1902.07153_SGCN: Simplifying Graph Convolutional Networks¶
引用: 4492(2025-09-24)
组织:
1Cornell University(康奈尔大学)
2Federal Institute of Ceara(塞阿拉联邦研究所, 巴西)
GitHub: https://github.com/Tiiiger/SGC
总结¶
核心思想:
通过移除GCN中的非线性激活函数,将复杂的多层图卷积网络简化为一个简单的线性模型,从而在保持甚至提升性能的同时,极大地提高了模型的效率和可解释性。
背景与动机
GCN的成功与问题:
2017年提出的GCN模型在图结构数据(如社交网络、引文网络)上取得了巨大成功。
标准的GCN通过聚合邻居节点的信息来更新当前节点的表示,每一层都包含特征传播(邻域聚合) 和非线性变换(激活函数) 两个步骤。
提出的质疑:
作者质疑GCN中复杂的非线性变换(如ReLU)是否是性能提升的关键。
通过实验观察发现,在引文网络等数据集中,GCN模型中的非线性操作带来的收益非常有限,反而引入了额外的复杂性和计算开销。
核心动机
既然非线性不那么重要,能否将其移除?如果可以,那么一个多层的GCN就可以被“展开”和“简化”,变成一个非常简单的模型。
SGCN
SGC的推导过程分三个步骤:
1.回顾标准GCN
一个标准的K层GCN的传播规则可以写为: $\( H^{(k)} = \sigma(\tilde{A} H^{(k-1)} W^{(k)}) \)$ 其中:
\( \tilde{A} \) 是经过归一化(添加自环)的邻接矩阵。
\( H^{(k)} \) 是第k层的节点特征。
\( W^{(k)} \) 是第k层的可训练权重矩阵。
\( \sigma \) 是非线性激活函数(如ReLU)。
2.移除非线性激活函数
SGC的核心操作是移除每一层(除最后一层外)的非线性激活函数。这样,每一层就变成了纯粹的线性变换。于是,一个K层的SGC可以表示为: $\( H^{(K)} = \tilde{A} ... \tilde{A} \tilde{A} X W^{(1)} W^{(2)} ... W^{(K)} \)$
3.合并线性变换 由于连续的线性变换可以合并为一个线性变换,我们可以将多次的特征传播和权重变换分开并合并:
特征传播的合并: 将K次对初始特征\( X \)的邻接矩阵乘法合并为一次:\( \tilde{A}^{K} X \)。这一步是固定的、与参数无关的预处理步骤。它相当于将每个节点的特征平滑(Smoothing)到其K-hop邻居的范围内。
权重变换的合并: 将K层的权重矩阵合并为一个单一的权重矩阵:\( W = W^{(1)} W^{(2)} ... W^{(K)} \)。
最终,SGC的模型被简化为一个极其简单的形式: $\( Y_{SGC} = \text{Softmax}(\tilde{A}^{K} X W) \)\( 这个形式与一个**简单的线性模型(逻辑回归)** 非常相似,唯一的区别是多了一个预处理步骤 \) \tilde{A}^{K} X $。
SGC的优势
计算效率高:
训练快: 由于模型本质上是线性的,训练时只需要学习一个权重矩阵\( W \),参数量远少于深层GCN。同时,昂贵的邻接矩阵计算(\( \tilde{A}^{K} X \))可以作为一次性预处理完成,大大加快了训练速度。
推理快: 模型简单,推理速度自然很快。
性能不俗,甚至更好:
在引文网络(Cora, Citeseer, Pubmed)等经典数据集上,SGC的性能与GCN等模型相当,甚至在某些数据集上略有提升。
作者认为,SGC通过避免非线性激活函数可能带来的“过拟合”,起到了某种正则化的效果,从而在简单任务上表现更稳健。
可解释性强:
SGC提供了一个清晰的图信号处理视角。操作 \( \tilde{A}^{K} X \) 可以看作一个低通滤波器,它平滑了图中的节点特征,使相邻节点的特征变得相似。这个滤波过程是确定的,不包含任何需要学习的参数。
模型的学习部分(\( W \))只负责对经过平滑后的特征进行分类。这种“特征预处理 + 线性分类器”的结构使得模型的行为更容易被理解和分析。
主要贡献:
提出了SGC模型: 一个简单、高效、可解释性强的图神经网络模型。
挑战了传统认知: 质疑了非线性激活在图卷积中的必要性,推动了社区对GNN本质的思考。
建立了与经典模型的联系: 将GNN与简单的线性模型和图信号处理理论联系起来,为理解GNN提供了一个新的视角。
核心结论: 这篇论文有力地证明了,GCN的强大性能主要来源于其邻域聚合(特征传播/平滑)机制,而非复杂的非线性变换。对于许多图学习任务,一个经过精心设计的、简单的线性模型已经足够强大。
后续影响: SGC成为GNN模型中的一个重要基线,启发了后续大量关于简化、加速和理解GNN的研究工作。它提醒研究人员,在追求模型复杂度的同时,不应忽视简单性、效率和可解释性的价值。
前提知识¶
图神经网络(Graph Neural Networks, GNNs)简介¶
简介
主要作用:从图结构数据中学习有效的特征表示,从而解决与图相关的各种机器学习任务。
类比:
卷积神经网络(CNN) 擅长处理欧几里得数据(如图像、文本),这些数据具有规则的空间结构(如像素网格、单词序列)。
图神经网络(GNN) 则专门设计用于处理非欧几里得数据(如图),这些数据具有不规则、复杂的关联结构。
核心思想:消息传递
GNN绝大多数都基于一个称为消息传递 的核心机制。这个过程非常直观,模拟了社会网络中的信息传播:
聚合:每个节点从它的邻居节点那里收集信息。
更新:每个节点根据收集到的邻居信息和自身的信息,来更新自己的状态。
通过多层这样的操作,每个节点最终的特征表示就不再仅仅是它自己的初始信息,而是包含了其所在 局部子图结构 的丰富信息。节点可以“感知”到多跳之外的邻居。
GNN的主要作用(应用领域)
节点级别任务 目标:预测图中每个节点的属性或角色。
节点分类:预测节点的类别标签。
典型示例:在学术引用网络中(节点是论文,边是引用关系),根据已标记的论文(如计算机、生物、物理)来预测未标记论文的研究领域。
现实应用:社交网络用户画像分类、金融反欺诈(判断用户是否为欺诈分子)。
边级别任务 目标:预测节点之间的关系或边的存在。
链接预测:预测两个节点之间是否存在缺失的链接或未来是否会产生链接。
典型示例:在社交网络中,向用户推荐可能认识的人(预测哪些用户之间应该建立好友关系)。
现实应用:知识图谱补全(预测两个实体间的关系)、药物相互作用预测(预测两种药物合并使用是否会产生反应)。
图级别任务 目标:对整个图进行预测,生成一个表示整个图的特征向量。
图分类:预测整个图的类别。
典型示例:在分子图中(节点是原子,边是化学键),判断一个分子是否有毒或是否适合作为药物。
现实应用:社交网络社区检测(判断一个子图属于哪种类型的社区)、代码网络检测(判断一段代码是否包含漏洞)。
为什么GNN如此强大和必要?
