2406.04770_WildBench: Benchmarking LLMs with Challenging Tasks from Real Users in the Wild¶
引用: 31(2025-08-25)
组织:
♡Allen Institute for AI
♢University of Washington
Hugging Face: https://hf.co/spaces/allenai/WildBench
总结¶
总结
附录中有 prompt
数据
数据来源:
WildBench 的任务数据来源于真实用户在如 Reddit、Stack Exchange、GitHub、Zhihu(知乎)等平台上提出的具有挑战性的自然语言问题。
数据来源:
WildBench 的任务来自 AI2 的 WildChat 项目,基于真实用户与聊天机器人的对话,当前版本 V2 包含 1024 个任务。
WildChat 数据集 包含一百万条真实用户的聊天记录,涵盖了写作、编程、数学、数据分析、角色扮演、计划制定等广泛任务,非常适合构建评估基准。
评估指标
WB-Reward(两两比较)
采用细粒度的模型响应两两比较方法,生成五种可能的结果:
明显更好、略好、略差、明显更差,或平局
对模型 X 与基线模型 Y 的表现进行打分:
X 明显优于 Y → +1
X 略优于 Y → +0.5
平局 → 0
X 略差于 Y → -0.5
X 明显差于 Y → -1
缓解长度偏差问题
简单方法: 如果胜出响应比失败响应多出超过 K 个字符,则将“略好/略差”的结果转换为“平局”
实验发现:K=500时与人类判断的相关性最高
WB-Score(独立评估)
单独评估模型输出的质量,因此它是一种快速且成本高效的评估指标
对每个回答进行 1 到 10 的评分
评分基于检查清单中定义的标准,包括回答的准确性、完整性、逻辑性和是否满足用户需求。
评分标准如下:
1–2:回答非常差,完全不相关。
3–4:回答较差,不能有效解决问题。
5–6:回答一般,存在事实错误或遗漏关键信息。
7–8:回答良好,但仍有改进空间。
9–10:回答优秀,完全满足用户需求。
分数重标定
最终的 WildBench-Score 为所有测试样例得分的平均值。
得分先减去 5,再乘以 2
将平均分 5 作为“最低可接受”标准,使得模型之间的差异更加明显
检查清单(Instance-Specific Checklists)
WildBench 为每一个测试查询生成一个检查清单(checklist)
每个清单包含 5 到 10 个问题,这些问题设计为可解释性强、易于验证
使用 GPT-4-Turbo 和 Claude-3-Opus 的回答进行整合,最终生成检查清单,以减少因单一模型判断带来的偏见
Task Categories
汇总分组(Consolidated Groups)
将原始的 12 个类别合并为 5 个主要类别
主要类别:
信息查询(Info Seeking)
合并了 “信息查询” 和 “建议请求”。数学与数据分析(Math & Data)
合并了 “数学” 和 “数据分析”。推理与规划(Reasoning & Planning)
合并了 “推理” 和 “规划”。创意任务(Creative Tasks)
包括 “创意写作” 和 “角色扮演” 等其他任务。编程与调试(Coding & Debugging)
原始12 个任务类别
信息查询(Information seeking)
用户请求关于各种主题的特定信息或事实。推理(Reasoning)
需要逻辑思维、问题解决或处理复杂概念的问题。规划(Planning)
用户需要帮助制定活动或项目的计划和策略。编辑(Editing)
包括编辑、重写、校对等与一般文本撰写相关的任务。编程与调试(Coding & Debugging)
用户寻求在编程中编写、审查或修复代码的帮助。数学(Math)
与数学概念、问题和计算相关的问题。角色扮演(Role playing)
用户参与需要模型扮演角色或角色设定的场景。数据分析(Data Analysis)
涉及对数据、统计的解释或执行分析任务的请求。创意写作(Creative Writing)
用户寻求在创作故事、诗歌等创意文本方面的帮助。建议请求(Advice seeking)
用户寻求在个人或职业问题上的建议或指导。头脑风暴(Brainstorming)
涉及产生想法、创造性思维或探索可能性的任务。其他(Others)
不符合上述任何类别的杂项任务。
Abstract¶
本研究介绍了 WildBench,这是一个用于评估大型语言模型(LLMs)的自动化评估框架,旨在通过真实且具有挑战性的用户查询对模型进行基准测试。WildBench 的数据集由 1,024 个示例组成,这些示例是从超过一百万条人与聊天机器人对话记录中精心筛选而来。
