2402.07630_G-Retriever: Retrieval-Augmented Generation for Textual Graph Understanding and Question Answering¶
引用: 246(2025-08-03)
组织:
1National University of Singapore
2University of Notre Dame
3Loyola Marymount University
4New York University
5Meta AI
总结¶
数据集GraphQA
综合性且多样化的图问答(Graph Question Answering, GraphQA)基准
目标
用于评估模型在多种图结构上进行问答能力的基准测试
涵盖常识推理、场景图问答和基于知识图谱的问答等任务
子数据集
ExplaGraphs
2,766个图,平均节点数5.17,边数4.25
基于常识概念和关系,用于常识推理任务,评估指标为准确率(Accuracy)。
SceneGraphs
100,000个图,平均节点数19.13,边数68.44
包括图像中的对象、属性和关系,用于场景图问答,评估指标为准确率。
WebQSP
4,737个图,平均节点数1370.89,边数4252.37
基于Freebase实体和关系,用于多跳知识图谱问答,评估指标为Hit@1。
G-Retriever架构
架构结合了图神经网络(GNN)、LLM和 RAG 的优势,旨在提升问答系统的准确性、可扩展性和可解释性
包含四个主要步骤:
索引(Indexing):对图中的节点和边进行预处理和嵌入,便于后续检索;
检索(Retrieval):基于查询从图中检索出最相关的节点和边;
子图构建(Subgraph Construction):通过优化算法构建一个包含最多相关信息的连通子图;
生成(Generation):使用图提示(graph prompt)和语言模型生成最终答案。
核心技术包括:
图神经网络(GNNs):用于提取图数据中的节点和边的关系信息。
大语言模型(LLMs)(如 Transformer 架构模型):负责自然语言理解和生成。
检索增强生成(RAG):从大规模知识库中检索相关信息,增强模型的回答准确性。
示例讲解¶
示例问题¶
用户提问:
“《盗梦空间》的导演是谁?他和《星际穿越》的导演是同一个人吗?”
G-Retriever 的处理步骤¶
1. 索引阶段(Indexing)¶
假设我们有一个电影知识图谱,包含以下节点和边(简化版):
节点(实体):
- 盗梦空间(电影)
- 克里斯托弗·诺兰(人物)
- 星际穿越(电影)
边(关系):
- 盗梦空间 --导演--> 克里斯托弗·诺兰
- 星际穿越 --导演--> 克里斯托弗·诺兰
G-Retriever 会使用预训练模型(如 Sentence-BERT)为每个节点和关系生成嵌入向量(即数值表示),并存储在图数据库中。
2. 检索阶段(Retrieval)¶
对用户提问编码:将问题“《盗梦空间》的导演是谁?…”转换为嵌入向量。
相似度搜索:在知识图谱中查找与问题最相关的节点和边。
匹配到的关键部分:
节点:盗梦空间、克里斯托弗·诺兰、星际穿越
边:导演关系
3. 子图构建(Subgraph Construction)¶
通过 PCST 算法 从知识图谱中提取一个紧凑的子图,确保信息完整且适合输入 LLM。
本例的子图可能如下(文本化表示):
[盗梦空间] --(导演)--> [克里斯托弗·诺兰] [星际穿越] --(导演)--> [克里斯托弗·诺兰]
4. 生成阶段(Generation)¶
将子图结构和原始问题一起输入 LLM(如 GPT-4),提示如下:
基于以下知识图谱信息回答问题:
'''
《盗梦空间》的导演是克里斯托弗·诺兰。
《星际穿越》的导演是克里斯托弗·诺兰。
'''
问题:“《盗梦空间》的导演是谁?他和《星际穿越》的导演是同一个人吗?”
