2305.02437_Selfmem: Lift Yourself Up: Retrieval-augmented Text Generation with Self Memory¶
引用:
组织:
链接
总结¶
图解¶
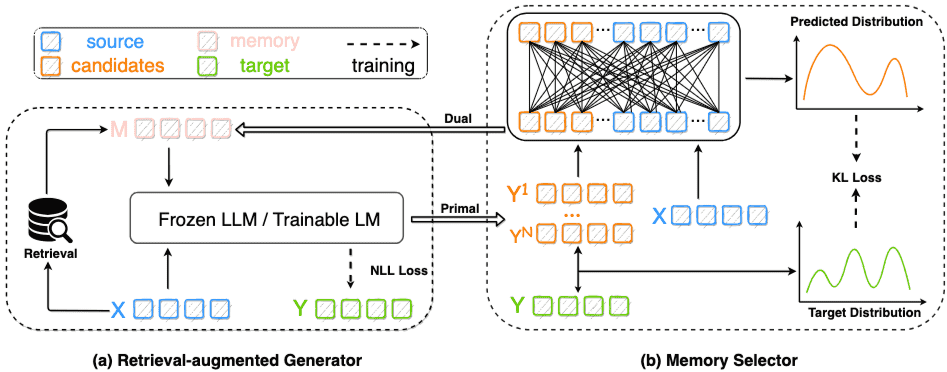
Figure 2: Overall framework.
说明
There are two components in Selfmem, a retrieval-augmented generator (a) and a memory selector (b).
For the primal problem, (a) takes source and memory as input to generate candidates for (b). For the dual problem, (b) takes as input source and generated candidates to select memory for (a).
From Moonlight¶
三句摘要¶
💡 本文提出了Selfmem框架,通过利用“更好的生成促进更好的记忆”这一对偶关系,解决了检索增强生成模型中固定记忆库的根本局限。
🔄 Selfmem通过迭代地使用检索增强生成器创建无限的记忆池,并利用记忆选择器从中选择一个输出作为后续轮次的记忆,从而实现自我提升。
🏆 该框架在神经机器翻译、抽象文本摘要和对话生成等任务中取得了最先进的性能,验证了自记忆在增强检索增强生成模型方面的巨大潜力。
关键词¶
Selfmem: 是本文提出的一种新颖的框架,旨在解决检索增强文本生成中记忆库受限的问题。它通过迭代地使用一个检索增强的生成器来创建一个无界记忆池,并利用一个记忆选择器从生成器的输出中选择一个作为下一轮生成的记忆,从而使模型能够利用自身的输出来提升生成质量。
Retrieval-augmented generation: 是一种文本生成范式,它为预训练的语言模型(包括小型模型或大型语言模型LLM)提供访问外部数据库(通常是训练语料库)的能力。通过信息检索技术,模型在生成文本时,不仅考虑输入文本,还会利用检索到的“记忆”(即外部知识或示例)来辅助生成过程。
Primal problem: 是论文中定义的一个概念,指的是“更好的记忆会促进更好的生成”。这意味着当模型能够访问更高质量、更相关的记忆时,其生成结果的质量也会随之提高。
Dual problem: 是本文提出的一个核心思想,它是“primal problem”的对偶。该思想认为,“更好的生成也会促进更好的记忆”。即,模型自身生成的更优输出,可以作为下一轮生成过程中更优质的记忆。
Memory selector: 是Selfmem框架的第二个核心组件。它的作用是接收由检索增强生成器在“候选模式”下生成的一系列候选输出,并根据特定的评估指标(如BLEU或ROUGE分数)从中选择一个最优的候选输出。被选中的输出随后将作为下一轮生成循环中检索增强生成器的“记忆”。
Retrieval-augmented generator: 是Selfmem框架的第一个核心组件。它负责接收源文本和检索到的(或自生成的)记忆作为输入,并生成目标文本的候选输出。该生成器可以采用两种范式:一种是微调小型模型,另一种是利用预训练的大型语言模型(LLM)进行少样本(few-shot)提示(prompting)。
Unbounded memory pool: 是指一个没有预设限制或固定大小的记忆库。在Selfmem框架中,这个无界记忆池是通过检索增强生成器迭代生成大量候选文本而形成的,它为记忆选择器提供了丰富的选择范围。
Self-memory: 指的是检索增强生成器自身生成的文本输出,这些输出被用作下一轮生成过程的记忆。这是Selfmem框架的关键创新点,它打破了传统检索增强生成依赖固定外部语料库的限制。
Fine-tuned small model: 是一种生成器(Gξ)的实现范式。在这种模式下,一个相对较小的模型在有标签数据和检索到的记忆的帮助下进行训练,以优化生成能力。
Few-shot LLM: 是一种生成器(Gξ)的实现范式。在这种模式下,一个大型语言模型(LLM)在少量(few-shot)示例的引导下(即in-context learning)进行推理,其参数通常是固定的。