在没有GNN之前,我们如何处理图数据?通常需要手动设计特征(如节点的度、中心性等),这个过程繁琐且依赖专家知识,难以捕捉复杂的深层模式。
GNN的强大之处在于:
端到端学习:GNN能够自动从图数据中学习特征,无需复杂、低效的特征工程。
结构感知:GNN的学习过程显式地考虑了图的结构信息,这是传统机器学习模型(如MLP)无法做到的。一个MLP处理节点时,会完全忽略节点之间的连接关系。
归纳式学习:许多GNN模型具备强大的泛化能力,可以在一个图上训练,然后直接应用于另一个未知的图结构(例如,训练一个分子属性预测模型,可以用来预测全新的分子)。
总结
图神经网络的主要作用就是作为一个强大的“图数据解码器”,通过消息传递机制,将图中节点、边和整个图的复杂结构信息与属性信息,有效地编码成计算机能够处理和学习的低维向量表示,从而赋能下游的各种预测和分析任务。
它是连接现实世界复杂关系系统与人工智能模型的关键桥梁。
图卷积网络(Graph Convolutional Network, GCN)简介¶
核心思想
借鉴卷积神经网络(CNN)在图像上的思想,将其推广到图结构数据上。
对比
CNN的卷积:在图像上,一个像素点的特征由其周围相邻的像素点(一个规则的局部区域)决定。卷积操作就是聚合这些邻居信息来更新中心像素。
GCN的图卷积:在图数据上,一个节点的特征应该由其本身和其相邻的节点(一个不规则的局部邻居)决定。图卷积操作就是聚合邻居节点信息来更新当前节点特征。
简单来说,GCN让图中的每个节点都与其邻居进行“通信”,交换信息,从而每个节点都能获得其局部图结构的上下文信息。
关键挑战与解决方案
挑战:图是不规则的非欧几里得数据,没有像图像那样固定的网格结构。 每个节点的邻居数量可能各不相同。
GCN(以2017年Kipf & Welling提出的半监督GCN为代表性模型)通过一个简单而有效的公式解决了这个问题:
\[ H^{(l+1)} = \sigma(\tilde{D}^{-\frac{1}{2}} \tilde{A} \tilde{D}^{-\frac{1}{2}} H^{(l)} W^{(l)}) \]这个公式是GCN的灵魂,我们来拆解它的各个部分:
邻接矩阵(A)与自环(~):
\( A \) 是图的邻接矩阵,表示节点之间的连接关系。
\( \tilde{A} = A + I \) 是添加了自环的邻接矩阵。这意味着在聚合邻居信息时,节点也会保留自身的信息(\( I \) 是单位矩阵)。这是非常重要的一步。
对称归一化( \(\tilde{D}^{-\frac{1}{2}} \tilde{A} \tilde{D}^{-\frac{1}{2}}\) ):
\( \tilde{D} \) 是 \( \tilde{A} \) 的度矩阵(一个对角矩阵,对角线上的值 \( D_{ii} \) 表示节点 \( i \) 的度数,即有多少个邻居)。
这个归一化操作是为了解决节点度數差异过大的问题。如果不归一化,度数高的节点在聚合后特征值会非常大,而度数低的节点特征值很小,这会导致梯度爆炸或消失问题,影响训练稳定性。对称归一化使得聚合过程更加稳定。
特征矩阵与权重矩阵:
\( H^{(l)} \) 是第 \( l \) 层所有节点的特征表示。第一层的输入 \( H^{(0)} \) 就是节点的原始特征矩阵 \( X \)。
\( W^{(l)} \) 是第 \( l \) 层可训练的权重矩阵,用于对聚合后的特征进行线性变换(特征维度映射)。
非线性激活函数(σ):
\( \sigma \) 是一个非线性激活函数(如ReLU),为模型引入非线性能力,使其能够学习更复杂的模式。
工作流程(消息传递视角)
将一层GCN理解为两个步骤,这也被称为消息传递:
聚合:对于每个节点,从其所有邻居节点(包括自身)那里收集它们的特征。
由 \( \tilde{D}^{-\frac{1}{2}} \tilde{A} \tilde{D}^{-\frac{1}{2}} H^{(l)} \) 完成。这个操作计算了所有邻居特征的加权平均。
更新:将聚合后的邻居特征与一个可学习的权重矩阵相乘,再通过一个非线性激活函数,生成节点新的、更丰富的特征表示。
由 \( \sigma( ... W^{(l)}) \) 完成。
堆叠多层GCN:通过堆叠多层GCN,每个节点可以接收到来自“邻居的邻居”的信息。例如:
1层GCN:节点感知到其一阶邻居(直接相连的节点)的信息。
2层GCN:节点感知到其二阶邻居的信息。
K层GCN:节点感知到其K-hop邻居的信息。这被称为感受野的扩大。
主要应用
GCN通常用于三类任务:
节点分类:预测图中每个节点的标签。例如,在引用网络中分类论文的主题。
图分类:预测整个图的标签。例如,判断一个分子结构是否具有某种毒性。
链接预测:预测两个节点之间是否存在边。例如,在社交网络中推荐好友。
总结与特点
优点:
简单有效:核心公式简洁,但在许多任务上表现优异。
端到端学习:无需复杂的特征工程,直接从图数据中学习。
考虑了结构信息:显式地利用图结构来指导学习过程。
缺点与局限性:
浅层模型:堆叠过多层数会导致过平滑问题,即所有节点的特征会变得非常相似,难以区分。
