2509.25140❇️_ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory¶
组织:
1University of Illinois Urbana-Champaign
2Google Cloud AI Research
3Yale University
4Google Cloud AI
引用: 3(2025-11-22)
总结¶
标签
tag: memory
remark: prompt(代表论文中有好的 prompt)
总结
MaTTS: Memory-aware Test-Time Scaling(记忆感知测试时扩展)
引用
https://mp.weixin.qq.com/s/ocgsPadP5VR9Ds7xTwqyzA
ReasoningBank
一种新型的智能体记忆框架。
它能够从成功与失败的经验中提炼出可复用的推理策略,抽象为可操作的原则,并通过闭环机制不断更新记忆库
提出记忆感知的测试时扩展(MaTTS)
通过深度探索单个任务而非广度扩展任务数量,生成多样化的探索路径,提供对比信号,从而帮助 ReasoningBank 提炼更通用的记忆。
设计动机
原始轨迹通常冗长且噪声多,难以直接复用。ReasoningBank 将经验提炼为结构化记忆项,便于后续使用。
记忆结构(Memory Schema)
标题(Title):简明标识核心策略;
描述(Description):一句话总结;
内容(Content):提炼的推理步骤、决策依据或操作洞见。
与代理的集成过程分为三步:
记忆检索(Memory Retrieval):基于当前任务上下文,通过嵌入相似性搜索获取 top-k 相关记忆项,注入系统指令;
记忆构建(Memory Construction):任务完成后,使用 LLM-as-a-judge 判断轨迹成功与否,分别提取有效策略或失败教训;
记忆整合(Memory Consolidation):将新记忆项加入 ReasoningBank,形成闭环记忆流程。
MaTTS:Memory-aware Test-Time Scaling
利用扩展过程中生成的丰富成功/失败轨迹,提升记忆提炼效果。
设计两种互补形式:
并行扩展(Parallel Scaling)
对同一任务生成多个轨迹,通过对比(self-contrast)识别一致推理模式,过滤错误解,提升记忆可靠性。
顺序扩展(Sequential Scaling)
在初始任务完成后迭代优化推理(self-refinement),中间笔记也作为记忆信号,记录未出现在最终解中的推理尝试和修正。
Future Directions
组合式记忆(Compositional Memory)
探索组合感知的记忆检索与整合机制,使智能体能够将互补的记忆项组合成更高层次的策略,
或形成可重复使用的宏操作(macros),从而提升在长期任务中的泛化能力和策略丰富性
高级记忆架构(Advanced Memory Architectures)
构建一个分层的、产品级的记忆架构栈,融合成熟的记忆范式:
情景记忆(episodic traces)用于保存任务上下文
工作记忆(working memory)用于维护会话内的状态
长期记忆(long-term memory)用于存储经过整合的知识,并引入遗忘与刷新机制
基于推理的控制器(reasoning-intensive controllers)
用于替换当前基于嵌入相似性的记忆检索机制
该类控制器能够分解查询、规划跨层级的多跳检索,并根据不确定性、时效性和检索成本等因素动态选择记忆内容。
结合基于学习的路由机制和整合策略,还可以实现整个过程的自动化。
最后成为一个可部署、可扩展的记忆服务系统,适用于多领域、多团队的复杂应用场景
三行摘要¶
💡 ReasoningBank 提出了一种新颖的记忆框架,它从代理人自我判断的成功和失败经验中提炼出可泛化的推理策略,使代理人能够随着时间推移不断学习和进化。
🚀 为增强这种学习能力,该研究引入了记忆感知测试时扩展(MaTTS),通过增加任务计算资源来生成多样化的交互经验,从而为 ReasoningBank 提供更丰富的对比信号以合成高质量记忆。
✅ 实验结果表明,在网页浏览和软件工程基准测试中,ReasoningBank 显著优于现有记忆机制,MaTTS 进一步放大了这些优势,共同确立了记忆驱动经验扩展作为代理自进化的新维度。
摘要-from Moonlight¶
本文提出了一种名为 ReasoningBank 的新型记忆框架,旨在解决大型语言模型(LLM)代理在长期运行任务中无法从历史交互中学习,从而重复错误并丢弃宝贵经验的限制。ReasoningBank 能够从代理自身判断的成功和失败经验中提炼出可泛化的推理策略。在测试时,代理会从 ReasoningBank 中检索相关记忆以指导其交互,并将新的学习成果整合回记忆库中,使其能力随时间不断增强。
核心方法论
ReasoningBank 的核心在于其独特的记忆构建和利用机制,它将经验抽象为结构化的记忆项。
记忆模式 (Memory Schema):ReasoningBank 中的记忆项被设计为结构化知识单元,它抽象掉了低级执行细节,同时保留了可迁移的推理模式和策略。每个记忆项包含三个部分:
标题 (Title):简洁地概括核心策略或推理模式。
