2405.16720_LAW: Large Scale Knowledge Washing¶
引用: 23(2025-08-23)
组织:
1University of California San Diego,
2University of Illinois Urbana-Champaign(伊利诺伊大学厄巴纳-香槟分校)
总结¶
简介
LAW (Large Scale Washing)
关键假设:
知识和推理能力在LLMs中是可解耦的(disentanglable)
MLP 层被认为是存储模型知识的主要部分(事实证明 MLP也有一些推理知识)
背景
大语言模型具有强大的记忆能力,能够记住大量世界知识,
但这也引发了对模型记忆隐私信息、有毒或敏感内容以及版权内容的担忧。
最直接的解决方案是在预训练阶段就人工标注和排除敏感数据。
然而,由于训练语料库规模极大,这种人工方式成本过高且不可行
机器“遗忘”(Machine Unlearning)的研究有了用武之地。
机器遗忘的研究现状
通过定义反向损失函数(reverse loss)并利用反向传播机制更新模型,
但这种方法可能会影响模型的流畅性和推理能力,
甚至在大量使用反向损失训练的情况下破坏模型结构。
两个方向
Unlearning Knowledge in Large Language Model(在大型语言模型中去除知识)
Model Editing of LLMs(大型语言模型的模型编辑)
LAW
方法
仅更新解码器型大语言模型中 MLP 层的权重,以实现知识洗白。
该方法受到模型编辑技术的启发,提出了一个新的目标函数,用于更新特定 MLP 层的权重,以实现知识的移除。
专注于从 LLM 中的 MLP 层中移除相关知识(因为 MLP 层被认为是存储模型知识的主要部分),从而实现知识清洗
贡献
新颖性在于通过更新特定的MLP层来达到知识和推理能力的解耦,这是一种新的尝试。
专注于大规模知识洗白(Large Scale Knowledge Washing)
目标是从大语言模型中消除大量事实性知识
定义了一个新问题
大规模知识清洗(Large Scale Knowledge Washing),其核心问题是:
如何在不严重影响模型推理能力的前提下,从大规模语言模型中清洗掉一组特定的知识
与模型编辑方法的区别
不引入新对象:仅移除目标三元组中的目标对象 \(O_i\),不添加任何新的内容。
核心观点对比
模型编辑:通过替换三元组来达到清洗目的,可能引入干扰。
知识清洗(本文方法):通过移除三元组中的事实来达到清洗目的,对模型推理能力的损害更小。
局限性:
本文所使用的知识集是基于三元组(triplets)的结构化数据。
然而,在实际场景中,大量知识是以纯文本形式存在的,且没有明确的三元组结构
因此,如何在非结构化文本中进行有效的知识清洗,是未来需要解决的问题
方法对比总览
方法 |
核心思想 |
训练方式 |
计算效率 |
主要优势 |
主要风险/劣势 |
|---|---|---|---|---|---|
FT |
暴力遗忘:全参数微调,直接覆盖原有知识。 |
全量微调 |
低 |
实现简单 |
极易破坏模型基础能力(灾难性遗忘) |
MEMIT |
精准外科手术:通过数学方法定位并直接修改模型中层参数中的特定知识。 |
非梯度更新 |
极高 |
效率极高,几乎瞬间完成;对通用能力影响小 |
需要复杂计算;超参数(λ)敏感,需精细调优 |
ME-FT |
即插即用:利用现有模型编辑框架进行微调。 |
(通常为)局部微调 |
中 |
使用方便,社区支持好 |
效果依赖于外部框架,可能不够灵活 |
FT-UL |
保守疗法:采用极低学习率进行少量轮次的微调。 |
全量/LoRA微调 |
中 |
简单有效,在遗忘和保留间平衡性好 |
仍需梯度更新,计算成本高于MEMIT |
WOH |
师生蒸馏:先训练一个“知道答案”的模型,再让原模型学习不包含该答案的分布。 |
两阶段微调 |
低 |
思想巧妙,理论上能更好地保留语言能力 |
过程最复杂,需要训练两个模型,计算成本最高 |
SeUL |
精准打击:只计算目标词位置的损失,极大限制参数更新范围。 |
全量/LoRA微调 |
中 |
最精细、最保守,最大程度保护无关知识 |
需要构造特定格式的数据 |
Abstract¶
本研究关注大规模知识洗白(Large Scale Knowledge Washing)这一问题,目标是从大语言模型中消除大量事实性知识。当前,大语言模型具有强大的记忆能力,能够记住大量世界知识,但这也引发了对模型记忆隐私信息、有毒或敏感内容以及版权内容的担忧。
已有研究通常通过定义反向损失函数(reverse loss)并利用反向传播机制更新模型,但这种方法可能会影响模型的流畅性和推理能力,甚至在大量使用反向损失训练的情况下破坏模型结构。