转导性:经典的GCN在训练时需要看到整个图结构,难以直接泛化到训练时未见过的新节点或新图( inductive learning 问题有待改进)。
对动态图处理能力有限。
尽管存在一些局限性,GCN作为图神经网络领域的奠基性工作之一,其思想深远地影响了后续的诸多模型(如GraphSAGE, GAT, GIN等)。
Abstract¶
图卷积网络(Graph Convolutional Networks, GCNs)及其变体
近年来,GCNs 及其变体受到了广泛关注,并已成为图表示学习的事实标准方法。这部分内容点明了研究的背景和当前方法的地位。
GCNs 的设计来源
GCNs 主要受到近期深度学习方法的启发,但因此可能继承了不必要的复杂性和冗余的计算。这是本文提出简化模型的动机。
本文的贡献
本文通过依次去除非线性激活函数和合并相邻层之间的权重矩阵,来减少模型的复杂度。这是文章的主要方法。
理论分析
作者对简化后的线性模型进行了理论分析,并证明该模型等价于一个固定低通滤波器后接一个线性分类器。这是文章的核心理论贡献,也是模型简化合理性的关键支撑。
实验验证
作者通过实验评估发现,这种简化并不会显著影响下游任务的准确性。这是文章的一个重要结论:模型简化后仍能保持性能。
其他优势
简化后的模型具有以下几个优点:
可扩展性:适用于更大的数据集;
可解释性:模型结构更简单,易于理解;
效率提升:速度比 FastGCN 快高达两个数量级,这是非常突出的性能提升。
会议信息
文章发表于顶级会议 ICML(International Conference on Machine Learning),表明其学术价值和影响力。
总结:本文提出了一种对 GCN 的简化方法,通过去除非线性和合并权重矩阵,构建了一个线性模型。理论分析表明其等价于低通滤波器与线性分类器的组合,实验结果验证了其性能不受影响,同时在速度、可扩展性和可解释性上都有显著提升。
1 Introduction¶
图卷积网络(GCNs)简介¶
图卷积网络(Graph Convolutional Networks, GCNs)是由 Kipf 和 Welling 于 2017 年提出的一种图形结构上的卷积神经网络变体。其核心思想是堆叠可学习的一阶谱滤波层,并在每层后接非线性激活函数,从而学习图的表示。GCNs 及其后续变体在多个领域(如引用网络、社交网络、应用化学、自然语言处理和计算机视觉)中都取得了最先进的结果。
算法复杂性的发展趋势¶
历史上,机器学习算法的发展趋势是从初始的简单模型(如线性感知机)演进到更复杂的模型(如多层神经网络、CNN)。这种复杂性的增加通常是为了应对简单模型无法解决的任务。然而,大多数现实世界中的分类器仍然是线性的(如逻辑回归),因为它们优化起来简单、解释性强。
GCNs 的复杂性问题¶
尽管 GCNs 是在神经网络复兴之后提出的,但它并没有遵循“从简单到复杂”的传统路径。相反,GCNs 基于多层神经网络建立,缺乏一个简单的线性前身。本文指出,GCNs 从深度学习继承了大量不必要的复杂性,这在某些应用中可能是负担。
本文的贡献:SGC 模型¶
为了解决这一问题,作者提出了一种简化版的 GCN 模型,称为 Simple Graph Convolution (SGC)。SGC 是通过移除 GCN 各层之间的非线性激活函数,并将整个网络简化为一个线性变换。实验表明,SGC 在性能上与 GCN 可比甚至更优,同时计算效率更高、参数更少。
SGC 的特点:¶
直观可解释,并提供了从图卷积角度的理论分析。
其特征提取对应于每个特征维度上应用一个固定滤波器。
SGC 中的“重归一化技巧”(添加自环)在谱域上缩小了图的频谱范围,从而产生低通滤波效果,使得特征在图上局部平滑。
实验结果与应用表现¶
在节点分类任务(引用网络、社交网络)中,SGC 的性能与 GCN 可比,但速度快得多,尤其在最大数据集 Reddit 上比 FastGCN 快两个数量级。
此外,SGC 还被推广到多种下游任务,包括:
文本分类
用户地理定位
关系抽取
零样本图像分类
在这些任务上,SGC 表现不逊于甚至优于基于 GCN 的方法。
总结¶
SGC 是一种简单、高效、可解释的图神经网络模型,适合那些对模型复杂性要求不高的应用场景。其代码已开源,便于研究者和开发者使用。
2 Simple Graph Convolution¶
本文借鉴 Kipf & Welling 的工作,介绍了图卷积网络(GCN)及其简化版本简单图卷积(SGC),并在节点分类任务中进行应用。图结构定义为 𝒢 = (𝒱, 𝐀),其中:
𝒱 是节点集合,包含 n 个节点 {v₁, …, vₙ};
𝐀 ∈ ℝⁿˣⁿ 是对称(通常稀疏)的邻接矩阵,其中 aij 表示节点 i 与 j 之间的边权重,若无边则为 0;
度矩阵 𝐃 = diag(d₁, …, dₙ) 是一个对角矩阵,其中 di 表示节点 i 的度(即邻接矩阵第 i 行的和)。
每个节点 vi 有一个 d 维的特征向量 𝐱i ∈ ℝd,所有节点的特征向量组成特征矩阵 𝐗 ∈ ℝn×d。每个节点属于 C 个类之一,可表示为 C 维的 one-hot 向量 𝐲i ∈ {0,1}C,仅部分节点有标签,目标是预测所有节点的类别。