描述 (Description):提供记忆项的简短总结。
内容 (Content):记录从过去经验中提炼出的推理步骤、决策依据或操作见解。 这些记忆项既可供人类理解,也可供机器使用。
ReasoningBank 与代理的集成:该集成通过一个闭环过程实现,包含三个步骤:
记忆检索 (Memory Retrieval):当代理面临新任务时,它使用当前查询上下文向 ReasoningBank 查询,通过基于嵌入的相似性搜索识别出 Top-\(k\) 个相关经验及其对应的记忆项。检索到的记忆项被注入到代理的系统指令中,作为额外的上下文指导决策。
记忆构建 (Memory Construction):当前任务完成后,代理分析新的经验以提取新的记忆项。首先,使用 LLM-as-a-judge (大型语言模型作为裁判) 对已完成轨迹的正确性进行代理自判断,将其标记为成功或失败,而无需真实标签。
对于成功经验,ReasoningBank 提取并验证有效的策略。
对于失败经验,ReasoningBank 提取反事实信号和陷阱,以形成预防性指导。 实践中,每个轨迹/经验可以提取多个记忆项。
记忆整合 (Memory Consolidation):新构建的记忆项通过简单的添加操作被整合到 ReasoningBank 中,从而维护一个不断演进的记忆库。
MaTTS: 记忆感知测试时扩展
在 ReasoningBank 这一强大的经验学习器的基础上,本文进一步引入了 Memory-aware Test-Time Scaling (MaTTS),通过扩展代理的交互经验来加速和多样化学习过程。传统的测试时扩展(TTS)虽然能生成大量探索轨迹,但可能未能有效利用同一问题上冗余探索产生的对比信号。MaTTS 通过精心设计,从扩展过程中生成的丰富成功和失败轨迹中学习,以更有效地组织记忆。
MaTTS 提出了两种互补的实现方式:
并行扩展 (Parallel Scaling):在并行设置中,代理在检索到的记忆项指导下,为同一个查询生成多条轨迹。通过比较和对比(self-contrast)不同的轨迹,代理可以识别出一致的推理模式,同时过滤掉虚假的解决方案,从而从单次查询的多次尝试中实现更可靠的记忆组织和更多样化的探索。
顺序扩展 (Sequential Scaling):在顺序设置中,代理在初始完成任务后,在单条轨迹内迭代地细化其推理过程(self-refinement)。在此过程中,自细化产生的中间笔记也作为有价值的记忆信号,因为它们捕获了可能不会出现在最终解决方案中的推理尝试、纠正和见解。
MaTTS 与 ReasoningBank 之间建立了强大的协同效应:高质量的记忆指导扩展的探索走向更有前途的路径,而丰富的经验反过来又铸就了更强大的记忆。这种正反馈循环将记忆驱动的经验扩展定位为代理的新维度扩展方式。
实验结果
本文在 Web 浏览基准(WebArena、Mind2Web)和软件工程基准(SWE-Bench-Verified)上进行了广泛实验。
ReasoningBank 的优越性:ReasoningBank 在所有数据集和 LLM 后端上,始终优于现有记忆机制(如存储原始轨迹或仅成功任务例程的方法),在有效性(相对提升高达 34.2%)和效率(交互步骤减少 16.0%)方面都有显著提升。
MaTTS 的增益:MaTTS 进一步放大了这些增益,并证明了其与 ReasoningBank 的最佳协同作用,使其成为记忆驱动经验扩展的关键组成部分。
泛化能力:ReasoningBank 能够通过更好的可迁移记忆,在跨任务、跨网站和跨领域设置中增强泛化能力,尤其是在需要最高泛化水平的跨领域设置中表现突出。
效率提升:ReasoningBank 不仅提高了成功率,还减少了完成任务所需的交互步骤,主要通过在正确路径上减少不必要的探索来实现。
记忆与扩展的协同作用:高质量的记忆能指导测试时扩展走向更有希望的路径,确保额外的轨迹转化为更高的成功率;反之,扩展也能带来更好的记忆组织,尤其是对于 ReasoningBank,它能从扩展的多样性中提取建设性的对比信号。
分析:
新兴行为:ReasoningBank 中的策略会随时间演变,从面向执行的程序性策略逐步发展为自适应的自我反思,最终形成更复杂、组合性的策略。
失败轨迹的整合:与基线方法不同,ReasoningBank 能够有效利用失败轨迹来提炼推理模式,将其转化为建设性信号,显著提升性能。
效率研究:性能提升主要来源于成功案例中步骤的显著减少,表明 ReasoningBank 帮助代理更直接地找到解决方案,而非简单地截断失败轨迹。
结论
本文的工作确立了记忆驱动的经验扩展作为一个新的扩展维度,使代理能够通过自然涌现的行为实现自我演进,为构建自适应、终身学习的代理提供了实用的途径。
Abstract¶
本章节提出了一个名为 ReasoningBank 的新型记忆框架,旨在解决大型语言模型代理在持续执行现实任务时无法从历史经验中学习的问题。该框架能够从代理自身的成功与失败经历中提炼出可泛化的推理策略。在测试阶段,代理可以从 ReasoningBank 中检索相关记忆来指导当前任务,并将新的经验反馈到记忆库中,从而实现持续提升。
在此基础上,作者进一步提出了 记忆感知的测试时扩展方法(MaTTS),通过增加计算资源生成更丰富、多样的经验,加速并优化学习过程。这些经验提供了更强的对比信号,有助于合成更高质量的记忆,而高质量的记忆又反过来指导更有效的扩展,形成记忆与扩展之间的良性循环。