为缓解这一问题,一些工作通过引入下游任务的数据来防止模型能力下降,但这要求模型对下游任务具有先验知识,限制了其通用性。同时,在消除旧知识的同时保持模型能力的平衡控制也是一项挑战。
为此,作者提出了LaW(Large Scale Washing)方法,该方法仅更新解码器型大语言模型中 MLP 层的权重,以实现知识洗白。该方法受到模型编辑技术的启发,提出了一个新的目标函数,用于更新特定 MLP 层的权重,以实现知识的移除。
实验结果表明,LaW 在消除目标知识的同时,最大程度保留了模型的推理能力,验证了方法的有效性。相关代码已开源,链接为:
https://github.com/wangyu-ustc/LargeScaleWashing。
1 Introduction¶
背景介绍¶
大语言模型(LLMs)具备广泛记忆知识和事实关系的能力,这已被多项研究证实(Chen et al.,2022;Alivanistos et al.,2022;Youssef et al.,2023;Wang et al.,2024c)。然而,这种记忆能力也带来了道德和法律上的担忧。具体而言,LLMs 记忆的可能包含个人敏感信息和受版权保护的内容。例如,《纽约时报》已就 OpenAI 使用其文章提起诉讼,要求保护其版权内容。
为避免这种非期望的知识记忆,最直接的解决方案是在预训练阶段就人工标注和排除敏感数据。然而,由于训练语料库规模极大,这种人工方式成本过高且不可行,因此促使了机器“遗忘”(Machine Unlearning)的研究发展。
机器遗忘的研究现状¶
当前的机器遗忘方法大多通过定义一种“遗忘损失”(本质上是遗忘数据集上“下词预测”的反向损失),然后通过反向传播来更新整个模型。尽管这些方法能在一定程度上实现知识遗忘,但大规模遗忘知识可能导致模型参数的大规模更新,从而损害模型在下游任务中的表现,尤其是依赖推理能力的任务。
为解决这一问题,一些研究尝试引入“效用损失”(以特定下游任务为目标)来同时优化“遗忘”和“效用”损失(Liu et al.,2024a)。但这类方法在强调模型泛化能力(无特定下游任务)时存在应用限制。
本文研究目标:大规模知识洗涤(Large Scale Knowledge Washing)¶
本文聚焦于一个新的研究问题:如何在尽可能不影响模型推理能力的前提下,大规模、彻底地遗忘知识? 我们将此问题称为**“大规模知识洗涤”**(Large Scale Knowledge Washing),如图1所示。
我们定义“推理能力”为模型在不依赖预先记忆的领域知识时,完成诸如基于上下文的问答或数学推理等任务的能力。这些任务主要依赖抽象模式识别和逻辑推理,而非单纯的记忆。
核心假设与方法设计¶
我们提出一个关键假设:知识和推理能力在LLMs中是可解耦的(disentanglable),这为我们的方法设计提供了理论基础。
基于此,我们提出了一种新的方法:LaW(Large Scale Washing),其灵感来自于模型编辑技术(如MEMIT)。MEMIT通过识别模型中负责特定事实预测的参数子集,并使用封闭形式的公式对其进行修改,从而实现知识编辑。而LaW在此基础上,专注于知识的删除。
与传统模型编辑方法不同,LaW 并不依赖封闭形式的解,而是定义了一个需优化的新目标函数,以适应知识洗涤的场景。这种方法考虑了多个现实限制,使得LaW在大规模应用中更具可行性。
主要贡献¶
LaW 方法的提出:LaW 能够在不显著损害模型推理能力的前提下,实现更彻底、更有效的知识洗涤。
模型无关性:LaW 适用于任何具有 MLP 层的 Transformer 模型。
实验验证:我们在两个小规模数据集和一个包含 332,036 个事实的、基于维基百科三元组构建的大规模数据集上进行了评估。结果表明,LaW 在移除目标知识方面优于现有方法,表现为更高的准确率和 QA-F1 分数。同时,LaW 保留了模型在推理任务上的表现,验证了其在知识洗涤中实现清晰、全面遗忘与推理能力保持良好平衡的潜力。
图1说明¶
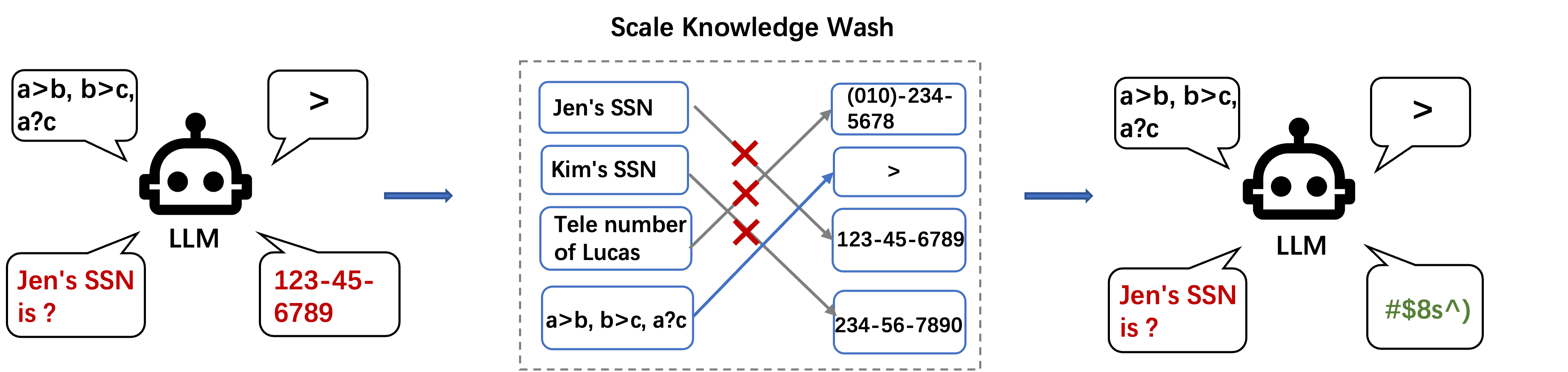
Figure 1: The diagram shows the process of Large Scale Knowledge Washing. We aim to remove private, toxic or copyright knowledge such as SSN from the LLM, while maintaining the model’s reasoning ability to answer questions such as “a>b,b>c,a?c” whose answer should be “>”.
