2407.10499_CIBench: Evaluating Your LLMs with a Code Interpreter Plugin¶
组织:
1Shanghai Artificial Intelligence Laboratory
2ShanghaiTech University
引用: 1(2025-07-20)
数据集
https://github.com/open-compass/opencompass/releases/download/0.2.4.rc1/cibench_dataset.zip
总结¶
简介
语言: 中文、英文
测试和衡量 LLM 的编程能力
两种评估模式
端到端模式
独立完成从理解指令到生成代码、调试并执行任务的全过程
Oracle 模式:
当模型执行失败时会提供正确代码,模拟人类指导,帮助模型在后续任务中提升表现
两种评估维度的指标
过程导向型指标(如工具调用率、可执行率)
结果导向型指标(如数值准确性、文本评分、可视化评分)
领域(data science problems):
data analysis,
visualization,
machine learning.
Abstract¶
本论文摘要提出了一种名为 CIBench 的交互式评估框架,用于全面评估基于大语言模型(LLM)的代理在使用代码解释器完成数据科学任务时的能力。由于当前对 LLM 代理的评估较为困难,限制了对其局限性的理解,因此该框架旨在解决这一问题。CIBench 包括一个通过 LLM 与人类合作构建的评估数据集,该数据集模拟了真实的交互式 IPython 工作流程。此外,该框架还包含两种评估模式:一种评估 LLM 在无人工协助下的能力,另一种则评估其在有人协助下的表现。作者在 CIBench 上对 24 个 LLM 进行了广泛的实验,分析了它们的表现,并为未来 LLM 在代码解释器使用方面的发展提供了有价值的见解。
1 Introduction¶
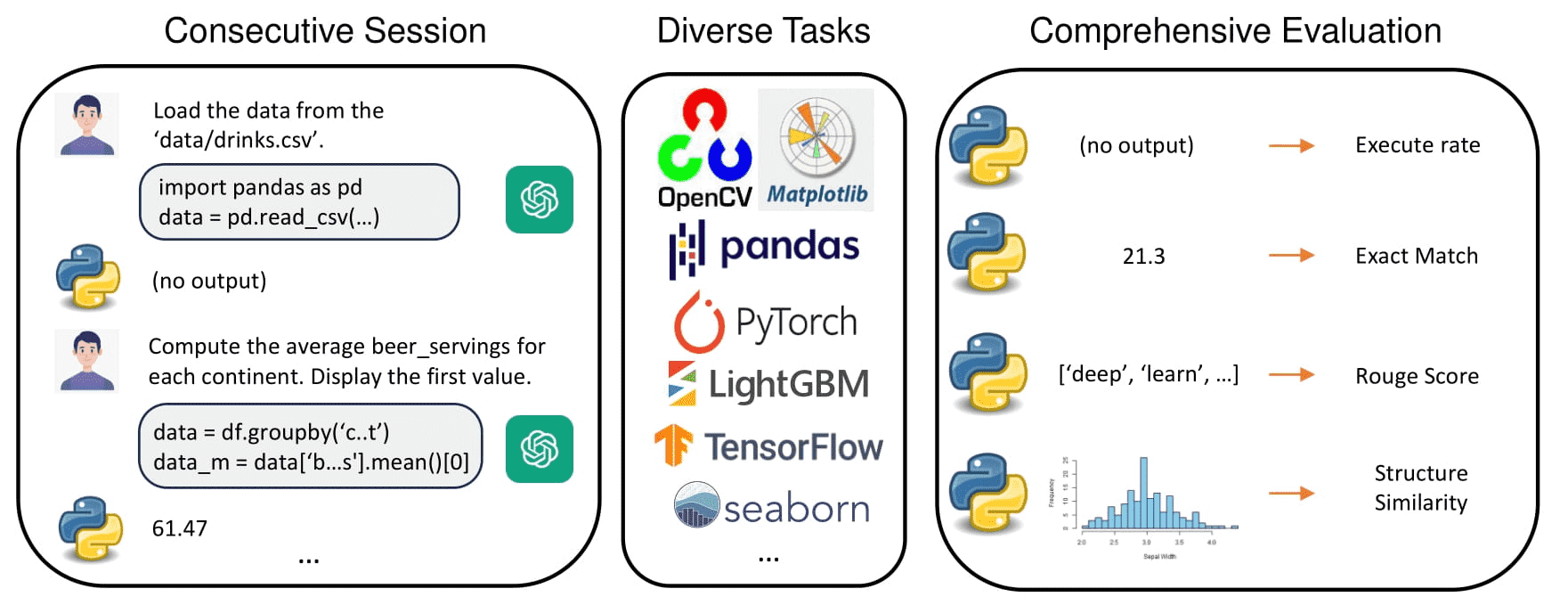
Figure 1:Features of our benchmark. Our benchmark consists of interactive sessions, diverse tasks covering various Python modules, and comprehensive evaluations (The tool-call rate is not displayed).