LLM 的输出:
“《盗梦空间》的导演是克里斯托弗·诺兰。他也是《星际穿越》的导演,因此是同一个人。”
LLM 总结¶
本章节介绍了 G-Retriever,这是一种基于“检索增强生成”(Retrieval-Augmented Generation, RAG)的方法,旨在提升对文本图(textual graph)的理解与问答性能。文章提出的问题背景是,传统的图问答系统在处理复杂、大规模的文本图数据时存在局限,尤其是在知识缺失或推理路径不明确的情况下。为此,G-Retriever 结合了信息检索和语言生成技术,利用外部知识库或文档来增强模型的推理能力。
具体而言,G-Retriever 架构分为两个主要模块:检索模块(用于从外部知识源中检索相关信息)和生成模块(基于检索结果生成答案)。这种方法不仅能够提升模型对复杂问题的理解能力,还能增强答案的可解释性和准确性。
文章还介绍了G-Retriever在多个文本图问答基准测试中的实验结果,表明该方法在多个指标上优于现有方法,尤其是在需要外部知识支持的任务中表现突出。此外,作者还分析了G-Retriever在不同检索策略和生成策略下的性能差异,进一步验证了其灵活性和鲁棒性。
总结来说,G-Retriever 通过引入检索增强机制,有效弥补了传统图问答模型在知识覆盖和推理能力上的不足,为文本图理解和问答任务提供了一种新的、高效的方法。
Abstract¶
本文提出了一种面向文本属性图的问答系统(G-Retriever),使用户可以通过对话式界面与图进行交互,提问并获得答案,同时高亮图中相关部分。传统方法虽将大语言模型(LLM)与图神经网络(GNN)结合,但多聚焦于节点分类等任务或在小规模/合成图上回答简单查询。本文则构建了一个面向真实场景的通用问答框架,适用于场景图理解、常识推理与知识图谱推理等多种任务。
为此,作者首先构建了GraphQA基准数据集,涵盖不同任务的数据。然后提出G-Retriever方法,引入首个适用于一般文本图的检索增强生成(RAG)方法,通过软提示微调提升图理解能力。为避免幻觉并处理超出LLM上下文窗口的图,该方法将RAG与图结构结合,转化为奖赏收集斯坦纳树优化问题。
实验结果表明,G-Retriever在多领域文本图任务中优于基线方法,可扩展性强且能有效缓解幻觉问题。论文代码和数据集已公开。
1 Introduction¶
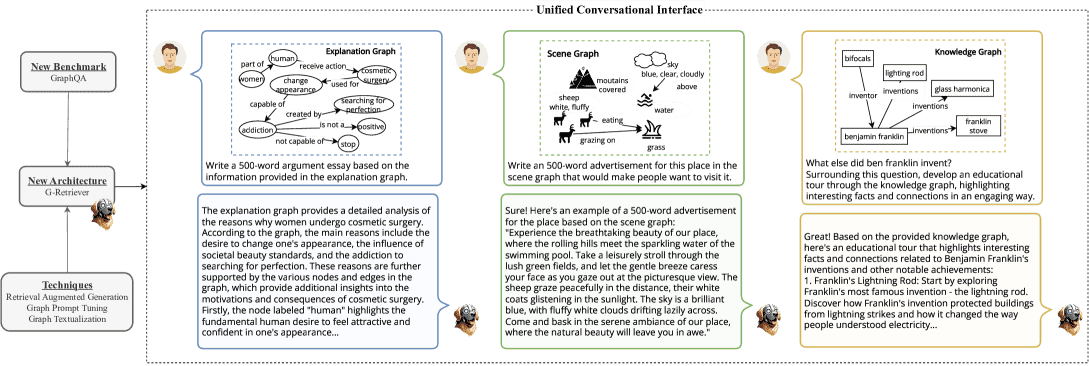
Figure 1:We develop a flexible question-answering framework targeting real-world textual graph applications via a unified conversational interface. Presented here are examples showcasing the model’s adeptness in handling generative and creative queries in practical graph-related tasks: common sense reasoning, scene understanding, and knowledge graph reasoning, respectively.
这篇论文的引言部分主要围绕G-Retriever这一新型问答框架展开,强调其在真实文本图(textual graphs)任务中的灵活性与实用性。以下是本章节内容的总结:
1. 图与大语言模型的结合¶
大语言模型(LLMs)在人工智能领域具有重大影响,尤其在处理复杂结构化数据(如图结构数据)方面潜力巨大。
现实世界中大量数据以图的形式存在,如互联网、电商网络、推荐系统和知识图谱等,其中许多图结构具有文本属性,适合结合LLMs进行处理。
现有研究多将图神经网络(GNNs)与LLMs结合以提升图推理能力,但大多集中在传统任务(如节点、边分类)或小型合成图上。
2. 本研究的目标:实现“与图聊天”¶
本文提出一种灵活的问答框架,旨在通过统一的对话接口,让用户能与复杂且真实世界中的图进行交互。
这是迈向直观图数据交互的关键一步,适用于多种图应用,如常识推理、场景理解和知识图谱推理等。
3. 提出一个新的GraphQA基准¶
当前缺乏一个专门针对图结构的问答(QA)基准。已有基准多关注节点度数、边存在性等简单任务。
本文提出一个适用于真实世界复杂图应用的GraphQA基准,涵盖常识推理、场景理解、知识图谱推理等任务,为评估模型能力提供统一标准。
4. G-Retriever框架的提出¶
为实现高效、有效的图问答任务(尤其是面对大型图时),提出G-Retriever框架,结合图神经网络、大语言模型和**检索增强生成(RAG)**的优势。
G-Retriever通过RAG组件从图中选择性地检索相关信息,解决了传统方法在信息丢失和幻觉问题上的局限。
5. 解决图LLM中的幻觉问题¶
LLM容易产生幻觉(hallucination),即生成的内容与事实不符。
基于图的LLM同样存在该问题,因为其无法从单一图嵌入中完整回忆图结构,导致在问答任务中生成错误的节点或边。
G-Retriever通过直接从图中检索信息,有效缓解了这一问题,实验结果表明其在答案准确性和解释性方面优于基线方法。
6. 提高图LLM的扩展性与效率¶
将图转换为自然语言文本以输入LLM的方法存在扩展性问题:节点和边较多时会导致超出输入长度限制。
