2509.06269_REMI: A Novel Causal Schema Memory Architecture for Personalized Lifestyle Recommendation Agents¶
引用: 0(2025-11-07)
组织:
Radian Group Inc.Bethesda USA
Sri Sivasubramaniya Nadar College Of Engineering Chennai India
AmazonSeattleUSA
总结¶
总结
核心内容
Personal Causal Knowledge Graph: 把用户的历史行为数据,构建个人因果知识图结构
Causal Reasoner Module: 基于个人知识图,进行推理,并生成可解释 causal explanations
Schema-Based Planner: 基于个人知识图,生成定制化行动方案
LLM Orchestration and Explanation Tracing: 通过组装各个模块的输出,生成可解释的推荐建议
评价指标
个性化显著度得分(Personalization Salience Score)
因果推理准确率(Causal Reasoning Accuracy)
关键词
因果模式记忆(Causal Schema Memory, CSM)
会话式AI
背景
个人因果知识图:记录用户的生活事件与习惯,形成个性化的因果结构。
因果推理引擎:支持以目标为导向的因果遍历,并融合外部知识和反事实推理(counterfactual reasoning)。
模式规划模块:检索可调整的计划模式,生成定制化的行动方案。
理想的生活方式AI代理应具备两个核心能力:
一是利用个人背景信息定制建议
二是提供透明的解释,将建议与用户自身数据和已知的因果关系联系起来
REMI
结合了三种范式的优点:
个人知识图谱:用于结构化的长期记忆
因果推理:用于推理个体的因果关系;
基于模式的规划:用于生成可操作且可解释的计划
目标:克服当前个性化推荐代理的局限性,实现更贴合用户需求的AI助手。
核心内容
Personal Causal Knowledge Graph(个人因果知识图 - 系统的“长期记忆”)
定义:用图结构来记录你个人生活数据的数据库。
节点:代表各种生活事件或状态(例如:“熬夜”、“高强度工作”、“下午喝咖啡”、“白天疲劳”)。
边:代表因果关系,有方向(例如:“熬夜” → “导致” → “白天疲劳”)。边上还可以标注关系的类型和强度(权重)。
特点:
多模态:可以整合来自不同来源的数据,比如手环的睡眠数据、日记里的心情记录等。
动态更新:随着你不断使用,这个图会越来越丰富和准确。
作用:
为所有后续的推理提供真实、个性化的数据基础,让建议不再是空谈。
Causal Reasoner Module(因果推理器 - 系统的“大脑”或“侦探”)
最核心的推理部分,它使用你的个人知识图来回答“为什么”的问题。
工作流程如下:
目标映射:
首先理解你的问题(如“如何提升下午的能量?”),然后在你的个人知识图中找到相关的节点(如“疲劳”、“低能量”)。
因果遍历与假设扩展:
从这些相关节点出发,在知识图中进行多步遍历,找出所有可能的因果链(例如:“下午喝咖啡” → “晚上失眠” → “睡眠不足” → “白天疲劳”)。
如果图中缺少某些环节,它会请LLM帮忙“假设”一个合理的中间原因补全链条。
路径评分:
生成多条可能的因果解释后,用LLM作为“裁判”来给这些解释打分,筛选出最合理、最相关的几条。
反事实推理:
进行“如果……那么……”的思维实验。
例如,“如果没有熬夜,疲劳问题会解决吗?”这有助于确定哪个原因是最关键的。
自我反思循环:在最终确定原因前,让LLM再检查一遍整个推理过程,确保逻辑严密,没有遗漏。
最终输出:一套经过严格验证的、个性化的因果因素列表。
Schema-Based Planner(基于 Schema 的规划器 - 系统的“解决方案工程师”)
推理器找到了“病因”,规划器就来开“药方”。
图式检索:
根据用户的问题和找出的原因,从一个预置的“最佳实践模板库”里找到合适的解决方案模板。
例如,针对“疲劳”,检索出“改善睡眠质量图式”。
实例化:
把这个通用的模板,用用户的个人数据进行填充,变成具体的、可执行的步骤。
例如,模板里是“解决睡眠不规律”,实例化后就变成“为你设定一个晚上11点前睡觉的固定作息”。
反事实验证:
在最终确定计划前,回到因果知识图里模拟一下:如果执行了这个计划(比如消除了“睡眠不规律”这个节点),那么“疲劳”的问题是否真的会得到改善?