本研究旨在评估大型语言模型(LLMs)在结合代码解释器解决数据科学问题方面的能力。现有的基准测试(如 GSM8K、MathBench、HumanEval)虽然在数学或编程任务的评估上具有价值,但未能全面反映 LLM 在实际应用中构建复杂流程的能力。尽管近期的一些工作(如 MINT、QwenAgent、CodeGen、DS-1000)有所改进,但仍存在单次交互或多任务限制等问题,未能真实模拟多轮、连续的代码执行场景。
为弥补这些不足,研究者引入了一个名为 CIBench 的新型评估框架,该框架包含连续且多样化的任务,以及全面的评估协议。CIBench 通过 LLM 与人类协作的方式构建任务,模拟真实的数据科学工作流程,涵盖数据处理、可视化和机器学习等多个方面。任务以 Jupyter Notebook 的形式组织,包含 10 至 15 个逐步递进的交互式问题,并支持多个可替换的数据集,从而确保任务的多样性和质量。
为了全面评估 LLM 的表现,CIBench 设计了两种评估模式:端到端模式和Oracle 模式。在端到端模式下,LLMs 需要独立完成从理解指令到生成代码、调试并执行任务的全过程;而在 Oracle 模式下,当模型执行失败时会提供正确代码,模拟人类指导,帮助模型在后续任务中提升表现。
此外,研究还引入了两种评估维度的指标:过程导向型指标(如工具调用率、可执行率)和结果导向型指标(如数值准确性、文本评分、可视化评分),以全面衡量模型在不同方面的表现。
通过在 CIBench 上对 19 个 LLM 进行的广泛实验,研究发现开源模型在使用像 PyTorch 和 TensorFlow 这样的深度学习框架时表现较差,整体性能比 GPT-4 滞后约 10%。总体而言,本研究的主要贡献包括:
构建了一个基于 LLM 与人类协作的数据科学任务基准 CIBench,模拟真实交互式代码执行场景;
提出了包含端到端和 Oracle 模式的创新评估策略,并引入多种细粒度评估指标;
对 24 个 LLM 在该基准上的表现进行了系统实验与分析,揭示了开源模型在使用复杂模块上的显著劣势。
3 CIBench¶
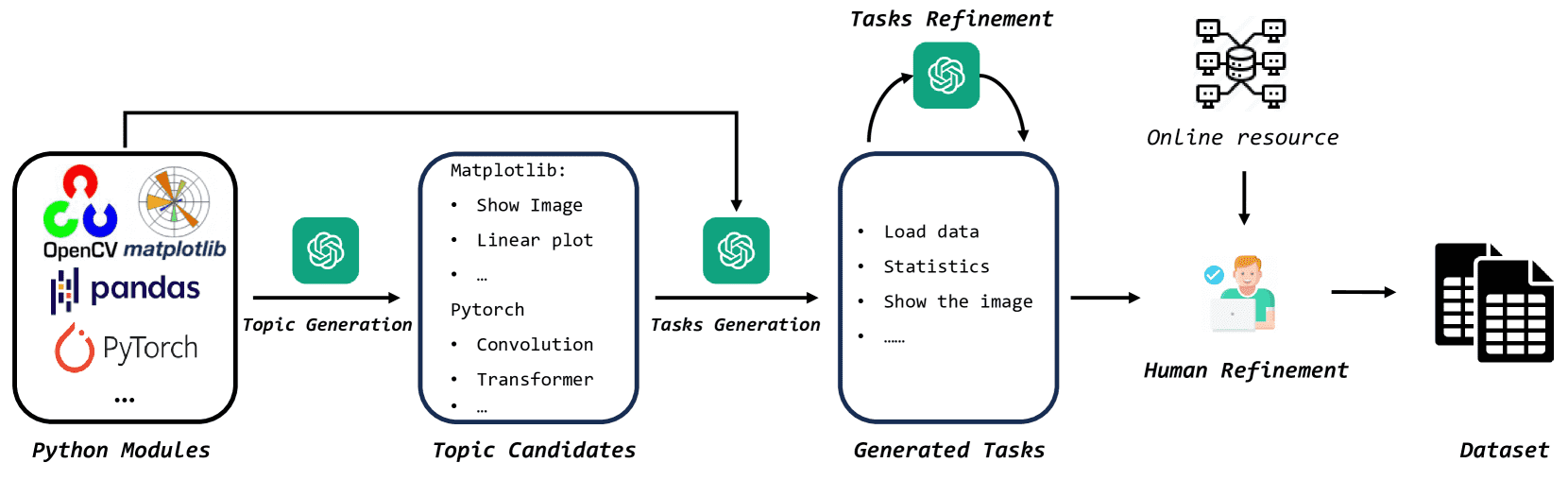
Figure 2:Overview of CIBench. CIBench first selects Python modules to generate candidate topics and then generates tasks based on these modules and the selected topic. Additionally, humans are engaged to generate new tasks to ensure diversity and filter out incorrect questions to enhance quality.
1. 评估数据集构建¶
📦 模块选择(Python Modules)¶
从数据科学领域挑选多个常见模块(详见原文 Table 2),覆盖:
数据清洗与处理(如 pandas)
可视化(如 matplotlib, seaborn)
图像分析、统计方法、数学计算等
