2407.01178_❇️Memory3: Language Modeling with Explicit Memory¶
引用: 6(2025-07-29)
组织:
1Center for LLM, Institute for Advanced Algorithms Research, Shanghai
2Moqi Inc
3Center for Machine Learning Research, Peking University
总结¶
简介
引入一种新的记忆形式——显式记忆
多级记忆层次结构(RAG → 显式记忆 → 模型参数)
显式记忆在写入和读取成本之间取得了良好平衡,适合存储中等频率使用的知识
显式记忆通过将知识编码为稀疏的注意力键值对,并在推理过程中直接调用这些记忆,减少了对模型参数的依赖
核心思想
将LLM的训练和推理成本建模为“知识写入成本”与“知识读取成本”的总和
核心思想
Knowledge分为2种
具体知识(Specific Knowledge):
抽象知识(Abstract Knowledge):
应该
把抽象知识训练到 LLM 中(自研)
把具体知识放到显式记忆中(外包)
两个重要现象:
现象1:记忆事实类知识(如”李白是唐朝诗人”)的能力只和总参数有关 → 这类知识可以外包给外部记忆库
现象2:解决数学题需要最少”思考深度”(如至少需要5步推导) → 必须保证足够的网络层数
关键定义
计算图(Computation Graph
同态映射(Homomorphism
电路(Circuit
知识(knowledge
实现(Realization
LLM 总结¶
文章《Memory3: Language Modeling with Explicit Memory》主要探讨了一种名为 Memory3 的语言模型,其核心特点是引入了显式记忆机制(Explicit Memory),以增强模型在处理语言任务时的推理能力与信息存储能力。
研究背景与动机:¶
传统语言模型(如 GPT、Transformer 等)依赖于隐式学习(implicit learning)来理解语言,虽然在生成任务中表现出色,但在需要长期记忆或复杂推理的任务中存在局限。作者提出 Memory3,旨在通过引入显式记忆模块,使模型能够主动存储和检索信息,从而提升其在需要记忆的任务中的表现。
主要内容与方法:¶
显式记忆模块:
Memory3 引入了一个显式的记忆存储器(memory bank),用于存储模型在处理过程中主动选择的重要信息。
模型可以根据当前输入内容,主动决定哪些信息需要存储,并在后续处理中检索这些信息进行推理。
记忆的编码与检索:
记忆信息通过可学习的编码机制进行表示,便于后期检索。
检索机制使用注意力机制(attention)从记忆中找到与当前输入最相关的条目,辅助模型生成更准确的输出。
训练策略:
作者设计了合适的训练目标,使模型在训练过程中学会如何有效使用记忆模块,包括何时存储、何时检索等。
实验与结果:¶
在多个需要记忆和推理能力的自然语言处理任务上(如问答、对话、逻辑推理等),Memory3 显示出优于传统语言模型的性能。
实验表明,显式记忆机制可以显著提升模型在处理长文本、多轮对话和逻辑推理任务中的表现。
总结:¶
《Memory3: Language Modeling with Explicit Memory》提出了一种新的语言模型架构,通过引入显式记忆机制,增强了模型的记忆和推理能力。该方法在多个任务中取得了良好的效果,为未来构建更智能、更具推理能力的语言模型提供了新的研究方向。
Abstract¶
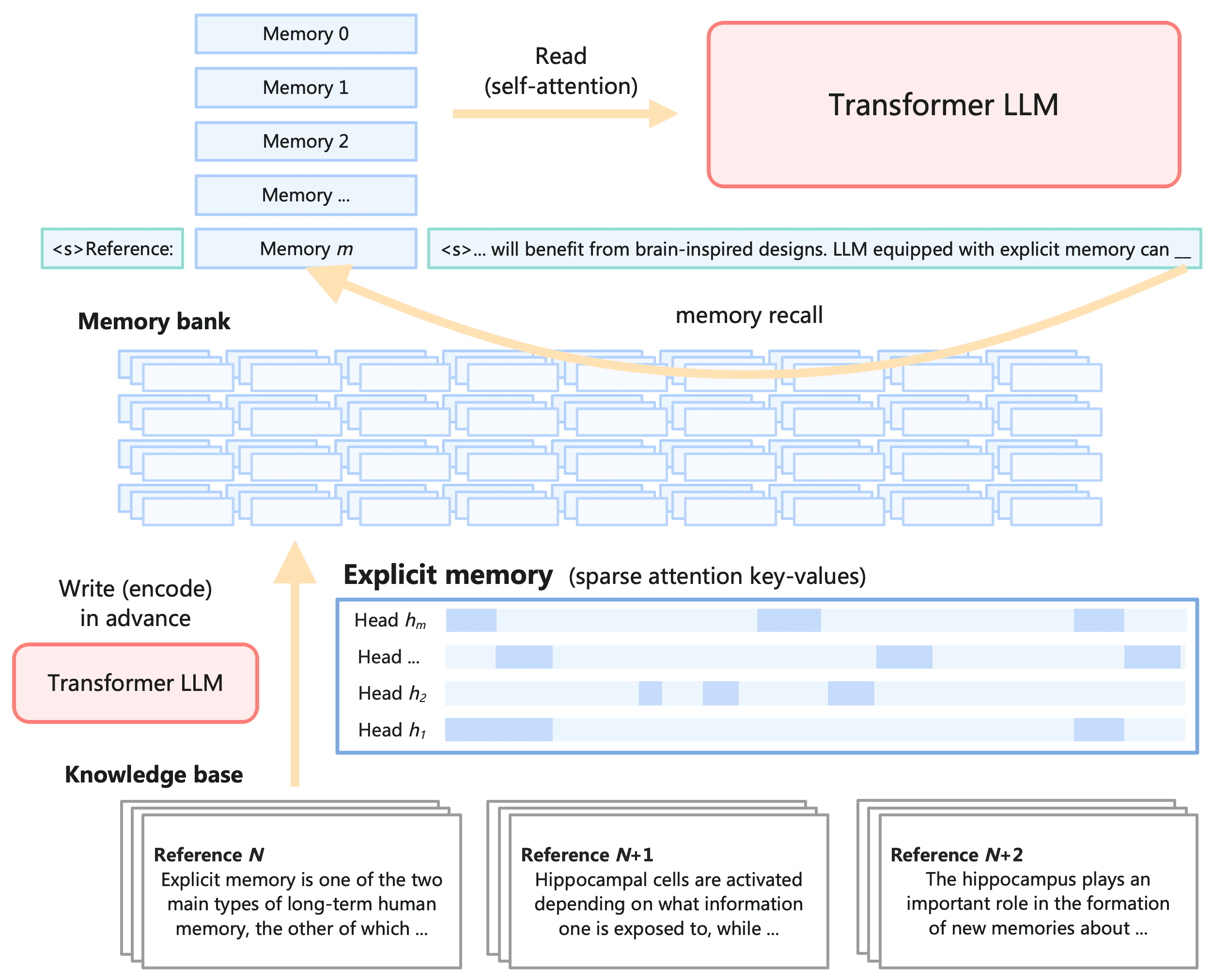
Figure 1:The Memory3 model converts texts to explicit memories, and then recalls these memories during inference. The explicit memories can be seen as retrievable model parameters, externalized knowledge, or sparsely-activated neural circuits.
该论文提出了一种名为 Memory3 的大语言模型(LLM),其核心创新在于引入显式记忆(explicit memory),以降低训练和推理成本。论文主要观点和贡献如下:
核心思想¶
受人脑记忆层级启发,作者提出为LLM引入显式记忆,作为比模型参数(隐式记忆)和上下文缓存(工作记忆)更经济的知识存储方式。
显式记忆可以被检索利用,从而减少对模型参数规模的依赖,降低训练和推理成本。
模型的知识可以分为“抽象知识”(由参数存储)和“显式知识”(由记忆存储),显式知识的外化使得模型规模可以更小,但性能仍可保持。
Memory3 模型特点¶
从头训练了一个2.4B参数的模型,在性能上超越了更大规模的LLM和RAG模型,同时在推理速度上优于RAG。
采用了两阶段预训练方案和记忆稀疏化机制,帮助模型高效地形成和存储显式记忆。
提出记忆电路理论(memory circuitry theory),支持知识从模型参数转移到显式记忆的可行性。
总结¶
该研究通过引入显式记忆机制,探索了一种新的大语言模型架构,试图以更小的模型规模实现高性能和低资源消耗。这为未来LLM的效率优化提供了新的思路,特别是在知识存储与利用方式上。
1 Introduction¶
概要¶
背景与问题¶
近年来,大型语言模型(LLMs) 由于其出色的表现而迅速流行起来。随着可扩展性规律和新兴能力的不断推动,LLMs 的规模越来越大,导致训练和推理成本急剧上升。为了降低这些成本,研究者们在多个方面进行优化,包括架构、数据质量、操作方式、并行计算、优化器、泛化理论和硬件等。
本研究的创新点¶
本文提出了一种优化知识存储的全新方法。作者将 LLM 训练和推理的总成本视为“知识编码”和“知识读取”两部分的总和,并提出了一个数学表达式:
其中:
\( \text{cost}_{\text{write}} \):将知识 \( k \) 编码为存储格式 \( m \) 的成本。
\( \text{cost}_{\text{read}} \):将知识 \( k \) 从格式 \( m \) 读取到推理中的成本。
\( n_k \):知识 \( k \) 在模型生命周期内的预期使用次数。
作者提出了一个新的存储格式——显式记忆(explicit memory),其特点是写入和读取成本均较低。它可以通过少量微调适配大多数 Transformer 模型,具有通用性。
显式记忆的优势¶
显式记忆作为 LLM 的第三种记忆形式(继“工作记忆”和“隐式记忆”),在模型中建立了如下记忆层级:
plain text (RAG) → explicit memory → model parameter
随着层级上升,写入成本增加,但读取成本减少。通过合理分配知识的存储位置,可以最小化总成本。
此外,显式记忆使得 LLM 更加高效。例如,显式记忆可以通过稀疏注意力键值(sparse attention key-values)实现,使得 LLM 可以:
处理更长的上下文,降低计算复杂度;
提高事实性,减少幻觉;
增强可解释性,便于模型自我审查或人类理解。
显式记忆通过将知识编码为稀疏的注意力键值对,并在推理过程中直接调用这些记忆,减少了对模型参数的依赖。这种设计使得现有大多数基于Transformer的模型在少量微调后即可支持显式记忆,具有良好的通用性和扩展性。作者将其方法命名为Memory3(第三种记忆形式),并展示了其在减少预训练成本、提升推理效率、增强事实性、减少幻觉、支持长文本处理等方面的优势。

Table 3:Analogy of the memory hierarchies of humans and LLMs.