这相当于一次“沙盘推演”,确保计划的有效性。
基于假设的规划:
当个人数据不足时(比如用户是新手),它会基于推理器提出的“假设原因”来生成试探性的建议,并标明这些是“可能对你有用”的尝试。
最终输出:一个为用户量身定制的、步骤清晰的、可执行的行动计划。
LLM Orchestration and Explanation Tracing(LLM编排器 - 系统的“金牌客服”)
它的任务不是进行核心推理,而是把前面所有组件的结果优美地、有逻辑地呈现给用户。
上下文组装:
将前面各个环节的产出(从用户日志中检索到的相关记忆片段、推理器找出的因果因素、规划器制定的行动计划)整理到一起,形成一个完整的提示词(Prompt)交给LLM。
保持可追溯性:
通过精心设计的提示词,要求LLM在最终回答中必须引用这些因果因素和个人记忆,从而向用户清晰地解释“我为什么给你这个建议”。
这使得整个推理过程是透明、可解释的。
LLM的角色:
在这里,LLM主要扮演一个语言生成者的角色。
因为所有硬核的推理和规划都已由前几个组件完成,LLM只需要忠实地、流畅地组织和表达这些信息,大大减少了它“胡编乱造”(幻觉)的可能性。
创新与优势
真正的个性化:核心是基于不断更新的个人因果图,而非静态的用户画像。
严谨的因果推理:引入了图思考/树思考(GoT/ToT)、反事实推理和自我反思等高级推理技术,让建议有坚实的逻辑基础。
结构化与灵活性的平衡:使用计划图式保证了建议的科学性和完整性,同时又通过实例化和假设规划来保持灵活性。
透明与可解释:整个流程强调“可追溯性”,最终的建议会明确告诉用户其依据,建立信任。
降低对LLM的依赖:将LLM置于一个受控的编排角色,让其负责最擅长的语言工作,而将容易出错的复杂推理交给专门模块,提升了系统的可靠性和可控性。
评价指标:
个性化显著度得分(Personalization Salience Score)
公式: \(\text{PSS} = \frac{1}{|C|} \sum_{c \in C} \mathbb{1}[\max_{r \in R} \text{sim}(c, r) \geq \tau]\)
其中:
\( c \in C \):用户上下文中的每个块(context item)
\( r \in R \):响应中的每个部分(response chunk)
\( \text{sim}(c, r) \):使用句子嵌入计算的余弦相似度
\( \tau \):相似度阈值,实验中设定为0.7
\( \mathbb{1}[\cdot] \):指示函数,当条件成立时为1,否则为0
得分越高,表示输出中包含的用户个人上下文信息越多,即个性化程度越高
因果推理准确率(Causal Reasoning Accuracy)
是否准确反映了因果图中的因果路径
设计目标和创新点
Personalized Causal Reasoning(个性化因果推理)
核心在于构建一个个人因果知识图谱,记录用户的事件(如日常活动、健康指标)及其因果关系
图谱使得系统能够识别用户问题的根本原因(例如能量低是因为睡眠质量差),而非依赖于通用的相关性
重点
因果图谱支持对用户问题的针对性推理,而非表面现象的匹配。
通过因果关系识别,系统能提供更准确、个性化的解释和建议。
Schema-Guided Planning(基于模板的规划)
使用一个行为模板库(schema templates),这些模板是对常见生活目标(如改善睡眠、减少压力)的抽象计划
当系统识别出可能原因后,会从模板库中检索合适的模板,并结合用户具体情况实例化,生成具体的、可执行的分步计划
重点
模板化方法使规划具有结构性和可解释性。
实例化过程可生成高度个性化的生活指导方案。
Explainability and Traceability(可解释性与可追溯性)
在生成推荐时,会附带解释,并确保这些解释可追溯到用户的个人数据和因果逻辑
系统在生成推荐时显式展示因果因素和计划步骤,以增强用户信任,并便于审查系统推理过程
重点
通过解释追踪机制,每个推荐步骤都能与知识图谱中的因果关系挂钩。
提升系统的透明度和可审计性,弥补传统AI系统的“黑箱”问题。
Multimodal Integration(多模态整合)
整合多种类型的个人数据,包括文本(如日记、聊天记录)、数值时间序列(如可穿戴设备数据)以及图像和音频