🧩 主题生成(Topic Candidates)¶
使用 GPT-4 为每个模块生成 50 个主题,确保全面覆盖模块功能,为后续问题生成提供结构化指导。
🧪 任务生成与优化(Tasks Generation & Refinement)¶
使用 GPT-4 按模板生成带有代码和输出的任务(Jupyter notebook 风格)
输出形式包括数值、结构化文本和图形
通过 “好/坏案例 + 修改提示” 的方式迭代优化,提升任务连贯性和简洁性
👨💻 人工精修(Human Refinement)¶
为克服 LLM 生成的内容重复性和准确性问题,采用两种手段提升数据多样性和质量:
模板泛化:从高质量教程中总结模板,通过少量修改适应不同数据集
数据集多样化:
GPT-4 生成虚拟数据集,控制字段与分布
收集近一年发布的新数据集,确保真实性与新颖性
最终,通过专家借助代码解释器人工校验问题与代码的准确性、运行时间等,提升整体质量。

Table 2: Selected Python modules and their categories.

Fig. 3. An example prompt of task generation.
Prompt:
Please create jupyter notebook experiment based on Python module {}. Please follow these rules:
1. The experiment should be conducted in a jupyter notebook manner, but use the markdown format.
2. The experiment should only use Python code.
3. The experiment has around 10-15 continuous steps, from the easiest to the hardest.
4. The step description should be concise.
5. The step description should be precise and contain exact parameter names and values to instruct.
6. Each step requires Python code to solve and the executed result should be the numeric answer, structured output, or visualized result.
7. Please use ‘matplotlib’ to visualize if necessary.
8. DO NOT have any steps to save or write any output files.
9. Please provide an input data file with an external link.
The experiment topic is {}. You should generate the experiment file without any other statements.