此外,作者还类比人类记忆系统,指出显式记忆的引入可以类比于人类将知识从工作记忆转化为长期记忆的过程,从而提高知识处理效率。通过实验验证,Memory3模型在多种任务中表现出色,超越了更大规模的SOTA模型,并在事实性和推理速度方面取得了显著提升。
论文结构¶
本文后续章节的安排如下:
Section 2:提出 Memory3 的理论基础,定义“知识”和“记忆”;
Section 3:讨论 Memory3 的基本设计;
Sections 4-6:详细介绍 Memory3 的预训练和微调过程;
Section 7:评估 Memory3 的性能;
Section 8:总结与未来研究方向。
1.1.2 稀疏计算(Sparse Computation)¶
为了解决知识检索与计算效率之间的矛盾,研究者探索了稀疏性架构,以减少每 token 的参数使用量。
Mixture-of-Experts (MoE):
使用稀疏路由机制,将每个 token 分配给少量专家模块,从而在参数规模和计算成本之间取得平衡。
常见设计中每个 Transformer 块包含多个 MLP 层,通过线性分类器选择最相关的专家。
进一步的优化如 QMoE 引入压缩技术以减少内存负担。
尽管参数效率有所提升(如 Arctic 模型的活跃参数比例约 3.5%),但提升上限通常在 4~32 倍之间。
深度混合架构(Mixture of Depth):
通过早期退出(early exit)或 top-k 路由机制,仅使用模型中部分层级进行计算,可将计算量降低至 12.5~50%。
更细粒度的稀疏性:
Deja Vu 为每层 MLP 或注意力层训练一个低成本网络,预测每个神经元或注意力头对当前 token 的相关性。
推理时保留每个 token 的前 5~15% MLP 神经元和 20~50% 注意力头,实现更细粒度的计算节省。
1.1.3 | 参数即记忆(Parameter as Memory)¶
部分研究将模型参数视为隐式记忆,认为某些神经元可以存储知识。
GPT 中的 MLP 神经元行为:
神经元可被视为键值对(Key-Value),其中第一层权重作为“键”,第二层权重作为“值”。
激活的键通常对应某些人类可理解的模式,值则用于生成最可能的下一个 token。
基于注意力的 GPT 变体:
提出仅由注意力层构成的 GPT 变体,将 MLP 的键值对作为“持久记忆”嵌入注意力机制中。
知识神经元:
发现 BERT 中的事实知识往往集中在少数 MLP 神经元中,称为“知识神经元”,可通过操作这些神经元更新模型知识。
神经网络中的超合(Superposition)现象:
研究发现,一个神经元可以存储多个不相关的概念,这种多语义性机制是神经网络表达复杂知识的一种方式。
总结¶
本节综述了当前语言模型中提升知识访问效率和计算效率的主要技术路线,包括:
检索增强训练:在预训练和微调中引入检索机制,提升模型对知识的访问能力。
稀疏计算架构:通过稀疏路由、混合专家和细粒度剪枝等方法减少计算开销。
参数作为隐式知识载体:揭示模型参数中存储知识的机制,为知识更新和模型优化提供了理论基础。
这些研究为本文提出的高效知识访问与存储方法提供了背景与对比。
2 | Memory Circuitry Theory¶
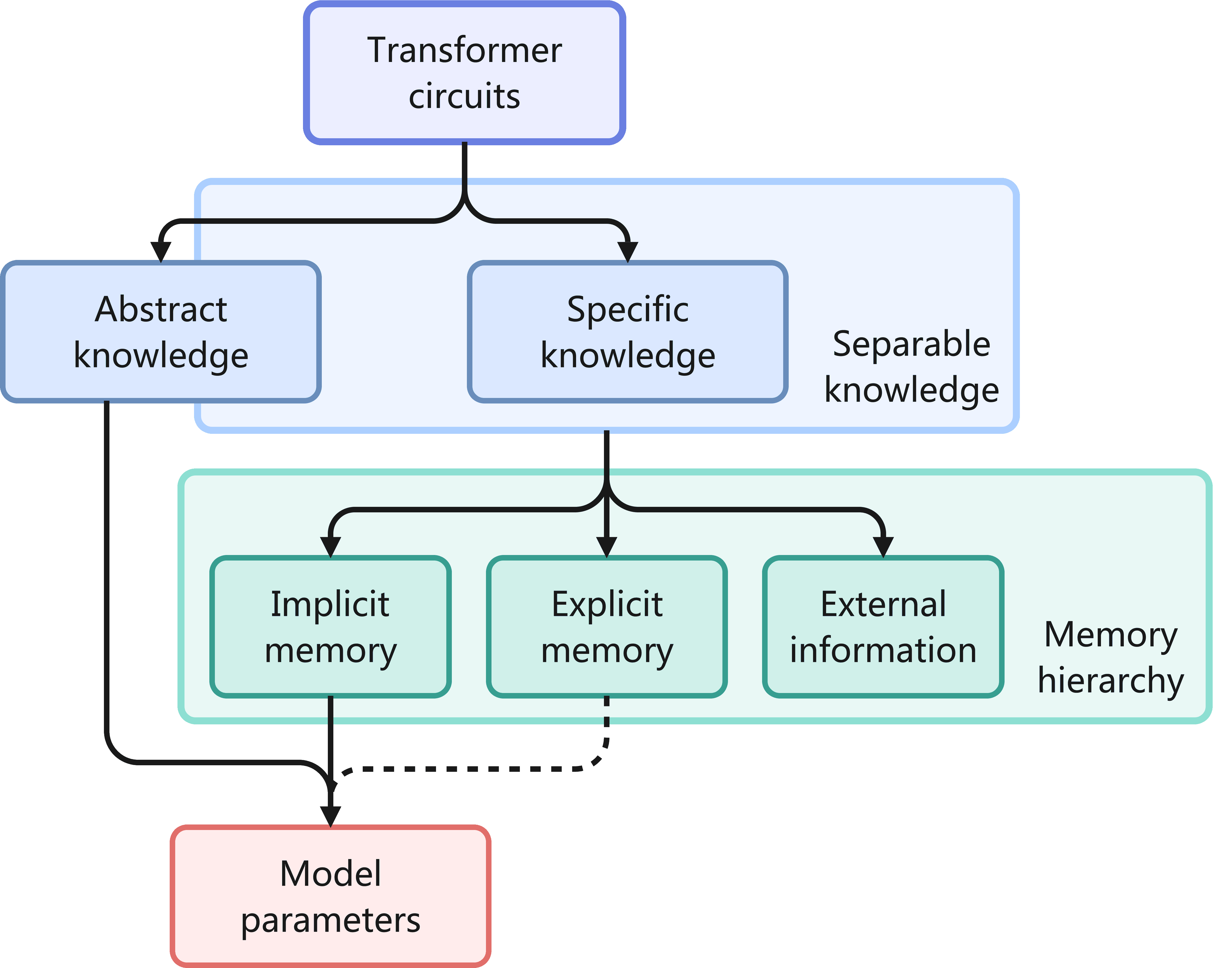
Figure 5:Categorization of knowledge and memory formats. The explicit memories, extracted from model activations, lie half-way between raw data and model parameters, so we use a dotted line to indicate that they may or may not be regarded as parameters.
本节介绍了记忆电路理论(Memory Circuitry Theory),旨在在大型语言模型(LLM)的背景下定义知识与记忆。该理论通过将LLM的计算过程分解为可重复的模块(称为“电路”),帮助我们理解哪些知识可以被提取为显式记忆(explicit memory),并指导适合读写显式记忆的模型架构设计。
2.1 | Preliminaries(预备知识)¶
本节旨在将语言模型的计算分解为更小、可重复的部分,分析哪些部分可以与模型分离。这些小部分被定义为“知识”,这有助于识别哪些知识可以外部化为显式记忆,从而建立记忆层次结构和轻量级主干模型。
行为主义方法的一个例子是定义为小子序列之间的输入输出关系。例如:
如果上下文包含“China”和“capital”,则输出“Beijing”。
如果输入是算术表达式(如“123×456=…”),则输出答案。
如果上下文形式为“[a][b]…[a]”,则输出“[b]”。
这些关系自然适用于自回归语言模型,因为它们可以看作是 n-gram 的升级版。
然而,行为主义方法不足以唯一确定知识,因为一个模型可能基于实际知识或记忆表来回答问题。因此,我们采用白盒方法,即包括模型内部计算在内的定义。
Figure 6:Illustration of three subgraphs. Left: A subgraph that inputs “the capital of China is” and outputs “Beijing”. The knowledge neuron is marked in red and the mover heads in green. Middle: Another subgraph with similar function using task-specific heads. Right: The induction-heads subgraph that inputs “[a][b]…[a]” and outputs [b], where [a], [b] are arbitrary tokens. The notations are introduced in Section 2.2. The locations of these attention heads and MLP neurons may be variable.
