2307.16789_ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs¶
引用: 776(2025-07-24)
组织:
1Tsinghua University
2ModelBest Inc.
3Renmin University of China
4Yale University
5WeChat AI, Tencent Inc.
6Zhihu Inc.
总结¶
研究目标
论文旨在提升大语言模型(LLMs)调用真实世界API工具的能力
使其能够处理复杂任务(如多步推理、多API组合等),从而更贴近实际应用场景。
ToolLLM框架
该框架包含三个核心部分
数据构建(Data Construction)
API收集:从RapidAPI Hub中自动收集了16,464个真实世界的RESTful API,涵盖49个类别。
指令生成:利用ChatGPT生成多样化的指令,涵盖单工具和多工具使用场景。
解决方案路径标注:通过ChatGPT为每个指令生成有效的API调用链(解决方案路径)。
模型训练(Model Training)
微调模型(如ToolLLaMA,基于LLaMA)以理解API描述、选择合适API、处理输入/输出
评估(Evaluation)
开发了自动评估工具ToolEval,用于评估模型的API使用能力
三个核心组件
ToolEval
有效评估模型性能,接近人工评估
API 检索器
在单工具和多工具任务中均优于传统方法
DFSDT
在复杂任务中表现出更强的求解能力,显著优于 ReACT
DFSDT
一种改进的深度优先搜索(DFS)算法,旨在在保证搜索效果的同时减少资源消耗
传统DFS问题:排序子节点耗费大量资源;
改进设计:采用预排序的DFS遍历方式,跳过排序步骤;
优势:
在简单任务中退化为ReACT,效率更高;
在复杂任务中接近DFS效果;
ToolEval
通过率(Pass Rate)
分为三种标签:Pass、Fail、Unsure
可解任务:根据是否成功回答问题、是否尝试所有工具等标准判断;
不可解任务:根据是否拒绝回答或错误回答判断。
胜率(Win Rate)
比较两个完成任务的路径,判断哪个更好
判断标准
信息丰富度;
事实准确性;
推理清晰度;
里程碑数量;
探索的API数量;
调用效率(重复调用少为优)。
LLM总结¶
这篇文章主旨是介绍一个名为 ToolLLM 的系统或方法,旨在帮助大型语言模型(LLMs)高效地掌握和使用超过 16000 个真实世界的 API(应用程序编程接口)。
总结如下:
文章内容总结:
研究背景与动机:
随着大型语言模型(LLMs)在各种任务中的广泛应用,模型与外部工具(如 APIs)的结合变得越来越重要。然而,实际应用中,LLMs 面临着理解、调用和整合大量 API 的挑战。由于 API 的种类繁多、参数复杂、文档不一,LLMs 难以直接有效地利用这些工具。提出 ToolLLM:
为了解决上述问题,作者提出了 ToolLLM——一个系统或方法框架,使 LLM 能够更好地理解和使用大量的真实世界 API。ToolLLM 提供了结构化的 API 学习机制,帮助模型掌握 API 的功能、参数和调用方式。核心方法与技术:
API 知识提取与表示: 通过解析 API 的文档,提取关键信息并构建结构化的知识表示,便于模型理解和调用。
交互式学习机制: 采用交互式学习方式,使模型在实际调用中不断学习和优化 API 的使用方式。