图1展示了大规模知识洗涤的过程。我们的目标是移除敏感、有害或受版权保护的知识(如SSN,社会安全号码),同时还要保持模型对逻辑类问题的回答能力(例如,“a > b, b > c, 那么 a ? c”应回答“>”)。
3 Preliminary¶
本节介绍了解码器仅结构的大语言模型的基本结构,以及先前用于模型编辑的策略。重点在于模型知识的存储方式和如何通过参数更新来实现知识的修改。
3.1 The Structure of Decoder-only Large Language Models¶
本小节描述了**解码器仅结构(Decoder-only)的大语言模型(LLM)**的前向传播过程,其结构可以表示为:
重点解释:
\( h_t^l \) 表示第 \( l \) 层中第 \( t \) 个 token 的隐藏状态。
模型结构包含两个主要部分:注意力机制(Attn) 和 多层感知机(MLP)。
\( W_{\text{in}}^l \) 和 \( W_{\text{out}}^l \) 是 MLP 层的权重。
该结构在 Meng et al. ([2023]) 和 Black et al. ([2021]) 中均有类似表达,说明这是当前主流的模型结构。
3.2 Previous Model Editing Strategy¶
本小节总结了已有模型编辑策略,特别是 ROME 和 MEMIT 的方法,用于修改模型中存储的事实知识。
1. 知识的存储与编辑目标¶
根据 Meng 等人的研究(2022, 2023),事实知识主要存储在 MLP 层的输出权重矩阵 \( W_{\text{out}}^{l_0} \) 中。
具体地,权重矩阵可以看作键-值对(key-value memories),即:
其中 \( K \) 是键向量的集合,\( V \) 是值向量的集合。
通过解该最小化问题,可以得到 \( W_0 \) 的表达式。
2. 知识编辑的数学基础¶
想要注入新的事实知识,需通过以下方式更新权重矩阵:
\( K_1 = [K, K_e] \)、\( V_1 = [V, V_e] \),表示旧知识和新知识的拼接。
解出的闭式解为:
其中 \( R = V_e - W_0 K_e \),表示新事实的残差。
3. ROME 和 MEMIT 的区别¶
ROME(单事实编辑):
只编辑一个特定的层 \( l_0 \)。
\( K_e \) 和 \( V_e \) 是列向量。
MEMIT(批量事实编辑):
编辑多个连续的层 \( \mathcal{R} = \{ l_0 - |\mathcal{R}| + 1, \cdots, l_0 \} \)。
\( K_e \) 和 \( V_e \) 是矩阵,支持多个事实的编辑。
将编辑量分散到多个层中,以减少单层参数的剧烈变化。
参数更新公式(对每一层 \( l \in \mathcal{R} \)):
其中 \( R^l = \frac{R^{l_0}}{l_0 - l + 1} \),即总残差平均分配到多层中。
4. 编辑策略的实现细节¶
编辑从底层到上层依次进行。
每次编辑后需重新计算 \( K_e^l \),以适应模型状态变化。
更多数学推导细节见附录 A。
总结:
本节详细介绍了解码器仅结构大语言模型的前向传播机制,以及如何通过修改 MLP 输出权重矩阵来实现知识编辑。重点在于利用线性代数方法(如最小二乘法)来更新模型参数,并提出了 ROME 和 MEMIT 两种不同规模的编辑策略。MEMIT 通过多层分散编辑的方式,进一步提升了编辑的稳定性和效果。
4 Problem Setup¶
在本节中,作者定义了一个新问题:大规模知识清洗(Large Scale Knowledge Washing),其核心问题是:
如何在不严重影响模型推理能力的前提下,从大规模语言模型中清洗掉一组特定的知识?