我们将输入输出关系的内部机制称为“电路”,并将知识定义为输入输出关系加上其对应的电路。通过操作这些电路,可以将许多知识从模型中提取出来,同时保持模型功能不变。
2.2 | Knowledge(知识)¶
核心概念¶
LLM的”知识”如何被定义?
作者认为,LLM的”知识”本质上是一种可复用的计算模式,通过**计算图(Computation Graph)**中的特定子电路(Subgraph)来体现。
(类比:人脑中的”知识”可能对应特定神经回路,LLM的”知识”对应特定参数组合的计算路径)
关键定义-计算图(Computation Graph, Definition 1)**¶
是什么:描述LLM处理文本时的完整计算过程,类似”神经网络的数据流图”
节点:每一层(注意力层/MLP层)的隐藏状态向量
边:
注意力边:token之间的注意力交互(如”猫”关注到”动物”)
MLP边:MLP神经元对特征的变换
边权重:用两种方式衡量影响:
干预法:如果去掉这条边,输出概率的变化(ℒ−ℒ|a=0)
梯度法:边对输出概率的敏感度(∂ℒ/∂a)
子图关联的输入/输出(Definition 1补充)**
关联输入:哪些token显著激活了这个子图(通过梯度∇𝐱判断)
关联输出:哪些token被这个子图显著影响(通过ℒi变化判断)
关键定义-同态映射(Homomorphism, Definition 2)¶
作用:判断两个子图是否属于同一类计算模式 S
规则:
层深度相同(如都在第3层)
token位置关系相同(如都是前一个词影响后一个词)
使用相同的注意力头或MLP神经元
关键定义-电路(Circuit, Definition 3)¶
本质:满足同态关系的子图集合,代表一种”知识”
判定条件:
在随机文本中高频出现
所有子图结构相似(同态)
边权重显著(对输出影响大)
输入-输出模式可解释(如”首都”→”北京”)
关键定义-知识(knowledge, Definition 4)¶
具体知识(Specific Knowledge):
输出固定(如”中国首都=北京”)
例子:知识神经元(Knowledge Neuron)
抽象知识(Abstract Knowledge):
输出不固定但模式可识别(如”[A][B]…[A]→[B]”)
例子:归纳头(Induction Head)
关键定义-实现(Realization, Definition 5)¶
定义:给定一个LLM和一个知识𝒦,如果文本𝐭=(𝑡₀,…𝑡ₙ)的计算图中存在属于𝒦的子图,则称𝐭是𝒦的一个实现
核心要点
什么是实现?
当某个具体文本的计算过程激活了知识𝒦对应的电路(子图),这个文本就是𝒦的”实现”。
类比:知识𝒦是”公式”,文本𝐭是”代入公式的具体例子”。
示例
如果𝒦是”首都查询知识”(𝒦的关联输入=国家名+”首都”,关联输出=首都名),那么:
文本”中国的首都是北京”是𝒦的实现
文本”法国的首都是巴黎”也是𝒦的实现
如果𝒦是”归纳头知识”(模式[A][B]…[A]→[B]),那么:
文本”苹果 甜 香蕉 苹果→甜”是𝒦的实现
关键区别
知识(𝒦):抽象的、可复用的计算模式(如”首都查询功能”)
实现(𝐭):具体体现该知识的文本实例(如”中国首都=北京”这个句子)
为什么重要?**
知识提取:通过分析大量文本的实现,可以反向识别LLM中存在的知识𝒦
可控生成:若要LLM应用特定知识𝒦,只需构造其实现文本(如提示工程)
关联关系
概念 |
本质 |
类比 |
与Realization的关系 |
|---|---|---|---|
知识(𝒦) |
抽象的计算模式 |
“数学公式” |
公式本身 |
电路(S) |
知识𝒦的具体子图实例 |
“公式的具体计算步骤” |
公式在某个例子中的计算过程 |
实现(𝐭) |
激活知识𝒦的文本 |
“代入公式的具体数字” |
公式的输入实例 |
经典案例¶
知识神经元(Example 3)
结构定位:特定MLP层的某个神经元(如第𝑙层第𝑚个神经元)
行为:当输入出现”中国”和”首都”时激活,输出”北京”
特点:典型的具体知识(输入模式明确,输出固定)
数学表达:\(\text{神经元激活值 } a^{l,m}_i = \text{ReLU}(W\cdot[\mathbf{x}^{2l}_\text{中国}; \mathbf{x}^{2l}_\text{首都}])\)
graph LR
A["输入: 中国"] -->|注意力| C[MLP第𝑙层]
B["输入: 首都"] -->|注意力| C
C -->|神经元𝑚激活| D["输出: 北京"]
归纳头(Example 4)
结构定位:两个协作的注意力头(如第𝑙层Headℎ和第𝑙+1层Headℎ′)
行为:完成模式补全(如”苹果 甜 → 香蕉 ?”→”甜”)
特点:典型的抽象知识(输入输出关系是模式化的)
数学表达:\(\mathbf{x}^{2l+2}_\text{输出} = \text{Softmax}(QK^T)\cdot V(\mathbf{x}^{2l}_\text{甜})\)
graph TB
A["位置0: 苹果"] --> B["位置1: 甜"]
B --> C["位置2: 香蕉"]
C --> D["位置3: 苹果"]
D -.->|Headℎ关注| B
B -.->|Headℎ′复制| E["预测: 甜"]
核心假设:完备性假设(Completeness, Assumption 1)¶
“LLM的所有重要计算都可以分解为若干电路的组合”
这意味着:
LLM的能力本质上由这些知识电路的集合决定
提升LLM效率的关键在于:
识别高频重要电路
优化电路的组织方式(如将具体知识外挂存储)
研究意义¶
理论价值:首次将LLM的”知识”形式化为可数学定义的对象
应用方向:
模型可解释性:通过电路分析理解LLM的决策机制
高效架构设计:将频繁使用的知识电路外置(如Memory3论文的核心思想)
通俗总结¶
作者把LLM看作一个由无数”小工具”(知识电路)组成的工具箱:
具体知识像专用工具(如”首都查询器”)
抽象知识像多功能工具(如”模式补全器”) 而LLM的强大能力,来自于这些工具的精妙组合与复用。
2.3 | Memory¶
这一节的核心问题是:哪些知识可以从LLM参数中分离出来,转移到更底层的记忆层级中? 作者通过两个关键定义和一项理论主张给出了答案。
Definition 6 可分离知识(Separable Knowledge)¶
▌ 核心条件
一个知识𝒦被称为可分离的,当且仅当存在另一个LLM(记为𝑀)满足:
知识缺失性:
𝑀本身不具备𝒦,对于𝒦的任何实现文本𝐭,𝑀无法高概率生成𝐭的输出部分(例如至少有一个输出token的生成概率≤50%)。
例:若𝒦是”首都知识”,𝑀无法独立生成”北京”作为”中国首都”的答案。
前缀可激发性:
存在一个特定前缀文本𝐭∗,当以𝐭∗为前缀时,𝑀能高概率(≥90%)生成𝒦的正确输出。
例:若𝐭∗=”以下是事实:中国首都是”,𝑀能补全”北京”。
▌ 实例说明
若𝒦是「中国首都=北京」:
𝑀本身无法回答”中国首都是_”
但给定前缀𝐭∗=”参考:中国首都是北京”,𝑀能正确补全
▌ 与可分离性的关系
graph LR
A[所有知识] --> B[可分离知识]
B --> C[可模仿知识]
B --> D[指令触发型知识]
分支情况处理
如果𝒦的同一输入对应多个可能输出(如”法国首都是巴黎/马赛?”),则在分支点对所有可能输出的概率求和。
Definition 7 可模仿知识(Imitable Knowledge)¶
▌ 强化版可分离性
在可分离知识的基础上增加更强条件:
**任何实现文本𝐭′**都能作为前缀𝐭∗来激活知识(而不仅限于特定前缀)。
本质:通过示例检索(Few-shot Prompting)即可复现知识
# 通过示例模仿知识 prompt = """ 问:中国首都是? 答:北京 问:法国首都是? 答:巴黎 问:日本首都是? 答:""" # 𝑀会输出"东京"
▌ 与可分离性的关系
可模仿性 ⊂ 可分离性
非模仿但可分离的例子:
使用抽象指令(而非具体示例)作为前缀,如𝐭∗=”请严格输出各国首都”。
Claim 1 理论主张¶
** 核心结论**
所有具体知识(Specific Knowledge)都是可模仿的,因此必然可分离。