实验表明,ReasoningBank 在多个网页浏览和软件工程任务中优于现有记忆机制,不仅提升了任务完成效果,也提高了效率;MaTTS 进一步增强了这些优势。研究结果表明,基于记忆的经验扩展 是一种新的扩展维度,使代理能够自我演化,并自然涌现出新的行为能力。
重点内容:
ReasoningBank 是核心创新,解决了代理无法从历史中学习的问题。
MaTTS 是对 ReasoningBank 的增强机制,通过资源扩展提升学习效率。
实验证明该方法在多个任务中表现优异,具有广泛的应用前景。
次要内容精简:
提到了与现有方法的对比,如仅存储原始轨迹或仅成功路径的方法,但未展开细节。
1 Introduction¶
1.1 背景与问题¶
随着大语言模型(LLMs)的快速发展,LLM 智能体(LLM agents)在处理需要多步骤环境交互的复杂现实任务中发挥着越来越重要的作用,例如网页浏览和计算机操作。然而,当前的智能体在面对持续、长期的任务流时,往往无法从过往经验中学习,导致重复错误、忽视有价值的经验,缺乏自我演化的机制。这凸显了构建具有记忆能力的智能体系统的必要性。
1.2 现有方法的局限性¶
目前的智能体记忆研究主要集中在存储和复用过往交互数据,但这些方法存在两个根本性问题:
缺乏高层次推理模式的提炼:仅复用原始交互轨迹或成功流程,难以形成可迁移的通用策略。
忽略失败经验的价值:过度强调成功经验,忽视失败中蕴含的重要教训。
因此,现有记忆机制多停留在被动记录层面,难以提供对未来的可操作性指导。
1.3 提出的方法:ReasoningBank¶
为解决上述问题,作者提出 ReasoningBank,一种新型的智能体记忆框架。它能够从成功与失败的经验中提炼出可复用的推理策略,抽象为可操作的原则,并通过闭环机制不断更新记忆库:
面对新任务时,智能体从 ReasoningBank 中检索相关记忆进行指导;
完成任务后,新经验被分析、提炼并重新整合进记忆库,实现自我演化。
1.4 记忆驱动的经验扩展:MaTTS¶
在此基础上,作者提出 记忆感知的测试时扩展(MaTTS),通过深度探索单个任务而非广度扩展任务数量,生成多样化的探索路径,提供对比信号,从而帮助 ReasoningBank 提炼更通用的记忆。
记忆与扩展的协同机制:高质量记忆引导扩展探索走向更优路径,而丰富的探索经验又进一步强化记忆。
这种正反馈循环形成了智能体的“记忆驱动经验扩展”这一新维度。
1.5 实验与效果¶
在多个复杂任务基准(如网页浏览任务 WebArena、Mind2Web,软件工程任务 SWE-Bench-Verified)上的实验表明:
有效性提升:相比基线方法,效果提升最高达 34.2%;
效率提升:所需交互步骤减少 16.0%;
关键组件:ReasoningBank 与 MaTTS 的协同效果最佳,是实现记忆驱动经验扩展的核心。
1.6 主要贡献¶
提出 ReasoningBank,首次从成功与失败经验中提炼通用推理策略;
引入 MaTTS,实现记忆与测试时扩展的协同,开辟了智能体的新扩展维度;
实验验证了方法在效果、效率及失败学习能力上的显著提升,并展现出智能体推理能力的逐步演化趋势。
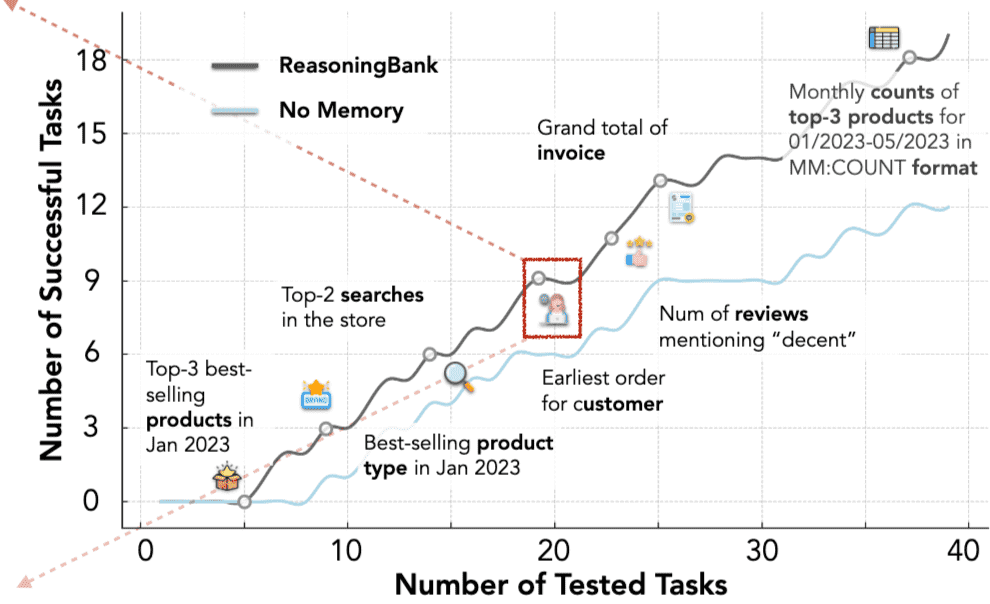
Figure 1:ReasoningBank induces reusable reasoning strategies, making memory items more transferrable for future use. This enables agents to continuously evolve and achieve higher accumulative success rates than the “No Memory” baseline on the WebArena-Admin subset.
3 Methodology¶
本章节主要分为三个部分:问题设定(§3.1)、提出的 ReasoningBank(§3.2)以及基于其的 Memory-aware Test-Time Scaling(MaTTS,§3.3)。
3.1 问题设定(Problem Formulation)¶
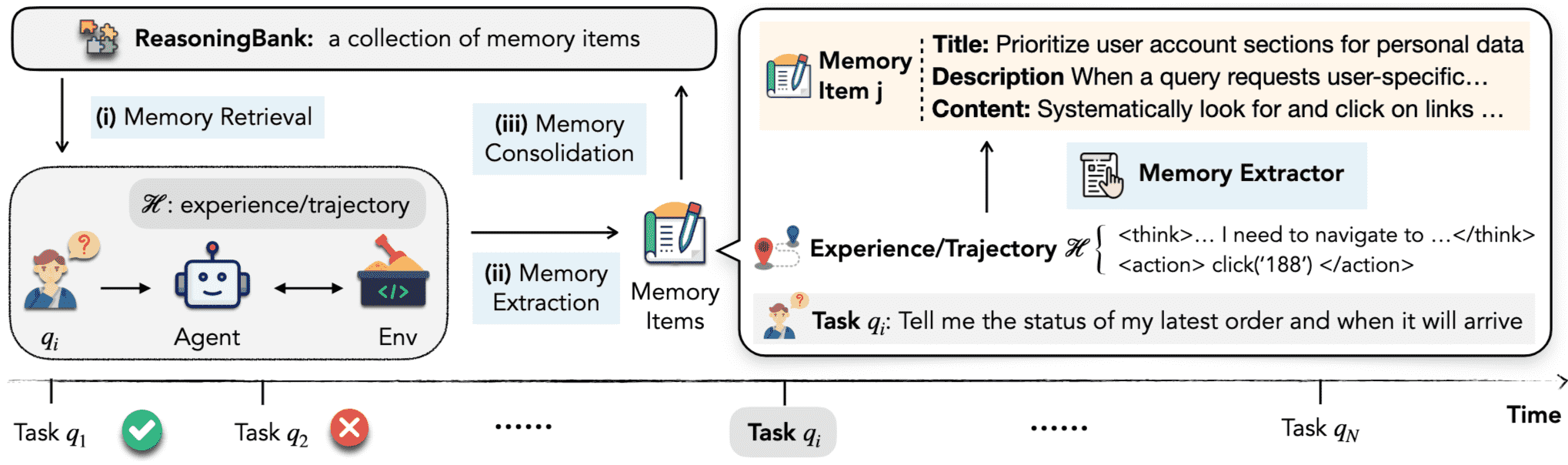
Figure 2 | Overview of ReasoningBank. Experiences are distilled into structured memory items with a title, description, and content. For each new task, the agent retrieves relevant items to interact with the environment, and constructs new ones from both successful and failed trajectories. These items are then consolidated into ReasoningBank, forming a closed-loop memory process.