为了实现 WildBench 的自动化评估,研究者提出了两个评估指标:WB-Reward 和 WB-Score,这两个指标都可以利用先进的 LLM(如 GPT-4-turbo)进行计算。WildBench 通过任务特定的检查清单系统化地评估模型输出,并提供结构化的解释以支持评分和比较,使得自动评估结果更加可靠和可解释。
WB-Reward 的重点¶
WB-Reward 采用细粒度的模型响应两两比较方法,生成五种可能的结果:明显更好、略好、略差、明显更差,或平局。与以往使用单一基线模型的评估方式不同,WildBench 使用了三个具有不同性能水平的基线模型,以确保评估的全面性和多样性。
此外,研究者提出一种简单方法来缓解长度偏差问题:如果胜出响应比失败响应多出超过 K 个字符,则将“略好/略差”的结果转换为“平局”。
WB-Score 的重点¶
WB-Score 单独评估模型输出的质量,因此它是一种快速且成本高效的评估指标。
WildBench 的评估结果¶
WildBench 的结果与 Chatbot Arena 上的人工投票 Elo 排名高度相关,尤其是在困难任务上。具体来说,WB-Reward 与顶级模型的 Pearson 相关系数达到 0.98。而 WB-Score 的相关系数为 0.95,优于 ArenaHard 的 0.91、AlpacaEval2.0 的 0.89(长度控制下的胜率)以及常规胜率的 0.87。
总结重点¶
WildBench 是一个基于真实用户查询的自动评估框架。
提出了两个评估指标:WB-Reward(两两比较) 和 WB-Score(独立评估)。
使用多个基线模型和引入长度偏差缓解方法,提升了评估的可靠性。
评估结果与人工评估高度相关,显示出 WildBench 在评估 LLM 性能上的有效性。
1 Introduction¶
本节介绍了当前大型语言模型(LLMs)评估方法的挑战与不足,并引出了本文提出的新评估框架 WildBench。
1.1 传统评估方法的局限性¶
LLMs 由于其强大的泛化能力,已被广泛应用于多种实际场景,但其性能评估仍然是一个棘手的问题,尤其是如何实现自动化、低成本的评估。
传统的基准数据集,如 MMLU,主要通过多选题来评估模型的推理能力,但无法有效反映真实用户提出的开放性问题。
Chatbot Arena 通过收集用户对模型输出的偏好进行排名,采用Elo评分系统,虽能反映用户偏好,但存在人力成本高、无法实时评估、数据不透明等问题。
1.2 现有自动化评估方法的不足¶
现有自动化评估方法,如 AlpacaEval、MT-bench 和 ArenaHard,通常使用 GPT-4 等高级 LLM 作为“评委”来评估模型回答质量。
然而,这些基准在任务构成与技能覆盖方面存在明显不足。例如:
MT-bench 仅包含 80 个手工构造任务,覆盖范围有限;
AlpacaEval 虽然包含 805 个任务,但任务简单且重复性高,如“澳大利亚的首都是哪里?”等;
ArenaHard 则聚焦于代码和调试任务,占比超过 57%,缺乏多样性。
这些评估方法无法真实反映真实用户问题的复杂性和多样性,限制了评估的全面性。
1.3 WildBench 的提出¶
为解决上述问题,本文提出 WildBench,一个基于真实用户交互数据的自动化评估框架:
数据来源:WildBench 的任务来自 AI2 的 WildChat 项目,基于真实用户与聊天机器人的对话,当前版本 V2 包含 1024 个任务。
任务筛选流程:
使用多个高级 LLM 分析任务所需的知识和技能,并标注其难度;
排除所有模型都认为“简单”的任务;
保留与原始 WildChat 数据分布一致的任务,确保任务的自然性和多样性;
任务还需经过人工审核。
任务特点:WildBench 任务通常涉及高阶推理,如:
编写与调试代码(有特定约束);
创造性写作(需满足风格和内容的多重约束);
设计复杂软件系统等。
与 AlpacaEval 相比,WildBench 任务更具挑战性,如图 1 所示。
1.4 WildBench 的评估机制¶
为实现可靠的自动评估,WildBench 采用以下设计思路:
任务特定检查表(Checklist):
参考人类评估开放性问题的方式,设计任务相关的评估标准;
引导 LLM 进行结构化、细粒度的评估,如图 4 所示。
零样本链式思维提示(Zero-shot Chain-of-Thoughts):
促使 LLM 生成逐步推理分析,提升判断的一致性与可靠性。
1.5 评估指标¶
WildBench 引入了两个主要评估指标:
WB-Reward:
用于模型对模型的成对比较,结果包括:A 明显更好、A 略好、平局、B 略好、B 明显更好。
