2502.18965_OneRec: Unifying Retrieve and Rank with Generative Recommender and Preference Alignment¶
组织:
KuaiShou Inc.Beijing, China
总结¶
说明
公司团队有深入调研(杜)
摘要
💡 OneRec提出了一种统一的端到端生成式推荐模型,旨在取代传统的多阶段级联检索与排序系统,从而简化推荐流程并解决其性能上限问题。
⚙️ 该模型采用编码器-解码器架构并集成稀疏MoE以扩展模型容量,通过会话级(session-wise)生成方式捕捉用户兴趣,而非传统的逐点预测。
✨ OneRec进一步通过迭代偏好对齐(IPA)模块与直接偏好优化(DPO)结合奖励模型,有效提升了生成结果的质量,并在快手(Kuaishou)的线上A/B测试中实现了1.6%的观看时长显著提升。
背景
基于生成式检索的推荐系统(Generative Retrieval-based Recommendation Systems, GRs)逐渐兴起,其通过自回归方式直接生成候选视频
主流推荐系统仍采用检索+排序的两阶段策略,生成模型仅在检索阶段作为候选选择工具,未能充分发挥其潜力。
现代推荐系统为了在效率与效果之间取得平衡,普遍采用级联排序策略。
典型的级联排序系统分为三个阶段:
召回(Recall):从海量物品中快速筛选出候选集。
预排序(Pre-ranking):对候选集进行初步排序,减少后续计算量。
排序(Ranking):对少量候选进行精细排序,输出最终推荐结果。
典型的级联排序系统局限性
各阶段通常独立训练,前一阶段的输出上限限制了后续阶段的性能,导致整体效果受限
OneRec
首个端到端统一生成式推荐模型,取代了传统复杂的多阶段级联学习框架
输入&输出
输入是用户的历史行为序列 ℋu
输出是一个视频列表(session)𝒮
“迭代式偏好对齐” 的核心算法
第1步:生成候选推荐
目标:使用当前的推荐模型 \( M_t \) 为每个用户生成多个不同的候选推荐列表。
方法:采用集束搜索。这是一种启发式搜索算法,可以生成N个(而不仅仅是1个)可能性较高的候选序列。
第2步:评估与打分
目标:使用一个预先训练好的奖励模型 \( R \) 来评判上一步生成的所有候选推荐列表的好坏。
奖励函数
公式:\( r_u^n = R(\bm{u}, \mathcal{S}_u^n) \)
接收用户特征 \( \bm{u} \) 和一个推荐列表 \( \mathcal{S}_u^n \),输出一个分数 \( r_u^n \)
这个分数代表了该推荐列表的“质量”(例如,用户是否会喜欢、观看时长等)。