重点内容:
代理配置(Agent Configuration)
本文聚焦于基于大语言模型(LLM)的代理(agent),其策略 πℒ(⋅|ℳ,𝒜) 由 LLM 参数化,依赖于记忆模块 ℳ 和动作空间 𝒜。
代理通过与环境交互完成任务,环境状态转移函数为 𝒯(st+1|st, at),任务包括网页浏览和软件工程(SWE)。
动作空间 𝒜 分别为网页操作和 bash 命令,记忆模块 ℳ 初始化为空,使用 ReasoningBank。
每个任务生成一个轨迹 (o0:t, a0:t),其中 o 是基于文本的网页结构或代码片段,a 是代理生成的动作。测试时学习(Test-Time Learning)
任务查询以流式方式到来,代理必须在没有未来任务信息和真实标签的情况下持续进化。
核心挑战是:如何从历史轨迹中提取和保存有用记忆;
如何有效利用这些记忆避免重复错误或重复发现已有策略。
3.2 ReasoningBank¶
重点内容:
设计动机
原始轨迹通常冗长且噪声多,难以直接复用。ReasoningBank 将经验提炼为结构化记忆项,便于后续使用。记忆结构(Memory Schema)
每个记忆项包含三个部分:标题(Title):简明标识核心策略;
描述(Description):一句话总结;
内容(Content):提炼的推理步骤、决策依据或操作洞见。
这些记忆项既可被人类理解,也可被代理使用。
与代理的集成
集成过程分为三步:记忆检索(Memory Retrieval):基于当前任务上下文,通过嵌入相似性搜索获取 top-k 相关记忆项,注入系统指令;
记忆构建(Memory Construction):任务完成后,使用 LLM-as-a-judge 判断轨迹成功与否,分别提取有效策略或失败教训;
记忆整合(Memory Consolidation):将新记忆项加入 ReasoningBank,形成闭环记忆流程。
非重点内容精简:
实现细节(如附录中的提示词和实现细节)未展开,仅强调流程简洁性以突出核心贡献。
3.3 MaTTS:Memory-aware Test-Time Scaling¶
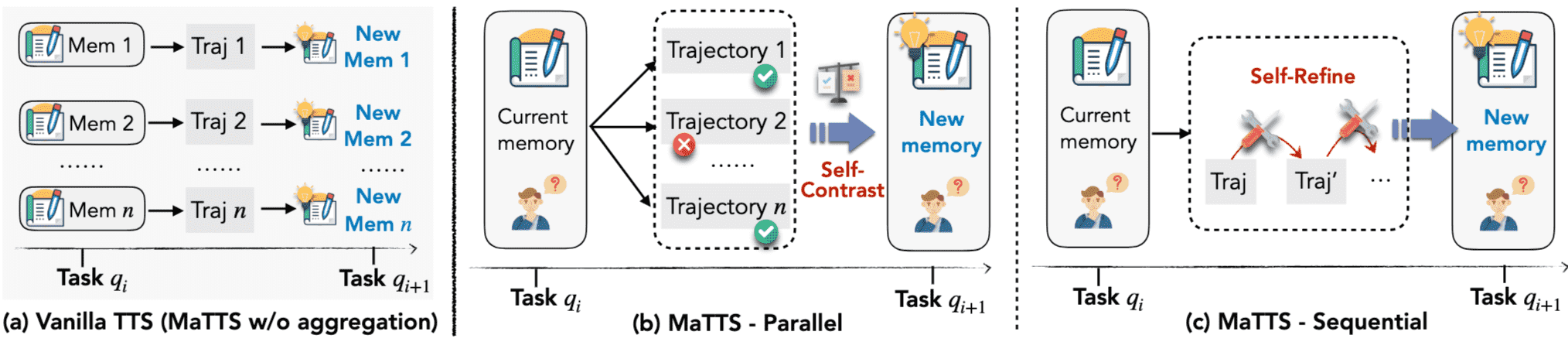
Figure 3 | Comparison of (a) vanilla TTS and MaT TS with (b) parallel scaling, where self-contrast across multiple trajectories curates reliable memory, and (c) sequential scaling, where self-refinement enriches memory with intermediate reasoning signals
重点内容:
背景与动机
测试时扩展(Test-Time Scaling)通过增加推理时计算资源生成更多探索轨迹,提升代理性能。
但直接结合 ReasoningBank 的方式(vanilla TTS)未能利用同一问题的多轨迹对比信号,效果受限。MaTTS 提出
提出 Memory-aware Test-Time Scaling(MaTTS),利用扩展过程中生成的丰富成功/失败轨迹,提升记忆提炼效果。
设计两种互补形式:并行扩展(Parallel Scaling) 和 顺序扩展(Sequential Scaling)。并行扩展(Parallel Scaling)
对同一任务生成多个轨迹,通过对比(self-contrast)识别一致推理模式,过滤错误解,提升记忆可靠性。顺序扩展(Sequential Scaling)
在初始任务完成后迭代优化推理(self-refinement),中间笔记也作为记忆信号,记录未出现在最终解中的推理尝试和修正。扩展因子 k
表示并行轨迹数或顺序优化步数。结合 ReasoningBank 后,两种策略都具备“记忆感知”能力,使测试时计算资源转化为高质量记忆。
非重点内容精简:
图3的结构图和附录中的实现细节(A.3节)仅作为补充,未展开讲解。
总结结构图(简化版):¶
3. Methodology
├── 3.1 问题设定
│ ├── 代理配置(LLM + ReasoningBank + 动作空间)
│ └── 测试时学习(流式任务 + 无监督进化 + 两大挑战)
├── 3.2 ReasoningBank
│ ├── 结构化记忆项(标题 + 描述 + 内容)
│ └── 三步集成:检索 → 构建 → 整合(闭环流程)
└── 3.3 MaTTS
├── 测试时扩展与 ReasoningBank 的结合问题
├── MaTTS 设计:并行扩展(对比) + 顺序扩展(自优化)
└── 扩展因子 k 与记忆质量提升的关系
4 Experiments¶
4.1 实验设置¶
本研究在WebArena、Mind2Web和SWE-Bench-Verified三个数据集上进行实验,分别测试代理在网页导航、跨任务泛化和代码问题解决方面的能力。对比的基线包括无记忆代理(No Memory)、基于轨迹的记忆(Synapse)和基于工作流的记忆(AWM)。实验基于Gemini-2.5和Claude-3.7模型,在BrowserGym和bash环境中进行,采用ReAct风格的交互方式。
评估指标包括任务成功率(Success Rate, SR)和平均交互步数(Step),以衡量代理的有效性和效率。更多实验细节(如数据集描述、基线方法、实现细节等)见附录B。
