2004.04906_DPR: Dense Passage Retrieval for Open-Domain Question Answering¶
引用: 4670(2025-09-20)
总结¶
背景
在DPR提出之前,开放域问答系统通常采用“检索器-阅读器”的流水线架构:
检索器:从庞大的知识库(如维基百科,包含数百万篇文章)中找出与问题相关的少量段落(例如,100个)。
阅读器(通常是一个强大的神经网络模型,如BERT):对检索到的段落进行精细阅读,从中找出答案。
核心问题:传统检索方法的瓶颈
系统性能瓶颈主要在于检索器。
主流检索器是像BM25这样的稀疏词袋模型。
工作原理:基于关键词匹配。它统计问题中的关键词在文档中出现的频率,但无法理解词汇的语义。
缺点:
词汇不匹配:如果问题和文档使用不同的词汇表达相同意思,BM25可能无法检索到。
例如,问题问“How tall is the tallest mountain?”,而相关文档中写的是“The height of Mount Everest is…”。
BM25可能因为“tall”和“height”不是同一个词而错过关键文档。
语义理解缺失:无法捕捉问题的深层语义。
DPR
重点在于改进开放域问答系统中的检索模块
目标是:将大量文本段落(如2100万段)映射到一个低维、连续的空间中,从而在运行时能高效检索出与输入问题最相关的前k个段落(如20–100个段落)。
核心思想是:用稠密向量(Dense Vector)来表示文本的语义,并通过向量相似度来进行检索。
核心内容:
向量化表示:
使用两个独立的预训练BERT模型(通常是BERT-base)作为编码器。
问题编码器 \( E_Q \):将问题(Question)映射为一个d维的稠密向量。
段落编码器 \( E_P \):将段落(Passage)映射为一个d维的稠密向量。
这些向量被称为“稠密嵌入”,因为它们是一个连续的、低维的(例如768维)实数向量,能够捕捉丰富的语义信息。
相似度计算:
问题和段落之间的相关性由它们向量的内积(或余弦相似度)来衡量。
相似度得分:\( \text{sim}(q, p) = E_Q(q)^T E_P(p) \)
核心假设:如果一个问题和一个段落是相关的,那么它们的向量在向量空间中的距离应该很近(内积值大)。
推理过程
离线阶段使用 \( E_P \) 对所有段落进行编码,并使用 FAISS 构建索引(支持大规模向量的快速检索)。
在线阶段,对输入问题编码为 \( v_q = E_Q(q) \),使用FAISS检索与 \( v_q \) 最接近的前k个段落。
模型调优训练
直接使用预训练的BERT模型(如用于句子对分类的任务)进行编码,效果并不好。关键在于如何针对“检索”这个特定任务进行优化。
DPR提出了一个高效的训练方法:
正样本与负样本:
正样本:对于一个给定的问题,已知的、包含正确答案的段落。
负样本:对于训练至关重要。DPR使用了三种类型的负样本:
随机负样本:从知识库中随机抽取的段落。
BM25负样本:用BM25检索到的、不包含答案但可能与问题有部分词汇重叠的段落。
批次内负样本(gold样本):在同一训练批次中,其他问题对应的正样本段落。这是非常有效的一种策略,相当于在一个批次内同时比较多个问题和不相关的段落,增加了训练难度和模型区分能力。
损失函数:
采用标准的对比学习损失函数(Noise Contrastive Estimation loss)。
目标很直观:最大化问题与正样本段落向量的相似度,同时最小化问题与负样本段落向量的相似度。
公式:\( L(q_i, p_i^+, p_{i,1}^-, ..., p_{i,n}^-) = -\log \frac{e^{\text{sim}(q_i, p_i^+)}}{e^{\text{sim}(q_i, p_i^+)} + \sum_{j=1}^{n} e^{\text{sim}(q_i, p_{i,j}^-)}} \)
整体系统流程
离线预处理:
将整个知识库(如维基百科的2100万个段落)用训练好的段落编码器 \( E_P \) 全部编码成稠密向量。
将这些向量存入一个向量数据库(例如,使用FAISS库)。FAISS对这种大规模的向量相似度搜索进行了高度优化,可以实现毫秒级的检索。
在线检索:
当一个新的问题到来时,用问题编码器 \( E_Q \) 将其编码为一个向量。
在FAISS索引中进行最近邻搜索,找出与问题向量最相似的K个段落向量(例如,K=100)。
将这K个段落返回给下游的阅读器模型(如BERT阅读器)去提取最终答案。
与BM25对比
在检索结果的定性差异上仍然存在显著区别。
BM25 对关键词和短语的敏感度较高,但在处理词汇变体或语义关系时表现不佳。
DPR 擅长语义表示,但在捕捉出现频率低但关键的短语上可能有所欠缺。
示例说明
问题:What is the body of water between England and Ireland?