数据被统一建模到个人知识图谱中,使系统能进行跨模态、上下文感知的推理
重点
支持多种数据输入方式,提升系统对用户上下文的理解能力
突破了传统基于文本的LLM系统的限制,实现更全面的个性化服务
创新点
个人因果知识图谱,
不仅从外部存储中检索相关信息,
还在此基础上进行因果推理,从而在回答之前进行中间推理步骤,而不仅仅是丰富提示内容。
这一方法区别于传统的RAG和k-NN-LM,强调了因果推理在生成过程中的重要性。
未来方向
主动学习:系统可主动询问用户以补充因果图谱缺失的信息(如“你昨天下午喝咖啡了吗?”);
多目标场景:应对生活方式因素(如睡眠、压力、饮食)之间的相互作用,实现复合目标的优化;
强化学习整合:系统可根据用户对建议的反馈,逐步优化策略,形成长期的个性化调整机制。
Abstract¶
本研究探讨了个性化AI助手在整合复杂的个人数据和因果知识方面所面临的挑战,指出当前AI助手提供的建议往往过于泛泛,缺乏解释性。为了解决这一问题,作者提出了一种名为 REMI 的架构,该架构基于 因果模式记忆(Causal Schema Memory, CSM),专为多模态生活方式代理设计。
核心架构与功能¶
个人因果知识图:记录用户的生活事件与习惯,形成个性化的因果结构。
因果推理引擎:支持以目标为导向的因果遍历,并融合外部知识和反事实推理(counterfactual reasoning)。
模式规划模块:检索可调整的计划模式,生成定制化的行动方案。
整个系统由一个 大型语言模型(LLM) 协调各组件,提供具有透明因果解释的回答,从而增强用户对AI建议的信任与理解。
评估与创新¶
引入了两个新的评价指标:个性化显著度得分(Personalization Salience Score) 和 因果推理准确率(Causal Reasoning Accuracy),用于系统化评估CSM的表现。
实验结果表明,基于CSM的代理在情境感知和用户一致性方面优于传统的LLM代理。
研究意义¶
本研究提出了一种创新的、结合增强记忆与因果推理的方法,推动了透明、可信的个性化AI生活方式助手的发展,尤其适用于时尚、个人健康与生活方式规划等领域。
关键词¶
因果推理、个性化、多模态推荐代理、知识图谱、可解释AI、大型语言模型
1. Introduction¶
近年来,大语言模型(LLMs)的进展使得AI代理能够实现流畅的交互和广泛的知识回忆。然而,当前的个人助理代理在个性化和可解释性方面存在关键限制。现成的基于LLM的代理通常生成“一刀切”式的建议,未能考虑个体的独特情况或因果历史。例如,研究表明,LLMs常常提供通用的、基于群体的建议,忽视了个人特定因素,这在诸如健康和生活方式等敏感领域中会降低其实用性。
这种缺乏个性化的根本原因在于代理无法将多种用户数据(如睡眠模式、压力来源或情绪日志)整合到其推理过程中。此外,LLM推荐背后的推理通常是隐式的,用户难以信任或理解这些建议。一个理想的生活方式AI代理应具备两个核心能力:一是利用个人背景信息定制建议,二是提供透明的解释,将建议与用户自身数据和已知的因果关系联系起来。
为了解决这些问题,本文提出了REMI,一种全新的因果模式记忆(CSM)架构,旨在设计个性化、多模态的生活方式代理。REMI的提出结合了三种范式的优点:
个人知识图谱:用于结构化的长期记忆;
因果推理:用于推理个体的因果关系;
基于模式的规划:用于生成可操作且可解释的计划。
通过将这些范式与LLM的能力相结合,REMI的目标是克服当前个性化推荐代理的局限性,实现更贴合用户需求的AI助手。
2. Research Objectives¶
本节阐述了REMI系统的设计目标和创新点,重点在于其如何通过因果推理、个性化规划、可解释性与多模态数据整合,实现更智能和透明的生活方式辅助系统。
Personalized Causal Reasoning(个性化因果推理)¶
REMI 的核心在于构建一个个人因果知识图谱,记录用户的事件(如日常活动、健康指标)及其因果关系。这一图谱使得系统能够识别用户问题的根本原因(例如能量低是因为睡眠质量差),而非依赖于通用的相关性。
重点内容:
因果图谱支持对用户问题的针对性推理,而非表面现象的匹配。
通过因果关系识别,系统能提供更准确、个性化的解释和建议。