2. 评估模式与指标¶
📊 评估模式(Evaluation Modes)¶
端到端模式(End-to-End Mode):
模型自主解决问题
模型自己需根据代码解释器的反馈进行自我调整和调试。
神谕模式(Oracle Mode):
模型会得到“正确答案”的提示(例如人类提供的代码和思路)。
模拟现实中模型与人类配合的情况。
模拟 Few-shot 或 In-Context 学习场景
📊 评估模式(Evaluation Modes)¶
过程导向指标(Process-Oriented Metrics):
工具调用率(Tool Call Rate):模型正确调用代码解释器的比例。
可执行率(Executable Rate):代码无错误执行的比例。
输出导向指标(Output-Oriented Metrics):
数值准确性(Numeric Accuracy):输出数值的正确性。
文本得分(Text Score):使用 ROUGE 指标评估结构化文本的质量。
可视化得分(Visualization Score):通过图像结构相似性评估可视化结果的质量,而非依赖昂贵的 GPT-4V。
总结¶
本章详细介绍了 CIBench 框架的构建过程和评估机制。通过一个高质量、多样化且贴近真实工作流程的数据集,结合端到端和神谕两种评估模式,以及多维度的评估指标(过程与输出),CIBench 能够全面衡量 LLM 在使用代码解释器解决数据科学任务时的表现,为进一步研究和优化 LLM 提供了有力支持。
4 Experiments¶
本章主要围绕CIBench基准对多个大语言模型进行实验和分析,主要涵盖以下内容:
1. 实验设置(Experiments Setup)¶
评估了包括开源模型和私有模型(如GPT-4)在内的19个聊天模型。
使用代码解释器插件进行推理测试,允许模型尝试最多3次。
实验在OpenCompass平台进行,代码解释器的Python模块版本在附录中详细列出。
评估指标包括:工具调用率(Tool)、可执行率(Exe)、数值准确率(Num)、文本得分(Text)、可视化得分(Vis)。
模型分为不同规模组进行对比,以提升比较的公平性和有效性。
2. 主要结果(Main Results)¶
模型性能表现:
7B组中,Llama-3-8B-Instruct表现最佳。
13B-20B组中,InternLM2-20B-Chat表现最优。
70B组中,Llama-3-70B-Instruct表现最佳,但整体得分比GPT-4-1106-preview低10%。
GPT-4-1106-preview和gpt-4o在所有模型中表现最佳,特别是在端到端模式下,显示出开源模型仍有较大提升空间。
模式比较:
Oracle模式(模拟人机协作)在大多数模型中优于端到端模式,表明LLM在人类辅助下能取得更好的结果。
模型规模与性能的关系:
模型规模越大,性能越强,符合已有研究趋势。
同一系列模型(如Mistral、InternLM、Qwen、Llama3)在各参数组中表现稳定,显示评估方法具有一致性和有效性。
3. 错误模式分析(Error Mode Analysis)¶
识别出四类常见错误:
指令执行错误:偏离或忽略用户指令。
幻觉错误:生成包含未定义变量或无关元素的代码。
推理错误:在处理复杂问题时出现逻辑错误。
代码错误:基础性代码错误。
GPT-4-1106-preview的错误比例分别为:31.9%、4.3%、40.4%、23.4%。
与现有基准(如IFEval、BBH、GSM8K、MATH、HumanEval、MBPP)的相关性分析显示,CIBench与这些基准有高相关性(Pearson系数 > 0.7),说明其能有效评估模型的指令执行、推理和编码能力。
4. 更多分析(More Analysis)¶
4.1 调试能力分析(Debug Ability Analysis)¶
在ReAct协议中,允许模型多次尝试,根据代码解释器的反馈进行调试。
实验显示,尝试次数越多,模型表现越好,尤其是2次尝试时提升显著。
最终设定尝试次数为3次,以平衡评估时间和性能。
4.2 可视化指标分析(Visualization Metric Analysis)¶
使用GPT-4V评估部分任务的可视化得分,并与结构相似性进行对比。
显示两者具有高度一致性,表明结构相似性可以作为简化评估指标。
