2303.14524_ChatRec: Towards Interactive and Explainable LLMs-Augmented Recommender System¶
引用: 438(2025-09-11)
组织:
Fudan University
Tongji University
University of California
总结¶
总结
快速看完
最后的 Appendix 中有 prompt
Paper引用说明
使用 LLM 作为会话式推荐系统的接口
ChatRec
无需进行模型训练,完全依赖于上下文学习
核心思想:
传统的推荐系统依赖于用户的历史点击、购买和评分等行为数据。
自然语言处理(NLP)技术为推荐系统提供了更丰富的用户偏好信息来源,如评论、社交媒体内容等。
方法设计:
Prompt构造模块是关键部分,整合以下四类输入生成自然语言提示:
用户-项目历史交互(点击、购买、评分)
用户画像(年龄、性别、兴趣)
用户当前查询(Qi)
对话历史(H<i)
基于候选集压缩的推荐
LLM 作用
将用户画像和历史行为转化为提示(prompt)
利用上下文学习,总结用户偏好
建立用户偏好与产品特征之间的关系
LLM基于用户偏好对候选集进一步过滤排序,用户看到的推荐更少、更精准。
消融实验
推荐系统的候选集排序是 Chat-Rec 性能的关键因素。
Top1 作为背景信息能有效提升推荐质量。
LLM 通过上下文学习能捕捉推荐系统的隐式知识,并将其用于排序优化。
Abstract¶
核心观点:
本研究提出了一种新的推荐系统范式 Chat-Rec(ChatGPT增强推荐系统),利用大语言模型(LLMs)来提升传统推荐系统的交互性与可解释性。通过将用户画像和历史交互转换为提示(prompt),Chat-Rec 利用**上下文学习(In-Context Learning)**有效学习用户偏好,并在用户和产品之间建立联系。
重点内容:
传统推荐系统的挑战:
交互性差、可解释性不足,限制了在实际系统中的广泛应用。
这些问题正是Chat-Rec所针对的核心问题。
Chat-Rec的核心创新:
基于Prompt的增强方式:通过结构化的提示将用户信息输入LLMs,提升其对用户偏好的理解能力。
上下文学习(In-Context Learning):无需显式训练模型,直接通过示例构建推荐逻辑。
跨域推荐能力:用户偏好可以迁移到不同领域的产品推荐上。
冷启动问题处理:通过提示注入新项目的相关信息,LLMs可以处理新物品的推荐。
实验结果:
在Top-K推荐任务中表现优于传统方法。
在零样本评分预测任务中也取得了良好效果,说明其泛化能力强。
研究意义:
提供了一种新的推荐系统改进方案。
探索了**AIGC(AI生成内容)**在推荐系统中的实际应用场景。
关键词:
LLMs、推荐系统、Prompt Engineering
1 Introduction¶
背景与趋势¶
随着模型规模和语料库的扩大,大语言模型(LLM)展现出了显著的能力,例如复杂推理、知识推理和外部鲁棒性。这些能力被称为涌现能力(Emergent Abilities),只有在模型参数达到一定阈值后才会显现。LLM的出现带来了研究范式的转变——传统上,下游任务通常依赖反向传播调整模型参数,而如今,LLM的发展使得研究人员和实践者可以通过构建提示(Prompt)在前向过程中实现学习,这种方式称为上下文学习(In-Context Learning, ICL)。
