开发者快速定位问题,尤其在前端开发中。
修改的上下文复杂度:即使修改量小,但如果需要大量上下文支持,也可能耗时较长。
结论:¶
SWE-bench M 的任务难度分布广泛,涵盖了从简单快速修复到需要大规模重构的复杂问题。这表明该数据集适合用于评估和跟踪模型在软件工程任务中的表现改进。
总结性观点¶
图像在软件问题描述中具有高度必要性,特别是在前端和用户界面相关问题中。
任务难度评估基于补丁大小、描述清晰度、图像辅助和上下文复杂度。
SWE-bench M 数据集在多样性和真实场景覆盖上表现良好,是评估模型和代理系统能力的有效工具。
Appendix E Limitations¶
本附录主要讨论了当前多模态AI系统(特别是SWE-Bench M基准)在应用和研究中的局限性,主要包括以下两个方面:
一、更广的覆盖范围(Broader Scope)¶
编程语言:当前的基准基于17个JavaScript库,共包含617个任务实例。然而,多模态内容不仅出现在JavaScript中,也广泛存在于Python、C++、Rust等其他编程语言的代码问题中,未来可扩展更多语言。
模态类型:当前主要使用文本、图像和视频,但GitHub等平台也支持音频文件或其他媒体形式,未来可纳入更多模态进行评估。
任务种类:当前任务覆盖了Web框架、数据可视化和语法高亮等领域,但仍有许多其他JavaScript库和应用场景未被包含。扩展任务范围将有助于更全面评估多模态系统,但也需要大量人力,因此作者选择优先保证任务质量。
二、改进模型与环境(Improved Models and Environments)¶
模型能力:尽管当前评估了现有模型,但未来仍有很大提升空间,例如引入更先进的模型(如GPT和Claude的新版本)。
环境工具:当前的SWE-Agent环境可以通过增强浏览能力、增加工具等方式进一步优化,从而提升多模态任务的处理性能。
总结¶
作者强调,虽然当前的研究在质量上有所突破,但在覆盖范围与系统能力上仍有显著提升空间。未来的研究可以围绕扩展语言、模态、任务类型,以及改进模型和工具环境展开,这将是推动多模态AI系统发展的关键方向。