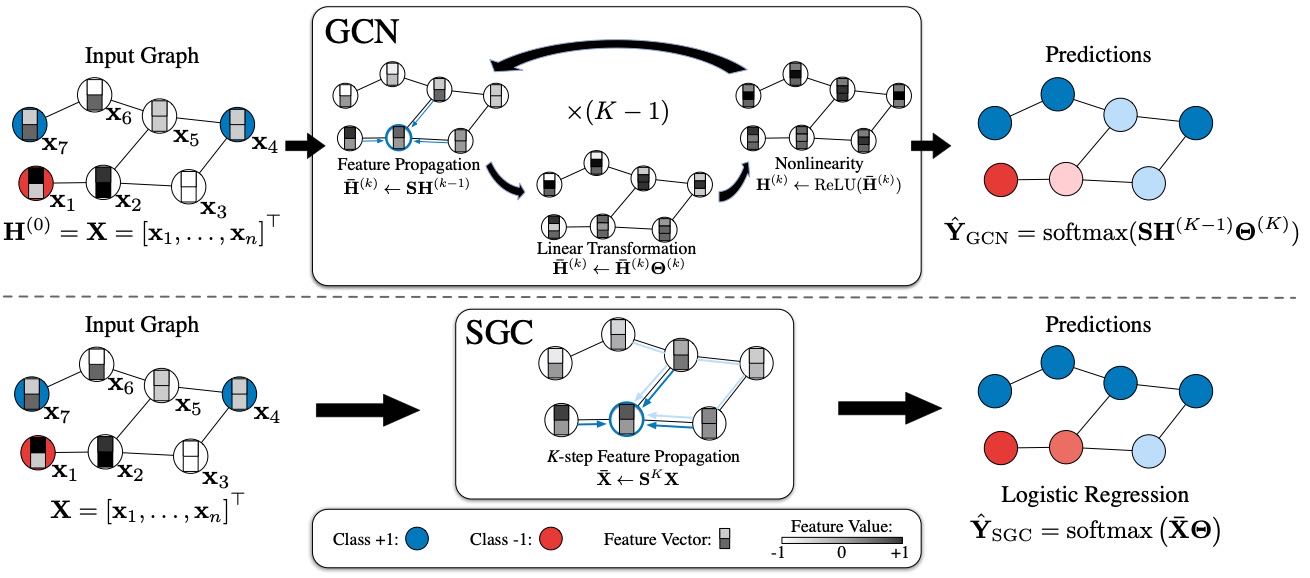
Figure 1. Schematic layout of a GCN v.s. a SGC
图解:
Top row: The GCN transforms the feature vectors repeatedly throughout K layers and then applies a linear classifier on the final representation.
Bottom row: the SGC reduces the entire procedure to a simple feature propagation step followed by standard logistic regression.
2.1 图卷积网络(Graph Convolutional Networks)¶
GCN 类似于 CNN 或 MLP,通过多层网络学习节点的新特征表示,用于后续的分类。
输入表示:¶
初始表示为原始特征矩阵:𝐇(0) = 𝐗。
网络结构:¶
K 层的 GCN 可以看作是 K 层的 MLP,但每一层在更新节点表示之前会对其邻接节点的特征进行加权平均。
每一层包括三个步骤:
特征传播(Feature propagation):将节点与其邻接节点的特征进行平均。
特征变换和非线性激活(Feature transformation and nonlinear activation):通过可学习的权重矩阵进行线性变换,并应用非线性激活函数(如 ReLU)。
分类器输出(Classifier):最后一层使用 softmax 输出类概率。
特征传播公式:¶
整体表示为: $\( \bar{\mathbf{H}}^{(k)} \leftarrow \mathbf{S} \mathbf{H}^{(k-1)} \)\( 其中 **𝐒** 是归一化的邻接矩阵,定义为: \)\( \mathbf{S} = \tilde{\mathbf{D}}^{-1/2} \tilde{\mathbf{A}} \tilde{\mathbf{D}}^{-1/2} \)$ 𝐀̃ 是带有自环的邻接矩阵(即 𝐀 + I),𝐃̃ 是其对应的度矩阵。
特征变换与激活:¶
通过权重矩阵 Θ(k) 进行线性变换,然后应用 ReLU: $\( \mathbf{H}^{(k)} \leftarrow \text{ReLU}(\bar{\mathbf{H}}^{(k)} \mathbf{\Theta}^{(k)}) \)$
分类器输出:¶
最终输出为 softmax 结果: $\( \hat{\mathbf{Y}}_{\text{GCN}} = \text{softmax}(\mathbf{S} \mathbf{H}^{(K-1)} \mathbf{\Theta}^{(K)}) \)$
2.2 简单图卷积(Simple Graph Convolution)¶
SGC 是对 GCN 的简化版本,其核心思想是:GCN 中的非线性激活函数并非关键,真正重要的是局部平滑(即特征传播)。
线性化(Linearization):¶
移除各层之间的非线性激活函数,仅保留最后一层的 softmax,得到线性模型: $\( \hat{\mathbf{Y}} = \text{softmax}(\mathbf{S}^K \mathbf{X} \mathbf{\Theta}) \)$ 其中 𝐒K 表示归一化邻接矩阵的 K 次幂,𝚯 是合并后的权重矩阵。
逻辑回归(Logistic Regression):¶
SGC 可以看作是两部分的结合:
特征提取(固定):𝐗̄ = 𝐒K𝐗,这是一个无参数的图平滑操作,相当于图结构上的特征预处理;
分类器:在 𝐗̄ 上进行多类逻辑回归,使用 softmax 输出最终预测。
优化细节(Optimization Details):¶
SGC 的训练退化为标准的逻辑回归问题,可以使用高效的二阶优化方法或随机梯度下降(SGD)。由于特征平滑操作是线性的、无参数的,SGC 的训练速度显著快于 GCN,尤其在图结构稀疏时表现更好。
总结:
GCN 是通过多层特征传播和非线性变换进行节点分类的模型。
SGC 通过移除非线性层,保留特征传播的线性部分,实现更高效的模型。
SGC 的计算可以拆解为:图结构特征平滑 + 线性分类器,等价于逻辑回归在预处理特征上的应用。
SGC 在保持预测性能的同时,显著降低了计算复杂度和训练时间,适用于大规模图任务。
3 Spectral Analysis¶
3.1 图卷积的预备知识¶
本节介绍了图卷积在图谱域(谱域)中的表示方法。图卷积类似于欧几里得域中的卷积,它依赖于图拉普拉斯矩阵(Graph Laplacian)的谱分解。
图拉普拉斯矩阵定义为 𝚫 = 𝐃 − 𝐀,或者它的归一化版本 𝚫sym = 𝐃⁻¹/₂𝚫𝐃⁻¹/₂。该矩阵是对称半正定的,可以进行特征分解:𝚫 = 𝐔𝚲𝐔ᵀ,其中 𝐔 是由正交归一化特征向量组成的矩阵,𝚲 是由特征值组成的对角矩阵。图谱分析中,特征向量相当于傅里叶基函数,特征值相当于频率。