截断文本会丢失关键信息,影响回答质量。
G-Retriever通过RAG机制只检索相关部分,在保持信息完整性的前提下提升了模型的效率和扩展性。
7. 针对图结构设计的RAG方法¶
当前的RAG方法多针对简单数据类型或知识图谱,缺少对通用文本图的支持。
本文提出一种新的子图检索方法,将问题建模为奖赏收集斯坦纳树(PCST)优化问题,考虑邻居信息,从而返回与查询最相关的子图,提升可解释性。
8. 本文的主要贡献¶
首次引入图结构的RAG方法,提升图任务的可扩展性与效率。
实现“与图聊天”,开发统一的对话式问答框架,适用于复杂真实图数据。
提出一个新的GraphQA基准,填补图问答领域的重要研究空白。
实验结果验证G-Retriever的性能,并在多个领域展示其有效性,并揭示图LLM中幻觉问题的普遍性。
总结¶
本论文提出了一种面向真实文本图的问答系统G-Retriever,通过结合GNN、LLM和RAG,实现了高效、准确、可扩展的图问答能力,并通过新基准和实验验证了其在多种任务中的优越性,为图与语言模型的融合提供了新的思路。
3 Formalization¶
本节对文本图、语言模型用于文本编码以及大语言模型和提示调优进行了形式化定义和说明,主要内容总结如下:
文本图(Textual Graphs)
文本图是一种节点和边都带有文本属性的图结构。形式化地表示为 \( G = (V, E, \{x_n\}_{n \in V}, \{x_e\}_{e \in E}) \),其中 \( V \) 是节点集合,\( E \) 是边集合,\( x_n \in D^{L_n} \) 和 \( x_e \in D^{L_e} \) 分别表示与节点 \( n \) 和边 \( e \) 相关的文本序列,\( D \) 是词汇表,\( L_n \) 和 \( L_e \) 分别表示节点和边文本的长度。语言模型用于文本编码(Language Models for Text Encoding)
在文本图中,语言模型(LMs)用于对节点和边的文本属性进行编码,以学习其语义表示。对于节点 \( n \),其文本 \( x_n \) 被编码为向量 \( z_n = \text{LM}(x_n) \in \mathbb{R}^d \),其中 \( d \) 是输出向量的维度。大语言模型与提示调优(Large Language Models and Prompt Tuning)
大语言模型(LLMs)采用了“预训练-提示-预测”的新范式,替代传统“预训练-微调”的方式:LLM 首先在大规模语料上训练以学习语言表示;
无需微调模型权重 \( \theta \),而是通过提示(prompt)引导模型完成特定任务;
输入为任务相关的提示 \( P \) 和输入序列 \( X \),模型输出为序列 \( Y = \{y_1, y_2, \ldots, y_r\} \),其概率分布定义为:
$\( p_\theta(Y|[P;X]) = \prod_{i=1}^r p_\theta(y_i | y_{<i}, [P;X]) \)$软提示调优(Soft Prompt Tuning):
提示以嵌入矩阵 \( P_e \in \mathbb{R}^{q \times d_l} \) 的形式表示,与输入嵌入 \( X_e \in \mathbb{R}^{p \times d_l} \) 拼接后输入模型;
模型通过最大化输出 \( Y \) 的似然进行训练,仅更新提示参数 \( P_e \),而固定模型权重 \( \theta \)。
本节要点总结:
形式化定义了文本图的结构与属性;
引入语言模型对图中节点和边的文本进行编码;
介绍了大语言模型基于提示调优的任务适配方法,强调通过软提示优化实现高效且无需微调的模型适配。
4 Proposed GraphQA Benchmark¶
该章节介绍了作者提出的GraphQA基准测试体系。GraphQA是一个综合性且多样化的图问答(Graph Question Answering, GraphQA)基准,旨在评估模型在不同领域、不同图结构下的问答能力。文章重点阐述了GraphQA的数据格式、包含的数据集及其统计特征,并介绍了每个数据集的背景和任务类型。
主要内容总结如下:¶
GraphQA的总体目标
GraphQA是一个用于评估模型在多种图结构上进行问答能力的基准测试,涵盖常识推理、场景图问答和基于知识图谱的问答等任务。使用的数据集及统计信息
ExplaGraphs:2,766个图,平均节点数5.17,边数4.25,基于常识概念和关系,用于常识推理任务,评估指标为准确率(Accuracy)。
SceneGraphs:100,000个图,平均节点数19.13,边数68.44,包括图像中的对象、属性和关系,用于场景图问答,评估指标为准确率。
WebQSP:4,737个图,平均节点数1370.89,边数4252.37,基于Freebase实体和关系,用于多跳知识图谱问答,评估指标为Hit@1。
数据格式
每个数据条目包含一个以自然语言格式表示的图、一个相关问题及一个或多个答案。图被转化为类似CSV的文本形式,便于模型处理。问题通常需要多跳推理才能得到答案。
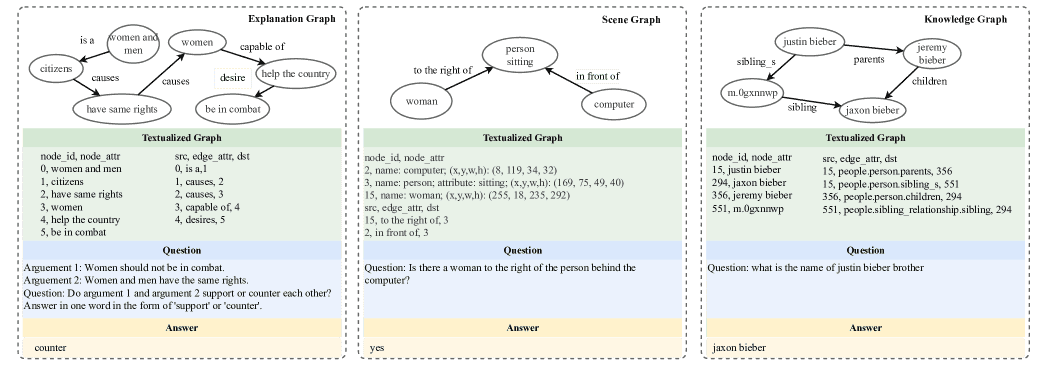
Figure 2:Illustrative examples from the GraphQA benchmark datasets.