关键概念解释¶
知识清洗(Knowledge Washing):指的是从语言模型中移除某些事实性三元组(triplets)。这些三元组可以被转化为单句的事实性陈述。
知识集合定义:
\[ \mathcal{E}_w = \{(s_i, r_i, o_i)\}_{i=1}^{m} \]其中,每个三元组 \( (s_i, r_i, o_i) \) 表示一个事实,\( m \) 是需要清洗的事实数量。
清洗方式说明¶
三元组转换为句子:例如,三元组 \( (James Gobbo, residence, Toorak) \) 会被转化为句子:James Gobbo resides in Toorak。
清洗目标:清洗后,模型在面对类似提示(如“James Gobbo resides in”)时,应生成随机答案或空答案。
保留能力:但在回答其他推理类问题时,模型的性能不应受到影响。
与模型编辑方法的区别¶
本研究的特点:
不引入新对象:仅移除目标三元组中的目标对象 \( o_i \),不添加任何新的内容。
效果目标明确:使模型在清洗后无法输出已移除的事实。
模型编辑方法(Model Editing):
通常会将目标三元组替换为新的三元组,例如:
\[ \mathcal{E}_{eos} \triangleq \{(s_i, r_i, \texttt{<EOS>})\}_{i=1}^{m} \]其中 \( \texttt{<EOS>} \) 是 GPT 风格模型的序列结束标记。
潜在问题:这种方式可能引入新的事实性关系,从而干扰模型原有的能力。
核心观点对比¶
模型编辑:通过替换三元组来达到清洗目的,可能引入干扰。
知识清洗(本文方法):通过移除三元组中的事实来达到清洗目的,对模型推理能力的损害更小。
总结重点¶
问题定义:大规模知识清洗旨在在不损害模型推理能力的前提下,移除特定事实。
知识表示:使用三元组表示事实,并将其转化为句子用于清洗。
清洗目标:模型在面对清洗后的知识时输出空或随机答案。
与模型编辑的区别:不引入新对象,避免干扰模型原有知识结构。
优势:相比模型编辑,知识清洗方法更安全、更可控。
5 Methodology¶
本节核心目标是:如何从模型权重中精确“洗掉”特定知识,同时尽量保留模型的其他知识(尤其是推理能力)。
1. 问题重述与设定:
模型原始权重
W0可以理解为通过关键矩阵K和值矩阵V来表征,满足关系W0 K K^T = V K^T(来自前面的公式2)。这意味着W0是在K的基础上,为了输出V而学习到的。知识编辑 (Model Editing) vs. 知识擦除 (Knowledge Erasure):
编辑:引入新知识
Ke(新键),目标是让模型对Ke输出新的值Ve。此时总键集是原始键K和新键Ke的拼接K1 = [K, Ke]。擦除:目标是让模型忘记原有知识的一个子集。这个子集由特定的键
Kw(是K的子集)和对应的值Vw表示。擦除后,模型应保留的键集是K2 = K \ Kw(即从K中移除Kw后剩下的部分)。
2. 理想目标与实际问题:
理想目标 (公式7):找到一个权重更新
Δ,使得更新后的权重(W0 + Δ)在K2上的输出,尽可能接近理想中应该对应的值V2(即与K2关联的原始值)。实际问题:我们无法直接获得
V2(甚至V),因为这些值本质上是模型预训练过程中内部产生的,是隐式的、难以显式获取的。
3. 问题重构:
为了解决
V2不可得的问题,作者将目标重构为公式8:Δ = argmin( ‖(W0+Δ)K - V‖² - γ ‖(W0+Δ)Kw - Vw‖² )公式8的直观解释:
第一项
‖(W0+Δ)K - V‖²:要求模型在所有原始知识K上的表现变化尽可能小。目的是保留模型原有的各种能力(包括推理)。第二项
-γ ‖(W0+Δ)Kw - Vw‖²:前面的负号意味着要最大化这个误差。目的是故意破坏模型在待擦除知识Kw上的表现,让它无法输出正确的Vw。超参数
γ:用于平衡“保留整体性能”和“擦除特定知识”这两个目标。
4. 进一步简化与近似:
通过对公式8中的第一项进行数学推导(利用
W0 = V K^T (K K^T)^-1这一关系),发现最小化‖(W0+Δ)K - V‖²等价于最小化‖ΔK‖²。这意味着我们不需要知道V,只需要关注权重更新Δ对键K的影响。对于第二项,作者用
W0 Kw来近似未知的Vw(即假设模型原始权重对Kw的输出就是正确的值Vw)。因此,最大化‖(W0+Δ)Kw - Vw‖²就变成了最大化‖ΔKw‖²(因为(W0+Δ)Kw - W0Kw = ΔKw)。最终简化后的目标 (公式9):
Δ = argmin( ‖ΔK‖² - γ ‖ΔKw‖² )即:寻找一个
Δ,它对整体键K的影响要小,但对特定待擦除键Kw的影响要大。
5. 约束优化形式:
公式9中的权衡(通过
γ)可能难以控制。作者将其转换为一个更直观的约束优化问题 (公式10):Δ = max( ‖ΔKw‖² ),约束条件为‖ΔK‖² / ‖K‖² ≤ β公式10的直观解释:
目标:最大化对擦除知识
Kw的破坏程度 (‖ΔKw‖²)。约束:限制对模型整体知识库
K的干扰程度 (‖ΔK‖²),将其控制在一个很小的阈值β以下(例如0.1)。
超参数