4.3 跨语言分析(Cross Language Analysis)¶
构建了中文版本的CIBench,评估模型在中文环境下的表现。
结果显示,大多数模型在中文任务中表现略差,尤其是DeepSeek-67B-Chat和Qwen-72B-Chat。
表明模型在多语言场景下仍需改进。
4.4 难度分析(Difficulty Analysis)¶
将任务按交互步骤数分为:易(<2步)、中(2-4步)、难(>4步)。
所有模型在难度增加时表现下降,说明模型对复杂任务的处理能力有限。
4.5 不同模块类别分析(Different Category Modules Analysis)¶
评估模型在不同模块任务中的表现(如数学、统计、建模等)。
模型在使用SciPy模块的任务中表现较好,但在需要高级编码和推理的建模任务中表现较差。
希望未来开源模型在建模任务上能有更好表现。
4.6 局限性(Limitations)¶
CIBench目前仅支持Python,但可拓展至其他语言。
评估指标在某些数据科学任务上(如使用PyTorch训练模型、涉及随机性任务)存在局限。
总结:¶
本章通过CIBench基准对LLM的代码生成和执行能力进行了全面评估,揭示了模型在不同规模、模式、语言、难度和模块任务中的表现。同时,分析了模型的错误类型、调试能力、可视化评估、跨语言适应性和性能瓶颈,提出了改进方向和未来研究重点。整体表明,虽然大型模型和GPT系列仍具优势,但开源模型在多语言和复杂任务方面仍有较大提升空间。
5 Conclusion¶
本章总结了论文的主要贡献和结论。作者提出了一个新的基准测试 CIBench,用于全面评估大语言模型(LLMs)在复杂数据科学任务中使用代码解释器的能力。该基准包含一个评估数据集,覆盖了数据科学中常用的 Python 模块,并提供了两种评估模式:分别衡量模型在有人类协助和无协助情况下的表现。数据集是通过 LLM 与人类协作的方式,利用交互式 IPython 会话构建的,模拟了真实的数据科学场景。
通过在 24 个 LLM 上进行的实验分析,作者发现当前 LLM 在处理某些类别模块时表现较差。基于这些实验结果,作者提出了未来 LLM 发展的几点建议,包括:增强模型根据反馈纠正错误的能力、提升其在多轮交互中理解用户意图的能力,以及最重要的,加强模型的推理能力。
Appendix A Dataset Details¶
总结:¶
本附录详细介绍了 CIBench 数据集的相关设置与统计信息,主要包括以下两部分内容:
A.1 模块版本设置¶
列出了在代码解释器中使用的 Python 模块及其版本,以便保证实验环境的一致性。主要包括:
Pandas 1.5.3
Matplotlib 3.7.2
Seaborn 0.13.0
Scikit-learn 1.2.1
PyTorch 1.13.1 和 1.131(注意版本重复但略有不同)
TensorFlow 2.14.0
LightGBM 4.1.0
NLTK 3.8
OpenCV-Python 4.8.1.78
SciPy 1.11.2
A.2 数据集统计¶
CIBench 数据集包含以下三类任务:
生成任务 (generation):210 题
模板任务 (template):147 题
中文模板任务 (template_cn):147 题
每类任务的输出形式包括:文本 (Text)、可视化 (Vis) 和 无需输出比较的其他任务 (Other)。总题数为 1900 题,其中:
文本输出:116 题
可视化输出:788 题
其他任务:492 题
总计:1900 题
该数据集全面覆盖了代码解释器在不同任务类型和输出形式下的评估需求。
Appendix B Construction Prompts and Rules¶
本章节主要介绍了在构建 CIBench 评估体系过程中所使用的提示(prompts)和质量控制规则,具体内容如下:
主题生成(Topic Generation):
用于生成主题的提示内容详见图13(Figure 13),该提示帮助生成评估所需的问题主题。问题细化(Question Refinement):
用于细化问题的提示分别展示在图14和图15(Figures 14 和 15),这些提示用于将初步主题转化为具体、清晰的问题。质量控制规则(Quality Control Rules):