Schema-Guided Planning(基于模板的规划)¶
REMI 使用一个行为模板库(schema templates),这些模板是对常见生活目标(如改善睡眠、减少压力)的抽象计划。当系统识别出可能原因后,会从模板库中检索合适的模板,并结合用户具体情况实例化,生成具体的、可执行的分步计划。
重点内容:
模板化方法使规划具有结构性和可解释性。
实例化过程可生成高度个性化的生活指导方案。
Explainability and Traceability(可解释性与可追溯性)¶
REMI 在生成推荐时,会附带解释,并确保这些解释可追溯到用户的个人数据和因果逻辑。系统在生成推荐时显式展示因果因素和计划步骤,以增强用户信任,并便于审查系统推理过程。
重点内容:
通过解释追踪机制,每个推荐步骤都能与知识图谱中的因果关系挂钩。
提升系统的透明度和可审计性,弥补传统AI系统的“黑箱”问题。
Multimodal Integration(多模态整合)¶
REMI 能够整合多种类型的个人数据,包括文本(如日记、聊天记录)、数值时间序列(如可穿戴设备数据)以及图像和音频。这些数据被统一建模到个人知识图谱中,使系统能进行跨模态、上下文感知的推理。
重点内容:
支持多种数据输入方式,提升系统对用户上下文的理解能力。
突破了传统基于文本的LLM系统的限制,实现更全面的个性化服务。
我们的贡献(Our Contributions)¶
新的架构设计(New Architecture)¶
REMI 是一种模块化架构,融合了因果知识图谱、推理引擎、基于模板的规划器和大语言模型(LLM),实现了个性化、可解释的生活方式辅助功能。
因果模板规划(Causal Schema Planning)¶
我们开发了一个新的基于因果的模板规划模块,它将抽象计划与个人因果因素相结合,连接了符号式规划和神经生成的优势。生成的计划既具有场景特定性,又保持可解释性。
可解释的输出(Explainable Output)¶
系统能够生成嵌入解释的响应,并通过一种解释追踪机制将每个推荐步骤与知识图谱中的因果关系链接。这种机制提升用户信任并支持系统推理过程的审查。
评估框架(Evaluation Framework)¶
我们提出了一个新的个性化推理代理的评估方法,包括两个新指标:个性化显著性得分(Personalization Salience Score, PSS) 和 因果推理准确度(Causal Reasoning Accuracy, CRA),用于量化代理推荐的个性化程度和准确性。
总体目标¶
REMI 旨在提升开放代理系统在个性化助理领域的前沿水平。它不仅记住用户信息,还能理解并利用因果关系来驱动推荐,从而生成可操作、因果支持的个性化生活方式建议。这种系统弥合了用户建模、推理与可解释推荐之间的差距,符合下一代推荐系统的发展方向。
最终目标:
通过增强个性化与透明性,REMI 能使用户将AI代理视为理解自身、值得信赖的日常助手,而不仅仅是一个通用聊天机器人。
4. Proposed Method¶
本节介绍了一种名为 Causal Schema Memory(CSM) 的推荐系统架构,用于个性化生活方式推荐(Personalized Lifestyle Recommendation)。该系统通过整合因果推理、知识图谱和规划模块,实现了对用户行为和需求的深度理解与个性化建议。
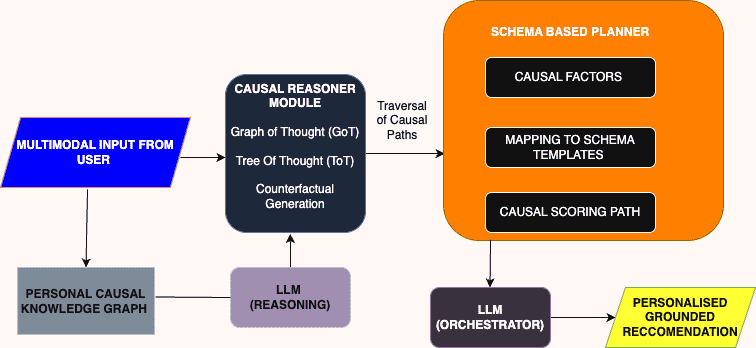
Figure 1.Overview of the Causal Schema Memory (CSM) architecture
图1 展示了 CSM 架构的总体结构,包含四个核心组件:
Personal Causal Knowledge Graph(个人因果知识图谱)
Causal Reasoner Module(因果推理模块)
Schema-Based Planner(基于模版的规划器)
LLM Orchestrator(大语言模型调度器)
4.1. Personal Causal Knowledge Graph(个人因果知识图谱)¶
这是整个系统的核心模块,用于存储用户的长期记忆,包括事件、习惯及其因果关系。
结构:
节点代表关键事件或状态(例如:不规律的睡眠、白天疲劳、高工作量、晚上摄入咖啡因),