β:直接控制了模型性能保留的程度。β越小,对模型原有能力的保护就越严格。K K^T的估计:由于无法获得真实的K,作者遵循MEMIT的方法,使用大规模文本语料库(如WikiText)的隐藏层激活值来估计K K^T这个矩阵。Kw的获取:对于要擦除的知识(如“ChatGPT is developed by OpenAI”),将提示词(“ChatGPT is developed by”)输入模型,并提取目标层输入处最后一个词(“by”)对应的隐藏状态(hidden state)作为Kw。
5.1 Practical Consideration (实际考虑)¶
1. Δ 的初始化 (Initialization):
问题:公式10的优化问题是非凸的,对初始值敏感,随机初始化容易得到次优解。
解决方案:使用 MEMIT 方法 计算出的权重更新矩阵作为初始值
Δ0。原因:MEMIT 本身也是一个模型编辑方法,它已经在“有效编辑”和“减少副作用”之间取得了较好的平衡,以此为起点进行优化,效果更好。
2. β 的选择 (Choices of β):
策略一(常量):直接设置一个小的常数,如
β = 0.2,严格限制整体改动幅度。策略二(自适应):
先用MEMIT初始化得到
Δ0。计算这个初始改动对整体键
K的影响程度β0 = ‖Δ0 K‖² / ‖K‖²。将约束放宽一点,例如设定
β = 1.1 * β0。这样既以MEMIT的表现为基础,又给了优化算法一定的搜索空间来寻找更好的解。
3. 目标知识集的连续消除 (Successive Elimination):
场景:当需要逐层更新多个层时。
策略:在更新下一层之前,先用当前已修改的模型检查一下,哪些知识已经被成功擦除了。然后只对那些尚未被擦除的知识进行下一层的优化。
好处:使优化过程更聚焦,效率更高,避免在已经解决的问题上浪费计算资源。
5.2 Discussions (讨论)¶
1. 知识与推理的解耦 (Disentanglement):
核心观点:MLP层既存储知识,又参与推理过程。修改权重会影响推理能力,这证明了二者是耦合的。
本文工作:本文的方法本质上是在尝试解耦这两种功能。目标是找到一种权重更新
Δ,能选择性地破坏特定知识,同时对推理能力的影响最小化。理论假设:作者假设Transformer中知识和推理能力在某种程度上是可分离的。注意力机制可能更侧重于推理流程,而MLP更侧重于知识存储。未来的研究可以探索哪些具体的“键-值”对主要负责推理。
2. 处理输出行为与幻觉 (Handling Output Behavior):
目标:本方法的目的不是让模型输出错误答案,而是降低模型对特定知识的置信度,让它“不知道”答案。
可能的结果:对于问题“ChatGPT is developed by”,模型不会再自信地输出“OpenAI”。但由于模型保持了语言流畅性,它可能会“胡编”一个答案(即产生幻觉),例如输出“Google”。
作者观点:幻觉问题不是本方法要解决的核心问题。这个问题可以通过后续的指令微调 (Instruction Tuning) 来解决,例如训练模型在不知道答案时说“我不知道”。
职责划分:
预训练:学习知识。
本方法:从预训练模型中移除特定知识。
指令微调:控制模型在不知道时的应答行为。
总结¶
本节详细介绍了大规模知识清洗的数学建模与优化方法,包括:
目标函数的重构:从直接删除到通过优化权重 \(\Delta\) 实现目标知识的削弱。
约束优化问题:在保留模型推理能力的前提下,最大化对目标知识的破坏。
实践策略:包括初始化方法、超参数选择、逐层优化等,以提高算法的稳定性和效果。
讨论与扩展:探讨了知识与推理能力的解耦可能性及对模型幻觉行为的潜在影响。
整体而言,这一方法为在不显著影响模型推理能力的前提下删除特定知识提供了可行框架。
6 Experiments¶
6.1 实验设置¶
本部分详细说明了实验中使用的模型、数据集、基线方法、评估指标和实现细节。
基线方法:
比较了多种知识编辑与遗忘(unlearning)方法。知识编辑方法:FT、MEMIT、ME-FT
知识遗忘方法:FT-UL、WOH、SeUL
模型与数据集:
使用 GPT2-XL(1.5B参数)和 GPT-J-6B(6B参数)作为主干模型。
数据集包括:zsRE(19,086个事实)、CounterFactual(20,877个事实)、Wiki-Latest(332,036个事实,来自维基百科的句子形式事实)。
评估指标:
知识清洗效果:Accuracy(正确预测比例)、QA-F1(生成结果与答案的匹配度)。
推理能力:在Lambda_openai、HellaSwag、Arc_Easy 任务上使用 lm-evaluation-harness 进行评估。
实现细节:
实验在8块A6000-48GB GPU上进行。
MEMIT和ME-FT使用开源代码,其他方法手动实现。
β参数设置为 β = 1.1β₀,β₀由MEMIT初始化计算而来。
主要结果表格:
表1展示了GPT2-XL在zsRE和CounterFactual上的性能比较。
表2展示了GPT2-XL和GPT-J-6B在Wiki-Latest上的表现。
6.2 整体性能比较¶
6.2.1 小规模知识清洗¶
本实验在zsRE和CounterFactual上测试不同方法的表现。
LaW(本文方法)在知识清洗的干净程度上优于其他方法,同时推理能力保持较好。
对比MEMIT和SeUL等微调基方法,在CounterFactual上表现出性能退化。
FT-UL表现不稳定,反向训练目标缺乏鲁棒性。
附录还提供了生成示例和改写查询的泛化实验。
6.2.2 大规模知识清洗¶
使用Wiki-Latest测试LaW在大规模知识清洗上的效果。