由于当前大语言模型(LLMs)在运行时间或文件大小控制方面存在局限,因此在最后阶段引入了人工质量检查。质量控制所采用的规则详见图16(Figure 16)。
本节内容为 CIBench 的构建流程提供了辅助工具和规则支持,以确保生成的问题在主题相关性、清晰度和可行性方面达到评估要求。
Appendix C Experiment Example Demo¶
本节内容总结如下:
在附录 C 的“实验示例演示”中,作者展示了实验的一个具体示例,相关图表见图 11 和图 12。这些图例用于说明实验的执行过程或结果,帮助读者更直观地理解实验的设计与实现方式。由于内容主要以图示呈现,文本部分较为简略,主要引导读者参考附录中的图示进行理解。
Appendix D Subjective Visualization Evaluation¶
本附录(D节)《主观可视化评估》主要介绍了用于主观可视化评分的提示内容。文中提到,所使用的提示内容如图17所示(链接指向的是论文中的相关部分)。该提示旨在通过可视化的方式评估模型输出结果的质量,从而进行主观评分。不过,具体提示内容需要参考图17以获得更详细的描述。
Appendix E Dataset Error Analysis¶
本章节对CIBench数据集的错误进行了分析,总结出模型生成代码中常见的四类错误:
指令遵循错误:模型未能按照指定指令生成代码,反映出对输入指令的理解和执行不到位。
幻觉错误:模型生成的代码中包含未定义的参数或无关变量,表现出生成内容缺乏准确性。
推理错误:在处理复杂问题时,模型生成的代码出现逻辑错误,反映出其在复杂任务中的推理能力不足。
代码错误:属于基础性代码生成错误,虽然看似简单,但暴露出模型在代码生成过程中的潜在缺陷。
这些错误类别有助于揭示当前大语言模型在代码解释器功能上的不足,为CIBench的进一步发展提供了有价值的参考依据。
Appendix F Human Annotator¶
本章节总结如下:
在论文的附录F中,作者们同时担任了CIBench数据集的标注员。他们的任务是为各种数据科学挑战创建模板任务,确保涵盖该领域广泛的概念。此外,这些任务的数据收集过程是无偏见的,且不涉及任何私人信息。
Appendix G Ethical Consideration¶
以下是该章节内容的总结:
附录 G:伦理考虑¶
本节重点介绍了在创建基准(benchmark)过程中所采取的伦理考虑措施,包括以下几点:
使用 GPT-4 和网络资源:基准数据集的构建使用了 GPT-4 和网络资源,确保了内容的丰富性和多样性。
专家处理数据:所有基准数据都经过专家处理,以排除任何私人信息,从而保护用户隐私。
文本优化与校对:使用 ChatGPT 进行文本优化和拼写错误的纠正,提高写作质量。
图例说明¶
图 11-12:展示了成功的模板任务示例,说明如何通过模板任务提升基准的多样性。
图 13-15:提供了主题生成和问题优化过程的提示(prompt)实例,展示如何构建具体、清晰的指令。
质量控制规则¶
为了确保数据集的质量,手动控制过程中遵循以下规则:
用户视角:所有问题必须从真实用户的角度编写。
文件路径:确保所有实验所需的外部文件在开头说明了文件路径。
运行时间:控制每个步骤的运行时间,理想情况下每个步骤的执行时间应小于 1 分钟。
文件大小:单个实验使用的文件大小应控制在 50MB 以内。
输出有效性:确保输出结果是有效且无歧义的。
主观可视化评分提示¶
该部分描述了如何评估 AI 生成的可视化图像质量。评分需从以下几个维度进行:
图像是否符合指令内容
图像细节表达是否完整
图像的美观性
评分范围为 1 到 10 分,其中 1-2 分表示图像完全不符合要求,9-10 分表示图像完全符合要求并具有优秀的美观性。
错误类型示例¶
本节展示了在实际运行过程中可能遇到的错误类型及其示例:
Following error:指代码未能正确执行用户指令,例如参数未定义或使用错误。
Hallucination error:指生成的代码与用户指令不一致,出现逻辑漏洞或错误的关键词。
Reasoning error:指代码逻辑错误,如使用错误的数据格式或方法。
Code error:指代码语法或执行错误,例如未导入模块或函数调用错误。
这些错误示例帮助开发者识别和避免在构建基准任务时可能遇到的问题。