对于定义在图上的信号 𝐱,其图傅里叶变换为 𝐱^ = 𝐔ᵀ𝐱,其逆变换为 𝐱 = 𝐔𝐱^。图卷积操作可以表示为:
其中 𝐆^ 是对角矩阵,对角线上的元素是谱滤波系数。
图卷积可以通过图拉普拉斯矩阵的多项式进行近似:
图卷积网络(GCN)采用了一阶多项式近似(k=1)的拉普拉斯矩阵展开,其形式为:
Kipf & Welling 进一步引入了 自环归一化技巧(renormalization trick),将传播矩阵替换为 𝐃~⁻¹/₂𝐀~𝐃~⁻¹/₂,其中 𝐀~ = 𝐀 + 𝐈,𝐃~ = 𝐃 + 𝐈。这一操作有助于缓解数值不稳定问题,并提升了模型性能。
3.2 SGC 与低通滤波¶
SGC(简化图卷积)实质上是基于拉普拉斯矩阵的谱域滤波器。在 K 层传播过程中,SGC 的谱滤波系数为:
然而,这种传播矩阵在高阶时会导致滤波系数爆炸,尤其是在低频(λi < 1)处信号被过度放大。因此,引入自环(renormalization trick)是关键的优化手段。
引入自环后,传播矩阵变为 𝐒~adj = 𝐃~⁻¹/₂𝐀~𝐃~⁻¹/₂。相应的谱滤波函数变为:
其中 λ~i 是归一化拉普拉斯矩阵的特征值。文献中的定理 1表明,添加自环后,图谱的最大特征值会减小,从而缩小了整个谱域的范围。这使得 SGC 在谱域上表现为一个 低通滤波器,即对低频信号(对应图中相邻节点的相似特征)进行增强,而抑制高频信号。
如图 2 所示,在 Cora 数据集上使用不同传播矩阵的谱系数变化表明,加入自环后,滤波器的谱响应更加稳定,且避免了负系数的出现,从而保证了传播过程的平滑性和稳定性。
重点总结:
谱分析框架揭示了图卷积的本质为在图谱域上的滤波操作。
SGC 是一种固定滤波器,其滤波效果通过传播矩阵的幂次(K)控制。
自环归一化技巧(renormalization trick)通过缩小谱域范围,使 SGC 成为低通滤波器,提升模型的性能与稳定性。
图 2 的实验结果验证了不同传播矩阵对特征传播的谱响应差异。
总之,SGC 通过图谱分析实现了对图结构中特征的平滑传播,是图神经网络中一种简洁而有效的模型。
5 Experiments and Discussion¶
总结:5 实验与讨论¶
本节评估了简化图卷积网络(SGC)在多个领域的表现,包括引用网络、社交网络以及多种下游任务,验证了SGC在性能和效率上的优势。
5.1 引用网络与社交网络¶
数据集与实验设置¶
作者在 Cora、Citeseer 和 Pubmed 三个引用网络数据集上评估了SGC的半监督节点分类性能。此外,在 Reddit 这个大规模社交网络数据集上,使用SGC预测社区结构。这些数据集的统计信息见表1。Reddit是最大的图数据集,包含233K个节点和11.6M条边。
实验中,SGC在引用网络上使用 Adam 优化器训练100轮,学习率为0.2,并使用超参数调优工具 Hyperopt 进行调参。在Reddit上,SGC使用 L-BFGS 优化器,无需正则化,仅需2次迭代即可收敛,展现出极高的效率。
对比模型¶
SGC与多个先进的图神经网络进行比较,包括 GCN、GAT、FastGCN、LNet、AdaLNet、DGI 和 GIN 等。作者使用公开实现或自行实现这些模型,并在相同设置下进行公平比较。
性能表现¶
在引用网络上,SGC的性能接近甚至略优于GCN和其他SOTA模型。例如,在 Citeseer 上,SGC比GCN高出约1%,这可能由于SGC参数更少,抗过拟合能力更强。
在Reddit上,SGC的性能超过 SAGE-GCN 和 FastGCN 等采样基方法1%以上,且训练速度更快。
作者指出,像 DGI 这样使用随机初始化的模型性能接近SGC,说明复杂的参数结构可能并不必要,甚至可能有害。
效率表现¶
SGC通过预计算 S^kX(其中 S 是图结构矩阵,k表示传播步数,X是节点特征)来减少计算和内存消耗。在大规模图如Reddit上,GCN因内存不足无法训练,而SGC则能够在GPU上快速运行。图3显示,SGC的训练速度比其他模型快两个数量级,且性能损失很小。
5.2 下游任务¶
作者将SGC扩展到五个下游任务:文本分类、半监督用户地理定位、关系抽取、零样本图像分类 和 图分类,验证SGC在不同任务中的泛化能力。
文本分类¶
SGC在多个文本分类数据集(如20NG、R8、R52等)上表现优异,准确率与GCN相当,但训练时间显著降低(如20NG上仅需19秒,比GCN快83.6倍)。SGC通过建立文档-词语图,使用PMI和TF-IDF作为边权重,实现高效分类。
半监督用户地理定位¶
SGC在 GEOTEXT、TWITTER-US 和 TWITTER-WORLD 数据集上优于GCN。特别是在TWITTER-WORLD上,SGC相比GCN节省了30+小时的训练时间,同时准确率略有提升。
关系抽取¶
SGC被嵌入到C-GCN框架中,替换GCN部分,形成C-SGC,在 TACRED 任务中达到新的SOTA准确率67.0%。
零样本图像分类¶
SGC在零样本图像分类任务中表现优异,尤其是在参数数量减少55%的情况下,其精度仍高于其他模型,说明SGC能有效应用于跨模态任务。
图分类¶