BM25 检索结果:返回了一段与“英国自行车协会”相关的文本,虽然包含关键词 England 和 Ireland,但与问题无关。
DPR 检索结果:返回了“爱尔兰海(Irish Sea)”的正确答案。
问题:Who plays Thoros of Myr in Game of Thrones?
BM25 检索结果:返回了一段包含“Thoros of Myr”这一关键短语的文本,因此准确。
DPR 检索结果:返回的是演员 Pål Sverre Hagen 的背景信息,但未提及 Thoros of Myr。
实验结果
论文在多个标准QA数据集(如Natural Questions, TriviaQA)上进行了实验
表明:
显著超越BM25:DPR在检索精度上大幅领先于强大的BM25基线。即使只检索20个段落,其召回率也远高于BM25检索100个段落的召回率。
端到端QA性能提升:由于检索到的段落质量更高,整个QA系统的最终答案准确率得到了显著提升。
效率与效果的平衡:虽然神经网络编码需要计算,但借助FAISS,检索速度非常快,满足了实际应用的需求。
主要贡献:
开创性方法:首次证明了端到端的稠密检索可以显著超越传统的稀疏检索方法,成为开放域检索的新范式。
简单有效的训练框架:提供了一个清晰、可复现的训练方案,特别是强调了负样本构建策略的重要性。
推动领域发展:启发了后续大量基于稠密检索的研究工作(如ANCE, DPR-PAQ等),使得稠密检索成为当前开放域QA和检索任务的主流技术。
简单比喻
传统BM25 就像一本字典的索引,只能通过精确的关键词来查找。
DPR 就像一位聪明的图书管理员,他理解了你的问题意图(语义),然后去书库里帮你找出意思相关的书籍,而不管你是否使用了和书上一样的词语。
Abstract¶
核心内容:
开放领域的问答系统依赖于高效的段落检索,以选择候选上下文。目前,传统的稀疏向量空间模型(如 TF-IDF 或 BM25)是这一任务的主流方法。
本文贡献:
本文展示了一种基于密集表示(dense representations)的检索方法的实用性。具体来说,使用一种简单的双编码器框架(dual-encoder framework),仅通过少量问题和段落学习嵌入表示(embeddings),就可以实现高效的检索。
实验结果:
在多个开放领域问答数据集上的评估表明,本文的密集检索器在 Top-20 段落检索准确率上,比强大的 Lucene-BM25 系统高出 9%-19%。此外,该密集检索器还帮助端到端问答系统在多个开放领域问答基准上取得了新的最优性能(state-of-the-art)。
1 Introduction¶
介绍开放域问答(Open-domain QA)¶
开放域问答任务的目标是通过大量文档来回答事实性问题。早期的问答系统通常非常复杂,包含多个组件,但近年来阅读理解模型的进展使得系统可以简化为两阶段框架:
上下文检索器(context retriever):首先从文档集合中筛选出一小部分可能包含答案的段落;
阅读器(reader):对这些段落进行深入分析,最终识别出答案。
虽然这种将开放域问答简化为阅读理解的策略很有道理,但在实践中常导致性能显著下降(例如,SQuAD v1.1 上的精确匹配得分从80%以上骤降至40%以下),这表明检索阶段的改进是关键。
传统与现代检索方法对比¶
传统方法(如 TF-IDF、BM25):基于关键词匹配的稀疏向量表示,利用倒排索引快速检索,效率高,但对语义差异较大的同义词或改写词不敏感。
现代方法(如 Dense Retrieval):采用密集语义编码,通过学习模型将问题与段落映射为向量空间中的高维向量,能够捕捉语义相似性,如将“bad guy”与“villain”匹配,因此更具灵活性与语义理解能力。
此外,密集编码是可学习的,可以通过调整嵌入函数来优化任务特定的表示形式。借助高效的内存数据结构(如最大内积搜索 MIPS),可以在保持速度的前提下实现高质量检索。
Dense Retrieval 的挑战¶
尽管密集检索具有优势,但其训练通常需要大量标注的问题-上下文对。在 ORQA 研究(Lee et al., 2019)之前,密集检索方法始终未能超越传统方法(如 BM25)。ORQA 提出了一种**逆闭合任务(ICT)**作为预训练目标,通过预测遮蔽句子的块来增强模型语义理解能力,再结合问答对进行微调,从而取得优于 BM25 的效果。
但 ORQA 也存在两个主要问题:
ICT 预训练计算成本高,且训练目标中普通句子是否真的能替代问题还不明确;
上下文编码器未在问答对上微调,其表示可能不是最优。
本文提出的问题与方法¶
本文提出关键问题:是否可以在没有额外预训练的情况下,仅使用问题与段落对来训练出更优的密集嵌入模型?