此外,链式推理(Chain-of-Thought)和指令学习(Instruct Learning)等技术的引入,进一步提升了LLM在推理能力和任务泛化能力方面的表现,从而推动其在多个领域的应用。
推荐系统面临的挑战¶
在大数据时代,手动信息搜索变得不可行,因此推荐系统被广泛用于自动推断用户偏好并提供高质量推荐服务。然而,现有推荐系统在实际部署中仍存在诸多问题:
交互性差、可解释性弱、反馈机制缺失;
冷启动问题——难以对新用户或新物品做出准确推荐;
跨域推荐困难;
依赖外部知识库(如知识图谱)或增强数据的多任务学习,来获取背景知识或通用知识。
LLM为解决这些问题提供了一种有前景的方案:它们可以生成更自然、更可解释的推荐,解决冷启动问题,并实现跨域推荐。同时,LLM具备更强的交互性和反馈机制,从而提升用户体验。更重要的是,LLM可以利用内部知识来提高推荐系统性能,而无需依赖外部检索器。
LLM在推荐系统中的应用现状¶
目前已有初步研究尝试将LLM用于推荐任务。这些方法通常将推荐任务建模为基于提示的自然语言任务,将用户-物品信息和特征通过个性化提示模板整合为模型输入。但目前LLM在推荐系统中仍作为训练过程的一部分参与建模。
本文提出的方法:Chat-Rec¶
本文提出了一种新颖的对话式推荐系统方法,称为Chat-Rec(ChatGPT增强推荐系统),该方法无需进行模型训练,完全依赖于上下文学习,从而实现更高效、更有效的推荐。
Chat-Rec具有以下特点:
支持多轮对话推荐,可以在对话过程中逐步细化用户偏好,更新候选推荐结果;
建立产品之间的偏好联系,从而提升跨域推荐能力;
在真实数据集上进行了Top-k 推荐和评分预测实验,实验结果表明 Chat-Rec 表现优异。
主要贡献¶
提出一种新的推荐系统范式 Chat-Rec,通过提示将传统推荐系统与 LLM 结合,利用 LLM 的上下文学习能力;
将 LLM 作为推荐系统接口,实现多轮推荐,提升系统的交互性与可解释性;
在真实数据集上进行实验验证,证明了 Chat-Rec 在 Top-k 推荐和评分预测任务中的有效性。
总结¶
本文从 LLM 涌现能力的背景出发,指出现有推荐系统存在的局限性,并提出一个不依赖训练的推荐系统范式 Chat-Rec,强调其在对话交互、可解释性、跨域推荐方面的优势,并通过实验验证其有效性。此研究为 ChatGPT 类对话 AI 在推荐系统中的应用 提供了新的技术路径。
3 Method¶
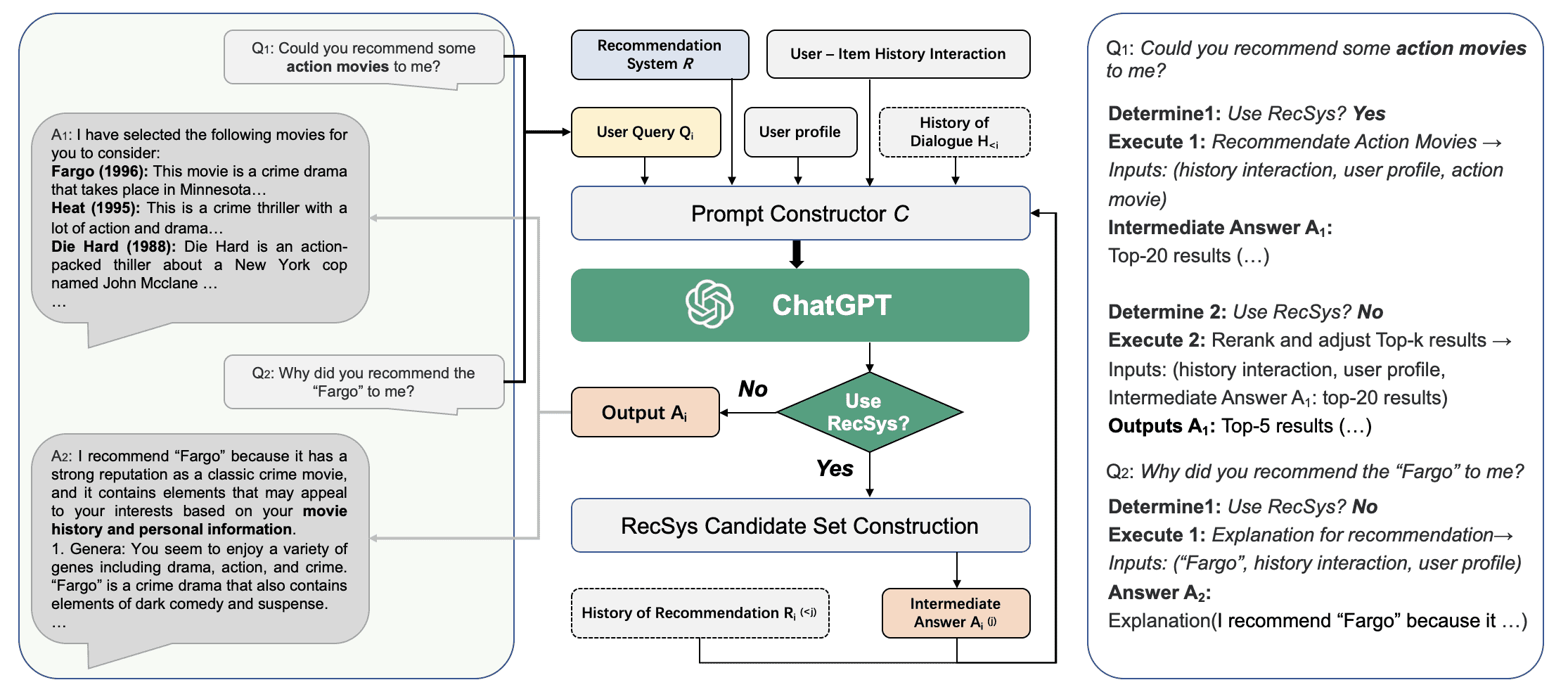
Figure 1:Overview of Chat-Rec. The left side shows a dialogue between a user and ChatGPT. The middle side shows the flowchart to how Chat-Rec links traditional recommender systems with conversational AI such as ChatGPT. The right side describes the specific judgment in the process.