大规模 API 掌握: 系统成功让 LLM 掌握了超过 16000 个真实世界 API,涵盖多个领域,如搜索、天气、日历、支付等。
实验与评估:
作者通过一系列实验验证了 ToolLLM 的有效性,包括 API 识别准确率、调用成功率、任务完成率等指标。结果表明,ToolLLM 显著提升了 LLM 在实际任务中使用工具的能力。应用与意义:
ToolLLM 的提出为构建更加智能化、实用化的 LLM 应用提供了基础。通过将 LLM 与丰富的 API 工具结合,能够实现更复杂、更贴近用户需求的智能服务,如自动化助手、智能客服、任务执行系统等。
总体而言,这篇文章介绍了一个创新性的系统 ToolLLM,旨在解决 LLM 在理解和使用大量外部 API 方面的挑战,具有重要的理论和实际应用价值。
Abstract¶
本研究主要探讨了当前开源大语言模型(LLMs)在使用外部工具(API)方面能力的不足,并提出了一种通用的工具使用框架 ToolLLM,以提升其执行复杂指令和调用API的能力。研究的主要内容和贡献如下:
问题背景:虽然开源大语言模型(如LLaMA)在语言任务上表现良好,但在使用外部工具(如API)方面存在明显不足。相比之下,商业模型(如ChatGPT)具有更强的工具使用能力。
解决方案——ToolLLM框架:该框架包含三个核心部分:数据构建(Data Construction)、模型训练(Model Training)和评估(Evaluation)。
数据构建——ToolBench:
API收集:从RapidAPI Hub中自动收集了16,464个真实世界的RESTful API,涵盖49个类别。
指令生成:利用ChatGPT生成多样化的指令,涵盖单工具和多工具使用场景。
解决方案路径标注:通过ChatGPT为每个指令生成有效的API调用链(解决方案路径)。
模型增强:
提出了一种基于深度优先搜索的决策树算法,用于增强模型的推理能力。
构建了一个神经API推荐器,帮助模型为每个指令推荐合适的API。
评估方法——ToolEval:开发了自动评估工具,用于评估模型的API使用能力。
实验结果:
基于ToolBench微调后的LLaMA模型(ToolLLaMA)表现出显著的复杂指令执行能力和良好的泛化性。
在APIBench数据集上,ToolLLaMA展示了强大的零样本(zero-shot)泛化能力。
在功能和性能上,ToolLLaMA与ChatGPT相当。
开源共享:研究代码、训练好的模型和演示已开源,便于后续研究者使用和验证。
总结来看,该研究通过构建高质量的工具使用数据集、改进模型推理算法和开发评估工具,有效提升了开源大语言模型的API使用能力,为实现更智能、实用的语言模型奠定了基础。
1 Introduction¶
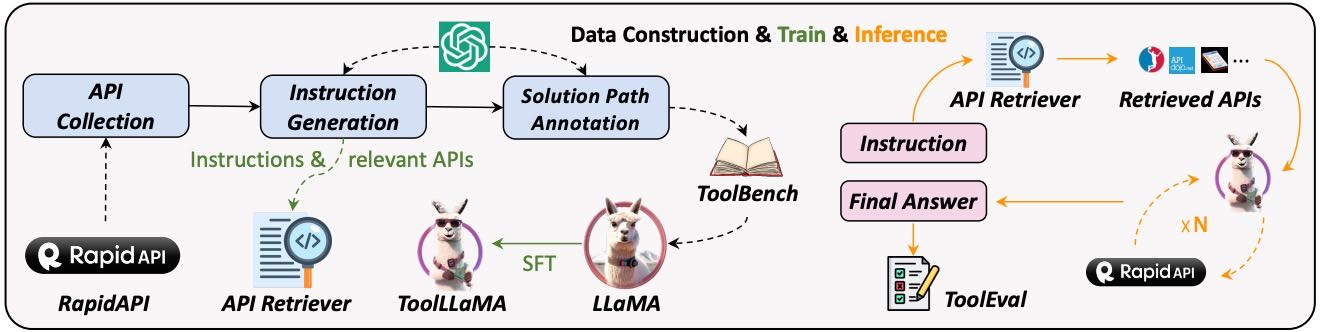
Figure 1: Three phases of constructing ToolBench and how we train our API retriever and ToolLLaMA. During inference of an instruction, the API retriever recommends relevant APIs to ToolLLaMA, which performs multiple rounds of API calls to derive the final answer. The whole reasoning process is evaluated by ToolEval.