作者使用标准预训练模型 BERT 和双编码器架构,专注于开发一个高效的训练方案,并通过一系列消融实验验证最终方法的有效性。
最终提出的方法非常简洁:最大化问题与相关段落的内积,并以一个批次内所有问题-段落对进行对比学习。
DPR 的性能表现¶
提出的Dense Passage Retriever (DPR) 表现出色:
在 Top-5 准确率上大幅超越 BM25(65.2% vs. 42.9%);
在开放域 QA 的端到端准确率上也优于 ORQA(41.5% vs. 33.3%);
结合现代阅读器模型,DPR 在多个开放检索 QA 数据集上取得了可比甚至优于更复杂系统的效果。
本文的贡献¶
证明了仅通过微调问题与段落的编码器,就可以大幅优于 BM25,无需额外预训练;
验证了在开放域问答中,更高的检索精度确实能带来更高的端到端 QA 性能,具备实际应用价值。
2 Background¶
本节介绍了论文中所研究的开放域问答(open-domain QA)问题的定义、任务设定以及相关系统结构。
问题定义¶
开放域问答的目标是:给定一个事实性问题(factoid question),例如“Who first voiced Meg on Family Guy?”或“Where was the 8th Dalai Lama born?”,系统需要从一个包含广泛主题的大型语料库中找到答案。
问答设定¶
本文假设采用的是抽取式问答(extractive QA)设置,即答案必须是从语料库中的一个或多个段落中的连续词序列(span)中提取出来的。
文本被预先划分成若干个固定长度的段落(passages)作为检索的基本单位。每个段落可以看作是一个词序列。
语料库 \( \mathcal{C} = \{p_1, p_2, \ldots, p_M\} \),其中 \( p_i \) 表示第 \( i \) 个段落,包含多个词 \( w_1^{(i)}, w_2^{(i)}, \ldots, w_{|p_i|}^{(i)} \)。
任务目标¶
给定问题 \( q \),系统需要在语料库中找到一个段落 \( p_i \),并从中提取出一个连续的词序列(span)作为答案。
由于语料库的规模可能非常大(从数百万文档到数十亿文档),系统必须包含一个高效的检索器(retriever)来缩小搜索范围。
检索器的功能¶
检索器 \( R(q, \mathcal{C}) \rightarrow \mathcal{C}_F \) 是一个函数,输入是问题 \( q \) 和语料库 \( \mathcal{C} \),输出是一个过滤后的较小文本集合 \( \mathcal{C}_F \subset \mathcal{C} \)。
\( |\mathcal{C}_F| = k \ll |\mathcal{C}| \),即过滤后的集合远小于原始语料库。
对于固定的 \( k \),检索器的性能可以通过top-k 检索准确率(top-k retrieval accuracy)来衡量:即在 \( \mathcal{C}_F \) 中包含正确答案的段落所占问题的比例。
补充说明¶
采用固定长度段落而不是自然段进行检索,实验表明其在检索效率和最终问答准确率上表现更好,这是受到 Wang 等人(2019)的研究支持。
也有一些例外方法,如 Seo 等人(2019)和 Roberts 等人(2020)分别采用检索+生成的方式进行问答,但本文聚焦于抽取式架构。
小结¶
本节重点介绍了开放域问答的基本设定:抽取式问答任务、固定长度段落作为检索单位、以及检索器在系统中的关键作用。其中,如何高效地从大规模语料中检索出包含答案的段落,是系统设计的核心问题之一。
3 Dense Passage Retriever (DPR)¶
本章重点在于改进开放域问答系统中的 检索 模块。DPR的目标是将大量文本段落(如2100万段)映射到一个低维、连续的空间中,从而在运行时能高效检索出与输入问题最相关的前k个段落(如20–100个段落)。
3.1 Overview¶
DPR由两个独立的编码器组成:
段落编码器 \( E_P(\cdot) \):将每个段落编码为一个长度为 \( d \) 的实数向量,并将所有段落构建索引以备检索。
问题编码器 \( E_Q(\cdot) \):将输入问题编码为相同长度的向量。通过计算该向量与索引中段落向量的相似度,检索最相关的k个段落。
相似度计算公式:¶
尽管可以使用更复杂的模型(如多层注意力网络)来计算相似度,但为了实现离线预编码和高效检索,DPR选择使用内积作为相似性度量。内积与余弦相似度和L2距离密切相关,且已被广泛研究和应用。通过消融实验,作者发现使用其他相似性函数效果相近,因此选择了更简单的内积函数,并通过学习更优的编码器提高性能。
编码器实现:¶
使用两个独立的 BERT-base(uncased)模型。