In-context learning: (ICL) 是一种在大型语言模型(LLM)上进行少样本学习(few-shot learning)的技术。它通过在模型的输入提示中提供少量(通常是几个)示例(包括输入和期望输出),来引导模型在没有梯度更新的情况下,对特定任务进行推理或生成。
Transformer: 是一种深度学习模型架构,在本文中被用作检索增强生成器(Gξ)和记忆选择器(Sθ)的构建块。它以其自注意力机制而闻名,能够有效地处理序列数据,非常适合文本生成和理解任务。
BM25: 是一种常用的信息检索算法,用于计算查询(query)与文档(document)之间的相关性得分。在Selfmem框架中,BM25被用作检索器(R),从数据存储D中检索与输入x最相关的记忆m。
BLEU: (Bilingual Evaluation Understudy) 是一种用于评估机器翻译质量的自动化指标。它通过计算机器翻译输出与参考翻译之间n-gram的重叠度来衡量翻译的准确性。在本文中,BLEU不仅用于评估翻译任务的最终性能,还被用作记忆选择器(Sθ)在机器翻译任务中的评估指标(∆)。
ROUGE: (Recall-Oriented Understudy for Gisting Evaluation) 是一组用于评估自动文摘(automatic summarization)质量的指标。它通过计算生成摘要与参考摘要之间的n-gram重叠度来衡量摘要的召回率。在本文中,ROUGE被用作文本摘要任务的评估指标,并且在某些情况下也被用作记忆选择器(Sθ)的评估指标(∆)。
摘要¶
Selfmem是一个旨在通过迭代生成和选择“自记忆”来增强检索增强文本生成(Retrieval-augmented Text Generation)的框架。该框架解决了传统检索增强模型受限于固定语料库记忆质量的问题。
1. 核心思想与双重问题 (Core Idea and Dual Problem) 论文的核心思想在于探索了“better generation also prompts better memory”这一“对偶问题 (dual problem)”,与传统检索增强中“better memory prompts better generation”的“原始问题 (primal problem)”形成互补。Selfmem通过一个迭代过程,利用检索增强生成器(Retrieval-augmented Generator)创建无限的记忆池,然后记忆选择器(Memory Selector)从这个池中选择一个输出作为下一次生成轮次的记忆(self-memory),从而实现了模型的自我提升。其关键洞察在于,在推理过程中,模型自身的输出比训练数据更接近数据分布。
2. 框架组成 (Framework Components) Selfmem框架包含两个核心组件:
检索增强生成器 (Retrieval-augmented Generator, \(G_\xi\)): 负责根据源文本 \(x\) 和记忆 \(m\) 生成目标文本 \(y\)。其操作可以基于两种范式:
微调小型模型 (Fine-tuned Small Model):训练可调参数的生成器。论文探讨了两种架构:
Joint-Encoder: 将 \(x\) 和 \(m\) 拼接作为编码器输入,即 \(H = \text{Encoder}(x \text{ [SEP] } m)\)。解码器通过注意力机制结合 \(H\) 进行自回归生成。
Dual-Encoder: 使用两个独立的编码器,一个用于 \(x\) (SourceEncoder),一个用于 \(m\) (MemoryEncoder),解码器通过双重交叉注意力 (dual cross attention) 结合它们的输出 \(H_x\) 和 \(H_m\)。
少样本 LLM (Few-shot LLM):使用固定的黑盒 LLM 进行推理,通过 In-context Learning 方式提供检索到的示例。 生成器通过最小化负对数似然损失(NLL loss)进行优化:\(L_{nll} = -\sum_{t=1}^{|y|}\log P_{G_\xi}(y_t|x, m, y_{<t})\)。