在 NCI1 和 COLLAB 图分类任务中,SGC与GCN性能相当,但远低于更复杂的 GIN 模型。在化学数据集 QM8 上,SGC的预测误差(MAE)为0.03,远高于AdaLNet和LNet的0.01,说明SGC在某些复杂图结构任务上仍有局限。
总体结论¶
SGC在多个领域表现优异,尤其是在效率方面具有显著优势。其简化结构不仅减少了计算资源消耗,还能在多种任务中达到与复杂模型相当甚至更好的性能。然而,在处理更复杂的图结构(如化学分子图)时,SGC仍有改进空间。
6 Conclusion¶
本节主要总结了简单图卷积网络(SGC)的研究成果以及其对理解图卷积网络(GCNs)的启发。
1. SGC 的简单性与性能¶
SGC 是图卷积模型的最简形式,其算法几乎可以视为“微不足道”:仅通过一个基于图的预处理步骤,后接标准的多类逻辑回归。令人意外的是,SGC 在多种图学习任务中的表现与当前最先进的图神经网络模型相当,甚至在某些情况下更优。此外,由于特征提取器 S^K 可以预先计算,SGC 的训练时间大大缩短。例如,在 Reddit 数据集上,SGC 的训练速度比基于采样的 GCN 快两个数量级。
重点:SGC 以极简的方式实现了高性能和高效率,是 GCN 的简化版本,对于实际应用具有重要意义。
2. 从卷积视角分析 SGC¶
除了实证分析,作者还从卷积的角度对 SGC 进行了解释,将其视为一种谱域(spectral domain)中的低通型滤波器。这种滤波器能够捕捉低频信号,对应于在图上对特征进行平滑处理。作者进一步解释了“重归一化技巧”(renormalization trick)的实证优势,表明该技巧通过压缩谱域,使滤波器更接近低通型特征。
重点:SGC 的性能优势不仅来源于其结构的简化,还与其在频谱域上的特性密切相关。
3. SGC 对 GCN 的启示¶
SGC 的表现表明,图卷积网络的强大表达能力可能主要来自于重复的图传播操作(SGC 保留了这一机制),而非非线性特征提取(SGC 中没有)。这为理解 GCN 的工作原理提供了新的视角,也说明图传播是图神经网络中的关键因素。
重点:GCN 的性能优势很可能来自图传播,而非复杂的非线性操作。
4. SGC 的潜在应用价值¶
基于其良好的性能、效率和可解释性,作者认为 SGC 可以在以下三个方面对社区产生重大帮助:
作为第一个尝试的模型,尤其是针对节点分类任务;
作为未来图学习模型的简单基线,便于比较和评估;
作为图学习研究的起点,遵循传统机器学习中“从简单模型出发,逐步发展复杂模型”的实践。
重点:SGC 是一个高效、可解释且性能优越的模型,具有广泛的应用潜力和研究价值。
Acknowledgement¶
本研究部分受到国家科学基金会(III-1618134、III-1526012、IIS-1149882、IIS-1724282 和 TRIPODS-1740822)、美国海军研究办公室(N00014-17-1-2175)、比尔及梅琳达·盖茨基金会以及 Facebook 研究的支持。我们感谢 SAP America Inc. 提供的慷慨支持。
Amauri Holanda de Souza Jr. 感谢巴西国家科学与技术发展委员会(CNPq)提供的资金支持。
我们感谢 Xiang Fu、Shengyuan Hu、Shangdi Yu、Wei-Lun Chao 和 Geoff Pleiss 的讨论支持,以及 Boyi Li 在图表设计方面的帮助。
Appendix A The spectrum of 𝚫~symsubscript~𝚫sym)¶
该附录主要讨论了带自环图上的对称归一化拉普拉斯矩阵(记为 𝚫~sym)的一些谱性质。它是图神经网络中常用的一种图拉普拉斯矩阵形式,具有差分算子的解释,即对任意信号 𝐱 ∈ ℝⁿ,有如下定义:
其中,\(\tilde{a}_{ij}\) 是图的邻接矩阵元素,\(d_i\) 是节点 \(i\) 的度,\(\gamma\) 是一个加权常数,用于防止除零操作。
Lemma 1. 非负性(Non-negativity of 𝚫~sym)¶
重点内容:
证明了矩阵 𝚫~sym 是对称半正定(symmetric positive semi-definite)。
通过二次型的形式,将矩阵作用在任意向量上,其结果可以表示为非负的平方项之和,从而证明其非负性。
Lemma 2. 零特征值(0 is an eigenvalue of 𝚫~sym)¶
重点内容:
证明了 0 是 𝚫~sym 的一个特征值。
通过其与原始图拉普拉斯矩阵之间的关系: $\( \tilde{\mathbf{\Delta}}_{\text{sym}} = \tilde{{\mathbf{D}}}^{-1/2} (\tilde{{\mathbf{D}}} - \tilde{{\mathbf{A}}}) \tilde{{\mathbf{D}}}^{-1/2} \)\( 并利用向量 \){\mathbf{v}}_1 = \tilde{{\mathbf{D}}}^{1/2}{\mathbf{v}}$ 作为特征向量,证明了 0 是其最小特征值。
Lemma 3. 特征值的上下界(Bounds on eigenvalues)¶