4.2 ReasoningBank 的实验结果¶
ReasoningBank 在多个数据集上均优于基线方法¶
表1、表2和表3展示了ReasoningBank在WebArena、SWE-Bench-Verified和Mind2Web上的实验结果。主要发现如下:
显著提升成功率:
在WebArena上,ReasoningBank相比无记忆代理,整体成功率提升了+8.3(Gemini-2.5-flash)、+7.2(Gemini-2.5-pro)和+4.6(Claude-3.7)。
在SWE-Bench-Verified上,ReasoningBank在Gemini-2.5-pro上达到57.4%的解决率,优于基线方法。
在Mind2Web的跨任务、跨网站和跨域设置中,ReasoningBank也持续优于其他方法,尤其在跨域任务中表现突出。更强的泛化能力:
在WebArena的Multi子集(跨多个网站)中,ReasoningBank比最强基线提升了+4.6%的成功率。而AWM等方法在该设置下表现下降。
在Mind2Web中,ReasoningBank在跨任务、跨网站和跨域设置中均表现优异,说明其记忆机制具有更强的可迁移性和鲁棒性。更高的效率:
ReasoningBank在多个任务中显著减少了完成任务所需的交互步数。例如在WebArena中,平均步数比“无记忆”减少了1.4步,比其他记忆基线减少了1.6步。
在SWE-Bench-Verified中,ReasoningBank也比基线方法平均节省了1.3~2.8步。
重点总结:
ReasoningBank在成功率、泛化能力和效率方面均优于现有方法,其关键在于更优的记忆提取策略,能够从多样化的经验中提取可迁移的推理知识。
4.3 MaTTS 的实验结果¶
MaTTS 在WebArena-Shopping子集上的表现¶
MaTTS是基于ReasoningBank的测试时扩展方法,支持并行和顺序扩展。实验对比了以下设置:
MaTTS w/o memory(无记忆)
MaTTS w/o aggregation(无聚合,即Vanilla TTS)
MaTTS(完整方法)
主要发现:¶
扩展策略提升性能:
随着扩展因子k的增加,成功率持续提升。在k=5时,MaTTS的并行扩展达到55.1%,顺序扩展达到54.5%。
而无记忆的MaTTS提升较小且不稳定。MaTTS优于Vanilla TTS:
在k=5时,MaTTS的并行扩展比Vanilla TTS高2.7%,顺序扩展高2.6%。这表明记忆感知的聚合机制有助于整合多条路径的推理信息,提升决策质量。并行扩展在大规模时更优:
在较小k时,顺序扩展表现略优;但随着k增大,其提升趋于饱和,而并行扩展通过多样化路径持续提升性能。
对于无记忆的Vanilla TTS,并行扩展始终优于顺序扩展。
重点总结:
MaTTS通过结合ReasoningBank的记忆机制和测试时扩展策略,显著提升了代理的性能,尤其在大规模并行扩展中表现突出。
4.4 记忆与测试时扩展的协同效应¶
更好的记忆机制提升扩展效果¶
图5展示了在WebArena-Shopping子集上,不同记忆机制下MaTTS在k=3时的表现。结果显示:
BoN(Best-of-3)表现:
无记忆的MaTTS BoN仅从39.0提升到40.6。
Synapse和AWM分别提升到42.8和45.5。
使用ReasoningBank的MaTTS BoN提升到52.4,说明高质量记忆能引导扩展生成更优路径。Pass@1表现:
对于Synapse和AWM,扩展反而导致Pass@1下降,说明扩展引入了噪声。
而使用ReasoningBank的MaTTS Pass@1从49.7提升到50.8,说明其能有效利用扩展带来的多样性,提取有用信息。
重点总结:
只有在高质量记忆机制(如ReasoningBank)的支持下,测试时扩展才能真正发挥作用,形成“记忆提升扩展,扩展反哺记忆”的良性循环。
总结¶
ReasoningBank在多个任务和模型上均优于现有记忆机制,显著提升成功率、泛化能力和效率。
MaTTS结合ReasoningBank和测试时扩展策略,进一步提升了代理性能,尤其在大规模并行扩展中表现最佳。
记忆与扩展的协同作用:高质量记忆机制不仅提升扩展效果,还能利用扩展带来的多样性优化自身记忆,形成正向反馈。
核心贡献:
本研究提出了一种高效、可扩展的代理记忆机制(ReasoningBank),并通过MaTTS实现了测试时的性能提升,为未来代理系统的自我演化提供了新思路。
5 Analysis¶
本节从三个方面对 ReasoningBank 进行深入分析:涌现行为、失败轨迹的整合、效率评估,并展示了其在不同场景下的表现与优势。
5.1 ReasoningBank 中的涌现行为¶
重点内容:
本节揭示了 ReasoningBank 中策略的动态演化过程,展示了智能体在测试阶段如何从低级操作逐步发展为高级推理。具体来说,策略演化分为四个阶段:
执行导向策略(如“寻找导航链接”):智能体遵循简单的操作规则。
自适应反思(如“重新验证标识符”):减少基础错误。
系统性检查(如利用搜索或过滤功能):确保结果的完整性。
组合策略(如交叉核对任务要求):进行综合判断与选项评估。
这种演化过程表明,ReasoningBank 能够支持智能体在测试阶段不断优化策略,实现从操作到推理的跃迁,体现了其类似强化学习的学习动态。
5.2 整合失败轨迹¶
重点内容:
本节通过对比实验验证了 ReasoningBank 在整合失败轨迹方面的能力。实验在 WebArena-Shopping 数据集上进行,使用 Gemini-2.5-flash 模型,比较了仅使用成功轨迹与同时使用成功和失败轨迹的效果。
基线方法(Synapse 和 AWM):仅从成功轨迹中构建记忆,无法有效利用失败信息,导致性能提升有限甚至下降。
ReasoningBank 的优势:
在仅使用成功轨迹时,性能为 46.5。
引入失败轨迹后,性能进一步提升至 49.7。
表明其能将失败转化为建设性信号,提升模型的泛化能力。
这说明 ReasoningBank 能有效利用失败经验,提升模型的鲁棒性和学习效率。
5.3 效率研究¶
重点内容:
本节分析了 ReasoningBank 在成功与失败案例中的交互步数,评估其效率提升来源。
实验结果(见表4):
ReasoningBank 在所有领域中均减少了平均步数。
成功案例中的步数减少尤为显著,例如在 Shopping 领域减少了 2.1 步(相对减少 26.9%)。
意义:
减少的步数主要来自成功路径的优化,而非简单截断失败尝试。
表明 ReasoningBank 能引导智能体更高效地做出决策,提升实际应用中的效率。
总结:
本章通过分析 ReasoningBank 的策略演化、失败利用与效率提升,展示了其在测试阶段学习中的优势。ReasoningBank 不仅能从失败中学习,还能引导智能体更高效地完成任务,体现了其在构建自演化智能体方面的潜力。
6 Conclusion¶
本节总结了论文的核心贡献与发现:
作者提出了 ReasoningBank,这是一种记忆框架,能够从成功与失败中提取策略层面的推理信号,并将其整合到测试时扩展(MaTTS)中。通过大量实验表明,ReasoningBank 能在提升性能的同时,减少不必要的探索。
进一步的结果揭示了记忆与扩展之间的强协同效应:
ReasoningBank 指导扩展过程朝向更有潜力的路径发展;
多样化的扩展路径反过来又为记忆系统提供了有价值的对比信号,从而丰富记忆内容。
此外,作者还对各个组件和涌现行为进行了详细分析。研究结果为构建具有适应性和终身学习能力的智能体提供了一条可行路径。关于未来研究方向和本方法的局限性,详见附录 D 与 E。
7 Acknowledgments¶
本章节对在论文准备过程中提供宝贵反馈的个人和团队表示感谢,包括Jiao Sun、Jing Nathan Yan以及来自Google Cloud AI Research的成员。该部分为常规致谢内容,未涉及具体技术细节,因此不做进一步展开。
Appendix A Experiment Details¶
本节详细介绍了在 WebArena 和 Mind2Web 等网页浏览任务中,使用第 4.1 节中提到的智能体系统实现 ReasoningBank 的具体细节。内容分为两个主要部分:A.1 ReasoningBank 使用的提示 和 A.2 实现细节,另有 A.3 MaTTS 的细节补充。
A.1 ReasoningBank 使用的提示¶
本部分展示了用于从智能体轨迹中提取记忆项的系统提示,分为以下三个子部分:
1. 记忆提取提示(Memory Extraction)¶

Figure 8 | System instructions for extracting memory items from agent trajectories: successful trajectories (summarizing why they succeed

Figure 8 | System instructions for extracting memory items from agent trajectories: failed trajectories (reflecting on failure and deriving lessons).
成功轨迹:提示强调分析成功原因,总结可迁移的推理策略。
失败轨迹:提示要求反思失败原因,并提出教训或预防策略。
输出格式限制为最多 3 个结构化的 Markdown 格式记忆项,确保简洁、非冗余、通用性强。
2. LLM 作为判断器的提示(LLM-as-a-Judge for Correctness Signals)¶
用于判断当前轨迹是否成功解决用户查询,输出“成功”或“失败”。
提示中包含用户查询、轨迹、网页最终状态和模型输出,供 LLM 判断。

Figure 9 | System instructions for obtaining binary signals indicating success or failures of the current trajectory.
3. 基于记忆的测试时扩展提示(Memory-aware Test-time Scaling)¶
并行扩展:比较多个轨迹,提取通用见解。
串行扩展:迭代检查单个轨迹,逐步优化答案。
Figure 10 | System instructions for memory-aware test-time scaling: the left panel shows parallel scaling (comparing multiple trajectories to extract generalizable insights), while the right panel shows sequential scaling (iteratively re-checking a trajectory to refine the final answer).