第3步:构建偏好对
目标:基于奖励分数,构建用于训练的“好”与“坏”的对比数据。
方法:对于每个用户 \( u \):
优胜者 \( \mathcal{S}_u^w \):从N个候选列表中,选出奖励分数最高的那个。
失败者 \( \mathcal{S}_u^l \):从N个候选列表中,选出奖励分数最低的那个。
这样就构成了一个偏好对 \( (\mathcal{S}_u^w, \mathcal{S}_u^l) \)
第4步:模型优化(核心)
目标:利用上一步构建的偏好对,更新模型,使其更倾向于生成“优胜者”那样的推荐,而不是“失败者”那样的推荐。
方法:使用 DPO(直接偏好优化) 损失函数来训练新模型 \( M_{t+1} \)。
\( M_{t+1} \) 是从旧模型 \( M_t \) 初始化而来的。
评估指标
Evaluation Metric
观看时长类:session watch time(swt)、view probability(vtr);
交互类:follow probability(wtr)、like probability(ltr);
Online A/B Test
评估指标:总观看时长(Total Watch Time) 和 平均观看时长(Average View Duration);
疑问点❓
奖励函数如何设计
Abstract¶
研究背景与问题¶
近年来,基于生成式检索的推荐系统(Generative Retrieval-based Recommendation Systems, GRs)逐渐兴起,其通过自回归方式直接生成候选视频。然而,当前主流推荐系统仍采用检索+排序的两阶段策略,生成模型仅在检索阶段作为候选选择工具,未能充分发挥其潜力。
本文贡献¶
本文提出OneRec,这是首个端到端统一生成式推荐模型,取代了传统复杂的多阶段级联学习框架。据作者所知,OneRec 是首个在真实工业场景中显著优于现有推荐系统的生成式模型。
OneRec 的三大核心设计¶
1. 编码器-解码器结构 + 稀疏 MoE 模型¶
结构设计:使用标准的编码器-解码器框架,编码用户历史行为序列,逐步解码出用户可能感兴趣的视频。
关键技术:引入稀疏 MoE(Mixture-of-Experts)结构,在不显著增加计算量的前提下提升模型容量。
重点说明:MoE 是关键,它解决了模型扩展与计算效率之间的矛盾,是实现大规模部署的基础。
2. 会话级生成(Session-wise Generation)¶
与传统方法对比:不同于传统的“逐点生成”(next-item prediction),OneRec采用会话级生成,一次性生成整个推荐序列。