本文主要介绍了一种名为 ToolLLM 的通用工具使用框架,旨在提升开源大语言模型(LLMs)与真实世界 API 进行交互的能力,以完成复杂任务。文章的主要内容和贡献总结如下:
1. 背景与动机¶
工具学习的目标:使大语言模型能够有效调用各种 API 来完成复杂任务,从而成为用户与应用程序间的高效中介。
现有问题:
闭源模型(如 GPT-4)表现优异但难以被研究者复现或改进;
开源模型(如 LLaMA)虽然具备语言能力,但缺乏对工具调用的优化;
当前的指令调优数据集在 API 多样性、多工具交互和推理能力方面存在局限。
2. ToolLLM 框架¶
为了提升开源模型的工具使用能力,作者提出了 ToolLLM 框架,包含三个主要部分:
(1) 数据构建:ToolBench¶
API 收集:从 RapidAPI 平台收集了 16,464 个真实 REST API,涵盖 49 个类别,为模型训练提供丰富的 API 样本。
指令生成:基于 ChatGPT 生成涵盖单工具与多工具交互的多样化指令,模拟真实复杂任务场景。
解决方案标注:对每个任务生成包含多轮推理与 API 调用的解决方案路径。为提升标注效率,提出 基于深度优先搜索的决策树(DFSDT),较传统 ReACT 方法更高效,尤其在处理复杂任务时表现优异。
(2) 模型训练:ToolLLaMA¶
通过在 ToolBench 上微调 LLaMA 模型,得到 ToolLLaMA。
实验结果显示:
ToolLLaMA 在单工具和复杂多工具任务上均表现优异,性能接近 ChatGPT,优于 Text-Davinci-003 和 Claude-2;
具备对未见过 API 的泛化能力,只需提供文档即可有效调用新 API;
DFSDT 显著提升了模型的推理和规划能力,优于传统 ReACT 方法。
(3) 评估:ToolEval¶
提出自动评估工具 ToolEval,通过 ChatGPT 实现对工具使用效果的评估。
评估指标:
Pass Rate(通过率):衡量模型在有限资源下完成任务的能力;
Win Rate(胜率):比较不同模型解决方案的质量;
ToolEval 被验证与人工评估高度相关,具备良好的可靠性与扩展性。
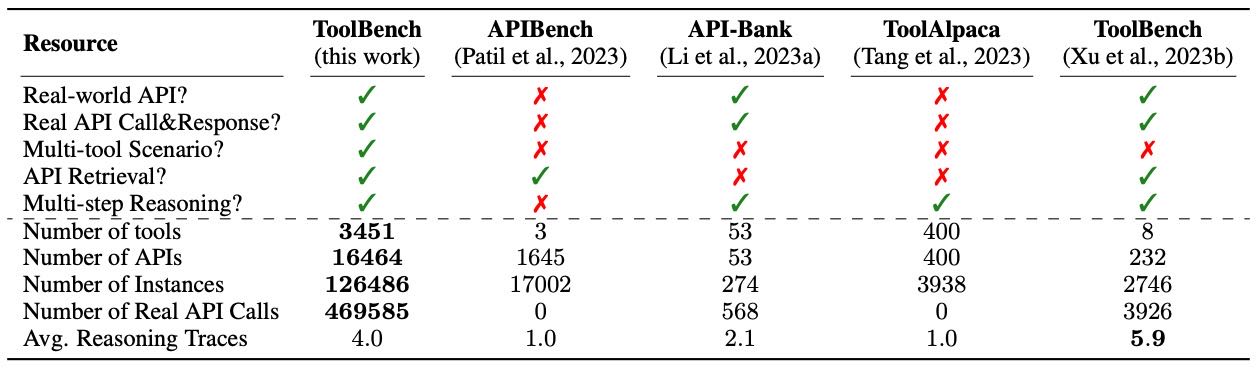
Table 1: A comparison of our ToolBench to notable instruction tuning dataset for tool learning.
3. 实验与结果¶
ToolLLaMA 性能优异:在多个维度上超越现有开源模型,且在某些指标上接近甚至匹敌闭源模型;
DFSDT 通用性强:可作为通用推理策略,提升模型在复杂任务中的决策能力;
API 检索器有效:训练了一个神经网络 API 检索器,能够从大量 API 中快速推荐相关工具,提升调用效率;
泛化能力强:在未参与训练的 OOD 数据集 APIBench 上也表现出色,接近专门为该数据集设计的 Gorilla 模型。
4. 总结¶
文章提出了一整套促进开源大语言模型掌握真实 API 的解决方案,涵盖数据构建、模型训练与评估体系,并通过 ToolLLM 框架取得了显著成果。该框架不仅提升了模型的工具调用能力,还推动了开源 AI 社区的工具学习研究发展。
2 Dataset Construction¶
本文第2章“数据集构建”主要介绍了ToolBench数据集的构建过程,共分为三个阶段:API收集、指令生成和解决方案路径标注。整个过程基于ChatGPT(gpt-3.5-turbo-16k)完成,仅需极少的人工监督,并且可以轻松扩展到新的API。