▌ 证明思路
构造抽象知识电路:
对于模式
[a][b]...[a'][b'](如”中国 北京 法国 巴黎”),构建三部分电路:特征检测层:识别[a]的共性(如”国家名”)
归纳头层:将[a’]关联到[b](类似Example 4)
微调层:根据[b]生成[b’](允许微小变化)
知识擦除与重组:
创建模型𝑀:通过微调使原始LLM”忘记”𝒦(如删除”首都”相关训练数据)
结合抽象电路后,𝑀能通过示例文本重新激活知识。
** 反例思考**
抽象知识(如数学推理能力)可能无法完全通过文本模仿实现,因此该主张的逆命题不一定成立。
▌ 证明逻辑
构造𝑀:通过微调使原LLM「遗忘」𝒦(如删除「中国首都=北京」的训练数据)
构造触发电路:
用归纳头机制检测输入模式(如”X 首都”)
通过单注意力头从前缀𝐭′中复制答案(如𝐭′=”法国 首都 巴黎” → 复制”巴黎”)
通用性:该电路可泛化到任何具体知识(因具体知识输出固定)
▌ 设计启示(Remark 1)
只需极简的跨文本注意力(如仅需关注𝐭′中的关键token对)
该思想直接指导了Memory3的架构设计
Definition 8.记忆层级(Memory Hierarchy)-记忆增强LLM的形式化¶
▌ 关键原则
写入-读取成本权衡:
高频知识:高写入成本 + 低读取成本(如模型参数)
低频知识:低写入成本 + 高读取成本(如外部检索)
动态分配:
根据知识使用频率𝑛,选择最小化总成本的记忆格式:
▌ 实例化
知识类型 |
记忆格式 |
人类类比 |
LLM实现 |
|---|---|---|---|
高频具体知识 |
模型参数 |
母语表达 |
知识神经元 |
中频知识 |
显式记忆 |
专业术语 |
记忆数据库 |
低频知识 |
外部文本 |
临时查资料 |
RAG检索 |
知识外置的实践意义¶
通过这三个定义,作者为Memory3架构提供了理论基础:
▌ 理论基础
具体知识(如事实)可直接外置到记忆库,通过检索增强生成(RAG)实现
抽象知识(如推理模式)仍需保留在参数中,但可通过提示工程调控
效率优化:分离后的小模型+记忆系统的计算成本远低于全能大模型
▌ 对LLM设计的启示
知识分离性:
具体知识(如事实)可安全外置,抽象知识(如推理)需保留在参数中
记忆架构:
需要支持多级记忆访问(如参数/内存/检索协同工作)
示例:Memory3的混合架构(第3章实现)
成本优化:
高频知识应「固化」到模型参数(高写入成本但快速读取)
低频知识动态加载(如检索增强)
▌ 典型案例对比
知识类型 |
可分离性 |
可模仿性 |
外置方法 |
|---|---|---|---|
国家-首都对应 |
✔ |
✔ |
存入数据库,RAG调用 |
归纳头模式 |
✔ |
❌ |
保留参数,Few-shot提示 |
数学证明能力 |
❌ |
❌ |
必须内化于模型参数 |
这种分类方式为构建高效的语言模型记忆层级提供了明确的设计准则。
▌ 附:知识分离性判断流程图
graph TD
A[给定知识𝒦] --> B{输出是否固定?}
B -->|是| C[具体知识→必然可分离]
B -->|否| D{是否可通过示例触发?}
D -->|是| E[抽象但可模仿→可分离]
D -->|否| F[需保留在参数中]
总结¶
本节内容围绕 LLM 的记忆增强机制展开,重点包括:
构建高效电路结构的关键特性;
对记忆增强 LLM 的形式化定义;
写函数与记忆格式的设计;
写成本与读成本之间的反比关系(记忆层次);
根据知识使用频率分配不同内存格式的策略。
这些内容为后续分析 LLM 如何高效利用显式记忆提供了理论基础。
3 | Design¶
▌ 设计目标
核心矛盾:为Transformer大模型设计显式记忆机制,平衡写入成本(存储知识)与读取成本(检索知识)
架构约束:
最小化对Transformer的修改(不新增可训练参数)
兼容现有LLM(通过微调即可升级)
▌ 写入成本
预处理阶段:
将参考数据写入持久化存储的显式记忆库
记忆单元来源:直接复用self-attention层的key-value向量
技术优势:
无训练开销(直接提取现有参数)
单文档独立处理,规避长上下文注意力计算瓶颈
▌ 读取成本
推理时操作:
从存储设备动态加载记忆单元
与常规上下文key-value并行参与self-attention计算
优化设计:
记忆单元精简:仅选取少量attention head的极简key-value
四重收益: ✓ 计算量增量最小化 ✓ GPU显存占用优化 ✓ 存储空间节约 ✓ 加载时间缩短
3.1 | Inference Process¶
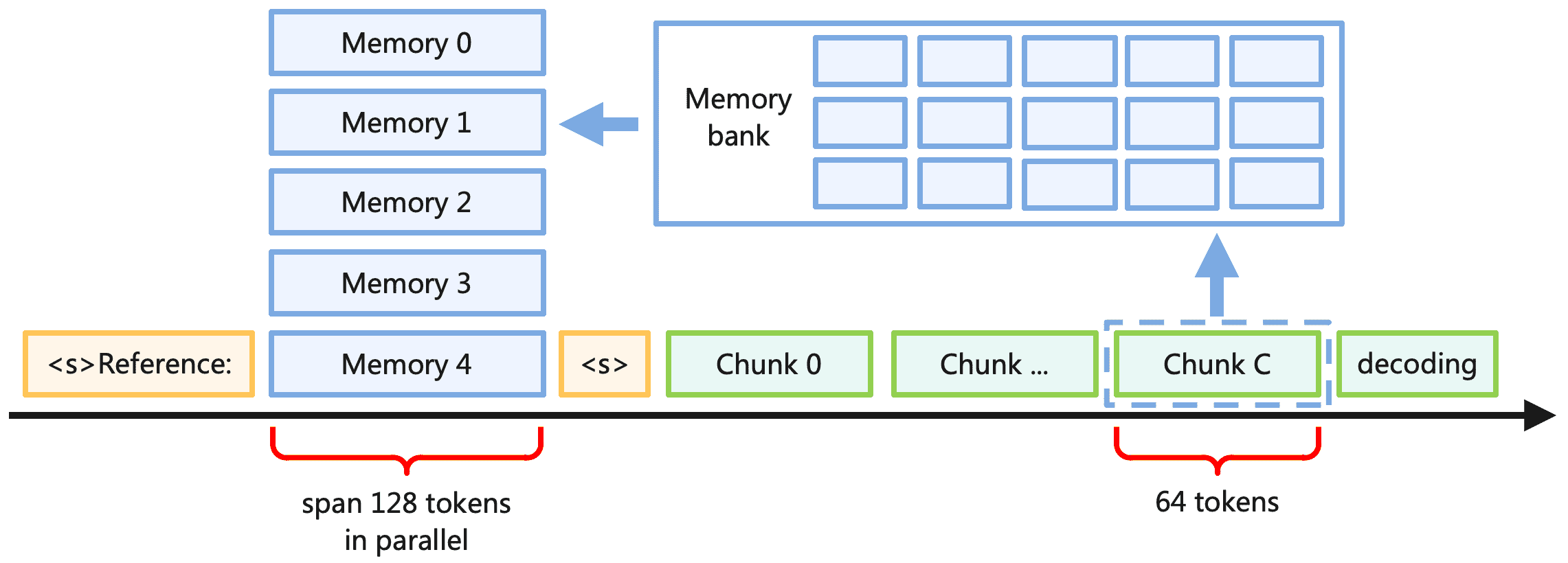
Figure 9:The decoding process of Memory3 with memory recall. Each chunk is a fixed-length interval of tokens, which may belong to either the prompt or generated text.
直白讲解¶
记忆库是什么?
就像一个大图书馆,存了1.1亿本”小册子”(每个小册子不超过128个字)
每本小册子被压缩成一种特殊格式的”记忆胶囊”(22层×2个钥匙/8个抽屉/8个小格子/每个格子80个数字)
使用前的准备(暖启动)
提前把所有小册子都做成”记忆胶囊”存在硬盘里
就像把纸质书都扫描成电子版,用的时候直接调取
实际使用时
每写64个字就暂停一下
用刚写的这64个字当”搜索关键词”
从图书馆找出5个最相关的”记忆胶囊”(用BERT模型找相似度)
继续写作文时可以参考这些胶囊里的内容
关键设计¶
每个参考可被转换为显式记忆(explicit memory),是一个形状为 (22,2,8,8,80) 的张量:
2 表示 key 和 value;
22 表示记忆层数量;
8 表示注意力头数量;
8 表示稀疏 token 数量;
80 表示每个头的维度。
推理前,Memory3 模型将所有参考转换为显式记忆,存储于硬盘或非易失性存储设备。推理时,每当某个参考被检索,其对应的显式记忆会被加载到 GPU 中,参与模型计算。
检索过程:
每生成 64 个 token,模型丢弃当前记忆,用这些 token 作为查询,检索 5 个新记忆,并继续使用这些记忆进行解码。
查询和参考都通过 BGE-M3 模型嵌入,并使用 FAISS 构建向量索引,通过余弦相似度进行检索。
记忆预处理(冷启动 vs 热启动)
冷启动:实时编码检索到的参考文本为显式记忆
热启动:预计算所有记忆并存储(节省推理时间)
缓存机制:
为节省加载时间,在 RAM 中维护一个固定大小的缓存,用于存储最近使用的显式记忆。由于相邻块常检索相同参考,缓存有效降低了加载成本。
可视化流程(Figure 9)¶
graph TB
A[输入提示] --> B[分块处理]
B --> C{每64token}
C -->|检索| D[记忆库]
C -->|生成| E[输出文本]
D --> F[显式记忆KV]
F --> G[注意力层融合]
备注¶
备注 2:理想情况下,检索应由 LLM 本身完成,因为 LLM 更了解自身需求。使用稀疏注意力查询直接检索显式记忆是可行的,且无需微调 LLM。
备注 3:RAG 的一个缺点是参考内容通常只是文本块而非完整文档。Memory3 通过将文档作为完整序列处理,然后将注意力 key-values 块化并稀疏化为显式记忆,解决了这个问题。
3.2 | Writing and Reading Memory¶
每个显式记忆是参考内容在自注意力层中一部分注意力头的 key-value 向量的子集。
推理时,模型通过将显式记忆与常规上下文 key-values 拼接,直接使用自注意力进行读取(见图 9)。
修改模型起始符 BOS 为 “⟨s⟩Reference:”,帮助模型区分参考内容和普通文本。
使用 RoPE(Rotary Position Encoding)进行并行位置编码,避免“中间丢失”现象(middle drop-off),同时增强上下文学习能力。
记忆是什么?