边表示因果关系(如:不规律睡眠 → 白天疲劳),
边的权重表示因果关系的强度。
多模态支持:事件节点可以整合来自不同来源的数据,例如智能手表的睡眠数据、日记文本等。
动态更新:系统会根据用户数据和反馈不断更新图谱,支持新增事件和因果边的调整。
实现方式:使用
networkx图结构实现,未来可扩展为图数据库(如Neo4j)。
重点:该图谱为后续的因果推理和推荐提供了基础,确保推荐基于用户的实际行为和历史数据。
4.2. Causal Reasoner Module(因果推理模块)¶
该模块负责从个人因果图谱中识别与用户问题相关的因果路径,通过多种推理策略(Graph-of-Thought、Tree-of-Thought)生成解释链。
4.2.1. Goal Mapping(目标映射)¶
目标识别:将用户问题映射到图谱中的相关节点。
嵌入相似搜索:使用双编码器模型进行个性化向量检索,匹配用户查询与图谱节点。
阈值机制:若检索结果不足,系统会使用通用知识生成假设性因果因素。
重点:通过个性化嵌入模型和假设生成机制,确保即便数据不充分,也能生成合理的因果链。
4.2.2. Causal Traversal and Hypothesis-Based Expansion(因果遍历与假设扩展)¶
因果路径探索:从目标节点出发,遍历因果图,最多探索3跳路径,生成因果链。
假设性扩展:若图谱中缺少关键中间节点,系统调用 LLM 弥补缺失的因果关系。
重点:通过因果图遍历和 LLM 假设推理相结合,极大增强了因果推理的完整性。
4.2.3. LLM-Based Path Scoring(LLM 路径评分)¶
路径评估:使用 LLM 对多个因果路径进行评分,保留最合理和最相关的解释链。
重点:LLM 作为“判断者”对路径的合理性进行筛选,提升推理质量。
4.2.4. Counterfactual Reasoning(反事实推理)¶
模拟干预:系统模拟改变图谱中的节点或边,检验因果路径的鲁棒性。
多角度验证:帮助识别其他可能的替代因素,增强推荐的全面性。
重点:通过反事实推理,验证因果链是否真正关键,避免推荐不相关或无效的建议。
4.2.5. Self-Reflection Loop(自我反思机制)¶
LLM 内部反思:对推荐原因进行逻辑检查,确保推荐的因果链完整、合理。
修正机制:若发现逻辑漏洞或不一致,触发替代路径或因果因素的重新评估。
重点:通过 LLM 驱动的反思机制,提升系统输出的可信度和逻辑性。
4.3. Schema-Based Planner(基于模版的规划器)¶
在识别出关键因果因素后,系统进入规划阶段,使用预定义的计划模版(Schema)生成具体建议。
4.3.1. Schema Retrieval(模版检索)¶
模版选择:根据用户问题和因果因素,从健康、健身等领域的最佳实践中选择合适的模版(例如“改善睡眠质量”的模版)。
重点:模版确保推荐的结构化和有效性,避免推荐无意义或随机建议。
4.3.2. Instantiation(模版实例化)¶
个性化填充:将通用模版中的占位符替换为用户的实际数据,例如:“建立一致的作息时间” → “每天晚上11点前上床”。
重点:通过填充用户数据,使推荐更加具体、可操作。
4.3.3. Counterfactual Verification(反事实验证)¶
验证假设:在推荐前模拟执行建议,检查是否能有效解决因果问题。
因果图模拟:通过删除或缓解因果节点,观察目标节点是否受影响。
重点:通过反事实验证,提高推荐的可靠性,避免无效或不充分的建议。
4.3.4. Hypothesis-Based Planning(假设性规划)¶
应对数据缺失:当数据不足时,使用 LLM 生成合理的假设性建议。
增强鲁棒性:确保系统在信息不完整时仍能提供实用建议。
重点:通过 LLM 的假设推理,保证系统在面对不确定信息时依然具备推荐能力。
4.4. LLM Orchestration and Explanation Tracing(LLM 调度与解释追踪)¶
最后一个阶段由 LLM Orchestrator 执行,负责将前序模块的输出整合为自然语言推荐。
4.4.1. Context Assembly(上下文组装)¶
多源信息整合:将用户查询、因果因素、推荐步骤、历史记录等整合为结构化输入。