2.1 API收集¶
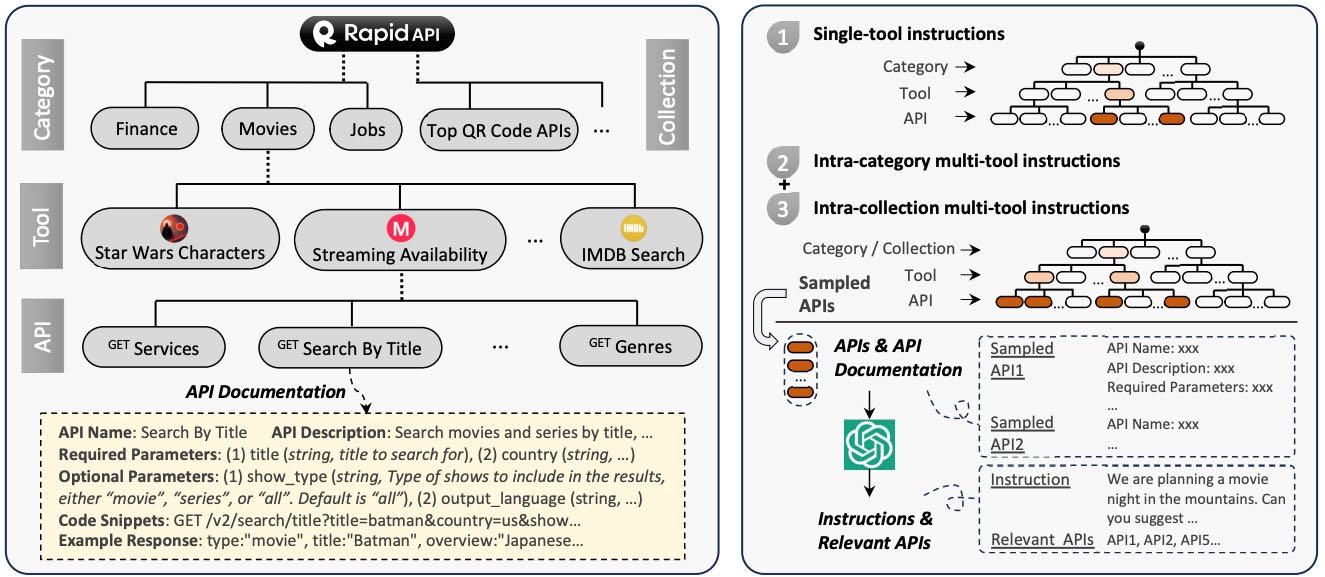
Figure 3: The hierarchy of RapidAPI (left) and the process of instruction generation (right).
背景概述:
RapidAPI是一个领先的API市场,提供了大量可供开发者使用的API,并通过粗粒度分类(49类)和细粒度集合(500+集合)对API进行组织,帮助开发者快速找到所需API。
API信息收集:
从RapidAPI中爬取工具信息,包括每个工具的名称、描述、URL和所属API;每个API记录其名称、描述、HTTP方法、参数、请求体、调用代码片段和示例响应。这些元数据对于LLM理解和使用API至关重要。
API筛选:
最初筛选出10,853个工具(53,190个API),但许多API质量不高(如返回404错误)。通过严格筛选,最终保留3,451个高质量工具(16,464个API)。
2.2 指令生成¶
目标与方法:
旨在生成多样化的API使用场景指令,尤其是支持单API与多API结合的场景,以提升LLM在实际应用中的泛化性和灵活性。通过采样不同API组合,然后为每个组合生成相应的指令。
生成过程:
从API集合中采样一组API(𝕊Nsub),使用ChatGPT生成与该组API相关的指令(Inst*)和相关API(𝕊rel)。
每个指令对应一组相关API,形成(instruction, relevant API)对,用于训练API检索器。
采样策略:
单工具指令(I1): 遍历每个工具生成指令。
多工具指令(I2、I3): 从同一类别或集合中采样2-5个工具(每个工具最多3个API),生成跨工具的指令,增强多样性。
总共生成约200k对指令与相关API,其中I1、I2、I3分别约为87k、85k和25k对。
2.3 解决方案路径标注¶
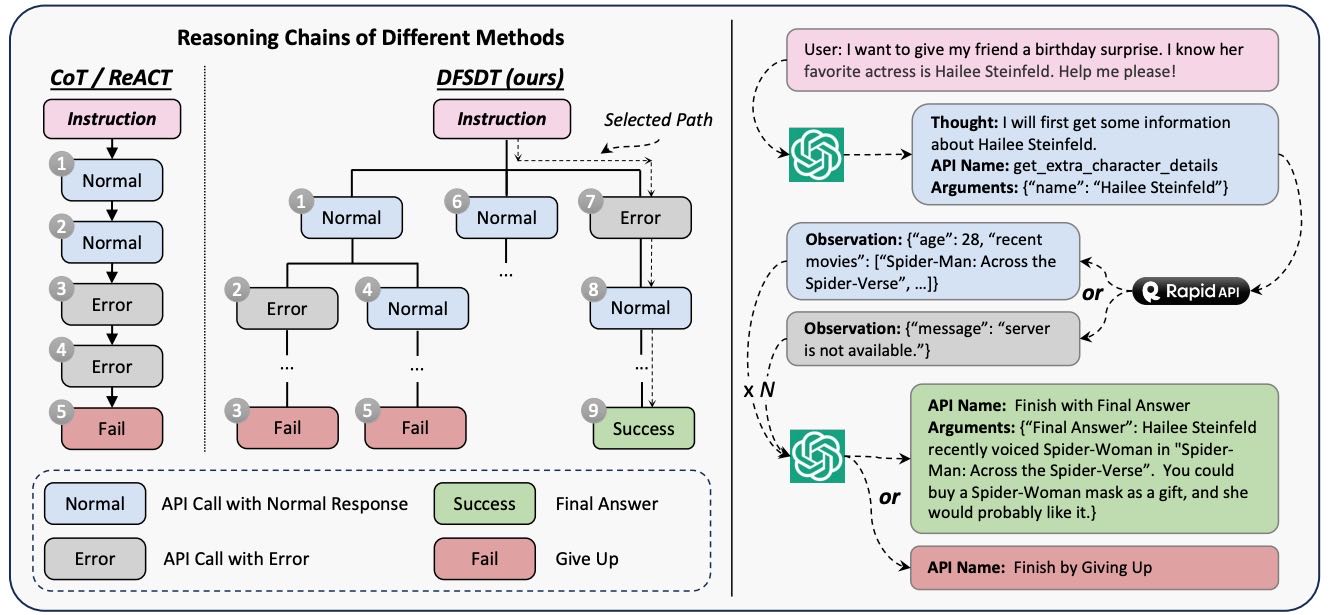
Figure 4: A comparison of our DFSDT and conventional CoT or ReACT during model reasoning (left). We show part of the solution path annotation process using ChatGPT (right).
任务目标:
为每个指令生成一个有效的API调用序列(解决方案路径),模拟LLM在实际应用中调用API的全过程。
标注过程:
使用ChatGPT进行多轮对话模拟,逐步生成API调用动作(at),并记录“Thought”、“API Name”和“Parameters”。
每个API被当作一个函数输入ChatGPT,帮助其理解调用方式。
提供两个终止函数:“Finish with Final Answer”(返回最终答案)和“Finish by Giving Up”(放弃任务)。
DFSDT(基于深度优先搜索的决策树):
改进传统CoT和ReACT方法的不足,如错误传播和探索不足。
构建决策树,通过DFS扩展搜索空间,允许模型在无效路径上回溯并尝试新路径。
最终生成126,486对(instruction, solution path)数据,用于训练ToolLLaMA模型。
总结¶
本章详细介绍了ToolBench数据集的构建流程,涵盖API的采集与筛选、多样化指令的生成以及多步API调用路径的自动标注。整个过程高度依赖ChatGPT,自动化程度高、人工干预少,确保了数据集的高质量与广泛适用性。最终构建的数据集为LLM学习和应用大量真实API提供了坚实的基础。