输出为 [CLS] token 的隐藏状态向量,因此维度 \( d = 768 \)。
推理过程:¶
离线阶段使用 \( E_P \) 对所有段落进行编码,并使用 FAISS 构建索引(支持大规模向量的快速检索)。
在线阶段,对输入问题编码为 \( v_q = E_Q(q) \),使用FAISS检索与 \( v_q \) 最接近的前k个段落。
3.2 Training¶
训练目标是使内积相似度成为一个有效的排序函数,这是一个典型的**度量学习(metric learning)**问题。训练数据形式如下:
每条训练样本包含一个问题 \( q_i \)、一个正样本段落 \( p_i^+ \) 和多个负样本段落 \( p_{i,j}^- \)。训练损失函数为负对数似然(negative log likelihood):
正样本与负样本:¶
正样本通常明确给出(如QA数据集中的答案段落)。
负样本则需从大规模语料中选择,是训练中关键但常被忽视的一环。
作者实验了三种负样本类型:
随机样本:语料中随机选取。
BM25匹配段落:与问题有关键词匹配但不含答案。
Gold样本:训练集中的其他问题对应的正样本段落。
最佳模型使用了同batch中的Gold样本和一个BM25负样本。
batch内负样本(In-batch negatives):¶
设一个batch包含 \( B \) 个问题和对应正样本段落,它们的嵌入矩阵为 \( \mathbf{Q} \) 和 \( \mathbf{P} \)。
计算相似度矩阵 \( \mathbf{S} = \mathbf{Q} \mathbf{P}^\top \),其中每个 (i,j) 元素表示问题 \( q_i \) 与段落 \( p_j \) 的相似度。
在这个batch中,共有 \( B^2 \) 个(q,p)对,其中 \( i=j \) 为正样本,其余为负样本。
该方法能大幅增加训练样本数量,提升编码学习效果。
重点总结:DPR通过构建两个独立BERT编码器进行高效检索,采用内积作为相似度度量,并通过精心设计的负样本选择和batch内负样本训练策略,显著提升了模型性能。
4 Experimental Setup¶
本节描述了我们实验中使用的数据和基本设置。内容分为两个主要部分:维基百科数据预处理和问答数据集。
4.1 维基百科数据预处理¶
本研究使用了2018年12月20日的英文维基百科快照作为答案的来源文档。我们首先应用了DrQA系统中提供的预处理代码,从维基百科中提取出干净的文本部分,并去除表、信息框、列表、歧义页面等半结构化数据。
然后,我们按照Wang等人(2019)的方法,将每篇文章拆分成不重叠的100字文本块(passages),作为基本检索单元,最终共生成了21,015,324个passages。虽然Wang等人也提出过使用重叠passages的方法,但我们发现其效果不如有不重叠版本好。
此外,每个passage前都会加上所属维基百科文章的标题,并添加一个**[SEP]标记**,用于模型训练和检索。
4.2 问答数据集¶
我们使用了五个问答数据集,并且保持与Lee等人(2019)相同的训练/验证/测试划分方法。以下是对每个数据集的简要描述:
Natural Questions (NQ):由真实的Google搜索查询生成的问题,答案是维基百科中的文本片段。
TriviaQA:包含网络上收集的问答题,答案也来自网络。
WebQuestions (WQ):通过Google建议API生成的问题,答案是Freebase中的实体。
CuratedTREC:来自TREC问答任务和其他网络资源的问题,用于开放领域的问答。
SQuAD v1.1:一个流行的阅读理解基准数据集,但因为它缺乏上下文,不适合开放领域问答,我们仍包括它以保证公平比较。
正确passage的选择¶
对于 TREC、WebQuestions 和 TriviaQA,由于只提供问题和答案,我们使用BM25检索系统从top-100中选择包含答案的passage作为正样本。若未找到,该问题将被丢弃。
对于 SQuAD 和 NQ,由于原始passage的处理方式与我们的候选passage不同,我们通过匹配将“黄金passage”替换为候选池中的对应passage。尽管这样提升有限,但有助于模型训练。
无法匹配的问题(如由于维基版本或预处理差异)也会被丢弃。表1展示了每个数据集中训练、验证和测试的原始问题数量及用于训练DPR的实际问题数量。
表格信息¶
表1 显示了所有数据集中问题的实际数量,列出了原始训练集、经过过滤后的实际训练问题数量。
表2 比较了不同模型(BM25、单模型DPR、多模型DPR等)在测试集上的Top-20和Top-100检索准确率,评估标准是前20或100个检索结果中包含答案的百分比。
重点在于:
单模型DPR在大部分数据集上的表现优于BM25。
多模型DPR在某些数据集(如TREC)上效果更好,但SQuAD上的效果有所下降。