数据集描述
三个数据集原本并非为GraphQA设计,但作者对其进行了标准化和格式化处理,使其统一适用于GraphQA任务。ExplaGraphs:用于生成解释图以支持辩论中的立场判断,任务为判断支持或反驳某种信念,使用准确率评估。
SceneGraphs:来自图像的场景图,涉及空间关系和多步推理,任务是基于文本描述回答问题。
WebQSP:基于Freebase的知识图谱问答,任务需要多跳推理,评估指标为Hit@1(即返回答案中第一个匹配的答案是否正确)。
该章节为后续的模型评估和实验奠定了数据基础,突出了GraphQA在多样化、复杂性和任务覆盖方面的优势。
5 G-Retriever¶
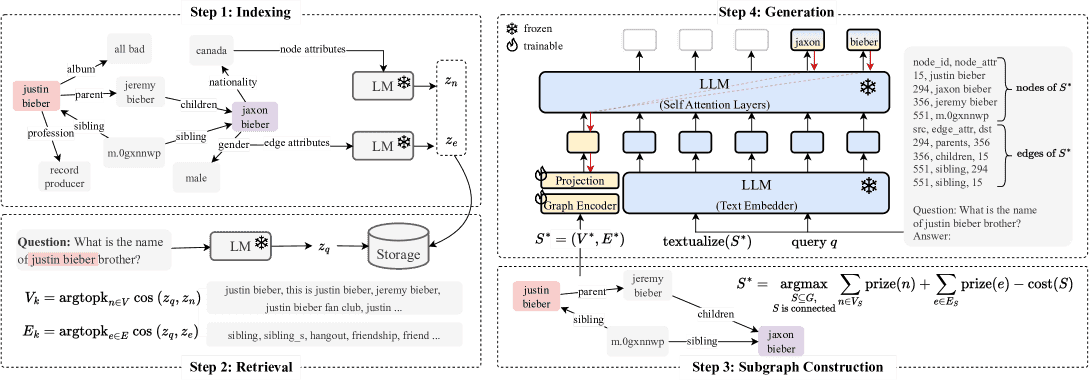
Figure 3:Overview of the proposed G-Retriever: 1) Indexing: Graphs are indexed for efficient query processing; 2) Retrieval: The most semantically relevant nodes and edges are retrieved, conditioned on the query; 3) Subgraph Construction: A connected subgraph is extracted, covering as many relevant nodes and edges as possible while maintaining a manageable graph size; 4) Generation: An answer is generated using a ‘graph prompt’, a textualized graph, and the query.