3 Experiments¶
本章节主要围绕 ToolLLM 框架的性能评估展开,通过多个实验验证其在实际应用中的有效性和优势。实验内容主要包括以下三个方面:
一、评估指标与初步实验¶
为了准确评估 ToolLLM 的性能,作者设计了一种名为 ToolEval 的评估方法,基于 ChatGPT 构建,采用两个关键指标:
Pass Rate(通过率):衡量在给定预算下完成任务指令的比例,反映模型的执行能力;
Win Rate(胜率):通过 ChatGPT 比较两种解决方案的优劣,体现模型方案的高质量。
实验显示,ToolEval 与人工评估的一致性较高(87.1% 的通过率和 80.3% 的胜率),证明了其在大规模 API 评估中的可靠性。
二、API 检索器的性能评估¶
作者引入基于 Sentence-BERT 构建的 API 检索器,以检索与指令相关的 API。通过对比传统方法 BM25 和 OpenAI 的 text-embedding-ada-002,使用 NDCG@1 和 NDCG@5 指标评估性能。
实验结果表明:
作者提出的 API 检索器在所有任务类型(I1、I2、I3)中均显著优于基线方法。
I1(单工具任务) 的检索效果优于 I2(同一类别多工具) 和 I3(跨类别多工具),说明多工具任务的检索难度更高。
平均 NDCG@1 达到 78.0%,NDCG@5 达到 84.9%,表明该检索器在大规模 API 环境中具有良好的实用性与扩展性。
三、DFSDT 与 ReACT 的对比实验¶
在解决方案路径标注阶段,作者比较了 DFSDT 与 ReACT 的性能。DFSDT 通过扩展搜索空间,提高了难任务的解决能力。
实验结果表明:
DFSDT 的通过率显著高于 ReACT,尤其是在复杂任务(I2 和 I3)中表现更优;
为了公平比较,作者提出了 ReACT@N 基线(多次执行 ReACT 直到成本与 DFSDT 相同),但即便如此,DFSDT 仍表现更佳;
DFSDT 通过高效探索搜索空间,能够标注更多任务,降低总体标注成本,尤其适合处理 ReACT 无法解决的“难例”。
总结¶
本章节通过系统实验验证了 ToolLLM 框架的三个核心组件(ToolEval、API 检索器、DFSDT)的有效性,结果表明:
ToolEval 能有效评估模型性能,接近人工评估;
API 检索器在单工具和多工具任务中均优于传统方法;
DFSDT 在复杂任务中表现出更强的求解能力,显著优于 ReACT,提升了标注效率和模型性能。
3.2 Main Experiments¶
3.2 主要实验总结¶
本节介绍了 ToolLLaMA 模型的主要实验设置和结果。实验旨在验证 ToolLLaMA 在不同场景和泛化能力下的性能表现。
模型训练¶
ToolLLaMA 基于 LLaMA-2 7B 模型,使用指令-解决方案对进行微调。
由于原始模型的上下文长度(4096)不足以处理较长的 API 响应,使用 位置插值法 将最大上下文扩展至 8192。
实验设置¶
为了评估模型的泛化能力,设计了三种泛化级别:
Inst.(新指令):相同 API 工具集下的新指令;
Tool(新工具):属于训练中见过的类别但未见过的工具;
Cat.(新类别):属于训练中未见过的类别工具。
实验分为三种任务类型:
I1(单工具指令):评估所有三个泛化级别;
I2(同类别多工具指令):评估 Inst. 和 Cat.;
I3(跨集合多工具指令):仅评估 Inst.。