优势:生成结果更连贯、自然,避免了人工规则组合生成结果的复杂性。
重点说明:这是生成式推荐系统在生成逻辑上的重要创新,提升了推荐的上下文一致性。
3. 迭代偏好对齐模块 + DPO 优化¶
DPO 在推荐中的挑战:NLP中常用的DPO依赖同时获取正负样本,但在推荐系统中,每个用户请求只能展示一次结果,难以获取对比样本。
解决方案:
构建奖励模型模拟用户反馈;
定制采样策略,适配推荐系统的在线学习特性;
引入迭代偏好对齐模块,提升生成质量。
重点说明:这是将DPO成功应用于推荐系统的关键创新,解决了实际部署中的样本获取难题。
实验与部署效果¶
实验结果:少量DPO样本即可有效对齐用户兴趣,显著提升生成质量。
工业部署:OneRec 已部署于快手(日活数亿用户的短视频平台)主场景,带来观看时长提升1.6%,效果显著。
重点说明:1.6%的提升在工业级系统中属于重大突破,说明该方法具备极强的实用价值。
关键词总结¶
生成式推荐(Generative Recommendation)
自回归生成(Autoregressive Generation)
语义化 Token(Semantic Tokenization)
直接偏好优化(Direct Preference Optimization, DPO)
总结¶
本论文提出了一种全新的端到端生成式推荐系统 OneRec,通过统一模型结构、会话级生成机制和基于DPO的偏好对齐模块,在真实工业场景中实现了显著的性能提升。这是生成式AI在推荐系统领域的重要里程碑。
1. Introduction¶
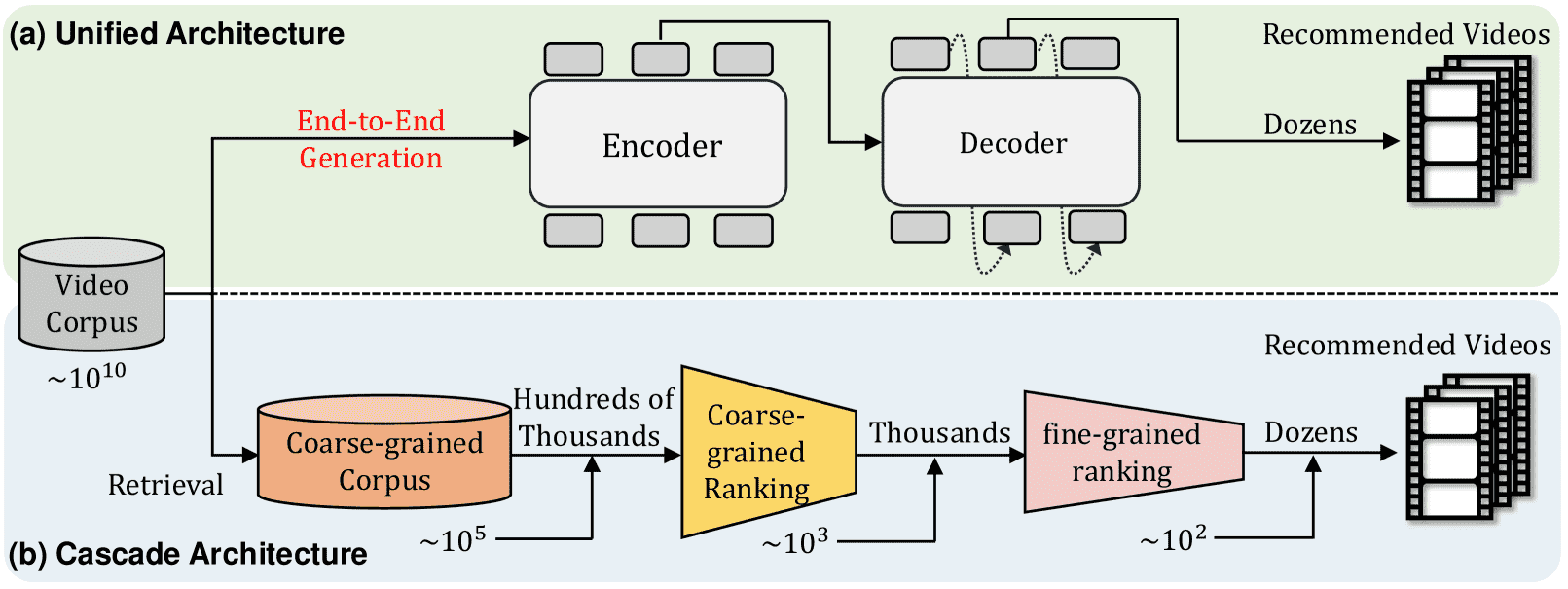
Figure 1.(a) Our proposed unified architecture for end-to-end generation. (b) A typical cascade ranking system, which includes three stages from the bottom to the top: Retrieval, Pre-ranking, and Ranking.
1.1 级联排序策略的现状¶
现代推荐系统为了在效率与效果之间取得平衡,普遍采用级联排序策略。典型的级联排序系统分为三个阶段:
召回(Recall):从海量物品中快速筛选出候选集。
预排序(Pre-ranking):对候选集进行初步排序,减少后续计算量。
排序(Ranking):对少量候选进行精细排序,输出最终推荐结果。
每个阶段都负责从输入中选出Top-k项传递给下一阶段,整体上在系统响应速度和排序准确性之间进行权衡。