本文介绍了G-Retriever,一种专为Textual Graph Question Answering(GraphQA)任务设计的新架构。该架构结合了图神经网络(GNN)、**大型语言模型(LLM)和检索增强生成(RAG)**的优势,旨在提升问答系统的准确性、可扩展性和可解释性。
主要内容总结:¶
1. G-Retriever 架构概述¶
G-Retriever 包含四个主要步骤:
索引(Indexing):对图中的节点和边进行预处理和嵌入,便于后续检索;
检索(Retrieval):基于查询从图中检索出最相关的节点和边;
子图构建(Subgraph Construction):通过优化算法构建一个包含最多相关信息的连通子图;
生成(Generation):使用图提示(graph prompt)和语言模型生成最终答案。
整个流程通过图提示增强语言模型的理解能力,同时避免了直接将整个图输入LLM所带来的上下文长度限制和幻觉问题。
2. 索引(Indexing)¶
使用预训练的文本模型(如 SentenceBERT)对图中的节点和边进行嵌入表示;
嵌入向量存储到近邻检索结构中,以便在检索阶段快速查找相似节点/边。
3. 检索(Retrieval)¶
将用户查询转化为嵌入向量,并与图中的节点和边进行余弦相似度计算;
根据相似度检索出Top-k 的相关节点和边;
该过程确保了从图中提取出最贴近用户意图的信息。
4. 子图构建(Subgraph Construction)¶
为避免信息过载,使用Prize-Collecting Steiner Tree (PCST) 算法构建一个连通的、信息密度高的子图;
该算法通过给不同节点和边分配不同的“奖励值”(根据查询的相关性),并考虑边的“成本”,以找到最优的子图;
对边的语义信息也进行了适配处理,通过引入“虚拟节点”机制扩展了PCST的应用范围。
5. 生成(Generation)¶
图编码器(Graph Encoder):使用 Graph Attention Network (GAT) 对子图进行结构建模,输出图级嵌入;
投影层(Projection Layer):通过 MLP 将图嵌入映射到 LLM 的嵌入空间;
文本化子图(Textualize Graph):将子图转换为自然语言描述,与查询拼接后输入 LLM;
图提示调优(Graph Prompt Tuning):将图嵌入和文本嵌入作为“软提示”输入 LLM,生成最终答案;
LLM 本身保持冻结状态,仅对图编码器和投影层进行微调,从而保留了 LLM 的原始语言能力。
技术亮点:¶
高效检索:通过 RAG 机制,避免了直接输入大图导致的上下文限制;
可扩展性:可以处理超出 LLM 上下文长度的图结构;
抗幻觉设计:通过直接从图中检索信息,减少了生成式模型的幻觉风险;
可解释性:返回的子图可用于解释答案的来源;
端到端训练:使用图提示调优方法,仅需微调图相关部分,即插即用。
总结:¶
G-Retriever 是一种针对文本图问答任务的高效、可扩展、可解释的模型架构。它通过结合图结构表示、语义检索和语言模型生成能力,实现了对复杂图数据的高质量问答处理,为 GraphQA 提供了新的解决思路。
6 Experiments¶
本章节主要讨论了G-Retriever模型在文本图理解与问答任务中的实验设置、性能表现、效率评估、幻觉缓解以及消融研究结果,内容总结如下:
6.1 实验设置¶
在索引阶段,使用SentenceBert对所有节点和边的属性进行编码;在生成阶段,采用Llama2-7b作为语言模型,Graph Transformer作为图编码器。更多细节见附录。
6.2 主要实验结果¶
测试了三种模型配置:
仅推理(Inference-only):使用冻结的LLM进行直接问答;
冻结LLM + 提示调优(Prompt Tuning):冻结LLM参数,仅调整提示;
调优LLM(Tuned LLM):结合LoRA对LLM进行微调。
在ExplaGraphs、SceneGraphs和WebQSP三个数据集上进行评估,结果显示:
G-Retriever在所有配置下均表现优于基线模型;
在冻结LLM + 提示调优设置中,G-Retriever相比传统方法平均提升40.6%;
在LoRA微调设置中,G-Retriever进一步提升性能,达到最佳效果。
6.3 效率评估¶
实验表明,G-Retriever通过图检索显著提升了效率:
SceneGraphs数据集:token减少83%,节点减少74%,训练时间减少29%;
WebQSP数据集:token减少99%,节点减少99%,训练时间减少67%; 这表明该方法在处理大规模图数据时具备高效性。
6.4 幻觉缓解¶
通过人工检查模型输出中的节点和边是否存在于实际图中,评估模型的幻觉情况。结果显示:
G-Retriever相比基线模型(图提示调优)减少了54%的幻觉;
模型输出中的有效节点、边和完整图的比例显著提升(详见表格)。
6.5 消融研究¶
消融实验验证了模型关键组件(如图编码器、投影层、文本化图、图检索)的有效性:
移除任何一个组件都会导致性能下降,其中图编码器和文本化图的影响最大(分别下降22.51%和19.19%);
图检索对整体性能也有显著贡献(下降9.43%);
模型在不同图编码器和不同规模的LLM上均表现出鲁棒性和性能提升。
补充内容¶
还进行了与其他图检索增强生成方法的对比、复杂度分析以及G-Retriever在“与图对话”场景中的应用演示,详细内容见附录。
总结:G-Retriever在文本图理解任务中表现出色,不仅在性能上优于现有方法,还在效率和幻觉缓解方面有显著优势。消融研究进一步验证了模型设计的有效性与鲁棒性。
7 Conclusion¶
本文的结论部分总结了以下内容:
研究贡献:作者引入了一个新的图问答基准(GraphQA),用于真实世界的图结构问题回答任务,并提出了G-Retriever模型。该模型在处理复杂和创造性的查询方面表现出色。
实验结果:G-Retriever在多个领域的文本图任务中优于现有基线模型,能够有效应对更大规模的图数据,并且在生成答案时具有较强的抗幻觉能力。
局限性与未来工作:目前G-Retriever采用的是静态检索组件,未来的研究可以探索更先进的可训练检索增强生成(RAG)方法,以进一步提升性能。
Acknowledgment¶
本章节为致谢部分,指出XB的研究得到了新加坡国立大学(NUS)资助项目(编号:R-252-000-B97-133)的支持。
Appendix A Impact Statements¶
本附录总结了研究工作的潜在影响。随着大语言模型(LLMs)被应用于越来越多的任务,其处理复杂结构化数据的能力变得愈发重要。本文旨在提升LLMs与图结构数据的交互能力,同时减少幻觉现象,从而增强模型的可靠性。此外,研究还通过返回检索到的子图以及采用对话式界面实现“与图对话”,提高了模型的可解释性,改善了人机交互体验,使模型行为更符合人类预期。
Appendix B Experiment¶
该论文的附录B部分详细描述了实验设置、模型配置、消融研究以及对图编码器和大语言模型(LLM)选择的分析,主要内容总结如下:
B.1 实验设置¶
硬件资源:使用 2 块 NVIDIA A100-80G GPU。
实验重复性:每个实验运行四次,使用不同的随机种子以确保结果的鲁棒性和可重复性。
模型组件配置¶
图编码器(Graph Encoder):采用 Graph Transformer,包含 4 层,每层 4 个注意力头,隐藏层维度为 1024。
大语言模型(LLM):基于开源的 Llama2-7b,使用 LoRA 进行微调,参数设置为:
lora_r = 8lora_alpha = 16dropout 率为 0.05
prompt tuning 时使用 10 个虚拟 token
最大文本长度为 512,最大生成 token 数为 32
图检索(PCST)设置:
SceneGraphs:节点和边各选前 3 个,边成本为 1
WebQSP:节点选前 3,边选前 5,边成本为 0.5
ExplaGraphs:由于图规模较小,保留全部图结构(k=0)
优化器:使用 AdamW,学习率 1e-5,权重衰减 0.05,学习率采用余弦半周期衰减,早停机制设置为 2 个 epoch
B.2 模型配置¶
实验中测试了三种模型配置:
仅推理(Inference-only)
使用冻结的 LLM,直接进行问答
包括以下几种提示方式:
Zero-shot:无额外示例
Zero-CoT:在问题后添加“Let’s think step by step.”
CoT-BAG:在图描述后添加“Let’s construct a graph with the nodes and edges first.”
KAPING:检索相关三元组并附加到问题中
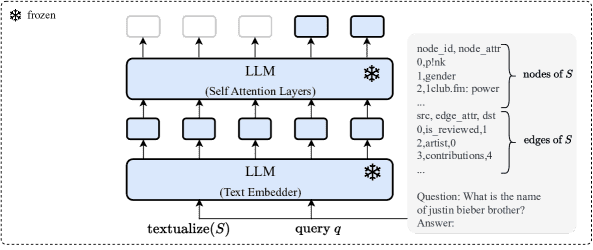
Figure 4:Model configuration 1) Inference-only.
冻结 LLM + 提示调优(Prompt Tuning)
仅调整提示部分,LLM 参数冻结
包括:
软提示调优(Soft Prompt Tuning)
GraphToken(图提示调优方法)
G-Retriever(本文提出的方法)
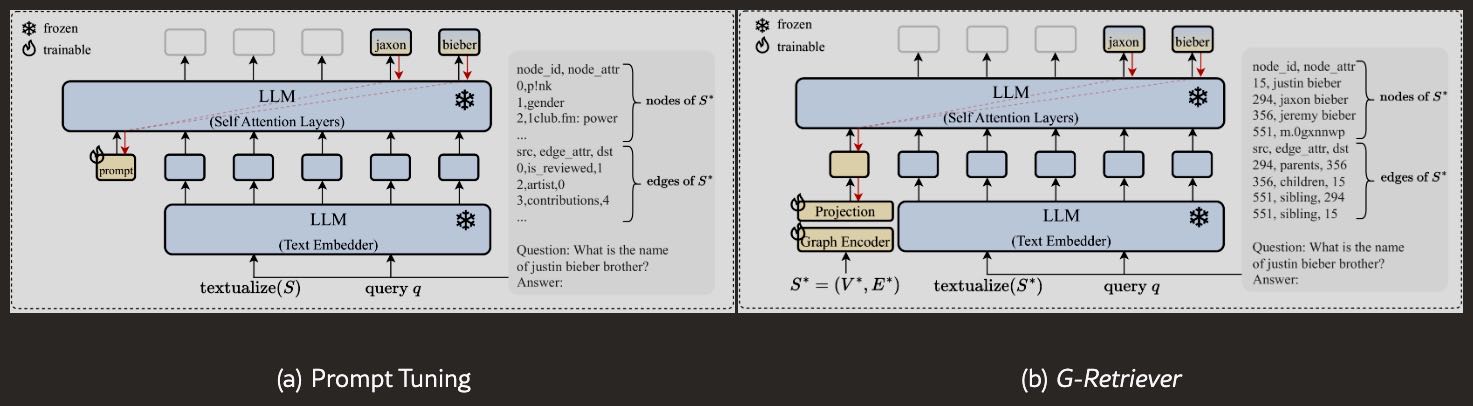
Figure 5:Model configuration 2) Frozen LLM w/ prompt tuning.