基线模型¶
比较模型包括:Vicuna、Alpaca 两种对通用对话训练的 LLaMA 变体;
还包括强大的“教师”模型:ChatGPT、Text-Davinci-003、GPT-4、Claude-2,并应用 ReACT 和 DFSDT 两种推理方法;
所有模型使用“真实 API”进行评估,仅 ToolLLaMA-DFSDT-Retriever 使用 API 检索器。
实验结果¶
Vicuna 和 Alpaca 在所有任务中均未通过,表明其指令跟随能力在工具使用领域存在明显缺陷;
DFSDT 在大多数情况下显著优于 ReACT,甚至 ChatGPT + DFSDT 优于 GPT-4 + ReACT;
ToolLLaMA + DFSDT 性能接近 GPT-4 + DFSDT,在所有任务中表现稳定,泛化能力突出;
API 检索器 的引入进一步提升了模型性能,表明其能够从大量 API(16,000+)中有效检索相关 API。
结论¶
ToolLLaMA 在工具使用能力方面展现出优异的泛化能力;
ToolBench 实验平台能够有效激发 LLM 的工具使用潜力;
DFSDT 是一种优于 ReACT 的推理方法;
API 检索器在实际应用场景中具有显著提升作用。
3.3 APIBench 上的分布外(OOD)泛化实验¶
进一步评估 ToolLLaMA 在 APIBench 数据集上的泛化能力,该数据集包含多个新领域(HuggingFace、TorchHub、TensorHub)。
实验设置¶
使用两个检索器:训练的 API 检索器 和 真实 API 检索器;
对比模型包括 Gorilla(基于 LLaMA-7B 的模型,分别在零样本和检索感知设置下训练);
评估指标包括 AST 准确率 和 幻觉率。
实验结果¶
ToolLLaMA + 我们的检索器 在 HuggingFace 和 TorchHub 上的 AST 准确率优于 Gorilla + BM25;
在相同的真实 API 检索器下,ToolLLaMA 优于 Gorilla-ZS;
ToolLLaMA 在跨领域、跨任务的复杂设置中表现出强大的泛化能力;
Gorilla 无法泛化到 ToolBench,因为后者涉及多步骤推理与多工具使用。
结论¶
ToolLLaMA 在 OOD 场景下依然表现出色,证明其强大的泛化能力;
API 检索器有效提升了模型在新领域中的表现;
ToolLLaMA 在工具使用任务上具备通用性,支持多种新 API 的使用。
5 Conclusion¶
本文总结如下:
本研究探讨了如何激发大语言模型(LLMs)的工具使用能力。首先,提出了一种指令调优数据集 ToolBench,该数据集涵盖了16个以上的真实世界API和多种实际应用场景,包括单工具和多工具任务。ToolBench的构建主要依赖于ChatGPT,仅需极少的人为监督。
此外,研究提出了DFSDT方法,以增强LLMs的规划与推理能力,使其能够战略性地导航推理路径。为进一步提高工具学习的评估效率,作者设计了自动评估器 ToolEval。通过对 LLaMA 进行 ToolBench 上的微调,得到了 ToolLLaMA 模型,其性能可与 ChatGPT 相媲美,并展现出对未见 API 的显著泛化能力。
研究还开发了一个神经 API 检索器,用于为每条指令推荐相关的 API,该检索器可与 ToolLLaMA 结合,形成更自动化的工具使用流程。实验结果表明,该流程在分布外领域中具有良好的泛化能力。
总体而言,这项研究为指令调优与工具使用在大语言模型中的结合方向提供了新的研究思路。