1.2 现有方法的局限性¶
尽管级联排序在实践中效率高,但各阶段通常独立训练,前一阶段的输出上限限制了后续阶段的性能,导致整体效果受限。虽然已有研究尝试通过增强各阶段之间的交互来提升性能,但仍然沿用传统的级联结构。
1.3 生成式推荐系统的兴起¶
近年来,生成式检索推荐系统(GRs) 成为新趋势。这类系统通过自回归方式直接生成候选物品的标识符,利用语义编码的物品ID来捕捉更丰富的语义信息。其生成特性使其在推荐多样性方面具有优势,但目前仅用于召回阶段,因为其推荐精度仍无法匹敌多阶段排序系统。
1.4 OneRec 的提出与核心创新¶
为解决上述问题,本文提出OneRec,一个统一的端到端生成式推荐框架,实现单阶段推荐。其主要创新点包括:
1.4.1 统一的编码器-解码器结构¶
借鉴大语言模型的扩展规律,通过MoE结构扩展模型容量,提升模型对用户兴趣的刻画能力。
1.4.2 会话级生成方式(Session-wise Generation)¶
不同于传统的逐点生成(point-by-point),采用会话级生成,考虑会话中物品之间的相对内容与顺序,使模型自主学习最优的会话结构,提升生成结果的连贯性与多样性。
1.4.3 基于偏好优化的生成质量提升¶
引入直接偏好优化(DPO),通过构建偏好对来提升生成质量。
提出迭代偏好对齐(IPA)策略,利用预训练奖励模型(RM)对生成结果进行排序,选取最优与最差样本进行优化。
1.5 实验与贡献¶
在大规模工业数据集上验证了OneRec的优越性。
进行了详尽的消融实验,验证各模块的有效性。
主要贡献总结:¶
提出OneRec:首个将生成模型统一应用于工业推荐系统的框架,显著超越传统多阶段排序流程。
强调模型容量与上下文信息的重要性:通过会话级生成提升预测准确性与多样性。
提出基于个性化奖励模型的自硬负样本选择策略:结合DPO优化,提升模型在广泛用户偏好下的泛化能力,通过离线实验与在线A/B测试验证其有效性。
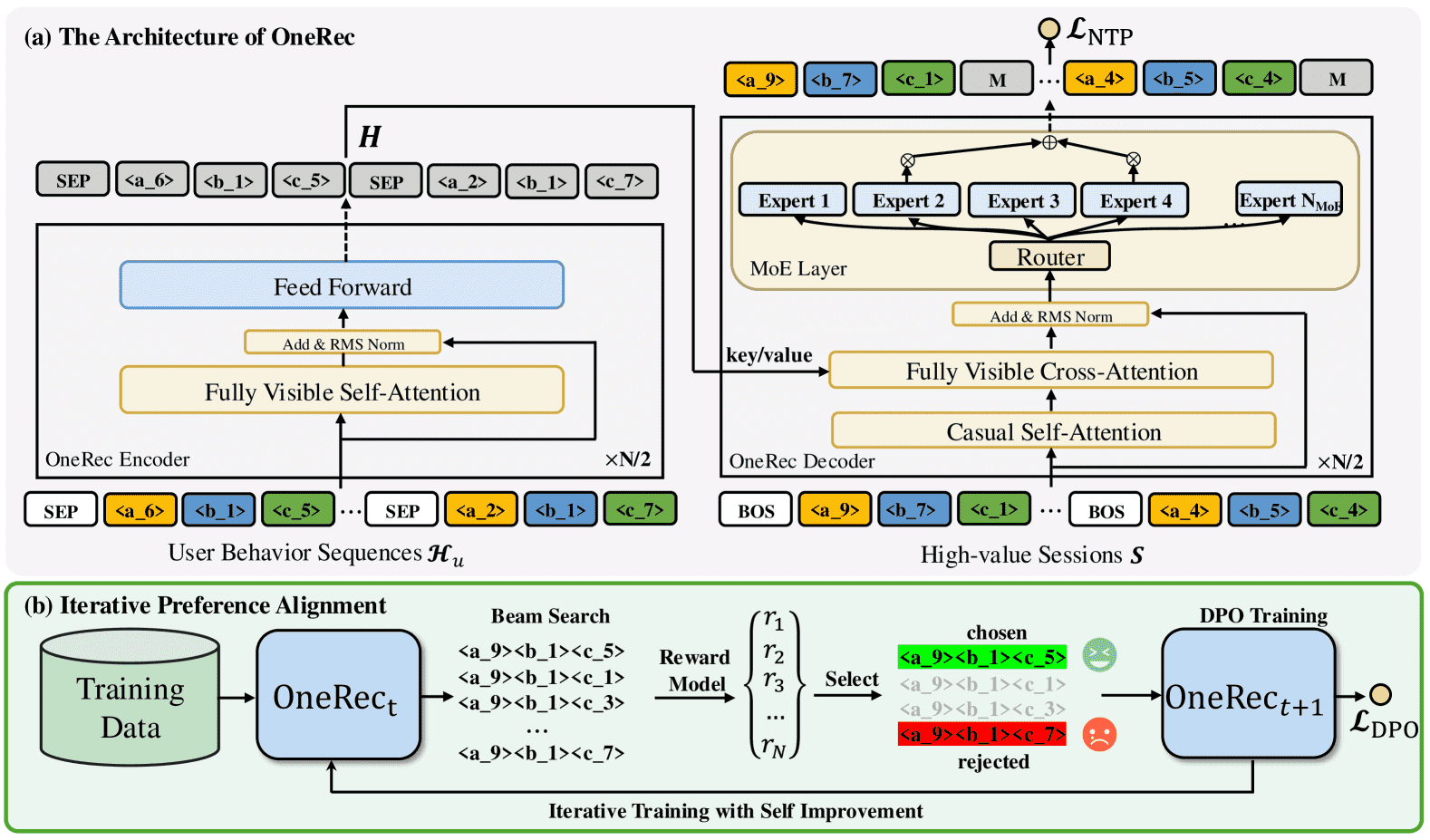
Figure 2.The overall framework of OneRec, consists of two stages: (i) the session training stage which train OneRec with session-wise data; (ii) the IPA stage which utilizes iterative direct preference optimization with self-hard negatives.