微调 LLM(LoRA)
使用 LoRA 对 LLM 进行微调
包括:
标准 LoRA 微调
G-Retriever + LoRA
B.3 消融研究¶
研究了 G-Retriever 的不同组件对性能的影响,包括以下三种配置:
无图编码器(w/o GraphEncoder):用可训练的虚拟 token 替代图编码器,共 10 个
无投影层(w/o Projection Layer):移除图编码器之后的投影层,图编码输出直接与 LLM token 拼接
无文本化图(w/o Textualized Graph):仅向 LLM 输入问题,不结合图结构
B.4 图编码器选择¶
测试了不同图神经网络作为图编码器的性能,包括:
GCN:Hit@1 为 70.70(WebQSP),0.8394(ExplaGraphs)
GAT:Hit@1 为 70.27(WebQSP),0.8430(ExplaGraphs)
Graph Transformer(本文使用):Hit@1 为 70.49(WebQSP),0.8516(ExplaGraphs)
结果显示,Graph Transformer 在 ExplaGraphs 上表现最优,表明其更适合处理结构更复杂的图数据。
B.5 LLM 选择¶
比较了不同规模的 LLM 对性能的影响:
Llama2-7b:Hit@1 为 70.49
Llama2-13b:Hit@1 为 75.58
结果显示,更大规模的 LLM 可以提升模型性能,说明方法能从更大的语言模型中获益。
总结¶
本附录详细记录了实验的实现细节、模型配置、组件消融分析以及模型选择的探讨,验证了 G-Retriever 方法在不同设置下的有效性与鲁棒性。实验表明,图编码器和 LLM 的选择对性能有显著影响,而使用更强大的 LLM 可进一步提升模型效果。
Appendix C GraphQA Benchmark¶
本节主要介绍了GraphQA基准与原始数据集在数据格式上的差异,并详细说明了其预处理步骤。通过对比原始数据集和GraphQA基准的格式,可以发现GraphQA统一了不同数据集的图表示形式,将实体和关系分别表示为节点和边,并通过标准化的方式简化了数据结构,便于图理解与问答任务的处理。
总结如下:
ExplaGraphs:
原始数据使用三元组表示关系。
GraphQA将其转换为图结构:每个三元组中的头实体和尾实体为节点,关系为边。
由于测试集标签不可用,只使用训练和验证集,并按照6:2:2的比例重新划分训练、验证和测试集。
SceneGraphs:
原始数据用于视觉推理,以JSON格式描述图像和场景图。
GraphQA去除了对图像的依赖,只保留场景图信息,并简化了对象ID。
从原始数据中随机抽取100k样本,并按6:2:2的比例划分数据集。
WebQSP:
原始数据使用三元组列表格式。
GraphQA将其转换为统一的图格式,并将所有单词转为小写,消除大小写差异。
采用原始数据集的划分方式。
总体而言,GraphQA基准通过统一图结构的表示方式,简化了原始数据集的格式,使不同来源的图数据能够适用于图理解与问答任务的模型训练和评估。
Appendix D Graph Retrieval-Augmented Generation (GraphRAG)¶
本章节主要讨论了Graph Retrieval-Augmented Generation (GraphRAG) 方法的相关实验与比较分析,主要内容总结如下:
D.1 与现有 GraphRAG 方法的对比¶
现有的 GraphRAG 方法大多专注于知识图谱(Knowledge Graphs),通常以节点、边或三元组(triples)为单位进行检索。而本文提出的方法有两大不同点:
应用于更广泛的文本图结构,而不仅限于知识图谱;
能够返回与查询最相关的子图(subgraph),而非仅返回若干个三元组。这使得方法能够更好地捕捉邻居信息,而非孤立地选择三元组。
D.2 检索中 K 值的影响¶
本节探讨了 k 值(最近邻数量)对检索效果的影响,采用 k 近邻算法进行检索。实验表明:
小 k 值可能导致关键信息遗漏;
大 k 值则可能引入冗余或干扰信息;
在 WebQSP 数据集上,通过改变 k 值(3, 5, 10, 20)进行实验,发现 Hit@1 指标在 k=10 时达到最佳效果。
因此,选择合适的 k 值(如通过交叉验证)是提升检索性能的重要因素。
D.3 相似性函数的选择¶
在相似性计算中,本文采用了余弦相似度(Cosine Similarity),这是视觉与语言模型中常用的相似性度量方式(如 CLIP 模型):
虽然不一定是最优选择,但具有通用性、代表性和高效性;
能够支持快速检索任务的需求。
D.4 检索质量的评估¶
本节通过检索子图是否包含正确标签来评估检索质量,并在 WebQSP 数据集上将本文的 G-Retriever 与 KAPING 方法进行对比:
KAPING(基于三元组检索):检索准确率为 60.81%;
G-Retriever(基于 PCST 的子图检索):检索准确率为 70.49%。
结果表明,本文方法通过结构化的子图检索(PCST 方法),能够更好地捕捉节点和边之间的连接关系,从而提升检索的准确性。
总结¶
本章节通过实验验证了 G-Retriever 方法在以下几个方面的优势:
适用于更广泛的文本图结构;