记忆选择器 (Memory Selector, \(S_\theta\)): 负责从生成器产生的候选池 \(C\) 中选择一个最佳候选 \(c\) 作为下一次迭代的记忆 \(m\)。选择基于一个特定的度量 \(\Delta(\cdot, \cdot)\),该度量是与生成质量相关的模型无关指标(如 BLEU、ROUGE),而非 \(P_{G_\xi}(y|x)\),以避免陷入生成器高置信区域而无法获取信息增益。 记忆选择器将源文本 \(x\) 和候选 \(c_i\) 的拼接作为输入,并产生一个关于候选池 \(C\) 的多项分布 \(p_{S_\theta}(c_i|x) = \frac{\exp(S_\theta(x \text{ [SEP] } c_i))}{\sum_{j=1}^{|C|} \exp(S_\theta(x \text{ [SEP] } c_j))}\)。 训练目标是最小化 \(S_\theta\) 的预测与由 \(\Delta(\cdot, \cdot)\) 确定的真实分数之间的 KL 散度:\(L_{kl} = -\sum_{i=1}^{|C|}p_M(c_i)\log p_{S_\theta}(c_i|x)\),其中 \(p_M(c_i) = \frac{\exp(\Delta(c_i, y)/\tau)}{\sum_{j=1}^{|C|} \exp(\Delta(c_j, y)/\tau)}\),\(\tau\) 是温度参数。推理时选择 \(S_\theta\) 评分最高的候选。
3. 迭代流程 (Iterative Process) Selfmem的迭代过程如下:
使用检索器 \(R\) 从数据集 \(D\) 中检索初始记忆 \(M\)。
(如果不是 LLM)使用 \(D\) 和 \(M\) 训练生成器 \(G_\xi\)。
\(G_\xi\) 在“候选模式 (candidate mode)”下,使用当前记忆 \(M\) 生成候选池 \(C\)。
使用 \(C\) 和度量 \(\Delta(\cdot, \cdot)\) 训练记忆选择器 \(S_\theta\)。
在验证集上,循环进行以下步骤直到收敛: a. \(S_\theta\) 从 \(C\) 中选择新的记忆 \(M\)。 b. \(G_\xi\) 在“候选模式”下,使用新的 \(M\) 生成新的候选池 \(C\)。
最终, \(G_\xi\) 使用最终选定的记忆 \(M\) 在“假设模式 (hypothesis mode)”下生成最终假设。
4. 实验与结果 (Experiments and Results)
任务: 机器翻译(JRC-Acquis)、抽象文本摘要(XSum, BigPatent)、对话生成(DailyDialog)。
范式: 可训练小型模型(Transformer-based)、少样本 LLM(XGLM)。
主要发现:
Selfmem显著提升了生成器的性能,因为自记忆与真实分布更相似,验证了“原始问题”。
自记忆(模型自身输出)比传统检索记忆与参考文本有更高的相似度,作为更有效的记忆。
在少样本 LLM 设置下,Selfmem 提供的更相似的演示示例显著提高了性能。
在摘要和对话任务中,Selfmem 取得了SOTA结果。
记忆选择器可以根据特定指标(如 BLEU 或 Distinct score)进行优化,以实现不同的生成属性(如高流畅度或高多样性),体现了框架的灵活性。
5. 进一步分析 (Further Analysis)
Sθ 的作用: 增强的 \(S_\theta\) 显著提高了生成质量。迭代过程显示,候选池的质量(由 oracle \(S_\theta\) 评估)持续提高,验证了模型“自我提升”的机制。
Gξ 的作用: 实验表明,即使固定生成器参数,其也能区分“好”与“坏”记忆,意味着生成器不是当前瓶颈。
频率分析: 检索增强模型,特别是自记忆增强的模型,在处理训练集中低频的“长尾输入 (long-tail inputs)”方面表现更优。
延迟分析: Selfmem相较于检索增强基线模型增加了推理时间,尤其在 CPU 上,但在 GPU 上效率更高。
6. 局限性 (Limitations)
计算资源消耗较高,特别是对于大型数据集和长文本,Transformer 的二次时间复杂度带来了挑战。
框架通用,但模型架构、训练目标和生成方法未针对特定任务进行定制化,可能还有进一步提升空间。