BM25 + DPR 的组合在多个指标上表现稳定。
总结¶
本节详细介绍了实验数据的来源和处理方式,重点包括维基百科的预处理流程与五个问答数据集的选择。通过定义“正样本passage”的方法,确保模型训练的准确性。最后通过多个表格展示了不同模型的性能对比,为后续实验结果分析奠定了基础。
5 Experiments: Passage Retrieval¶
5.1 主要结果¶
本节评估了 Dense Passage Retriever (DPR) 的检索性能,并与传统方法(如 BM25)进行对比,探讨了 DPR 与传统方法的输出差异、不同训练策略的效果以及运行时效率。
DPR 模型训练设置:
使用 in-batch negative 的训练设置(第3.2节)。
批次大小为 128,每个问题额外添加 1 个 BM25 负面段落。
对于大规模数据集(如 NQ、TriviaQA、SQuAD),训练最多 40 个 epochs;对于小数据集(如 TREC、WQ),训练最多 100 个 epochs。
学习率为 \(10^{-5}\),使用 Adam 优化器,线性学习率调度并带有预热(warm-up)和 Dropout 率 0.1。
多数据集训练:
为了构建一个通用的检索器,将多个数据集(除 SQuAD 外)的训练数据合并训练。
SQuAD 被排除的原因是其数据集中在少量维基百科文档中,引入了不必要的偏见。
对比传统方法:
同时测试了 BM25 和 BM25+DPR(通过线性组合两者的得分)。
通过 BM25 和 DPR 各选出前三千个段落,然后进行重排序,使用 BM25(q, p) + λ·sim(q, p),其中 λ=1.1。
实验结果:
在除 SQuAD 之外的所有数据集上,DPR 总体表现优于 BM25,尤其是在 top-20 准确率上差距显著(如 NQ 上 DPR 达 78.4%,而 BM25 为 59.1%)。
TREC(小数据集) 从多数据集训练中受益明显,而 NQ 和 WQ 改进较小,TriviaQA 略有下降。
SQuAD 表现较低 的原因:
问题是在看到段落后生成的,导致高词法重合,有利于 BM25。
数据集仅来自 500 多篇维基百科文章,训练数据分布偏倚。
图表说明:
图 1 展示了 DPR 使用 1000 个训练样本即可超越 BM25,说明 DPR 在小样本情况下表现良好。
5.2 模型训练的消融实验¶
样本效率¶
使用不同数量的训练样本测试 DPR 的性能。
在 NQ 的开发集上,使用 1000 个样本训练的 DPR 已优于 BM25。
随着样本数量从 1k 增加到 59k,准确率持续提升。
in-batch negative 训练¶
对比不同负样本来源(随机、BM25、Gold):
在 top-k ≥20 的情况下,负样本来源对性能影响不大。
in-batch negative 训练(同一批次内的负样本)显著提升性能。
主要优势在于更高效地利用已有负样本,增加训练样本数量。
批量越大,性能提升越明显。
增加 BM25 负样本(hard negatives)可进一步提升性能,但增加多个效果不显著。
Gold passages 的影响¶
使用与原始标注上下文匹配的段落作为正样本。
使用距离监督的 BM25 段落(包含答案但非上下文)作为正样本时,性能下降约 1 个百分点。
相似度函数与损失函数¶
测试了多种相似度函数(如 cosine、L2 distance)和损失函数(如 triplet loss)。
dot product 和 L2 性能较好,triplet loss 对结果影响不大。
跨数据集泛化¶
DPR 在非 IID(非独立同分布)数据集上(如 WebQuestions、TREC)表现良好。
直接用 NQ 训练的 DPR 在 WebQuestions 上 top-20 准确率为 69.9%,TREC 上为 86.3%,虽然比微调模型低 3-5 个百分点,但仍显著优于 BM25。
5.3 定性分析¶
DPR 与 BM25 的检索差异:
BM25 对关键词和短语敏感。
DPR 更擅长捕捉语义关系和词法变化。
附录 C 提供了多个示例和进一步讨论。
5.4 运行时效率¶
DPR 的检索效率:
通过 FAISS 内存索引,DPR 每秒可处理 995 个问题,每个问题返回 top-100 段落。
BM25 的效率:
每秒仅能处理 23.7 个问题(每个 CPU 线程)。
索引构建时间:
构建 2100 万段落的 FAISS 索引需要 8.5 小时。
构建 Lucene 倒排索引仅需 30 分钟。
然而,DPR 的嵌入计算可以并行处理,仅需 8.8 小时(8 个 GPU)。
表 4:端到端 QA 准确率(Exact Match)¶
训练方式 |
模型 |
NQ |
TriviaQA |
WQ |
TREC |
SQuAD |
|---|---|---|---|---|---|---|
单数据集 |