采用基于子图的检索方式,优于孤立三元组检索;
通过选择合适的 K 值和余弦相似度,实现高效的检索任务;
实验结果表明,在 WebQSP 数据集上,该方法在检索准确率方面优于现有方法。
这些分析为 GraphRAG 在文本图理解与问答任务中的应用提供了坚实的实验依据。
Appendix E Discussion on the Complexity¶
本章总结如下:
附录E 复杂性讨论总结¶
E.1 GNN、LLM与GraphRAG的集成¶
G-Retriever 是一个结合图神经网络(GNN)、大语言模型(LLM)和图检索增强生成(GraphRAG)优势的框架。当前流行的“LLM+X”方法(如 Llava、MiniGPT-4 和 Flamingo)主要是将 LLM 与其他模态的编码器结合,以增强其多模态能力,这类方法在理解和实现上相对简单。
GraphRAG 的集成在实现上并不复杂,可以在预处理阶段完成,也可以在运行时动态实现,无需额外训练,因此不会显著增加时间或计算复杂度。相反,它能够大幅减少图的规模(例如在 WebQSP 数据集中可减少 99% 的节点),从而显著提升整体运行效率(例如在 WebQSP 上将运行时间从 18.7 分钟/轮次缩减至 6.2 分钟/轮次)。
E.2 计算资源与实验结果¶
实验在两块 A100 GPU(每块 80GB)上进行,使用 Llama2-7b 模型和 WebQSP 数据集。训练批次大小为 16,评估批次大小为 32。实验结果表明,G-Retriever 在准确率(Hit@1)和运行时间上均优于其他方法,尤其是在结合 LoRA 微调时,Hit@1 达到 73.79%,运行时间仅 6.9 分钟/轮次。GraphRAG 显著提升了检索效率,减少了图的规模,从而加快了系统整体运行速度。
Appendix F Hallucination in Graph LLMs¶
本节主要探讨了图神经网络语言模型(Graph LLMs)中的“幻觉”(Hallucination)问题,特别是在SceneGraphs数据集中的表现,并引入了一种新的方法G-Retriever来减少这种现象。
主要内容总结:¶
基线方法:
使用了MiniGPT-4模型,并将其适配到图结构的上下文中,方法是通过一个可训练的图神经网络(GNN)将图编码为“软提示”,输入到冻结的LLM中(称为LLM+Graph Prompt Tuning)。
选择图提示调优作为基线,而不是将图转化为文本,是因为图的文本表示通常超出LLM的输入长度限制。
实验设计:
要求LLM回答与图相关的问题,并在回答中列出支持其答案的图中的节点或边。
由于缺乏标准答案,通过人工检查100个回答,验证模型引用的节点和边是否真实存在于图中。
评估指标:
使用三个指标评估模型的“忠实度”:
有效节点比例(Valid Nodes)
有效边比例(Valid Edges)
完全有效的节点-边集合比例(Fully Valid Graphs)
实验结果:
LLM+Graph Prompt Tuning基线方法的效果较差:
仅31%的节点和12%的边是有效的,整体有效节点-边集合仅占8%。
G-Retriever方法显著优于基线:
有效节点比例提升至77%,有效边为76%,完全有效的引用集合达到62%。
表明G-Retriever在减少图结构上下文中的幻觉方面具有显著优势,特别是在同时准确引用节点和边的任务中。
总结:¶
本节通过定量分析表明,G-Retriever方法在图语言模型中能有效减少幻觉现象,显著提升了模型对图结构信息的引用准确性。这为在复杂图结构上进行文本理解和问答任务提供了更可靠的技术路径。
Appendix G Demonstrations¶
本章节主要展示了G-Retriever模型在不同数据集上的交互能力,包括ExplaGraphs、SceneGraphs和WebQSP。具体通过表格和图像形式呈现了模型如何处理创造性问题并生成相应的文本输出,例如撰写议论文、广告文和教育性旅游介绍等。主要内容总结如下:
ExplaGraphs示例
模型基于一个关于“女性接受整容手术”的图,撰写了一篇500字的议论文。
分析了女性整容的动机,包括社会审美标准、寻求完美、以及整容成瘾等问题。
模型能够结合图中的节点和边,提炼出整容背后的复杂心理和社会因素,并进行结构化论述。
SceneGraphs示例
模型基于一个描述自然景色的图(包括羊群、山脉、水池等)生成了一幅图像,并撰写了一篇500字的旅游广告。
文章描绘了宁静优美的自然风光,突出其吸引力和放松氛围,展示了模型通过图结构生成富有画面感和吸引力的文本的能力。
WebQSP数据集示例
模型围绕“本杰明·富兰克林还发明了哪些东西”这一问题,进行了知识图谱的探索,生成了一个教育性旅游介绍。
内容包括富兰克林的多项发明(如双光眼镜、弗兰克林炉、避雷针)及其历史影响,并通过与其他发明家(如Prokop Diviš)的联系,拓展了科学史的视角。
总体展示
模型展示了其在处理结构化图数据基础上生成创意性文本的能力,适用于多种应用场景,如教育、宣传和知识传播。
通过不同任务(撰写文章、广告、旅游介绍)展示了模型的灵活性和对上下文的深度理解。
该章节通过三个具体数据集的实例,验证了G-Retriever在文本生成和知识推理方面的强大能力,为模型的实用性提供了直观的展示。