就像学霸读书时做的”知识卡片”:
每张卡片只记录最关键的几句话(8个关键token)
卡片分类存放在不同科目的文件夹里(22个网络层×8个注意力头)
写记忆(做笔记)
预习阶段:
# 把课本知识做成卡片 for 每一段文本 in 知识库: 提取关键问答对(key-value) # 就像划重点 存到对应的文件夹 # 按学科分类
特点:一次性整理好,以后直接用
读记忆(开卷考试)
考试时:
每写完一页答卷(生成64个token)
就快速翻阅5张相关卡片(检索5个记忆)
把卡片内容抄到草稿纸上(加载到GPU)
关键技巧:
graph LR
当前写作内容 --> 磁贴(检索系统)
磁贴 --> 卡片1
磁贴 --> 卡片2
卡片内容 --> 当前注意力计算
为什么比传统方法好?
普通RAG:带着整本参考书考试,找答案慢
Memory3:带着精编笔记考试,精准快速
特殊设计解析
“参考书模式”标记:就像给笔记加彩色标签,让大脑知道”现在是在查笔记”
卡片并行摆放:所有笔记平铺在桌面上,避免堆叠时中间的笔记被压住看不见
实际效果
速度快:每次只查5张精简卡片
质量高:卡片内容经过神经网络精选
省内存:只缓存最近用过的卡片
举个具体例子: 当模型被问到”爱因斯坦的成就”时:
先在知识库找到相关段落
提取出关键信息:E=mc²、光电效应、相对论…
把这些关键词像便利贴一样”贴”在模型的注意力机制里
生成回答时就会自然引用这些信息
3.3 | Memory Sparsification and Storage¶
关键挑战:注意力 key-values 占用太多空间,需要强烈压缩。
压缩维度:
层维度:只将前半部分注意力层设为记忆层(memory layers),后半部分为常规注意力层。
头维度:使用 GQA(Grouped Query Attention),每个 key-value 头由多个 query 头共享,实现 20% 稀疏化。
token 维度:从 128 个 token 中选择 8 个,基于注意力权重进行稀疏化。
头维度:可选使用向量量化(FAISS 构建)压缩 key-value 向量,压缩率约 11.4 倍。
存储优化:原始显式记忆库大小为 7.17PB,压缩后为 45.9TB 或 4.02TB,适合 GPU 集群存储。
部署方案:显式记忆库和索引存储在云端,设备仅需保存模型参数和解码器。推理时,设备将查询向量发送至云端,云端检索并返回压缩记忆。
备注 4:通过验证任务评估注意力头对长距离上下文的贡献程度,可选择一小部分头作为记忆头,提升效率。
备注 5:每个参考只需被一个注意力头读取,可采用类似 MoE 的机制,将参考路由到少量头,进一步提升稀疏性。
▌ 1. 要解决什么问题? 想象Transformer模型需要记住海量知识,如果直接把所有知识都存成原始神经网络的参数,会导致:
硬盘根本存不下(需要7000TB!)
推理时GPU内存爆炸(无法实时计算)
▌ 2. 怎么压缩记忆? 论文用了”四重瘦身法”:
① 层数减肥(像选楼层)
44层的模型只选前22层存记忆
就像图书馆只开放1-22层,其他楼层不放书
② 注意力头减肥(像选书架)
每层原本40个”记忆书架”,现在只留8个
用”组团借书卡”(GQA)让多个读者共享一个书架
③ 单词减肥(像选书页)
每篇文章128个单词,只保留最重要的8个
选择标准:哪个单词被其他单词关注最多(通过注意力权重计算)
④ 向量减肥(像压缩图片)
每个单词的记忆向量从80维压到7维
类似把高清图片转成小尺寸但不影响识别
▌ 3. 最终效果如何?
原始需要 700万GB 硬盘 → 压缩后只要 4000GB
相当于把整个图书馆压缩成一个书架
▌ 4. 实际怎么使用?
写记忆:提前把知识压缩成”精华包”存硬盘
例:”爱因斯坦” → 只存”相对论 E=mc²”等关键信息
读记忆:用时快速加载到GPU
就像查字典时直接翻到标红的重点词条
▌ 5. 为什么能这样压缩?
大脑原理:我们记事情也不是逐字存储,而是记关键点
实验发现:模型只用少量”记忆神经元”就能有效回忆
▌ 通俗类比: 就像准备考试时:
傻办法:把整本教材背下来(原始Transformer)
聪明办法:只记老师划的重点+自己的笔记摘要(Memory3)
3.4 | Model Shape¶
目标:最小化总成本,使得模型参数(隐式记忆)只存储抽象知识和高频具体知识,而其余具体知识外部化为显式记忆。
模型参数设定:
参数规模 P = 2.4B;
模型结构为 L=44(Transformer 层数),H=40(注意力头数),Hkv=8(key-value 头数),dh=80(头维度),W=3200(MLP 宽度)。
训练目标:最大化抽象知识与具体知识的容量比,在固定参数规模下优化 L 与 H 的比值。
实验验证:通过控制实验发现 L:H≈1 的结构在训练初期损失下降更快,因此采用该比例配置。
注意机制:采用 GQA,减少 key-value 头数量;MLP 层数为 2,无偏置,符合现代标准设定。
▌ 1. 核心思想类比: 想象你要组建一个科研团队,有2.4亿元预算:
具体知识 = 资料库(可以外包给图书馆)
抽象知识 = 研究员的大脑(需要高智商人才) 这篇论文说的就是:应该把大部分钱用来雇佣更多教授(增加层数L),而不是买更多书籍(扩大参数P)
▌ 2. 模型结构选择的依据:
层数(L)就像研究团队的”职称等级”:
44层 = 44级职称(从助理教授到院士)
越深层=越强的抽象思维能力
注意力头(H)就像团队的”专业方向”:
40个头=40个不同学科组
更多方向=更强的多任务处理能力
▌ 3. 为什么这样分配参数: 实验发现两个重要现象:
现象1:记忆事实类知识(如”李白是唐朝诗人”)的能力只和总参数有关 → 这类知识可以外包给外部记忆库
现象2:解决数学题需要最少”思考深度”(如至少需要5步推导) → 必须保证足够的网络层数
▌ 4. 具体配置的含义: 以最终采用的44层/40头为例:
每层相当于一个”研究所”
每个注意力头相当于所里的”课题组”
头维度80=每个课题组的”研究人员数量” 这样的结构特别适合:
底层(1-22层):处理基础语言特征(像研究所的实验室)
中层(23-33层):进行知识整合(像学术委员会)
高层(34-44层):完成抽象推理(像院士团队)
▌ 5. GQA设计的好处: 把40个课题组分成8个”大方向”(8个键值头):
查询时可以灵活组合(40种问法)
但存储知识时只需记8个版本的答案 → 相当于建立8个共享资料库,节省存储空间
▌ 6. 最终效果: 这样的设计就像:
雇佣了大量高级研究人员(深网络)
建立高效的共享资料系统(GQA)
把琐碎资料存在外部图书馆(显式记忆) 用2.4B参数实现了:
普通模型需要10B参数才能达到的推理能力
同时保持处理具体知识的高效率
简单来说,这个设计的精髓就是:把参数的”编制”尽量分配给负责抽象思维的”高级人才”(深层网络),而把具体知识存储外包出去。
3.5 | Training Designs¶
本节重点介绍Memory3模型的训练设计,目标是通过学习抽象知识来减少模型对具体知识的依赖,从而降低训练计算量。传统的大模型训练往往同时学习抽象和具体知识,而本文认为应重新设计训练方案,以优化模型学习抽象知识的能力。
形象讲解¶
▌ 核心思想(就像做菜)
传统LLM训练 = 把所有食材(知识)一锅炖 → 成本高效果差
Memory3的做法 = 先分类处理:
抽象知识(如数学原理)→ 让模型学习
具体知识(如明星生日)→ 存到外接”移动硬盘”(显式记忆)
▌ 为什么需要特殊训练方法(好比运动员训练)
传统训练:要求”记忆+推理”全能 → 训练量大
现在只需专攻”推理”单项 → 需要调整训练计划:
数据:只给需要动脑的内容(如数学题)
初始化:从小脑量开始训练(避免死记硬背)
正则化:严格防止死记硬背(类似控制饮食)
▌ 具体改进方案(三个关键调整)
数据选择: 就像教孩子数学时: ✓ 用纯算术题(抽象) ✗ 不用带明星年龄的数学题(避免分心)
参数初始化: 类似”从简单题开始训练”:
传统:直接给复杂题
Memory3:从更基础的题开始(调小初始化范围)
权重衰减: 相当于”强制复习重点”:
加大惩罚力度,让模型专注通用解法
防止记住具体题目答案
简单说就是:既然不用记那么多具体知识了,训练方法也要跟着改,就像专攻马拉松的运动员和十项全能选手的训练方法肯定不同。
1. 数据(Data)¶
关键目标是使用高浓度的抽象知识和尽可能少的具体知识的预训练数据。
已有研究表明,数据中如果混入大量具体知识(如随机数字),会导致模型无法有效学习抽象知识,除非模型规模大幅增加。
Phi-3模型的数据组成与这一目标一致,其训练数据强调推理能力,避免包含过于具体的信息。
2. 初始化(Initialization)¶
使用较小标准差的参数初始化(如标准差小于 -1/2 的指数级)可以鼓励模型学习组合推理而非简单记忆。
通过一个算术数据集的实验发现,模型在初始化参数较小时更容易理解规则的结构而非死记硬背。
理论上,这种初始化方式有助于模型进入“稀疏解”区域,避免陷入“核函数/临界区域”中。
3. 权重衰减(Weight Decay)¶
增大权重衰减系数(如大于 0.1)有助于模型学习泛化性更强的表示。
实验显示,这种方式能加速模型从“训练准确但测试失败”到“训练和测试都成功”的过渡(即“grokking”现象)。
理论上,生成模型比回归模型更需要强正则化,以防止生成分布退化为训练数据本身。
总结¶
推荐的训练策略包括:
使用强调抽象知识、减少具体信息的数据;
小初始化;
大权重衰减。
但当前版本的Memory3模型由于处于初步阶段,尚未尝试这些优化设计,希望在后续版本中加以实现。
3.6 | Two-stage Pretrain(两阶段预训练)¶
Memory3模型在预训练期间学习如何写入和读取显式记忆,这一过程通过在训练数据前拼接检索到的参考内容,并在自注意力机制中集成这些显式记忆。
形象讲解¶
为什么需要两个阶段?