3. Methods¶
本节提出了 OneRec,这是一个通过单阶段检索方式生成目标项目的端到端框架。文章按照以下结构展开:
3.1. Preliminary(初步特征工程)¶
重点内容:
OneRec 的输入是用户的历史行为序列 ℋu,输出是一个视频列表(session)𝒮。
每个视频 𝒗i 用多模态嵌入 ei 表示,并通过残差 K-Means 量化算法进行编码,以解决传统 RQ-VAE 方法中的“沙漏现象”(hourglass phenomenon)。
量化过程采用多级平衡机制,每一级生成一个码本 𝒞l,并通过最小化残差来生成语义 token。
精简讲解:
作者提出了一种改进的量化方法,通过平衡 K-Means 算法来优化码本,确保每个簇包含相同数量的视频,从而提升编码的平衡性和语义表达能力。
3.2. Session-wise List Generation(会话级列表生成)¶
重点内容:
与传统“点对点”推荐不同,OneRec 采用“会话级”生成方式,即根据用户历史行为生成一个包含多个视频的推荐列表。
会话定义为一次用户请求返回的 5-10 个视频,要求满足观看数量、观看时长、用户互动等质量标准。
模型目标是 ℳ(ℋu) = 𝒮,即根据用户历史行为生成推荐列表。
模型结构:
基于 T5 架构,采用 Transformer 编码器-解码器结构。
编码器处理用户历史行为序列,解码器使用 MoE(Mixture of Experts)结构提升模型扩展性。
使用交叉熵损失(NTP loss)进行训练。
精简讲解:
OneRec 通过 Transformer 架构建模用户行为,并使用 MoE 提升解码效率,最终通过 NTP 损失训练生成高质量推荐列表。
3.3. Iterative Preference Alignment with RM(基于 RM 的迭代偏好对齐)¶
重点内容:
引入奖励模型(RM)来评估生成的会话质量,并通过 DPO(Direct Preference Optimization)方法迭代优化模型。
RM 通过目标感知表示(target-aware representation)和自注意力机制建模会话内项目关系,并使用多任务塔预测多个奖励指标(如观看时间、互动行为等)。
使用 DPO 损失函数进行偏好对齐,选择最优和最差响应对模型进行迭代优化。
算法流程:
使用 RM 为每个用户生成多个响应,并选择奖励最高和最低的响应构建偏好对。
使用偏好对训练新模型 Mt+1,损失函数结合 DPO 损失。
算法 2 展示了整个迭代优化过程。
精简讲解:
通过 RM 评估生成结果质量,并使用 DPO 进行偏好对齐,使模型在迭代中不断优化推荐效果。
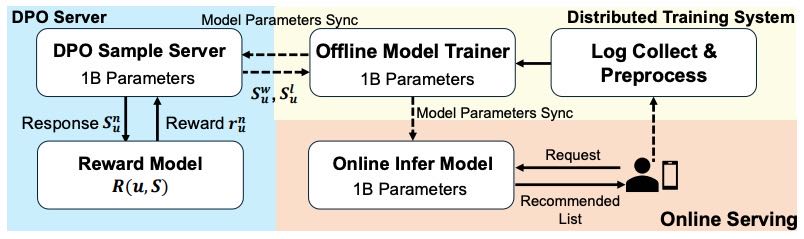
Figure 3: Framework of Online Deployment of OneRec.