与同类研究不同,WildBench 使用三个基线模型进行比较,而非单一模型,从而提供更全面的评估。
WB-Score:
用于单独模型的评分,评估其输出质量,更具快速与经济性。
为避免“长文本偏好”问题(LLM 通常偏向较长输出),引入了长度惩罚机制,在输出显著较长时将轻微胜利或失败视为平局。
1.6 与人工评估的对比¶
WildBench 的两个指标与 Chatbot Arena 的人工 Elo 排名高度相关:
WB-Reward 与人工排名的 皮尔逊相关系数为 0.98;
WB-Score 为 0.95;
显著高于 ArenaHard(0.91)和 AlpacaEval2.0(0.87),说明 WildBench 的评估结果更加贴近人类判断,验证了其有效性与公平性。
1.7 总结¶
WildBench 是一个基于真实用户任务、具有高度挑战性的自动评估框架,解决了现有方法在任务覆盖、多样性、评估效率等方面的不足。通过使用 LLM 作为“评委”,结合任务引导与长度惩罚机制,WildBench 实现了与人工评估高度一致的自动评估,为 LLM 的性能评测提供了新的方向。
2 WildBench Data Curation¶
本节主要介绍 WildBench 中用于评估大语言模型(LLMs)任务的数据整理过程。目标是确保所选任务不仅代表现实中的使用场景,而且难度足够,能够区分不同 LLM 的能力。
表 1:LLM 对齐基准的统计比较(单位:字符)¶
数据集 |
#任务数 |
#轮次 |
聊天历史 |
查询长度 |
提示长度 |
真实用户 |
任务标签 |
评价方式 |
|---|---|---|---|---|---|---|---|---|
MT-Bench |
80 |
2 |
✔️ |
202.2 |
动态 |
❌ |
✔️ |
分数 |
AlpacaEval |
805 |
1 |
❌ |
164.9 |
164.9 |
❌ |
❌ |
成对 (ref=1) |
ArenaHard |
500 |
1 |
❌ |
406.4 |
406.4 |
✔️ |
❌ |
成对 (ref=1) |
WildBench |
1,024 |
≤5 |
✔️ |
978.5 |
3402.1 |
✔️✔️ |
✔️ |
分数+成对 (ref=3) |
WildBench 相比其他数据集具有更多任务、更长的上下文、更真实的用户交互,并采用了更全面的评估方式。
2.1 从 WildChat 中挖掘具有挑战性的任务¶
WildBench 的任务主要来源于 WildChat 数据集(Zhao 等人,2024),该数据集包含一百万条真实用户的聊天记录,涵盖了写作、编程、数学、数据分析、角色扮演、计划制定等广泛任务,非常适合构建评估基准。
基本过滤¶
为了确保任务的质量和多样性,采取了以下过滤步骤:
长度控制:过滤掉查询长度过短(<10 token)或过长(>3000 token)的任务。
对话轮次限制:保留最多 5 轮对话,避免多主题混乱。
语言筛选:仅保留英文数据。
内容筛选:去除有毒对话、低质量内容。
任务多样性:通过 SentenceBERT 计算查询的余弦相似度,过滤相似度 > 0.9 的任务。
用户多样性:为每个唯一设备保留最后一次对话,避免同一用户重复任务。
难度标注¶
使用 GPT-4-Turbo、Claude-3-Sonnet 和 Opus 对任务进行难度评分(1-5 分)。剔除所有模型都评分为“非常容易”或“容易”的任务,最终保留难度适中的任务。
人工标注¶
为提高任务质量,采用 GPT-4-Turbo 提取查询意图,并由人工审核去除无意义任务。最终保留 1,024 个高质量任务,并确保覆盖多种任务类别。
动态更新与数据泄露防护¶
WildBench 是一个动态基准,定期更新以反映新型用户交互。目前已发布 V1(2024 年 3 月)和 V2(2024 年 5 月)两个版本。为防止训练模型利用 WildChat 数据进行数据泄露,与 WildChat 团队合作确保采样任务不会出现在 WildChat 数据集中。
2.2 WildBench 统计数据¶
基本统计¶
WildBench 与其他主流基准(如 AlpacaEval、MT-Bench、ArenaHard)相比,具有以下特点:
真实用户来源:仅 ArenaHard 和 WildBench 使用真实用户交互,而非专家或众包任务。
任务分布更均衡:WildBench 的任务分布比 ArenaHard 更广泛,避免过度集中于编程和调试任务。
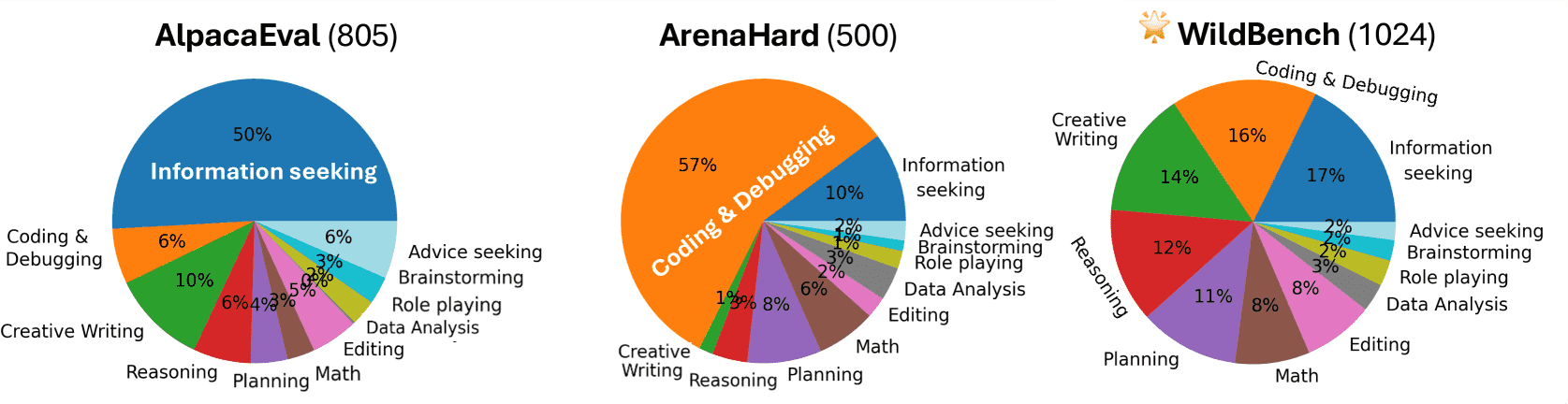
Figure 3:Distribution of task categories in AlpacaEval, ArenaHard, and WildBench.