就像教小孩学习:
先学基础认字(warmup阶段)
再学用字典查生字(continual阶段)
如果一开始就给字典,孩子根本不会用,反而干扰学习
具体两个阶段:
Warmup阶段(热身):
普通语言模型训练
不用外部记忆
目标:建立基础语言理解能力
Continual阶段(持续训练):
加入记忆功能
每64个token可以查看5个”记忆笔记”
目标:学会有效使用记忆
关键技巧:
记忆共享:多个文本块共用记忆,减少计算量(类似同学之间传阅笔记)
防作弊检测:确保训练文本和记忆内容不能太相似(超过90%相似就排除)
实验发现:
直接带记忆训练 → 模型根本学不会用记忆
先普通训练再加记忆 → 模型能学会有效利用记忆
类比理解: 想象学习驾驶:
第一阶段:在空旷场地练习基础操作(warmup)
第二阶段:实际上路学习使用导航(continual) 如果一开始就直接上路用导航,新手司机根本处理不过来
这种设计确保了模型先掌握基本能力,再学习如何借助外部记忆增强表现,就像人类的学习过程一样。
1. 两阶段训练设计¶
第一阶段:Warmup(预热)
使用普通预训练方式,不引入显式记忆。第二阶段:Continual Train(持续训练)
引入显式记忆,模型通过实时编码参考内容并利用这些记忆进行推理。
关键发现:
从零开始训练时,直接使用显式记忆效果不佳,训练损失没有明显下降。
但若以普通预训练的检查点为基础,再进行引入显式记忆的持续训练,训练损失会显著下降。
因此,Memory3模型需要一个无记忆的预热阶段,以帮助模型理解记忆的结构和用法。
2. 降低持续训练成本¶
在推理阶段,每个64-token块会访问5个显式记忆(相当于5个128-token的参考段),输入token数增加10倍。
在训练阶段,为了降低成本,允许不同块共享参考内容。
每个训练序列由32个块组成,总共引入4096个参考token。
为节省计算资源,参考token的隐藏状态在经过最后一个记忆层后即被丢弃,因为它们不再参与训练token的更新。
3. 防止信息泄露¶
为防止训练序列与参考内容高度重复,设置了一个重合度限制(overlap > 90% 的不允许)。
重合度计算方式是:两个序列的最长公共子序列长度除以参考序列长度。
此外,要求重合部分的token在位置上也不能太分散,以防止重合度被高估。
总结¶
Memory3 通过引入显式记忆机制,实现了高效检索和存储大规模知识的目标。其设计在保持 LLM 架构不变的前提下,通过稀疏注意力、向量检索、云端存储等策略,显著降低了显式记忆的计算和存储成本。该模型不仅适用于大规模 GPU 集群,也便于部署在边缘设备上。通过优化模型结构和稀疏化策略,Memory3 在提升模型知识覆盖能力的同时,兼顾了训练和推理效率。
4 | Pretraining Data¶
本节主要介绍Memory3模型预训练数据的收集与筛选流程,包括预训练数据集的构建方法以及知识库(参考数据集)的建立。
4.1 | Data Collection(数据收集)¶
预训练数据主要来源于英文和中文文本,包括网页、书籍、代码、监督微调数据(SFT)和合成数据。整体数据量庞大,未筛选前约为200TB(英文)和500TB(中文)。
英文数据主要来自RedPajamaV2、SlimPajama和The Piles,这三个数据集在预处理前合计为200TB。
中文数据主要来自Wanjuan、Wenshu和MNBVC,合计约500TB。
代码数据来源于GitHub,选取的是星标数最高的仓库。
SFT数据也被包含在预训练数据中,但由于在预训练阶段所有token都参与损失计算(而非仅答案部分),因此被视为普通文本处理。
另外还包含部分合成数据以增加多样性。
4.2 | Filtering(数据筛选)¶
数据筛选分为三个步骤:去重(Deduplication)、规则过滤(Rule-based Filtering)和模型过滤(Model-based Filtering)。
去重(Deduplication):大部分数据集使用MinHash算法进行去重,但RedPajamaV2已经自带去重标签,因此无需额外处理。
规则过滤(Rule-based Filtering):采用启发式规则,过滤掉不适合训练的低质量文本。例如:
文档中英文字符比例过高;
单词平均长度超过10个字符;
包含过多非字母字符(如网页源码、随机数字);
独立词比例异常高;
单字节熵过低(即内容重复性过高)等。
模型过滤(Model-based Filtering):使用一个微调后的Tiny-BERT模型作为质量评分器。该模型基于XinYu-70B通过提示生成的方式标注了10,000个样本,使其学会判断文本的“信息量”,评分范围为0到5。最终,该BERT模型用于对整个数据集进行评分和筛选。
备注6:Memory3的预训练数据应强调抽象知识,减少具体知识,以利于模型学习并在推理中避免干扰。但当前的“信息量”评分可能偏向具体知识,因此未来版本将转向更侧重推理能力的模型过滤方法。
筛选后的预训练数据总包含约4万亿个token。
4.3 | Tokenizer(分词器)¶
分词器主要支持中英文混合文本:
英文词汇基于LLaMA2的32000个token。
中文词汇通过**字节对编码(BPE)**生成,训练语料为20GB的中文新闻和电子书。
去重后最终词汇表共包含60299个token。
4.4 | Knowledge Base(知识库)¶
知识库(参考数据集)在训练和推理阶段作为显式记忆的来源,用于检索补充信息,如图1所示。知识库中的文本被切分为128个token以下的片段,以适应模型设计要求。
数据来源包括:
英文维基百科(Wikipedia)
WikiHow
中文百科(baike)
学术风格的中英文书籍
中文新闻
高质量代码
合成数据
总参考量为1.1×10⁸条记录,每条记录长度为128个token。
为防止评估数据泄露,评估时会对检索到的参考内容进行重合度检测,若与问题重合度超过阈值(2/3),则会被丢弃。该方法与持续训练时的去重方法类似,用于保障评估的可信度。
备注7:目前知识库的构建依赖人工偏好,未来将转向模型导向的方法,通过参考内容对验证损失的降低程度来衡量其有效性。
总结¶
本章系统介绍了Memory3模型预训练数据的构建过程。从大规模英文和中文数据的采集,到多步骤的高质量筛选,再到定制化的分词器和知识库的构建,每个环节都体现出对数据质量与模型训练效率的重视。未来将通过模型驱动的方式进一步优化数据筛选和知识库构建策略,以提升模型的推理能力和知识管理能力。
5 | Pretrain¶
本节详细描述了 Memory3 模型的预训练过程。预训练分为两个阶段(two-stage pretrain),并采用memory-augmented data(记忆增强数据)的方式,设计参考了论文第 3.6 节的内容。在 warmup 阶段,模型发展出必要的阅读理解能力,这为后续 continual train 阶段 中的记忆形成提供了基础。
5.1 | Set-up(设置)¶
训练框架与精度设置:使用 Megatron-DeepSpeed 框架,采用混合精度训练(bfloat16 模型参数和激活、float32 AdamW 状态)。
批量大小:训练批量大小约为 400 万 token,序列长度为 2048(不包括参考 token)。
权重衰减:使用常见的 0.1。
学习率安排:采用 MiniCPM 提出的 “warmup-stable-decay” 学习率调度,相较于通常的 cosine 调度,该方法在降低训练损失方面效果更优。学习率线性增长到最大值后保持一段时间,最后 10% 步数快速衰减至接近 0。实验初步验证了该调度的有效性。
重点:尽管该学习率调度表现良好,但由于训练过程中频繁出现损失激增和发散(loss divergence),最终不得不手动降低学习率以稳定训练。
训练数据总量:原计划 warmup 和 continual train 阶段均使用完整的 4T token 数据集(参见第 4 节)。但由于损失发散问题严重,两个阶段均提前终止。
5.2 | Warmup Stage(预热阶段)¶
目标:在该阶段,模型不引入显式记忆(explicit memory),主要建立基础的语言建模能力。
训练表现:训练损失和学习率调度如图 13 所示。在每次发生严重损失发散时,会从上一个检查点重新训练,但将学习率降低。最终在约 3.1T token 时,即使降低学习率也无法避免发散,训练终止。
重点:该阶段的训练损失曲线和学习率安排显示出模型的不稳定行为,表明 warmup 阶段本身已经接近发散的边缘。
5.3 | Continual Train Stage(持续训练阶段)¶
引入显式记忆:这是 Memory3 的核心创新点,模型在该阶段开始使用显式记忆来辅助语言建模。
训练速度:由于需要在每一步实时将检索出的参考内容编码为显式记忆,训练速度变慢,每一步的耗时是 warmup 阶段的 两倍以上。
训练表现:训练损失和学习率调度如图 14 所示。在约 120B token 时,损失发散变得不可控,训练被迫停止。