重点内容:
设 \(\beta_1 \leq \beta_2 \leq \cdots \leq \beta_n\) 是矩阵 \({\mathbf{D}}^{-1/2}{\mathbf{A}}{\mathbf{D}}^{-1/2}\) 的特征值,\(\alpha_1 \leq \alpha_2 \leq \cdots \leq \alpha_n\) 是矩阵 \(\tilde{{\mathbf{D}}}^{-1/2}{\mathbf{A}} \tilde{{\mathbf{D}}}^{-1/2}\) 的特征值,证明了: $\( \alpha_1 \geq \frac{\max_i d_i}{\gamma + \max_i d_i} \beta_1, \quad \alpha_n \leq \frac{\min_i d_i}{\gamma + \min_i d_i} \)$
通过瑞利商(Rayleigh quotient)和变量替换,结合 \(\beta_1 < 0\) 的性质,给出了 \(\alpha_1\) 的下界。
Theorem 1 的证明¶
重点内容:
证明了 𝚫~sym 的最大特征值 \(\tilde{\lambda}_n\) 满足: $\( \tilde{\lambda}_n < \lambda_n \)\( 其中 \)\lambda_n$ 是原始对称归一化拉普拉斯矩阵的最大特征值。
利用 Lemma 3 的结果,结合矩阵关系: $\( \tilde{\mathbf{\Delta}}_{\text{sym}} = {\mathbf{I}} - \gamma \tilde{{\mathbf{D}}}^{-1} - \tilde{{\mathbf{D}}}^{-1/2} {\mathbf{A}} \tilde{{\mathbf{D}}}^{-1/2} \)\( 通过最大特征值的定义和不等式处理,最终得出 \)\tilde{\lambda}_n < \lambda_n$。
总结¶
本附录系统地分析了带自环图下的对称归一化拉普拉斯矩阵 𝚫~sym 的谱性质,重点包括:
非负性(证明该矩阵是对称半正定的)。
零特征值的存在性(0 是其最小特征值)。
特征值的严格上界(通过构造上下界和瑞利商分析)。
最大特征值的严格小于原始矩阵(这对图卷积网络的收敛性和稳定性分析有重要意义)。
这些结论为理解图卷积网络中不同归一化方法的数学性质提供了理论支持。
Appendix B Experiment Details¶
Node Classification(节点分类)¶
关键发现:在Reddit数据集上使用SGC(简化图卷积)时,将特征归一化为零均值和单位方差是至关重要的。
Training Time Benchmarking(训练时间基准测试)¶
实验背景:Chen等人(2018)在CPU上对比了FastGCN的训练时间,但由于不同报告之间的数值难以直接比较,因此难以横向评估。
优化发现:FastGCN的性能在较小的早停窗口(10个epoch)下有所提升,因此可以有效减少训练时间。
数据汇总:图3的实验数据详见表8和表9。
表8:Citation Network(引用网络)上的训练时间(秒),平均10次运行结果¶
模型 |
Cora |
Citeseer |
Pubmed |
|---|---|---|---|
GCN |
0.49 |
0.59 |
8.31 |
GAT |
63.10 |
118.10 |
121.74 |
FastGCN |
2.47 |
3.96 |
1.77 |
GIN |
2.09 |
4.47 |
26.15 |
LNet |
15.02 |
49.16 |
266.47 |
AdaLNet |
10.15 |
31.80 |
222.21 |
DGI |
21.24 |
21.06 |
76.20 |
SGC(重点) |
0.13 |
0.14 |
0.29 |
重点结论:SGC在三种引用网络上均表现出极低的训练时间,远低于其他模型,显示出其计算效率的优势。
表9:Reddit数据集上的训练时间(秒)¶
模型 |
时间(秒) ↓ |
|---|---|
SAGE-mean |
78.54 |
SAGE-LSTM |
486.53 |
SAGE-GCN |
86.86 |
FastGCN |
270.45 |
SGC(重点) |
2.70 |
重点结论:SGC在Reddit上同样具有显著的训练时间优势,仅需2.7秒,远低于其他模型。
Text Classification(文本分类)¶
方法细节:Yao等人(2019)使用one-hot编码表示词和文档节点。
SGC训练设置:在传播后将特征归一化到[0,1]区间,并使用L-BFGS优化器训练3步。
超参数调优:仅对权重衰减进行调优,使用hyperopt工具,迭代60次。
限制说明:TextGCN无法应用这种特征归一化,因为传播矩阵无法预先计算。
Semi-supervised User Geolocation(半监督用户地理定位)¶
模型替换:将4层的带有Highway连接的GCN替换为K=3的SGC。