本章介绍了Chat-Rec框架的核心方法,旨在通过将对话式AI(如ChatGPT)与传统推荐系统结合,实现交互式、可解释的推荐。整个方法包括四个主要部分:桥接推荐系统与LLMs、基于候选集压缩的推荐、冷启动推荐、跨领域推荐。
3.1 Bridge Recommender Systems and LLMs(连接推荐系统与LLMs)¶
核心思想:¶
传统的推荐系统依赖于用户的历史点击、购买和评分等行为数据。
自然语言处理(NLP)技术为推荐系统提供了更丰富的用户偏好信息来源,如评论、社交媒体内容等。
大型语言模型(LLMs)如ChatGPT能够生成自然语言回复,提升用户体验。
方法设计:¶
提出一个增强型推荐模块,结合用户行为、用户画像、当前查询和对话历史,与任意推荐系统 R 接口。
若任务为推荐任务,则调用推荐系统生成候选集;否则直接输出解释性回复。
Prompt构造模块是关键部分,整合以下四类输入生成自然语言提示:
用户-项目历史交互(点击、购买、评分)
用户画像(年龄、性别、兴趣)
用户当前查询(Qi)
对话历史(H<i)
流程与示例:¶
第一轮问答中,用户请求动作电影推荐,系统调用推荐模块生成候选集(如Top-20),再通过LLM优化生成Top-5。
第二轮中用户提问“为什么推荐《 Fargo 》”,系统调用解释模块,基于用户兴趣和电影特征生成解释回复。
图2展示了交互式推荐的典型场景,LLM在推荐和解释中均发挥作用,并能考虑伦理问题。
3.2 Recommendation Based on Candidate Set Compression(基于候选集压缩的推荐)¶
问题背景:¶
传统推荐系统生成的候选集通常过大,用户难以处理。
推荐系统性能仍有很大提升空间。
方法设计:¶
通过LLM来压缩候选集,提高推荐效率与准确性。
LLM的关键作用:
将用户画像和历史行为转化为提示(prompt)
利用上下文学习,总结用户偏好
建立用户偏好与产品特征之间的关系
LLM基于用户偏好对候选集进一步过滤排序,用户看到的推荐更少、更精准。
3.3 Cold-start Recommendations(冷启动推荐)¶
问题背景:¶
冷启动问题是传统推荐系统的难点,尤其是对新物品的推荐。
LLM(如ChatGPT)的知识仅到2021年9月,无法推荐2021年之后的内容(如2023年电影)。
解决方案:¶
引入外部信息,如新物品的描述和元数据。
生成新物品的嵌入向量,并计算与用户查询的相似度,从而匹配相关推荐。
构造包含新物品信息的提示,输入LLM生成推荐。
图3展示了在加入外部信息后,ChatGPT能有效推荐新电影,解决了冷启动问题。
3.4 Cross-Domain Recommendations(跨领域推荐)¶
核心思想:¶
传统推荐系统难以跨领域迁移用户偏好(如从电影到书籍)。
LLM具有广泛的知识,可以理解多个领域的物品关系。
方法设计:¶
LLM基于用户在某一领域的偏好(如电影),推荐其他领域的物品(如书籍、电视剧、播客、游戏)。
LLM利用其预训练跨领域知识作为“知识迁移桥梁”,实现跨领域推荐。
图4展示了一个场景:用户在获得电影推荐后,请求其他类型作品的推荐,LLM能根据电影偏好推荐多种其他类型作品。
意义:¶
跨领域推荐显著拓展了推荐系统的覆盖范围和推荐多样性。
传统方法难以实现这一功能,而LLM增强了系统在该方面的表现。
总结¶
本章全面介绍了Chat-Rec框架在交互式推荐、候选集压缩、冷启动和跨领域推荐等方面的创新方法。重点在于:
Prompt构造模块是系统的核心,整合用户信息生成自然语言提示;
LLM在推荐中的多重作用:生成推荐、解释推荐、过滤优化候选集;
冷启动与跨领域推荐是传统推荐系统的难点,LLM的引入显著提升了系统能力。
该方法为下一代推荐系统提供了新的技术方向,使推荐过程更加个性化、可解释和交互化。
4 Experiment¶
4.1 数据集与实验设置¶
数据集:实验使用的数据集是 MovieLens 100K,这是一个真实世界推荐系统的基准数据集。数据集包含 943名用户 对 1,682部电影 的 100,000条评分,评分范围为 1 到 5。数据中还包含 用户人口统计信息(如年龄、性别、职业、邮编)与 电影元信息(如标题、上映年份、类型)。