表2显示,LaW在知识遗忘的准确性(Acc)和QA-F1上表现最佳。
微调基方法(如FT、FT-UL)在大规模数据下容易破坏模型性能。
相比之下,LaW在保持推理能力的同时,实现了更低的知识保留率。
6.2.3 无关知识保留¶
评估模型在知识遗忘过程中对无关知识的保留能力。
表3显示LaW与MEMIT在保留无关知识方面表现相当。
附录中还提供了对类邻近提示(neighborhood prompts)的分析。
6.2.4 模型流利性分析¶
通过计算模型在CC-MAIN-2024-10数据集中的log perplexity,评估模型流利性。
表4显示MEMIT和LaW对模型流利性影响较小,而FT-UL和SeUL在大规模数据下明显破坏流利性。
6.3 消融研究¶
初始化Δ的消融¶
对Δ矩阵的初始化方式进行了研究,比较了随机初始化和MEMIT初始化。
结果显示,使用MEMIT初始化显著提升了模型性能。
表5表明MEMIT初始化在CounterFactual上表现优于随机初始化。
β参数的影响¶
β用于控制知识清洗和保留之间的平衡。
表6显示,随着β增大,知识清洗更彻底,但推理能力下降,体现了清洗与保留之间的权衡。
设置β = 1.1β₀在多个数据集上表现最佳。
总结¶
本章通过详细的实验设置和多方面的性能比较,验证了LaW在大规模知识清洗任务中的优越性,尤其在知识清洗效果和模型鲁棒性方面表现突出。消融研究进一步揭示了模型设计的关键因素,如初始化方式和β参数设置。
7 Conclusion, Limitation, and Future Work¶
本节总结了论文的主要贡献、方法的局限性以及未来的研究方向。
主要贡献:
本文提出了“大规模知识清洗”(Large Scale Knowledge Washing)这一新问题,其目标是在大规模语言模型(LLMs)中移除已有的知识。为解决该问题,作者借鉴了模型编辑的方法,提出了名为 LaW(Large Scale Washing)的新方法。该方法通过设计一个新的目标函数,专注于从 LLM 中的 MLP 层中移除相关知识(因为 MLP 层被认为是存储模型知识的主要部分),从而实现知识清洗。
实验结果:
实验表明,LaW 在知识清洗方面是有效的。当使用与知识集相关的查询进行测试时,模型的准确率显著下降,说明相关知识已被成功移除。同时,模型的推理能力在很大程度上得以保留,说明清洗过程并未明显损害模型的其他功能。
重点结论:
作者提出了一种有效的知识清洗算法,并展示了知识与推理能力可以部分解耦的可能性,这是本文的核心贡献之一。
局限性:
一个主要局限在于,本文所使用的知识集是基于三元组(triplets)的结构化数据。然而,在实际场景中,大量知识是以纯文本形式存在的,且没有明确的三元组结构,这可能使知识清洗变得更加困难。因此,如何在非结构化文本中进行有效的知识清洗,是未来需要解决的问题。
未来工作:
作者计划在未来工作中进一步探索更彻底的知识清洗方法,并将 LaW 框架扩展到更新、更复杂的 LLM 架构中,以验证其通用性和适应性。
总结而言,本文提出了一个关键问题并提出了可行的解决方法,为知识可控的 LLM 提供了新的思路,但仍需在通用性和复杂场景中继续完善。
Ethics Statement¶
本研究的重点是开发 LaW(大规模知识清洗方法),旨在 在不损害大型语言模型(LLMs)推理能力的前提下,移除其中敏感、私人或受版权保护的信息。研究团队明确承认,在 LLMs 中存在此类信息以及从模型中“遗忘”这些信息的过程 中,存在相关的伦理考量。
数据隐私与合规¶
在实验中,用于遗忘的数据集均来源于公开数据源,包括:
zsRE(Levy 等,2017)
CounterFactual(Meng 等,2022)
Wikipedia 三元组
这些数据 不包含任何个人或敏感信息,从而在数据使用方面确保了隐私与合规性。此部分为研究的重点内容之一,强调了数据来源的合法性与安全性。
伦理合规¶
在整个研究过程中,团队 严格遵守了 ICLR 的伦理准则,并 以诚信的态度进行了研究,尊重所有适用的法律和伦理标准。同时,也 认真考虑了研究可能带来的更广泛的社会影响,是本研究中另一项重要的伦理考虑。
重点总结¶
LaW 的核心目标:在保留模型推理能力的同时,安全地移除敏感信息,这是研究的重点。
数据来源的合法性与隐私性:强调使用公开数据,不涉及个人隐私。
伦理标准的遵守:研究过程遵循 ICLR 伦理准则,并关注社会影响,这是研究的伦理基础。
Reproducibility Statement¶
本节重点说明了研究结果的可复现性保障措施。
作者明确表示已确保实验结果的可复现性。重点内容在于:文章在第6.1节(实验设置)中提供了清晰、详细的实验配置说明,为读者复现实验提供了充分依据。此外,作者还将代码作为补充材料提供,这是确保可复现性的关键步骤,有助于验证实验结果的可靠性。
不重要的内容(如一般性声明)已适当精简。
Appendix A Mathematical Details of Preliminary¶
模型结构概述¶
本节首先介绍了基于 Transformer 架构的仅解码器型大语言模型(decoder-only LLM)的数学结构,重点在于其预测下一个 token 的机制。给定前 t-1 个 token 的序列,模型对第 t 个 token 的预测概率分布为:
其中:
\( h_{t-1}^L \):表示第 t-1 个 token 在第 L 层的隐藏状态;