总结¶
3.1 节:介绍 OneRec 的特征工程,重点在于视频嵌入的量化方法和码本优化。
3.2 节:提出会话级推荐任务,设计基于 Transformer 的生成模型,并使用 NTP 损失训练。
3.3 节:引入 RM 评估生成质量,并通过 DPO 进行迭代优化,提升模型性能。
整体来看,OneRec 通过统一检索与排序,结合生成式推荐与偏好对齐,实现了高质量的推荐系统。
4. System Deployment¶
本节介绍了 OneRec 推荐系统在实际工业场景中的部署情况,整体部署架构分为三个核心部分:训练系统、在线服务系统和 DPO 样本服务器。
1. 系统结构与流程¶
OneRec-1B 模型被用于在线服务,兼顾了稳定性与性能。
系统使用用户交互日志作为训练数据,训练流程分为两个阶段:
第一阶段:使用下一个词预测目标(ℒNTP) 训练初始模型(seed model);
第二阶段:模型收敛后,引入DPO 损失(ℒDPO) 进行偏好对齐,提升推荐质量。
在训练中采用了 XLA 加速 和 bfloat16 混合精度训练,以优化计算效率和内存使用。
2. 模型同步与部署¶
训练完成的模型参数会同步到:
在线推理模块:用于实时推荐服务;
DPO 样本服务器:用于基于用户偏好的数据筛选。
3. 推理阶段优化(重点内容)¶
为了提升在线推理性能,系统实现了以下两个关键优化措施:
键值缓存解码机制 + float16 量化:显著降低 GPU 显存占用;
128 束宽的束搜索(beam search)配置:在生成质量与响应延迟之间取得良好平衡。
此外,得益于MoE 架构,推理时仅激活约 13% 的模型参数,大幅节省计算资源。
总结¶
本节详细描述了 OneRec 的工业级部署方案,强调了训练与推理阶段的优化策略,特别是在性能、效率和资源利用方面的关键设计。
5. Experiment¶
本章主要通过离线实验、消融实验和在线A/B测试三部分来验证 OneRec 的有效性与性能优势。
5.1. Experimental Settings¶
5.1.1. Implementation Details(实现细节)¶
本节介绍了 OneRec 的训练与优化配置:
使用 Adam优化器,初始学习率为 2×10⁻⁴;
使用 NVIDIA A800 GPU 进行训练;
DPO采样比例 rDPO 设置为 1%;
每个用户通过 beam search 生成 128 个候选响应;
语义标识符聚类使用 3层码本,每层包含 8192 个簇;
MoE(混合专家)架构包含 24个专家,每次前向传播激活 2个专家;
会话建模中,使用 5个目标会话项 和 256个历史行为项 作为上下文。
这些参数设置为后续实验提供了基础。
5.1.2. Baseline Methods(基线方法)¶
本节列举了多个推荐系统和偏好优化的代表性方法作为对比基线,包括:
传统推荐模型:SASRec、BERT4Rec、FDSA;
基于语义标识的模型:TIGER;
DPO及其变体:DPO、IPO、cDPO、rDPO、CPO、simPO、S-DPO。
这些方法涵盖了点对点推荐、序列建模、以及基于人类偏好的优化策略,用于全面评估 OneRec 的性能。
5.1.3. Evaluation Metric(评估指标)¶
评估指标包括:
观看时长类:session watch time(swt)、view probability(vtr);
交互类:follow probability(wtr)、like probability(ltr);
使用预训练的奖励模型对推荐结果进行评分,计算各项指标的平均奖励值。
5.2. Offline Performance(离线性能)¶
本节展示了 OneRec 与基线方法在离线数据集上的对比结果,主要发现如下:
OneRec 的生成式会话建模优于传统方法:
相比 TIGER-1B,OneRec-1B 在 swt 上提升 1.78%,在 ltr 上提升 3.36%;
说明生成式建模在保持推荐多样性与上下文一致性方面更具优势。