实验设置:从原始数据中随机选取 200 名用户进行实验。表1提供了实验所用数据集的详细统计信息,包括用户数量、电影数量、评分数量、评分范围和数据密度(6.304%)。
评估指标:
Top-k 推荐任务:使用 Precision、Recall 和 NDCG。
评分预测任务:使用 RMSE 和 MAE。
4.2 基线方法¶
实验中比较了以下 传统推荐算法 和 LLM 增强的推荐系统:
传统推荐方法:¶
LightFM:融合协同过滤与内容推荐的混合模型。
LightGCN:基于图的协同过滤模型,使用简化版图卷积神经网络。
Item-KNN:基于物品相似性的邻域推荐方法。
Matrix Factorization (MF):将用户和物品映射到低维潜在空间进行推荐的经典方法。
LLM 增强方法(Chat-Rec):¶
使用 GPT-3 和 GPT-3.5 系列的三个代表性模型:
gpt-3.5-turbo:聊天优化,能力较强。
text-davinci-003:任务质量高、输出长,适合语言任务。
text-davinci-002:基于监督微调,与 003 相似但训练方式不同。
模型命名如 “Chat-Rec (gpt-3.5-turbo)” 表示使用相应模型构建的 Chat-Rec 框架。
4.3 实验结果与分析¶
4.3.1 Top-5 推荐结果(重点)¶
实验结果(表2)表明:
Chat-Rec 框架在 Top-5 推荐中优于传统推荐方法。
text-davinci-003 表现最佳,NDCG 提高了 11.01%,Precision 提高 6.93%。
Precision 提升明显,但 Recall 略有下降(比 LightGCN 低 3.51%),说明模型更注重推荐质量而非覆盖率。
gpt-3.5-turbo 的性能略逊于 text-davinci-003 和 text-davinci-002,说明其更适合对话任务,而非推荐任务中的推理能力。
模型 |
Precision |
Recall |
NDCG |
|---|---|---|---|
LightGCN |
0.3030 |
0.1455 |
0.3425 |
Chat-Rec (gpt-3.5-turbo) |
0.3103 |
0.1279 |
0.3696 |
Chat-Rec (text-davinci-003) |
0.3240 (+6.93%) |
0.1404 (-3.51%) |
0.3802 (+11.01%) |
Chat-Rec (text-davinci-002) |
0.3031 |
0.1240 |
0.3629 |
4.3.2 评分预测结果(重点)¶
实验结果(表3)表明:
Chat-Rec 在评分预测上表现优于大多数传统模型,说明 LLM 可以通过上下文学习用户偏好与历史交互,预测用户评分。
text-davinci-003 表现最优:RMSE 为 0.785(比 Item-KNN 低 15.86%),MAE 为 0.593(比 Item-KNN 低 19.21%)。
gpt-3.5-turbo 表现较差,说明其更适合对话交互,而非数值预测任务。
LightGCN 未被纳入评分预测实验,因其在该任务上效果不佳。
模型 |
RMSE |
MAE |
|---|---|---|
Item-KNN |
0.933 |
0.734 |
Chat-Rec (text-davinci-003) |
0.785 (+15.86%) |
0.593 (+19.21%) |
Chat-Rec (text-davinci-002) |
0.8309 |
0.6215 |
Chat-Rec (gpt-3.5-turbo) |
0.969 |
0.756 |
重要结论:LLM 无需依赖传统推荐系统即可预测用户评分,说明其强大的上下文学习和推理能力。
4.3.3 推荐优化机制(重点)¶
实验中发现,Chat-Rec 的核心优势在于:
优化候选集排序:LLM 能识别推荐系统中排名靠后但用户可能喜欢的电影。
通过重新排序提升推荐质量,结合电影知识和用户偏好进行推理。
实验验证了推荐系统与 LLM 的协同效应:LLM 可基于用户画像和候选集上下文,提供更个性化的排序。