类似 RAG 架构:通过 FAISS 向量检索系统,补充用户相关记忆,增强上下文理解。
重点:通过多源信息融合,确保推荐基于全面且相关的上下文。
4.4.2. Maintaining Traceability(维持可追溯性)¶
解释透明:在输出中明确标注因果因素和相关事件,使用户能理解推荐的逻辑依据。
依赖注入机制:在 LLM 提示中显式加入因果链和记忆片段,确保输出的因果链不丢失。
重点:通过提示设计确保推荐过程的可解释性,增强用户信任。
4.4.3. LLM Considerations(LLM 使用策略)¶
LLM 使用策略:LLM 仅用于自然语言生成,不负责核心推理,避免幻觉问题。
模型选择:使用 Gemini-2.0-Flash,注重输出的流畅性和逻辑性。
重点:LLM 的角色被精确定位为“语言输出器”,保证系统输出的准确性和可解释性。
总结¶
REMI 的 CSM 架构通过 个人因果知识图谱、因果推理模块、基于模版的规划器 和 LLM 调度器 四个核心组件,实现了对用户行为的深度分析与个性化推荐。系统通过 因果推理 找出问题根源,通过 规划模版 生成结构化建议,通过 LLM 实现自然语言输出与解释,最终输出 具体、可操作、可解释的个性化建议。
该方法强调 数据驱动、因果推理、透明性和用户个性化,为个性化推荐系统提供了一种新范式。
5. Evaluation Framework¶
本章节主要评估REMI架构的性能,通过与两个基线代理(baseline agent)进行定量实验对比:
Memory-Only LLM(仅记忆型LLM)
该代理仅使用个人数据进行记忆检索(RAG风格),不进行因果推理或规划。Ablated CSM(无模式规划器)
该变体使用因果图遍历来识别相关因素,但省略了基于模式的规划,LLM直接从因果因素中生成建议。
为了评估系统性能,作者引入了两个主要评估指标,详见以下两个子章节。
5.1. Personalization Salience Score(个性化显著度得分,PSS)¶
衡量标准:
该指标用于衡量响应在多大程度上反映了用户的特定背景和个人信息。
定义公式如下:
其中:
\( c \in C \):用户上下文中的每个块(context item)
\( r \in R \):响应中的每个部分(response chunk)
\( \text{sim}(c, r) \):使用句子嵌入计算的余弦相似度
\( \tau \):相似度阈值,实验中设定为0.7
\( \mathbb{1}[\cdot] \):指示函数,当条件成立时为1,否则为0
得分越高,表示输出中包含的用户个人上下文信息越多,即个性化程度越高。
5.2. Causal Reasoning Accuracy(因果推理准确性,CRA)¶
衡量标准:
该指标评估代理的解释和规划是否与因果图中的有效因果路径一致。
定义公式如下:
其中:
\( f \in F \):因果图中的每个因果因素(causal factor)
\( R \):整体响应的嵌入表示
\( \text{sim}(f, R) \):因果因素与响应之间的余弦相似度
\( \tau \):相似度阈值,与PSS相同(0.7)
得分越高,表示在最终输出中引用了越多的因果解释,即因果推理的准确性越高。
总结¶
本章节重点介绍了REMI系统的评估框架,通过两个关键指标(PSS 和 CRA)对比了REMI与两种基线模型在个性化表现和因果推理能力上的差异。
PSS 关注的是输出是否包含用户个人上下文信息。
CRA 评估的是输出是否准确反映了因果图中的因果路径。
6. Results and Findings¶
本节总结了在28个不同情境中对REMI系统的评估,重点介绍了其中两个典型案例,并对整体表现进行了分析。
6.1. 情境:午后疲倦与工作效率(Scenario: Afternoon Fatigue and Work Focus)¶
输入内容包括:
用户档案数据(Table 1):用户为“夜猫子”,咖啡因耐受中等,平均睡眠时间5.5小时,职业为软件工程师。
用户事件日志(Table 2):记录了睡眠、心情、咖啡摄入和工作效率等信息。
向量日志(Vector Log):用户描述了自己在下午感到疲倦、工作效率低、咖啡有时有效但有时无效。
用户查询:用户问:“我总是下午感到疲倦和精神模糊,该怎么办?”