Appendix¶
本章节为附录部分,通常用于补充正文内容,包括数据表格、代码、参考文献、术语解释或其他辅助性材料。附录内容虽不直接参与核心论述,但对理解研究方法、验证结果或扩展知识具有重要参考价值。建议读者根据具体研究需求,结合正文内容有选择地查阅相关内容。
Appendix A Implementation Details¶
这篇论文的附录A主要介绍了实现细节,涵盖从API筛选、响应压缩、模型训练(ToolLLaMA)、搜索算法(DFSDT)、评估方法(ToolEval)到实验结果的多个方面。以下是各部分的总结:
A.1 API筛选(Filtering RapidAPI)¶
为确保ToolBench工具集的可靠性和功能性,作者执行了两步筛选过程:
基本功能测试:剔除无法正常工作的API;
响应评估:通过调用API并评估响应时间与质量,过滤掉响应时间过长或内容质量差(如HTML源码、错误信息)的API。
A.2 API响应压缩(API Response Compression)¶
由于大型语言模型(LLMs)的上下文长度有限,作者对API的响应进行压缩处理,以去除冗余信息,同时保留关键内容。具体方法为:
利用ChatGPT分析每个API的响应示例,删除无关字段;
提供3个上下文学习示例,帮助ChatGPT学习压缩策略;
在推理过程中,若API响应长度超过1024个token,则进行压缩,若仍过长则截取前1024个token;
通过人工评估验证,该方法能保留关键信息,同时去除噪声。
A.3 ToolLLaMA模型训练(Training ToolLLaMA)¶
训练模式:采用多轮对话模式;
数据格式:与ChatGPT保持一致;
超参数设置:学习率 \(5 \times 10^{-5}\),warmup比例 \(4 \times 10^{-2}\),总批大小64,最大序列长度8192,位置插值比例2;
训练过程:训练两轮,选择在验证集上表现最好的模型用于测试。
A.4 DFSDT算法(DFSDT)¶
DFSDT是一种改进的深度优先搜索(DFS)算法,旨在在保证搜索效果的同时减少资源消耗:
传统DFS问题:排序子节点耗费大量资源;
改进设计:采用预排序的DFS遍历方式,跳过排序步骤;
优势:
在简单任务中退化为ReACT,效率更高;
在复杂任务中接近DFS效果;
成本:OpenAI API调用复杂度从 \(O(n \log n)\) 降至线性;
模型兼容性:ToolLLaMA可以结合ReACT或DFSDT进行推理。
A.5 ToolEval评估方法(ToolEval)¶
1. 通过率(Pass Rate)¶
评估模型是否完成任务,分为三种标签:Pass、Fail、Unsure。规则根据任务是否可解进行区分:
可解任务:根据是否成功回答问题、是否尝试所有工具等标准判断;
不可解任务:根据是否拒绝回答或错误回答判断。
2. 胜率(Win Rate)¶
比较两个完成任务的路径,判断哪个更好,判断标准包括:
信息丰富度;
事实准确性;
推理清晰度;
里程碑数量;
探索的API数量;
调用效率(重复调用少为优)。
3. 与人工评估对比¶
通过300条测试指令的人工评估,验证ChatGPT评估器的可靠性:
通过率一致性:87.1%;
胜率一致性:80.3%;
说明ChatGPT评估器可以较好地模拟人类判断。
4. 评估挑战¶
工具使用评估比传统任务(如对话)更复杂,因可能有无限种正确路径。人类专家之间也存在分歧,说明该领域仍需进一步研究。
A.6 APIBench实验细节¶