长上下文任务¶
WildBench 包含最多 4 轮对话,反映复杂、多轮的用户交互。超过 20% 的对话包含多轮交互。此外,WildBench 的查询长度更长,这是因为 WildChat 使用的 GPT-4-Turbo 支持高达 128K 上下文 token,展示真实用户交互的复杂性。因此,WildBench 更适合评估 LLM 在长上下文中的问题解决能力。
任务类别¶
为了细致分析 LLM 的能力,WildBench 将任务分为 12 类,基于对 ShareGPT 查询的分析和任务意图标注。具体类别详见附录 A。
从任务类别分布图来看:
WildBench 相比 AlpacaEval 和 ArenaHard 更加平衡。
AlpacaEval 和 ArenaHard 的任务主要集中在“信息检索”和“编程调试”两个类别(各超过 50%)。
总结:WildBench 是一个基于真实用户交互构建的高质量任务集,具有更长的上下文、更广的任务类别分布和更高的任务挑战性。其动态更新机制和防数据泄露设计使其成为评估大语言模型能力的理想基准。
3 Automatic Evaluation with WildBench¶

Figure 4:Evaluation framework for WildBench. There are two metrics: WB-Score for individual evaluation and WB-Reward for pairwise evaluation. The checklist is used to guide the evaluation process. The length penalty is used to mitigate the length bias. WB-Reward and WB-Score both have strong correlations with human-based ranking of LLMs on Chatbot Arena.
本节介绍如何使用 WildBench 对大型语言模型(LLMs)进行自动评估。主要内容包括:
3.1 实例特定的检查清单(Instance-Specific Checklists)¶
重点内容:
为了解决LLM评估中的主观性和模糊性问题,WildBench 为每一个测试查询生成一个检查清单(checklist)。
每个清单包含 5 到 10 个问题,这些问题设计为可解释性强、易于验证。
使用 GPT-4-Turbo 和 Claude-3-Opus 的回答进行整合,最终生成检查清单,以减少因单一模型判断带来的偏见。
清单经过人工审核,并作为 LLM 评估者的提示,用于评估不同模型的回答质量。
示例中以 G20 任务为例,展示了检查清单的部分问题,例如:
是否包含1200字以上?
语言是否优美并使用了丰富词汇?
是否包含大量关于G20对全球经济、贸易和发展的事实数据?
总结:检查清单提供了标准化的评估框架,使模型评估更系统、更可解释,是 WildBench 评估体系的关键组成部分。
3.2 成对评估与 WB-Reward 指标(Pairwise Evaluation with WB-Reward Metric)¶
重点内容:
WildBench-Reward(WB-Reward)是一种成对评估指标,用于比较两个模型的回答质量。
评估流程:¶
提供结构化的问题链,引导 LLM 评估者分析用户问题和对话历史。
LLM 评估两个模型的回答,并分析其优劣。
最终给出判断:哪个回答更好,并解释原因。
与人类评估方式类似,确保评估过程的细致和可解释性。
WB-Reward 分数计算:¶
根据比较结果,对模型 X 与基线模型 Y 的表现进行打分:
X 明显优于 Y → +1
X 略优于 Y → +0.5
平局 → 0
X 略差于 Y → -0.5
X 明显差于 Y → -1
降低长度偏见(Mitigating Length Bias):¶
LLM 通常倾向于更长的回答,这可能导致评估偏差。
引入长度惩罚机制:如果胜出的回答比败者长于某个阈值 K,就将“略优/略差”判定为“平局”。
阈值 K 可由用户自定义,实现个性化评估。
基线模型选择:¶
为减少单一基线模型带来的偏见,使用了三个基线模型(GPT-4-Turbo、Claude-3-Haiku、Llama-2-70B-chat)。
最终的 WB-Reward(Mix)是这三个模型在 1024 个例子上的平均得分,以提高评估的稳定性。
总结:WB-Reward 是 WildBench 的核心评估指标之一,通过成对比较和结构化清单评估,使得模型间的性能差异更清晰,并通过长度惩罚机制降低偏见。
3.3 单独评估与 WB-Score 指标(Individual Evaluation with WB-Score Metric)¶
重点内容:
WB-Score 是一种模型独立评估指标,用于对单个模型的回答质量进行评分。
评分定义:¶
使用 GPT-4-Turbo 对每个回答进行 1 到 10 的评分。
评分基于检查清单中定义的标准,包括回答的准确性、完整性、逻辑性和是否满足用户需求。
评分标准如下:
1–2:回答非常差,完全不相关。
3–4:回答较差,不能有效解决问题。
5–6:回答一般,存在事实错误或遗漏关键信息。
7–8:回答良好,但仍有改进空间。
9–10:回答优秀,完全满足用户需求。