输出内容:
图示(Figure 2):展示了用户的生活习惯(如睡眠、咖啡摄入)与午后疲倦之间的因果关系图。
检索上下文(Retrieved Context):提取了用户描述的事件和档案信息。
提取的因果因素(Extracted Causal Factors):识别出睡眠不足和咖啡作用不稳定的因果关系链。
生成的行动计划(Generated Action Plan):
建议用户规律作息,尽量在午夜前入睡;
改善午餐选择和补水以避免能量下降;
下午1点到2点之间进行短暂活动;
有需要时在下午2点前喝咖啡,并跟踪其效果;
每周根据观察调整计划。
量化评估:
个性化显著性得分(PSS):0.92(接近满分,表现优秀);
因果推理准确率(CRA):0.60(表现中等)。
✅ 重点总结:此案例展示了REMI如何结合用户的生活习惯与主观感受,生成个性化的行动计划,并展现其在个性化上的优势,但在因果推理方面仍有提升空间。
6.2. 情境:我应该给我的狗取什么名字(Commonsense Hypothesis Generation)¶
生成的行动计划:
观察与联结:观察狗的外貌、性格、行为等2-3天,记录关键特征;
命名分类:按照外观、性格、人类名字、流行文化、食物、自然等类别进行命名;
生成并筛选:每个类别生成5-10个名字,朗读并筛选出3-5个候选;
测试名称:在接下来的一天中测试候选名称;
最终决定:选择最自然、合适的名字并开始使用。
✅ 重点总结:此案例展示了REMI在常识性问题上的推理能力,能够基于用户提供的有限信息(如“刚养狗”)生成结构化、易执行的命名建议,体现出其在生成指导性建议方面的灵活性。
6.3. 整体评估(Overall Scores)¶
PSS得分(个性化显著性):REMI在所有测试中表现稳定,得分在0.85-0.92之间,明显高于基线模型(0.68-0.82),说明其在个性化上下文建模方面具有优势。
CRA得分(因果推理准确率):
REMI在所有情况下均优于基线模型,得分范围在0.4-0.8之间;
基于记忆的模型CRA为0.0,无法进行因果推理;
使用部分结构化因果图的模型得分中等但不稳定(0.2-0.6);
强调因果图与结构化推导机制对因果推理的重要性。
✅ 重点总结:REMI在需要因果推理的场景中,仍能保持高PSS得分,说明其可以在不依赖记忆数据的情况下,进行个性化且准确的因果推理。这表明REMI在结合个性化与推理能力方面是目前方法中较为稳健的模型。
总结:本节通过两个典型情境和整体评分对比,展示了REMI系统在个性化推荐和因果推理方面的优势。在需要因果链分析的复杂场景中,REMI的表现优于基于记忆或简化解构的模型,证明了其因果图与结构化规划机制的有效性。
7. Discussion¶
本节讨论了REMI系统在个性化AI、可解释性、模块化设计、挑战与限制、未来发展方向以及个性化智能体潜力等方面的贡献与意义。以下是对各部分的总结:
7.1. 推动个性化AI的发展(Advancing Personalized AI)¶
本部分重点强调了REMI系统通过构建个人因果知识图谱,为AI代理实现真正的个性化奠定基础。与传统千篇一律的虚拟助手不同,REMI能够根据用户的个人数据提供差异化建议。例如在健康领域,不同用户的失眠原因可能不同(如咖啡因或焦虑),系统可据此提出不同的解决方案。
核心贡献:展示了如何通过用户特定的因果模型增强大型语言模型(LLM),实现更安全有效的个性化AI。这为未来个性化AI的发展提供了实践路径。
7.2. 可解释性与信任(Explainability and Trust)¶
本节指出,可解释性在生活方式和健康相关的AI中是必要条件而非可选项。用户在了解建议背后原因时,更易信任并采纳建议。REMI通过其显式的因果推理路径,缓解了LLM“黑箱”问题。其模块化透明设计使得关键推理过程可被检查和理解,符合在高风险决策中对可解释性AI的呼声。
重点强调:REMI的设计满足了可解释性与用户信任的需求,尤其适合敏感领域如健康和生活方式管理。
7.3. 模块化与可扩展性(Modularity and Extensibility)¶
REMI的架构设计具有高度的模块化,各组件(如记忆、推理、规划、生成)可独立改进或替换。例如:
若有更先进的因果发现算法,可替换推理模块;
若有更优的计划库,可扩展schema模块;
可替换LLM以适应模型升级或设备部署需求。
重要意义:这种模块化使REMI成为一个研究多种推理机制(如符号因果推理与神经生成)交互的平台。同时也意味着该系统具备通用性,不仅适用于健康领域,也可拓展至个人理财、教育等领域。