在APIBench上的泛化实验中,作者未对ToolLLaMA进行训练更新,而是将其视为一个能选择API并生成自然语言描述输出的函数。未考虑零样本设置(无API描述的提示),因为APIBench中的API在训练中未曾出现。
总结¶
附录A系统地介绍了ToolBench和ToolLLaMA的实现细节,包括:
API筛选与响应压缩机制;
ToolLLaMA的训练参数与策略;
DFSDT算法的优化设计;
ToolEval的评估标准与实验验证;
APIBench上的泛化能力分析。
这些细节为模型的可靠性、效率和评估提供了理论与实践支持。
A.7 Prompts for Instruction Generation¶
这篇文章详细描述了用于指令生成的提示模板和解决方案路径注解的提示模板,主要分为以下几个部分:
1. 指令生成提示(Instruction Generation Prompts)¶
1.1 单工具指令生成任务描述¶
用户将获得一个工具及其所有可用API函数的描述和参数。
任务是生成10个多样、创新、详细的用户查询,每个查询必须使用该工具的多个API函数。
查询的前7个需要非常具体,每个查询以不同方式组合多个API调用,并包含必要的参数。
最后3个查询应为复杂、长场景的描述,调用所有API来提供帮助。
每个查询中的相关API不能重复使用,需尽量减少不同查询间的API重叠。
查询要求直接提供参数,不得询问API调用,而是直接陈述需求。
示例展示了如何结合多个API进行查询。
1.2 多工具指令生成任务描述¶
用户将获得多个工具,每个工具的API函数、描述和参数。
任务是生成10个创新的用户查询,每个查询需调用多个工具的API函数。
查询的结构、语气、长度和主题需多样化,涵盖“自己”、“朋友”、“家庭”和“公司”等多个方面。
每个查询需调用2到5个API函数,不能只调用一个。
查询中不得明确指出使用哪个API,而是直接陈述需求。
查询长度应不少于30个词。
1.3 提供的API示例¶
示例包括“EntreAPI Faker”工具中的多个API,如“Longitute”(生成随机经度)、“Boolean”(随机布尔值)、“Past”(生成过去日期)等。
每个API都包含URL、描述、方法和参数等信息。
2. 解决方案路径注解提示(Solution Path Annotation Prompts)¶
2.1 系统提示¶
用户扮演“Tool-GPT”,利用多个工具和功能完成任务。
每一步需分析当前状态,决定下一步操作,执行函数调用,并根据结果进入新状态。
任务完成后,调用“Finish: give_answer”函数提供最终答案,或调用“Finish: give_up_and_restart”重启任务。
思考需简洁(最多五句话),如果尝试失败可多次尝试,每次尝试一个不同条件。
2.2 多样化用户提示¶
如果这是用户首次尝试某任务,可继续尝试;若已尝试过但失败,则需参考之前尝试的动作,并生成不同的新动作。
用户需要确保每次操作都与之前不同,避免重复路径。
2.3 任务描述模板¶
任务描述将动态插入,用户需根据任务内容进行分析并执行相应API函数。
提示中提供了“Finish”函数的使用说明,包括“give_answer”和“give_up_and_restart”两种返回类型。
总结¶
本文提供了一套用于生成多样化用户指令的模板,包括单工具和多工具两种场景,每个指令需调用多个API并结合具体参数。
还提供了一种解决方案路径注解的方法,模拟系统如何逐步分析任务、执行API调用并最终给出答案。
文章强调了指令和查询的多样性、创新性与复杂性,同时提供了详细示例,帮助更好地理解如何构建和生成符合要求的指令和查询。