重点:该阶段的训练发散比原计划的 4T token 数据要早得多。一个可能的原因是 continual train 阶段是从 warmup 阶段将要发散时的检查点初始化的,因此本身已处于不稳定状态。虽然 continual train 阶段使用了较小的学习率,但这只是延缓了发散,并未彻底解决问题。
总结¶
预训练整体结构:两阶段预训练(warmup + continual train)+ 显式记忆增强数据。
关键挑战:训练过程中频繁出现的损失发散问题,迫使两个预训练阶段均提前终止。
创新与稳定性权衡:虽然 continual train 阶段引入了显式记忆,是模型的核心创新点,但其计算开销和训练稳定性问题成为实际部署中的主要障碍。
未来改进方向:可能需要优化学习率调度、改进显式记忆的编码方式,或增强模型的鲁棒性以应对大规模训练中的不稳定性。
6 | Fine-tuning and Alignment¶
6 | 微调与对齐¶
本节主要介绍 Memory3 模型的微调过程,包括监督微调(SFT) 和 直接偏好优化(DPO) 两种方法。
6.1 | 监督微调(Supervised Finetuning)¶
Memory3 的监督微调借鉴了 StableLM 的方法,使用了多个公开的 SFT 数据集进行训练,这些数据集可通过 Hugging Face Hub 获取。具体包括以下数据集:
数据集 |
来源 |
样本数量 |
|---|---|---|
UltraChat |
HuggingFaceH4/ultrachat_200k |
194,409 |
WizardLM |
WizardLM/WizardLM_evol_instruct_V2_196k |
80,662 |
SlimOrca |
Open-Orca/SlimOrca-Dedup |
143,789 |
ShareGPT |
openchat/openchat_sharegpt4_dataset |
3,509 |
Capybara |
LDJnr/Capybara |
7,291 |
Deita |
hkust-nlp/deita-10k-v0 |
2,860 |
MetaMathQA |
meta-math/MetaMathQA |
394,418 |
多轮对话(合成) |
synthetic |
20,000 |
数学(合成) |
synthetic |
20,000 |
常识(合成) |
synthetic |
150,000 |
知识(合成) |
synthetic |
270,000 |
重点内容:
每个训练样本包含一个或多个轮次的问答对。
为防止过长的对话影响训练效率,移除了超过八轮的样本。
除了真实数据外,还引入了合成数据,重点覆盖多轮对话、数学、常识和知识领域。
使用 余弦学习率调度,最大学习率为 \(5 \times 10^{-5}\),前 10% 为线性预热(warmup)阶段。
权重衰减设为 0.1,批量大小为 512,最大序列长度为 2048 个 token。
共训练 3 个 epoch。
6.2 | 直接偏好优化(Direct Preference Optimization)¶
在监督微调之后,Memory3 进一步通过 DPO(Direct Preference Optimization)进行微调,以对齐人类偏好并提升对话能力。
重点内容:
DPO 数据集包括以下三类:
通用对话(UltraFeedback Binarized)
数学问题(Distilabel Math)
编程问题(Synth Code)
使用 余弦学习率调度,最大学习率为 \(4 \times 10^{-6}\)。
DPO 损失函数中的反温参数 \(\beta\) 设置为 0.01。
DPO 带来的性能提升在 第 7.2 节(关于对话能力评估)中进行了展示,说明其有助于提升模型的对话表现。
总结:
Memory3 在训练过程中结合了监督微调(SFT)和直接偏好优化(DPO)两种方法,前者通过多样化数据提升模型的通用能力,后者则聚焦于对齐人类偏好和改进对话表现。整体训练策略注重数据多样性、模型效率以及最终的对话质量。
7 | Evaluation¶
7 | 评估¶
本部分评估了 Memory3 模型的综合能力、对话能力、专业能力(法律与医学领域)、事实性与幻觉问题,以及推理速度。模型与当前最先进的 LLM(大型语言模型)和 RAG(检索增强生成)模型进行了比较。
7.1 | 综合能力¶
在综合能力评估中,作者采用了 Huggingface 领跑榜中的多个任务,并加入了两个中文任务。评估结果如表16所示,主要指标包括 ARC-C、HellaSwag、MMLU、Winogrande、GSM8k、CEVAL 和 CMMLU 等。Memory3 在非嵌入参数仅为 2.4B 的情况下,在多个任务上表现优于参数量更大的模型,例如 Llama2-7B 和 Llama2-13B,其平均性能提升了 2.51%。
此外,作者展示了使用向量压缩技术的 Memory3 模型,结果表明记忆压缩(压缩为原大小的 8.75%)对性能无明显影响。在零样本任务上,Memory3 表现优于 Retro++ XXL 模型(参数量 9.5B)。
7.2 | 对话能力¶
在对话能力评估中,作者使用了 MT-Bench 多轮对话基准测试。表格18展示了 Memory3 在 MT-Bench 中的得分,与多个主流模型(如 Phi-3、Mistral、Qwen 等)进行比较。尽管参数量较小,Memory3 在 DPO 微调后得分达到 5.80,优于部分参数量更大的模型,如 Vicuna-7B 和 Falcon-40B-Instruct。
7.3 | 幻觉与事实性¶
LLMs 容易产生幻觉,即生成不准确或虚构的内容。因此,作者对 Memory3 的事实性进行了评估,使用 TruthfulQA、HaluEval 和 HalluQA(中英文数据集)进行测试。表19显示,Memory3 在多个数据集上表现最佳,尤其在 TruQA 和 HalluQA 上得分显著高于其他模型。这表明,显式记忆机制有助于减少幻觉,提升事实准确性。
7.4 | 专业任务¶
为了验证 Memory3 在特定专业领域的适应能力,作者分别测试了法律和医学任务。法律任务基于中国司法考试数据集(JEC-QA),医学任务基于 C-Eval 和 MMLU 的医学相关子集。作者通过扩展知识库引入领域特定参考文献,并验证 Memory3 的推理性能。结果显示,Memory3 在法律和医学任务上均优于多个 RAG 模型和 LLM(如 MiniCPM、Gemma、Llama 等),尤其是在引用量为 3 至 5 时表现最佳。
7.5 | 推理速度¶
最后,作者评估了 Memory3 的推理速度,以每秒生成的 token 数作为衡量标准。测试在 A800 GPU 和 Jetson AGX Orin 端侧设备上运行,与 RAG 模型进行对比。表21展示了各模型在有无检索情况下的吞吐量。结果表明,尽管 Memory3 需要频繁检索显式记忆,其吞吐量仍优于多个同规模模型。
值得注意的是,当前实现存在一定的性能瓶颈,例如显式记忆从磁盘加载到 GPU 的延迟,以及基于 Python 的 chunkwise attention 实现。作者计划通过优化代码,如使用 CUDA 核心实现 chunkwise attention,以提升性能。
总结¶
Memory3 通过引入显式记忆机制,在综合能力、对话能力、专业任务、事实性与推理速度等方面表现出色,尤其是在小参数量下能够达到甚至超过大模型的性能。同时,显式记忆机制不仅提升了模型的事实准确性,还降低了部署和更新知识的成本,具有良好的工业应用潜力。
8 | Conclusion¶
8 | 结论¶
总体目标¶
本研究的目标是降低大语言模型(LLM)的训练和推理成本,或者说,构建一个在性能上媲美更大的、更慢的LLM,但效率更高的模型。
研究者从“知识操作”的新视角分析了LLM,将LLM的计算成本视为“知识”在不同内存格式之间传输的成本。文中指出了两个效率低下的原因:知识的非最优放置以及知识遍历问题。
为了解决这两个问题,作者提出了显式内存(explicit memory)这一新型内存格式,并配合新的训练方案和模型架构。初步实验中的Memory3-2B模型展现出比许多更大规模的SOTA模型更强的能力和更高的推理速度,甚至优于基于检索增强生成(RAG)的技术。
未来工作方向¶
1. 基于抽象知识的高效训练¶
理想情况下,Memory3模型的训练成本应与少量的不可分知识成正比,接近人类的学习效率。一种方法是过滤训练数据,最大化抽象知识、最小化具体知识(具体可参考第3.5节和第4.2节的备注6)。此外,模型应该具备自我评估训练数据质量的能力,忽略无用的token。
2. 类人能力的探索¶
如引言所述,显式内存设计支持一些有趣的认知功能,包括:
处理无限上下文(通过工作记忆向显式记忆的转换);
记忆巩固(显式记忆向隐式记忆的转换);
有意识推理(对记忆召回过程进行反思)。
这些设计可能进一步提升Memory3的效率和推理能力。
3. 显式内存的紧凑表示¶
人类的显式记忆可以分为情景记忆(特定经历)和语义记忆(普遍事实)。这一分类与文中提出的“具体知识”和“抽象知识”相对应。当前的Memory3显式内存更接近于情景记忆,因为每个记忆都直接对应一个参考文本。为了提升推理能力,可以尝试为Memory3引入语义记忆,例如通过对情景记忆进行归纳得到。