7.4. 挑战与限制(Challenges and Limitations)¶
尽管REMI具有诸多优势,但仍面临以下挑战:
7.4.1. 数据需求(Data Requirements)¶
构建有效的个人因果图谱需要足够的用户数据。对数据较少的“冷启动”用户,图谱可能过于稀疏。解决办法是引入外部知识,并通过提问引导用户补充信息。随着交互增多,图谱将逐步完善。
7.4.2. LLM对齐问题(LLM Alignment)¶
虽然LLM的角色被限制在表达层面,但仍可能生成不适当或过于自信的内容。因此,使用高质量、经过指令微调的模型并设置安全机制是必要的。此外,LLM可能在解释部分“润色”因果链,因此需要通过结构化输出等方式进行约束验证。
7.4.3. 可扩展性(Scalability)¶
对于单个用户,计算负荷较轻,但若部署到大量用户层面,维护多个个性化图谱并运行推理将带来计算压力。未来可通过缓存、优化数据库及批量处理LLM调用来缓解。由于用户数据独立性强,系统具备良好的并行化能力。
7.5. 未来方向(Future Directions)¶
REMI的架构为以下几个方向提供了可能性:
主动学习:系统可主动询问用户以补充因果图谱缺失的信息(如“你昨天下午喝咖啡了吗?”);
多目标场景:应对生活方式因素(如睡眠、压力、饮食)之间的相互作用,实现复合目标的优化;
强化学习整合:系统可根据用户对建议的反馈,逐步优化策略,形成长期的个性化调整机制。
这些方向使得REMI不仅具备当下实用性,也为长尾领域的个性化AI提供了可持续演化路径。
7.6. 个性化智能体的潜力(Potential of Personalized Agents)¶
REMI代表了一种“开放世界”智能体,能随着时间推移学习和推理。通过开源系统设计,作者鼓励研究社区探索该架构的潜力。设想未来可建立一个“个性化智能体”基准,任务是基于个人事件数据输出因果化、可解释的建议,并将PSS和CRA等指标纳入评估体系。
此外,REMI的架构支持混合AI(符号+神经)系统,为LLM提供了一种外部“记忆”和“理解”机制。这种设计有助于构建更可靠、可解释的智能系统。
总结观点:REMI是迈向真正个性化AI的重要一步,展示了因果知识和基于schema的规划如何提升LLM在个性化场景中的能力。REMI的方向具有巨大潜力,有助于开发真正能改善用户生活并赢得信任的AI系统。
8. Conclusion¶
提出REMI系统与因果模型架构¶
本节首先介绍了REMI系统,它是当前个性化多模态生活代理的一种创新架构。该架构名为因果模式记忆(Causal Schema Memory, CSM),整合了以下四个核心组件:个人因果知识图谱、因果推理引擎、基于模式的规划器和大语言模型(LLM)协调机制。
REMI通过构建用户特定的因果图谱来实现深度个性化,并通过明确的推理路径和模式驱动的计划提供可解释的推荐建议。这一机制可以有效整合用户多源异构数据,建立统一的“原因”与“结果”模型,从而生成有明确依据的定制化建议。
评估框架与实验结果¶
为验证REMI的性能,研究者提出了一套新的评估框架和指标,用以严格评估系统的个性化和可解释性。初步实验结果显示,基于CSM的代理在提供相关且可信指导方面显著优于传统的LLM代理。
具体表现包括:
REMI的建议能够频繁且准确地结合用户背景信息(最多达3倍);
在多数测试场景中,准确识别问题的根本原因;
提供用户可理解的推理链,增强系统透明度和可信度。
方法创新:因果推理与对话系统的融合¶
本研究的创新点在于将因果推理和规划技术与会话式AI相结合。通过在LLM中引入知识图谱、因果遍历和反事实分析等原理性推理方法,REMI展示了构建基于个体数据的推理型智能代理的可能性。
这种将符号方法(symbolic)与神经方法(neural)结合的方式,为构建强大且透明的AI系统提供了新思路。它不仅是一个内容生成器,更是一个具备推理与问题解决能力的智能代理。
总体贡献与未来展望¶
REMI在提高AI代理的个性化、因果性和可解释性方面迈出了重要一步。通过为代理引入模式记忆与个人因果性,我们朝着构建真正智能的日常伙伴AI迈进,它不仅能回答问题,更能理解用户情境并以透明、有意义的方式帮助用户提升。
此外,这种方法扩展了推荐系统的边界,使其从静态偏好向动态推断用户目标、意图感知的因果推理转变,并提供随时间适应的可解释计划建议。我们相信,这种融合不同AI范式的系统,是下一代个性化AI的发展方向,并希望REMI能为AI、人机交互(HCI)、健康信息学等领域的研究者提供坚实的起点,用于开发新模块(如更强大的推理引擎)或探索新应用场景(如心理健康辅导、教育辅导等)。