BM25+BERT |
26.5 |
47.1 |
17.7 |
21.3 |
33.2 |
单数据集 |
ORQA |
33.3 |
45.0 |
36.4 |
30.1 |
20.2 |
单数据集 |
BM25 |
32.6 |
52.4 |
29.9 |
24.9 |
38.1 |
DPR |
41.5 |
56.8 |
34.6 |
25.9 |
29.8 |
|
BM25+DPR |
39.0 |
57.0 |
35.2 |
28.0 |
36.7 |
|
多数据集 |
DPR |
41.5 |
56.8 |
42.4 |
49.4 |
24.1 |
多数据集 |
BM25+DPR |
38.8 |
57.9 |
41.1 |
50.6 |
35.8 |
DPR 与 BM25+DPR 在多个数据集上表现优于现有方法。
多数据集训练 提升了 DPR 的泛化能力,尤其在 WQ 和 TREC 上。
总结¶
本节通过一系列实验验证了 DPR 在开放域问答中的有效性,尤其在大规模数据集上的检索能力优于传统方法如 BM25。此外,DPR 在训练效率、样本利用率和跨数据集泛化上也表现出优势,尽管在索引构建上牺牲了一些时间成本,但在实时检索上具有显著优势。
6 Experiments: Question Answering¶
在这一节中,作者探讨了不同的段落检索器(passage retrievers)如何影响最终的问答(QA)准确性。
6.1 端到端问答系统¶
作者构建了一个端到端的问答系统,可以直接插入不同的检索器系统进行比较。除了检索器之外,系统还包括一个神经阅读器(neural reader),它负责输出问题的答案。
给定从检索器中获取的最多100个段落,阅读器为每个段落分配一个段落选择分数,并从每个段落中提取一个答案跨度(answer span),并为其分配一个跨度得分。最终的答案是选择段落选择分数最高的段落中的最佳跨度。
段落选择模型通过问题与段落之间的交叉注意力机制(cross-attention)实现,作为重排序器。虽然交叉注意力在大规模语料库中难以直接用于检索相关段落,但在少量候选段落中表现良好,因为其具有比传统的双编码器模型(如 Eq. 1 所示的 sim(q, p))更强的能力。
具体实现中,作者使用了 BERT(base,uncased) 来表示第 i 个段落,定义了以下三个概率分布:
\( P_{\text{start},i}(s) \):第 i 个段落中第 s 个词作为答案起始位置的概率;
\( P_{\text{end},i}(t) \):第 i 个段落中第 t 个词作为答案结束位置的概率;
\( P_{\text{selected}}(i) \):第 i 个段落被选中的概率。
这些概率通过 softmax 函数计算,并使用可学习的向量 \( \mathbf{w}_{\text{start}}, \mathbf{w}_{\text{end}}, \mathbf{w}_{\text{selected}} \) 来参数化。
训练中,作者对每个问题从检索器返回的前100个段落中选取1个正样本和 \( \tilde{m}-1 \) 个负样本(\( \tilde{m} = 24 \)),并最大化以下目标:
正段落中所有正确答案跨度的对数似然;
正段落被选择的概率的对数似然。
训练时,使用了不同的批量大小(大型数据集如 NQ、TriviaQA、SQuAD 使用 16 批,小型数据集如 TREC、WQ 使用 4 批),并在开发集上调整参数 k。
对于小数据集的“多数据集设置”(Multi setting),作者使用在 Natural Questions 上训练的阅读器进行微调。
所有实验均在 8 个 32GB GPU 上进行。
6.2 结果¶
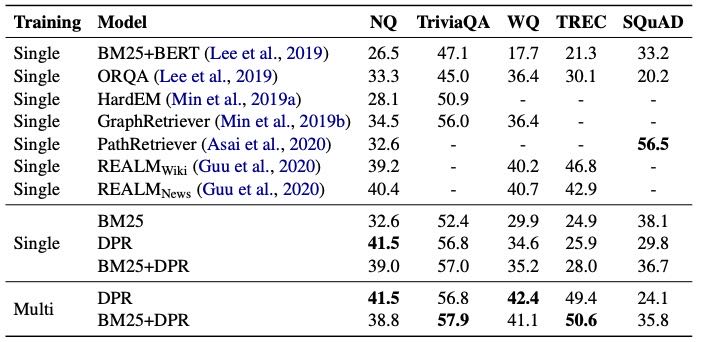
Table 4: End-to-end QA (Exact Match) Accuracy. The first block of results are copied from their cited papers. \(REALM_{Wiki}\) and \(REALM_{News}\) are the same model but pretrained on Wikipedia and CC-News, respectively. Single and Multi denote that our Dense Passage Retriever (DPR) is trained using individual or combined training datasets (all except SQuAD). For WQ and TREC in the Multi setting, we fine-tune the reader trained on NQ.