A.2 实现细节¶
本部分详细说明了记忆提取、检索、生成、整合和存储的具体实现方式。
1. 记忆提取(Memory Extraction)¶
使用基于 LLM 的提取流程,将原始轨迹转化为结构化记忆项。
每条轨迹最多提取 3 个记忆项,包含标题、描述和内容。
使用与智能体系统相同的 LLM(温度设为 1.0)。
成功与失败轨迹均用于提取记忆项,分别提供正向策略与反例教训。
使用 LLM 分类器判断轨迹成功与否(温度设为 0.0 以确保确定性)。
2. 记忆检索与响应生成(Memory Retrieval and Response Generation)¶
使用 gemini-embedding-001 对任务查询进行嵌入。
使用余弦相似度在记忆库中进行搜索,选择 top-k 个最相似的记忆项(默认 k=1)。
将检索到的记忆项整合进智能体提示中,引导其判断是否使用这些记忆。
3. 记忆整合(Memory Consolidation)¶
每完成一个新查询,就将新生成的记忆项添加进记忆库。
采用最简整合策略,不进行剪枝,以突出 ReasoningBank 本身的贡献。
未来可引入合并、遗忘等机制。
4. ReasoningBank 存储结构¶
以 JSON 格式存储,每条记录包括任务查询、原始轨迹和记忆项。
每个记忆项包含 {title, description, content}。
预先计算查询嵌入并存储,以提高检索效率。
每次独立运行都保留记忆库,支持测试阶段持续积累经验。
A.3 MaTTS 细节¶
1. MaTTS 使用的提示¶
并行扩展:提供多个轨迹(成功与失败),引导模型进行对比推理,识别成功模式与失败原因。
串行扩展:反复检查自身轨迹,通过迭代确保一致性与修正错误,无需外部判断。
2. Best-of-N 计算细节¶
给定任务查询和 N 条轨迹,使用与智能体系统相同的 LLM 选择最佳答案。
所有轨迹一次性输入模型,使用特定提示(见图11)引导其选择最优结果。

Figure 11 | System instructions for obtaining the best answer from 𝑁 candidate trajectories for BoN calculation.
总结¶
本附录全面展示了 ReasoningBank 在记忆提取、检索、整合与测试时扩展(MaTTS)中的实现细节。重点包括:
记忆提取:通过结构化提示从成功与失败轨迹中提取可迁移策略。
LLM 判断器:用于判断轨迹成功与否,作为记忆提取的基础。
记忆检索与整合:采用嵌入+相似度搜索机制,结合简单整合策略。
MaTTS 扩展机制:通过并行对比与串行迭代提升推理能力。
实现细节:统一 LLM 设置、JSON 存储结构、嵌入预计算等,确保系统高效运行。
整体设计强调简洁性与可扩展性,为未来改进(如更复杂的整合机制)提供了基础。
Appendix B Details for Experiment Settings¶
B.1 网页浏览实验设置¶
数据集¶
本节详细介绍了在第4.1节中提到的网页浏览代理所使用的实验设置。实验基于以下两个主要数据集:
WebArena(Zhou et al., 2024):涵盖多个领域的通用网页导航任务,包括购物、行政、GitLab(代码)、Reddit(论坛)等。测试实例总数为684,684个,各领域任务数量如下:
购物:187个
行政:182个
GitLab:180个
Reddit:106个
多任务:29个
Mind2Web(Deng et al., 2023):用于测试代理在跨任务、跨网站、跨领域的泛化能力。测试实例总数为13,411,341个,设置如下:
跨任务:252个
跨网站:177个
跨领域:912个
重点说明:这两个数据集分别用于评估代理在通用网页操作和泛化能力方面的表现,具有大规模和多样性。
基线方法¶
与以下几种增强记忆机制的代理方法进行对比:
Vanilla:无记忆模块的基础LLM代理,作为对照组;
Synapse:将历史轨迹作为上下文记忆进行复用;
AWM:从轨迹中抽象出可复用的工作流,提取更高层次的模式。
重点说明:这三类方法代表了从无记忆到轨迹复用再到模式抽象的演进路径,为评估ReasoningBank提供了全面的对比基础。
实现细节¶
使用的LLM包括:Gemini-2.5-Flash、Gemini-2.5-Pro、Claude-3.7-Sonnet,通过Vertex AI API调用。
使用BrowserGym作为WebArena的执行环境,每条查询最多30步。
代理采用ReAct风格实现,解码温度设为0.7。
重点说明:模型选择覆盖了不同家族(Gemini vs. Claude)和同一家族内的不同版本(Flash vs. Pro),有助于分析模型差异对性能的影响。
评估指标¶
WebArena:
有效性:成功解决用户查询的百分比(success rate),使用LLM模糊匹配和精确字符串匹配验证答案。
效率:完成每个查询所需的平均步骤数。
Mind2Web:
元素准确率:是否选中了正确的页面元素;
动作F1值:是否在元素上执行了正确的动作;
步骤成功率:元素和动作都正确时的综合指标;
任务成功率:所有步骤都成功完成的任务比例。
重点说明:Mind2Web的评估更细粒度,强调每一步的准确性和整体任务完成度。
B.2 软件工程实验设置¶
B.2.1 实验设置¶
数据集¶
使用SWE-Bench-Verified(Jimenez et al., 2024):包含500个高质量、人工验证的代码修复任务,每个任务需生成一个补丁以解决输入问题,并通过所有测试脚本。
重点说明:该数据集强调真实代码库中的问题解决能力,具有高验证标准。
评估指标¶
问题解决率:生成的补丁通过所有测试脚本的比例;
补丁应用率:成功应用补丁到代码库的比例;
效率指标:代理完成每个任务的平均步骤数。
实现细节¶
实现方式参考mini-SWE-Agent(Yang et al., 2024):仅使用Bash命令,不引入额外工具或结构;
采用ReAct代理循环;