4.4 消融实验(重点)¶
使用 text-davinci-003 进行消融实验,研究 prompt 设计 和 temperature 参数 对模型性能的影响。
实验变量:¶
w/random:候选集随机排序。
w/top1:不使用推荐系统的 Top1 作为背景知识。
temperature:控制输出的随机性,0 表示确定性输出,1 表示最大随机性。
实验发现:¶
候选集排序 对性能有显著影响。例如,当温度为 0.9 时,NDCG 从 0.3802 降至 0.3653(下降 3.92%)。
缺少 Top1 推荐 时,性能大幅下降(如 NDCG 从 0.3802 降至 0.3055,下降 19.65%)。
最佳温度为 0.9,输出具有适当随机性,能平衡多样性与准确性。
结论:¶
推荐系统的候选集排序是 Chat-Rec 性能的关键因素。
Top1 作为背景信息能有效提升推荐质量。
LLM 通过上下文学习能捕捉推荐系统的隐式知识,并将其用于排序优化。
总结¶
本实验通过在 MovieLens 100K 数据集上对比多种推荐模型,验证了 Chat-Rec 框架结合大语言模型(LLMs)在 Top-k 推荐与评分预测任务中的有效性。重点结论如下:
text-davinci-003 表现最佳,显示其在推荐任务中的强学习与推理能力。
gpt-3.5-turbo 虽然对话能力强,但推荐性能较弱。
LLM 可无需训练即可通过上下文学习用户偏好,优化推荐系统候选集排序。
候选集排序与 Top1 信息对模型性能有显著影响,提示推荐系统与 LLM 的协同设计对推荐质量至关重要。
5 Conclusion¶
本文提出了Chat-Rec,这是一个通过将用户信息和用户-物品交互转换为提示(prompt)来连接推荐系统与大语言模型(LLMs)的方法。重点在于,该方法通过LLMs的提示机制,实现了对推荐系统的增强。
我们评估了该方法在top-k推荐任务和零样本电影评分预测任务中的表现。结果表明,LLMs在提升推荐系统的交互性、可解释性和跨领域推荐方面具有显著潜力。
此外,实验强调了提示(prompt)在该方法中的关键作用。通过在提示中隐式表达推荐系统中的知识,可以有效提升推荐效果,这是本文的重要发现之一。
Appendix 0.A Implementation Details¶
0.A.1 提示词(Prompts)¶
在本节中,列出了用于Top-k 推荐和零样本电影评分任务的提示词(prompt)。

Figure 6:Prompt for top-k recommendation task.
图6 展示了 Top-k 推荐任务的提示词。这类提示用于引导大语言模型(LLMs)生成前 k 个推荐的电影列表。

Figure 7:Prompt for moving rating task.
图7 展示了电影评分任务的提示词。该任务要求模型在没有训练数据的情况下(zero-shot),根据用户输入的信息预测其对电影的评分。
0.A.2 示例输出(Example Answers)¶
在实际实验过程中,大语言模型输出的响应并不总是符合预期格式,特别是当模型的温度(temperature)较高时,输出的随机性较大,容易出现格式错误或内容不完整的问题。
在 表4 中,总结了部分失败的输出案例,例如:
示例 |
问题描述 |
是否正确 |
|---|---|---|
正确的电影列表格式输出 |
符合格式要求 |
✅ |
电影名称格式不规范(如冠词位置错误) |
未按电影行业规范输出名称 |
❌ |
输出的电影数量不足或过多 |
输出项数不一致,有时为4,有时为19 |
❌ |
输出中缺少电影 ID |
当要求格式为 |
❌ |
关键点:模型输出的格式一致性是实验中一个需要注意的问题。不匹配格式的输出会自动重试,以确保最终结果的正确性。因此,设计合理的提示词和对输出格式的校验是提升实验可靠性的关键。
总结:
本附录详细说明了用于两个任务(Top-k 推荐和零样本电影评分)的提示词设计。
强调了模型输出格式的重要性,并提供了实际中可能出现的格式错误案例。
在模型调用过程中,对不符合格式的输出会自动重试,确保实验结果的稳定性。