表4总结了最终的端到端 QA 结果,通过精确匹配(exact match)衡量,且进行了轻微的规范化处理(如 Chen et al. 和 Lee et al. 所述)。
从结果可以看出:
更高的检索准确率通常意味着更好的最终 QA 结果;
在所有数据集中,DPR 检索出的段落生成的答案比 BM25 更准确(除 SQuAD 外);
对于大型数据集(如 NQ、TriviaQA),使用多个数据集训练的模型与使用单一数据集训练的模型表现相当;
对于小型数据集(如 WQ、TREC),使用多数据集训练的模型有明显优势;
DPR 在五个数据集中的四个上达到了 新的 SOTA 性能,在 exact match 准确率上高出 1% 到 12%。
此外,作者将 DPR 与 ORQA 和 REALM 进行了对比:
ORQA 和 REALM 使用了额外的预训练任务和昂贵的端到端训练方法;
DPR 仅通过训练一个强大的段落检索模型(基于问答对),就能在 NQ 和 TriviaQA 上超过它们;
额外的预训练任务对于小数据集可能更有助益,但在大数据集上,DPR 的方法已经足够强大。
为了对比不同的训练策略,作者在 Natural Questions 上进行了联合训练(joint training)的消融实验,结果为 39.8 EM,略低于 DPR 的性能,说明独立训练检索器和阅读器的策略更有效。
另外值得注意的是:
DPR 的阅读器可以处理多达 100 个段落,并能在一个 GPU 上进行批量处理,推理延迟保持在约 20ms;
对比 ORQA 的 5 个段落设置,DPR 的 50 个段落设置仅损失少量准确率(EM 40.8 vs 41.5),而其段落长度更短,计算复杂度更低;
ORQA 的段落长度(288 word pieces)明显长于 DPR 的 100 tokens,因此其计算复杂度更高。
总结¶
本节通过实验验证了不同段落检索器对 QA 性能的影响,重点展示了 DPR 的优越性。通过独立训练强大的段落检索器和阅读器,作者在多个数据集上达到了 SOTA 性能,并优于 ORQA 和 REALM 等更复杂的联合训练系统。实验还表明,DPR 的方法在大规模数据上表现优异,且推理效率较高。
8 Conclusion¶
本文展示了密集检索(dense retrieval)在开放域问答任务中可以超越并可能取代传统的稀疏检索方法。尽管一个简单的双编码器方法(dual-encoder approach)已经表现得相当出色,但作者强调,成功训练密集检索模型需要一些关键要素,这一点尤为重要。
此外,通过实证分析和消融实验,作者发现更复杂的模型框架或相似度函数并不一定带来性能提升。这说明,在密集检索任务中,模型的复杂性并非决定性能的唯一因素。重点在于合理的设计和关键训练要素的把握。
最终,借助提升后的检索性能,本文在多个开放域问答基准测试中取得了新的最佳结果(state-of-the-art results),这进一步验证了密集检索方法的优越性。
Acknowledgments¶
文章作者对匿名评审人表达了感谢,感谢他们在评论和建议方面提供的帮助。这一部分内容简洁,未涉及具体细节,主要体现作者对评审工作的尊重与感激之情。
Appendix A Distant Supervision¶
在使用 Natural Questions 数据集训练最终的 DPR(Dense Passage Retrieval)模型 时,我们选择了与黄金上下文(gold context)最匹配的段落作为正样本段落。
由于有些问答数据集仅包含问题与答案对,没有标注的上下文,因此一个值得探讨的问题是:在使用包含答案的段落作为正样本(即远程监督设置的情况下),模型性能是否会有显著下降。
在实验中,我们将问题和答案联合作为查询,使用 Lucene-BM25 进行检索,从中选取包含答案的最顶部段落作为正样本。
重点内容:
表5 展示了 DPR 模型在原始设置(有标注上下文)和远程监督设置(仅用答案所在段落)下的性能对比。
不重要内容简述:
该部分主要介绍实验方法和设置,强调在缺乏标注上下文的情况下,是否可用的答案段落仍能有效训练 DPR 模型。
Appendix B Alternative Similarity Functions & Triplet Loss¶
本节介绍了除了点积(DP)和基于 softmax 的负对数似然(NLL)之外,作者还尝试了欧几里得距离(L2)和三元组损失(Triplet Loss)。
重点内容:
使用的相似度函数:除了 DP 和 NLL,作者还实验了 L2 和 Triplet Loss。
处理方式:
在使用 softmax 之前,L2 的相似度得分会被取负。
在使用三元组损失时,针对点积得分,作者对问题与正样本、负样本之间的相似度取了负号。
三元组损失的 margin:设置为 1。
实验设置:所有附加实验均使用与基线(DP, NLL)相同的超参数设置。
结果汇总:表6 中总结了实验结果。
补充说明:
值得注意的是,表5(Gold)和表6 (DP, NLL)中报告的“基线”检索准确率略高于表 3 中的结果。
这是因为在这些分析实验中使用了更优的超参数设置,其详细信息已记录在作者公开的代码中。
总结:
本节主要展示了作者在相似度函数上的扩展实验,包括 L2 和三元组损失的应用方式,以及在相同超参数下的实验结果。同时指出实验中使用的超参数配置优于之前版本,这也是检索准确率略有提升的原因。
Appendix C Qualitative Analysis¶
概述¶
虽然 DPR 在整体表现上优于 BM25,但两者在检索结果的定性差异上仍然存在显著区别。BM25 对关键词和短语的敏感度较高,但在处理词汇变体或语义关系时表现不佳。而 DPR 擅长语义表示,但在捕捉出现频率低但关键的短语上可能有所欠缺。表格 7 中通过两个例子展示了这一现象。
示例分析¶
示例 1:BM25 的检索结果无关,DPR 表现良好¶
问题:What is the body of water between England and Ireland? (英格兰和爱尔兰之间的水域是什么?)