其他工程优化方向¶
除了上述研究方向,还有许多工程层面的改进空间,例如:
实现内部化的检索过程,将稀疏注意力查询与显式记忆键匹配(备注2);
更稀疏的显式内存头,结合路由机制(备注5);
完整保留上下文的内存提取(备注3);
根据机器偏好编译知识库(备注7);
降低显式内存的时间消耗,使其与计算开销成比例(备注8)。
这些工程改进将有助于提升模型的性能与效率。
Acknowledgement¶
致谢¶
本研究得到了中国国家自然科学基金委(NSFC)重点项目“可解释与通用下一代人工智能”的资助(项目编号:92270001)。
作者感谢徐志强教授、林舟翰教授、刘芳睿、杭良凯、陶子扬、王啸星、王明哲、金永琪、何浩田、黄冠华、胡伊荣等人提供的有建设性的讨论。
Appendix A Cost Estimation¶
本节提供了图 4(见参考文献)的计算过程,将“成本”等价于计算量(以 Tflops 为单位)。使用的是 2.4B 参数的 Memory3 模型作为骨干模型。
模型参数设定¶
Transformer 块数量:L = 44
查询头数量:H = 40,键值头数量 Hkv = 8
头维度:dh = 80,隐藏维度 d = 3200
MLP 宽度:W = d
词表大小:nvocab = 60416
记忆层深度:Lmem = 22
知识与记忆相关的设定¶
每个知识 𝒦 通过一个长度为 128 token 的文本表示
每个记忆头存储 8 token
每个 chunk 长度为 64 token
目标是比较 隐式记忆(Implicit Memory)、显式记忆(Explicit Memory) 和 RAG(Retrieval-Augmented Generation) 的成本
A.1 | Implicit Memory¶
(隐式记忆)
写入成本(Training Cost)¶
假设知识 𝒦 写入模型参数需要 1 步训练
训练 cost 公式为:
\[ \text{cost}_{\text{write}} \approx 2.24~\text{TFlops} \]写入成本来源于模型参数更新所需的计算量,包括嵌入、注意力、MLP 等所有模块
读取成本(Inference Cost)¶
下界设为 0,因为隐式记忆无需额外操作
但实际中其读取成本与模型调用次数有关,难以估计
为公平比较,设为 0
A.2 | Explicit Memory¶
(显式记忆)
写入成本¶
写入主要包括:
Lmem 层自注意力操作
Lmem - 1 层 MLP
Lmem 次 token 稀疏化操作
总成本公式为:
\[ \text{cost}_{\text{write}} \approx 0.308~\text{TFlops} \]
读取成本¶
读取时,一个 chunk 访问记忆模块中的 token
成本来源为注意力操作
总成本公式为:
\[ \text{cost}_{\text{read}} \approx 1.44 \times 10^{-4}~\text{TFlops} \]
A.3 | External Information¶
(RAG)
写入成本¶
RAG 的写入成本设为 0,因为知识作为文本存储
读取成本¶
读取时,插入外部参考文本,导致注意力复杂度增加
成本公式为:
\[ \text{cost}_{\text{read}} \approx 0.624~\text{TFlops} \]
总结与对比¶
不同方式的总成本(写入 + 读取)如下:
其中 n 为知识的使用次数。在 n ∈ (0.494, 13400) 时,显式记忆的总成本最低,是最优选择。
附注:知识保留问题(Remark 9)¶
当模型参数更新时(如微调),隐式和显式记忆都可能失效
通用做法是加入部分预训练数据防止灾难性遗忘
显式记忆在模型更新后也需重新生成,才能被读取
未来研究方向:设计对模型更新更鲁棒的记忆机制
总结¶
本附录通过量化模型参数更新、显式记忆构建和外部知识插入的计算量,对比了三种知识存储方式的成本。结果显示,在合理使用频率范围内,显式记忆是最优选择。同时,也指出模型更新对知识存储的挑战,为后续研究指明方向。
Appendix B Vector Compression¶
附录 B 向量压缩¶
本节主要介绍了与正文第3.3节和第7.1节中讨论的向量量化器(vector quantizer)相关的实现细节。
关键向量量化器的结构¶
文中使用了 FAISS 的复合索引(composite index),其索引类型为 OPQ20x80-Residual2x14-PQ8x10。该量化器的主要作用是将 80 维的 bfloat16 向量 压缩为 14 维的 uint8 向量。通过这种方式,向量的存储空间大大减少,压缩率约为:
重点说明:这里的压缩率计算方式是将原始向量的总字节数(每个 bfloat16 占 2 字节,共 80 维)除以压缩后的向量总字节数(每个 uint8 占 1 字节,共 14 维)。因此,压缩效率较高,对存储和检索性能都有显著帮助。
向量量化器的训练过程¶
为了训练该量化器,作者采取了以下步骤:
样本采集:从知识库中均匀且独立地采样参考内容(references),以确保训练数据的广泛性和代表性。
编码为显式记忆:使用 Memory3-2B-SFT 模型 将这些参考内容编码为显式记忆中的键值向量(key-value vectors)。
输入量化器:将这些键值向量输入到向量量化器中,用于训练和优化量化过程。
重点说明:采样过程是无偏的,即不偏向于任何特定任务在评估中可能检索到的内容。这样可以确保量化器的泛化能力,使其在面对多样化任务时具有稳定的性能表现。
总结¶
本节详细介绍了向量压缩的技术实现,特别是使用 FAISS 的复合索引来高效压缩高维向量的方法。同时,强调了训练数据的采样策略,确保训练过程的无偏性与泛化能力。这些技术共同支持了 Memory3 模型中显式记忆机制的高效实现。
Appendix C Supplementary Evaluation Results¶
附录 C 补充评估结果总结¶
1. 训练阶段的性能增长(Table 22)¶
该部分记录了 Memory3-2B 在三个训练阶段(warmup、continual train、SFT)上的测试得分变化。这些测试任务包括 ARC-C、HellaSwag、MMLU、Winogrande、GSM8k、CEVAL 和 CMMLU,涵盖了中英文任务。
Warmup 阶段:平均得分为 42.13,各项任务得分普遍较低。
Continual train 阶段:平均得分上升至 45.12,表明训练有所进展。但如果不使用记忆系统(without memory),得分则为 42.89,说明记忆系统有一定帮助。
SFT 阶段:平均得分显著提升至 63.31,各项任务表现均有大幅提升。在不使用记忆系统的对比中,得分下降至 60.80,说明记忆系统在这一阶段对性能有较大提升。
重点内容:
Memory3 的 SFT 阶段表现突出,说明显式记忆对性能有显著帮助。
作者提出,若在 warmup 阶段减少损失发散,可能会进一步提升 continual train 阶段的性能。
2. 过滤阈值对评估结果的影响(Table 23)¶
评估系统在检索过程中引入了一个防止抄袭的过滤机制,用于移除与问题高度重叠的参考内容。过滤阈值设置为 2/3,以避免直接复制。
不同过滤阈值下的模型表现基本稳定,说明评估问题并未大量出现在记忆库中。
没有过滤(no filter)时,平均得分为 63.71,与 2/3 阈值下的 63.31 接近,表明过滤机制对最终结果影响不大。
不使用记忆系统的对比结果为 60.80,进一步说明显式记忆提升了模型表现。
重点内容:
模型得分在不同过滤阈值下保持稳定,说明评估问题与记忆内容的重叠有限。
显式记忆在所有情况下都提升了表现。
3. 几何提示对评估任务的影响(Table 24)¶
这部分研究了模型在few-shot(少量样本)和0-shot(无样本)设置下的表现差异。
Few-shot 模式:使用少量样本(如 ARC-C 25 个,MMLU 5 个等),平均得分为 63.31,且使用记忆系统后表现优于不使用。
0-shot 模式:不提供任何示例,平均得分下降至 58.23,但在某些任务上(如 GSM8k)得分显著提高(13.50 vs 10.46),显示记忆系统在无提示情况下更能发挥优势。
显式记忆的提升效果从 few-shot 的 2.51% 提升到 0-shot 的 3.70%,说明记忆系统在无样本提示下更具价值。
重点内容:
在无样本提示(0-shot)情况下,显式记忆对模型性能的提升更明显。
几何提示的设置对模型表现有显著影响,尤其是在 GSM8k 等任务中。
总结¶
附录 C 详细展示了 Memory3-2B 在不同训练阶段和评估设置下的性能表现,主要结论如下:
训练阶段:SFT 阶段性能提升最大,显式记忆系统对性能有正向影响。
过滤机制:过滤阈值对最终结果影响较小,说明模型并没有大量依赖已有知识的直接复制。
几何提示:在 0-shot 模式下,显式记忆的提升效果更明显,说明记忆系统在缺乏样本提示时更有价值。
这些补充结果进一步验证了 Memory3 中显式记忆模块的有效性。