分数重标定:¶
最终的 WildBench-Score 为所有测试样例得分的平均值。
得分先减去 5,再乘以 2:
\( S' = (S - 5) \times 2 \)这种方式将平均分 5 作为“最低可接受”标准,使得模型之间的差异更加明显。
总结:WB-Score 提供了对每个模型的独立评估,适用于大规模评估场景。通过标准化评分和重标定,提高了评估的区分度和可读性。
总体总结¶
WildBench 的自动评估体系包括三个重要部分:
检查清单:增强评估的可解释性与系统性。
WB-Reward:基于成对比较的评估指标,体现模型之间的相对性能。
WB-Score:对单个模型的独立评估,提供更细粒度的评分。
通过结合人类判断与 LLM 评估的长处,并引入检查清单与长度惩罚机制,WildBench 实现了在实际用户任务中对 LLM 的高效、可解释的评估。
4 Results & Analysis¶
本节对WildBench上不同模型的性能进行了分析。内容主要分为三个部分:排行榜分析、WildBench得分与ChatbotArena Elo评分的相关性分析,以及消融实验与讨论。以下是各部分的重点总结:
4.1 领先榜分析(Leaderboard Analysis)¶
模型性能分层¶
根据实验结果,WildBench将模型自然地划分为三个性能层次:
Tier 1:性能优于Claude 3 Haiku;
Tier 2:性能优于Llama-2-70B-chat,但低于Claude 3 Haiku;
Tier 3:性能低于Llama-2-70B-chat。
任务类别性能差异¶
WildBench的一大特点是能够按任务类别(如信息检索、创意生成、数学推理等)对模型进行对比,从而识别模型在不同任务上的优劣势。例如,大型模型如GPT-4-Turbo-0409和Claude 3 Opus在所有任务中都表现良好,而开源模型如Llama-3-8B-Inst和Yi-1.5-34B-chat在编程和数学任务上表现较弱。
小模型是否能超越大模型?¶
在AlpacaEval-2.0排行榜中,Llama-3-8B-Inst-SimPO表现优于其70B版本,但WildBench的结果显示其总体性能仍略逊于70B模型。这表明AlpacaEval可能存在任务选择偏差和评估提示方法的不足,而Llama-3-8B-Inst-SimPO在WildBench中仍是最优的小模型之一。
长度偏倚问题(Length bias)¶
WildBench的评估机制对响应长度具有鲁棒性。例如,Llama-2-70B-chat与Llama-3-70B-Inst输出长度相近,但排名相差较大;Yi-1.5-6B输出长度最长,但排名靠后。这说明WildBench强调响应质量而非长度。此外,WildBench引入长度惩罚机制,用户可在实时排行榜上自定义长度惩罚参数,以平衡长度和质量的权衡。
4.2 与人类判断的相关性(Correlation to Human Judgment)¶
为验证WildBench评估结果与人类判断的一致性,作者将其与ChatbotArena的Elo评分进行了比较。主要分析了以下指标:
WB-Reward
WB-Score
AlpacaEval winrate (WR)
Length-controlled winrate (LC)
Arena-Hard scores
相关性度量¶
作者使用了三种相关性指标:皮尔逊相关(Pearson)、斯皮尔曼相关(Spearman)和肯德尔相关(Kendall’s tau)。
核心发现¶
WB-Reward 和 WB-Score 与ChatbotArena Elo评分的相关性最强,特别是在排名靠前的模型(top 6)中表现尤为突出。
使用Claude 3 Haiku作为基线模型进行比较时,相关性最高。
与AlpacaEval等其他指标相比,WildBench在衡量模型整体性能方面更贴近人类判断。
4.3 消融实验与讨论(Ablation Studies and Discussions)¶
1. Checklist的作用¶
实验表明,使用Checklist可以提高评估结果与人类偏好之间的相关性。当移除Checklist时,Pearson相关系数从0.925下降到0.905,说明Checklist对提高评估质量有积极作用。
2. 长度惩罚参数K的选择¶
对不同长度惩罚参数(K = 100, 200, 500, 1000, ∞)进行实验后,发现K=500时与人类判断的相关性最高。说明适当控制长度惩罚有助于减少长度偏倚问题。
3. 多个LLM作为评估者的效果¶
作者尝试使用多个模型(如GPT-4、Claude 3 Opus、Mistral-Large)作为评估者,但发现它们对最终模型排名的影响较小。因此,推荐在实际应用中使用单个LLM以节省成本和时间。未来版本中将探索更高效的多模型评估策略。
4. 数据分布与ChatbotArena的对比¶
尽管WildBench与ChatbotArena平台的数据分布不同,但两者都基于真实用户提交的任务,目标一致,因此其评估结果具有较高的相关性。WildBench的高相关性主要归功于其真实用户任务的多样性与挑战性。
5. WildBench的两种评估指标¶
WildBench提供了两种主要评估指标:
WB-Score:
单模型评分(1-10分)
使用Checklist和CoT提示
评估效率高,成本低