硬件配置:GEOTEXT实验在Nvidia GTX-1080Ti上运行,TWITTER-NA和TWITTER-WORLD在Xeon Silver 4114 CPU上运行。
模型结构:保留两个线性变换层(而不是全部合并),可能有助于性能的微小提升,但模型仍保持线性。
Relation Extraction(关系抽取)¶
模型替换:将2层GCN替换为K=2的SGC。
结构调整:移除中间Dropout层。
超参数保持:学习率和正则化参数不变,遵循Zhang等人(2018c)的方法,根据验证集早停选出最佳准确率。
Zero-shot Image Classification(零样本图像分类)¶
模型替换:将6层GCN替换为包含6层MLP和K=6的SGC的模型。
结构细节:
GCN模型结构为:2048, 2048, 1024, 1024, 512, 2048。
新模型为:512, 512, 512, 1024, 1024, 2048 加上SGC。
训练细节:
仅在SGC的输出上使用Dropout。
不进行Dropout率或其他参数的调优,直接使用GCNZ代码的默认参数:
学习率:0.001
权重衰减:0.0005
Dropout率:0.5
优化器:ADAM(300轮训练)
总结:¶
本附录详细描述了SGC在多个任务(节点分类、训练时间对比、文本分类、用户地理定位、关系抽取、零样本图像分类)中的实验配置和结果。SGC在所有任务中均表现出计算效率高的优势,尤其是在训练时间方面显著优于其他图神经网络模型。实验设计细致,强调了对超参数的合理调整和对不同任务中SGC的适配性。
Appendix C Additional Experiments¶
Random Splits for Citation Networks(引用网络的随机分割)¶
重点内容:
由于引用网络(如Cora、Citeseer、PubMed)数据量有限,导致模型性能在不同随机分割下不稳定,因此额外进行了10次实验以评估模型的鲁棒性。
方法: 保持验证集和测试集不变,仅对训练集进行随机分割。
结果示例: 表10展示了不同模型在随机分割下的测试准确率,标注了标准差(±)和异常值过滤(<0.7/0.65/0.75)。
模型 |
Cora(%) |
Citeseer(%) |
Pubmed(%) |
|---|---|---|---|
GCN |
80.53±1.40 |
70.67±2.90 |
77.09±2.95 |
GIN |
76.94±1.24 |
66.56±2.27 |
74.46±2.19 |
LNet |
74.23±4.50† |
67.26±0.81† |
77.20±2.03† |
AdaLNet |
72.68±1.45† |
71.04±0.95† |
77.53±1.76† |
GAT |
82.29±1.16 |
72.6±0.58 |
78.79±1.41 |
SGC |
80.62±1.21 |
71.40±3.92 |
77.02±1.62 |
结论: SGC在大多数情况下表现稳定,且与GCN、GAT等模型接近,说明其具备良好的性能和鲁棒性。
Propagation choice(传播矩阵选择)¶
重点内容:
研究了不同传播矩阵对SGC性能的影响,分析其在不同传播步数(K)下的表现。
传播矩阵类型:
标准邻接矩阵(Normalized Adjacency)
随机游走邻接矩阵(Random Walk Adjacency)
增广邻接矩阵(Augmented Adjacency)
Chebyshev 一阶传播矩阵(1-order Cheby)
关键发现:
**增广传播矩阵(含自环)**表现更好,更稳定。
非增广传播矩阵(如标准化邻接矩阵)在奇数次传播时性能显著下降,原因是其高频信号被负系数干扰。
增加自环后,最大特征值从约2降至约1.5,减小了谱范围,从而减少了负系数对高频信号的影响。
结论: 增加自环可以改善传播矩阵的谱特性,提升SGC的性能稳定性。
Data amount(数据量的影响)¶
重点内容:
评估了不同训练数据量下模型的表现,验证SGC是否具备与GCN相当的建模能力。
方法: 在Cora数据集上,使用不同数量的训练样本(1、5、10、20、40、80)分别训练SGC和GCN模型。
结果(表11):
# Training Samples |
SGC(%) |
GCN(%) |
|---|---|---|
1 |
33.16 |
32.94 |
5 |
63.74 |
60.68 |
10 |
72.04 |
71.46 |
20 |
80.30 |
80.16 |
40 |
85.56 |
85.38 |
80 |
90.08 |
90.44 |
结论:
当训练样本较少时(<5),SGC甚至优于GCN。
随着训练样本增加,SGC和GCN的性能差距缩小。
该实验表明,SGC在数据量较少时仍具备良好的泛化能力,建模能力不低于GCN。
总结¶
本附录用多个实验验证了SGC模型的鲁棒性和性能优势:
在引用网络的随机分割下,SGC表现稳定。
使用增广传播矩阵可提升性能和稳定性。
在低数据量下,SGC表现优于或接近GCN,具备良好的建模能力。
这些实验为SGC的实用性提供了有力的实证支持。