基线方法包括:
无记忆;
Synapse;
不使用AWM,因为mini-SWE-Agent的Bash命令空间是开放的,难以提取固定工作流。
重点说明:该设置强调代理在受限环境下的自主推理与执行能力,避免依赖外部工具。
总结¶
本附录详细列出了ReasoningBank在网页浏览和软件工程两个应用场景下的实验设置,包括:
使用的数据集及其任务类型;
对比的基线方法;
模型实现细节(LLM选择、执行环境、代理结构);
评估指标(从任务成功率到步骤级准确率)。
核心重点在于通过多维度、大规模的实验设置,全面评估ReasoningBank在不同任务和环境下的性能表现与泛化能力。
Appendix C Additional Analyses¶
C.1 检索经验数量的影响¶
本节通过在WebArena-Shopping子集上使用Gemini-2.5-flash进行消融实验,研究不同数量的检索经验对性能的影响。
关键发现:
引入相关记忆显著提升性能:从无记忆的39.0提升到使用1条经验的49.7。
随着经验数量增加,成功率逐渐下降(如使用22条经验为46.0,33条为45.5,44条为44.4)。
结论:
虽然记忆能提供有价值指导,但过多经验可能引入冲突或噪声。
记忆的相关性和质量比数量更重要。
C.2 Pass@k分析¶
本节通过Pass@k指标分析在WebArena-Shopping子集上使用Gemini-2.5-flash时,记忆感知扩展(memory-aware scaling)对性能的影响。
主要结论:
MaTTS w/o aggregation(即Vanilla TTS) 已能提升样本效率,使测试时学习更接近强化学习(RL)训练方式。例如在k=2时,其性能为50.8,优于无记忆的MaTTS(47.6)。
加入记忆感知扩展后(MaTTS),性能进一步提升:
在k=2时仍保持高效(51.3)。
随着k增大,性能持续增长,在k=5时达到62.1,显著优于无记忆版本(52.4)。
总结:
MaTTS不仅提升效率,还能促进多样化生成,从而提升Pass@k表现。
C.3 案例研究¶
本节通过两个具体案例展示ReasoningBank在任务完成准确性和效率方面的优势。
案例1:利用记忆识别最早订单日期(图14)¶
问题:用户需找出最早购买日期。
对比:
基线模型(无记忆)仅查看“最近订单”,错误输出最近日期。
ReasoningBank 通过回忆过往推理提示,探索完整购买历史,正确识别出最早订单日期。
案例2:提升导航效率(图15)¶
问题:在购物任务中寻找“Men”类商品。
对比:
基线模型因重复低效浏览,耗时29步仍未找到正确分类。
ReasoningBank 利用存储的分类过滤推理经验,直接定位相关商品,仅用10步完成任务。
总结:
ReasoningBank通过记忆复用,显著提升任务完成的准确率和效率。
Appendix D Future Directions¶
本节简要探讨了在 ReasoningBank 和 MaTTS 基础上可能的未来研究方向。
组合式记忆(Compositional Memory)¶
当前框架将每次经验提炼为多个记忆项,在面对新查询时,系统会检索相似经验并独立重用其相关记忆项。这种设计强调了记忆内容的作用,但未考虑记忆项之间可能的组合方式。未来的研究可以探索组合感知的记忆检索与整合机制,使智能体能够将互补的记忆项组合成更高层次的策略,或形成可重复使用的宏操作(macros),从而提升在长期任务中的泛化能力和策略丰富性。
高级记忆架构(Advanced Memory Architectures)¶
目前的系统设计较为简洁,下一步自然是要构建一个分层的、产品级的记忆架构栈,融合成熟的记忆范式:
情景记忆(episodic traces)用于保存任务上下文(Fountas et al., 2025);
工作记忆(working memory)用于维护会话内的状态(Lumer et al., 2025);
长期记忆(long-term memory)用于存储经过整合的知识,并引入遗忘与刷新机制(Wang et al., 2025b)。
此外,当前基于嵌入相似性的记忆检索机制也可以进一步升级为基于推理的控制器(reasoning-intensive controllers)(Shao et al., 2025),该类控制器能够分解查询、规划跨层级的多跳检索,并根据不确定性、时效性和检索成本等因素动态选择记忆内容。结合基于学习的路由机制和整合策略,还可以实现整个过程的自动化。
这些改进将使 ReasoningBank 与 MaTTS 融合后成为一个可部署、可扩展的记忆服务系统,适用于多领域、多团队的复杂应用场景。
Appendix E Limitations¶
尽管 ReasoningBank 在实证表现上较强,并提出了一个将记忆作为扩展维度的实用范式,但它仍存在一些局限性,指出了未来研究的方向。
对记忆内容的关注¶
本研究的重点是如何整理和利用记忆内容(例如整合失败轨迹、构建提炼后的推理线索)。因此,我们并未广泛比较其他记忆架构(如情景记忆或分层记忆)。这些设计关注的是正交问题(即记忆的形式/结构),而我们的贡献在于确定应存储和重用哪些内容。未来可以探索将这些不同架构与我们的方法结合的可能性。
记忆检索与整合的简化设计¶
为了更清晰地评估记忆内容质量的影响,我们有意采用了基于嵌入的简单检索机制和直接的整合策略。虽然更复杂的策略(如自适应检索、分层整合)可以与我们的框架兼容并可能提升性能,但这并非本文的重点。这种设计选择确保了我们观察到的效果可以明确归因于面向推理的记忆内容设计。
对大语言模型作为判断器的依赖¶
在我们的实现中,轨迹的成功与失败信号由一个作为判断器的大语言模型(LLM)来确定。虽然这种自动标注方式使得在没有真实反馈的情况下也能进行可扩展评估,但在任务模糊或判断模型本身出错时可能会引入噪声。尽管我们的结果表明框架在噪声下仍具有一定的鲁棒性,但未来的工作可以引入更强的验证器、人工反馈机制或集成判断方法,以提高记忆归纳的可靠性。