WB-Reward:
与多个基线模型进行对比
更全面,但成本是WB-Score的3-4倍
两者互补,官方排行榜结合使用,用户可根据实验需求选择适合的指标。
总结¶
WildBench通过真实用户任务对多个大语言模型进行了系统评估,揭示了模型在不同任务类别上的表现差异,验证了其对长度偏倚的鲁棒性,并与ChatbotArena的Elo评分显示出高度相关性。同时,WildBench提供了灵活的评估机制(如Checklist、长度惩罚),支持用户自定义,是目前较为全面且贴近人类判断的LLM评估基准之一。
6 Conclusion and Future Directions¶
本研究中,作者介绍了 WildBench,这是一个用于通过真实用户查询评估大语言模型(LLMs)的基准测试平台。
WildBench 数据的一个重要特点是其自然任务分布的“真实世界用户查询”,这使得它更贴近实际使用场景。为了使用收集到的数据评估 LLM 的性能,作者提出了一种类似思维链(CoT)的 LLM 作为评估者的方法,以提升评估的可解释性并减少模糊性。此外,还引入了长度惩罚机制,以缓解 LLM 作为评估者时存在的长度偏差问题。实验结果显示,本文提出的两个主要评估指标 WB-Reward 和 WB-Score 与人类判断有很强的相关性,优于现有评估方法。
作者进一步展示了大量实验和分析结果,评估了涵盖40 个大语言模型(包括专有模型和开源模型)在 WildBench 上的表现。通过在不同任务类别中对得分进行详细分类分析,WildBench 能够揭示不同模型的优势与劣势。
引入 WildBench 的目的是提供一个真实、动态且抗污染能力强的评估框架,以准确反映 LLM 的实际能力。作者表示将持续维护该基准测试平台,以便未来持续评估新出现的 LLM 在未见过的任务上的表现。
Appendix A Task Categories¶
在 2.2 小节 中,我们提到将任务细分为 12 个类别,以便对大语言模型(LLM)的能力进行细致分析。以下是这 12 个任务类别的定义:
1. 12 个任务类别¶
信息查询(Information seeking)
用户请求关于各种主题的特定信息或事实。推理(Reasoning)
需要逻辑思维、问题解决或处理复杂概念的问题。规划(Planning)
用户需要帮助制定活动或项目的计划和策略。编辑(Editing)
包括编辑、重写、校对等与一般文本撰写相关的任务。编程与调试(Coding & Debugging)
用户寻求在编程中编写、审查或修复代码的帮助。数学(Math)
与数学概念、问题和计算相关的问题。角色扮演(Role playing)
用户参与需要模型扮演角色或角色设定的场景。数据分析(Data Analysis)
涉及对数据、统计的解释或执行分析任务的请求。创意写作(Creative Writing)
用户寻求在创作故事、诗歌等创意文本方面的帮助。建议请求(Advice seeking)
用户寻求在个人或职业问题上的建议或指导。头脑风暴(Brainstorming)
涉及产生想法、创造性思维或探索可能性的任务。其他(Others)
不符合上述任何类别的杂项任务。
2. 任务类别的汇总分组(Consolidated Groups)¶
为了更方便地进行任务层面的分析,我们将原始的 12 个类别合并为 5 个主要类别:
信息查询(Info Seeking)
合并了 “信息查询” 和 “建议请求”。数学与数据分析(Math & Data)
合并了 “数学” 和 “数据分析”。推理与规划(Reasoning & Planning)
合并了 “推理” 和 “规划”。创意任务(Creative Tasks)
包括 “创意写作” 和 “角色扮演” 等任务。
其余类别也纳入了这五组中,这些合并后的类别如图 5 所示。
3. WildBench 任务轮次分布(Number of Turns)¶
图 8 显示了 WildBench 中对话轮次(turns)的分布情况,用于分析任务的交互复杂度。由于这是双盲审稿阶段,相关链接指向 allenai,将在审稿结束后更新。补充材料的 zip 文件包含评估脚本、排行榜和数据源代码。
总结重点¶
任务分类细分为 12 个类别,便于细化分析模型能力。
为简化分析,合并为 5 个主要组别:信息查询、数学与数据、推理与规划、创意任务、其他。
图 8 展示了任务轮次的分布,用于衡量交互复杂性。
补充材料提供数据和代码,将用于后续研究和评审。
Appendix B More Information on WildBench Data¶
本章节主要介绍了WildBench数据集的补充信息,结构如下:
1. 对话轮次分布(The distribution of the number of turns in WildBench)¶
WildBench中对话的轮次分布可以在图8中查看。这是重点内容,有助于了解任务的复杂程度和交互的深度。
该分布图展示了真实用户任务中对话的长度分布,是评估模型对话能力的重要参考。
2. 数据集访问与信息(dataset documentation, metadata, and the public subset)¶
WildBench的数据集文档、元数据和公开子集可通过以下链接访问:https://huggingface.co/datasets/allenai/WildBench/viewer/v2。