少量 DPO 训练即可显著提升性能:
使用 1% 的 DPO 样本训练,OneRec-1B+IPA 在 swt 上提升 4.04%,在 ltr 上提升 5.43%;
表明即使少量偏好优化也能有效对齐生成结果。
IPA 策略优于其他 DPO 变体:
IPA 在多个指标上表现优于其他 DPO 方法;
一些 DPO 基线甚至不如未对齐的 OneRec 基线模型,说明 IPA 的迭代偏好挖掘更有效。
5.3. Ablation Study(消融实验)¶
5.3.1. DPO Sample Ratio Ablation(DPO采样比例消融)¶
将 DPO 采样比例从 1% 提高到 5%,性能提升有限;
但 GPU 资源消耗线性增长(5% 消耗 5倍于1% 的资源);
结论:1% 的采样比例在性能与资源之间取得了最佳平衡,达到最大性能的 95%,仅需 20% 的资源。
5.3.2. Model Scaling Ablation(模型规模消融)¶
随着模型参数从 0.05B 增加到 1B,性能持续提升;
OneRec-0.1B 相比 0.05B 提升 14.45%;
后续每增加参数规模(0.2B、0.5B、1B)均有 5% 左右的提升;
结论:OneRec 具有良好的模型扩展性。
5.4. Prediction Dynamics of OneRec(OneRec 的预测动态)¶
展示了不同码本层的预测概率分布;
OneRec+IPA 相比基线模型在预测分布上表现出更强的置信度偏移,说明 IPA 有效引导模型生成偏好结果;
第一层预测的不确定性(熵值 6.00)高于后续层(第二层平均熵 3.71,第三层 0.048);
原因:自回归解码机制中,前层继承更多解码不确定性,后层因上下文积累而更集中。
5.5. Online A/B Test(在线A/B测试)¶
在快手主页面视频推荐场景中进行在线测试,使用 1% 流量;
评估指标:总观看时长(Total Watch Time) 和 平均观看时长(Average View Duration);
OneRec-1B+IPA 相比当前多阶段推荐系统:
总观看时长提升 1.68%;
平均观看时长提升 6.56%;
结论:OneRec 在线部署后显著提升推荐效果,带来可观的平台收益。
总结¶
本章通过离线实验、消融分析、预测动态分析和在线A/B测试,全面验证了 OneRec 的有效性:
OneRec 在生成式推荐建模中优于传统点对点方法;
少量 DPO 训练结合 IPA 策略显著提升性能;
模型具有良好的扩展性,参数增加带来持续性能提升;
在线部署验证了其在真实场景中的实用价值。
6. Conclusion¶
本章节总结了论文的核心内容与贡献,主要包括以下几个方面:
一、模型结构与计算效率¶
作者提出了一种基于MoE(Mixture of Experts)架构的工业级单阶段生成推荐解决方案(OneRec),通过高效扩展模型参数,实现了高计算效率。这一设计为大规模工业推荐系统提供了可扩展的蓝图。
二、上下文建模的重要性¶
研究发现,在会话级(session-wise)生成方式中对目标物品的上下文信息进行建模具有必要性。相比传统的点对点(point-wise)建模方式,序列化的上下文建模更能准确捕捉用户的动态偏好变化。
三、提升泛化能力的策略¶
为了提升OneRec在不同用户偏好模式下的泛化能力,作者提出了迭代偏好对齐(IPA)策略,有效增强了模型适应多样用户行为的能力。
四、实验验证与效果分析¶
通过大量的离线实验和在线A/B测试,验证了OneRec在推荐效果和效率方面的优势。然而,分析也指出模型在某些交互指标(如点赞)上仍存在不足,尽管在用户观看时长上有明显提升。
五、未来研究方向¶
未来的工作将聚焦于增强生成推荐系统的多目标建模能力,以进一步提升用户体验。
重点内容总结:
MoE架构提升了模型扩展性与效率。
会话级上下文建模优于点对点建模。
IPA策略增强了模型对多样用户偏好的适应性。
模型在线上提升了观看时长,但在点赞等交互指标上仍有改进空间。