\( W_y \):语言模型头(language model head),用于预测下一个 token 的分布;
\( L \):模型的总层数。
Transformer 层的计算流程¶
Transformer 每一层的隐藏状态更新公式如下:
关键元素包括:
Attn:注意力机制;
\( \gamma \):layer normalization;
\( \sigma \):激活函数(如 ReLU);
\( W_{in}^l \)、\( W_{out}^l \):该层的输入和输出权重矩阵。
编辑请求的定义¶
知识编辑请求 \( \mathcal{E}_{edit} \) 由三元组序列组成:
其中 \( s_i \) 表示“subject”(主题),\( r_i \) 表示“relation”(关系),\( o_i \) 表示“object”(对象),且保证对于任意两个不同编辑请求,其(s, r)对不能相同但 o 不同,以避免冲突。
MLP 层的权重更新方法¶
在 MEMIT 方法中,Transformer 的 MLP 层权重 \( W_{out}^l \) 被视为“键值记忆”结构,通过以下方式更新:
目标:调整 MLP 层权重 \( W_0 \),使得对于新编辑请求 \( (s_e, r_e, o_e) \),模型可以正确预测新的值;
数学形式:通过最小化 Frobenius 范数的误差来求解增量矩阵 \( \Delta \):
其中:
\( K_1 \):由原有 key \( K \) 和新增 key \( K_e \) 拼接而成;
\( V_1 \):由原有 value \( V \) 和新增 value \( V_e \) 拼接而成。
增量矩阵 \( \Delta \) 的解析解¶
该问题的最小二乘解为:
最终可以简化为:
其中 \( R = V_e - W_0 K_e \),表示编辑请求引入的残差。
多层编辑策略(Multiple Layer Editing)¶
为了提高模型的鲁棒性,MEMIT 提出修改多个层,而非只修改一个层。具体做法为:
将残差 \( R \) 分布在多个层中;
从底层到顶层逐层修改,每层的增量为:
其中 \( R^l = \frac{R}{L - l + 1} \),表示每层的残差分配比例。
\( K_e^l \) 需要随着编辑过程重新计算,以反映当前层的状态变化。
总结(重点内容)¶
模型结构:基于 Transformer 的语言模型,通过 MLP 层预测下一个 token;
编辑目标:在不重新训练模型的前提下,通过修改 MLP 层权重,实现对知识的编辑;
数学方法:将 MLP 层视为键值映射结构,通过最小二乘法求解增量矩阵;
多层编辑:为了提升模型鲁棒性,将编辑影响分布于多个层,避免单层修改导致的不稳定性;
核心公式:
\(\Delta = R K_e^T (K K^T + K_e K_e^T)^{-1}\)
多层编辑中 \(\Delta^l = R^l K_e^{l,T} (K^l K^{l,T} + K_e^l K_e^{l,T})^{-1}\)
本附录为理解 MEMIT 的数学基础提供了清晰的框架,强调了如何通过线性代数方法在神经网络中进行高效的参数更新,以实现知识编辑的目标。
Appendix B Implementation Details¶
1. 全量微调(Full Training, FT)¶
学习率设置:对于 GPT2 模型,学习率设为 1e-6;对于 GPT-J-6B 模型,学习率设为 1e-4。
训练轮数:所有模型均训练 5555 轮。
实验发现:随着训练时间的增加,模型在知识集合上可以达到零准确率(zero accuracy),但在 Lambda_openai 数据集上的困惑度(perplexity)异常高(> 10¹⁰),说明模型可能已过度拟合或出现严重过拟合现象。
2. MEMIT 方法¶
关键参数:MEMIT 方法中引入了一个超参数 λ(lambda),用于计算矩阵 \(KK^T = \lambda C\),其中 \(C\) 是在大规模数据集上计算出的平均变量(详见 Meng 等人 2023 年的工作)。
参数配置:不同设置下的 λ 值详见 表7。
效果:在这些配置下,模型可以获得良好的知识擦除准确率,同时几乎不损害模型的推理能力(推理任务性能下降极小)。
3. ME-FT 方法¶
实现来源:基于开源 GitHub 页面的代码(注释提供链接)。
配置使用:对于 zsRE 和 CounterFactual 任务,沿用该网站提供的配置。对于 Wiki-Latest,使用与 CounterFactual 相同的配置,仅更换数据来源文件。
4. FT-UL 方法¶
学习率设置:
GPT2-XL:学习率设为 1e-6;
GPT-J-6B:学习率设为 1e-5。
训练轮数:
GPT2-XL:每个数据集训练 1111 轮;
GPT-J-6B:每个数据集训练 5555 轮。
说明:LoRA 训练通常比全量微调更耗时,因此为 GPT-J-6B 设置了更多训练轮次。
5. WOH 方法¶
第一阶段训练:
使用从三元组 \(ℰ_w\) 中生成的句子进行训练,学习率设为 1e-6,训练 1 轮。
第二阶段训练:
采用 Eldan & Russinovich(2023)论文中的目标函数(Eq. 1)更新目标模型。
学习率设为 5e-5,训练 1 轮。
6. SeUL 方法¶
训练方式:
使用从三元组 \((s_i, r_i, o_i)\) 中生成的句子,并仅在目标输出 \(o_i\) 的 span 上计算损失。
训练设置:所有模型和数据集均训练 3 轮,学习率设为 1e-6。
训练方式区别:
GPT2-XL:全量微调;
GPT-J-6B:使用 LoRA 进行微调。
表7:MEMIT 方法的配置¶
模型 |
zsRE |
CounterFactual |
Wiki-Latest |
|---|---|---|---|
GPT2-XL |
20,000 |
20,000 |
100,000 |
GPT-J-6B |
50,000 |
100,000 |
100,000 |
说明:该表展示了不同模型和任务下 MEMIT 方法使用的数据量配置。
小结¶
本附录详细记录了各基线方法的训练参数与实现细节,重点在于不同模型(GPT2-XL 与 GPT-J-6B)、不同任务(zsRE、CounterFactual、Wiki-Latest)下的学习率、训练轮数、以及 LoRA 等微调方法的应用方式。MEMIT 方法的超参数 λ 对模型知识擦除效果起到关键作用,而 SeUL 和 WOH 则通过不同的损失函数设计,实现了对特定知识的编辑或删除。
Appendix C Additional Experiments¶
C.1 模型选择¶
本研究基于MEMIT框架进行实现,目前该框架仅针对GPT-2和GPT-J提供了有效的实现。尽管尝试将MEMIT适配到LLaMA(特别是llama2-7b),但其效果评分未超过0.75,而GPT-2和GPT-J的效果评分则达到了0.96以上(参考Meng et al., 2023)。作者推测这可能是由于配置问题,例如选择合适的层进行修改、调整等式(15)中的参数,或使用更适合LLaMA预训练集的数据来估计协方差矩阵。解决这些问题需要进行大量与本文方法无关的调整。因此,作者决定在实验中专注于GPT-2和GPT-J。这一选择有助于公平且聚焦地评估所提出的方法LAW,而LLaMA的集成则被视为未来研究的有希望方向。
C.2 推理数据集描述¶
本研究在三个推理数据集上进行了实验:
Lambda_openai(Paperno et al., 2016):LAMBADA数据集通过词预测任务测试计算文本理解能力。它包含叙事文本,模型必须使用广泛背景来预测最后一个词,而不仅仅是最后一个句子。该数据集包括原始测试集和德语、西班牙语、法语和意大利语的翻译。
HellaSwag(Zellers et al., 2019):HellaSwag数据集是一个评估常识自然语言推理(NLI)能力的基准,要求模型以符合人类常识的方式完成句子。该数据集要求模型预测合理的句子结尾,测试其对日常场景和上下文的理解。
ARC_Easy(Clark et al., 2018):ARC_Easy是ARC数据集的一个子集,包含小学水平的多选科学问题,相较完整集更简单。它包含标准算法能正确回答的问题。
C.3 额外实验结果¶
C.3.1 总体性能比较¶
表8、表9和表10展示了GPT2-XL和GPT-J-6B模型在zsRE、CounterFactual和Wiki-Latest数据集上的总体性能。这些表格比较了不同方法在准确性(Acc)、QA-F1分数、困惑度(PPL)等指标上的表现。重点在于观察LAW方法在知识擦除后的性能,尽管其在某些指标上表现较差,但其随机回答的特点表明其成功忘记了特定知识。
C.3.2 GSM8k上的额外实验¶
为研究知识擦除算法在数学推理任务上的影响,作者在GSM8k数据集上进行了实验。选择最强基线MEMIT进行比较。结果表明,LAW方法在不引入新知识的情况下,通过擦除旧知识,表现出一定的泛化能力。
C.3.3 重述查询上的额外实验¶
为了研究知识遗忘的泛化能力,作者在zsRE和MCF数据集的重述查询上进行了实验。结果显示,LAW方法在不同形式的查询中仍能保持一致性,尽管其准确性较低,但其能够随机回答表明其成功擦除了特定知识。
C.3.4 无关知识保留分析¶
通过使用来自zsRE和CounterFactual数据集的邻近提示,作者评估了模型在特定事实擦除后保留无关知识的能力。结果表明,LAW方法在保留无关知识方面表现良好,QA-F1分数相对稳定。
C.3.5 消融研究¶
Δ初始化的消融研究¶
作者测试了不同初始化方法对Δ的影响。结果显示,不同的初始化方法对模型性能有显著影响,MEMIT初始化通常表现最佳。
β选择的消融研究¶
研究了不同β值对模型性能的影响,结果显示,β值的选择对模型的准确性和困惑度有显著影响,其中β=0.2表现较为平衡。
知识集的连续消除¶
通过在修改每一层前筛选模型能正确回答的知识点,作者研究了连续消除(SE)技术的影响。结果显示,启用SE可以实现更彻底的知识擦除,但会略微影响推理能力。
C.3.6 案例研究¶
通过可视化不同方法在zsRE、CounterFactual和Wiki-Latest数据集上的表现,作者展示了LAW方法在擦除知识后的效果。结果显示,LAW方法能够随机回答问题或返回“None”,表明其成功擦除了特定知识,而其他方法可能仍预测正确答案或生成无意义内容。这一结果突出了LAW方法的目标:忘记现有知识,而不是注入新知识。
结论¶
本文通过一系列额外实验,验证了LAW方法在知识擦除任务中的有效性。尽管LAW在某些指标上表现不如其他方法,但其随机回答和保留无关知识的能力表明其成功实现了知识遗忘的目标。未来的工作可进一步研究LAW在LLaMA等其他模型上的应用。