该链接是重点内容,研究人员可以通过此链接获取数据并进行进一步的研究和使用。
3. 数据许可与责任说明(license and responsibility)¶
数据集发布在AI2的ImpACT许可证下,被归类为“低风险”资源,说明其在使用上相对安全合规。
数据发布方对任何版权侵权问题承担全部责任,这为使用者提供了法律上的保障。
4. 数据的长期维护与更新(long-term availability and maintenance)¶
数据发布方承诺长期维护数据集,并会持续更新以确保其相关性和实用性。
总结:
本附录详细介绍了WildBench数据集的访问方式、数据分布、许可信息和维护策略。重点内容包括图8中对话轮次的分布情况和数据集的获取链接,这对于研究者了解和使用WildBench具有重要意义。
Appendix C More Information on WildBench Evaluation¶
本章节主要介绍了如何复现WildBench公有子集的评估结果。
评估结果的复现
作者指出,他们对WildBench公开子集的评估结果是可以通过公开的评估脚本进行复现的。这些脚本托管在GitHub上,网址为 https://github.com/allenai/WildBench/。模型生成脚本的位置
对于每个模型的生成脚本,作者已经放在了该仓库的scripts文件夹下,路径为 https://github.com/allenai/WildBench/tree/main/scripts。这部分内容是重点,因为它是实现结果复现的关键步骤之一。评估生成结果的脚本
用于评估生成结果的脚本位于 https://github.com/allenai/WildBench/tree/main/evaluation。这也是重点内容,因为评估过程是验证模型性能的重要环节。总结
本附录提供了复现评估结果所需的所有资源链接,便于其他研究者验证和拓展相关工作。
Appendix D Prompt Template for Pairwise Evaluation Metric WB-Reward¶
本附录主要介绍用于两两对比评估的提示模板,用于评估两个AI模型输出的质量。该模板分为三个主要部分:指令说明、对话历史与模型输出,以及评估规则与输出格式。目的是指导LLM评估器对两个响应进行系统性对比,最终输出一个评估结果。
# Instruction(指令部分)¶
该部分明确评估者的角色和任务:
评估者需作为专家评价者,对两个AI模型(响应A和响应B)生成的输出进行质量对比;
输入包括:用户问题、对话历史和两个模型响应;
评估者需先理解任务背景,再根据后续提供的检查清单和规则进行评估。
# Conversation between User and AI(对话部分)¶
这部分展示了评估时所需的所有对话内容:
## History(历史对话)¶
使用标记
<|begin_of_history|>和<|end_of_history|>包裹,用于展示用户与AI之前的对话历史;验证评估者是否能够结合上下文进行判断。
## Current User Query(当前用户问题)¶
使用标记
<|begin_of_query|>和<|end_of_query|>包裹,展示当前用户提出的问题;评估者需要结合上下文理解此问题的意图和任务目标。
## Response A 和 Response B(模型响应A和B)¶
使用标记
<|begin_of_response_A|>到<|end_of_response_B|>分别展示两个模型的响应;评估对象为这两个响应的质量、完整性、准确性等。
# Evaluation(评估部分)¶
这部分是评估的核心,分为检查清单(Checklist)、评估规则(Rules)和输出格式(Output Format)。
## Checklist(检查清单)¶
使用标记
<|begin_of_checklist|>和<|end_of_checklist|>包裹评估者应当参考的检查项;该清单为评估提供方向,但评估者不应仅限于清单中的内容进行判断。
## Rules(评估规则)¶
评估者应基于用户问题和对话历史,对响应A和B进行比较;
需首先写出分析过程,并列出使用的检查清单条目;
最终输出五个评估等级中的一种:
A++:A远优于B;
A+:A略优于B;
A=B:A与B质量相当;
B+:B略优于A;
B++:B远优于A;
需要提供三类理由:
两响应表现相当的理由;
A优于B的理由;
B优于A的理由。
## Output Format(输出格式)¶
评估结果需以JSON格式输出,包含以下字段:
"analysis of A":对A的分析;"analysis of B":对B的分析;"reason of A=B":A与B表现相同之处;"reason of A>B":A优于B之处;"reason of B>A":B优于A之处;"choice":最终评估结果(A++、A+、A=B、B+、B++)。
重点总结¶
本模板用于两两对比两个模型输出的质量;
评估者需结合上下文,并依据检查清单进行系统评估;
最终输出需结构化为JSON格式,明确列出分析和评估结果;
重点在于评估过程的系统性和评估结果的可解释性,而非主观判断。
如需进一步了解评估流程,可参考文中提到的 Section 3.2,其中详细介绍了WB-Reward的评估方法。