BM25 检索结果:返回了一段与“英国自行车协会”相关的文本,虽然包含关键词 England 和 Ireland,但与问题无关。
DPR 检索结果:返回了“爱尔兰海(Irish Sea)”的正确答案。
关键点:DPR 能够通过语义匹配(如 body of water → sea, channel)找到答案,而 BM25 仅依赖关键词匹配,无法理解语义。
示例 2:BM25 表现更好,DPR 未能捕捉关键短语¶
问题:Who plays Thoros of Myr in Game of Thrones? (在《权力的游戏》中谁扮演 Thoros of Myr?)
BM25 检索结果:返回了一段包含“Thoros of Myr”这一关键短语的文本,因此准确。
DPR 检索结果:返回的是演员 Pål Sverre Hagen 的背景信息,但未提及 Thoros of Myr。
关键点:BM25 对稀有但关键的短语敏感,而 DPR 在语义匹配时未能捕捉到该短语。
表格分析¶
表格 5:不同训练方式下的检索准确率¶
方法 |
Top-1 |
Top-5 |
Top-20 |
Top-100 |
|---|---|---|---|---|
Gold |
44.9 |
66.8 |
78.1 |
85.0 |
Dist. Sup. |
43.9 |
65.3 |
77.1 |
84.4 |
Gold:使用与标准答案匹配的段落进行训练,表现略好。
Dist. Sup.:使用 BM25 检索到的包含答案的段落进行训练,表现稍差但接近 Gold。
重点:说明训练数据的选择对模型效果有一定影响,但差异较小。
表格 6:不同相似度和损失函数下的检索准确率¶
相似度 |
损失函数 |
Top-1 |
Top-5 |
Top-20 |
Top-100 |
|---|---|---|---|---|---|
DP |
NLL |
44.9 |
66.8 |
78.1 |
85.0 |
Triplet |
41.6 |
65.0 |
77.2 |
84.5 |
|
L2 |
NLL |
43.5 |
64.7 |
76.1 |
83.1 |
Triplet |
42.2 |
66.0 |
78.1 |
84.9 |
Top-N 准确率:不同相似度(DP、L2)和损失函数(NLL、Triplet)对结果有影响,但变化幅度不大。
重点:DP + NLL 的表现最好,但差异不显著,说明模型优化空间有限。
表格 7:BM25 和 DPR 检索结果对比¶
问题 |
BM25 检索结果 |
DPR 检索结果 |
|---|---|---|
What is the body of water between England and Ireland? |
British Cycling 相关内容 |
Irish Sea 信息 |
Who plays Thoros of Myr in Game of Thrones? |
No One 集数内容 |
Pål Sverre Hagen 生平信息 |
重点:通过具体例子展示 DPR 更关注语义,而 BM25 更依赖关键词,二者各有优劣。
总结¶
本部分通过定性分析和实验结果对比,指出:
BM25:对关键词敏感,但在语义理解和稀有短语捕捉上不足。
DPR:擅长语义匹配,但在处理稀有短语或关键词缺失时可能失败。
实验结果:训练方式和模型配置对性能有一定影响,但整体差异不大。
Appendix D Joint Training of Retriever and Reader¶
在我们的联合训练方案中,我们固定了段落编码器(passage encoder),仅允许**问题编码器(question encoder)**接收来自联合损失函数(retriever + reader)的反向传播信号。这种设计使得我们可以在模型更新时不重新构建基于 HNSW 的 FAISS 索引,从而实现高效且低延迟的检索。
损失函数设计¶
我们的损失函数主要遵循 ORQA 的方法,该方法使用以下两个部分的对数概率:
检索器模型中选出的**正段落(positive passages)**的对数概率;
阅读器模型中选出的正确片段和段落的对数概率。
由于段落编码器是固定的,我们可以在计算检索器损失时使用更多的检索段落。
具体实现细节¶
每个 mini-batch 中,我们为每个问题获取 top 100 个段落,并使用一种类似in-batch negative的方法进行训练:即,所有检索到的段落向量参与整个 batch 中所有问题的损失计算。
训练 batch size 设置为 16,这相当于每个问题能用到 1,600 个段落来计算检索器的损失。
阅读器部分仍使用每个问题的 24 个段落,这 24 个段落是从 top 100 中选出的 5 个正段落和 30 个负段落。
初始模型设置¶
问题编码器的初始状态是基于 DPR 模型在 NQ 数据集上预训练得到的。
阅读器的初始模型是 BERT-base。
实验结果¶
尽管进行了联合训练,但在端到端问答任务上的表现并没有比传统的“检索器 + 阅读器”独立训练流程更好。例如,在 NQ 开发集上的Exact Match(精确匹配)得分仍为 39.8,与单独训练阅读器模型时的结果相同。
重点总结:
联合训练方案通过固定段落编码器,实现高效检索;
结合 in-batch negative 方法提升检索器训练效果;
阅读器使用少量高质量段落进行精读;
最终在问答任务上并未带来性能提升。