Appendix E Prompt Template for Individual Evaluation Metric WB-Score¶
本附录介绍了一个用于个体评估的提示模板,适用于 WB-Score 评估指标。该模板分为三个主要部分,结构清晰、功能明确,用于指导评估人员(这里是 LLM 判定器)对 AI 模型的回答进行评分。内容包括指令、对话历史与响应、评估规则与格式等。
# Instruction(指令)¶
这部分明确了评估者的角色与任务:
角色:评估者需扮演“专家评估员”,负责评估 AI 生成回复的质量。
任务:评估者将获得用户的问题和 AI 的回应,并需仔细阅读用户问题和对话历史,进行任务分析,再根据后续提供的 检查列表 和 评分规则 对回复质量进行评估。
这是整个评估过程的引导部分,重点在于明确评估者的职责与任务流程。
# Conversation between User and AI(用户与 AI 的对话)¶
这一部分展示了对话的结构,分为三个子部分:
## History(对话历史)¶
用
<|begin_of_history|>和<|end_of_history|>包裹,用来展示用户与 AI 之前的对话历史。内容为占位符:
{$history},在实际使用中会被真实对话内容替换。作用:帮助评估者理解当前问题的上下文,非常重要,因为评估不能脱离上下文进行。
## Current User Query(当前用户问题)¶
用
<|begin_of_query|>和<|end_of_query|>标记当前用户提出的问题。占位符为:
{$user_query}。作用:明确当前需要评估的具体问题。
## AI Response(AI 回答)¶
用
<|begin_of_response|>和<|end_of_response|>包裹 AI 生成的答案。占位符为:
{$model_output}。作用:这是评估对象,评估者将基于此进行打分和分析。
总结:本部分为评估提供了必要的语境信息,是评估工作的输入基础。
# Evaluation(评估)¶
评估部分包括检查列表、评分规则和输出格式。
## Checklist(检查列表)¶
用
<|begin_of_checklist|>和<|end_of_checklist|>包裹评估时的检查项。占位符为:
{$checklist},实际内容会根据评估任务的不同而变化。作用:为评估者提供参考标准,但评估不应局限于检查列表,需结合上下文和实际判断。
## Rules(评分规则)¶
评分规则从 1 到 10 分,详细划分为五个等级,每级都有说明:
1~2 分:回答非常差,完全无意义。
3~4 分:回答较差,无法有效解决问题。
5~6 分:回答一般,存在事实错误或关键信息缺失。
7~8 分:回答较好,但仍有一定提升空间。
9~10 分:回答优秀,能有效帮助用户解决问题。
评分流程要求:
评估者需先进行分析,列出使用的检查项;
然后根据检查项进行评分;
最终输出应包括分析、强项、弱项和评分。
此部分是评估的核心规则,明确评分标准和流程,对评估的一致性非常重要。
## Output Format(输出格式)¶
评估结果需以 JSON 格式输出,包含以下字段:
strengths(强项):对 AI 回答优点的分析。
weaknesses(弱项):对 AI 回答缺点的分析。
score(评分):1~10 之间的分数。
示例输出格式如下:
{
"strengths": "[analysis for the strengths of the response]",
"weaknesses": "[analysis for the weaknesses of the response]",
"score": "[1~10]"
}
此格式标准化了评估结果,便于后续统计与分析。
总结¶
本附录提供了一个结构清晰、功能明确的 WB-Score 个体评估模板,用于 LLM 评估器对 AI 回答进行质量评估。其核心结构包括:
指令部分:明确评估任务与流程;
对话数据:提供上下文与用户问题、AI 回答;
评估规则与输出格式:指导评估者如何分析、判断并输出结果。
此模板强调上下文理解与系统化的评估流程,是进行高质量 AI 输出评估的重要工具。
Appendix F Full WildBench Leaderboard¶
排行榜时间点与图表¶
这些排行榜展示了 WildBench 中的模型表现,评估任务来源于真实用户的挑战性任务。
WB-Elo 指标(重点)¶
为提高排行榜的更新效率与稳定性,作者引入了一个新的评估指标:WB-Elo。
WB-Elo 的构建方式:
基于原有指标 WB-Reward 和 WB-Score。
将这些指标**转化为成对比较(pairwise comparisons)**数据。
在此基础上,结合现有的 LMSYS Elo 排名系统进行 Elo 评分更新。
优势:
提高了排行榜更新的速度与稳定性。
排行榜查看方式¶
用户可通过访问项目网站 https://huggingface.co/spaces/allenai/WildBench 查看并互动查看最新结果。
生成信息(可略)¶
本节内容由 LaTeXML 工具 于 2024 年 10 月 5 日自动生成。
总结重点:本附录介绍了 WildBench 的完整排行榜及其更新情况,强调了新指标 WB-Elo 的引入及其改进效果,并提供了查看排行榜的在线方式。